
What should be done to IR algorithms to meet current, and possible future, hardware trends.
27
Hardware Developments and Algorithm Design: “What should be done to IR algorithms to meet current, and possible future, hardware trends?” Simon Jonassen Department of Computer and Information Science Norwegian University of Science and Technology
-
Upload
simon-lia-jonassen -
Category
Technology
-
view
70 -
download
0
Transcript of What should be done to IR algorithms to meet current, and possible future, hardware trends.

Hardware Developments and Algorithm Design:
“What should be done to IR algorithms to meet current, and possible future, hardware trends?”
Simon Jonassen Department of Computer and Information Science Norwegian University of Science and Technology

This talk is not about…. Uncovered, but highly related topics:
– Query processing on specialized hardware, including GPU. – Succinct indexes, suffix arrays, wavelet trees, etc. – Map-Reduce and machine learning. – Green and Cloud computing. – Distributed query processing. – Shared memory and NUMA. – Scalability and availability. – Solid-state drives. – Virtualization. – …
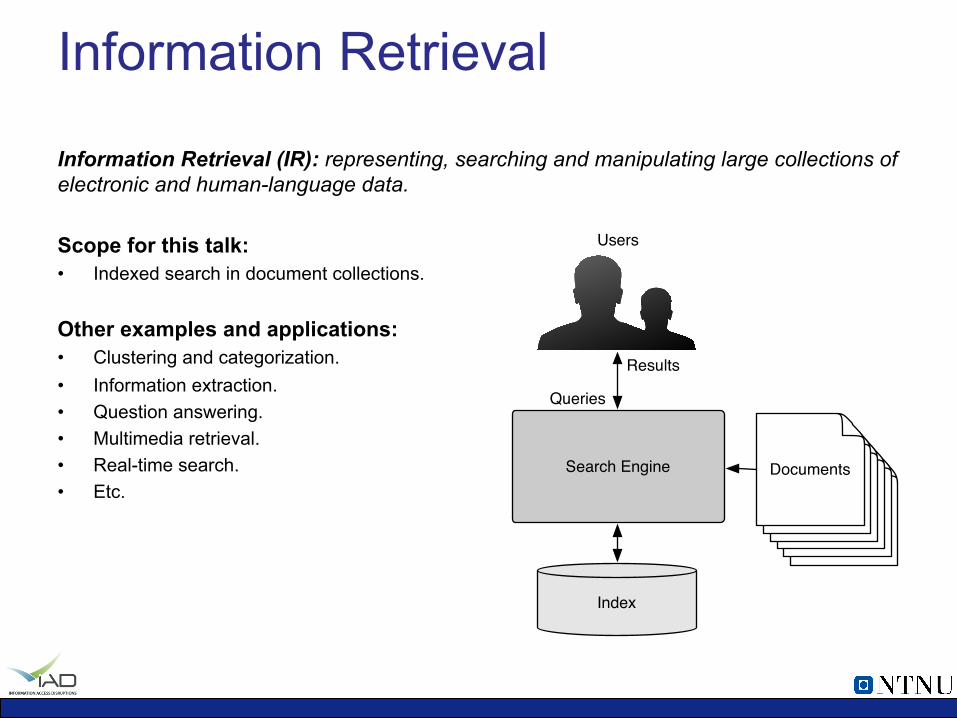
Information Retrieval
Information Retrieval (IR): representing, searching and manipulating large collections of electronic and human-language data. Scope for this talk: • Indexed search in document collections.
Other examples and applications: • Clustering and categorization. • Information extraction. • Question answering. • Multimedia retrieval. • Real-time search. • Etc.
Index
Search EngineDocuments
Documents
Results
Queries
Users

Search in inverted indexes
Posting lists: • Contain document IDs and frequencies. • May also contain scores, context ID, positions and other information. • Ordered by document, frequency or impact.
Query processing: • Term- vs document-at-a-time. • Boolean vs score-based evaluation. • Pruning.
Other alternatives: • Bitmaps, trees, etc.
Other matters: • Preprocessing:
– E.g., stemming. • Two-phase search. • Postprocessing:
– E.g., snippet generation. • Static pruning, result cache, etc.
© apple.com

Recent hardware trends seen from a naïve IR perspective
Scope for this talk.
4x512MB-
2GHz--
80GB-
4x2x3GHz++
4x8GB+
512GB
fast!
not so fast =( fast!
super fast!!!
2002 2012
Dis
kPr
oces
sor
Mai
n M
emor
y
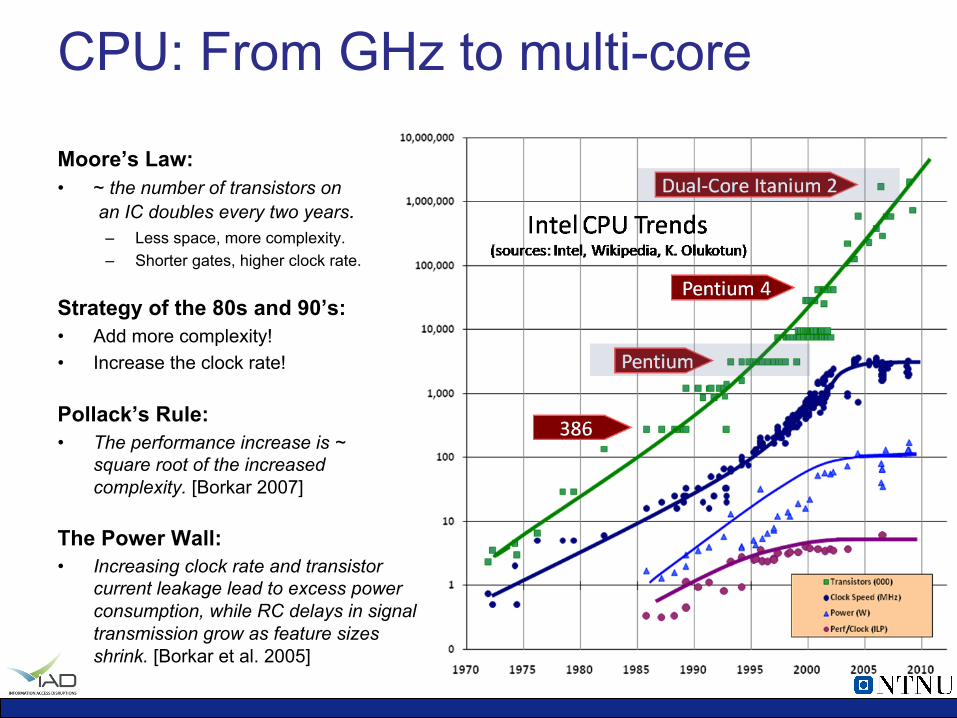
CPU: From GHz to multi-core
Moore’s Law: • ~ the number of transistors on
an IC doubles every two years. – Less space, more complexity. – Shorter gates, higher clock rate.
Strategy of the 80s and 90’s: • Add more complexity! • Increase the clock rate!
Pollack’s Rule: • The performance increase is ~
square root of the increased complexity. [Borkar 2007]
The Power Wall: • Increasing clock rate and transistor
current leakage lead to excess power consumption, while RC delays in signal transmission grow as feature sizes shrink. [Borkar et al. 2005]

Instruction-level parallelism – ”It’s not about GHz’s, but how you spend them!”
Pipeline length: 31 (P4) vs 14 stages (i7). Multiple execution units and out-of-order execution: • i7: 2 load/store address, 1 store data,
and 3 computational operations can be executed simultaneously.
Dependences and hazards: • Control: branches.* • Data: output dependence,
antidependence (naming). • Structural: access to the same
physical unit of the processor.
Simultaneous multi-threading (“Hyper-threading”): • Duplicate certain sections of a processor (registers etc., but not execution units). • Reduces the impact of cache miss, branch misprediction and data dependency stalls. • Drawback: logical processors are most likely to be treated just like physical processors.
(*[Dean 2010]: a branch misprediction costs ~5ns)

Computer memory hierarchy
source: [Jahre 2010]
(1ms = 1 000 µs = 1 000 000 ns; 1ns = 3 clock cycles at 3GHz or 29.8cm of light travel)
Level Latency Size Technology Managed by Registers <<1ns ?1KB CMOS Compiler L1 Cache (on-‐chip) <1ns 4x32KBx2 SRAM Hardware L2 Cache (off-‐chip) 2.5ns 4x256KB SRAM Hardware L3 Cache (shared) 5ns 8MB SRAM Hardware Main Memory 50ns 4x8GB+ DRAM OS Solid-‐State Drive <100µs 512GB-‐ NAND Flash Hardware/OS/User Hard-‐Disk Drive 3-‐12ms 1TB+ MagneXc Hardware/OS/User
(Intel Core i7-‐260
0K)
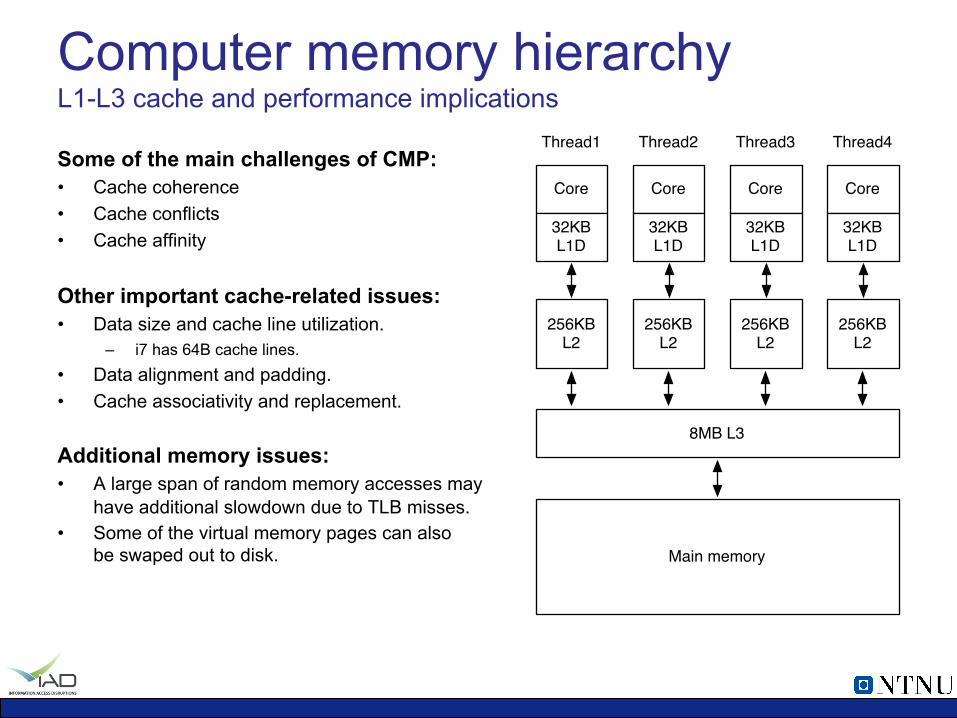
Computer memory hierarchy L1-L3 cache and performance implications
Some of the main challenges of CMP: • Cache coherence • Cache conflicts • Cache affinity
Other important cache-related issues: • Data size and cache line utilization.
– i7 has 64B cache lines. • Data alignment and padding. • Cache associativity and replacement.
Additional memory issues: • A large span of random memory accesses may
have additional slowdown due to TLB misses. • Some of the virtual memory pages can also
be swaped out to disk.
Core
32KBL1D
Core
32KB L1D
256KBL2
256KBL2
8MB L3
Main memory
Thread1 Thread2
Core
32KBL1D
Core
32KB L1D
256KBL2
256KBL2
Thread3 Thread4

Writing efficient IR algorithms –”The troubles with radix sort are in implementation, not in conception.” (McIlroy et al. 1993)
In-Place MSB Radix Sort: [Birkeland 2008, Gorset 2011] • Starting from the most significant byte. • For each of the 256 combinations: count
the cardinality and Initialize the pointers. • Apply Counting-Sort (shown on the right). • Recursively apply on the less significant
byte until the least significant byte; use insertion sort if the range is too small.
Complexity: • O(kN), where k = 4 for 32-bit integers. • Has also been shown to be 3x faster than the native Java/C++
QuickSort implementation on large 32-bit integer arrays [Gorset 2011]. Benefits from: • Memory usage. • Comparing groups of bits at once. • Swaps instead of branches.
code: https://github.com/gorset/radix

Writing efficient IR algorithms Cache- and processor-efficient query processing Modern compression methods for IR: • BP, S9/S16, PFOR, NewPFD, etc. • Fast, superscalar and branch-free. • Loops/methods can be generated by a script.
While compression works on chunks of postings, query processing itself remains posting-at-a-time. What about: • Branches and loops? • Cache utilization? • ILP utilization? • Candidates and results?
Interesting alternatives and trade-offs: • Impact-ordered vs document-ordered lists. • Term vs document-at-a-time processing. • Posting list iteration vs random access. • Mixed vs two-phase search. • Bitmaps vs posting lists.
code: https://github.com/javasoze/kamikaze

source: [Zukowski 2009]
Writing efficient IR algorithms Some experience from Databases
Vector-at-a-time execution [Zukowski 2009] provides a good trade-off between tuple and column-at-a-time execution: • Less time spent in interpretation logic. • “SIMDization” and data alignment. • Parallel memory access (prefetching).
• In-cache execution.
Loop compilation can be another alternative, especially if the application already has a tuple-at-a-time API. • [Sompolski et al. 2011] show that
plain loop compilation can be inferior to vectorization and motivate further combination of the two techniques.
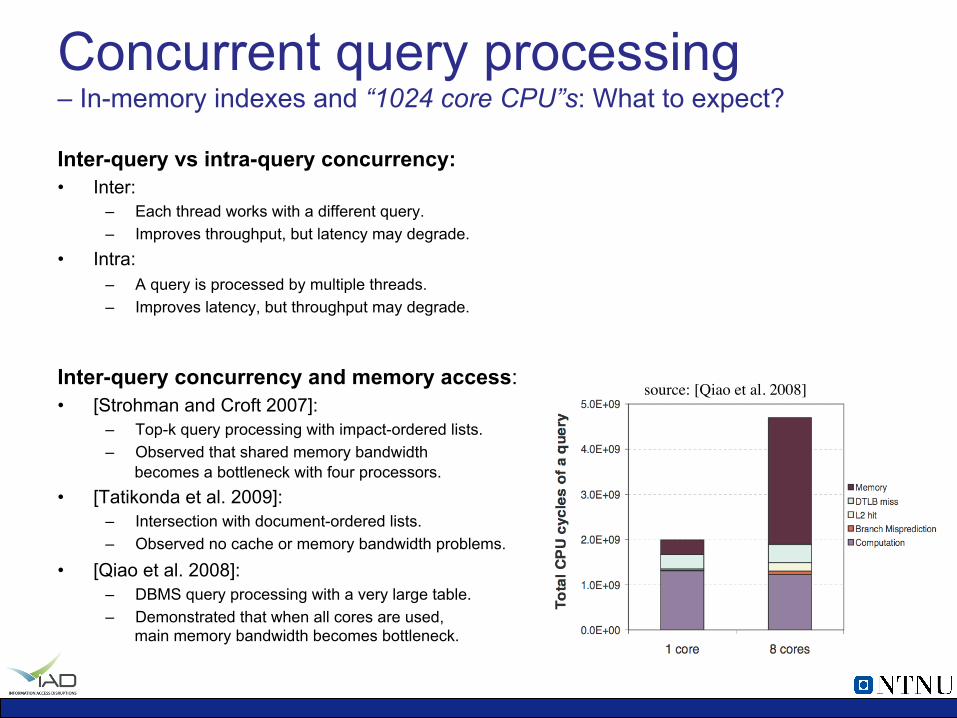
Concurrent query processing – In-memory indexes and “1024 core CPU”s: What to expect?
Inter-query vs intra-query concurrency: • Inter:
– Each thread works with a different query. – Improves throughput, but latency may degrade.
• Intra: – A query is processed by multiple threads. – Improves latency, but throughput may degrade.
Inter-query concurrency and memory access: • [Strohman and Croft 2007]:
– Top-k query processing with impact-ordered lists. – Observed that shared memory bandwidth
becomes a bottleneck with four processors. • [Tatikonda et al. 2009]:
– Intersection with document-ordered lists. – Observed no cache or memory bandwidth problems.
• [Qiao et al. 2008]: – DBMS query processing with a very large table. – Demonstrated that when all cores are used,
main memory bandwidth becomes bottleneck.
source: [Qiao et al. 2008]

Concurrent query processing – In-memory indexes and “1024 core CPU”s: What to expect?
Intra-query concurrency and memory access: • [Lilleengen 2010]:
– CPU simulator for Vespa Search Engine Platform (Yahoo! Trondheim). – Evaluated intra-query concurrency, its scalability, impact on the
processor caches and performance under various workloads.
Other ideas: • [Qiao et al. 2008] studied efficient memory scan sharing
for multi-core CPUs in databases. Suggested solution: – Each core gets a batch of queries, restricted by the
estimated working set size. – Queries in each batch share memory scans, i.e., a
block of data is fed to through all queries in the batch. – Note: queries operate on a single but very large table.
• Batch optimizations similar to those presented by [Ding et al. 2011] can be interesting on sub-query level.
– Query reordering. – Reusing partial results.
source: [Qiao et al. 2008]
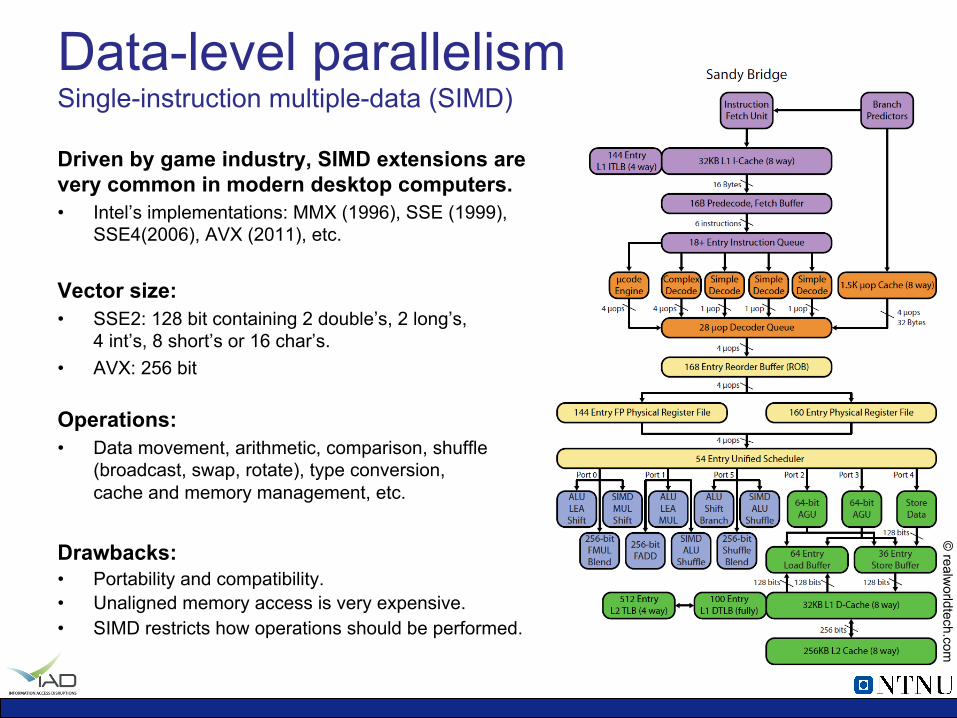
Data-level parallelism Single-instruction multiple-data (SIMD)
Driven by game industry, SIMD extensions are very common in modern desktop computers. • Intel’s implementations: MMX (1996), SSE (1999),
SSE4(2006), AVX (2011), etc.
Vector size: • SSE2: 128 bit containing 2 double’s, 2 long’s,
4 int’s, 8 short’s or 16 char’s. • AVX: 256 bit
Operations: • Data movement, arithmetic, comparison, shuffle
(broadcast, swap, rotate), type conversion, cache and memory management, etc.
Drawbacks: • Portability and compatibility. • Unaligned memory access is very expensive. • SIMD restricts how operations should be performed.
© realw
orldtech.com

Data-level parallelism Single-instruction multiple-data (SIMD)
Example, SIMD-based optimizations/algorithms: • [Chhugani et al. 2008] – integer sorting (cache-aware merge sort). • [Lemire and Boytsov 2012] – integer compression (SIMD-BP128). • [Ladra et al. 2012] – rank, select in bit-sequences, Horspool algorithm. Fast intersection of sorted 32-bit integer lists: • Two vectors can be intersected either by computing a mask of common (32b) elements and
rotating one of the vectors or by using PCMPESTRM (obtains a mask of common 16b elements).
• PCMPESTRM variant requires a custom data structure when integers are larger than 216.
• Requires more comparisons than a simple scalar intersection, but runs much faster (PCMPESTRM: ~5.4x speedup with one million elements in each list and selectivity around 30%).
• [Schlegel et al. 2011, Katsov 2012].
© [Katsov 2012]

© Venray Technologies
–“What would Google do?”
Scale matters! (based on Jeff Dean’s talks [Dean 2009, Dean 2010]): • “Don’t design to scale infinitely:
~5x–50x growth good to consider, >100x probably requires rethink and rewrite.”
• Buying 2x more machines, rather than buying better machines. • Low-end storage and networking hardware; in-memory data. • Single machine performance is not important. • Key focus: distribution and availability. • Interference between your (multiple) jobs and
random cron tasks.
Facebook is rumored to be testing out low- power ARM processors in their data centers. • Challenges and opportunities of using a large
number of slower but more energy-efficient nodes coupled with low-power storage have been discussed by [Vasudvan et al. 2011].

One more thing… Java!
Bytecode and Just-in-time (JIT) compilation: • Java bytecode is halfway between the human-readable and machine code. • Bytecode can be interpreted by JVM or compiled to machine code at runtime. • JIT/HotSpot tricks: inlining, dead-code elimination, optimization/deoptimization. • Intrinsics: some functions can be replaced by machine instructions (e.g., popcount, max/min). Concurrent processing in Java: • Powerful and flexible features (e.g., thread pools, synchronous data structures, Fork/Join). • To be efficient, needs a careful understanding of
synchronization and the Java memory model. • Does not provide any affinity or low-level thread control. Garbage collection (GC) and memory management: • Multiple areas/generations: eden and survivor (young),
tenured (old), permgen (internal). • Minor (young generation) vs major (old generation) GC. • Low-pause vs high-throughput GC algorithms. • Escape analysis.

One more thing… Java!
Efficiency tips: • Data:
– Avoid big class hierarchies. Write simple and when applicable immutable objects. – Avoid creating unnecessary objects, use primitives. – Avoid frequent allocation of very large arrays.
• Methods: – Write compact, clean, reusable and when applicable static methods.
• Concurrency: – Divide and conquer! – Minimize synchronization and resource sharing between threads.
• Development: – Correctness over performance. – Use existing collections and libraries. – Learn to profile, version control and unit-test your code.

Conclusions
• Processors are getting faster and more advanced. However, these improvements are becoming more challenging to harness by memory-intensive applications, such as IR.
• Future IR algorithms should pay more attention to the CPU and cache-related issues. • Understanding of the hardware and programming language principles and their
interaction is essential for realization of conception advantage in performance of an actual implementation.
• Certain optimizations and performance improvements can be limited to the chosen architecture and/or technology. For large-scale and heterogeneous IR systems such optimizations may be less beneficial, economically infeasible or even impossible.
• Low-power RISC processors are capable of delivering higher performance-per-watt as well as performance-per-$ when compared to the high-end/desktop processors. However, it remains unclear whether they can be more advantageous for efficient IR and which challenges they may introduce.

References: 1. Birkeland: “Searching large data volumes with MISD processing”, PhD Thesis, NTNU 2008. 2. Borkar: "Thousand core chips: a technology perspective”, In Proc. DAC 2007, pp.746-749. 3. Borkar et al.: “Platform 2015: Intel® Processor and Platform Evolution for the Next Decade”, Intel 2005. 4. Bosworth: “The Power Wall: Why aren’t modern CPUs faster? What happened in the late 1990’s?”, 2011. 5. Büttcher et al.: “Information Retrieval: Implementing and Evaluating Search Engines”, 2010. 6. Chhugani et al.: “Efficient Implementation of Sorting on Multi-Core SIMD CPU Architecture”, In Proc. VLDB 2008, pp.
1313-1324. 7. Clark: “Facebook stretches ARM chips in datacentre tests”, ZDNet news article, 24th September 2012. 8. Dean: “Challenges in Building Large-Scale Information Retrieval Systems”, keynote at WSDM 2009. 9. Dean: “Building Software Systems at Google and Lessons Learned”, talk at Standford University 2010. 10. Ding et al.: “Batch Query Processing for Web Search Engines”, In Proc. WSDM 2011, pp. 137-146. 11. Evans and Verburg: “Well Grounded Java Developer: Vital Techniques of Java 7 and polyglot programming”, 2013. 12. Gorset: http://erik.gorset.no/2011/04/radix-sort-is-faster-than-quicksort.html, 2010. 13. Hennessy and Patterson: “Computer Architecture: A Quantitative Approach”, 3rd ed., 2003. 14. Jahre: “Managing Shared Resources in Chip Multiprocessor Memory Systems”, PhD Thesis, NTNU 2010. 15. Katsov: http://scalable.wordpress.com/2012/06/05/fast-intersection-sorted-lists-sse/, 2012. 16. Ladra et al.: “Exploiting SIMD instructions in current processors to improve classical string algorithms”, In Proc. ADBIS 2012,
pp. 254-267. 17. Lemire and Boytsov: “Decoding billions of integers per second through vectorization”, CoRR abs/1209.2137, 2012. 18. Lilleengen: “Parallel query evaluation on multicore architectures”, Master Thesis, NTNU 2010. 19. Qiao et al.: “Main-Memory Scan Sharing For Multi-Core CPUs”, PVLDB 2008:1(1), pp. 610-621. 20. Schlegel et al.: “Fast Sorted-Set Intersection using SIMD Instructions”, In ADMS Workshop, VLDB 2011. 21. Strohman and Croft: “Efficient Document Retrieval in Main Memory”, In Proc. SIGIR 2007, pp. 175-182. 22. Tatikonda et al.: “On efficient posting list intersection with multicore processors”, In Proc. SIGIR 2009, pp. 738-739. 23. Vasudevan et al.: “Challenges and Opportunities for Efficient Computing with FAWN”, In Proc. SIGOPS 2011, pp. 34-44. 24. Zukowski: “Balancing Vectorized Query Execution with Bandwidth-Optimized Storage”, PhD Thesis, University of
Amsterdam 2009.

Thanks!!!

(backup slides)
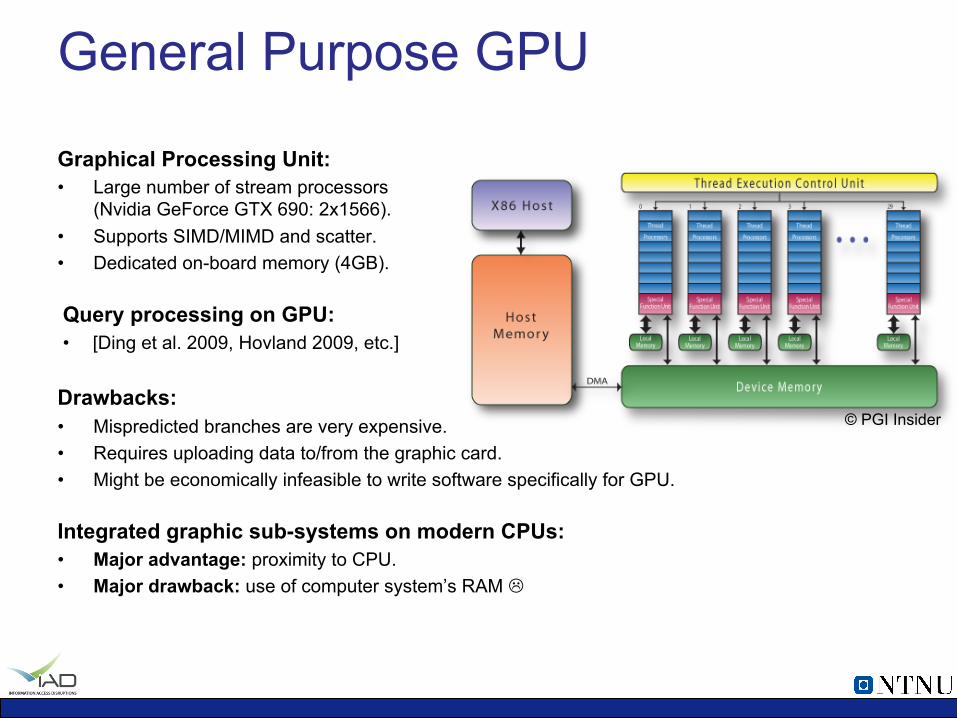
General Purpose GPU
Graphical Processing Unit: • Large number of stream processors
(Nvidia GeForce GTX 690: 2x1566). • Supports SIMD/MIMD and scatter. • Dedicated on-board memory (4GB).
Query processing on GPU: • [Ding et al. 2009, Hovland 2009, etc.]
Drawbacks: • Mispredicted branches are very expensive. • Requires uploading data to/from the graphic card. • Might be economically infeasible to write software specifically for GPU.
Integrated graphic sub-systems on modern CPUs: • Major advantage: proximity to CPU. • Major drawback: use of computer system’s RAM L
© PGI Insider

Solid-State Drives
Based on NAND floating gate transistors. Each disk is a redundant array of NAND. Cannot delete/overwrite individual pages. • Consequence: frequent writes are
problematic and write performance degrades with aging.
• Solutions: 128MB+ on-board memory, background garbage collection, trimming, overprovisioning.
• Other (SandForce DuraWhite): compression, deduplication and differencing.
Lifetime is limited due to writes, but modern SSD should last as long as HDD. Single-level vs multi-level charge: • SLC is more reliable, but expensive • MLC may have larger capacity/cheaper, but is less reliable.

Solid-State vs Hard-Disk Drives
SSD was found to improve the performance of several applications such as spatial query processing with R-trees ([Emrich et al. 2010]). January 2013: A 3TB HDD and 32GB DRAM cost less than a 512GB SSD. SSD may be considered as infeasible for large data centers • see the discussion in the paper by
[Ananthanarayanan et a. 2011].
SSD and HDD can be combined in the same system. (eg., [Risvik 2013])
SSD and HDD require different trade-offs. Some other numbers [Dean 2010]: Send 2KB over 1 Gbps network 20µs Round trip within same datacenter 500µs Send packet CA-‐>Netherlands-‐>CA 150ms
Access Dme Bandwidth Price Capacity HDD 3-‐12ms <140MB/s <0.05$/GB 1TB+ SSD <100µs <600MB/s 0.5-‐1$/GB 512GB-‐ DRAM <50ns <21GB/s 5-‐10$/GB 32GB-‐

References: 1. Ananthanarayanan et al.; “Disk-Locality in Datacenter Computing Considered Irrelevant”, In Proc. HotOS Workshop at
USENIX 2011. 2. Chhugani et al.: “Efficient Implementation of Sorting on Multi-Core SIMD CPU Architecture”, In Proc. VLDB 2008, pp.
1313-1324. 3. Emrich et al.: “On the Impact of Flash SSDs on Spatial Indexing”, In Proc. DaMoN 2010, pp. 3-8. 4. Hovland: “Throughput Computing on Future GPUs”, Master Thesis, NTNU 2009. 5. Hutchinson: “Solid-state revolution: in-depth on how SSDs really work”, ARS Technica, 2012. 6. Risvik et al.: “Maguro, a system for indexing and searching over very large text collections”, In Proc. WSDM 2013, To
appear.
![1 Comparison and Combination of NLPQL and MOGA Algorithms ... · 52 amount of optimisation work was done owing to the effective optimisation algorithms[4, 5, 6, 53 7]. Taghavifar](https://static.fdocuments.in/doc/165x107/5eca88d6f2d1b3176f62bcb7/1-comparison-and-combination-of-nlpql-and-moga-algorithms-52-amount-of-optimisation.jpg)

















