
Web Data Management - Home, WAMDM, Database …idke.ruc.edu.cn/xfmeng/course/Seminar on IT/2006-3-15...
136
Web Data Management Xiaofeng Meng Web Data Management Lab School of Information Renmin University of China
Transcript of Web Data Management - Home, WAMDM, Database …idke.ruc.edu.cn/xfmeng/course/Seminar on IT/2006-3-15...

Web Data Management
Xiaofeng Meng
Web Data Management LabSchool of Information
Renmin University of China

The previous Web: things are just on the surface

The current Web: Getting “deeper”with non-trivial access

How to enable effective access to the deep Web?
Apartments.com
Cars.com Amazon.com
Biography.com
401carfinder.com411localte.com

Amy is a new graduate, just moving to her new career
Finding sources:Wants to find papers– Where can she search papers? (DBLP, Citeseer.com, google.scholar)Wants to buy a house – Where can she look for houses in her town? (realtor.com)Wants to write a grant proposal. (NSF Award Search) Wants to check for patents. (uspto.gov)
Querying sources:Then, she needs to learn the grueling details of querying

Exploring and integrating deep Web
Explorer• source discovery• source modeling• source indexing
Integrator• source selection• schema integration• query mediation
FIND sources
QUERY sources
unified query interface
db of dbs
Amazon.comCars.com
411localte.com
Apartments.com

Our survey found…
Challenge reassured:450,000 online databases1,258,000 query interfaces307,000 deep web sites3-7 times increase in 4 years
Insight revealed:Web sources are not arbitrarily complex“Amazon effect” – convergence and regularity naturally emerge

Web database & search interface
Web database (database search engine): Web-accessible database
Data are structured and are stored in database systems.Data are accessible through a Web interface.Result pages are dynamically generated by embedding data in HTML files.

Objective
Web database integrationthe process of enabling unified access to multiple Web databases in the same application domain.
Requirements:High precision.Maximum automation.Proper and effective user interactions.

Key topics
Web interface integrationWeb data extractionResults annotation
Our work focuses on the later two topics.

Web query interface (1)
Query interface identificationConstruct a schema of the elements in the form structure.
Query interface connectionProgrammatically connect to each DBSE for passing queries and receiving results.
Query interface integration (search engine integration)

Key topics
Web interface integrationWeb data extraction
Results annotation
Our work focuses on the later two topics.

Web Data Extraction:
Web page diversityData intensive pages : Multi-records pageData record pages : Single record page

Web Data Extraction:
ApproachWrapper Induction: Wrapper generation and maintenance
Rule-based System, e.g. W4F, Lixto, SGWrap
Machine Learning Techniques, e.g. FETCH
Automatic Extraction: Directly find data recordsView Web Page as a Token Stream, e.g. RoadRunnerView Web Page as a Tree Structure, e.g. [Reis 04], DEPTAView Web page as Image, Visual processing
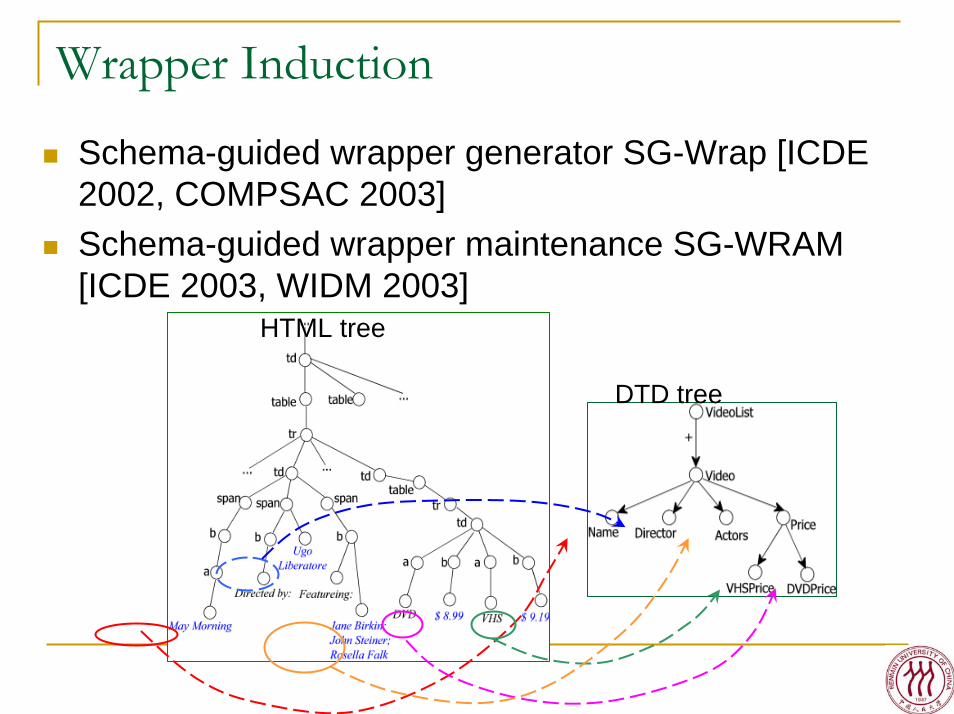
Wrapper Induction
Schema-guided wrapper generator SG-Wrap [ICDE 2002, COMPSAC 2003] Schema-guided wrapper maintenance SG-WRAM [ICDE 2003, WIDM 2003]
HTML tree
DTD tree

Automatic data extraction(1)Multi-records page
Automatically extracting data from data-rich web pages. [DASFAA 2005]
Block-list
Semantic Block
HTML page Tree representation
Block-list
Semantic Block

Automatic data extraction(2)Single-record page
RecipeCrawler: Collecting Recipe Data from WWW Incrementally[WAIM2006]
RecipeWeb Sites
RecipeBlogs
RecipeOnlineForum
Monitor
...Web
Pages Crawler
AutomatedExtractor
RecipeDB
InteractiveAnnotation
WWW
ExtractedData
RecipeViewSystem
RecipeCrawler System
RecipeView Application
Notify
CheckRecipeWeb
Pages
RecipeView System
Utilize
RecipeCategoryPages
Classifier

Automatic data extraction(3)
Vision-based web data records extractionOur objective is to extract these data records only based on visual information of web pages, which is HTML language independent
Web Page
B1
B1_1
B1_2
B2 B3
B2_1
B2_2
B3_1
B3_2
B3_3
B3_4
B1 B2 B3
B1_1 B1_2 B2_1 B2_2 B3_1 B3_2 B3_3 B3_4

Information extraction (1)
IntroductionSchema-guided wrapper generator
A supervised approachSchema-guided wrapper maintenance
An automatic approachAutomatic wrapper induction
Recipe dataVisual extraction

Introduction to information extraction
Information Extraction is originally the task of locating specific information from a natural language document, and is a particularly useful sub-area of natural language processing. A key element of data extraction systems is a set of text extraction rules or extraction patterns that identify relevant information to be extracted.

Introduction to information extraction (cont.)
Wrapper for Web pageprovide uniform mechanism for extracting data from semi-structured sources (HTML, text, …)transform semi-structured sources into structured
Restaurants inSanta Monica?
Name AddressChinois on Main 2709 Main St.Chao Dara 13 Union Sq.? ...

Schema-guided wrapper generator (1)
FeaturesUser-Defined SchemaTree representation of the html documentSupervised Wrapper GenerationExpressing Extraction Rule in XQuery

Schema-guided wrapper generator (2)
Schema Guided Wrapper GeneratorFeatures
Generating extraction rules with the guidance of user-defined schemaThe wrapper generated based on the rules could be more accurate and better reflect the users requirements. Using different schemas, the wrapper can be easily integrated into the different data integration process.

Schema-guided wrapper generator (3)User provides schema (DTD) for the target data
<!ELEMENT VideoList (Video+)>
<!ELEMENT Video (Name, Director, Actors, Price)>
<!ELEMENT Name (#PCDATA)><!ELEMENT Director (#PCDATA)><!ELEMENT Actors (#PCDATA)>
<!ELEMENT Price (VHSPrice, DVDPrice)>
<!ELEMENT VHSPrice (#PCDATA)><!ELEMENT DVDPrice (#PCDATA)>
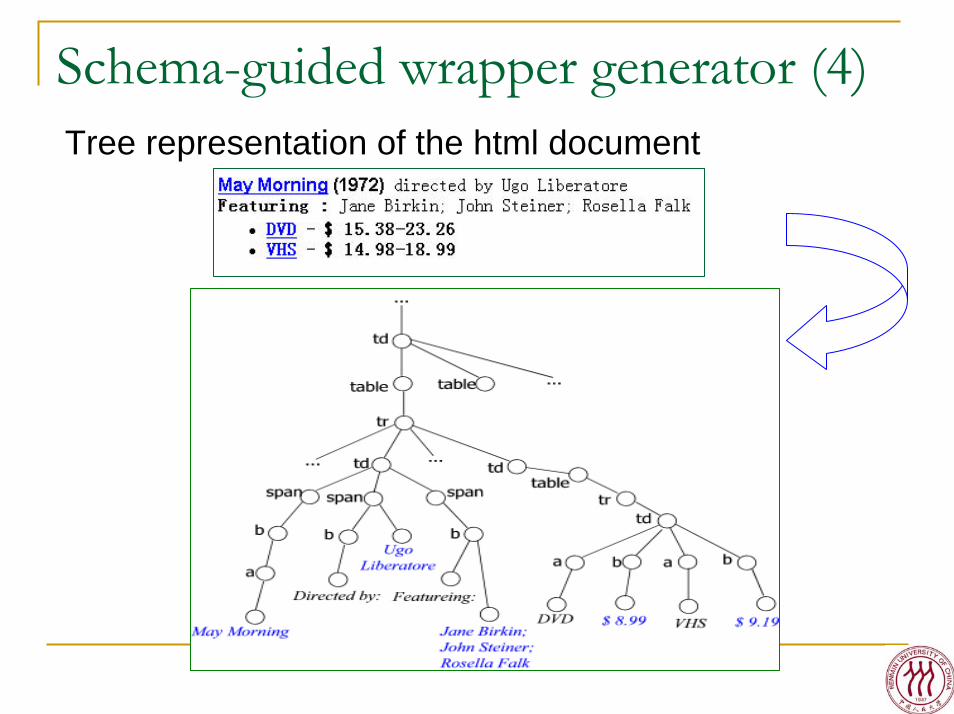
Schema-guided wrapper generator (4)Tree representation of the html document

Schema-guided wrapper generator (5)Using a GUI toolkit, users can map data items in HTML pages to elements in DTD
HTML page DTD tree

Schema-guided wrapper generator (6)Internally, the system computes the mappings from the corresponding HTML tree to the DTD treeThen generates the extraction rule
HTML tree
DTD tree

Schema-guided wrapper generator (7)• Extraction rule expression:
•Expressing Extraction Rule in XQuery
Template := "{"LetClause | ForClause"RETURN" "<" Tagname " >"
( (Template)+ | "$" variable | ExtractionFun )"</" Tagname ">"
"}"ForClause := " FOR" "$" variable " IN " XPathexpressionLetClause := " LET " "$" variable ":=" XPathexpressionExtractionFun := ( split | match | range ) " (" "$" variable ")"

Schema-guided wrapper generator (8)
An example extraction rule
Example
FOR $vedio IN $vedioList/body/div[0]/table[4]/tr[0]/td[2]/table/tr[0] /td[1]RETURN
<vedio>{ LET $name = $vedio/span[0]/b[0]/a[0]/text()[0] RETURN
<name> $name </name>}
</vedio> Paths to the data itemsValue of the data item

Schema-guided wrapper generator (9)
Current improvements

Information extraction (1)
IntroductionSchema-guided wrapper generator
A supervised approachSchema-guided wrapper maintenance
An automatic approachAutomatic wrapper induction
Recipe dataVisual extraction

Schema-guided wrapper maintenance
Problem & exampleSystem overviewWrapper Maintenance (four steps):
Data-Feature DiscoveryItem RecoveryBlock ConfigurationRule Re-induction

Wrappers for Web Sources
Extract information from Web pagesUsed in many Web-based applications
HTML Documents Wrapper
Wrapper
Wrapper
RDBMS
……… ………
Programs
XML
Application(e.g., data
Integration)

ProblemThe Web are very dynamic: contents, page structuresOriginal wrappers can stop working: rely on Web page structuresRe-generating wrappers is not easy: heavy workload to system developers
ChangedDocuments Original Wrapper
Original Wrapper
Original Wrapper Extract nothing …
Incomplete results
……… ………
Incorrect results

Example
The original wrapper fails due to the structure change.

Problems
Wrapper verification: Is a wrapper is operating correctly?
Several studies have been conducted on the verification problem:E.g., computing the similarity between a wrapper’s expected and observed output, “regression test”
Wrapper maintenance: how to automatically modify a wrapper when the pages have changed? Focus of this work

Schema-guided wrapper maintenance
Problem & exampleSystem overview
Wrapper Maintenance (four steps):Data-Feature DiscoveryItem RecoveryBlock ConfigurationRule Re-induction

The SG-WRAM System
Wrapper Maintainer
Wrapper Generator
Wrapper Executor
Data Feature Discovery
Data Item Recovery
Block Configuration
Rule Re-induction
Documents Changed Documents
XML Repository
RuleSchema
Wrapper

Schema-guided wrapper maintenance
Problem & exampleSystem overview
Wrapper Maintenance (four steps):Data-Feature DiscoveryItem RecoveryBlock ConfigurationRule Re-induction

Annotations for data itemsDescribe the semantic meaning of a data itemIndicate the location of the data item Specified by the user using the GUIRecorded in the function of “contains(pathToAnnotation, annotationValue)” in XPath
/body/div[0]/table[4]/tr[0]/td[2]/table[1]/tr[0]/td[1]/text()[0][contains(null,"directed by")]
Data values in HTML page Annotations
May Morning -
Ugo Liberatore directed by
Jane Birkin; John Steiner; Rosella Falk Featuring
15.38-23.26 DVD
14.98-18.99 VHS

Intuition of the maintenance approach
The page structure could changeObservation: many “features” of data items are more static, e.g.:
Hyperlink AnnotationPattern
These features can help us find the new places of the old data items

Step 1: Data-feature discovery
Compute features of the data items in the original page
ID DTD Element L (hyperlink) A (annotation) P (data pattern)
1 Name True NULL [A-Z][a-z]{0,}
2 Director False Directed by [A-Z][a-z]{0,}
3 Actors False Featuring [A-Z][a-z]{0,}(.)*
4 VHSPrice False VHS [$][0-9]{0,}[0-9](.)[0-9]{2}
5 DVDPrice False DVD [$][0-9]{0,}[0-9](.)[0-9]{2}

Data-Pattern Feature
A syntactic featureRepresented as a regular expression
E.g. $ 15.38 [$][0-9]{0,}[0-9](.)[0-9]{2}Can be extracted using existing technologies, e.g., [Brin98], [GHQR98], [LM00]

Annotations and Hyperlinks
Get annotation and hyperlink information from the original page
Checking the XQuerybased extraction ruleHyperlink: step of “…/a/…”in the pathAnnotation: function of “contains()”
{ LET $actors = $vedio/text()[contains(
/preceding-sibling::b[0],"Featuring")] RETURN
<actors> $actors </actors>}
{ LET $name = $vedio/span[0]/b[0]/a[0]/text()[0]RETURN
<name> $name </name>}
Hyperlink Indication
Annotation ValuePath from data item to annotation

Step 2: Data-Item Recovery
Traverse the new HTML tree following the depth-first traversal orderUse the old features to identify potential data items using 3 matching conditions:
HyperlinkAnnotationData pattern

Example[A-Z][a-z]{0,}
Check hyperlink
Check data pattern
okokRecognize a data item
Find annotation
yes Find value starting from
annotation
Check datapattern
Recognize
a data item
[$][0-9]{0,}[0-9](.)[0-9]{2}

Results of Data Item Recovery
A mapping list including all the recognized data itemsEach mapping contains
Value of the data itemPath to it in the HTML treePath of the corresponding DTD element
A sample mapping:M1’ (D: “May”,HP: …/table[0]/tr[0]/td[1]/span[0]/b[0]/a[0]/text()[0],SP: VideoList/Video/Name )

Step 3: Block ConfigurationObservation: Data items are located in semantic blocksConforms to the user-defined schemaData items are grouped in semantic blocks
Partial-MatchFull-Match
Over-Match

Computing “Full Match” Blocks
“Full match”blocks
Identify the level in a top-down mannerCheck the level by recursively considering the matches between candidate blocks and the schema

Results of Block ConfigurationA set of blocks that can fully match with the DTDEach of them is represented as a list of mappings
Examples
No. Element PATH
1 Title …table[1]/tr[0] /td[1]/span[0]/b[0]/a[0]/text()[0]
2 Director …table[1]/tr[0]/ /td[1]/span[1]/text[contains( /preceding-sibling::b[0],"Directed by")]
3 Actors …table[1]/tr[0]/ /td[1]/span[2]/text()[contains(/preceding-sibling::b[0],"Featuring")]
4 Title …table[2]/tr[0] /td[1]/span[0]/b[0]/a[0]/text()[0]
5 Director …table[2]/tr[0]/ /td[1]/span[1]/text[contains( /preceding-sibling::b[0],"Directed by")]
6 Actors …table[2]/tr[0]/ /td[1]/span[2]/text()[contains(/preceding-sibling::b[0],"Featuring")]

Step 4: Rule Re-Induction
Semantic blocks contain mappings from data items in HTML to DTD elementsInduce new extraction rule by calling the induction algorithm in wrapper generatorRefine the rule by trying to ensure the extraction rule cover all other semantic blocks
Generalization is necessary

Information extraction (1)
IntroductionSchema-guided wrapper generator
A supervised approachSchema-guided wrapper maintenance
An automatic approachAutomatic wrapper induction
Data rich page extractionRecipe dataVisual extraction

Automatic wrapper induction
Introduction and motivationPage model Overview of the approachKey sub-problems
Block segmentationDifferentiating roles of data items and schema inductionRule induction and wrapper generationUser interactions

Features of automatic data extraction
We focus on pages from data-intensive sites.Through web query interface (search engine)
Features of automatic approaches compared with existing non-automatic approaches
Do not need to have priori knowledge of pages to be extractedNo wrapper maintenanceNo human interactionsThe extracted results do not have semantic meaning requiring results annotation

Example pages to be extracted
We focus on pages launched from web query interface.

Automatic wrapper induction
IntroductionPage modelOverview of the approachKey sub-problems
Block segmentationDifferentiating roles of data items and schema inductionRule induction and wrapper generationUser interactions

HTML tree representation
The HTML document is parsed into a tree representation using Jtidy.HTML path
XPath expressions (with predicates)Precisely describe the location of a data item (a node) in the HTML tree structure
E.g. //table[0]/tr[0]/td[0]/#text[0]Occurrence-path
The list of nodes from the root to the certain nodeE.g. //table/tr/td/#text
Without considering predicatesA occurrence-path may cover more than one node

Existing model of page creationProposed in `` Extracting structure data from web pages”, Arasu, A., Garcia-Molina, H. A value X (taken from a database shown on the left) is encoded into a page using template T. The page resulting from encoding of X using T by λ(T, X).

Database schema and page schema
• Page schema defines the contents to be extracted in the pages<!ELEMENT BookList (Book+)><!ELEMENT Book (Title, Price,
Availability, Author|Authors, Publisher?, PubDate, Format)>
<!ELEMENT Title (#PCDATA)><!ELEMENT Price (#PCDATA)><!ELEMENT Availability (#PCDATA)><!ELEMENT Author (#PCDATA)><!ELEMENT Authors (Person*)><!ELEMENT Person (#PCDATA)><!ELEMENT Publisher (#PCDATA)><!ELEMENT PubDate (#PCDATA)><!ELEMENT Format (#PCDATA)>
Database schema defines the contents in the hidden database
Title Price Avail.. …
… … … …

Extended page model considering schemaPage creation
Encoding data values from database into template Database schema (s1) page schema (s2)Encoding creating schema instances of the page schemaλ(s1, s2): transform the values from database into the page schema, for each record in the database, it creates an corresponding instance (called semantic block) in the web pages
Hidden database
Page schemas
λ(s1, s2)values
Output pages
s1s2

Extended page model considering schema (cont.)
Semantic block: Each semantic block is an instance of the corresponding page schema.
Have the situations of Optional (?), Disjunction (|) and Iteration (*, +).In an HTML tree, a semantic block could correspond to a single sub-tree, or several sibling sub-trees.A semantic block represents a record in the pages.Semantic blocks of the same schema have the same role.
Block-list: A set of semantic blocks having the same role.

Example of semantic block and block-list (1)
block-list 1block-list 2
block-list 3

Example of semantic block and block-list (2)
Block-list
Semantic Block
HTML page Tree representation
Semantic Block
Block-list

Extended page model considering schema (cont.)
A page may contain more that one block-list.If there’re more than one record in the page, there’re more than one semantic block.A data item is a value encoded in the pages.The extraction problem can be resolved at different level.

Automatic wrapper induction
IntroductionPage modelOverview of the approachKey sub-problems
Block segmentationDifferentiating roles of data items and schema inductionRule induction and wrapper generationUser interactions

Overview of the approach
Page creationEncoding data values from database into template Database schema page schema
Encoding creating schema instances
Data extractionDecoding data values from pagesInducing page schema from schema instances
Decoding extracting schema instances

Overview of the approach (cont.)
Four-step procedure of automatic extraction to recur the page schema and extracting data
Discover schema instances (block-list and semantic blocks) in the sample page.Differentiating roles of data items.Inducing schema, computing extraction rule and generating wrappers.

Automatic wrapper induction
IntroductionPage model and problem statementProblem statementKey sub-problems
Block segmentationDifferentiating roles of data items and schema inductionRule induction and wrapper generationUser interactions

Block segmentation (1)
This part is still on developing and improving.To get instances of the page schema(s) from the sample pages.
Extracting block-lists and semantic blocks.Selecting proper sample pages
Approach 1: pages resulted from the same keywords inputting to the search engine, e.g. we usually get a list of pages from one query.
We prefer this kind of sample pages.Approach 2: pages resulted from the same search engine using different keywords.

Block segmentation (2)
Observation 1: The main differences between two real web pages created from the same template are the differences between their schema instances (semantic blocks).Observation 2: Data objects (record) in result pages share a common HTML tag structure and are listed continuously.
More sample pages are needed if there’re only few, e.g. only one, data objects in one page. The data objects of them are combined to make sure we get a list of data objects, just like discovered from one page.

Block segmentation (3)Observation 3: If there’re more than one block-list in a page, they usually locate at different subtrees.
This observation is correct in most of the web sites we tested.
block-list 1block-list 2
block-list 3

Block segmentation (4)
Discover schema instances (semantic blocks)Getting different subtrees from sample pages through tree comparing.
Difference 1: Same structure but different valuesDifference 2: Different structure and different values
Computing block-lists by dividing the different subtrees into groups, subtrees in which have the same HTML path to their roots.Discovering semantic blocks inside each block-list.

Block segmentation (5)
Select which block-list to extract detailed dataIt’s necessary to be able to select which block-list the user is interested in.
Previous work on automatic extraction does not provided such capability, but simply extracts all the different values between two sample pages.Significant block-list: the block-list containing the main parts of the data encoded in the pages.

Block segmentation (6) : example
Different subtrees, divided into two block-lists, between two pages from the same query

Block segmentation (7) : example
• Semantic blocks extracted from the significant block-list.
• With paths normalized.
• Each of the path represents a subtree containing a data object
//table[12]/tr[0]/td[0]/table[1]/tr[0]/td[0]/form[0]/table[1]/tr[0]/td[2]
//table[12]/tr[0]/td[0]/table[1]/tr[0]/td[0]/form[0]/table[1]/tr[2]/td[2]
//table[12]/tr[0]/td[0]/table[1]/tr[0]/td[0]/form[0]/table[1]/tr[4]/td[2]
//table[12]/tr[0]/td[0]/table[1]/tr[0]/td[0]/form[0]/table[1]/tr[6]/td[2]
//table[12]/tr[0]/td[0]/table[1]/tr[0]/td[0]/form[0]/table[1]/tr[8]/td[2]
//table[12]/tr[0]/td[0]/table[1]/tr[0]/td[0]/form[0]/table[1]/tr[10]/td[2]

Block segmentation (8)
Considerations for improvements:Visual information: the repeated blocks have the feature that they have repetition on visual effects.Invariant strings: a list of repeated blocks have a repetition of some invariant strings.Sample pages: get two kinds of pages by submitting two queries, valid and invalid queries, to the query interface.
An invalid query returns a page without useful blocks.Comparing the invalid page to the valid pages reduces the search scope.

Differentiating roles of data items (1)Two data items have the same role if they are corresponded to the same element in the schema.For each data item in a semantic block, we want to find out data items having the same role in other semantic blocks.The approach is call Item Identification.

Differentiating roles of data items (2)
Challenges of Item IdentificationIterations: The instances of these schema elements can iteratively appear in the page. Iterations are the most common cases in the real web pagesOptionals: Given a schema element, we cannot find corresponding data values in every semantic blocks. Optionals are represented by the cardinality“?”.Disjunctions: E.g. “a|b”, which means at the corresponding relative position can be “a” or “b”, but only one of them.

Differentiating roles of data items (3): example
optional
iteration
Disjunction or optional

Differentiating roles of data items (4)
Simple identification problemThe pages have regular structure: data items of the same role have the same HTML path inside the semantic blocks.Most of the pages can be resolved by simple labeling.Rule of HTML path: Two data items with the same HTML path inside the semantic blocks have the same role.
The path starts from the root of the semantic block and ends at the node(s) containing the values.

Differentiating roles of data items (5)• Example of simple identification
Each row is a semantic block. //td[0]/b[0]/#text[0]

Differentiating roles of data items (6)
Complex identification problemThe data items of the same role do not have the same HTML path in all the blocksTheoretical problems
Discovering optionalsDiscovering disjunctions: can be resolved by handling optionals. E.g. a|b a?, b? in HTML pagesDiscovering iterations

Differentiating roles of data items (7)
Observation: The items in the semantic blocks can be classified into two categories:
Template items, which may be contents of the template of the pages, e.g. invariant strings.Data values, which are the values we want to extract from web pages.
Main idea of the approach: Dividing the semantic blocks into smaller cells for improving the precision of item identification.Different granularities in our consideration:Semantic blocks divided sections
path-groups final data items

Differentiating roles of data items (8)
• Example of template items

Differentiating roles of data items (9)Features of template items
Template items of the same role have the samevalue occurring in all the semantic blocks.Template items of the same role have the sameoccurrence-path.The syntactic features, mainly the pattern of the values, of the annotations in the semantic blocks are usually similar.
E.g. all the items ending with a colon are template items in the example page.
The features are used to discover possible template items from semantic blocks.

Differentiating roles of data items (10)
Dividing block into smaller cells (for further steps) using discovered template items.
Firstly building full-divisionThen divide each semantic block.
Full-divisionContaining all the template items occurring in the semantic blocks.Each slot between two template items may contain data items. All the data items in a slot are called a Section.
{0} Our Low Price: {1} Availability: {2}Author: {3} Authors: {4} Publisher: {5}Publish Date: {6} Format: {7}

Differentiating roles of data items (11)Each semantic block is divided into sections by comparing the list of discovered template items with the full-division (suppose the Id(section) gets the ID of a section).
For each pair of neighboring template items ti and ti+1 in a semantic block, we first find out all the sections {sj … sk} contained between ti and ti+1 in the full division. After that, the ID of the section s0 between ti and ti+1 is assigned to be (Id(sj)-Id(sk));As to the section s0 just before the first template item t0 in the semantic blocks,we first find the section sj just before t0in the full-division, then the ID of s0 is assigned to be (0-Id(sj)); conversely the last section is handled.

Differentiating roles of data items (12)
The relation between a section s’ in a semantic block and a section s in the full-division can be one of the follows:
If Id(s) equals Id(s’), the two sections have the same role. If Id(s) is included by Id(s’), which means that Id(s) locates at the range specified by the starting ID and ending ID of Id(s’), we know that there exists situation of optionals.If the intersection of Id(s) and Id(s’) is not empty, the two sections are called possibly matched. And here exists at least one pair of path-groups having the same role in the two matched sections.

Differentiating roles of data items (13)
• Example of dividing semantic blocks into sections using the template items.
{0} Our Low Price: {1} Availability: {2}Author: {3~5} Publish Date: {6} Format: {7}
{0} Our Low Price: {1} Availability: {2~3} Authors: {4} Publisher: {5}Publish Date: {6} Format: {7}
{0} Our Low Price: {1} Availability: {2}Author: {3} Authors: {4} Publisher: {5}Publish Date: {6} Format: {7}
Containing optionals
Full-division

Differentiating roles of data items (14)Further segmentation inside a section:
Path-group: Two neighboring data items are divided into two path-groups if they do not have the same occurrence path.Inside path-groups are the actual data items: there may be more than one data item in .
Path-groups
Data items
Example of path-groups in a semantic block

Differentiating roles of data items (15)Rules for complex labeling
Rule of Occurrence-Path: (i) Two items from different semantic blocks with different occurrence paths have different roles; (ii) Two items in the same section with different occurrence paths have different roles.Rule of Visual info: Two items with different visual effects usually have different roles.Rule of Context: Two items with different contexts have different roles.Rule of Syntactic Feature: Items with the same syntactic features (e.g. patterns in regular expression) may have the same role.

Differentiating roles of data items (16)
Computing matching between data itemswe compute an aggregate similarity of two data items d1 and d2, denoted as Sim(d1; d2), based on all the four above rules.The functions RO, RC, RS and RV correspond to the four rules presented above. For each of them, it takes value 1 if the two data items satisfy the certain rule, else its value is 0.λ(i = 1; 2; 3; 4) is the weight of each rule which shows the importance of the rule in the process.If the similarity are larger than a pre-given threshold, we know that the data items match most of the above rules and are considered to have the same role.The aggregate similarity greatly decreases the chance that one of the rule’s failure resulting an incorrect identification.

Differentiating roles of data items (17)
The procedure of complex identificationThe order of handling: Semantic blocks divided sections path-groups data itemsIntuitively, the complex identification problem is achieved through differentiating roles of sections, and then differentiating roles of path-groups and data items inside the set of matched path-groups.
The results: each data item in the semantic blocks is assigned a role, which indicates are corresponding element in the schema.

Differentiating roles of data items (18)
Detecting iterationsUse the separators between iterated data items
E.g. in our example page, there exists the separator `&’Iterations inside a path-group is detected by computing the similarity of all the data items in it.
E.g. path-groups p={d1,d2} and p’={d1’,d2’,d3’}, suppose p and p’ have the same role and Sim(d1,d2), Sim(d1’,d2’,d3’) are larger than the pre-defined threshold, we find that there exist iterations in these path-groups.
Iterations at the level of semantic blocks are automatically detected by find more than one block.

Differentiating roles of data items (19)
Detecting optionalsData items having the same role do not appear in all the compatible sections.
Detecting disjunctionsThe problem of detecting disjunctions is transformed into detecting optionals: in HTML pages we conclude that the situation (a? | b?) equals the situations (a?) and (b?) without losing exactness.

Differentiating roles of data items (20) : results of this stepLabel Sample 1 Sample 2
A Developing Java Web services …B $33.25 …C In Stock: Usually Ships in … …D NULL …E Ramesh Nagappan …
Rima P. Sringanesh …Robert Skoczylas …
F John Wiley & Sons …G 2/1/2003 …H Paperback …

Inducing schema, computing extraction rule and generating wrappers (1)
• constructing the schema tree from labeled items
• focusing on the cardinalities (?, +/*, |) of schema elements
• the hierarchical structure represents the structure of contents in the semantic blocks

Inducing schema, computing extraction rule and generating wrappers (2)
Use the rule induction system in SG-Wrap (schema-guided wrapper generator)
XPath based extraction ruleThe finally output wrapper is a piece of Java program.

Key topics
Accessing to web query interface and interface integrationInformation extraction
Results annotationIntegration and applications
Our work focuses on the later three topics.

Results annotation (1)Task: Attach a semantic meaning to each data item extracted through the above steps.The results of automatic extraction do not contain semantic meaning.Results annotation is related to semantic Web:
Semantic annotation of the Web.Four approaches:
Assumption: Labels of values are on the result page and are close to the values.The web query interface can provide some labels.In most of the sites exists two kinds of pages: list pages and detail pages. Labels on these two kinds of pages can usually help the annotation problem of each other.Methods from ontology.

Results annotation (2)• Examples that labels locate at the result page.
Label Data itemList Price $39.95Buy new $27.96In-store Pickup $35.96Used & new $24.89

Results annotation (3)
Extracting labels locating in the results pageSearch for voluntary labels in table headers.Search for labels near the data items.
Considering the visual information, the label of a data item is usually arranged near the data item: (i) in the same string of the data item; (ii) in the same row before or after the data item; (ii) in the same column of the data item; etc.Considering the ``distance” between the data items and labels (Investigated in L. Arlotta, V. Crescenzi, G. Mecca, P. Merialdo. Automatic Annotation of Data Extracted from Large Web Sites. WebDB, 2003).

Results annotation (4)Extracts labels in the web query interface
The schema of the interface and the schema of the results page always have intersections. The keywords submitted to the interface decide the contents of the data objects in the results page.
Case1: the same keyword repeatedly appear in the results page, e.g. when the keyword is a string.Case2: the certain data items (related to the same schema element) in the data objects are always included by the input keywords. For instance, the numeric domains (e.g. the departure and arrival date in travel plan), etc.More … (still on investigating)

Results annotation (5) : example query interface
Author
Title
Subject
ISBN
Publisher
Used only
Format
Reader age
Language
Publication dateSort results byHas corresponding data item the results page.

Results annotation (6)
Use the intersections of list pages and detailed pages
List pages: pages directly acquired from the query interface.Detailed pages: pages acquired from the hyperlinks of the data items in the list pages.
For each data object in the list pages, there may be several detailed pages.
Usually the detailed pages provide more information and labels than the list pages.The detailed pages’ schema are usually different to the list pages’ schema: name of element, contained element, etc.

Results annotation (7): examples of list page and detailed page
• Some data items can be annotated by the comparing between list pages and detailed pages.
• Edition Paperback
• Availability Usually ships within 24 hours

Results annotation (8)
Label data attributes in conventional formats. This applies to date, email, price, etc.
E.g. use the pattern for a set of data items belonging to the same schema element.

Information extraction (1)
IntroductionSchema-guided wrapper generator
A supervised approachSchema-guided wrapper maintenance
An automatic approachAutomatic wrapper induction
Data rich page extractionRecipe dataVisual extraction

RecipeCrawler: Collecting Recipe Data from WWW Incrementally
Recipe Web Pagesone web page contains only one recordfollow an underlying templateoptional attributes.

a bc

RecipeCrawlerAn Incremental Data Extraction System
Goal: building a robust system to collect structural recipe datafrom WWW continuously.
After crawling initial web pages, it should extract data from them.Whenever adding new records, the system should be aware of it and also extract new data as soon as possible
The mission of RecipeCrawler is to provide RecipeView with the recipe data records which are embedded in web pages.
RecipeView is a user-centered multimedia view application built on top of the recipe database and provide user continuous, flexible user experience.
Input: A number of recipe Web sites.Output: Recipes on those Web sites in structural forms.

RecipeCrawlerThe Overview
RecipeWeb Sites
RecipeBlogs
RecipeOnlineForum
Monitor
...
WebPages Crawler
AutomatedExtractor
RecipeDB
InteractiveAnnotation
WWW
ExtractedData
RecipeViewSystem
RecipeCrawler System
RecipeView Application
Notify
CheckRecipeWeb
Pages
RecipeView System
Utilize
RecipeCategoryPages
Classifier

The Challenge and The Goal
The ChallengeIt is unpractical to crawl all the recipe pages from a web siteIt is almost impossible to induce a general template from first batch of recipe web pages
The GoalIncrementally crawling specific web pagesIncrementally extracting web pages for data records

Incrementally Crawling Specific Web Pages
Challenge 1It is unpractical to crawl all the recipe pages from a web site
Incrementally crawling is necessary.Monitoring index facilities, such as indices of recipe Web SiteNew links can be detected by comparing new index page to old one.How to justify the new link pointing to recipe page?
The data extracted previously can be uitilized.

Incrementally Crawling Specific Web Pages
Link URL
HTMLPath
Link Text
Naïve comparing updated web page with old version can detected “new links”.How to clarify them?
Intuitively, justify based link pattern or text pattern may work.However…

Incrementally Crawling Specific Web Pages
Text patterns“Fowl Stuffed Duck” v.s. “70% Discount! Beijing Duck!”
Link patternshttp://www.nicemeal.com/recipes/beijing/duck-1.htmlhttp://www.nicemeal.com/recipes/beijing/BeijingDuckAd.html
However, HTML Path/html/body/…/table[6]/tr[1]/td[0]/… (Fowl Stuffed Duck)/html/body/…/table[6]/tr[2]/td[0]/… (Stewed Assorted Lotus)/html/body/…/p/… (70% Discount! Beijing Duck!)
On the other hand, we also have extracted data recordsOur Strategy:
Link Pattern -> HTML Path -> Text Pattern
Link Text Link URL HTML Path ...Record 1 Stewed... /html/body... ...Record 2 Steamed... /html/body... ...Record 3 Sauteed... /html/body... ...
http://nice...http://nice...http://nice...
Extracted Data

Incrementally Automated Data Extraction
Challenge 2It is almost impossible to induce a general wrapper from first batch of recipe web pages
FormulationFor a Web Site, suppose the first batch of Web Pages (P1, P2, … , P10) can be crawled at once.Then the Web Pages (P11, P12, … , P20) will be added one by one later.Usually wrapper generated from first batch will not work in second batch, so automated data extraction is preferred.

Incrementally Automated Data Extraction
Partial Template Alignment (PTA)Proposed in DEPTAThe basic idea is to merge trees recursively
PTA can help us to do incrementally data extraction, except
How to handle repeatable attributes?How to extract partial data when tree can not be merged?

Incrementally Automated Data ExtractionP
a b e
T1
d
P
a d e
T2
d f
T2
P
a d+ e
T2
f
P
a b ed f
1 2 3 4 5 6a b d ea d d e f
t1t2
a c d d e fa c d f
t3t4t5 a b c d
Our algorithm is based on PTA, except
It only start from the biggest web page of current batch.Sibling matching will handle the repeatable attribute.When we can not find an attribute an insert location, we merge its value into possible node.When possible value is matched in future, a new attribute is possibly identified.
To be simple, each character denoting a subtree like “<LI>Materials: <BR>Beef 150g</LI>”

P
a b ed f
P
a b ed f
c
P
a d
T4
a dc f
P
a b ed f
c P
a b ed fc
P
a d e
T3
d
P
c f
1 2 3 4 5 6a b d ea d d e f
t1t2
a c d d e fa c d f
t3t4t5 a b c d
(T1,T2)
P
a c
T5 P
a b d

Automated Extraction and Interactive Annotation
AutomatedExtractor
InteractiveAnnotation
RecipeData
RecipeWeb
Pages
RecipeCategoryPages
CategoryData
Notify when new attribute discovered
SystemAdministrator
RecipeRecord
Select annotated attribute and Join according to URL

Information extraction (1)
IntroductionSchema-guided wrapper generator
A supervised approachSchema-guided wrapper maintenance
An automatic approachAutomatic wrapper induction
Data rich page extractionRecipe dataVisual extraction

Vision-based web data records extraction
More and more Web DBs and search engines emerging in web. It is important for integrating heterogeneous information sources on the web.
Most of the useful information is obtained by posting queries to query interfaces.
Our objective is to extract these data records only based on visual information of web pages, which is HTML language independent.

Our approach is implemented in three steps:Step 1 build Visual Block tree by visual contents of response pages
Step 2 discover data region in Visual Block treeStep 3 extract data records from data region
Data regionResponse page
Data records

Limitations of previous works
The pages not written by HTML language
HTML language is still evolutional
More and more web pages adopt CSS and JavaScript
If HTML language is replaced by a new language in future

Interesting visual observations for response pages
Position Feature (PF)Data region always crosses by the perpendicular bisector of the response pageThe area of data region is big enough (relative to the area of whole page)
Layout Feature (LF)The data records align as flush leftData records are adjoining, not overlapped and have the same space
Appearance Feature (AF)Similar size of images in data recordsSimilar fonts used in data records

Experiments
Data setSizeQuality
Performance measuresPrecisionRecallRevision
Experimental resultsCompared with MDR

Data set
SizeCompletePlanet.More than 2000 web sites More than 10,000 pages
QualityDuplicate web sitesWeb search engines

Performance measures
Traditional measuresc
r
DRrecallDR
=e
cDRprecisionDR
=
t c
t
WS WSrevisionWS−
=
New measures

An interesting example for revision
A1 A2 A3
DRe Drc DRe Drc DRe Drc
Web site 1 10 9 9 11 10 10 10Web site 2 10 9 9 11 10 10 10Web site 3 10 9 9 11 10 10 10Web site 4 10 9 9 11 10 10 10Web site 5 10 9 9 11 10 0 0
precision 100% 90.9% 80%
recall 90% 100% 80%
revision 100% 100% 20%
DRr

Experimental resultsVEB MDR
Total data records(DRr) 18944
Extracted data records(DRe) 18859 11443
Correct data records(DRc) 17940 9680
Total pages 980
Total web sites 196
Correct web sites 160 87
precision 95.1% 84.6%
recall 94.7% 51.1%
revision 18.4% 55.6%

Other WorkWeb Data Integration
Schema Guided Wrapper GenerationSGWRAP: ICDE2002, JCST Vol.17(4)
Schema Guided Wrapper MaintenanceSGWRAM: ICDE2003, WIDM2003
Automatically extracting data from data-rich web pages: DASFAA2005Native XML Database System-OrientX
XML index: SIGMOD2004, ICDE2005Schema based storage strategy: VLDB2003Numbering Schema: WWWJ, DASFAA2004XML View: DASFAA2004
Mobile DatabaseMobile Transaction: DASFAA2001, JCST Vol.17(4), 计算机学报,软件学报Moving Object Model - FTMOD: DEXA2003Moving Object Index Update: DASFAA’2003, WAIM2006DyNSA: A Dynamic Navigation System: APWeb2006Embedded Database System for PDA, mobile phone: Flash based DBMS

Summary
Paper Research System Research
Mobile Data “小金灵”
Web Data SG-WRAPOrientI
XML Data OrientX
Mobile Web ?

The end~Any question?
Thanks


The end~Any question?
Thanks

















