








Languages
Pages
Legal


Cheap Parlor Tricks, Counting, and Clustering
Derek GottfridThe New York Times October 2009

Evolution of Hadoop @ NYTimes.com

Early Days - 2007 Solution looking for a problem

SolutionWouldn’t it be cool to use lots of EC2 instances
(it’s cheap; nobody will notice)
Wouldn’t it be cool to use Hadoop
(MapReduce Google style is awesome)

Found a Problem Freeing up historical archives of NYTimes.com 1851-1922

Problem Bits Articles are served as PDFs
Really need PDFs from 1851-1981
PDFs are dynamically generated
Free = more traffic
Real deadline

BackgroundWhat goes into making a PDF of a NYTimes.com article?
Each article is made up of many different pieces - multiple columns, different sized headings, multiple pages, photos.

Simple Answer Pre-generate all 11 million PDFs and serve them statically.
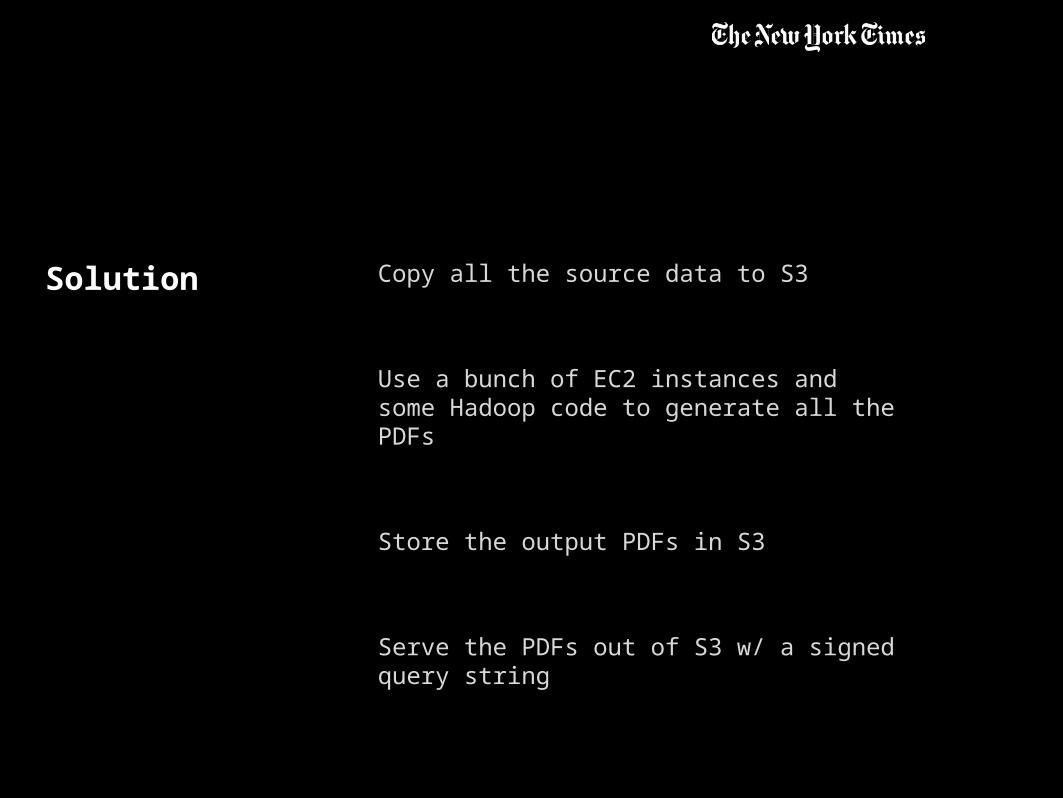
Solution Copy all the source data to S3
Use a bunch of EC2 instances and some Hadoop code to generate all the PDFs
Store the output PDFs in S3
Serve the PDFs out of S3 w/ a signed query string

A Few Details Limited HDFS - everything loaded in and out of S3
Reduce = 0 - only used for some stats and error reporting

Breakdown 4.3 TB of source data into S3
11M PDFS - 1.5 TB output
$240 for EC2 - 24hrs x 100 machines

TimesMachinehttp://timesmachine.nytimes.com

Currently - 2009 All that darn data - Web Analytics

Data Registration / Demographic
Articles 1851 - today
Usage Data / Web Logs

Counting Classic cookie tracking - let’s add it up
Total PV
Total unique users
PV per user

A Few Details Using EC2 - 20 Machines
Hadoop 0.20.0
12+TB of data
Straight MR in Java
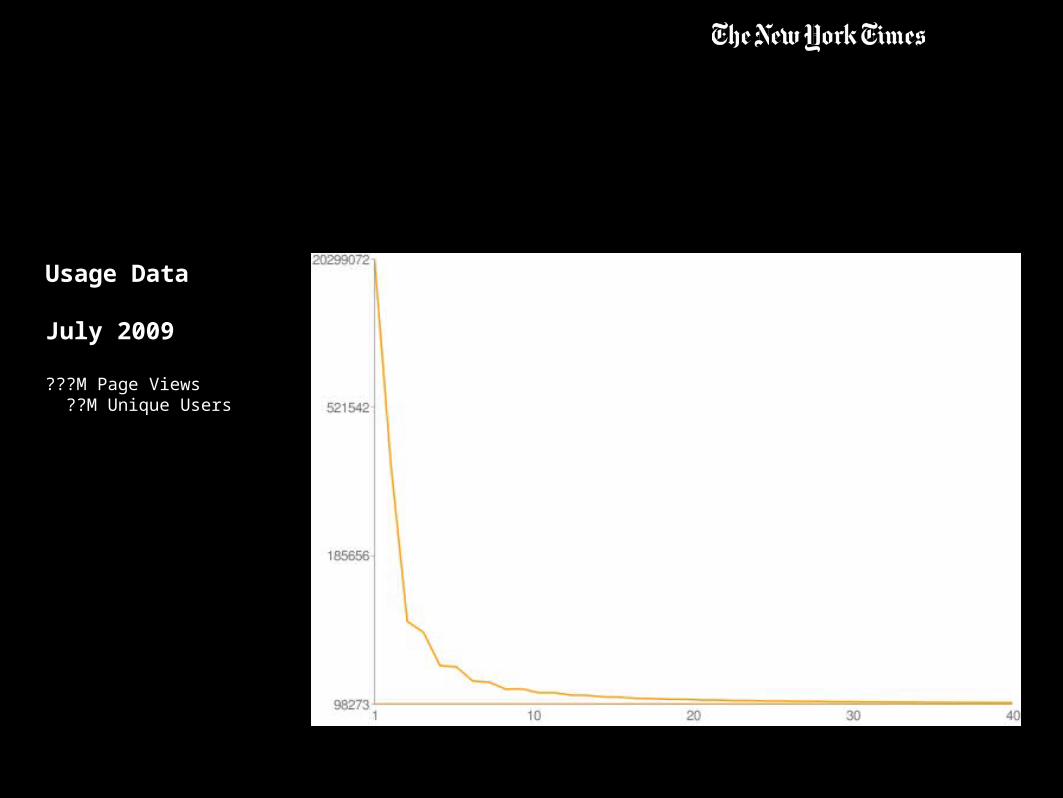
Usage Data
July 2009
???M Page Views ??M Unique Users

Merging Data Usage data combined with demographic data.

Twitter Click Backs By Age Group
July 2009

Merging Data Usage data with article meta data

Usage Data combined with Article Data
July 2009
40 Articles

Usage Data combined with Article Data
July 2009
40 Articles

Products Coming soon...

Clustering Moving beyond simple counting and joining
Join usage data, demographic information, and article meta data
Apply simple k-means clustering

Clustering

Clustering

Conclusion Large scale computing is transformative for NYTimes.com.
Top Related