






Languages
Pages
Legal


Advanced Computing Technology Center
May, 2005
pSIGMA
A Symbolic Instrumentation Infrastructure to Guide Memory Analysis
Simone Sbaraglia

2
Advanced Computing Technology Center
May, 2005
– Why pSIGMA?
– pSIGMA Highlights
– pSIGMA Infrastructure
– Examples
– Next steps
– Questions/Answers
AGENDA

3
Advanced Computing Technology Center
May, 2005
Why pSIGMA?
– Understanding and tuning memory system performance of scientific applications is a critical issue, especially on shared-memory systems
– None of the memory analysis tools currently available combines fine-grained information and flexibility (what-if questions and architectural changes)
– To implement performance tools, we rely on instrumentation libraries (DPCL, Dyninst).
– These libraries are not performance-oriented:– If the probe is invoked on a mem. operation, there is no information about the effect of the mem. op.
on the memory subsystem (hit/miss, prefetches, invalidations, c2c transfers, evictions etc)
– The description of the rules that should trigger the probe cannot use performance metrics (“invoke the probe on each L1 miss”)
– These libraries are not symbolic:– If a probe function is invoked on a memory operation, there is no information about which data
structure/function the mem op refers to.
– The description of the rules that should trigger the probe cannot use symbolic entities in the source program (“invoke the probe every time the array A is touched”)

4
Advanced Computing Technology Center
May, 2005
pSIGMA Highlights• Symbolic, performance-oriented infrastructure for instrumentation of parallel
applications.
• Main Features:
– Injects user-supplied probes into a parallel application
– Operates on the binary, allows compiler optimization
– Provides symbolic and memory-performance information to the probes
– The rules that should trigger the probe are specified using symbolic names and memory-related performance metrics
– Provides information at the granularity of individual instructions
– Activate/deactivate the instrumentation during program execution
– Dynamically turn on/off generation/handling of certain events based on other events
– Supports MPI and (almost) OMP applications
– Builtin probes to detect memory bottlenecks on a data-structure basis
– Builtin parametric memory simulator
– Prefetching API for user-defined prefetching algorithms with builtin IBM algorithms
– Simulate data-structure changes (padding)
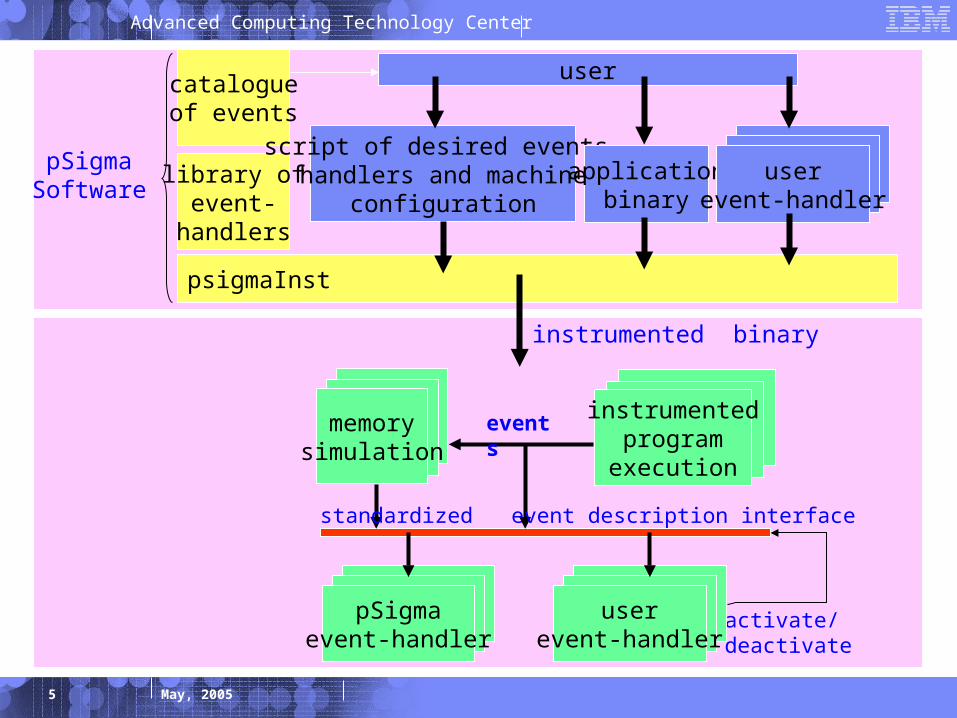
5
Advanced Computing Technology Center
May, 2005
activate/deactivate
instrumented binary
pSigmaSoftware
catalogueof events
library ofevent-
handlers
psigmaInst
script of desired events,handlers and machine
configurationapplication
binaryuser
event-handler
user
duringexecution
memorysimulation
instrumentedprogram
execution
userevent-handler
pSigmaevent-handler
instrumented binary
standardized event description interface
events

6
Advanced Computing Technology Center
May, 2005
Specification of Events: event_description file
• Set of directives, each specifying an event and the corresponding action
• An event is either a predicate on the current operation (eg. operation is a load, or was an L1 miss) or a predicate on the state of the system (L1 miss count exceeded a constant)
• Events can use symbolic names and performance metrics
• Events can be combined using logical operators
• Events can be qualified by a context, if the event is to be considered only for certain data structures/functions.
• The event description also specifies the parameters of the memory system to simulate

7
Advanced Computing Technology Center
May, 2005
Specification of Events: event_description file
directive ::= on event [and/or event and/or …] do actionevent ::= instrEvent [context]
| counter [context] relOp counter [context]
instrEvent ::= load, store, L1miss, L2hit, malloc, free, f_entry, f_exit,…context ::= for data-structure in function
counter ::= L1Misses, L2Misses, Loads, Hits, …relOp ::= greater than, smaller than, equal to
Examples:
– on Load for A in F do call myHandler
– on L1Miss for A in F do call myHandler
– on L1Miss for A in F and (L1Misses for A in F > 1000) do call myHandler
• A GUI is provided to build the event_description file, instrument and run the application

8
Advanced Computing Technology Center
May, 2005

9
Advanced Computing Technology Center
May, 2005

10
Advanced Computing Technology Center
May, 2005

11
Advanced Computing Technology Center
May, 2005
Standardized event description interfaceThe event handlers have access to the following information:
• InstructionData: characterizes the instruction that triggered the event
– Instruction that triggered the event– Virtual address of the instruction– FileName, FunctionName, lineNum of the instruction– Opcode (load,store, function call, …)– Address and symbol loaded or stored– Current stack pointer– Data loaded or stored– Address and number of bytes allocated or freed
• MemoryData: characterizes the memory impact of the instruction
– Hit/miss in each level, evicted lines, prefetched lines, …
• CumulativeData: represents the current state of the system
– InstructionsExecuted, Loads, Stores, Hits, Misses, PrefetchedLines, PrefetchedUsedLines, …

12
Advanced Computing Technology Center
May, 2005
Example:parameter (nx=512, ny=512)real a1(nx,ny), a2(nx,ny), a3(nx,ny)do id = 1,nd do jd=1,nd do iy=1,ny do ix=1,nx ixy = ix + (iy-1)*nx a1(ix,iy) = a1(ix,iy) + c11(ixy, id, jd)*b1(ixy, jd) + c12(ixy, id, jd)*b2(ixy, jd) + … a2(ix,iy) = a2(ix,iy) + c11(ixy, id, jd)*b1(ixy, jd) + c12(ixy, id, jd)*b2(ixy, jd) + … a3(ix,iy) = a3(ix,iy) + c11(ixy, id, jd)*b1(ixy, jd) + c12(ixy, id, jd)*b2(ixy, jd) + … end do end do end doend do
Event Description File:on load for a1 do call myHandleron store for a1 do call myHandleron load for a2 do call myHandleron store for a2 do call myHandleron load for a3 do call myHandleron store for a3 do call myHandlernCaches 2TLBEntries 256TLBAssoc 2-wayTLBRepl LRU…

13
Advanced Computing Technology Center
May, 2005
Event Handler:
• myHandler is invoked when a1, a2, a3 are touched. It computes the TLB Hit Ratio for a1, a2, a3
void myHandler(unsigned int *p) {resultPtr cacheresult;char *symbName;
/* get a pointer to the cache result structure */ cacheresult = getCacheResult(0);
/* symbol name */ symbName = getSymbolName(p)
if (!strcmp(symbName, "a1@array1")) { Accesses[0]++; Hits[0] += cacheresult->tlbResult[0]; } else if (!strcmp(symbName, "a2@array1")) { Accesses[1]++; Hits[1] += cacheresult->tlbResult[0]; } else if (!strcmp(symbName, "a3@array1")) { Accesses[2]++; Hits[2] += cacheresult->tlbResult[0]; }}

14
Advanced Computing Technology Center
May, 2005
Memory Profile for a1, a2, a3L1 L2 TLB
Data: a1Load Hit Ratio: 96% 99% 7%Store Hit Ratio: 99% 16% -
Data: a2Load Hit Ratio: 97% 50% 7%Store Hit Ratio: 99% 16% -
Data: a3Load Hit Ratio: 96% 59% 0.1%Store Hit Ratio: 99% 17% -
Restructured Kernel:
parameter (nx=512, ny=512)real a1(nx+1,ny), a2(nx+1,ny), a3(nx+1,ny)…
New Memory Profile for a1, a2, a3
L1 L2 TLBData: a1
Load Hit Ratio: 96% 99% 99%Store Hit Ratio: 99% 16% -
Data: a2Load Hit Ratio: 97% 50% 98%Store Hit Ratio: 99% 16% -
Data: a3Load Hit Ratio: 96% 59% 96%Store Hit Ratio: 99% 17% -

15
Advanced Computing Technology Center
May, 2005
Builtin event handlers: Memory Profile
– Execute functional cache simulation and provide memory profile
– Power3/Power4 architectures prefetching implemented
– Write-Back/Write-Through caches, replacement policies etc
archFile specifies:– Number of cache levels
– Cache size, line size, associativity, repl. policy, write policy, prefetching algorithm
– Coherency level
– Multiple machines can be simulated at once

16
Advanced Computing Technology Center
May, 2005
SiGMA Memory Analysis Flow
sourcefiles
tracefiles
binary
sigmaInst
Repository
architectureparameters
QueryOutputMemory
Profile
SigmaInst
binary
SimulatorAddress
Map

17
Advanced Computing Technology Center
May, 2005
Memory Profile:
Provide counters such as hits, misses, cold misses foreach cache level
each function
each data structure
each data structure within each function
Output sorted by the SIGMA memtime:SUM( LoadHits(i)*LoadLat(i) + StoreHits(i)*StoreLat(i) ) +
#TLBmisses * Lat(TLBmiss)
memtime should track wall time for memory bound applications

18
Advanced Computing Technology Center
May, 2005
L1 L2 L3 TLB MEM FUNCTION: calc1 (memtime = 0.0050)
Load Acc/Miss/Cold 522819/2252/1 2252/345/0 345/0/0 784419/126/0 0/-/- Load Acc/Miss Ratio 232 6 - 6225 - Load Hit Ratio 99.57% 84.68% 100.00% 99.98% - Est. Load Latency 0.0008 sec 0.0000 sec 0.0000 sec 0.0001 sec 0.0000 sec Load Traffic - 238.38 Kb 43.12 Kb - 0.00 Kb ………
FUNCTION: calc2 (memtime = 0.0042)
Load Acc/Miss/Cold 622230/2631/0 2631/1661/0 1661/0/0 814269/94/0 0/-/- Load Acc/Miss Ratio 236 1 - 8662 - Load Hit Ratio 99.58% 36.87% 100.00% 99.99% - Est. Load Latency 0.0010 sec 0.0000 sec 0.0001 sec 0.0001 sec 0.0000 sec Load Traffic - 121.25 Kb 207.62 Kb - 0.00 Kb ………
L1 L2 L3 TLB MEM DATA: u (memtime = 0.0012)
Load Acc/Miss/Cold 167710/708/0 708/317/0 317/0/0 216097/31/0 0/-/- Load Acc/Miss Ratio 236 2 - 6970 - Load Hit Ratio 99.58% 55.23% 100.00% 99.99% - Est. Load Latency 0.0003 sec 0.0000 sec 0.0000 sec 0.0000 sec 0.0000 sec Load Traffic - 48.88 Kb 39.62 Kb - 0.00 Kb ……….DATA: v (memtime = 0.0012)
Load Acc/Miss/Cold 167710/721/0 721/316/0 316/0/0 216097/31/0 0/-/- Load Acc/Miss Ratio 232 2 - 6970 - Load Hit Ratio 99.57% 56.17% 100.00% 99.99% - Est. Load Latency 0.0003 sec 0.0000 sec 0.0000 sec 0.0000 sec 0.0000 sec Load Traffic - 50.62 Kb 39.50 Kb - 0.00 Kb ……….
Memory Profile Output

19
Advanced Computing Technology Center
May, 2005
Memory Profile Viewer – Data Structure Focus

20
Advanced Computing Technology Center
May, 2005
Output from any subspace in the 3D space
SIGMA Repository
Cont
rol
Stru
ctur
e
Data Structure
Metr
ics
Select from list of data Structure in the .addr file
File,Function,Code segment
TLB Misses,Cache Misses,Hit Ratio.…

21
Advanced Computing Technology Center
May, 2005
Visualiz: Repository and Query Language
• Build tables and lists
• ASCII and bar-chart output
• Support arithmetic operators (+ - * / ./)
• Compute derived Metrics

22
Advanced Computing Technology Center
May, 2005
Partial Instrumentation
Statically select functions to instrument:sigmaInst –d –dfunc f1,f2,…,fn appbin
Dynamically select code sections to instrument:#include "signal_sigma.h“
for (lp=1; lp<NIT; lp++) { /* start sigma */ if ((lp == 2) || (lp==7)) { signal_sigma(TRACE_ON, lp); }
for ( i=0; i<n; i++ ) { for ( k=0; k< n; k++ ) { u[n * i + k] = 0.0; f[n * i + k] = rhs; } }
/* stop sigma */ if ((lp == 2) || (lp==7)) { signal_sigma(TRACE_OFF, lp); }}

23
Advanced Computing Technology Center
May, 2005
• Unless the entire application is instrumented, there will be some inaccuracy in the results
• Use dynamic selection at phase or loop boundaries or when the cache can be assumed ‘cold’
• Use sigma signals to reset the cache
• Ongoing research to find optimal sampling techniques
• Ongoing research on automatic sampling

24
Advanced Computing Technology Center
May, 2005
Bultin Event Handlers: Trace Generation
• Generate a compressed memory trace
• The cache simulation can run on the compressed trace
• Control-Flow based Trace Compression (Patented):
– Compress the addresses produced by each instruction separately
– Capture strides, repetitions, nested patterns
– Compression is performed online
– Compress all trace events, not only addresses

25
Advanced Computing Technology Center
May, 2005
Trace Compression Rate# Mem References Uncompressed Trace Compressed Trace Compression Rate
NAS bt.A 13,279,268,500 61.8 Gb 325 Mb 194.71NAS cg.A 1,735,939,092 8.8 Gb 3.52 Gb 2.5NAS ep.A 4,698,767,861 22.3 Gb 2.56 Gb 8.71NAS ft.A 8,576,076,276 40 Gb 870 Mb 47.08NAS is.A 1,325,400,450 1.32 Gb 540 Mb 2.5NAS lu.A 7,819,640,763 36.42 Gb 37 Kb 1,024NAS mg.A 6,309,492,654 29.4 Gb 17 Mb 1770.91NAS sp.A 8,986,253,493 41.8 Gb 323 Mb 132.51swim 1023 129,171,002 615 Mb 8.3 Kb 75874array1 45,650,677 217 Mb 6 Kb 37034mmblock 6,500,000 29.7 Mb 0.0014 Mb 21,214.29Bitonic sort 16,300,000 100 Mb 66.5 Mb 1.50Rec. mmult 18,900,000 102.1 Mb 101.1 Mb 1.01Red black SOR 137,100,000 574.3 Mb 14.6 Mb 39.34SPEC applu 59,500,000 243.6 Mb 0.17 Mb 1,432.94SPEC hydro2d 130,300,000 643.8 Mb 0.83 Mb 775.66SPEC mgrid 100,200,000 415 Mb 0.4 Mb 1,037.50SPEC swim 147,900,000 685.6 Mb 0.011 Mb 62,327.27SPEC wupwise 375,900,000 2.6 Gb 477.6 Mb 5.57
Average 2,836,750,567 13.05 Gb 471.69 Mb 28.3

26
Advanced Computing Technology Center
May, 2005
Bultin Event Handler: detecting False Sharing (work in progress):
Target: memory performance of shared-memory apps (infinite cache)
– Detect cache misses due to invalidation
– Detect false-sharing misses
– Measure c2c transfers
– Provide suggestions for code rearrangement to minimize false-sharing misses and/or minimize cache invalidations and/or maximize c2c transfers
– Remapping of data structures– Remapping of computation– Changing scheduling policy

27
Advanced Computing Technology Center
May, 2005
pSigma and the New HPC Toolkit (4Q2005)– Look at all aspects of performance (communication, processor, memory, sharing of
data) from within a single interface
– Operate on the binary – no source code modification
– Provide information in terms of symbolic names
– Centralized GUI for instrumentation and analysis
– Dynamic instrumentation capabilities
– Graphics capabilities (bar charts, plots etc)
– Simultaneous instrumentation for all tools (one run!)
– Query capabilities: compute derived metrics and plot them
– Selective instrumentation of MPI functions

28
Advanced Computing Technology Center
May, 2005
pSigma in the new HPC toolkit
pSigma
Binary Application
PeekPerf GUI
Communication Profiler
CPU Profiler
Memory Profiler
Shared-Memory Profiler I/O Profiler
Visualization
Query
Analysis
Instrumented Binary
execution
Binary instrumentation

29
Advanced Computing Technology Center
May, 2005

30
Advanced Computing Technology Center
May, 2005

31
Advanced Computing Technology Center
May, 2005
Next Steps
• Linux porting
• Complete the support for shared-memory apps
• More handlers (sharing of data, data flow, etc)
• Support 64-bit applications
• Support C++ codes

Advanced Computing Technology Center
May, 2005
Questions / Comments
Top Related