
Visual information retrieval from large distributed online
9
COMMUNICATIONS OF THE ACM December 1997/Vol. 40, No. 12 63 Digital images and video are becoming an integral part of human communica- tion. The ease of creating and capturing digital imagery has enabled its prolif- eration, making our interaction with online information sources largely visual. We increasingly use visual content to express ideas, report news, and educate and entertain each other. But how can we search for visual information? visual information management v Try WebSEEk, an Internet search system that integrates textual and visual features for categorizing images and videos, and MetaSEEk, a meta-search system that links to various visual search systems. Shih-Fu Chang, John R. Smith, Mandis Beigi, and Ana Benitez Visual Information Retrieval from Large Distributed Online Repositories ALGERIA/HOLTON COLLECTION/ SUPERSTOCK Rock Fresco, Tassili N-Ajjer Plateau, Cave of Tan, Zoumaitor, Algeria
Transcript of Visual information retrieval from large distributed online

COMMUNICATIONS OF THE ACM December 1997/Vol. 40, No. 12 63
Digital images and video are becoming an integral part of human communica-
tion. The ease of creating and capturing digital imagery has enabled its prolif-
eration, making our interaction with online information sources largely visual.
We increasingly use visual content to express ideas, report news, and educate
and entertain each other. But how can we search for visual information?
vis
ual
info
rmat
ion
ma
nag
emen
tv
Try WebSEEk, an Internet search system that integrates textual
and visual features for categorizing images and videos, and MetaSEEk,
a meta-search system that links to various visual search systems.
Shih-Fu Chang, John R. Smith,
Mandis Beigi, and Ana Benitez
Visual Information Retrieval
from Large Distributed
Online Repositories
ALG
ERIA
/H
OLT
ON
CO
LLEC
TIO
N/
SUPE
RST
OC
K
Rock Fresco, Tassili N-Ajjer Plateau, Cave of Tan, Zoumaitor, Algeria

Can solutions be developed that are as effective asexisting text and nonvisual information searchengines? With the increasing numbers of distributedrepositories and users, how can we design scalablevisual information retrieval systems?
Digital imagery is a rich and subjective source of information. For example, different people extractdifferent meanings from the same picture. Theirresponse also varies over time and in different view-ing contexts. A picture also has meaning at multiplelevels—description, analysis, and interpretation—as
described in [10]. Visual information is also repre-sented in multiple forms—still images, videosequences, computer graphics, animations, stereo-scopic images—and expected in such future applica-tions as multiview and 3D video. Furthermore,visual information systems demand large resourcesfor transmission, storage, and processing. These fac-tors make the indexing, retrieval, and managementof visual information a great challenge.
Based on our experience developing visual infor-mation systems in Web-based environments, wehave analyzed the present and future of such systems,focusing on search and retrieval from large, distrib-uted, online visual information repositories. As acase study, we describe a recently developed Inter-net-based system called WebSEEk. We also describethe prototype of an Internet meta-visual informationretrieval system called MetaSEEk, which is analo-gous to text-based meta-search engines on the Web.And we explore the challenges in developing scal-able visual information retrieval systems for futureonline environments.
Content-Based Visual QueryRecent progress has been made in developing effi-cient and effective visual information retrieval sys-tems. Some systems, such as Virage, QBIC,VisualSEEk, and VideoQ [1, 3, 6, 11], providemethods for retrieving digital images and videos byusing examples and/or visual sketches. To queryvisual repositories, the visual features of the imagery,such as colors, textures, shapes, motions, and spa-tiotemporal compositions, are used in combinationwith text and other related information. Low-levelvisual features may be extracted with or withouthuman intervention.
One characteristic of these systems is that thesearch is approximate, requiring a computed assess-ment of visual similarity. The items returned at thetop of the list of query results have the greatest sim-ilarity with the query input. But the returned itemsrarely have an “exact” match to the attributes speci-fied in the query. Figure 1 shows image and videosearch examples based on visual similarity queries.
Such systems can also use direct input fromhumans and other supporting data to better indexvisual information. For example, video icons in [4]are generated by a manual process for annotatingobjects in videos, like people and boats, and seman-tic events, like sunsets. Text indexes have also beengenerated from the captions and transcripts ofbroadcast video [8] for retrieving news video.
Visual summarization complements visual search.By decomposing the video, through, say, automated
64 December 1997/Vol. 40, No. 12 COMMUNICATIONS OF THE ACM
Figure 1. Feature-based visual query. Query 1 uses thelocal color regions and spatial structures to find imagesof a sunset or flower. Query 2 adds the motion featureto find relevant video clips, such as high jumps. (Videos
courtesy Action Sports Adventure, Inc. and HotShots/Cool Cuts, Inc.)

scene detection, a more spatially or temporally com-pact presentation of the video can be generated. Forexample, [12] has described news video summariza-tion systems, with efficient browsing interfacesusing video event detection and clustering. Othershave developed techniques for automated videoanalysis of continuous video sequences to generatemosaic images for improved browsing and indexing.
Other researchers have begun seeking to automatethe assignment of semantic labels to visual content.For example, through a process of learning from userinteraction, the FourEyes system develops maps fromvisual features to semantic classes [9]. Furthermore,by manually developing specific models for visualclasses using visual features, such as animals and
nude people, techniques for automatically detectingthese images are also being developed [7].
Classifying Retrieval SystemsVisual information retrieval systems have been usedin many application domains, including libraries,museums, scientific data archives, photo stockhouses, and Web search engines. We classify thesesystems using the following criteria:
• Automation. The visual features of the images andvideos extracted and indexed by the system areused for interactive content-based visual querying.Visual information retrieval systems differ indegree of automation of feature extraction andindex generation. Automatic methods are typi-cally appropriate only for low-level feature extrac-tion, involving, say, colors, textures, and motions.Generation of higher-level semantic indexes usu-ally requires human input and/or system training.
Some semiautomatic systems take initial inputfrom humans, such as manual selection of imageobjects and features, and are then used to generatethe feature indexes.
• Multimedia features. Multimedia content containsinformation in many modalities, includingimages, video, text, audio, and graphics. Visualinformation retrieval systems differ in their treat-ment of the multiple modalities. Typically, ifmultiple modalities are considered, they areindexed independently. Integration of multiplemodalities has been investigated in a few systems[8, 11] but is not yet fully exploited.
• Adaptability. Most systems use a static set of pre-viously extracted features. Selection of these fea-
tures by the system designer involves trade-offs inindexing costs and search functionalities. How-ever, due to the subjective nature of visual search,there is a need to be able to dynamically extractand index features to adapt to the changing needsof users and applications.
• Abstraction. Retrieval systems differ in the level ofabstraction in which content is indexed. Forexample, images may be indexed at the featurelevel (color, texture, and shape), object level (mov-ing foreground object), syntax level (video shot),and semantic level (image subject). Most auto-matic retrieval systems aim at low-level features,while high-level indexes are generated manually.Interaction among different levels is an excitingbut unsolved issue.
• Generality. Retrieval systems differ as to speci-ficity of the domain of visual information. Forexample, customized feature sets can be developedto incorporate specific domain knowledge, such as
COMMUNICATIONS OF THE ACM December 1997/Vol. 40, No. 12 65
Can solutions be developedthat are as effective as
existing text and nonvisualinformation search engines?

for medical and remote-sensing applications.More general systems aim at indexing uncon-strained visual information, such as that on theInternet.
• Content collection. Retrieval systems differ in themethods by which new visual information can beadded. For example, in a dynamic visual informa-tion retrieval system, the content of the system’sdatabase may be collected by software robots,
such as those that automatically traverse the Web.In other systems, such as those for online newsarchives and photo stock houses, visual informa-tion can be added manually.
• Categorization. Retrieval systems differ in theireffort to categorize visual information into seman-tic ontologies. As visual information repositorieshave grown, we have found that interfaces allow-ing navigation through the semantic ontologies ofvisual information are very useful. However, effec-tive image-categorization schemes have not beenexplored thus far.
• Compressed domain processing. Retrieval systems alsodiffer in their approach to processing visual infor-mation. For example, it is possible to perform fea-ture extraction directly on compressed images andvideos. Compressed-domain processing avoidsexpensive expansion of the data.
The criteria for federating content-based retrievalin multiple large distributed repositories may be dif-ferent from those already described. We propose aframework for developing a visual information
retrieval meta-search engine, motivated by theappearance of meta-search engines that federateWeb-document searching [10].
WebSEEk for Internet Visual Information RetrievalThe Web’s rich collection of visual information isintegrated with a vast variety of nonvisual informa-tion. Although there are many popular search
engines for nonvisual information, visual infor-mation search engines are only just appearing.
Visual information on the Web is highlydistributed, minimally indexed, and schema-less. To explore visual information on the Web,we developed WebSEEk, a semiautomaticimage search and cataloging engine [11] whoseobjective is to provide a visual search gatewayfor collecting, analyzing, indexing, and search-ing for the Web’s visual information. Figure 2shows a high-level system diagram for Web-SEEk, which serves as an aggregation point forthe Web’s distributed visual information andacts as a server for Web querying, retrieving,and manipulating of indexed visual informa-tion. WebSEEk stores the meta-data, visualsummaries, and pointers to the visual informa-tion sources.
According to our classification criteria,WebSEEk is semiautomatic, uses static visual fea-tures and textual key terms, indexes unconstrainedvisual content, uses a customized semantic ontology,and collects visual information using autonomoussoftware agents.
WebSEEk’s image and video collection process is achieved by Web spiders. Visual information isdetected by mapping the file name extensions to theobject types according to the Multipurpose InternetMail Extensions (MIME) labels (such as .gif, .jpg,.qt, .mpg, and .avi). Based on the images and videocollected during a three-month period in 1996, 85%of visual information collected consists of colorimages, 14% contains gray-scale or black & whiteimages, and 1.5% contains video. The current sys-tem has indexed approximately 650,000 images and10,000 video sequences.
WebSEEk takes the following approaches to han-dling the challenges of Internet visual informationretrieval:
• Multimedia meta-data. Most online visual infor-mation does not exist in isolation; it is usuallyaccompanied by other related information. Forexample, WebSEEk uses Web URL addresses andhtml tags associated with the images and videos
66 December 1997/Vol. 40, No. 12 COMMUNICATIONS OF THE ACM
• Content Aggregation• Content Analysis• Search Engine
VIR Systems
DistributedContentServers
Clients
• Search• Retrieve
• Browse• Edit
Figure 2. A high-level system architecture for Internet visual information retrieval
to extract key terms for direct indexing and classi-fication of visual content.
• Feature extraction and indexing. The large num-ber of images and videos indexed by WebSEEklimits the amount of processing that can be per-formed in responding to a user’s query. To achievea content-based query response time of less thantwo seconds, WebSEEk uses a novel indexingscheme for fairly simple color features—binarycolor sets and color histograms.
• Image manipulation for efficient viewing. Visualquery is an iterative, interactive process. Full-reso-lution images are not needed until the final stage,when the user issues an explicit request. Reduced
representations of images or video can beefficiently extracted on the fly or in advance.For video, automatic video shot segmenta-tion and key-frame selection are used.
• Semantic ontology and subject classification.The systems that require users to browsethrough pages of thumbnail views of imagesand videos are not suitable for large visualinformation retrieval systems. We are find-ing that users prefer to navigate within aclearly defined hierarchical semantic space.For example, by analyzing WebSEEk usagepatterns, we found that semantic navigationis the most popular access method in thissystem. Once the user is within a smallerclass of visual information, content-basedmethods are important for organizing,browsing, and viewing the content in that space.
Unlike ordinary image database applica-tions, Internet visual information retrieval sys-
tems lack a well-defined schema or set of meta-data.Therefore, we use a set of the common attributes ofthe images and videos on the Web. WebSEEkextracts key terms from the URL addresses and htmltags of images and videos on the Web and uses themto map the images and videos into one or more of thesubject classes in WebSEEk’s semantic ontology.Table 1 lists examples of descriptive and nondescrip-tive key terms and their mappings into classes of thesemantic ontology.
WebSEEk’s semantic ontology contains more than2,000 classes and uses a multilevel hierarchy. It isconstructed semiautomatically in that initially,human assistance is required in the design of thebasic classes and their hierarchy. Then, periodically,additional candidate classes are suggested by thecomputer and verified with human assistance. Table1 also includes example classes in the semantic ontology.
Because many textual terms areambiguous, automatic subject classifi-cation using simple key terms is notperfect. However, its overall perfor-mance classifying visual informationfrom the Web is quite good. We havefound that WebSEEk’s classificationsystem is over 90% accurate in assign-ing images and videos to semanticclasses. Performance is also verified bythe popularity of WebSEEk’s Webapplication; in its initial deployment,WebSEEk has processed more than
COMMUNICATIONS OF THE ACM December 1997/Vol. 40, No. 12 67
. . . . . .
WAIS WAIS WAIS
query interface query interface query interface
Client
Display and User Interface(query specification)
(result merger)(format converter)
Meta-search Engine
query dispatcher
preformance monitor
. . . . . .
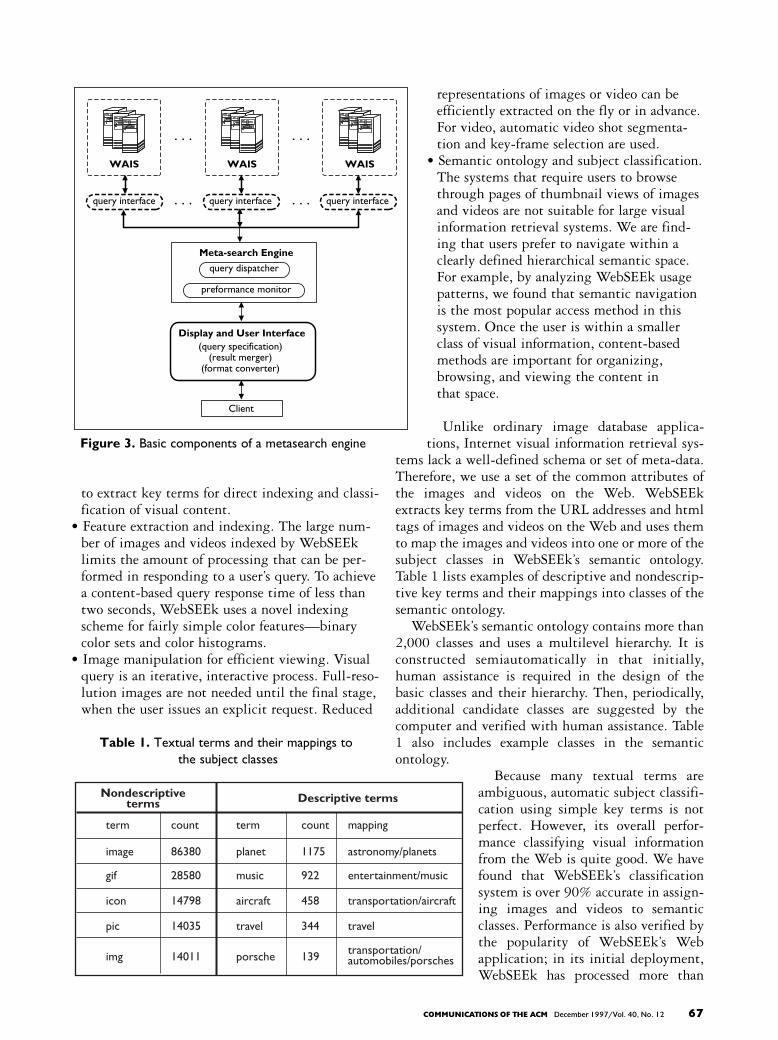
Figure 3. Basic components of a metasearch engine
Nondescriptiveterms Descriptive terms
term count term count mapping
image 86380 planet 1175 astronomy/planets
gif 28580 music 922 entertainment/music
icon 14798 aircraft 458 transportation/aircraft
pic 14035 travel 344 travel
img 14011 porsche 139 transportation/automobiles/porsches
Table 1. Textual terms and their mappings tothe subject classes

1,600,000 query and browse operations. The systemcurrently serves thousands of queries daily.
As shown in Table 2, subject-based queries are themost popular search method for images and videos(accounting for 53.5% of queries). Content-basedqueries account for only 3.7% of all queries. How-ever, this disparity may be partly influenced by thelimitations of the content-based search functions inthe current system.
Meta-Search Engines for ImagesThe proliferation of text search engines on the Web has motivated recent research in integrated search, ormeta-search, engines [5]. Meta-search engines serveas common gateways linking users to multiple coop-erative or competitive search engines. They acceptquery requests from users, sometimes along withuser-specified query plans to select target searchengines. Meta-search engines may also keep track ofthe past performance of each of the various search
engines and use it in selecting target search enginesfor future queries.
A working meta-search engine includes threebasic components (see Figure 3) [5]: The dispatchingcomponent selects target search engines for eachquery; the query interface component translates theuser-specified query into scripts compatible witheach target search engine; and the display interfacecomponent merges the query results from all thesearch engines. It may also perform format conver-sion or image manipulation to produce a list of dis-playable images for the client.
Our prototype meta-image search engine,MetaSEEk, has allowed us to research the issuesinvolved in querying large, distributed online visualinformation sources [2]. MetaSEEk’s target searchengines include VisualSEEk/WebSEEk, QBIC, andVirage. The front-end interface allows browsing ofrandom images from different engines. The user may
select different visual fea-tures in the query and entertext (such as a URL or key-words) for the query. Figure4 shows the user interface ofthis Web-based system,including color percentage,color layout, and texture,supported by the three tar-get search engines. Usersmay search for images based
on image examples or text [2]. Our experience withthe initial MetaSEEk deployment has yielded severallessons:
• Feature consistency. Although the target searchengines support querying based on color features,different feature sets and query methods are used.For example, color histograms are used by all tar-get engines. However, the color spaces, distancemetrics, and indexing methods are different inthese systems. The mapping of each user-selectedfeature in MetaSEEk to those used in the targetengines is based on the system’s best effort.
• Query results merging. Image-match scores are notconsistently returned by the target retrieval sys-tems. Without match scores, the meta-searchengine merges the result lists based on the ranksof the matches in each individual list. In a moreadvanced implementation, the meta-engine may
68 December 1997/Vol. 40, No. 12 COMMUNICATIONS OF THE ACM
Figure 4. The MetaSEEk query interface, which allowsusers to brows images from and issue content-basedqueries to different target search engines. (Images in
yellow are from QBIC; white from Virage; and red from VisualSEEk.)
Browse
totaloperations
subjectnavigations
visualbrowsing
subject-basedqueries
text-basedqueries
basic con-tent-basedqueries(color dis-tribution)
advancedcontent-basedqueries(Visual-SEEk)
828,802 354,512 189,612 175,359 120,832 30,256 1,336
42.8% 22.9% 21.2% 14.6% 3.7% 0.2%
Query
%
#
Table 2. Usage patterns of an Internet visual information retrieval engine (WebSEEk)

recompute simple visual features from the imagesreturned from the various systems and rank themon the fly.
• Special functionalities. Each of the retrieval sys-tems has special functionalities and limitations. Forexample, Virage allows the user to weight the mul-tiple visual features in a query—color, texture,composition, and structure. On the other hand,QBIC and VisualSEEk support custom searchesusing visual sketches. Since functionality differsamong target search engines, it is difficult todevelop a common interface for all the systems in ameta-search engine.
• Performance evaluation. The lack of effective evalua-tion metrics or benchmarks for retrieval systems isa critical issue. Difficulty in evaluating retrievaleffectiveness is due to the subjectivity of visualsimilarity and the lack of a standard visual infor-mation corpus in the research community. Withoutstandard performance metrics, it is difficult for themeta-engine to monitor the performance of differ-ent target engines and make recommendations forsubsequent queries. For example, the labels NoResults and Visit are used in [5] to report queryeffectiveness. But in visual information retrievalsystems, the queries usually return a fixed-size setof nearest neighbors without regard for the actualthreshold of similarity. In practice, determinationof an appropriate threshold of similarity is difficult,especially when the queries involve multiple fea-tures and arbitrary weightings.
Toward Scalable Internet Visual Retrieval SystemsAlthough visual information retrieval systems are stillonly emerging, it is important to understand the chal-lenges in developing scalable solutions. A scalableInternet retrieval solution needs to solve three mainproblems: heterogeneity, complexity, and bandwidth.
Heterogeneity. Unlike text documents, visualmaterial does not share consistent formats, indexes,or meta-data. This issue was brought to the fore inour initial experiments with meta-search engines.Dozens of formats are used for representing imagesand videos on the Web. Many different techniquesare used for implementing content-based searchingin retrieval systems. There is also no standard forinteroperability between systems. For example, evenat the semantic level, ontologies are custom-devel-oped for the target systems.
These problems must be solved to improve inter-operability. Standardization of the representation ofmeta-data should provide a uniform method for
labeling visual information at the semantic level.Such standardization will enhance interoperabilityamong different retrieval systems and improve theeffectiveness of individual systems. As with thedevelopment of standards for meta-data for text doc-uments, such recent efforts as that of CNI/OCLCMetadata have been made to extend the meta-dataschemes to images. A standard taxonomy for graphicmaterials has been proposed by the Library of Con-gress. And the audiovisual research community hasstarted to investigate development of a standard fordescribing multimedia information in MPEG-7.
The diversity of visual features and indexingschemes could be resolved by developing a distrib-uted database query protocol, such as that used ininformation retrieval—the EXPLAIN operationproposed in Z39.50. Such a facility would allowclients to dynamically configure to the types of con-tent and visual features indexed by the retrieval sys-tems. For example, we found that the typical visualfeatures indexed in visual information retrieval sys-tems can refer to global or local content, be pixel- orregion-based, describe intraobject attributes and/orinterobject relationships, and include spatial and/ortemporal features. These systems should have meth-ods of describing the indexed information and queryfacilities to a generic client.
The various visual features and query metrics canalso include count-based feature sets, such as his-tograms, vector-based feature sets and/or use Euclidean-norms, quadratic-norms, and/or trans-form-domain metrics. By developing a standard forcommunicating the types of features and the associ-ated metrics used by retrieval systems, functionalmappings may be generated that allow transparentquerying among multiple retrieval systems. Havingthe means of translating and interpreting querymethods and results, a visual information retrievalmeta-search engine could integrate the results ofqueries of multiple retrieval systems more effectively.
Complexity. The process of searching through arepository of visual information is complex. Forexample, users may not know what they are lookingfor or how to describe the content they seek. The cat-aloging of the images or video into a fixed subjecthierarchy provides a partial solution. But catalogingis limited, in that it provides only a limited numberof directions in which the content can be found.
Online visual information retrieval systems canhelp solve this problem by supporting interactivebrowsing and dynamic querying. Users would beable to preview the initial search results, providefeedback as to the relevance of the returned items,
COMMUNICATIONS OF THE ACM December 1997/Vol. 40, No. 12 69

and refine queries efficiently. Particularly in theInternet context, previews of query results reducethe amount of transmission required for full-resolu-tion images and videos.
Furthermore, summarization of visual informa-tion for improved browsing and querying may beperformed at several content levels. For example, thedatabase statistics for each attribute or subject, say,the number of images with red regions or images inthe subject class “nature,” can be cues for users whilealso being used to optimize queries. Summaries canalso be visual. Examples include mosaic images,video key-frame summaries, and video programtransitional graphs. Querying may be improved byusing only the dominant attributes of the visualinformation summaries.
The challenging application environment ofInternet visual information retrieval makes effectivevisual information searching even more critical anddifficult. For example, consider in an image meta-search system the difficulty of giving relevance feed-back to individual retrieval sources. How can thequery results from distributed sources be manipu-lated to conduct follow-up queries, so images fromone retrieval system can be used to query otherretrieval systems? And how can the visual meta-search engine initiate a content-based query usingfeatures not globally available in those systems?
Solving this problem requires that more “intelli-gence” be added directly to the image and video rep-resentations. For example, images should not besimply passive arrays of pixel values. Instead, theyshould be “active,” including methods that generate,
manipulate, and describe their content. Theimages and videos may also be rendered in dif-ferent ways and at different resolution levels,without requiring modification of the raw data.The coding algorithms should be dynamicallyself-configuring. And new features should beavailable for dynamic extraction and use in visualmatching at query time. Recent developmentalong these lines involves MPEG-4 for object-oriented multimedia representation and FlashPix for efficient image transport, display,and rendering.
As the amount of visual information on theInternet increases, the methods for accessing anddisseminating it will change. For example, wehave discussed only a “pull”-based paradigm forvisual information retrieval systems in whichusers are active in connecting to visual informa-
tion servers and in specifying the search and/orbrowse operations. These users are also directlyinvolved in manipulating search results and retriev-ing the images and/or videos of interest. However,the pull paradigm for visual information is limited.
In a more advanced system, the visual informationservers and/or agents may learn to detect users’visual information needs. For example, the systemmay observe the types of visual information a partic-ular user typically retrieves. In this case, a “push”system can automatically provide visual informationusing a subscription-based model. New visual infor-mation would simply arrive at the user’s desktopwithout requiring the user’s involvement in theprocess.
Bandwidth. Slow Internet response time is a criti-cal constraint for today’s visual information retrievalsystems. Image and video compression reduce theamount of bandwidth and storage required by thesesystems. But network and storage constraints arestill fundamental limitations in their performance.For example, downloading a 10-second MPEG-1video clip takes 10 seconds over a T1 dedicated line,two minutes over a 128Kbps ISDN line, and up tonine minutes over a 28.8Kbps modem. Downloadtime clearly influences user interaction with Internetvisual information retrieval.
The progressive storage and retrieval of imagesand videos provides a method for viewing the queryresults from a rough-to-fine scale. Although notwidely used, several scalable compression schemeshave been included in the high-profile MPEG-2video standard. Open image standards, like Flash-Pix, also include multitile, multiresolution features.In future video standards, such as MPEG-4, content-
70 December 1997/Vol. 40, No. 12 COMMUNICATIONS OF THE ACM
Figure 5. Scalable solutions for Internet visual information retrieval
Image/VideoUsenet
VIRSystems
. . . . . .
(Progressive Query)(Query Preview)(Visual Summary)
TransparentSearch Gateway
(Compressed-DomainFiltering)
(Visual Subject Models)(User Preference)
IntelligentSoftware Agents
• Open APIs• CB Represen- tation• Metadata Standard
• Open APIs• CB Represen- tation• Metadata Standard
• Open APIs• CB Represen- tation• Metadata Standard
(PUSH)(PULL)
VIRSystems

based scalability is being considered as a way of sup-porting independent access to objects of interests invideo scenes.
For such compression standards as JPEG, MPEG-1, and MPEG-2, functionalities can be developed inthe compressed domain. Assuming that visual infor-mation is stored and transmitted in compressedform, great savings in computation and bandwidthcan be achieved by avoiding decompression of theimages and videos. Using compressed-domainapproaches, operations, such as key-frame selection,feature extraction, and visual summarization, areperformed without fully expanding the data.
In summary, visual information retrieval fromlarge, distributed, online repositories requires eightcritical components: a meta-data representation stan-dard; open content-based query protocols; effectivemethods for summarizing visual information; furtherexploitation of query previewing techniques; explo-ration of both push and pull methods; better meth-ods of progressive storage and retrieval of visualinformation; improved functionalities of the imageand video representations; and methods of operatingdirectly on compressed visual information. Figure 5shows an architecture including these components.
Conclusions The Internet contains a growing wealth of visualinformation. But the technologies for searching for itare inadequate. In the short term, the Internet’s lim-ited bandwidth constrains some of the functionalityof visual information retrieval systems. However, wealready see deployment of such sophisticatedretrieval applications as virtual museums, onlinenews reporting, stock-photography systems, and on-demand streaming video retrieval.
Developing and integrating the potential varietyof search methods for visual information is a greatchallenge. Every day we find new retrieval systemsthat provide new types of search methods we callgenerically “Query by X.” X can refer to an imageexample; a visual sketch; a specification of visual fea-tures, such as color, texture, shape, and motion; akeyword; or a semantic class. The emergence ofvisual information retrieval search engines on theWeb is accelerating the pace of R&D for content-based visual querying. However, deploying this tech-nology in the unconstrained and distributed Webenvironment is especially challenging. Several criti-cal barriers remain, including heterogeneity of thevisual information, lack of interoperable retrievalsystems, the distributed and transient nature of theWeb’s visual information, and the limited band-width for transmitting visual information. Develop-
ment of scalable solutions for visual information sys-tems requires contributions from many disciplines,as well as better assessments of user needs and appli-cation requirements.
References1. Bach, J., Fuller, C., Gupta, A., Hampapur, A., Horowitz, B.,
Humphrey, R., Jain, R., and Shu, C. Virage image search engine: Anopen framework for image management. In Proceedings of the Symposiumon Storage & Retrieval for Image and Video Databases IV, IS&T/SPIE (SanJose, Calif., Feb. 1996).
2. Beigi, M., Benitez, A., and Chang, S.-F. MetaSEEk: A content-basedmeta-search engine for images. To appear in Proceedings of the Symposiumon Storage and Retrieval for Image and Video Databases VI, IS&T/SPIE (SanJose, Calif., Jan. 1998). (See demo at http://www.ctr.columbia.edu/metaseek.)
3. Chang, S.-F., Chen, W., Meng, H., Sundaram, H., and Zhong, D.VideoQ: An automatic content-based video search system using visualcues. In Proceedings of ACM Multimedia 1997 (Seattle, Wa., Nov. 1997).(See demo at http://www.ctr.columbia.edu/videoq.)
4. Davis, M. Media Streams: An iconic language for video annotation.Telektronikk 89, 4 (1993), 59–71.
5. Drelinger, D., and Howe, A. Experiences with selecting search enginesusing meta-search. To appear in ACM Trans. Inf. Syst.
6. Flickner, M., Sawhney, H., Niblack, W., Ashley, J., Huang, Q., Dom,B., Gorkani, M., Hafner, J., Lee, D., Petkovic, D., Steele, D., andYanker, P. Query by image and video content: The QBIC system. IEEEComput. 28, 9 (Sept. 1995), 23–32.
7. Forsyth, D., Malik, J., Fleck, M., Greenspan, H., Leung, T., Belongie,S., Carson, C., and Bregler, C. Finding pictures of objects in large col-lections of images, Tech. Rep. CSD-96-905, Dept. of EECS, ComputerScience Div., Univ. of California, Berkeley, 1996.
8. Hauptmann, A., and Smith, M. Text, speech, and vision for video seg-mentation: The Informedia project. In Proceedings of AAAI Fall Sympo-sium, Computational Models for Integrating Language and Vision (Boston,Nov. 10–12, 1995).
9. Minka, T., and Picard, R. An image database browser that learns fromuser interaction. Tech. Rep. 365, MIT Media Laboratory and ModelingGroup, 1996.
10. Shatford, S. Analyzing the subject of a picture: A theoretical approach.Cat. Classif. Q. 6, 3 (Spring 1986).
11. Smith, J., and Chang, S.-F. Visually searching the Web for content.IEEE Multimedia 4, 3 (Summer 1997), 12–20. (See also Tech. Rep. 459-96-25 and demo., Columbia Univ., http://www.ctr.columbia.edu/web-seek.)
12. Zhang, H., Low, C., and Smoliar, S. Video parsing and browsing usingcompressed data. J. Multimedia Tools Appl. 1, 1 (Mar. 1995), 89–111.
Shih-Fu Chang ([email protected]) is an associate pro-fessor in the Department of Electrical Engineering and the NewMedia Technology Center at Columbia University in New York.John R. Smith ([email protected]) is a member of theresearch staff at the IBM Thomas J. Watson Research Center inHawthorne, N.Y.Mandis Beigi ([email protected]) is a graduate student inthe Department of Electrical Engineering in Columbia Universityin New York.Ana Benitez ([email protected]) is a graduate student in theDepartment of Electrical Engineering in Columbia University inNew York.
Permission to make digital/hard copy of part or all of this work for personal or class-room use is granted without fee provided that copies are not made or distributed forprofit or commercial advantage, the copyright notice, the title of the publication andits date appear, and notice is given that copying is by permission of ACM, Inc. To copyotherwise, to republish, to post on servers, or to redistribute to lists requires prior spe-cific permission and/or a fee.
© ACM 0002-0782/97/1200 $3.50
c
COMMUNICATIONS OF THE ACM December 1997/Vol. 40, No. 12 71


















