







Languages
Pages
Legal


It’s all about performance: Using Visual C++ 2012 to maximize your hardware
Jim Radigan - Dev Lead/Architect C++ OptimizerDon McCrady - Dev Lead C++ Amp #2113-013

Mission:
Go under the coversMake folks aware of massive hardware resources Then how C++ exploits it.
….By covering PPL, Amp or “doing nothing” !

3,100,000 Transistors

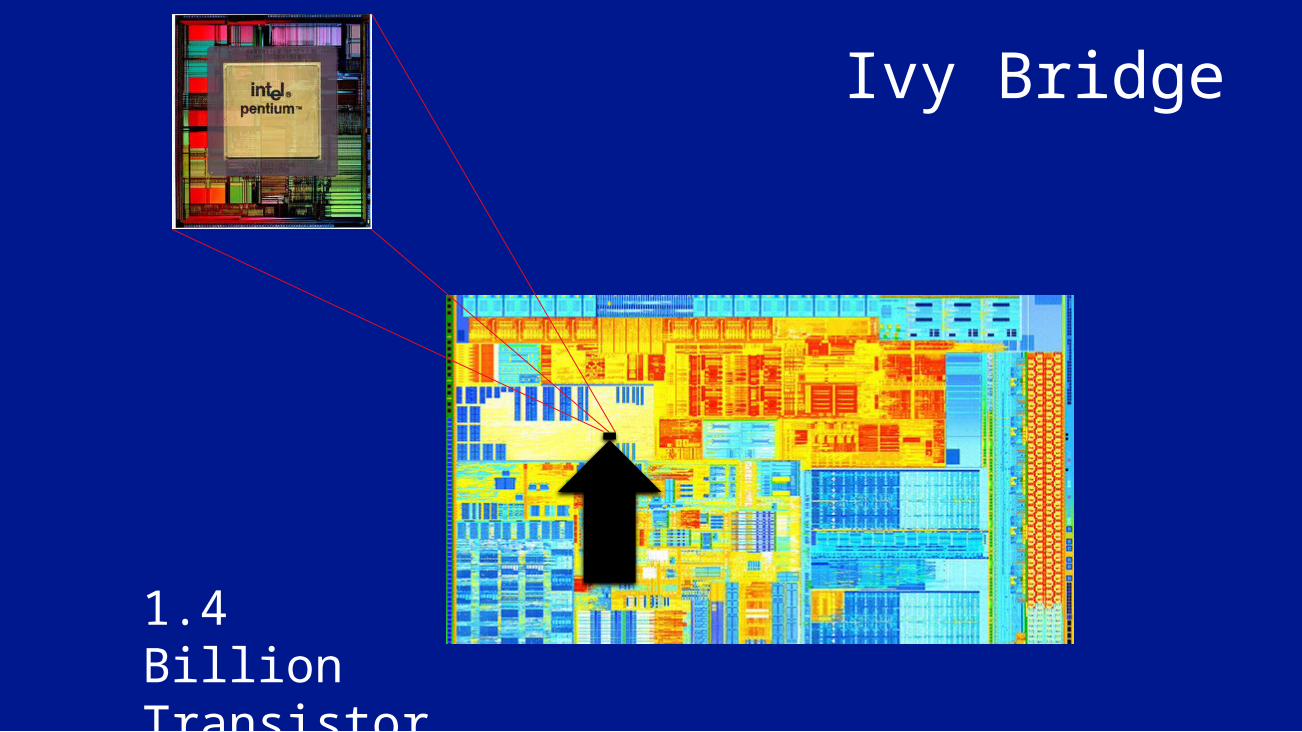
Ivy Bridge
1.4 Billion Transistors

TEGRA 3 - 5 cores / 128 bit vector instructions

Going Native
• You’ve been hearing about native C++ Renaissance
• This is what its all about – exploiting the harware

Ivy Bridge C++ PPL AMP

1. Hardware2. C++ auto vec+par3. C++ PPL4. C++ AMP
Agenda
$87.7 B
$100 .0B +

Super ScalarVectorVector + ParallelSPMD
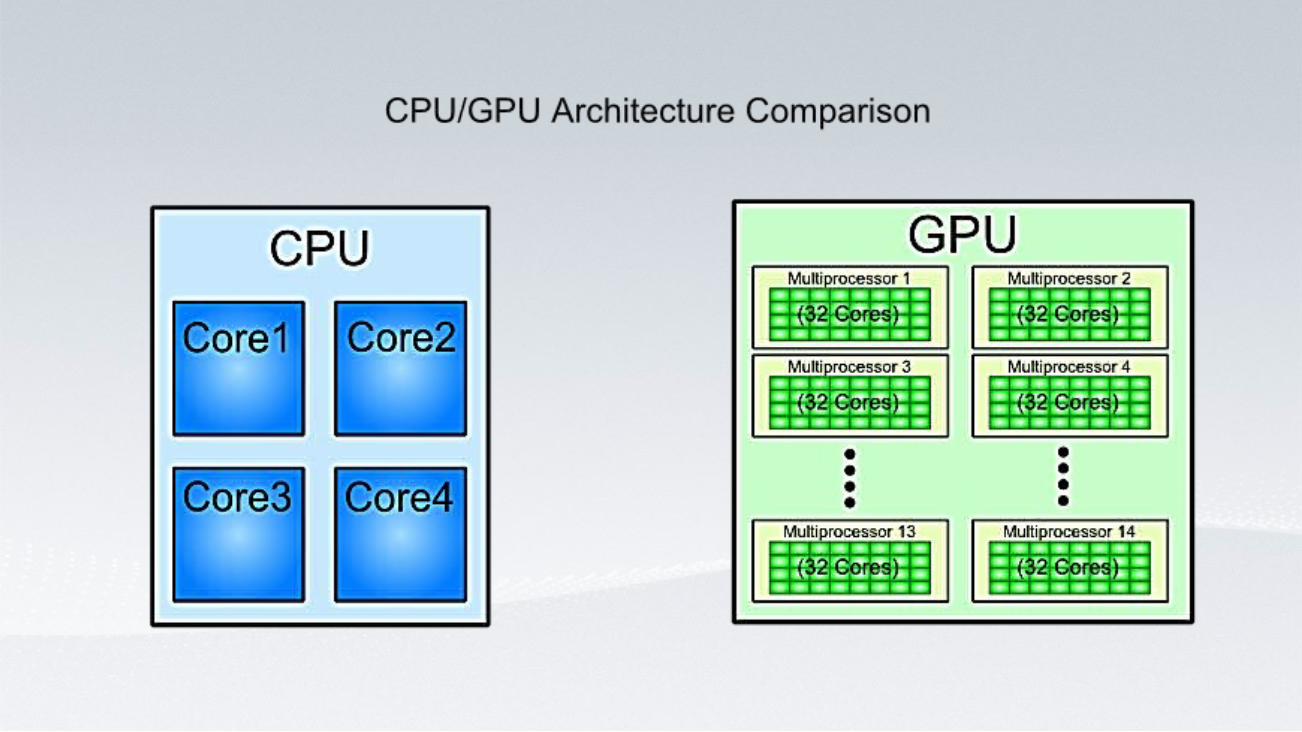
Hardware – Forms of Parallelism
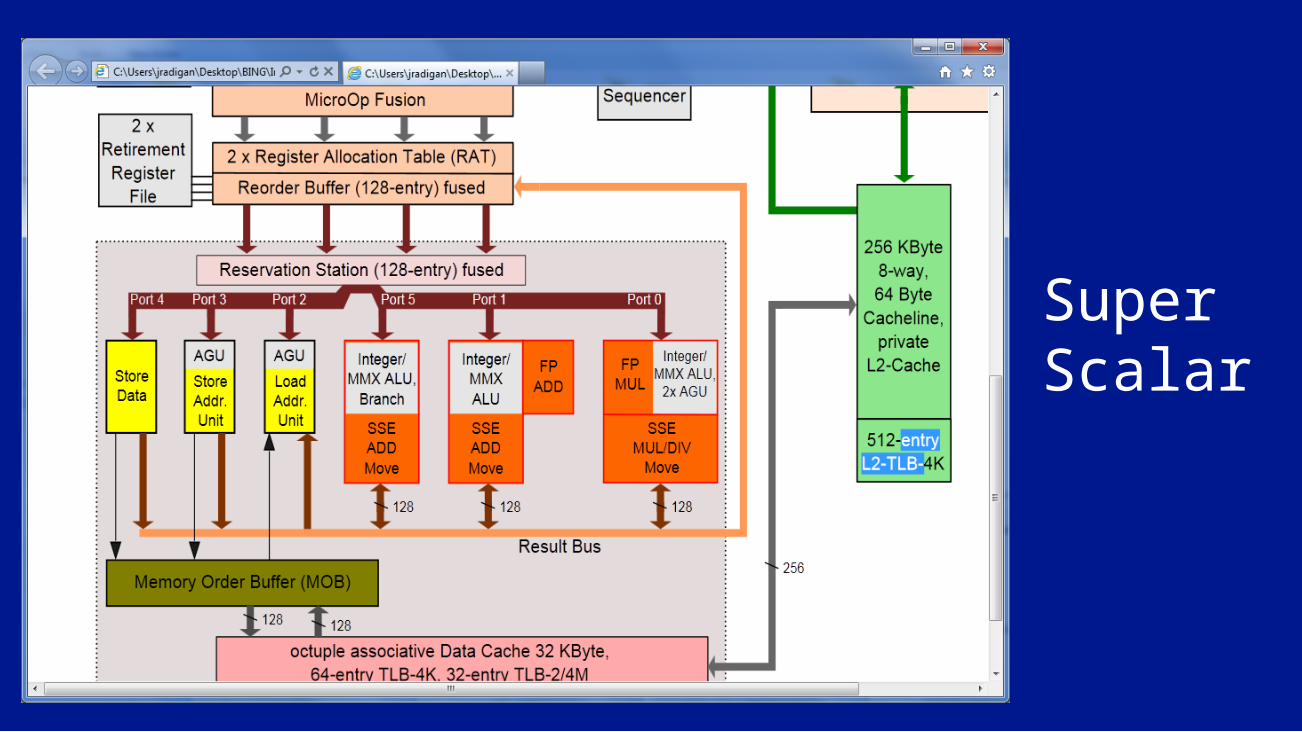
Super Scalar

Super Scalar – instruction level parallelism
• 20% of ILP resides in a basic block• 60% resides across two adjacent “basic blocks”• 20% is scattered though the rest of the code

Super Scalar - needs speculative executionbar;140: r0 = 42141: r1 = r0 + r3142: M[r1] = r1143: zflag = r3 – r2144: jz foo145 …
… … 188: 189:foo; 190: r4 = 0 191: r5 = 0 192: r6 = 0 193: M[r1] = 0

Super Scalar - Path of certain executionbar;
140: r0 = 42
141: r1 = r0 + r3 142: M[r1] = r1
143: zflag = r3 – r2144: jz fooWhen NO branches between a micro-op and retiring to the visible
architectural state – its no longer speculative
foo; 190: r4 = 0
191: r5 = 0
192: r6 = 0
193: M[r1] = 0

Super Scalar – enables C++ vectorizationVOID FOO (int *A, int * B, int *C) {
&& ( &A[1000] < &B[0] ) … && ( &A[1000] < &C[0] ) ) {
IF ( ( _ISA_AVAILABE == 2) …
… FAST VECTOR/PARALLEL LOO P …ELSE … SEQUENTIAL LOOP …
SSE 4.2 ?
Pointer overlap

Vector
B[0] B[1] B[2] B[3]
A[0] A[1] A[2] A[3]
A[0] + B[0] A[1] + B[1] A[2] + B[2] A[3] + B[3]
xmm0
“addps xmm1, xmm0 “
xmm1
xmm1
+

Vector - CPU
+
r1 r2
r3
add r3, r1, r2
SCALAR(1 operation)
v1 v2
v3
+
vectorlength
vadd v3, v1, v2
VECTOR(N operations)
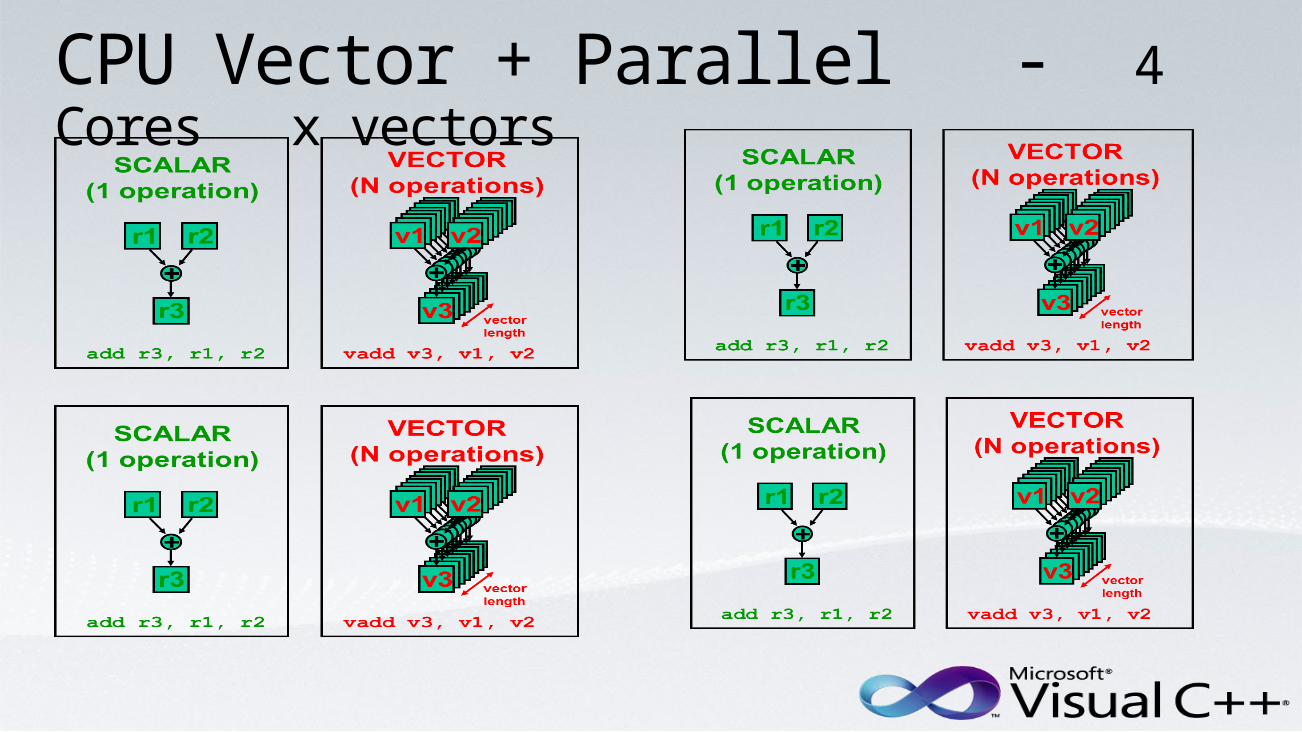
CPU Vector + Parallel - 4 Cores x vectors

… float x = input[threadID]; float y = func(x); output[threadID] = y;…
threadID 76543210
Arrays of Parallel Threads - SPMD
• All threads run the same code (SPMD)• Each thread has an ID that it uses to compute
memory addresses and make control decisions

1. Hardware
2. C++ auto vec+par3. C++ PPL4. C++ AMP
Agenda

C++ Vectorizer – VS2012 Compiler
Super ScalarVectorVector + Parallel

Simple vector add loop
for (i = 0; i < 1000/4; i++){ movps xmm0, [ecx] movps xmm1, [eax] addps xmm0, xmm1 movps [edx], xmm0 }
for (i = 0; i < 1000; i++) A[i] = B[i] + C[i];
Compiler look across loop iterations !

Compiler or “Do it yourself” C++void add(float* A, float* B, float* C, int size) {
for (int i = 0; i < size/4; ++i) { p_v1 = _mm_loadu_ps(A); p_v2 = _mm_loadu_ps(B); res = _mm_sub_ps(p_v1,p_v2); _mm_store_ps(C,res);
….
C++ or Klingon

Vector - all loads before all stores
B[0] B[1] B[2] B[3]
A[0] A[1] A[2] A[3]
A[0] + B[0] A[1] + B[1] A[2] + B[2] A[3] + B[3]
xmm0
“addps xmm1, xmm0 “
xmm1
xmm1
+

Legal to vectorize ?
FOR ( j = 2; j <= 5; j++) A( j ) = A (j-1) + A (j+1)
Not Equal !!
A (2:5) = A (1:4) + A (3:7)
A(3) = ?

Vector Semantics
− ALL loads before ALL stores
A (2:4) = A (1:4) + A (3:7)
VR1 = LOAD(A(1:4))VR2 = LOAD(A(3:7))VR3 = VR1 + VR2 // A(3) = F (A(2) A(4))STORE(A(2:4)) = VR3

Vector Semantics
Instead - load store load store ...
FOR ( j = 2; j <= 257; j++)A( j ) = A( j-1 ) + A( j+1 )
A(2) = A(1) + A(3)A(3) = A(2) + A(4) // A(3) = F ( A(1)A(2)A(3)A(4) )A(4) = A(3) + A(5)A(5) = A(4) + A(6) …

Doubled the optimizer
A ( a1 * I + c1 ) ?= A ( a2 * I’ + c2)

for (size_t j = 0; j < numBodies; j++) { D3DXVECTOR4 r;
r.x = A[j].pos.x - pos.x; r.y = A[j].pos.y - pos.y; r.z = A[j].pos.z - pos.z;
float distSqr = r.x*r.x + r.y*r.y + r.z*r.z; distSqr += softeningSquared;
float invDist = 1.0f / sqrt(distSqr); float invDistCube = invDist * invDist * invDist; float s = fParticleMass * invDistCube;
acc.x += r.x * s; acc.y += r.y * s; acc.z += r.z * s;}
Complex C++ Not just arrays!
Legal vect+par?

Hard! Compiler reports why it failed to vectorize or parallelize
cl /Qvect-report:2 /O2 t.cpp
cl /Qpar-report:2 /O2 t.cpp

Vector + Parallel “4 Cores x vector of 4 ops”

void foo() { #pragma loop(hint_parallel(4)) for (int i=0; i<1000; i++) A[i] = B[i] + C[i];}
void foo() { CompilerParForLib(0, 1000, 4, &foo$par1, A, B, C);}
foo$par1(int T1, int T2, int *A, int *B, int *C){ for (int i=T1; i<T2; i+=4)
movps xmm0, [ecx] movps xmm1, [eax] addps xmm0, xmm1 movps [edx], xmm0}
Parallelism + vector
foo$par1(0, 249, A, B, C); core 1 instrfoo$par1(250, 499, A, B, C); core 2 instrfoo$par1(500, 749, A, B, C); core 3 instrfoo$par1(750, 999, A, B, C); core 4 instr
Runtime Vectorized + and parallel

The Bigger Picture
SCLRUNIT
VECTUNIT
SCLRUNIT
VECTUNIT
SCLRUNIT
VECTUNIT
SCLRUNIT
VECTUNIT

Vector + parallel Demo
Dev10/Win7 - fully optimizednovec_concrt.avi
Dev11/Win8 – fully optimizedvec_omp.avi

Not your grandfather’s vectorizer for (k = 1; k <= M; k++) {
mc[k] = mpp[k-1] + tpmm[k-1]; if ((sc = ip[k-1] + tpim[k-1]) > mc[k]) mc[k] = sc; if ((sc = dpp[k-1] + tpdm[k-1]) > mc[k]) mc[k] = sc; if ((sc = xmb + bp[k]) > mc[k]) mc[k] = sc; mc[k] += ms[k]; if (mc[k] < -INFTY) mc[k] = -INFTY;
dc[k] = dc[k-1] + tpdd[k-1]; if ((sc = mc[k-1] + tpmd[k-1]) > dc[k]) dc[k] = sc; if (dc[k] < -INFTY) dc[k] = -INFTY;
if (k < M) { ic[k] = mpp[k] + tpmi[k]; if ((sc = ip[k] + tpii[k]) > ic[k]) ic[k] = sc; ic[k] += is[k]; if (ic[k] < -INFTY) ic[k] = -INFTY; } }
for (k = 1; k <= M; k++) { dc[k] = dc[k-1] + tpdd[k-1]; if ((sc = mc[k-1] + tpmd[k-1]) > dc[k]) dc[k] = sc; if (dc[k] < -INFTY) dc[k] = -INFTY;
for (k = 1; k <= M; k++) { if (k < M) { ic[k] = mpp[k] + tpmi[k]; if ((sc = ip[k] + tpii[k]) > ic[k]) ic[k] = sc; ic[k] += is[k]; if (ic[k] < -INFTY) ic[k] = -INFTY; }}
for (k = 1; k < M; k++) { ic[k] = mpp[k] + tpmi[k]; if ((sc = ip[k] + tpii[k]) > ic[k]) ic[k] = sc; ic[k] += is[k]; if (ic[k] < -INFTY) ic[k] = -INFTY; }

Vector control flow algebra− ID source code that looks like this (in a loop):
if (X > Y) { Y = X;
}
− vectorizer could create: Y = MAX(X, Y)

Vector control flow “pmax xmm1, xmm0 “
pmax
A[0] > B[0] ? A[0] : B[0]
A[1]> B[1] ? A[1] : B[1]
A[2] > B[2] ? A[2] : B[2]
A[3] > B[3] ? A[3] : B:[3]
B[0] B[1] B[2] B[3]
A[0] A[1] A[2] A[3]
xmm1
xmm1
xmm0

Not your grandfather’s vectorizer
for (k = 1; k <= M; k++) { mc[k] = mpp[k-1] + tpmm[k-1]; mc[k] = MAX( ip[k-1] + tpim[k-1], mc[k]) mc[k] = MAX (dpp[k-1] + tpdm[k-1]) > mc[k]) mc[k] = MAX (xmb + bp[k], mc[k]) mc[k] = MAX (mc[k], -INFTY) } for (k = 1; k <= M; k++) {
dc[k] = dc[k-1] + tpdd[k-1]; dc[k] = MAX (mc[k-1] + tpmd[k-1],dc[k]) dc[k] = MAX (dc[k], -INFTY) } for (k = 1; k <= M; k++) { ic[k] = mpp[k] + tpmi[k]; ic[k] = MAX (ip[k] + tpii[k],ic[k]) ic[k] += is[k]; ic[k] = MAX (ic[k],-INFTY) }}
−
if ( __isa_availablility > SSE2 && NO_ALIASISIN ) {
Vector loop
Scalar loop
Vector loop

Vector Math Libary
15x faster

for (i=0; i<n; i++) { a[i] = a[i] + b[i]; a[i] = sin(a[i]);}
for(i=0; i<n; i=i+VL) { a(i : i+VL-1) = a(i : i+VL-1) + b(i : i+VL-1); a(i : i+VL-1) = _svml_Sin(a(i : i+VL-1));}
NEW Run-Time Library
HW SIMD instruction
Vectorization – targeting vector library

Parallel and vector – on by default
for (int i = 0; i < _countof(a); ++i) {
float dp = 0.0f; for (int j = 0; j < _countof(a); ++j){ float fj = (float)j; dp += sin(fj) * exp(fj); } a[i] = dp; }
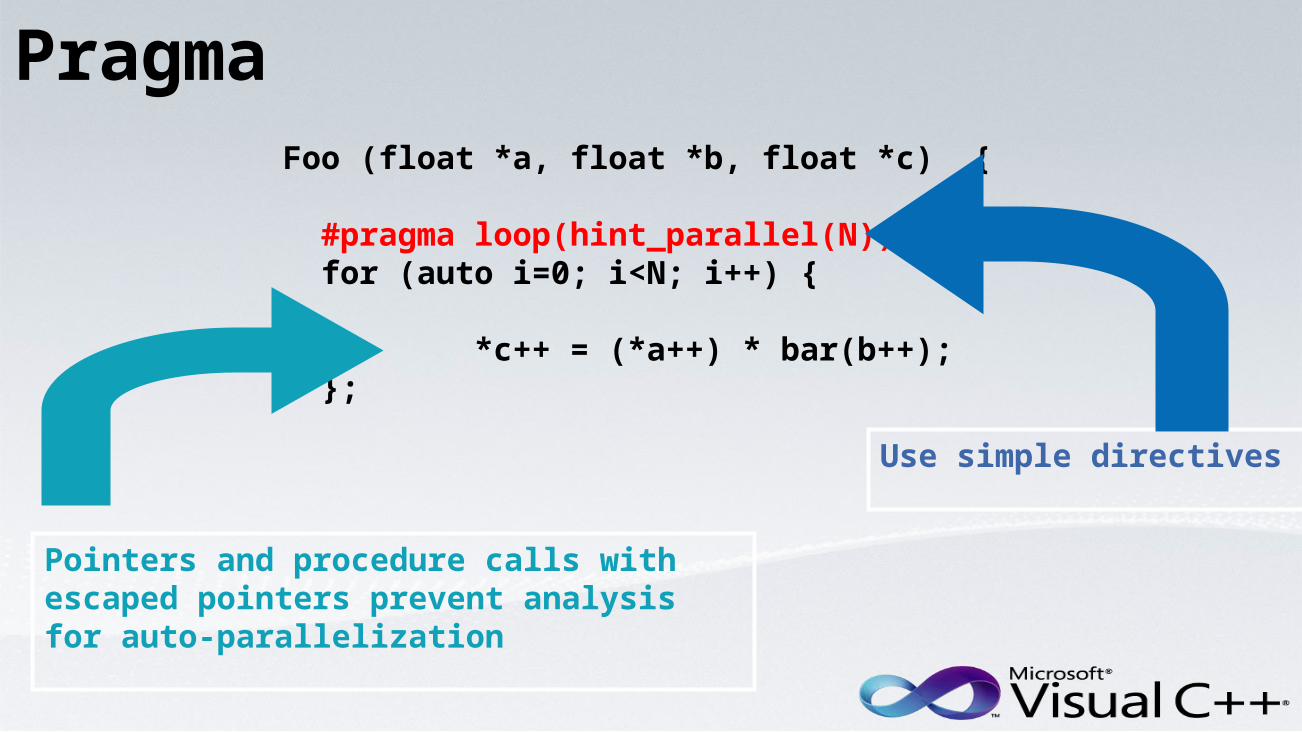
Foo (float *a, float *b, float *c) { #pragma loop(hint_parallel(N)) for (auto i=0; i<N; i++) {
*c++ = (*a++) * bar(b++); };
Pointers and procedure calls with escaped pointers prevent analysis for auto-parallelization
Use simple directives
Pragma
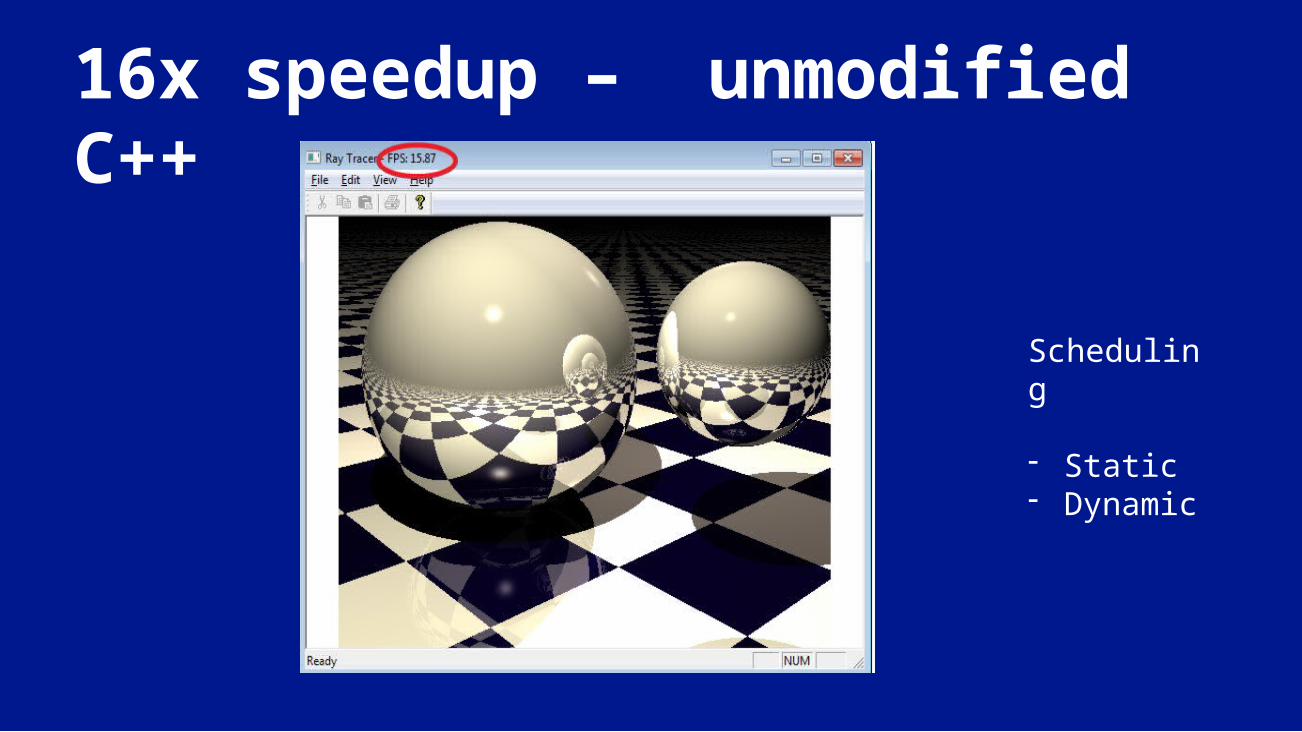
16x speedup – unmodified C++
Scheduling
- Static- Dynamic

…and compiler selects scheduler strategyfor (int l = top; l < bottom; l++){ for (int m = left; m < right; m++ ){
int y = *(blurredImage + (l*dimX) +m);
ySourceRed += (unsigned int) (y & 0x00FF0000) >> 16; ySourceGreen += (unsigned int) (y & 0x0000ff00) >> 8; ySourceBlue += (unsigned int) (y & 0x000000FF); averageCount++;
}}

Software – “no magic bullet”
C++ vectorizer -cpu
for (int i=0; i<1000; i++) A[i] = B[i] + C[i];
C++ PPL- cpu
parallel_for (0, 1000, 1, [&](int i) { A[i] = B[i] + C[i]; } );
C++ AMP - gpu
parallel_for_each ( e, [&] (index<2> idx) restrict(amp)
{ c[idx] = b[idx] + a[idx]; } );copy(c,pC);

Software
C++ vectorizer
for (int i=0; i<1000; i++)
C++ PPL
parallel_for (0, 1000, 1, [&](int i) { } );
C++ AMP
parallel_for_each( e, [&] (index<2> idx) restrict(amp)
{ } );copy(c,pC);

Built with C++
Windows 8 SQL Office
Mission critical correctness and compile time

Parallel Programming Libaray
PPL for C++

3 PPL constructs – simple but huge value
• parallel_invoke( [&]{quicksort(a, left, i-1, comp);}, [&]{quicksort(a, i+1, right, comp);} );
• parallel_for (0, 100, 1, [&](int i) { /* …*/ } );
vector<int> vec; • parallel_for_each (vec.begin(), vec.end(), [&](int&
i) { /* ... */ });

PPL and DEMO
• Dynamic Range Stealing• Scalable• Low Task Granularity

Mandelbrot - #include <ppl.h>
parallel_for (0, dim, [&](int i) { for (int j=0; j<dim; ++j)
setMandelbrotColor (j,i,a,dim, maxIter, minReal, minImaginary, maxReal); });
for (int i = 0; i < dim; ++i) { for (int j=0; j<dim; ++j) { setMandelbrotColor (j,i,a,dim, maxIter, minReal, minImaginary, maxReal); }}
{ if (iter >= maxIter) *a=0xFF000000; //black else //a gradient from red to yellow { unsigned short redYellowComponent = ~(iter * 32000/maxIter) ; unsigned int xx = 0x00FFF000; //0 Alpha + RED xx = xx|redYellowComponent; xx <<= 8; *a = xx; } }

C++ AMP
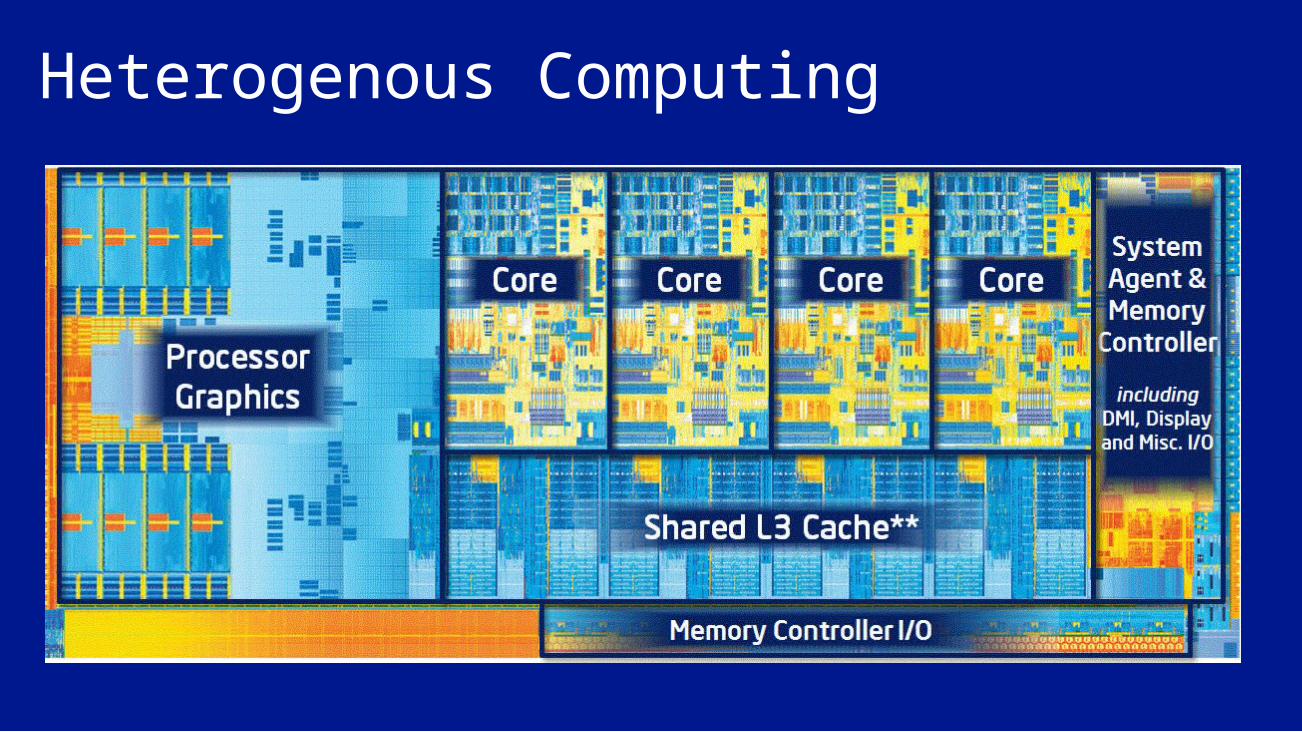
Heterogenous Computing

C++ AMP is……a programming model for expressing data parallel algorithms and exploiting heterogeneous systems using mainstream tools for productivity, portability and performance.
…just C++, with a language extension and supporting library.
…part of Visual Studio 2012
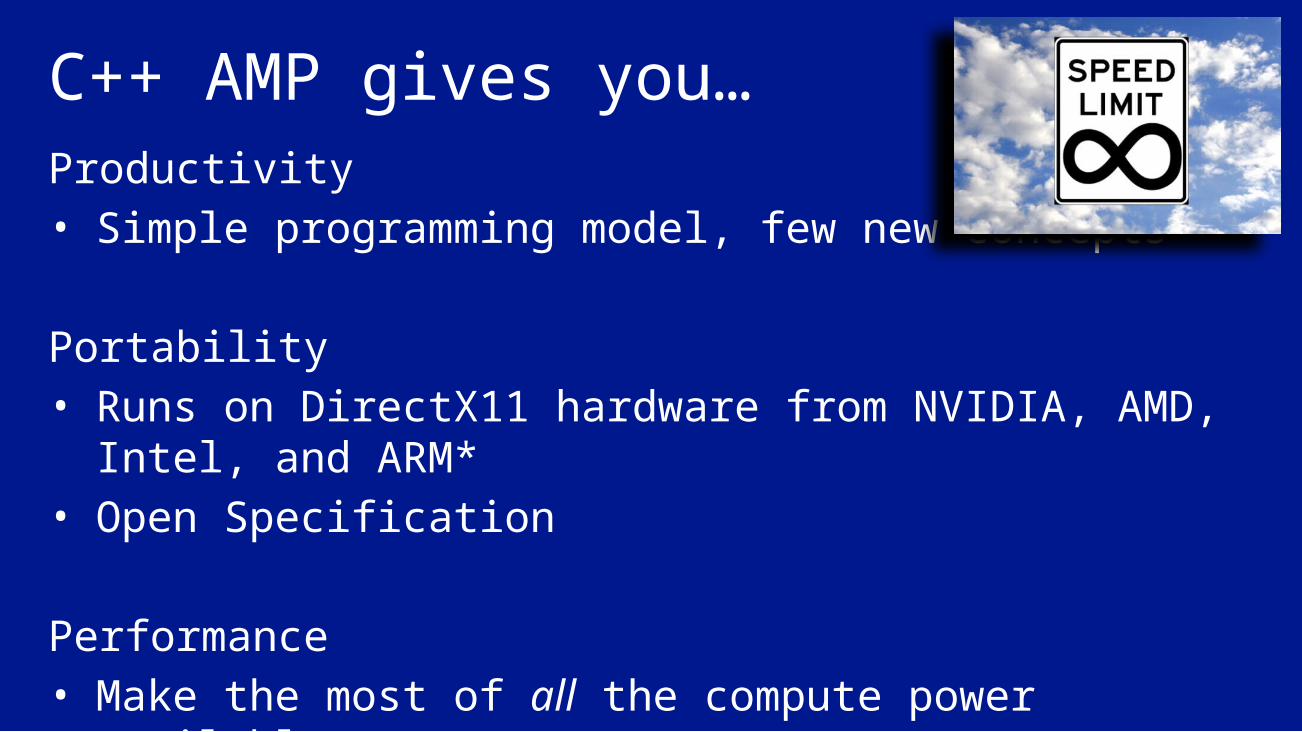
C++ AMP gives you…Productivity• Simple programming model, few new concepts
Portability• Runs on DirectX11 hardware from NVIDIA, AMD, Intel,
and ARM*• Open Specification
Performance• Make the most of all the compute power available

1. #include <iostream>2. 3.
4. int main()5. {6. int v[11] = {'G', 'd', 'k', 'k', 'n', 31, 'v', 'n', 'q', 'k', 'c'}; 7. 8. for (int idx = 0; idx < 11; idx++)9. {10. v[idx] += 1;11. } 12. for(unsigned int i = 0; i < 11; i++)13. std::cout << static_cast<char>( v[i]);14. }

1. #include <iostream>2. #include <amp.h>3. using namespace concurrency;
4. int main()5. {6. int v[11] = {'G', 'd', 'k', 'k', 'n', 31, 'v', 'n', 'q', 'k', 'c'}; 7. 8. for (int idx = 0; idx < 11; idx++)9. {10. v[idx] += 1;11. } 12. for(unsigned int i = 0; i < 11; i++)13. std::cout << static_cast<char>( v[i]);14. }
amp.h: header for C++ AMP libraryconcurrency: namespace for library

1. #include <iostream>2. #include <amp.h>3. using namespace concurrency;
4. int main()5. {6. int v[11] = {'G', 'd', 'k', 'k', 'n', 31, 'v', 'n', 'q', 'k', 'c'}; 7. array_view<int> av(11, v);8. for (int idx = 0; idx < 11; idx++)9. {10. v[idx] += 1;11. }
12. for(unsigned int i = 0; i < 11; i++)13. std::cout << static_cast<char>( v[i]);14. }
array_view: wraps the data to operate on the accelerator. array_view variables captured and
associated data copied to accelerator (on demand)

1. #include <iostream>2. #include <amp.h>3. using namespace concurrency;
4. int main()5. {6. int v[11] = {'G', 'd', 'k', 'k', 'n', 31, 'v', 'n', 'q', 'k', 'c'}; 7. array_view<int> av(11, v);8. for (int idx = 0; idx < 11; idx++)9. {10. av[idx] += 1;11. }
12. for(unsigned int i = 0; i < 11; i++)13. std::cout << static_cast<char>( av[i]);14. }
array_view: wraps the data to operate on the accelerator. array_view variables captured and
associated data copied to accelerator (on demand)

C++ AMP “Hello World”
• File -> New -> Project• Empty Project• Project -> Add New Item• Empty C++ file
1. #include <iostream>2. #include <amp.h>3. using namespace concurrency;
4. int main()5. {6. int v[11] = {'G', 'd', 'k', 'k', 'n', 31, 'v', 'n', 'q', 'k', 'c'}; 7. array_view<int> av(11, v);8. parallel_for_each(av.extent, [=](index<1> idx) restrict(amp)9. {10. av[idx] += 1;11. }); 12. for(unsigned int i = 0; i < 11; i++)13. std::cout << static_cast<char>(av[i]);14. }
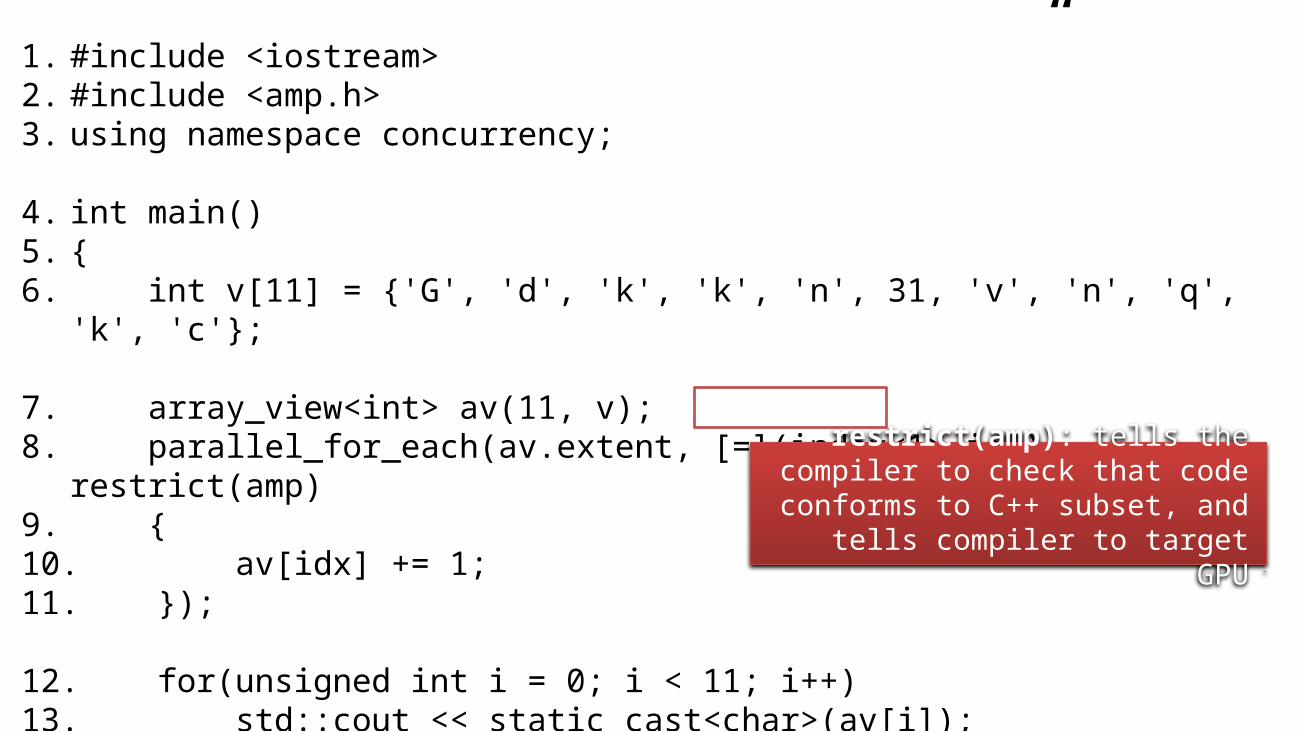
parallel_for_each: execute the lambda on the accelerator once per thread
extent: the parallel loop bounds or “shape”
index: the thread ID that is running the lambda, used to index into data
C++ AMP “Hello World”
• File -> New -> Project• Empty Project• Project -> Add New Item• Empty C++ file
1. #include <iostream>2. #include <amp.h>3. using namespace concurrency;
4. int main()5. {6. int v[11] = {'G', 'd', 'k', 'k', 'n', 31, 'v', 'n', 'q', 'k', 'c'}; 7. array_view<int> av(11, v);8. parallel_for_each(av.extent, [=](index<1> idx) restrict(amp)9. {10. av[idx] += 1;11. }); 12. for(unsigned int i = 0; i < 11; i++)13. std::cout << static_cast<char>(av[i]);14. }
restrict(amp): tells the compiler to check that code conforms to C++ subset, and
tells compiler to target GPU
C++ AMP “Hello World”
• File -> New -> Project• Empty Project• Project -> Add New Item• Empty C++ file
1. #include <iostream>2. #include <amp.h>3. using namespace concurrency;
4. int main()5. {6. int v[11] = {'G', 'd', 'k', 'k', 'n', 31, 'v', 'n', 'q', 'k', 'c'}; 7. array_view<int> av(11, v);8. parallel_for_each(av.extent, [=](index<1> idx) restrict(amp)9. {10. av[idx] += 1;11. }); 12. for(unsigned int i = 0; i < 11; i++)13. std::cout << static_cast<char>(av[i]);14. }
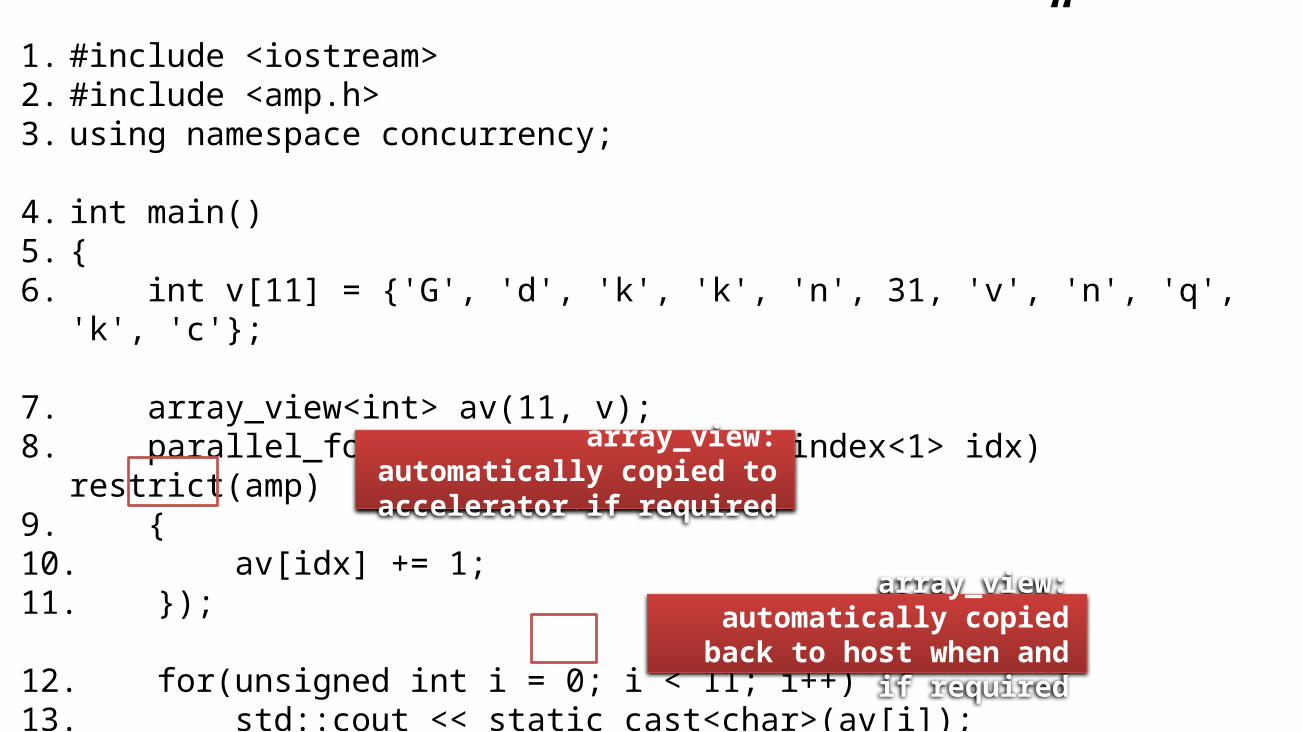
array_view: automatically copied to accelerator if required
array_view: automatically copied back to host when and if required

Resourcesbook http://www.gregcons.com/cppamp/
videos http://channel9.msdn.com
spechttp://blogs.msdn.com/b/nativeconcurrency/archive/2012/02/03/c-amp-open-spec-published.aspx
forum http://social.msdn.microsoft.com/Forums/en/parallelcppnative/threads
http://blogs.msdn.com/nativeconcurrency/

Processor Roadmap - Going native!!
32nm 22nm 22nm 14nm 10nm
Nehalem
Nehalem Westmere
Sandy Bridge
Sandy Bridge Ivy Bridge
Haswell
Haswell Broadwell
Skylake
Skylake Skymont
256 bit AVX(2)256 bit AVX128 bit SSE
You are here (3D tri-state transistors)
Top Related