

Workshop in R and GLMs: #4
24
-
Upload
rashad-stokes -
Category
Documents
-
view
23 -
download
0
description
Workshop in R and GLMs: #4. Diane Srivastava University of British Columbia [email protected]. Exercise. Fit the binomial glm survival = size*treat 2. Fit the bionomial glm parasitism = size*treat 3. Predict what size has 50% parasitism in treatment “0”. - PowerPoint PPT Presentation
Transcript of Workshop in R and GLMs: #4

Exercise
1. Fit the binomial glm survival = size*treat
2. Fit the bionomial glm parasitism = size*treat
3. Predict what size has 50% parasitism in treatment “0”

Predicting size for p=0.5, treat=0
Output from logistic regression with logit link: predicted loge (p/1-p) = a+bx
So when p=0.5, solve log(1)=a+bx

Coefficients: Estimate Std. Error z value Pr(>|z|) (Intercept) -2.38462 0.16780 -14.211 <2e-16 ***size 0.76264 0.04638 16.442 <2e-16 ***treat 0.28754 0.23155 1.242 0.214 size:treat -0.09477 0.06357 -1.491 0.136
What is equation for treat 0? treat 1?

Rlecture.csv
0
10
20
30
40
50
60
70
80
90
100
0 2 4 6 8
Size
Par
asit
ism
(%
)
0
10
20
30
40
50
60
70
80
0 1 2 3 4 5 6 7
Size
Gro
wth
0
0.2
0.4
0.6
0.8
1
1.2
0 1 2 3 4 5 6 7
Size
Sur
viva
l
3.12

Model simplification
1. Parsimonious/ Logical sequence (e.g. highest order interactions first)
2. Stepwise sequence
3. Bayesian comparison of candidate models (not covered)

0
2
4
6
8
10
12
0 2 4 6
Plant size
Lo
git
par
asit
ism
0
2
4
6
8
10
12
0 2 4 6
Plant size
Lo
git
par
asit
ism
ANCOVA: Difference between categories….
Constant, doesn’t depend on size
Depends on size
size*treat ns size*treat sig

Deletion testsHow to change your model quickly:model2<-update(model1,~.-size:treat)
How to do a deletion test:anova(reduced model, full model, test="Chi")
1. Test for interaction in logit parasitism ANCOVAIf not sig, remove and continue. If sig, STOP!
2. Test covariate If not sig, remove and continue. If sig, put back and continue
3. Test main effect

Code for “parasitism” analysis
> ds<-read.table(file.choose(), sep=",", header=TRUE); ds> attach(ds)> par<-cbind(parasitism, 100-parasitism); par> m1<-glm(par~size*treat, data=ds, family=binomial)> summary(m1)> m2<-update(m1, ~.-size:treat)> summary(m2)> anova(m2,m1, test="Chi")> m3<-update(m2, ~.-size)> anova(m3,m2, test="Chi")> m3<-update(m2, ~.-treat)> anova(m3,m2, test="Chi")

Context (often) matters!What is the p-value for treat in:
size+treat?
treat?
Stepwise regression:
step(model)

8 11109
Jump height (how high ball can be raised off the ground)
Feet off ground
Total SS = 11.11

7
7.5
8
8.5
9
9.5
10
10.5
11
4.5 5.5 6.5 7.5 8.5
Height (ft)
Ju
mp
(ft
)
X variable parameter SS F1,13 p
Height +0.943 9.96 112 <0.0001of player

7
7.5
8
8.5
9
9.5
10
10.5
11
105 125 145 165 185 205
Weight (lbs)
Ju
mp
(ft
)
X variable parameter SS p
Weight +0.040 7.92 32 <0.0001of player
F1,13

Why do you think weight is + correlated with jump height?

An idea
Perhaps if we took two people of identical height, the lighter one might actually jump higher? Excess weight may reduce ability to jump high…

7
7.5
8
8.5
9
9.5
10
10.5
11
4 5 6 7 8
Height (lbs)
Ju
mp
(ft
)
lighterheavier
X variable parameter SS F p
Height +2.133 9.956 803 <0.0001Weight -0.059 1.008 81 <0.0001
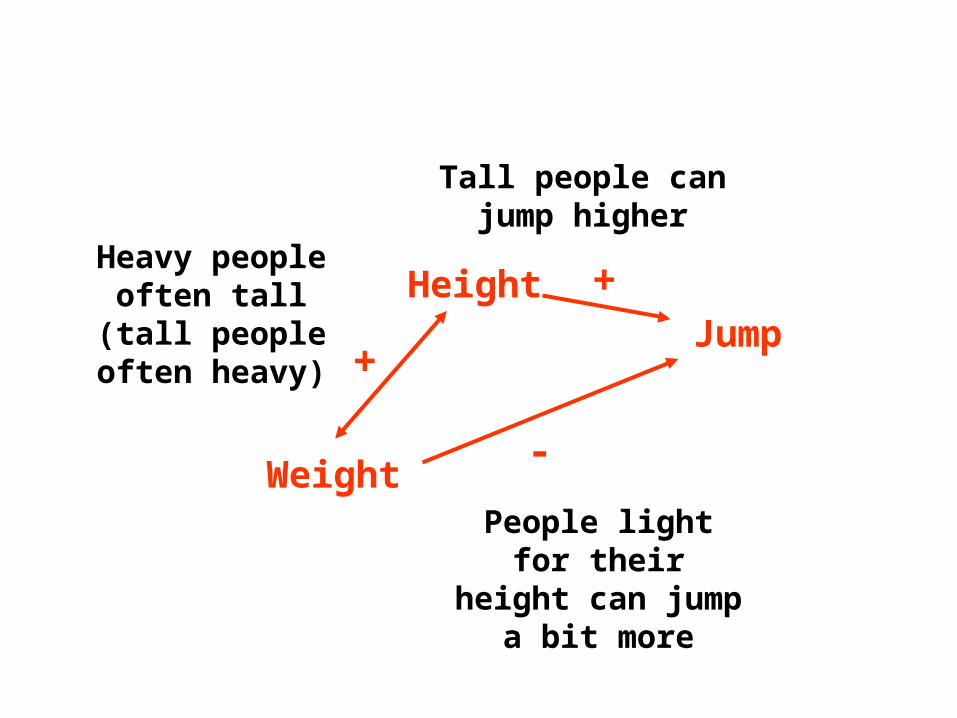
Heavy people often tall (tall people often
heavy)
Tall people can jump higher
People light for their height can jump a bit more
Weight
HeightJump
+
+
-

Species.txt
Rothamsted Park Grass experiment started in 1856

Exercise (species.txt)diane<-read.table(file.choose(), header=T); diane;
attach(diane)
Univariate trends:
plot(Species~Biomass)
plot(Species~pH)
Combined trends:
plot(Species~Biomass, type="n");
points(Species[pH=="high"]~Biomass[pH=="high"]);
points(Species[pH=="mid"]~Biomass[pH=="mid"], pch=16);
points(Species[pH=="low"]~Biomass[pH=="low"], pch=0)

Exercise (species.txt)
1. With a normal distribution, fit pH*Biomass
• check model dignostics• test interaction for significance
2. With a poisson distribution, fit pH *Biomass
• check model dignostics• test interaction for significance

0 2 4 6 8 10
1020
3040
Biomass
Spe
cies
0 2 4 6 8 10
1.0
2.0
3.0
Biomass
log(
Spe
cies
)
0 2 4 6 8 10
1.0
2.0
3.0
Biomass
log(
Spe
cies
)
Moral of the story:
Make sure you KNOW what you are modelling!

Exercise (species.txt)
1. Fit glm: Species~pH, family=gaussian
2. Test if low and mid pH have the same effect
• this is a planned comparison

Further reading
Statistics: An Introduction using R
(M.J. Crawley, Wiley publishers)
Extending the linear model with R
(JJ Faraway, Chapman & Hall/CRC)

Code for “Species” analysis
> m1<-glm(Species~pH*Biomass, family=gaussian, data=diane)> summary(m1)> m2<-update(m1, ~.-pH:Biomass)> anova(m2,m1, test="Chi")> par(mfrow=c(2,2)); plot(m1)> m3<-glm(Species~pH*Biomass, family=poisson, data=diane)> m4<-update(m3, ~.-pH:Biomass)> anova(m4,m3, test="Chi")> par(mfrow=c(2,2)); plot(m3)>PH<-(pH!="high")+0> m5<-glm(Species~pH, family=gaussian, data=diane)> m6<-update(m5, ~.-pH+PH)> anova(m6,m5, test="Chi")


















