
Word embeddings for social goods
131
Word embeddings for social goods Kyiv Deep Learning Study Group #1 Sergii Gavrylov
-
Upload
sergii-gavrylov -
Category
Data & Analytics
-
view
98 -
download
0
Transcript of Word embeddings for social goods

Word embeddings for social goods
Kyiv Deep Learning Study Group #1Sergii Gavrylov

Overview● Problem description
● Data preprocessing
● Bag-of-words
● Continuous bag-of-words
● Weighted continuous bag-of-words
● Convolutional neural network

www.drivendata.org

Box-Plots for Education

Dataset features

Dataset labels
FunctionObject_Type
Operating_StatusPosition_Type
Pre_KReportingSharing
Student_TypeUse

Dataset labels

Loss functionMulti-multi-class log loss
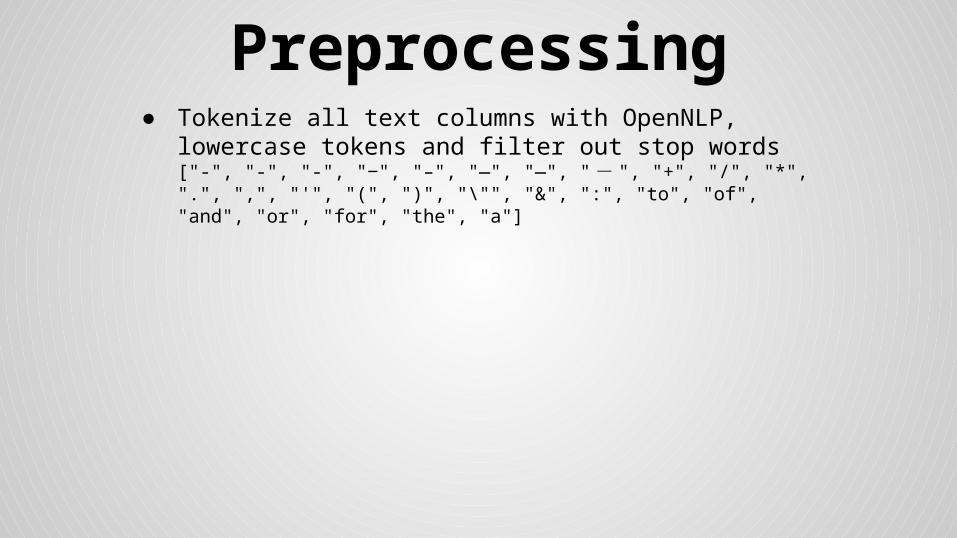
Preprocessing● Tokenize all text columns with OpenNLP, lowercase tokens
and filter out stop words ["‐", "‐", "-", "‒", "–", "—", "―", "- ", "+", "/", "*", ".", ",", "'", "(", ")", "\"", "&", ":", "to", "of", "and", "or", "for", "the", "a"]

Preprocessing● Tokenize all text columns with OpenNLP, lowercase tokens
and filter out stop words ["‐", "‐", "-", "‒", "–", "—", "―", "- ", "+", "/", "*", ".", ",", "'", "(", ")", "\"", "&", ":", "to", "of", "and", "or", "for", "the", "a"]
● Perform softmax normalization for all float columns
● Replace all NaNs in float columns with 0

Preprocessing● Tokenize all text columns with OpenNLP, lowercase tokens
and filter out stop words ["‐", "‐", "-", "‒", "–", "—", "―", "- ", "+", "/", "*", ".", ",", "'", "(", ")", "\"", "&", ":", "to", "of", "and", "or", "for", "the", "a"]
● Perform softmax normalization for all float columns
● Replace all NaNs in float columns with 0
● Keep floats intact, replace NaNs with the specified value
or

Word representation
One-hot encoding
social [0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0]public [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0]

Bag-of-wordsText column features

Bag-of-wordsText column features
Sub_Object_Description
employees
wages
salaries
services
personal

Bag-of-wordsText column features
Sub_Object_Description
employees
wages
salaries
services
personal [0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0]
[0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0]
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0]
[0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0]

Bag-of-wordsText column features
Sub_Object_Description
employees
wages
salaries
services
personal [0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0]
[0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0]
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0]
[0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0]
Sub_Object_Description_bow [0, 1, 0, 1, 0, 1, 1, 0, 0, 0, 1, 0, 0]
∑

Bag-of-words
● Concatenated BOW features and floats comprise final feature
vector.

Bag-of-words
● Concatenated BOW features and floats comprise final feature
vector.
● Replace FTE field NaNs with -1, Total filed NaNs with -20000

Bag-of-words
● Concatenated BOW features and floats comprise final feature
vector.
● Replace FTE field NaNs with -1, Total filed NaNs with -20000
● Train sklearn.ensemble.RandomForestClassifier

Bag-of-words
● Concatenated BOW features and floats comprise final feature
vector.
● Replace FTE field NaNs with -1, Total filed NaNs with -20000
● Train sklearn.ensemble.RandomForestClassifier
● Score: 0.8671

Bag-of-words(+) Pros
● Simplicity

Bag-of-words(+) Pros
(-) Cons
● Simplicity
● Notion of word similarity is undefined with one-hot encoding

Bag-of-words(+) Pros
(-) Cons
● Simplicity
● Notion of word similarity is undefined with one-hot encodingsocial [0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0]
public [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0]

Bag-of-words(+) Pros
(-) Cons
● Simplicity
● Notion of word similarity is undefined with one-hot encodingsocial [0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0]
public [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0]
● Impossible to generalize to unseen words

Bag-of-words(+) Pros
(-) Cons
● Simplicity
● Notion of word similarity is undefined with one-hot encodingsocial [0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0]
public [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0]
● Impossible to generalize to unseen words
● One-hot encoding can be memory inefficient

Word representation
Distributed representation
social [-0.56, 8.65, 5.32, -3.14]public [-0.42, 9.84, 4.51, -2.71]
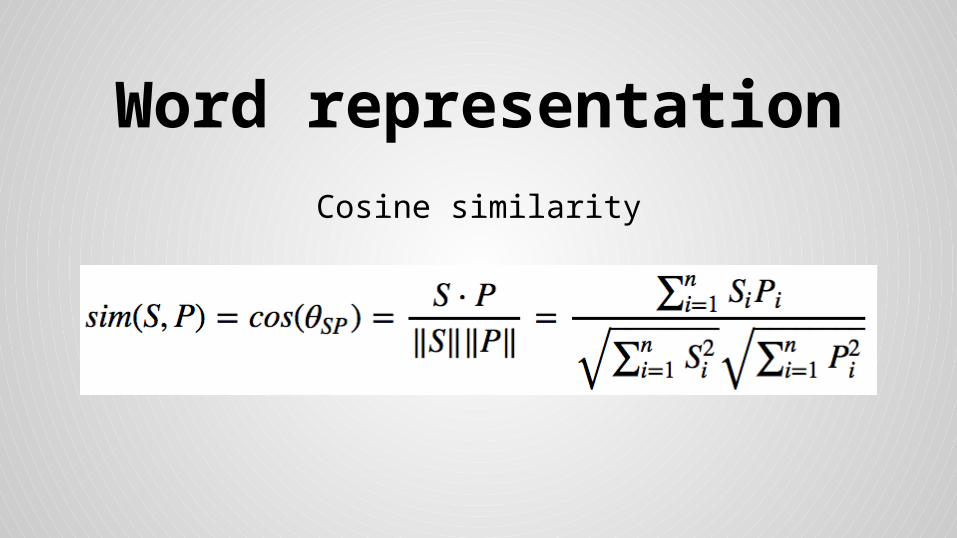
Word representation
Cosine similarity
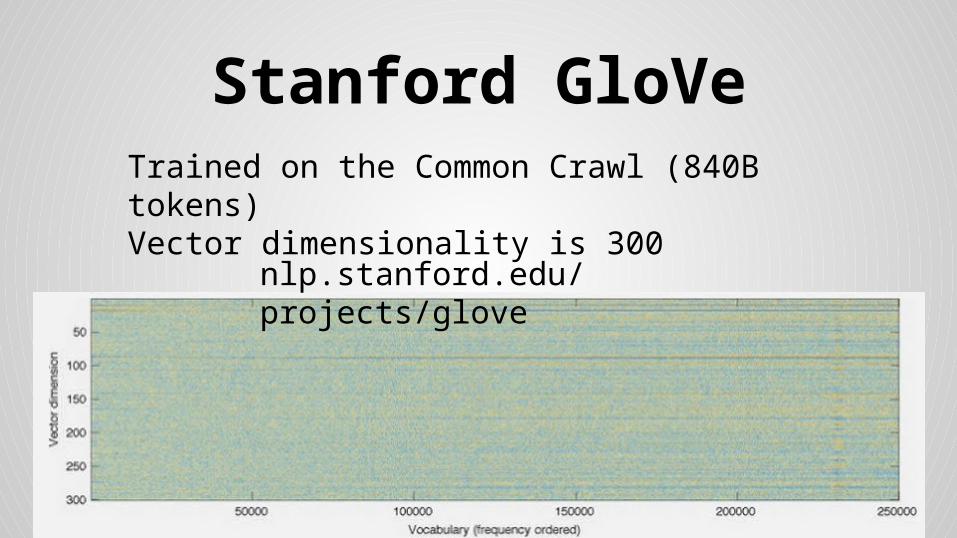
Stanford GloVeTrained on the Common Crawl (840B tokens)Vector dimensionality is 300
nlp.stanford.edu/projects/glove

Sub_Object_Description
Function_Description
...
Text columns
Continuous bag-of-words

personal
employees
wages
salaries
services
instructional
staff
training
services
words words
Sub_Object_Description
Function_Description
...
Text columns
...
Continuous bag-of-words

personal
employees
wages
salaries
services
instructional
staff
training
services
words vectors words vectors
Sub_Object_Description
Function_Description
...
Text columns
...
Continuous bag-of-words

personal
employees
wages
salaries
services
instructional
staff
training
services
words vectors words vectors
Sub_Object_Description
Function_Description
∑ ∑
...
Text columns
...
Continuous bag-of-words

personal
employees
wages
salaries
services
instructional
staff
training
services
words vectors words vectors
Sub_Object_Description
Function_Description
∑ ∑
CBOW features
...
Text columns
...
...
Continuous bag-of-words

personal
employees
wages
salaries
services
instructional
staff
training
services
words vectors words vectors
Sub_Object_Description
Function_Description
∑ ∑
CBOW features
...
Text columns
...
...
Continuous bag-of-words

Continuous bag-of-words
● Concatenated CBOW features and floats comprise the final
feature vector.

Continuous bag-of-words
● Concatenated CBOW features and floats comprise the final
feature vector.
● Replace FTE field NaNs with -1, Total filed NaNs with -20000

Continuous bag-of-words
● Concatenated CBOW features and floats comprise the final
feature vector.
● Replace FTE field NaNs with -1, Total filed NaNs with -20000
● Train sklearn.ensemble.RandomForestClassifier

Continuous bag-of-words
● Concatenated CBOW features and floats comprise the final
feature vector.
● Replace FTE field NaNs with -1, Total filed NaNs with -20000
● Train sklearn.ensemble.RandomForestClassifier
● Score: 0.6616

Continuous bag-of-words
(+) Pros
● Simplicity

Continuous bag-of-words
(+) Pros
● Simplicity
● Possible to generalize to unseen words

Continuous bag-of-words
(+) Pros
● Simplicity
● Possible to generalize to unseen words
(-) Cons
● All words are equal

Continuous bag-of-words
(+) Pros
● Simplicity
● Possible to generalize to unseen words
(-) Cons
● All words are equal, but some words are more equal than others

Weighted CBOWText column features

Weighted CBOWText column features
Sub_Object_Description
employees
wages
salaries
services
personal

Weighted CBOWText column features
Sub_Object_Description
employees
wages
salaries
services
personal

Weighted CBOWText column features
Sub_Object_Description
employees
wages
salaries
services
personal

Weighted CBOWText column features
Sub_Object_Description
employees
wages
salaries
services
personal

Weighted CBOWText column features
Sub_Object_Description
employees
wages
salaries
services
personal

Weighted CBOWText column features
Sub_Object_Description
employees
wages
salaries
services
personal

Weighted CBOWText column features
Sub_Object_Description
employees
wages
salaries
services
personal

Weighted CBOWText column features
Sub_Object_Description
employees
wages
salaries
services
personal

Weighted CBOWText column features
Sub_Object_Description
employees
wages
salaries
services
personal

Weighted CBOWText column features
Sub_Object_Description
employees
wages
salaries
services
personal

Weighted CBOWText column features
Sub_Object_Description
employees
wages
salaries
services
personal

Weighted CBOWText column features
Sub_Object_Description
employees
wages
salaries
services
personal

Weighted CBOWText column features
Sub_Object_Description
employees
wages
salaries
services
personal

Weighted CBOWText column features
Sub_Object_Description
employees
wages
salaries
services
personal ×
×
×
××

Weighted CBOWText column features
Sub_Object_Description
employees
wages
salaries
services
personal ×
×
×
××
∑
Sub_Object_Description_wcbow

Weighted CBOWText column features
Sub_Object_Description
employees
wages
salaries
services
personal ×
×
×
××
∑
Sub_Object_Description_wcbow

Weighted CBOW
● Concatenated WCBOW features and floats compose the final
feature vector.

Weighted CBOW
● Concatenated WCBOW features and floats compose the final
feature vector.
● Use softmax normalization for float columns

Weighted CBOW
● Concatenated WCBOW features and floats compose the final
feature vector.
● Use softmax normalization for float columns
● Replace all float NaNs with 0

Weighted CBOW
● Concatenated WCBOW features and floats compose the final
feature vector.
● Use softmax normalization for float columns
● Replace all float NaNs with 0
● Train softmax jointly with θc parameters

Weighted CBOW
● Concatenated WCBOW features and floats compose the final
feature vector.
● Use softmax normalization for float columns
● Replace all float NaNs with 0
● Train softmax jointly with θc parameters
● Score: 0.9159

Weighted CBOWWhy so poorly?

Weighted CBOWWhy so poorly?
H1: Softmax is not so powerful as Random forest

Weighted CBOWWhy so poorly?
H1: Softmax is not as powerful as Random Forest
H2: Model assumes that for describing relevant words it is enough to use one direction per column in the word space

How many directions should a good model
have?

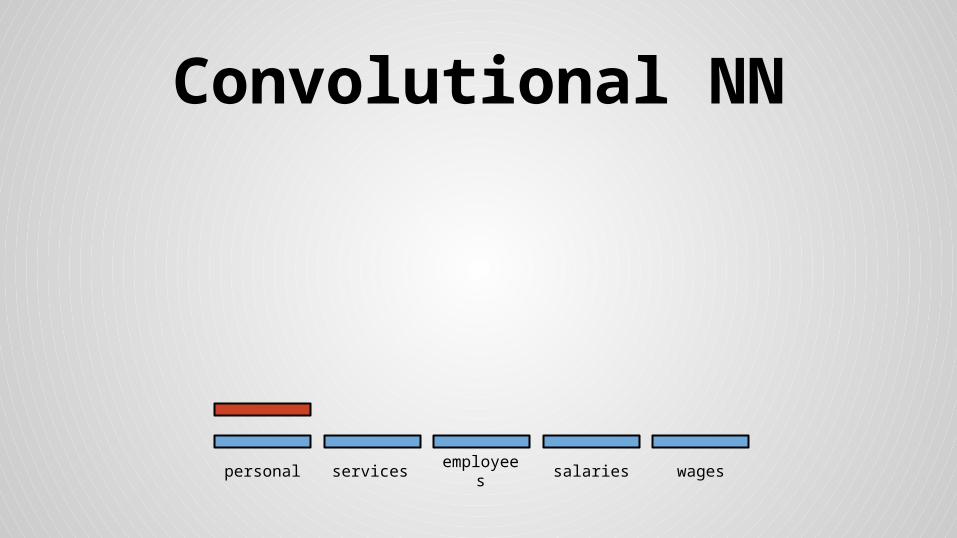
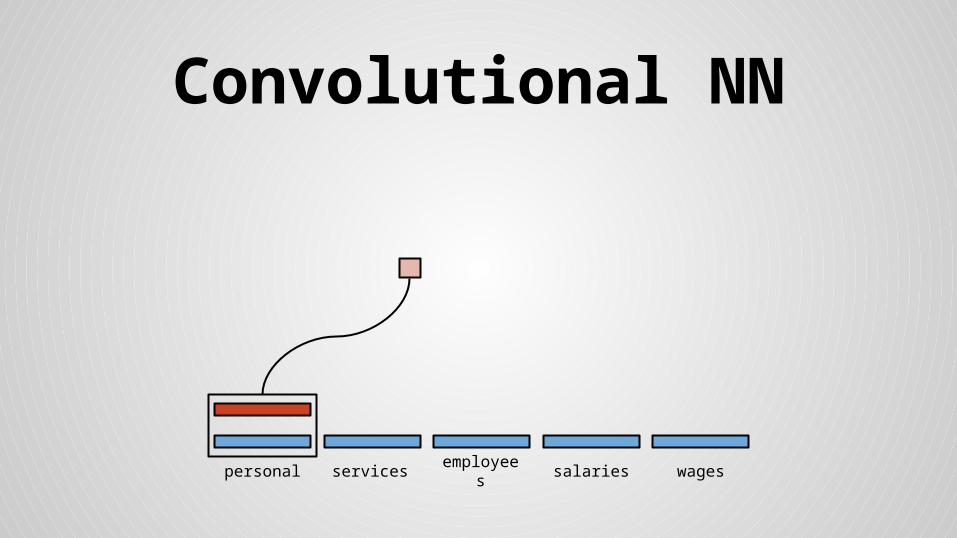
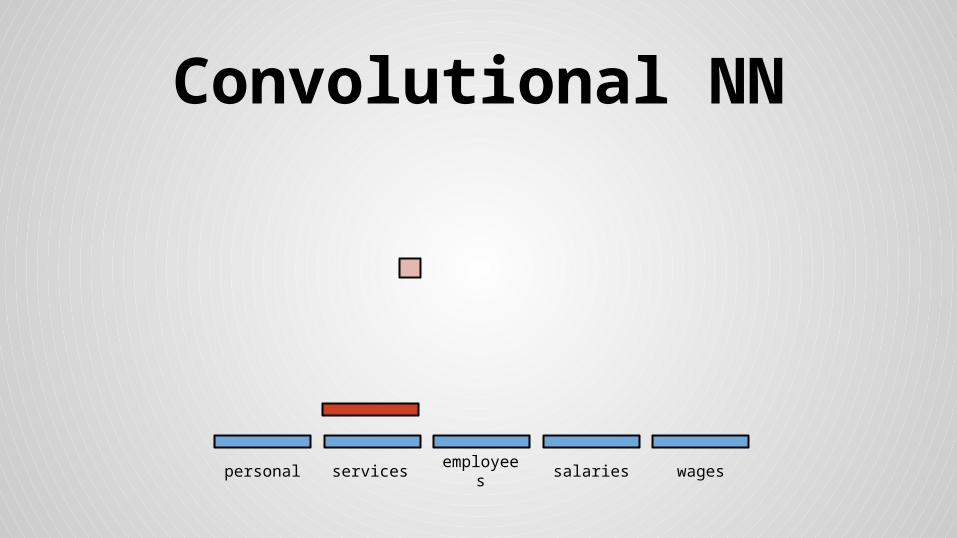
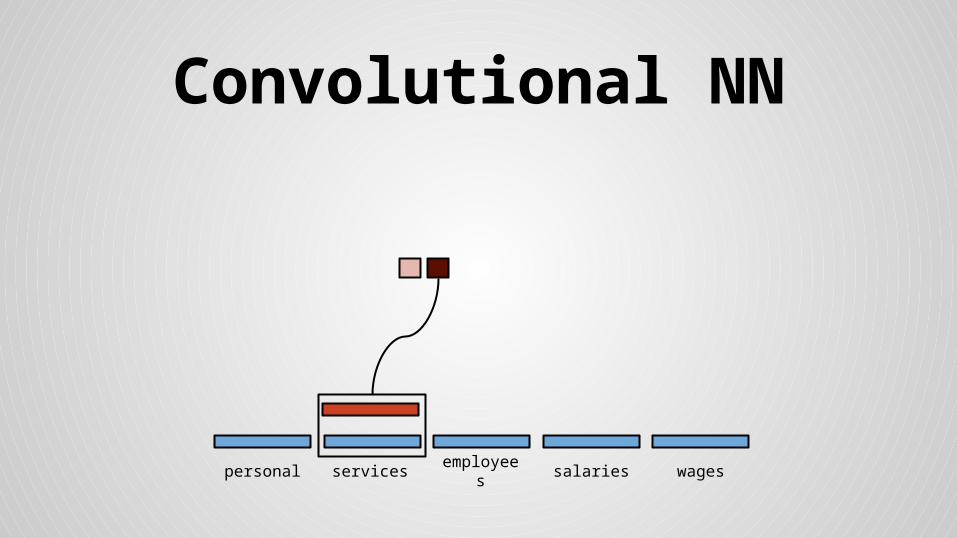
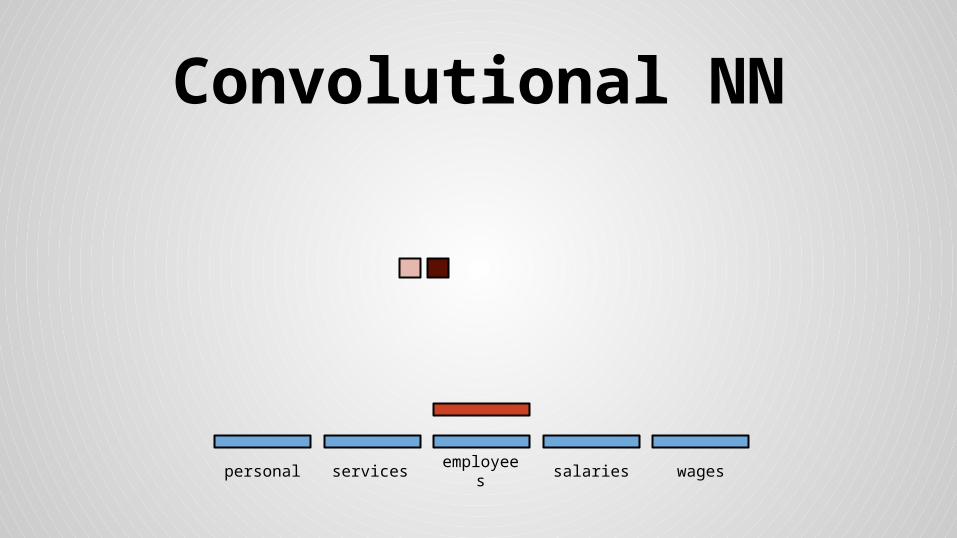
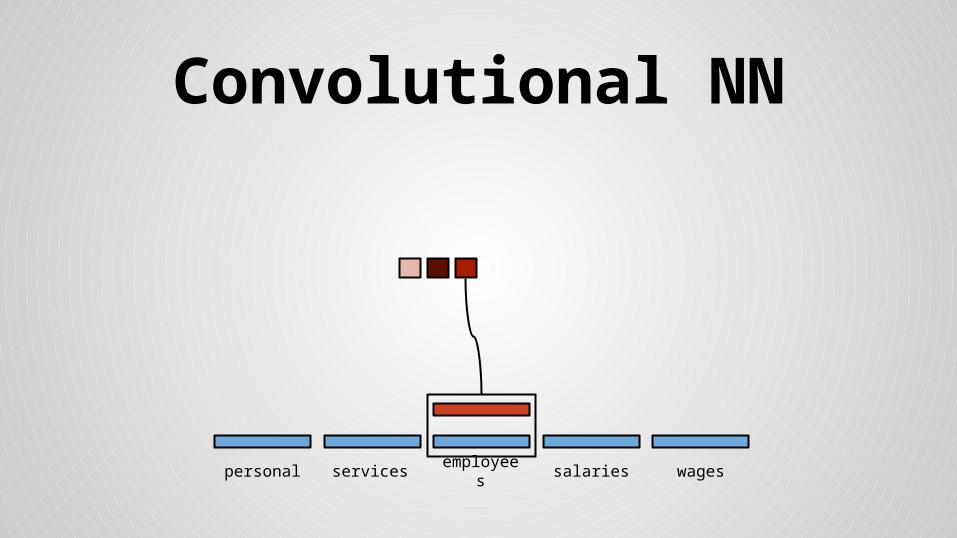
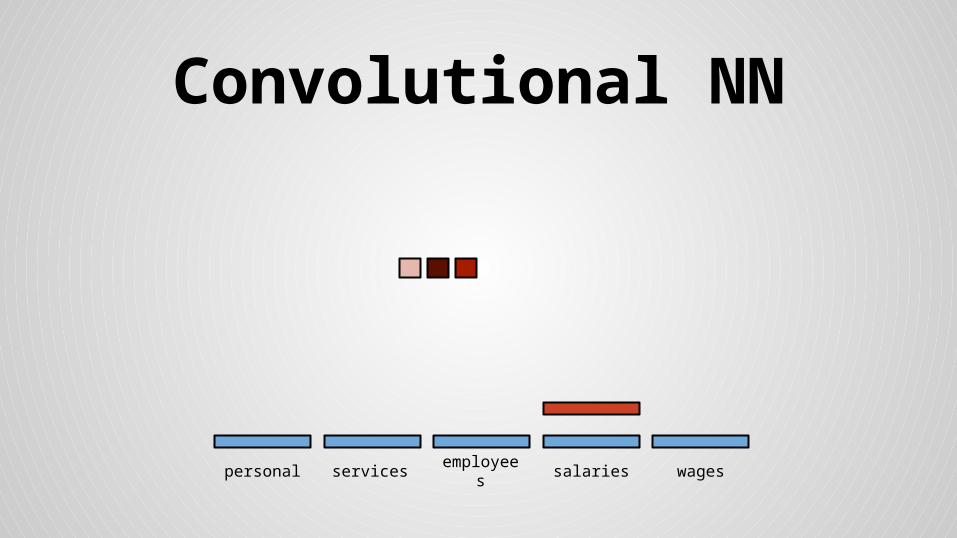
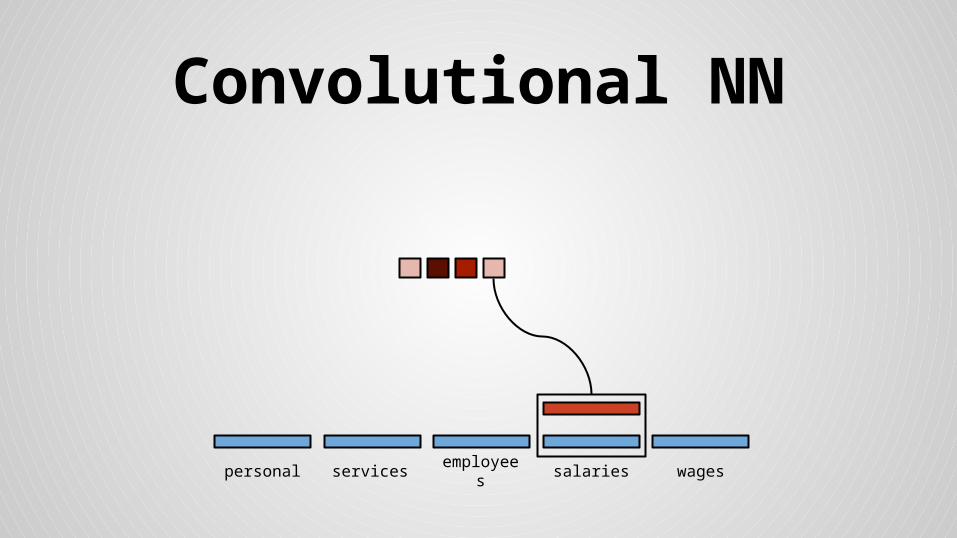
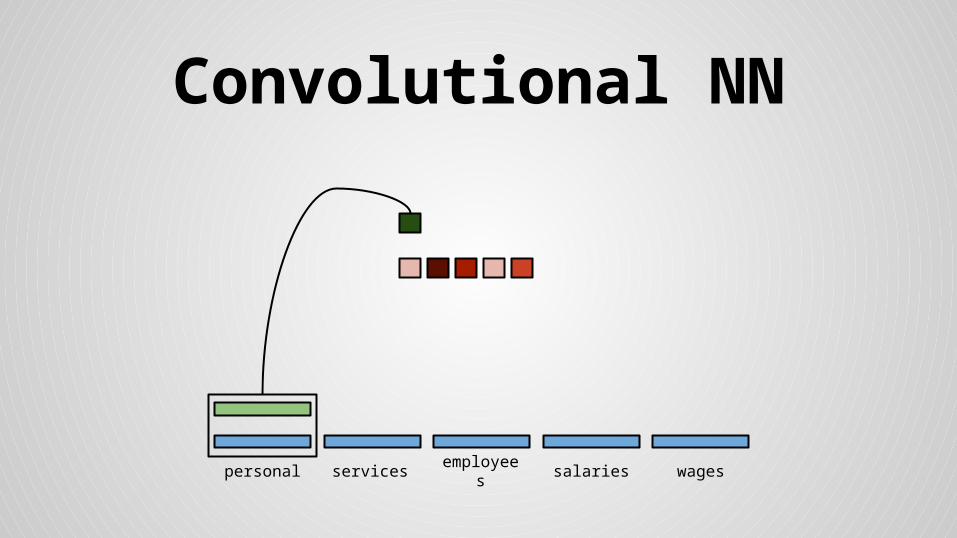
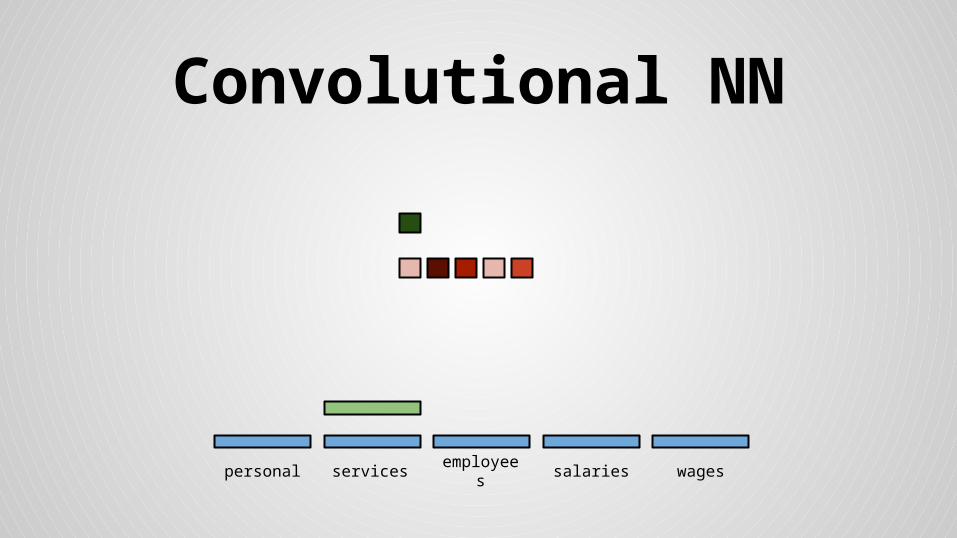
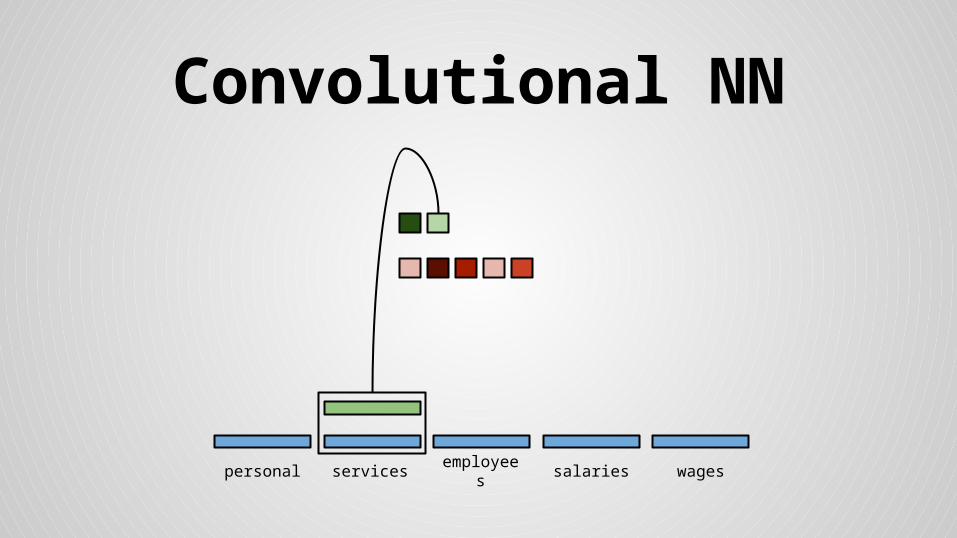
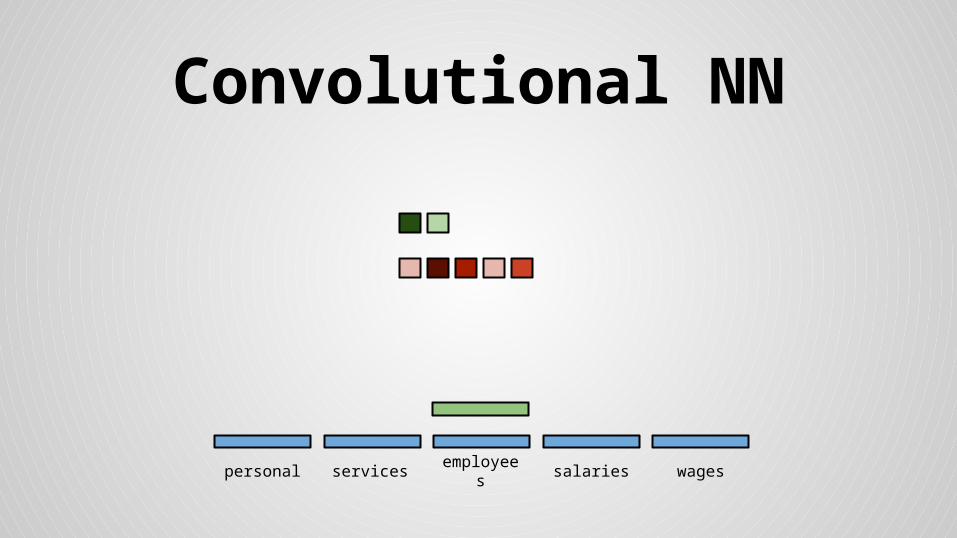
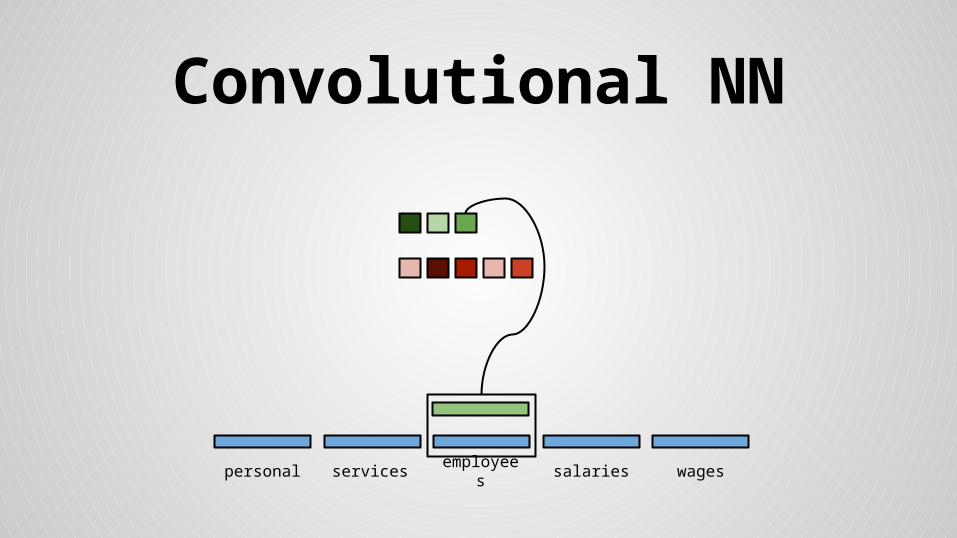
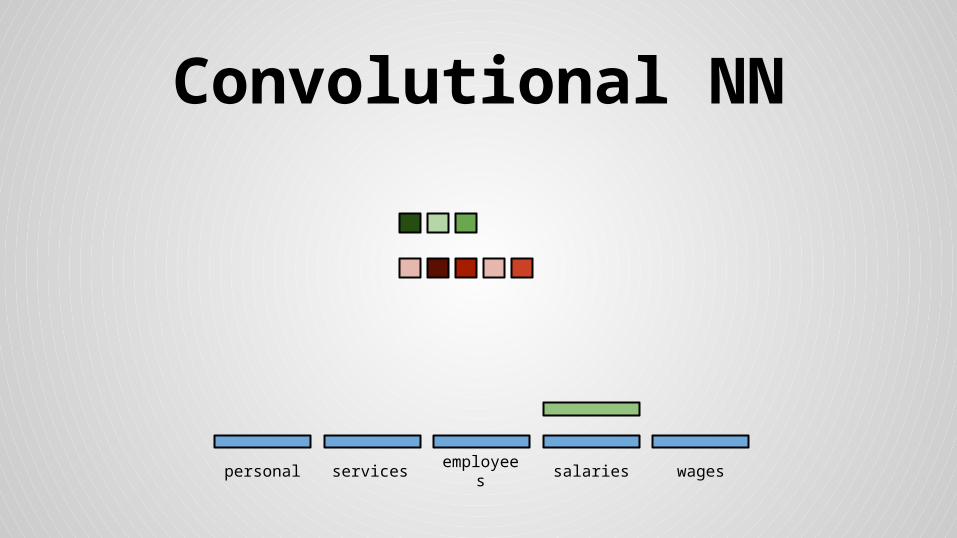
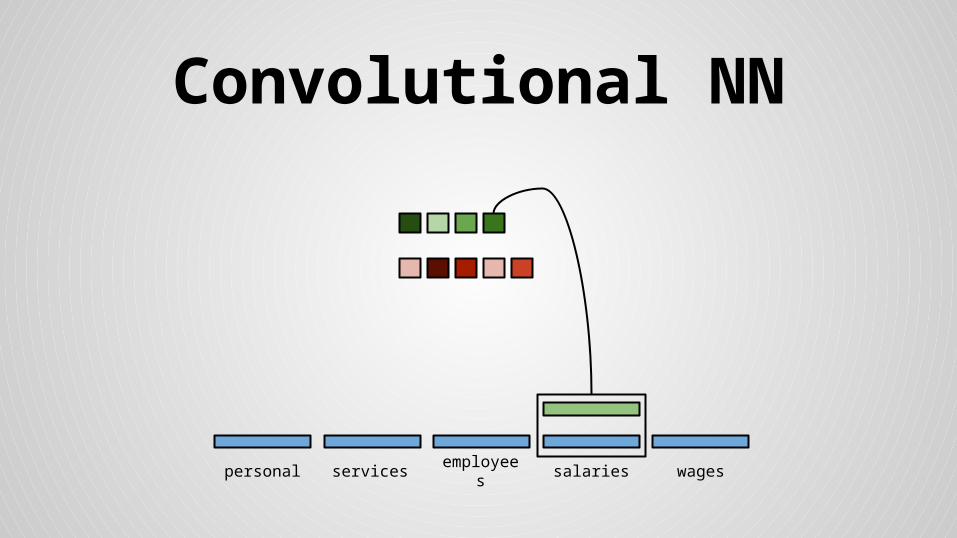
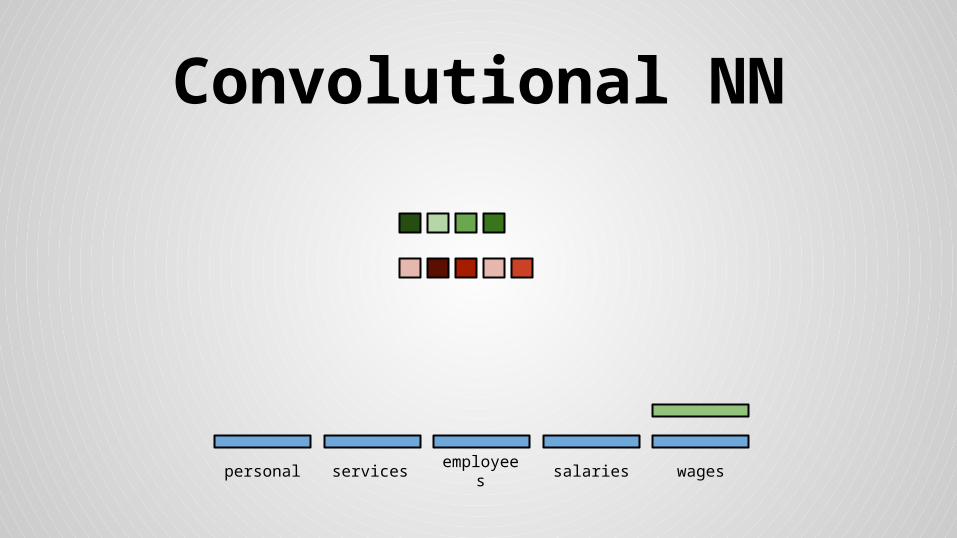
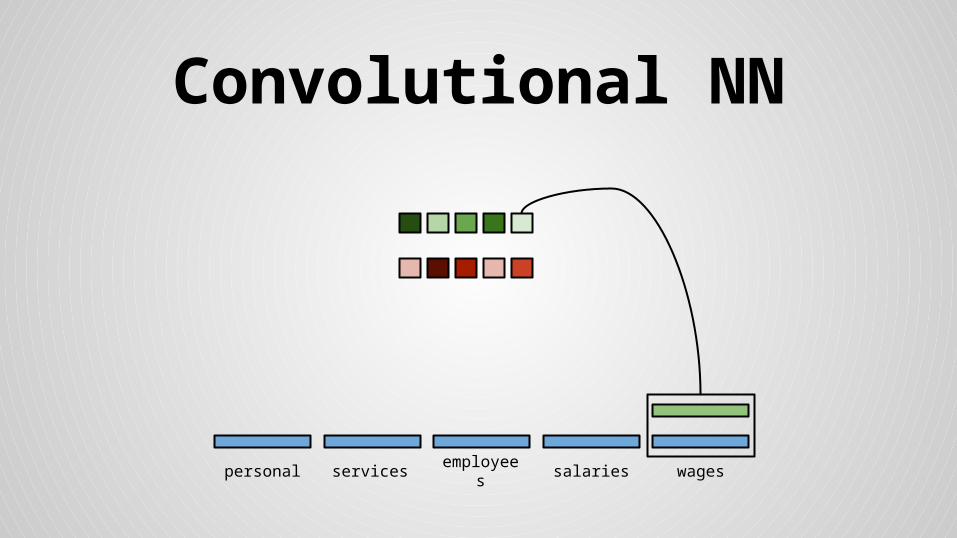
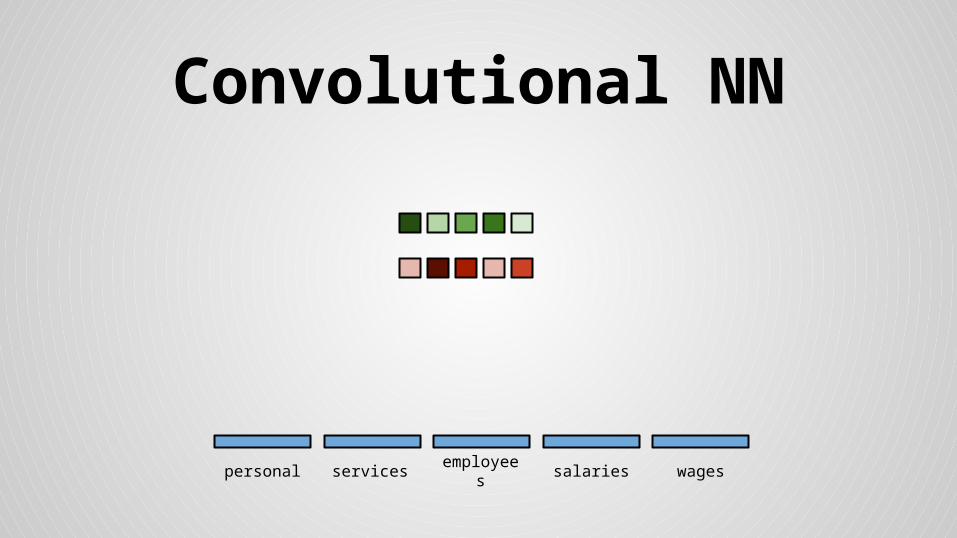
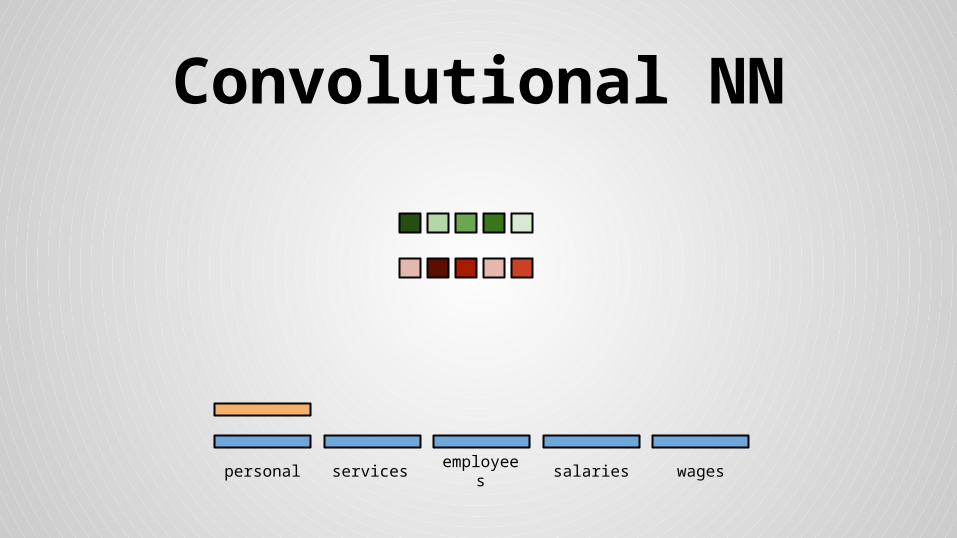
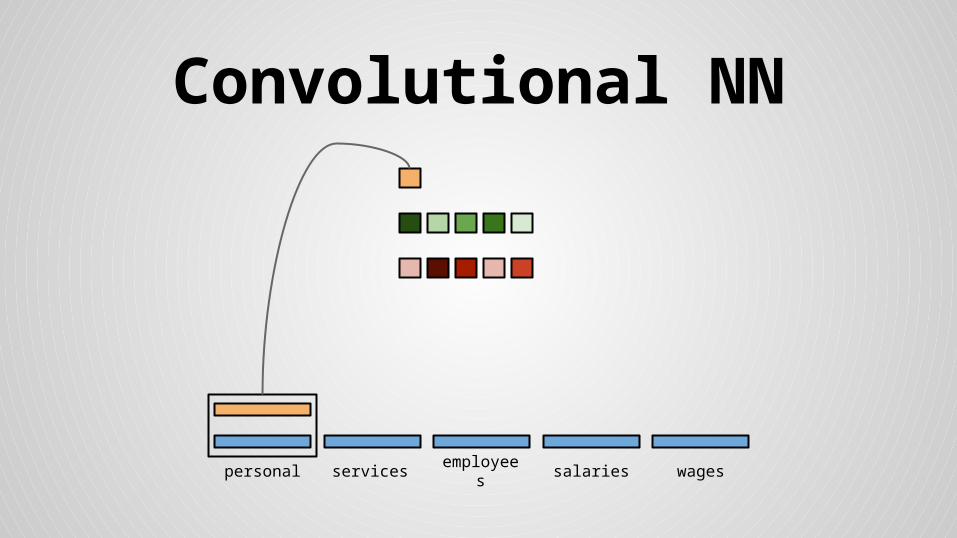
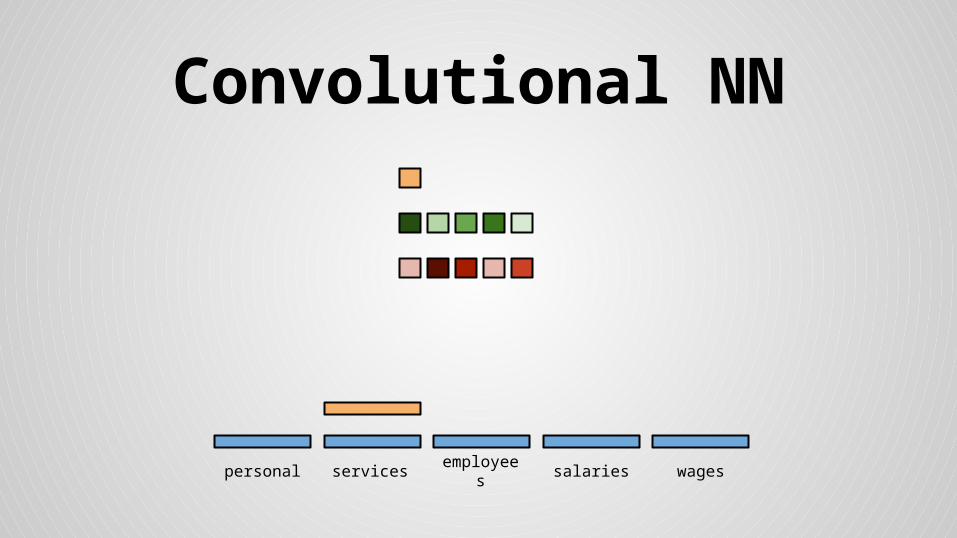
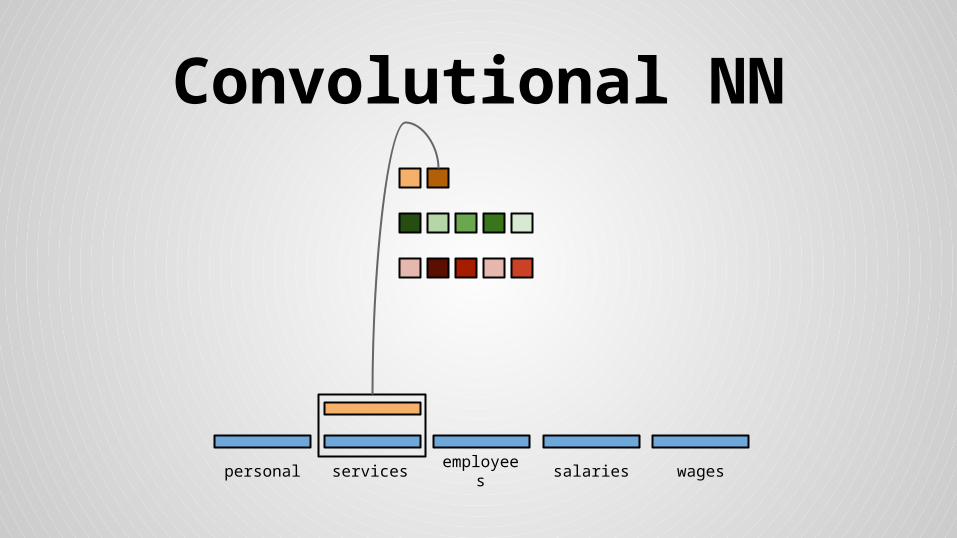
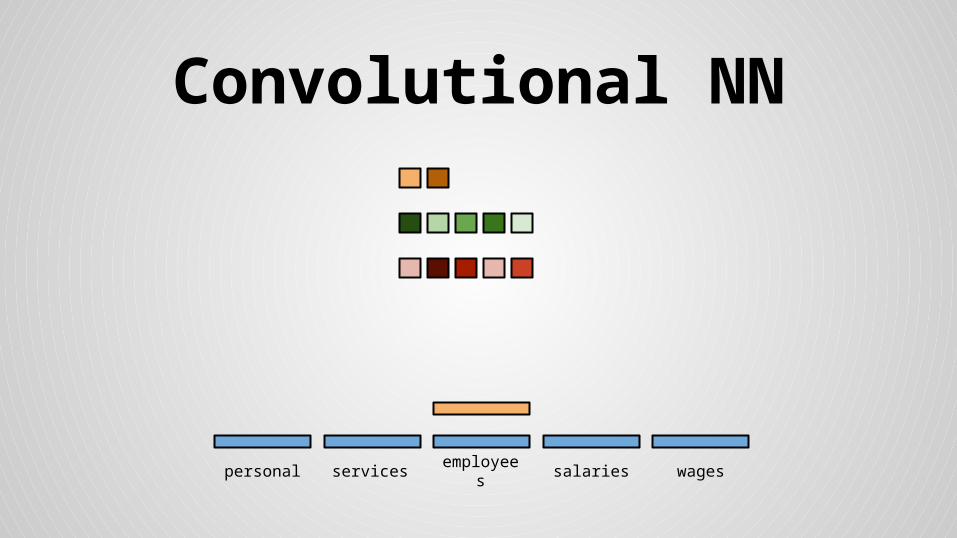
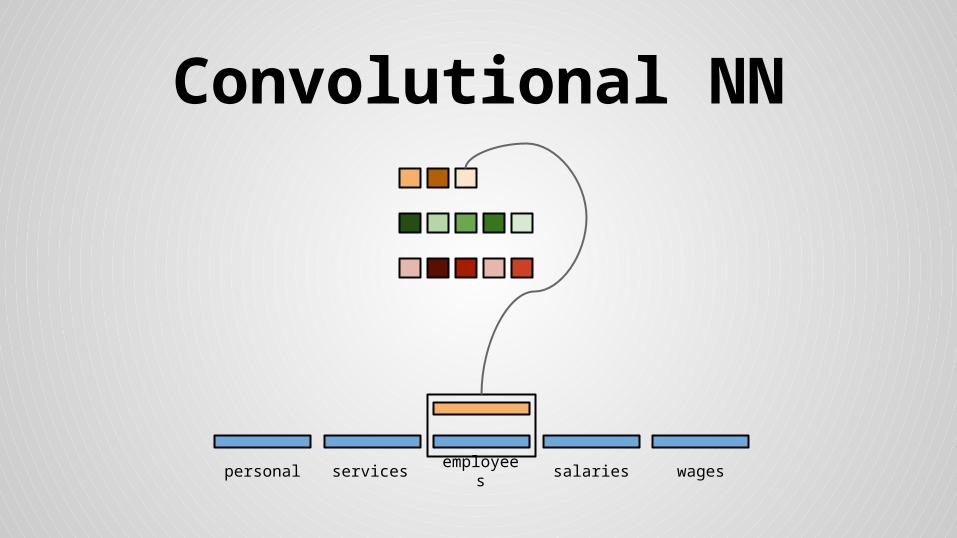
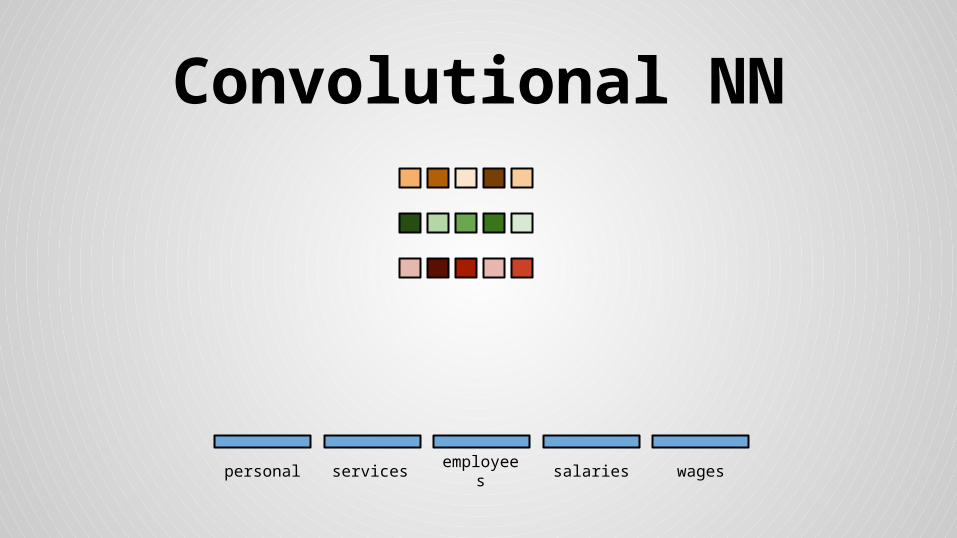
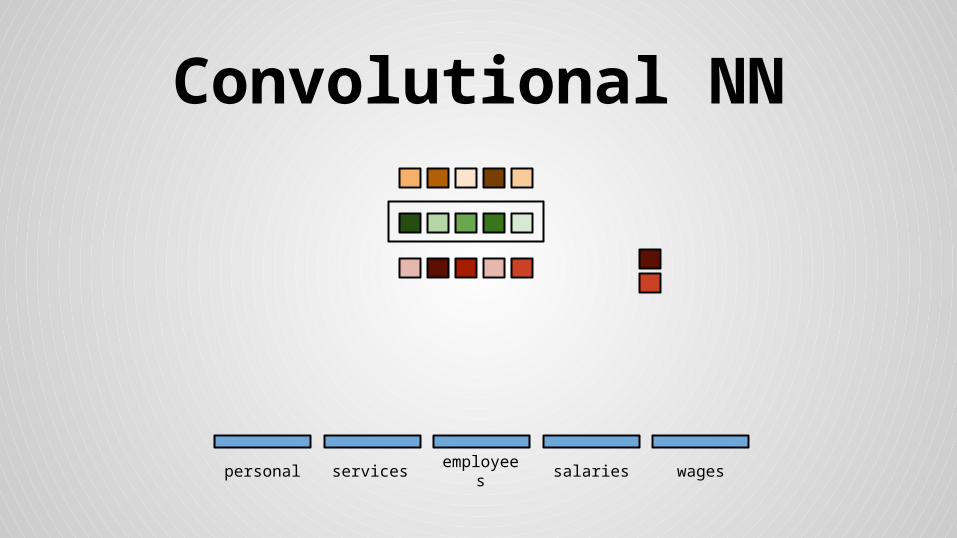
Convolutional NN
personal services wagessalariesemployees
Convolutional NN
personal services wagessalariesemployees
Convolutional NN
personal services wagessalariesemployees
Convolutional NN
personal services wagessalariesemployees
Convolutional NN
personal services wagessalariesemployees
Convolutional NN
personal services wagessalariesemployees
Convolutional NN
personal services wagessalariesemployees
Convolutional NN
personal services wagessalariesemployees
Convolutional NN
personal services wagessalariesemployees
Convolutional NN
personal services wagessalariesemployees
Convolutional NN
personal services wagessalariesemployees
Convolutional NN
personal services wagessalariesemployees
Convolutional NN
personal services wagessalariesemployees
Convolutional NN
personal services wagessalariesemployees
Convolutional NN
personal services wagessalariesemployees
Convolutional NN
personal services wagessalariesemployees
Convolutional NN
personal services wagessalariesemployees
Convolutional NN
personal services wagessalariesemployees
Convolutional NN
personal services wagessalariesemployees
Convolutional NN
personal services wagessalariesemployees
Convolutional NN
personal services wagessalariesemployees
Convolutional NN
personal services wagessalariesemployees
Convolutional NN
personal services wagessalariesemployees
Convolutional NN
personal services wagessalariesemployees
Convolutional NN
personal services wagessalariesemployees
Convolutional NN
personal services wagessalariesemployees
Convolutional NN
personal services wagessalariesemployees
Convolutional NN
personal services wagessalariesemployees
Convolutional NN
personal services wagessalariesemployees
Convolutional NN
personal services wagessalariesemployees
Convolutional NN
personal services wagessalariesemployees
Convolutional NN
personal services wagessalariesemployees
Convolutional NN
personal services wagessalariesemployees
Convolutional NN
personal services wagessalariesemployees
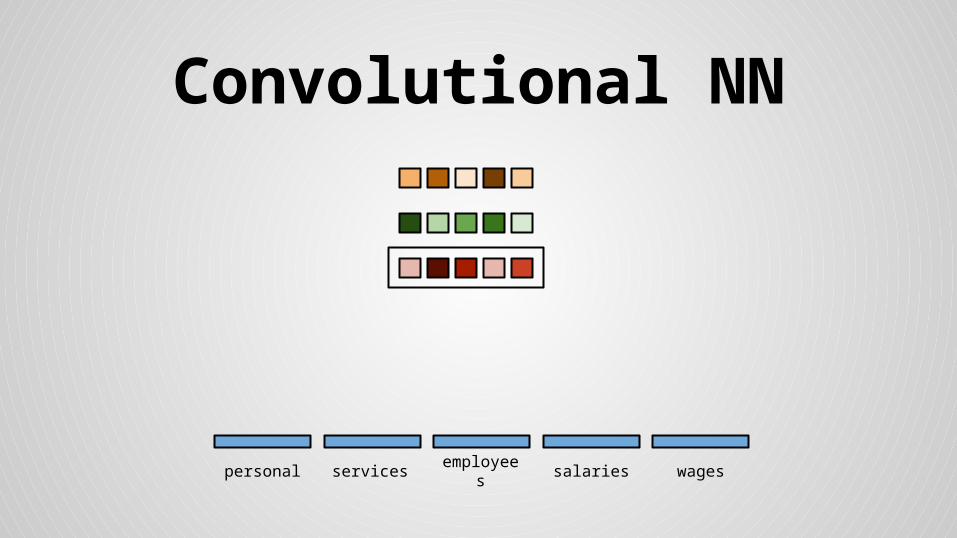
Convolutional NN
personal services wagessalariesemployees
Convolutional NN
personal services wagessalariesemployees
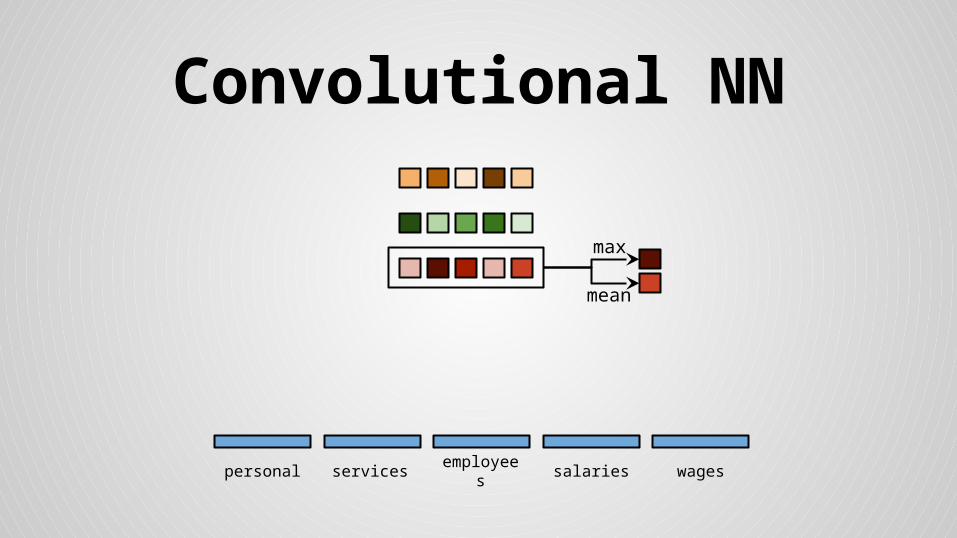
Convolutional NN
personal services wagessalariesemployees
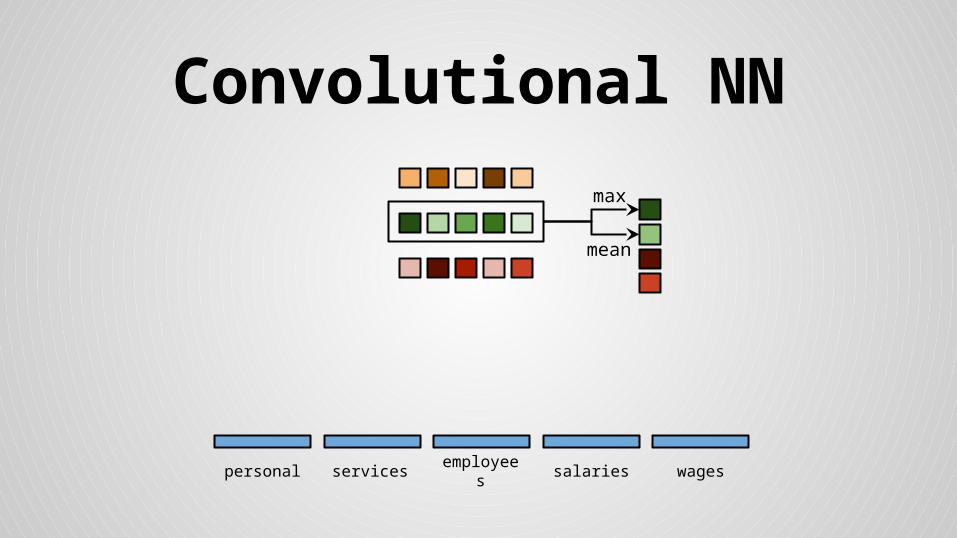
mean
max
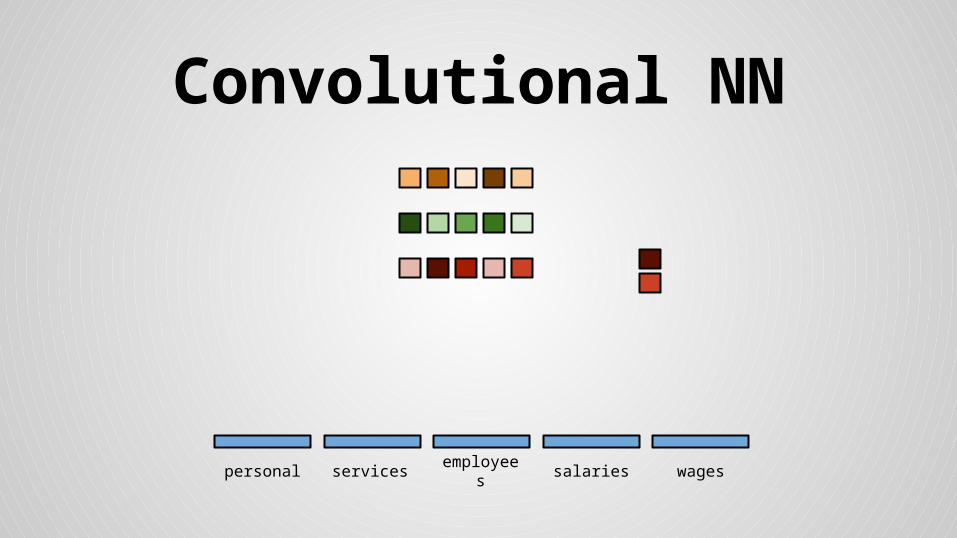
Convolutional NN
personal services wagessalariesemployees
Convolutional NN
personal services wagessalariesemployees
Convolutional NN
personal services wagessalariesemployees
mean
max
Convolutional NN
personal services wagessalariesemployees
Convolutional NN
personal services wagessalariesemployees
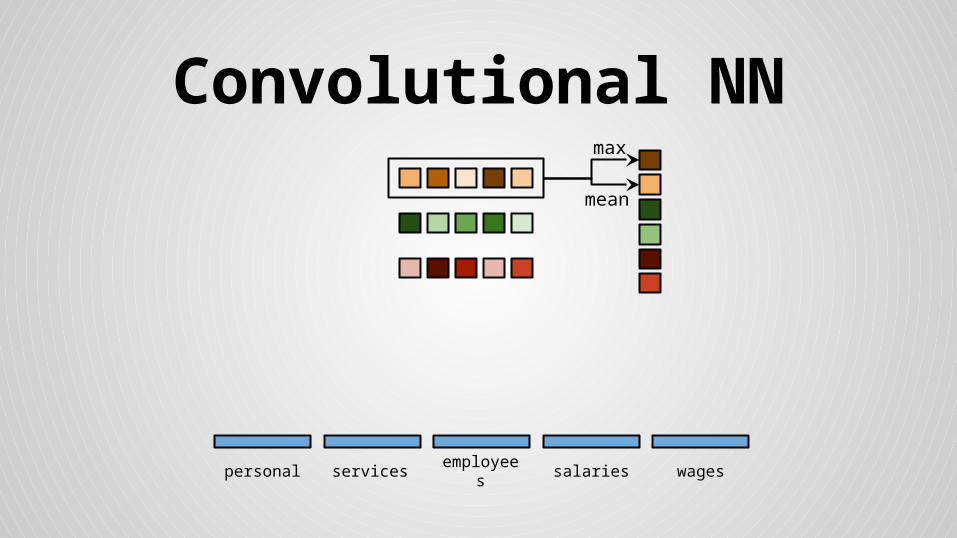
Convolutional NN
personal services wagessalariesemployees
max
mean
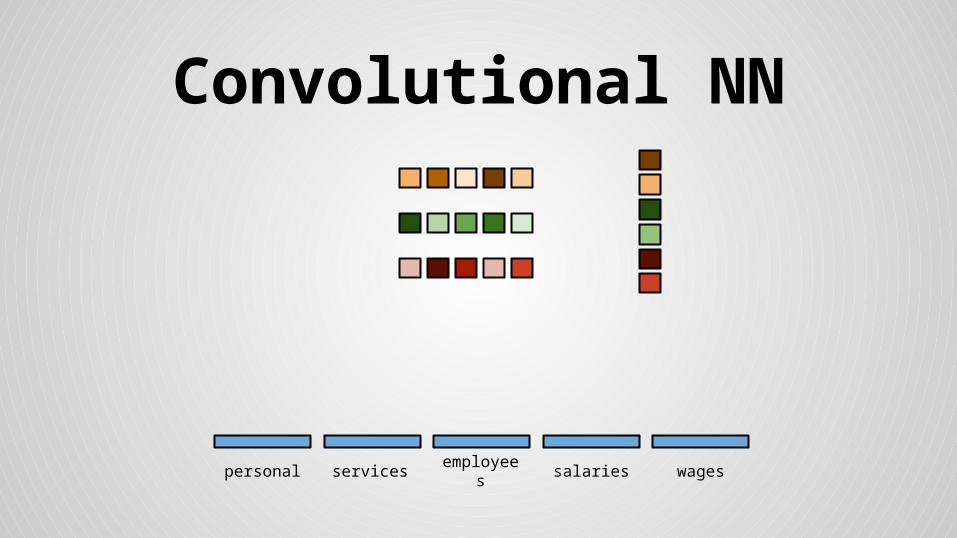
Convolutional NN
personal services wagessalariesemployees

Convolutional NN
employees
wages
salaries
services
personal
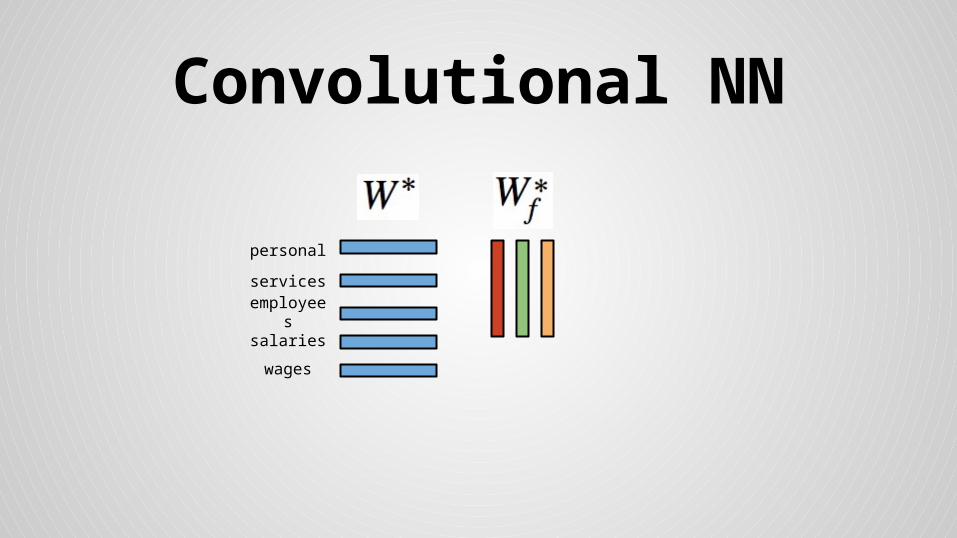
Convolutional NN
employees
wages
salaries
services
personal
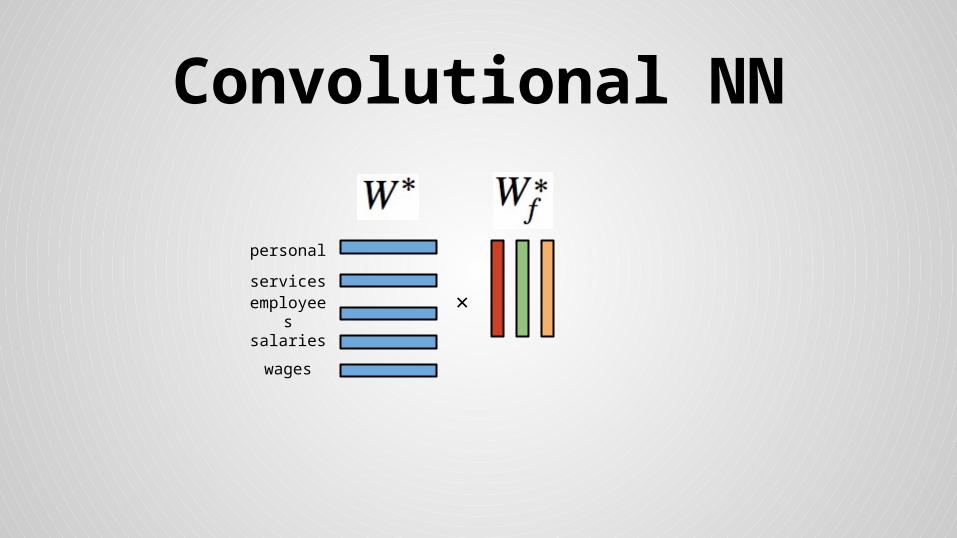
Convolutional NN
employees
wages
salaries
services
personal
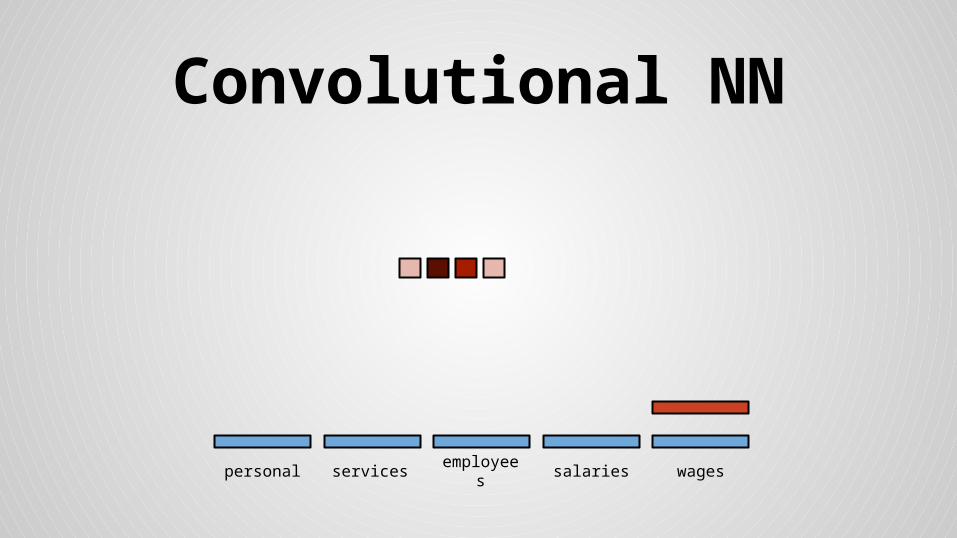
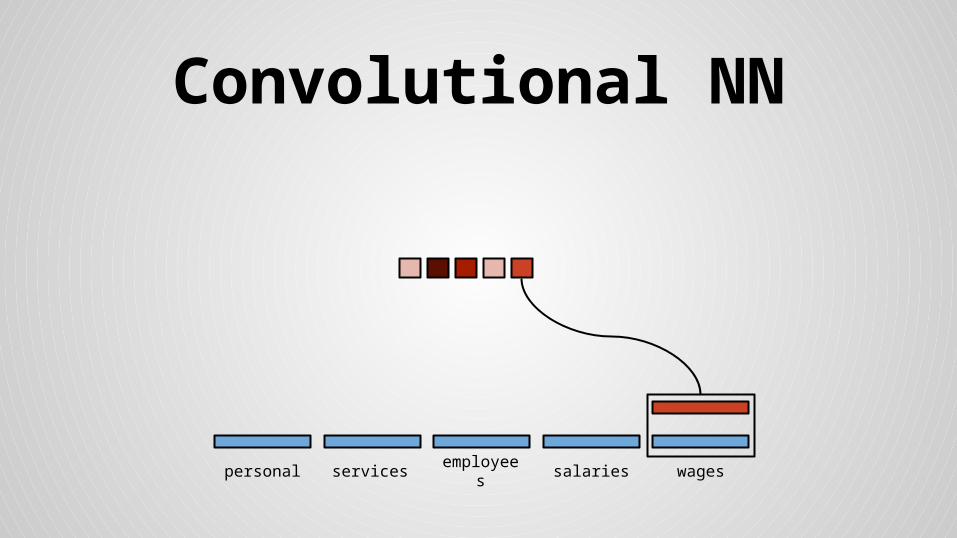
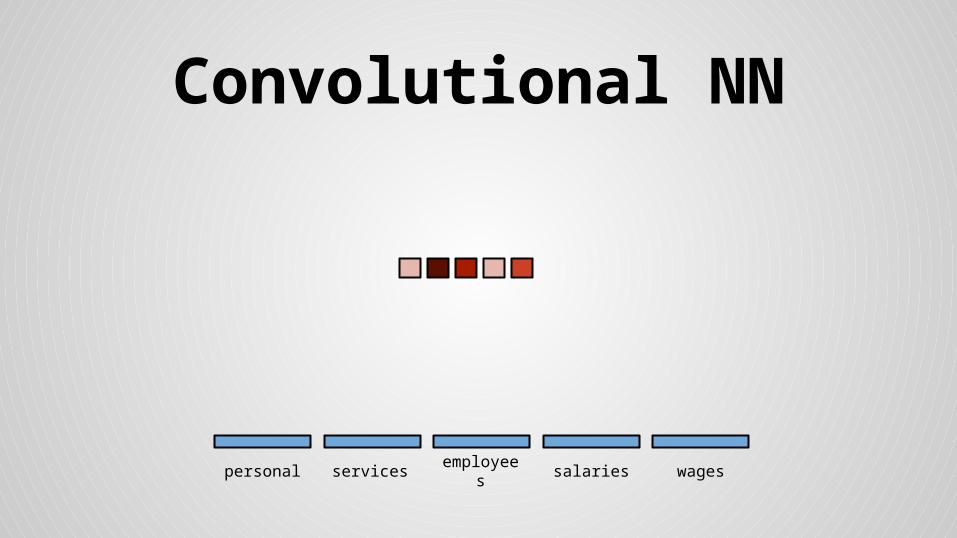
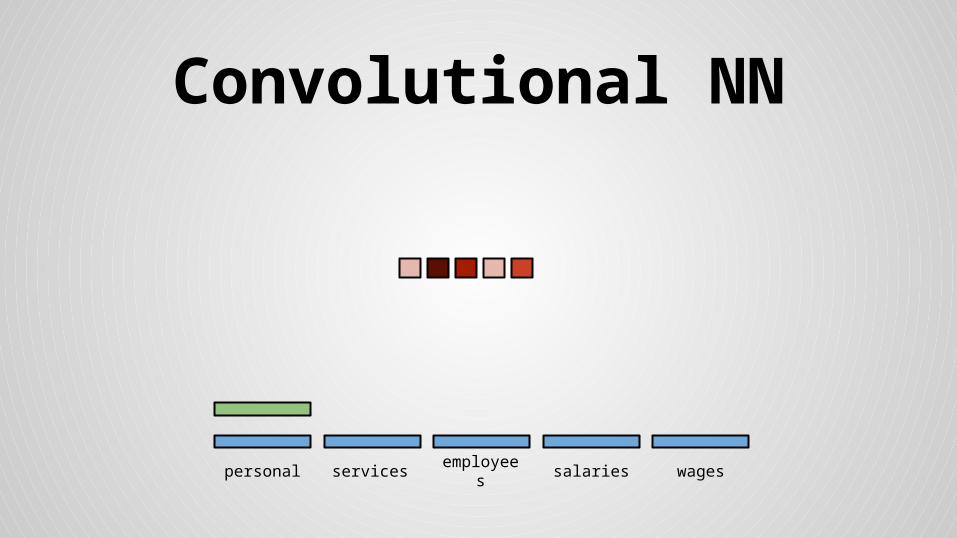
×
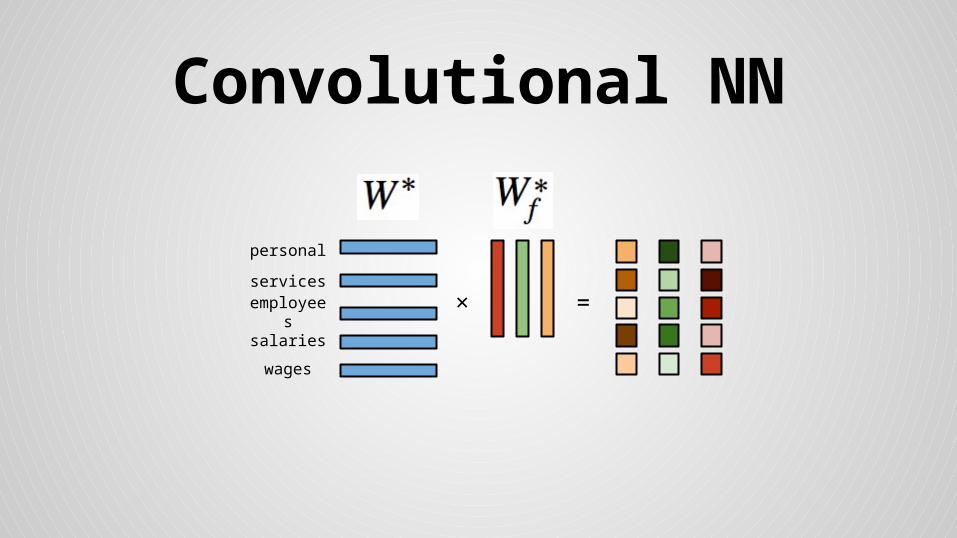
Convolutional NN
employees
wages
salaries
services
personal
× =

Convolutional NN
employees
wages
salaries
services
personal
× =
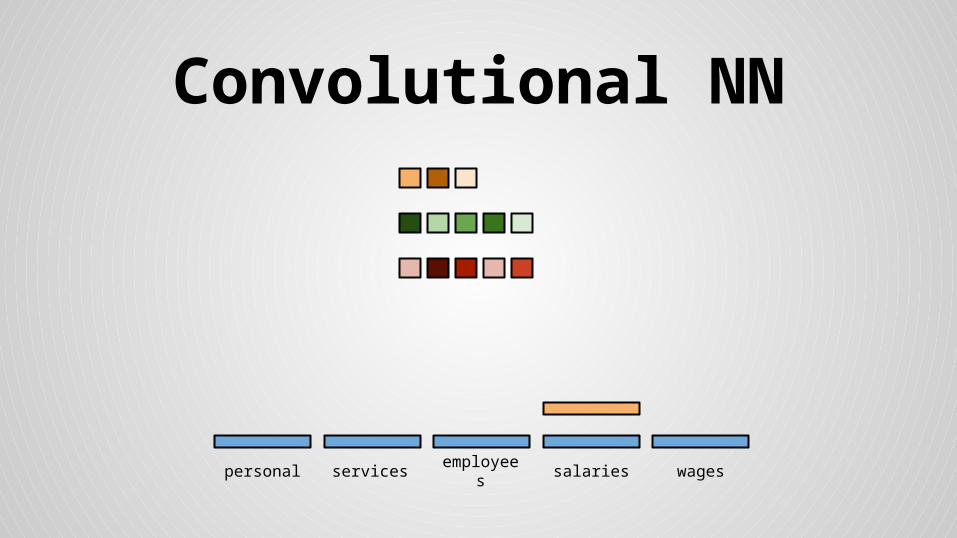
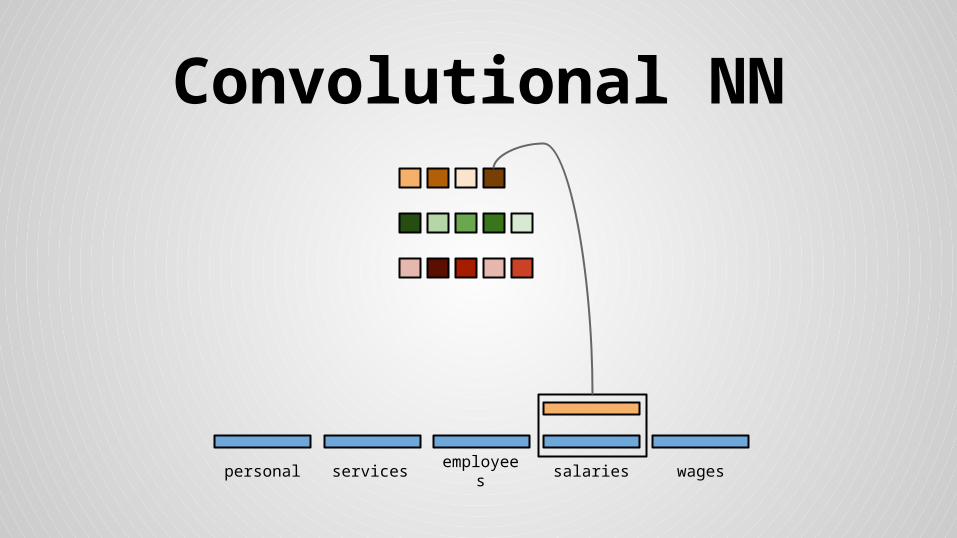
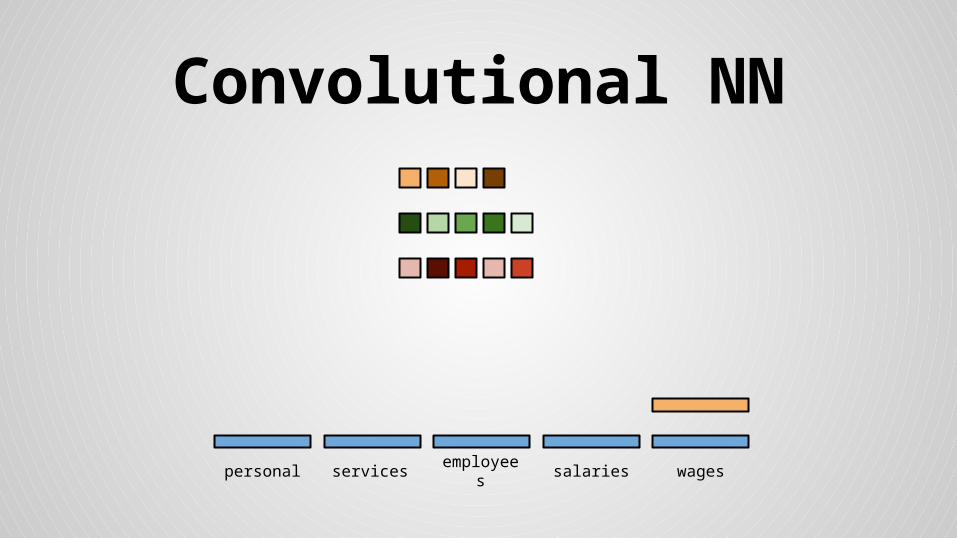
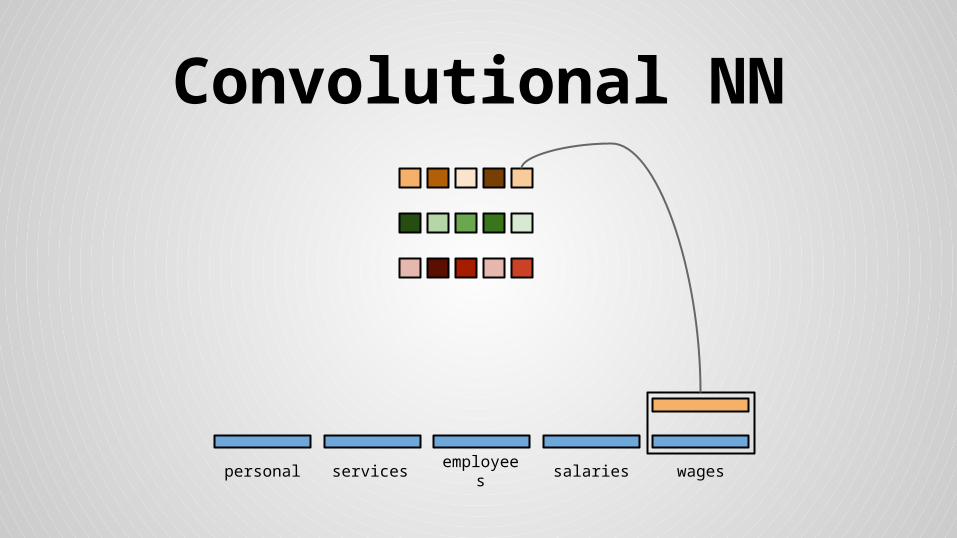
Stride size = word dimensionality

Convolutional NN
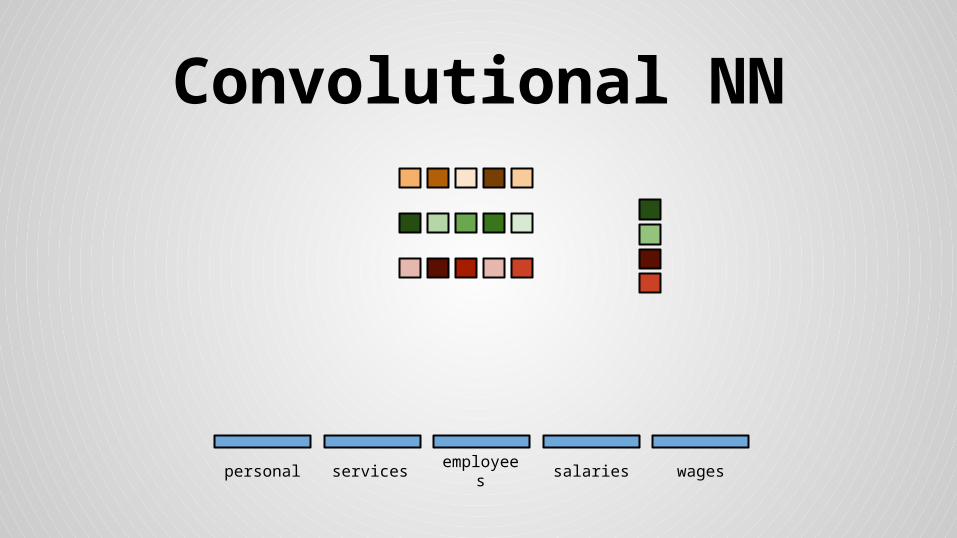
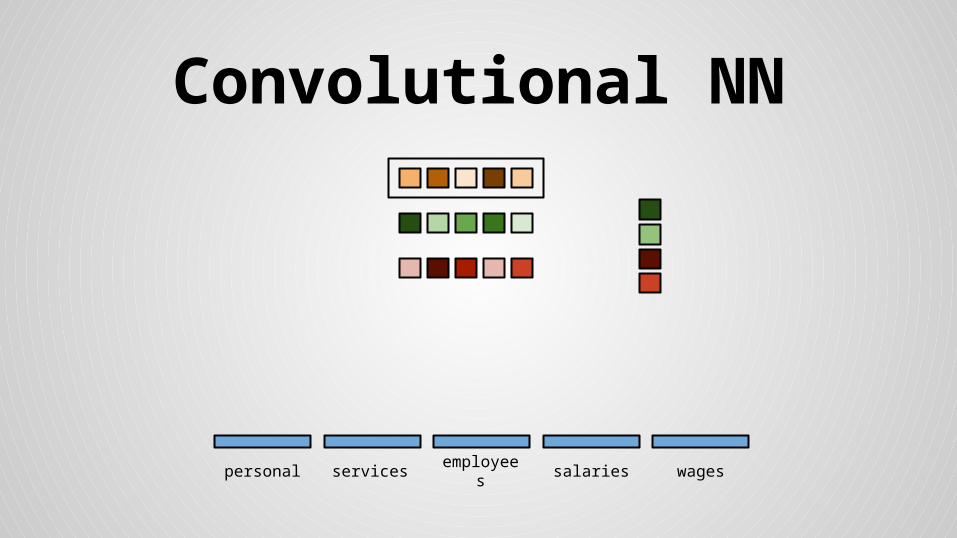
● Concatenated mean and max values for feature maps and floats form the final
feature vector

Convolutional NN
● Concatenated mean and max values for feature maps and floats form the final
feature vector
● Use softmax normalization for float columns

Convolutional NN
● Concatenated mean and max values for feature maps and floats form the final
feature vector
● Use softmax normalization for float columns
● Replace all float NaNs with 0

Convolutional NN
● Concatenated mean and max values for feature maps and floats form the final
feature vector
● Use softmax normalization for float columns
● Replace all float NaNs with 0
● Train softmax with Wf parameters jointly

● Concatenated mean and max values for feature maps and floats form the final
feature vector
● Use softmax normalization for float columns
● Replace all float NaNs with 0
● Train softmax with Wf parameters jointly
● Score: 0.6932
Convolutional NN

Convolutional NNWhy is it not as good as CBOW + RF?

Convolutional NNWhy is it not as good as CBOW + RF?
● There is fewer parameters

Convolutional NNWhy is it not as good as CBOW + RF?
● There is fewer parameters
● The performance is still comparable to CBOW+RF. Therefore, using cnn
is a sensible idea.

Convolutional NNWhy is it not as good as CBOW + RF?
● There is fewer parameters
● The performance is still comparable to CBOW+RF. Therefore, using cnn
is a sensible idea.
● Probably, we could gain more from this type of feature learner if we go
deeper

Final model
● Train RF on the concatenated CBOW features and NN logits

Final model
● Train RF on the concatenated CBOW features and NN logits
● Train 2 CBOW classifiers, 2 NN classifiers, 2 meta-classifiers
and blend them

Final model
● Train RF on the concatenated CBOW features and NN logits
● Train 2 CBOW classifiers, 2 NN classifiers, 2 meta-classifiers
and blend them
● Score: 0.5228
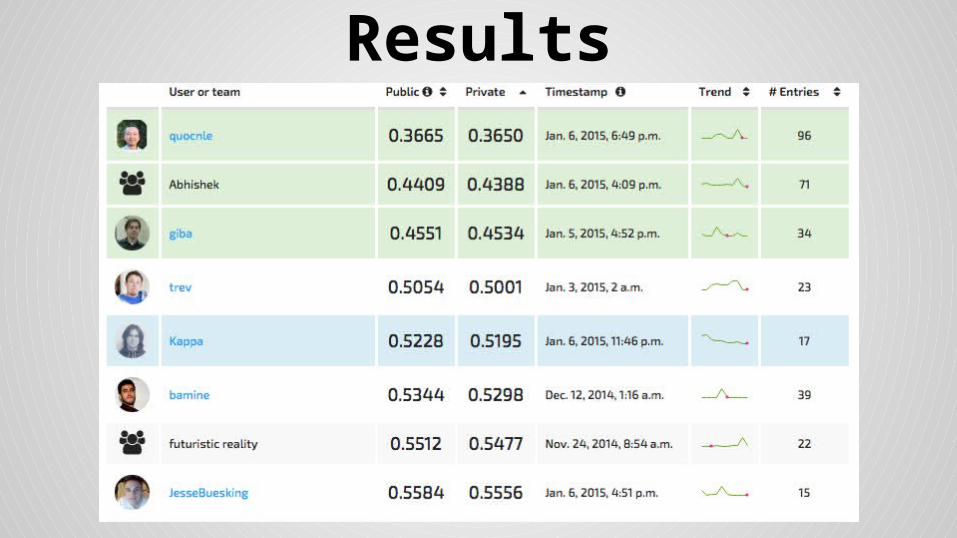
Results

Conclusion
● Explore your data before doing any analysis
● Keep trying
● Ensembles are powerful
● Participating in competitions provides a great
learning opportunity


















