
Voice Based Retrieval System Prajna Bhandary CMSC - 676 ...
20
Voice Based Retrieval System Prajna Bhandary CMSC - 676 UMBC May 4, 2020
Transcript of Voice Based Retrieval System Prajna Bhandary CMSC - 676 ...

Voice Based Retrieval System
Prajna Bhandary
CMSC - 676 UMBC
May 4, 2020

Abstract
Voice based systems are likely to soon take over text based systems in the coming future.
Although we use text based approach for network access today, almost all roles of text can be
accomplished by voice. Voice based system, refers to a system that accepts voice as a form of
input with a query and/or gives out an output in a voice format for a given query. This report
summarizes some of the possible models that are required to develop a voice based system. It
also includes some examples of some already developed system prototypes that have been
researched.
There has been an idea circulating that lets you use a telephone to access information and
having a computer with a proper internet connection will not be a necessity. But, in order to do
that we have to dig deeper to speech recognition information retrieval system.

Chapter 1
Introduction This chapter introduces the types of voice based systems and the requirements of the voice
based systems. Voice based retrieval systems are gaining popularity among researchers in the
field of machine learning, artificial intelligence and neural networks. Apart from the fact that they
are a perfect platform to help visually challenged individuals, they also help in the advancement
of technology as it is.
1.1 Tasks of Voice Based Systems
There are three different tasks of a voice based system.
1.1.1 Using Text Queries to retrieve spoken documents
This type is also referred to as Spoken Document Retrieval and has been considered and
researched for a long time. For example, in the last decade in the TREC (Text REtrieval
Conference) Spoken Document Retrieval track, very good retrieval performance based on ASR
one-best results for the spoken documents was obtained as compared to that on human
reference transcripts, although using relatively long queries and relatively long target documents
[5]. It was then realized that considering much shorter queries and much shorter spoken
segments with much poorer recognition accuracies should be a more realistic scenario [2].
1.1.2 Using spoken queries to retrieve text documents
This has usually been referred to as Voice Search [6]. The information to be retrieved is usually
an existing text database such as those in directory assistance applications, although with
lexical variations and so on but primarily without recognition uncertainty.
1.1.3 Using spoken queries to retrieve spoken documents
In this case the speech recognition uncertainty exists on both sides of the queries and the
documents, and therefore naturally this is a more difficult task. This type of systems have
gained a lot of recognition in recent times and various technology methods are being applied for
this case. In an example effort, the task was considered as a problem of query-by-example
[20]. In another example effort, the lattices of the query and the documents were aligned and
compared using the graphical model. People also tried to directly match the query and the
content on the signal level [7], as other examples. There have been advancements in this case
but still a lot of word needs to be done here.
Text-Based Voice-Based
Resources Rich resources-huge quantities of text documents available over the internet Quantity continues to increase exponentially due to convenient access
Spoken/multimedia content are the new trend Can be realized even sooner given mature technologies
Accuracy Retrieval accuracy is acceptable to users and are properly ranked and filtered
Problems with speech recognition errors, especially for spontaneous speech under adverse environments
User-system Interaction
Retrieved documents easily summarised on-screen thus easily scanned and selected by the user User may easily select query terms suggested for next iteration retrieval in an interactive process
Spoken/multimedia documents easily summarised on-screen thus difficult to scan and select Lacks efficient user system interaction
Table 1. Comparison between text-based and Voice-based systems[2]

1.2 Comparison between text-based and Voice-based systems
Table 1 lists the comparison between voice-based and text-based information retrieval in terms
of Resources, Accuracy and User-system Interaction.
First, consider the resources, there are rich resources of huge text documents available and it
continues to be available. Voice Based systems on the other hand have a disadvantage as
there are not many spoken documents as of it that are available. Though there has been a
significant increase in the spoken documents and methods of accepting spoken queries.
Second, considering the accuracy with which the documents are retrieved for a given query
text-based system has an acceptable method that is properly marked and filtered. On the other
hand, the Voice based systems have problems with speech recognition. The problem persists
especially for spontaneous speech under adverse environments.
Third, in case of the user-style interaction spoken/multimedia documents are easily summarised
on screen which makes it difficult to scan and select. It also lacks efficient user system
interacted systems. Comparatively, text-based systems retrieves documents easily summarised
on-screen thus easily scanned and selected by the user. The users are easily able to select a
query they wish and the system is able to suggest query terms for the next iteration retrieval in
an interactive process which is very challenging for the Voice-based systems.
1.4 Methodology for Voice-based System
The Voice-based System of the type that accepts voice as an input and produces voice output
usually follows the following steps or requirements.
1.4.1 Speech to text Conversion

The input is in a speech format. A number of speech recognition techniques such as linear
timescaled word template matching, dynamic timewarped word-template matching (find the
phonemes, assemble into words and assemble into sentences)and hidden Markov models
(HMM) were used in olden times. Of all the available techniques, HMMs are currently yielding
the best performance due to its computational speed and accuracy.[3]
1.4.2 Pattern Matching
It is done to match the query words with the available database to find the best match for the
relevant document. Usually, the query is divided into keywords and the keywords are matched
with the available database containing the documents. The best matched document is then
retrieved as an output.
1.4.3 Text to Speech Conversion
The document thus fetch is in a text format and needs to be converted to speech format.
Text-to-speech synthesis takes place in several steps. The TTS systems get a text as input,
which it first must analyze and then transform into a phonetic description. Then in a further step
it generates the prosody. From the information now available, it can produce a speech signal.[1]

Chapter 2
Survey of Relevant Work
This section includes the relevant research work that has been made with respect to building a
voice based system. This section first talks about the possible techniques that can be used to
overcome the difficulties as discussed in chapter 1. It then talks about different systems that the
researchers have been able to build to overcome the challenges.
2.1 Retrieval Accuracy for Voice based Retrieval systems
If we can recognise the spoken query with an accuracy of 100% then the relevant document
thus retrieved will also be 100% accurate. But, unfortunately this is never true. Wherever there
is speech considered recognition errors are inevitable and recognition errors are not even
predictable or controllable. Many approaches have been considered to handle the recognition
errors here. Use of confusion matrices or fuzzy matching techniques to tolerate recognition
errors to a certain extent [8], use of lattices rather than 1-best output to consider multiple
recognition hypotheses so as to include more correct results, and use of subword units to try to
handle the out-of-vocabulary (OOV) words to some degree are good examples. There are two
major approaches discussed in a research paper as follows:
2.1.1 Lattice-based Approaches

If all utterances in the spoken segments are represented as lattices with multiple alternatives
rather than 1-best output, certainly the probability that the correct words are included and
considered can be higher. However, much more noisy words are also included which cause
some trouble, although they can be discriminated against with some scores such as posterior
probabilities, while some important words (e.g. OOV words) may still be missing.[2]
2.1.1.1 Position-Specific Posterior Lattices (PSPL)
The basic idea of PSPL is to calculate the posterior probability prob of a word W at a specific
position pos (actually the sequence ordering in a path including the word W) in a lattice for a
spoken segment d as a tuple (W, d, pos, prob). Such information is actually hidden in the lattice
L of d since in each path of L we clearly know the position (or sequence ordering) of each word.
Since it is very likely that more than one path includes the same word in the same position, we
need to aggregate over all possible paths in a lattice that include a given word at a given
position.[2]
2.1.1.2 Confusion Network (CN)
This approach was proposed earlier to cluster the word arcs in a lattice into several strictly linear
clusters of word alternatives, referred to as the Confusion Network (CN) [9]. In each cluster,
posterior probabilities for the word alternatives are also obtained. The original goal of CN was
focused on the WER minimization for ASR, since it was shown that this structure gives better
expected word accuracy [9]. In the retrieval task here, however, we consider CN as a compact
structure representing the original lattice, giving us the proximity information of each word arc.

Figure 2. (a) The ASR lattice, (b) all paths in (a)
PSPL locates a word in a segment according to the position (or sequence ordering) of the word
in a path. CN on the other hand, Clustering several words in a segment according to similar time
spans and word pronunciation as shown in figure 3.
Figure 3. d) the constructed PSPL structure, (e) the constructed CN structure, where W 1 , W 2 , … are words and by W 1 :p 1 we mean W 1 and its posterior probability p 1 in a specific clusters[2]
2.1.2 Subword Units
Word/Subword-based lattice information was converted into a weighted finite state machine
(WFSM) in an earlier work [10]. The query word/subword sequence was then located in the

WFSM using exact-matching. A two-stage approach was used in another work [11]: audio
documents were first selected by approximated term frequencies, and then a detailed lattice
search was performed to determine the exact locations.[2]
The detailed study of Subwords Units is another topic entirely and requires more research to
include in this report.
2.2 User-Interaction for Voice Based Retrieval System
For voice-based information retrieval, we don’t have any interactive or dialogue scenario yet as
compared to text-based information retrieval. Unlike the written documents with well structured
paragraphs and titles, the multimedia and spoken documents are both very difficult to browse,
since they are just audio/video signals.[2] There are many approaches described but this report
only focuses on three of those types.
2.2.1 Multi-model dialogues
In this concept, for a query given by the user, the retrieval system produces a topic hierarchy
constructed from the retrieved spoken documents that are to be searched. [2] Every node on
the Topic hierarchy represents a cluster of retrieved documents and is labeled by a topic(or a
keyword). The user’s query is expanded and they get to choose which subquery best fits the
query they want an output for. This process is called a multi-modal dialogue process because
the system responds in a form of a hierarchy of sub questions that try to find the desired
document as shown in the figure.

Figure 4. The multi-modal dialogue scenario for convenient user-system interaction.[2]
2.2.2 Semantic Analysis of Spoken Document
In PLSA, a set of latent topic variables is defined, T k , k = 1, 2, . . . , K, to characterize the
“term-document” co-occurrence relationships, as shown in Figure 9. We can notice from the
figure that the documents are not directly fetched from the terms but are first put through P(tj
|Tk), the probability that the term t j is used in the latent topic k , as well as P(Tk |di). That’s the
likelihood that di addresses the latent topic Tk . The PLSA model can be optimized with an EM
algorithm by maximizing a carefully defined likelihood function[13].
Figure 5. Graphical representation of the Probabilistic Latent Semantic Analysis (PLSA) model.[2]

2.2.3 Key Term Extraction from Spoken Document
Key terms have long been used to identify the semantic content of documents.[2] The only
difference here is that the key terms need to be extracted automatically from spoken documents
which are dynamically generated and updated from time to time. In fact, key terms have also
been found useful in constructing retrieval models. One of the example parameters is explained
below [12].
2.2.3.1 Latent Topic Significance
The latent topic significance score of a term tj with respect to a topic Tk , Stj Tk , is defined as:
where n(tj , di ) is the occurrence count of the term tj in a document di , and P(Tk |di ) is
obtained from a PLSA model trained with a large corpus. In the above given equation the term
frequency of tj in a document di , n(tj , di ), is further weighted by a ratio which has to do with
how the document di is focused on the topic Tk , since the denominator of the ratio is the
probabilities that the document d i is addressing all other topics different from Tk . After
summation over all documents a higher Sdi ,(Tk ) obtained in the equation given above implies
the tj term tj has a higher frequency in the latent topics Tk than other latent topics, and is thus
more important in the latent topic Tk .

Chapter 3
Compare and Contrast Relevant Work
There are many systems proposed to overcome the challenges as discussed in the previous
chapter. This section will discuss one of the recent systems that was proposed and that has
proven to be efficient compared to other existing systems.
2.1 Voice based system using bag of words
This part of the section describes the proposed model for a voice based system that could
overcome the challenges as mentioned in the above sections. There were many models
proposed in various papers. This one was the most efficient among the others.
The following IR model follows the following steps:
● Speech based Request (input)
● Creating BOW(Bag of Words)
● Pattern Matching
● Text to Speech reply (output)
2.3.1. Speech based Request(input)
The input is in the form of a voice and that needs to be converted into text. The conversion of
text to speech can be done using multiple ways but there are a lot of challenges in order to do
that. The foremost challenge is recognising speech. The Hidden Markov model(HMM) was used
in olden times. The recorded signal is compared with the original signal where the method of

MFCC is used in feature extraction[1] and the result stored is saved as a text document. This
type of pattern matching is adopted only in few cases where the questions are pre-entered.[3]
In this model a fuzzy logic is used to match the speech of different accents. Eg. The word
“Vector” has different pronunciations and so the fuzzy logic represents every word by a fuzzy
set. Now since this is very specific to fit in a generic model of speech recognition, we can have a
more general model of fuzzification of phonemes. This model is applied to spoken sentences.
One fuzzy set is based on accents, the second one the speeds of pronunciation and the third on
emphasis.
2.3.2 Creating Bag-Of-Words
A bag-of-words is a representation of text that describes the occurrence of words within a
document. It involves two things:
A. A vocabulary of known words.
B. A measure of the presence of unknown words.
The steps followed while using a bag of words are:
1. Collect Data: This step includes collecting all the documents that are necessary for the
system we are building.
2. Create Vocabulary: The documents are tokenized to sensible words called vocabulary.
3. Create Document Vector: The tokenized words are then vectorised to create document
vectors.
4. Managing Vocabulary: The words can be grouped together if they are similar to a certain
topic.

5. Scoring Words: The words are scored based on their occurences in a document.
6. TF-IDF: The term frequency and the inverse term frequency are calculated.
2.3.3 Pattern Matching
Boyer-Moore(BM) algorithm is used which positions the pattern over the leftmost characters in
the text and attempts to match it from right to left. If no mismatch occurs then the pattern is
found otherwise, the algorithm computes a shift by an amount by which the pattern is moved to
the right before a new matching is undertaken. The shift is computed using two heuristics:[1]
A. match heuristic
Match all characters previously matched and
B. Occurence heuristics
To bring different character to the position in the text that caused the mismatch
2.3.4 Text to Speech Reply
After getting the text it must analyse and then transform into a phonetic description. An NLP
module Digital SIgnal Processing(DSP) is used for this purpose. DSP transforms the symbolic
information received to audible one as follows:
A. text analysis:
First, the text is segmented into tokens. The token-to-word conversion creates the
orthographic form of the token. For example Mr is mister and humber like 2 are
transformed to two. There are some rules that need to be considered in this case as not
all words are pronounced the same way.

There is a problem of application of pronunciation rules. After the text analysis is completed
pronunciation rules can be applied. Silent letters in a word(h in caught) or several phonemes
like(m in maximum), these words need to be considered based on the silent letters and
phoneme characters. The solutions for this problem can be solved by the two ways proposed:
1. Dictionary based solution: A dictionary can be used where all forms of possible
words are stored.
2. Rule based solution: rules are generated from the phonological knowledge of
dictionaries. Only words with come exception on pronunciation are included
The two applications differ significantly in the size of their dictionaries. The dictionary-based
solution is many times larger than the rules-based solution’s dictionary of exception. However,
dictionary-based solutions can be more exact than rule-based solutions if they have a large
enough phonetic dictionary available.

Chapter 4
Conclusions The different approaches thus described in chapter 2 section 2.1 had varied results with respect
to the index size among different approaches as shown in figure 6.
Figure 6.The tradeoff between MAP and index size for the different approaches considered [47].
There has been a significant rise in systems that are being proposed for voice retrieval
systems that solves the challenges as discussed in chapter 2.
The proposed model described in chapter 3 had a comparison result of Voice Processed and
Voice replied as shown in figure 7.
Figure 7. Number of Voice Input vs. Number of Voice Output.
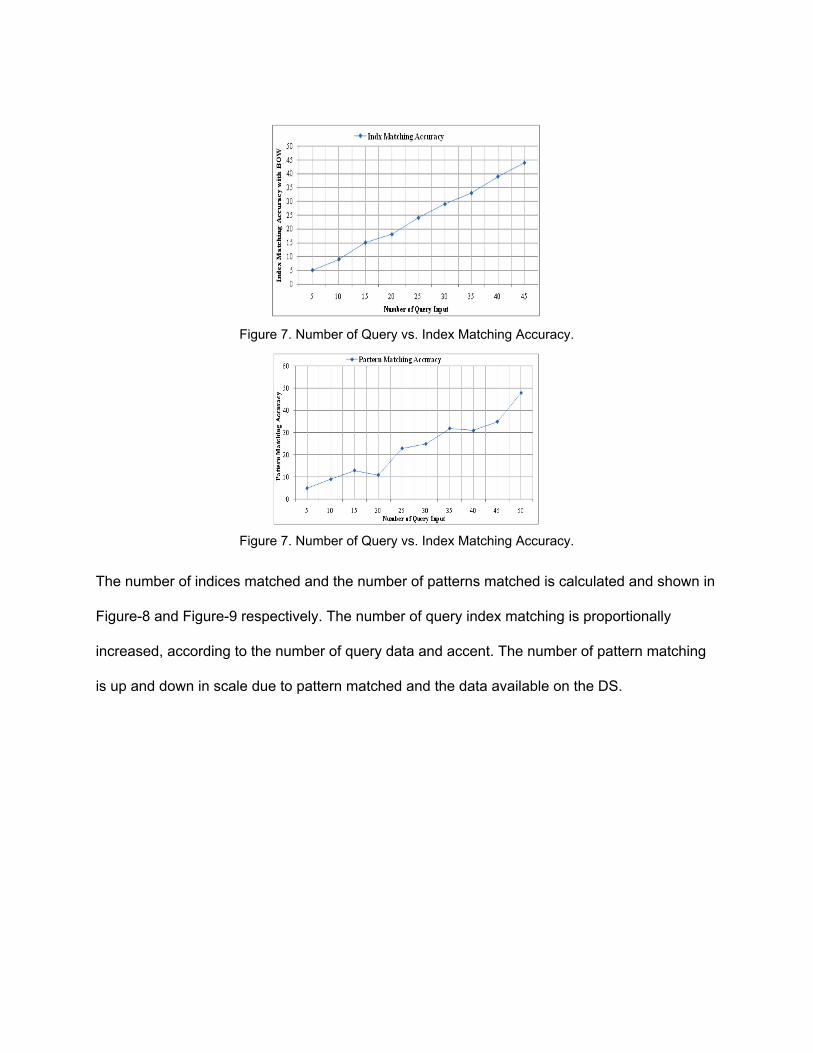
Figure 7. Number of Query vs. Index Matching Accuracy.
Figure 7. Number of Query vs. Index Matching Accuracy.
The number of indices matched and the number of patterns matched is calculated and shown in
Figure-8 and Figure-9 respectively. The number of query index matching is proportionally
increased, according to the number of query data and accent. The number of pattern matching
is up and down in scale due to pattern matched and the data available on the DS.

References [1] R. Uma, B. Latha. “An efficient voice based information retrieval using bag of words based indexing”, International Journal of Engineering & Technology [2] Lin-shan Lee and Yi-cheng Pan. “Voice-based Information Retrieval- how far are we from the text-based information retrieval?”, 2009 IEEE [3] Kiruthika M, Priyadarsini S, Rishwana Roshan K, Shifana Parvin V.M, Dr. G. Umamaheshwari. “Voice Based iNformation Retrieval System”, International Journal of Innovative Research in Science, Engineering and Technology [4]Personal Voice Based Information Retrieval System, patent [5] http://trec.nist.gov/ [6]Y. Wang, D. Yu, Y.-C. Ju, A. Acero, “An Introduction to Voice Search”, IEEE Signal Processing Magazine, May 2008, pp. 29-38. [7] T. K. Chia, K. C. Sim, H. Li, H. T. Ng, “A Lattice-based Approach to Query-by-Example Spoken Term Retrieval”, SIGIR 2008, pp. 363-370. [8] J. Mamou, B. Ramabhadran, “Phonetic Query Expansion for Spoken Document Retrieval”, Interspeech 2008, pp. 2106-2109. [9] L. Mangu, E. Brill, and A. Stolcke, “Finding consensus in speech recognition: Word error minimization and other applications of confusion networks”, Computer Speech and Language, vol. 14, no. 4, pp. 373-400, Oct 2000. [10] M. Saraclar and R. Sproat, “Lattice-based search for spoken utterance retrieval”, in HLT 2004. [11] P. Yu, K. J. Chen, C. Y. Ma, and F. Seide, “Vocabulary-independent indexing of spontaneous speech”, IEEE Trans. Speech Audio Process., vol. 13, no. 5, pp. 635.643, 2005. [12] ] Sheng-Yi Kong and Lin-shan Lee “Improved Spoken Document Summarization Using Probabilistic Latent Semantic Analysis (PLSA)”, International Conference on Acoustics, Speech and Signal Processing, Toulouse, France, May 2006, pp. I941-944. [13] T. Hofmann, “Probabilistic latent semantic analysis”, Uncertainty in Artificial Intelligence, 1999.

[14] Ondrej Chum, James Philbin, Josef Sivic, Michael Isard, and Andrew Zisserman. Total recall:Automatic query expansion with a generative feature model for object retrieval. In ICCV, pages1–8, 2007. [15] HHerv´eJ´egou, MatthijsDouze, and CordeliaSchmid. Improving bag-of-features for largescale image search. International Journal of Computer Vision, 87(3):316–336, 2010. [16] Lakra, Sachin, et al. "Application of fuzzy mathematics to speechto-text conversion by elimination of paralinguistic content." arXiv preprint arXiv: 1209.4535 (2012). [17] Kleber, Florian, Markus Diem, and Robert Sablatnig, "Form classification and retrieval using bag of words with shape features of line structures"-IS&T/SPIE Electronic Imaging, International Society for Optics and Photonics, 2013. [18] RupaliS Chavan, Ganesh. S Sable, “An Overview of Speech Recognition Using HMM”, IJCSMC, Vol. 2, Issue. 6, June 2013.


















