7 Chapter 7 The University Lab: Conceptual Design Hachim Haddouti.
date post
19-Dec-2015Category
view
215download
1
XML und Data Management - Introduction -
Hachim HaddoutiAl Akhawayn University
SSE
http://mail.alakhawayn.ma/~H.Haddouti

Hachim Haddouti
Table of Conetnt
Intro Motivation Semi structured data Why do we need semistructured data? What is semistructured data?

Hachim Haddouti
Motivation
Some data really is unstructured Examples:
– World Wide Web– Data exchange formats– Data Integration

Hachim Haddouti
Motivation - Web
Why do we want to treat the Web as a database?– Maintain integrity– Query based on structure (as opposed to content)– Introduce some “organization”
However, Web has no structure, refer to it as enormous graph Some people claim database research community missed the
boat when it comes to the World Wide Web

Hachim Haddouti
Motivation – Data Formats
Much (most?) of the world’s data is in data formats– Formats defined for interchange and archiving of data
Formats vary in generality– ASN.1, EDI quite general– Scientific data formats tend to be “fixed schema”
Textual representation given by data formats not immediately translatable into standard relation/object-oriented representation

Hachim Haddouti
ASN.1
Abstract Syntax Notation number One (ASN.1)– International standard that aims at specifying data used
in communication protocols– e.g., format for transporting data between two layers of
a network operating system Now used for storing bibliographic and genetic data Want more, go to www.asn1.elibel.tm.fr/en/introduction/

Hachim Haddouti
Sample ASN.1 Module
Module-order DEFINITIONS AUTOMATIC TAGS ::=
BEGINOrder ::= SEQUENCE {
header Order-header, items SEQUENCE OF Order-line }
Order-header ::= SEQUENCE { reference NumericString (SIZE (12)), date NumericString (SIZE (8)) -- MMDDYYYY --, client Client, payment Payment-method }
Client ::= SEQUENCE { name PrintableString (SIZE (1..20)), street PrintableString (SIZE (1..50)) OPTIONAL, postcode NumericString (SIZE (5)), town PrintableString (SIZE (1..30)), country PrintableString (SIZE (1..20)) DEFAULT "France" }
Payment-method ::= CHOICE { check NumericString (SIZE (15)), credit-card Credit-card, cash NULL }
Credit-card ::= SEQUENCE { type Card-type, number NumericString (SIZE (20)), expiry-date NumericString (SIZE (6)) -- MMYYYY -- }
Card-type ::= ENUMERATED {cb(0), visa(1), eurocard(2), diners(3), american-express(4)} -- etcEND

Hachim Haddouti
EDI
EDI = Electronic Data Interchange Provides a collection of standard message formats and element
dictionary to support exchange of data via any electronic messaging service

Hachim Haddouti
Sample EDI Invoice File
ISA~00~ ~00~ ~ZZ~YOUR COMM-ID ~14~SLKP COMM-ID ~000227~1053~U~00401~000000012~0~P~> GS~IN~YOUR COMM-ID~SLKP COMM-ID~20000227~1053~3~X~004010 ST~810~0001 BIG~19991118~001001~19990926~11441~~~DR N1~RE~REMIT COMPANY, INC~92~002377703 N3~P.O. BOX 111 N4~ANYTOWN~NC~27106 N1~ST~SARA LEE FOOTWEAR N3~SHIPPING STREET N4~OUR TOWN~PA~17855 N1~BT~SARA LEE FOOTWEAR~92~10 N3~470 W. HANES MILL RD N4~WINSTON SALEM~NC~27105 ITD~05~3~~~~~60 DTM~011~19991118 IT1~0001~1470~YD~2~~BP~BUYERPART PID~F~~~~Square Rubber Hose TDS~294000 ISS~1470~YD CTT~1~1470 SE~19~0001 GE~1~3 IEA~1~000000012

Hachim Haddouti
Motivation - Browsing
To query database, one needs to understand schema Schemas may be hard to understand, users may want to start by
querying data with little or no knowledge of schema– Where in database is string “Casablanca”?– Are there integers in database greater than 216?– What objects in db have attribute name that starts with “act”?
Some extensions to relational query languages have been proposed for such queries

Hachim Haddouti
Motivation – Integration of Heterogeneous Data
With the growing amount of information distributed in multiple sources, comes an increased need for tools and algorithms to provide integrated, unified interface to information
Information integration is another application which calls for flexible, dynamic, self-describing data model

Hachim Haddouti
Content from Multiple Sources
Supplier
ProductCatalog
Pricing
Supplier
ProductCatalog
ERP(P + D)
3rd partycontent
Delivery
SupplierInformation
Who offers thecheapest 10+ Nm motor,
matching with my XYZ123 drive, operating <12V, available
within 2 days ?
…and, if possible, is apreferred supplier

Hachim Haddouti
Supply Chain Management
Credible Inc.Flaky Inc.
OutstandingCustomer
Orders
Shipments toACME
Flaky Inc.’s shipment is coming two days later than needed… Given the state of our inventory, expected orders, identity (and value) of customers, and pricing and
delivery options, how can we satisfy our best customer at the price we promised them?
ProductReturns
SalesPipeline
Info
Shipments toACME
ExpectedSupplies
Pricing &Delivery

Hachim Haddouti 14
… Or Viewed in Different Terms
“Heterogeneities are everywhere”
• Different interfaces• Different data representations• Duplicate and inconsistent information
PersonalDatabases
Digital Libraries
Scientific Databases
WorldWideWeb

Hachim Haddouti 15
Integrated View of Heterogeneous Data
Integration System
• Collects and combines information• Provides integrated view, uniform user interface• Supports sharing
WorldWideWeb
Digital Libraries Scientific Databases
PersonalDatabases

Hachim Haddouti
World of Data Access and Integration Servers
Provide to the eBusiness application unified access to the data sources
Data of multiple sources appear as if they come from one (potentially virtual) database
as ubiquitous as application servers Driven by initiatives in
– Customer Relationship Management– Supply Chain Management– eCommerce and eContent– Business Intelligence and Warehousing

Hachim Haddouti
Most-Generic Integration System Architecture
. . .Information
Source
Wrapper
Integrator
. . .
Clients
Wrapper
InformationSource
Wrapper
InformationSource

Hachim Haddouti
How Do We Represent Data in the Integration System?
Relational Data Model– Set of rows and columns– Fixed set of simple data types
Data cube– Specialized warehouse management system – Uses a single, multi-dimensional relation as model
Neither!! Both models are too rigid to accommodate heterogeneous data from multiple sources

Hachim Haddouti
Bottom Line
We need a bridge between the repositories where the data resides (e.g., data warehouse, transactional databases) and where it is used (Web interface, business application)
Data model that allows for the exchange of data with structure
Relaxes the strictures of existing, highly structured database systems

Hachim Haddouti
New Data Model:Semistructured Data Model

Hachim Haddouti
Semistructured Data: Particularities (1)
Structure is irregular – data heterogeneities– Pieces of data missing– Extra information is recorded (annotations)– Type variations (Dollars/Euros – Address)
Structure may be implicit– Often in files: text + grammar (e.g., SGML)
• Need to parse – structuring may be hidden

Hachim Haddouti
Semistructured Data: Particularities (2)
Structure may be partial– Parts of data lack structure (e.g., images)– Some data may yield little structure (e.g., plain text)
Types are only indicative– Unlike databases, some sources may not have strict typing
policy

Hachim Haddouti
Semistructured Data: Particularities (3)
A-priori schema vs. a-posteriori:– Database: Fix schema, then populate– Web: design a lot of Web pages, then define schema to
facilitate access Schema is large Schema often ignored in queries
– IR queries and browsing

Hachim Haddouti
Semistructured Data: Particularities (4)
Schema is rapidly evolving Data element type is eclectic
– Structure of a piece of information may depend on point of view
– e.g., Person object contains, name, address, phone as strings and picture as gif file

Hachim Haddouti
Example
{name: “Alan”, tel: 2157786, email: “[email protected]”}
{name: {first: “Alan”, last: “Black”}, tel: 2157786, email: “[email protected]”}
Different from usual tuples in that we allow duplicates:
{name: “Alan”, tel: 2157786, tel: 2159989, email: “[email protected]”}

Hachim Haddouti
Graph Representation
“Alan” 2157786“[email protected]”
nametel
“Alan”
2157786“[email protected]”
name
telemail
“Black”
first last
node
edges

Hachim Haddouti
Example
Possible to describe sets of tuples:
{person:
{name: “Alan”, tel: 2157786, email: “[email protected]”},
person:
{name: “Sara”, tel: 2344381, email: “[email protected]”},
person:
{name: “Fred”, tel: 7767546, email: “[email protected]”}
}

Hachim Haddouti
Example – Variations in Structure
Possible to describe sets of heterogeneous tuples:{person:
{name: “Alan”, phone: 2157786, email: “[email protected]”},
person:
{name: {first: “Sara”, last: “Green”},
tel: 2344381,
email: [email protected]
},
person:
{name: “Fred”, tel: 7767546, height: 6’4”}
}

Hachim Haddouti
Base Types
Numbers: (1234, 45, 4532, …) Strings: (“Alan”, “ssdrf”, “[email protected]”, …) Labels: (name, email, …) Distinguishable by syntax Other types such as gif, date, wav, etc. can be added as
needed– Each value has a tag that indicates its type and possibly
an encoding– Most data formats have their own tagging

Hachim Haddouti
Representing Relational Databases
Relational schema r1(a,b,c) and r2(c,d)– r1 and r2 are relations, – a, b, c, d column names
Instance is some data that conforms to this specification– Usually depicted as rows in table

Hachim Haddouti
Pictorially
a b cr1
a1 b1 c1
a2 b2 c2
a3 b3 c3
c dr2
c2 d1
c3 d2
c4 d3

Hachim Haddouti
Self-describing Approach
Using our new model and syntax, we can describe the whole database formally as: {r1: i1, r2: i2}, where i1 and i2 are sets of rows
{r1: {row: {a: a1, b: b1, c: c1},
row: {a: a2, b: b2, c: c2},
row: {a: a3, b: b3, c: c3}
}, r2: {row: {c: c2, d: d2},
{row: {c: c3, d: d3},
{row: {c: c4, d: d4}
}}

Hachim Haddouti
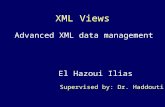
Other Representations
r1 r2
row row row
rowrow
row
ab
c ab
c ab
c
a1 b1 c1 a2 b2 c2 a3 b3 c3
c d c d c d
c2 d2 c3 d3 c4 d4
Hachim Haddouti
Other Representations
r1r2
ab
c ab
c ab
c
a1 b1 c1 a2 b2 c2 a3 b3 c3
c d c d c d
c2 d2 c3 d3 c4 d4
r2 r2r1 r1

Hachim Haddouti
OIDOID unique identifier or NULL LabelLabel character string descriptor
TypeType atomic data type or set ValueValue atomic value or set of object
references
Common model for heterogeneous information exchange, “schema-less”
Each object:
OIDOID LabelLabel TypeType ValueValue
“Help pages” for labels Two query languages
The Object Exchange Model (OEM)

Hachim Haddouti
OEM
Provides:– Flexibility: rigid domain models not needed for those
software components which do not require one– Extensibility: information servers can use whatever
information is available and can rapidly make its knowledge available on an experimental basis
– Stability: the structure of the information remains stable even as new information is added
Removes dependencies on compile-time object definitions

Hachim Haddouti
Representing Semistructured Data Using OEM
<book, {t1, a1}> t1: <title, “Database and ...”> a1: <author, “Jeff Ullman”>
Label
Set Value
Atomic Value
MemoryAddresses

Hachim Haddouti
Representing Semistructured Data Using OEM
<collection, {b1, a1, ...}>b1: <book, {t, a}> t: <title, “Database and ...”> a: <author, {n, p}>
n: <name, “Jeff Ullman”>p: <picture, “/gifs/ullman.gif”>
a1: <article, {v, w, x}>v: <author, “Gio Wiederhold”>w: <title, “Mediators in the …”>x: <journal, “IEEE Computer”>...

Hachim Haddouti
Example: ACeDB
ACeDB (a C. elegans Database) Genome database system developed since 1989 primarily by Jean Thierry-
Mieg (CNRS, Montpellier) and Richard Durbin (Sanger Institute) Provides custom database kernel, with non-standard data model designed
specifically for handling scientific data flexibly AceDB is used both for managing data within genome projects, and for
making genomic data available to the wider scientific community.
– Popular with biologists for its flexibility and ability to accommodate missing data
– Underlying data model is quite general

Hachim Haddouti
Sample AceDB Schema
?person name firstname UNIQUE Text - at most one first name
lastname UNIQUE Text - at most one last name
tel Int - several numbers
?book authors ?person - set of persons
title UNIQUE Text - at most one title
chapter-headings Int UNIQUE Text - array of strings
…

Hachim Haddouti
Sample ACeDB Data
&ASmith person name firstname “Alan” - ASmith is key/OID
lastname “Smith”
&JMiller person name firstname “Janet” lastname “Miller”
&LH17.23.15 authors &ASmith
&JMiller
title “A Very Very Brief History of Time”
chapter-headings 1 “The Beginning”
chapter-headings 2 “The Middle”
chapter-headings 3 “The End”
…

Hachim Haddouti
Is ACeDB Semistructured?
Any label other then top identifier can be missing OID’s provided by user ACeDB requires schema, but data may be missing, no strong typing (labels instead)

Hachim Haddouti
Proposal for Generic SS Data Syntax
Semistructured data expressions: ssd-expressions– Standard syntax for labels and for atomic values– Object identifiers start with ampersand, e.g., &123
<ssd-expression>::= <value> | oid<value>|oid
<value>::= atomicvalue | <complexvalue>
<complexvalue>::= {label:<ssd-expression>, … , label:<ssd-expression>}

Hachim Haddouti
Example
{person: &o1{name: “Mary”, age: 45, child: &o2, child: &o3
}, person: &o2{name: “John”,
age: 17, relatives: {mother: &o1,
sister: &o3}},
person: &o3{name: “Jane”, country: Canada, mother: &o1 }
}

Hachim Haddouti
Pictorially (edge-labeled graph)
person personperson
&o1 &o2 &o3
name age name
relativesage
name country
“Mary” 45 “John” 17 “Jane” “Canada”
mothersister
mother
childchild

Hachim Haddouti
Terminology
Terminology used to describe semistructured data is that of basic graph theory

Hachim Haddouti
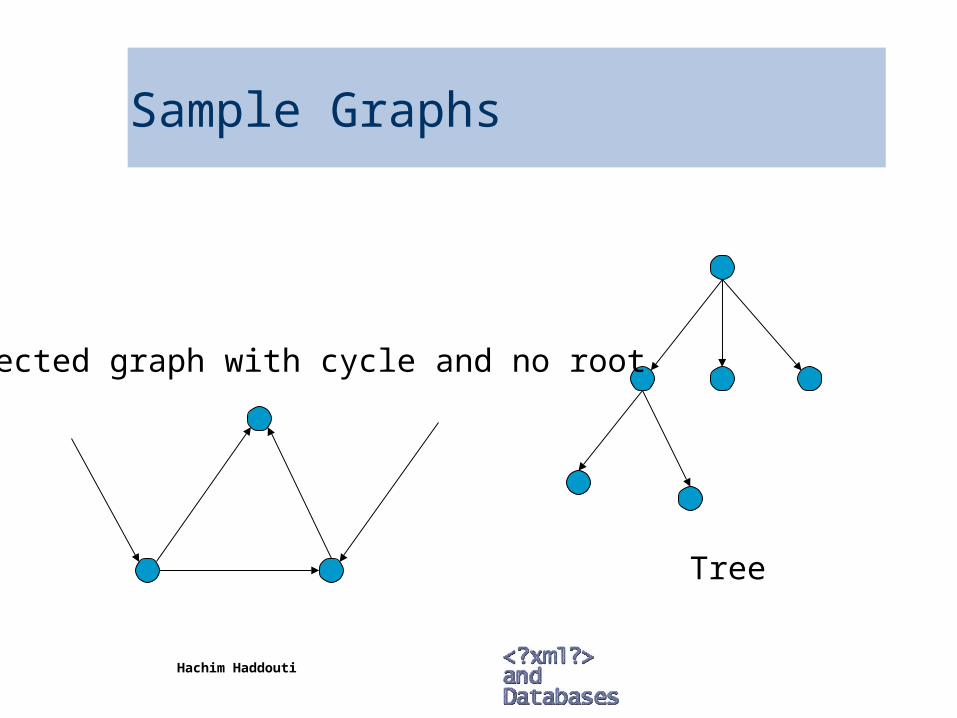
Basic Graph Theory
Graph (N,E) set of nodes N and set of edges E Each edge e is associated with a pair of nodes, source node s(e)
and target node t(e) Path is a sequence e1, e2, … , ek edges such that t(ei) = s(ei+1), 1
i k-1
– Number of edges in path is length Node r is root for graph (N,E) if there is a path from r to n for every
node in N, n r A cycle in a graph is a path between a node and itself
– Graph with no cycles is acyclic A rooted graph is s tree if there is a unique path from r to n for
every n N, nr
Hachim Haddouti
Sample Graphs
Tree
Directed graph with cycle and no root

Hachim Haddouti
Summary
Def.: Semistructured data model
Is a syntax for data with no separate syntax for types, i.e., data that has no separate schema language or data definition language.
Data graph vs ssd-expressions Our semistructured data model is that of an edge-labeled
graph
– Each edge has a label















![[PPT]Database Systems: Design, Implementation, and …H.Haddouti/DB_Implementation_case... · Web viewTitle Database Systems: Design, Implementation, and Management Subject Chapter](https://static.fdocuments.in/doc/165x107/5ac556c47f8b9af91c8d8dac/pptdatabase-systems-design-implementation-and-hhaddoutidbimplementationcaseweb.jpg)