
ARM CoreSight Architecture Specification v2.0 - ARM Information

White Paper
Reimagining Voice in the Driving SeatRecognition Technologies® & ARM® for the Next Generation Automobile

Contents
1 Introduction 3
2 Why a Larger Vocabulary is Better for In-Vehicle Voice Control 3
3 ARM in Automotive Infotainment Systems 4
4 Combining Speaker & Speech Recognition: A Complete Automotive Voice Solution 5
5 Leaning into the Future: Embedded Voice and the Connected Car 8
6 Off The Line Performance: Real-time Speaker Segmentation, Enrollment, Identification, 9
Verification & Transcription
7 Recognition Technologies SDK 11
8 Summary 12
9 References 12
10 Authors 12
Recognition Technologies® | ARM® 2

1 Introduction
The modern automotive cockpit is sophisticated andloaded with smart technologies; however, it has littlevalue if the driver finds it difficult to use. Existingsmart in-vehicle infotainment (IVI) interfaces havegreatly improved the cockpit experience, but voice todate has not delivered on its potential to bridge thegap between hands-free, in-vehicle control and saferdriving [1]. Motivation from users for in-vehicle voiceinterfaces has never been higher. According to the2016 KPCB Internet Trends Report, over 60% ofrespondents use voice when their hands are occupied[2]. In the U.S., 36% of respondents reported that thecar was their primary setting for voice usage [2]. Yetexisting systems are problematic as they are known tobe unreliable, which has resulted in userabandonment and a broad based level ofdissatisfaction. In 2015, the J.D. Power Initial QualityStudy found that the rate of complaints for in-carvoice recognition systems is nearly four times the rateof reported problems with transmissions [3]. Drivers aswell as passengers seek on-demand, real-time voicecontrols that match high accuracy with easyoperability and reliability. Therefore, a new model ofvoice operation is required.
“Voice-activated command systems andtheir software often are badly outdated orunreliable, leading to a tide of customercomplaints and research questioning howsafe they really are.” The Wall Street Journal [4]
Large vocabulary speech recognition engines offer amuch improved solution over existing limitedvocabulary engines. Utilizing advanced techniquessuch as deep neural networks, large vocabularyspeech recognition engines provide superior learningand recognition capabilities and allow for thecomplex patterns of human speech to be accuratelycaptured and recognized. Porting such an engine tomobile processors allows automakers to integrate alarge vocabulary engine that facilitates natural speechinput and leverages on-board, off-line functionalityfor critical control services. This provides anattractive solution for automakers whose customers
are seeking unconstrained natural speech recognitionwith improved accuracy and application scope.
Comparing continuous speech recognition withexisting in-vehicle voice systems is like speakingwith a native speaker versus a non-native speaker. Inorder to have the highest probability of success whenspeaking with a non-native speaker, it is oftennecessary to speak more slowly, use common wordsor phrases and repeat often. This process is similar toexisting in-vehicle voice systems. Continuous speechrecognition, on the other hand, is similar to speakingwith a native speaker in that it allows for a muchbroader and more natural interaction between boththe user and the system. By expanding thevocabulary, the user in this system is free to converseas if having a conversation with a native speaker.
It is clear that an in-vehicle voice advancement isneeded that resolves existing reliability issues and isable to fully operate in off-line mode. This whitepaper discusses a complete voice solution that bestfits the needs of the next generation automotivecockpit.
2 Why a Larger Vocabulary is Better for In-Vehicle Voice Control
In a world where more than 6,000 languages arespoken, speech is the basis of everyday life [5]. Speechis a fundamental form of human connection. It allowshumans to communicate, articulate, vocalize,recognize, understand, and interpret. Within speech,each person has a unique vocabulary. This is a set ofwords within a language that is understood andfamiliar to that person. Data collected by researchersfrom an independent American-Brazilian researchproject [6] found that native English-speaking adultsunderstood an average of 22,000 to 32,000vocabulary words and learned about one word a day.Non-native English-speaking adults knew an averagerange of 11,000 to 22,000 English words and learnedabout 2.5 words a day. Most current embedded in-vehicle recognition systems use a vocabulary size ofless than 10,000 words and usually use at any point amuch narrower context-based vocabulary, which isconsidered to be a limited vocabulary [7]. However,the words that comprise a native English-speaking
Recognition Technologies® | ARM® 3

adult's vocabulary can vary greatly from that of anon-native English-speaking adult, partly due toaccents and dialects. Dialects are distinct fromlanguages as a dialect is a manifestation of a languagethat differs from the original in terms ofpronunciation, vocabulary, and grammar. Forexample, in the U.S. alone, dialects range from thebasic three – New England, Southern, andWestern/General America – to more than 24 others [8].Therefore, accents and dialects increase thevocabulary size needed for a recognition system to beable to correctly capture and process a wide range ofspeakers within a single language.
To begin to understand the complex task that a speechrecognition system is faced with it is worth assessingthe size of the targeted language. In 2010, researchersfrom Harvard University and Google [9] estimated thata total of 1,022,000 words comprise the Englishlanguage, with that number increasing byapproximately 8,500 new words per year. However,in many cases these figures include differentiterations of the same word, many of which arearchaic in modern English. It is generally believedthat there are more than 150,000 words in current use[10]. When comparing this number to the averagevocabulary size of a native English-speaking adult, itis clear that a recognition system with a 10,000 wordor less vocabulary is not large enough. This type oflimited vocabulary system may result in the user'svocabulary being unrecognized when outside theframe of reference.
When combining the average users' vocabulary withdialect and accent variations, the result is a largevocabulary foundation of more than 150,000 words.Large vocabulary, continuous speech recognitionsystems promotes the freedom of speaking to anunconstrained system and offers a significantperformance increase and a much improved solutionover existing constrained systems that use restrictivegrammar, limited vocabulary, keyword and phrasespotting. With the continually improving computingpower and compact size of mobile processors, largevocabulary engines that promote the use of naturalspeech are now available for the automotive market.The footprint for such an engine has been optimizedand downsized to offer an attractive option forautomakers whose customers are seekingunconstrained, natural language interfaces with
improved accuracy and embedded on a mobileprocessor.
3 ARM® in Automotive InfotainmentSystems
With more than 85% of infotainment systems andmany other applications, such as dashboard and bodybuilt with ARM®-based chips, today's automotiveexperience is founded on ARM technology. Acommon architecture across all electronics andsupport from a leading tools ecosystem enables carmakers and their suppliers to rapidly innovate in bothhardware and software. These innovations aretransforming safety, reducing energy consumption,and improving driver experiences.
IVI is the front line in offering a better userexperience (UX) to drivers and passengers, for amore comfortable and efficient journey. Theautomotive industry is keen to provide a seamless UXto a customer base who already enjoy a polishedmobile UX every day. More computing performancewill be required in IVI to support not only betterhardware, such as multiple larger displays with higherresolution, Heads Up Displays (HUD) and bettersurround speaker systems, but also software tocontrol these systems more easily. Thanks to newregulation to restrict the use of mobile phones whiledriving, gesture and voice commands willincreasingly become the interface of choice in IVI.Speech recognition, in particular, is already enteringour daily life in the mobile and consumer space (e.g.Amazon Alexa®, Google Home®). Natural languageprocessing is becoming an important UXrequirement. ARM will support next generation IVIwith higher performance and power-efficiencyprocessors and power-optimization technology toprovide a significant boost to these rich, context-aware experiences.
ARM Cortex®-A applications processors are alreadywidely used in today’s infotainment systems. Themajority of current infotainment systems run onCortex-A7 and Cortex-A15 central processing unit(CPU) cores. Next generation systems will useCortex-A53, Cortex-A57, and Cortex-A72. Cortex-A72 is the highest performance CPU from ARM
Recognition Technologies® | ARM® 4

(3.5x performance of Cortex-A15), and is applicablefor enterprise infrastructure, mobile, consumer, andautomotive. It brings very compelling single-threadedperformance, which in automotive is of particularinterest for real-time voice recognition. Furthermore,the requisite performance is less than 1/3rd the powerconsumption of competitor solutions. Cortex-A53 is avery power-efficient processor with a 40%performance increase over its predecessor, theCortex-A7. Architecturally, the Cortex-A53 is fullycompatible with the Cortex-A57 and Cortex-A72 andsupports the ARM big.LITTLE™ configurations forthese high performance cores.
ARM big.LITTLE processing is a power-optimization technology where high-performanceARM CPU cores are combined with the mostefficient cores in a single chip to deliver peak-performance capacity, higher sustained performance,and increased parallel processing performance, atsignificantly lower average power. The latestbig.LITTLE software and platforms can save 75% ofthe CPU energy consumption in low to moderateperformance scenarios and can increase theperformance by 40% in highly threaded workloads.Automotive is known as a heat and power constrainedenvironment where this kind of energy managementis very applicable. Infotainment systems encompassaudio, radio, video processing, navigation, and manyinterrupts from the vehicle’s controller area network(CAN). LITTLE processors can filter out and handlethe low-intensity tasks, leaving the big processors toutilize all available resources for tasks that requirehigh performance. ARM is engaging leadingoperating system vendors such as QNX®, AutomotiveGrade Linux® (AGL), GENIVI® and Android® onoptimizing software to best take advantage of thebig.LITTLE processor configuration.
Figure 1. ARM® Cortex-A Portfolio
Figure 2. Measured power savings on a Cortex-A15MP4-Cortex-A7 MP4 big.LITTLE MP SoC relativeto a Cortex-A15 MP4 SoC
4 Combining Speaker & Speech Recognition: A Complete Automotive Voice Solution
In a speech recognition application, it is not the voiceof the individual that is being recognized but thecontents of his/her speech. However, in order toachieve highly accurate, in-vehicle voice control it ishighly preferable to identify who the speaker is andsegment the turns of each speaker throughout theinteraction.
Once the audio from the speaker(s) is captured by thein-car microphones and converted into amathematical representation of sound, commonlyknown as a waveform, the combination of text-independent speaker recognition and large vocabularyspeech recognition allows for in-vehicle voice controlversatility and the achievement of acceptableaccuracies.
Effective speaker recognition calls for thesegmentation of the audio stream, detection and/ortracking of speakers, and identification of thosespeakers. The recognition engine provides fusionfunctionality, combining the scores of both thespeaker and speech engines and leading to a fusedresult that is used to make decisions more readily.The engine also provides the results of the individualengines in conjunction with the fused results so thatany generic In-Vehicle Infotainment client application
Recognition Technologies® | ARM® 5

may utilize the information in a way that would suitethe practical application, such as real-time usercontrol directives.
Figure 3. Diagram of a full IVI speaker diarizationsystem including speech transcription andconnectivity to cloud-based services (See Figure. 4)
In combining both speaker and speech recognition forthe cockpit environment, the RecoMadeEasy® enginereturns a collation of the following:
1. Speaker segmentation of incoming audio stream
2. Identification of in-vehicle speaker(s)3. Verification of in-vehicle speaker(s) 4. Transcription of the in-vehicle audio stream5. Posting of the above collated results in either
Extensible Markup Language (XML) or JavaScript Object Notation (JSON) via an
Application Programming Interface (API) to Human Machine Interface (HMI)
RecoMadeEasy® is comprised of multiple speakerrecognition branches, both simple and compound.Simple branches that are self contained consist ofspeaker verification, speaker identification, andspeaker and event classification. Compound branchesthat utilize one or more of the simple manifestationswith added techniques consist of speakersegmentation and time-stamping, speaker detectionand speaker tracking. Most speaker recognitionsystems are limited to text dependencies such as fixedtext expectations, pre-defined text prompts or and/orlanguage restrictions. RecoMadeEasy® is a purelytext-independent and language-independent systemthat only relies on the vocal tract characteristics of thespeaker and makes no assumption about the contextof the speech. This indicates that an individual mayenroll her/his voice into the system in one languageand be identified or verified in a completely differentlanguage. This is useful for being able to handleverification and identification processes across anynumber or languages. In fact, the speaker recognitionengine has been used for more than 100 languages.
In a typical in-vehicle usage case, there are oftenmultiple speakers including the driver and passengerswho want to interact with the voice system. In orderto fully and accurately transcribe the interaction, it isnecessary to know the speaker of each statement.When there is an enrolled model for each speaker,and prior to identifying the active speaker, the audioof that speaker is segmented and separated fromadjoining speakers. In the absence of a prior model,the system labels a new speaker as an “Unknown”speaker.
As the audio is being segmented and separated, open-set identification is conducted. The audio streamsegment is compared against all in-vehicle enrolledspeaker models and the speaker ID of the model withthe closest match is returned. In addition to matchingthe audio segment against known models, it is alsocompared to rejection models which are used toreturn an Unknown label for a speaker who has notbeen enrolled in the system before – this constitutesthe “open-set” aspect of the identification.
Recognition Technologies® | ARM® 6

In the case of verification, the engine is used to verifythe identity of users based on the vocal characteristicsby receiving a random user prompt, to be evaluatedby the speech recognition engine. The provided ID ofthe user is then used to retrieve the model for thatperson from a database and the speech signal of thespeaker is compared against the existing speakermodel to verify.
In parallel to the execution of the numerous speakerrecognition functions, the audio stream is passed tothe speech recognition engine with the loadedvocabulary to produce the recognized text. Theengine handles different user dialects and accents andgenerates a full speech to text transcription. Thespeech recognition engine uses a streaming interface,where the recognizer in the form of listeners and theclient both run on the embedded device. Any lightgeneric client capable of using a websocket interfacemay stream audio/video in any codec that issupported by GStreamer-1.0, including MP3, OggVorbis, Free Lossless Audio Codec (FLAC), MP4,Pulse Code Modulation (PCM) or other codecs suchas those supported by a standard Waveform AudioFile Format (WAVE), to one such listener and getback real-time results of the transcript with optionalalternative results, including likelihood scores.
Based on experience, close to 30% of the audioframes in a normal audio segment are silence frames[11]. In speech recognition, the extraneous silencesegments will produce spurious nonsense words bytaking leaps through different arcs of Hidden MarkovModels. RecoMadeEasy® includes silencesegmentation as a standard component via the use ofenergy thresholding, advanced features and modelbased techniques. In this way, the algorithm is used toestimate the threshold along the time line. Differentthresholds may be established automatically toidentify silence or non-speech signals adaptively. Byeliminating silence/non-speech, the accuracy of thetranscription is increased and reduces un-necessaryprocessing energy and, in some cases, bandwidthutilization.
For the engine to function at its full potential and toallow in-vehicle users to speak naturally and beunderstood – even in a far-field, noisy environment,pre-processing techniques are integrated to helpimprove the quality of the audio input to the
recognition system. The microphone peripheralconverts automobile noise sources both inside andoutside the vehicle to signal. These include tire andwind noise while the vehicle is in motion, enginenoise, and noise produced by the car radio, fan,windscreen wipers, horn and turn signals. The engineleverages audio input pre-processing, which runs onthe ARM® NEON DSP and radically improves theaccuracy by bettering the quality of voice signalspassed to the speech recognition engine forprocessing.
RecoMadeEasy® is a combination of both enginesinto a single interface engine, capable of performingmany tasks on audio streams. For example, a fulldiarization of an audio file may be done using theengine by segmenting the audio file into differentportions where uniform events happened such aswhere an individual speaks or non-speech eventshappen. In addition, the speaker identification isperformed on each segment to provide the identity ofthe speakers in the stream. Non-speech events in thestream are also tagged using the classificationcapability of the speaker recognition portion of theengine. In parallel, the speech recognition engineprovides a full real-time transcript of the audio in thestream. The engine is capable of handling manydifferent dialects and accents in a single large-vocabulary transcription engine, whilesimultaneously processing audio segmentation andspeaker identification. The result is an embeddedengine that can process a real-time audio stream thatincludes multiple speakers. The embedded enginealso tags each segment with the identity of thespeaker and transcribes the conversation whileproviding timestamps for every turn in the transcript.
Furthermore, due to the large overlap of underlyingmodeling techniques between speaker and speechrecognition systems, being developed by RecognitionTechnologies, both engines share all necessary C++libraries, reducing duplication of loaded sharelibraries. This is in contrast to less desirable alternatescenarios where independent speaker recognition andspeech recognition engines may be used. This optimalusage of resources such as memory and processingare essential in an embedded environment.
Recognition Technologies® | ARM® 7

Features of the RecoMadeEasy® Engine
• Speaker Recognition: Fast Match for Large Populations (Speaker Identification, Verification, Classification, Detection, Tracking and Segmentation)
• Speech Recognition: 150,000-200,000 Word Vocabularies
• Custom Vocabularies can be easily created and used in combination with the main vocabulary
• Full Feature Control though Configuration Files
• Multiple Interfaces – C++ SDK, Graph-Based Interface, Web Services
• Handles Client Streaming – Integrating through WebSocket and native interprocess communication and supporting GStreamer 1.0 supported media
• Native Multi-Threading Support• Default Configuration Evaluated and
Adjusted Frequently through Benchmarking• Inclusion and Support of Benchmarking
Scripts and Environments• Built-in Multiuser Support with Full
Configuration Independence Across Users• Linked with ffmpeg and GStreamer libraries
for extensive codec support and streaming
5 Leaning into the Future: Embedded Voice and the Connected Car
Automakers are developing next generation cars thatintegrate a variety of new technologies that will makecars more digitally connected. Advanced cloud-basedtechnologies that rely on distributed computing, suchas natural language processing, artificial intelligence,machine learning in combination with speechrecognition are commonplace. Connected servicessuch as intelligent personal assistants (e.g. AmazonAlexa®, Google Home®) that provide natural languageinterfaces for conversational voice interaction arenow widely used. These services are a combination ofcloud-based speech recognition and natural languageprocessing, where audio voice data is captured andtransmitted over a wireless network. However, inreal-time automotive cockpit environments, the use of
these cloud-based technologies presents significantsystem and user concerns. According to VDCResearch, major threats against connected cars fallinto two categories: safety and data privacy [12]. Allconnected devices are at risk of some form of attack.Transmitting user voice data over a wireless networkpresents serious user safety and privacy concerns.Attackers, able to penetrate either the car or cloudprovider ends, would be able to access users’ personalbiometric information. Once biometric information iscompromised, it cannot be changed like a password.RecoMadeEasy® only stores statistical models aboutthe biometric and not the biometric itself, therefore,the user’s biometric cannot be compromised in thisway. From a network standpoint, the transmitting ofaudio voice data per second to the cloud is over 300times larger than text data per second, and thecumulative volume of voice data transmitted to thecloud presents serious ongoing bandwidth and latencyconcerns when scaled.
Cloud-based speech recognition systems are a greatsolution when full, uninterrupted and secure access toa cloud server is guaranteed. However, in real-timeautomotive cockpit environments, this is not the caseand cars have to be able to reliably perform at taskeven in the presence of service interruption. In orderto limit the number of potential points of failure,localized processing is highly preferred overcentralized servers wherein each vehicle is capable ofcollecting and processing its own voice data. This isachieved by combining fully optimized anddownsized embedded speech recognition with thecontinuously improving computing power andcompact size of ARM® mobile processors. However,rather than simply writing off cloud-basedtechnologies for automotive use and reverting back toembedded technologies, a hybrid model is desirablethat exemplifies the positive benefits of both models.It is achievable for both models to work inconjunction with one another to extend systemfunctionality, increase system efficiency and provideuser security, privacy and protection.
Cloud-based speech recognition systems have twostreaming limitations to address when transmittingvoice audio data over a wireless network. First, thedata rate or the size of the audio file per second ofdata is transmitted on average at 128 kbps, meaningthat each one-second chunk of user voice audio
Recognition Technologies® | ARM® 8

comprises about 128 kilobits of data. This would beachieved using Ogg Vorbis, MP3, or other lossycompression techniques. Second, the bandwidth orthe connection speed to the cloud controls theautomotive cockpit application’s ability to transmitaudio to the cloud. Cloud providers have to pay fortheir bandwidth usage and have to balance highquality performance with network bandwidth costs.Since voice audio data is the most dominating part ofthe data, the data rate and the bandwidth per linewould be essentially the same. Therefore, in order tocalculate the approximate bandwidth requirements,the number of concurrent lines that need to besupported are multiplied by the data rate.
In contrast, transmitting textual data on the slowestvoice modem is minimal. For example, if we take thefastest speaker in the world who speaks at a rate of586 words per minute, it would come to less than 10words per second. An average word has 4.5 letters,therefore, this would make it 45 bytes per second orabout 0.36 kilobits per second. It should be noted thatthe average person does not speak that fast. Despitetaking into consideration the required JSON orVoiceXML tags, the bandwidth needed to transmitremains realistic.
When comparing the transmitting of audio voice dataversus text data to the cloud, it becomes quite clearthat performing speech recognition processing locallyis an obvious solution for optimizing bandwidthconsumption and providing significant bandwidthsavings. The textual and audio voice data bandwidthlevels differ by two orders of magnitude. In thishybrid model, mission critical concerns such as usersecurity, privacy and protection are addressed byprocessing user speech natively on the device as wellas ensuring continuous availability. Non-missioncritical dimensions, such as natural languageprocessing, can be processed in the cloud and usesonly low bandwidth, textual data as the mode ofbilateral transmission. Therefore, by prioritizing andmodularizing both mission and non-mission criticalprocesses by running RecoMadeEasy® speaker andspeech recognition as an embedded process, we areable to extend system functionality, increase systemefficiency such as bandwidth optimization andprovide critical user security, privacy and protection.
Figure 4. A hybrid model for embedded speechrecognition and cloud-based natural languageprocessing
6 Off The Line Performance: Real-time Speaker Segmentation, Enrollment, Identification, Verification & Speech Transcription
Speaker Enrollment, Verification andIdentification
In order to fully and accurately diarize anyinteraction, it is necessary to know the speaker ofeach statement. An enrollment model is generated foreach speaker based ideally on 60 seconds of speakeraudio data, however the shortest enrollment time-frame may be as little as eight seconds. For open-setspeaker identification, audio stream segments arecompared against all enrolled speaker models and theclaimed speaker ID of the model with the closestmatch is returned. In addition to matching the audiosegment against known models, it is compared torejection models which are used to return anUnknown label for a speaker who has not beenenrolled in the system before. However, it should benoted that the RecoMadeEasy® Speaker and SpeechRecognition engines do not require a claimed speakerID to be passed to the system in order for the speakersegmentation, identification, and speech transcriptionto be performed.
In order for speaker verification to be evaluated bythe engine, the engine requires two pieces ofinformation; the first is a claimed ID and the secondis an audio segment that is used to verify the identity
Recognition Technologies® | ARM® 9
of the speaker based on the vocal characteristics. Theprovided ID of the user is then used to retrieve themodel for that person from a database and the speechsignal of the speaker is compared against the initialenrollment speaker model to verify.
The performance results, as detailed in all of thebelow figures, were generated using a medley of TEDtalks. The medley is comprised of eight TEDspeakers, including male and female and native andnon-native English speakers. The total audio stream isone minute and twenty-five seconds with eachspeaker turn lasting approximately ten seconds. Codeoptimization of the engine has been performed thataims at meeting prime requirements for embeddedsystems such as timing accuracy, code size efficiency,low memory usage, time pressure, reliability, andrecognition performance.
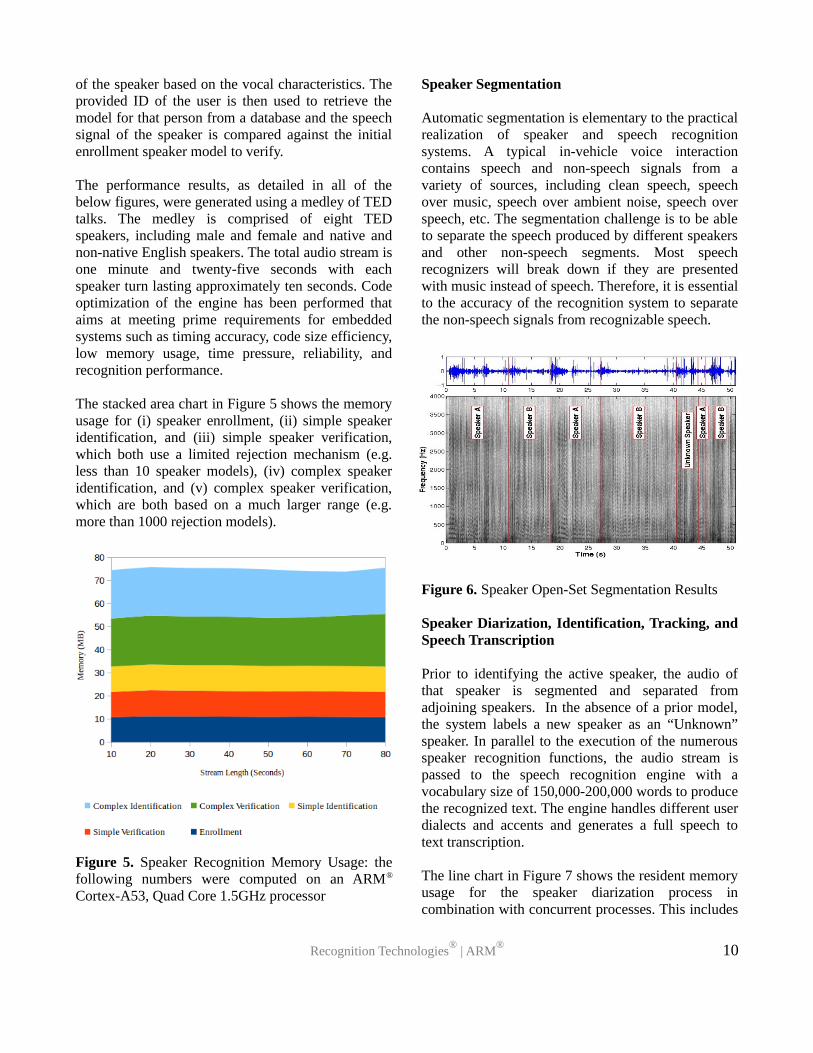
The stacked area chart in Figure 5 shows the memoryusage for (i) speaker enrollment, (ii) simple speakeridentification, and (iii) simple speaker verification,which both use a limited rejection mechanism (e.g.less than 10 speaker models), (iv) complex speakeridentification, and (v) complex speaker verification,which are both based on a much larger range (e.g.more than 1000 rejection models).
Figure 5. Speaker Recognition Memory Usage: thefollowing numbers were computed on an ARM®
Cortex-A53, Quad Core 1.5GHz processor
Speaker Segmentation
Automatic segmentation is elementary to the practicalrealization of speaker and speech recognitionsystems. A typical in-vehicle voice interactioncontains speech and non-speech signals from avariety of sources, including clean speech, speechover music, speech over ambient noise, speech overspeech, etc. The segmentation challenge is to be ableto separate the speech produced by different speakersand other non-speech segments. Most speechrecognizers will break down if they are presentedwith music instead of speech. Therefore, it is essentialto the accuracy of the recognition system to separatethe non-speech signals from recognizable speech.
Figure 6. Speaker Open-Set Segmentation Results
Speaker Diarization, Identification, Tracking, andSpeech Transcription
Prior to identifying the active speaker, the audio ofthat speaker is segmented and separated fromadjoining speakers. In the absence of a prior model,the system labels a new speaker as an “Unknown”speaker. In parallel to the execution of the numerousspeaker recognition functions, the audio stream ispassed to the speech recognition engine with avocabulary size of 150,000-200,000 words to producethe recognized text. The engine handles different userdialects and accents and generates a full speech totext transcription.
The line chart in Figure 7 shows the resident memoryusage for the speaker diarization process incombination with concurrent processes. This includes
Recognition Technologies® | ARM® 10
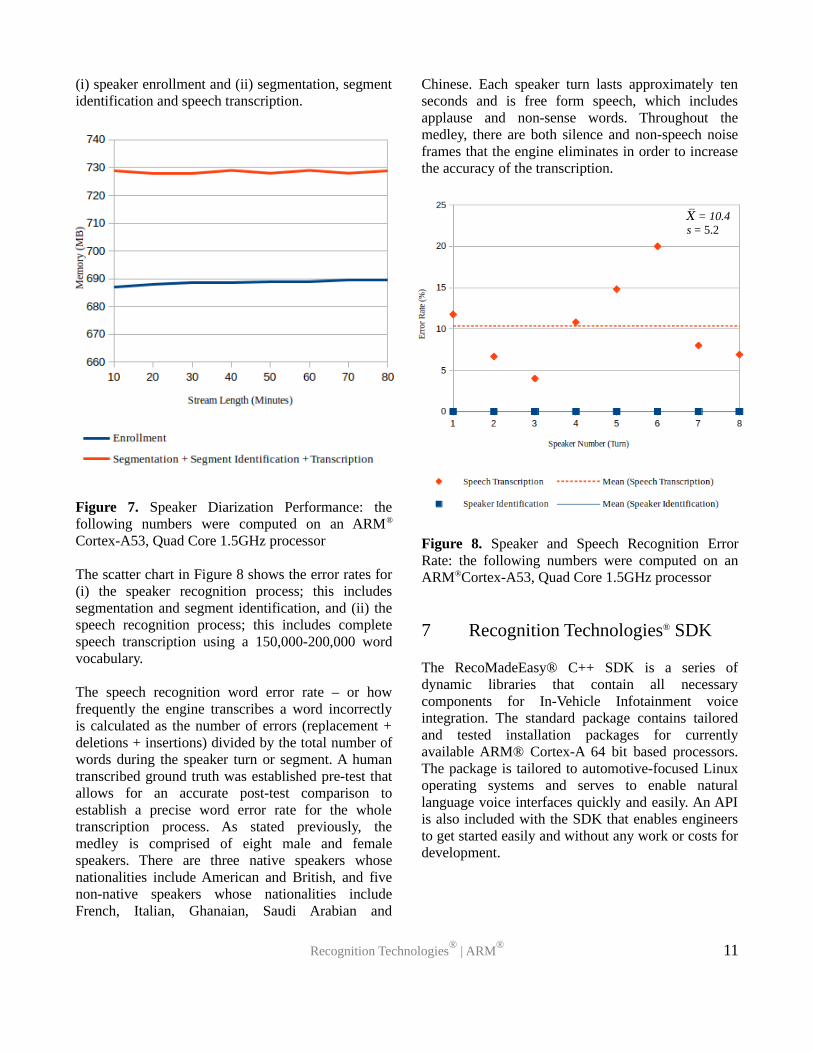
(i) speaker enrollment and (ii) segmentation, segmentidentification and speech transcription.
Figure 7. Speaker Diarization Performance: thefollowing numbers were computed on an ARM®
Cortex-A53, Quad Core 1.5GHz processor
The scatter chart in Figure 8 shows the error rates for(i) the speaker recognition process; this includessegmentation and segment identification, and (ii) thespeech recognition process; this includes completespeech transcription using a 150,000-200,000 wordvocabulary.
The speech recognition word error rate – or howfrequently the engine transcribes a word incorrectlyis calculated as the number of errors (replacement +deletions + insertions) divided by the total number ofwords during the speaker turn or segment. A humantranscribed ground truth was established pre-test thatallows for an accurate post-test comparison toestablish a precise word error rate for the wholetranscription process. As stated previously, themedley is comprised of eight male and femalespeakers. There are three native speakers whosenationalities include American and British, and fivenon-native speakers whose nationalities includeFrench, Italian, Ghanaian, Saudi Arabian and
Chinese. Each speaker turn lasts approximately tenseconds and is free form speech, which includesapplause and non-sense words. Throughout themedley, there are both silence and non-speech noiseframes that the engine eliminates in order to increasethe accuracy of the transcription.
Figure 8. Speaker and Speech Recognition ErrorRate: the following numbers were computed on anARM®Cortex-A53, Quad Core 1.5GHz processor
7 Recognition Technologies® SDK
The RecoMadeEasy® C++ SDK is a series ofdynamic libraries that contain all necessarycomponents for In-Vehicle Infotainment voiceintegration. The standard package contains tailoredand tested installation packages for currentlyavailable ARM® Cortex-A 64 bit based processors.The package is tailored to automotive-focused Linuxoperating systems and serves to enable naturallanguage voice interfaces quickly and easily. An APIis also included with the SDK that enables engineersto get started easily and without any work or costs fordevelopment.
Recognition Technologies® | ARM® 11
= 10.4X̅s = 5.2

RecoMadeEasy® C++ SDK and API
• Unified API and SDK for both engines ◦ Simple and Short API Header◦ Fully Configurable Through Simple
Configuration Files• Small Application and Libraries
◦ C++ code for Client Application◦ C++ code for Standalone Application◦ Speaker Recognition, 16 Libraries◦ Speech Recognition, 10 Libraries
• Complete Error and Warning Handling and Propagation to the Main Application
• Very Small Memory Footprint◦ Each Speaker Model is only 204kB
The RecoMadeEasy® SDK can be obtained by contacting Recognition Technologies: [email protected]
8 Summary
Voice recognition engines, like automotive engines,are not all built equal. Combining speaker and largevocabulary speech recognition systems offers asignificant increase in accuracy, performance, andapplication scope over existing systems that havelimited vocabulary, keyword, and phrase spotting.Combining this type of engine with the continuouslyimproving computing power and compact size ofARM® processors makes continuous natural speechinterfaces accessible for in-vehicle purposes. TheRecoMadeEasy® SDK serves as a completeautomotive cockpit voice solution that runs nativelyon automotive-focused Linux operating systems. TierOne companies can integrate the series of dynamiclibraries and offer car makers a fully embedded andcustomizable voice interaction experience for theirIVI products.
9 References
[1] "2016 U.S. Initial Quality Study." J.D. Power, 22 June 2016.[2] Meeker, Mary. "2016 KPCB Internet Trends Report." Kleiner Perkins Caufield & Byers, 1 June 2016. [3] Murtha, Philly. "2015 Initial Quality Study: Top 10 Reported Problems." J.D. Power, 1 July 2015.[4] White, Joseph B. "The Hassle of ‘Hands Free’ Car Tech." Wall Street Journal, 23 Nov. 2014.[5] "Ethnologue: Languages of the World."Ethnologue Web. Ed. Raymond G. Gordon. SIL International, 2005.[6] Little, Regina. "Vocabulary of Native and Non-native Speakers: The Lifelong Pursuit ofLanguage Learning." Cyracom, 3 Nov. 2013.[7] Ivanecký, J., & Mehlhase, S. "Today’s Challenges for Embedded ASR."Mathematical and Engineering Methods in Computer Science. Vol. 8934. Springer, 2014. 16-29.[8] Wolfram, W., & Schilling-Estes, N. “American English: Dialects and Variation.” Oxford: Basil Blackwell, 1998.[9] Michel, Jean-Baptiste et al. “Quantitative Analysis of Culture Using Millions of Digitized Books.” Science, 2011. 176–182.[10] "How Many Words Are There in the English Language?" Oxford English Dictionary, May 2016.[11] Beigi, Homayoon. “Fundamentals of Speaker Recognition.” Springer, 2011[12] https://www.vdcresearch.com
All trademarks are the property of their respectiveowners.
10 Authors
Mark Sykes - Recognition Technologies, Inc.Homayoon Beigi - Recognition Technologies, Inc.Soshun Arai - ARM Limited.
Recognition Technologies® | ARM® 12


















