VariantSpark - Bioinformaticsbioinformatics.org.au/.../Denis-Bauer_2016-Winter-School.pdfBig ideas...
53
VariantSpark applying Spark‐based machine learning methods to genomic information HEATH & BIOSECURITY Dr Denis Bauer | Bioinformatics | @allPowerde 5 July 2016
Transcript of VariantSpark - Bioinformaticsbioinformatics.org.au/.../Denis-Bauer_2016-Winter-School.pdfBig ideas...

VariantSparkapplying Spark‐based machine learning methods to genomic information
HEATH & BIOSECURITY
Dr Denis Bauer | Bioinformatics | @allPowerde5 July 2016

Talk Overview
2 |
• Background: CSIRO and Medical Genomics Data• Methods: HPC and Hadoop/Spark and NGS data processing • VariantSpark: Processing genomic data from over 1000 individuals
VariantSpark | Denis C. Bauer | @allPowerde

Team CSIRO
Presentation title | Presenter name3 |
5319talented staff
$1billion+ budget
Workingwith over2800+industry partners
55sites across Australia
Top 1%of global research agencies
Each year6 CSIRO
technologies contribute$5 billion tothe economy
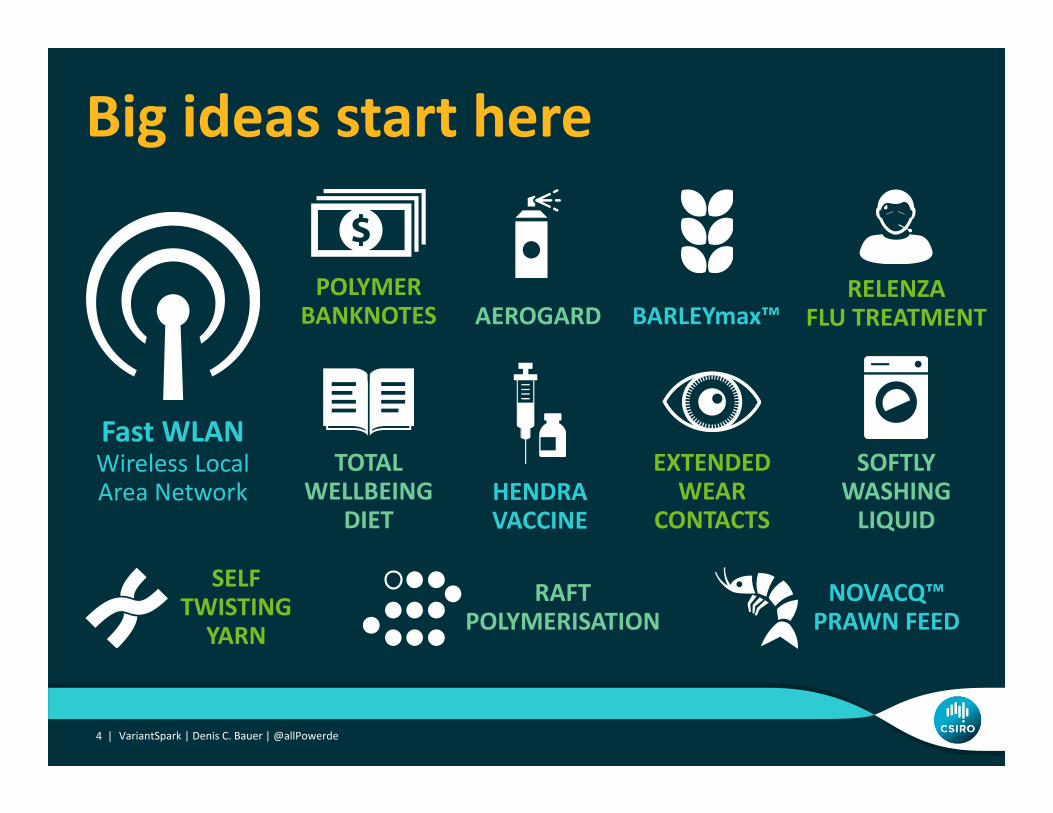
Big ideas start here
4 | VariantSpark | Denis C. Bauer | @allPowerde
EXTENDED WEAR
CONTACTS
POLYMER BANKNOTES
RELENZA FLU TREATMENT
Fast WLANWireless Local Area Network
AEROGARD
TOTAL WELLBEING
DIET
RAFT POLYMERISATION
BARLEYmax™
SELF TWISTING YARN
SOFTLY WASHING LIQUID
HENDRA VACCINE
NOVACQ™ PRAWN FEED

Convenient cardiac rehabilitationEnhancing relationship between patient and mentor
Digital data collection Equitable access
World's first, clinically validated smartphone based Cardiac Rehab: uptake + 30% and completion +70%
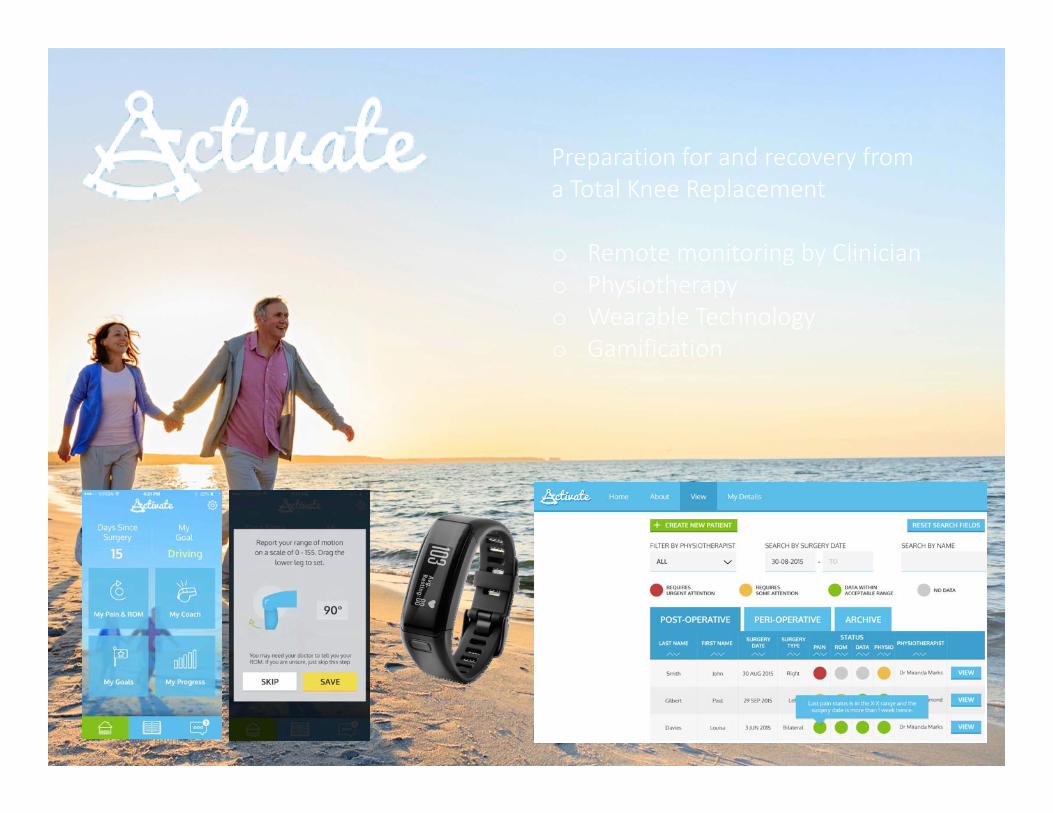
Changing the Health Services Game | Jill Freyne 6 |
Preparation for and recovery from a Total Knee Replacement
o Remote monitoring by Cliniciano Physiotherapyo Wearable Technologyo Gamification

Genomic sequencing can lead to a successful diagnosis in up to 50% of cases where traditional genetic testing failed and is on average 96% cheaper
7 |
Bauer et al. Trends Mol Med. 2014 PMID: 24801560
VariantSpark | Denis C. Bauer | @allPowerde

100,000 Genomes project70,000 individuals by 2017
The cancer genome atlas11,000 samples 2015
Genomics projects are getting bigger
VariantSpark| Denis C. Bauer @allPowerde | Page 5
The HapMap Project270 samples 2002
Human genome~1 sample
1000 Genome Project1097 samples 2012
ASPREE4000 healthy 70+ year olds
Project MinE15,000 people with ALS
Single samples are around 200GB in size

What makes a clinical grade pipeline?
VariantSpark | Denis C. Bauer | @allPowerde9 |
• The sheer volume of new data necessitates new approaches. Computational genomics must progress from file formats to APIs, from local hardware to the elasticity of the cloud, from a cottage industry of poorly maintained academic software to professional‐grade, scalable code, and from one‐time evaluation by publication to continuous evaluation by online benchmarks.
Paten et al. The NIH BD2K center for big data in translational genomics JAMIA 2015

Application programming interface (API)
VariantSpark | Denis C. Bauer | @allPowerde10 |
1
• API aims to provide all the building blocks, which are then put together by the programmer.
• It defines functionalities independent of their respective implementations.
by chorally
Adapted from Wikipedia

VariantSpark | Denis C. Bauer | @allPowerde11 |11 |

VariantSpark | Denis C. Bauer | @allPowerde12 |12 |

NGSANE API
VariantSpark | Denis C. Bauer | @allPowerde13 |

NGSANE Currently supports
• Transfer data (smbclient)
• Quality Control (GATK, FastQC, RNA‐SeQC, custom summaries,
user code)
• Trimming (Cutadapt,Trimgalore, Trimmomatic)
• Mapping (BWA,Bowtie1,Bowtie2,Tophat)
• Transcript Quantification
(cufflinks, htseq, bedtools)
• Variant calling (GATK, samtools)
• Variant annotation(annovar)
• 3D Genome structure (Hicup, fit‐hi‐c, Hiclib, Homer)
VariantSpark | Denis C. Bauer | @allPowerde14 |14 |

Elasticity in the Cloud
VariantSpark | Denis C. Bauer | @allPowerde15 |
2
Elastic cloud compute… is like an In-room sound system
Benefits:• Instant availability of adequately powered system• Images can be shared and everything on it is automatically version controlled

For details see https://github.com/BauerLab/ngsane/wiki/How-to-use-the-virtual-machine
VariantSpark | Denis C. Bauer | @allPowerde16 |16 |

Professional‐grade software
VariantSpark | Denis C. Bauer | @allPowerde17 |
3
• Reproducibility, e.g. config files and version control• Documentation, e.g. wiki• Testing, e.g. Smoke Testing, also known as “Build Verification Testing”, is a type of software testing that comprises of a non‐exhaustive set of tests that aim at ensuring that the most important functions work.

Assessexperimentalsuccessquickly
VariantSpark | Denis C. Bauer | @allPowerde18 |18 |

VariantSpark| Denis C. Bauer @allPowerde | Page 6
API to add new analysis tools
Available as AMI to run on elastic clouds
Smokebox to set up as continuous integration server
Efficient scalability

Efficient scalability3
Kelly et al. Churchill: an ultra-fast, deterministic, highly scalable and balanced parallelization strategy for the discovery of human genetic variation in clinical and population-scale genomics Genome Biology 2015
Bespoke parallelizatione.g. Churchill
Chromosomal splite.g. NGSANE
MapReducee.g. GATK queue
VariantSpark | Denis C. Bauer | @allPowerde20|

Automating ‘bespoke’ parallelization?
HPC: Petaflops• Storage for checkpointing• Surprised by H/W failure• Code: simulation, rendering• Less persistent data, ingress & egress
• Dense compute• CPU + GPU• Bandwidth to other servers
Big Data: Petabytes• Storage of low‐value data• H/W failure common• Code: frequency, graphs, machine‐learning, rendering
• Ingress/egress problems• Dense storage of data• Mix CPU and data• Spindle:core ratio

Map Reduce as Execution Pardigm
• Failure is inevitable fault tolerance build-in• Linear scalability massive parallelisation, minimal communication • Hide the complexities from developers expressive programming model

• Good• Finally analytics at scale • Fault tolerance etc.
• Bad• Foreign and low level programming model• Rigid data structure• Hard to support multistep processes• Everything goes to disk• Slow scheduling• Constrained execution model
Why Hadoop Was Not Enough?

Hadoop2.0: YARN and helper APIs

Software exampleSum up all numbers in a file
10 20 50
Hello 10 there
It’s 11 pm
101

Improved usability at the expense of control

Fast, expressive cluster computing system compatible with Apache Hadoop
• Improves efficiency through:• In‐memory computing primitives• General computation graphs
• Improves usability through:• Rich APIs in Java, Scala, Python,R• Interactive shell Scala and Python• Can work with iPython notebook• Functional programming
What is [Apache] Spark?

Let’ talk about loops
Map
Flatten
Filter
Fold

Less rigid structure
• for loop in an example of the imperative programming (especially the explicit indexed loop) • tell the computer how to loop through a collection
• map, filter etc., are more “declarative” • tell the computer what the result should look like• how it loops through it is irrelevant (mostly)
Compared to …

Example: Spark Word Count
VariantSpark | Denis C. Bauer | @allPowerde30 |
Shuffle Shuffle

All in one ‐ BDAS

• Scalable• Capable to scaling to 1000s of nodes and demonstrated to work with petabytes of data.
• However, also ideal for Amazon/Google/Microsoft clouds• In‐house clusters• Or commodity hardware.
• Multiple languages (Scala, Python, Java)
• Uses Resilient Distributed Datasets (RDDs)• Fault tolerant• Can be operated on in parallel• In memory caching!
Apache SparkLightning‐Fast Cluster Computing
http://spark.apache.org/VariantSpark| Denis C. Bauer @allPowerde | Page 6

• ADAM is a genomics analysis platform built on Spark– By amplab at Berkeley international Data standards (GA4GH)– Set of APIs and file formats for processing genomic data
• Better storage (Parquet): Data format 5‐25% reduced file size compared to bam without loss (unlike CRAM)
• Automatic balanced parallelization and robust execution (Spark)
• Specific workflows for variant calling, RNA seq analysis,…
What are the alternatives to “Bespoke parallelization”: Hadoop/Spark
Presentation title | Presenter name | Page 33

34 | VariantSpark | Denis C. Bauer | @allPowerde
Spark Summit 2016 (June) by Frank Austin Nothaft (UC Berkeley)
(70TB)

• Also offers advanced analysis,– e.g. genome clustering using Spark libraries for Machine Learning
• However, – Overhead: Input data needs to be converted to ADAM‐format– Inefficiency: using dense vectors
ADAM also offers tertiary analysis
35 | VariantSpark | Denis C. Bauer | @allPowerde

VariantSpark
Mllib*
VCF
VariantSpark is the interface enabling Spark’s MLlib machine learning algorithms to be applied to genomics data
e.g. grouping samples by genomic profile
Input Genomics Application Result
Larg
e sc
ale
com
pute
VariantSpark| Denis C. Bauer @allPowerde | Page 8
* VariantSpark also uses Spark.ML

VariantSpark
VariantSpark| Denis C. Bauer @allPowerde | Page 9
BMC Genomics 2015, 16:1052 PMID: 26651996 (IF=4)

Cluster individuals into ethnic groups based on their genomic profiles
www.cloudaccess.eu
1000 x 40 Million variants Matrix *
Kmeans
Predict super population
14 ethnic groups and
s u p e rpopulations
VariantSpark| Denis C. Bauer @allPowerde | Page 10
* VariantSpark can also process phase 3 data: 3000 individuals and 80 million variants

Variant Call Format
• Line for every variant• Columns for individuals (samples)• 0|0 = no variant• 0|1, 1|0, 1|1, etc. = alternate allele (homozygous)
bioinf.comav.upv.es
VariantSpark| Denis C. Bauer @allPowerde | Page 8

Comparison to other implementations
• Preprocessing: converting location‐centric VCF genotypes into sample‐centric numerical vectors
• Clustering: Kmeans
• ADAM (BigData Genomics): Spark implementation with dense matrix
• Hadoop: MapReduce without in‐memory caching
0
1000
2000
Python R
Hadoo
pAda
mADMIXTUREVari
antSpa
rk
method
time
in s
econ
ds taskbinary−conversion
clustering
pre−processing
Chromosome 22; VM on Microsoft Azure with A7 Linux instance and 8 cores, 56GB memory running Ubuntu.
103 75 29 28 18 4 min
VariantSpark| Denis C. Bauer @allPowerde | Page 12

Scaling VariantSpark to the whole genome
• Pre‐processing: scales seamlessly as processes are independent
• Clustering: memory consumption increases linear with number of variants (24GB) due to additional distance measurements between variants and k‐means centroids
• As total memory was the limiting factor on our infrastructure the number of simultaneously used nodeshad to be reduced; increasing runtime.
pre−processing clustering
404550556065
510152025
0
20000
40000
executorsm
emory
time
20 40 60 80 100 20 40 60 80 100
number of variants (%)
valu
e
variableexecutors
memory
time
CSIRO Spark Cluster: Whole genome; Hadoop 2.5.0, managed by cloudera’s CDH 5. We use Spark 1.3.1. This 13 node cluster has a total of 416 cores and 1.22TB memory.
VariantSpark| Denis C. Bauer @allPowerde | Page 13

Clustering result
• (adjusted Rand index) ARI = 0.84, with ‐1 (independent labeling) and 1 (perfect match)
• Majority of American (AMR) individuals being placed in the same group as Europeans (EUR), likely reflecting their migrationalbackgrounds.
• ADMIXTURE (state‐of‐the‐art tool for population structure determination) returns a low ARI of 0.25
Admixture: Alexander, D.H., Novembre, J., Lange, K.: Fast model-based estimation of ancestry in unrelated individuals. Genome Res 19(9), 1655–1664 (2009)
VariantSpark| Denis C. Bauer @allPowerde | Page 11

Can we do better: supervised learningFeature 1 Feature 1 Feature 1 Feature 1 Class
1 1 2 1 ▲
2 0 0 0
0 0 2 0
0 1 1 1 ▲
…
2 1 2 1 ▲
2 2 2 2 ▲
2 2 2 2 ▲
1 0 0 0
VariantSpark| Denis C. Bauer @allPowerde | Page 12

Curse of dimensionality: Meaning 1
• A dataset that has more features than samples can cause overfitting as feature values can accidentally correlate with the prediction value in in such a high dimensional space.
Presentation title | Presenter name44 |
“Hughes phenomenon” More features than samples

Logistic Regression
• Logistic Regression• Time: 30 hours• ARI: 0.93• However, logistic regression is prone to over fit the data.
• Random Forest• Ensemble of weak regressors ‐> self‐limiting and hence robust to overfitting • However, the implementation in the Spark library could not scale beyond Chromosome 1
VariantSpark| Denis C. Bauer @allPowerde | Page 13

Curse of dimensionality: Meaning 2
• An algorithm that does not scale well to high‐dimensional data, typically due time or memory scaling with the number of dimensions of the data.
• Spark ML was designed for ‘Big’ low dimensional data.
Usual BigData: e.g. Customer InfoMany samples with few features
“Cursed” BigData: e.g. GenomicsModerate number of samples with many features
Can be handled by dedicated executer Feature set too large to be handled by single executer
VariantSpark| Denis C. Bauer @allPowerde | Page 13

Cursed Forest: Big and wide data
• Supervised learning on genomics data is hampered by the two types of ‘Curse of dimensionality’
• Implementation of random forest algorithm for robustly dealing with ‘wide’ high‐dimensional data
• Doesn’t use “unsplittable” vectors like Spark ML• Data can be split in different ways
Presentation title | Presenter name47 |

Spark ML vs Cursed Forest
Size Standard random forest (Spark ML)
Cursed Forest
Chromosome 1 1hr 22min 4GB, (driver: 8GB)
1hr 8min4GB, (driver: 4GB)
Chromosome 1‐2 5hr 22min4GB, (driver: 16GB)
1hr 10min4GB, (driver: 4GB)
Chromosome 1‐22 Fail 1hr 30min4GB, (driver: 4GB)
VariantSpark | Denis C. Bauer | @allPowerde48 |

Whole genome information improves ethnicity prediction
VariantSpark | Denis C. Bauer | @allPowerde49 |

Ethnicity prediction on whole genome
Presentation title | Presenter name50 |
Method Accuracy (10‐fold CV)
Runtime Memory
Kmeans(SparkML)
unsupervised 0.82 31 h 24 GB
LogisticRegression (SparkML)
supervised 0.93 30 h 24 GB
CursedForest
supervised 0.96 7 h 8 GB

VariantSpark | Aidan O'Brien
Apache ZeppelinA web‐based notebook that enables interactive data analytics.
51 |

Three things to remember
• VariantSpark is an interface bringing bigLearning tasks to genomicsapplications. It can cluster 3000 individuals and 80 million variantsin under 30 hours using minimal memory (24GB)
• Cursed Forest solves the curse of dimensionality for machinelearning on genomic data and is included in VariantSpark
• Zeppelin will provide VariantSpark with a notebook‐style interfacefor visualizing genomic data and ML results
https://github.com/BauerLab/VariantSpark

HEALTH AND BIOSECURITY
Thank youHealth & BiosecurityDenis C. Bauert +61 2 9123 4567e [email protected] http://bioinformatics.csiro.au
More talks online: Twitter:http://www.slideshare.net/allPowerde @allPowerde
Aidan O’BrienLaurence WilsonTim KahlkeTransformational Bioinformatics Team, CSIROFormer membersBill WilsonFiroz AnwarNeil Saunders
Funding:National Health and Medical Research Council;National Breast Cancer Foundation;CSIRO's Transformational Capability Platform;CSIRO’s IM&T;Science and Industry Endowment Fund
Buske et al., Bioinformatics Jan 2014
O’Brien et al., BMC Genomics Dec 2015
Wilson et al., in preparation
GT-Scan2Chromatin aware CRISPR target finder
in preparation
O’Brien et al., in preparation
Piotr SzulGi GuoRobert DunneData61 CSIRO, Australia