







Languages
Pages
Legal


Dissemination and Synchronization for Mobility (and Beyond)
Michael FranklinUC Berkeley
MDM Tutorial7 January 2001

© 2001 Michael J. Franklin MDM 2001 Tutorial 2
Outline1. Dissemination vs. Synchronization2. Architectural Concepts
– Types of nodes– Data Delivery Mechanisms– User Profiles
3. Data Dissemination– DBIS Toolkit, Xfilter, Continuous Queries
4. Synchronization– for PDAs: Palm HotSync, Edison, SyncML– Data Recharging– Consistency for weakly connected devices
5. Wrap Up

© 2001 Michael J. Franklin MDM 2001 Tutorial 3
Intro: Data Dissemination
• disseminate – 1. To scatter widely, as in
sowing seed.– 2. To spread abroad,
promulgate. disseminate information
• In a data management context, this refers to the proactive distribution of relevant data to users.
• Examples:– News feeds, stock tickers, event broadcasts,
SPAM, …

© 2001 Michael J. Franklin MDM 2001 Tutorial 4
Intro: Data Synchronization
• synchronize – 1. To cause to occur or
operate with exact coincidence in time or rate.
– 2. To cause to occur or operate at the same time as something else.
• In a data management context this refers to making base data and device-cached data consistent.
• Examples:– Palm HotSync, Email (?), disconnected
operation

© 2001 Michael J. Franklin MDM 2001 Tutorial 5
Discussion
• From the definitions, you might think that the two concepts are completely unrelated, but are they?
• Examples:– Email Lists/On-line communities– Groupware apps such as shared calendars– AvantGo
• What are the essential characteristics that distinguish one from the other?
• How related? How different?

© 2001 Michael J. Franklin MDM 2001 Tutorial 6
Tutorial Goals• To identify common infrastructure to support
large scale data distribution: dissemination and syncrhonization.
• To describe recent and on-going research in supporting dissemination.
• To describe existing synchronization protocols and future directions for them.
• To outline avenues for continuing research and infrastructure development.

© 2001 Michael J. Franklin MDM 2001 Tutorial 7
2. Architectural Concepts• Dissemination and Sync are inherently distributed;
– Both require a Network architecture.• A key concept is that of an Overlay Network
1. “application-level” network built on top of Internet protocols; interacts with the “regular” internet.
2. May use both public and private communication links.
3. Exploits “Data Centers” deployed around the world.
4. Content Routing can be done at the application level so can be based on application and data semantics.
5. Caching, Prefetching, Staging, etc. can be done transparently.
6. E.g., CDNs such as Akami, FastForward Networks

© 2001 Michael J. Franklin MDM 2001 Tutorial 8
Architecture (continued)
• We will focus on three key aspects of such architectures:
1. Types of nodes in the system.2. Options for data delivery mechanisms.3. Representation of data needs and
preferences through user profiles.

© 2001 Michael J. Franklin MDM 2001 Tutorial 9
i) Types of Nodes
• Clients– Interact with end user, may cache data and
updates• Client Proxies
– Deal with disconnection, provide network interface• Data Sources
– The ultimate repositories for data• Intermediaries (“Information Brokers”)
– Provide storage/caching, application level routing– value added data processing– communications transducing
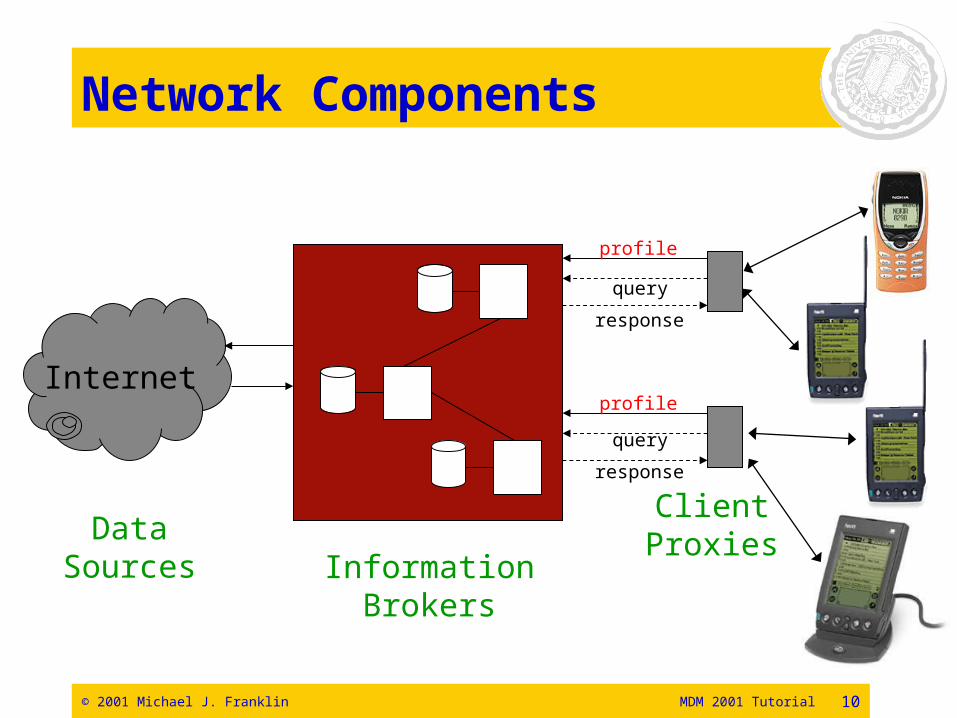
© 2001 Michael J. Franklin MDM 2001 Tutorial 10
Network Components
Internet
profile
query
response
profile
query
response
DataSources Information
Brokers
ClientProxies

© 2001 Michael J. Franklin MDM 2001 Tutorial 11
ii) Data Delivery Options• There are many ways to move data between
sources and receivers:• Pull vs. Push
– Does the data move because the receiver asked for it or because the source decided to send it?
• Periodic vs. Aperiodic– Does the data move according to a predefined
schedule or is movement event/demand driven?• Unicast vs. 1 to N
– Does the data go to a single receiver or many?• Reliability Guarantees
– best effort, guaranteed once, transactional…

© 2001 Michael J. Franklin MDM 2001 Tutorial 12
Data Delivery Mechanisms
PushPull
Aperiodic Periodic
Unicast 1-to-n Unicast 1-to-n
Aperiodic Periodic
Unicast 1-to-n Unicast1-to-n
request/response
on-demandbroad-cast
polling pollingw\snoop
Email lists
publish/subscribe
Person- alizedNews
Broad-castdisks
Dimensions are largely orthogonal – all combinations are potentially useful.
[Franklin & Zdonik, OOPSLA 97]
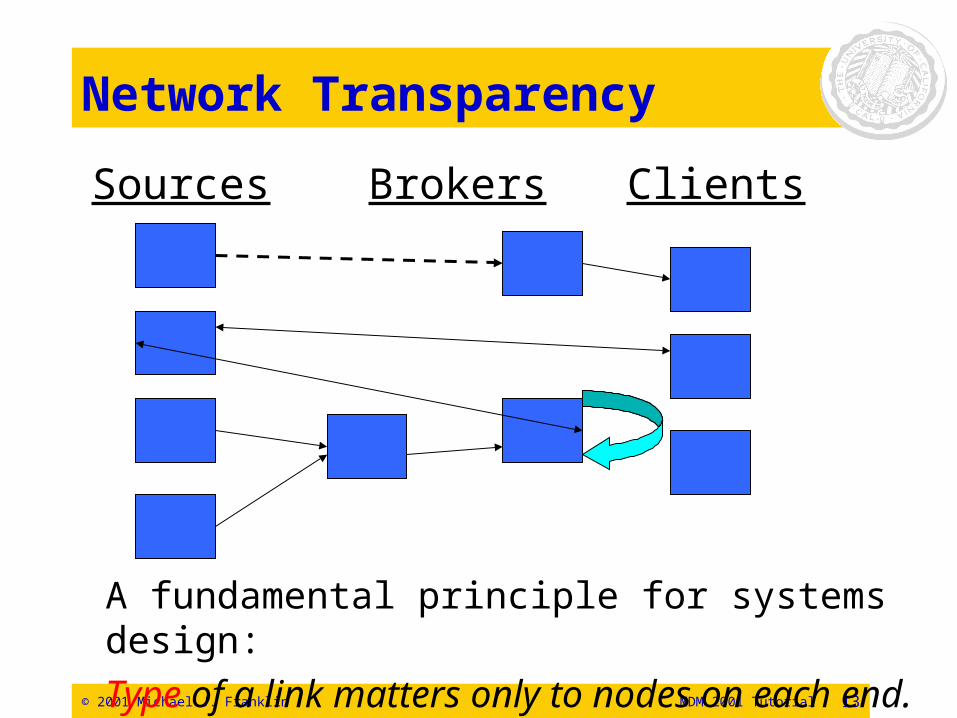
© 2001 Michael J. Franklin MDM 2001 Tutorial 13
Network Transparency
ClientsBrokersSources
A fundamental principle for systems design:
Type of a link matters only to nodes on each end.

© 2001 Michael J. Franklin MDM 2001 Tutorial 14
iii) User Profiles• An expression of a user’s (or group of users)
data interests and priorities.• Must be Declarative:
– Query languages enabled modern database systems.– Profile languages will enable next generation
information management.• Sources:
– users– learned (implicitly or through feedback)– hybrid– collaborative/clustering approaches

© 2001 Michael J. Franklin MDM 2001 Tutorial 15
Why are Profiles Needed?
• Necessary for push-based dissemination– how else to know what to send to user?
• Useful for optimizing data synchronization– can precompute data to be transferred to user– can identify potential hot spots
• Also can be used for data management– Caching– Staging at brokers and proxies– Prefetching– Precomputation of customized data views

© 2001 Michael J. Franklin MDM 2001 Tutorial 16
Profile ContentsThree main components:
1) Domain Specification: content-based, declarative specifications of user interests (read “queries”).
2) Utility Specification: Specifications of user priorities and dependencies among data items and requirements for resolution, freshness, ordering, etc.
3) User Context information: where, when, who, what. Useful for tailoring data delivery to users based on their current and future needs.

© 2001 Michael J. Franklin MDM 2001 Tutorial 17
Example ProfileWHERE
<article><subject> Database <\><title> $t <\><year> $y <\><conference> $c <\>
<\> ELEMENT AS $XIN (www.cs.*.edu/*/$S), $S conforms to “bib.dtd”CONSTRUCT $XUTILITY ( $X )
(10 * ( $c = “SIGMOD” OR $c = “VLDB”)) +(8 * ( $c = “EDBT” OR $c = “ICDE”) +(100 * ( $a = “Gray”)) -(2001 - $y)

© 2001 Michael J. Franklin MDM 2001 Tutorial 18
Summary So Far• Despite initial impressions, Dissemination and
Synchronization are closely related.– A common infrastructure can support both.
• Basis is an overlay network with application-level routing, transparent caching, staging, etc.– Nodes are clients, proxies, brokers, and sources.– Various data delivery mechanisms combined via
network transparency.
• User profiles are the key to push-based delivery, precomputation, and network data management.
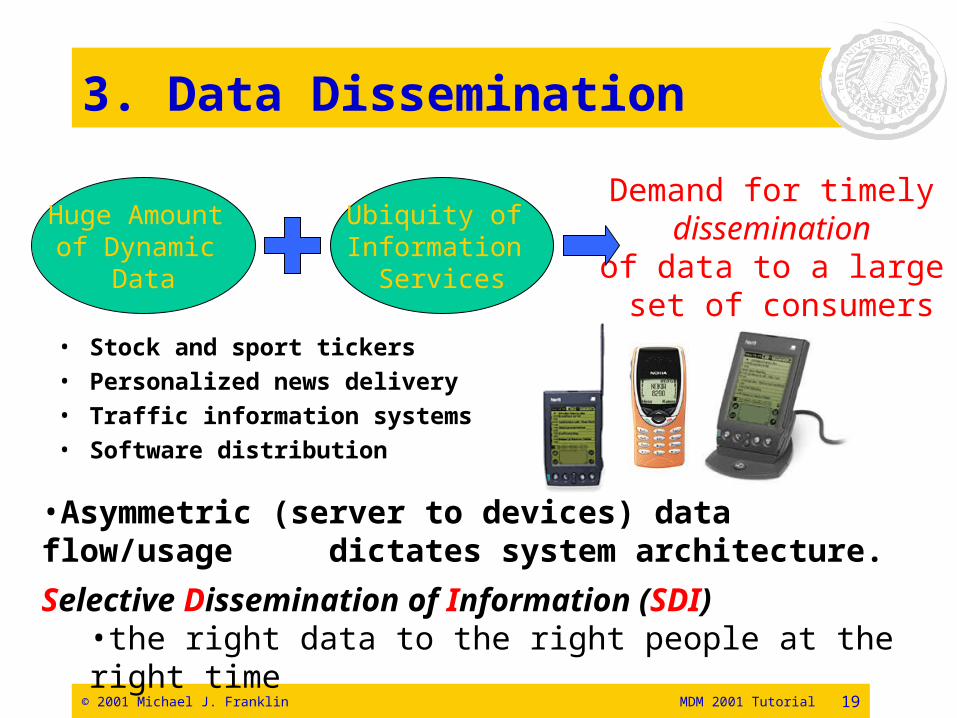
© 2001 Michael J. Franklin MDM 2001 Tutorial 19
3. Data Dissemination
• Stock and sport tickers• Personalized news delivery• Traffic information systems• Software distribution
Selective Dissemination of Information (SDI)•the right data to the right people at the right time
Demand for timely dissemination
of data to a large set of consumers
Huge Amount of Dynamic
Data
Ubiquity of Information
Services
•Asymmetric (server to devices) data flow/usage dictates system architecture.

© 2001 Michael J. Franklin MDM 2001 Tutorial 20
Dissemination Topics
1. The DBIS Toolkit
2. XFilter: efficient routing and filtering of XML documents.
3. Related Database technologies: triggers and continous queries.

© 2001 Michael J. Franklin MDM 2001 Tutorial 21
Dissemination-Based Information Systems (DBIS)• Outgrowth of “Broadcast Disks” project.
SIGMOD 95 (Acharya et al.)• Framework proposed OOPSLA 97 (Franklin & Zdonik)• Toolkit description/demo SIGMOD 99 (Altinel et al.)• XML-based Profile system (Xfilter) in
VLDB 00 (Altinel & Franklin)• Profile learning techniques in
ICDE 00 (Cetintemel, Franklin, Giles)
• Now part of “Data Centers” NSF ITR Project with Stan Zdonik @ Brown & Mitch Cherniack @ Brandeis- focus on profile-based data management

© 2001 Michael J. Franklin MDM 2001 Tutorial 22
DBIS Framework
The DBIS Framework is based on three fundamental principles:
1) No one data delivery mechanism is best for all situations (e.g., apps, workloads, topologies).2) Network Transparency: Must allow different mechanisms for data delivery to be applied at different points in the system.3) Topology, routing, and delivery mechanism should
vary adaptively in response to system changes.
Goal is to provide a library of components from which to construct dissemination apps.

© 2001 Michael J. Franklin MDM 2001 Tutorial 23
DBIS Example
1-to-n pushServerDB
Proxy cache
An example:
Can vary dynamically
Unicast pull
Proxy cache
Proxy cache
Unicast pull
Unicast pull

© 2001 Michael J. Franklin MDM 2001 Tutorial 24
DBIS Toolkit
• Data Source Library – wraps data sources to encapsulate communication and convert data.
• Client Library – encapsulates comm., converts queries and profiles, monitors and filters data.
• Information Broker – primary component of the DBIS. Handles communication transducing, caching, scheduling, profile management and matching.
• Catalog Manager (master)• Real-Time Performance Monitoring Tool and
Control Panel.
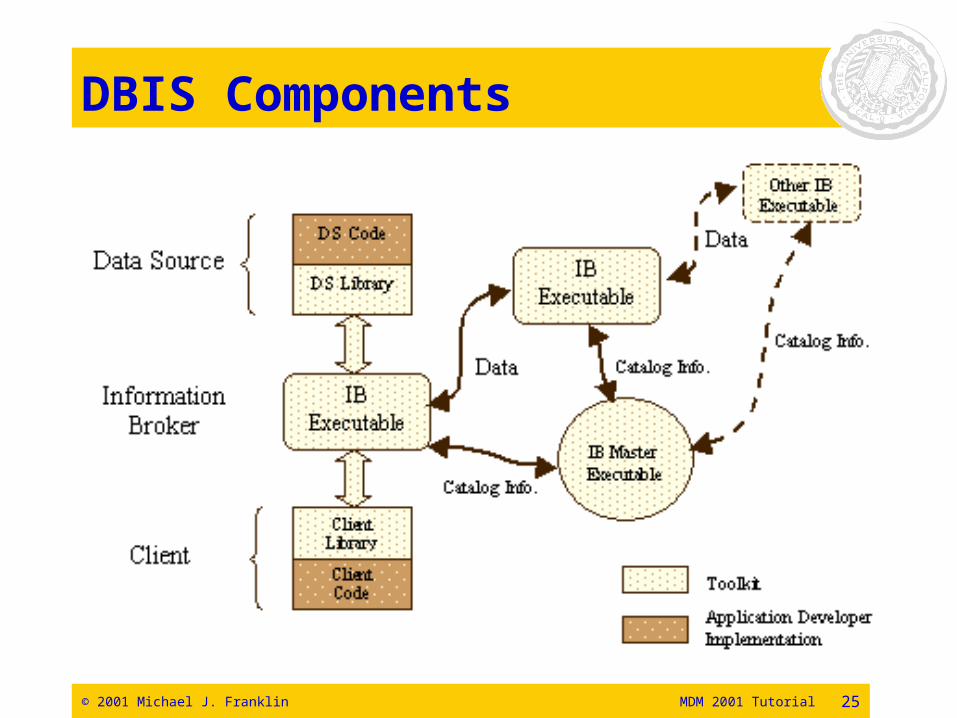
© 2001 Michael J. Franklin MDM 2001 Tutorial 25
DBIS Components
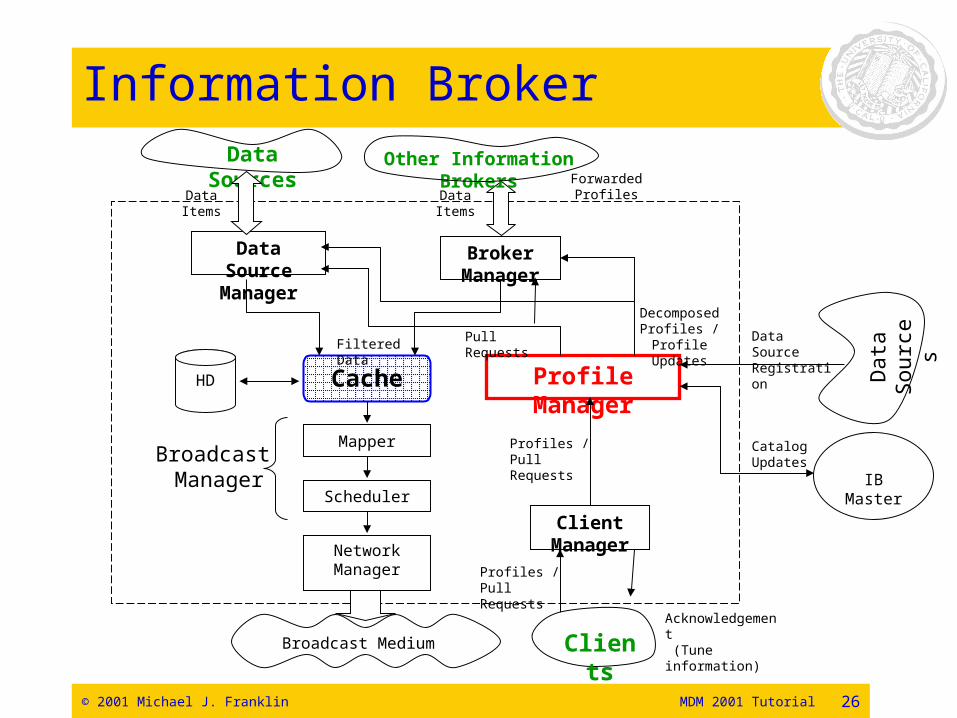
© 2001 Michael J. Franklin MDM 2001 Tutorial 26
Cache
Network Manager
Profile Manager
ClientManager
Acknowledgement (Tune information)
Data SourceManager
Profiles / Pull Requests
Decomposed Profiles /
Profile Updates
ForwardedProfiles
Data Source Registration
Pull Requests
Catalog Updates
Broker Manager
Data Sources
Data ItemsData Items
Dat
a S
ourc
es
IB Master
ClientsBroadcast Medium
Other Information Brokers
Profiles / Pull Requests
HD
Filtered Data
Mapper
Scheduler
Broadcast Manager
Information Broker

© 2001 Michael J. Franklin MDM 2001 Tutorial 27
More on Brokers• Brokers are middleware components that can
act as both clients and servers.• Must support data caching
– Needed to convert pushed-data to pulled-data– Also allows implementation of hierarchical caching
• Profile Management– Profiles needed for push– Allow informed data management: prefetch,
staging, etc.• Profile Matching
– No profile language sufficient for all applications.– Need an API for adding app-specific profiling

© 2001 Michael J. Franklin MDM 2001 Tutorial 28
DBIS Toolkit

© 2001 Michael J. Franklin MDM 2001 Tutorial 29
DBIS Research Issues
• Each data delivery mechanism has unique aspects– Broadcast Disks - scheduling., caching,
prefetching, updates, error handling,…– On-demand Broadcast - scheduling, data staging– Publish/Subscribe- large-scale filtering,
channelization• Security/Fault-tolerance/Reliability• End-to-End network design and control• Fundamental performance tradeoffs
• Profile Languages and Processing

© 2001 Michael J. Franklin MDM 2001 Tutorial 30
XFilter: XML Document Filtering• Provides efficient filtering (routing) of XML
documents against many XPath profiles by:– Representation of XPath queries as Finite State
Machines (FSMs)– Sophisticated FSM indexing and processing– Enhancements to avoid “query” skew
• Accepts any XML document (no DTDs needed)• Implemented in the DBIS-Toolkit and as a stand-
alone library• Developed by Mehmet Altinel for his Ph.D. work,
Published in [Altinel & Franklin, VLDB 2000]

© 2001 Michael J. Franklin MDM 2001 Tutorial 31
Why XML-Based SDI?
• XML is becoming the dominant format for data exchange on the Internet
• XML provides structural and semantic cues
• Query languages for XML have been developed
• The combination of XML encoding and expressive query languages allows the creation of highly focused and accurate profiles

© 2001 Michael J. Franklin MDM 2001 Tutorial 32
The challenge is to efficiently and quickly match incoming XML documents against the potentially huge set of user profiles.
An XML-Based SDI System
XML Conversion
XML Documen
ts Filter Engine
User Profiles
Users
Filtered Data
Data Sources

© 2001 Michael J. Franklin MDM 2001 Tutorial 33
XPath as a Profile Language
• W3C recommendation (used for path expressions in XSLT and XPointer)
• Has the right level of expressiveness for SDI
– Operates on a single document at a time
– Can address any node in an XML document using
hierarchical relationships, wildcards and element node
filters
• In XFilter, we use XPath to describe predicates over entire documents
– If the result contains at least one element of a document,
then the document satisfies the XPath expression

© 2001 Michael J. Franklin MDM 2001 Tutorial 34
Important XPath Features
• Parent/Child (‘/’) and Ancestor/Descendant
(‘//’): /catalog/product//msrp
• Wildcards (match any single element):
/catalog/*/msrp
• Element Node Filters to further refine the
nodes:
– Filters can contain nested path expressions
//product[price/msrp < 300]/nameFilter applied to
product element node
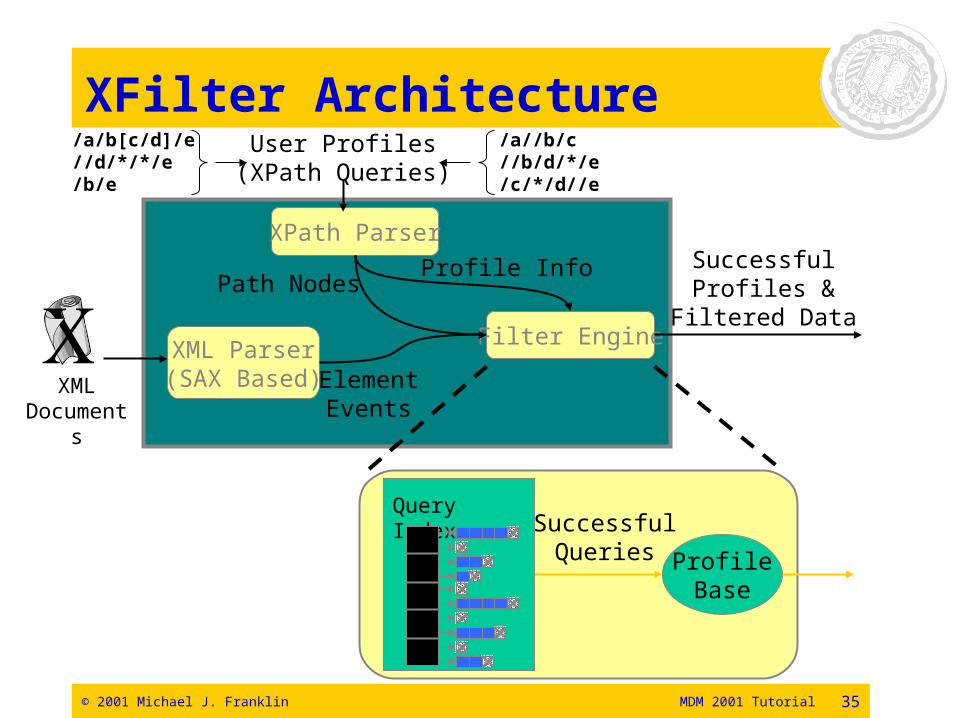
© 2001 Michael J. Franklin MDM 2001 Tutorial 35
XFilter Architecture
XPath Parser
Filter Engine
Path NodesProfile Info
XML Document
s
XML Parser(SAX Based)Element
Events
SuccessfulProfiles &
Filtered Data
ProfileBase
SuccessfulQueries
Query Index
User Profiles(XPath Queries)
/a//b/c//b/d/*/e/c/*/d//e
/a/b[c/d]/e//d/*/*/e/b/e

© 2001 Michael J. Franklin MDM 2001 Tutorial 36
XML Parsing and Filtering
• Event-based XML Parsing using SAX API
• XML documents are converted to a linear sequence of events that drive the execution of the filter
• Callback functions are implemented to deal with the different events
– Start Element
– Element Data
– End Element

© 2001 Michael J. Franklin MDM 2001 Tutorial 37
Filter Engine• Tricky aspects of the XPath language:
– Checking the order of elements in the queries– Handling wildcards and descendent operators– Evaluating filters that are applied to element
nodes (Nested path expressions)• Solution:
– Convert each XPath query into a Finite State Machine (FSM)• A profile is considered to be satisfied when
its final state is reached– Index the states of FSMs for efficient
evaluation

© 2001 Michael J. Franklin MDM 2001 Tutorial 38
FSM Representation• Each element node is a state
• A state is represented using a Path Node structure (Contains information to process current state):– Compare the level of element name in input document
with the level value of the path node
– Evaluate the element node filter if there is any
– Locate next path nodes for the state change in the FSM representation
– Calculate the level values of next states using relative distance values (in terms of levels) stored in the path nodes
– Not generated for wildcard (“*”) nodes
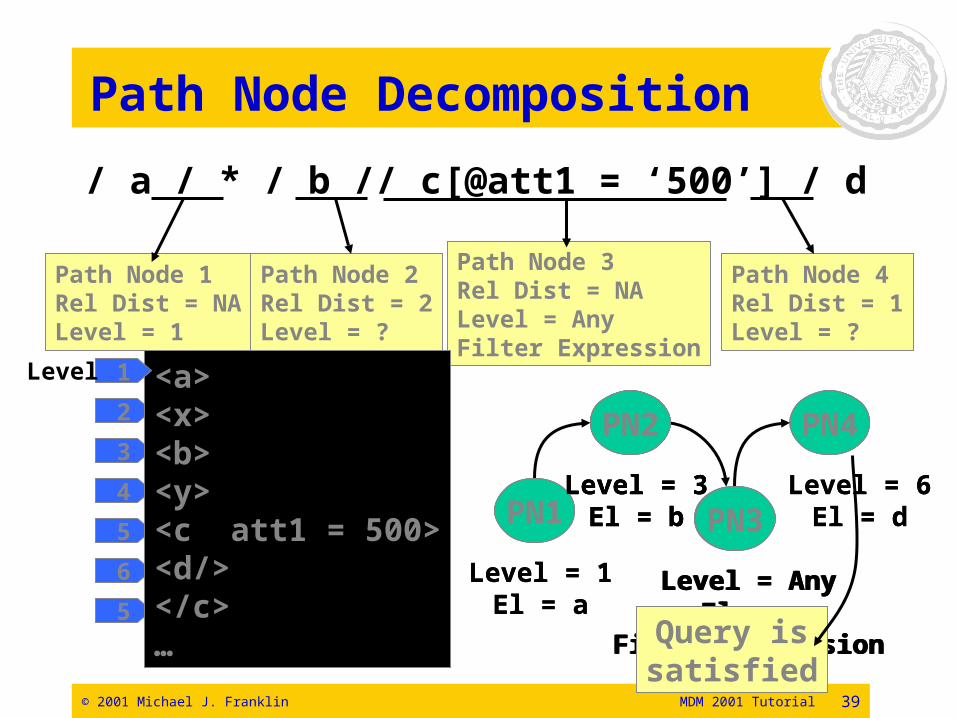
© 2001 Michael J. Franklin MDM 2001 Tutorial 39
Path Node Decomposition
/ a / * / b // c[@att1 = ‘500’] / d
Path Node 1Rel Dist = NALevel = 1
Path Node 2Rel Dist = 2Level = ?
Path Node 3Rel Dist = NALevel = AnyFilter Expression
Path Node 4Rel Dist = 1Level = ?
2
3
4
5
6
5
PN2
PN3
PN4
<a><x><b><y> <c att1 = 500><d/> </c>…
PN1
Level = 1El = a
PN1
1Level
PN2
Level = 3El = b PN3
Level = AnyEl = c
Filter Expression
PN4
Level = 6El = d
PN2
Level = 3El = b PN3
Level = AnyEl = c
Filter Expression
Level = 1El = a
PN1
PN2
Level = 3El = b PN3
Level = AnyEl = c
Filter Expression
PN4
Level = 6El = d
Query issatisfied

© 2001 Michael J. Franklin MDM 2001 Tutorial 40
Handling Multiple Queries
• Hash table based on the element names in the queries
• Each node contains two lists of path nodes:
– Candidate List: Stores the path nodes that represent current state of each query
– Wait List: Stores the path nodes that represent the future states
• State transition is represented by promoting a path node from the Wait List to the Candidate List
• Initial distribution of path nodes has a significant impact on performance
Key insight for scalable SDI:Index the queries instead of the data
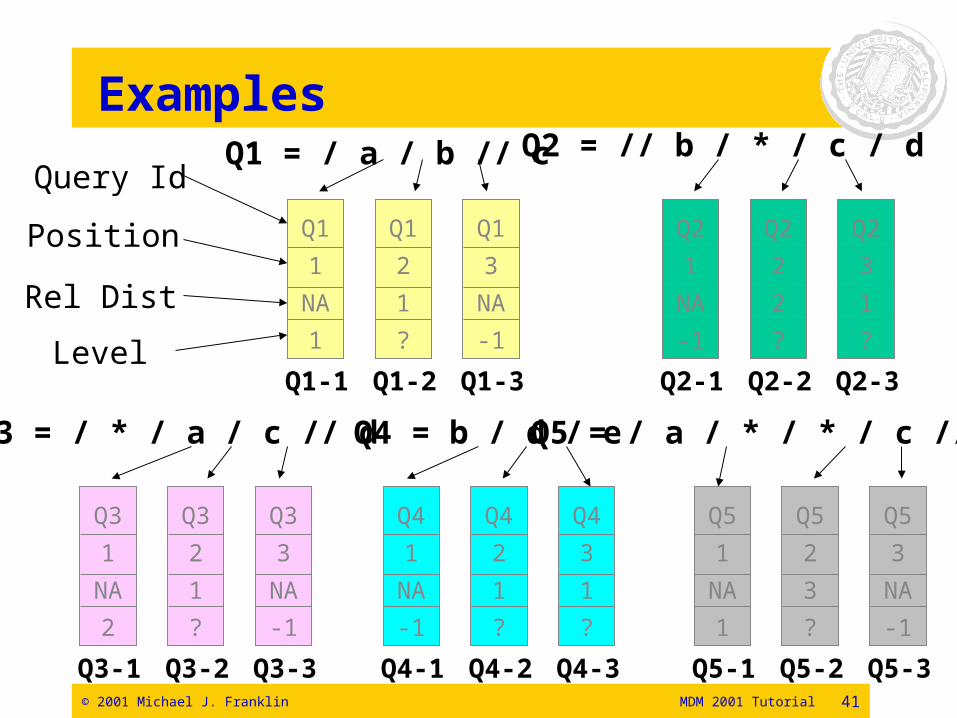
© 2001 Michael J. Franklin MDM 2001 Tutorial 41
Examples
Q1 = / a / b // c
Q1
1
NA
1
Q1
2
1
?
Q1
3
NA
-1
Q1-1 Q1-2 Q1-3
Q2 = // b / * / c / d
Q2
1
NA
-1
Q2
2
2
?
Q2
3
1
?
Q2-3Q2-2Q2-1
Q3 = / * / a / c // d Q4 = b / d / e Q5 = / a / * / * / c // e
Q3
3
NA
-1
Q3
2
1
?
Q3
1
NA
2
Q3-3Q3-2Q3-1
Q5
1
NA
1
Q5-1
Q5
2
3
?
Q5-2
Q5
3
NA
-1
Q5-3
Q4
1
NA
-1
Q4-1
Q4
2
1
?
Q4-2
Q4
3
1
?
Q4-3
Query Id
Position
Rel Dist
Level

© 2001 Michael J. Franklin MDM 2001 Tutorial 42
Query Index Construction
z
a
b
c
d
e
WL
CLQ2-1
Q2-2
Q2-3
Q3-1
Q3-2
Q3-3
Element Hash Table
CL : Candidate ListWL: Wait List
WL
Q1-1
Q1-2
Q1-3
WL CL
WL
CL
CL
WL CL
Q4-1
Q4-2
Q4-3
Q5-1
Q5-2
Q5-3

© 2001 Michael J. Franklin MDM 2001 Tutorial 43
Enhanced Algorithms
• Drawbacks of the “Basic” approach:
– Query skew: hot elements are likely to have very long Candidate Lists
– Unnecessary evaluations of queries for which the input document contains only a subset of the required element names
• Two enhancement strategies:
– List Balance
– Prefiltering

© 2001 Michael J. Franklin MDM 2001 Tutorial 44
List Balance Algorithm
• When adding an FSM to the Query Index, select a “pivot” Path Node whose element has the shortest Candidate List length
• Treat the pivot node as the initial state of the FSM
– Attach the portion of FSM that precedes the pivot node as a prefix
– Evaluate the prefix as a precondition by using a stack of traversed element nodes in the XML document

© 2001 Michael J. Franklin MDM 2001 Tutorial 45
FSMs in List BalanceQ1 = / a / b // c
Q1
1
NA
1
Q1
2
1
?
Q1
3
NA
-1
Q1-1 Q1-2 Q1-3
Q2 = // b / * / c / d
Q2
1
NA
-1
Q2
2
2
?
Q2
3
1
?
Q2-3Q2-2Q2-1
Q3 = / * / a / c // d
Q3
2
NA
-1
Q3
1
1
?
a
X
X
NA
2
Q3-2Q3-1
Query Id
Position
Rel Dist
Level
Q4 = b / d / e
X
X
NA
-1
Q4-1
Q4
2
1
?
Q4-2
Q4
1
1
?
b
Q5 = / a / * / * / c // e
X
X
NA
1
X
X
3
?
Q5
1
NA
-1
a, c
Q5-1Prefix

© 2001 Michael J. Franklin MDM 2001 Tutorial 46
Query Index in List Balance
CL : Candidate ListWL: Wait List
Q1-1
Q1-2
Q1-3
WL CL
WL CL
WL CL
WL CL
WL CL
Q2-1
Q2-2
Q2-3
Q3-1
Q3-2
Element Hash Table
Q4-1
Q4-2 Q5-1
z
a
b
c
d
e

© 2001 Michael J. Franklin MDM 2001 Tutorial 47
Prefiltering
• Implemented as an initial pass that is performed before processing the queries
• Based on Yan’s [Yan 94] Key Based algorithm
• Each input XML document is parsed twice– In the first pass:
• Match the element names for each query with the document
– In the second pass:
• Consider only the queries that passed the first step
• Selectivity of the Prefiltering step determines its benefit.

© 2001 Michael J. Franklin MDM 2001 Tutorial 48
Nested Path Expressions
• Element Node Filters may contain other XPath queries
• Nested query is treated like a separate query
• For relative execution, initial state of nested query is activated after parent element node is satisfied.
• If result not available, assume true and “mark” for later re-evaluation.
a b e
c dQ1 = / a // b[ c / d = 100] / e
Q2Q2
Q1

© 2001 Michael J. Franklin MDM 2001 Tutorial 49
Performance Evaluation
• Experimental Environment– NITF DTD is used to generate input documents and
queries (Contains 158 elements organized in 7 levels with 588 attributes)
– IBM’s XML Generator is used to create input documents
– We implemented a similar XPath query generator
• Workload Parameters to Examine– Scalability of the algorithms
– Different document and query settings
© 2001 Michael J. Franklin MDM 2001 Tutorial 50
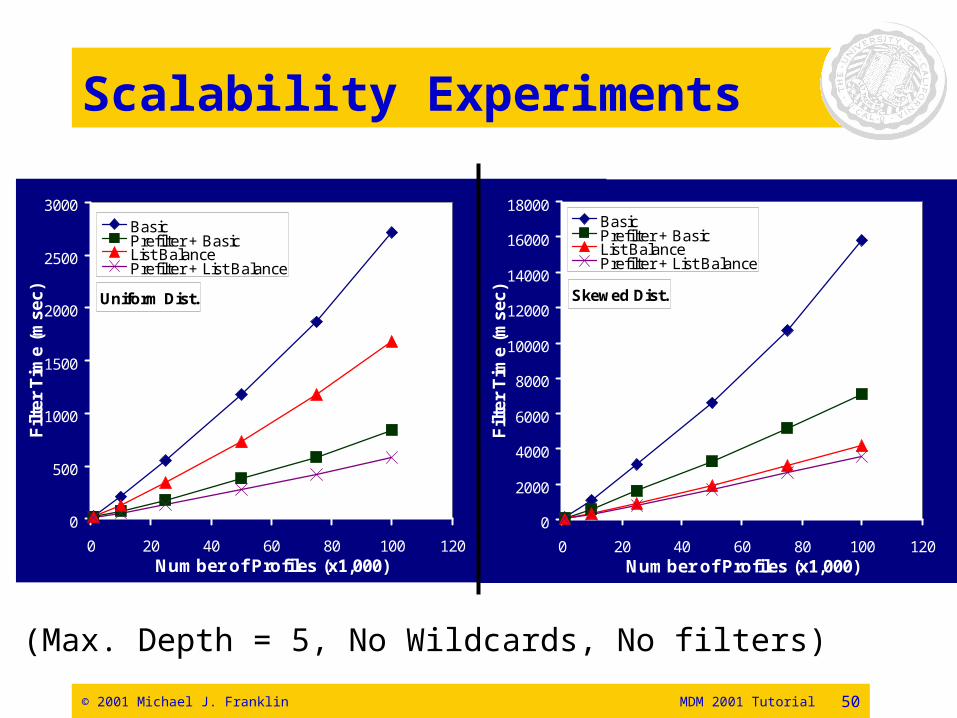
Scalability Experiments
Uniform Dist.
0
500
1000
1500
2000
2500
3000
0 20 40 60 80 100 120Number of Profiles (x1,000)
Fil
ter
Tim
e (m
sec)
BasicPrefilter + BasicList BalancePrefilter + List Balance
(Max. Depth = 5, No Wildcards, No filters)
Skewed Dist.
0
2000
4000
6000
8000
10000
12000
14000
16000
18000
0 20 40 60 80 100 120Number of Profiles (x1,000)
Fil
ter
Tim
e (m
sec)
BasicPrefilter + BasicList BalancePrefilter + List Balance

© 2001 Michael J. Franklin MDM 2001 Tutorial 51
Document Depth Experiments
Uniform Dist.
0
500
1000
1500
2000
2500
0 2 4 6 8 10 12Maximum Depth
Fil
ter
Tim
e (m
sec)
BasicPrefilter + BasicList BalancePrefilter + List Balance
Skewed Dist.
0
1000
2000
3000
4000
5000
6000
7000
8000
9000
10000
0 2 4 6 8 10 12Maximum Depth
Fil
ter
Tim
e (m
sec)
BasicPrefilter + BasicList BalancePrefilter + List Balance
(# of Profiles = 50,000, No Wildcards, No filters)
© 2001 Michael J. Franklin MDM 2001 Tutorial 52
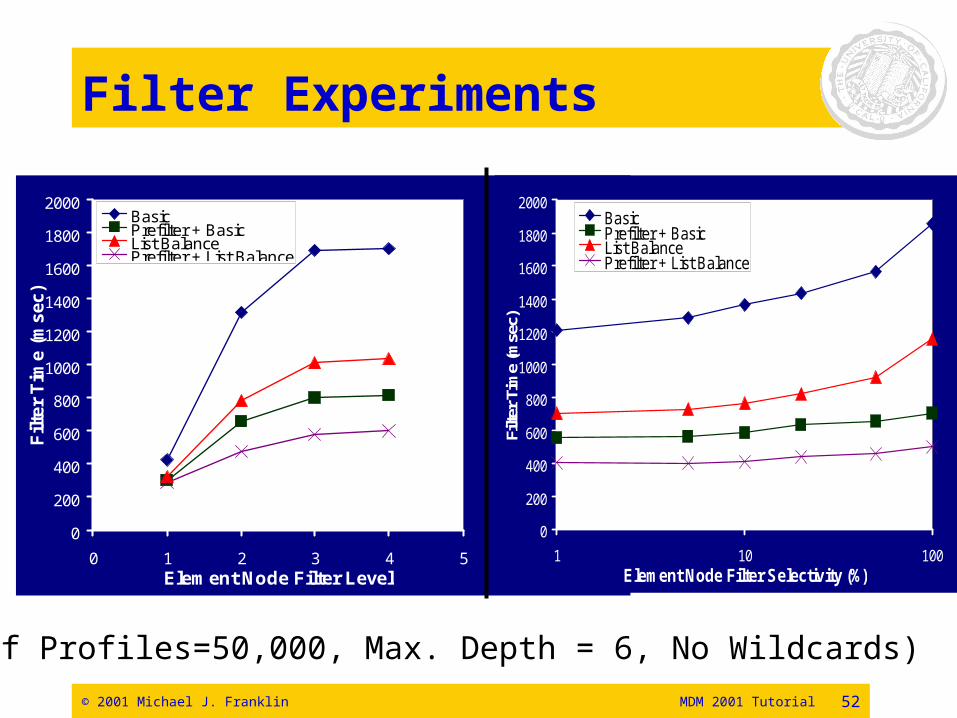
Filter Experiments
0
200
400
600
800
1000
1200
1400
1600
1800
2000
0 1 2 3 4 5Element Node Filter Level
Fil
ter
Tim
e (m
sec)
BasicPrefilter + BasicList BalancePrefilter + List Balance
0
200
400
600
800
1000
1200
1400
1600
1800
2000
1 10 100Element Node Filter Selectivity (%)
Filte
r Ti
me
(mse
c)
BasicPrefilter + BasicList BalancePrefilter + List Balance
(# of Profiles=50,000, Max. Depth = 6, No Wildcards)

© 2001 Michael J. Franklin MDM 2001 Tutorial 53
XFilter Summary
• XFilter was designed for scalable filtering and content-based routing of XML documents– Sophisticated indexing mechanisms and a modified Finite
Sate Machine approach to filter XML documents efficiently
• XPath query language is used in the profile model to define expressive user profiles– Avoids overwhelming the users with irrelevant data
• Performance – XFilter is suitable for Internet-scale applications
– Enhancements provide substantial improvements

© 2001 Michael J. Franklin MDM 2001 Tutorial 54
Related Approaches
• SIFT [Yan & Garcia-Molina, TODS 2000]– Explored both Boolean and Similarity-based
matching models (more of an IR perspective).– Also examined aspects of distributed filtering.
• Database Continuous Queries– Xerox Parc [Terry et al., SIGMOD 92]– NiagraCQ (Wisconsin) [Chen et al., SIGMOD 00]– OpenCQ (OGI/Georgia Tech) [Liu et al., TKDE 99]– Employ database queries and grouping
(common-subexpression) approaches.

© 2001 Michael J. Franklin MDM 2001 Tutorial 55
Related Approaches(continued)• Trigger Systems for “Active Databases”
– [Widom & Finklestein, SIGMOD 90]– [Stonebraker et al., SIGMOD 90]– Not focused on filtering and routing per se, so
more general, complex and less scalable.• More recent work on triggers has focused
on scalability [Hanson et al., ICDE 99] • Change Detection in Semi-structured data
[Chawathe et al, ICDE 98]• Interesting issues are a) how much functionality
is needed and b) how much history is used.
© 2001 Michael J. Franklin MDM 2001 Tutorial 56
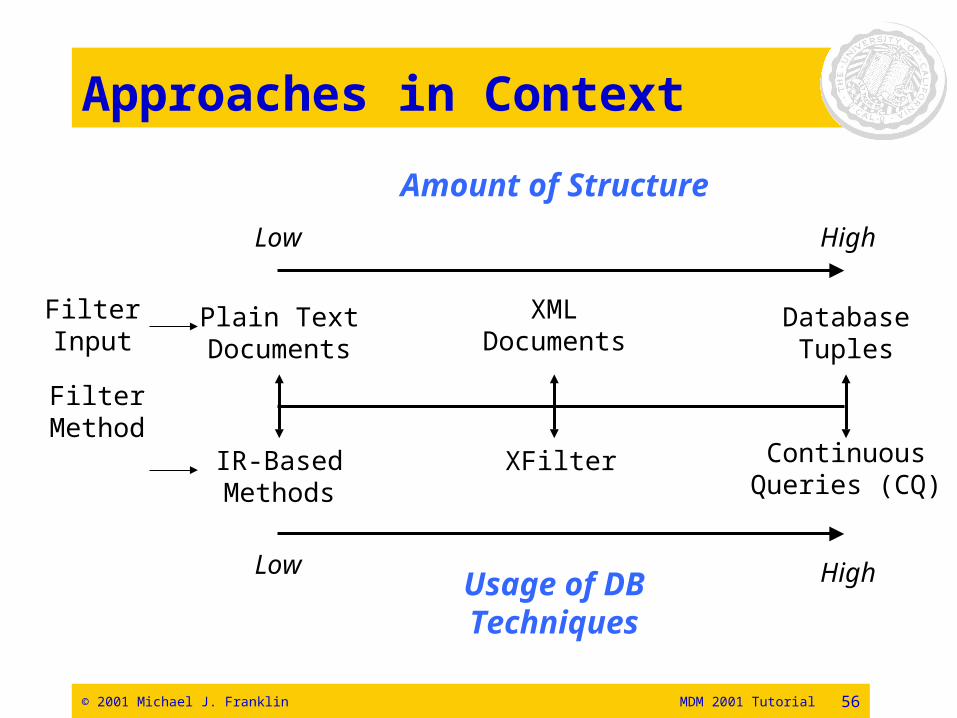
Approaches in Context
Amount of Structure
Low High
FilterInput
FilterMethod
Plain TextDocuments
IR-BasedMethods
XMLDocuments
DatabaseTuples
XFilter ContinuousQueries (CQ)
Usage of DBTechniques
Low High

© 2001 Michael J. Franklin MDM 2001 Tutorial 57
Summary of Data Dissemination
• Described the DBIS architecture for deploying dissemination-based applications.– User profiles play a key role here.
• XFilter is an information filtering/routing system aimed at very large-scale systems.
• Similar problems (to varying degrees of scale) have been addressed in databases in the context of continuous queries and active databases.– Xfilter can exploit these approaches, esp. for
common sub-expr., and history-based filtering.

© 2001 Michael J. Franklin MDM 2001 Tutorial 58
4. Synchronization
• Question: why/when is synchronization needed?
– i.e., What is wrong with good old ACID transaction models?

© 2001 Michael J. Franklin MDM 2001 Tutorial 59
Why Synchronize?• Needed primarily due to disconnection.
– If always connected, then could something stricter.
– Efficiency concerns and long-running transactions also may be motivations.
• The basic idea:– Clients cache secondary copies of data– Servers retain “copies of record”– Updates happen without two-phase commit.– Synchronization process attempts to make
these mutually consistent.• Upates on server sent to client, and vice-
versa• Run conflict resolution when a problem arises

© 2001 Michael J. Franklin MDM 2001 Tutorial 60
Synchronization Topics
1. Device Synchronization• PalmOS HotSync• “Edison” Database-supported extensions• SyncML Industry Standard
2. Data Recharging
3. Consistency in Weakly Connected Environments

© 2001 Michael J. Franklin MDM 2001 Tutorial 61
Palm HotSync Background
• Metadata kept both at Device and on the Desktop.• Data on device is stored as records in PalmDBs.
– Each PalmDB is associated with an application– Each record has a set of status bits.
• Indicate if record has been created, modified, or deleted since last synchronization.
• The HotSync Manager runs on the desktop machine– Contains conduits, downloadable code for synchronizing with
specific applications.
• Desktop maintains it’s own copies of the palmDBs, including it’s own versions of the status bits.– Also maintains a snapshot of each palmDB taken immediately
after most recent synchronization.

© 2001 Michael J. Franklin MDM 2001 Tutorial 62
HotSync Protocol
• Device initiates synchronization protocol. Can run in one of two modes:
• Fast Sync– Was device last synced with this desktop?– If so, then hand held sends data and status only for those
records whose status bits are set.– Conduit can do efficient comparison of bits, update its
copy of palmDB and send updates to the device.
• Slow Sync– Else, can’t compare bits – device sends entire palmDB to
the conduit, which does a field by field comparison to figure out what changed.

© 2001 Michael J. Franklin MDM 2001 Tutorial 63
Protocol (continued)
• By comparing status bits (and possibly palmDB snapshots) the synchronization logic determines what actions to perform.
• Examples:
– Created at desktop send to device.
– Deleted at device, not changed on desktop delete from desktop.
– Updated on desktop, not on device send to device.
– Updated on both raise an exception (invoke manual conflict resolution).

© 2001 Michael J. Franklin MDM 2001 Tutorial 64
Problems with HotSync• Can’t Sync with desktops not previously
configured for syncing with that device and applications.– some limited solutions are emerging for this, but restricted by
(lack of) reliability of the desktop.
• Large performance penalty for synchronizing with multiple desktops (home/office problem).– can be a problem at server too, if it has to handle lots of
devices.
• No support for synchronizing with multi-user concurrent data sources.– No notion of “interest” in a subset of the records in a
database.– Many slow syncs and lots of snapshots to keep

© 2001 Michael J. Franklin MDM 2001 Tutorial 65
Database-Supported Sync
• The EDISON project at UC Berkeley is addressing these shortcomings with an ORDB-backed server.– driven by Matt Denny, [Denny & Franklin, ?? 01]
• Server maintains shared data and synchronization metadata for all devices.
• Users interests in subsets of shared data sources are expressed using predicates (a.k.a. profiles?).
• Utilizes proxies (“sync nodes”) running on network access points.– Sync nodes communicate with the server to obtain necessary
metadata and data records.– They also execute synchronization logic.

© 2001 Michael J. Franklin MDM 2001 Tutorial 66
EDISON (continued)• Eliminates the one snapshot per
device/data source pair by:– Incremental logging of metadata at the data source – Either push or pull network protocols to get the
correct updates to the synchronization points
• Devices always use Fast Sync– Use of shared server regardless of access point used
results in always consistent metadata.
• Caching techniques can be used to stage metadata at sync nodes, but not needed for even fairly large systems (1000’s of devices).
© 2001 Michael J. Franklin MDM 2001 Tutorial 67
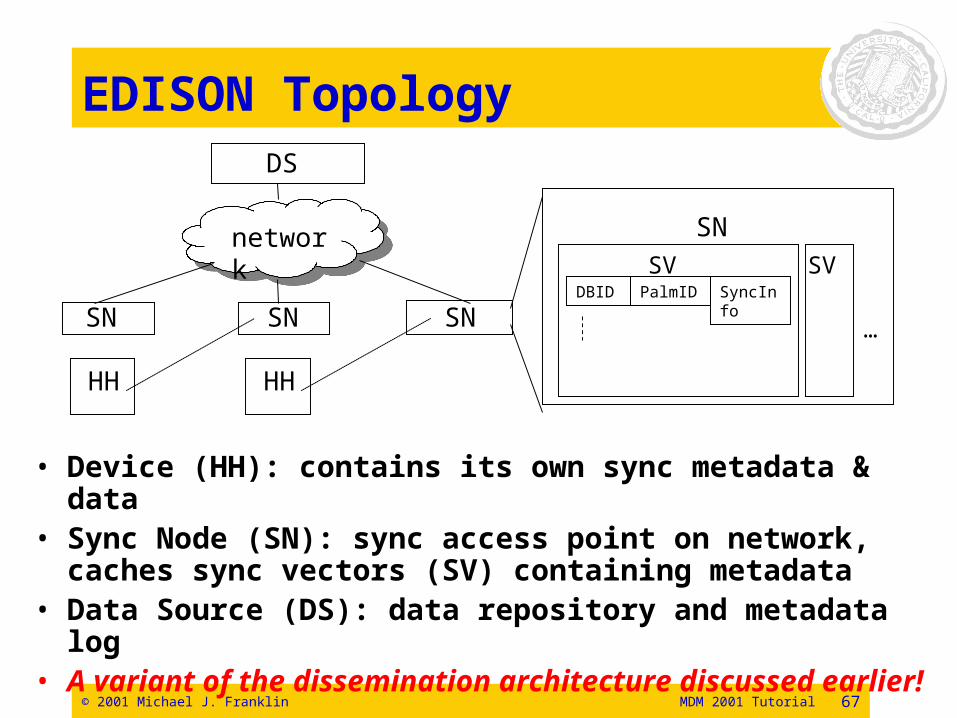
EDISON Topology
• Device (HH): contains its own sync metadata & data• Sync Node (SN): sync access point on network,
caches sync vectors (SV) containing metadata• Data Source (DS): data repository and metadata log • A variant of the dissemination architecture
discussed earlier!
DS
SN SN SN
HH HH
network SN
SV SV
…
DBID PalmID SyncInfo

© 2001 Michael J. Franklin MDM 2001 Tutorial 68
EDISON Protocol (1st Phase)
• 1st phase: Compare HH data to SV1. HH initiates sync by connecting to an SN.2. SN sends INIT message to DS3. DS sends its copy of the SV and all the updates
which occurred since last sync for this HH4. Gets all modified records from the HH, and
creates an appropriate action to send to the DS • Uses Palm’s synchronization logic, but instead
of acting directly on the data, Edison creates actions for the DS
HH SN DS4
2
3
1

© 2001 Michael J. Franklin MDM 2001 Tutorial 69
EDISON (Phase 2)
• Phase 2: Commit changes to data to DS1. SN batches actions into 1 network message and
sends to DS2. The DS performs the following as one
transaction:• Logs metadata changes for all sync vectors
interested in same data• Sends updated data values back to sender SN• Could also send updates to other “interested”
SNs if caching was being done.
HH SN DS
1
2
© 2001 Michael J. Franklin MDM 2001 Tutorial 70
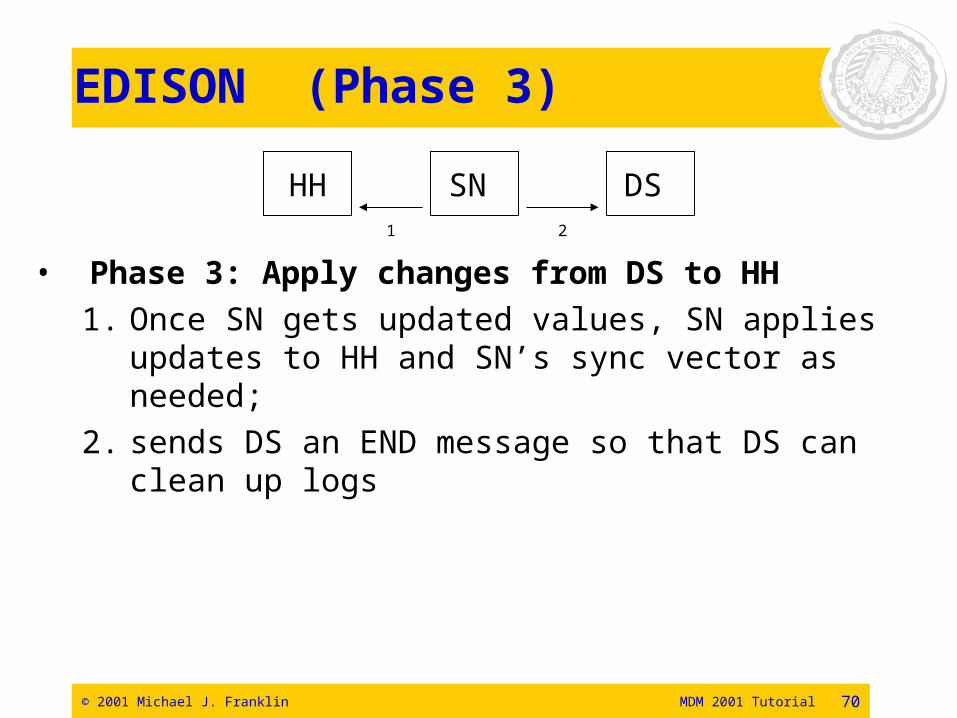
EDISON (Phase 3)
• Phase 3: Apply changes from DS to HH1. Once SN gets updated values, SN applies
updates to HH and SN’s sync vector as needed; 2. sends DS an END message so that DS can clean
up logs
HH SN DS1 2

© 2001 Michael J. Franklin MDM 2001 Tutorial 71
EDISON Summary
• Initial Performance Studies show that system scales quite well.– Assuming synch frequencies of several times a day, server
is very lightly loaded even with many thousands of clients.– Amount of data transferred over the wire is small.
• In future, synching may be much more frequent and devices will hold more and more data.
• In such cases, protocol can be extended to cache metadata and data at Sync Nodes– this offloads data access from servers, as well as
synchronization processing.

© 2001 Michael J. Franklin MDM 2001 Tutorial 72
SyncML Standard
• Industry Consortium with most major players: Ericsson, Nokia, Motorola, Palm, Psion, IBM, …
• Goal is to enable cross-format, cross-system synchronization.
• Simple architecture:– Client: PDA, Phone or PC; intermittently connected.– Server: typically PC or Server; continuously
available.• Consists of a standard set of message types,
each represented as an XML document.• Supports different interaction models including
“request/response” and “blind push”

© 2001 Michael J. Franklin MDM 2001 Tutorial 73
SyncML Sync Types
1. Two-way – “normal (fast) sync”, client sends first.
2. Slow-sync – client sends all data
3. One-way, client only – client sends only modified records to server; server does not send to client
4. Refresh, client only – client sends entire DB to server
5. One-way, server only
6. Refresh, server only
7. Server Alerted – Sync initiated by server (push?)

© 2001 Michael J. Franklin MDM 2001 Tutorial 74
SyncML (continued)
• Standard requires servers to maintain mappings between its own record IDs and the IDs of records as kept by the client.
• Conflict Resolution logic is (of course) dealt with abstractly by the standard. It provides standard status codes that can be used to implement typical policies.
• Contains support for authentication of clients and servers.
• www.syncml.org

© 2001 Michael J. Franklin MDM 2001 Tutorial 75
“Data Recharging”
• An alternative approach to data synchronization…
• A merger of dissemination and synchronization approaches.
• Joint work w/ Mitch Cherniack and Stan Zdonik as part of the Data Centers project.

© 2001 Michael J. Franklin MDM 2001 Tutorial 76
Data Recharging - Motivation
• Mobile devices require 2 resources: power and data– It is impractical to be continuously connected to
fixed sources of these.• Devices cope with disconnection using caching:
– Power cached in rechargeable batteries– Data cached in hot-synched memory
• Recharging the power is easy…– Anywhere, Anytime, “Hands-off” operation,
Flexible connection duration• Recharging the data, well, we just covered
that.

© 2001 Michael J. Franklin MDM 2001 Tutorial 77
Data Recharging (continued)
“Make recharging data as simple as recharging power”
• Anywhere – no need to connect to your home machine,
• Anytime – no prior arrangements necessary,
• “Hands-off” operation – system knows what you need
• Flexible connection duration – the longer you stay connected, the better your device-resident data gets.

© 2001 Michael J. Franklin MDM 2001 Tutorial 78
Some Questions
• How to know where the user will be?– and do we care?
(for context – yes, for staging -??)• How to know what the user wants?• How to prioritize data delivery?
• The answer is User Profiles

© 2001 Michael J. Franklin MDM 2001 Tutorial 79
“Data Recharging” Profiles• Recall, the three main components:
1) Content-based specifications of user interests(read “queries”)
2) Specifications of user priorities/requirements,priority ordering, resolution, freshness,
dependencies
3) User Context information – where, when, who, what
This info is available in the user’s PIM data!

© 2001 Michael J. Franklin MDM 2001 Tutorial 80
First cut at Profile Model
• Items of Interest Defined Explicitly (URLs)– Dependencies and alternatives expressed in a tree– “Values” assigned to individual items
• Tree is built with special operators– Choose (n) – Value obtained for up to any n children– First (n) – Value obtained for up to n children in order
(e.g., for progressive resolution).– And – Value obtained only if all children are delivered.
• Total value of a “data charge” can be computed bottom up using simple formulas.
• (based on M.S. work by Danny Tom @ UC Berkeley)

© 2001 Michael J. Franklin MDM 2001 Tutorial 81
Profile Example
Choose(2)
First (2) First (2)
First (2)
ANDChoose(1)
Time of Quote
Addendumto
News Story
Stock Name Current Price
News Story
Graph(low res)
Graph(hi res)

© 2001 Michael J. Franklin MDM 2001 Tutorial 82
Exploiting Profiles• Need to use profiles to choose contents of a data
charge (not just evaluate them)• Want to maximize value delivered in a charge
without having to spend too much time choosing.• Two optimization problems:
– Bounded (known) sync time– Unknown sync time
• Bounded case is an instance of the “precedence-constrained knapsack problem”
• Can be implemented using approximations or various types of heuristics.
• Initial results indicate that approximations of the PCKP approach work best.

© 2001 Michael J. Franklin MDM 2001 Tutorial 83
On-going Profile Work
• Current work on recharging profiles has taken on more of a database query processing approach.
• The idea is to separate the specification of interests from the calculation of “utility”.
• Like database query languages, these profile languages should be declarative.
• Then, calculating the contents of a charge becomes more like a query optimization and execution proceedure.
• Watch this space for more details…

© 2001 Michael J. Franklin MDM 2001 Tutorial 84
Recharging - Research Agenda• Profile Definition and Maintenance• Update Storage and Preparation• Efficient integration of "recharge" updates with
existing cached data.– Recharge, Trickle Charge, Jump Start...
• Consistency Guarantees• Global Data Staging
• More generally, Data Recharging blurs the line between synchronization and dissemination, can it be used for both?– How to exploit improved connectivity?

© 2001 Michael J. Franklin MDM 2001 Tutorial 85
Data Caching and Consistency
• Synchronization in Peer-to-peer environments is more complicated than in the less symmetric PDA-based approaches.
• Centralized algorithms require connectivity at specific times.
• Alternative: Epidemic Algorithms • Conflict detection: timestamps, version vectors,
…– Conflict Handling (update commitment):
• Optimistic (resolution) - Manual except in limited domains,• Pessimistic (avoidance) - primary copy, write-all
or voting-based.
• Previous work: Bayou, Ficus, Coda, …

© 2001 Michael J. Franklin MDM 2001 Tutorial 86
Epidemic Protocol Illustration
(Picture is by way of Ugur Cetintemel)

© 2001 Michael J. Franklin MDM 2001 Tutorial 87
Deno - Cetintemel and Keleher
Pessimistic, Asynchronous (epidemic), voting-based“Bounded” weighted-voting:
– Each replica is assigned a currency ci s.t. 0 ci 1.0
– Total currency in the system is bounded, i.e., ci=1.0
– Currency can be re-distributed for optimization or planned disconnection.
An update’s life:
– Sites issue tentative updates– Updates and votes are propagated in a pair-wise fashion– Updates gather votes as they pass through sites– An update commits when it gathers plurality of votes

© 2001 Michael J. Franklin MDM 2001 Tutorial 88
Decentralized Commitment
• An update u wins an election with plurality
• A site s maintains:– votes(u): the sum of votes u
gained so far– unknown: the sum of votes
unknown to s (i.e., 1.0 – votes(u), for u)
• u commits iff for all u’ <> u,votes(u) > votes(u') + unknown
Issues: time to commit; abort rates
s1Oi
(s1, 0.20, u1)
votes(u1) = 0.20
unknown = 0.80
(s1, 0.20, u1)
(s5, 0.20, u1)
votes(u1) = 0.40
unknown = 0.60
(s1, 0.20, u1)
(s5, 0.20, u1)(s6, 0.15, u2)
votes(u1) = 0.40
votes(u2) = 0.15
unknown = 0.45
(s1, 0.20, u1)
(s5, 0.20, u1)(s6, 0.15, u2)(s2, 0.15, u1)
votes(u1) = 0.55
votes(u2) = 0.15
unknown = 0.30
u1 commits!
s1Oi
(s1, 0.20, u1)
votes(u1) = 0.20
unknown = 0.80
(s1, 0.20, u1)
(s4, 0.20, u2)
votes(u1) = 0.20votes(u2) = 0.20
unknown = 0.60
(s1, 0.20, u1)
(s4, 0.20, u2)
(s6, 0.25, u3)
votes(u1) = 0.20votes(u2) = 0.20votes(u3) = 0.25
unknown = 0.35
(s1, 0.20, u1)
(s4, 0.20, u2)
(s6, 0.25, u3)
(s2, 0.25, u2)
votes(u1) = 0.20votes(u2) = 0.45votes(u3) = 0.25
unknown = 0.10
u2 commits!

© 2001 Michael J. Franklin MDM 2001 Tutorial 89
Wrap Up• Data Dissemination and Synchronization are indeed,
closely related.• A common set of architectural concepts can and
should be used.– These can be deployed as an overlay network.
• The key is to tackle these problems as data management issues, not only as networking problems.
• At the heart of all of these systems is an expressive, highly-functional user profile management system.
Profiling languages and evaluation algorithms will enable the next generation of data
intensive applications.

© 2001 Michael J. Franklin MDM 2001 Tutorial 90
Acknowledgements
• Mehmet Altinel – XFilter, DBIS Toolkit• Ugur Cetintemel – Deno• Mitch Cherniack – Data Recharging• Matt Denny – EDISON, Data Recharging • Pete Keleher - Deno• Danny Tom – Data Recharging• Stan Zdonik – DBIS and Data Recharging
Top Related