







Languages
Pages
Legal


RNN Implementation
on FPGA
Xilin Yin, Libin Bai, Yue Xie, Wenxuan Mao
1

Outline
● Objective
● Software: training, results and network parameters
● Hardware: modules and architecture
2

Objective
● Character-by-character Language Model (LSTM)● Software training on GPU● Hardware implementation on FPGA● Simplify LSTM/RNN algorithm● Reduce LSTM /RNN parameters for FPGA
3

LSTM Formula
4

Model Training● Modified from open source python RNN example using GRU and word-by-word
training model.● Training data: 44 MB of reddit post● 64 characters per chunk● 724205 chunks● Training on Microsoft Windows Azure NC6 instance● Approximately 40 hours ( 2.5x faster than CPU )● Source code: https://github.com/belugon/rnn-tutorial-gru-lstm
5

Example Language Model Output● If you are respace, moved out the volucth and he's the guy lise the nice defens.● I can liss in some better fun whan it complist up vlcceed cute your custogying.● I see those be your uwwellem would taken like gone stock to long stratempyen
the whole reyer raluting reals e-anitary enfriends.● Expimination is much they far of the fantaria with our rards of strend people
will always all doing now.● Friend on some such a girl guts, not eep to the already form of about no plan
Eyladual producting from inesting right no det an rritur.
6
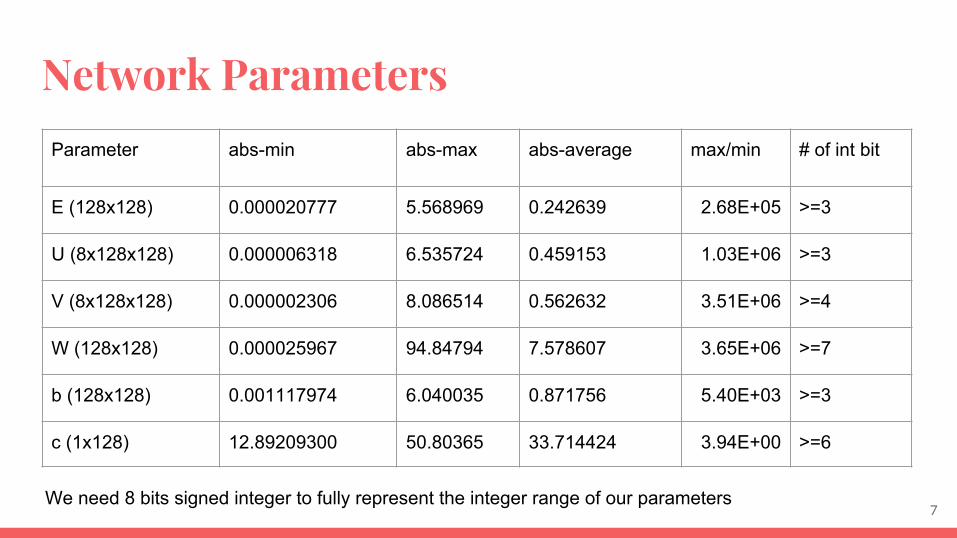
Network Parameters
7
Parameter abs-min abs-max abs-average max/min # of int bit
E (128x128) 0.000020777 5.568969 0.242639 2.68E+05 >=3
U (8x128x128) 0.000006318 6.535724 0.459153 1.03E+06 >=3
V (8x128x128) 0.000002306 8.086514 0.562632 3.51E+06 >=4
W (128x128) 0.000025967 94.84794 7.578607 3.65E+06 >=7
b (128x128) 0.001117974 6.040035 0.871756 5.40E+03 >=3
c (1x128) 12.89209300 50.80365 33.714424 3.94E+00 >=6
We need 8 bits signed integer to fully represent the integer range of our parameters

Parameter Range (0-100)
8
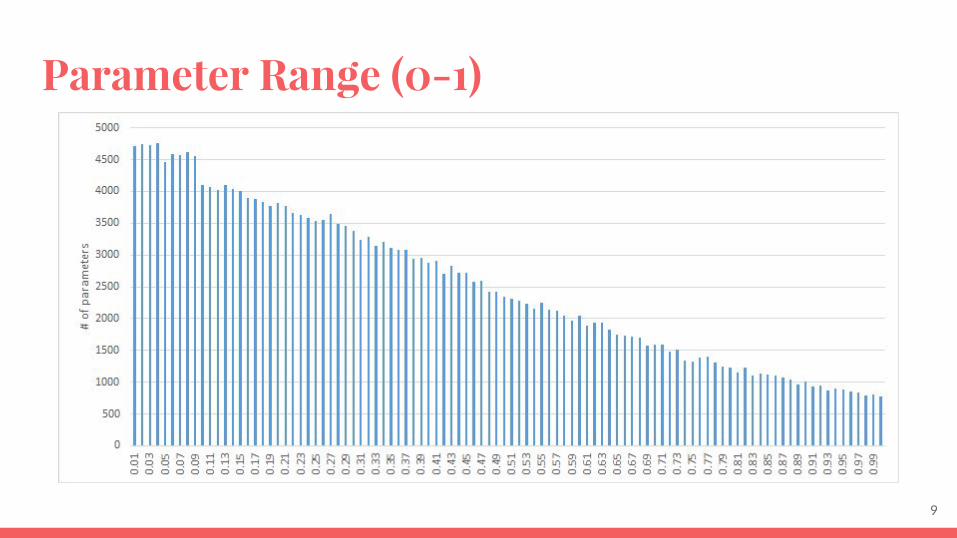
Parameter Range (0-1)
9

Information Lost● Network parameter truncated to 16 bit fix point representation.● 1bit sign + 7 bit int + 8 bit fraction● Range: (-127.996) -- (-0.004) and (0.004 -- 127.996)● 15.3% parameters (abs) between 1 and 95. Represented by 7+1(sign) bit
integer and 8 bit fraction● 84.7% parameters (abs) between 0 and 1. Represented by 8 bit fraction only● 0.64% parameters (abs) truncated due to 0.004 cutoff
10
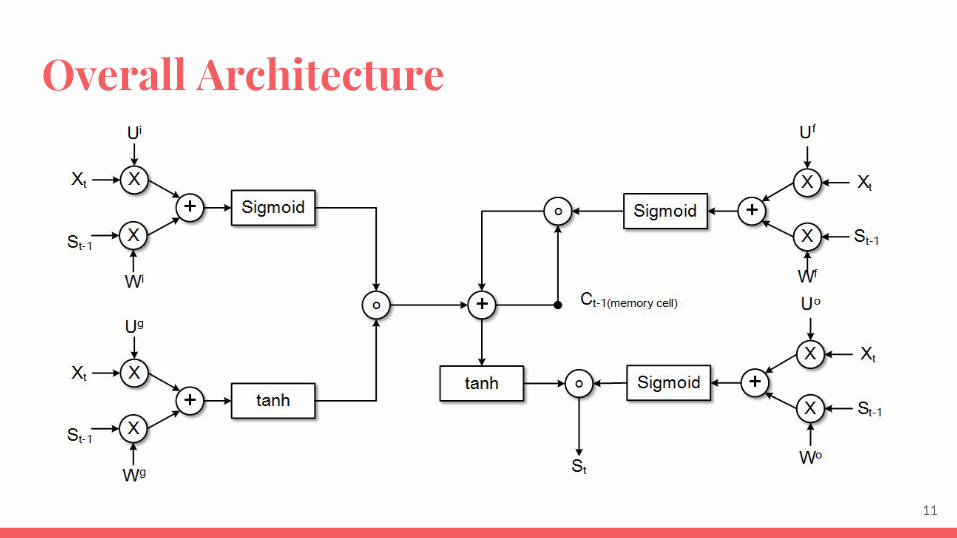
Overall Architecture
11
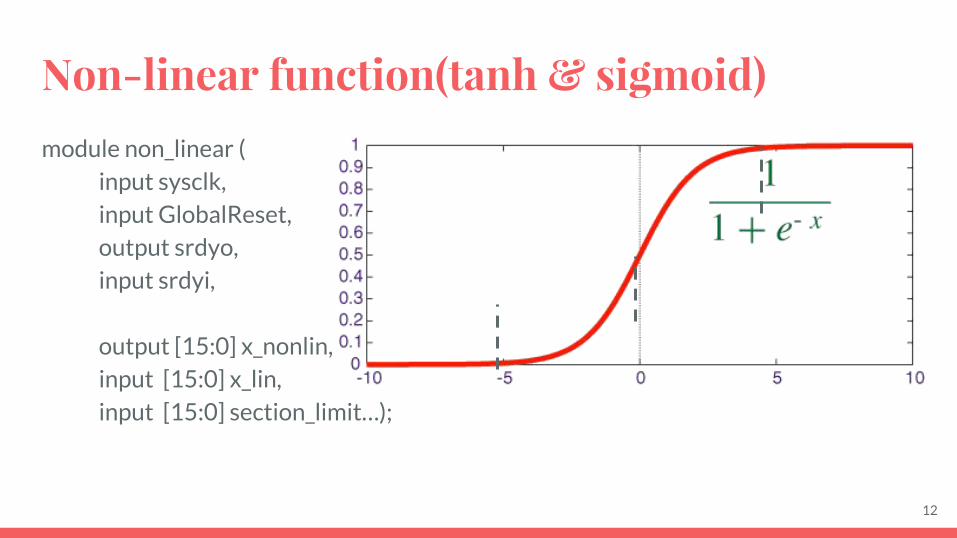
Non-linear function(tanh & sigmoid)
module non_linear ( input sysclk, input GlobalReset, output srdyo, input srdyi,
output [15:0] x_nonlin, input [15:0] x_lin, input [15:0] section_limit…);
12

Non-linear function(tanh & sigmoid)
13
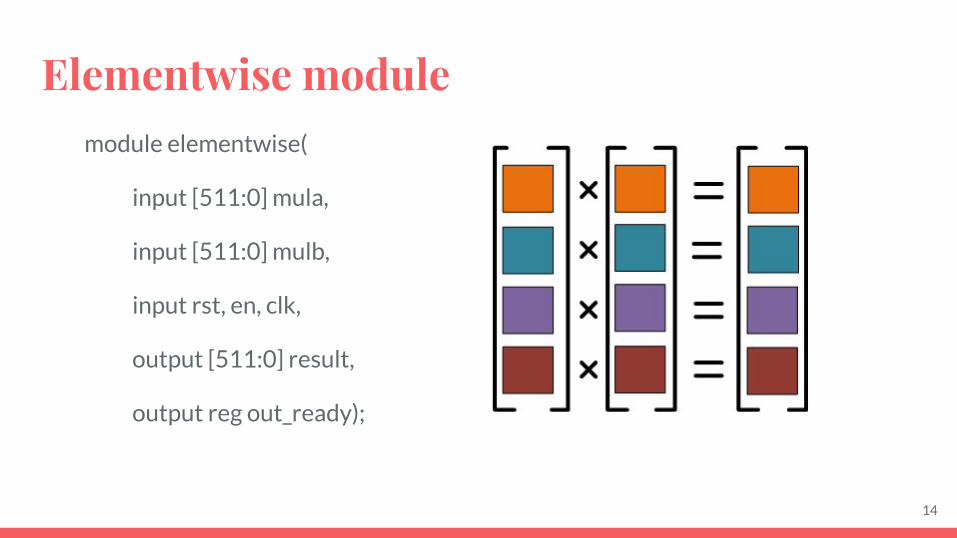
Elementwise modulemodule elementwise(
input [511:0] mula,
input [511:0] mulb,
input rst, en, clk,
output [511:0] result,
output reg out_ready);
14
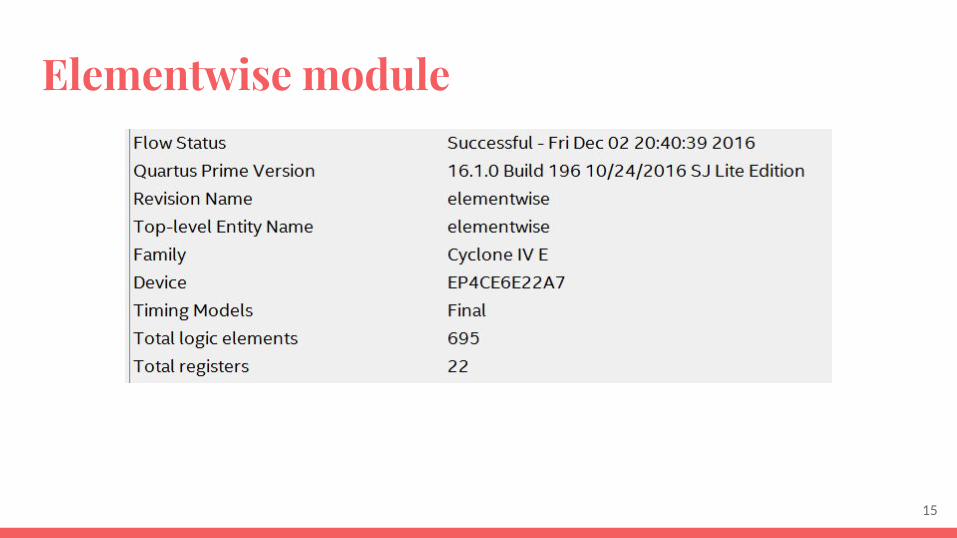
Elementwise module
15
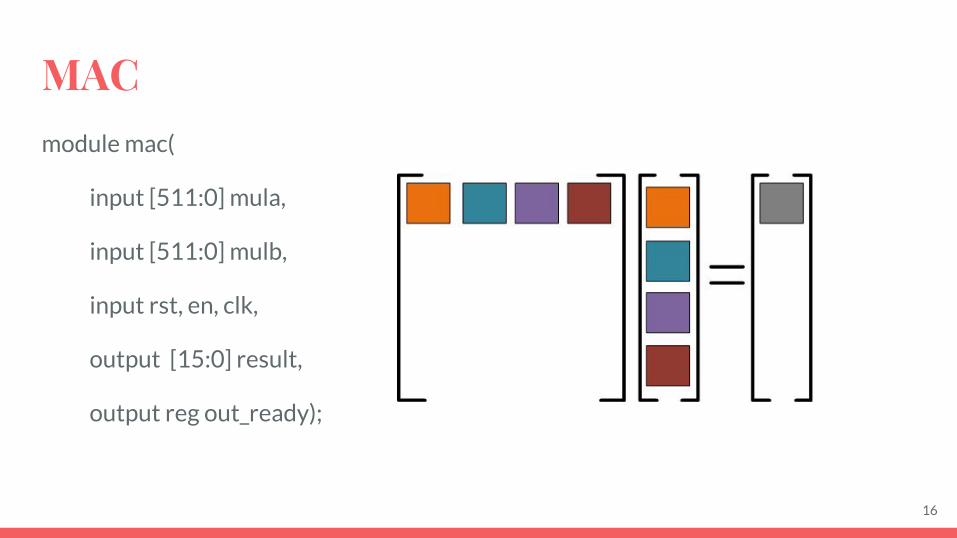
MACmodule mac(
input [511:0] mula,
input [511:0] mulb,
input rst, en, clk,
output [15:0] result,
output reg out_ready);
16
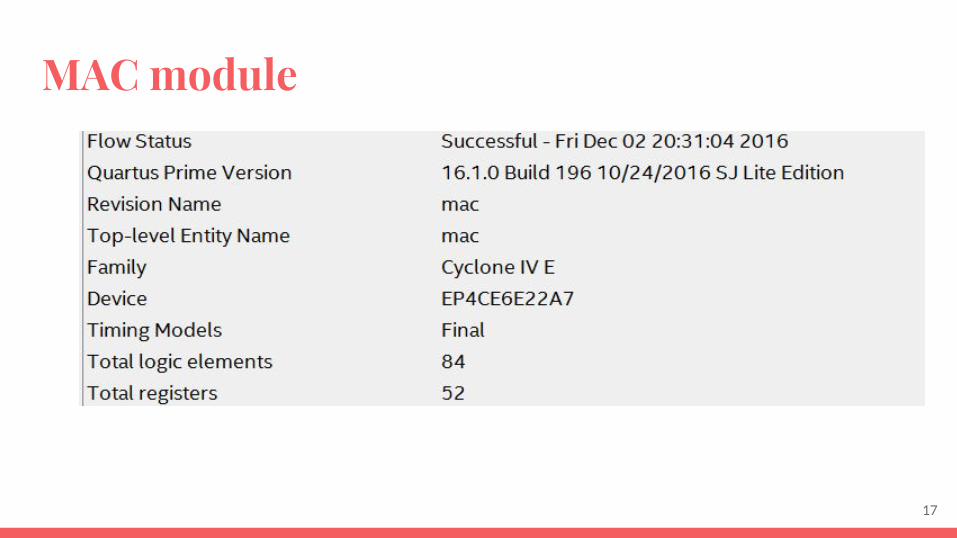
MAC module
17
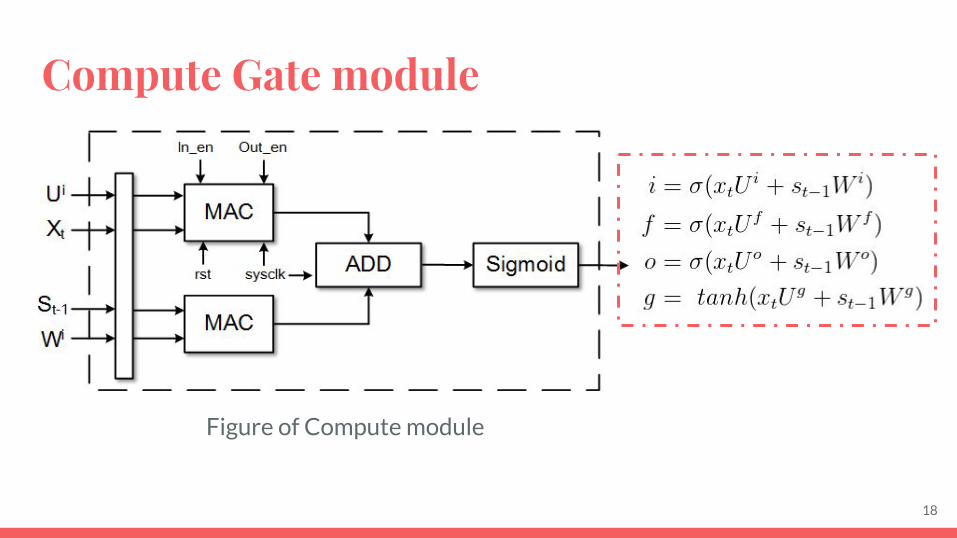
Compute Gate module
Figure of Compute module
18

Compute module
19
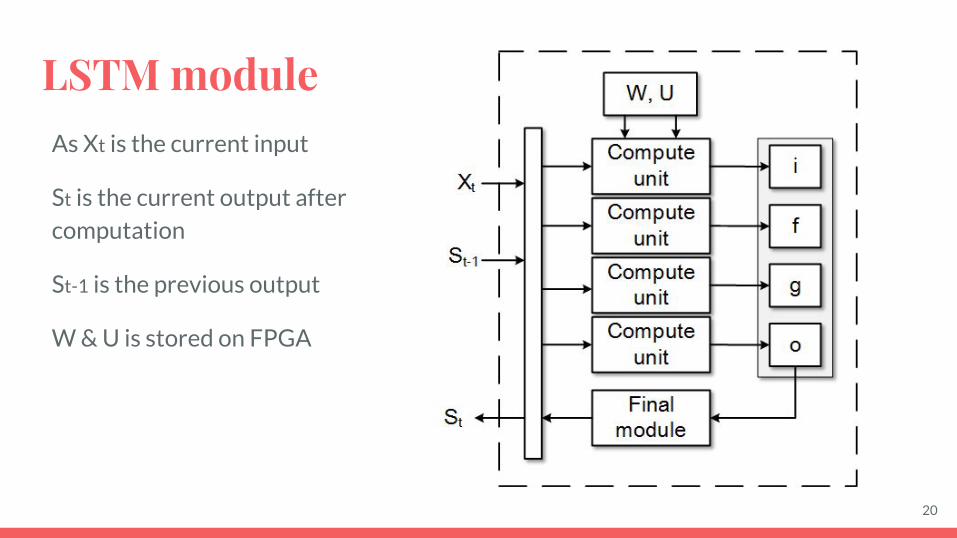
LSTM moduleAs Xt is the current input
St is the current output after computation
St-1 is the previous output
W & U is stored on FPGA
20

THANK YOU!
21

Reference[1] X. Chang, B. Martini and E. Culurciello, Recurrent Neural Networks Hardware Implementation on FPGA, v4 ed., West Lafayette: ARXIV, 2016. https://arxiv.org/abs/1511.05552v4[2]M. Sundermeyer, R. Schluter, and H. Ney. LSTM neural networks for language modeling. In INTERSPEECH, 2010.http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.248.4448&rep=rep1&type=pdf
22
Top Related