
What is the Big Data Really About - Zhejiang · PDF fileWhat is the Big Data Really About...
21
What is the Big Data Really About Eigen Tech. Co-founder Jian Xue
Transcript of What is the Big Data Really About - Zhejiang · PDF fileWhat is the Big Data Really About...

What is the Big Data
Really About
Eigen Tech Co-founder Jian Xue
Outline
Whatrsquos big data Definition amp characteristics
Whatrsquos data product Characteristics and constituents
Metrics amp measurements
AB testing
Main directions of Eigen Tech
Definition of Big Data
From Wikipedia
Big data is a term for data sets that are so large or complex that traditional data
processing applications are inadequate to deal with them Challenges include analysis
capture data curation search sharing storage transfer visualization querying
updating and information privacy The term big data often refers simply to the use
of predictive analytics user behavior analytics or certain other advanced data
analytics methods that extract value from data and seldom to a particular size of data
set
4Vrsquos Big Data (from IBM)
Volume (scale of data)
ndash 40 ZB data by 2020 an increase of 300 times from 2005
Variety (complexity of data)
ndash Different types of data source search engine social network communication records etc
ndash Different forms structured data multimedia data (speech natural language image video)
Velocity (analysis of streaming data)
ndash High speed IO and data transmission
ndash Real time
Veracity (uncertainty of data)
Difference between Big Data and Before
Less limitations on data formats much more data becomes useful
Weak causal relationship between different variables and features
With big data technology we can acquire much more value from data
Big data is alive
Characteristics
ndash Statistic correction
ndash Self-adaptation
ndash Closed-loop
Constituents
ndash Data and data flow
ndash Peopledevelopers operators and customers
ndash Algorithms and systems
ndash Metrics and measurements
ndash AB testing
Whatrsquos Data Product
Why Metrics
If you canrsquot measure it you canrsquot improve it (by William Thomson)
What kind of things can be used as metrics Data
ndash Offline NDCG precisionrecall RMSE
ndash Online Real scenarios and real users mostly based on AB testing CTR revenueuser queriesuser
Overall evaluation criteria (also called goal metrics or key metrics)
ndash Metrics defined to help the system move toward the success of the
servicebusiness
ndash Getting agreement on OEC is a huge step forward
ndash Choice of OEC evolves as the service grows over time toward the North Star
Overall Evaluation Criteria (OEC)
Quality 1 ndash Directionality Aligns with user experience and business
success (eg sessionuser)
Quality 2 ndash Sensitivity Actionable and can help to make decisions
quickly with limited cost (eg CTR)
ndash Easy to find metrics with one good qualities but hard to find ones with both
ndash No metric is applicable anywhere Fully understand a metric including directionality sensitivity and applicability
Define Metrics for Metrics
Evaluate Metric Qualities
Validation corpus
ndashA set of high quality past experiments reviewed by a panel of experts with high
confidence on their goodness (not applicable of new products)
Degradation experiment
ndashMuch easier to degrade or even screw up user experience deliberately than to
improve it
ndashEg delaying a web page for search engine and online websites downgrading to
a known inferior service
Why keep track of hundreds or thousands of metrics
Guardrail metrics
ndash Help guard against situations when goal metrics give wrong signals
ndash 1st scenario Goal metrics are not applicable
ndash 2nd scenario Goal metrics are not able to measure
ndash Having clear directional interpretation is important
Debugging metrics
ndash Help us understand why goal metrics move or not move
ndash Especially important for rate metrics Keep track of denominator
ndash Being sensitive is more important for debugging metrics
Understand Roles of Metrics
Decompose Metric Sensitivity
P(detect change) = P(change) P(detect change | change)
If not move understand which part is the bottleneck
ndash Movement probability How often the metric move in response to the changes we test
Eg sessionsuser Insensitive because it is hard to change user engagement behavior
within short time
ndash Statistical power If a metric does move how likely we are able to detect the movement
Eg revenueuser Insensitive because of high variance and low statistical power
Choose Right Rate Metrics
Rate metrics
ndash Have denominators that are not randomized Eg session success rate CTR etc
ndash Have bounded values and less likely to be affected by outliers
Two rules when using rate metrics
ndash Keep the denominator and numerator as debugging metrics
ndash Choose the rate metric whose denominator is relatively stable
Introduction to AB testing
A methodology using randomized experiments with two variants
The goal is to identify changes that increase an outcome of
interest in user behavior
Simple steps
ndashDefine two variants to be compared a control and a treatment
ndashRandomly assign users to one of the variants
ndashWait
ndashCalculate the aggregate outcome of interest for users assigned to control and
treatment
ndashPerform statistical tests to determine the probability of observing such a difference
between control and treatment due to random chance
Assign users to flights
Multiple numberlines
Users are simultaneously assigned to a bucket on N numberlines using independent hash functions
Users assigned to a bucket on one numberline are equally distributed across all buckets on another
numberline
Experiments within one numberline have equal impacts on controls and treatments on another
numberline
What is required to make multiple numberline
experimentation work
Experiments on one numberline must not semantically
conflict with an experiment on another numberline
Experiments on one numberline must not technically conflict
with an experiment on another numberline
No interactions between the experiments
Flash Resalt
Due to experimentation which operates on consistent buckets you can left over
effects within buckets
Usually the effect is small but in cases it can be very large
This breaks the assumption of randomized assignment
Flash resalt re-guarantees such assumption
Whatrsquos AA testing
Observe and compare the behavior of the users that will be in the control and
the users that will be in the treatment before the experiment begins
In expectation if the randomized assignment holds this will show no
differences among the flights
Main Directions of Eigen Tech
Chatbot
Machine reading
Semantic search
Knowledge graph
Risk control anti-fraud
Optimization of supply chain
Questions
Please contact jianxueaidiggercom for more discussions

Outline
Whatrsquos big data Definition amp characteristics
Whatrsquos data product Characteristics and constituents
Metrics amp measurements
AB testing
Main directions of Eigen Tech
Definition of Big Data
From Wikipedia
Big data is a term for data sets that are so large or complex that traditional data
processing applications are inadequate to deal with them Challenges include analysis
capture data curation search sharing storage transfer visualization querying
updating and information privacy The term big data often refers simply to the use
of predictive analytics user behavior analytics or certain other advanced data
analytics methods that extract value from data and seldom to a particular size of data
set
4Vrsquos Big Data (from IBM)
Volume (scale of data)
ndash 40 ZB data by 2020 an increase of 300 times from 2005
Variety (complexity of data)
ndash Different types of data source search engine social network communication records etc
ndash Different forms structured data multimedia data (speech natural language image video)
Velocity (analysis of streaming data)
ndash High speed IO and data transmission
ndash Real time
Veracity (uncertainty of data)
Difference between Big Data and Before
Less limitations on data formats much more data becomes useful
Weak causal relationship between different variables and features
With big data technology we can acquire much more value from data
Big data is alive
Characteristics
ndash Statistic correction
ndash Self-adaptation
ndash Closed-loop
Constituents
ndash Data and data flow
ndash Peopledevelopers operators and customers
ndash Algorithms and systems
ndash Metrics and measurements
ndash AB testing
Whatrsquos Data Product
Why Metrics
If you canrsquot measure it you canrsquot improve it (by William Thomson)
What kind of things can be used as metrics Data
ndash Offline NDCG precisionrecall RMSE
ndash Online Real scenarios and real users mostly based on AB testing CTR revenueuser queriesuser
Overall evaluation criteria (also called goal metrics or key metrics)
ndash Metrics defined to help the system move toward the success of the
servicebusiness
ndash Getting agreement on OEC is a huge step forward
ndash Choice of OEC evolves as the service grows over time toward the North Star
Overall Evaluation Criteria (OEC)
Quality 1 ndash Directionality Aligns with user experience and business
success (eg sessionuser)
Quality 2 ndash Sensitivity Actionable and can help to make decisions
quickly with limited cost (eg CTR)
ndash Easy to find metrics with one good qualities but hard to find ones with both
ndash No metric is applicable anywhere Fully understand a metric including directionality sensitivity and applicability
Define Metrics for Metrics
Evaluate Metric Qualities
Validation corpus
ndashA set of high quality past experiments reviewed by a panel of experts with high
confidence on their goodness (not applicable of new products)
Degradation experiment
ndashMuch easier to degrade or even screw up user experience deliberately than to
improve it
ndashEg delaying a web page for search engine and online websites downgrading to
a known inferior service
Why keep track of hundreds or thousands of metrics
Guardrail metrics
ndash Help guard against situations when goal metrics give wrong signals
ndash 1st scenario Goal metrics are not applicable
ndash 2nd scenario Goal metrics are not able to measure
ndash Having clear directional interpretation is important
Debugging metrics
ndash Help us understand why goal metrics move or not move
ndash Especially important for rate metrics Keep track of denominator
ndash Being sensitive is more important for debugging metrics
Understand Roles of Metrics
Decompose Metric Sensitivity
P(detect change) = P(change) P(detect change | change)
If not move understand which part is the bottleneck
ndash Movement probability How often the metric move in response to the changes we test
Eg sessionsuser Insensitive because it is hard to change user engagement behavior
within short time
ndash Statistical power If a metric does move how likely we are able to detect the movement
Eg revenueuser Insensitive because of high variance and low statistical power
Choose Right Rate Metrics
Rate metrics
ndash Have denominators that are not randomized Eg session success rate CTR etc
ndash Have bounded values and less likely to be affected by outliers
Two rules when using rate metrics
ndash Keep the denominator and numerator as debugging metrics
ndash Choose the rate metric whose denominator is relatively stable
Introduction to AB testing
A methodology using randomized experiments with two variants
The goal is to identify changes that increase an outcome of
interest in user behavior
Simple steps
ndashDefine two variants to be compared a control and a treatment
ndashRandomly assign users to one of the variants
ndashWait
ndashCalculate the aggregate outcome of interest for users assigned to control and
treatment
ndashPerform statistical tests to determine the probability of observing such a difference
between control and treatment due to random chance
Assign users to flights
Multiple numberlines
Users are simultaneously assigned to a bucket on N numberlines using independent hash functions
Users assigned to a bucket on one numberline are equally distributed across all buckets on another
numberline
Experiments within one numberline have equal impacts on controls and treatments on another
numberline
What is required to make multiple numberline
experimentation work
Experiments on one numberline must not semantically
conflict with an experiment on another numberline
Experiments on one numberline must not technically conflict
with an experiment on another numberline
No interactions between the experiments
Flash Resalt
Due to experimentation which operates on consistent buckets you can left over
effects within buckets
Usually the effect is small but in cases it can be very large
This breaks the assumption of randomized assignment
Flash resalt re-guarantees such assumption
Whatrsquos AA testing
Observe and compare the behavior of the users that will be in the control and
the users that will be in the treatment before the experiment begins
In expectation if the randomized assignment holds this will show no
differences among the flights
Main Directions of Eigen Tech
Chatbot
Machine reading
Semantic search
Knowledge graph
Risk control anti-fraud
Optimization of supply chain
Questions
Please contact jianxueaidiggercom for more discussions

Definition of Big Data
From Wikipedia
Big data is a term for data sets that are so large or complex that traditional data
processing applications are inadequate to deal with them Challenges include analysis
capture data curation search sharing storage transfer visualization querying
updating and information privacy The term big data often refers simply to the use
of predictive analytics user behavior analytics or certain other advanced data
analytics methods that extract value from data and seldom to a particular size of data
set
4Vrsquos Big Data (from IBM)
Volume (scale of data)
ndash 40 ZB data by 2020 an increase of 300 times from 2005
Variety (complexity of data)
ndash Different types of data source search engine social network communication records etc
ndash Different forms structured data multimedia data (speech natural language image video)
Velocity (analysis of streaming data)
ndash High speed IO and data transmission
ndash Real time
Veracity (uncertainty of data)
Difference between Big Data and Before
Less limitations on data formats much more data becomes useful
Weak causal relationship between different variables and features
With big data technology we can acquire much more value from data
Big data is alive
Characteristics
ndash Statistic correction
ndash Self-adaptation
ndash Closed-loop
Constituents
ndash Data and data flow
ndash Peopledevelopers operators and customers
ndash Algorithms and systems
ndash Metrics and measurements
ndash AB testing
Whatrsquos Data Product
Why Metrics
If you canrsquot measure it you canrsquot improve it (by William Thomson)
What kind of things can be used as metrics Data
ndash Offline NDCG precisionrecall RMSE
ndash Online Real scenarios and real users mostly based on AB testing CTR revenueuser queriesuser
Overall evaluation criteria (also called goal metrics or key metrics)
ndash Metrics defined to help the system move toward the success of the
servicebusiness
ndash Getting agreement on OEC is a huge step forward
ndash Choice of OEC evolves as the service grows over time toward the North Star
Overall Evaluation Criteria (OEC)
Quality 1 ndash Directionality Aligns with user experience and business
success (eg sessionuser)
Quality 2 ndash Sensitivity Actionable and can help to make decisions
quickly with limited cost (eg CTR)
ndash Easy to find metrics with one good qualities but hard to find ones with both
ndash No metric is applicable anywhere Fully understand a metric including directionality sensitivity and applicability
Define Metrics for Metrics
Evaluate Metric Qualities
Validation corpus
ndashA set of high quality past experiments reviewed by a panel of experts with high
confidence on their goodness (not applicable of new products)
Degradation experiment
ndashMuch easier to degrade or even screw up user experience deliberately than to
improve it
ndashEg delaying a web page for search engine and online websites downgrading to
a known inferior service
Why keep track of hundreds or thousands of metrics
Guardrail metrics
ndash Help guard against situations when goal metrics give wrong signals
ndash 1st scenario Goal metrics are not applicable
ndash 2nd scenario Goal metrics are not able to measure
ndash Having clear directional interpretation is important
Debugging metrics
ndash Help us understand why goal metrics move or not move
ndash Especially important for rate metrics Keep track of denominator
ndash Being sensitive is more important for debugging metrics
Understand Roles of Metrics
Decompose Metric Sensitivity
P(detect change) = P(change) P(detect change | change)
If not move understand which part is the bottleneck
ndash Movement probability How often the metric move in response to the changes we test
Eg sessionsuser Insensitive because it is hard to change user engagement behavior
within short time
ndash Statistical power If a metric does move how likely we are able to detect the movement
Eg revenueuser Insensitive because of high variance and low statistical power
Choose Right Rate Metrics
Rate metrics
ndash Have denominators that are not randomized Eg session success rate CTR etc
ndash Have bounded values and less likely to be affected by outliers
Two rules when using rate metrics
ndash Keep the denominator and numerator as debugging metrics
ndash Choose the rate metric whose denominator is relatively stable
Introduction to AB testing
A methodology using randomized experiments with two variants
The goal is to identify changes that increase an outcome of
interest in user behavior
Simple steps
ndashDefine two variants to be compared a control and a treatment
ndashRandomly assign users to one of the variants
ndashWait
ndashCalculate the aggregate outcome of interest for users assigned to control and
treatment
ndashPerform statistical tests to determine the probability of observing such a difference
between control and treatment due to random chance
Assign users to flights
Multiple numberlines
Users are simultaneously assigned to a bucket on N numberlines using independent hash functions
Users assigned to a bucket on one numberline are equally distributed across all buckets on another
numberline
Experiments within one numberline have equal impacts on controls and treatments on another
numberline
What is required to make multiple numberline
experimentation work
Experiments on one numberline must not semantically
conflict with an experiment on another numberline
Experiments on one numberline must not technically conflict
with an experiment on another numberline
No interactions between the experiments
Flash Resalt
Due to experimentation which operates on consistent buckets you can left over
effects within buckets
Usually the effect is small but in cases it can be very large
This breaks the assumption of randomized assignment
Flash resalt re-guarantees such assumption
Whatrsquos AA testing
Observe and compare the behavior of the users that will be in the control and
the users that will be in the treatment before the experiment begins
In expectation if the randomized assignment holds this will show no
differences among the flights
Main Directions of Eigen Tech
Chatbot
Machine reading
Semantic search
Knowledge graph
Risk control anti-fraud
Optimization of supply chain
Questions
Please contact jianxueaidiggercom for more discussions

4Vrsquos Big Data (from IBM)
Volume (scale of data)
ndash 40 ZB data by 2020 an increase of 300 times from 2005
Variety (complexity of data)
ndash Different types of data source search engine social network communication records etc
ndash Different forms structured data multimedia data (speech natural language image video)
Velocity (analysis of streaming data)
ndash High speed IO and data transmission
ndash Real time
Veracity (uncertainty of data)
Difference between Big Data and Before
Less limitations on data formats much more data becomes useful
Weak causal relationship between different variables and features
With big data technology we can acquire much more value from data
Big data is alive
Characteristics
ndash Statistic correction
ndash Self-adaptation
ndash Closed-loop
Constituents
ndash Data and data flow
ndash Peopledevelopers operators and customers
ndash Algorithms and systems
ndash Metrics and measurements
ndash AB testing
Whatrsquos Data Product
Why Metrics
If you canrsquot measure it you canrsquot improve it (by William Thomson)
What kind of things can be used as metrics Data
ndash Offline NDCG precisionrecall RMSE
ndash Online Real scenarios and real users mostly based on AB testing CTR revenueuser queriesuser
Overall evaluation criteria (also called goal metrics or key metrics)
ndash Metrics defined to help the system move toward the success of the
servicebusiness
ndash Getting agreement on OEC is a huge step forward
ndash Choice of OEC evolves as the service grows over time toward the North Star
Overall Evaluation Criteria (OEC)
Quality 1 ndash Directionality Aligns with user experience and business
success (eg sessionuser)
Quality 2 ndash Sensitivity Actionable and can help to make decisions
quickly with limited cost (eg CTR)
ndash Easy to find metrics with one good qualities but hard to find ones with both
ndash No metric is applicable anywhere Fully understand a metric including directionality sensitivity and applicability
Define Metrics for Metrics
Evaluate Metric Qualities
Validation corpus
ndashA set of high quality past experiments reviewed by a panel of experts with high
confidence on their goodness (not applicable of new products)
Degradation experiment
ndashMuch easier to degrade or even screw up user experience deliberately than to
improve it
ndashEg delaying a web page for search engine and online websites downgrading to
a known inferior service
Why keep track of hundreds or thousands of metrics
Guardrail metrics
ndash Help guard against situations when goal metrics give wrong signals
ndash 1st scenario Goal metrics are not applicable
ndash 2nd scenario Goal metrics are not able to measure
ndash Having clear directional interpretation is important
Debugging metrics
ndash Help us understand why goal metrics move or not move
ndash Especially important for rate metrics Keep track of denominator
ndash Being sensitive is more important for debugging metrics
Understand Roles of Metrics
Decompose Metric Sensitivity
P(detect change) = P(change) P(detect change | change)
If not move understand which part is the bottleneck
ndash Movement probability How often the metric move in response to the changes we test
Eg sessionsuser Insensitive because it is hard to change user engagement behavior
within short time
ndash Statistical power If a metric does move how likely we are able to detect the movement
Eg revenueuser Insensitive because of high variance and low statistical power
Choose Right Rate Metrics
Rate metrics
ndash Have denominators that are not randomized Eg session success rate CTR etc
ndash Have bounded values and less likely to be affected by outliers
Two rules when using rate metrics
ndash Keep the denominator and numerator as debugging metrics
ndash Choose the rate metric whose denominator is relatively stable
Introduction to AB testing
A methodology using randomized experiments with two variants
The goal is to identify changes that increase an outcome of
interest in user behavior
Simple steps
ndashDefine two variants to be compared a control and a treatment
ndashRandomly assign users to one of the variants
ndashWait
ndashCalculate the aggregate outcome of interest for users assigned to control and
treatment
ndashPerform statistical tests to determine the probability of observing such a difference
between control and treatment due to random chance
Assign users to flights
Multiple numberlines
Users are simultaneously assigned to a bucket on N numberlines using independent hash functions
Users assigned to a bucket on one numberline are equally distributed across all buckets on another
numberline
Experiments within one numberline have equal impacts on controls and treatments on another
numberline
What is required to make multiple numberline
experimentation work
Experiments on one numberline must not semantically
conflict with an experiment on another numberline
Experiments on one numberline must not technically conflict
with an experiment on another numberline
No interactions between the experiments
Flash Resalt
Due to experimentation which operates on consistent buckets you can left over
effects within buckets
Usually the effect is small but in cases it can be very large
This breaks the assumption of randomized assignment
Flash resalt re-guarantees such assumption
Whatrsquos AA testing
Observe and compare the behavior of the users that will be in the control and
the users that will be in the treatment before the experiment begins
In expectation if the randomized assignment holds this will show no
differences among the flights
Main Directions of Eigen Tech
Chatbot
Machine reading
Semantic search
Knowledge graph
Risk control anti-fraud
Optimization of supply chain
Questions
Please contact jianxueaidiggercom for more discussions

Difference between Big Data and Before
Less limitations on data formats much more data becomes useful
Weak causal relationship between different variables and features
With big data technology we can acquire much more value from data
Big data is alive
Characteristics
ndash Statistic correction
ndash Self-adaptation
ndash Closed-loop
Constituents
ndash Data and data flow
ndash Peopledevelopers operators and customers
ndash Algorithms and systems
ndash Metrics and measurements
ndash AB testing
Whatrsquos Data Product
Why Metrics
If you canrsquot measure it you canrsquot improve it (by William Thomson)
What kind of things can be used as metrics Data
ndash Offline NDCG precisionrecall RMSE
ndash Online Real scenarios and real users mostly based on AB testing CTR revenueuser queriesuser
Overall evaluation criteria (also called goal metrics or key metrics)
ndash Metrics defined to help the system move toward the success of the
servicebusiness
ndash Getting agreement on OEC is a huge step forward
ndash Choice of OEC evolves as the service grows over time toward the North Star
Overall Evaluation Criteria (OEC)
Quality 1 ndash Directionality Aligns with user experience and business
success (eg sessionuser)
Quality 2 ndash Sensitivity Actionable and can help to make decisions
quickly with limited cost (eg CTR)
ndash Easy to find metrics with one good qualities but hard to find ones with both
ndash No metric is applicable anywhere Fully understand a metric including directionality sensitivity and applicability
Define Metrics for Metrics
Evaluate Metric Qualities
Validation corpus
ndashA set of high quality past experiments reviewed by a panel of experts with high
confidence on their goodness (not applicable of new products)
Degradation experiment
ndashMuch easier to degrade or even screw up user experience deliberately than to
improve it
ndashEg delaying a web page for search engine and online websites downgrading to
a known inferior service
Why keep track of hundreds or thousands of metrics
Guardrail metrics
ndash Help guard against situations when goal metrics give wrong signals
ndash 1st scenario Goal metrics are not applicable
ndash 2nd scenario Goal metrics are not able to measure
ndash Having clear directional interpretation is important
Debugging metrics
ndash Help us understand why goal metrics move or not move
ndash Especially important for rate metrics Keep track of denominator
ndash Being sensitive is more important for debugging metrics
Understand Roles of Metrics
Decompose Metric Sensitivity
P(detect change) = P(change) P(detect change | change)
If not move understand which part is the bottleneck
ndash Movement probability How often the metric move in response to the changes we test
Eg sessionsuser Insensitive because it is hard to change user engagement behavior
within short time
ndash Statistical power If a metric does move how likely we are able to detect the movement
Eg revenueuser Insensitive because of high variance and low statistical power
Choose Right Rate Metrics
Rate metrics
ndash Have denominators that are not randomized Eg session success rate CTR etc
ndash Have bounded values and less likely to be affected by outliers
Two rules when using rate metrics
ndash Keep the denominator and numerator as debugging metrics
ndash Choose the rate metric whose denominator is relatively stable
Introduction to AB testing
A methodology using randomized experiments with two variants
The goal is to identify changes that increase an outcome of
interest in user behavior
Simple steps
ndashDefine two variants to be compared a control and a treatment
ndashRandomly assign users to one of the variants
ndashWait
ndashCalculate the aggregate outcome of interest for users assigned to control and
treatment
ndashPerform statistical tests to determine the probability of observing such a difference
between control and treatment due to random chance
Assign users to flights
Multiple numberlines
Users are simultaneously assigned to a bucket on N numberlines using independent hash functions
Users assigned to a bucket on one numberline are equally distributed across all buckets on another
numberline
Experiments within one numberline have equal impacts on controls and treatments on another
numberline
What is required to make multiple numberline
experimentation work
Experiments on one numberline must not semantically
conflict with an experiment on another numberline
Experiments on one numberline must not technically conflict
with an experiment on another numberline
No interactions between the experiments
Flash Resalt
Due to experimentation which operates on consistent buckets you can left over
effects within buckets
Usually the effect is small but in cases it can be very large
This breaks the assumption of randomized assignment
Flash resalt re-guarantees such assumption
Whatrsquos AA testing
Observe and compare the behavior of the users that will be in the control and
the users that will be in the treatment before the experiment begins
In expectation if the randomized assignment holds this will show no
differences among the flights
Main Directions of Eigen Tech
Chatbot
Machine reading
Semantic search
Knowledge graph
Risk control anti-fraud
Optimization of supply chain
Questions
Please contact jianxueaidiggercom for more discussions

Characteristics
ndash Statistic correction
ndash Self-adaptation
ndash Closed-loop
Constituents
ndash Data and data flow
ndash Peopledevelopers operators and customers
ndash Algorithms and systems
ndash Metrics and measurements
ndash AB testing
Whatrsquos Data Product
Why Metrics
If you canrsquot measure it you canrsquot improve it (by William Thomson)
What kind of things can be used as metrics Data
ndash Offline NDCG precisionrecall RMSE
ndash Online Real scenarios and real users mostly based on AB testing CTR revenueuser queriesuser
Overall evaluation criteria (also called goal metrics or key metrics)
ndash Metrics defined to help the system move toward the success of the
servicebusiness
ndash Getting agreement on OEC is a huge step forward
ndash Choice of OEC evolves as the service grows over time toward the North Star
Overall Evaluation Criteria (OEC)
Quality 1 ndash Directionality Aligns with user experience and business
success (eg sessionuser)
Quality 2 ndash Sensitivity Actionable and can help to make decisions
quickly with limited cost (eg CTR)
ndash Easy to find metrics with one good qualities but hard to find ones with both
ndash No metric is applicable anywhere Fully understand a metric including directionality sensitivity and applicability
Define Metrics for Metrics
Evaluate Metric Qualities
Validation corpus
ndashA set of high quality past experiments reviewed by a panel of experts with high
confidence on their goodness (not applicable of new products)
Degradation experiment
ndashMuch easier to degrade or even screw up user experience deliberately than to
improve it
ndashEg delaying a web page for search engine and online websites downgrading to
a known inferior service
Why keep track of hundreds or thousands of metrics
Guardrail metrics
ndash Help guard against situations when goal metrics give wrong signals
ndash 1st scenario Goal metrics are not applicable
ndash 2nd scenario Goal metrics are not able to measure
ndash Having clear directional interpretation is important
Debugging metrics
ndash Help us understand why goal metrics move or not move
ndash Especially important for rate metrics Keep track of denominator
ndash Being sensitive is more important for debugging metrics
Understand Roles of Metrics
Decompose Metric Sensitivity
P(detect change) = P(change) P(detect change | change)
If not move understand which part is the bottleneck
ndash Movement probability How often the metric move in response to the changes we test
Eg sessionsuser Insensitive because it is hard to change user engagement behavior
within short time
ndash Statistical power If a metric does move how likely we are able to detect the movement
Eg revenueuser Insensitive because of high variance and low statistical power
Choose Right Rate Metrics
Rate metrics
ndash Have denominators that are not randomized Eg session success rate CTR etc
ndash Have bounded values and less likely to be affected by outliers
Two rules when using rate metrics
ndash Keep the denominator and numerator as debugging metrics
ndash Choose the rate metric whose denominator is relatively stable
Introduction to AB testing
A methodology using randomized experiments with two variants
The goal is to identify changes that increase an outcome of
interest in user behavior
Simple steps
ndashDefine two variants to be compared a control and a treatment
ndashRandomly assign users to one of the variants
ndashWait
ndashCalculate the aggregate outcome of interest for users assigned to control and
treatment
ndashPerform statistical tests to determine the probability of observing such a difference
between control and treatment due to random chance
Assign users to flights
Multiple numberlines
Users are simultaneously assigned to a bucket on N numberlines using independent hash functions
Users assigned to a bucket on one numberline are equally distributed across all buckets on another
numberline
Experiments within one numberline have equal impacts on controls and treatments on another
numberline
What is required to make multiple numberline
experimentation work
Experiments on one numberline must not semantically
conflict with an experiment on another numberline
Experiments on one numberline must not technically conflict
with an experiment on another numberline
No interactions between the experiments
Flash Resalt
Due to experimentation which operates on consistent buckets you can left over
effects within buckets
Usually the effect is small but in cases it can be very large
This breaks the assumption of randomized assignment
Flash resalt re-guarantees such assumption
Whatrsquos AA testing
Observe and compare the behavior of the users that will be in the control and
the users that will be in the treatment before the experiment begins
In expectation if the randomized assignment holds this will show no
differences among the flights
Main Directions of Eigen Tech
Chatbot
Machine reading
Semantic search
Knowledge graph
Risk control anti-fraud
Optimization of supply chain
Questions
Please contact jianxueaidiggercom for more discussions

Why Metrics
If you canrsquot measure it you canrsquot improve it (by William Thomson)
What kind of things can be used as metrics Data
ndash Offline NDCG precisionrecall RMSE
ndash Online Real scenarios and real users mostly based on AB testing CTR revenueuser queriesuser
Overall evaluation criteria (also called goal metrics or key metrics)
ndash Metrics defined to help the system move toward the success of the
servicebusiness
ndash Getting agreement on OEC is a huge step forward
ndash Choice of OEC evolves as the service grows over time toward the North Star
Overall Evaluation Criteria (OEC)
Quality 1 ndash Directionality Aligns with user experience and business
success (eg sessionuser)
Quality 2 ndash Sensitivity Actionable and can help to make decisions
quickly with limited cost (eg CTR)
ndash Easy to find metrics with one good qualities but hard to find ones with both
ndash No metric is applicable anywhere Fully understand a metric including directionality sensitivity and applicability
Define Metrics for Metrics
Evaluate Metric Qualities
Validation corpus
ndashA set of high quality past experiments reviewed by a panel of experts with high
confidence on their goodness (not applicable of new products)
Degradation experiment
ndashMuch easier to degrade or even screw up user experience deliberately than to
improve it
ndashEg delaying a web page for search engine and online websites downgrading to
a known inferior service
Why keep track of hundreds or thousands of metrics
Guardrail metrics
ndash Help guard against situations when goal metrics give wrong signals
ndash 1st scenario Goal metrics are not applicable
ndash 2nd scenario Goal metrics are not able to measure
ndash Having clear directional interpretation is important
Debugging metrics
ndash Help us understand why goal metrics move or not move
ndash Especially important for rate metrics Keep track of denominator
ndash Being sensitive is more important for debugging metrics
Understand Roles of Metrics
Decompose Metric Sensitivity
P(detect change) = P(change) P(detect change | change)
If not move understand which part is the bottleneck
ndash Movement probability How often the metric move in response to the changes we test
Eg sessionsuser Insensitive because it is hard to change user engagement behavior
within short time
ndash Statistical power If a metric does move how likely we are able to detect the movement
Eg revenueuser Insensitive because of high variance and low statistical power
Choose Right Rate Metrics
Rate metrics
ndash Have denominators that are not randomized Eg session success rate CTR etc
ndash Have bounded values and less likely to be affected by outliers
Two rules when using rate metrics
ndash Keep the denominator and numerator as debugging metrics
ndash Choose the rate metric whose denominator is relatively stable
Introduction to AB testing
A methodology using randomized experiments with two variants
The goal is to identify changes that increase an outcome of
interest in user behavior
Simple steps
ndashDefine two variants to be compared a control and a treatment
ndashRandomly assign users to one of the variants
ndashWait
ndashCalculate the aggregate outcome of interest for users assigned to control and
treatment
ndashPerform statistical tests to determine the probability of observing such a difference
between control and treatment due to random chance
Assign users to flights
Multiple numberlines
Users are simultaneously assigned to a bucket on N numberlines using independent hash functions
Users assigned to a bucket on one numberline are equally distributed across all buckets on another
numberline
Experiments within one numberline have equal impacts on controls and treatments on another
numberline
What is required to make multiple numberline
experimentation work
Experiments on one numberline must not semantically
conflict with an experiment on another numberline
Experiments on one numberline must not technically conflict
with an experiment on another numberline
No interactions between the experiments
Flash Resalt
Due to experimentation which operates on consistent buckets you can left over
effects within buckets
Usually the effect is small but in cases it can be very large
This breaks the assumption of randomized assignment
Flash resalt re-guarantees such assumption
Whatrsquos AA testing
Observe and compare the behavior of the users that will be in the control and
the users that will be in the treatment before the experiment begins
In expectation if the randomized assignment holds this will show no
differences among the flights
Main Directions of Eigen Tech
Chatbot
Machine reading
Semantic search
Knowledge graph
Risk control anti-fraud
Optimization of supply chain
Questions
Please contact jianxueaidiggercom for more discussions

Overall evaluation criteria (also called goal metrics or key metrics)
ndash Metrics defined to help the system move toward the success of the
servicebusiness
ndash Getting agreement on OEC is a huge step forward
ndash Choice of OEC evolves as the service grows over time toward the North Star
Overall Evaluation Criteria (OEC)
Quality 1 ndash Directionality Aligns with user experience and business
success (eg sessionuser)
Quality 2 ndash Sensitivity Actionable and can help to make decisions
quickly with limited cost (eg CTR)
ndash Easy to find metrics with one good qualities but hard to find ones with both
ndash No metric is applicable anywhere Fully understand a metric including directionality sensitivity and applicability
Define Metrics for Metrics
Evaluate Metric Qualities
Validation corpus
ndashA set of high quality past experiments reviewed by a panel of experts with high
confidence on their goodness (not applicable of new products)
Degradation experiment
ndashMuch easier to degrade or even screw up user experience deliberately than to
improve it
ndashEg delaying a web page for search engine and online websites downgrading to
a known inferior service
Why keep track of hundreds or thousands of metrics
Guardrail metrics
ndash Help guard against situations when goal metrics give wrong signals
ndash 1st scenario Goal metrics are not applicable
ndash 2nd scenario Goal metrics are not able to measure
ndash Having clear directional interpretation is important
Debugging metrics
ndash Help us understand why goal metrics move or not move
ndash Especially important for rate metrics Keep track of denominator
ndash Being sensitive is more important for debugging metrics
Understand Roles of Metrics
Decompose Metric Sensitivity
P(detect change) = P(change) P(detect change | change)
If not move understand which part is the bottleneck
ndash Movement probability How often the metric move in response to the changes we test
Eg sessionsuser Insensitive because it is hard to change user engagement behavior
within short time
ndash Statistical power If a metric does move how likely we are able to detect the movement
Eg revenueuser Insensitive because of high variance and low statistical power
Choose Right Rate Metrics
Rate metrics
ndash Have denominators that are not randomized Eg session success rate CTR etc
ndash Have bounded values and less likely to be affected by outliers
Two rules when using rate metrics
ndash Keep the denominator and numerator as debugging metrics
ndash Choose the rate metric whose denominator is relatively stable
Introduction to AB testing
A methodology using randomized experiments with two variants
The goal is to identify changes that increase an outcome of
interest in user behavior
Simple steps
ndashDefine two variants to be compared a control and a treatment
ndashRandomly assign users to one of the variants
ndashWait
ndashCalculate the aggregate outcome of interest for users assigned to control and
treatment
ndashPerform statistical tests to determine the probability of observing such a difference
between control and treatment due to random chance
Assign users to flights
Multiple numberlines
Users are simultaneously assigned to a bucket on N numberlines using independent hash functions
Users assigned to a bucket on one numberline are equally distributed across all buckets on another
numberline
Experiments within one numberline have equal impacts on controls and treatments on another
numberline
What is required to make multiple numberline
experimentation work
Experiments on one numberline must not semantically
conflict with an experiment on another numberline
Experiments on one numberline must not technically conflict
with an experiment on another numberline
No interactions between the experiments
Flash Resalt
Due to experimentation which operates on consistent buckets you can left over
effects within buckets
Usually the effect is small but in cases it can be very large
This breaks the assumption of randomized assignment
Flash resalt re-guarantees such assumption
Whatrsquos AA testing
Observe and compare the behavior of the users that will be in the control and
the users that will be in the treatment before the experiment begins
In expectation if the randomized assignment holds this will show no
differences among the flights
Main Directions of Eigen Tech
Chatbot
Machine reading
Semantic search
Knowledge graph
Risk control anti-fraud
Optimization of supply chain
Questions
Please contact jianxueaidiggercom for more discussions

Quality 1 ndash Directionality Aligns with user experience and business
success (eg sessionuser)
Quality 2 ndash Sensitivity Actionable and can help to make decisions
quickly with limited cost (eg CTR)
ndash Easy to find metrics with one good qualities but hard to find ones with both
ndash No metric is applicable anywhere Fully understand a metric including directionality sensitivity and applicability
Define Metrics for Metrics
Evaluate Metric Qualities
Validation corpus
ndashA set of high quality past experiments reviewed by a panel of experts with high
confidence on their goodness (not applicable of new products)
Degradation experiment
ndashMuch easier to degrade or even screw up user experience deliberately than to
improve it
ndashEg delaying a web page for search engine and online websites downgrading to
a known inferior service
Why keep track of hundreds or thousands of metrics
Guardrail metrics
ndash Help guard against situations when goal metrics give wrong signals
ndash 1st scenario Goal metrics are not applicable
ndash 2nd scenario Goal metrics are not able to measure
ndash Having clear directional interpretation is important
Debugging metrics
ndash Help us understand why goal metrics move or not move
ndash Especially important for rate metrics Keep track of denominator
ndash Being sensitive is more important for debugging metrics
Understand Roles of Metrics
Decompose Metric Sensitivity
P(detect change) = P(change) P(detect change | change)
If not move understand which part is the bottleneck
ndash Movement probability How often the metric move in response to the changes we test
Eg sessionsuser Insensitive because it is hard to change user engagement behavior
within short time
ndash Statistical power If a metric does move how likely we are able to detect the movement
Eg revenueuser Insensitive because of high variance and low statistical power
Choose Right Rate Metrics
Rate metrics
ndash Have denominators that are not randomized Eg session success rate CTR etc
ndash Have bounded values and less likely to be affected by outliers
Two rules when using rate metrics
ndash Keep the denominator and numerator as debugging metrics
ndash Choose the rate metric whose denominator is relatively stable
Introduction to AB testing
A methodology using randomized experiments with two variants
The goal is to identify changes that increase an outcome of
interest in user behavior
Simple steps
ndashDefine two variants to be compared a control and a treatment
ndashRandomly assign users to one of the variants
ndashWait
ndashCalculate the aggregate outcome of interest for users assigned to control and
treatment
ndashPerform statistical tests to determine the probability of observing such a difference
between control and treatment due to random chance
Assign users to flights
Multiple numberlines
Users are simultaneously assigned to a bucket on N numberlines using independent hash functions
Users assigned to a bucket on one numberline are equally distributed across all buckets on another
numberline
Experiments within one numberline have equal impacts on controls and treatments on another
numberline
What is required to make multiple numberline
experimentation work
Experiments on one numberline must not semantically
conflict with an experiment on another numberline
Experiments on one numberline must not technically conflict
with an experiment on another numberline
No interactions between the experiments
Flash Resalt
Due to experimentation which operates on consistent buckets you can left over
effects within buckets
Usually the effect is small but in cases it can be very large
This breaks the assumption of randomized assignment
Flash resalt re-guarantees such assumption
Whatrsquos AA testing
Observe and compare the behavior of the users that will be in the control and
the users that will be in the treatment before the experiment begins
In expectation if the randomized assignment holds this will show no
differences among the flights
Main Directions of Eigen Tech
Chatbot
Machine reading
Semantic search
Knowledge graph
Risk control anti-fraud
Optimization of supply chain
Questions
Please contact jianxueaidiggercom for more discussions

Evaluate Metric Qualities
Validation corpus
ndashA set of high quality past experiments reviewed by a panel of experts with high
confidence on their goodness (not applicable of new products)
Degradation experiment
ndashMuch easier to degrade or even screw up user experience deliberately than to
improve it
ndashEg delaying a web page for search engine and online websites downgrading to
a known inferior service
Why keep track of hundreds or thousands of metrics
Guardrail metrics
ndash Help guard against situations when goal metrics give wrong signals
ndash 1st scenario Goal metrics are not applicable
ndash 2nd scenario Goal metrics are not able to measure
ndash Having clear directional interpretation is important
Debugging metrics
ndash Help us understand why goal metrics move or not move
ndash Especially important for rate metrics Keep track of denominator
ndash Being sensitive is more important for debugging metrics
Understand Roles of Metrics
Decompose Metric Sensitivity
P(detect change) = P(change) P(detect change | change)
If not move understand which part is the bottleneck
ndash Movement probability How often the metric move in response to the changes we test
Eg sessionsuser Insensitive because it is hard to change user engagement behavior
within short time
ndash Statistical power If a metric does move how likely we are able to detect the movement
Eg revenueuser Insensitive because of high variance and low statistical power
Choose Right Rate Metrics
Rate metrics
ndash Have denominators that are not randomized Eg session success rate CTR etc
ndash Have bounded values and less likely to be affected by outliers
Two rules when using rate metrics
ndash Keep the denominator and numerator as debugging metrics
ndash Choose the rate metric whose denominator is relatively stable
Introduction to AB testing
A methodology using randomized experiments with two variants
The goal is to identify changes that increase an outcome of
interest in user behavior
Simple steps
ndashDefine two variants to be compared a control and a treatment
ndashRandomly assign users to one of the variants
ndashWait
ndashCalculate the aggregate outcome of interest for users assigned to control and
treatment
ndashPerform statistical tests to determine the probability of observing such a difference
between control and treatment due to random chance
Assign users to flights
Multiple numberlines
Users are simultaneously assigned to a bucket on N numberlines using independent hash functions
Users assigned to a bucket on one numberline are equally distributed across all buckets on another
numberline
Experiments within one numberline have equal impacts on controls and treatments on another
numberline
What is required to make multiple numberline
experimentation work
Experiments on one numberline must not semantically
conflict with an experiment on another numberline
Experiments on one numberline must not technically conflict
with an experiment on another numberline
No interactions between the experiments
Flash Resalt
Due to experimentation which operates on consistent buckets you can left over
effects within buckets
Usually the effect is small but in cases it can be very large
This breaks the assumption of randomized assignment
Flash resalt re-guarantees such assumption
Whatrsquos AA testing
Observe and compare the behavior of the users that will be in the control and
the users that will be in the treatment before the experiment begins
In expectation if the randomized assignment holds this will show no
differences among the flights
Main Directions of Eigen Tech
Chatbot
Machine reading
Semantic search
Knowledge graph
Risk control anti-fraud
Optimization of supply chain
Questions
Please contact jianxueaidiggercom for more discussions

Why keep track of hundreds or thousands of metrics
Guardrail metrics
ndash Help guard against situations when goal metrics give wrong signals
ndash 1st scenario Goal metrics are not applicable
ndash 2nd scenario Goal metrics are not able to measure
ndash Having clear directional interpretation is important
Debugging metrics
ndash Help us understand why goal metrics move or not move
ndash Especially important for rate metrics Keep track of denominator
ndash Being sensitive is more important for debugging metrics
Understand Roles of Metrics
Decompose Metric Sensitivity
P(detect change) = P(change) P(detect change | change)
If not move understand which part is the bottleneck
ndash Movement probability How often the metric move in response to the changes we test
Eg sessionsuser Insensitive because it is hard to change user engagement behavior
within short time
ndash Statistical power If a metric does move how likely we are able to detect the movement
Eg revenueuser Insensitive because of high variance and low statistical power
Choose Right Rate Metrics
Rate metrics
ndash Have denominators that are not randomized Eg session success rate CTR etc
ndash Have bounded values and less likely to be affected by outliers
Two rules when using rate metrics
ndash Keep the denominator and numerator as debugging metrics
ndash Choose the rate metric whose denominator is relatively stable
Introduction to AB testing
A methodology using randomized experiments with two variants
The goal is to identify changes that increase an outcome of
interest in user behavior
Simple steps
ndashDefine two variants to be compared a control and a treatment
ndashRandomly assign users to one of the variants
ndashWait
ndashCalculate the aggregate outcome of interest for users assigned to control and
treatment
ndashPerform statistical tests to determine the probability of observing such a difference
between control and treatment due to random chance
Assign users to flights
Multiple numberlines
Users are simultaneously assigned to a bucket on N numberlines using independent hash functions
Users assigned to a bucket on one numberline are equally distributed across all buckets on another
numberline
Experiments within one numberline have equal impacts on controls and treatments on another
numberline
What is required to make multiple numberline
experimentation work
Experiments on one numberline must not semantically
conflict with an experiment on another numberline
Experiments on one numberline must not technically conflict
with an experiment on another numberline
No interactions between the experiments
Flash Resalt
Due to experimentation which operates on consistent buckets you can left over
effects within buckets
Usually the effect is small but in cases it can be very large
This breaks the assumption of randomized assignment
Flash resalt re-guarantees such assumption
Whatrsquos AA testing
Observe and compare the behavior of the users that will be in the control and
the users that will be in the treatment before the experiment begins
In expectation if the randomized assignment holds this will show no
differences among the flights
Main Directions of Eigen Tech
Chatbot
Machine reading
Semantic search
Knowledge graph
Risk control anti-fraud
Optimization of supply chain
Questions
Please contact jianxueaidiggercom for more discussions

Decompose Metric Sensitivity
P(detect change) = P(change) P(detect change | change)
If not move understand which part is the bottleneck
ndash Movement probability How often the metric move in response to the changes we test
Eg sessionsuser Insensitive because it is hard to change user engagement behavior
within short time
ndash Statistical power If a metric does move how likely we are able to detect the movement
Eg revenueuser Insensitive because of high variance and low statistical power
Choose Right Rate Metrics
Rate metrics
ndash Have denominators that are not randomized Eg session success rate CTR etc
ndash Have bounded values and less likely to be affected by outliers
Two rules when using rate metrics
ndash Keep the denominator and numerator as debugging metrics
ndash Choose the rate metric whose denominator is relatively stable
Introduction to AB testing
A methodology using randomized experiments with two variants
The goal is to identify changes that increase an outcome of
interest in user behavior
Simple steps
ndashDefine two variants to be compared a control and a treatment
ndashRandomly assign users to one of the variants
ndashWait
ndashCalculate the aggregate outcome of interest for users assigned to control and
treatment
ndashPerform statistical tests to determine the probability of observing such a difference
between control and treatment due to random chance
Assign users to flights
Multiple numberlines
Users are simultaneously assigned to a bucket on N numberlines using independent hash functions
Users assigned to a bucket on one numberline are equally distributed across all buckets on another
numberline
Experiments within one numberline have equal impacts on controls and treatments on another
numberline
What is required to make multiple numberline
experimentation work
Experiments on one numberline must not semantically
conflict with an experiment on another numberline
Experiments on one numberline must not technically conflict
with an experiment on another numberline
No interactions between the experiments
Flash Resalt
Due to experimentation which operates on consistent buckets you can left over
effects within buckets
Usually the effect is small but in cases it can be very large
This breaks the assumption of randomized assignment
Flash resalt re-guarantees such assumption
Whatrsquos AA testing
Observe and compare the behavior of the users that will be in the control and
the users that will be in the treatment before the experiment begins
In expectation if the randomized assignment holds this will show no
differences among the flights
Main Directions of Eigen Tech
Chatbot
Machine reading
Semantic search
Knowledge graph
Risk control anti-fraud
Optimization of supply chain
Questions
Please contact jianxueaidiggercom for more discussions

Choose Right Rate Metrics
Rate metrics
ndash Have denominators that are not randomized Eg session success rate CTR etc
ndash Have bounded values and less likely to be affected by outliers
Two rules when using rate metrics
ndash Keep the denominator and numerator as debugging metrics
ndash Choose the rate metric whose denominator is relatively stable
Introduction to AB testing
A methodology using randomized experiments with two variants
The goal is to identify changes that increase an outcome of
interest in user behavior
Simple steps
ndashDefine two variants to be compared a control and a treatment
ndashRandomly assign users to one of the variants
ndashWait
ndashCalculate the aggregate outcome of interest for users assigned to control and
treatment
ndashPerform statistical tests to determine the probability of observing such a difference
between control and treatment due to random chance
Assign users to flights
Multiple numberlines
Users are simultaneously assigned to a bucket on N numberlines using independent hash functions
Users assigned to a bucket on one numberline are equally distributed across all buckets on another
numberline
Experiments within one numberline have equal impacts on controls and treatments on another
numberline
What is required to make multiple numberline
experimentation work
Experiments on one numberline must not semantically
conflict with an experiment on another numberline
Experiments on one numberline must not technically conflict
with an experiment on another numberline
No interactions between the experiments
Flash Resalt
Due to experimentation which operates on consistent buckets you can left over
effects within buckets
Usually the effect is small but in cases it can be very large
This breaks the assumption of randomized assignment
Flash resalt re-guarantees such assumption
Whatrsquos AA testing
Observe and compare the behavior of the users that will be in the control and
the users that will be in the treatment before the experiment begins
In expectation if the randomized assignment holds this will show no
differences among the flights
Main Directions of Eigen Tech
Chatbot
Machine reading
Semantic search
Knowledge graph
Risk control anti-fraud
Optimization of supply chain
Questions
Please contact jianxueaidiggercom for more discussions

Introduction to AB testing
A methodology using randomized experiments with two variants
The goal is to identify changes that increase an outcome of
interest in user behavior
Simple steps
ndashDefine two variants to be compared a control and a treatment
ndashRandomly assign users to one of the variants
ndashWait
ndashCalculate the aggregate outcome of interest for users assigned to control and
treatment
ndashPerform statistical tests to determine the probability of observing such a difference
between control and treatment due to random chance
Assign users to flights
Multiple numberlines
Users are simultaneously assigned to a bucket on N numberlines using independent hash functions
Users assigned to a bucket on one numberline are equally distributed across all buckets on another
numberline
Experiments within one numberline have equal impacts on controls and treatments on another
numberline
What is required to make multiple numberline
experimentation work
Experiments on one numberline must not semantically
conflict with an experiment on another numberline
Experiments on one numberline must not technically conflict
with an experiment on another numberline
No interactions between the experiments
Flash Resalt
Due to experimentation which operates on consistent buckets you can left over
effects within buckets
Usually the effect is small but in cases it can be very large
This breaks the assumption of randomized assignment
Flash resalt re-guarantees such assumption
Whatrsquos AA testing
Observe and compare the behavior of the users that will be in the control and
the users that will be in the treatment before the experiment begins
In expectation if the randomized assignment holds this will show no
differences among the flights
Main Directions of Eigen Tech
Chatbot
Machine reading
Semantic search
Knowledge graph
Risk control anti-fraud
Optimization of supply chain
Questions
Please contact jianxueaidiggercom for more discussions
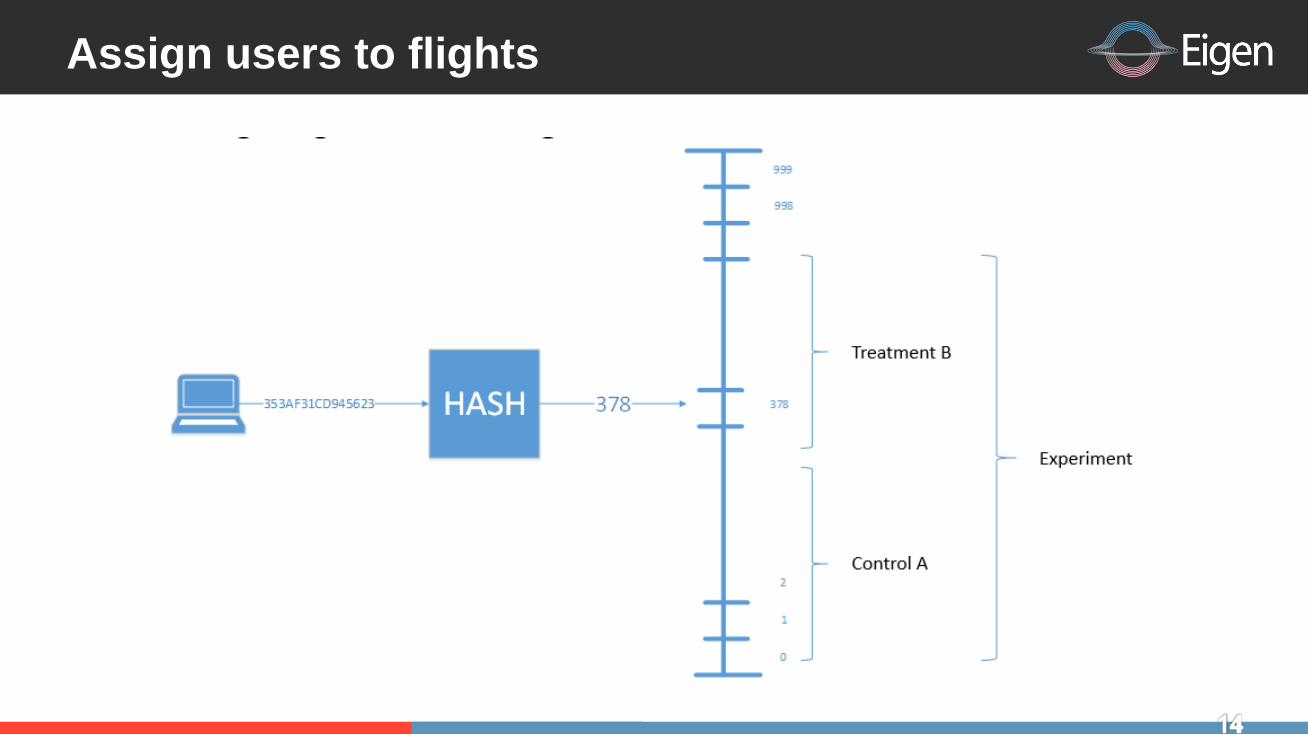
Assign users to flights
Multiple numberlines
Users are simultaneously assigned to a bucket on N numberlines using independent hash functions
Users assigned to a bucket on one numberline are equally distributed across all buckets on another
numberline
Experiments within one numberline have equal impacts on controls and treatments on another
numberline
What is required to make multiple numberline
experimentation work
Experiments on one numberline must not semantically
conflict with an experiment on another numberline
Experiments on one numberline must not technically conflict
with an experiment on another numberline
No interactions between the experiments
Flash Resalt
Due to experimentation which operates on consistent buckets you can left over
effects within buckets
Usually the effect is small but in cases it can be very large
This breaks the assumption of randomized assignment
Flash resalt re-guarantees such assumption
Whatrsquos AA testing
Observe and compare the behavior of the users that will be in the control and
the users that will be in the treatment before the experiment begins
In expectation if the randomized assignment holds this will show no
differences among the flights
Main Directions of Eigen Tech
Chatbot
Machine reading
Semantic search
Knowledge graph
Risk control anti-fraud
Optimization of supply chain
Questions
Please contact jianxueaidiggercom for more discussions
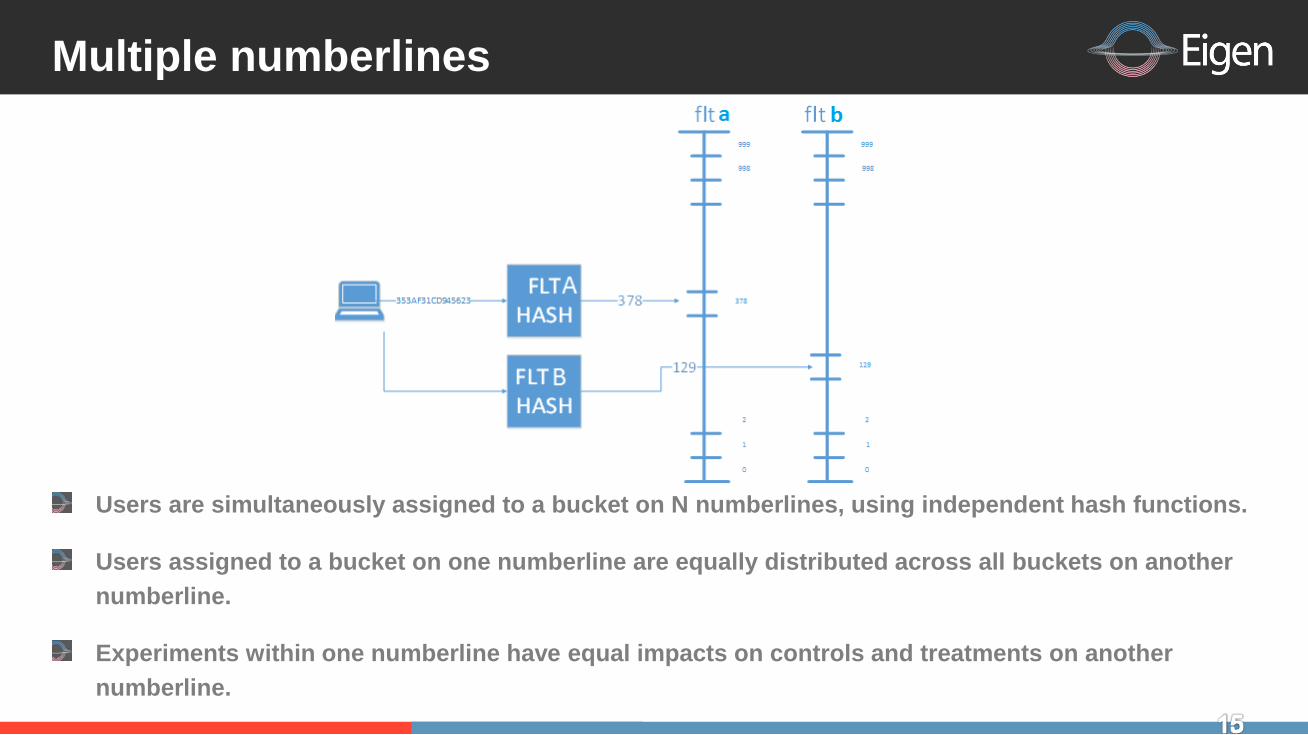
Multiple numberlines
Users are simultaneously assigned to a bucket on N numberlines using independent hash functions
Users assigned to a bucket on one numberline are equally distributed across all buckets on another
numberline
Experiments within one numberline have equal impacts on controls and treatments on another
numberline
What is required to make multiple numberline
experimentation work
Experiments on one numberline must not semantically
conflict with an experiment on another numberline
Experiments on one numberline must not technically conflict
with an experiment on another numberline
No interactions between the experiments
Flash Resalt
Due to experimentation which operates on consistent buckets you can left over
effects within buckets
Usually the effect is small but in cases it can be very large
This breaks the assumption of randomized assignment
Flash resalt re-guarantees such assumption
Whatrsquos AA testing
Observe and compare the behavior of the users that will be in the control and
the users that will be in the treatment before the experiment begins
In expectation if the randomized assignment holds this will show no
differences among the flights
Main Directions of Eigen Tech
Chatbot
Machine reading
Semantic search
Knowledge graph
Risk control anti-fraud
Optimization of supply chain
Questions
Please contact jianxueaidiggercom for more discussions

What is required to make multiple numberline
experimentation work
Experiments on one numberline must not semantically
conflict with an experiment on another numberline
Experiments on one numberline must not technically conflict
with an experiment on another numberline
No interactions between the experiments
Flash Resalt
Due to experimentation which operates on consistent buckets you can left over
effects within buckets
Usually the effect is small but in cases it can be very large
This breaks the assumption of randomized assignment
Flash resalt re-guarantees such assumption
Whatrsquos AA testing
Observe and compare the behavior of the users that will be in the control and
the users that will be in the treatment before the experiment begins
In expectation if the randomized assignment holds this will show no
differences among the flights
Main Directions of Eigen Tech
Chatbot
Machine reading
Semantic search
Knowledge graph
Risk control anti-fraud
Optimization of supply chain
Questions
Please contact jianxueaidiggercom for more discussions
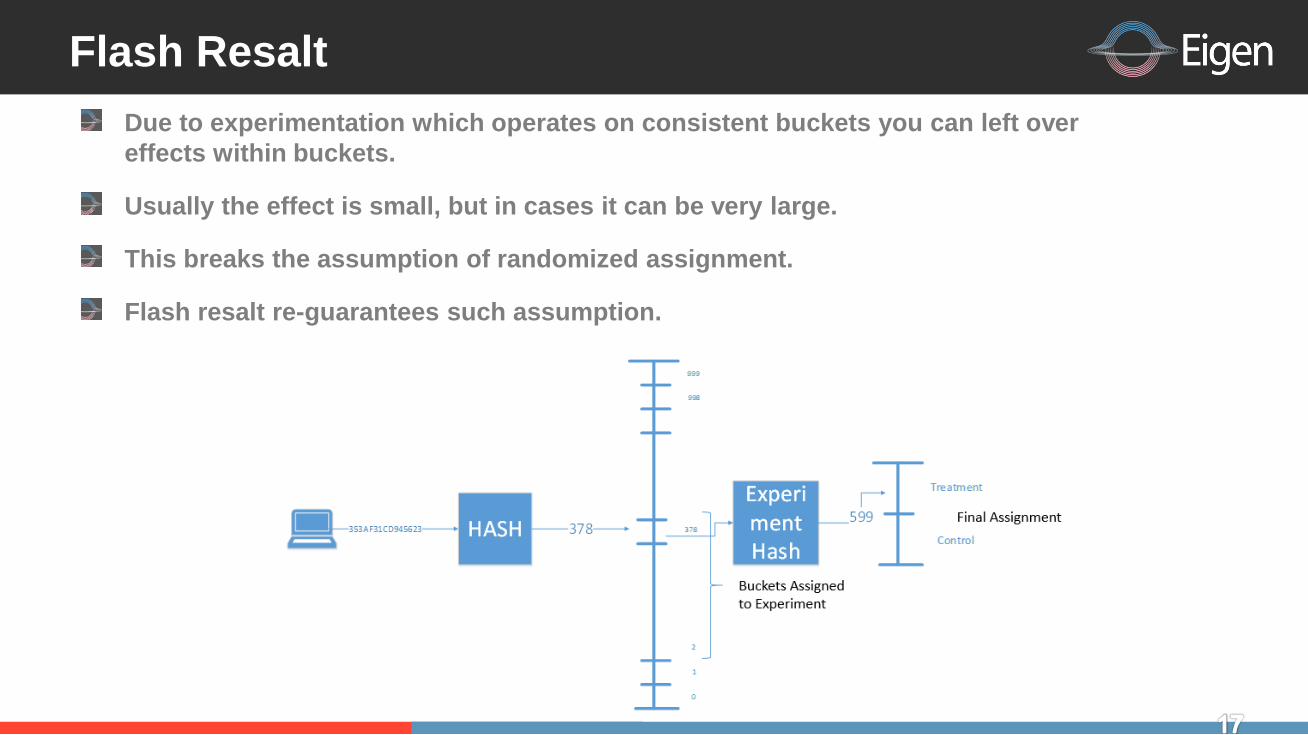
Flash Resalt
Due to experimentation which operates on consistent buckets you can left over
effects within buckets
Usually the effect is small but in cases it can be very large
This breaks the assumption of randomized assignment
Flash resalt re-guarantees such assumption
Whatrsquos AA testing
Observe and compare the behavior of the users that will be in the control and
the users that will be in the treatment before the experiment begins
In expectation if the randomized assignment holds this will show no
differences among the flights
Main Directions of Eigen Tech
Chatbot
Machine reading
Semantic search
Knowledge graph
Risk control anti-fraud
Optimization of supply chain
Questions
Please contact jianxueaidiggercom for more discussions
Whatrsquos AA testing
Observe and compare the behavior of the users that will be in the control and
the users that will be in the treatment before the experiment begins
In expectation if the randomized assignment holds this will show no
differences among the flights
Main Directions of Eigen Tech
Chatbot
Machine reading
Semantic search
Knowledge graph
Risk control anti-fraud
Optimization of supply chain
Questions
Please contact jianxueaidiggercom for more discussions

Main Directions of Eigen Tech
Chatbot
Machine reading
Semantic search
Knowledge graph
Risk control anti-fraud
Optimization of supply chain
Questions
Please contact jianxueaidiggercom for more discussions

Questions
Please contact jianxueaidiggercom for more discussions


















