



![arXiv:1612.04403v1 [cs.SI] 13 Dec 2016 · 3 Okcupid Dataset Online dating profiles provide a good source of data for our purposes. Users are encouraged to give full and rich descriptions](https://static.fdocuments.in/doc/165x107/60663a3693479b3a6e5dbf17/arxiv161204403v1-cssi-13-dec-2016-3-okcupid-dataset-online-dating-proiles.jpg)



Languages
Pages
Legal


Introduction
Problem andMotivation
Approach
ResourceInstance andType Extraction
ResourceSamplingApproaches
Constructingprofiles:Dataset-topicgraph
Topic RankingApproaches
ExperimentalSetup
Baselines
EvaluationResults
Efficiency ofDataset Profiling
Scalability ofDataset Profiling
Conclusions
A Scalable Approach for Efficiently GeneratingStructured Dataset Topic Profiles
Besnik Fetahu1, Stefan Dietze1, Bernardo Pereira Nunes2, MarcoAntonio Casanova2, Davide Taibi3, Wolfgang Nejdl1
1L3S Research Center, Leibniz Universitat Hannover2Department of Informatics - PUC-Rio
3Institute for Educational Technologies, CNR
May 29, 2014

Introduction
Problem andMotivation
Approach
ResourceInstance andType Extraction
ResourceSamplingApproaches
Constructingprofiles:Dataset-topicgraph
Topic RankingApproaches
ExperimentalSetup
Baselines
EvaluationResults
Efficiency ofDataset Profiling
Scalability ofDataset Profiling
Conclusions
1 Introduction
2 Problem and Motivation
3 ApproachResource Instance and Type ExtractionResource Sampling ApproachesConstructing profiles: Dataset-topic graphTopic Ranking Approaches
4 Experimental SetupBaselines
5 Evaluation ResultsEfficiency of Dataset ProfilingScalability of Dataset Profiling
6 Conclusions

Introduction
Problem andMotivation
Approach
ResourceInstance andType Extraction
ResourceSamplingApproaches
Constructingprofiles:Dataset-topicgraph
Topic RankingApproaches
ExperimentalSetup
Baselines
EvaluationResults
Efficiency ofDataset Profiling
Scalability ofDataset Profiling
Conclusions
1 Introduction
2 Problem and Motivation
3 ApproachResource Instance and Type ExtractionResource Sampling ApproachesConstructing profiles: Dataset-topic graphTopic Ranking Approaches
4 Experimental SetupBaselines
5 Evaluation ResultsEfficiency of Dataset ProfilingScalability of Dataset Profiling
6 Conclusions

Introduction
Problem andMotivation
Approach
ResourceInstance andType Extraction
ResourceSamplingApproaches
Constructingprofiles:Dataset-topicgraph
Topic RankingApproaches
ExperimentalSetup
Baselines
EvaluationResults
Efficiency ofDataset Profiling
Scalability ofDataset Profiling
Conclusions
Introduction
• Increasing amount of Web Data
• Data heterogeneity: representation, language, quality anddomains
• Sparsely connected datasets
• Lack of descriptive metadata about datasets
• Exhaustive techniques for data analysis
• Efficiency heavily dependent on information need
• Ease of access and representation of datasets

Introduction
Problem andMotivation
Approach
ResourceInstance andType Extraction
ResourceSamplingApproaches
Constructingprofiles:Dataset-topicgraph
Topic RankingApproaches
ExperimentalSetup
Baselines
EvaluationResults
Efficiency ofDataset Profiling
Scalability ofDataset Profiling
Conclusions
Introduction
• Increasing amount of Web Data
• Data heterogeneity: representation, language, quality anddomains
• Sparsely connected datasets
• Lack of descriptive metadata about datasets
• Exhaustive techniques for data analysis
• Efficiency heavily dependent on information need
• Ease of access and representation of datasets

Introduction
Problem andMotivation
Approach
ResourceInstance andType Extraction
ResourceSamplingApproaches
Constructingprofiles:Dataset-topicgraph
Topic RankingApproaches
ExperimentalSetup
Baselines
EvaluationResults
Efficiency ofDataset Profiling
Scalability ofDataset Profiling
Conclusions
Introduction
• Increasing amount of Web Data
• Data heterogeneity: representation, language, quality anddomains
• Sparsely connected datasets
• Lack of descriptive metadata about datasets
• Exhaustive techniques for data analysis
• Efficiency heavily dependent on information need
• Ease of access and representation of datasets

Introduction
Problem andMotivation
Approach
ResourceInstance andType Extraction
ResourceSamplingApproaches
Constructingprofiles:Dataset-topicgraph
Topic RankingApproaches
ExperimentalSetup
Baselines
EvaluationResults
Efficiency ofDataset Profiling
Scalability ofDataset Profiling
Conclusions
Introduction
• Increasing amount of Web Data
• Data heterogeneity: representation, language, quality anddomains
• Sparsely connected datasets
• Lack of descriptive metadata about datasets
• Exhaustive techniques for data analysis
• Efficiency heavily dependent on information need
• Ease of access and representation of datasets

Introduction
Problem andMotivation
Approach
ResourceInstance andType Extraction
ResourceSamplingApproaches
Constructingprofiles:Dataset-topicgraph
Topic RankingApproaches
ExperimentalSetup
Baselines
EvaluationResults
Efficiency ofDataset Profiling
Scalability ofDataset Profiling
Conclusions
Introduction
• Increasing amount of Web Data
• Data heterogeneity: representation, language, quality anddomains
• Sparsely connected datasets
• Lack of descriptive metadata about datasets
• Exhaustive techniques for data analysis
• Efficiency heavily dependent on information need
• Ease of access and representation of datasets

Introduction
Problem andMotivation
Approach
ResourceInstance andType Extraction
ResourceSamplingApproaches
Constructingprofiles:Dataset-topicgraph
Topic RankingApproaches
ExperimentalSetup
Baselines
EvaluationResults
Efficiency ofDataset Profiling
Scalability ofDataset Profiling
Conclusions
Introduction
• Increasing amount of Web Data
• Data heterogeneity: representation, language, quality anddomains
• Sparsely connected datasets
• Lack of descriptive metadata about datasets
• Exhaustive techniques for data analysis
• Efficiency heavily dependent on information need
• Ease of access and representation of datasets

Introduction
Problem andMotivation
Approach
ResourceInstance andType Extraction
ResourceSamplingApproaches
Constructingprofiles:Dataset-topicgraph
Topic RankingApproaches
ExperimentalSetup
Baselines
EvaluationResults
Efficiency ofDataset Profiling
Scalability ofDataset Profiling
Conclusions
Introduction
• Increasing amount of Web Data
• Data heterogeneity: representation, language, quality anddomains
• Sparsely connected datasets
• Lack of descriptive metadata about datasets
• Exhaustive techniques for data analysis
• Efficiency heavily dependent on information need
• Ease of access and representation of datasets

Introduction
Problem andMotivation
Approach
ResourceInstance andType Extraction
ResourceSamplingApproaches
Constructingprofiles:Dataset-topicgraph
Topic RankingApproaches
ExperimentalSetup
Baselines
EvaluationResults
Efficiency ofDataset Profiling
Scalability ofDataset Profiling
Conclusions
1 Introduction
2 Problem and Motivation
3 ApproachResource Instance and Type ExtractionResource Sampling ApproachesConstructing profiles: Dataset-topic graphTopic Ranking Approaches
4 Experimental SetupBaselines
5 Evaluation ResultsEfficiency of Dataset ProfilingScalability of Dataset Profiling
6 Conclusions

Introduction
Problem andMotivation
Approach
ResourceInstance andType Extraction
ResourceSamplingApproaches
Constructingprofiles:Dataset-topicgraph
Topic RankingApproaches
ExperimentalSetup
Baselines
EvaluationResults
Efficiency ofDataset Profiling
Scalability ofDataset Profiling
Conclusions
Why dataset profiling?
• Growing number of datasets: 227 datasets
• Data represented as triples: 31 billion triples
• Multi-lingual content: 18 languages
• Broad set of topics covered
• Inter-dataset links
Domain # Data. TriplesMedia 25 1,841,852,061Geographic 31 6,145,532,484Government 49 13,315,009,400Publications 87 2,950,720,693Cross-domain 41 4,184,635,715Life sciences 41 3,036,336,004User-generated 20 134,127,413

Introduction
Problem andMotivation
Approach
ResourceInstance andType Extraction
ResourceSamplingApproaches
Constructingprofiles:Dataset-topicgraph
Topic RankingApproaches
ExperimentalSetup
Baselines
EvaluationResults
Efficiency ofDataset Profiling
Scalability ofDataset Profiling
Conclusions
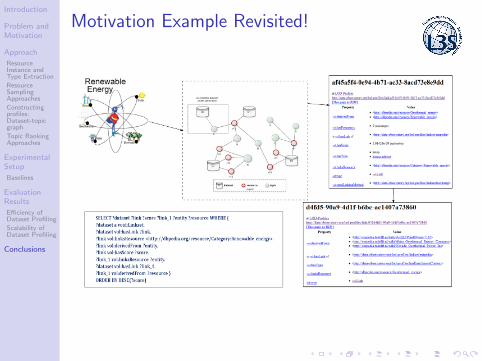
Why dataset profiling?
Find datasets covering the domain of “Renewable Energy”?
• Sparsity: Datasets that cover the topic?• 38 out of 228 datasets contain
topic coverage information.
• Scalability: Use SPARQL filter clause?• regex(*) filter clause needs
to check all triples that containa specific keyword.
• Disambiguity: What are all the possible forms ofrenewable energy?
• solar energy, wind energy, geothermal. . .

Introduction
Problem andMotivation
Approach
ResourceInstance andType Extraction
ResourceSamplingApproaches
Constructingprofiles:Dataset-topicgraph
Topic RankingApproaches
ExperimentalSetup
Baselines
EvaluationResults
Efficiency ofDataset Profiling
Scalability ofDataset Profiling
Conclusions
Why dataset profiling?
Find datasets covering the domain of “Renewable Energy”?
• Sparsity: Datasets that cover the topic?• 38 out of 228 datasets contain
topic coverage information.
• Scalability: Use SPARQL filter clause?• regex(*) filter clause needs
to check all triples that containa specific keyword.
• Disambiguity: What are all the possible forms ofrenewable energy?
• solar energy, wind energy, geothermal. . .

Introduction
Problem andMotivation
Approach
ResourceInstance andType Extraction
ResourceSamplingApproaches
Constructingprofiles:Dataset-topicgraph
Topic RankingApproaches
ExperimentalSetup
Baselines
EvaluationResults
Efficiency ofDataset Profiling
Scalability ofDataset Profiling
Conclusions
Why dataset profiling?
Find datasets covering the domain of “Renewable Energy”?
• Sparsity: Datasets that cover the topic?• 38 out of 228 datasets contain
topic coverage information.
• Scalability: Use SPARQL filter clause?• regex(*) filter clause needs
to check all triples that containa specific keyword.
• Disambiguity: What are all the possible forms ofrenewable energy?
• solar energy, wind energy, geothermal. . .

Introduction
Problem andMotivation
Approach
ResourceInstance andType Extraction
ResourceSamplingApproaches
Constructingprofiles:Dataset-topicgraph
Topic RankingApproaches
ExperimentalSetup
Baselines
EvaluationResults
Efficiency ofDataset Profiling
Scalability ofDataset Profiling
Conclusions
1 Introduction
2 Problem and Motivation
3 ApproachResource Instance and Type ExtractionResource Sampling ApproachesConstructing profiles: Dataset-topic graphTopic Ranking Approaches
4 Experimental SetupBaselines
5 Evaluation ResultsEfficiency of Dataset ProfilingScalability of Dataset Profiling
6 Conclusions
Introduction
Problem andMotivation
Approach
ResourceInstance andType Extraction
ResourceSamplingApproaches
Constructingprofiles:Dataset-topicgraph
Topic RankingApproaches
ExperimentalSetup
Baselines
EvaluationResults
Efficiency ofDataset Profiling
Scalability ofDataset Profiling
Conclusions
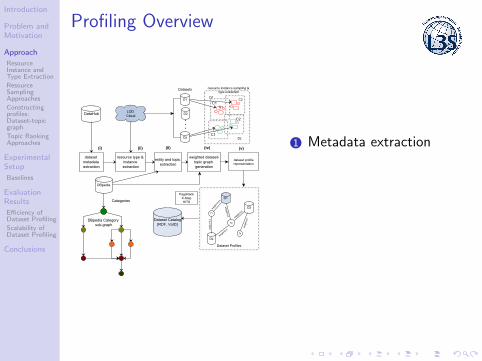
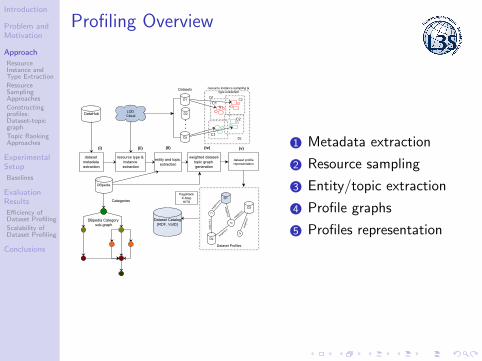
Profiling Overview
1 Metadata extraction
2 Resource sampling
3 Entity/topic extraction
4 Profile graphs
5 Profiles representation
Introduction
Problem andMotivation
Approach
ResourceInstance andType Extraction
ResourceSamplingApproaches
Constructingprofiles:Dataset-topicgraph
Topic RankingApproaches
ExperimentalSetup
Baselines
EvaluationResults
Efficiency ofDataset Profiling
Scalability ofDataset Profiling
Conclusions
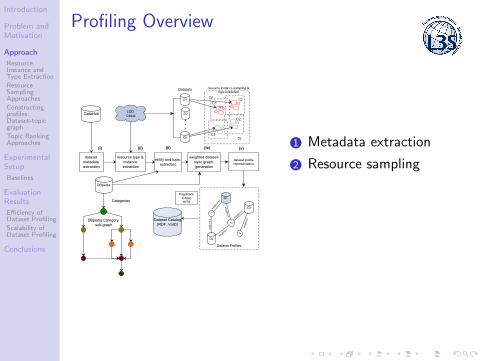
Profiling Overview
1 Metadata extraction
2 Resource sampling
3 Entity/topic extraction
4 Profile graphs
5 Profiles representation
Introduction
Problem andMotivation
Approach
ResourceInstance andType Extraction
ResourceSamplingApproaches
Constructingprofiles:Dataset-topicgraph
Topic RankingApproaches
ExperimentalSetup
Baselines
EvaluationResults
Efficiency ofDataset Profiling
Scalability ofDataset Profiling
Conclusions
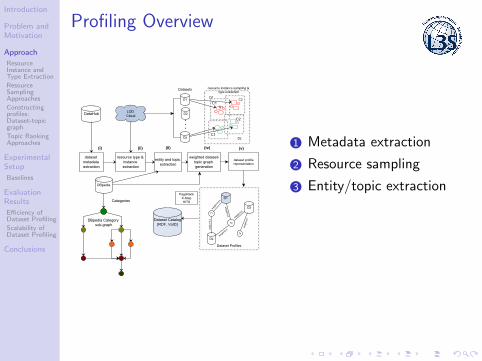
Profiling Overview
1 Metadata extraction
2 Resource sampling
3 Entity/topic extraction
4 Profile graphs
5 Profiles representation
Introduction
Problem andMotivation
Approach
ResourceInstance andType Extraction
ResourceSamplingApproaches
Constructingprofiles:Dataset-topicgraph
Topic RankingApproaches
ExperimentalSetup
Baselines
EvaluationResults
Efficiency ofDataset Profiling
Scalability ofDataset Profiling
Conclusions
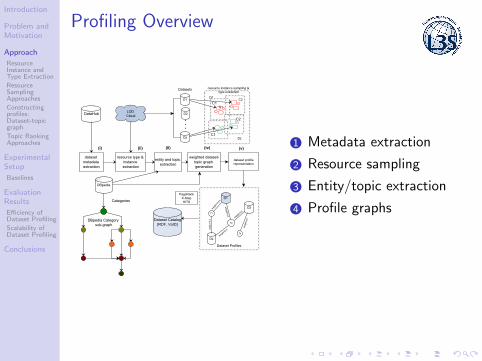
Profiling Overview
1 Metadata extraction
2 Resource sampling
3 Entity/topic extraction
4 Profile graphs
5 Profiles representation
Introduction
Problem andMotivation
Approach
ResourceInstance andType Extraction
ResourceSamplingApproaches
Constructingprofiles:Dataset-topicgraph
Topic RankingApproaches
ExperimentalSetup
Baselines
EvaluationResults
Efficiency ofDataset Profiling
Scalability ofDataset Profiling
Conclusions
Profiling Overview
1 Metadata extraction
2 Resource sampling
3 Entity/topic extraction
4 Profile graphs
5 Profiles representation
Introduction
Problem andMotivation
Approach
ResourceInstance andType Extraction
ResourceSamplingApproaches
Constructingprofiles:Dataset-topicgraph
Topic RankingApproaches
ExperimentalSetup
Baselines
EvaluationResults
Efficiency ofDataset Profiling
Scalability ofDataset Profiling
Conclusions
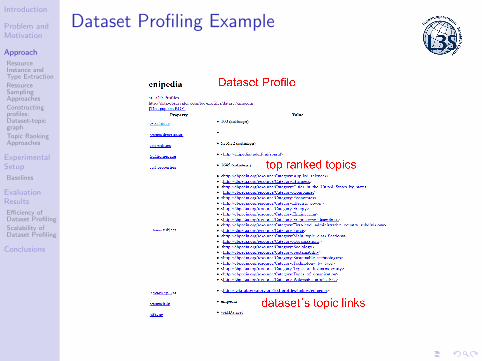
Dataset Profiling Example

Introduction
Problem andMotivation
Approach
ResourceInstance andType Extraction
ResourceSamplingApproaches
Constructingprofiles:Dataset-topicgraph
Topic RankingApproaches
ExperimentalSetup
Baselines
EvaluationResults
Efficiency ofDataset Profiling
Scalability ofDataset Profiling
Conclusions
Dataset Profiling Example

Introduction
Problem andMotivation
Approach
ResourceInstance andType Extraction
ResourceSamplingApproaches
Constructingprofiles:Dataset-topicgraph
Topic RankingApproaches
ExperimentalSetup
Baselines
EvaluationResults
Efficiency ofDataset Profiling
Scalability ofDataset Profiling
Conclusions
Dataset Profiling Example

Introduction
Problem andMotivation
Approach
ResourceInstance andType Extraction
ResourceSamplingApproaches
Constructingprofiles:Dataset-topicgraph
Topic RankingApproaches
ExperimentalSetup
Baselines
EvaluationResults
Efficiency ofDataset Profiling
Scalability ofDataset Profiling
Conclusions
Dataset Profiling Example
Introduction
Problem andMotivation
Approach
ResourceInstance andType Extraction
ResourceSamplingApproaches
Constructingprofiles:Dataset-topicgraph
Topic RankingApproaches
ExperimentalSetup
Baselines
EvaluationResults
Efficiency ofDataset Profiling
Scalability ofDataset Profiling
Conclusions
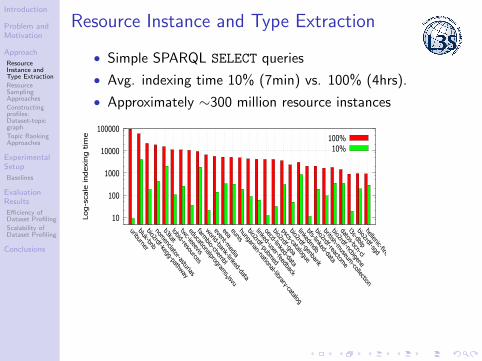
Resource Instance and Type Extraction
• Simple SPARQL SELECT queries
• Avg. indexing time 10% (7min) vs. 100% (4hrs).
• Approximately ∼300 million resource instances
10
100
1000
10000
100000
uriburner
bluk-bnb
bio2rdf-kegg-pathway
nomenclator-asturias
b3kat
lobid-resources
twc-ieeevis
educationalprogramss isvu
farmbio-chem
bl
world-bank-linked-data
event-media
eeaeunishungarian-national-library-catalog
bio2rdf-pubmed
linked-user-feedback
oecd-linked-data
bio2rdf-goa
pscs-catalogue
bio2rdf-genbank
linkedmdb
bfs-linked-data
bio2rdf-reactome
british-museum-collection
bio2rdf-ncbigene
datos-bcn-cl
l3s-dblp
bio2rdf-sgd
hellenic-fire-brigade
Log-s
cale
indexin
g t
ime 100%
10%

Introduction
Problem andMotivation
Approach
ResourceInstance andType Extraction
ResourceSamplingApproaches
Constructingprofiles:Dataset-topicgraph
Topic RankingApproaches
ExperimentalSetup
Baselines
EvaluationResults
Efficiency ofDataset Profiling
Scalability ofDataset Profiling
Conclusions
Resource Sampling ApproachesEntity and Topic Extraction
Resource Sampling
• random: randomly select a resource instance for analysis
• weighted: weigh a resource by the number of datatypeproperties used to describe it wk = |f (rk)|/max{|f (rj)|}
• centrality: weigh a resource by the number of typesused to describe it ck = |C ′
k |/|C |
Topic Extraction
• Resources as documents by combining all textual literals
• Perform NED1 and extract corresponding DBpedia entities
• Extract topics as DBpedia categories from entities viadcterms:subject
1DBpedia Spotlight

Introduction
Problem andMotivation
Approach
ResourceInstance andType Extraction
ResourceSamplingApproaches
Constructingprofiles:Dataset-topicgraph
Topic RankingApproaches
ExperimentalSetup
Baselines
EvaluationResults
Efficiency ofDataset Profiling
Scalability ofDataset Profiling
Conclusions
Resource Sampling ApproachesEntity and Topic Extraction
Resource Sampling
• random: randomly select a resource instance for analysis
• weighted: weigh a resource by the number of datatypeproperties used to describe it wk = |f (rk)|/max{|f (rj)|}
• centrality: weigh a resource by the number of typesused to describe it ck = |C ′
k |/|C |
Topic Extraction
• Resources as documents by combining all textual literals
• Perform NED1 and extract corresponding DBpedia entities
• Extract topics as DBpedia categories from entities viadcterms:subject
1DBpedia Spotlight

Introduction
Problem andMotivation
Approach
ResourceInstance andType Extraction
ResourceSamplingApproaches
Constructingprofiles:Dataset-topicgraph
Topic RankingApproaches
ExperimentalSetup
Baselines
EvaluationResults
Efficiency ofDataset Profiling
Scalability ofDataset Profiling
Conclusions
Resource Sampling ApproachesEntity and Topic Extraction
Resource Sampling
• random: randomly select a resource instance for analysis
• weighted: weigh a resource by the number of datatypeproperties used to describe it wk = |f (rk)|/max{|f (rj)|}
• centrality: weigh a resource by the number of typesused to describe it ck = |C ′
k |/|C |
Topic Extraction
• Resources as documents by combining all textual literals
• Perform NED1 and extract corresponding DBpedia entities
• Extract topics as DBpedia categories from entities viadcterms:subject
1DBpedia Spotlight

Introduction
Problem andMotivation
Approach
ResourceInstance andType Extraction
ResourceSamplingApproaches
Constructingprofiles:Dataset-topicgraph
Topic RankingApproaches
ExperimentalSetup
Baselines
EvaluationResults
Efficiency ofDataset Profiling
Scalability ofDataset Profiling
Conclusions
Constructing profiles: Dataset-topic graph
1 Profile graph nodes: datasets,
resources, topics
2 Weighted graph edges: ∆〈D, t〉3 Edge weights: ∆〈Di , t〉 6= ∆〈Dj , t〉4 Compute ∆〈Di , t〉 by assessing the
importance of t given the resourcesof Di as prior knowledge
5 The given prior knowledge biasesthe importance of t in the profilegraph towards Di
2
6 Incrementally add datasets in theprofile graph, by simply computingthe weights ∆〈Dk , t〉
2Scott White and Padhraic Smyth. 2003. Algorithms for estimating relativeimportance in networks. In 9th ACM SIGKDD (KDD ’03).

Introduction
Problem andMotivation
Approach
ResourceInstance andType Extraction
ResourceSamplingApproaches
Constructingprofiles:Dataset-topicgraph
Topic RankingApproaches
ExperimentalSetup
Baselines
EvaluationResults
Efficiency ofDataset Profiling
Scalability ofDataset Profiling
Conclusions
Topic Ranking ApproachesTopic filtering
Topic pre-filtering:
NTR(t,D) =Φ(·,D)
Φ(t,D)+
Φ(·, ·)Φ(t, ·)
• Filter noisy topics
• φ(·, ·) - number of entitiesassociated with topic t
• Closely related to the tf-idfweighting scheme
Topic Ranking
• PageRank with Priors (PRankP)
• HITS with Priors (HITSP)
• K-Step Markov (KStepM)

Introduction
Problem andMotivation
Approach
ResourceInstance andType Extraction
ResourceSamplingApproaches
Constructingprofiles:Dataset-topicgraph
Topic RankingApproaches
ExperimentalSetup
Baselines
EvaluationResults
Efficiency ofDataset Profiling
Scalability ofDataset Profiling
Conclusions
1 Introduction
2 Problem and Motivation
3 ApproachResource Instance and Type ExtractionResource Sampling ApproachesConstructing profiles: Dataset-topic graphTopic Ranking Approaches
4 Experimental SetupBaselines
5 Evaluation ResultsEfficiency of Dataset ProfilingScalability of Dataset Profiling
6 Conclusions

Introduction
Problem andMotivation
Approach
ResourceInstance andType Extraction
ResourceSamplingApproaches
Constructingprofiles:Dataset-topicgraph
Topic RankingApproaches
ExperimentalSetup
Baselines
EvaluationResults
Efficiency ofDataset Profiling
Scalability ofDataset Profiling
Conclusions
Experimental Setup
Datasets and Ground-truth
• 129 dataset from lod-cloud3
• 6 ground-truth datasets with manually assigned topicindicators for their resources
Dataset Properties #Resources
yovistoskos:subject, dbp:{subject, class,
discipline, kategorie, tagline} 62879
oxpoints dcterms:subject,dc:subject 37258
socialsemweb-thesaurusskos:subject, tag:associatedTag,dcterms:subject
2243
semantic-web-dog-food dcterms:subject, dc:subject 20145lak-dataset dcterms:subject, dc:subject 1691
Evaluation Metrics
• NDCG@k (k=1, . . . , 1000)
• Compare the induced ranking by the graphical modelsagainst the ideal ranking
3At the time of experimentation only 129 dataset endpoints wereresponsive.

Introduction
Problem andMotivation
Approach
ResourceInstance andType Extraction
ResourceSamplingApproaches
Constructingprofiles:Dataset-topicgraph
Topic RankingApproaches
ExperimentalSetup
Baselines
EvaluationResults
Efficiency ofDataset Profiling
Scalability ofDataset Profiling
Conclusions
Baselines
• tf-idf: Consider resources as documents. Extract foreach dataset the top {50, 100, 150, 200} terms.
• LDA: Consider dataset as documents4. Extract topweighted topic terms. For every dataset extract top {50,100, 150, 200} with a number of topics {10, 20, 30, 40,50}.
4In this case it does not matter if datasets are considered at theresource level or aggregated.

Introduction
Problem andMotivation
Approach
ResourceInstance andType Extraction
ResourceSamplingApproaches
Constructingprofiles:Dataset-topicgraph
Topic RankingApproaches
ExperimentalSetup
Baselines
EvaluationResults
Efficiency ofDataset Profiling
Scalability ofDataset Profiling
Conclusions
1 Introduction
2 Problem and Motivation
3 ApproachResource Instance and Type ExtractionResource Sampling ApproachesConstructing profiles: Dataset-topic graphTopic Ranking Approaches
4 Experimental SetupBaselines
5 Evaluation ResultsEfficiency of Dataset ProfilingScalability of Dataset Profiling
6 Conclusions
Introduction
Problem andMotivation
Approach
ResourceInstance andType Extraction
ResourceSamplingApproaches
Constructingprofiles:Dataset-topicgraph
Topic RankingApproaches
ExperimentalSetup
Baselines
EvaluationResults
Efficiency ofDataset Profiling
Scalability ofDataset Profiling
Conclusions
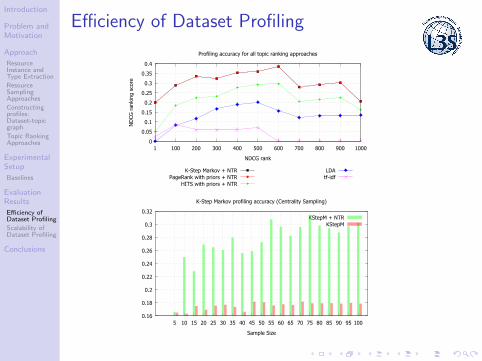
Efficiency of Dataset Profiling
0
0.05
0.1
0.15
0.2
0.25
0.3
0.35
0.4
1 100 200 300 400 500 600 700 800 900 1000
ND
CG r
anki
ng s
core
NDCG rank
Profiling accuracy for all topic ranking approaches
K-Step Markov + NTRPageRank with priors + NTR
HITS with priors + NTR
LDAtf-idf
0.16
0.18
0.2
0.22
0.24
0.26
0.28
0.3
0.32
5 10 15 20 25 30 35 40 45 50 55 60 65 70 75 80 85 90 95 100
Sample Size
K-Step Markov profiling accuracy (Centrality Sampling)
KStepM + NTRKStepM
Introduction
Problem andMotivation
Approach
ResourceInstance andType Extraction
ResourceSamplingApproaches
Constructingprofiles:Dataset-topicgraph
Topic RankingApproaches
ExperimentalSetup
Baselines
EvaluationResults
Efficiency ofDataset Profiling
Scalability ofDataset Profiling
Conclusions
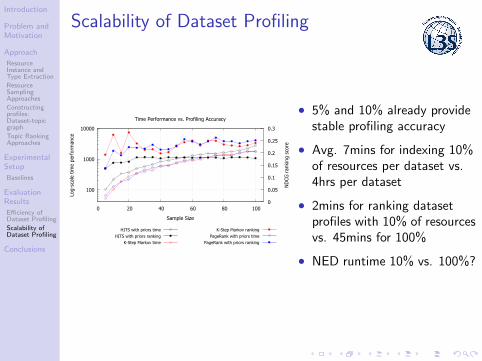
Scalability of Dataset Profiling
100
1000
10000
0 20 40 60 80 100 0
0.05
0.1
0.15
0.2
0.25
0.3
Log-
scal
e tim
e pe
rfor
man
ce
ND
CG r
anki
ng s
core
Sample Size
Time Performance vs. Profiling Accuracy
HITS with priors timeHITS with priors ranking
K-Step Markov time
K-Step Markov rankingPageRank with priors time
PageRank with priors ranking
• 5% and 10% already providestable profiling accuracy
• Avg. 7mins for indexing 10%of resources per dataset vs.4hrs per dataset
• 2mins for ranking datasetprofiles with 10% of resourcesvs. 45mins for 100%
• NED runtime 10% vs. 100%?
Introduction
Problem andMotivation
Approach
ResourceInstance andType Extraction
ResourceSamplingApproaches
Constructingprofiles:Dataset-topicgraph
Topic RankingApproaches
ExperimentalSetup
Baselines
EvaluationResults
Efficiency ofDataset Profiling
Scalability ofDataset Profiling
Conclusions
Motivation Example Revisited!

Introduction
Problem andMotivation
Approach
ResourceInstance andType Extraction
ResourceSamplingApproaches
Constructingprofiles:Dataset-topicgraph
Topic RankingApproaches
ExperimentalSetup
Baselines
EvaluationResults
Efficiency ofDataset Profiling
Scalability ofDataset Profiling
Conclusions
Conclusions and Future Work
• Structured dataset profiles
• Scalable approach through sampling
• Efficient profiling through topic filtering and ranking
• Incremental generation of dataset profiles
• Dataset profiles as a set of links (entity and topic links)
• Provenance information of links (e.g. resources fromwhich an entity is extracted)
• Profiles for dataset recommendation, search, etc.
Resources
• Profiles Endpoint:http://data-observatory.org/lod-profiles/sparql
• Profiles Webpage:http://data-observatory.org/lod-profiles/

Introduction
Problem andMotivation
Approach
ResourceInstance andType Extraction
ResourceSamplingApproaches
Constructingprofiles:Dataset-topicgraph
Topic RankingApproaches
ExperimentalSetup
Baselines
EvaluationResults
Efficiency ofDataset Profiling
Scalability ofDataset Profiling
Conclusions
Thank you! Questions?#eswc2014Fetahu
Top Related