







Languages
Pages
Legal


Introduction to Biomedical Information Retrieval Dolf Trieschnigg

Overview
§ Part 1: Introduction to Information Retrieval § What is information retrieval? § Indexing languages / a crowdexing experiment § Retrieval models § Evaluation
§ Part 2: Biomedical Information Retrieval and Text Mining § Dealing with terminology § PubMed
§ Information Retrieval, Fact Extraction, Knowledge Discovery
2 Jul 2014 2

What is information retrieval?
§ Information retrieval is defined as a field concerned with “the structure, analysis, organization, storage, searching, and retrieval of information” (Salton, 1968).
§ Finding relevant information in large amounts of irrelevant information
§ Not only text: also images, music, videos, persons etc.
2 Jul 2014 3

Schematically
2 Jul 2014 4
Information need
Query
Query formulation
Retrieved documents Feedback
Matching and ranking
Documents
Indexed documents
Indexing

For example
2 Jul 2014 5
Information need: I want to buy a new car and consider buying a Jaguar, what models do they have?

2 Jul 2014 6
✅
✅ ✅
✅ ✅

It's a game!
2 Jul 2014 7
Information need
Query
Query formulation
Retrieved documents Feedback
Matching and ranking
Documents
Indexed documents
Indexing
Indexer predicts how user will formulate query
User guesses how indexer has chosen representation

A small crowd-indexing experiment
2 Jul 2014 8

Some questions
§ What terms to use: words, phrases, entities? § Which terms to include? § Are all terms equally important? § How to deal with numbers? § How to deal with word variations?
2 Jul 2014 9

Some observations (hopefully ;-))
§ You chose an indexing unit, with a certain specificity § You made a selection of words to include, resulting in a certain
exhaustivity § Probably you don't agree
§ Some terms are more important than others § Important information is implicit § Terms can be ambiguous § How consistent do you think you are?
2 Jul 2014 10

Let's automate this
§ Tokenization: how to extract indexing terms automatically? § Models: how to match queries to documents?
2 Jul 2014 11

Tokenization
Get indexing terms from text automatically 1. Lowercase text
"US" is the same as "us" 2. Extract words
"Hepatitus-A" 3. Stopword removal
"To be or not to be" 4. Stemming
University à Univers Universe à Univers
2 Jul 2014 12
Late rally sends Dutch into quarter-finals. Netherlands produce a late comeback to rescue their World Cup dream and deny Mexico a first quarter-final in 28 years.

Tokenization
Get indexing terms from text automatically 1. Lowercase text
"US" is the same as "us" 2. Extract words
"Hepatitus-A" 3. Stopword removal
"To be or not to be" 4. Stemming
University à Univers Universe à Univers
2 Jul 2014 13
late rally sends dutch into quarter-finals. netherlands produce a late comeback to rescue their world cup dream and deny mexico a first quarter-final in 28 years.

Tokenization
Get indexing terms from text automatically 1. Lowercase text
"US" is the same as "us" 2. Extract words
"Hepatitus-A" 3. Stopword removal
"To be or not to be" 4. Stemming
University à Univers Universe à Univers
2 Jul 2014 14
late rally sends dutch into quarter finals netherlands produce a late comeback to rescue their world cup dream and deny mexico a first quarter final in 28 years

Tokenization
Get indexing terms from text automatically 1. Lowercase text
"US" is the same as "us" 2. Extract words
"Hepatitus-A" 3. Stopword removal
"To be or not to be" 4. Stemming
University à Univers Universe à Univers
2 Jul 2014 15
late rally sends dutch quarter finals netherlands produce late comeback rescue world cup dream deny mexico first quarter final 28 years

Tokenization
Get indexing terms from text automatically 1. Lowercase text
"US" is the same as "us" 2. Extract words
"Hepatitus-A" 3. Stopword removal
"To be or not to be" 4. Stemming
University à Univers Universe à Univers
2 Jul 2014 16
late ralli send dutch quarter final netherland produc late comeback rescu world cup dream deni mexico first quarter final 28 year

Retrieval models
§ Boolean retrieval § Retrieve all matching documents
§ Ranked retrieval § Most relevant document first § A mathematical function:
§ F(Query, Document): score
§ Two classic retrieval models
§ Based on Vector Spaces § Based on Language Models
2 Jul 2014 17

Vector Space model
§ Documents and queries are multi-dimensional vectors (each word is a dimension)
§ Rank documents by the angle between the vectors
2 Jul 2014 18
document
query
θ

Probabilistic language models
§ Documents are urns-of-words § Queries are sampled from these urns
§ Rank urns by the probability of sampling the user's query
2 Jul 2014 19
P (Q|D) =Y
q2Q
P (q|D)
late
ralli send
dutch
quarter final netherland
produc

Typical ingredients to a retrieval model
§ Term importance: TF.IDF § Local importance: frequency of term in the document (TF) § Global importance: frequency of term in the collection (IDF)
§ Document importance § Based on e.g.:
§ Authority § In-links (PageRank) § Citation counts
§ User clicks
2 Jul 2014 20

Evaluation: is it any good?
§ Real world § Unleash it, get millions of happy users from advertisers and crush the
competition § Do a scientific (measurable, repeatable) experiment, evaluating
§ The quality of the search results § Speed and cost of indexing
§ Speed and cost of searching § Attractiveness of the user interface § …
2 Jul 2014 21

2 Jul 2014 22
✅
✅ ✅
✅ ✅
5 out of 12 results are relevant

Modeling relevance
§ Typically § Binary: a document is relevant or not § Independent: each document is assessed on its own
§ Alternatively § Graded relevance
§ Categorize relevant results (aspects, facets, nuggets)
§ Is this realistic?
§ Not really but it makes calculations a lot easier
2 Jul 2014 23

The traditional IR experiment
§ Ingredients: document collection, topics and relevance judgments
§ Task: for each topic retrieve 1000 relevant documents
§ Evaluation: rank precision, average precision (MAP)
2 Jul 2014 24
4.5 mln MEDLINE citations
Topic Doc.id Relevant? 1 1223 Yes 1 1218 Yes 1 1219 No … … …
Topic Rank Doc. id 1 1 1283 ✖ 1 2 1218 ✔ 1 3 3482 ✖ … … … …
1. What is the role of PrnP in mad cow disease?
2. What is the role of IDE in Alzheimer’s disease?
3. What is the role of MMS2 in cancer?
4. …

Text Retrieval Conference (TREC)
§ Annual conference organized by NIST “to encourage research in [IR] from large text collections”
§ Many participants take part in a tracks: web, blog, genomics, microblog, chemical, entities, legal, federated web…
§ Main ingredients: § document collection § information needs and queries
§ relevance judgments
2 Jul 2014 25
Some evaluation metrics
§ For sets of results § Precision § Recall § F-Measure
§ Ranked results
§ Rank precision: P@5, P@10, R-Precision § Average precision § Reciprocal rank
§ Cumulative Gain (graded judgements)
2 Jul 2014 26

Basic measures of performance: precision and recall
2 Jul 2014 27
True positives
(#TP)
False negatives
(#FN)
False positives
(#FP)
True negatives
(#TN)
Relevant
Not relevant
Match No match
System says:
User says:
Recall = #TP
#TP + #FN Precision =
#TP
#TP + #FP

Basic measures of performance: precision and recall
§ Precision: get me only relevant results § Recall: give me all relevant results
2 Jul 2014 28
Document collection
Relevant Retrieved
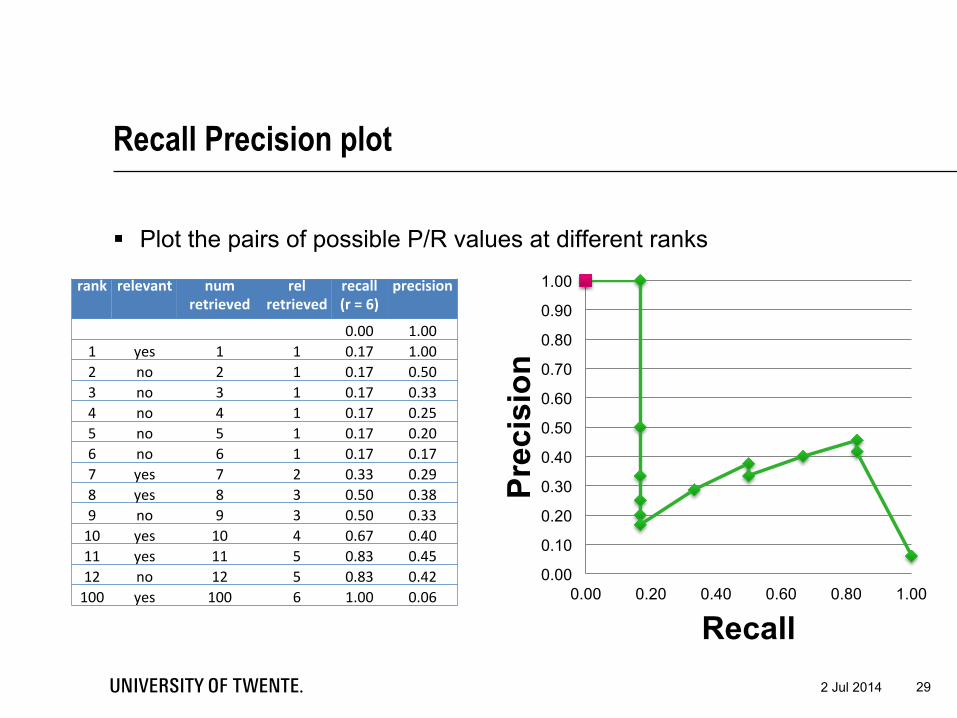
Recall Precision plot
§ Plot the pairs of possible P/R values at different ranks
2 Jul 2014 29
rank relevant num retrieved
rel retrieved
recall (r = 6)
precision
0.00 1.00 1 yes 1 1 0.17 1.00 2 no 2 1 0.17 0.50 3 no 3 1 0.17 0.33 4 no 4 1 0.17 0.25 5 no 5 1 0.17 0.20 6 no 6 1 0.17 0.17 7 yes 7 2 0.33 0.29 8 yes 8 3 0.50 0.38 9 no 9 3 0.50 0.33 10 yes 10 4 0.67 0.40 11 yes 11 5 0.83 0.45 12 no 12 5 0.83 0.42 100 yes 100 6 1.00 0.06
0.00
0.10
0.20
0.30
0.40
0.50
0.60
0.70
0.80
0.90
1.00
0.00 0.20 0.40 0.60 0.80 1.00
Prec
isio
n
Recall

Comparing retrieval systems graphically
§ Average over large number of queries
2 Jul 2014 30
0
0.2
0.4
0.6
0.8
1
0 0.2 0.4 0.6 0.8 1
Pre
cisi
on
Recall
CLMEAGL
KNNMTI
MetaMap

Rank precision: P@X, R-Precision
§ Rank precision: precision after retrieving X documents § R-precision: precision after retrieving R documents
§ Where R is total number of relevant documents
§ When do you want to use Rank precision, when R-precision?
2 Jul 2014 31

2 Jul 2014 32
✅
✅ ✅
✅ ✅

Rank precision: P@X, R-Precision
§ P@5 § P@10 § P@12 § R-precision
2 Jul 2014 33

Rank precision: P@X, R-Precision
§ P@5 = 1/5 = 0.2 § P@10 = 4/10 = 0.4 § P@12 = 5 /12 = 0.417 § R-precision: not possible
2 Jul 2014 34

Average precision
§ Calculates a trade-off between precision and recall § Average precision at recall points
§ Average P@k for relevant documents (at rank k)
§ For the example, calculate the AP (assume num rel docs=6) § Relevant docs at ranks: 1, 7, 8, 10, 11
2 Jul 2014 35

Reciprocal rank
§ Inverse of rank of first hit § First hit at rank 1: 1/1 § First hit at rank 10: 1/10
§ Useful for evaluating
§ Translation systems § Known-item search § Navigational queries
2 Jul 2014 36

Normalized discounted cumulative gain (nDCG)
§ Some documents are more important than others § E.g. search for facebook
§ Uses graded relevance judgements
2 Jul 2014 37

The surprising part
§ Retrieval systems based on automatic weighted bag-of-words document representations performs similar or better than to systems based on manual controlled vocabulary indexing (Cleverdon, '60s)
"This conclusion is so controversial and so unexpected that it is bound to throw considerable doubt on the methods which have been used (...) A complete recheck has failed to reveal any discrepancies (...) there is no other course except to attempt to explain the results which seem to offend against every canon on which we were trained as librarians."
2 Jul 2014 38

Wrap up (part I)
§ Information retrieval is all about finding relevant information § Different indexing languages can be used
§ Manual/automatic § Controlled/uncontrolled
§ Retrieval models match and rank documents
§ Evaluation typically uses a fixed collection, topics and judgments
§ Automatic indexing performs surprisingly well!
2 Jul 2014 39

Overview
§ Part 1: Introduction to Information Retrieval § What is information retrieval? § Indexing languages / a crowdexing experiment § Retrieval models § Evaluation
§ Part 2: Biomedical Information Retrieval and Text Mining § Dealing with terminology § PubMed & MeSH
§ Information Retrieval, Fact Extraction, Knowledge Discovery
2 Jul 2014 40

What is biomedicine?
2 Jul 2014 41
Biomedicine/ Life sciences
biology
chemistry
physics
biomechanics
biochemistry
bioinformatics
genomics
cell biology
biophysics
genetics
developmental biology
immunology
ecology
botany
food science
biotechnology microbiology
oncology
systems biology
zoology
immunogenetics
medicine
computational neuroscience
environmental science

What is biomedicine?
§ A large number of related disciplines § “Studying the structure, function, growth, origin, evolution or distribution of
living organisms and their natural environments”
2 Jul 2014 42

They like to publish
2 Jul 2014 43
§ MEDLINE: § A bibliographic database § Exponential growth § Manually indexed (MeSH) § 2014 statistics
§ 21 mln references § 5,600 journals § 2013: 700,000 additions

To give you an idea of 700,000 papers / year
§ If reading a paper takes you 15 minutes § And you work 60 hours a week, 50 weeks per year § You would need more than 58 years to read 700,000 articles
2 Jul 2014 44
“It’s called ‘reading’. It’s how people install new software into their brains”

A sample MEDLINE entry
§ Authors & Affiliations § Title § Journal § Publication date § Abstract § MeSH terms
2 Jul 2014 45

The importance of information retrieval
2 Jul 2014 46
“A month in the laboratory can save an hour in the library”
F. Westheimer (1912-2007), professor of Chemistry at Harvard University

Information retrieval in the text mining landscape
§ Information retrieval § Finding information § Find information about P53
§ Information extraction § Extracting facts § Which proteins interact with P53
§ Knowledge discovery § Discovering new knowledge § Hypothesis generation
2 Jul 2014 47
[Hersh, 2009]

Ultimate goal: literature-based discovery
§ Combine what we know to find something new § Swanson Linking (late ’80s): “combining disjoint literatures”
2 Jul 2014 48
Known from literature Fish oiló Blood viscosity
Known from literature Blood viscosity ó Raynaud’s disease
Fish oil as a treatment for Raynaud’s disease

Terminology: a challenge for biomedical IR
§ Biomedical concepts are represented by terms § What is a concept?
§ “an abstract idea, a general notion” ~ something interesting § Examples of biomedical concepts
§ Diseases
§ Organisms § Genes § Proteins
§ Chemicals § …
2 Jul 2014 49
“mad cow disease” “BSE” “Bovine spongiform encephalopathy”
Mad cow disease

Characteristics of biomedical terminology
§ Complex § Inconsistent § Many synonyms § Ambiguous
2 Jul 2014 50

Biomedical terminology is complex
§ Many compound terms § nuclear factor kappa-light-chain-
enhancer of activated B cells § 85% of the terms consist of more than
one word (Nenadic et al, 2005) § Frequent use of ad hoc abbreviations
§ TRADD binds to the TNF receptor-associated factor 2 (TRAF-2) that recruits NF-kB-inducible kinase (NIK).
2 Jul 2014 51

Biomedical terminology is inconsistent
§ 75% of the authors do not use official gene symbol or full gene names (Chen et al., 2005)
§ Frequent spelling variation: § NF-kB, nfkb, NF kappa B § syt4, syt iv
§ Fast changing terminology:
§ How many synonyms of Mexican flu can you think of?
2 Jul 2014 52
novel influenza A (H1N1), 2009 H1N1 flu, new influenza A virus, pandemic H1N1/09 virus, novel H1N1 virus, A/California/07/2009 (H1N1), H1N1 influenza, H1N1 Virus, Mexican Virus, swine influenza, SI, Pig Flu, Swine-Origin Influenza A H1N1 Virus, Influenza A Virus, H1N1 Subtype, ...

Biomedical terminology is inconsistent
“Biologists would rather share their toothbrush than a gene name” Michael Ashburner, professor of biology at the University of Cambridge
2 Jul 2014 53

Biomedical terminology contains many synonyms
§ Nuclear Factor-kappa B § Immunoglobulin Enhancer-Binding Protein § Ig-EBP-1, Ig EBP 1, IgEBP1 § NF-kB, NFkappaB, NF-kappa-B, NF-kappa beta § Transcription Factor NF kB
§ NF kapa beta
2 Jul 2014 54

Biomedical terminology is highly ambiguous
§ Abbreviations: PSA § prostate specific antigen § psoriasis arthritis § poultry science association § … (100 more)
§ Use of general English terms § white protein § big brain protein
§ hr
2 Jul 2014 55

Quiz
§ What is the effect of these characteristics? (on precision/recall) § How can an IR system deal with these characteristics?
2 Jul 2014 56
Mad cow disease
Mad cow disease “mad cow disease” “BSE”
Breast self-examination “BSE” “BSE”
Will be missed
Will be incorrectly matched
query document

Quiz
§ What is the effect of these characteristics? § Vocabulary mismatch between query and (relevant) documents § Missing synonyms: low recall § Using ambiguous terms: low precision
§ How can an IR system deal with these characteristics?
§ Incorporate domain knowledge, for instance § Sophisticated lexical analysis § Query/document expansion
§ Concept representations § ….
2 Jul 2014 57

Biomedical Search in Practice: PubMed
2 Jul 2014 58

Let’s search PubMed
2 Jul 2014 59

Let’s search PubMed
2 Jul 2014 60

PubMed
§ Searches the MEDLINE database § Boolean matching § It uses multiple indexing vocabularies:
§ Manual controlled vocabulary index (MeSH) & § Automatic uncontrolled vocabulary index (free text)
§ By default, sorted by publication date (newest first) § Automatic query mapping and expansion
2 Jul 2014 61

MeSH
§ A controlled vocabulary for indexing biomedical documents § 24,000 main descriptors + qualifiers § Hierarchically organized (DAG)
2 Jul 2014 62

Example MeSH descriptor
2 Jul 2014 63

2 Jul 2014 64

§ Main descriptor/qualifier
§ * indicates important
2 Jul 2014 65

2 Jul 2014 66

FACTS on MeSH
§ Organizing principle: “to conceptually partition the literature” § Hierarchy: Is-a and part-of relationships § Yearly updates, no re-indexing § Average: 9 MeSH descriptors per document § Manually assigned, also based on full-text
2 Jul 2014 67

Automatic free text vs. manual contr. vocabulary indexing
§ PubMed uses both: § Automatic free text indexing
§ Cheap, fast and trivial to maintain § Ambiguous
§ Manual controlled vocabulary indexing (MeSH)
§ Easy to understand and unambiguous § Very expensive, slow, hard to maintain
2 Jul 2014 68

A simple knowledge discovery system
1. Detect biomedical concepts 2. Detect concept relationships 3. Find novel relationships
2 Jul 2014 69
A B
B C
A
C
?

1. Detect biomedical concepts
§ Biomedical named entity § … recognition § … classification § … identification
2 Jul 2014 70
Significant differences in incubation times
in sheep infected with bovine
spongiform encephalopathy result from
variation at codon 141 in the PRNP gene.

1. Detect biomedical concepts
§ Biomedical named entity § … recognition § … classification § … identification
2 Jul 2014 71
Significant differences in incubation times
in sheep infected with bovine
spongiform encephalopathy result from
variation at codon 141 in the PRNP gene.

1. Detect biomedical concepts
§ Biomedical named entity § … recognition § … classification § … identification
2 Jul 2014 72
Significant differences in incubation times
in sheep infected with bovine
spongiform encephalopathy result from
variation at codon 141 in the PRNP gene.
organism
disease
gene

1. Detect biomedical concepts
§ Biomedical named entity § … recognition § … classification § … identification
2 Jul 2014 73
Significant differences in incubation times
in sheep infected with bovine
spongiform encephalopathy result from
variation at codon 141 in the PRNP gene.
MeSH: sheep, domestic
MeSH: encephalopathy, bovine spongiform
Entrez Gene: PRNP prion protein [ Ovis aries ]

Challenges in detecting biomedical concepts
§ Biomedical terminology is hard to deal with § (complex, inconsistent, many synonyms, ambiguous)
§ Fundamental issues: § How to deal with limited resources?
§ Incompleteness
§ Errors § Inconsistencies
§ How to encode knowledge?
§ Granularity § Relationships
2 Jul 2014 74
Significant differences in incubation times in sheep infected with bovine spongiform encephalopathy result from variation at codon 141 in the PRNP gene.
PRNP – prion protein [Homo sapiens] Prnp – prion protein [Mus musculus] PRNP – prion protein [Ovis aries] PRNP – prion protein [Bos taurus] …
Domestic sheep? Ruminants?

Some controlled vocabularies for biomedical IR
2 Jul 2014 75
Domain knowledge stored in terminological resources

Typical approaches to concept detection
§ Combine recognition and classification § Scan for x (genes) § Use patterns (“… gene”) § Use context: e.g. surrounding verbs (inhibit, enhance, reduce, …)
§ Identification
§ Dictionary lookup with flexible tokenization/matching § Disambiguation based on context
2 Jul 2014 76

2. Detect concept relationships
§ Extract facts: formalize what is already known
2 Jul 2014 77
Significant differences in incubation times in sheep infected with bovine spongiform encephalopathy result from variation at codon 141 in the PRNP gene.
Mad cow disease has a relationship with PRNP gene

Challenges in detecting relationships
§ Errors in concept detection propagate § Negations
§ We are sure there is no relationship whatsoever between X and Y § (Un)certainty, authority, contradictions and changing insights
§ X might enhanceY
§ The data clearly proves that X is caused by Y [Stapel et al] § We used to believe that X causes Y
2 Jul 2014 78

Typical approaches to detecting relationships
§ For finding untyped relationships § Use co-occurrence in document or sentence
§ For finding typed relationships § Use templates (i.c.w. bootstrapping)
§ “[gene] enhances [disease]” § Shallow/full parsing
2 Jul 2014 79
High recall, Low precision
High precision, Low recall

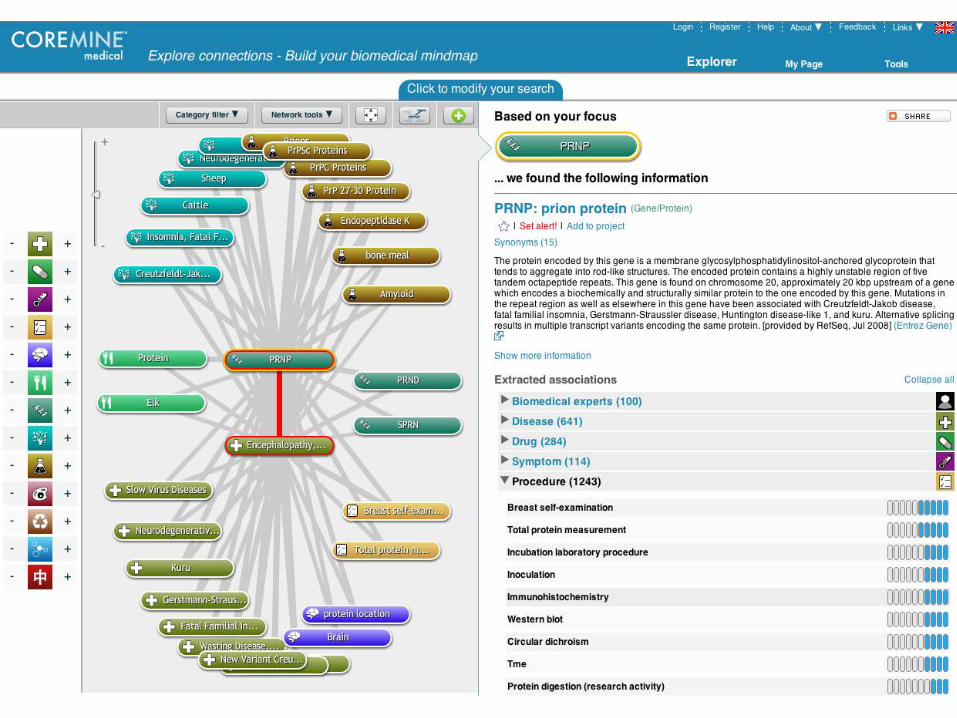
Example: CoreMine medical
§ Explore associated concepts (grouped by type) § www.coremine.com
2 Jul 2014 80

2 Jul 2014 81
2 Jul 2014 82
83
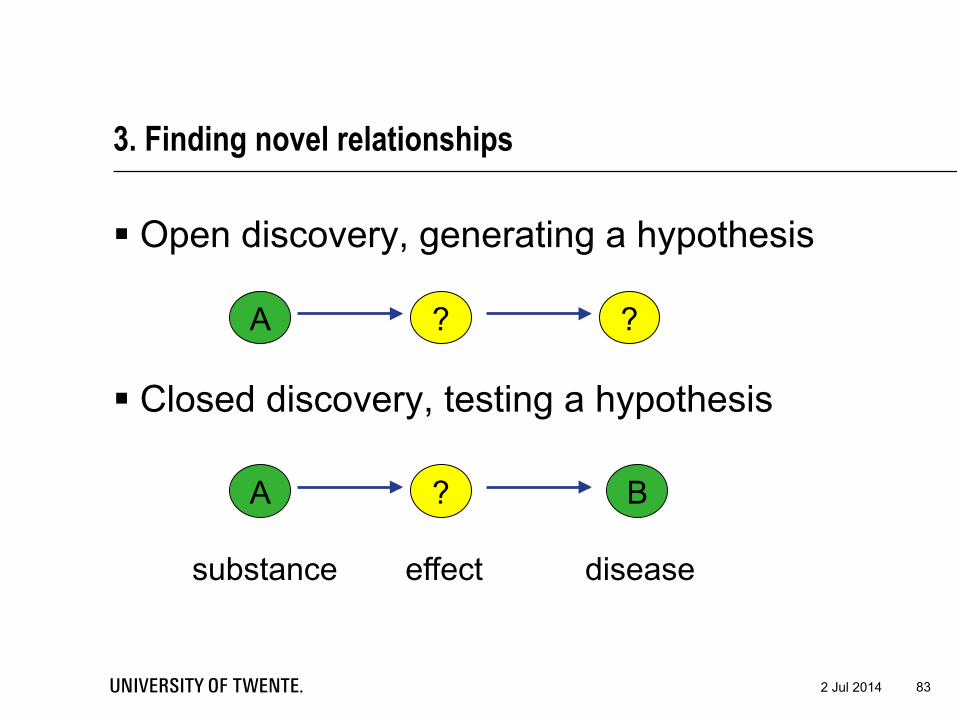
3. Finding novel relationships
§ Open discovery, generating a hypothesis
§ Closed discovery, testing a hypothesis
A B ?
A ? ?
substance effect disease
2 Jul 2014

84
Open discovery Closed discovery
Weeber et al 2001 2 Jul 2014

2 Jul 2014 85
Challenges in finding new relationships
§ Full automatic discovery not possible § how to take into account common knowledge § In what direction to explore
è Discovery support tool, guided search of knowledge

Example: Anni (Erasmus MC, Rotterdam)
§ Start with a set of “interesting” concepts (e.g. a list of genes) § For each concept, obtain concept-profiles
§ “you shall know a [concept] by the company it keeps”
§ Cluster based on concept-profiles
2 Jul 2014 86
Genome Biology 2008, 9:R96
http://genomebiology.com/2008/9/6/R96 Genome Biology 2008, Volume 9, Issue 6, Article R96 Jelier et al. R96.2
their relations. Concepts come with a definition, a semantictype, and a list of synonymous terms and can be linked toonline databases. We identify references to concepts in textswith our concept recognition software Peregrine [19]. Theidea behind Anni is to relate or associate concepts to eachother based on their associated sets of texts. Texts can belinked to a concept through automatic concept recognition,but also by using manually curated annotation databases. Thetexts associated with a concept are characterized by a so-called concept profile [18] (see Figure 1 for an introductioninto the technology behind Anni). A concept profile consistsof a list of related concepts and each concept in the profile hasa weight to signify its importance. Concept profiles have beensuccessfully used to infer functional associations betweengenes [18,20] and between genes and Gene Ontology (GO)codes [21] to infer novel genes associated with the nucleolus[22], and to identify new uses for drugs and other substancesin the treatment of diseases [8].
Anni 2.0 provides a generic framework to explore conceptprofiles and facilitates a broad range of tasks, including liter-ature based knowledge discovery. The tool provides conceptsand concept profiles covering the full scope of the UnifiedMedical Language System (UMLS) [23], a biomedical ontol-
ogy. The user is given extensive control to query for directassociations (based on co-occurrences), to match conceptprofiles, and to explore the results in several ways, forinstance with hierarchical clustering. Several types of onto-logical relations can be used in Anni. Semantic type informa-tion, which indicates whether a concept is about, for example,a gene or a drug, can be used to group concepts. This allows,for instance, a query as to whether a gene of interest has anassociation with any of the available diseases. Hierarchical'parent/child' relations are also available and can be visual-ized. They can be used to explore the relations in a group ofconcepts or to expand a query by identifying relevant relatedconcepts in the hierarchy. An important feature of Anni istransparency: all associations can be traced back to the sup-porting documents. In this way, Anni can also be used toretrieve documents about concepts of interest, therebyexploiting the mapping of synonyms and the resolution ofambiguous terms by our concept recognition software.
Previously, we illustrated the utility of concept profiles toretrieve functional and relevant associations between varioustypes of concepts [18,21,22]. Here, we evaluate our toolthrough two use cases. First we use Anni to analyze a DNA
The technology behind Anni at a glanceFigure 1The technology behind Anni at a glance. Yellow balls indicate ontology concepts.
The ontology is based on the UMLS and a gene dictionary. For each concept, it contains names, a definition and/or links to external databases.
For many concepts, a set of documents has been retrieved pertaining to that concept.
Concepts mentioned in these documents were identified with our concept-recognition software.
In the concept profile of concept X, concepts that are typical for documents pertaining to concept X have a high weight.
By querying the concept profiles, you can find concepts that have a direct relation with the query concept.
By matching concept profiles, you can find concepts that have many intermediate concepts in common. Concepts that are not directly linked in MEDLINE could turn out to be closely related.
UMLS Genes
Ontology Concept X
Concept A
Concept B
Concept A
Concept B
Concept C
Concept X
Query concept
Query concept
Concept X
Concept X
??
?
?
It will take Anni several seconds to compute the clustering. The clustering view shows a dendogram
and a heatmap. The intensity in the heatmap shows the similarity between concept profiles of the
concepts. Concepts with highly similar concept profiles will cluster together. You can zoom in and out,
and increase or decrease the sensitivity of the dendogram and heatmap.
By clicking on a line in the dendogram, you can select a cluster as shown in Illustration 6.
Illustration 5: The new concept set is selected, and we now click the cluster button.
Illustration 6: Selection of a cluster in the cluster view. The concepts in
the selected cluster are shown in the bottom panel.
See http://www.biosemantics.org/
~J.R. Firth, 1957

Wrap up (part 2)
§ Text mining tools are a necessity for biomedical research § For finding and analyzing literature § As a driver for new research
§ Handling biomedical terminology is a challenge § Building an effective text mining application is finding a delicate balance
between what is possible and what is needed
2 Jul 2014 87
Top Related