
What%is%A%Computer? - web.njit.edurlopes/Mod3.1.pdf · ... Speculation , Vector, DSP ... " How to...
65
What is A Computer? Three key components Computation Communication Storage (memory) 1
Transcript of What%is%A%Computer? - web.njit.edurlopes/Mod3.1.pdf · ... Speculation , Vector, DSP ... " How to...
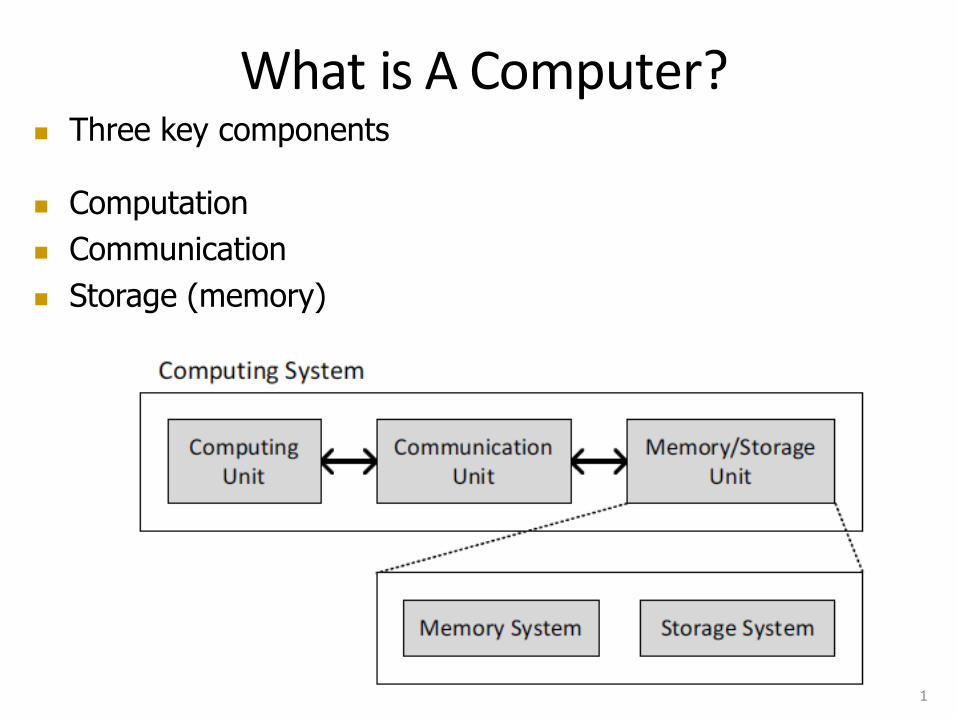
What is A Computer? n Three key components
n Computation n Communication n Storage (memory)
1

2
What is Computer Architecture?
• Func6onal opera6on of the individual HW units within a computer system, and the flow of informa6on and control among them.
Technology Programming Language Interface
Interface Design (ISA)
Measurement & Evaluation
Parallelism
Computer Architecture:
Applica6ons OS
Hardware Organiza-on

3
Computer Architecture Topics
Instruction Set Architecture
Pipelining, Hazard Resolution, Superscalar, Reordering, Prediction, Speculation, Vector, DSP
Addressing, Protection, Exception Handling
L1 Cache
L2 Cache
DRAM
Disks, WORM, Tape
Coherence, Bandwidth, Latency
Emerging Technologies Interleaving Memories
RAID
VLSI
Input/Output and Storage
Memory Hierarchy
Pipelining and Instruction Level Parallelism

4
Computer Architecture Topics
M
Interconnection Network S
P M P M P M P ° ° °
Topologies, Routing, Bandwidth, Latency, Reliability
Network Interfaces
Shared Memory, Message Passing, Data Parallelism
Processor-Memory-Switch
Multiprocessors Networks and Interconnections

5
Issues for a Computer Designer • Func6onal Requirements Analysis (Target)
– Scien6fic Compu6ng – HiPerf floa6ng pt. – Business – transac6onal support/decimal arith. – General Purpose –balanced performance for a range of tasks
• Level of soWware compa6bility – PL level
• Flexible, Need new compiler, portability an issue – Binary level (x86 architecture)
• Li\le flexibility, Portability requirements minimal • OS requirements
– Address space issues, memory management, protec6on • Conformance to Standards
– Languages, OS, Networks, I/O, IEEE floa6ng pt.

The Von Neumann Model/Architecture
6
n Also called stored program computer (instructions in memory). Two key properties:
n Stored program q Instructions stored in a linear memory array q Memory is unified between instructions and data
n The interpretation of a stored value depends on the control signals
n Sequential instruction processing q One instruction processed (fetched, executed, and completed) at a
time q Program counter (instruction pointer) identifies the current instr. q Program counter is advanced sequentially except for control transfer
instructions
When is a value interpreted as an instruction?

The Von-‐Neumann Model / Computer
CONTROL UNIT
IP Inst Register
PROCESSING UNIT
ALU TEMP
MEMORY
Mem Addr Reg
Mem Data Reg
INPUT
OUTPUT
7

Dataflow Model / Computer
8
n Von Neumann model: An instruction is fetched and executed in control flow order q As specified by the instruction pointer q Sequential unless explicit control flow instruction
n Dataflow model: An instruction is fetched and executed in data flow order q i.e., when its operands are ready q i.e., there is no instruction pointer q Instruction ordering specified by data flow dependence
n Each instruction specifies “who” should receive the result n An instruction can “fire” whenever all operands are received
q Potentially many instructions can execute at the same time n Inherently more parallel

von Neumann vs Dataflow n Consider a von Neumann program
q What is the significance of the program order? q What is the significance of the storage locations?
v <= a + b; w <= b * 2; x <= v -‐ w y <= v + w z <= x * y
+ *2
-‐ +
a b
Sequential
* Dataflow
z n Which model is more natural to you as a programmer?
9

More on Data Flow n In a data flow machine, a program consists of data flow
nodes q A data flow node fires (fetched and executed) when all it
inputs are ready n i.e. when all inputs have tokens
n Data flow node and its ISA representation
10
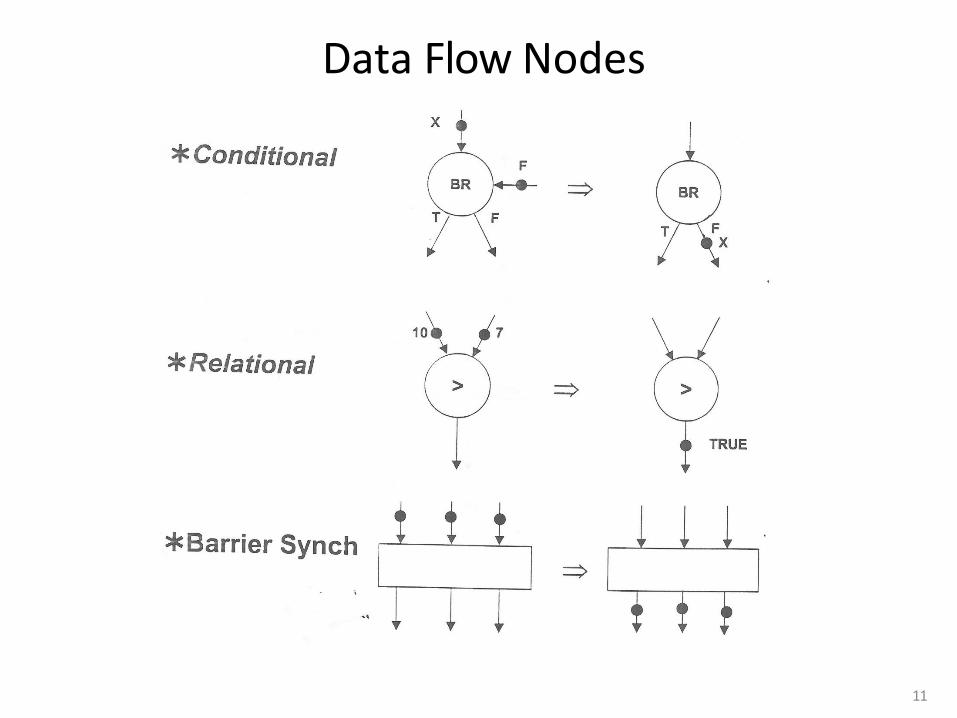
Data Flow Nodes
11

What is Computer Architecture?
Journal of R&D, April 1964 12
n ISA+implementation definition: The science and art of designing, selecting, and interconnecting hardware components and designing the hardware/software interface to create a computing system that meets functional, performance, energy consumption, cost, and other specific goals.
n Traditional (only ISA) definition: “The term architecture is used here to describe the attributes of a system as seen by the programmer, i.e., the conceptual structure and functional behavior as distinct from the organization of the dataflow and controls, the logic design, and the physical implementation.” Gene Amdahl, IBM

What is an ISA? n Instructions
q Opcodes, Addressing Modes, Data Types q Instruc6on Types and Formats q Registers, Condi6on Codes
n Memory q Address space, Addressability, Alignment q Virtual memory management
n Call, Interrupt/Exception Handling n Access Control, Priority/Privilege n I/O: memory-‐mapped vs. instr. n Task/thread Management n Power and Thermal Management n Multi-‐threading support, Mul6processor support 13
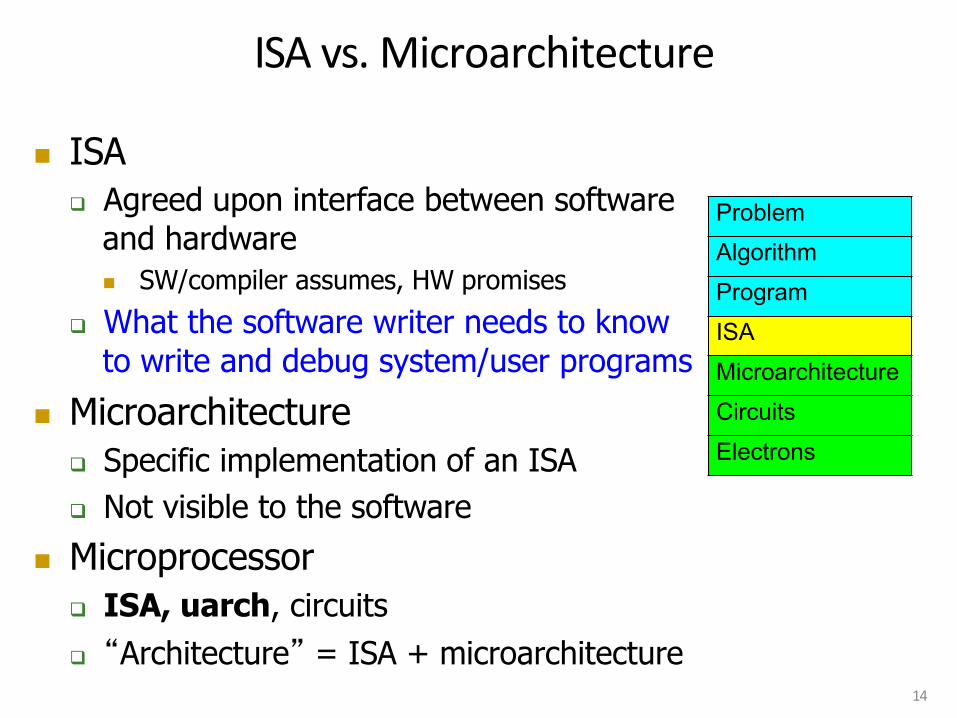
ISA vs. Microarchitecture
q “Architecture” = ISA + microarchitecture 14
n ISA q Agreed upon interface between software
and hardware n SW/compiler assumes, HW promises
q What the software writer needs to know to write and debug system/user programs
n Microarchitecture q Specific implementation of an ISA q Not visible to the software
n Microprocessor q ISA, uarch, circuits
Problem Algorithm
Program
ISA
Microarchitecture
Circuits
Electrons

ISA vs. Microarchitecture
15
n What is part of ISA vs. uarch? q Gas pedal: interface for “acceleration”
q Internals of the engine: implement “acceleration”
n Implementation (uarch) can be various as long as it satisfies the specification (ISA) q Add instruction vs. Adder implementation
n Bit serial, ripple carry, carry lookahead adders are all part of microarchitecture
q x86 ISA has many implementations: 286, 386, 486, Pentium, Pentium Pro, Pentium 4, Core, …
n Microarchitecture usually changes faster than ISA q Few ISAs (x86, ARM, SPARC, MIPS, Alpha) but many uarchs
q Why?

Microarchitecture
16
n Implementation of the ISA under specific design constraints and goals
n Anything done in hardware without exposure to software q Pipelining q In-order versus out-of-order instruction execution q Memory access scheduling policy q Speculative execution q Superscalar processing (multiple instruction issue?) q Clock gating q Caching? Levels, size, associativity, replacement policy q Prefetching? q Voltage/frequency scaling? q Error correction?

Property of ISA vs. Uarch?
17
n ADD instruction’s opcode n Number of general purpose registers n Number of ports to the register file n Number of cycles to execute the MUL instruction n Whether or not the machine employs pipelined instruction
execution
n Remember q Microarchitecture: Implementation of the ISA under specific
design constraints and goals

Design Point
18
n A set of design considerations and their importance q leads to tradeoffs in both ISA and uarch
n Considerations q Cost q Performance q Maximum power consumption q Energy consumption (battery life) q Availability q Reliability and Correctness q Time to Market
n Design point determined by the “Problem” space (application space), or the intended users/market
Problem Algorithm
Program
ISA
Microarchitecture
Circuits
Electrons

Tradeoffs: Soul of Computer Architecture
19
n ISA-level tradeoffs
n Microarchitecture-level tradeoffs
n System and Task-level tradeoffs q How to divide the labor between hardware and software
n Computer architecture is the science and art of making the appropriate trade-offs to meet a design point q Why art?
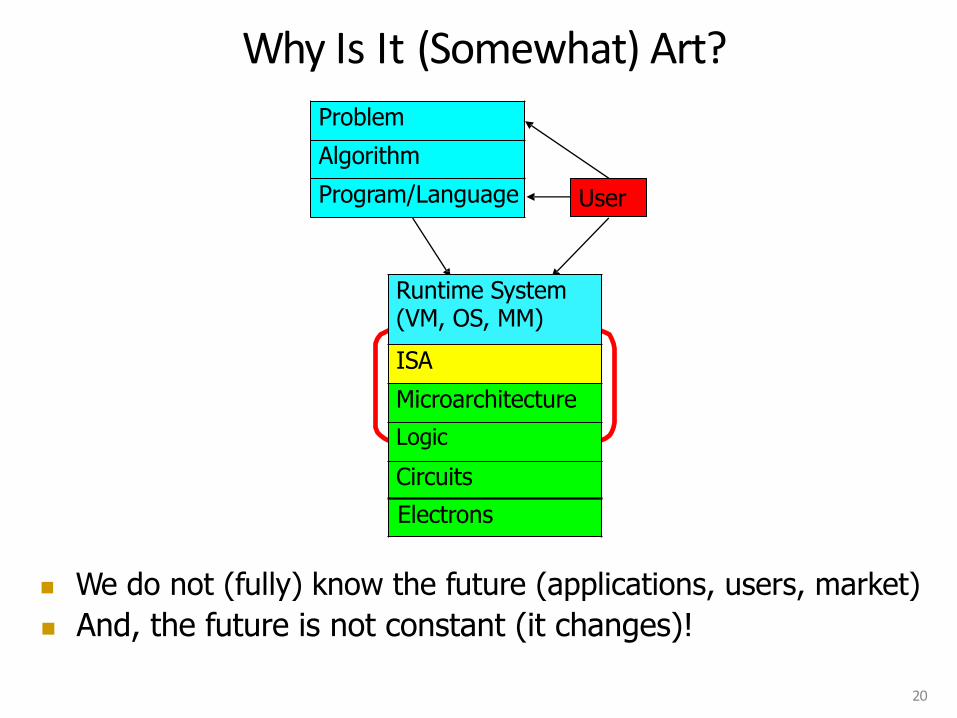
Why Is It (Somewhat) Art?
User
n We do not (fully) know the future (applications, users, market)
20
Problem
Algorithm
Program/Language
Runtime System (VM, OS, MM)
ISA
Microarchitecture Logic
Circuits
Electrons
n And, the future is not constant (it changes)!

ISA-‐level Tradeoff: Instruc6on Pointer
21
n Do we need an instruction pointer in the ISA? q Yes: Control-driven, sequential execution
n An instruction is executed when the IP points to it n IP automatically changes sequentially (except for control flow
instructions) q No: Data-driven, parallel execution
n An instruction is executed when all its operand values are available (data flow)
n Tradeoffs: MANY high-level ones q Ease of programming (for average programmers)? q Ease of compilation? q Performance: Extraction of parallelism? q Hardware complexity?

ISA vs. Microarchitecture Level Tradeoff
22
n A similar tradeoff (control vs. data-driven execution) can be made at the microarchitecture level
n ISA: Specifies how the programmer sees instructions to be executed q Programmer sees a sequential, control-flow execution order vs. q Programmer sees a data-flow execution order
n Microarchitecture: How the underlying implementation actually executes instructions q Microarchitecture can execute instructions in any order as long
as it obeys the semantics specified by the ISA when making the instruction results visible to software n Programmer should see the order specified by the ISA

The Von-‐Neumann Model
23
n All major instruction set architectures today use this model q x86, ARM, MIPS, SPARC, Alpha, POWER
n Underneath (at the microarchitecture level), the execution model of almost all implementations (or, microarchitectures) is very different q Pipelined instruction execution: Intel 80486 uarch q Multiple instructions at a time: Intel Pentium uarch q Out-of-order execution: Intel Pentium Pro uarch q Separate instruction and data caches
n But, what happens underneath that is not consistent with the von Neumann model is not exposed to software q Difference between ISA and microarchitecture
24
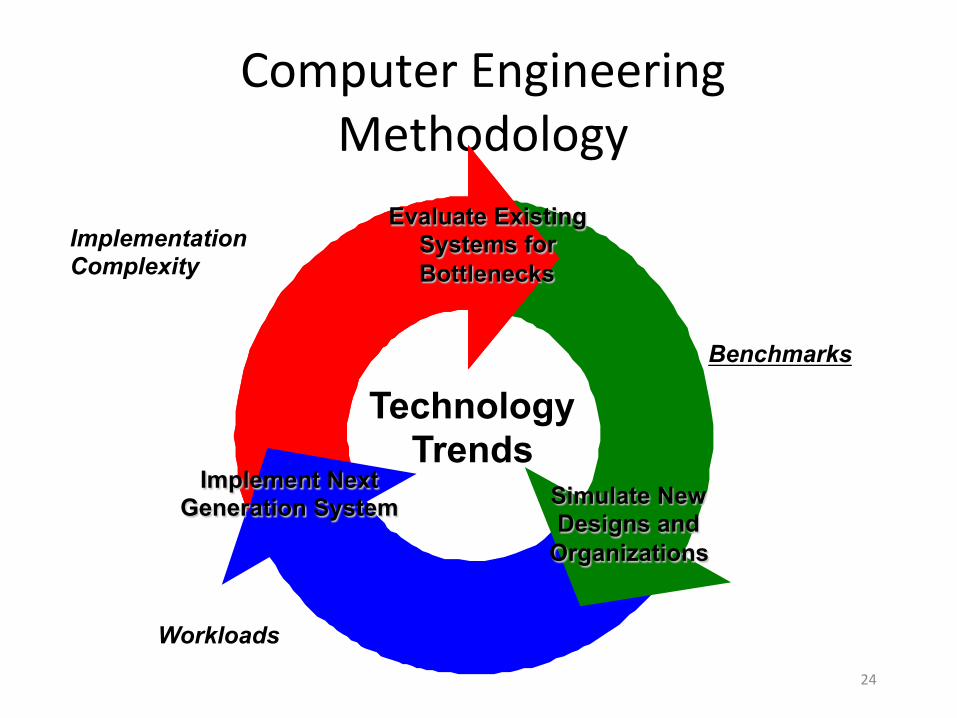
Computer Engineering Methodology
Evaluate Existing Systems for Bottlenecks
Simulate New Designs and
Organizations
Implement Next Generation System
Technology Trends
Benchmarks
Workloads
Implementation Complexity
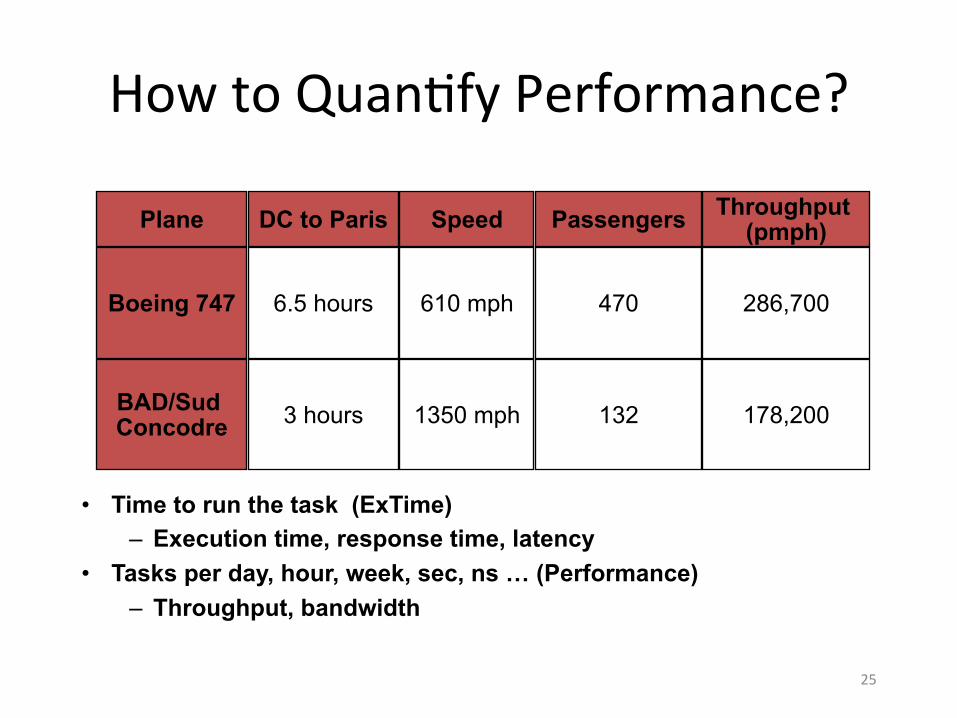
25
How to Quan6fy Performance?
• Time to run the task (ExTime) – Execution time, response time, latency
• Tasks per day, hour, week, sec, ns … (Performance) – Throughput, bandwidth
Plane
Boeing 747
BAD/Sud Concodre
Speed
610 mph
1350 mph
DC to Paris
6.5 hours
3 hours
Passengers
470
132
Throughput (pmph)
286,700
178,200

26
The Bo\om Line: Performance and Cost or Cost and
Performance? "X is n times faster than Y" means
ExTime(Y) Performance(X)
--------- = ---------------
ExTime(X) Performance(Y)
• Speed of Concorde vs. Boeing 747 • Throughput of Boeing 747 vs. Concorde • Cost is also an important parameter in the equation which is why
concordes are being put to pasture!

27
Measurement Tools
• Benchmarks, Traces, Mixes • Hardware: Cost, delay, area, power es6ma6on • Simula6on (many levels)
– ISA, RT, Gate, Circuit • Queuing Theory • Rules of Thumb • Fundamental “Laws”/Principles • Understanding the limita-ons of any measurement tool is crucial.

28
Metrics of Performance
Compiler
Programming Language
Application
Datapath Control
Transistors Wires Pins
ISA
Function Units
(millions) of Instructions per second: MIPS (millions) of (FP) operations per second: MFLOP/s
Cycles per second (clock rate)
Megabytes per second
Answers per month Operations per second

29
Performance Evalua6on • “For be\er or worse, benchmarks shape a field” • Good products created when have:
– Good benchmarks – Good ways to summarize performance
• Given sales is a func6on in part of performance rela6ve to compe66on, investment in improving product as reported by performance summary
• If benchmarks/summary inadequate, then choose between improving product for real programs vs. improving product to get more sales; Sales almost always wins!
• Execu&on &me is the measure of computer performance!

ADVANCED COMPUTER ARCHITECTURE'S
Dr. Stallings holds a PhD from M.I.T. in Computer Science and a B.S. from Notre Dame in electrical engineering
In over 20 years in the field, he has been a technical contributor, technical manager, and an executive with several high-technology firms. Currently he is an independent consultant
whose clients have included computer and networking manufacturers and customers, software development firms, and leading-edge government research institutions. .

INTEL and OTHERS
• We will investigate what computer architecture enhancements etc., there are and highlight how and why INTEL incorporated them as the 80x86 family evolved.
• We can start with the now famous paper in the
early 1970's in which Stalling noted six major points of advancement that have directed how and why computer architecture changes have been made.

Stallings six major points Computer CPU Families
1) The family concept was introduced by IBM copied shortly later by DEC and of course we are all now familiar with in the evolution of the Intel 80x86
2) Micro programmed Control Unit This was initial suggested as early as 1951 by Wilkes, in its current form it supports the family concept found in the Intel 80x86, further it offers healthy competition.

Families Families represent a manufacturers device model where each successive Genera6on of product builds upon the previous genera6on. For microprocessors, this includes items such as the instruc6on Set and func6onal core architecture.
. . . . . . . . . . . . . . .
Intel 4004 Intel Haswell
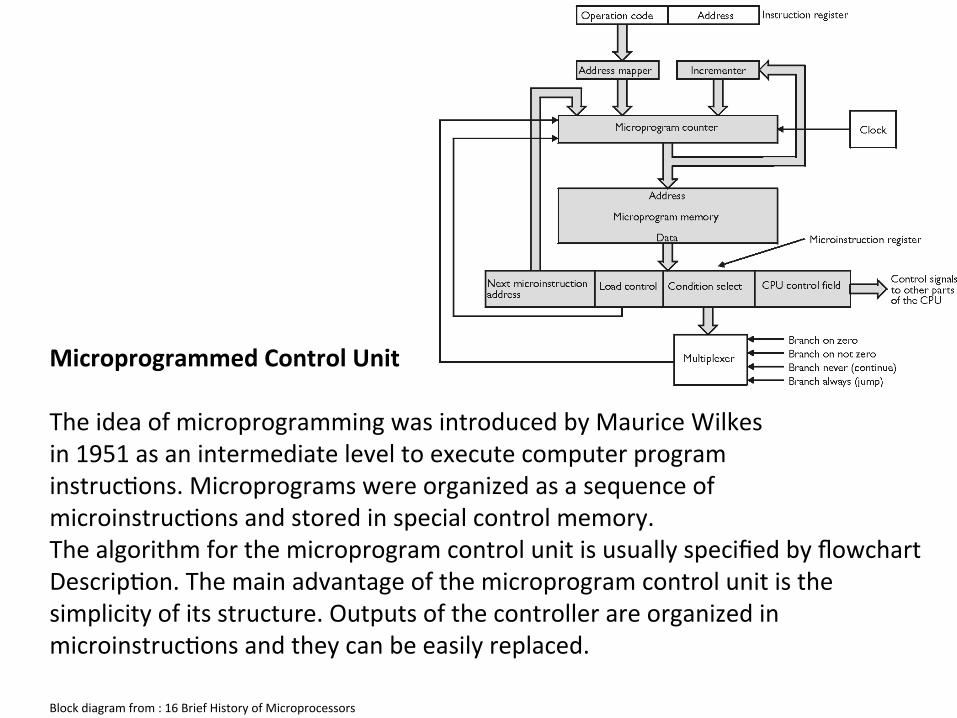
Microprogrammed Control Unit The idea of microprogramming was introduced by Maurice Wilkes in 1951 as an intermediate level to execute computer program instruc6ons. Microprograms were organized as a sequence of microinstruc6ons and stored in special control memory. The algorithm for the microprogram control unit is usually specified by flowchart Descrip6on. The main advantage of the microprogram control unit is the simplicity of its structure. Outputs of the controller are organized in microinstruc6ons and they can be easily replaced.
Block diagram from : 16 Brief History of Microprocessors

Stallings six major points
Cache Memory 3) The use of cache concepts was again devised as early as 1968, the inclusion of either write-back or write-through cache into the basic memory hierarchy dramatically improves overall system performance.
Pipelining 4) Pipelining instruction processing within the CPU allows a pseudo means of parallelism into what is essentially a sequential processing model of Fetch - Execute. This has always been available on the 80x86 family in various forms.
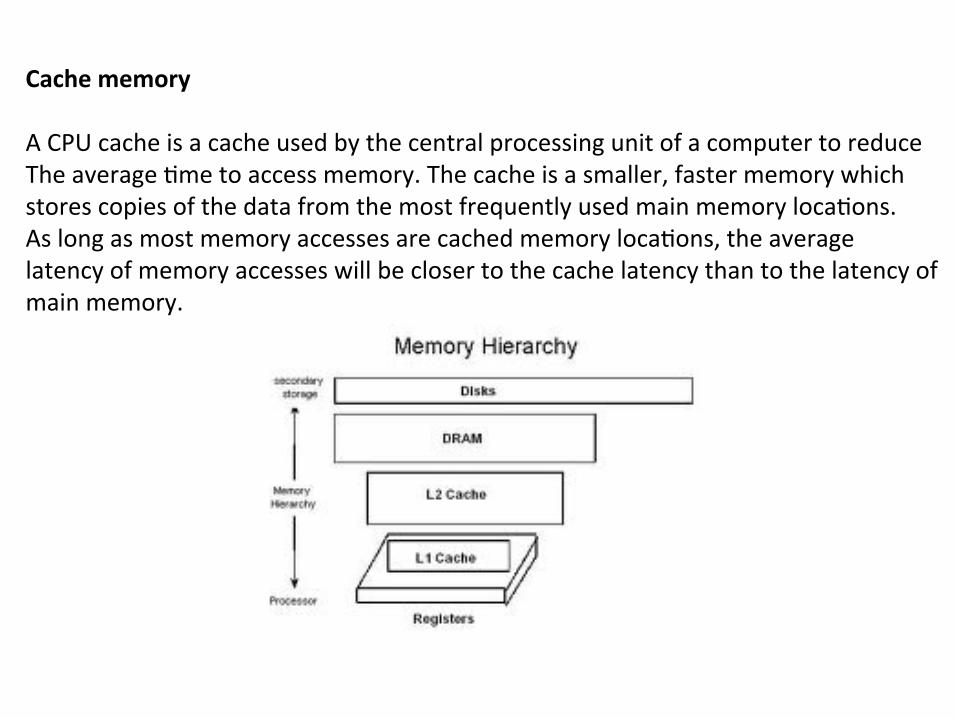
Cache memory A CPU cache is a cache used by the central processing unit of a computer to reduce The average 6me to access memory. The cache is a smaller, faster memory which stores copies of the data from the most frequently used main memory loca6ons. As long as most memory accesses are cached memory loca6ons, the average latency of memory accesses will be closer to the cache latency than to the latency of main memory.

PIPELINING
• Instruction Pipeline. – Execution of a single instruction is broken down into
the following steps: Instruction Fetch : - Get binary pattern from memory. Instruction Decode : - Decide what the instruction is going
to do Data Fetch : - Get any required data (binary patterns) from memory associated with the instruction just decoded. Instruction Execution: - Perform the operation

Stallings six major points
Multiple Processing 5) By using more than one processing element this offers parallelism to the overall system process with the possibility of significant performance enhancements. The problems associated with such a system approach is the sequential nature of most analysis and programming tools.
RISC Architecture 6) This offers the most significant architecture changes since it can support basic CPU models built from other than the classic Von Neuman model.

Multiple processsing - Multiple ALU’s
• A logical advance is to increase the number of ALU's. – The sequential nature of most programs, means
multiple ALU's only make sense if you dedicate there tasks, i.e. Integer Arithmetic Operations, Integer Logical Operations etc.
• SuperPipelined • This was the next logical advance.

SUPERPIPLINED
• This is the concept of double or more clocking the CPU internally relative to the external clock speed.
Inst Fetch Inst Decode Data Fetch Execute Inst Fetch Inst Decode Data Fetch Execute
Inst Fetch Inst Decode Data Fetch Execute Inst Fetch Inst Decode Data Fetch Execute
Tradi6onal pipelined architectures have a single pipeline stage for each of: instruc6on fetch, instruc6on decode, memory read, ALU opera6on and memory write. A superpipelined processor has a pipeline where each of these logical steps may be subdivided into mul6ple pipeline stages.

SUPERSCALAR
• Leading from the idea of multiple pipelines, an important new element in the CPU design was needed, a pipeline dispatcher that controlled which pipeline to use for the start of the next cycle.
Inst Fetch Inst Decode Data Fetch Execute Inst Fetch Inst Decode Data Fetch Execute
Inst Fetch Inst Decode Data Fetch Execute Inst Fetch Inst Decode Data Fetch Execute Inst Fetch Inst Decode Data Fetch Execute Inst Fetch Inst Decode Data Fetch Execute
-------------------------------------------------------------------------------à Time
A superscalar processor executes more than one instruc6on during a clock cycle by simultaneously dispatching mul6ple instruc6ons to redundant func6onal units on the processor. Each func6onal unit is not a separate CPU core but an execu6on resource within a single CPU such as an arithme6c logic unit, a bit shiWer, or a mul6plier.

Arithmetic Pipeline
• The most obvious example of this is the use of floating point co-processing.
• Initially these were external and could not offer
true parallelisms, however newer CPU designs use internal techniques and combining this with SuperPipelined and SuperScaler concepts the floating point processor is simply another parallel functional element working at a double or greater clock speed.

RISC, or Reduced Instruc6on Set Computer. is a type of microprocessor architecture that u6lizes a small, highly-‐op6mized set of instruc6ons, rather than a more specialized set of instruc6ons oWen found in other types of architectures.
Certain design features have been characteris6c of most RISC processors: one cycle execu-on -me: RISC processors have a CPI (clock per instruc6on) of one cycle. This is due to the op6miza6on of each instruc6on on the CPU and a technique called ; pipelining: a techique that allows for simultaneous execu6on of parts, or stages, of instruc6ons to more efficiently process instruc6ons; large number of registers: the RISC design philosophy generally incorporates a larger number of registers to prevent in large amounts of interac6ons with memory Typically RISC machines employ a Harvard internal architecture having a large number of internal buses. rather than a Von Neuman architecture.
RISC

DIGITAL SIGNAL PROCESSORS
• As well as the architecture development on RISC and CISC application specific processing devices have also been developed that have interesting architectural structures.
• The DSP is intended for specific signal processing, Mobile phones being an obvious example. – Fast hardware multiplication – On chip memory ROM and Registers. ( Harvard
Architecture) – Special Registers for repetitive operations - adds etc. – Floating point support

Characteristics of Computer Architecture
• In his now famous clarification of computer taxonomy in 1966 Michael J.Flynn described the architecture of a computer system as a series of basic classification.
1. SISD (Single Instruction, Single Data stream) 2. MISD (Multiple Instruction Single Data streams) 3. SIMD ( Single Instruction, Multiple Data streams) 4. MIMD ( Multiple Instruction, Multiple Data streams)

SISD & MISD
• SISD - This is the conventional single processor system, the one in use by INTEL on the 80x86 family, such designs will normally be based on the Von Neumann model for a stored program machine but equally the Harvard model could be used.
• MISD - There have been relatively few examples of
this type of architecture. A vector processor which is developed for the sole purpose of repetitive calculation on a large amount of vector data items is the closest to the pure definition of this classification.

SIMD • Conven6onal Computers. • Pipelined Systems • Mul6ple-‐Func6onal Unit Systems • Pipelined Vector Processors • Includes most computers encountered in everyday life
MISD • A Single Data Stream passes through mul6ple processors • Different opera6ons are triggered on different processors • Systolic Arrays • Wave-‐Front Arrays

SIMD
• Such systems are characterised as single controller units which have available slave processing elements. Typical examples being Array Processor The typical architecture being.
Control Unit
P1 P2 P3 P4 Processing Elements
Communications
M1 M2 M3 M4Random Accessmemory modules
Main memory access Point
Instruction stream
Data Stream

SIMD • Mul6ple Processors Execute a Single Program • Each Processor operates on its own data • Vector Processors • Array Processors • PRAM Theore6cal Model

SIMD Computers • One Control Processor • Several Processing Elements (PE) • All Processing Elements execute the same instruc6on at the same 6me • Interconnec6on network between PE’s determines memory access and PE interac6on

MIMD
• This is characterised as Multiple processors in either a tight or loosely coupled configuration. Those that share memory on a Common bus are tightly coupled.
• Loosely coupled require a communications network to offer the interconnection.
Problems.. • The inherent amount of parallelism in these systems
depends on whether a problem can be identified that lends itself to the implementation.
• The splitting of the design to use the available processing element fully.

MIMD • Mul6ple Processors cooperate on a single task • Each Processor runs a different program • Each Processor operates on different data • Many Commercial Examples Exist

Tightly and Loosely Coupled Systems
I/O
Processor B Memory Processor
A
I/O
Processor C
I/O
Tightly Coupled Architecture
Processor C
I/O
Memory
Processor B
I/O
MemoryProcessor
A
I/O
Memory
Communications
Network
Loosely Coupled Architecture

Microarchitectural Parallelism • Parallelism => perform multiple operations simultaneously
– Instruction-level parallelism • Execute multiple instructions at the same time • Multiple issue • Out-of-order execution • Speculation • Branch prediction
– Thread-level parallelism (hyper-threading) • Execute multiple threads at the same time on one CPU • Threads share memory space and pool of functional
units
– Chip multiprocessing • Execute multiple processes/threads at the same time
on multiple CPUs • Cores are symmetrical and completely independent but
share a common level-2 cache

Parallel Processor Programming Issues • Parallel Computers are Difficult to Program • Automa6c Paralleliza6on Techniques are only Par6ally Successful • Programming languages are few, not well supported, and difficult to use. • Parallel Algorithms are difficult to design.

Parallelizing Code • Implicitly – Write Sequen6al Algorithms – Use a Parallelizing Compiler – Rely on compiler to find parallelism • Explicitly – Design Parallel Algorithms – Write in a Parallel Language – Rely on Human to find Parallelism

Mul6-‐Processors • Mul6-‐Processors generally share memory, while mul6-‐computers do not.
– Uniform memory model – Non-‐Uniform Memory Model – Cache-‐Only
• MIMD Machines

Mul6-‐Computers • Independent Computers that Don’t Share Memory. • Connected by High-‐Speed Communica6on Network • More 6ghtly coupled than a collec6on of independent computers • Cooperate on a single problem

Computer Clusters • A computer cluster consists of a set of loosely or
6ghtly connected computers that work together so that, in many respects, they can be viewed as a single system.
• Unlike grid computers, computer clusters have each node set to perform the same task, controlled and scheduled by soWware.
• The components of a cluster are usually connected to each other through fast local area networks.
• Typically, all of the nodes use the same hardware and the same opera6ng system, but not always.

A Beowulf Cluster • A computer cluster of what are normally iden6cal,
commodity-‐grade computers networked into a small local area network with libraries and programs installed which allow processing to be shared among them. The result is a high-‐performance parallel compu6ng cluster from inexpensive personal computer hardware.
• Beowulf clusters normally run a Unix-‐like opera6ng system, such as BSD, Linux, or Solaris, normally built from free and open source soWware. Commonly used parallel processing libraries include Message Passing Interface (MPI) and Parallel Virtual Machine (PVM).

High Performance Compu6ng – HPC • A supercomputer is a computer at the frontline of contemporary processing
capacity – which can happen at trillions of floa6ng point opera6ons per second.
• Introduced in the 1960s, made ini6ally and, for decades, primarily by Seymour Cray at Control Data Corpora6on (CDC), Cray Research and subsequent companies bearing his name or monogram.
Cray-‐2 at the Computer History Museum In Mountain View Ca.

The Cray-‐2 was a supercomputer with four vector processors built with emi\er-‐coupled logic and made by Cray Research star6ng in 1985. Cray had previously a\acked the problem of increased speed with three simultaneous advances: more func-onal units to give the system higher parallelism, -ghter packaging to decrease signal delays, and faster components to allow for a higher clock speed. The classic example of this design is the CDC 8600, which packed four CDC 7600-‐like machines based on ECL logic into a 1 x 1 meter cylinder and ran them at an 8 ns cycle speed (125 MHz). Unfortunately the density needed to achieve this cycle 6me led to the machine's downfall. The circuit boards inside were densely packed, and since even a single malfunc6oning transistor would cause an en6re module to fail, packing more of them onto the cards greatly increased the chance of failure. Another design problem was the increasing performance gap between the processor and main memory. In the era of the CDC 6600 memory ran at the same speed as the processor, and the main problem was feeding data into it. Cray solved this by adding ten smaller computers to the system, allowing them to deal with the slower external storage (disks and tapes) and "squirt" data into memory when the main processor was busy. Main memory banks were arranged in quadrants to be accessed at the same 6me, allowing programmers to sca\er their data across memory to gain higher parallelism.

Instead of making one larger circuit board, each "card" would instead consist of a 3-‐D stack of eight, connected together in the middle of the boards using pins s6cking up from the surface (known as "pogos" or "z-‐pins"). The cards were packed right on top of each other, so the resul6ng stack was only about 3 inches high. With this sort of density there was no way any conven6onal air-‐cooled system would work; there was too li\le room for air to flow between the ICs. Instead the system would be immersed in a tank of a new inert liquid from 3M, Fluorinert. The cooling liquid was forced sideways through the modules under pressure, and the flow rate was roughly one inch per second. The heated liquid was cooled using chilled water heat exchangers and returned to the main tank.

The power consump6on of the Cray-‐2 was 150 -‐ 200 kW. Each ver6cal stack of logic modules sat above a stack of power modules which powered 5 volt busbars, each of which delivered about 2200 amps. The Cray-‐2 was powered by two motor-‐generators, which took in 480 V three-‐phase.
Inside front view of Cray-‐2 No wire was longer than 3 feet

• In one approach (e.g., in distributed compu6ng), a large number of discrete computers (e.g., laptops) distributed across a network (e.g., the Internet) devote some or all of their 6me to solving a common problem; each individual computer (client) receives and completes many small tasks, repor6ng the results to a central server which integrates the task results from all the clients into the overall solu6on.
• In another approach, a large number of dedicated processors are placed in close proximity to each other (e.g. in a computer cluster); this saves considerable 6me moving data around and makes it possible for the processors to work together (rather than on separate tasks), for example in mesh and hypercube architectures.
High Performance Compu6ng – HPC


















