
Www Thelearningpoint Net Computer Science Data Structures Qu

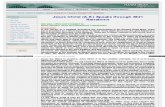
RAID-1, or Mirroring;Courtesy Colin M. L. Burnett
You are here: Home / Technical Deep Dive / Redundancy in Data Storage: Part 1: RAID Levels
Redundancy in Data Storage: Part 1: RAID LevelsDECEMBER 13, 2010 BY MICHAEL LYLE 3 COMMENTS
I recently read Joe Onisick’s piece, “Have We Taken Data Redundancy Too Far?” I think Joe raises a good point,and this is a natural topic to dissect in detail after my previous article about cloud disaster recovery and businesscontinuity. I, too, am concerned by the variety of data redundancy architectures used in enterprise deployments andthe duplication of redundancy on top of redundancy that often results. In a series of articles beginning here, I willfocus on architectural specifics of how data is stored, the performance implications of different storage techniques,and likely consequences to data availability and risk of data loss.
The first technology that comes to mind for most people when thinking of data redundancy is RAID, which stands forRedundant Array of Independent Drives. There are a number of different RAID technologies, but here I will discussjust a few. The first is mirroring, or RAID-1, which is generally employed with pairs of drives. Each drive in a RAID-1set contains the exact same information. Mirroring generally provides double the random access read performanceof a single disk, while providing approximately the same sequential read performance and write performance. Theresulting disk capacity is the capacity of a single drive. In other words, half the disk capacity is sacrificed.
A useful figure of merit for data redundancy architectures is MTTDL, or MeanTime To Data Loss, which can be calculated for a given storage technologyusing the underlying MTBF, Mean Time Between Failures, and MTTR, MeanTime To Repair/Restore redundancy. All “mean time” metrics really specify anaverage rate over an operating lifetime; in other words, if the MTTDL of anarchitecture is 20 years, there is a 1/20 = approximately 5% chance in any givenyear of suffering data loss. Similarly, MTBF specifies the rate of underlyingfailures. MTTDL includes only failures in the storage architecture itself, andnot the risk of a user or application corrupting data.
For a two-drive mirror set, the classical calculation is:
This is a common reason to have hot-spares in drive arrays; allowing anautomatic rebuild significantly reduces MTTR, which would appear to alsosignificantly increase MTTDL. However…
While hard drive manufacturers claim very large MTBFs, studies such as this one have consistently found numberscloser to 100,000 hours. If recovery/rebuilding the array takes 12 hours, the MTTDL would be very large, implying anannual risk of data loss of less than 1 in 95,000. Things don’t work this well in the real world, for two primaryreasons:
The optimistic assumption that the risk of drive failure for two drives in an array is uncorrelated. Because disksin an array were likely sourced at the same time and have experienced similar loading, vibration, andtemperature over their working life, they are more likely to fail at the same time. Also, some failure modes havea risk of simultaneously eliminating both disks, such as a facility fire or a hardware failure in the enclosure ordisk controller operating the disks.It is also assumed that the repair will successfully restore redundancy if a further drive failure doesn’t occur. Unfortunately, a mistake may happen if personnel are involved in the rebuild. Also, the still-functioning drive isunder heavy load during recovery and may experience an increased risk of failure. But perhaps the mostimportant factor is that as capacities have increased, the Unrecoverable Read Error rate, or URE, has becomesignificant. Even without a failure of the drive mechanism, drives will permanently lose blocks of data at this
specified (very low) rate, which generally varies between 1 error per 1014 bits read for low-end SATA drives to 1
per 1016 for enterprise drives. Assuming that the drives in the mirror are 2 TB low-end SATA drives, and there isno risk of a rebuild failure other than by unrecoverable read errors, the rebuild failure rate is 17%.
With the latter in mind, the MTTDL becomes:
Search Define the Cloud
Search this website… SEARCHSEARCH
Blogroll
Blades Made Simple
Follow me on twitter
Health IT Guy
IOS Hints
M. Sean McGee's Blog
Network Static
Pivot Point
Private Cloud Tech Center
Rational Survivability
Scott Lowe's Blog
The Security Blogger
View Yonder
WWT Data Center Services Team Blog
Tags
aci Big Data blades Brocade business drivers
CIFS cisco citrix cloud cloud
challenges Cloud ComputingCloudStack Consolidation cooling DataCenter DataCenter data center
virtualization DCB DCBX disaster recovery EMC
Emulex FCoE Fibre Channel HP I/OConsolidation IOC iSCSI NetAppnetworking Networkvirtualization NFS Open Source
OpenStack Private CloudPublic Cloud ROI SDN ServersStorage UCS VDI
Virtualization vmware VN-Tag
Disclaimer
All brand and company names are used foridentification purposes only. These pages are not
About Define The CloudAbout Define The Cloud About the FounderAbout the Founder ArchivesArchives Cloud SearchCloud Search Data Center QuotesData Center Quotes DonateDonate
converted by Web2PDFConvert.com

RAID 1+0: Mirroring and Striping;Courtesy MovGP
RAID-5 and RAID-6; Courtesy Colin M. L. Burnett
When the rebuild failure rate is very large compared to 1/MTBF:
In this case, MTTDL is approximately 587,000 hours, or a 1 in 67risk of losing data per year.
RAID-1 can be extended to many drives with RAID-1+0, wheredata is striped across many mirrors. In this case, capacity and
often performance scales linearly with the number of stripes. Unfortunately, so does failure rate. When one movesto RAID-1+0, the MTTDL can be determined by dividing the above by the number of stripes. A ten drive (five stripesof two-disk mirrors) RAID-1+0 set of the above drives would have a 15% chance of losing data in a year (againwithout considering correlation in failures.) This is worse than the failure rate of a single drive.
Because of the amount of storage required for redundancy in RAID-1, itis typically only used for small arrays or applications where dataavailability and performance are critical. RAID levels using parity arewidely used to trade-off some performance for additional storagecapacity.
RAID-5 stripes blocks across a number of disks in the array (minimum3, but generally 4 or more), storing parity blocks that allow one drive tobe lost without losing data. RAID-6 works similarly (with morecomplicated parity math and more storage dedicated to redundancy)but allows up to two drives to be lost. Generally, when a drive fails in aRAID-5 or RAID-6 environment, the entire array must be reread torestore redundancy (during this time, application performance usuallysuffers.)
While SAN vendors have attempted to improve performance for parityRAID environments, significant penalties remain. Sequential writes canbe very fast, but random writes generally entail reading neighboringinformation to recalculate parity. This burden can be partially eased by remapping the storage/parity locations ofdata using indirection.
For RAID-5, the MTTDL is as follows:
Again, when the RFR is large compared to 1/MTBF, the rate of double complete drive failure can be ignored:
However, here RFR is much larger as it is calculated over the entire capacity of the array. For example, achieving anequivalent capacity to the above ten-drive RAID-1+0 set would require 6 drives with RAID-5. The RFR here would beover 80%, yielding little benefit from redundancy, and the array would have a 63% chance of failing in a year.
Properly calculating the RAID-6 MTTDL requires either Markov chains or very long series expansions, and there issignificant difference in rebuild logic between vendors. However, it can be estimated, when RFR is relatively large,and an unrecoverable read error causes the array to entirely abandon using that disk for rebuild, as:
Evaluating an equivalent, 7-drive RAID-6 array yields an MTTDL of approximately 100,000 hours, or a 1 in 11 chanceof array loss per year.
The key things I note about RAID are:
The odds of data loss are improved, but not wonderful, even under favorable assumptions.Achieving high MTTDL with RAID requires the use of enterprise drives (which have a lower unrecoverable errorrate).RAID only protects against independent failures. Additional redundancy is needed to protect against correlated
identification purposes only. These pages are notsponsored or sanctioned by any of thecompanies mentioned; they are the sole workand property of the authors. While the author(s)may have professional connections to some ofthe companies mentioned, all opinions are thatof the individuals and may differ from officialpositions of those companies. This is a personalblog of the author, and does not necessarilyrepresent the opinions and positions of hisemployer or their partners.
This work by Joe Onisick is licensed under aCreative Commons Attribution-ShareAlike 3.0Unported License
converted by Web2PDFConvert.com

Rating: 0 (from 0 votes)
failures (a natural disaster, a cabinet or backplane failure, or significant covariance in disk failure rates.)RAID only provides protection of the data written to the disk. If the application, users, or administrators corruptdata, RAID mechanisms will happily preserve that corrupted data. Therefore, additional redundancymechanisms are required to protect against these scenarios.
Because of these factors, additional redundancy is required in conventional application deployments, which I willcover in subsequent articles in this series.
Images in this article created by MovGP (RAID-1+0, public domain) and Colin M. L. Burnett (all others, CC-SA) fromWikipedia.
This series is continued in Redundancy in Data Storage: Part 2: Geographical Replication.
About the Author
Michael Lyle (@MPLyle) is CTO and co-founder of Translattice, and is responsible for the company’s strategictechnical direction. He is a recognized leader in developing new technologies and has extensive experience indatacenter operations and distributed systems.
Rating: 5.0/5 (5 votes cast)
Redundancy in Data Storage: Part 1: RAID Levels, 5.0 out of 5 based on 5 ratings
Related posts:
1. Have We Taken Data Redundancy too Far?2. Redundancy in Data Storage: Part 2: Geographical Replication3. Storage Protocols4. Data Center Bridging5. The Cloud Storage Argument
FILED UNDER: TECHNICAL DEEP DIVE TAGGED WITH: BUSINESS CONTINUITY, DISASTER RECOVERY, RAID,REDUNDANCY
Comments
Michael Zandstra says:November 8, 2012 at 7:18 am
Hi Michael,
I was wondering if you could give a little more depth to this article concerning your formula’s. I’ve calculatedsome through, and I don’t get the same numbers as you do for RAID-5 and RAID-6. Since there is noexplaination what you precisely did, I can’t figure out who made the error.
Regards,
Michael Zandstra
Reply
Trackbacks
Tweets that mention Redundancy in Data Storage: Part 1: RAID Levels — Define The Cloud -- Topsy.com says:December 13, 2010 at 2:17 pm
[...] This post was mentioned on Twitter by Joe Onisick, Michael Lyle. Michael Lyle said: I've begun a series onredundancy architectures at @jonisick 's definethecloud: http://www.definethecloud.net/redundancy-1-raid-levels[...]
Reply
Efficiency & Reliability in the Cloud | Entrepreneur Resources: Small Business Blog says:May 31, 2012 at 9:31 am
333333333
converted by Web2PDFConvert.com

[...] of the all-important scaling of resources inherent to cloud computing is a little word called “redundancy.” It’snot a new concept, but it plays an essential role here in keeping information available [...]
Reply
Speak Your Mind
Name *
Email *
Website
POST COMMENT
Notify me of follow-up comments by email.
Notify me of new posts by email.
RETURN TO TOP OF PAGERETURN TO TOP OF PAGE COPYRIGHT © 2014 · COPYRIGHT © 2014 · GENESIS FRAMEWORKGENESIS FRAMEWORK · · WORDPRESSWORDPRESS · · LOG INLOG IN
converted by Web2PDFConvert.com



![[www. mojet. net] 2016 Malaysian Online Journal of Educational ...](https://static.fdocuments.in/doc/165x107/589844a71a28ab40488b66b7/www-mojet-net-2016-malaysian-online-journal-of-educational-.jpg)












