
Vision friendly video coding towards new standard H.265/HPVC Manoranjan Paul Research Fellow School...
46
Vision friendly video coding towards new standard H.265/HPVC Manoranjan Paul Research Fellow School of Computer Engineering, Nanyang Technological University Faculty Member, Charles Sturt University, Australia (from January 2011) 25 th December 2010 at AUST, Bangladesh © 2010 Manoranjan Paul. All Rights Reserved. http://sites.google.com/site/ manoranjanpaulpersonalweb/
-
Upload
marjory-berry -
Category
Documents
-
view
217 -
download
2
Transcript of Vision friendly video coding towards new standard H.265/HPVC Manoranjan Paul Research Fellow School...

Vision friendly video coding towards new standard H.265/HPVC
Manoranjan Paul
Research Fellow School of Computer Engineering, Nanyang Technological University
Faculty Member, Charles Sturt University, Australia (from January 2011)
25th December 2010 at AUST, Bangladesh
© 2010 Manoranjan Paul. All Rights Reserved.
http://sites.google.com/site/manoranjanpaulpersonalweb/

Outline
• Personal Information in Brief• Video Compression and Video Coding• Video/Image Quality Assessment• Computer Vision & Video Coding• Eye Tracking Technology & Visual Attention• Abnormal Event Detections• New Research Areas• Conclusions
© 2010 Manoranjan Paul. All Rights Reserved.

Other people involved in the Research Works
© 2010 Manoranjan Paul. All Rights Reserved.
• Prof. Michael Frater, UNSW• Prof. John Arnold, UNSW• Prof. Laurence Dooley, Monash• A/Prof. Manzur Murshed, Monash• A/Prof. Weisi Lin, NTU• A/Prof. Chiew Tong Lau, NTU • A/Prof. Bu- Sung Lee, NTU• Dr. Chenwei Deng, NTU• Dr. Mahfuzul Haque, Monash• Dr. Golam Sorwar, SCU• Dr. Fan Zhang• Anmin Liu, NTU• Zhouye Gu, NTU

Personal Information
© 2010 Manoranjan Paul. All Rights Reserved.
• Education:– PhD, Monash University (2005). Thesis title: Block-based very low bit rate video
coding techniques using pattern templates. -nominated for Mollie Holman Gold Medal, 2006.
– Bachelor of Computer Science and Engineering (4 years honors degree with research project), Bangladesh University of Engineering and Technology, Dhaka, Bangladesh (1997). Thesis Supervisor: Professor Chowdhury Mofizur Rahman
• Employments:– Current Position:
• Faculty Member, Charles Sturt University, Australia (From January 2011)• Research Fellow, Nanyang Technological University, Singapore (World Rank 69),
CI: Professor Weisi Lin.
– Previous Positions: • Research Fellow and Lecturer (05/06~03/ 09), Monash University (World Rank
45), Under ARC Discovery Grant, CI: Professor Manzur Murshed.• Research Fellow, Under an ARC DP project, ADFA, The University of New South
Wales (World Rank 47), CI: Professor Michel Frater.• Assistant Lecturer (11/ 01~04/05), Monash University, Australia.• Assistant Professor (10/00~10/01), Ahsanullah University of Science and
Technology, Bangladesh. • Lecturer (09/97~09/00), Ahsanullah University of Science and Technology,
Bangladesh.

Personal Information Cont…
© 2010 Manoranjan Paul. All Rights Reserved.
• Research:– Publish 50+ International articles– Deliver keynote speech in the IEEE ICCIT conference, 2010– Organize a special session on the IEEE ISCAS 2010 on “Video coding” – Supervise 5 PhD students and examine 5 PhD and MS theses – Editor of (i) International Journal of Engineering and Industries (IJEI)
and (ii) Special Issues (2008, ‘09, ‘10, & ‘11) of Journal of Multimedia.– Served Program Committee member for 15 International Conferences.
• Research Quality:– Publish 7 IEEE Transactions Papers in TIP(3), TCSVT(3), and TMM (1)
• IEEE TIP: IF: 4.6, Top rank journal in Image Processing, JCR Rank: Q1• IEEE TCSVT: IF: 4.3, Top ranked journal in Video Technology, JCR Rank: Q1• IEEE TMM: IF: 2.9, Top ranked journal in Multimedia, JCR Rank: Q1
– Publish 25+ IEEE Conf. e.g., ICIP(6), ICASSP(4), MMSP(3), ICPR(1), ISCAS(1)
– An ARC DP grant awarded from my PhD works– Obtained $80,000 Competitive grant money– Involve reviewing of IEEE TIP, IEEE TCSVT, IEEE TMM, IEEE SPL, IEEE CL.– Publications H-index is 7 (according to Google)

Outline
• Personal Information in Brief• Video Compression and Video Coding• Video/image Quality Assessment• Computer Vision & Video Coding• Eye Tracking Technology & Visual Attention• Abnormal Event Detections• New Research Areas• Conclusions
© 2010 Manoranjan Paul. All Rights Reserved.

Why Video Compression and Video Coding
© 2010 Manoranjan Paul. All Rights Reserved.
Original ICE video sequence Frame 46 Frame 61
• A number of frames (comprises video) going through faster in front of us provides moving picture impression i.e., video
• One second video requires = 25×288×352×8×3 bits = 59,400 kilo bits• Whereas YouTube supports only 384 kilo bits per second• Thus, we need to compress the video data by 200 times • To compress data we need Video Coding• Video Coding Standards: Motion JPEG, MPEG-2, MPEG-4, H.264, H.265

Video Coding Steps (H.264)
© 2010 Manoranjan Paul. All Rights Reserved.
First Frame of Tennis video Frame Difference
• Frame encoding format is IPPP…, IBBP…, or IBPBP…
• Processed P-frame using small block, Macroblock, 16×16 pixel block
• For more compression try to match each block into the already coded frames, Motion Estimation
• Further divided the 16×16 block into 16×8, 8×16, 8×8, 8×4, 4×8, and 4×4
• Then select the best Mode using bit rates (R), distortions (D), and Lagrangian parameter (λ)
16
16
Macroblock
Figure: Block Matching Technique
X Y M(otion
2d+1+M
2d+1+M
MB of Reference frame
d
d
Motion Vector (u,v)
M
M (k,l)
(k+u, l+v)
MB of Current frame
Search Window of Reference Frame
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 221
2
3
4
5
6
7
8
9
10
11
12
13
14
15
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 221
2
3
4
5
6
7
8
9
10
11
12
13
14
15
)()( ii mRmDJ

1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 221
2
3
4
5
6
7
8
9
10
11
12
13
14
15
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 221
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16 16 pixels block
88
Limitations of Variable Block Size ME and MC
© 2010 Manoranjan Paul. All Rights Reserved.
• A Frame or picture divided into 16×16
pixel blocks for coding
• Each block may have different motions
thus, 16×16, to 4×4 blocks are used to
estimate motion
Observations
• At low bit rate the largest block (i.e.,
16×16) is selected more than 60~70%.
• At the higher bit rate 16×16 is 20~30 %
but smallest block 8×8) 40~50%.
• The variable-block size ME & MC of
H.264 is not effective, as expected, at
Low Bit Rates
A Frame or Picture of a video
(a) Frame #2 of Miss America sequence, (b) different size blocks,
(c) & (d) different size blocks of Frame #2 at low and high bit rate respectively.

Exploitation of Intra-Block Temporal Redundancy by Pattern Templates
Fig. An example on how pattern-based coding can exploit the intra-block temporal redundancy
in improving coding efficiency
© 2010 Manoranjan Paul. All Rights Reserved.

Pattern-based video coding at LBR Published in IEEE Transaction on Image Processing 2010 and IEEE TCSVT 2005
© 2010 Manoranjan Paul. All Rights Reserved.
Pattern-matching
A set of pre-defined pattern templates
• A block has foreground and background
• Pattern matching can separates them
• Encoding foreground and skipping background
provides compression
• Motion estimation using only moving regions also
provides computational efficiencyObservation:
• The PVC provides 1.0~2.0dB PSNR improvement
or 10~20% more compression compared to the
H.264 at LBR
• The PVC provides 20~30% computational
reductions compared to the H.264

Arbitrary-Shaped Pattern Templatespublished in IEEE SPL 2007
© 2010 Manoranjan Paul. All Rights Reserved.
Moving regions distributions
Clustering the moving regions
Highest magnitude 64 pixels positions
The final pattern template
Pattern templates from different
video sequencesRate-distortion performance comparison
• Pre-defined pattern templates sometimes cannot approximate the
object shapes properly
• Arbitrary-shaped pattern templates generated from video can
better approximate the object shapes, thus provides better coding
performance
• ASPVC provides 0.5dB PSNR or 5% more compression
compared the PVC

Singular Value Decomposition (SVD)
DCT VS. SVD
Coefficient distribution of the120th frame after DCT
Coefficient distribution of the 120th frame after SVD
DCT
Original Image DCT Coefficients
2D-SVD
Original Image 2D-SVD Coefficients
2D-SVD yields fewer high amplitude coefficients (dark spots in the coefficient matrix)
© 2010 Manoranjan Paul. All Rights Reserved.
• Hybrid Video Codec (MPEG-1, -2, -4, H.263/4)
Advantage: Exploits temporal redundancy by motion estimation, high compression
Disadvantage: High computational complexity, Inter-frame dependency, not support random frame access function, error propagation
• Intra-frame Video Codec (Motion JPEG, Motion JPEG2000)
Advantage: Low computational complexity, Inter-frame independency, Support random access to each frame, Facilitate video editing, no error propagation
Disadvantage: Low compression

The Framework of SVD Video Codec
Published in IEEE ICIP 2010
Input Video sequence
i=1...n16 x 16
MB group Bi
eigenvector matrix of every MB Bi
16x16 coefficient
matrix group Mi
Coefficient matrix group
Normalized frames
Mean frame
Group Information Headfile1Coefficient matrix of
frame 1Headfile2
Headfile 3
Coefficient matrix of frame 2
Coefficient matrix of frame 3 …...
meanA
iA
Normalization Coefficients
i=1...n
'i FA
Frames subtracted by meanframe
i=1...n
'iA
Mean Frame substraction
JPEG Compression
2D-SVD
OperationsOperation
Result
Frame Normalization
Quantization & Entropy Coding
ilU
irU
• SVD is 100 times faster than the H.264 video coding standard• Suitable for mobile video phone & surveillance video coding• Image quality gain 5.0dB compared to Motion J2K• Better for random access and noisy transmission
© 2010 Manoranjan Paul. All Rights Reserved.
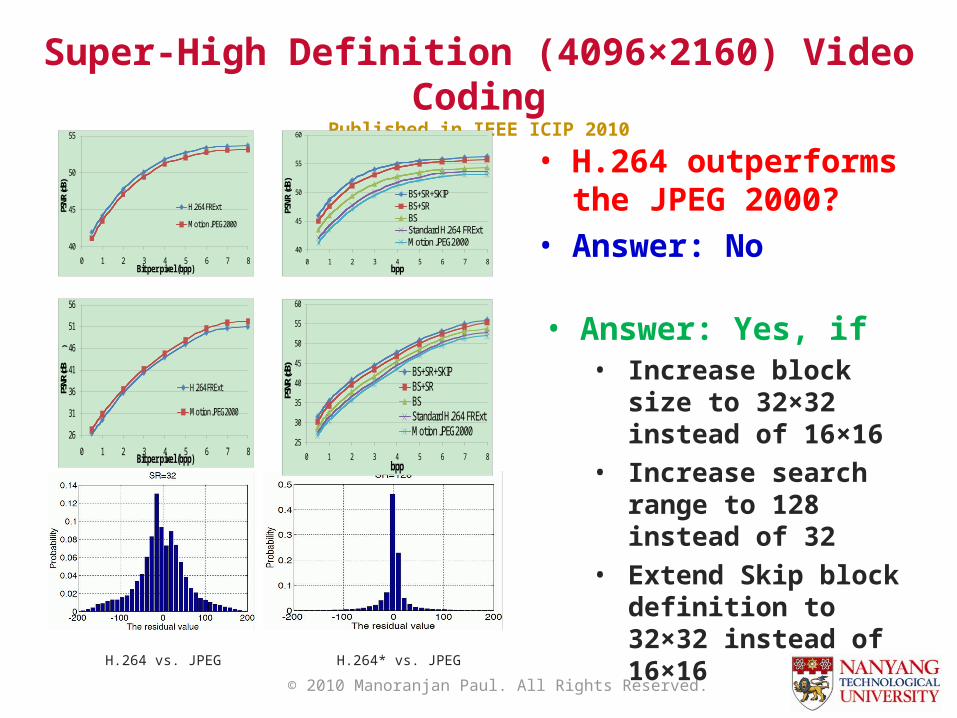
Super-High Definition (4096×2160) Video Coding
Published in IEEE ICIP 2010
• H.264 outperforms the JPEG 2000?
• Answer: No
© 2010 Manoranjan Paul. All Rights Reserved.
40
45
50
55
0 1 2 3 4 5 6 7 8
PSNR
(dB)
Bit per pixel (bpp)
H.264 FRExt
Motion JPEG2000
26
31
36
41
46
51
56
0 1 2 3 4 5 6 7 8
PSNR
(dB
)
Bit per pixel (bpp)
H.264 FRExt
Motion JPEG2000
40
45
50
55
60
0 1 2 3 4 5 6 7 8
PSNR
(dB)
bpp
BS+SR+SKIPBS+SRBSStandard H.264 FRExtMotion JPEG2000
25
30
35
40
45
50
55
60
0 1 2 3 4 5 6 7 8
PSNR
(dB)
bpp
BS+SR+SKIPBS+SRBSStandard H.264 FRExtMotion JPEG2000
H.264 vs. JPEG H.264* vs. JPEG
• Answer: Yes, if • Increase block size to
32×32 instead of 16×16
• Increase search range to 128 instead of 32
• Extend Skip block definition to 32×32 instead of 16×16

Optimal Compression Plane for Video Coding
Accepted in IEEE ICIP 2010 and IEEE Transactions on Image Processing 2010*
© 2010 Manoranjan Paul. All Rights Reserved.
Figure: Different Compression Planes such as XY, TX, and TY
sourcevideo
determine PPU size
adaptive compression plane transform for each PPU
X
Y
determine optimal
compression plane
video coding
standards
coded bits
TX
TY
XY
0 0.5 1 1.5 2
20
24
28
32
36
40
bpp
psnr
XYOCP(N=32)OCP(N=128)
0 0.5 1 1.5 2
20
24
28
32
36
bpp
psnr
XYOCP(N=32)OCP(N=128)
0 0.5 1 1.5 2
12
16
20
24
28
32
36
40
bpp
psnr
XYOCP
Figure: Rate-distortion performance using JPEG 2000 and H.264 for Mobile, Tempete, and Tempete video sequences (left to right)

Occlusion Handling using Multiple Reference Frames
(MRFs)
Frame 1
Frame 2
Frame 3
Frame 4
Frame 5
Frame 6
Motion estimation and
compensation
Frame 18
Uncovered
backgroundLight changed
Frame 18 Frame 30
Repetitive motion
Silent video sequence
• To encode current frame, a video encoder uses previously encoded multiple frames for
the best matched frame
• The MRFs (using up to 16 frames in the H.264) technique outperforms the technique of
using only one reference frame when:
• Repetitive motion
• Uncovered background
• Non-integer pixel displacement
• Lighting change, etc.
Disadvantages
– Required k (number of reference frames) times computations
– Required k times more memory in encoder and decoder
– No improvement if relevant features are missing
What happens if the cycle of features exceeds the k reference frames© 2010 Manoranjan Paul. All Rights Reserved.

Dual Reference Frames: A Sub Set of MRFs
• Dual (short term and long term) reference frames technique instead of MRFs
technique gains popularity instead of MRFs
• Short term reference frame (STR): Immediate previous frame for foreground.
• Long term reference (LTR) frame for stable background.
• One of the previously coded frame is selected for LTR
• Selecting and updating LTR frame is complicated
• Cannot capture uncovered background for the most of the time
• Cannot capture stable background
• May not be effective for implicit background and foreground referencing
• To capture uncovered background, repetitive motions, etc. we need a ground truth
background
• but in the changing environment it is almost impossible to get the background of a
video
• thus, we need to model a Most Common Frame of A Scene (MCFIS) using video
frames.

McFIS: The Most Common Frame of a Scene
published in IEEE ICASSP-10, ICIP-10, ISCAS-10
© 2010 Manoranjan Paul. All Rights Reserved.
Original ICE video sequence Background Generation
Observation:
• A true background can capture a major portion of a scene
• Difference between the current frame and background provides object
• Coding only foreground provides coding efficiency

McFIS for Background Areas Accepted in IEEE Transactions on Image Processing 2010* & ICASSP-10
• Instead of MRFs, a McFIS is enough
• A McFIS enables the possibility of capturing a whole
cycle of features
• The immediate previous frame is for moving areas and
the McFIS is for background regions.
• Less computation (60% saving) in ME&MC is
required using McFIS
• Improvement around 1.0dB PSNR compared to the
existing methods
Implicit foreground (STR) and background (LTR, i.e., McFIS)
referencing where black regions are referenced from the STR
and other regions are referenced using McFIS
© 2010 Manoranjan Paul. All Rights Reserved.
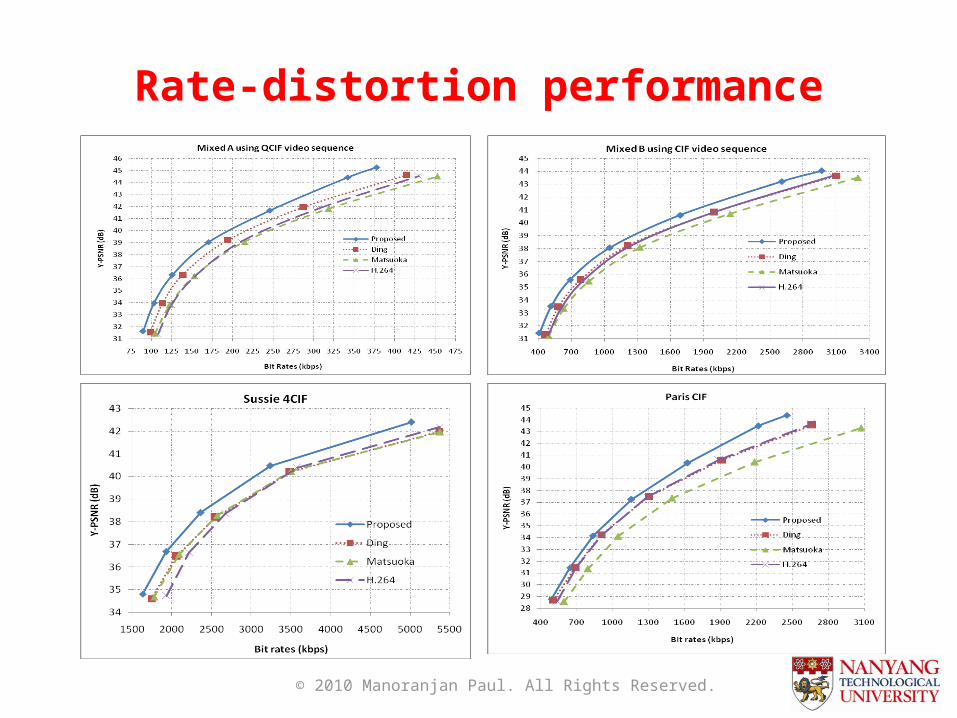
Rate-distortion performance
© 2010 Manoranjan Paul. All Rights Reserved.

Scene Change Detection by McFIS
• Two mixture video sequences created• A simple SCD detection algorithm using the
McFIS has been developed (i.e., SAD between McFIS and Current frame)
• Compare our results with Ding et al. IET IP 2008• The proposed SCD algorithm is better
© 2010 Manoranjan Paul. All Rights Reserved.

Adaptive GOP Determination by SCD
• I-frame requires two to three times more bits than P or B-frame • if a sequence does not contain any scene changes or extremely high motion
activity, insertion of I-frames reduces the coding performance• Optimal I-frame insertion using adaptive GOP and SCD improves coding
performance • We have compared our results with other two latest algorithms• The proposed AGOP method outperforms existing methods
NUMBER OF I-FRAMES FOR MIXED VIDEO A AND B OF 700 FRAMES
Methods QPs
Number of I-framesMixed Video A Mixed Video BSCD AGOP SCD AGOP
ProposedAlgorithm
40 10 0 10 028 10 0 10 020 10 0 10 0
Ding’sAlgorithm
40 10 0 10 1128 10 0 10 420 10 0 10 4
Matsuoka’sAlgorithm
40 9 21 40 2128 9 21 40 2120 10 21 39 21
© 2010 Manoranjan Paul. All Rights Reserved.

McFIS as an I-frameAccepted in IEEE Trans. on Cir. & Sys. for Video Technology 2010* & IEEE
ISCAS-10
• A frame being the first frame is not the best I-frame
• An ideal I-frame should have the best similarity
with other frames, thus better for P/B-frames in
terms of bits and image quality
• Insertion of more than one I-frame within a scene
degrades the coding performance
Conventional Frame Format Proposed
More background area using McFIS
© 2010 Manoranjan Paul. All Rights Reserved.
Computational Time Reductions

McFIS for Reducing Quality Fluctuations
• Better I-frames are
generated for coding
efficiency
• More consistent bit
per frame and image
quality by the
proposed method
• The proposed method
improved 1.5dB
PSNR
• Better for Scene
Change Detection
Fluctuation of PSNRs
Fluctuation of Bits per frame
© 2010 Manoranjan Paul. All Rights Reserved.
Rate-Distortion performance
Rate-Distortion performance

Coded Videos using Different Schemes
© 2010 Manoranjan Paul. All Rights Reserved.
Original Video

H.264 Mode Selection by Distortion Only
published in IEEE Transactions on Multimedia 2009
© 2010 Manoranjan Paul. All Rights Reserved.
• The H.264 supports a number of modes such as
intra, skip, direct, 16×16 16×8, 8×16, 8×8, 8×4,
4×8, and 4×4 to encode a 16×16 block
• The H.264 requires around 10 time more
computational times compared to the H.263
• Thus, limited powered devices (mobile phone,
PDA, etc.) can not use H.264
• Mode selection using only bits from motion
vectors and headers with entropy bits
provides 12% reductions of computational
time
• Modified Lagrangian Multiplier is also
derived
• Only 0.1dB PSNR may be degraded
)( DCTHMVLM RRRDJ
Tii
LM
mn RmRmJm
i
)())((argmin
)( HMVmDist RRDJ
H.264 mode selection
New H.264 mode selection

Mode Selection Using Phase Correlation
© 2010 Manoranjan Paul. All Rights Reserved.
Different peaks for different kinds of motions
Phase correlation provides relative motion between two blocks
To direct mode selection we exploit this object motion
For example,
o one big peak-> no motion
o One small peak-> single motion
o Two peaks-> multiple motions
Relationship of motion inconsistence metric, δ with
object movements
Direct Mode Selection from Binary Matrix

Direct Mode Selection for Efficient Coding
published in IEEE Transactions on IP 2010
© 2010 Manoranjan Paul. All Rights Reserved.
Mode Selection by the H.264
Mode Selection by the our method
Time saving 60~90% compared to H.264
Rate-Distortion performance sometimes better compared to the H.264
• Time saving 60~90% compared to H.264
• Rate-distortion performance is comparable to the H.264
• Can be applied to other fast mode selection schemes

Outline
• Personal Information in Brief• Video Compression and Video Coding• Video/Image Quality Assessment• Computer Vision & Video Coding• Eye Tracking Technology & Visual Attention• Abnormal Event Detection• New Research Areas• Conclusions
© 2010 Manoranjan Paul. All Rights Reserved.

Video/Image Quality Assessmentpublished in IEEE ICME 2010 and IEEE Transactions on CSVT 2010
© 2010 Manoranjan Paul. All Rights Reserved.
Figure: Image Decomposition; (a) Original Barbara Image, (b) Structural part, and (c) Texture part
Figure: Block diagram of pixel domain Just Noticeable Distortion (JND) model

Outline
• Personal Information in Brief• Video Compression and Video Coding• Video/Image Quality Assessment• Computer Vision & Video Coding• Eye Tracking Technology & Visual Attention• Abnormal Event Detections• New Research Areas• Conclusions
© 2010 Manoranjan Paul. All Rights Reserved.

Environment (objects, background, shadow, etc.)
ModelingHow to extract the active regions from surveillance video stream?
Challenges!!
•Background initialization is not a practical approach in real-world
•Dynamic nature of background environment due to illumination
variation, local motion, camera displacement and shadow
Background Subtraction
- =
Current frame Background Moving foreground
© 2010 Manoranjan Paul. All Rights Reserved.

Modeling using Gaussian Mixtures
Sky
Cloud
Leaf
Moving Person
Road
Shadow
Moving Car
Floor
Shadow
Walking
People
P(x)
xµ
σ2
P(x)
xµ
σ2
P(x)
xµ
σ2
P(x)
Sky
Cloud
Person
Leaf
x (Pixel intensity)
© 2010 Manoranjan Paul. All Rights Reserved.
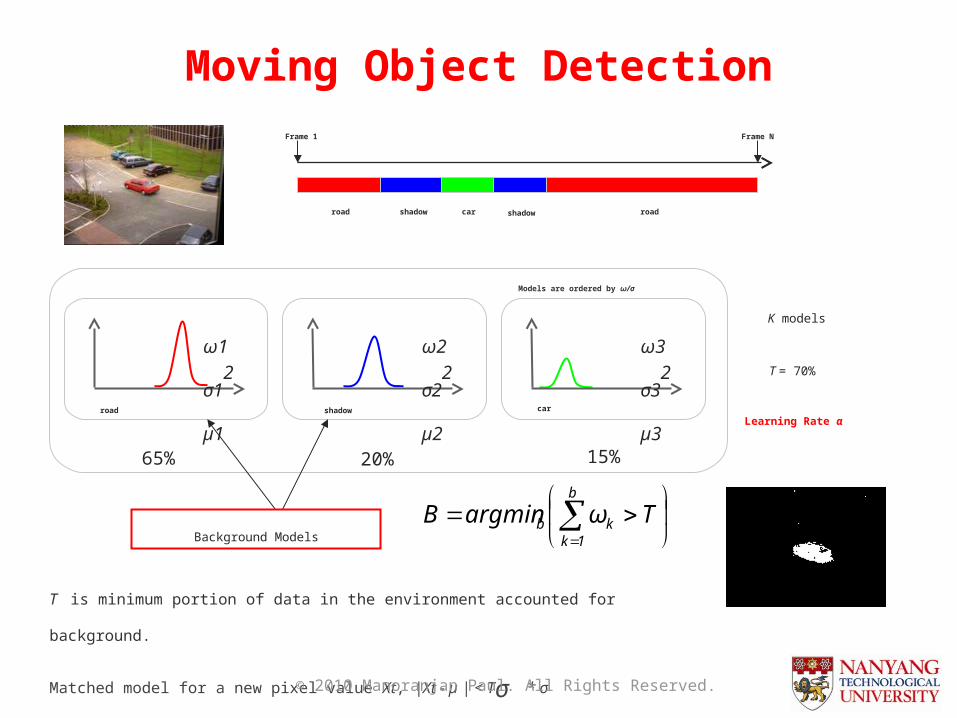
Moving Object Detection
ω1
σ12
µ1
road
ω2
σ22
µ2
shadow
ω3
σ32
µ3
car
road shadow car roadshadow
Frame 1 Frame N
65% 20% 15%
b
1kkb TωargminB
Background Models
T = 70%
T is minimum portion of data in the environment accounted for background.
Matched model for a new pixel value Xt, |Xt - µ | < Tσ * σ
Models are ordered by ω/σ
K models
Learning Rate α
© 2010 Manoranjan Paul. All Rights Reserved.

Dynamic Background Modelingpublished in IEEE ICPR-08, AVSS-8, and MMSP-08
© 2010 Manoranjan Paul. All Rights Reserved. Original ICE video sequence Background Generation
Observation:
• Predefined background/foreground ratio does not work for all cases
• Background generation using mean makes tailing effect
• Unnecessary background models using existing modelingContributions:
• Make environment independent to work in any environment
• Provide emphasis on recent changes to avoid tailing effect
• New criteria to avoid multiple models for the same environment component

(1)
(2)
(3)
(4)
(5)
(1) PETS2000; (2) PETS2006-B1; (3) PETS2006-B2; (4) PETS2006-B3; and (5) PETS2006-B4.
Object Detections - 1First Frame Test
Frame
Ground
Truth
Sfm Lf Pf
© 2010 Manoranjan Paul. All Rights Reserved.

(6)
(7)
(8)
(9)
(10)
(11)
(12)
Object Detections - 2
(6) Bootstrap; (7) Camouflage; (8) Foreground Aperture; (9) Light Switch; (10) Moved Object; (11) Time Of Day; and (12) Waving Tree
First Frame Test
Frame
Ground
Truth
Sfm Lf Pf
© 2010 Manoranjan Paul. All Rights Reserved.

Object Detections - 3
(13)
(14)
(13) Football; and (14) Walk
First Frame Test
Frame
Ground
Truth
Sfm Lf Pf
© 2010 Manoranjan Paul. All Rights Reserved.

Outline
• Personal Information in Brief• Video Compression and Video Coding• Video/Image Quality Assessment• Computer Vision &Video Coding• Eye Tracking Technology & Visual Attention• Abnormal Event Detections• New Research Areas• Conclusions
© 2010 Manoranjan Paul. All Rights Reserved.

Eye Tracking Technology & Visual Attention
Recent Research
© 2010 Manoranjan Paul. All Rights Reserved.
Figure: Three Types of Eye trackers
Figure: Original image, eye movement and fixation when observers asked for free observations, when asked to determine age of the
people, when asked to determine people positions (left to right picture).
Figure: Different heat maps for normal (left)
and abnormal driving (right)
Figure: Heat map using eye tracker (left) and salience map (right)

Outline
• Personal Information in Brief• Video Compression and Video Coding• Video/Image Quality Assessment• Computer Vision & Video Coding• Eye Tracking Technology & Visual Attention• Abnormal Event Detections• New Research Areas• Conclusions
© 2010 Manoranjan Paul. All Rights Reserved.

On Going ProjectAbnormal event detection using vision friendly video coding
© 2010 Manoranjan Paul. All Rights Reserved.
This project contributes on:
• Interactive 3D Video Technology
• Eye Tracking technology
• Visual attention modeling
• Abnormal event detection

New Research Areas
• 3D Video– 3D Video Coding– Multi-view Video Coding– Depth Estimation– Free-View Videos– Distributed Video Coding
© 2010 Manoranjan Paul. All Rights Reserved.

Conclusions• Improve compression and video quality
– Pattern-based (regular and arbitrary-shaped) video coding– Super-High Definition (SHD) video coding– Video coding for uncovered background and occlusions– Optimal compression plane (OCP) selection– Singular Value Decomposition-based video coding
• Reduce computational complexity in video coding– Phase correlation-based direct mode selection– Simplified Lagrangian function for low-cost mode selection
• Image Decomposition and Quality Assessment– Separating structure and texture areas of an image
• Background modeling & Object Detection– Object detection from the challenging environments
• Panic-driven event detection– Event detection using low-level features
• Eye tracking technology & visual attention modeling– Human-centric regions of interest selection
© 2010 Manoranjan Paul. All Rights Reserved.

Thank you!
Email: [email protected]
© 2010 Manoranjan Paul. All Rights Reserved.
http://sites.google.com/site/manoranjanpaulpersonalweb/


















