
Variable neighborhood Prediction of temporal collective profiles by Keun-Woo Lim, Telecom ParisTech
33
VARIABLE NEIGHBORHOOD PREDICTION OF TEMPORAL COLLECTIVE PROFILES Presentation for EuroIoTA ’16 Speaker: Keun-Woo Lim Telecom Paristech 24-11-2016
-
Upload
euroiota -
Category
Data & Analytics
-
view
62 -
download
1
Transcript of Variable neighborhood Prediction of temporal collective profiles by Keun-Woo Lim, Telecom ParisTech

VARIABLE NEIGHBORHOOD
PREDICTION OF TEMPORAL
COLLECTIVE PROFILES
Presentation for EuroIoTA ’16
Speaker: Keun-Woo Lim
Telecom Paristech
24-11-2016

Brief Overview
What do we do in this work?
Analysis of temporal collective profiles (time-series)
Use of mobile datasets (cellular, Wi-Fi)
Real–time & Lightweight prediction (online prediction)
What do we try to achieve?
Better prediction accuracy
Lower computational complexity
Better application & use case

Contents
Contents Introduction
Methodology
Prediction
Outlier Detection
Future Work

Introduction

Temporal collective profiles
Representation of data that aggregate behavior of
group of individuals – over time
Can be categorized in various ways
“Daily Profiles”
What are collected?
Basic telephone calls and SMS?
However, we want to focus on more specific matters
Specific application data
Usage of Internet service

Why do we analyze these data?
For “online network analysis”
Real-time prediction of the near-future
Recognition of sudden changes/outliers
Timely adaptation
Use cases
Resource allocation
Traffic handling
Social behavior

Requirements
Low computational complexity
Lightweight prediction methods
Accuracy
Still have to be accurate

Dataset
Cellular mobile dataset
1-week data from 90 lacs in Paris
More than 500 daily profiles
Wi-Fi cloud dataset
122 days (March 1st to June 30th, 2014)
60 million URL connection logs
(Top 20 mobile applications)

Methodology

What should we do with daily profiles?
Daily profiles can be:
Very similar to each other (same day, location, etc.)
Very different too (outlier, events)
We use methods to calculate similarity
Cluster similar profiles
Distinguish different profiles

Previous work (Offline analysis)1
Utilization of clustering methods (UPGMA)
With similarity comparison techniques (DTW, quantiles)
Not ideal in online data analysis
Clustering may take long time (𝑂(𝑀2𝑁3)with DTW)
1K. Lim, S. Secci, L. Tabourier, B. Tebbani, “Characterizing and predicting mobile application usage,”
https://hal.archives-ouvertes.fr/hal-01345824/document

Profile similarity
We use two examples of similarity measures
(M values in a time-series)
Euclidean distance (ED) = Θ(M)
Dynamic time warping (DTW) = Θ(M2)
For specific dataset containing N profiles,
ED = Θ(N2M)
DTW = Θ(N2M2)
to compare all with each other
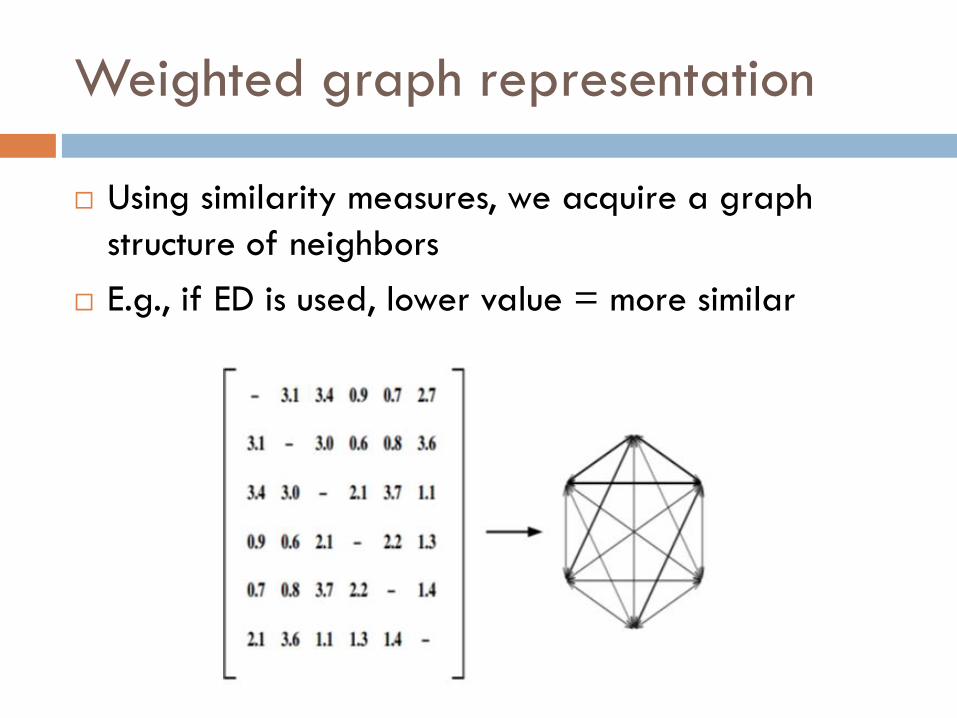
Weighted graph representation
Using similarity measures, we acquire a graph
structure of neighbors
E.g., if ED is used, lower value = more similar

Filtering paths
Filter neighbors with high distance
Depending on the value of α, the number of neighbors
change for all profiles

Visualization of graph structure
Example graph structure for ED – cellular dataset

Variable Neighborhood Prediction
(VNP)

Principle of VNP
For a new day 𝑥𝑛(𝑡), we configure
𝑡0 = 0, 𝑡1 = 0~24, 𝑡2 = 24 (hour)
Objective
Observation period = 𝑥𝑛 𝑡0, 𝑡1 Create a temporal profile to predict 𝑥𝑛 𝑡1, 𝑡2
Find 𝑥 from the observation period
The closest profile 𝑥, in 𝑥 𝑡0, 𝑡1 and 𝑥𝑛 𝑡0, 𝑡1

Find the neighbors
Using closest neighbor 𝑥, we find the group of
neighbors 𝑁𝑛 to be used for prediction
For any other profile y of the training set,
𝑦 ∈ 𝑁𝑛 𝑖𝑖𝑓𝑠 𝑥𝑛 𝑡0, 𝑡1 , 𝑦 𝑡0, 𝑡1 ≤ 𝑎 ∙ 𝑠 𝑥𝑛 𝑡0, 𝑡1 , 𝑥 𝑡0, 𝑡1

Creating the prediction profile
Using 𝑁𝑛, formulate the prediction
𝑥𝑛 𝑡 =σ𝑦∈𝑁𝑛 𝑠(𝑥𝑛,𝑦)∙𝑦(𝑡)
σ𝑦∈𝑁𝑛 𝑠(𝑥𝑛,𝑦)
Simply put, it is the weighted average over the profiles
of its neighborhood

Training Parameter 𝑎
𝑎 can be tuned to select the optimal number of
neighbors
Variable neighborhood search to find the 𝑎 that yields
the highest accuracy over time
E.g. 1.0 < 𝑎 < 10.0
Drawbacks
Increase in complexity (recalculate for each 𝑎)

Calculating multiple 𝑡1
For a more fine-grained prediction, multiple 𝑡1 can
be used in one day
Repetition of the VNP (e.g. per-hour analysis)

Handling Complexity - VNP
Computation of calculating neighborhood of target day per 𝑎 :
ED = Θ(NM)
DTW = Θ(NM2)
Depending on N, this can be large in practice
Also, in case of multiple 𝑡1 analysis, large M can also impact

Handling Complexity - Graph
Can be heavy
ED = Θ(N2M)
DTW = Θ(N2M2)
Luckily, graph representation is only updated once per day
Although, needed for various M in case of multiple 𝑡1 analysis
Also, space partitioning can be used to reduce time
Via Kd-tree
This can reduce complexity of ED to Θ(log(N)M)

Prediction Analysis

Prediction accuracy analysis
Prediction through relative error, defined as
𝜀 =σ𝑡=𝑡1
𝑡2 𝑥𝑛 𝑡 − 𝑥𝑛 𝑡2
σ𝑡=𝑡1
𝑡2 𝑥𝑛 𝑡2
Comparison with closest neighbor (𝑎 =1), UPGMA
𝑡1 = 12
cellular data - ED cellular data - DTW

Effect of changing 𝑡1
Per-hour analysis
The length of observation period may also effect the performance
of prediction
cellular data - ED cellular data - DTW

Time consumption
The required time can be acceptable for both methods in a
per-hour analysis.
However, need caution for DTW when many profiles are used
cellular data - ED cellular data - DTW
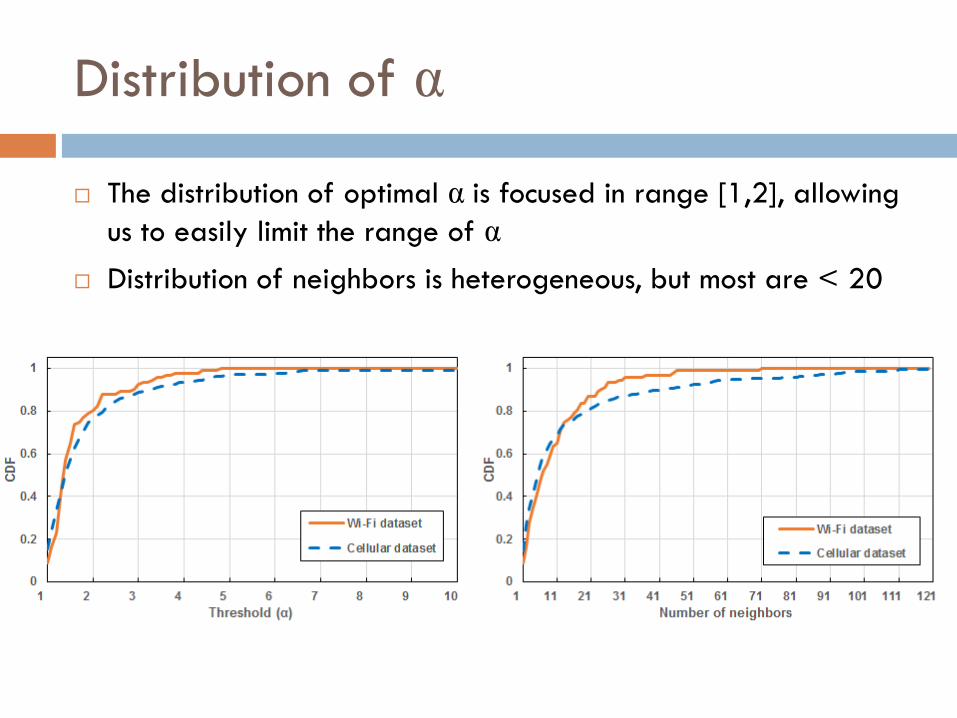
Distribution of α
The distribution of optimal α is focused in range [1,2], allowing
us to easily limit the range of α
Distribution of neighbors is heterogeneous, but most are < 20

Conclusion & Future work

Conclusion & Future work
We have proposed a methodology for online
prediction of mobile time-series datasets
Acceptable time for our current dataset
Can be used for other time-series datasets in various
IoT environment
Further studies include
Testing in a bigger scale dataset

Any Questions?

Appendix – Wi-Fi data prediction
Wifi data - ED Wifi data - DTW


















