







Languages
Pages
Legal


© aSup-2007
Inference about Means and Mean Differences
1
Chapter 9INTRODUCTION TO t STATISTIC

© aSup-2007
Inference about Means and Mean Differences
2
Preview-1 In the previous chapter, we presented
the statistical procedure that permit researcher to use sample mean to test hypothesis about an unknown population
Remember that the expected value of the distribution of sample means is μ, the population mean
σM = σ√n
z =M - μ
σM

© aSup-2007
Inference about Means and Mean Differences
3
THE PROBLEM WITH z-SCORE A z-score requires that we know the
value of the population standard deviation (or variance), which is needed to compute the standard error
In most situation, however, the standard deviation for the population is not known
In this case, we cannot compute the standard error and z-score for hypothesis test. We use t statistic for hypothesis testing when the population standard deviation is unknown

© aSup-2007
Inference about Means and Mean Differences
4
THE t STATISTIC:AN ALTERNATIVE TO z
The goal of the hypothesis test is to determine whether or not the obtained result is significantly
greater than would be expected by chance.

© aSup-2007
Inference about Means and Mean Differences
5
Introducing t Statistic
σM =σ√n
Now we will estimates the standard error by simply substituting the sample variance or standard deviation in place of the unknown population value
SM =s√n
Notice that the symbol for estimated standard error of M is SM instead of
σM , indicating that the estimated value is computed from sample data rather than from the actual population parameter

© aSup-2007
Inference about Means and Mean Differences
6
z-score and t statistic
σM = σ√n
z =M - μ
σM
SM = s√n
t =M - μ
SM

© aSup-2007
Inference about Means and Mean Differences
7
The t Distribution Every sample from a population can be
used to compute a z-score or a statistic If you select all possible samples of a
particular size (n), then the entire set of resulting z-scores will form a z-score distribution
In the same way, the set of all possible t statistic will form a t distribution

© aSup-2007
Inference about Means and Mean Differences
8
The Shape of the t Distribution The exact shape of a t distribution
changes with degree of freedom There is a different sampling
distribution of t (a distribution of all possible sample t values) for each possible number of degrees of freedom
As df gets very large, then t distribution gets closer in shape to a normal z-score distribution

© aSup-2007
Inference about Means and Mean Differences
9
HYPOTHESIS TESTS WITH t STATISTIC
The goal is to use a sample from the treated population (a treated sample) as the determining whether or not the treatment has any effectKnown population before treatment
Unknown population after treatment
μ = 30 μ = ?
TREATMENT

© aSup-2007
Inference about Means and Mean Differences
10
HYPOTHESIS TESTS WITH t STATISTIC As always, the null hypothesis states that the
treatment has no effect; specifically H0 states that the population mean is unchanged
The sample data provides a specific value for the sample mean; the variance and estimated standard error are computed
t =sample mean
(from data)
Estimated standard error (computed from the sample data)
population mean (hypothesized from H0)-

© aSup-2007
Inference about Means and Mean Differences
11
A psychologist has prepared an “Optimism Test” that is administered yearly to graduating college seniors. The test measures how each graduating class feels about it future. The higher the score, the more optimistic the class. Last year’s class had a mean score of μ = 19. A sample of n = 9 seniors from this years class was selected and tested. The scores for these seniors are as follow:
19 24 23 27 19 20 27 21 18On the basis of this sample, can the psychologist
conclude that this year’s class has a different level of optimism than last year’s class?
LEARNING CHECK

© aSup-2007
Inference about Means and Mean Differences
12
STEP-1: State the Hypothesis, and select an alpha level
H0 : μ = 19 (there is no change)
H1 : μ ≠ 19 (this year’s mean is different)
Example we use α = .05 two tail

© aSup-2007
Inference about Means and Mean Differences
13
STEP-2: Locate the critical region Remember that for hypothesis test with t
statistic, we must consult the t distribution table to find the critical t value. With a sample of n = 9 students, the t statistic will have degrees of freedom equal to
df = n – 1 = 9 – 1 = 8 For a two tailed test with α = .05 and df =
8, the critical values are t = ± 2.306. The obtained t value must be more extreme than either of these critical values to reject H0

© aSup-2007
Inference about Means and Mean Differences
14
STEP-3: Obtain the sample data, and compute the test statistic
Find the sample mean
Find the sample variances
Find the estimated standard error SM
Find the t statistic
SM = s√n
t =M - μ
SM

© aSup-2007
Inference about Means and Mean Differences
15
STEP-4: Make a decision about H0, and state conclusion
The obtained t statistic (t = 2.626) is in the critical region. Thus our sample data are unusual enough to reject the null hypothesis at the .05 level of significance.
We can conclude that there is a significant difference in level of optimism between this year’s and last year’s graduating classes
t(8) = 2.626, p<.05, two tailed
© aSup-2007
Inference about Means and Mean Differences
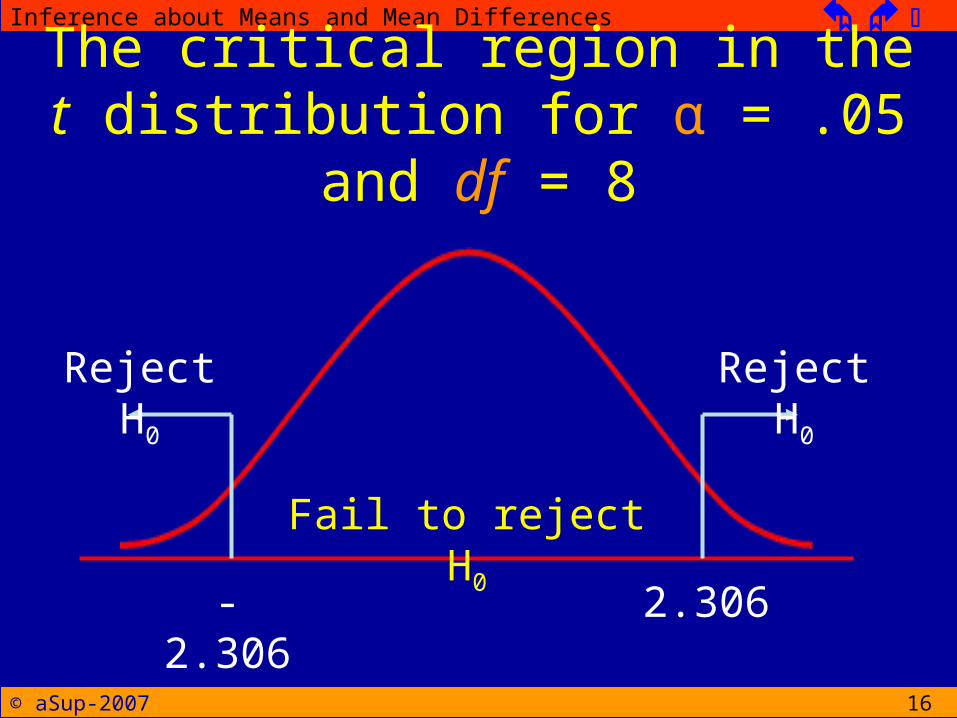
16
The critical region in thet distribution for α = .05 and df
= 8
Reject H0 Reject H0
Fail to reject H0
-2.306 2.306

© aSup-2007
Inference about Means and Mean Differences
17
DIRECTIONAL HYPOTHESES AND ONE-TAILED TEST
The non directional (two-tailed) test is more commonly used than the directional (one-tailed) alternative
On other hand, a directional test may be used in some research situations, such as exploratory investigation or pilot studies or when there is a priori justification (for example, a theory previous findings)
© aSup-2007
Inference about Means and Mean Differences
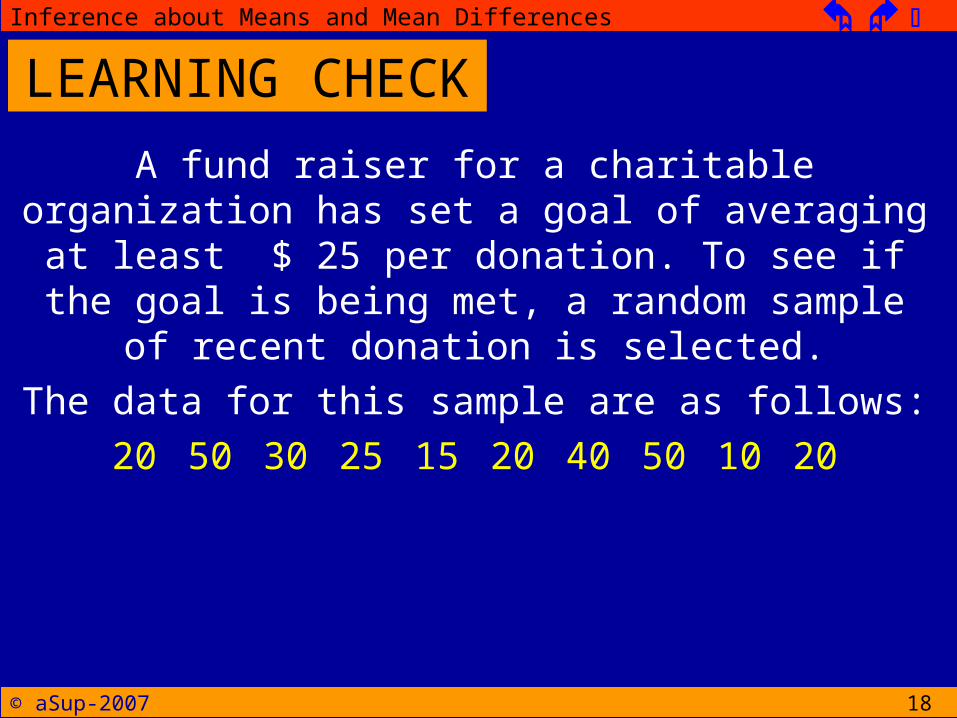
18
A fund raiser for a charitable organization has set a goal of averaging at least $ 25 per donation. To see if the goal is being met, a random sample of
recent donation is selected.The data for this sample are as follows:20 50 30 25 15 20 40 50 10 20
LEARNING CHECK

© aSup-2007
Inference about Means and Mean Differences
19
The critical region in thet distribution for α = .05 and df
= 9
Reject H0
Fail to reject H0
1.883

© aSup-2007
Inference about Means and Mean Differences
20
Chapter 10THE t TEST FOR TWO
INDEPENDENT SAMPLES

© aSup-2007
Inference about Means and Mean Differences
Preview-2 In many research situations, however,
its difficult or impossible for a researcher to satisfy completely the rigorous requirement of an experiment
In these situations, a researcher can often devise a research strategy (a method of collecting data) that is similar to an experiment but fails to satisfy at least one of the requirement of a true experiment
21

© aSup-2007
Inference about Means and Mean Differences NonExperimental and Quasi
Experimental Although these studies resemble
experiment, they always contain a confounding variable or other threat to internal validity that is an integral part of the design and simply cannot be removed
The existence of a confounding variable means that these studies cannot establish unambiguous cause-and-effect relationship and, therefore, are not true experiment
22

© aSup-2007
Inference about Means and Mean Differences NonExperimental and Quasi
Experimental … is the degree to which the research
strategy limits the confounding and control threats to internal validity
If a research design makes little or no attempt to minimize threats, it is classified as nonexperimental
A quasi experimental design makes some attempt to minimize threats to internal validity and approach the rigor of a true experiment
23

© aSup-2007
Inference about Means and Mean Differences
In an experiment… … a researcher typically creates
treatment condition by manipulating an IV, then measures participants to obtain a set of scores within each condition
If the score in one condition are significantly different from the other score in another condition, the researcher can conclude that the two treatment condition have different effects
24

© aSup-2007
Inference about Means and Mean Differences NonExperimental and Quasi
Experimental Similarly, a nonexperimental study
also produces group of scores to be compared for significant differences
One variable is used to create groups or conditions, then a second variable is measured to obtain a set of scores within each condition
25

© aSup-2007
Inference about Means and Mean Differences NonExperimental and Quasi
Experimental In nonexperimental and quasi-
experimental studies, the different groups or conditions are not created by manipulating an IV
The groups usually defined in terms of a preexisting participant variable (male/female) or in term of time (before/after)
26

© aSup-2007
Inference about Means and Mean Differences
27
Single sample techniques are used occasionally in real research, most research studies require the comparison of two (or more) sets of data
There are two general research strategies that can be used to obtain of the two sets of data to be compared:○ The two sets of data come from the two
completely separate samples (independent-measures or between-subjects design)
○ The two sets of data could both come from the same sample (repeated-measures or within subject design)
© aSup-2007
Inference about Means and Mean Differences
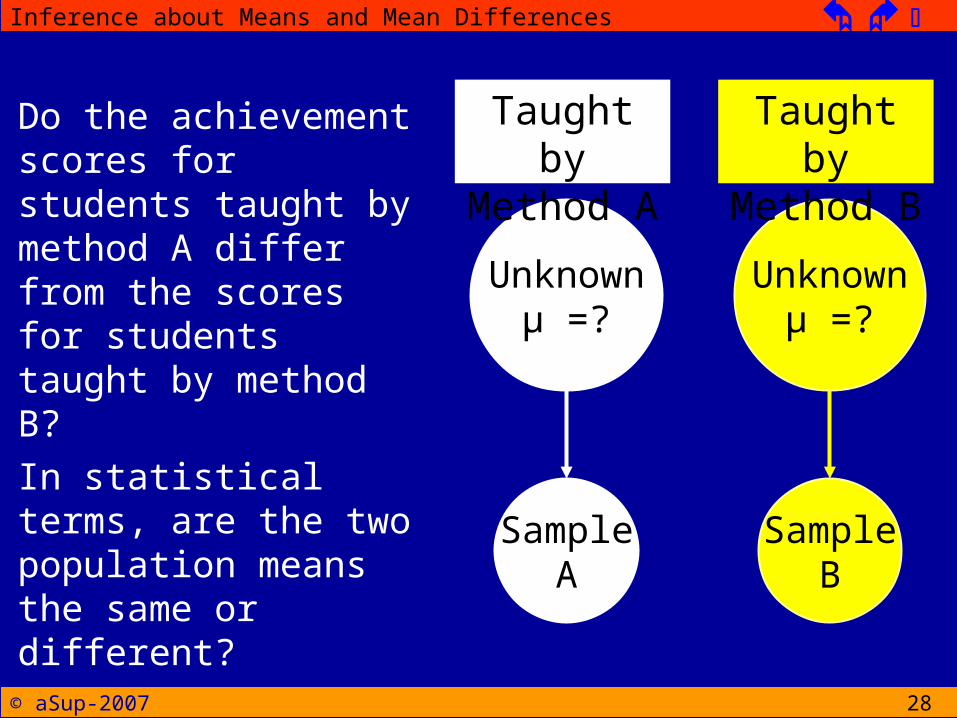
28
Do the achievement scores for students taught by method A differ from the scores for students taught by method B?In statistical terms, are the two population means the same or different?
Unknownµ =?
SampleA
Unknownµ =?
SampleB
Taught by
Method A
Taught by
Method B

© aSup-2007
Inference about Means and Mean Differences
29
THE HYPOTHESES FOR AN INDEPENDENT-MEASURES TEST
The goal of an independent-measures research study is to evaluate the mean difference between two population (or between two treatment conditions)
H0: µ1 - µ2 = 0 (No difference between the population means)
H1: µ1 - µ2 ≠ 0 (There is a mean difference)

© aSup-2007
Inference about Means and Mean Differences
30
THE FORMULA FOR AN INDEPENDENT-MEASURES
HYPOTHESIS TEST
In this formula, the value of M1 – M2 is obtained from the sample data and the value for µ1 - µ2 comes from the null hypothesis
The null hypothesis sets the population mean different equal to zero, so the independent-measures t formula can be simplifier further
t =sample mean
difference
estimated standard error
population mean difference-
=M1 – M2
S (M1 – M2)

© aSup-2007
Inference about Means and Mean Differences
31
THE STANDARD ERROR
To develop the formula for S(M1 – M2) we will consider the following points:
Each of the two sample means represent its own population mean, but in each case there is some error
SM = s2
n√SM1-M2 = s1
2
n1√s2
2
n2+

© aSup-2007
Inference about Means and Mean Differences
32
POOLED VARIANCE The standard error is limited to
situation in which the two samples are exactly the same size (that is n1 – n2)
In situations in which the two sample size are different, the formula is biased and, therefore, inappropriate
The bias come from the fact that the formula treats the two sample variance

© aSup-2007
Inference about Means and Mean Differences
33
POOLED VARIANCE for the independent-measure t
statistic, there are two SS values and two df values
SP2 = SS
nSM1-M2 = s1
2
n1√s2
2
n2+

© aSup-2007
Inference about Means and Mean Differences
34
HYPOTHESIS TEST WITH THE INDEPENDENT-MEASURES t
STATISTICIn a study of jury behavior, two samples of participants were provided details about a trial in which the defendant was obviously
guilty. Although Group-2 received the same details as Group-1, the second group was also
told that some evidence had been withheld from the jury by the judge. Later participants were asked to recommend a jail sentence. The length of term suggested by each participant is presented. Is there a significant difference between the two groups in their responses?

© aSup-2007
Inference about Means and Mean Differences
35
THE LENGTH OF TERM SUGGESTED BY EACH
PARTICIPANTGroup-1 scores: 4 4 3 2 5 1 1 4Group-2 scores: 3 7 8 5 4 7 6 8
There are two separate samples in this study. Therefore the analysis will use the independent-measure t test

© aSup-2007
Inference about Means and Mean Differences
36
STEP-1: State the Hypothesis, and select an alpha level
H0 : μ1 - μ2 = 0 (for the population, knowing evidence has been withheld has no effect on the suggested sentence)
H1 : μ1 - μ2 ≠ 0 (for the population, knowledge of withheld evidence has an effect on the jury’s response)
We will set α = .05 two tail

© aSup-2007
Inference about Means and Mean Differences
37
STEP-2: Identify the critical region For the independent-measure t statistic,
degrees of freedom are determined bydf = n1 + n2 – 2 = 8 + 8 – 2 = 14
The t distribution table is consulted, for a two tailed test with α = .05 and df = 14, the critical values are t = ± 2.145.
The obtained t value must be more extreme than either of these critical values to reject H0

© aSup-2007
Inference about Means and Mean Differences
38
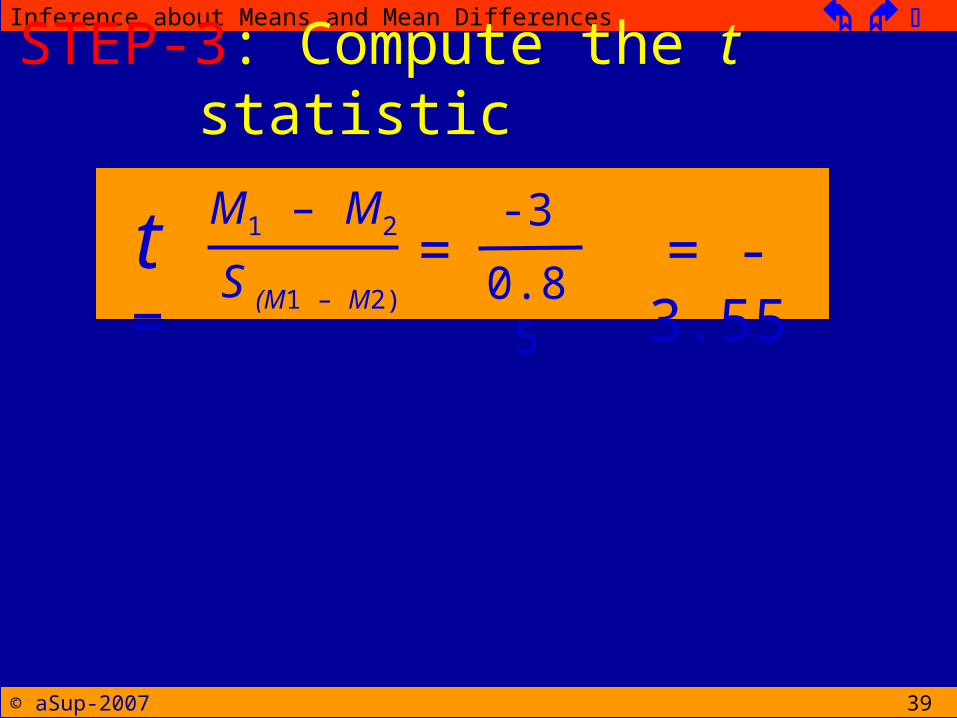
STEP-3: Compute the test statistic
Find the sample mean for each groupM1 = 3 and M2 = 6
Find the SS for each groupSS1 = 16 and SS2 = 24
Find the pooled variance, andSP
2 = 2.86
Find estimated standard errorS(M1-M2) = 0.85
© aSup-2007
Inference about Means and Mean Differences
39
STEP-3: Compute the t statistic
t = M1 – M2
S (M1 – M2)
=-3
0.85= -3.55

© aSup-2007
Inference about Means and Mean Differences
40
STEP-4: Make a decision about H0, and state conclusion
The obtained t statistic (t = -3.53) is in the critical region on the left tail (critical t = ± 2.145). Therefore, the null hypothesis is rejected.
The participants that were informed about the withheld evidence gave significantly longer sentences,
t(14) = -3.55, p<.05, two tails

© aSup-2007
Inference about Means and Mean Differences
41
The critical region in thet distribution for α = .05 and df
= 14
Reject H0 Reject H0
Fail to reject H0
-2.145 2.145

© aSup-2007
Inference about Means and Mean Differences
42
LEARNING CHECK
The following data are from two separate independent-measures experiments. Without doing any calculation, which experiment is more likely to demonstrate a significant difference between treatment A and B? Explain your answer.
EXPERIMENT A EXPERIMENT BTreatment
ATreatment
BTreatment
ATreatment
B
n = 10 n = 10 n = 10 n = 10M = 42 M = 52 M = 61 M = 71
SS = 180 SS = 120 SS = 986 SS = 1042

© aSup-2007
Inference about Means and Mean Differences
43
A psychologist studying human memory, would like to examine the process of
forgetting. One group of participants is required to memorize a list of words in the evening just before going to bed.
Their recall is tested 10 hours latter in the morning. Participants in the second group memorized the same list of words in he morning, and then their memories tested 10 hours later after being awake
all day.
LEARNING CHECK
© aSup-2007
Inference about Means and Mean Differences
44
LEARNING CHECK
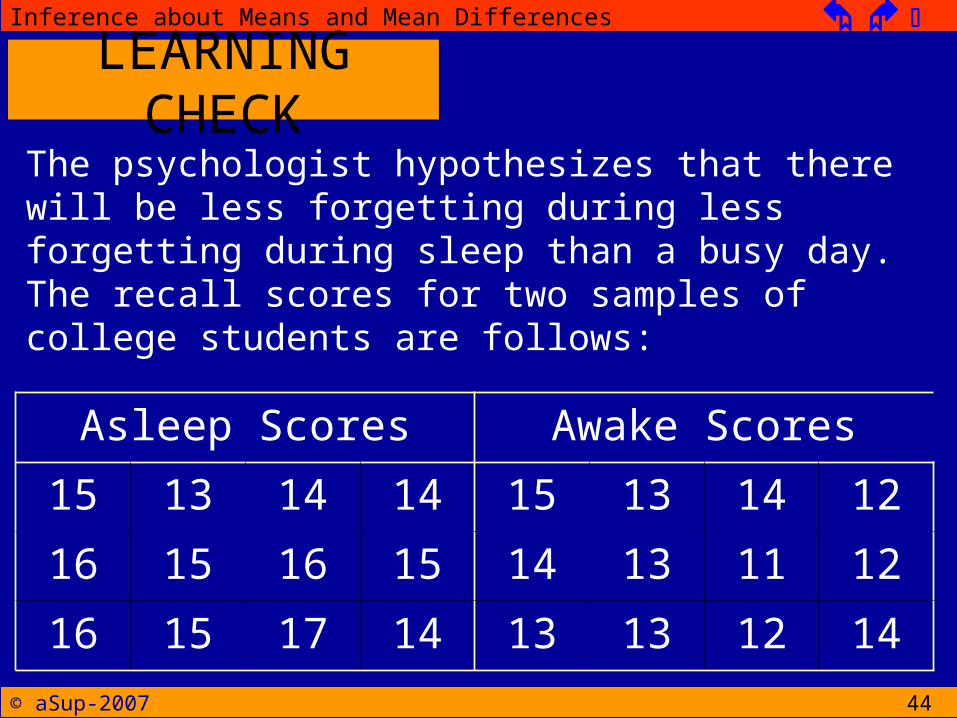
The psychologist hypothesizes that there will be less forgetting during less forgetting during sleep than a busy day. The recall scores for two samples of college students are follows:
Asleep Scores Awake Scores
15 13 14 14 15 13 14 12
16 15 16 15 14 13 11 12
16 15 17 14 13 13 12 14

© aSup-2007
Inference about Means and Mean Differences
45
Sketch a frequency distribution for the ‘asleep’ group. On the same graph (in different color), sketch the distribution for the ‘awake’ group.Just by looking at these two distributions, would you predict a significant differences between two treatment conditions?
Use the independent-measures t statistic to determines whether there is a significant difference between the treatments. Conduct the test with α = .05
LEARNING CHECK

© aSup-2007
Inference about Means and Mean Differences
46
Chapter 11THE t TEST FOR TWO RELATED SAMPLES

© aSup-2007
Inference about Means and Mean Differences
OVERVIEW With a repeated-measures design, two
sets of data are obtained from the same sample of individuals
The main advantage of a repeated-measures design is that it uses exactly the same individual in all treatment conditions.
47

© aSup-2007
Inference about Means and Mean Differences The Hypotheses for a Related-Samples
Test As always, the null hypotheses states that
for the general population there is no effect, no change, or no difference. H0: X2 - X1 = μD = 0
The alternative hypotheses states that there is a treatment effect that causes the scores in one treatment condition to be systematically higher (or lower) than the scores in the other condition. In symbols H1: μD ≠ 0
48

© aSup-2007
Inference about Means and Mean Differences The t Statistic for Related
Samples The t statistic for related samples is
structurally similar to the other t statistics
One major distinction of the related samples t is that is based on difference scores rather than raw scores (X values)
49

© aSup-2007
Inference about Means and Mean Differences The t Statistic for Related
Samples
or
t =sample statistic
estimated standard error
population parameter-
=MD – μD
SMD
S2 =SSn-1
=SSdf
S =SSdf√
SMD = S2
n-1√or SMD
=S
df√

© aSup-2007
Inference about Means and Mean Differences
51
LEARNING CHECKPeople with agoraphobia are so filled with
anxiety about being in public places that they seldom leave their homes. Knowing this is a difficulty disorder to treat, a researcher tries a long-term treatment.A sample of individuals report how often they have ventured out of the house in the past month. Then they have receive relaxation training and are introduce to trips away from the house at gradually increasing durations.After 2 months of treatment, participants report the number of trip out of the house they made in the last 30 days.

© aSup-2007
Inference about Means and Mean Differences
52
Person Before (X1) After (X2) Difference (D)
A
B
C
D
E
F
G
0
0
3
3
2
0
0
4
0
14
23
9
8
6
?
?
?
?
?
?
?Does the treatment have a significant effect on the number of trips a person takes?Test with α = .05 two tails
Top Related