







Languages
Pages
Legal


Article
SynthesizingEvidence in PublicPolicy Contexts:The Challengeof Synthesis WhenThere Are Onlya Few Studies
Jeffrey C. Valentine1, Sandra Jo Wilson2,David Rindskopf3, Timothy S. Lau1,Emily E. Tanner-Smith2, Martha Yeide4,Robin LaSota4, and Lisa Foster4
AbstractFor a variety of reasons, researchers and evidence-based clearinghousessynthesizing the results of multiple studies often have very few studiesthat are eligible for any given research question. This situation is lessthan optimal for meta-analysis as it is usually practiced, that is, byemploying inverse variance weights, which allows more informative
1 University of Louisville, Louisville, KY, USA2 Vanderbilt University, Nashville, USA3 The Graduate Center, City University of New York, New York, NY, USA4 Development Services Group, Bethesda, MD, USA
Corresponding Author:
Jeffrey C. Valentine, University of Louisville, 309 CEHD, Louisville, KY 40292, USA.
Email: [email protected]
Evaluation Review1-24
ª The Author(s) 2016Reprints and permission:
sagepub.com/journalsPermissions.navDOI: 10.1177/0193841X16674421
erx.sagepub.com
at LIBERTY UNIV LIBRARY on November 1, 2016erx.sagepub.comDownloaded from

studies to contribute relatively more to the analysis. This article out-lines the choices available for synthesis when there are few studies tosynthesize. As background, we review the synthesis practices used inseveral projects done at the behest of governmental agencies and pri-vate foundations. We then discuss the strengths and limitations of dif-ferent approaches to meta-analysis in a limited informationenvironment. Using examples from the U.S. Department of Education’sWhat Works Clearinghouse as case studies, we conclude with a discus-sion of Bayesian meta-analysis as a potential solution to the challengesencountered when attempting to draw inferences about the effective-ness of interventions from a small number of studies.
Keywordsmethodological development, content area, education, content area,research synthesis, systematic review, meta-analysis, Bayesian statistics
A number of evidence-based practice repositories or clearinghouses have
been created that attempt to summarize evidence in ways that are useful in
public policy contexts, including the What Works Clearinghouse (WWC;
http://ies.ed.gov/ncee/wwc/), SAMHSA’s National Registry of Evidence-
Based Programs and Practices (NREPP; http://www.nrepp.samhsa.gov/),
the Office of Justice Programs’ CrimeSolutions.gov (http://www.crimeso
lutions.gov/), and others. These repositories review and summarize evi-
dence on programs and practices in education, social welfare, and crime
and justice and share a similar mission of attempting to produce reliable
and valid syntheses of the literature in their coverage areas. Clearing-
houses often make methodological choices that tend to limit the number
of studies that are available for review. These choices include (a) narrowly
defining the research question and (b) not carrying out thorough and
systematic searches for potentially relevant studies. In the sections below,
we briefly describe these choices and their implications. We then discuss
options for synthesizing evidence, including narrative reviewing, vote
counting, and traditional approaches to meta-analysis. When there are few
studies to synthesize, we show that many common synthesis options are
suboptimal and that even the most recommend synthesis options (classical
fixed effect or random effects meta-analysis) are problematic. We con-
clude by demonstrating that a Bayesian approach to meta-analysis is a
potential solution to the issues raised when trying to synthesize a small
number of studies.
2 Evaluation Review
at LIBERTY UNIV LIBRARY on November 1, 2016erx.sagepub.comDownloaded from

The Scope of the Research Question
Many evidence-based clearinghouses focus on narrowly defined programs
(e.g., aggression replacement training) rather than focusing on more broadly
defined practices (e.g., social skills interventions) or programs with targeted
outcome interests (e.g., any school-based program that targets dropout).
Although this narrow focus is aligned with the types of decisions typically
made by practitioners and policy makers (i.e., ‘‘Will this program work for
my school?’’), it has implications for the types of conclusions that might be
drawn from a limited number of studies. First, among programs that target
the same outcome (e.g., dropout prevention programs), specific intervention
components are likely to be similar across different interventions. That is,
if there are 10 school dropout prevention programs and each of these
programs has five elements, it is safe to say that there will not be 50
unique components across the 10 programs. Carrying out separate reviews
of these interventions will tend to mask the similarities across programs
and will impede efforts to investigate the extent to which different inter-
vention components are associated with program success. The second
important implication of narrowly defined research questions is that,
almost by definition, there will be fewer studies to review. That is, there
surely will be a larger number of studies of social skills interventions than
there will be of one specific type of social skills intervention like aggres-
sion replacement training. Therefore, the narrow focus of most research
question posed by clearinghouses limits the number of studies that can be
reviewed.
Searching the Literature
Regardless of the scope of the intervention at issue (whether we’re inter-
ested in finding all of the studies on a particular branded program or have a
broader question about the impacts of social skills training), it is clear that
including different sets of studies in a synthesis can lead to different
conclusions about the effects of a program or practice. And, generally
speaking, if we want to know about the effects of an intervention on an
outcome, we are better off having access to all of the studies that have
been conducted on that intervention rather than to only a selected portion
of that literature. Furthermore, the most defensible conclusions can only
be drawn from having the complete set of available research. One major
challenge to identifying this comprehensive set of studies arises from
publication bias, which refers to the tendency of the published literature
Valentine et al. 3
at LIBERTY UNIV LIBRARY on November 1, 2016erx.sagepub.comDownloaded from

to suggest effects that are larger than those observed in the unpublished
studies (Dwan et al., 2000). Publication bias occurs because study authors
are less likely to submit for publication, and journal editors and peer
reviewers are less likely to accept studies that do not have statistically
significant findings on their primary outcomes. These behaviors are attri-
butable in part to a persistent disregard for statistical power and to com-
mon misconceptions regarding the interpretation of probability values
arising from null hypothesis significance tests. Sample size and probabil-
ity values are related (i.e., holding everything else constant, a study with a
larger sample will yield p values that are smaller than a study with a
smaller sample). Therefore, studies with small samples that by chance
happen to find relatively large effects will be more likely to be pub-
lished—and hence easier to find—than studies with small samples that
do not find relatively large effects. This results in an evidence base that
suggests effects that are larger than they really are and therefore in a bias
against the null hypothesis.
A second challenge in identifying the complete evidence base is associ-
ated with both the capacity of clearinghouses to conduct comprehensive
literature searches and with the practice of intentionally selecting studies
with particular characteristics or from particular sources for review. These
actions limit the literature reviewed from the outset. For example, some
clearinghouses accept nominations from outside researchers or developers
for inclusion. If the clearinghouse only has studies voluntarily submitted by
an intervention’s developer, a clear concern is that the developer might
submit studies for review that might not be representative of the effects
that the intervention actually produces. As can be seen in Table 1, even
though best practice is to conduct a comprehensive and systematic search,
not all clearinghouses attempt to locate all of the potentially relevant studies
that have been conducted. In addition, the scientific skills needed to imple-
ment a comprehensive search should not be underestimated, and generally
speaking, a professional librarian with training in retrieval for systematic
reviews should be involved (Rothstein & Hopewell, 2009). Finally, a high
degree of subject matter expertise is often needed to find the so-called
‘‘gray’’ literature, for example, studies commissioned for foundations and
governmental agencies for which there is not a strong publication incentive.
In our experience, evidence-based clearinghouses face a particular chal-
lenge in this regard because some of them may not have the degree of
expertise, either in the substantive research question or in general literature
retrieval techniques, to carry out a robust literature search even if they have
the goal of doing so.
4 Evaluation Review
at LIBERTY UNIV LIBRARY on November 1, 2016erx.sagepub.comDownloaded from

Tab
le1.
Study
Iden
tific
atio
n,A
sses
smen
t,an
dSy
nth
esis
Acr
oss
Eig
ht
Evi
den
ce-B
ased
Cle
arin
ghouse
s.
Cle
arin
ghouse
Fundin
gH
ow
are
Studie
sLo
cate
d?
How
IsSt
udy
Qual
ity
Ass
esse
d?
How
Are
the
Res
ults
of
Multip
leSt
udie
sSy
nth
esiz
ed?
Blu
epri
nts
for
Hea
lthy
Youth
Dev
elopm
ent
U.S.
Dep
artm
ent
ofJu
stic
e’s
Offic
eofJu
venile
Just
ice
and
Del
inquen
cyPre
vention
Nom
inat
ions
supple
men
ted
with
per
iodic
liter
ature
sear
ches
Chec
klis
tth
atgu
ides
initia
las
sess
men
tofst
udy.
The
chec
klis
tad
dre
sses
inte
rnal
,co
nst
ruct
,an
dst
atis
tica
lco
ncl
usi
on
valid
ity
Rule
bas
ed—
tobe
elig
ible
for
‘‘model
pro
gram
’’des
ignat
ion,Blu
epri
nts
requir
esat
leas
tone
random
ized
contr
olle
dtr
ial(R
CT
)an
done
‘‘hig
h-q
ual
ity’
’quas
i-ex
per
imen
taldes
ign
(QED
)C
alifo
rnia
Evi
den
ce-
Bas
edC
lear
ingh
ouse
for
Child
Wel
fare
Cal
iforn
iaD
epar
tmen
tof
Soci
alSe
rvic
es,O
ffic
eof
Child
Abuse
Pre
vention
Lite
ratu
rese
arch
esfo
rpublis
hed
,pee
r-re
view
edar
ticl
es;s
upple
men
ted
by
study
refe
rence
spro
vided
by
pro
gram
repre
senta
tive
Guid
eto
hel
pre
view
ers
asse
ssle
velofre
sear
chev
iden
ce,ad
dre
ssin
gin
tern
alan
dco
nst
ruct
valid
ity
Vote
counting—
the
‘‘ove
rall
wei
ght’’
ofev
iden
cesu
pport
sth
eben
efit
of
the
pra
ctic
e
Coal
itio
nfo
rEvi
den
ce-B
ased
Polic
y
Phila
nth
ropic
org
aniz
atio
ns
Nom
inat
ions
ofR
CT
sof
publis
hed
or
unpublis
hed
studie
s
Chec
klis
tth
atgu
ides
revi
ewer
asse
ssm
ent
of
study.
The
chec
klis
tad
dre
sses
inte
rnal
,co
nst
ruct
,an
dst
atis
tica
lco
ncl
usi
on
valid
ity
Rule
bas
ed—
tobe
elig
ible
for
‘‘top
tier
’’des
ignat
ion,
pro
gram
sm
ust
hav
ebee
nst
udie
din
atle
ast
two
site
s
(con
tinue
d)
5
at LIBERTY UNIV LIBRARY on November 1, 2016erx.sagepub.comDownloaded from
Tab
le1.
(continued
)
Cle
arin
ghouse
Fundin
gH
ow
are
Studie
sLo
cate
d?
How
IsSt
udy
Qual
ity
Ass
esse
d?
How
Are
the
Res
ults
of
Multip
leSt
udie
sSy
nth
esiz
ed?
Cri
meS
olu
tions.
gov
U.S
.D
epar
tmen
tofJu
stic
e’s
Offic
eofJu
stic
ePro
gram
sN
om
inat
ions
supple
men
ted
by
per
iodic
liter
ature
sear
ches
for
publis
hed
or
unpublis
hed
studie
s.R
evie
ws
gener
ally
incl
ude
am
axim
um
ofth
ree
studie
s
Scori
ng
inst
rum
ent
on
four
dim
ensi
ons:
conce
ptu
alfr
amew
ork
,in
tern
alva
lidity,
pro
gram
fidel
ity,
and
outc
om
es.It
ems
are
sum
med
within
(but
not
acro
ss)
cate
gori
es
Rule
bas
ed—
anal
gori
thm
isuse
dto
cate
gori
zest
udie
sin
to‘‘e
ffec
tive
,’’‘‘p
rom
isin
g,’’
and
‘‘no
effe
cts’’ca
tego
ries
;th
eal
gori
thm
may
be
supple
men
ted
by
exper
tju
dgm
ent
Nat
ional
Reg
istr
yof
Evi
den
ce-B
ased
Pro
gram
san
dPra
ctic
es
U.S
.D
epar
tmen
tofH
ealth
and
Hum
anSe
rvic
es,
Subst
ance
Abuse
and
Men
talH
ealth
Serv
ices
Adm
inis
trat
ion
Nom
inat
ions
supple
men
ted
by
per
iodic
liter
ature
sear
ches
ofp
ublis
hed
and
unpublis
hed
studie
s.O
nly
studie
sth
atsh
ow
ast
atis
tica
llysi
gnifi
cant,
posi
tive
effe
ctar
ein
cluded
‘‘Qual
ity
ofre
sear
ch’’
rating
toolth
atad
dre
sses
inte
rnal
,co
nst
ruct
,an
dst
atis
tica
lco
ncl
usi
on
valid
ity.
Am
ean
qual
ity
rating
ispro
duce
dby
aver
agin
gsc
ore
sac
ross
the
item
s
Synth
esis
isle
ftto
the
adhoc
judgm
ent
ofth
ere
view
ers
Pro
mis
ing
Pra
ctic
esN
etw
ork
Phila
nth
ropic
org
aniz
atio
ns
Nom
inat
ions
and
per
iodic
liter
ature
sear
ches
for
publis
hed
or
unpublis
hed
studie
s
Studie
sar
eas
sess
ed(loose
ly)
on
inte
rnal
valid
ity
(whet
her
the
com
par
ison
group
is‘‘c
onvi
nci
ng’’)
and
stat
istica
lco
ncl
usi
on
valid
ity
(sam
ple
size
).O
ther
aspec
tsofst
udy
qual
ity
asas
sess
edon
aca
se-b
y-ca
sebas
is.
Nar
rative
revi
ew
(con
tinue
d)
6
at LIBERTY UNIV LIBRARY on November 1, 2016erx.sagepub.comDownloaded from

Tab
le1.
(continued
)
Cle
arin
ghouse
Fundin
gH
ow
are
Studie
sLo
cate
d?
How
IsSt
udy
Qual
ity
Ass
esse
d?
How
Are
the
Res
ults
of
Multip
leSt
udie
sSy
nth
esiz
ed?
What
Work
sC
lear
ingh
ouse
U.S
.D
epar
tmen
tof
Educa
tion’s
Inst
itute
of
Educa
tion
Scie
nce
s
Syst
emat
iclit
erat
ure
sear
ches
incl
udin
gpublis
hed
and
unpublis
hed
sourc
es;
studie
sm
entioned
innat
ional
med
ia
Scori
ng
rubri
cth
atfo
cuse
son
inte
rnal
,co
nst
ruct
,an
dst
atis
tica
lco
ncl
usi
on
valid
ity
Unw
eigh
ted
met
a-an
alys
is
What
Work
sin
Ree
ntr
yU
.S.D
epar
tmen
tofJu
stic
e’s
Bure
auofJu
stic
eA
ssis
tance
Per
iodic
liter
ature
sear
ches
for
publis
hed
or
unpublis
hed
studie
sw
hic
har
esc
reen
edan
dca
tego
rize
dac
cord
ing
toco
din
gfr
amew
ork
Tw
oas
pec
tsofst
udie
sar
eas
sess
ed:in
tern
alva
lidity
(res
earc
hdes
ign)
and
stat
istica
lco
ncl
usi
on
valid
ity
(sam
ple
size
),su
pple
men
ted
by
exper
tju
dgm
ent.
Studie
sm
ust
hav
ebee
npee
r-re
view
edor
conduct
edby
indep
enden
tre
sear
cher
s
Rule
bas
ed—
tore
ceiv
eth
ehig
hes
tra
ting
(‘‘hig
h’’
vs.
‘‘bas
ic’’)
,th
ere
must
be
one
hig
h-q
ual
ity
RC
Tor
two
hig
h-q
ual
ity
QED
sth
atpas
sth
ein
itia
lst
udy
qual
ity
asse
ssm
ent.
This
rule
can
be
modifi
edat
the
dis
cret
ion
ofan
exper
tre
view
er
7
at LIBERTY UNIV LIBRARY on November 1, 2016erx.sagepub.comDownloaded from

Synthesizing the Studies
Once studies have been located, they are typically screened for relevance,
coded, and quality appraised. The next major task confronting researchers
and evidence-based clearinghouses is to synthesize the studies, that is, to
determine what the studies collectively reveal about the effect under inves-
tigation. Because meta-analyses allow researchers to (a) transparently reach
a conclusion about the extent to which an intervention is effective and (b)
statistically investigate sources of heterogeneity (Higgins & Green, 2011),
when multiple studies that examine the same outcome are available, there is
little debate among statisticians that the best way to integrate the results of
the studies is by using some form of meta-analysis. In practice, however,
researchers (including the evidence-based clearinghouses) use a variety of
techniques to arrive at conclusions or statements regarding the effectiveness
of interventions. These include (a) narrative reviewing, (b) vote counting,
(c) setting rules regarding the number of studies that have statistically
significant results, and (d) a variety of forms of meta-analysis. Each of
these techniques is discussed below.
Narrative reviewing. In the past, reviewing the literature on a set of related
studies relied exclusively on a narrative review, in which a scholar would
gather some studies that were relevant, read them, then pronounce on what
those studies had to say. Typically, little attention was paid to whether the
studies could claim to be representative of the studies that had been con-
ducted, and almost nothing was said about the standards of proof that were
employed during the review (in other words, the pattern of results that would
lead the reviewer to conclude that the intervention ‘‘works’’). This lack of
transparency, forethought even, leads to conclusions that are more likely to be
a product of the reviewer’s experiences, preferences, and cognitive algebra.
Further, the results of narrative reviews—which unfortunately continue to
be common—are often presented in impressionistic terms, with little insight
provided about the magnitude of the observed effect (i.e., how much of an
effect the intervention had on participants). Scholars have increasingly
recognized that narrative literature reviews do not meet the standards of
rigor and transparency required in primary research, precipitating the
increased use of systematic review methods (see Cooper & Hedges, 2009,
for a review of the history and issues related to narrative reviewing).
Vote counting. Sometimes used in conjunction with a narrative review, vote
counting in its most common form is based on counting (as a ‘‘vote’’) the
8 Evaluation Review
at LIBERTY UNIV LIBRARY on November 1, 2016erx.sagepub.comDownloaded from

statistical significance of the results observed in the studies that are being
reviewed. For example, if one study found statistically significant effects
for an intervention, the researcher would count that as a vote that the
intervention works. If another study failed to reject the null hypothesis, the
researcher would count that as a vote that the intervention does not work. If
another study finds harmful effects, the researcher would count that as a
vote that the intervention ‘‘harms.’’ When all studies have been processed
this way, the category with the most votes wins.
Vote counting is a seriously limited inferential procedure, in part
because it requires that most studies must have statistically significant
results in order for the claim to be made that an intervention works. Unfor-
tunately, in most circumstances when using vote counting, it is unaccepta-
bly probable that studies will not reach the same statistical conclusion, even
if they are estimating the same population parameter (e.g., if the interven-
tion really is effective). The fundamental problem is that for vote counting
to work reasonably, the underlying studies all need to be conducted with
very high levels of statistical power. Unfortunately, relatively few studies
have very high statistical power, and on average in the social sciences,
statistical power is only about .50 (Cohen, 1962; Pigott, Valentine, Polanin,
& Williams, 2013; Sedlmeier & Gigerenzer, 1989). If two independent
studies are conducted with statistical power of .80 (meaning that both have
an 80% chance of correctly rejecting a false null hypothesis), in only 64% of
cases will both studies result in a correct rejection of the null hypothesis. If
both studies are conducted with statistical power of .50, then in only 25% of
cases will both studies result in a correct rejection of the null hypothesis. If
there are three studies, only 50% of time would we expect at least two of the
studies to be statistically significant, given that all three studies were con-
ducted with power of .50. As such, because studies are typically not highly
powered, in most current real-world contexts, vote counting is an approach
with an unacceptably high error rate (by failing to detect real intervention
effects when they exist). In fact, Hedges and Olkin (1985) demonstrated the
counterintuitive result that, in many situations common in social research
(i.e., interventions with moderate effects investigated in studies with mod-
erate statistical power), vote counting based on statistical significance has
less statistical power as more studies are available.
Rule setting. A particularly egregious version of vote counting involves
setting rules for the number of studies that need to have statistically signif-
icant outcomes in order to conclude that an intervention works. Most com-
monly, the requirement is for at least two ‘‘good’’ studies that reveal
Valentine et al. 9
at LIBERTY UNIV LIBRARY on November 1, 2016erx.sagepub.comDownloaded from

statistically significant effects. As a form of vote counting, it shares the
overreliance on statistical significance testing and the neglect of statistical
power with that technique. It has the additional disadvantage of neglecting
the number of studies that have been conducted. It is one thing if two of the
two studies conducted on an intervention yielded statistical significance. It
is quite another if 2 of the 20 studies conducted reached statistical signifi-
cance. Unfortunately, as will be seen, these types of rules are relatively
common, and systems that simply require two studies to meet some thresh-
old of quality while ignoring the total number of studies that have been
conducted run the risk of making this serious inferential error.
Meta-analysis. Meta-analysis is another method for synthesizing the results
of multiple studies. As will be seen, it is not a perfect solution (especially
when there are few studies), but given the need for a synthesis, it is better
than the alternatives (Valentine, Pigott, & Rothstein, 2010). Although there
are many varieties of meta-analysis, we focus below on three: fixed effect,
random effects, and unweighted meta-analysis. We briefly introduce the
strengths and limitations of each.
Fixed effect meta-analysis starts with the assumption that all of the
studies in the meta-analysis are estimating the same population parameter.
One way of thinking about this assumption is that if the studies in the meta-
analysis were all infinitely large, they would all have exactly the same
effect size. Meta-analysis usually involves arriving at a weighted average
of the study effect sizes—this means that the mean effect size from a meta-
analysis is computed like any other weighted mean. The trick is in finding
the right weights. Most fixed effect meta-analyses use inverse variance
weighting, in which studies are weighted by a function of their sample size.
Therefore, large studies are given relatively more weight in the meta-
analysis than smaller studies.
The main limitation of a fixed effect meta-analysis is the assumption that
all studies in the analysis are estimating the same population parameter.
This assumption implies the fixed effect model is most appropriate if the
studies are highly similar to one another along important dimensions that
contribute to variation in effect sizes (Hedges & Vevea, 1998) or in other
words, if the studies are close replications of one another (i.e., they are very
similar on all the dimensions that matter, including they specifics of inter-
vention implementation, the sample, the measured outcomes, and so on). In
reality, this is a difficult bar to reach, as most studies of the same interven-
tion are probably not close replicates of one another. Instead, they are likely
‘‘ad hoc’’ replications that vary in known and unknown ways (Valentine
10 Evaluation Review
at LIBERTY UNIV LIBRARY on November 1, 2016erx.sagepub.comDownloaded from

et al., 2011). This means that conceptually the fixed effect model is often
not a good fit.
Random effects meta-analysis relaxes the assumption that all studies are
estimating the same population parameter. Instead, studies are conceptua-
lized as part of a distribution of plausible effect sizes that vary around a
mean population effect size. Effects from studies in a meta-analysis are
therefore expected to vary from one another due to both known and
unknown study characteristics in addition to random sampling error. Like
fixed effect meta-analysis, random effects meta-analysis involves comput-
ing a weighted effect size. In the random effects model, studies are
weighted by a function of their sample size and by an estimate of the extent
to which the study estimates ‘‘disagree’’ with one another (called the
between-studies variance). Relative to the fixed effect model, the random
effects model is generally more conservative. The confidence intervals
arising from a random effects analysis will never be smaller and are usually
larger than their fixed effect counterparts, making it less likely that the
statistical conclusion following from an inferential test involving a random
effects estimate will be a type I error (i.e., an incorrect rejection of a true
null hypothesis).
However, one critical limitation of the random effects approach is that
the estimate of one key parameter in the analysis, the between-studies
variance, is poor when the number of studies is small (as a rule of thumb,
a bare minimum of five studies in the meta-analysis is needed to support
estimation of the between-studies variance, although very often many more
studies will be needed; Viechtbauer, 2005). As a result, the estimated mean
effect size and confidence intervals can be either too large or too small
relative to what they ‘‘should’’ be, depending on whether the between-
studies variance is over- or underestimated.
The last meta-analytic technique we will discuss in this section is
unweighted meta-analysis. Here, the mean effect size is computed as
straight mean of the observed effects (i.e., the sum of the effect sizes
divided by the number of studies). While simple, this method of meta-
analysis has two undesirable properties. First, it is a type of fixed effect
analysis but is less efficient than its more commonly implemented cousin.
That is, the standard errors arising from an unweighted meta-analysis are
larger than the standard errors from a fixed effect analysis using inverse
variance weights (unless the sample sizes are equal across studies in which
case the standard errors will be equal in the inverse variance weighted fixed
effect and unweighted meta-analyses). This means that in most cases, the
unweighted meta-analysis will have a larger confidence interval than the
Valentine et al. 11
at LIBERTY UNIV LIBRARY on November 1, 2016erx.sagepub.comDownloaded from

inverse variance weighted model. The other undesirable property is that an
unweighted meta-analysis is more vulnerable to the effects of publication
bias than the inverse variance weighted fixed effect model. One signal that
publication bias might be operating is the commonly observed negative
correlation between sample size and effect size in a meta-analysis (i.e., as
sample size increases, effect size decreases). This negative correlation
means that smaller studies are observing larger effects than larger studies
are observing possibly because small studies that find small effects are
being systematically censored from the literature. Because the unweighted
model does not involve weighting by sample size, it will be more affected
by publication bias than the inverse variance weighted fixed effect model
will be. Stated differently, weighted models generally have a degree of
built-in protection against the effects of publication bias because relatively
small studies have relatively less weight.
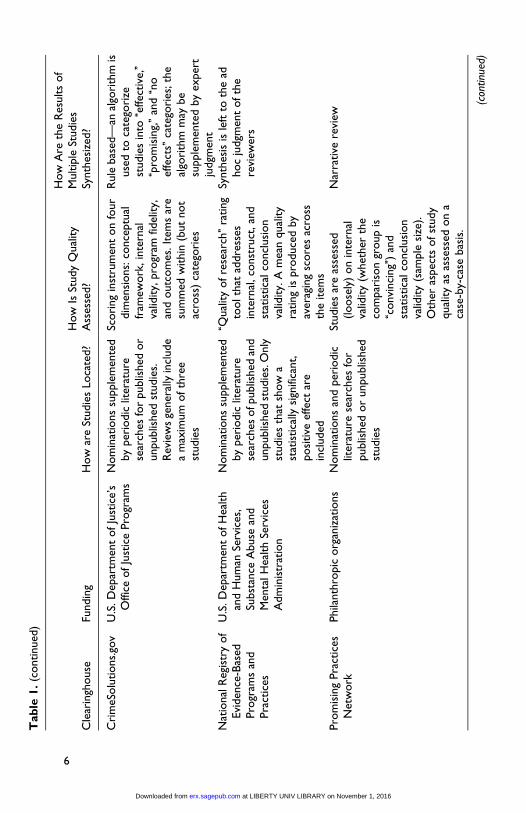
Evidence-Based Clearinghouses
With these quality indicators as background, we turn now to a brief over-
view of the ways that several evidence-based clearinghouses carry out their
syntheses. We present how evidence is located, how the quality of the
located studies is assessed, and how the results of multiple studies are
synthesized. In all, we researched practices of eight registries, using only
information provided on their websites. Table 1 summarizes study identi-
fication, study review, and outcomes synthesis practices across eight regis-
tries across a variety of funding sources: Blueprints for Healthy Youth
Development, California Evidence-Based Clearinghouse, Coalition for
Evidence-Based Policy, Crimesolutions.gov, NREPP, Promising Practices
Network, WWC, and What Works in Reentry.
Across these eight registries, three of them identify studies through
nominations, supplemented by periodic literature searches (Blueprints,
Crimesolutions.gov, and NREPP). One registry, the Coalition for
Evidence-Based Policy, identifies studies through nomination only. For the
California Evidence-Based Clearinghouse for Child Welfare, nominations
of studies are secondary to the literature searches. For the WWC and What
Works in Reentry Clearinghouse, only systematic literature searches are
used. Seven of the eight registries include published and unpublished stud-
ies. The California Evidence-Based Clearinghouse for Child Welfare only
searches for published, peer-reviewed studies.
Most of the registries reviewed for this article use rules to synthesize the
results of studies. For example, What Works in Reentry assigns its highest
12 Evaluation Review
at LIBERTY UNIV LIBRARY on November 1, 2016erx.sagepub.comDownloaded from

rating for interventions with one high-quality randomized controlled trial or
two high-quality quasi-experimental designs (QEDs). Three of the registries
use some form of vote counting (Blueprints, Crimesolutions.gov, and
NREPP). Only one clearinghouse (the WWC) conducts meta-analysis in
order to synthesize effect sizes reported across studies.
Synthesizing Studies in an Information PoorEnvironment
Although not all evidence-based clearinghouses conduct formal syntheses,
our review suggests that when they do it is clear that most of these are based
on a very small number of studies (e.g., two or perhaps three). For example,
between January 2010 and September 2014, the WWC conducted 56 meta-
analyses. The mean number of studies in the meta-analyses was 2.8, and
both the mode and the median were 2.0. As we discussed earlier, the small
number of studies evident across clearinghouses is partly a consequence of
the relatively narrow focus of most synthesis efforts carried out by these
organizations. That is, these clearinghouses tend to focus on specific inter-
ventions themselves rather than on the interventions as a class (e.g., they
focus on a specific brand of a nurse visiting program rather than on nurse
visiting programs as a whole). Shifting the focus to a more abstract level
might admit more studies into the meta-analysis and might also allow for
moderator tests that directly address dimensions relevant to decision-
making (e.g., comparing studies that involve more or less intensive doses
of nurse visits).
Assuming that, for whatever reason, only a small number of studies is
available for review, how should evidence-based clearinghouses synthesize
the evidence across studies? As we have seen, relative to more common
alternatives the unweighted meta-analytic model almost certainly yields
upwardly biased estimates of the mean effect size (i.e., effect size estimates
that are larger than they should be) and implies a confidence interval that is
almost always wider than would be produced under the more common fixed
effect analytic model (i.e., the estimates are less precise than they should
be). Both the unweighted model and the inverse variance weighted fixed
effect model invoke a strong assumption—that the studies are highly similar
to one another—and this assumption is probably not true in most syntheses.
The random effects model provides a better conceptual fit than these, but
statistically, when the number of studies is small, the estimate of the
between-studies variance is poor. As such, the random effects model is
statistically not a good choice for most syntheses, as they are currently
Valentine et al. 13
at LIBERTY UNIV LIBRARY on November 1, 2016erx.sagepub.comDownloaded from

conducted by evidence-based clearinghouses. For these reasons, none of the
common meta-analytic models seem to be highly appropriate for evidence-
based clearinghouses.
What, then, should researchers and evidence-based clearinghouses do,
given that they have few studies to synthesize? Researchers and evidence-
based clearinghouses could consider not synthesizing studies if there are too
few to support a synthesis (Valentine et al., 2010). If waiting for more
evidence is not an option, meta-analysis is the best option. It is a better
option than narrative reviewing because it is more transparent and less
reliant on the reviewer’s cognitive algebra. It is also better than vote count-
ing and rule setting because these latter techniques have properties that
make them even more objectionable than meta-analysis. Thus, we recom-
mend meta-analysis not because it is ideal but because it is better than the
alternatives. We recommend fixed effect meta-analysis because we believe
it is a better option than the random effects model when there are few
studies to synthesize.
However, a viable alternative is to consider the possibility of carrying
out a Bayesian meta-analysis. As we will describe, a Bayesian meta-
analysis can be carried out in a way that is analogous to inverse variance
weighted fixed and random effects meta-analysis and has two major ben-
efits relative to the more common meta-analytic methods. First, we have
already noted that, conceptually, the random effects model is usually the
best fit. Bayesian meta-analysis provides a better way of carrying out a
random effects meta-analysis when the number of studies is small. The
second benefit is that Bayesian statistics are easier for users to interpret
accurately and lend themselves more naturally to decision support than the
statistics that arise from a classical statistics framework.
Bayesian Statistics: An Introduction
Many readers will likely have encountered the term ‘‘Bayesian statistics’’
perhaps without understanding what it implies for data analysis. Briefly,
classical statistics and Bayesian statistics conceptualize probability in fun-
damentally different ways. In classical statistics, the probability of an event
is the proportion of times that the event occurs in a long series of situations
in which it is given the opportunity to occur. For example, if we flip an
equally weighted coin a very large number of times, we expect that heads
will be on top half the time. An example of the complexities of this view can
be seen in the proper, formal interpretation of a probability value arising
from a null hypothesis significance test. Specifically, a p value can be
14 Evaluation Review
at LIBERTY UNIV LIBRARY on November 1, 2016erx.sagepub.comDownloaded from

formally defined this way: Assuming that the null hypothesis is true, the p
value represents the probability of observing an effect at least as large as the
one observed (with probability defined as the proportion of times that an
effect at least as large as the observed effect would be obtained given a very
large—really, infinite—number of samples).
The interpretation of a confidence interval in classical statistics relies on
similar reasoning. A 95% confidence interval can be described this way:
‘‘Assume that a very large number of samples of size n are drawn, and a
confidence interval is computed for each sample. Of these confidence inter-
vals, 95% will contain the true population parameter.’’ Note that this is not
equivalent to saying that there is a 95% chance that the parameter is within
the confidence interval: The probability statement is about a very large
number of intervals, not about the interval that was observed, and not about
population parameter.
Most users of statistics find these correct definitions unwieldy and dif-
ficult to understand. In fact, misconceptions are common. Many users, for
example, interpret a p value as the probability that the null hypothesis is
true. But because the interpretation of the p value is conditional on the null
hypothesis being true, we can’t then say that the null hypothesis is false
when we collect the data and observe some small value of p. Tricky logic
like this is one of the main reasons that misconceptions in the classical
statistical framework are so common.
In classical statistics then, the locus of uncertainty (the probability) lies
in the event (i.e., the event has a certain probability of occurring). Bayesian
statistics start with a different view of probability, specifically that events
are fixed (they either will or will not happen), and the locus of uncertainty is
in the observer (e.g., the intervention is either effective or it is not, but we
are uncertain about its effectiveness). In fact, Bayesian statistics can be
thought of as a formal method for using the results of a study to update
what we thought we knew about the effects of the intervention before we
conducted that study. And happily, Bayesian statistics can be implemented
in all of the major statistics software packages and are easier to understand
than statistics arising from the classical framework. The Bayesian frame-
work also lends itself more naturally to decision support. For example, a
Bayesian analysis can provide an estimate of the probability that the inter-
vention’s effects are greater than 0 (analogous to a null hypothesis signifi-
cance test in classical statistics, but with an accurate interpretation that
many users will be able to understand), or the probability that an effect is
larger than some critical threshold. As an example of the latter, assume that
a teen pregnancy program is operating in a context in which 15% of the
Valentine et al. 15
at LIBERTY UNIV LIBRARY on November 1, 2016erx.sagepub.comDownloaded from

female population experiences a pregnancy as a teen. A policy maker might
believe that for a pregnancy prevention intervention to be worthwhile, the
intervention’s effect must be greater than 4 percentage points (i.e., the
intervention would need to reduce the teen pregnancy rate below 11%).
A Bayesian analysis can support statements like ‘‘There is a 97% chance
that the intervention is effective and a 74% chance that its effects are large
enough to be important.’’ Classical statistics offers no framework for mak-
ing statements like these.
Of course, as is true of life in general (where nothing is free), all of these
good things come with a cost: The need to specify what is known about the
effects of the intervention before conducting the study. In Bayesian statis-
tics, this is known as a prior. Priors can be based on anything (including
subjective beliefs), but most Bayesians advocate using formal data (e.g., a
previous meta-analysis on a related question) or expert opinion (ideally
elicited from a range of experts). Priors can be thought of as varying in
terms of how informative they are, that is, how precise they are about the
distribution and location of the parameters under study. Weakly informative
priors suggest a position of prior ignorance of not knowing very much at all
about the effects of a given intervention. At other times, a stronger prior
might be appropriate. For example, if several good studies on the effects of
a well-established program have been conducted, then the distribution of
effects observed in those studies might be a good basis for quantifying what
is known about the intervention prior to conducting the new study.
There is a long history of debates between classical statisticians and
Bayesian statisticians. These debates do not center on the math involved
but instead on the nature of probability and, in particular, on the proper
interpretation of Bayesian results given the prior. That is, many classical
statisticians worry that the results of a Bayesian analysis are dependent on
the essentially arbitrary priors chosen. Because a Bayesian analysis can be
thought of as a weighted synthesis between the prior and the actual data, in
large data situations (e.g., a meta-analysis with several studies of reasonable
size or a large randomized trial), this concern tends to be mitigated because
the data will usually overwhelm the prior. In information-poor environ-
ments (e.g., a meta-analysis based on two studies), the prior has the poten-
tial to be more influential—in fact, very strong priors can overwhelm the
data in these situations.
Options for selecting priors in public policy contexts. Because priors can exert a
large influence on results in many public policy contexts, they need to be
selected with care. In public policy contexts, we believe two strategies for
16 Evaluation Review
at LIBERTY UNIV LIBRARY on November 1, 2016erx.sagepub.comDownloaded from

choosing priors are most defensible. First, as articulated by Press (2003), it
may be important to choose a prior that most people will find acceptable.
Generally speaking, broad acceptability is more likely when the prior is not
very informative. For example, the prior might specify that the interven-
tion’s effects are likely to be distributed over a certain range. This distri-
bution could be uniform over that range, suggesting that we know very little
about the intervention’s effects or have some other form (e.g., they could be
normally distributed, which would suggest that we know somewhat more
about the effects of the intervention). Press refers to these as ‘‘public policy
priors’’ because the fact that the inferences that arise from the analysis will
rarely be strongly influenced by the prior, even in an information poor
environment, makes them particularly useful for public policy problems.
When feasible, an alternative that should also gain broad acceptance is to
use empirical information to form the prior. For example, between January
2010 and September 2014, the WWC released eight intervention reports on
the effects of elementary school math interventions. The effect sizes in
these studies ranged from a low of d ¼ �.09 to a high of d ¼ þ.52. If a
95% confidence interval is placed around each study’s effect size, then this
suggests that the smallest plausible value in this area is about �.23 and the
largest plausible value is about þ.76. As such, a relatively uninformative
public policy prior suggesting that the effects of elementary school math
interventions range from �.23 to þ.76 seems both reasonable and defen-
sible. Alternatively, if the effects of elementary math interventions are
thought to be reasonably normally distributed, then the prior could reflect
this and the width of the distribution could be estimated empirically. The
main difference between a prior based on a uniform distribution of effects
and a prior based on a normal distribution of effects is that in a uniform
distribution, all effect sizes in the distribution are equally likely. In a normal
distribution, effect sizes around the center of the distribution are thought to
be more likely than effects in the tails. For the WWC’s elementary school
math interventions, the variance of the distribution of effect sizes is about
.033. The prior could be centered at 0 (which is advantageous as it makes
the analysis closely analogous to a null hypothesis significance test in
classical statistics) or at the center of the empirical distribution (e.g., the
median effect size in this distribution is about d ¼ þ.15, so that could be
used as the center). In this case, the difference in results generated by these
two different centers will be negligible (because the variance is relatively
large, suggesting that 99% of effect sizes should fall within a range of �.38
to þ.71).
Valentine et al. 17
at LIBERTY UNIV LIBRARY on November 1, 2016erx.sagepub.comDownloaded from

Illustrating the effects of priors. To illustrate the conditions under which the
prior has a large effect on the conclusions arising from a meta-analysis, we
chose three WWC intervention reports—one relatively large and two rela-
tively small—and conducted random effects Bayesian meta-analysis using
two different priors for the population mean m: A relatively uninformative
prior that assumes a uniform effect size over the range of WWC effect sizes
observed in meta-analyses conducted to date and a somewhat informative
prior that assumes a normal distribution with a variance based on the
WWC’s existing meta-analyses. Random effects meta-analyses require an
additional prior on the between-studies variance component t2, and for this,
we used a relatively uninformative prior that assumes a half normal distri-
bution with a large variance (which was derived using all of the studies that
the WWC included in meta-analyses conducted between January 2010 and
September 2014).
Linked learning communities. The ‘‘large’’ meta-analysis was taken from a
WWC intervention report on learning communities (U.S. Department of
Education, 2014b). There were six studies that met inclusion criteria that
measured the effects of learning communities on student credit accumula-
tion; all six of these studies were randomized experiments. The sample sizes
ranged from 1,071 to 1,534 with a total student sample size of 7,419.
Standardized mean difference effect sizes ranged from�.02 toþ.08. Using
inverse variance weights, both fixed effect and random effects estimates
suggested a mean effect size of þ.025 with a standard error (SE) of .023
(p ¼ .28).
With the results of classical inverse variance weighted fixed effect and
random effects meta-analyses presented for reference, the results of the
Bayesian meta-analyses are:
Meta-Analytic Model Type of Prior for m Mean Effect SizeStandard
Error
Classical randomeffects
NA .025 .023
Bayesian randomeffects
Relativelyuninformative
.025 .032
Bayesian randomeffects
Somewhat informative .024 .031
18 Evaluation Review
at LIBERTY UNIV LIBRARY on November 1, 2016erx.sagepub.comDownloaded from

As can be seen, these results are not sensitive to the choice of the prior
and are very close to what was obtained in the inverse variance weighted
meta-analyses. These happy things occurred because the data—six rela-
tively large randomized experiments—essentially swamped the prior.
Unfortunately in public policy contexts, most analyses are not based on
this much information, and as such the choice of the prior will often have
the potential to be more consequential as illustrated below. It is worth
noting that the standard errors for the Bayesian random effects meta-
analyses were larger than their classical random effects counterpart. This
occurred because the classical empirical estimate of the between-studies
variance component was 0 (when the assumptions of the fixed effect model
are met, the random effects model reduces to the fixed effect model). How-
ever, as discussed earlier, the estimate of the between-studies variance is poor
when there are few studies, and in fact experts in meta-analysis assert that the
choice between the fixed effect and the random effects model should be made
conceptually, not empirically (in part because the empirical estimates can be
poor; see Hedges & Vevea, 1998). The Bayesian framework influenced the
estimate of the between-studies variance component by bringing in informa-
tion from the WWC’s prior experiences, and this resulted in a somewhat
more conservative estimate of the SE that was also more consistent with the
underlying conceptualization of the random effects model.
Repeated reading. The first ‘‘small’’ meta-analysis is repeated reading
(U.S. Department of Education, 2014a). Two studies met inclusion criteria;
these assessed the effect of the intervention on reading comprehension. The
sample sizes for the two studies were 16 and 62. Standardized mean dif-
ference effect sizes were þ.28 and þ.05. Using inverse variance weights,
both fixed effect and random effects estimates suggested a mean effect size
of þ.097 with a SE of .227 (p ¼ .67).
Using the same priors as in the previous example, the results of the
Bayesian meta-analyses are:
Meta-Analytic Model Type of Prior for m Mean Effect SizeStandard
Error
Classical randomeffects
NA .097 .227
Bayesian randomeffects
Relativelyuninformative
.130 .298
Bayesian randomeffects
Somewhat informative .065 .291
Valentine et al. 19
at LIBERTY UNIV LIBRARY on November 1, 2016erx.sagepub.comDownloaded from

In this example, the impact of the informativeness of the prior is easier to
see. Using the somewhat informative prior, which assumed a normal dis-
tribution, the meta-analytic effects were ‘‘pulled’’ toward the center of that
distribution (i.e., 0). The relatively uninformative prior, which assumed a
uniform distribution, resulted in effects that were slightly larger and slightly
more variable (as reflected in the increased standard error). Again, the
standard errors from the Bayesian analyses were larger than the SE from
the classical random effects analysis (in which the estimate of the between-
studies variance was 0).
Doors to discovery. The second small meta-analysis, on the preschool
literacy curriculum doors to discovery, included two studies that assessed
the effects of the intervention on print knowledge (U.S. Department of
Education, 2013). The sample sizes for the two studies were 37 and 365.
Standardized mean difference effect sizes were þ.69 and þ.08. It is worth
noting how different both the effect sizes and the sample sizes are and that
the large effect is paired with a very small sample. In cases like this (i.e.,
very different effect sizes estimated with very different sample sizes), the
random effects estimate will tend to converge on the unweighted estimate
(here, about .39). Indeed, using inverse variance weights, the random
effects meta-analysis suggested a mean effect size of d ¼ .300 (SE ¼.293), p ¼ .31.
Using the same priors as in the previous examples, the results of the
Bayesian meta-analyses are:
Here, the estimate from the classical random effects meta-analysis is
larger than both of the estimates from the Bayesian analyses. In essence,
the priors from the Bayesian analyses moderated the effects of the large
degree of observed heterogeneity, resulting in estimated effects that are
somewhat closer to the fixed effect mean of d ¼ þ.10.
Meta-Analytic Model Type of Prior for m Mean Effect SizeStandard
Error
Classical randomeffects
NA .300 .293
Bayesian randomeffects
Relativelyuninformative
.226 .284
Bayesian randomeffects
Somewhat informative .161 .287
20 Evaluation Review
at LIBERTY UNIV LIBRARY on November 1, 2016erx.sagepub.comDownloaded from

The effects of very strong priors. As a final demonstration of the impact of
priors on small meta-analyses, assume that we have a very strong belief that
the real effect size for doors to discovery is uniformly distributed between
þ.40 and þ.60. In this case, the mean meta-analytic effect size would
increase to d ¼ þ.43 with a very small standard error. Of course, this
illustrates a point: In an information-poor environment, priors matter, and
poorly chosen priors can have a tremendous influence on the final results. In
this case, the prior is a poor and indefensible choice in part because the
range of expected effect sizes is far too narrow. As such consumers of
research that utilized a Bayesian approach need to attend to the priors that
were used, the justification for those priors, and to any sensitivity analyses
that were done illustrating the impact of the priors.
Conclusion
Several key points emerged from our review of evidence-based clearing-
houses, which face a number of challenges to successfully fulfilling their
missions. Chief among these are the difficulties inherent in assembling the
evidence base, quality appraising the evidence, and synthesizing the evi-
dence is a manner that permits valid and useful inferences. We discussed the
importance of each of these aspects of systematic reviewing and highlighted
some of the traps lying in wait for unsuspecting researchers. Based on our
review, there is wide variation in how evidence-based clearinghouses
approach their work. One aspect of work across clearinghouses that is
consistent is the tendency to define research questions narrowly. This
means that clearinghouses are often in an ‘‘evidence poor’’ environment
(i.e., their syntheses have a small number of studies). This feature of clear-
inghouse syntheses has important implications for the methods used deter-
mine what the body of relevant studies reveals about the research question
being asked. In particular, the most appropriate synthesis method (i.e.,
random effects meta-analysis) requires more studies than are usually avail-
able to clearinghouses. We recommend the Bayesian approach to statistics
in general, and to meta-analysis in particular, as a partial solution to the
problems associated with arriving at inferences regarding program effec-
tiveness when there are few studies to synthesize. We do this by showing
how clearinghouses can exploit two different types of priors (i.e., noninfor-
mative priors and priors based on similar studies) to generate more credible
estimates of program effectiveness. The Bayesian approach has additional
advantages of yielding statistics that are interpreted in a way that is similar
to the way that most people incorrectly interpret classical statistics and
Valentine et al. 21
at LIBERTY UNIV LIBRARY on November 1, 2016erx.sagepub.comDownloaded from

supporting decision-making more effectively than classical statistics (e.g.,
by allowing researchers to estimate the probability that the effect is larger
than some preestablished critical threshold). However, the need for and
importance of priors in a Bayesian analysis means that care needs to be
exercised in selecting them. Even with this caution in mind, we believe the
Bayesian approach offers a promising way of addressing the problem that
most evidence-based clearinghouses face, namely, that synthesis is difficult
when there are few studies to review.
Authors’ Note
The views expressed are those of the authors and do not necessarily represent the
positions or policies of the Institute of Education Sciences or the U.S. Department of
Education.
Acknowledgment
Betsy Becker, Spyros Konstantopoulos, Bruce Sacerdote, and Chris Schmid pro-
vided helpful feedback on portions of this article.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research,
authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research,
authorship, and/or publication of this article: The work reported herein was sup-
ported in part by the U.S. Department of Education’s Institute of Education Sciences
(Contract ED–IES–12–C–0084).
References
Cohen, J. (1962). The statistical power of abnormal-social psychological research:
A review. Journal of Abnormal and Social Psychology, 65, 145–153.
Cooper, H., & Hedges, L. V. (2009). Research synthesis as a scientific process. In H.
Cooper, L. V. Hedges, & J. C. Valentine (Eds.), The handbook of research synthesis
and meta-analysis (2nd ed., pp. 3–18). New York, NY: Russell Sage Foundation.
Dwan, K., Altman, D. G., Arnaiz, J. A., Bloom, J., Chan, A. W., Cronin, E.,
. . . Williamson, P. R. (2008). Systematic review of the empirical evidence of
study publication bias and outcome reporting bias. PLoS One, 3, e3081. doi:10.
1371/journal.pone.0003081
Hedges, L. V., & Olkin, I. (1985). Statistical methods for meta-analysis. Orlando:
FL: Academic Press.
22 Evaluation Review
at LIBERTY UNIV LIBRARY on November 1, 2016erx.sagepub.comDownloaded from

Hedges, L. V., & Vevea, J. L. (1998). Fixed-and random-effects models in meta-
analysis. Psychological Methods, 3, 486–504.
Higgins, J. P. T., & Green, S. (Eds.). (2011). Cochrane handbook for systematic
reviews of interventions (Version 5.1.0). Retrieved from www.cochrane-hand
book.org
Pigott, T. D., Valentine, J. C., Polanin, J. R., & Williams, R. T. (2013). Outcome-
reporting bias in education research. Educational Researcher, 42, 424–432. doi:
0013189X13507104
Press, S. J. (2003). Subjective and objective Bayesian statistics: Principles, models,
and applications (2nd ed.). Hoboken, NJ: John Wiley and Sons.
Rothstein, H. R., & Hopewell, S. (2009). Grey literature. In H. Cooper, L. V.
Hedges, & J. C. Valentine (Eds.), The handbook of research synthesis and
meta-analysis (2nd ed., pp. 103–128). New York, NY: Russell Sage Foundation.
Sedlmeier, P., & Gigerenzer, P. (1989). Do studies of statistical power have an effect
on the power of studies? Psychological Bulletin, 105, 309–316.
U.S. Department of Education, Institute of Education Sciences, What Works
Clearinghouse. (2013, June). Early childhood education intervention report:
Doors to Discovery™. Retrieved from http://whatworks.ed.gov
U.S. Department of Education, Institute of Education Sciences, What Works
Clearinghouse. (2014a, May). Students with learning disabilities intervention
report: Repeated reading. Retrieved from http://whatworks.ed.gov
U.S. Department of Education, Institute of Education Sciences, What Works
Clearinghouse. (2014b, November). Developmental students in postsecondary
education intervention report: Linked learning communities. Retrieved from
http://whatworks.ed.gov
Valentine, J. C., Biglan, A., Boruch, R. F., Castro, F. G., Collins, L. M., Flay,
B. R., . . . Schinke, S. P. (2011). Replication in prevention science. Prevention
Science, 12, 103–117.
Valentine, J. C., Pigott, T. D., & Rothstein, H. R. (2010). How many studies do you
need? A primer on statistical power in meta-analysis. Journal of Educational and
Behavioral Statistics, 35, 215–247.
Viechtbauer, W. (2005). Bias and efficiency of meta-analytic variance estimators in
the random-effects model. Journal of Educational and Behavioral Statistics, 30,
261–293.
Author Biographies
Jeffrey C. Valentine is professor and coordinator of the Educational Psychology,
Measurement, and Evaluation program in the College of Education and Human
Development at the University of Louisville. He is an internationally recognized
Valentine et al. 23
at LIBERTY UNIV LIBRARY on November 1, 2016erx.sagepub.comDownloaded from

expert in research synthesis and meta-analysis. He is the co-chair of the Training
Group of the Campbell Collaboration, a Statistical Editor in the Cochrane Colla-
boration, and co-editor of the Handbook of Research Synthesis and Meta-Analysis,
2nd Edition.
Sandra Jo Wilson is associate director of Peabody Research Institute (PRI), co-
director of the Meta-Analysis Center at PRI, and a research assistant professor in the
Department of Special Education at Vanderbilt University. She also serves as the
editor for the Education Coordinating Group of the Campbell Collaboration.
David Rindskopf is distinguished professor of Educational Psychology and Psy-
chology at the City University of New York Graduate School. He is a fellow of the
American Statistical Association and the American Educational Research Associa-
tion, past president of the Society for Multivariate Experimental Psychology, and
past editor of the Journal of Educational and Behavioral Statistics. His research
interests are Bayesian statistics, categorical data, latent variable models, and multi-
level models.
Timothy S. Lau is a doctoral candidate at the University of Louisville. His interests
include systematic reviewing and meta-analysis, and educational technology.
Emily E. Tanner-Smith is an Associate Research Professor at the Peabody
Research Institute and Department of Human and Organizational Development at
Vanderbilt University, and is co-director of the Meta-Analysis Center at the Pea-
body Research Institute. Her areas of expertise are in substance use and addiction,
adolescent behavior and development, and applied research methods.
Martha Yeide is a senior research analyst at Development Services Group, Inc.
where she reviews studies and develops content for evidence-based repositories in
education, juvenile and criminal justice, and behavioral health.
Robin LaSota is a senior research scientist at Development Services Group, Inc.
She is a mixed-methods researcher focused on how schools and postsecondary
institutions can better support students to be successful through the P-20 educational
system. She works to support evidence-based decision-making in education, crim-
inal justice, and human services through the conduct of study reviews and the
development of products highlighting findings from rigorously-conducted research.
Lisa Foster is associate professor and chair of Quantitative Research at Liberty
University. As a veteran educator (25þ years), she has taught at the elementary,
secondary, and postsecondary levels, and has conducted and/or evaluated research
in the areas of fidelity, educational leadership, literacy, math, and postsecondary
education.
24 Evaluation Review
at LIBERTY UNIV LIBRARY on November 1, 2016erx.sagepub.comDownloaded from
Top Related