







Languages
Pages
Legal


Improving Data Cache Performance Under a Cache Miss
J. Dundas and T. MudgeSupercomputing ‘97
Laura J. Spencer, [email protected] Gast, [email protected], Spring 2000 UW/Madison

Automatic I/O Hint Generation through Speculative Execution
F. Chang and G. GibsonSOSDI ‘99

Similar algorithms in different worlds
The Run Ahead paper tries to hide cache miss latencyThe I/O Hinting paper tries to hidedisk read latency

Basic Concept: Prefetching RunAhead via Shadow Thread
Prefetch Try to get long-latency events started as soon
as possible
Shadow Thread Start a copy of the program to run-ahead to
find the next few long-latency events
Let the RunAhead Speculate Don’t let your shadow change any of your
data Every time your shadow goes off-track put it
back on-track

Shadow Code
Prefetch Far enough ahead to hide latency Perhaps incorrectly
Runs speculatively during stall Don’t wait for the data Contents might be invalid Keep shadow values privately Suppress exceptions
Stay ahead until end of leash Low confidence of being on-track Outrunning resources
b c + d
f e / b
c a[b]
if (d == 1) then . . .

Talk Roadmap
Show how to RunAheadBackup the Registers, Speculate under stallCopy-on-Write the RAM, Speculate when stalled
How far to speculate?Fill DMAQ with prefetchesA constant number of hints (if on-track)
Experimental ResultsDundasChang

Simple ArrayExamplefor(int i = 0;i<size;i++) { r[i] = a[i] + b[i];}
LD a[0]
LD b[0]
LD a[1]
LD b[1]
for(int i = 0;i<size;i++) { _r[i]=prefetch(a[i])+prefetch(b[i]);}
PreFetch(b[0]);
PreFetch(a[1]);
PreFetch(b[1]);
PreFetch(a[2]);
sleep
sleep
Run ahead *
cache miss
execute
execute
* Only needs execution logic (which would be wasted)

Long-latency Events
Miss in L2 cache costing 100-200 cycles Whenever L1 cache misses, start shadow
Decide which values will be needed next and place them into Direct Memory Access Queue as prefetch
[1]DMAQ
[2] [3] [4]
prefetch value 1
prefetch value 2
prefetch value 3
[5] [6] [7] [8]
The longer the miss, the more chance thisthread has of finding useful things to prefetch
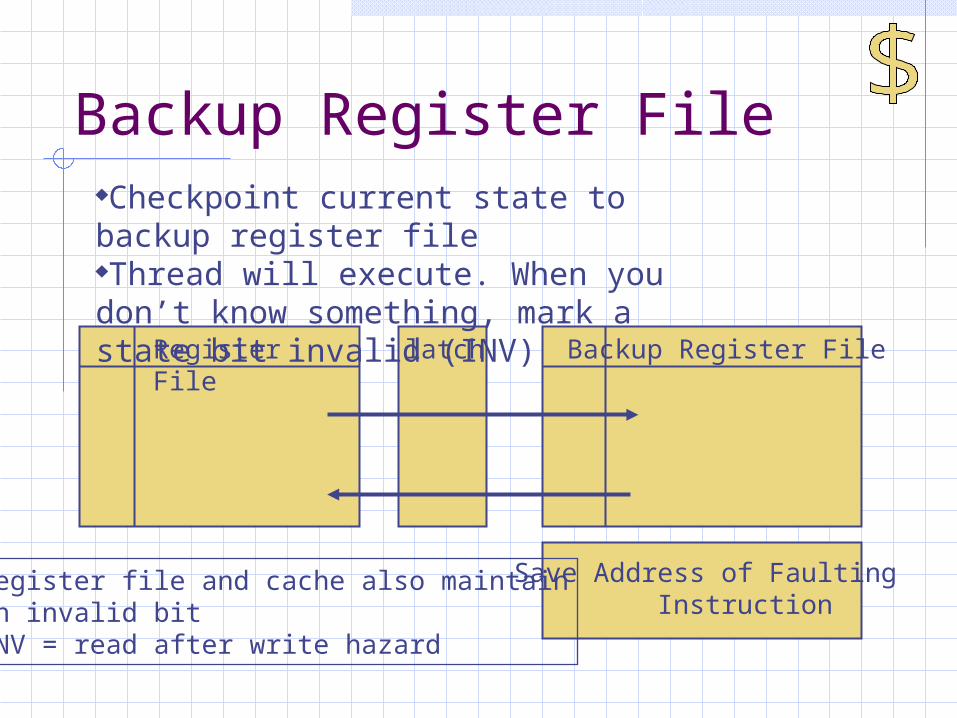
Backup Register File
Register File
Backup Register Filelatch
Save Address of Faulting Instruction
Checkpoint current state to backup register fileThread will execute. When you don’t know something, mark a state bit invalid (INV)
Register file and cache also maintainan invalid bitINV = read after write hazard

What is invalid?
Register-to-register op: mark dest reg INV if any source reg is INVLoad op: marks dest reg INV if address reg is INV load causes miss prev store marked cache INV
Store op: marks cache INV if address is known and no miss would occur
*If store does not mark cache INV, LD may use INV data

Disks in 1973
"The first guys -- when they started out to try and make
these disks -- they would take an epoxy paint mixture,
ground some rust particles into it, put that in a Dixie cup,
strain that through a women's nylon to filter it down, and
then pour it on a spinning disk and let it spread out as it was
spinning, to coat the surface of the disk.”
Source: http://www.newmedianews.com/032798/ts_harddisk.html
Rotational Latency? 65 milliseconds (1973)vs. 10 milliseconds (2000)
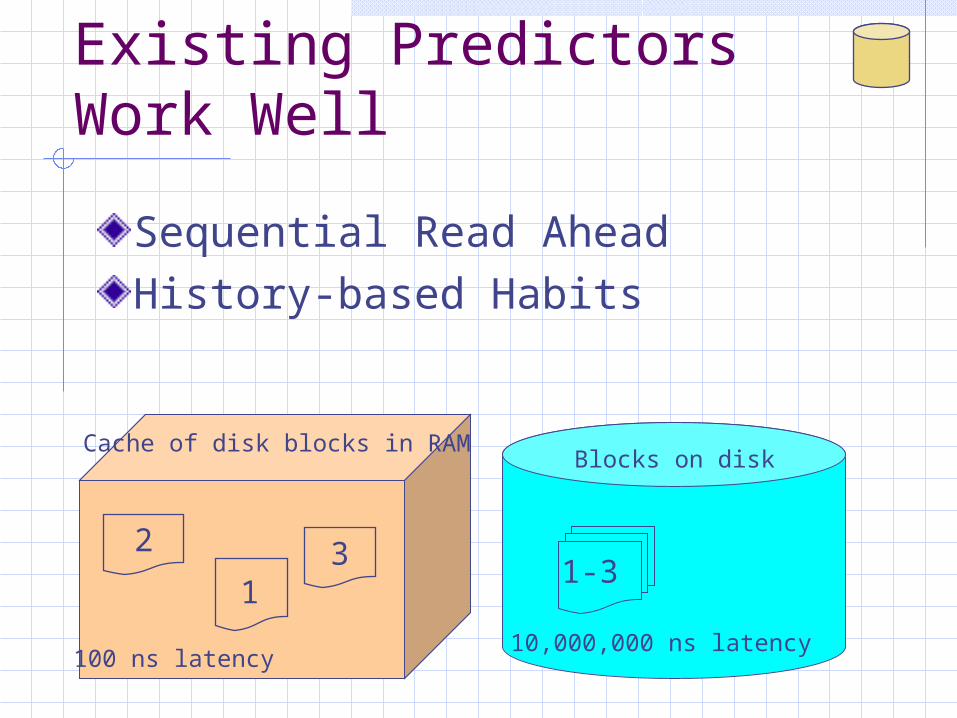
Existing Predictors Work Well
Sequential Read AheadHistory-based Habits
32
11-3
Cache of disk blocks in RAM
100 ns latency10,000,000 ns latency
Blocks on disk

Sequential Read Ahead
Prefetch a few blocks ahead Read Ahead / Stay Ahead Works well with Scatter / Gather
65
4
4-6

What about random reads?
Programmer could manually modify app tipio_seg tipio_fd_seg
Good performance, if human is smart
Hard to do Old programs Hard to predict how far ahead to prefetch
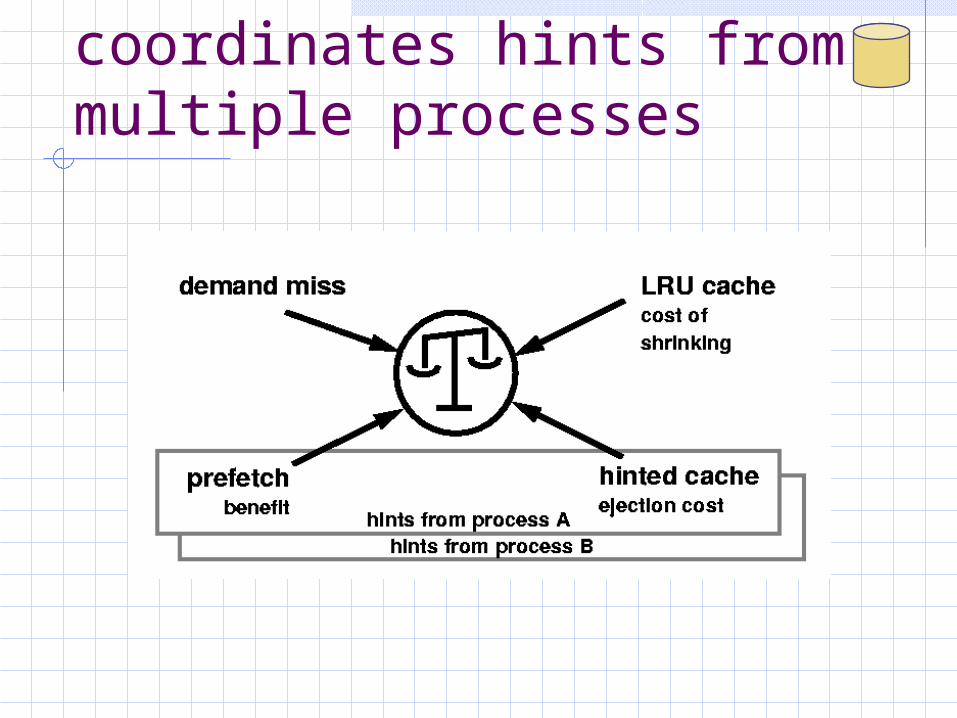
Kernel thread coordinates hints from multiple processes

Sample TIPIO
/* Process records from file f1 */ /* Prefetch the first 5 records */ tipio_seg(f1,0,5*REC_LEN);
/* Process the records */ for (rec = 0; ; rec++) { tipio_seg(f1, (rec+5)*REC_LEN, REC_LEN); bytes = read(f1, REC_LEN, bf); if (bytes < 0) break; process(bf); }
Warning: over-simplification of tipio_seg
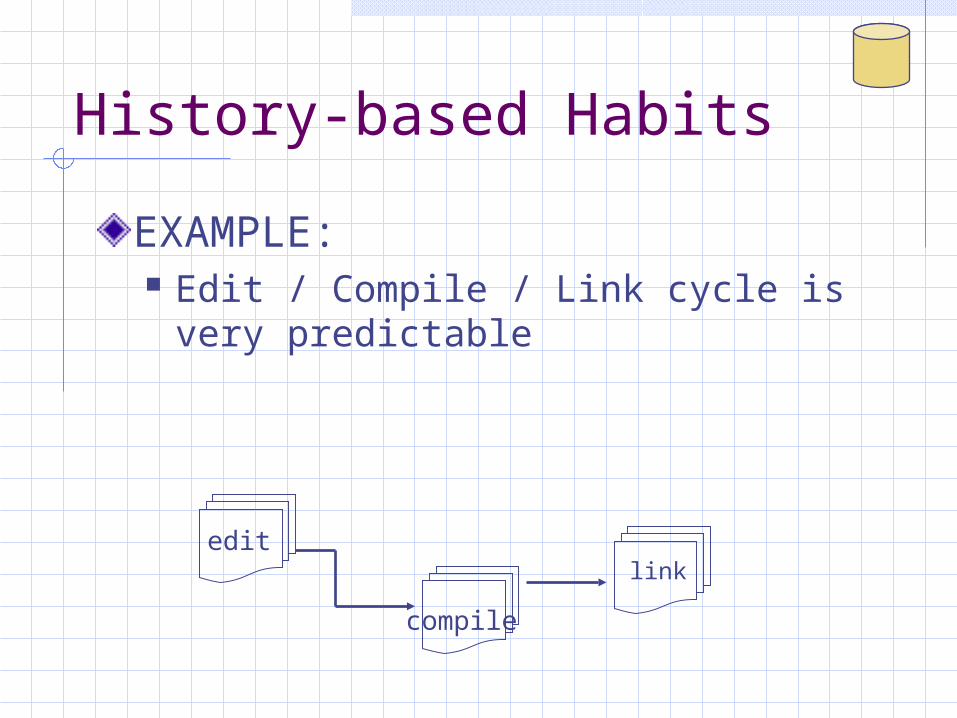
History-based Habits
EXAMPLE: Edit / Compile / Link cycle is very
predictable
edit
compile
link
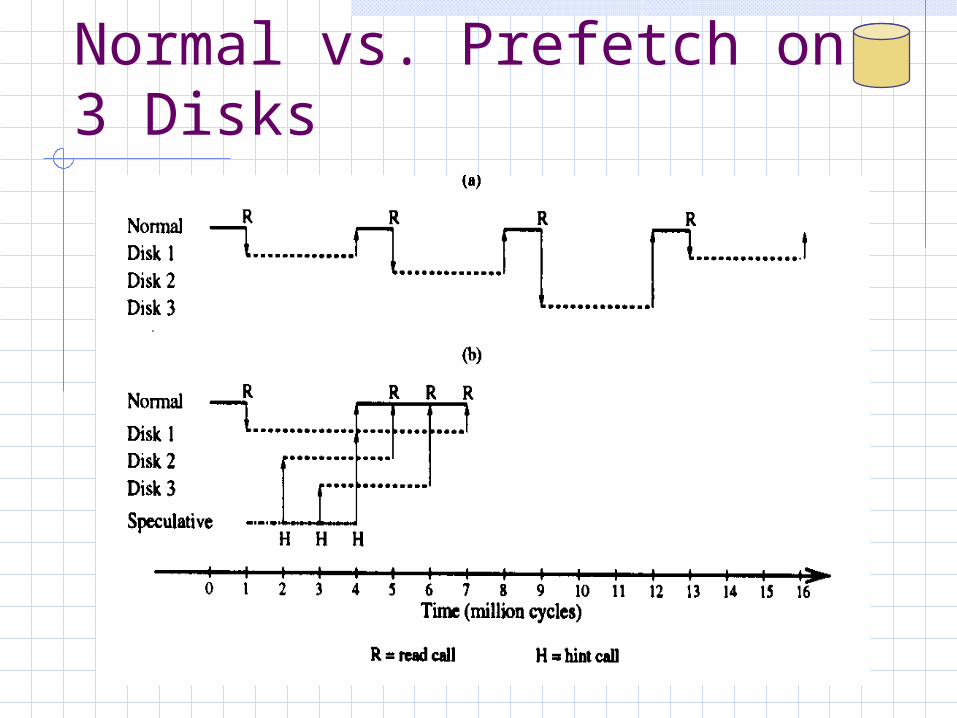
Normal vs. Prefetch on 3 Disks

Too Much Prefetch?
Disk head busy and far away when an unexpected useful read happensSpeculated block becomes victim before it is used

Chang / Gibson Approach
Create a kernel thread w/ shadow codeRun speculatively when real code stalls Copy-on-write for all memory stores Ignore exceptions (e.g. div by 0)
Speculation is safe No real disk writes Shadow page table
Predicts reads far in advance Perhaps incorrectly

Staying on-track
Hint Log If next hinted read == this read Then on-track Else
OOPS
234126924084094105416171819Spec
Real
What if actual program reads 23, 412, 6, then 88!

Staying On Track - 2 ways
Conservative Approach Stop when you reach an INV branch
and wait for the main thread to return
Aggressive Approach Use branch prediction to go beyond
branch and stop only when cache miss has been serviced
* Aggressive approach can execute farther, but may introduce useless fetches

Possible prefetch results
Generate prefetch using correct addressFill up DMAQ, drop the prefetchUsed incorrect addressPrefetch is redundant with an outstanding cache-line fetch

Fetch Parallelism
prefetch value 1prefetch value 2
prefetch value 3Use value 1
main
Use value 2Use value 3
* Prefetching overlaps cache misses rather than paying each sequentially

If I/O Gets Off-Track
Real Process copies registers to shadow thread’s register save areaLights “restart” flagThen performs blocking I/O Which causes shadow thread to run Shadow thread grabs a copy of the real
stack Invalidates copy-on-write pages Cancels all hints: tipio_cancel_all

Overhead in I/O case
Before Read Check hint log If OK, continue else restart spec thread with MY stack and MY registers right here

Overhead in cache case
Add the backup register fileAdd INV bits in the cache
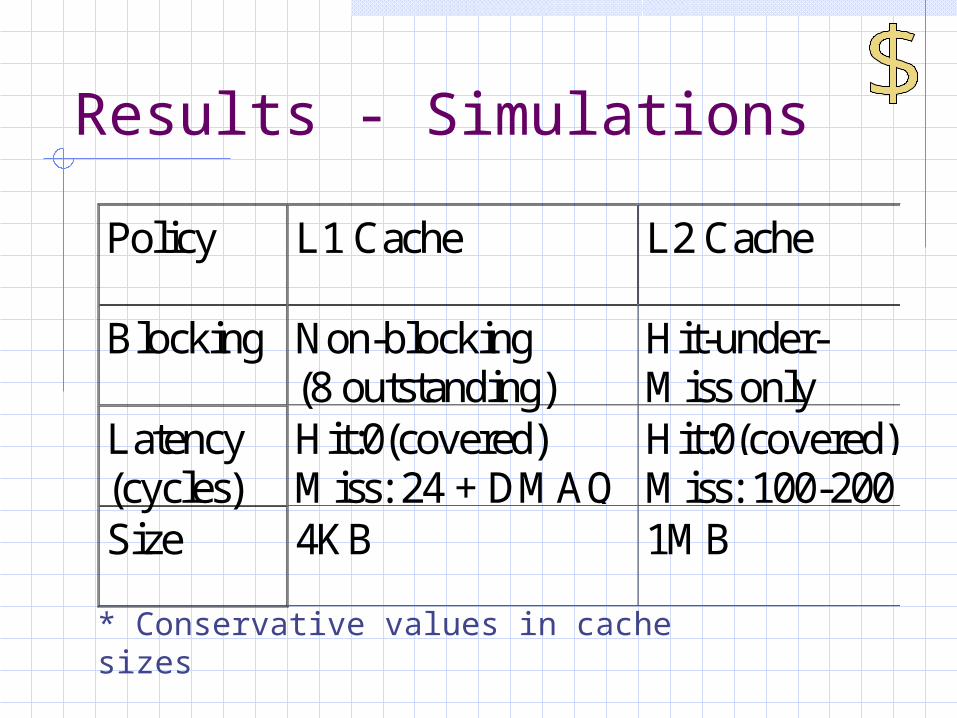
Results - Simulations
Policy L1 Cache L2 Cache
Blocking Non-blocking(8 outstanding)
Hit-under-Miss only
Latency(cycles)
Hit:0(covered)Miss: 24 + DMAQ
Hit:0(covered)Miss: 100-200
Size 4KB 1MB
* Conservative values in cache sizes
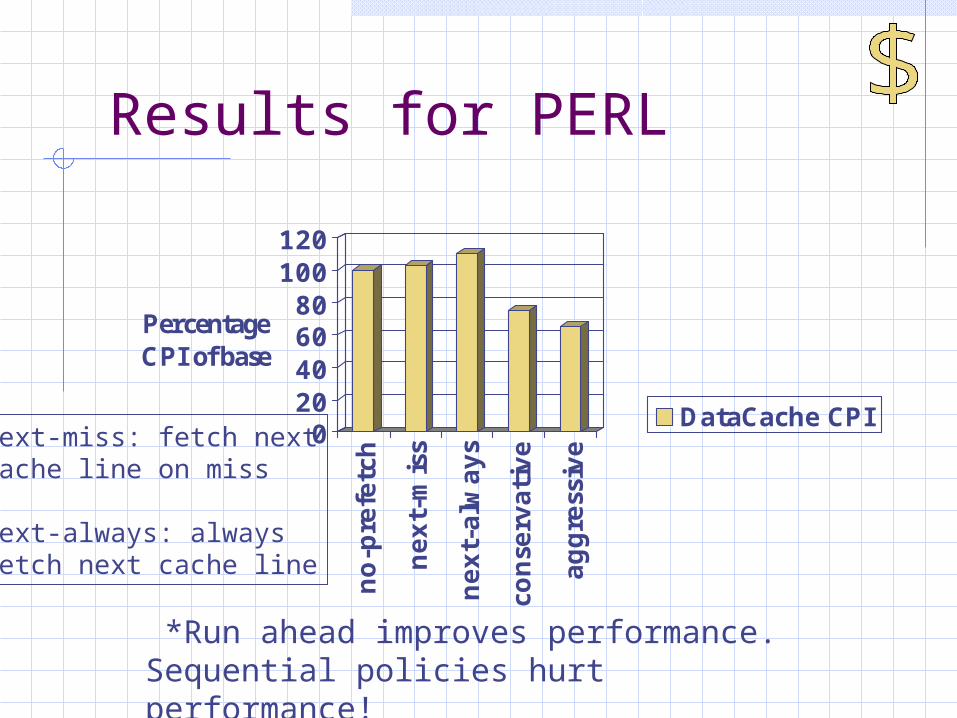
Results for PERL
020406080
100120
Percentage CPI of base
no-p
refe
tch
next-
mis
s
next-
alw
ays
conse
rvati
ve
aggre
ssiv
e
DataCache CPI
*Run ahead improves performance. Sequential policies hurt performance!
next-miss: fetch nextcache line on miss
next-always: alwaysfetch next cache line
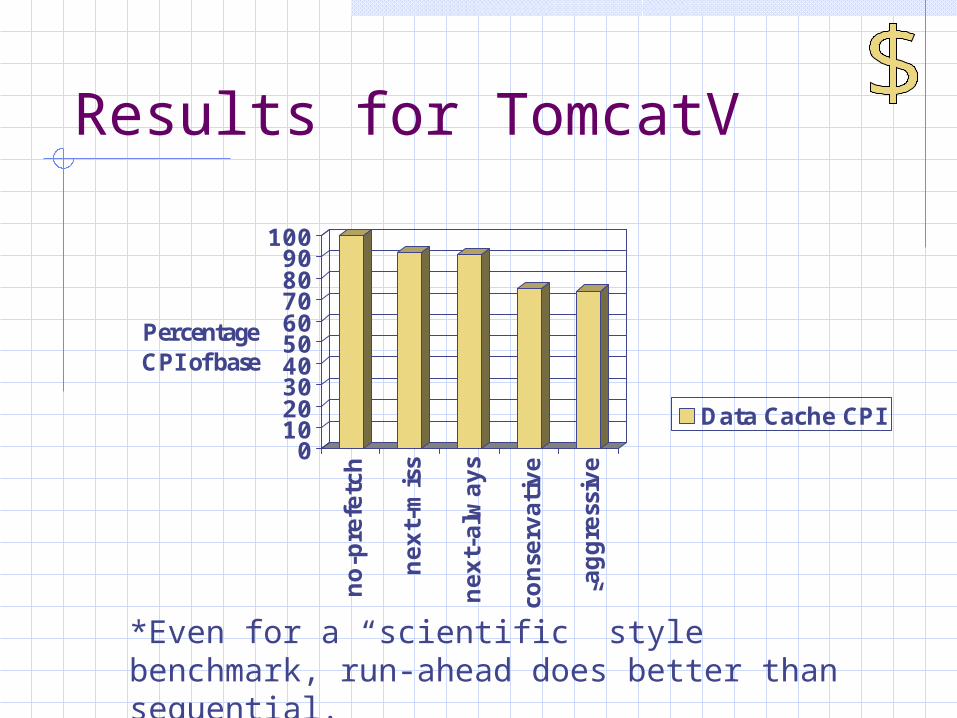
Results for TomcatV
0102030405060708090
100
Percentage CPI of base
no-p
refe
tch
next-
mis
s
next-
alw
ays
conse
rvati
ve
aggre
ssiv
e
Data Cache CPI
*Even for a “scientific” style benchmark, run-ahead does better than sequential.
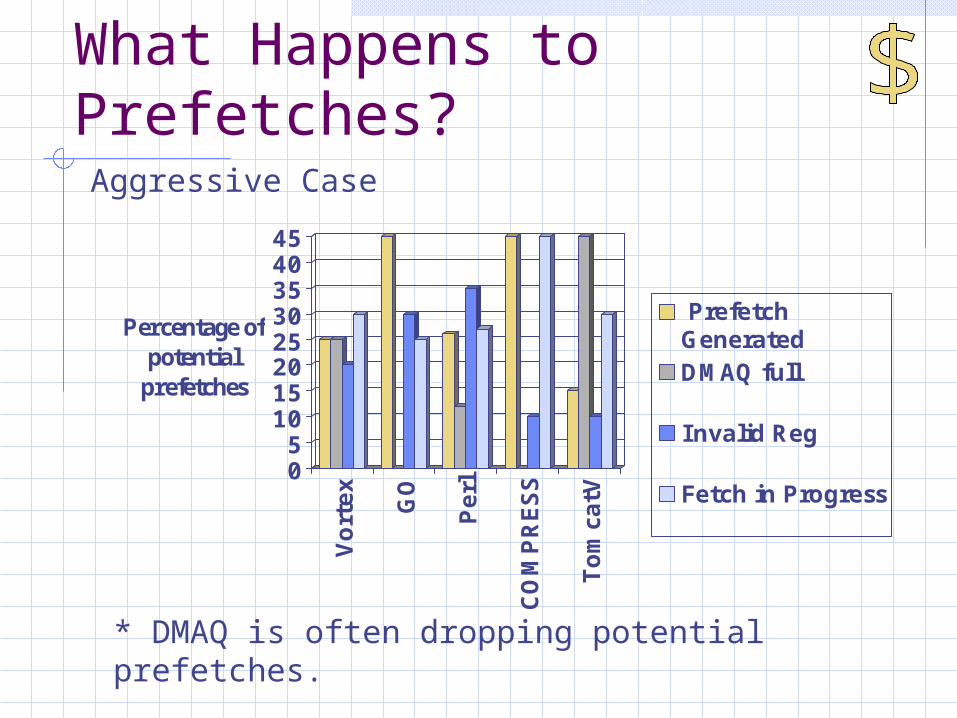
What Happens to Prefetches?
05
1015202530354045
Percentage of potential
prefetches
Vort
ex
GO
Perl
CO
MPR
ESS
Tom
catV
PrefetchGeneratedDMAQ full
Invalid Reg
Fetch in Progress
* DMAQ is often dropping potential prefetches.
Aggressive Case
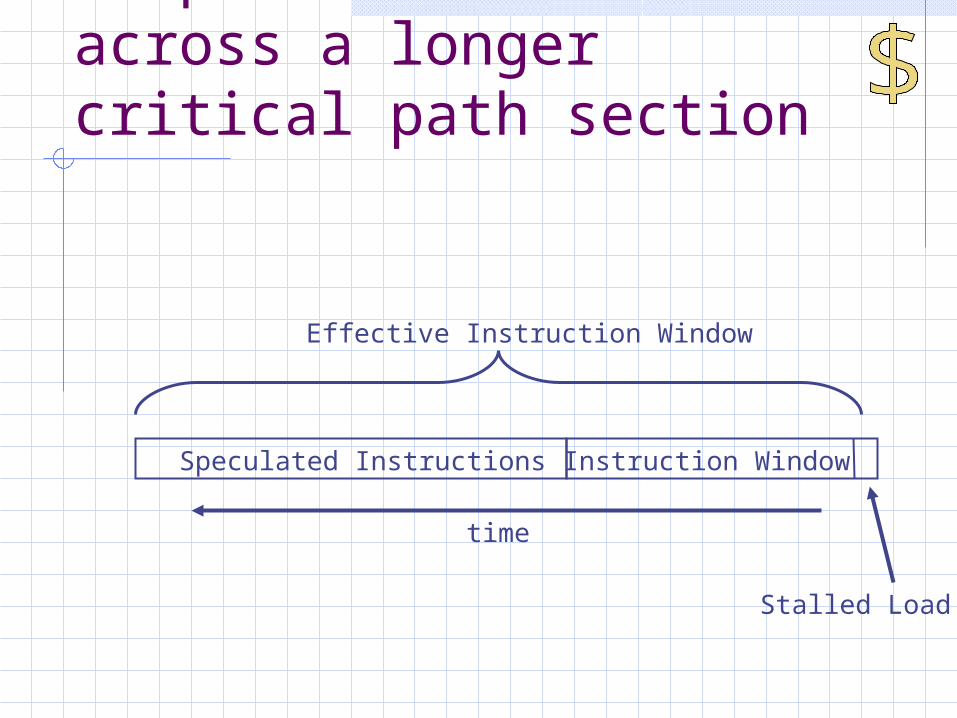
Prepare resources across a longer critical path section
Instruction Window
Stalled Load
Effective Instruction Window
time
Speculated Instructions

I/O Spec Hint Tool
Transforms subject binary into speculative code solely to predict I/O Add copy-on-write checks Fix dynamic memory allocations (malloc ...) Fix control transfers that cannot be statically
resolved (jump tables, function pointer calls) remove system calls (printf, fprintf, flsbuf, ...)
Complex control transfers stop specCould benefit from code slicing

Experimental Setup
12 MByte disk cachePrefetch limited to 64 blocks4 disks, striped 64 KBytes per stripe
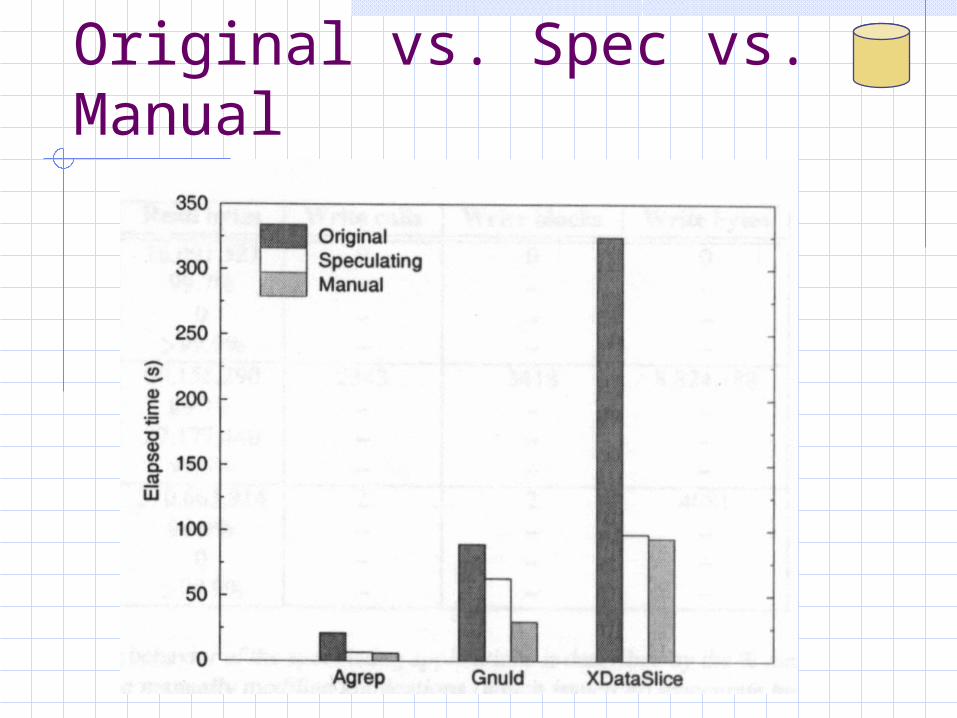
Original vs. Spec vs. Manual
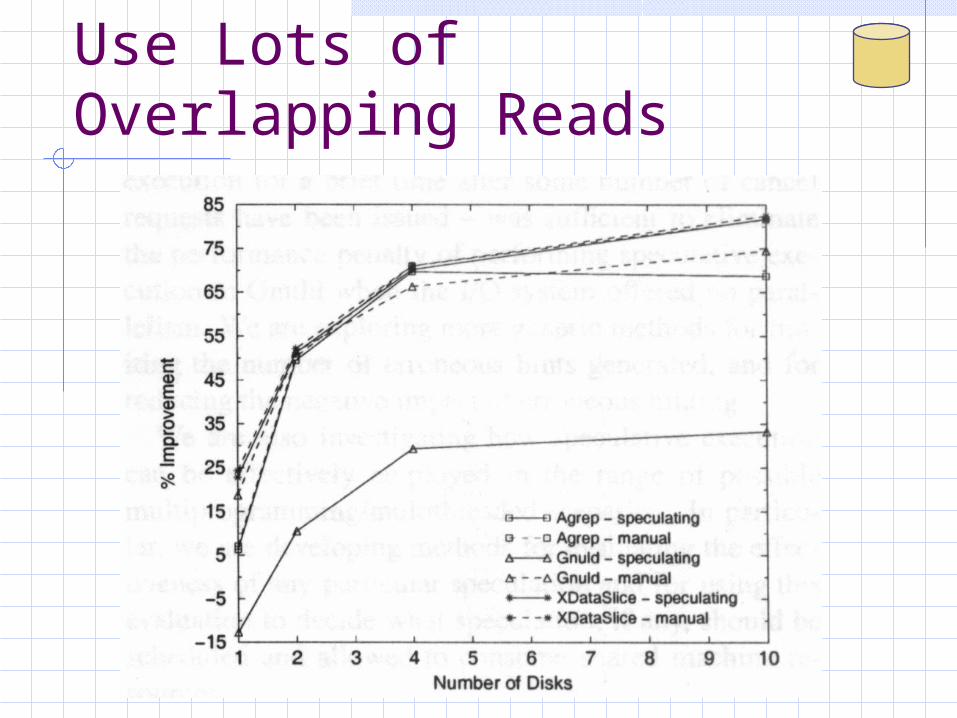
Use Lots of Overlapping Reads

Conclusion
Response time can benefit from hints The latencies being hidden are getting
bigger (in terms of instruction opportunities) every year
Static hinting is too hard And not smart enough
Dynamic run-ahead can get improvements Without programmer involvementThought to leave you with: Do these techniques attack the critical path or do they mitigate resource constraints?
Top Related