






Languages
Pages
Legal


B-Trees
Chapter 9

Limitations of binary search
• Though faster than sequential search, binary search still requires an unacceptable number of accesses for data files with more than 1000 records
• Resorting the index after each record is inserted is not practical if the index cannot be kept in memory

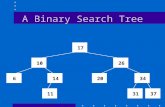
9.3 Binary search tree index
• Tree structure includes pointers to left and right index nodes in addition to a key (and data record pointer)
• Each left node defines a subtree with smaller keys, each right node with larger
• Pointers make sorting the index unnecessary. Why?

Binary tree balance problem
• Building the tree from the root by inserting randomly ordered incoming records results in paths to some leaves that are much longer than others
• Performance is unacceptably poor for keys on remote paths
• Keeping the tree balanced is non-trivial

KF
FB SD
WSPAHNCL
AX DE FT JD NR RF TK YJ
LV
MB
NP
TS
TM
ND
LA
NK
UF

A
YW
X
H I M
Balanced AVL tree

9.3.2 Paged binary trees
• multiple binary nodes are located on the same page (sector) on secondary storage
• each disk seek returns several nodes in a search path, reducing search complexity from log2N to logk+1N
• random insertions cause imbalance which cannot be easily fixed because keys must be shifted to different pages throughout the tree

Multi-record index
• number of records in a data file exceeds the maximum number of keys allowed in a single record index
• index must still be maintained in sorted order (across multiple records) to allow binary search

Searching multi-record index
• total number of keys (data records) is N
• each index record holds k keys
• for binary search, first look at the index record in the middle of the index file
• compare search key to smallest and largest keys in current index record

record 1keys 1 : k
record 2keys k+1 : 2k
record N/2kkeys N/2k + 1 : N/2
record N/k + 1keys N - N mod k : N
Starting recordfor binary search
Multi-record index file

9.4 Multilevel indexing
• Level-1 index is a multi-record index for the entire data file
• Each higher level index below the root is a multi-record index to the index below it
• Root level index is a single record• Though multilevel index is entry sequenced
in that the records at each level need not be ordered, record insertion is still a problem

9.5 B-trees• insertion problem of simple multilevel
index is solved by (1) using partially filled index records(2) splitting records when they fill up, instead of
shifting keys to the next record
• when an index node is split, the largest key in the new node is promoted to the next higher index level
• at worst, insertion causes one node at each level to split

DC TS
Initial node contains keys C, D, S, and T.
C D S T
A
D T
A
A DC
Figure 9.14 Growth of a B-tree
Insertion of A causes node to split.A new root node is created and the largest key in each leaf node placed in the root.
Key A can now be inserted in the correct leaf node.

9.7 B-Tree implementation
• Class BTreeNode (supports index record)– subclass of SimpleIndex class– template class allows different types of keys– uses same Search method as SimpleIndex
• Class BTree (supports B-tree index file)– uses RecordFile object to access index file– FindLeaf method sets an array of pointers,
Nodes, to define a search path

9.9-10 Formal definition
• The order of a B-tree (m) is the maximum number of descendents for each node.
• Every node except the root and leaves must have at least m/2 descendents.
• The root must have at least 2 descendents unless it is a leaf (i.e., the only node).
• All leaves are on the same level.• The leaf level is a complete index.

Implications of formal definition
• Path length is the same for all searches, and is equal to the tree depth, since only the leaf nodes point to data records.
• The worst case depth can be computed for a B-tree with a given order and number of keys (see § 9.11 in the text)

Deletion
• maintaining balance requires that each index node hold no more than m keys and no fewer than m/2 keys
• when insertion causes overflow (more than m keys) in a node, it is split
• what happens when deletion results in “underflow” (fewer than m/2 keys)?

Situations arising from deletion
(Figure 9.21)
a) Victim node has more than m/2 keys, and key to be deleted is not the largest key.
b) Victim node has more than m/2 keys, and key to be deleted is the largest key.
c) Victim node has exactly m/2 keys.

Merging and Redistribution
• Needed for situation c), when deletion leaves fewer than m/2 keys.
• Two options:– merge with a sibling that has m/2 or
m/2 + 1 keys
– move at least 1 key from a sibling that has at least m/2 + 1 keys

Questions• What is the minimum and maximum
number of siblings a node can have?• Is it possible that there are no siblings
available with which to merge or redistribute after a deletion?
• Is it possible to have a choice of either merging with or redistributing from the same sibling?
• Is it ever possible to merge two nodes without first deleting at least one key?

B*tree and Redistribution
• Redistribution may be used optionally to improve storage utilization
• B*tree uses redistribution during insertion to maintain each node 2/3 full (rather than 1/2, as results from simply splitting)
• Notes on B*trees by Jan Jannink: http://www.cise.ufl.edu/~jhammer/classes/b_star.html

9.15 Page buffering
• Keep a page buffer, or collection of index pages in memory.
• Whenever an index page is needed, first look for it in the page buffer. If it’s there, you save seeking for it on the disk.
• If a needed index page is not in the buffer, load it into the buffer from the disk

Page replacement schemes
• If a needed index page is not in the buffer, but the buffer is full, a page must be replaced.
• LRU replacement scheme is based on the assumption of temporal locality.
• Page height scheme favors pages on higher levels. Why?
Top Related