
Video Arrays for Real-Time Tracking of Persons, Head and...
25
Machine Vision and Applications, Omnidirectional Vision, Special Issue, October 2001. Video Arrays for Real-Time Tracking of Persons, Head and Face in an Intelligent Room Kohsia S. Huang and Mohan M. Trivedi Computer Vision and Robotics Research (CVRR) Laboratory University of California, San Diego 9500 Gilman Drive, La Jolla, CA 92093-0407, USA E-mail: [email protected] ; [email protected] Website: http://cvrr.ucsd.edu/ Abstract Real-time 3D person, head and face tracking are critically important for natural interactions among humans in an intelligent environment. Trackers based on multiple networked cameras estimate human positions and heights more accurately and robustly than single camera or binocular trackers. The goal of this paper is to first present a comparative evaluation of two types of 3D tracking systems, namely Omnidirectional- and Rectilinear- Video Array Trackers (VAT), then apply 3D tracking to head and face tracking. The O-VAT uses N-ocular stereo algorithm to estimate the planar location of a person, and height is estimated using camera optical and geometrical properties. The networked omnicamera system then uses the 3D person tracks to perform head and face tracking. The R-VAT uses a calibrated rectilinear camera network to estimate human location and height, and keeps track of human path by a Kalman filter. Extensive sets of experimental studies involving multiple people in a fully functional intelligent room are conducted. This allows comparative evaluation of the two different types of multicamera trackers operating in a common testbed. Performance of the two VATs is compared on accuracy, speed, computational complexity, robustness to environment, repeatability, calibration efficiency, and system reconfigurability. We also develop the necessary perspective transforms and active camera control algorithms for capturing and tracking faces of people who are walking or sitting in an intelligent room. An experimental evaluation study is presented to demonstrate the fully integrated person, head and face tracking system. Keywords -- Omnidirectional vision, video camera arrays, 3D person tracking, head and face tracking, intelligent environments, performance evaluation, real-time vision systems, active vision, motion tracking, perspective transforms.
Transcript of Video Arrays for Real-Time Tracking of Persons, Head and...

Machine Vision and Applications, Omnidirectional Vision, Special Issue, October 2001.
Video Arrays for Real-Time Tracking ofPersons, Head and Face in an Intelligent Room
Kohsia S. Huang and Mohan M. Trivedi
Computer Vision and Robotics Research (CVRR) LaboratoryUniversity of California, San Diego
9500 Gilman Drive, La Jolla, CA 92093-0407, USAE-mail: [email protected]; [email protected]
Website: http://cvrr.ucsd.edu/
Abstract
Real-time 3D person, head and face tracking are critically important for naturalinteractions among humans in an intelligent environment. Trackers based on multiplenetworked cameras estimate human positions and heights more accurately and robustlythan single camera or binocular trackers. The goal of this paper is to first present acomparative evaluation of two types of 3D tracking systems, namely Omnidirectional-and Rectilinear- Video Array Trackers (VAT), then apply 3D tracking to head and facetracking. The O-VAT uses N-ocular stereo algorithm to estimate the planar location of aperson, and height is estimated using camera optical and geometrical properties. Thenetworked omnicamera system then uses the 3D person tracks to perform head and facetracking. The R-VAT uses a calibrated rectilinear camera network to estimate humanlocation and height, and keeps track of human path by a Kalman filter. Extensive sets ofexperimental studies involving multiple people in a fully functional intelligent room areconducted. This allows comparative evaluation of the two different types of multicameratrackers operating in a common testbed. Performance of the two VATs is compared onaccuracy, speed, computational complexity, robustness to environment, repeatability,calibration efficiency, and system reconfigurability. We also develop the necessaryperspective transforms and active camera control algorithms for capturing and trackingfaces of people who are walking or sitting in an intelligent room. An experimentalevaluation study is presented to demonstrate the fully integrated person, head and facetracking system.
Keywords -- Omnidirectional vision, video camera arrays, 3D person tracking, headand face tracking, intelligent environments, performance evaluation, real-time visionsystems, active vision, motion tracking, perspective transforms.

Machine Vision and Applications (S ubmitted Oct. 2001)
Huang and Trivedi: Video Arrays for Real-Time Tracking of Persons, Head and Face in anIntelligent Room 1
1. Introduction: Research Context and OverviewThis research is performed as a part of a larger project associated with the design,
development, and applications of intelligent environments [11] [14] [15] [16]. Theintelligent environment considered is an indoor area, similar to a classroom, a meeting orconference room, a theater or a laboratory. An important requirement is to let thehumans do their activities naturally. In other words, we do not require humans to adaptto the environments but would like the environment to adapt to the humans. This designguideline places some challenging requirements on the computer vision algorithms forthe system. Multiple video streams, from a wide range of perspectives and resolutions,need to be accurately and efficiently analyzed. The processing and analysis algorithmsneed to cover a wide spectrum, from the lower signal processing levels to the highersemantic and context levels. Accurate, robust, and efficient means for tracking multiplepeople in these environments, as well as tracking of the head and faces of people, is acritical requirement. This motivates us to examine, develop, and evaluate a range ofalternate multiple video based tracking algorithms.
Figure 1: General architecture and tasks of visual information capture and analysissystem (VICAS) for intelligent environments.
A general structure and tasks associated with the visual information capture andanalysis system (VICAS) for intelligent environments is illustrated in Figure 1. The
Real-Time Visual Information Capture
3D TrackingPerson Location,
Bounding Volume,Velocity
Visual Information AnalysisHead and Face Tracking,
Face Recognition,Posture/Gesture Recognition,Posture/Movement Analysis
Event Detection,… etc.
Graphical User InterfacePerson Tracks, Face Tracking, Person IDs,
Gestures, Events,… etc.Data Archiving/Communication
Active Camera ControlArray Selection, Camera Selection,PTZ Control (Mechanical/Digital)
Video Array

Machine Vision and Applications (S ubmitted Oct. 2001)
Huang and Trivedi: Video Arrays for Real-Time Tracking of Persons, Head and Face in anIntelligent Room 2
overall goal of this system is to derive useful information captured by video networks,which can provide accurate awareness of the space and various activities taking place inthem in real-time. Events detected in the space allow for active control of the videonetworks thus providing an efficient means for humans and spaces to interact [15] [16].Two of the most important visual processing functionalities in the system are associatedwith accurate and efficient means for 3-D tracking of people who walk in these spacesand with 3D tracking of their heads and faces as they undertake transactions of theirnormal activities. 3D tracking derives spatial information of humans within the 3D spacecovered by the video networks. Other visual information processing requires the systemto capture close-up videos of human faces, gestures, and other body parts to perform face,gesture, and posture recognition and movement analysis [7]. The systems should becapable of “actively” directing the most appropriate cameras for capturing the higherresolution visual information. This can be accomplished by real-time control of thevarious pan, tilt, and zoom functions of the video cameras. The three degrees of freedomfor pan, tilt, and zoom can be controlled either by an electromechanical means or by fullydigital means. The mechanical approach can typically provide higher resolution video,however it also requires better calibration, slower performance, and limited numbers ofsimultaneous focus of attentions. The fully digital approach compensates for theselimitations, with limitations on resolution.
Multiple camera arrays have better tracking accuracy and robustness than single orbinocular camera systems since spatial redundancy between camera coverage can beutilized [1] [2] [3] [4] [13] [14] [18]. For the camera networks, there are basically twosomewhat opposite ways in which the indoor spaces can be visually captured. These are:
(1) Outside-in-coverage: Can be realized by placing an array of multiple rectilinearcameras on the walls and ceilings.
(2) Inside-out-coverage: Can be realized by placing an array of cameras to capture widearea panoramic images from some no-obtrusive vantage points within the environments.An array of omnidirectional cameras seems to be most effective in this regard.
Our research aims at developing a detailed understanding of the video network basedVICAS system for intelligent environments. This is accomplished by systematic designand empirical evaluation in real-world testbeds of the above competing approaches. Wedevelop the framework, architecture and control structure, and acquisition and analysisalgorithms, which can allow for detailed experimental evaluations using real-worldtestbeds. According to the camera network applied, two video array intelligent systemsare considered as the representatives: the Intelligent Meeting Room (IMR) system [6]which utilizes outside-in rectilinear camera arrays, and Networked OmnidirectionalVideo Array (NOVA) system [5] which utilizes inside-out Omni-Directional VisionSensor (ODVS) network. They each have different real-time 3D tracking algorithmsdesigned on the specific video array. Since tracking algorithms directly influence theoverall system performance, it is of interest to compare the two tracking algorithms usingsystematic, extensive experimental studies. Such experimental evaluation ofmulticamera-based tracking is quite unique, as we are able to compare their performancein exactly the same testbed. We can thus determine the strengths and limitations of theomni-arrays and rectilinear arrays as applied to the same tasks in a common testbed. Italso provides insights in the development of a hybrid approach which may be needed in

Machine Vision and Applications (S ubmitted Oct. 2001)
Huang and Trivedi: Video Arrays for Real-Time Tracking of Persons, Head and Face in anIntelligent Room 3
intelligent environments. In addition, the active control of the video array for higherresolution video capture and tracking of the human face is also considered.
In this paper, we first introduce and compare the IMR and NOVA intelligent systemsaiming at 3D person and head tracking. Then we investigate the two real-time 3D persontracking algorithms on ODVS network [5] [13] and rectilinear camera network [6] [8][15] respectively. Experimental and empirical performances are then compared betweenthese two types of tracking algorithms. We also develop the necessary perspectivetransforms and active camera control algorithms for capturing and tracking faces ofpeople who are walking or sitting around a table in an intelligent room. An experimentalevaluation study is presented to demonstrate the fully integrated person, head and facetracking system.
2. NOVA and IMR: A Comparative OverviewThe NOVA system [5] is a representative of the intelligent room architecture in
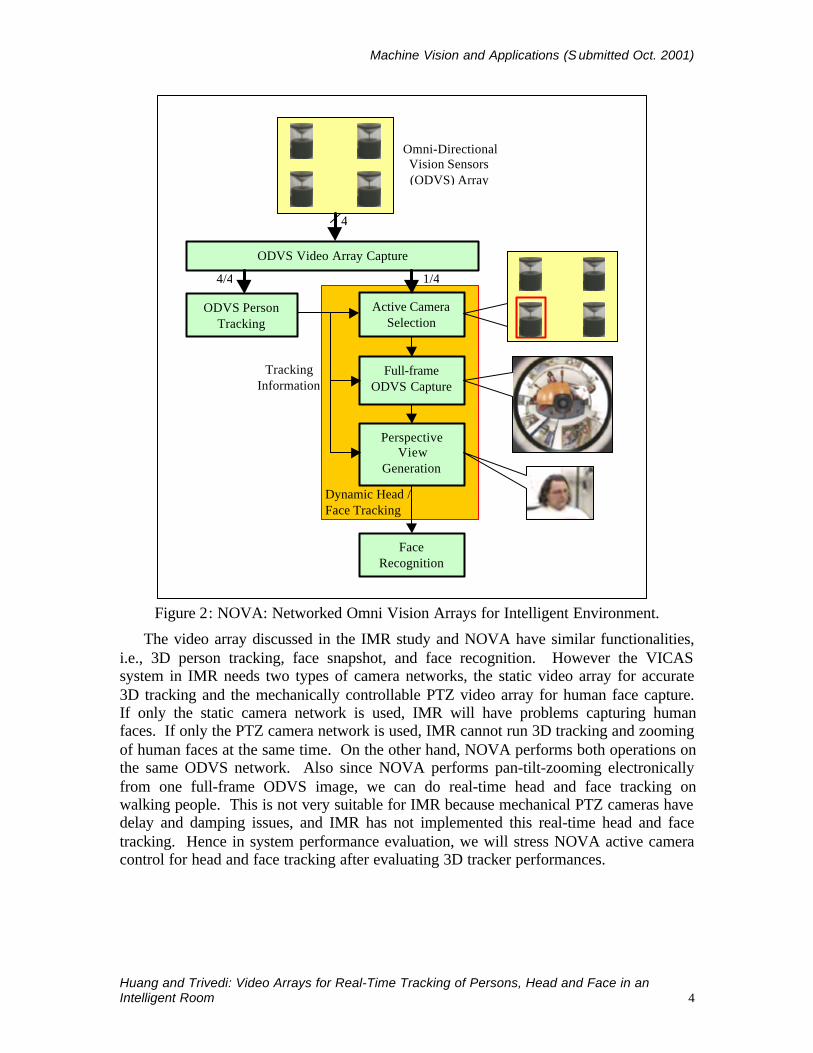
Figure 1. The NOVA system is designed on an ODVS network of inside-out coverage.The ODVS network is installed on a meeting table in the testbed room. With inside-outcoverage in a meeting room setting, faces of the participants can be easily capturedbecause people sitting around the meeting table are facing the ODVSs. A more detailedstructure of the NOVA system is shown in Figure 2. It is composed of ODVS arraycapturing, 3D person tracking, active camera selection, and view generation for head andface tracking. The 3D ODVS tracker running on one computer detects and tracks peopleand send the tracks to another computer. On the second computer, which analyzes visualinformation, single ODVS signal can be captured in full frame. Utilizing the 3D trackinginformation, the Active Camera Selection (ACS) and Dynamic View Generation (DVG)modules latch on a human head by a perspective view generated from the full-frameODVS image. The face image can be tracked in real-time within the perspective viewand then be identified.
The IMR system [6] is a multimodal indoor intelligent system designed for meetingroom or class room setup. It utilizes a network of wide-angle static rectilinear cameras, anetwork of mechanical PTZ cameras, and a microphone array. The video part of IMR isa straightforward implementation of the architecture in Figure 1 on an outside-inapproach. The input to the 3D tracker is the static camera network installed at the ceilingcorners of the testbed room. The input to the visual information analysis is the PTZcamera network installed at the wall corners of the room. The 3D tracker derives humancentroid location, velocity, and bounding cylinder of a person to the visual informationanalysis module. In the visual information analysis module, the best view cameraselection chooses an optimum PTZ camera to take a face snapshot of a person andperforms face recognition. If the person moves close to a white board, it will also haveone PTZ camera zoomed to the person’s face according to face orientation in order tocapture the talk.
Machine Vision and Applications (S ubmitted Oct. 2001)
Huang and Trivedi: Video Arrays for Real-Time Tracking of Persons, Head and Face in anIntelligent Room 4
Figure 2: NOVA: Networked Omni Vision Arrays for Intelligent Environment.
The video array discussed in the IMR study and NOVA have similar functionalities,i.e., 3D person tracking, face snapshot, and face recognition. However the VICASsystem in IMR needs two types of camera networks, the static video array for accurate3D tracking and the mechanically controllable PTZ video array for human face capture.If only the static camera network is used, IMR will have problems capturing humanfaces. If only the PTZ camera network is used, IMR cannot run 3D tracking and zoomingof human faces at the same time. On the other hand, NOVA performs both operations onthe same ODVS network. Also since NOVA performs pan-tilt-zooming electronicallyfrom one full-frame ODVS image, we can do real-time head and face tracking onwalking people. This is not very suitable for IMR because mechanical PTZ cameras havedelay and damping issues, and IMR has not implemented this real-time head and facetracking. Hence in system performance evaluation, we will stress NOVA active cameracontrol for head and face tracking after evaluating 3D tracker performances.
ODVS Video Array Capture
ODVS PersonTracking
FaceRecognition
TrackingInformation
4/4
Omni-DirectionalVision Sensors(ODVS) Array
4
1/4
Active CameraSelection
PerspectiveView
Generation
Full-frameODVS Capture
Dynamic Head /Face Tracking

Machine Vision and Applications (S ubmitted Oct. 2001)
Huang and Trivedi: Video Arrays for Real-Time Tracking of Persons, Head and Face in anIntelligent Room 5
3. O-VAT: Omnidirectional Video Array Tracker
Figure 3: O-VAT: Omnidirectional Video Array Tracker.
The main advantage of the omnidirectional vision sensors (ODVS) is the coverage [9][10] [13]. It provides the maximum (360 degrees) coverage using a single camera. Themain disadvantage is low resolution. We propose utilization of an array of multiple
Panorama
ShadowDetection &
Segmentation
AzimuthAngles
N-ocularStereo
Moving TrackFiltering
WeightedAveraging
HeightEstimation
TopmostPixels
Object BlobsObject Profiles
x-y Measurements z Measurements
Output Tracks
Omni Video Array
Panorama
ShadowDetection &
Segmentation
Panorama
ShadowDetection &
Segmentation
Panorama
ShadowDetection &
Segmentation
DataAssociation
Associated x-yMeasurements
TrackInitialization /Termination
Human Objectswith Past
Measurements
Track CandidatesUnassociatedMeasurements /Empty Tracks
Tracks
Averaged zMeasurements
Tracks

Machine Vision and Applications (S ubmitted Oct. 2001)
Huang and Trivedi: Video Arrays for Real-Time Tracking of Persons, Head and Face in anIntelligent Room 6
ODVS to develop an effective 3D tracker of human movements and faces. The O-VATwe have developed can be considered an extension of the 2-D person tracking systempresented in [13].
The 3D person tracker utilizing four ODVSs is shown in Figure 3. The four ODVSsare calibrated in advance on their locations, heights, azimuth directions, and internalparameters. Each ODVS video is unwrapped into a panoramic view. Backgroundsubtraction is performed on the panoramas. As shown in Figure 4, first a 1D profile ofthe current panorama frame is formed by accumulating pixel differences to thebackground in each column of the panorama. The background profile is formed by themaximum value for each column of the 1D profiles in 30 frames. Also, the mean andvariance for each pixel are evaluated and the statistics of brightness distortion, α, andchrominance distortion, CD, for each pixel are evaluated to determine thresholds forshadow detection,
(1)
Figure 4: O-VAT based operation of multiperson real-time tracking. Raw images from 4ODVS are displayed in the left top corner. Unwarped video streams and movingforeground pixel histograms are shown on the right. The bottom left image showstracking results.
++
+
+
=
222222
1
B
BB
G
GG
R
RR
B
B
G
G
R
R
III
σ
µ
σ
µ
σ
µ
σµ
σµ
σµ
α

Machine Vision and Applications (S ubmitted Oct. 2001)
Huang and Trivedi: Video Arrays for Real-Time Tracking of Persons, Head and Face in anIntelligent Room 7
(2)
Foreground and shadow can be differentiated by the values of α and CD at each pixel[12]. Each panoramic column corresponds to an azimuth angle viewing from ODVS.When a person or an object is presented, it will be detected from the background profileof each ODVS as the white histogram profile in Figure 4. Shadow detection andbackground subtraction are performed in the detected range to extract foreground objectsas the marked silhouettes. The azimuth angle of the person relative to an ODVS isestimated as the center of the detected object. Knowing the locations of the four ODVSs,the x-y planar location of the person or object can be determined by the triangulationmethod illustrated in the lower-left window in Figure 4. This localization mechanism iscalled N-ocular and is detailed in [13]. Error compensation measures are applied tohandle ghost situations and people near the baselines of two ODVSs. The measured x-ylocations are then associated to the nearest human track.
After the instantaneous x-y measurement of person is available, height z of the personcan be estimated. For each panorama, the topmost pixel of the person’s segment isdetected. Since the planar location of the person was previously estimated, the distanceof the person to the corresponding ODVS can be computed. Then the height of personHperson can be estimated by similar triangle as
(3)
where bloby is the topmost point of the person’s blob, horizony is the horizon on the
panorama, pixelH is the pixel height of the panorama, panoramaR is the radius of cylindrical
screen of the panorama, focusupperH is the physical height of the upper focus of the ODVS
hyperboloid mirror, and ODVStopersond is the estimated planar distance between the personand ODVS. The final estimate of the person’s height is a weighted sum of the estimatesfrom the four ODVSs. The weight is the inverse of the distance between person andODVS. Thus the x-y-z location is measured and associated to a human object.
The tracks are kept by the human objects of the tracker. A new track is initialized ifan unassociated measurement exists. If no new measurements are associated to it for aperiod, the track is terminated. The track is displayed if new measurements are added toit for several frames, as shown in Figure 4. The estimated human height is displayed incentimeters under the clipped human image in the result window. The final 3D outputtrack is a moving average of the track positions in the past 0.5 seconds.
ODVStoperson
focusupperperson
panorama
pixelhorizonblob
d
HH
R
Hyy −=
− )(
222
−+
−+
−=
B
BB
G
GG
R
RR IIICD
σµα
σµα
σµα
Machine Vision and Applications (S ubmitted Oct. 2001)
Huang and Trivedi: Video Arrays for Real-Time Tracking of Persons, Head and Face in anIntelligent Room 8
4. R-VAT: Rectilinear Video Array TrackerRectilinear cameras are commonly used in 2D [3] [18] or 3D [1] [2] [4] human
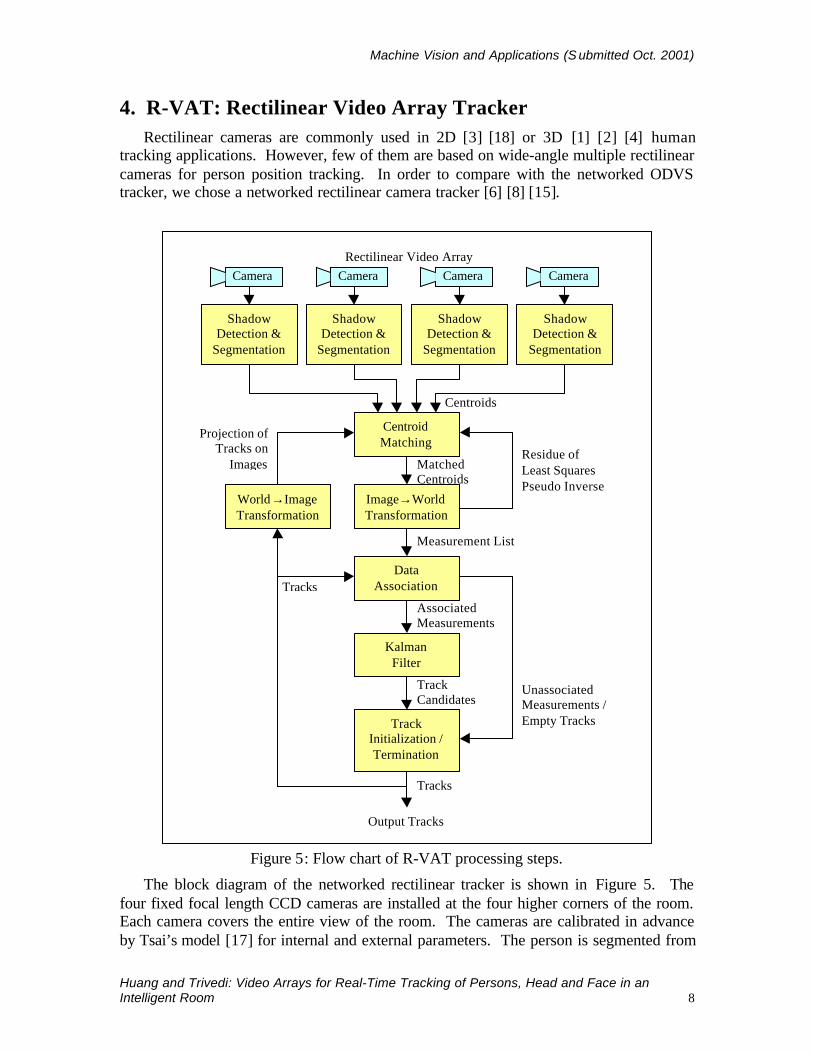
tracking applications. However, few of them are based on wide-angle multiple rectilinearcameras for person position tracking. In order to compare with the networked ODVStracker, we chose a networked rectilinear camera tracker [6] [8] [15].
Figure 5: Flow chart of R-VAT processing steps.
The block diagram of the networked rectilinear tracker is shown in Figure 5. Thefour fixed focal length CCD cameras are installed at the four higher corners of the room.Each camera covers the entire view of the room. The cameras are calibrated in advanceby Tsai’s model [17] for internal and external parameters. The person is segmented from
ShadowDetection &
Segmentation
CentroidMatching
Image→WorldTransformation
World→ImageTransformation
DataAssociation
KalmanFilter
TrackInitialization /Termination
Centroids
Projection ofTracks on
Images
Measurement List
Residue ofLeast SquaresPseudo Inverse
AssociatedMeasurements
Tracks
Output Tracks
UnassociatedMeasurements /Empty Tracks
Camera CameraCamera Camera
Tracks
MatchedCentroids
Rectilinear Video Array
TrackCandidates
ShadowDetection &
Segmentation
ShadowDetection &
Segmentation
ShadowDetection &
Segmentation

Machine Vision and Applications (S ubmitted Oct. 2001)
Huang and Trivedi: Video Arrays for Real-Time Tracking of Persons, Head and Face in anIntelligent Room 9
the camera images by background subtraction. Same shadow detection using equations(1) and (2) is performed to remove shadow interference. A forgetting factor is alsoapplied on the background modeling so the segmentation can update its background.Centroids of the segments are then matched between the cameras with reference to thepredicted current track. For each centroid, the following equation is generated,
(4)
where the r’s and T’s are available from Tsai’s calibration algorithm, and o’s arecomputed from the image coordinates of the centroid. The 3D location [ ]Tzyx=x can beestimated by putting together the equation pairs of the centroids and take pseudo inverseas ( ) bAAAx TT 1−≈ . A combination of the centroids is accepted and added to themeasurement list if the residue of pseudo inverse,
2Axb − , is small enough. The
measured 3D position is then associated to an existing track θ by maximizing thelikelihood ( )θΛ as
(5)
where Z is the measurement list, M is the number of measurements, and )|( θizp is aGaussian probability with respect to the Mahalanobis distance of the measurement zi tothe predicted location of track θ. The assigned measurement is used to update a Kalmanfilter which models the track,
(6)
where the state [ ]Tzyxzyx '''=x and output [ ]Tzyx=z , F and H are derived usingNewton’s laws of motion, v models random acceleration of human motion, and w modelsmeasurement error. Kalman filter predicts the next location of the track and theprediction is fed back to centroid matching to accelerate the matching process. If ameasurement in the measurement list has no track associated with it, a new track isstarted and validated after several frames. A track is terminated if no measurement isassociated with it for several frames. Kalman filter states of the valid tracks are the finaloutput of the networked rectilinear tracker.
5. Performance Evaluations of O-VAT and R-VATIn an intelligent room application, the accuracy of the 3D tracker determines
robustness of the overall system. In this section we evaluate system performance inexperiments on tracking people both walking and sitting, and tracking heads and faces ofpeople. Besides quantitative accuracy, other performance indices include speed,computational complexity, robustness to environments, repeatability, calibration, andsystem reconfigurability.
Both the networked ODVS tracking system and the networked rectilinear trackingsystem are embedded in our 6.7m-by-3.3m meeting room testbed called AVIARY, as
( ) ( ) ( )( ) ( ) ( ) 121332
2629528427
1319218117××× =⇔
−=−+−+−−=−+−+−
bxAoTTzroryrorxroroTTzroryrorxror
zy
zx
+=+=+
kkk
kkk
wxHzvxFx 1
( ) ( ) CM
iizpZp
1)|(maxarg|maxargmaxarg
===Λ θθθ
θθθ

Machine Vision and Applications (S ubmitted Oct. 2001)
Huang and Trivedi: Video Arrays for Real-Time Tracking of Persons, Head and Face in anIntelligent Room 10
shown in Figure 6. The four camera ODVS network is installed on the four corners of arectangular meeting table sitting in the middle. The four rectilinear cameras are equippedwith wide-angle lenses and are installed at the four higher corners of the room so thateach rectilinear camera covers the entire room. Four mechanical pan-tilt-zoom (PTZ)cameras are installed at the mid-height of the four corners.
Figure 6: The AVIARY intelligent meeting room testbed. Upper left: An ODVS imagecovering the entire room. Upper right: A rectilinear image of the interior of the room.Lower: Panorama unwrapped from the ODVS image, showing the placement of cameranetworks.
Accuracy
The accuracy of the 3D ODVS tracker is evaluated on tracking people walking and iscompared to 3D rectilinear tracker [6] [8] [15]. A rectangular walking path is defined inour testbed around the meeting table. The ODVS network is mounted 1.2 meters aboveground to cover sitting people but cannot cover standing adults. Therefore to evaluatewalking people in 3D, we invited a group of children to walk over the test pattern in thelaboratory, as shown in Figure 7. Adult participants were also invited, yet their heightcould not be estimated by O-VAT.
Omnicameras
MechanicalPTZ cameras
Rectilinearcameras
Omnicameras
Rectilinearcameras
MechanicalPTZ cameras

Machine Vision and Applications (S ubmitted Oct. 2001)
Huang and Trivedi: Video Arrays for Real-Time Tracking of Persons, Head and Face in anIntelligent Room 11
Figure 7: Volunteers walking over the test tracks during a two-person 3D trackingexperiment.
A vast amount of experiments were conducted to compare the tracking accuracy ofO-VAT and R-VAT. While the participants were walking, both O-VAT and R-VATwere logging the x-y locations as well as the height estimations simultaneously. Thelogged data were plotted for comparison offline. For the experiments, track pointsranging from 200 to 400 were logged for O-VAT and R-VAT respectively. The metricswe applied for accuracy comparison were mean offset from the designated path andstandard deviation of the track estimates.
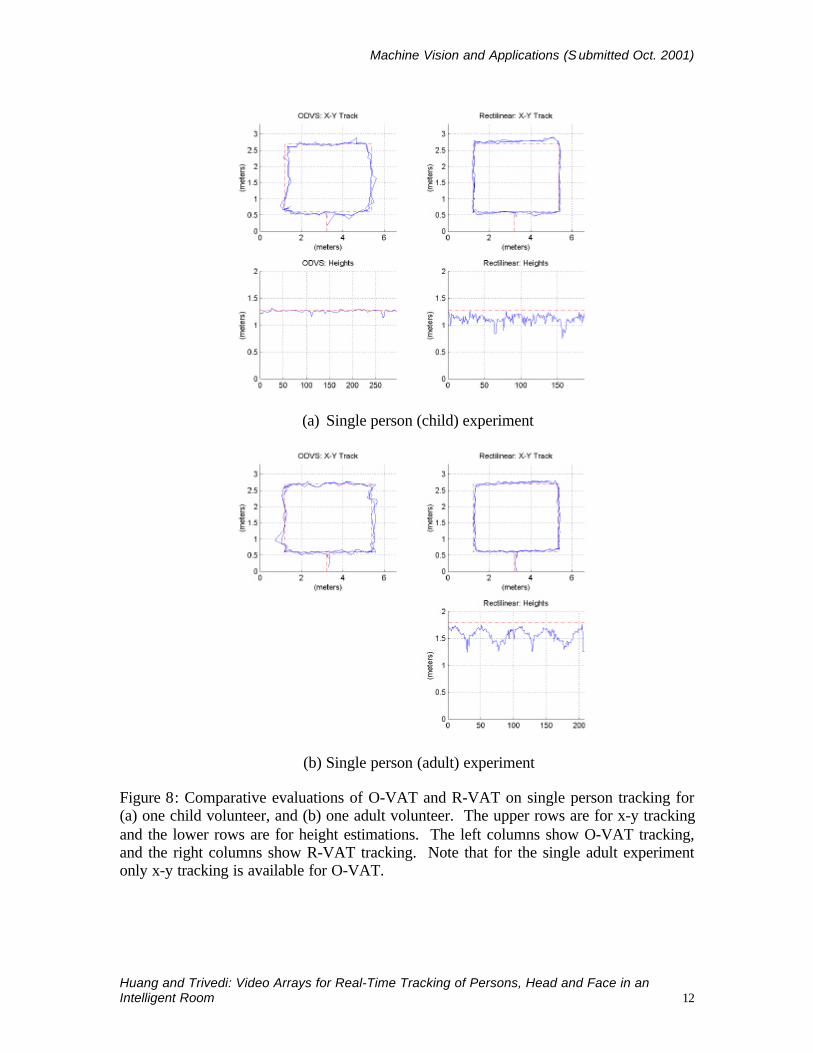
Specifically, we are seeking to evaluate 2D and 3D tracking accuracy with respect tothe number of children and adults between O-VAT and R-VAT. As shown in Figure 8,single person accuracy is first compared for both child and adult participants. Formultiple people, 2 and 3 child experiments are conducted for a full 3D accuracycomparison, as shown in Figure 9. Two to four adult experiments are compared in Figure10. In these adult cases, 2D accuracy is compared between O-VAT and R-VAT, whileheight estimation is only evaluated for R-VAT. The evaluated accuracy is summarized inTable 1.
Machine Vision and Applications (S ubmitted Oct. 2001)
Huang and Trivedi: Video Arrays for Real-Time Tracking of Persons, Head and Face in anIntelligent Room 12
(a) Single person (child) experiment
(b) Single person (adult) experiment
Figure 8: Comparative evaluations of O-VAT and R-VAT on single person tracking for(a) one child volunteer, and (b) one adult volunteer. The upper rows are for x-y trackingand the lower rows are for height estimations. The left columns show O-VAT tracking,and the right columns show R-VAT tracking. Note that for the single adult experimentonly x-y tracking is available for O-VAT.

Machine Vision and Applications (S ubmitted Oct. 2001)
Huang and Trivedi: Video Arrays for Real-Time Tracking of Persons, Head and Face in anIntelligent Room 13
(a) Multiple person (2 children) experiment
(b) Multiple person (3 children) experiment
Figure 9: Comparative evaluations of O-VAT and R-VAT on multiple children trackingfor (a) two child volunteers, and (b) three child volunteers. The upper rows are for x-ytracking and the lower rows are for height estimations. The left columns show O-VATtracking, and the right columns show R-VAT tracking.

Machine Vision and Applications (S ubmitted Oct. 2001)
Huang and Trivedi: Video Arrays for Real-Time Tracking of Persons, Head and Face in anIntelligent Room 14
(a) Multiple person (2 adults) experiment
(b) Multiple person (3 adults) experiment

Machine Vision and Applications (S ubmitted Oct. 2001)
Huang and Trivedi: Video Arrays for Real-Time Tracking of Persons, Head and Face in anIntelligent Room 15
(c) Multiple person (4 adults) experiment
Figure 10: Comparative evaluations of O-VAT and R-VAT on multiple adults trackingfor (a) two adult volunteers, (b) three adult volunteers, and (c) four adult volunteers. Theupper rows are for x-y tracking and the lower rows are for height estimations. The leftcolumns show O-VAT tracking, and the right columns show R-VAT tracking. Note thatfor height estimation only R-VAT data is available for the adult cases.
TABLE 1SUMMARIZATION OF TRACKING ACCURACY COMPARISONS OF O-VAT AND R-VAT INTERMS OF MAXIMUM MEAN OFFSETS AND STANDARD DEVIATIONS. 2D TRACKING ANDHEIGHT ESTIMATION ARE EVALUATED ON SINGLE PERSON AND MULTIPLE PEOPLETRACKING. HEIGHT ESTIMATION IS NOT VALID FOR O-VAT ON ADULT CASES.*NOTE THAT IN THE 3 CHILDREN CASE, O-VAT HEIGHT ESTIMATES OF THE THIRD CHILDARE DISCARDED FROM THE ACCURACY CALCULATION BECAUSE THE HEAD-TOP POINT OFTHE CHILD IN CAMERA IMAGE WAS CHOPPED OFF OCCASIONALLY.
O-VAT R-VATx-y (2-D) Height z x-y (2-D) Height z
Tracking Accuracy(cm)
∆µmax σ ∆µmax σ ∆µmax σ ∆µmax σChild 10 12 0 3 10 3 15 12Single PersonAdult 12 12 10 5 30 12Child 10 12 0 3 10 5 15 152Adult 20 15 10 5 35 15Child 10 15 0 3* 10 10 20 203Adult 20 15 10 12 35 30
MultiplePeople
4 Adult 20 15 15 20 35 40Note: ∆µmax is the maximum mean offset; σ is the standard deviation.

Machine Vision and Applications (S ubmitted Oct. 2001)
Huang and Trivedi: Video Arrays for Real-Time Tracking of Persons, Head and Face in anIntelligent Room 16
According to Table 1, for both single child and single adult cases, the x-y maximummean offsets are comparable and the x-y standard deviation of O-VAT is larger than R-VAT. For multiple children, the O-VAT and the R-VAT have a comparable x-ymaximum mean offset and still, the x-y standard deviation of O-VAT is larger than R-VAT. However, R-VAT exhibits a faster rate of increase in x-y standard deviation. Forheight estimations, in the child cases, O-VAT obviously outperforms R-VAT. O-VATheight estimations are unbiased, while R-VAT height estimations have large offsets andthe offsets increase with number of children. The O-VAT height standard deviations areconstant, but those taken by R-VAT increase rapidly with number of children. Formultiple adult participants, the x-y maximum mean offset of R-VAT is better. Thisshould due to better calibration procedure for R-VAT. However, the x-y standarddeviation of R-VAT increases rapidly with number of people. On the other hand, O-VATx-y standard deviations are kept constant. After 3 people, O-VAT has better x-y standarddeviation performance. For height estimations of adult cases, only R-VAT is valid. BothR-VAT height mean offsets and standard deviations are very large. The R-VAT heightstandard deviations also degrade rapidly with number of people. It is due to the fact thatas the number of people increases, the chance that one person occludes another willincrease rapidly in a small room. This situation is less likely to happen on O-VATbecause the ODVSs are standing upright. People walking in circles can be distinguishedeasily by ODVSs. Hence O-VAT standard deviations for both x-y and height estimationare relatively immune to number of people.
Thus, we can conclude that O-VAT height estimation outperforms R-VAT. For x-ytracking, R-VAT performs better when there are fewer people in the room. However, R-VAT standard deviations degrade rapidly as the number of people increases. After 3people, the O-VAT performs better than R-VAT. The O-VAT standard deviationperformances can be further improved if Kalman filter is applied on tracks like therectilinear tracker.
Speed
When the two trackers are tested on the same platform (dual Pentium 866MHz,256MB RAM) and one person is being tracked, the rectilinear tracker runs at about 3frames per second and the ODVS tracker runs at about 5 frames per second. Thereforethe rectilinear tracker is approximately 1.7 times slower than the ODVS tracker.
Computational Complexity
From Figure 3 and Figure 5, the rectilinear tracker is equipped with shadow detection,maximum likelihood data association, Kalman filter track modeling, and backgroundupdating. The ODVS tracker is equipped with shadow detection, nearest neighborhooddata association, and a 0.5 second track moving average. The rectilinear tracker is morecomplicated computationally, which is verified by the execution speed.

Machine Vision and Applications (S ubmitted Oct. 2001)
Huang and Trivedi: Video Arrays for Real-Time Tracking of Persons, Head and Face in anIntelligent Room 17
Robustness to Environmental Changes
For the ODVS tracker, the background is updated manually by user command. Therectilinear tracker can update the background automatically with a forgetting factor. Thusalthough more complex, the rectilinear tracker is more robust to environmental changes.However, the drawback of the forgetting factor is that a person will be absorbed intobackground if he stays for too long.
Repeatability
The two trackers are embedded in the same room and the illumination is constantover time. We have operated the two systems several hundred times and overnight. Theperformance of the two trackers has been very consistent in these experiments.
Calibration
Both O-VAT and R-VAT need careful calibration to yield accurate results. Tsai’scalibration algorithm [17] is commonly applied to calibrate both external and internalparameters of rectilinear cameras. By calibrating the rectilinear cameras to a commongrid, the parameters can be determined efficiently. On the other hand, there is currentlyno calibration procedure for the hyperboloid mirror ODVSs. Internal parameters aresupplied by the manufacturer and the accuracy depends on the manufacturing. Externalparameters are measured manually. First an origin of a coordinate system is defined inthe room such as a corner of two walls. The x-y location and height for each ODVS aremeasured. The orientation of each ODVS can then be calculated from objects of knownlocation in the ODVS image. Horizon in the ODVS image is determined by puttingmarks of ODVS height on the four walls. The accuracy of the calibrated externalparameters is within one centimeter.
System Reconfigurability
System reconfigurability can be defined as: for two systems with the same type ofinfrastructure, we say a system has higher reconfigurability if it allows more functionalitythan the other does. In this manner, the ODVS network has higher reconfigurabilitybecause with the same set of ODVS network, the system not only allows tracking but alsoallows electronic pan-tilt-zoom simultaneously. On the other hand, the rectilinearnetwork, without adding pan-tilt-zoom cameras, can only do tracking on the static cameranetwork. Electronic zooming into a person’s face is unsatisfactory because the face istoo small and obscure in the wide-angle static rectilinear cameras.
It should also be noted that as compared to rectilinear pan-tilt-zoom cameras, theODVS network does not require mechanical motion of the cameras at all. Thus the speedand system reconfigurability are increased. In addition, since the ODVSs are placed inthe midst of the meeting participants, omnicameras have the advantageous viewingangles of the faces from a closer distance. Unobtrusive electronic pan-tilt-zoom cangenerate perspective views of people’s faces. Therefore ODVS network is very suitablefor meeting room setup.

Machine Vision and Applications (S ubmitted Oct. 2001)
Huang and Trivedi: Video Arrays for Real-Time Tracking of Persons, Head and Face in anIntelligent Room 18
cZRf
rM
MI +
=
cmRZ MM +=
−
++=
22
2
21
mba
macmRM
In summary, the comparisons between the ODVS tracker and the rectilinear trackerare listed in Table 2.
TABLE 2SUMMARIZATION OF THE PERFORMANCE EVALUATIONS BETWEEN
3D ODVS TRACKER AND RECTILINEAR TRACKER.
Tracker Parameter O-VAT R-VATx-y Accuracy Better if > 3 people Better if ≤ 3 peoplez Accuracy (if valid) Excellent WorseSpeed Faster SlowerComplexity Lower HigherRobustness Static AdaptiveRepeatability High HighCalibration Manual AutomaticReconfigurability Excellent Restricted
6. Real-Time Head and Face Tracking: Algorithms andEvaluations
Head and face tracking is an integrated dynamic operation of the intelligent system.It needs the track of a person to have a PTZ camera zooming to person’s head and facewhile the person is walking or sitting. As mentioned in section 2, the rectilinear IMRsystem has not implemented head and face tracking for walking people. Thus in thissection we will be evaluating such functionality for NOVA system (Figure 2) alone.
The purpose of head and face tracking in NOVA system is to latch onto a human faceby a perspective view generated from a full frame ODVS video. Given the location ofthe human head from the 3D O-VAT, the most nearby ODVS in the array is chosen togenerate the perspective view. If the person moves, NOVA switches to another camera.A perspective view can be generated electronically from a full-frame ODVS video. FromFigure 11, an object point (RO, ZO) in 3D space can be projected onto the CCD imageplane pixel ( )fcrI −−− , by the following equations
(7)
where
(8)
(9)

Machine Vision and Applications (S ubmitted Oct. 2001)
Huang and Trivedi: Video Arrays for Real-Time Tracking of Persons, Head and Face in anIntelligent Room 19
O
OOO
I RcZRcacZca
cafr
2222
22
)(2)()(
)(
−+−−+
−=
O
O
RcZ
m−
=
−−
=
=
−=
−=
=
=
φφθφθ
θθ
φφθφθ
cossinsinsincos
100
,0
cossin
010
,sin
cossincoscos
001
RvRuRn
−
−−
=φφ
φθθφθ
φθθφθ
cos0sinsinsincoscossin
sincossincoscos
R
−=++=
p
ppp
pvu
FLFLvu
zyx
Rnvu
and slope m of the line connecting the object point to the upper focus (0, c) is
(10)
An equivalent formulation derived from polar coordinates [10] is
(11)
The perspective view is a rectilinear screen (Figure 12) whose viewing point is at theupper focus of the hyperboloid in Figure 11. The rectilinear screen can be specified bythe pan angle θ, the tilt angle φ, and the effective focal length FL. The normal vector nand unit vectors u and v of the rectilinear screen can be represented in terms of the 3D x-y-z coordinate system as
(12)
where R is the rotation matrix which rotates the x’-y’-z’ coordinates to x-y-z coordinatesin Figure 12,
(13)
Note that n vector parallels x’, u vector parallels –y’, and v vector parallels z’respectively in Figure 12. Thus a screen point P in u-v coordinate ( )pp vu , can be relatedto the 3D x-y-z system by
(14)
Then the x-y-z coordinates of P can find its associated pixel in CCD plane with equations(7) to (11) and the perspective view can be generated electronically. Head and facetracking of NOVA is thus carried out by calculating the associated θ, φ, and FL of humanhead with respect to the chosen ODVS to zoom into human face automatically. NOVAalso allows users to specify the pan, tilt, and zoom factors manually.
Figure 13 shows dynamic head and face tracking for walking child volunteers. Figure14 shows head and face tracking for sitting adult participants. Demonstration clips ofautomatic person and head and face tracking on ODVS network are available at:
http://cvrr.ucsd.edu/pm-am/demos/index.html

Machine Vision and Applications (S ubmitted Oct. 2001)
Huang and Trivedi: Video Arrays for Real-Time Tracking of Persons, Head and Face in anIntelligent Room 20
Figure 11: Optical modeling of hyperboloid mirror ODVS. The lens center of the CCDcamera is placed at the lower focus of the hyperboloid. This mechanism depicts how anobject point in 3D space is mapped to the CCD image plane.
Figure 12: ODVS perspective view generation. The viewing point is the upper focus ofthe hyperboloid in Figure 11. A rectilinear screen in 3D space is specified by a pan angleθ, a tilt angle φ, and an effective focal length FL which determines the zooming factor.The associated CCD image pixels of the points on the rectilinear screen can bedetermined from Figure 11. The generated perspective view is used for head and facetracking in the NOVA system.
(−b, a)
R
Z
(0, c)
(0, −c)
(RM, ZM)
(RO, ZO)
(−rI, −c−f)
f
Object
Image
HyperboloidalMirror
Focus
Focus
Hyperboloid Equation:
and 222 bac +=
12
2
2
2=−
b
R
a
Z
CCD
v
u
x’n
y’
z’
x
y
z
θ
φViewingPoint
FL(xp,yp,zp)
P(up,vp)

Machine Vision and Applications (S ubmitted Oct. 2001)
Huang and Trivedi: Video Arrays for Real-Time Tracking of Persons, Head and Face in anIntelligent Room 21
Figure 13: Sequential images of NOVA head and face tracking for walking childvolunteers. The participants walked in circles around a meeting table where the ODVSarray sits. Relative locations of the images are marked on the floor plans. Dotted lineson the floor plans partition the approximate duty regions of each ODVS. Images whosemarks fall in one duty region were taken by the associated ODVS.
6 7 9
1 2 3 4 5
8 10
67
9
1 2
3
45
8
10
4
7 8
1 2 3 5
6 9 10
47
8
1
23
56
9
10

Machine Vision and Applications (S ubmitted Oct. 2001)
Huang and Trivedi: Video Arrays for Real-Time Tracking of Persons, Head and Face in anIntelligent Room 22
Figure 14: Image sequences of NOVA head and face tracking for static (sitting) people.Heads and faces are always latched on independent of facing angles. Note that the fourODVSs are color coded. Pictures taken by a specific ODVS are bordered by the samecolor as the ODVS. The first person and the second person are respectively latched on bytwo different ODVSs, while the third person is moving around and two ODVS are jointlylatching on the person.
Effectiveness
Head and face tracking is regarded as successful if the human head or face is fullykept within the perspective view. For the adult cases, when person is walking, the torsois tracked because the height is beyond ODVS coverage. If the person walks faster than1.6m/sec, the NOVA system would have problem fully catching onto the person due to adelay between the tracking output and the concurrent human position. When the personis sitting, the face is 100% latched on no matter of facing angles. For the child cases, thehead or face of the child participant can be 92% tracked by the dynamically generatedperspective view when the child is walking slower than 1.6m/sec. The instances whenNOVA did not fully latch onto the person’s head or face were happening when the activecamera was being handed over to another by hardware switching. The hardwareswitching delay is about 0.5 second.
Person 1
Person 3
12
3
Person 2

Machine Vision and Applications (S ubmitted Oct. 2001)
Huang and Trivedi: Video Arrays for Real-Time Tracking of Persons, Head and Face in anIntelligent Room 23
7. Concluding RemarksIn this paper we presented the general intelligent environment architecture. NOVA
and IMR systems are introduced and compared. The trackers of them, i.e., O-VAT andR-VAT are described and then compared experimentally. O-VAT provides highlyaccurate height estimation, better speed, and less complexity than R-VAT, also NOVAhas better system reconfigurability. R-VAT has better calibration efficiency and betterx-y planar tracking accuracy when there are limited number of people in the room.NOVA head and face tracking is evaluated alone to show its effectiveness. It tracks theface of a sitting person perfectly, but when tracking the head of a walking person, theperson cannot walk too fast.
For the future work, we can fuse the two system operations so that the advantages ofthe two networks can be combined. For example, x-y measurements and heightestimation of both O-VAT and R-VAT can be fused to yield a most accurate 3D tracking.Statistical data association and track modeling can also be applied to O-VAT. For headand face tracking, O-VAT can drive rectilinear pan-tilt-zoom cameras if a very highresolution image is needed and the person is not moving too much. Other fusion schemesare also possible to best utilize those different types of video networks.
Also in the future, more work can be done to enhance the capability of visualinformation analysis. We currently have face recognition available for the tracked faces.However, since the humans are to be interact with the system naturally, we cannot takeface snapshots in a fully controlled location and condition. Hence the background of theface snapshot and face shading are always changing. According to our experience, singleframe face recognition is not reliable. We are currently working toward a streaming facerecognition (SFR) which takes sequences of face images for recognition. Preliminaryresults show that the SFR scheme is very promising.
AcknowledgmentsOur research is supported by the California Digital Media Innovation Program
(DiMI) program. Main sponsors of the research are Sony Electronics, CompaqComputers, DaimlerChrysler, and Caltrans. We are pleased to acknowledge theassistance of our colleagues, especially Ms. Ivana Mikic, during the course of thisresearch. The authors also thank the volunteers for their participation in the experimenttrials, especially appreciate the fourth graders from Solana Highlands Elementary Schoolfor their enthusiastic and patient participation over the six week long study period.
References[1] C. Bregler and J. Malik, “Tracking People with Twists and Exponential Maps,”
Proc. IEEE Conf. on Comp. Vis. Patt. Recog., pp. 8-15, 1998.[2] D. Gavrilla and L. Davis, “3D Model-based Tracking of Humans in Action: A
Multi-view Approach,” Proc. IEEE Conf. on CVPR, p. 73-80, 1996.

Machine Vision and Applications (S ubmitted Oct. 2001)
Huang and Trivedi: Video Arrays for Real-Time Tracking of Persons, Head and Face in anIntelligent Room 24
[3] I. Haritaoglu, D. Harwood, and L. Davis, "W4 : Who? When? Where? What? A RealTime System for Detecting and Tracking People," Proc. IEEE Int'l. Conf. onAutomatic Face and Gesture Recognition, pp. 222-227, Apr. 1998.
[4] T. Horprasert, I. Haritaoglu, D. Harwood, L. Davis, C. Wren, and A. Pentland,“Real-Time 3D Motion Capture,” Proc. PUI, Nov. 1998.
[5] K. S. Huang and M. M. Trivedi, “NOVA: Networked Omnivision Arrays forIntelligent Environment,” Proc. SPIE Conf. on Applications and Science of NeuralNetworks, Fuzzy Systems, and Evolutionary Computation IV, Vol. 4479, Jul.-Aug.2001.
[6] I. Mikic, K. S. Huang, and M. M. Trivedi, “Activity Monitoring and Summarizationfor an Intelligent Meeting Room,” Proc. IEEE Workshop on Human Motion, Dec.2000.
[7] I. Mikic, E. Hunter, M. M. Trivedi, and P. Cosman, "Articulated Body PostureEstimation from Multi-Camera Voxel Data", IEEE Int’l. Conf. on Comp. Vis. andPatt. Recog., Kauai, Hawaii, Dec. 2001.
[8] I. Mikic, S. Santini, and R. Jain, “Tracking Objects in 3D using Multiple CameraViews,” Proc. ACCV 2000, Taipei, Taiwan, Jan. 2000.
[9] S. Nayar, “Catadioptric Omnidirectional Camera,” Proc. IEEE Conf. on Comp. Vis.Patt. Recog., pp. 482-488, Jun. 1997.
[10] Y. Onoe, K. Yamazawa, H. Takemura, and N. Yokoya, “Telepresence by Real-Time View-Dependent Image Generation from Omnidirectional Video Streams,”Computer Vision and Image Understanding, Vol. 71, No. 2, pp. 154-165, Aug.1998.
[11] A. Pentland and T. Choudhury, “Face Recognition for Smart Environments,” IEEEComp. Mag., pp. 50-55, Feb. 2000.
[12] A. Prati, I. Mikic, C. Grana, and M. M. Trivedi, “Shadow Detection Algorithms forTraffic Flow Analysis: A Comparative Study,” Proc. IEEE IntelligentTransportation Systems Conf., Oakland, CA, Aug. 2001.
[13] T. Sogo, H. Ishiguro, and M. M. Trivedi, “Real-Time Target Localization andTracking by N-Ocular Stereo,” Proc. IEEE Workshop on Omnidirectional Vision,pp. 153-160, Jun. 2000.
[14] R. Stiefelhagen, J. Yang, and A. Waibel, "Simultaneous Tracking of Head Poses ina Panoramic View, " Proc. Int'l. Conf. on Pattern Recognition – ICPR 2000, Sep.2000.
[15] M. M. Trivedi, K. S. Huang, and I. Mikic, “Intelligent Environments and ActiveCamera Networks, “ Proc. IEEE Int’l. Conf. on Sys., Man, and Cybern., pp. 804-809, Oct. 2000.
[16] M. M. Trivedi, I. Mikic, and S. Bhonsle, “Active Camera Networks and SemanticEvent Database for Intelligent Environments,” Proc. IEEE Conf. on Comp. Vis. andPatt. Recog., Jun. 2000.
[17] R. Tsai, “A Versatile Camera Calibration Technique for High-Accuracy 3DMachine Vision Metrology Using Off-the-Shelf TV Cameras and Lenses,” IEEE J.of Robotics and Automation, Vol. RA-3, No. 4, pp. 323-344, Aug. 1987.
[18] C. Wren, A. Azarbayejani, T. Darell, and A. Pentland, “Pfinder: Real-TimeTracking of the Human Body,” IEEE Trans. on Pattern Analysis and MachineIntelligence, Vol. 19, No. 7, pp. 780-785, Jul. 1997.

















