






Languages
Pages
Legal


Learning Structured Models for Phone Recognition
Slav Petrov, Adam Pauls, Dan Klein

Acoustic Modeling

Motivation
Standard acoustic models impose many structural constraints
We propose an automatic approach
Use TIMIT Dataset MFCC features Full covariance Gaussians (Young and Woodland, 1994)

Phone Classification
? ? ? ? ? ? ? ? ??

Phone Classification
æ

HMMs for Phone Classification

HMMs for Phone Classification
Temporal Structure

Standard subphone/mixture HMM
Temporal Structure
Gaussian Mixtures
Model Error rate
HMM Baseline 25.1%

Our ModelStandard Model
Single Gaussians
Fully Connected

Hierarchical Baum-Welch Training
32.1%
28.7%
25.6%
HMM Baseline 25.1%
5 Split rounds 21.4%
23.9%

Phone Classification Results
Method Error Rate
GMM Baseline (Sha and Saul, 2006) 26.0 %
HMM Baseline (Gunawardana et al., 2005) 25.1 %
SVM (Clarkson and Moreno, 1999) 22.4 %
Hidden CRF (Gunawardana et al., 2005) 21.7 %
Our Work 21.4 %
Large Margin GMM (Sha and Saul, 2006) 21.1 %
Phone Recognition
? ? ? ? ? ? ? ? ?

Standard State-Tied Acoustic Models

No more State-Tying

No more Gaussian Mixtures

Fully connected internal structure

Fully connected external structure

Refinement of the /ih/-phone

Refinement of the /ih/-phone

Refinement of the /ih/-phone

Refinement of the /ih/-phone

Refinement of the /l/-phone

Hierarchical Refinement Results
0.24
0.26
0.28
0.3
0.32
0.34
0.36
0.38
0 500 1000 1500 2000
Number of States
Error Rate
Split and Merge, Automatic Alignment Split Only
HMM Baseline 41.7%
5 Split Rounds 28.4%

Merging
Not all phones are equally complex Compute log likelihood loss from merging
Split model Merged at one node
t-1 t t+1 t-1 t t+1

Merging Criterion
t-1 t t+1
t-1 t t+1

Split and Merge Results
0.24
0.26
0.28
0.3
0.32
0.34
0.36
0.38
0 500 1000 1500 2000
Number of States
Error Rate
Split and Merge Split Only
Split Only 28.4%
Split & Merge 27.3%

0
5
10
15
20
25
30
35
ae ao ay eh er ey ih f r s sil aa ah ix iy z cl k sh n
vcl ow l
m t v
uw aw ax ch w th el dh uh p
en oy hh jh ng y b d dx g zh epi
HMM states per phone

ey eh ao
0
5
10
15
20
25
30
35
ae ao ay eh er ey ih f r s sil aa ah ix iy z cl k sh n
vcl ow l
m t v
uw aw ax ch w th el dh uh p
en oy hh jh ng y b d dx g zh epi
HMM states per phone
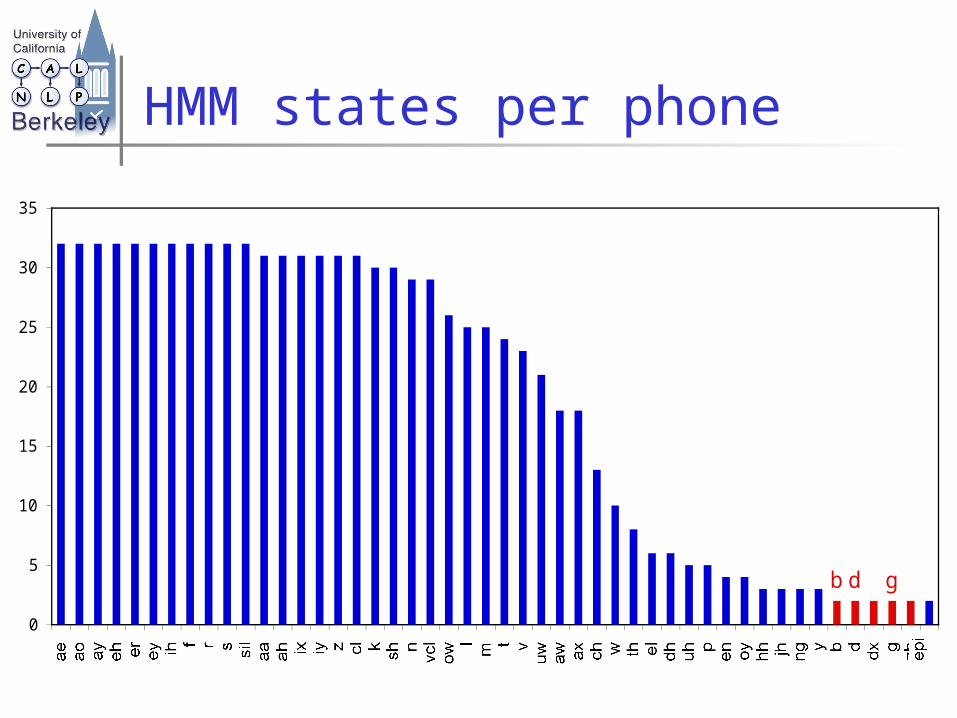
g d b
0
5
10
15
20
25
30
35
ae ao ay eh er ey ih f r s sil aa ah ix iy z cl k sh n
vcl ow l
m t v
uw aw ax ch w th el dh uh p
en oy hh jh ng y b d dx g zh epi
HMM states per phone

Alignment
0.24
0.26
0.28
0.3
0.32
0.34
0.36
0.38
0 500 1000 1500 2000
Number of States
Error Rate
Split and Merge Split Only Split and Merge, Automatic Alignment
Hand Aligned 27.3%
Auto Aligned 26.3%
Results

0
5
10
15
20
25
30
35
ae ao ay eh er ey ih aa ah ix iy ow uw aw ax el uh en oy f r s z k sh n l m t v ch w th dh
p hh jh ng
y b d dx g zh sil cl vcl epi
Hand Aligned Auto Aligned
Alignment State Distribution

Inference
State sequence: d1-d6-d6-d4-ae5-ae2-ae3-ae0-d2-d2-d3-d7-d5
Phone sequence:d - d - d -d -ae - ae - ae - ae - d - d -d - d - d
Transcription d - ae - d
Viterbi
Variational
???

Variational Inference
Variational Approximation:
Viterbi 26.3%
Variational 25.1%
: Posterior edge marginals
Solution:

Phone Recognition Results
Method Error Rate
State-Tied Triphone HMM (HTK)
(Young and Woodland, 1994)27.7 %
Gender Dependent Triphone HMM
(Lamel and Gauvain, 1993) 27.1 %
Our Work 26.1 %
Bayesian Triphone HMM
(Ming and Smith, 1998) 25.6 %
Heterogeneous classifiers
(Halberstadt and Glass, 1998) 24.4 %

Conclusions
Minimalist, Automatic Approach Unconstrained Accurate
Phone Classification Competitive with state-of-the-art discriminative
methods despite being generative
Phone Recognition Better than standard state-tied triphone models

Thank you!
http://nlp.cs.berkeley.edu
Top Related