







Languages
Pages
Legal


Data Pipelines and Telephony Fraud Detec5on Using Machine Learning
Presented by Eugene Shulga Pla;orm Engineer Elana Woldenberg Pla;orm Engineer

1.Data Pipelines 2.Fraud Detec5on
Agenda
2

Data Pipelines

Massive amount of data
4
CDRs (Call Detail Records) Hundreds of millions
SIP messages Billions
LRN (Local RouCng Number) Hundreds of millions

Telnyx Recipe
• Message rouCng and reliable delivery (KaIa, RabbitMQ) • Storage (Cassandra, Postgres) • Real Cme aggregaCon (Spark Streaming) • Batch and ad-hoc analysis (Spark and Notebooks) • VisualizaCon (Kibana, Grafana)
5

Cloud Agnos5c
6
Requirements • Cannot use cloud specific data soluCons • Flexible enough for HA • All the services and servers are built with Docker • Single deployment script for any cloud with Docker, Swarm and Ansible
Challenges • Every cloud is different. Different APIs, hardware profiles, and performance • What about data migraCon/replicaCon?

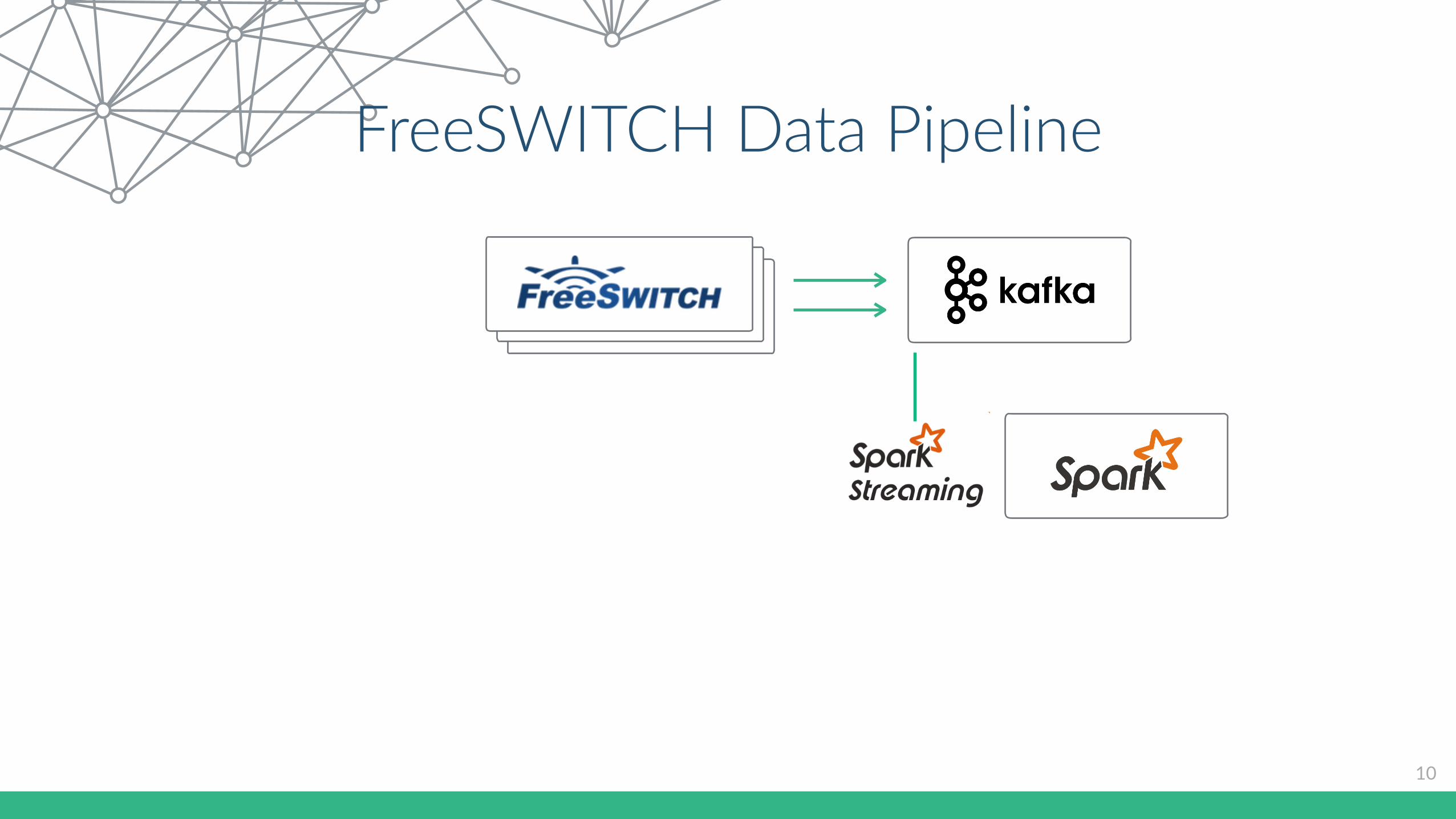
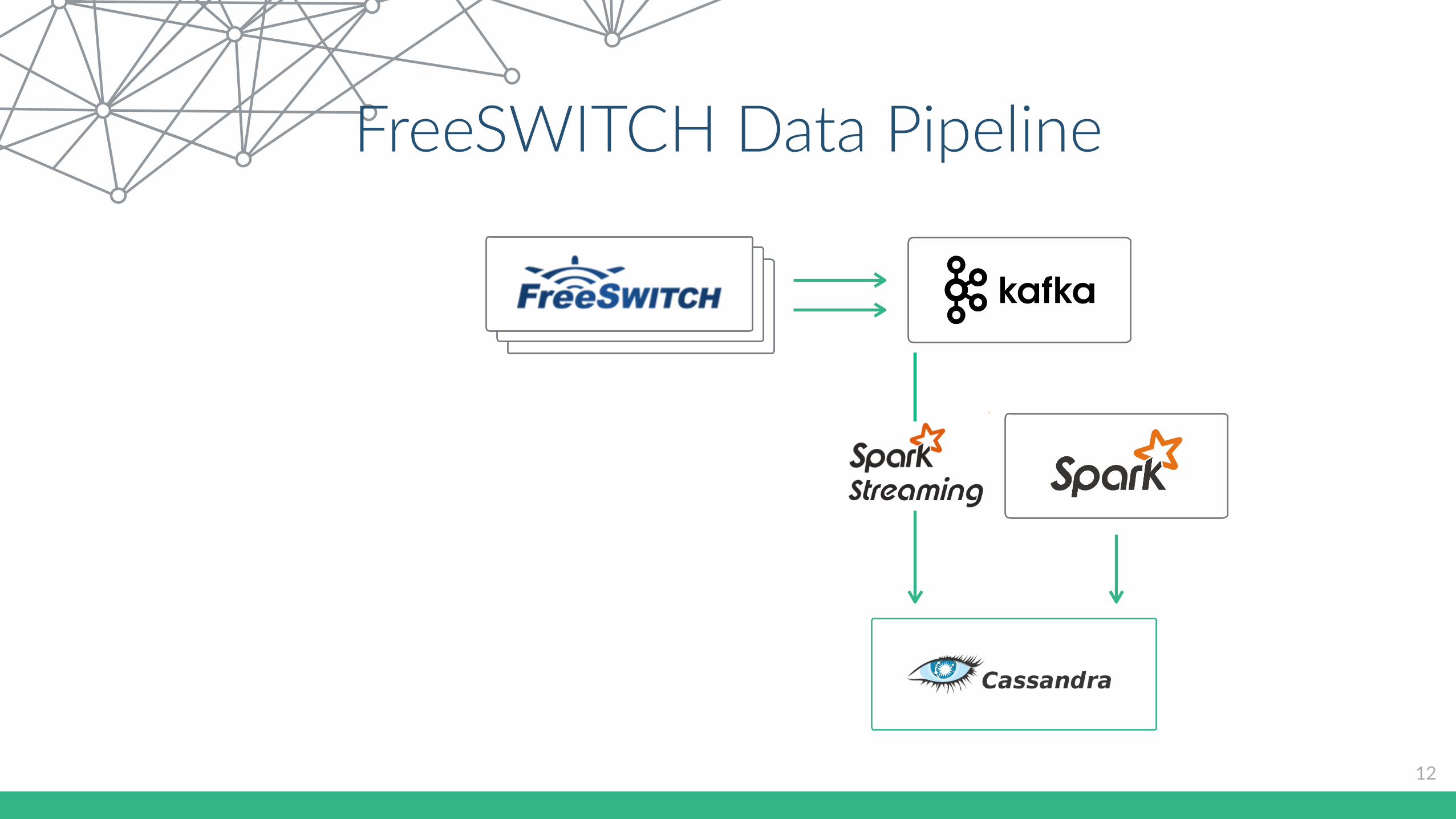
FreeSWITCH Data Pipeline
7
Fraud Detec+on
• All the data flows to Apache KaIa
• Spark Streaming for real Cme processing
• Cassandra and Spark batch jobs for hourly, daily, weekly analysis

FreeSWITCH Data Pipeline
8

KaLa
9
Pros • High throughput distributed
messaging • AutomaCc recovery from broker
failures • Decouples data pipelines • Handles massive data load • Data distribuCon and parCConing
across nodes • Distributed log implementaCon
Cons • Zookeeper, support/monitoring tools
FreeSWITCH Data Pipeline
10

Apache Spark Programming Model
• RDD (Resilient Distributed Dataset) a collecCon of objects stored in memory or disk across the cluster
• RDDs have acCons and transformaCons • All the transformaCons are lazy, once acCon is called Spark creates a DAG
(Directed Acyclic Graph) and submits it to Scheduler • Task Scheduler which launches tasks via cluster manager (Spark Standalone,
Yarn, Mesos)
11
FreeSWITCH Data Pipeline
12

Spark Cassandra Integra5on
13
App Spark Worker (JVM)
Cassandra
Executor
Executor
Spark Worker (JVM)
Spark Worker (JVM)
Spark Worker (JVM)
Executor
Executor
Cassandra
Cassandra
Spark Master (JVM)
Node 1
Node 2
Node 3
Node NCassandra
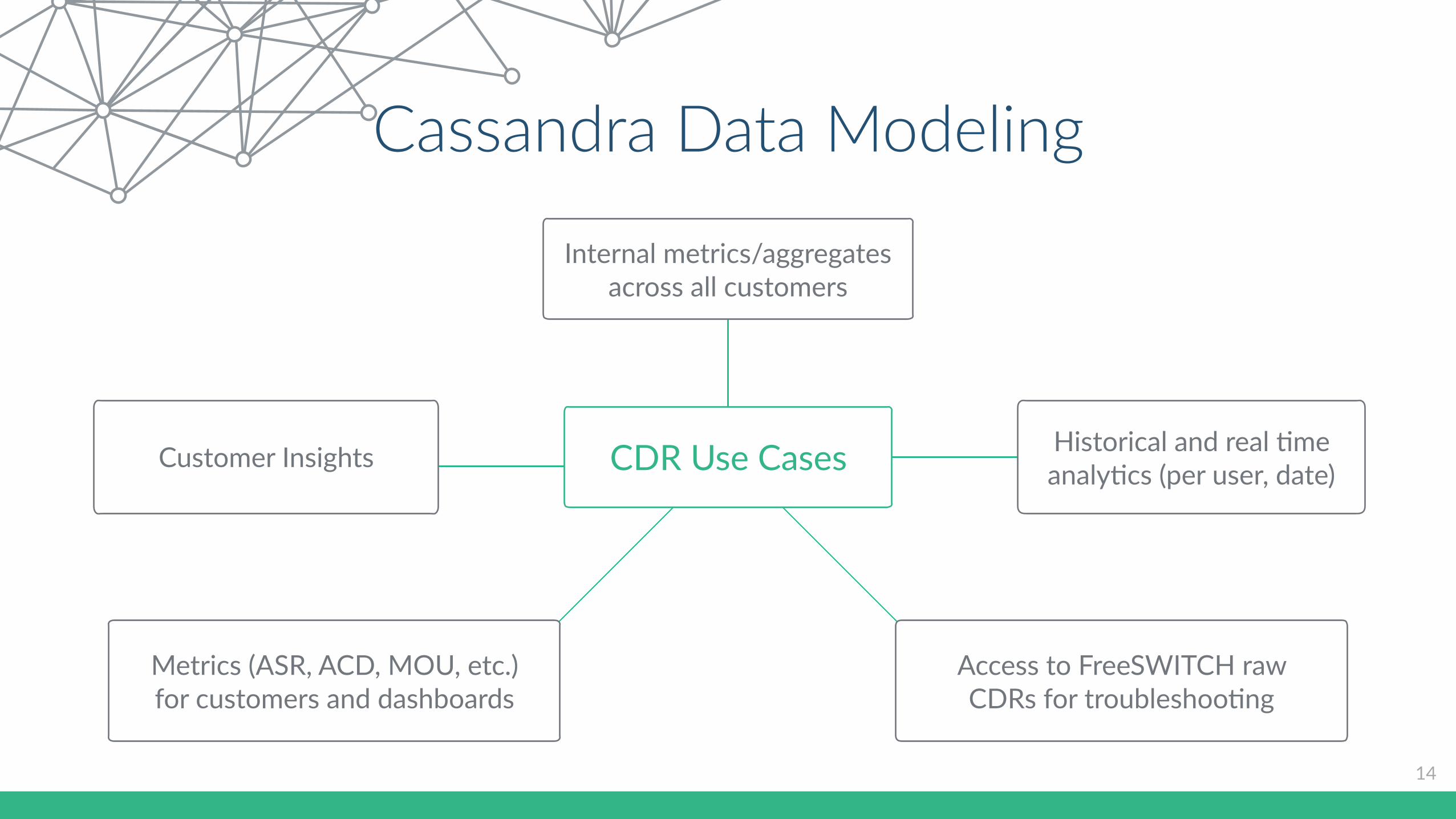
Cassandra Data Modeling
14
CDR Use Cases
Internal metrics/aggregates across all customers
Historical and real Cme analyCcs (per user, date)
Metrics (ASR, ACD, MOU, etc.) for customers and dashboards
Customer Insights
Access to FreeSWITCH raw CDRs for troubleshooCng

Distributed System ChallengesIdempotency Helps with scale, greatly simplifies processing
Par++oning Split data to handle scale and isolate failure
Consistency model Trade off between throughput and consistency
Denormaliza+on/duplica+on SomeCmes data redundancy is good
15
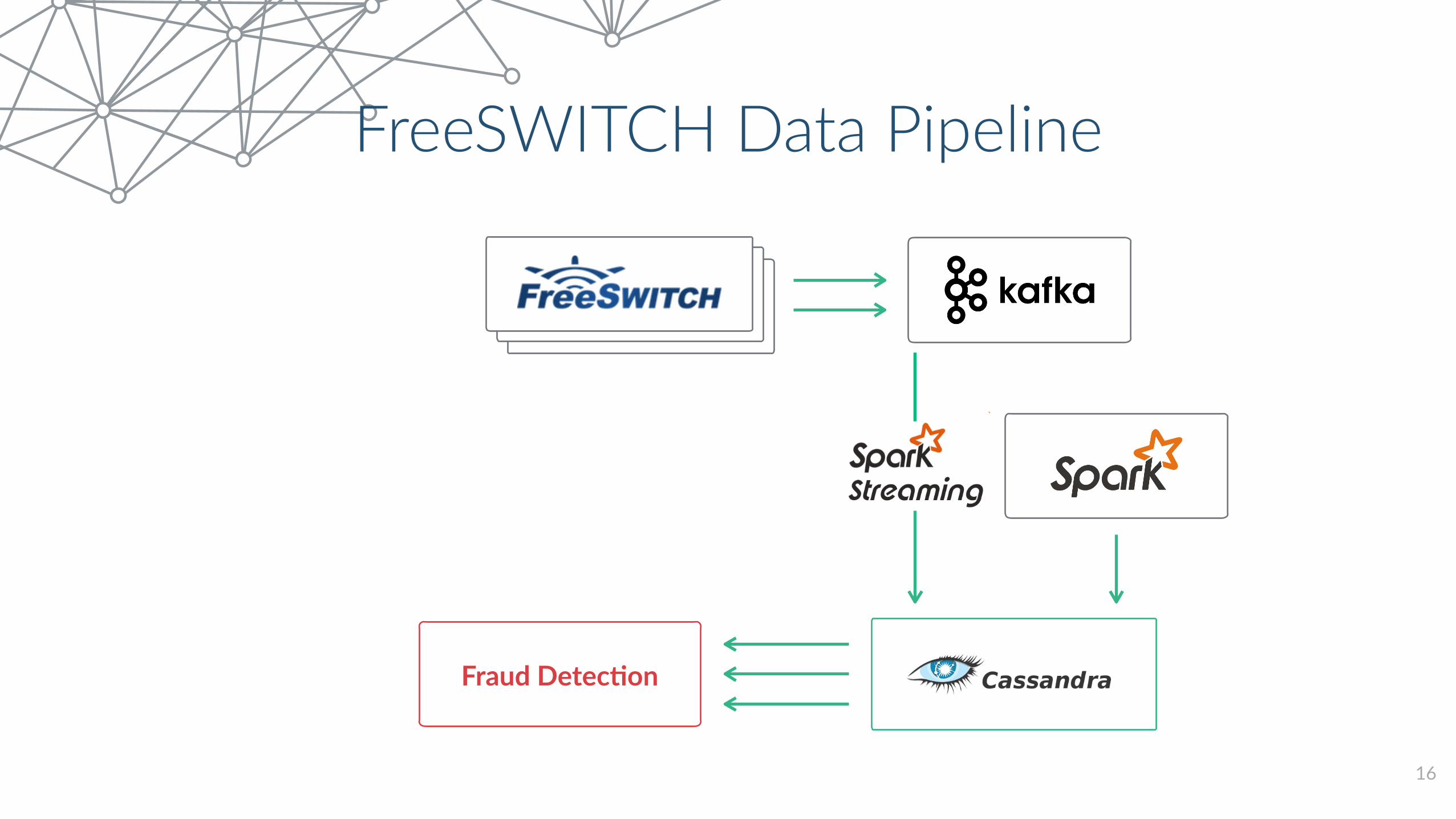
FreeSWITCH Data Pipeline
16
Fraud Detec+on

Fraud Detec5on

18
What is fraud in Telecom?Hint: $$$$
Fraud Detec5on
• How does a carrier detect usage fraud?
• What does usage fraud look like?
19

Steps of Fraud Detec5on
20
1. Collect the data a. Time series
2. Process the data a. Asynchronous b. Scale horizontally
3. Detect anomalies a. StaCc b. Dynamic
4. Alert

Process the DataHow to handle huge datasets without sacrificing speed or quality?
21
Golang + Worker Pools + Asynchronous
Telegraph + InfluxDB + Grafana
Open Source Proprietary

Detect Anomalies
StaCc • Thresholds
Dynamic (PredicCve) • StaCsCcs
- Mean / Standard DeviaCon • Machine Learning
- K Means Clustering
- MulCvariate Gaussian DistribuCon
22

Alert
23
APIMessaging layer
Push Pull

Q & A
Presented by Eugene Shulga Pla;orm Engineer Elana Woldenberg Pla;orm Engineer
Top Related