
Web Crawler
26
SEARCH ENGINE SUBMITTED BY : Tantan ( )
-
Upload
vaibhavtyagi111 -
Category
Internet
-
view
88 -
download
1
Transcript of Web Crawler

SEARCH ENGINESUBMITTED BY :
Tantan ( )

INTRODUCTION

DEFINATIONS1. Search engine : A search engine is an
information retrieval system designed to help find information stored on a computer system suchas on the World Wide Web inside a corporate or proprietary network, or in a personal computer
2. Crawler : A web crawler (also known as a Web
spider or Web robot) is a program or automated script which browses the World Wide Web in a methodical, automated manner. Other less frequently used names for Web crawlers are ants, automatic indexers, bots, and worms .

3. Indexing : Search engine indexing entails how data is collected, parsed, and stored to facilitate fast and accurate retrieval
4. URL normalization : URL normalization (or URL canonicalization) is the process by which URLs are modified and standardized in a consistent manner. The goal of the normalization process is to transform a URL into a normalized or canonical URL so it is possible to determine if two syntactically different URLs are equivalent.

Algorithm used
•Page rank algorithm-Topic sensitive page rank•Hiltop algorithm •Learning to rank •Iamge meta search •Linear search problem

Way Of Processing
Research •Select Common Search Engine•Study their algorithms.•Watching there results.•Concluding from there results

Research• We have chosen three Search Engines-• GOOGLE, ASK and YAHOO.• Various keyword have been taken for the
comparison procedure.• We have tried to compare the results with respect to
that of Google, as it is known for its efficient output.• We also have arranged their preference in a matrix
form, varying from GOOGLE to- ASK and YAHOO ,whose printed copy are attached.
• We realize that the GOOGLE search engine is one of the best available to us ,as the results shown by it are beneficial as well as efficient in its own ways.

04/15/2023
Why GOOGLE is preferred???
Due to its good results as compared to others.Results are obtained in sorted order.Complexity-search time is dependent on how
things are finding.Few shortcoming of other engines-Various links that are not required also
appears on the screen. And few of the links are repeated on the same page which obstructs the appearance of others links that might be important for the user.

System Features

System Features
•Page rank •Utilize result to improve search result.

• Page rank• We assume page A has pages T1...Tn which point to
it . The parameter d is a damping factor which can be set between 0 and 1. We usually set d to 0.85. Also C(A) is defined as the number of links going out of page A. The PageRank of a page A is given as follows:
• PR(A) = (1-d) + d (PR(T1)/C(T1) + ... + PR(Tn)/C(Tn))
• Note that the PageRanks form a probability distribution over web pages, so the sum of all web pages' PageRanks will be one.

• PageRank or PR(A) can be calculated using a simple iterative algorithm, and corresponds to the principal eigenvector of the normalized link matrix of the web

Explanation
•We assume there is a "random surfer" who is given a web page at random and keeps clicking on links, never hitting "back" but eventually gets bored and starts on another random page. The probability that the random surfer visits a page is its Page Rank. And, the d damping factor is the probability at each page the "random surfer" will get bored and request another random page.

Cont..• Another intuitive justification is that a page can
have a high Page Rank if there are many pages that point to it, or if there are some pages that point to it and have a high Page Rank. Intuitively, pages that are well cited from many places around the web are worth looking at. Also, pages that have perhaps only one citation from something like the Yahoo! homepage are also generally worth looking at. If a page was not high quality, or was a broken link, it is quite likely that Yahoo's homepage would not link to it.

Text Based searching• The text of links is treated in a special way in our
search engine. Most search engines associate the text of a link with the page that the link is on. In addition, we associate it with the page the link points to. This has several advantages.
• First, anchors often provide more accurate descriptions of web pages than the pages themselves.
• Second, anchors may exist for documents which cannot be indexed by a text-based search engine, such as images, programs, and databases. This makes it possible to return web pages which have not actually been crawled.

Cont..
•Note that pages that have not been crawled can cause problems, since they are never checked for validity before being returned to the user. In this case, the search engine can even return a page that never actually existed, but had hyperlinks pointing to it. However, it is possible to sort the results, so that this particular problem rarely happens.

Other criteria
•It has location information for all hits and so it makes extensive use of proximity in search.
•Google keeps track of some visual presentation details such as font size of words. Words in a larger or bolder font are weighted higher than other words.
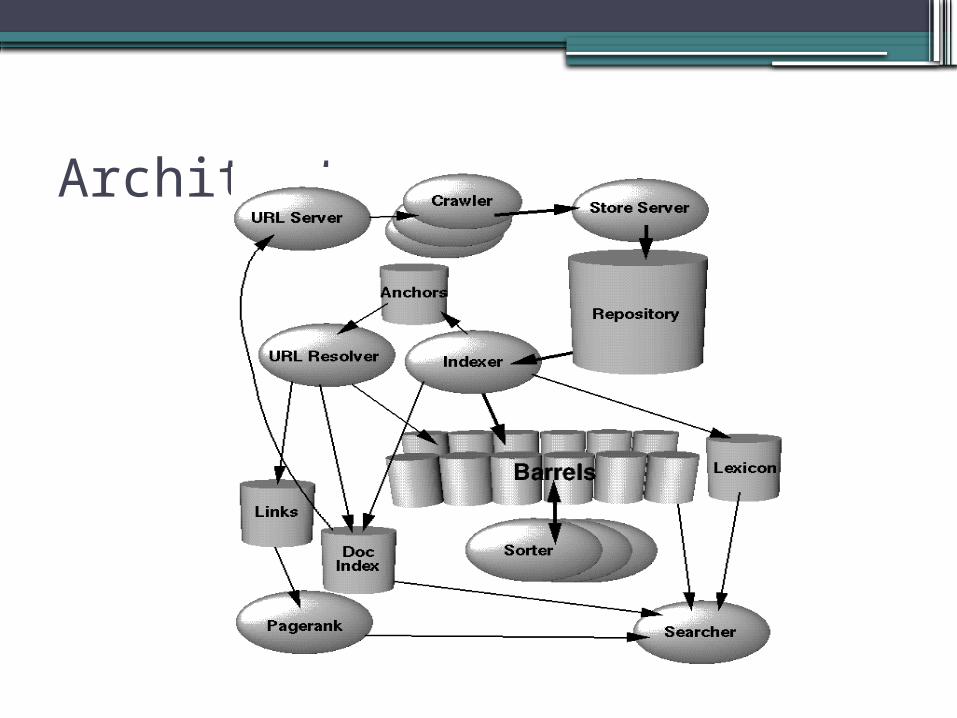
Architecture



Future Work A large-scale web search engine is a complex
system and much remains to be done. Our immediate goals are to improve search efficiency and to scale to approximately 100 million web pages. Some simple improvements to efficiency include query caching, smart disk allocation, and subindices. Another area which requires much research is updates.
We are planning to add simple features supported by commercial search engines like boolean operators, negation, and stemming.





THANK YOU


















