
1 Part 2: Modelling XML Data Managing XML and Semistructured Data.
description

XML Data Compression
Greg Leighton, Jim Diamond, Tomasz Müldner
February 18, 2005

Overview A (brief) introduction to data compression XML lossless data compression New XML Compression Programs
AXECHOP TREECHOP

XML Data Compression A (brief) introduction to XML Techniques for achieving XML compression
Traditional approaches – Huffman, LZ Specialized approaches
XML Compression Programs XMill XGrind XPRESS

eXtensible Markup Language separate syntax from semantics support semi-structured data support internationalization and platform
independence is self-describing (through labeling of the
tree)

eXtensible Markup Language : 2
XML is a framework for defining markup languages: no fixed collection of markup tags each XML language is specialized for its own
application domain a common set of generic tools supports
processing documents
XML: textual convention to represent tagged trees

eXtensible Markup Language : 3<?xml version=“1.0” encoding=“UTF-8”?><Employees> <Employee id=“123456”> <Name>Homer Simpson</Name> <Department>Sector 7-G</Department> </Employee> <Employee id=“123457”> <Name>Frank Grimes</Name> <Department>Sector 7-G</Department> </Employee> …</Employees>
Element
Attribute
Data Value

eXtensible Markup Language : 4 Correctness of an XML document:
Well-formed: complies with XML syntax Valid: obeys the structure described in a
grammar, such as XML schema document
Two kinds of XML parsers: SAX DOM
Why Compress XML?
XML is verbose: Each non-empty element tag must end with
a matching closing tag -- <tag>data</tag> Ordering of tags is often repeated in a
document (e.g. multiple records) Tag names are often long

XML Compressors
• View XML as a tree
• Separate the tree structure and what is stored in leaves
• Save the tree structure so that it can be restored
• The compressed file may or may not remember the tree structure
breadfruit tree
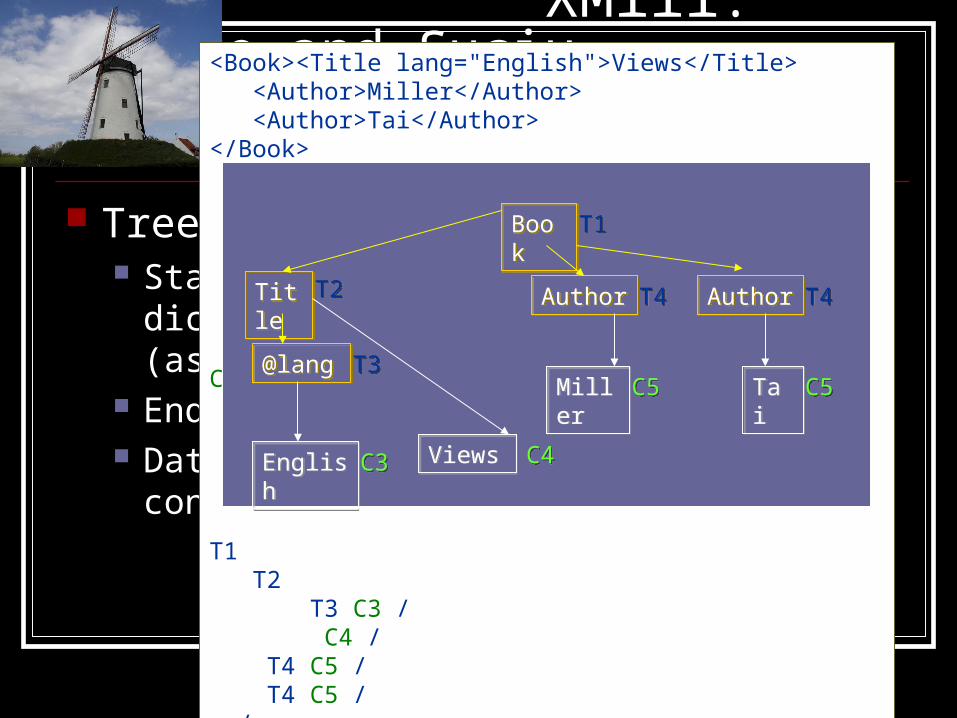
XMill: Liefke and Suciu
Tree structure: Start tags and attribute names are dictionary-
encoded (as T1, T2, etc.)
End tags replaced with ‘/’ token Data values are replaced with their container
number
<Book><Title lang="English">Views</Title> <Author>Miller</Author> <Author>Tai</Author></Book>
T1 T2 T3 C3 / C4 / T4 C5 / T4 C5 / /
T1 T2 T3 C3 / C4 / T4 C5 / T4 C5 / /
@lang@lang T3T3
BookBook
TitleTitle
T1T1
T2T2 AuthorAuthor T4T4 AuthorAuthor T4T4
EnglishEnglish
MillerMiller TaiTai
ViewsViewsC3C3 C4C4
C5C5 C5C5

XMill: Liefke and Suciu
For each ending tag or attribute there is a separate data container
Different semantic compressors can be used for various containers (gzip)
Compressed file does not remember the original structure

XMill: Decompression Decompressor loads and unzips each
container and the decompressed structure container is parsed
Whenever a data value is found in the structure, the next value is pulled from the corresponding data container and the appropriate semantic decompressor (if applicable) is applied to get back the original data value

XGrind: Tolani & Haritsa The structure of original XML document is
retained by the compression process:
Compress at the granularity of individual element and attribute values.

XGrind Operations on the compressed file
Querying the compressed document Exact and prefix-match require no decompression Range or partial-match require on-the-fly
decompression of element/attribute values that appear in the query
Updates Testing Validity (against the compressed DTD)
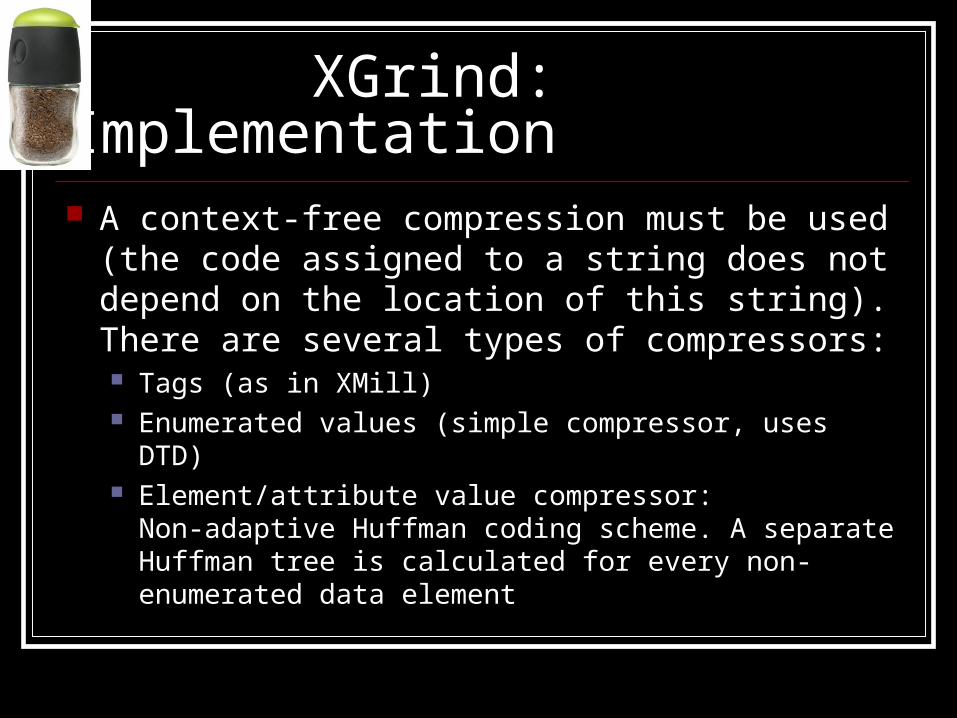
XGrind: Implementation A context-free compression must be used
(the code assigned to a string does not depend on the location of this string). There are several types of compressors: Tags (as in XMill) Enumerated values (simple compressor, uses DTD) Element/attribute value compressor:
Non-adaptive Huffman coding scheme. A separate Huffman tree is calculated for every non-enumerated data element
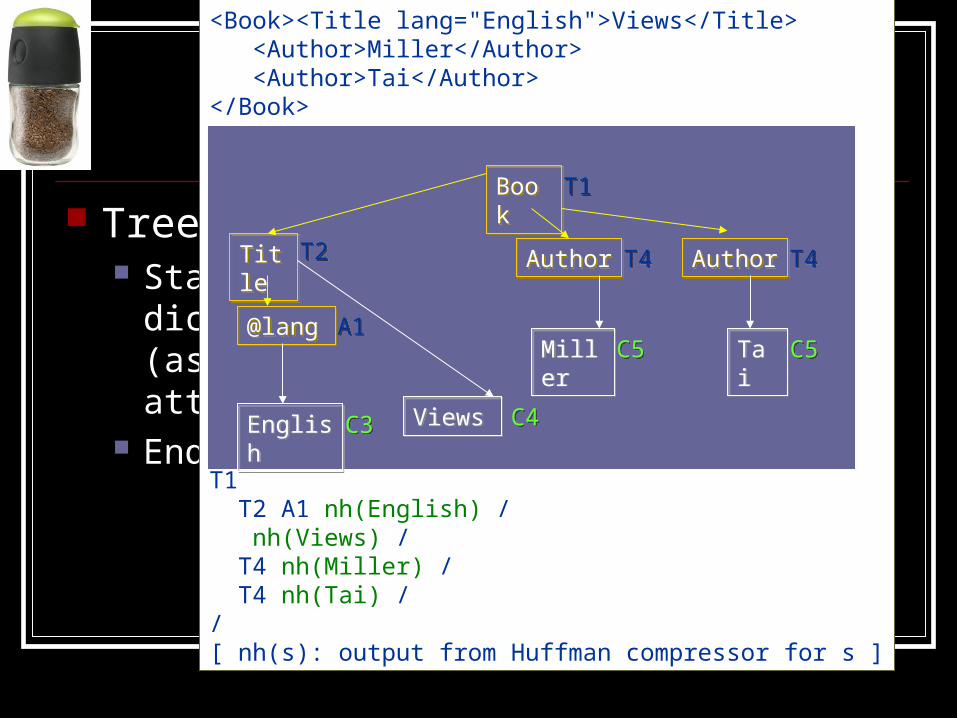
XGrind
Tree structure: Start tags and attribute names are dictionary-
encoded (as T1, T2, for tags and A1, A2 for attributes)
End tags replaced with ‘/’ token
<Book><Title lang="English">Views</Title> <Author>Miller</Author> <Author>Tai</Author></Book>
T1 T2 A1 nh(English) / nh(Views) / T4 nh(Miller) / T4 nh(Tai) / /[ nh(s): output from Huffman compressor for s ]
@lang@lang A1A1
BookBook
TitleTitle
T1T1
T2T2 AuthorAuthor T4T4 AuthorAuthor T4T4
EnglishEnglish
MillerMiller TaiTai
ViewsViewsC3C3 C4C4
C5C5 C5C5
XGrind: Querying The query engine works on the
compressed document; it consists of a lexer and a parser
The query (the path and the predicate) are compressed
The parser checks if the current path matches the query path and the compressed data value satisfy the compressed predicate

XMLPPM A modification of the prediction-by-
partial matching (PPM) text compression scheme.
To process XML data, the encoder chooses the appropriate PPM model from a set of several models depending on the current context supplied by the built-in SAX parser

AXECHOP and TREECHOP AXECHOP: attempts to achieve highest-
possible compression ratio by reordering original document
TREECHOP: willing to sacrifice a bit on compression ratio in order to preserve original XML structure and enable querying to be carried out on compressed document

AXECHOP: Key Features Uses a grammar-based approach for
compressing XML document structure Outperforms general-purpose text compressors
(e.g. gzip) by as much as 30% on XML Operates offline (decompression can’t start until
entire compressed file has been received) Suited for XML data archiving, not for XML
messaging applications (e.g. Web Services)

Grammar-based Compression Achieves compression by producing a
context-free grammar that uniquely derives the input sequence
Define a separate production for each repetition in the input For second and subsequence occurrences,
encode the LHS of the production rather than the pattern on the RHS

Grammar-based Compression: Example
Original Input:
abcdbcabc
Generated Grammar:
S aAdAaA
A bc
AXECHOP: Compression Strategy
1. Perform a re-ordering of the XML document during SAX parsing
Use a byte-based encoding scheme to record the structure of the document – the “structure string”
Place data values for each element and attribute in a separate container to localize repetitions
AXECHOP: Compression Strategy 3
2. Apply Multilevel Pattern Matching (MPM) algorithm to obtain grammar-based compression of the document structure
3. Compress the contents of each data value container using the Burrows-Wheeler block-sorting algorithm
4. Write compressed data to output file

AXECHOP Compression: Example

AXECHOP Compression: Example 3Original Structure String:1 132 2 128 130 3 4 133 128 130 4 133 128 130 130 130
S A B E L K J 130 3
A C D F L M K 4 133
B E F G 1 132 L 128 130
C G H H 2 128 M 130 130
D J K
MPM-Generated Grammar:

AXECHOP: Decompression Strategy
1. Decompress the MPM code to obtain the document structure
2. Perform inverse BWT to get back the contents of each data value container
3. Perform a single pass through the reconstituted structure string
AXECHOP: Implementation Written in C++ Designed to be modular
instead of using MPM as structural compressor, can insert a different compressor
BWT can be swapped with a different container compressor

AXECHOP: Experimental Results

AXECHOP: Conclusions AXECHOP achieves 2nd best average compression rate
over a varied corpus of XML files Future work:
Speed up compression through code optimization Use a form of PPM in place of BWT for dictionary
compression (PPM often achieves a better compression rate but tends to be slow)
Define an XML-conscious grammar-based compression scheme, instead of using “general-purpose” MPM

TREECHOP: Key Features Carries out an online compression of the XML
document tree Since original document structure is maintained
throughout compression, querying can be carried out without requiring decompression
Intended for XML messaging scenarios, where documents are being transmitted over a network
Encoding and querying strategies are based on the XPath standard
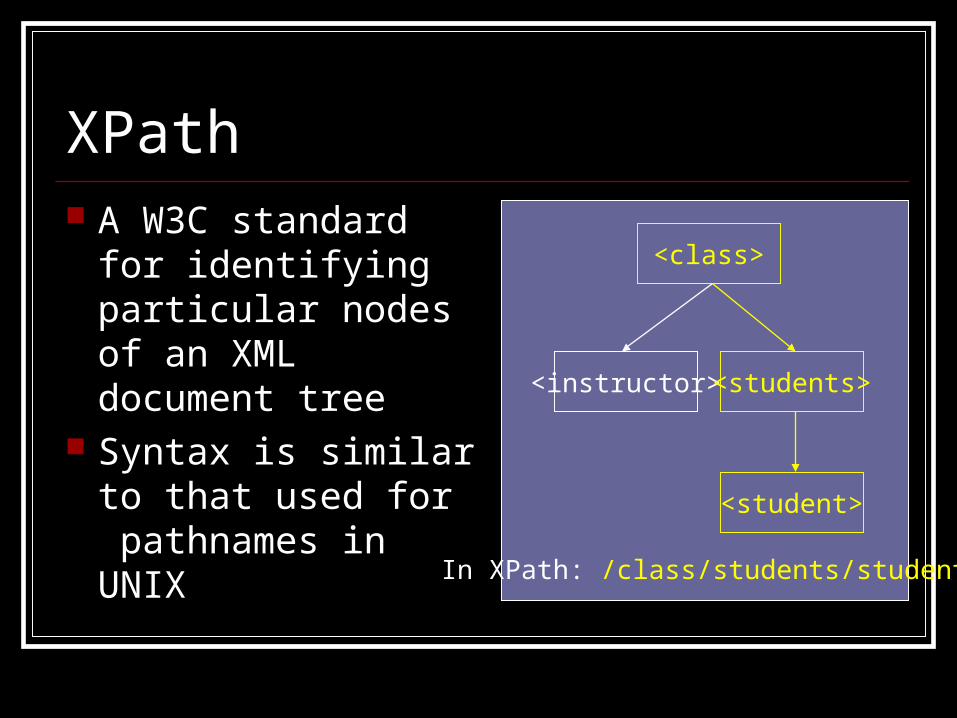
XPath A W3C standard for
identifying particular nodes of an XML document tree
Syntax is similar to that used for pathnames in UNIX
<class>
<instructor> <students>
<student>
In XPath: /class/students/student

TREECHOP: Compression Strategy
1. Perform SAX parsing
2. Generate document tree
3. Assign a binary code word to each non-leaf tree node
4. Write tree encoding to compression stream

TREECHOP: Generating the Tree Encoding has 3 important properties:
Each tree node inherits its parent’s code as a prefix
Two nodes share the same code word iff they have the same XPath location, as traced from tree root downwards
Maintains the structure of the original document throughout the compression process

TREECHOP: Tree Encoding Scheme
Given a non-leaf node N with parent node P, where N is the i-th distinct child node of P:

TREECHOP: Example XML File

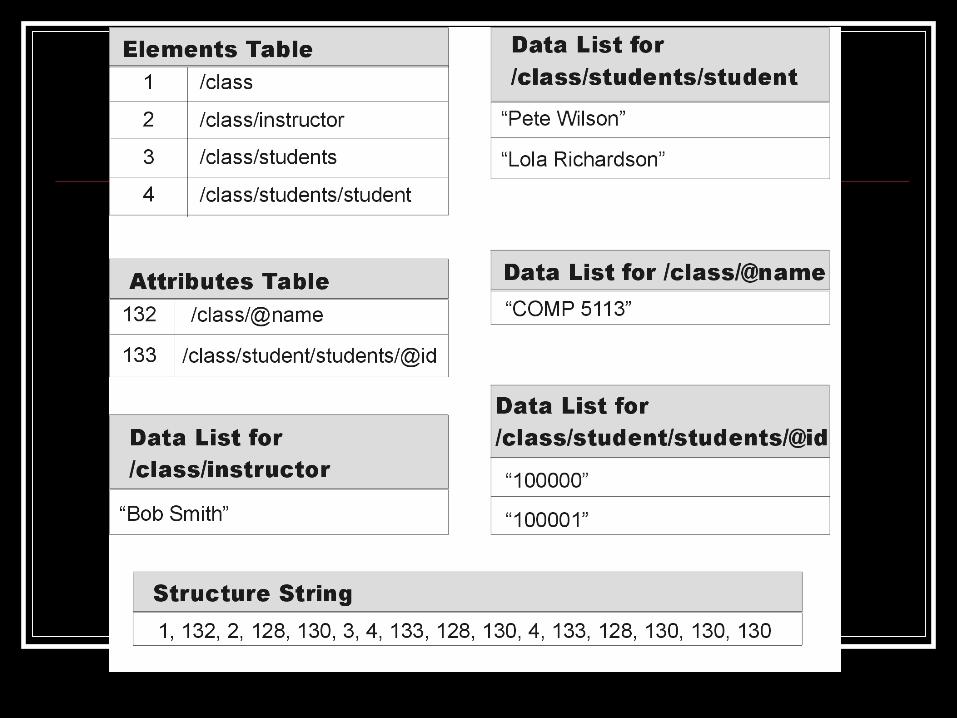
TREECHOP: Example Tree<class>
@name <students><instructor>
<student> <student>
@id @id
“COMP 5113” “Bob Smith”
“100000” “100001”“Pete Wilson” “Lola Richardson”

TREECHOP: Example Tree<class>
@name <students><instructor>
<student> <student>
@id @id
“COMP 5113” “Bob Smith”
“100000” “100001”“Pete Wilson” “Lola Richardson”
00
0000 00010 00011
0001100 0001100
000110000 000110000

TREECHOP: Writing the Tree Encoded tree is written to compression stream in
depth-first order Non-leaf nodes: written as 4-tuple (L, C, T, D)
L is a byte indicating bit length of code word C is a sequence of bytes containing code word T is a byte indicating node type (e.g. element) D is textual data stored in the node (e.g. element
name) - reserved byte values are used to signal beginning/end of stream of raw character data

TREECHOP: Writing the Tree 2 For 2nd and subsequent occurrences of a
non-leaf node, only the 2-tuple (L, C) is transmitted – decoder can then infer T and D
Leaf nodes are written in the manner of D, above – as a stream of raw character data

TREECHOP: Decompression Strategy A code table is used to
keep track of code words processed thus far
Allows future occurrences of a particular (L, C) pair to be mapped to the proper data type & value

TREECHOP: Decompression Strategy 2
To maintain proper nesting, a stack is used When a new tree node is processed, continue
popping until the node on top of stack does not share a common code word prefix with current node
Last popped node is the parent of the current node

TREECHOP: Querying Queries are expressed using XPath Once the equivalent code word for the
query predicate has been determined, query matches can be quickly located by searching through the compression stream for other occurrences of the code word

TREECHOP: Querying Example

TREECHOP: Querying Example 2Search for all occurrences of ‘/class/students/student’
1. Discover code word for ‘/class’ 002. Discover code word for ‘/class/students’
000113. Discover code word for ‘/class/students/student’
00011004. Extract data contained in next occurring leaf
node “Pete Wilson”5. Scan through remainder of compression stream,
looking for occurrences of code word 0001100 – occurs once more and the associated data value (“Lola Richardson”) is extracted

TREECHOP: Current State Java-based implementation is partially
completed Modeled after existing java.net package
(e.g. XMLSocket corresponds to Socket)
Future Work Finish implementation of TREECHOP Use TREECHOP to validate compressed
document using compressed grammars Applications for XML filtering Compressed stylesheets

Questions?








![XCOMP: AN XML COMPRESSION TOOLtozsu/publications/distdb/Weimin.pdf · Chapter1 Introduction 1.1 Overview XML,theeXtensibleMarkupLanguage[24],isbecomingastandardformatfordata storageandexchange,inparticularovertheInternet.](https://static.fdocuments.in/doc/165x107/5e8b5c2201f9a0761972745c/xcomp-an-xml-compression-tool-tozsupublicationsdistdbweiminpdf-chapter1-introduction.jpg)









