
Web Scraping with Python
106
using python web scraping
-
Upload
paul-schreiber -
Category
Technology
-
view
669 -
download
8
Transcript of Web Scraping with Python

using pythonweb scraping

Paul [email protected] [email protected] @paulschreiber






☁


</>

Fetching pages➜ urllib➜ urllib2➜ urllib (Python 3)➜ requests

import'requests'page'='requests.get('http://www.ire.org/')
Fetch one page

import'requests'base_url'=''http://www.fishing.ocean/p/%s''
for'i'in'range(0,'10):'''url'='base_url'%'i'''page'='requests.get(url)
Fetch a set of results

import'requests'page'='requests.get('http://www.ire.org/')'with'open("index.html",'"wb")'as'html:'''html.write(page.content)
Download a file

Parsing data➜ Regular Expressions➜ CSS Selectors➜ XPath➜ Object Hierarchy➜ Object Searching

<html>'''<head><title>Green'Eggs'and'Ham</title></head>'''<body>''''<ol>'''''''<li>Green'Eggs</li>'''''''<li>Ham</li>''''</ol>'''</body>'</html>

import're'
item_re'='re.compile("<li[^>]*>([^<]+?)</li>")'item_re.findall(html)
Regular Expressions DON’T DO THIS!

from'bs4'import'BeautifulSoup'
soup'='BeautifulSoup(html)'[s.text'for's'in'soup.select("li")]
CSS Selectors

from'lxml'import'etree'from'StringIO'import'*'
html'='StringIO(html)'tree'='etree.parse(html)'[s.text'for's'in'tree.xpath('/ol/li')]
XPath

import'requests'from'bs4'import'BeautifulSoup'page'='requests.get('http://www.ire.org/')'soup'='BeautifulSoup(page.content)'
print'"The'title'is'"'+'soup.title
Object Hierarchy

from'bs4'import'BeautifulSoup'
soup'='BeautifulSoup(html)'[s.text'for's'in'soup.find_all("li")]
Object Searching


import'csv'
with'open('shoes.csv',''wb')'as'csvfile:'''''shoe_writer'='csv.writer(csvfile)'''''for'line'in'shoe_list:'''''''''shoe_writer.writerow(line)'
Write CSV

output'='open("shoes.txt",'"w")'for'row'in'data:'''''output.write("\t".join(row)'+'"\n")'output.close()'
Write TSV

import'json'
with'open('shoes.json',''wb')'as'outfile:'''''json.dump(my_json,'outfile)'
Write JSON




workon'web_scraping

WTA RankingsEXAMPLE 1


WTA Rankings➜ fetch page➜ parse cells➜ write to file

import'csv'import'requests'from'bs4'import'BeautifulSoup'
url'=''http://www.wtatennis.com/singlesZrankings''page'='requests.get(url)'soup'='BeautifulSoup(page.content)
WTA Rankings

soup.select("#myTable'td")
WTA Rankings
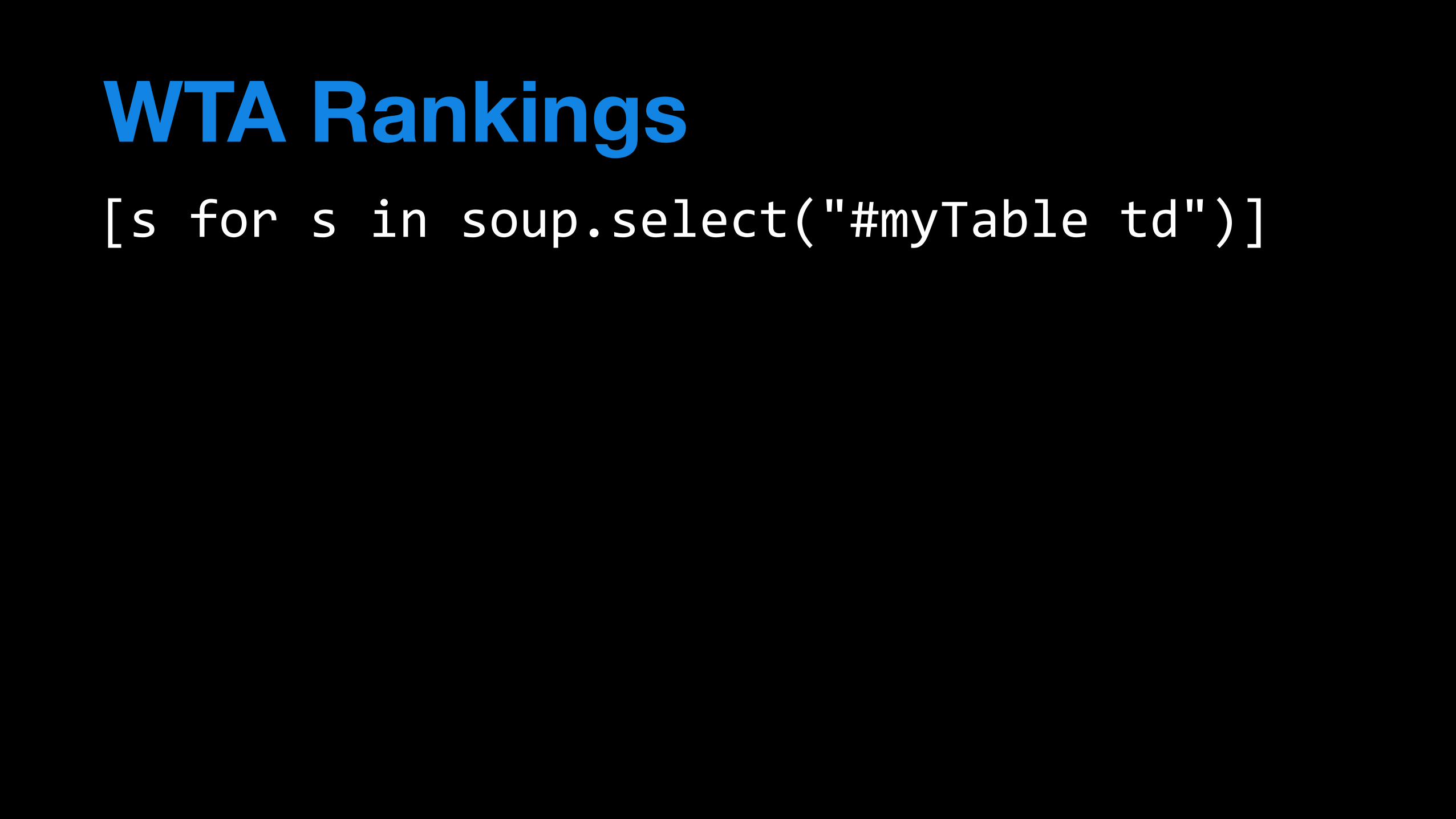
[s'for's'in'soup.select("#myTable'td")]
WTA Rankings


[s.get_text()'for's'in'soup.select("#myTable'td")]
WTA Rankings


[s.get_text().strip()'for's'in'soup.select("#myTable'td")]
WTA Rankings


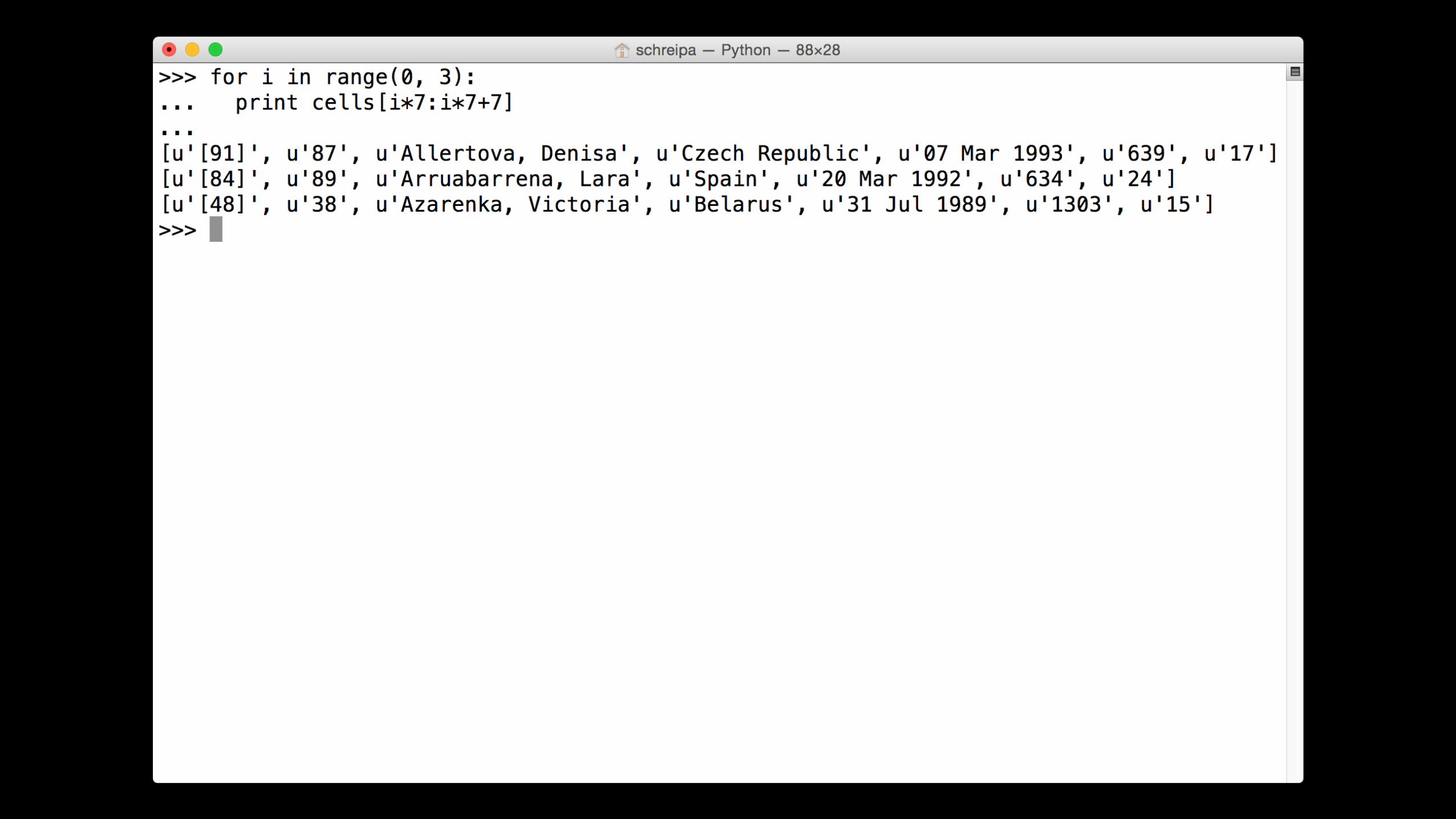
cells'='[s.get_text().strip()'for's'in'soup.select("#myTable'td")]
WTA Rankings

for'i'in'range(0,'3):'''print'cells[i*7:i*7+7]
WTA Rankings

with'open('wta.csv',''wb')'as'csvfile:'''wtawriter'='csv.writer(csvfile)'''for'i'in'range(0,'3):'''''wtawriter.writerow(cells[i*7:i*7+7])
WTA Rankings

NY Election BoardsEXAMPLE 2


NY Election Boards➜ list counties➜ loop over counties➜ fetch county pages➜ parse county data➜ write to file

import'requests'from'bs4'import'BeautifulSoup'
url'=''http://www.elections.ny.gov/CountyBoards.html''page'='requests.get(url)'soup'='BeautifulSoup(page.content)
NY Election Boards

soup.select("area")
NY Election Boards



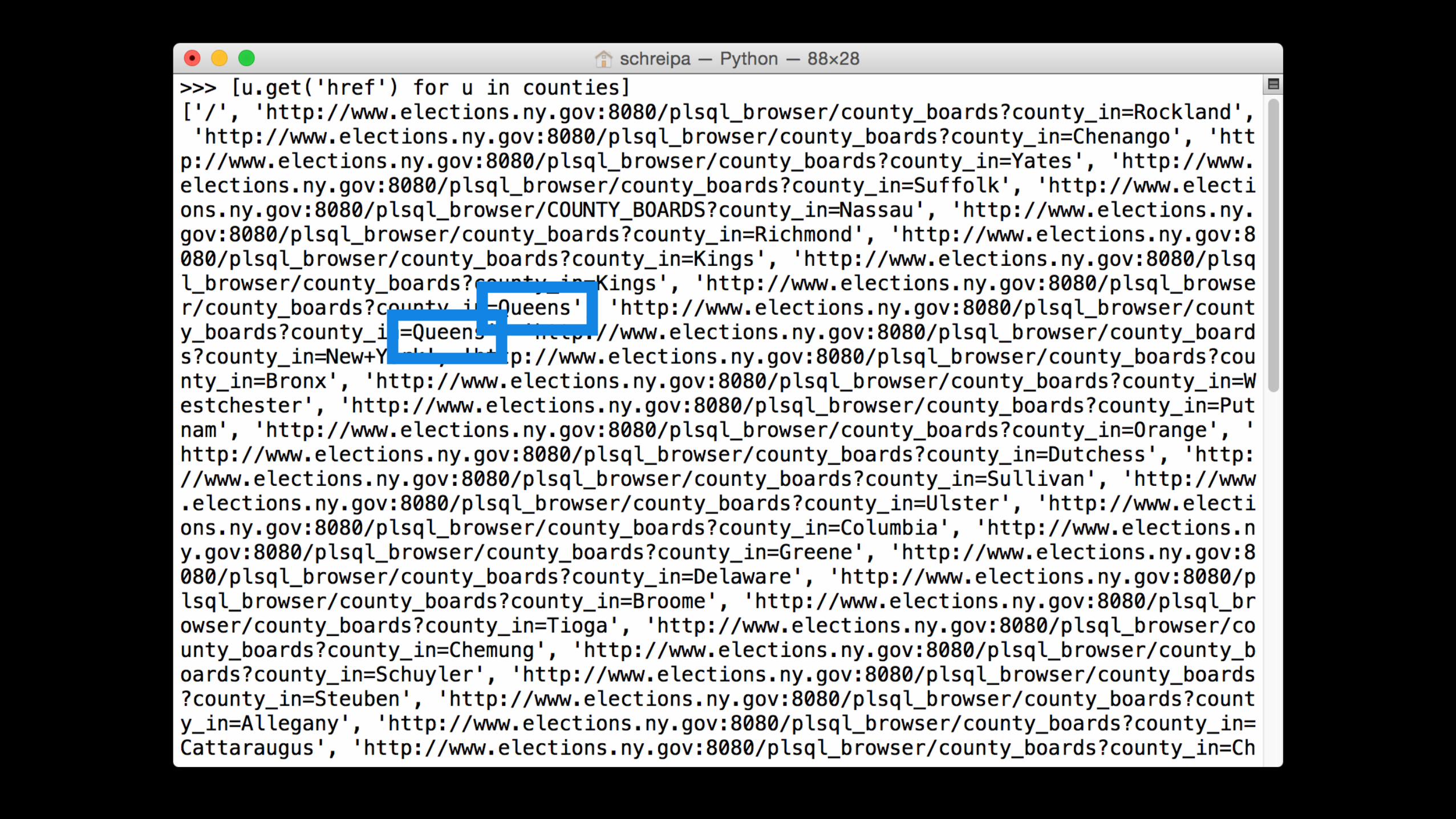

counties'='soup.select("area")'county_urls'='[u.get('href')'for'u'in'counties]
NY Election Boards


counties'='soup.select("area")'county_urls'='[u.get('href')'for'u'in'counties]'county_urls'='county_urls[1:]'county_urls'='list(set(county_urls))
NY Election Boards

for'url'in'county_urls[0:3]:'''''print'"Fetching'%s"'%'url'''''page'='requests.get(url)'''''soup'='BeautifulSoup(page.content)'''''lines'='[s'for's'in'soup.select("th")[0].strings]'''''data.append(lines)
NY Election Boards

output'='open("boards.txt",'"w")'for'row'in'data:'''''output.write("\t".join(row)'+'"\n")'output.close()
NY Election Boards

ACEC MembersEXAMPLE 3


ACEC Members➜ loop over pages➜ fetch result table➜ parse name, id, location➜ write to file

import'requests'import'json'from'bs4'import'BeautifulSoup'
base_url'=''http://www.acec.ca/about_acec/search_member_firms/business_sector_search.html/search/business/page/%s'
ACEC Members

url'='base_url'%'1'page'='requests.get(url)'soup'='BeautifulSoup(page.content)'soup.find(id='resulttable')
ACEC Members


url'='base_url'%'1'page'='requests.get(url)'soup'='BeautifulSoup(page.content)'table'='soup.find(id='resulttable')'rows'='table.find_all('tr')
ACEC Members

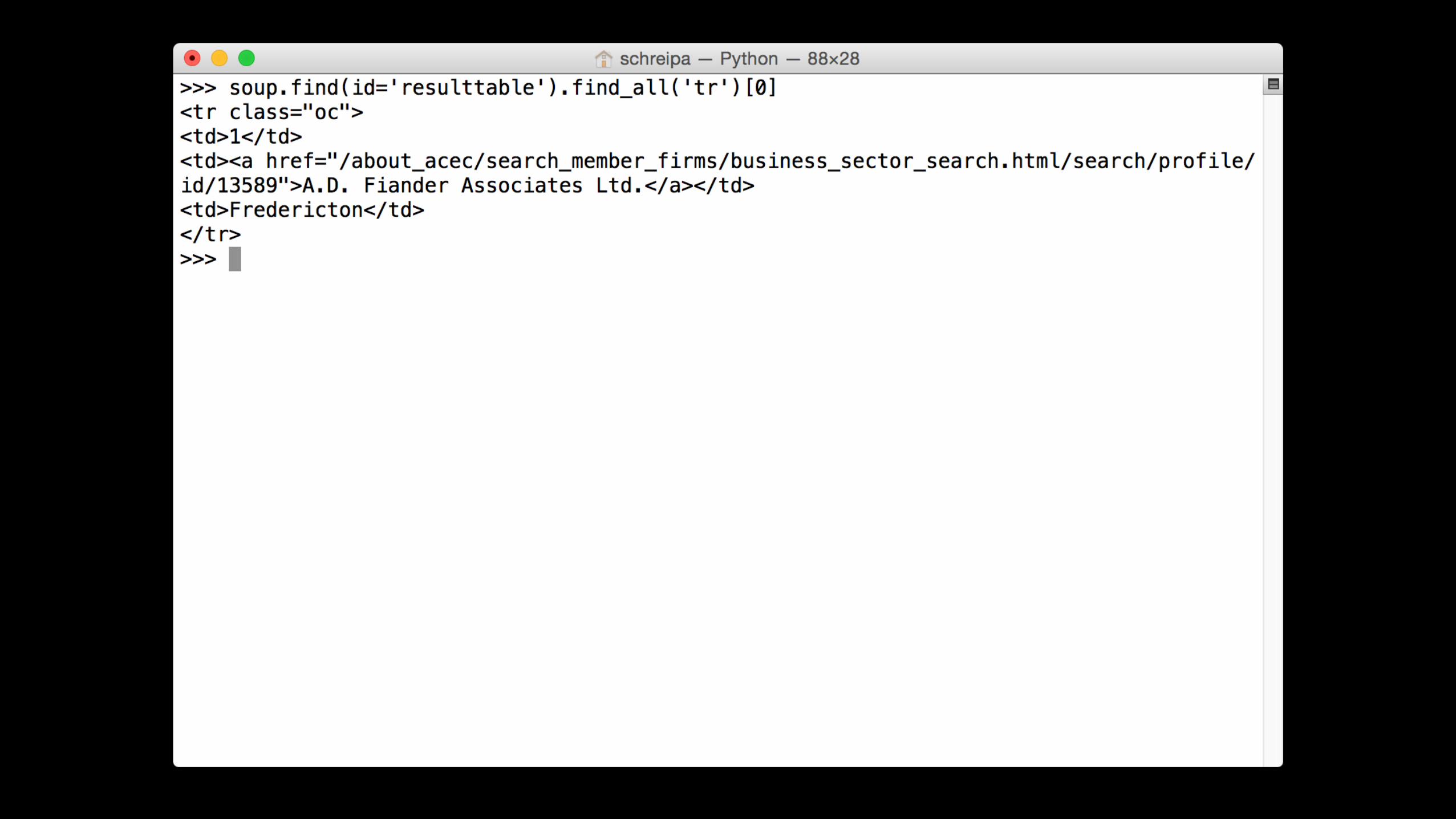

url'='base_url'%'1'page'='requests.get(url)'soup'='BeautifulSoup(page.content)'table'='soup.find(id='resulttable')'rows'='table.find_all('tr')'columns'='rows[0].find_all('td')
ACEC Members
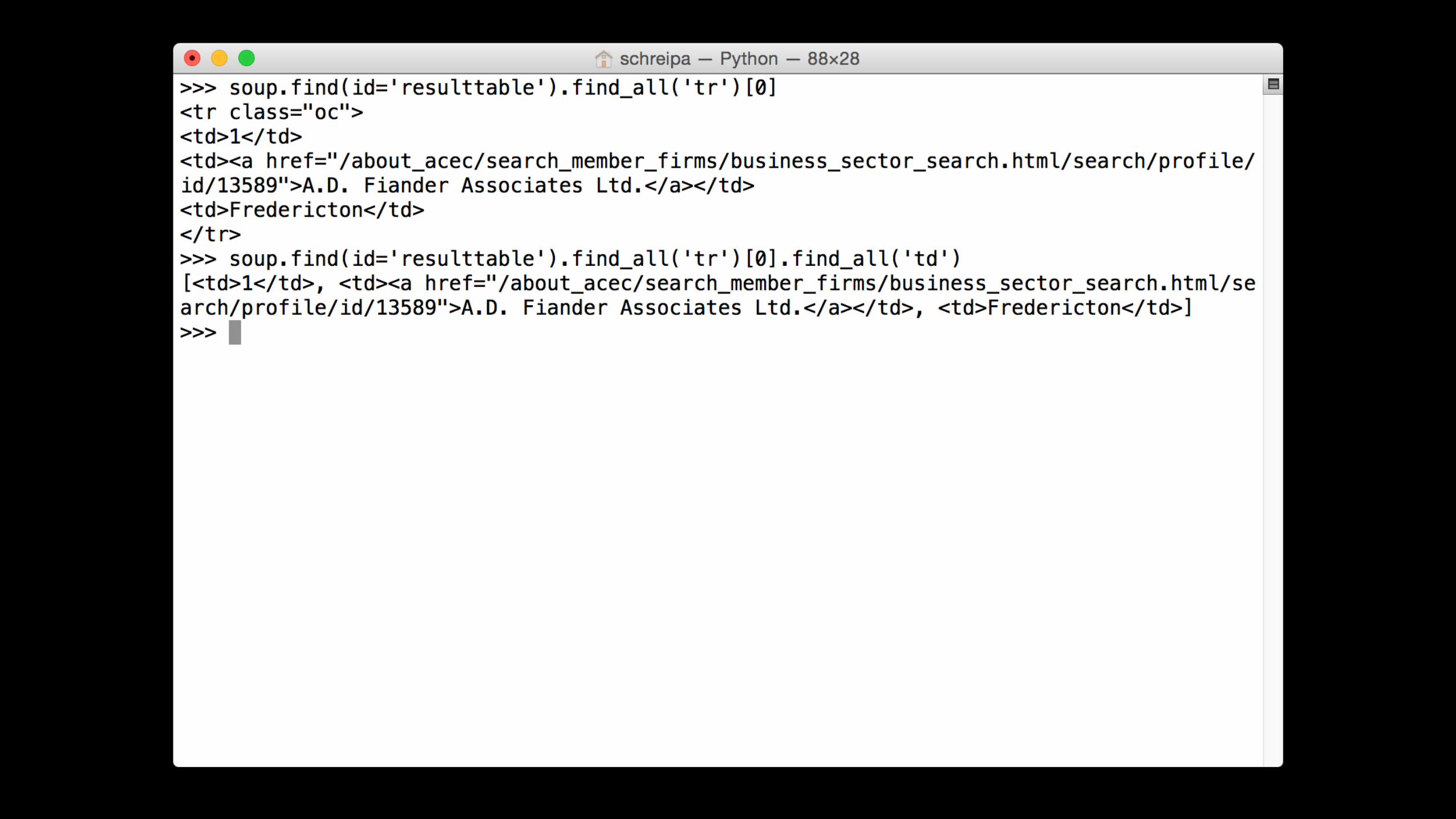

columns'='rows[0].find_all('td')'company_data'='{''''name':'columns[1].a.text,''''id':'columns[1].a['href'].split('/')[Z1],''''location':'columns[2].text'}
ACEC Members

start_page'='1'end_page'='2'
result'='[]
ACEC Members

for'i'in'range(start_page,'end_page'+'1):'''''url'='base_url'%'i'''''print'"Fetching'%s"'%'url'''''page'='requests.get(url)'''''soup'='BeautifulSoup(page.content)'
''''table'='soup.find(id='resulttable')'''''rows'='table.find_all('tr')
ACEC Members




''for'r'in'rows:'''''columns'='r.find_all('td')'''''company_data'='{''''''''name':'columns[1].a.text,''''''''id':'columns[1].a['href'].split('/')[Z1],''''''''location':'columns[2].text'''''}'''''result.append(company_data)'
ACEC Members

with'open('acec.json',''w')'as'outfile:'''''json.dump(result,'outfile)
ACEC Members


</>


Python Tools➜ lxml➜ scrapy➜ MechanicalSoup➜ RoboBrowser➜ pyQuery

Ruby Tools➜ nokogiri➜ Mechanize

Not coding? Scrape with:➜ import.io➜ Kimono➜ copy & paste➜ PDFTables➜ Tabula

☁


page'='requests.get(url,'auth=('drseuss',''hamsandwich'))
Basic Authentication


page'='requests.get(url,'verify=False)
Self-signed certificates
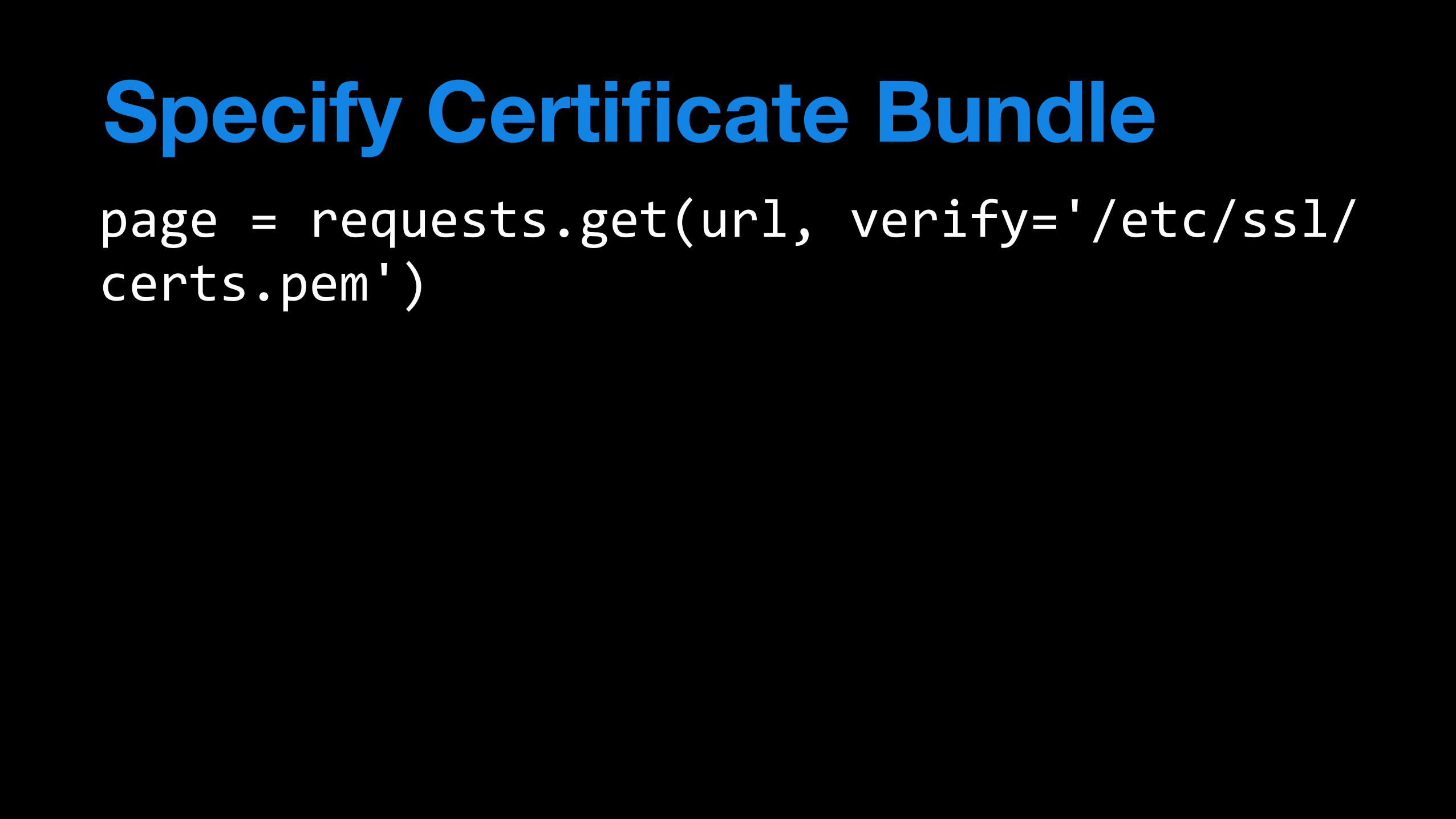
page'='requests.get(url,'verify='/etc/ssl/certs.pem')
Specify Certificate Bundle

requests.exceptions.SSLError:5hostname5'shrub.ca'5doesn't5match5either5of5'www.arthurlaw.ca',5'arthurlaw.ca'5
$'pip'install'pyopenssl'$'pip'install'ndgZhttpsclient'$'pip'install'pyasn1
Server Name Indication (SNI)


UnicodeEncodeError:''ascii','u'Cornet,'Aliz\xe9','12,'13,''ordinal'not'in'range(128)''
Fix myvar.encode("utfZ8")
Unicode


page'='requests.get(url)'if'(page.status_code'>='400):'''...'else:'''...
Server Errors

try:'''''r'='requests.get(url)'except'requests.exceptions.RequestException'as'e:'''''print'e'''''sys.exit(1)'
Exceptions

headers'='{''''''UserZAgent':''Mozilla/3000''}'
response'='requests.get(url,'headers=headers)
Browser Disallowed

import'time'
for'i'in'range(0,'10):'''url'='base_url'%'i'''page'='requests.get(url)'''time.sleep(1)
Rate Limiting/Slow Servers

requests.get("http://greeneggs.ham/",'params='{'name':''sam',''verb':''are'})
Query String
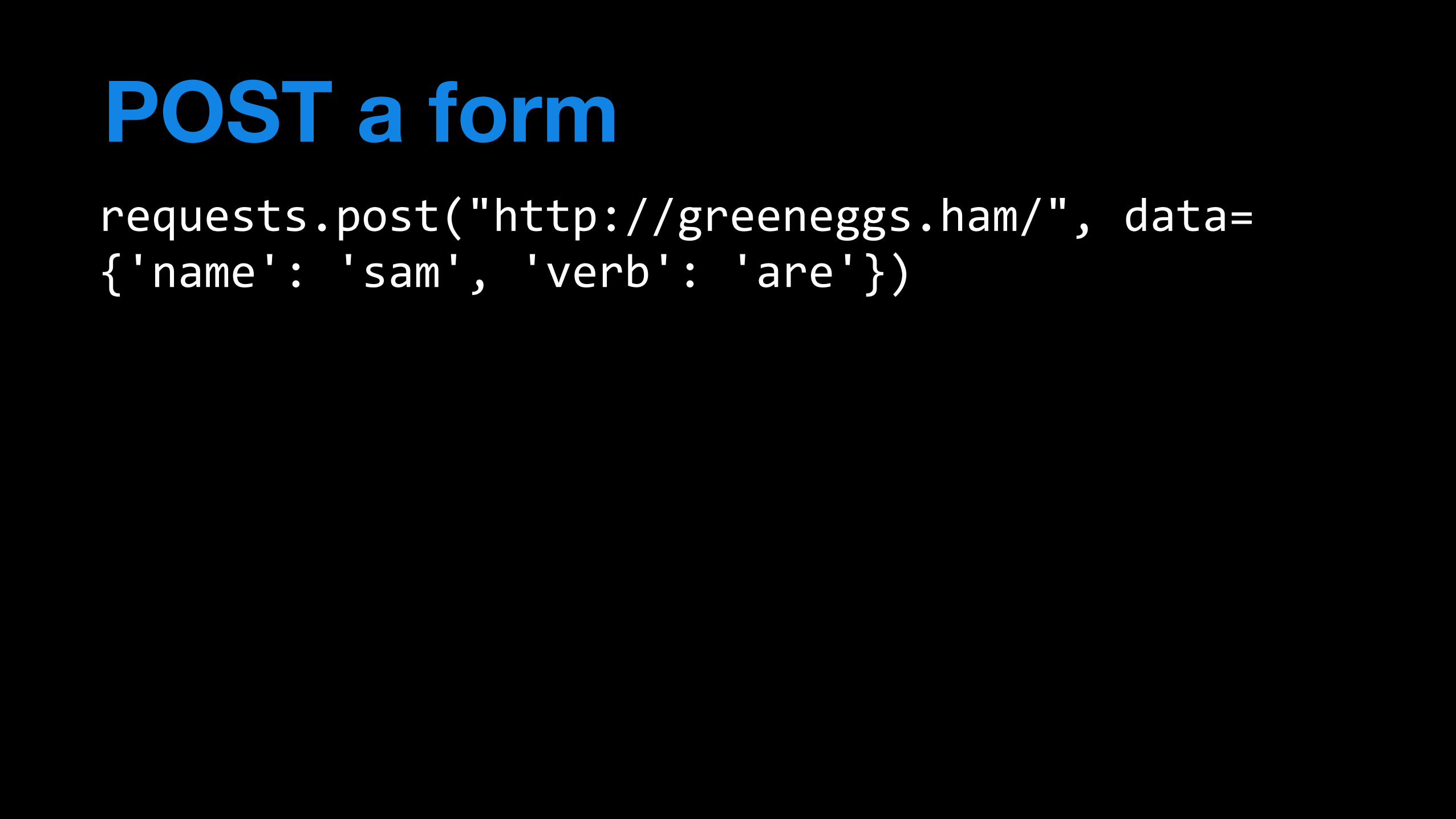
requests.post("http://greeneggs.ham/",'data='{'name':''sam',''verb':''are'})
POST a form


paritcipate

<strong>'''<em>foo</strong>'</em>


!

github.com/paulschreiber/nicar15

Many graphics from The Noun ProjectBinoculars by Stephen West. Broken file by Maxi Koichi.Broom by Anna Weiss. Chess by Matt Brooks.Cube by Luis Rodrigues. Firewall by Yazmin Alanis.Frown by Simple Icons. Lock by Edward Boatman.Wrench by Tony Gines.










![Web Scraping with PHP - php[architect]Web Scraping with PHP, 2nd Ed. III 1. Introduction 1 Intended Audience 1 How to Read This Book 2 Web Scraping Defined 2 Applications of Web Scraping](https://static.fdocuments.in/doc/165x107/5f8efea7104d3f44e5247b03/web-scraping-with-php-phparchitect-web-scraping-with-php-2nd-ed-iii-1-introduction.jpg)







