
What’s next ?? Today 3.3 Protein function 10.3 Protein secondary structure prediction 17.3 Protein...
36
What’s next ?? 3.3 Protein function 10.3 Protein secondary structure predictio 17.3 Protein tertiary structure prediction 24.3 Gene expression & Gene networks 31.3 RNA structure and function 7.4 Advances in Bioinformatics
-
date post
21-Dec-2015 -
Category
Documents
-
view
218 -
download
0
Transcript of What’s next ?? Today 3.3 Protein function 10.3 Protein secondary structure prediction 17.3 Protein...

What’s next ??
Today 3.3 Protein function 10.3 Protein secondary structure prediction 17.3 Protein tertiary structure prediction 24.3 Gene expression & Gene networks 31.3 RNA structure and function
7.4 Advances in Bioinformatics

Predicting Protein Function

proteinRNADNA

Biochemical function(molecular function)
What does it do?Kinase???Ligase???
Page 245

Function based onligand binding specificity
What (who) does it bind ??
Page 245

Function basedon biological process
What is it good for ??Amino acid metabolism?
Page 245

Function based oncellular location
DNA RNA
Page 245
Where is it active?? Nucleolus ?? Cytoplasm??

Function based oncellular location
DNA RNA
Page 245
Where is the RNA/Protein Expressed ??Brain? Testis? Where it is under expressed??

GO (gene ontology)http://www.geneontology.org/
• The GO project is aimed to develop three structured, controlled vocabularies (ontologies) that describe gene products in terms of their associated
• molecular functions (F)• biological processes (P) • cellular components (C)
Ontology is a description of the concepts and relationships that can exist for an agent or a community of agents

GO Annotations RIM11 GO evidence and references
Molecular Function glycogen synthase kinase 3 activity (ISS)protein serine/threonine kinase activity (IDA)
Biological Process protein amino acid phosphorylation (IGI, ISS)proteolysis (IGI)response to stress (IGI, IMP)sporulation (sensu Fungi) (IMP)
Cellular Component cytoplasm (IDA)
Extracted from SGD Saccharomyces Genome Database

Inferring protein function Bioinformatics approach
• Based on homology
• Based on the existence of
known protein domains (the protein signature)

Inferring protein function based on sequence homology

Homologous proteinsRule of thumb:Proteins are homologous if 25% identical (length >100)DNA sequences are homologous if 70% identical

Homologs
Proteins with a common evolutionary origin
Paralogs - Proteins encoded within a given species that arose from one or more gene duplication events.
Orthologs - Proteins from different species that evolved by speciation.
Hemoglobin human vs Hemoglobin mouse
Hemoglobin human vs Myoglobin human

COGsClusters of Orthologous Groups of proteins
> Each COG consists of individual orthologous proteins or orthologous sets of paralogs.
> Orthologs typically have the same function, allowing transfer of functional information from one member to an entire COG.
DATABASE
Refence: Classification of conserved genes according to their homologous relationships. (Koonin et al., NAR)

Inferring protein function based on the protein signature

The Protein Signature
Signature: • Existence of a known protein domain or motif
Domain: • A region of a protein that can adopt a 3D structure
Motif (or fingerprint):• a short, conserved region of a protein• typically 10 to 20 contiguous amino acid residues
examples: zinc finger domain immunoglobulin domain

DNA Binding domainZinc-Finger

Protein Domains
• Domains can be considered as building blocks of proteins.
• Some domains can be found in many proteins with different functions, while others are only found in proteins with a certain function.

Varieties of protein domains
Page 228
Extending along the length of a protein
Occupying a subset of a protein sequence
Occurring one or more times
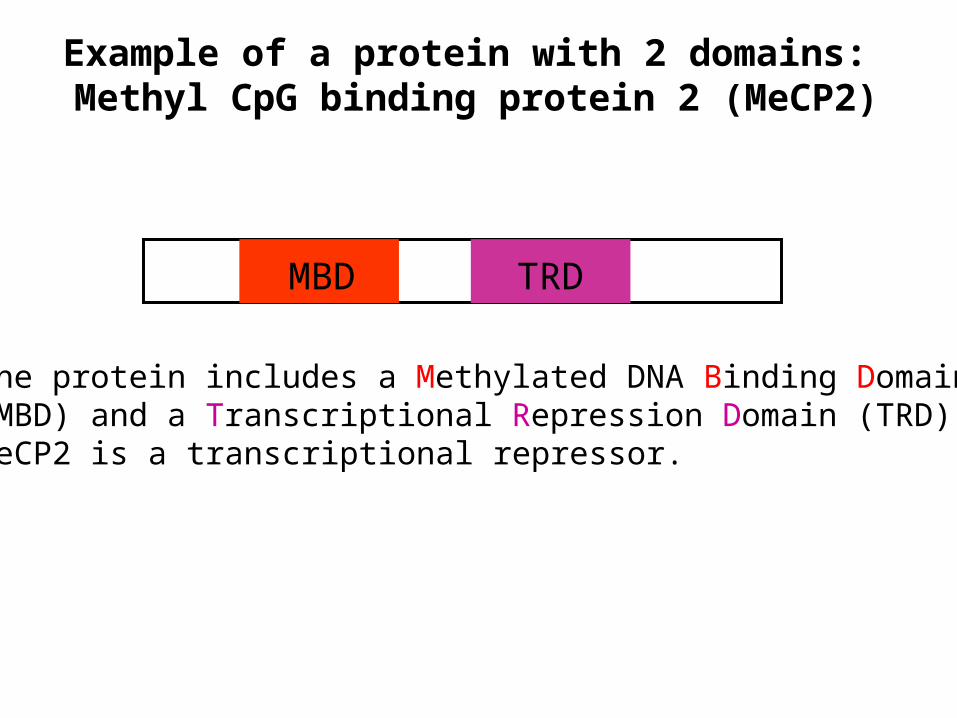
Example of a protein with 2 domains: Methyl CpG binding protein 2 (MeCP2)
MBD TRD
The protein includes a Methylated DNA Binding Domain(MBD) and a Transcriptional Repression Domain (TRD).MeCP2 is a transcriptional repressor.

Result of an MeCP2 blastp search:A methyl-binding domain shared by several proteins

Are proteins that share only a domain homologous?

PROSITE
• ProSite is a database of protein domains that can be searched by either regular expression patterns or sequence profiles.
Zinc_Finger_C2H2 Cx{2,4}Cx3(L,I,V,M,F,Y,W,C)x8Hx{3,5}H

Pfam
> Database that contains a large collection of multiple sequence alignments of protein domains
Based on Profile hidden Markov Models (HMMs).

Profile HMM (Hidden Markov Model)
D16 D17 D18 D19
M16 M17 M18 M19
I16 I19I18I17
100%
100% 100%
100%
D 0.8S 0.2
P 0.4R 0.6
T 1.0 R 0.4S 0.6
X XX X
50%
50%D R T RD R T SS - - SS P T RD R T RD P T SD - - SD - - SD - - SD - - R
16 17 18 19
HMM is a probabilistic model of the MSA consisting of a number of interconnected states
Match
delete
insert

Pfam
> Database that contains a large collection of multiple sequence alignments of protein domains
Based on Profile hidden Markov Models (HMMs).
> The Pfam database is based on two distinct classes of alignments
–Seed alignments which are deemed to be accurate and used to produce Pfam A-Alignments derived by automatic clustering of SwissProt, which are less reliable and give rise to Pfam B

Physical properties of proteins

DNA binding domains have relatively high frequency of basic (positive) amino acids
M K D P A A L K R A R N T E A AR R S S R A R K L Q R M
GCN4
zif268 M E R P Y A C P V E S C D R R FS R S D E L T R H I R I H T
myoDS K V N E A F E T L K R C T S S N
P N Q R L P K V E I L R N A I R

Transmembrane proteins have a unique hydrophobicity pattern

Physical properties of proteins
Many websites are available for the analysis ofindividual proteins for example:EXPASY (ExPASy)UCSC Proteome BrowserProtoNet HUJI
The accuracy of the analysis programs are variable. Predictions based on primary amino acid sequence (such as molecular weight prediction) are likely to be more trustworthy. For many other properties (such asposttranslational modification of proteins by specific sugars), experimental evidence may be required rather than prediction algorithms.
Page 236

Knowledge Based Approach
• IDEA Find the common properties of a protein
family (or any group of proteins of interest) which are unique to the group and different
from all the other proteins. Generate a model for the group and predict
new members of the family which have similar properties.

Knowledge Based Approach
• Generate a dataset of proteins with a common function (DNA binding protein)
• Generate a control dataset • Calculate the different properties which are characteristic
of the protein family you are interested for all the proteins in the data (DNA binding proteins and the non-DNA binding proteins
• Represent each protein in a set by a vector of calculated features and build a statistical model to split the groups
Basic Steps1. Building a Model

Support Vector Machine (SVM)To find a hyperplane that maximallyseparates the DNA-binding from non-DNA bindinginto two classes
Input space Feature space
Kernelfunction
?
newproteinstructure
DNA binding
Non-DNA binding
=[x1, x2, x3…]
=[y1, y2,y3…]

• Calculate the properties for a new protein
And represent them in a vector
• Predict whether the tested protein belongs to the family
Basic Steps2. Predicing the function of a new protein

Database and Tools for protein families and domains
• InterPro - Integrated Resources of Proteins Domains and Functional Sites
• Prosite – A dadabase of protein families and domain • BLOCKS - BLOCKS db • Pfam - Protein families db (HMM derived)• PRINTS - Protein Motif fingerprint db • ProDom - Protein domain db (Automatically generated) • PROTOMAP - An automatic hierarchical classification of Swiss-Prot
proteins • SBASE - SBASE domain db • SMART - Simple Modular Architecture Research Tool • TIGRFAMs - TIGR protein families db


















