
VMworld 2014: Extreme Performance Series
49
Extreme Performance Series - Understanding Applications that Require Extra TLC for Better Performance on vSphere - Deep Dive VAPP2305 Vishnu Mohan, VMware, Inc Reza Taheri, VMware, Inc
-
Upload
vmworld -
Category
Technology
-
view
132 -
download
1
Transcript of VMworld 2014: Extreme Performance Series

Extreme Performance Series - Understanding Applications that Require Extra TLC for Better Performance on vSphere - Deep Dive
VAPP2305
Vishnu Mohan, VMware, Inc Reza Taheri, VMware, Inc

CONFIDENTIAL 2
Disclaimer • This presentation may contain product features that are currently under development. • This overview of new technology represents no commitment from VMware to deliver these
features in any generally available product. • Features are subject to change, and must not be included in contracts, purchase orders, or
sales agreements of any kind.
• Technical feasibility and market demand will affect final delivery. • Pricing and packaging for any new technologies or features discussed or presented have not
been determined.

CONFIDENTIAL 3
VMware Customer Survey – BCA Workloads Virtualized • Microsoft Exchange, Microsoft SQL, and Microsoft SharePoint are the top 3 virtualized
applications; gaining ground with Oracle and SAP workloads being virtualized as well.
38%
53%
43%
25% 25% 18%
41%
56%
47%
34% 28% 28%
47%
57% 52%
41% 35%
40%
60% 58% 59%
51% 49% 53%
Microsoft Exchange
Microsoft Sharepoint
Microsoft SQL Oracle Middleware
Oracle DB SAP
Jan 2010 Jun 2011 Mar 2012 Jun 2013
Source: VMware customer survey, Jan 2010, Jun 2011, Mar 2012, June 2013 Question: Total number of instances of that workload deployed in your organization and the percentage of those instances that are virtualized .
CONFIDENTIAL 4
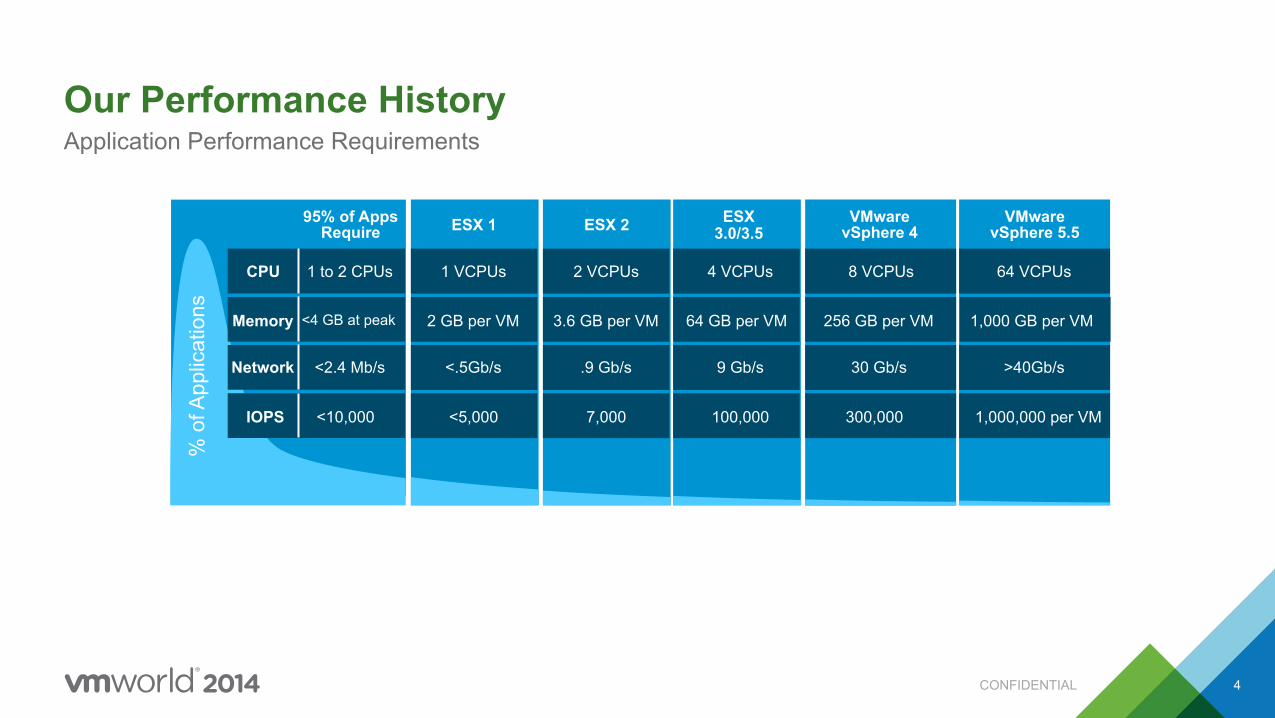
Our Performance History Application Performance Requirements
% o
f App
licat
ions
95% of Apps
Require
IOPS
Network
Memory
CPU
<10,000
<2.4 Mb/s
<4 GB at peak
1 to 2 CPUs
VMware vSphere 4
300,000
30 Gb/s
256 GB per VM
8 VCPUs
ESX
100,000
9 Gb/s
64 GB per VM
4 VCPUs
VMware vSphere 5.5
1,000,000 per VM
>40Gb/s
1,000 GB per VM
64 VCPUs
ESX 2
7,000
.9 Gb/s
3.6 GB per VM
2 VCPUs
ESX 1
<5,000
<.5Gb/s
2 GB per VM
1 VCPUs
3.0/3.5

CONFIDENTIAL 5
TPC-VMS (Database Consolidation) - Virtual
0
200
400
600
800
1000
1200
1400
Virtual VMStpsE
457.55
468.11
470.31
Thro
ughp
ut S
core
HP Proliant DL385 G8
OLTP Instance3
OLTP Instance2
OLTP Instance1

CONFIDENTIAL 6
TPC-E - Physical
0
200
400
600
800
1000
1200
1400
1600
Native tpsE
1416.37
Thro
ughp
ut S
core
HP Proliant DL385 G8
OLTP Instance1

CONFIDENTIAL 7
Outline of This Talk • We will present 5 performance-sensitive application classes
– I/O Intensive Applications • Bandwidth • Latency
– Applications That Incur High Memory Address Translation Costs – Applications That Demonstrate a High Rate of Sleep-Wakeup Cycles – Applications That Bang on the Timer – Latency-Sensitive Applications
• We will show how vSphere handles the demands of these applications – We summarize what is required to achieve good performance for these classes
• Best practices • Tuning recommendations • Nothing replaces good engineering judgment!
– We also list remaining challenges for each class

CONFIDENTIAL 8
Scope of This Presentation • Data collected from multiple sources
– Customers – In-house performance stress tests
• Work in progress
• Focus is on the compute side – vSAN, vNAS, NSX pose their own challenges
• Focusing on application classes that require extra TLC for better performance when virtualized – Not looking for vSphere bugs! – The same issues are present on any hypervisor
• A qualitative analysis

CONFIDENTIAL 9
What This Talk Is NOT About • Let’s not talk about
– Creating many VMs, and putting VMDKs on the same physical disk – Not upgrading to vSphere 5.5, virtualHW.version=10, VMXNET3, PVSCI, etc. – Not following best practices – Not following good engineering sense!! – vSphere bugs that have already been reported
• Having said that, there are gray areas in our definitions – If an application achieves good performance by setting a tunable, is it still a fundamentally challenging
application for virtualization?

I/O Intensive (High IOPS) Applications

CONFIDENTIAL 11
Herculean IO • More than 1 Million IOPS from 1 VM
Hypervisor: vSphere 5.1 Server: HP DL380 Gen8 CPU: 2 x Intel Xeon E5-2690, HT disabled Memory: 256GB HBAs: 5 x QLE2562 Storage: 2 x Violin Memory 6616 Flash Arrays VM: Windows Server 2008 R2, 8 vCPUs and 48GB. Iometer Config: 4K IO size w/ 16 workers
• http://blogs.vmware.com/performance/2012/08/1millioniops-on-1vm.html
• http://www.vcritical.com/2012/08/who-needs-a-million-iops-for-a-single-vm
CONFIDENTIAL 12
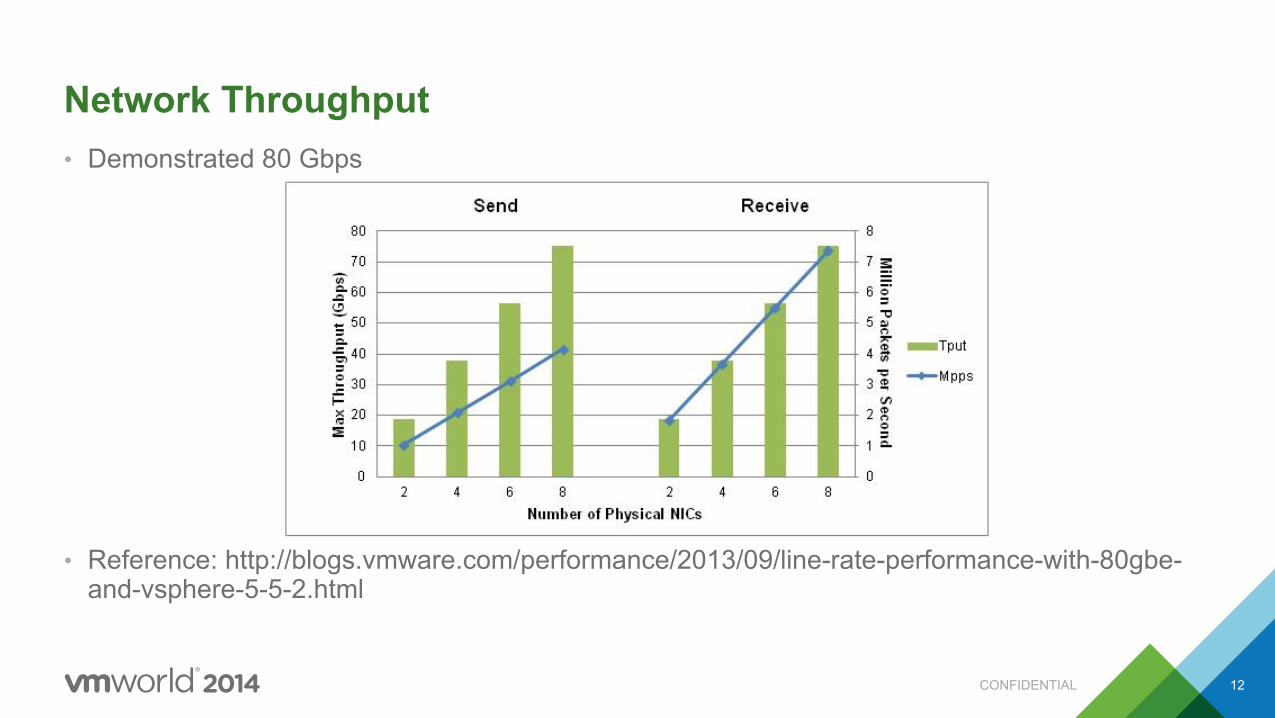
Network Throughput • Demonstrated 80 Gbps
• Reference: http://blogs.vmware.com/performance/2013/09/line-rate-performance-with-80gbe-and-vsphere-5-5-2.html

CONFIDENTIAL 13
1M Disk IOPS • A storage (or networking) I/O has to go through both the guest and the host stacks • Cost of this scales nearly linearly with the throughput
– We measure 44 microseconds of CPU processing costs for a storage I/O • At 1M IOPS, that’s 44 cores worth of CPU usage!
– In practice, coalescing and economies of scale cut this cost down drastically
• 1M IOPS blog at http://blogs.vmware.com/performance/2012/08/1millioniops-on-1vm.html – 8 vCPU Windows guest maxed out – VMKernel also used around 8 cores worth of processing power – Careful benchmark, scheduler, and system-level tuning in both the guest and the ESX host
• Specific tuning is very benchmark and configuration dependent

CONFIDENTIAL 14
1M Network Packets/Second • Can handle over 1M Packets/Sec in vSphere 5.5 • Working on pushing this higher in the next release. Stretch goals of:
– 4M Packets/Sec – Running a 40Gb NIC at line rate
• On the Rx side, VMKernel uses ~4 cores worth of processing – Tx Side is the same or better
• It can be achieved, but there are CPU costs

CONFIDENTIAL 15
Dealing with the CPU Costs of High I/O Rates • Achieving high storage IOPS or high networking packet rates is challenging
– Application and guest tuning tricks are known to customers or benchmarkers who aim for drag racing results
– When virtualized, the hypervisor needs the same level of TLC as the application and the guest OS
• There are additional CPU costs in the VMKernel – vSphere reduces this by:
• Aggressive guest interrupt coalescing • Aggressive coalescing of requests at issue time
– Further tuning • There is always pass-through • Use RDMs if you need to lower CPU utilization by a few percent and are willing to sacrifice the benefits of VMFS

Storage I/O Latency Example 1: Super Fast SSD devices

CONFIDENTIAL 17
Problem Statement • SSD access times are heading towards the 10’s of microseconds
– SSD (SATA, SAS, PCIe): 10’s usec latency, 10K ~ 100K IOPS – Memory Channel Storage (FlashDIMM): 3-5 usec latency, 100K IOPS – NVMe (Flash): Low 10’s usec latency, 100’s ~ 1000’s of thousands IOPS – NVMe (PCM): 80 nanosecond read, 10’s~100’s usec write
• vSphere processing costs per I/O are also in the 10’s of microseconds

CONFIDENTIAL 18
Example of a Customer’s Observation • Virtualizing an app had a 40% penalty
– NAS on NetApp – Turns out NetApp device was caching data in SSD – So the vSphere overhead was of the same magnitude as that of the disk access

Storage I/O latency Example 2: Database Log I/O

CONFIDENTIAL 20
Low Latency Storage IO • 1M IOPS, <2ms latency, 8KB block size, 32 OIO’s
Reference: www.vmware.com/files/pdf/1M-iops-perf-vsphere5.pdf

CONFIDENTIAL 21
Problem Statement • Storage I/O has higher latency in virtual
– True for all hypervisors – Usually not a noticeable problem for Data access
• Long (5+ms) latency because: – Random I/O – Many threads banging on the same spindle
– Not OK for Redo Log • Short (<1ms latency)
– Sequential I/O – Single-threaded – Write-only
• Top 5 wait events in Oracle AWR • Cannot cover with multiprogramming
– More threads means more waiting threads
• So look to trade more CPU cycles to achieve minimum latency for the database logs

CONFIDENTIAL 22
Trade Off CPU Cycles for Latency • vSphere aims for lower CPU usage by batching I/O operations
– Asynchronous request passing from vHBA to VMKernel
• On the issuing path: – Initiate I/O immediately
• For LSI Logic vHBA – scsiNNN.async = "FALSE“ – Or scsiNNN.reqCallThreshold = 1
• default reqCallThreshold value is 8 – Or change the value for all LSILogic vHBAs on the ESX host:
• esxcfg-advcfg -s x /Disk/ReqCallThreshold • For PVSCSI, starting with vSphere 2015
– scsiNNN.reqCallThreshold = 1 – As well as dynamic, self-tuning!

CONFIDENTIAL 23
Trade Off CPU Cycles for Latency, continued… • vSphere aims for lower CPU usage by batching I/O operations
– Virtual Interrupt Coalescing – vSphere automatically suspends interrupt coalescing for low IOPS workloads
• On the completion path: – Avoid Virtual Interrupt Coalescing
• Put the log device on a vHBA by itself – Low IOPS means no waiting to coalesce interrupts
• Or explicitly disable Virtual Interrupt Coalescing – For PVSCSI: scsiNNN.intrCoalescing=“False” – For other vHBAs, scsiNNN.ic=“False”

CONFIDENTIAL 24
Bottom Line • An issue on all hypervisors • More noticeable as storage access times shrink faster than processor cycle times
• But only an issue if application performance is directly proportional to disk access time – Multiprogramming usually covers this
• Even with all the workarounds, log latency can be longer in virtual – Running Oracle TPC-C on 8-way, virtual matches native log device latency of 0.4ms – On 32-way, redo log latency on native is 0.66ms, virtual is 0.85ms – Log latency has a bigger impact than data latency
• Because it is typically much faster (even with spinning drives)
– DBMS are sensitive to log latency – Trade off CPU cycles for minimum latency for log
• There is always pass-through • Has been a challenge for networking all along; so more progress can be found there

Expensive Address Translation Costs

CONFIDENTIAL 26
Virtual Memory in a Native OS
• Applications see contiguous virtual address space, not physical memory
• OS defines VA -> PA mapping – Usually at 4 KB granularity – Mappings are stored in page tables
• HW memory management unit (MMU) – Page table walker – TLB (Translation Look-aside Buffer)
Process 1 Process 2
Virtual Memory
VA
Physical Memory
PA
0 4GB 0 4GB
TLB fill hardware
VA PA TLB
%cr3
VA→PA mapping
. . .
26

CONFIDENTIAL 27
Virtualizing Virtual Memory
• To run multiple VMs on a single system, another level of memory virtualization is required – Guest OS still controls virtual to physical mapping: VA -> PA – Guest OS has no direct access to machine memory (to enforce isolation)
• VMM maps guest physical memory to actual machine memory: PA -> MA
Virtual Memory
Physical Memory
VA
PA
VM 1 VM 2
Process 1 Process 2 Process 1 Process 2
Machine Memory
MA
27

CONFIDENTIAL 28
Virtualizing Virtual Memory
• VMM builds “shadow page tables” to accelerate the mappings – Shadow directly maps VA -> MA – Can avoid doing two levels of translation on every access – TLB caches VA->MA mapping – Leverage hardware walker for TLB fills (walking shadows) – When guest changes VA -> PA, the VMM updates shadow page tables
Shadow Page Tables
Virtual Memory
Physical Memory
VA
PA
VM 1 VM 2
Process 1 Process 2 Process 1 Process 2
Machine Memory
MA
28

CONFIDENTIAL 29
2nd Generation Hardware Assist Nested/Extended Page Tables
VA MA TLB
TLB fill hardware
guest VMM
Guest PT ptr
Nested PT ptr
VA→PA mapping
PA→MA mapping
. . .
29

CONFIDENTIAL 30
Analysis of EPT/NPT • MMU composes VA->PA and PA->MA mappings on the fly at TLB fill time • Benefits
– Significant reduction in “exit frequency” • Page faults require no exits • Context switches require no exits
– No shadow page table memory overhead – Better scalability for vSMP
• Aligns with multi-core: performance through parallelism
• Costs – More expensive TLB misses: O(n2) cost for page table walk,
where n is the depth of the page table tree

CONFIDENTIAL 31
Virtualized Address Translation • H/W Assist is much cheaper than Software MMU for:
– Administration of Page Tables – Applications with a lot of process creation/exits
• EPT doubles performance for compiling Apache web server
• All in all, H/W assist for TLB miss processing has been a great performance boost across the board
• Even for an OLTP workload with static processes and high TLB miss rate – EPT is 3% better than S/W MMU – We spend ~7-10% of the time in EPT
• That’s the time the CPU spends in two-dimensional page table walks

CONFIDENTIAL 32
But There Are Rare Corner Cases: • Customer Java Application
– 62GB heap and very poor locality of memory access – Native DTLB miss rate: 18M/sec/core at peak, 13M/sec/core on average
• Cycles spent in DTLB miss processing peaks at 19%, average 14% – Exceptionally high cycle counts!
• Customer observed a 30-40% drop in performance for this app when virtualized – Collected TLB stats (miss rates; cycles in EPT; etc.) to investigate:
• vmkperf on vSphere • perf on Linux
– Average of 16% of overall time in EPT processing • Plus indirect costs!
– Peaking at 27% for several minutes
• Switch to S/W MMU – Performance gap dropped from 30-40% to 17%

CONFIDENTIAL 33
Bottom Line • A scant few applications have this high a TLB miss rate • But for applications that do, there is a noticeable performance drop when virtualized
– One of the rare use cases for vSphere S/W MMU • Better processors and larger pages will be the ultimate solution
• If you suspect TLB miss issues, check for it with “perf stat” or vmkperf
• For all but the rare application, the Hardware MMU is faster

High Rate of Sleep-Wakeup

CONFIDENTIAL 35
Sleep-Wakeup Problem Statement • Ping-Pong architecture • Typically, a Producer-Consumer relationship
– Synchronization mechanism relies on sleeping when a thread finds the mutex locked, and waking up when the mutex is unlocked
– When the waiting thread sleeps, the native/guest OS puts the core into an idle state
• On native, the OS uses the MONITOR and MWAIT instructions – Put the core into a low-power sleep state and wait on the resched flag – On lock release, the native OS writes to the resched flag, and the core sleeping with MWAIT wakes up
• On virtual, we do not (always) emulate the MWAIT instruction – Guest OS has to use a Rescheduling Interrupt (RES) to wake up the sleeping core – RES interrupts are delivered using Inter-Processor Interrupts (IPIs), which are expensive
• Same phenomenon can be observed on KVM

CONFIDENTIAL 36
Sleep-Wakeup Problem at a Customer • Running vSphere 5.5 on IvyBridge processors with RHEL 6.5 • Started off at 1/6 of the performance on native
• Initial triage pointed to two known issues: – Supervisor Mode Execution Protection (SMEP) on IvyBridge can cause a performance problem
• KB 2077307 • Fixed in 5.5 Update 1 or 5.1 Update 1 • 3-4X improvement in a pathologically bad case
– Flexpriority • KB 2040519 • Can change from default if H/W fix (microcode update) is applied • 4X improvement in a pathologically bad case

CONFIDENTIAL 37
Sleep-Wakeup Solutions and Workarounds • Apply knows patches and fixes
– SMEP • Fixed in 5.5 Update 1 or 5.1 Update 1
– Flexpriority • Enable explicitly after applying hardware microcode patch • But still ~70% of native
• Avoid the Resched Interrupts/IPIs altogether! – boot the guest with idle=poll
• Performance almost on par with native • Expensive in terms of power
– Use taskset to run all threads on the same vCPU • Bound by processing power of 1 vCPU

CONFIDENTIAL 38
Bottom Line • Need to apply known bug fixes/updates/etc. • But still noticeable performance issue:
– If there is a Very High rate of Sleep/Wakeup – If the producer/consumer threads do nothing but communicate, and there is no other activity in the VM – If there are no changes made to guest OS/Application to avoid using RES Interrupts

Banging on the Timer

CONFIDENTIAL 40
Problem Statement • Timers are a known virtualization issue
– Correctness – Cost
• Older ESX releases were poll-driven; vSphere is now interrupt-driven
• Accessing the timer has CPU overhead – vSphere 5.5 has made great improvements
• Most applications should not have an issue anymore

CONFIDENTIAL 41
Timer Access Overhead • Guest OS
– No issues in newer Linux releases – Windows might still have a problem because Windows is tick driven.
• If the guest timer has fallen behind, vSphere tries to gradually adjust the clock to catch up. During this time, we exit on TSC reads, which is expensive.
• Not an issue if in steady state and the VM is not getting descheduled
• vMotion – If the VM migrates to a processor of sufficiently different frequency, we will have to exit on every TSC
read to scale the frequency – When frequencies are close, we adjust frequencies only occasionally, and only during this period do we
exit – AMD avoids this by using frequency scaling
• But vSphere does not take advantage of that yet

Latency-Sensitive Applications

CONFIDENTIAL 43
Performance of Latency Sensitivity Feature Reference: http://www.vmware.com/files/pdf/techpaper/latency-sensitive-perf-vsphere55.pdf

CONFIDENTIAL 44
Latency-sensitive Applications • Same issues on all hypervisors • Bands
• Band 1: <10us, not a good candidate for virtualization • Band 2: 10s of microseconds
– Good support since 5.1 • Latency • Jitter
• Band 3: 100s of us to milliseconds – Surprisingly, might not be a good candidate because customers may not be willing to set Latency Sensitivity to High
• Requires following best practices and the instructions in the white paper

Summary

CONFIDENTIAL 46
Summary • Although inherent performance problems are rare
– Some apps require TLC – Apply best practices – Apply workarounds – Consider changes to Application design
• We continually work on vSphere to improve performance when dealing with corner cases

CONFIDENTIAL 47
Acknowledgements • Seongbeom Kim • Lenin Singaravelu
• Jin Heo • Jinpyo Kim
• Tian Luo
• Adrian Marinescu • Cedric Krumbein
• Jianzhe Tai
• Rishi Mehta • Jeff Buell
• Lance Berc • Joshua Schnee
• Nikhil Bathia
• Bhavesh Davda • Josh Simon

Thank You

Fill out a survey Every completed survey is entered into a
drawing for a $25 VMware company store gift certificate


















