
An MIC is an MIC is an MIC, isnt it? Gunnar Kahlmeter Clinical microbiology Växjö, Sweden.

VäxjöUniversity
School of Mathematics and System Engineering
Reports from MSI - Rapporter från MSI
Klassiska populationsmodeller kontrastokastiska
En simuleringsstudie ur matematiskt och datalogisktperspektiv
Ingela Jönsson & Mattias Nilsson
Jun2008
MSIVäxjö UniversitySE-351 95 VÄXJÖ
Report 08053ISSN 1650-2647ISRN VXU/MSI/MA/E/--08053/--SE


Ingela Jönsson & Mattias Nilsson
Klassiska populationsmodeller kontra stokastiskaEn simuleringsstudie ur matematiskt och datalogiskt
perspektiv
Kandidatuppsats
Matematik
2008
Växjö University


Abstract
In this interdisciplinary study, three classic population models will be studied from amathematical view: Malthus’ growth, Verhulst’s logistic model and Lotka-Volterra’smodel for hunter and prey. The classic models are being compared to the stochastic ones.The stochastic models studied are the birthdeath processes and their diffusion approxima-tion. Comparisons are made by averaging simulations.
It requires numerous simulations to carry out the comparisons. The simulations mustbe carried out on a computer and this is where the computer science emerges to the project.The models, along with the handling of the results, have been implemented in both Mat-Lab and in C in order to allow a comparison between the two languages whilst executingthe above mentioned study. Attempts to time optimization and an evaluation concern-ing the user-friendliness regarding the implementation of mathematical problems will beperformed.
Mathematic conclusions, which have been drawn, are that the averaging solutions donot always coincide with the traditional models when they are being simulated over largetime. In the logistic model and in Lotka-Volterra’s model the stochastic simulations willsooner or later die when the time is moving towards infinity, whilst their deterministicrepresentation keeps on living. In the exponential model, the mean values of the stochasticsimulations and of the deterministic solution coincide. There is, however, a large spreadfor the stochastic simulations when they are carried out over a large time.
Computer scientific conclusions drawn from the study includes that when it comes toimplementing a few models, along with the handling of the results, to be used repeatedly,C is the most appropriate language as it proved to be significantly faster during execution.However, all of the difficulties during the implementation of mathematical problems inC must be kept in mind. These difficulties can be avoided if the implementation insteadtakes place in MatLab, where a numerous of mathematical functions and solutions willbe available.Key-words: Stochastic simulation, population growth, population model, Malthus, expo-nential population growth, Verhulst, logistic population growth, Lotka-Volterra, diffusionapproximation, birthdeath process, time optimization, C, MatLab, matrix memory alloca-tion, MatLab clear.
Sammanfattning
I detta tvärvetenskapliga arbete studeras från den matematiska sidan tre klassiska popula-tionsmodeller: Malthus tillväxtmodell, Verhulsts logistiska modell och Lotka-Volterras jägarebytesmodell. De klassiska modellerna jämförs med stokastiska. Destokastiska modeller som studeras är födelsedödsprocesser och deras diffusionsapprox-imation. Jämförelse görs med medelvärdesbildade simuleringar.
Det krävs många simuleringar för att kunna genomföra jämförelserna. Dessa simu-leringar måste utföras i datormiljö och det är här den datalogiska aspekten av arbetetkommer in. Modellerna och deras resultathantering har implementerats i både MatLaboch i C, för att kunna möjliggöra en undersökning om skillnaderna i tidsåtgången mellande båda språken, under genomförandet av ovan nämnda jämförelser. Försök till tidsopti-mering utförs och även användarvänligheten under implementeringen av de matematiskaproblemen i de båda språken behandlas.
iii

Följande matematiska slutsatser har dragits, att de medelvärdesbildade lösningarnainte alltid sammanfaller med de klassiska modellerna när de simuleras på stora tidsin-tervall. I den logistiska modellen samt i Lotka-Volterras modell dör förr eller senare destokastiska simuleringarna ut när tiden går mot oändligheten, medan deras deterministiskarepresentation lever vidare. I den exponentiella modellen sammanfaller medelvärdet av destokastiska simuleringarna med den deterministiska lösningen, dock blir spridningen storför de stokastiska simuleringarna när de utförs på stora tidsintervall.
Datalogiska slutsatser som har dragits är att när det kommer till att implementera fåmodeller, samt resultatbearbetning av dessa, som ska användas upprepade gånger, är Cdet bäst lämpade språket då det visat sig vara betydligt snabbare under exekvering än vadMatLab är. Dock måste hänsyn tas till alla de svårigheter som implementeringen i C drarmed sig. Dessa svårigheter kan till stor del undvikas om implementeringen istället sker iMatLab, då det därmed finns tillgång till en uppsjö av väl lämpade funktioner och färdigamatematiska lösningar.Nyckelord: Stokastisk simulering, populationstillväxt, populationsmodell, Malthus, ex-ponentiell populationstillväxt, Verhulst, logistisk populationstillväxt, Lotka-Volterra, dif-fusionsapproximation, födelsedödsprocess, tidsoptimering, C, MatLab, matris minnesal-lokering, MatLab clear.
Vårt tack till
Vi vill rikta ett stort tack till våra handledare, Roger Pettersson och Gösta Sundberg vidVäxjö universitet, för att de har hjälpt till med att svara på frågor angående arbetet, att dehar introducerat oss till lämplig litteratur samt varit ett stöd för oss under hela arbetsgån-gen.
iv

Innehåll
1 Introduktion 11.1 Bakgrund . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11.2 Problemformulering . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11.3 Avgränsningar . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11.4 Rapportstruktur . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
2 Historiskt erkända populationsmodeller 3
3 Teorin bakom diffusionsapproximationen 4
4 Modellbeskrivning 74.1 Exponentiell populationstillväxt . . . . . . . . . . . . . . . . . . . . . . 74.2 Logistisk populationstillväxt . . . . . . . . . . . . . . . . . . . . . . . . 84.3 Lotka-Volterra . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
5 Beskrivning av programkoderna 115.1 Implementering . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 115.2 Exponentiell modell . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
5.2.1 Deterministisk differentialekvation . . . . . . . . . . . . . . . . . 135.2.2 Diffusionsapproximerad differentialekvation . . . . . . . . . . . 135.2.3 Födelsedödsprocess . . . . . . . . . . . . . . . . . . . . . . . . . 14
5.3 Logistisk modell . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 145.3.1 Deterministisk differentialekvation . . . . . . . . . . . . . . . . . 155.3.2 Diffusionsapproximerad differentialekvation . . . . . . . . . . . 155.3.3 Födelsedödsprocess . . . . . . . . . . . . . . . . . . . . . . . . . 15
6 Bearbetning av modellerna 176.1 Exponentiell populationstillväxt . . . . . . . . . . . . . . . . . . . . . . 176.2 Logistisk populationstillväxt . . . . . . . . . . . . . . . . . . . . . . . . 236.3 Lotka-Volterra . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
7 Resultatdiskussion kring modellerna 457.1 Exponentiell populationstillväxt . . . . . . . . . . . . . . . . . . . . . . 457.2 Logistisk populationstillväxt . . . . . . . . . . . . . . . . . . . . . . . . 457.3 Lotka-Volterra . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 47
8 Metod för testerna 498.1 Värde för simuleringar . . . . . . . . . . . . . . . . . . . . . . . . . . . 498.2 Slumptalshantering . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 498.3 Tidtagning . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 508.4 Omfattning av testerna . . . . . . . . . . . . . . . . . . . . . . . . . . . 50
9 Genomförandet av testerna 529.1 Exponentiell - Test 01 . . . . . . . . . . . . . . . . . . . . . . . . . . . . 52
9.1.1 Beskrivning av programkod . . . . . . . . . . . . . . . . . . . . 529.1.2 Tidsresultat samt resultatdiskussion . . . . . . . . . . . . . . . . 52
9.2 Exponentiell - Test 02 . . . . . . . . . . . . . . . . . . . . . . . . . . . . 539.2.1 Beskrivning av programkod . . . . . . . . . . . . . . . . . . . . 539.2.2 Tidsresultat samt resultatdiskussion . . . . . . . . . . . . . . . . 54
v

9.3 Exponentiell - Test 03 . . . . . . . . . . . . . . . . . . . . . . . . . . . . 559.3.1 Beskrivning av programkod . . . . . . . . . . . . . . . . . . . . 559.3.2 Tidsresultat samt resultatdiskussion . . . . . . . . . . . . . . . . 56
9.4 Logistisk - Test 01 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 569.4.1 Beskrivning av programkod . . . . . . . . . . . . . . . . . . . . 569.4.2 Tidsresultat samt resultatdiskussion . . . . . . . . . . . . . . . . 56
9.5 Logistisk - Test 02 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 579.5.1 Beskrivning av programkod . . . . . . . . . . . . . . . . . . . . 579.5.2 Tidsresultat samt resultatdiskussion . . . . . . . . . . . . . . . . 58
10 Slutdiskussion 5910.1 Slutsats . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5910.2 Svårigheter . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6010.3 Öppna frågor . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 61
Referenser 63
A Programkod exponentiell modell 64
B Programkod logistisk modell 68
vi

1 Introduktion
I detta arbete kommer de två vetenskaperna matematik och datalogi att vävas samman.Ett av skälen till att genomföra detta tvärvetenskapliga examensarbete är att både få möj-ligheten att fördjupa sig inom sitt eget område, men även att erhålla mycket kunskap frånvarandras respektive vetenskap. Två skilda problemformuleringar skapas för att illustreragränserna mellan inriktningarna, men under arbetets gång kommer gränsöverskridandesamarbete att utföras, då de båda problemen i mångt och mycket är beroende av varandra.
1.1 Bakgrund
Från ett matematiskt perspektiv studeras i detta arbete tre olika populationsmodeller.Modellerna går att uttrycka med en deterministisk differentialekvation. Den determinis-tiska ekvationens lösning beskriver bara hur populationen beter sig i medeltal, men sägeringenting om spridningen för populationen. Genom att uttrycka modellerna stokastisktsom en diffusionsapproximerad differentialekvation och som en födelsedödsprocess ärdet möjligt att fånga upp spridningen för respektive modell. Då det krävs många simu-leringar för att kunna få fram statistiska egenskaper så som väntevärde, standardavvikelseoch konfidensintervall behöver en dator användas. Med hjälp av datorsimuleringar ska detvara möjligt att jämföra de deterministiska lösningarna med de stokastiska för att se hurstor spridningen är.
Valet föll på att använda MatLab för att realisera de matematiska problemen dels för attdet är ett vanligt verktyg att arbeta med då matematiska beräkningar utförs, dels på grundav att det har visat sig vara ett väl lämpat språk att arbeta med de aktuella problemeni. MatLab visade emellertid tidigt under den matematiska delen av arbetet indikationerpå att ett större antal simuleringar skulle ta väldigt lång tid att genomföra. Då det krävsmånga simuleringar för att få bra värden på de medelvärdesbildande lösningarna, kan detfrån ett datalogiskt perspektiv vara av intresse att undersöka huruvida något annat språkän just MatLab kan genomföra dessa på ett mer tidseffektivt sätt.
1.2 Problemformulering
Det matematiska syftet med arbetet är att studera huruvida stokastiska medelvärdesbil-dade lösningar sammanfaller med deterministiska. Även konfidensintervall för stokastiskasimuleringar beräknas för att se hur stor spridningen är. De populationsmodeller somkommer att ingå i arbetet är Malthus exponentiella, Verhulsts logistiska och Lotka-Volterras jägarebytesmodell.
Det datalogiska syftet med arbetet är att undersöka om det kan vara en idé att använda Cistället för MatLab, när det handlar om simulering samt resultatberäkning av ovan nämndapopulationsmodeller. Undersökningen kommer att omfatta en jämförelse mellan hur det äratt implementera matematiska problem i de olika språken samt tidsaspekten under självautförandet av beräkningarna. Den kommer även innehålla försök till tidsoptimering på deframarbetade programkoderna.
1.3 Avgränsningar
Valet föll på att studera Malthus, Verhulsts och Lotka-Volterras modeller eftersom deofta nämns som välkända i litteratur som behandlar tillväxtmodeller. Det finns många an-dra tillväxtmodeller som kunde studerats istället och två exempel på sådana är BenjaminGompertzs ekvation och Schaefers modell [1]. En annan liknande modell är Holling-Tanners ekvation [2].
1

Det hade varit väldigt intressant att göra en jämförelse mellan MatLab och FORTRANdå arbetet handlar om matematik. Tyvärr saknas både kunskap och erfarenhet av att arbetai FORTRAN och därför väljs det alternativet bort. Följande redogörelse går att läsa redani förordet i [3]:
”To obtain high performance, the MATLAB software is written inoptimized C, with some important inner loops coded in assemblylanguage.”
Innebär det då att MatLab och C har samma prestanda under körning? Frågan om vilketspråk det istället kunde vara intressant att jämföra MatLab med, blev genast enklare att gesvar på efter att ha läst ovanstående beskrivning av MatLab. Det blir en jämförelse mellanMatLab och C som kommer att genomföras i detta arbete.
De matematiska modeller som innefattas i jämförelsen mellan MatLab och C är Malthusexponentiella samt Verhulsts logistiska. Lotka-Volterras modell kommer inte att ingå i dendatalogiska delen av arbetet, då de matematiska bitarna runt denna fortfarande var oklaravid tidpunkten för arbetets början.
1.4 Rapportstruktur
Rapporten inleds med en historisk tillbakablick på de populationsmodeller som kommeratt behandlas. Vidare presenteras det hur diffusionsapproximation kan tillämpas på mod-ellerna samt en mer ingående redogörelse av dessa. I nästa steg beskrivs de programkodersom kommer att användas för att utföra simuleringarna av de olika populationstillväx-terna. Efter dessa kommer en detaljerad redovisning över lösningarna av de matematiskaproblemen. Sedan följer en diskussion runt de matematiska resultaten som har observer-ats från respektive modell. Inför testerna som berör de båda programspråken beskrivstillvägagångssättet och därefter resultatdiskussioner kring de utförda testerna. Arbetetavrundas med en slutdiskussion där slutsatser, svårigheter samt öppna frågor behandlas.
2

2 Historiskt erkända populationsmodellerDet har publicerats många böcker och teorier om olika sätt att beskriva populationstillväx-ter. En av de första att beskriva populationstillväxter var Thomas Robert Malthus somenligt [4] 1798 gav ut boken ”An Essay on the Principle of Population”. I [2] beskrivsMalthus modell som
dN(t)dt
= λN(t),
där N(t) är antal individer i populationen vid tiden t och λ är en tillväxtkonstant. Malthusteori säger att så länge det finns mat och utrymme kommer populationen alltid att växaexponentiellt. Malthus tillväxtmodell växer väldigt fort och redan vid relativt små tiderantar N stora värden.
Enligt webbplatsen [5] publicerade Pierre Francois Verhulst en teori 1839. I [2] beskrivsVerhulst teori som
dN(t)dt
= rN(t)(1− N(t)K
),
där N(t) är antal individer i populationen vid tiden t, r är den naturliga tillväxttaktenoch K är en övre begränsning i hur stor populationen kan bli. Verhulst modell är allmäntkänd som en logistisk tillväxtmodell. Till skillnad från Malthus modell har den logistiskamodellen en övre begränsning, det vill säga att gränsvärdet av lim
t→∞N(t) = K. Med detta
menar Verhulst att efter en viss tid kommer populationen att ställa in sig i stationaritet.Enligt [4] utvecklade Alfred James Lotka och Vito Volterra en ekvation i mitten på
1920-talet som idag är känd som Lotka-Volterras ekvation. Lotka-Volterras ekvationbeskriver två populationer som beror på varandra och hur deras populationsstorlekarförändras med tiden. Lotka-Volterras ekvationssystem beskrivs i [2] som{
dN1(t)dt = N1(t)(r1−b1N2(t))
dN2(t)dt = N2(t)(−r2 +b1N1(t)),
där N1(t) respektive N2(t) är antal individer i en viss population vid tiden t och där r1är födelsetakten för N1 och r2 är dödstakten för N2. Konstanten b1 representerar mötenmellan grupperna N1 och N2 där den ena gruppen gynnas och den andra gruppen miss-gynnas. Lotka-Volterras ekvation är även känd som en jägarebytesekvation, vilket ger enbra förklaring till varför de olika populationerna gynnas respektive missgynnas vid mötensinsemellan.
Malthus, Verhulsts och Lotka-Volterras klassiska ekvationer har alla varsin determin-istisk lösning. Dessa lösningar beskriver bara hur populationen beter sig i medeltal ochsäger inget om spridningen. Genom att göra datorsimulerade populationsutvecklingar sombygger på ovannämndas teorier är det möjligt att undersöka hur stor spridningen egentli-gen är.
3

3 Teorin bakom diffusionsapproximationenFör att öka förståelsen bakom diffusionsapproximationens giltighet har handledaren [6]skisserat hur ett bevis, som visar att en logistisk födelsedödsprocess kan approximerasmed en diffusionsprocess, skulle kunna se ut. Anledningen till att ett försök till bevis tasupp är att trots digert sökande har inte litteratur som visar diffusionsapproximationensgiltighet hittats. För detta fall finns det däremot en hel del referenser som hävdar giltighetmen dessa referenser tycks sakna riktiga bevis, varvid det infinnes tvivel om dessa gåratt lita på. Den litteratur som ligger närmast att täcka detta fall är [7] kapitel 11. Hand-ledaren [6] vill infoga en brasklapp om att det någonstans kan finnas fel i argumentennedan.
Syftet med nedanstående avsnitt, nedtecknad från [6], är att undersöka huruvida enlogistisk födelsedödsprocess N, med födelseintensiteten
λi = i(a1−b1i), i≤ a1
b1
och dödsintensitetenµi = i(a2 +b2i), i≤ a1
b1,
kan approximeras med en diffusionsprocess Y som löser den stokastiska differentialekva-tionen
dY = (λ (Y )−µ(Y ))dt +√
λ (Y )+ µ(Y )dW,
där W är en Brownsk rörelse, vilket kan utläsas från [2] och [8]. Här är λ och µ utvidgadetill funktioner på hela R, det vill säga λ (x) = x(a1 − b1x) och µ(x) = x(a2 + b2x) förx ∈ [0, a1
b1] och λ (x) = µ(x) = 0 för x /∈ [0, a1
b1].
För att undersöka diffusionsapproximationens giltighet, låt λn(x) = x(a1 − nb1x),µn(x) = x(a2 + nb2x) för x ∈ [0, a1
b1] och λn(x) = µn(x) = 0 för x /∈ [0, a1
b1]. Inför en an-
nan process, Xn = Nn , vilket innebär att Xn från en position i
n hoppar upp 1n steg med inten-
siteten λn( in) och hoppar ner 1
n steg med intensiteten µn( in). Notera till exempel skillnaden
mellan λ (x) och λn(x) och att nλn( in) = λ (i). För processen Xn gäller att
E[ f (Xn(h))|Xn(0) = x] = f (x+1n)nλn(x)h+ f (x− 1
n)nµn(x)h
+ f (x)(1−nλn(x)h−nµn(x)h)+o(h),
där o(h)h → 0 då h→ 0. Generatorn för Xn blir då
GXn f (x) = limh→0
E[ f (Xn(h))|Xn(0) = x]− f (x)h
= nλn(x)( f (x+1n)− f (x))+nµn(x)( f (x− 1
n)− f (x)).
Taylorutveckling av GXn f (x) ger
GXn f (x) = (λn(x)−µn(x)) f ′(x)+1
2n(λn(x)+ µn(x)) f ′′(x)+O(
1n),
där |O(1n)| ≤ C(x)
n där C ej beror på n.Innan diskussionen fullföljs kan det vara lämpligt att studera en stokastisk differen-
tialekvation på formendX = b(X)dt +σ(X)dW. (3.1)
4

Lemma 3.1. En lösning till (3.1) har generatorn
G f (x) = b(x) f ′(x)+12
σ2(x) f ′′(x). (3.2)
Väsentligheterna i beviset av Lemma 3.1: För att visa att ekvation (3.1) har generatorn(3.2) används Itôs formel,
f (Xh) = f (X0)+∫ h
0b(Xs) f ′(Xs)+
12
σ2(Xs) f ′′(Xs)ds
+∫ h
0σ(Xs) f ′(Xs)dWs.
Generatorn blir då
G f (x) = limh→0
E[ f (Xh)|X0 = x]− f (x)h
= limh→0
∫ h0 E[b(Xs) f ′(Xs)+ 1
2σ2(Xs) f ′′(Xs)]ds+0h
=b(x) f ′(x)+12
σ2(x) f ′′(x).
Nu framgår det att processen Xn = Nn har generatorn GXn f (x) vilken för stora n är
approximativt
(λn(x)−µn(x)) f ′(x)+1
2n(λn(x)+ µn(x)) f ′′(x) =: GX̃n
f (x),
där X̃n löser den stokastiska differentialekvationen
dX̃n = (λn(X̃n)−µn(X̃n))dt +1√n
√λn(X̃n)+ µn(X̃n)dW. (3.3)
Låt Yn = nX̃n. Då fås
dYn =n(λn(X̃n)−µn(X̃n))dt +√
n√
λn(X̃n)+ µn(X̃n)dW
=n(λn(Yn
n)−µn(
Yn
n))dt +
√n
√λn(
Yn
n)+ µn(
Yn
n)dW
=(λ (Yn)−µ(Yn))dt +√
λ (Yn)+ µ(Yn)dW. (3.4)
Notera att utseendet på de speciella logistiska intensiteterna utnyttjades för att få nλn(Ynn )=
λ (Yn) och nµn(Ynn ) = µ(Yn). Notera även att Xn ≈ X̃n, N = nXn och att Yn = nX̃n men det
är inte säkert att N ≈ Yn (Jämför följderna xn = 1n och x̃n = 0. För stora n är xn ≈ x̃n
men nxn = 1 och nx̃n=0.). Nu har det i stora drag visats att Xn = Yn kan approximeras
med X̃n givet av (3.3). Det är däremot oklart om Yn = nX̃n, som uppfyller (3.4), verkligenapproximerar N för stora n [6].
Vad gäller diffusionsapproximationen för Malthus modell kan beviset genomföras medsamma teknik, fast enklare. Fallet täcks av [7].
Lotka-Volterras modell kan enligt [9] approximeras med ett diffusionsapproximeratdifferentialekvationssystem enligt
d[
N1(t)N2(t)
]=
[N1(t)(r1−b1N2(t))
N2(t)(−r2 +b1N1(t))
]dt +C
[dW1dW2
],
5

där störningarna W1 och W2 är två oberoende Brownska rörelser. Matrisen C uppfyllerCCT = B,
B =[
r1N1(t)+b1N1(t)N2(t) −b1N1(t)N2(t)−b1N1(t)N2(t) b1N1(t)N2(t)+ r2N2(t)
].
För den som är intresserad av djupare läsning samt härledning av B och C, se [9].
6

4 ModellbeskrivningI detta kapitel förklaras tre olika populationsmodeller: en ren födelseprocess, en logistiskmodell och en modell där två olika populationer beror på varandra.
4.1 Exponentiell populationstillväxt
Den första modellen som studeras är Malthus rena födelsemodell. För att få en begripligbild av vad som studeras, formuleras modellen som en födelsedödsprocess N(t). Varje nyfödelse sker, enligt [2], med födelseintensiteten λn = nλ . Antal individer i populationenvid tiden t ges av N(t) och λ är en tillväxtkonstant, se figur 4.1. Eftersom det är en renfödelsemodell som studeras är dödsintensiteten µn = 0. Tiden mellan två födslar är expo-nentialfördelad enligt Exp( 1
λn), vilket innebär att ju fler individer det finns i populationen,
desto tätare kommer födslarna att komma.
Figur 4.1: I Malthus rena födelseprocess föds individer med intensiteten λn = nλ och dörmed intensiteten µn = 0.
En mindre verklighetsnära modell av den ovan beskrivna födelsedödsprocessen är attapproximera födelsemodellen med en differentialekvation som störs med ett brus, enstokastisk differentialekvation,
dN(t) = λN(t)dt +√
λN(t)dW, (4.1)
där dW är en störning heuristiskt skrivet som
dW =√
dtN(0,1) (4.2)
och där N(0,1) är en normalfördelad slumpvariabel. Att Malthus födelsedödsprocess kanapproximeras med (4.1) är hämtat från [7].
En ytterligare förenkling av modellen är att bortse från bruset i ekvation (4.1), vilketger oss Malthus klassiska födelsemodell som säger att tillväxten växer enligt
dN(t) = λN(t)dt. (4.3)
De tre ovan nämnda sätten att beskriva en populationsutveckling är olika noggranna påatt förklara verkligheten. Födelsedödsprocessen som beskrivs i figur 4.1 är den beskrivn-ing som ligger närmast verkligheten, medan Malthus klassiska beskrivning är en väldigtförenklad modell och säger bara hur populationen beter sig i medeltal. Eftersommodellerna beskriver verkligheten på olika sätt är de även olika svåra att lösa. Ekva-tion (4.3) har en deterministisk lösning medan de andra två måste simuleras för att kunnalösas.
7

4.2 Logistisk populationstillväxt
Den andra modellen som studeras är Verhulsts logistiska modell, vilket är en utvidgningav den första modellen som beskrevs i avsnitt 4.1. Nu kan även populationens individerdö samt att populationen inte kan växa sig hur stor som helst.
För att få en begriplig bild av vad det är som studeras formuleras Verhulsts klassiskamodell om till en födelsedödsprocess N(t) enligt figur 4.2, med födelseintensiteten
λn = n(a1−b1n), n≤ a1
b1
och med dödsintensiteten
µn = n(a2 +b2n), n≤ a1
b1,
där a1, a2, b1 och b2 är positiva konstanter. Att intensiteterna λn och µn ska vara precissom beskrivits ovan är hämtat i [2] kapitel 3.
När populationen ökar minskar λn samtidigt som µn ökar. Detta innebär att popula-tionen både kan dö ut eller växa sig stor, dock kan populationen aldrig bli större än a1
b1.
Anledningen till att n uppåt är begränsat av a1b1
är att födelseintensiteten λn alltid är positivoch då är a1
b1det största värdet λn kan anta utan att bli negativ. Konstanterna a1 och b1 är
ett mått på tillväxten och konstanterna a2 och b2 är ett mått på dödligheten. Tiden mel-lan två händelser är exponentialfördelad enligt Exp( 1
λn+µn). Det innebär att tiden mellan
händelserna är slumpartad.
Figur 4.2: I den logistiska födelsedödsprocessen föds individer med intensiteten λn =n(a1−b1n) och dör med intensiteten µn = n(a2 +b2n), där n är antal individer vid tident.
En mindre verklighetsnära modell av den ovan beskrivna födelsedödsprocessen är attapproximera den med en differentialekvation som störs med ett brus,
dN(t) = (λ (N(t))−µ(N(t)))dt +√
λ (N(t))+ µ(N(t))dW, (4.4)
där λ (N(t)) = N(t)(a1−b1N(t)) och µ(N(t)) = N(t)(a2 +b2N(t)). Jämför med kapitel 3,ekvation (3.4). Störning dW ges av ekvation (4.2). För att få en mer förståelig bild av
8

ekvation (4.4) skrivs
dN(t) =(λ (N(t))−µ(N(t)))dt +√
λ (N(t))+ µ(N(t))dW=(N(t)(a1−b1N(t))−N(t)(a2 +b2N(t)))dt
+√
N(t)(a1−b1N(t))+N(t)(a2 +b2N(t))dW
=N(t)((a1−a2)− (b1 +b2)N(t))dt +√
N(t)((a1 +a2)+(b2−b1)N(t))dW.
Sätts sedan r = a1−a2 och s = b1 +b2 fås slutligen
dN(t) = N(t)(r− sN(t))dt +√
N(t)((a1 +a2)+(b2−b1)N(t))dW. (4.5)
En ytterligare förenklad modell av födelsedödsprocessen som beskrivs i figur 4.2 är attbortse från bruset i ekvation (4.5), vilket ger Verhulsts klassiska logistiska modell somsäger att populationen förändras enligt
dN(t) = N(t)(r− sN(t))dt. (4.6)
Notera att substitutionen s = rK ger Verhulsts ekvation på samma form som den beskrevs
i avsnitt 2.De tre ovan nämnda sätten att beskriva logistiska populationsutvecklingar är olika nog-
granna på att förklara verkligheten. Födelsedödsprocessen som beskrivs i figur 4.2 är denbeskrivning som ligger närmst verkligheten, medan ekvation (4.6) är en väldigt förenk-lad modell och säger bara hur populationen beter sig i medeltal. Ekvation (4.6) har endeterministisk lösning medan de stokastiska måste simuleras för att kunna lösas.
4.3 Lotka-Volterra
Den tredje modellen som studeras är Lotka-Volterras modell där två populationer, N1 ochN2, beror på varandra. Bägge populationerna kan öka och minska, se figur 4.3. Modellenär konstruerad på så sätt att när en individ från population N1 träffar en annan individ frånpopulation N2 gynnas population N2 medan population N1 missgynnas. En mer matema-tisk bild av hur populationerna beror på varandra ges av{
dN1(t) = N1(t)(r1−b1N2(t))dtdN2(t) = N2(t)(−r2 +b1N1(t))dt,
(4.7)
där N1(t) är antal individer i population N1 vid tiden t, N2(t) är antal individer i populationN2 vid tiden t, r1 är födelsetakten för N1 och r2 är dödstakten för N2. Konstanten b1representerar möten mellan grupperna N1 och N2 där den ena gruppen gynnas och denandra gruppen missgynnas. För att bättre förstå modellen antag till exempel att gruppN1 är bytesdjur och grupp N2 är jägare och när de träffas gynnas jägarna samtidigt sombytesdjuren missgynnas [2].
Formuleras problemet som en födelsedödsprocess ökar N1 med födelseintensitetenB1 = r1N1 och minskar med dödsintensiteten D1 = b1N1N2. På samma sätt ökar N2 medfödelseintensiteten B2 = b1N1N2 och minskar med dödsintensiteten D2 = r2N2. Att N1 ochN2 ökar och minskar med just dessa intensiteter är hämtat från [2] kapitel 6. Tiden mellantvå händelser är en exponentialfördelad slumpvariabel enligtExp( 1
B1+B2+D1+D2).
Det diffusionsapproximerade differentialekvationssystemet av Lotka-Volterras ekva-tion beskrivs enligt [9] som
d[
N1(t)N2(t)
]=
[N1(t)(r1−b1N2(t))
N2(t)(−r2 +b1N1(t))
]dt +C
[dW1dW2
], (4.8)
9

Figur 4.3: I Lotka-Volterras födelsedödsprocess beror två olika populationer, N1 ochN2, på varandra där bägge populationerna både kan öka och minska i antal med oli-ka intensiteter. Populationerna N1 och N2 ökar med intensiteterna B1 = r1N1 respektiveB2 = b1N1N2, på samma sätt minskar de med intensiteterna D1 = b1N1N2 respektiveD2 = r2N2.
där dW1 och dW2 är två oberoende störningar precis som i de andra modellerna och är likamed
√dtN(0,1), där N(0,1) är normalfördelad slump med medelvärde 0 och standard-
avvikelse 1. Matrisen C uppfyller CCT = B,
B =[
r1N1(t)+b1N1(t)N2(t) −b1N1(t)N2(t)−b1N1(t)N2(t) b1N1(t)N2(t)+ r2N2(t)
].
Ekvation (4.7) har en deterministisk lösning men beskriver inte verkligheten specielltbra, medan ekvation (4.8) ger en bättre bild av verkligheten. Att formulera modellen ifigur 4.3 som en födelsedödsprocess är den beskrivning som ligger närmast verkligheten.De två modeller som har en icke deterministisk lösning måste simuleras för att kunnalösas.
10

5 Beskrivning av programkodernaFöljande kapitel innehåller en beskrivning av hur programkoderna realiserar de matema-tiska modellerna, samt arbetet för att nå dit.
5.1 Implementering
Det har under arbetets gång fokuserats mycket på att få programkoderna i MatLab ochC så lika varandra som respektive språk tillåter, för att kunna jämföra dem på ett rättvistsätt. Helt identiska verkar det dock inte gå att få dem, då MatLab innehåller en hel delstandardfunktioner som C helt och hållet saknar. Skillnaderna mellan svårigheten att pro-grammera i de båda språken kommer fram extra mycket vid användandet av matematiskafunktioner i MatLab. Ett exempel på detta är uträkningen av medelvärdena i en matris.Kolumn för kolumn ska medelvärdena beräknas, för att sen lagras i en array på sammaposition som den aktuella kolumnen har i matrisen. I MatLab behövs det inte ägnas entanke åt kontroll av storlekar på rader eller kolumner, utan uträkningen av medelvärdena imatrisen går att lösa på det sätt, som visas i programkod 5.1. I C krävs det en hel del merarbete och kontroll för att utföra samma uträkning, som det visas i programkod 5.2.
...array=mean(matrix,1);...
Programkod 5.1: Medelvärdesuträkning från matris i MatLab.
...for (j=0;j<size; j++){
for(k=0;k<no_of_sims; k++){
means = means + matrix[k][j];}array[j] = means/no_of_sims;means=0;
}...
Programkod 5.2: Medelvärdesuträkning från matris i C.
Ett annat exempel på skillnader mellan språken är vid uppsökning av värden i en ma-tris. Programkod 5.3 visar på hur det i MatLab skapas en ny array, där storleken bestämsav det totala antal nollor som finns på andra raden i en matris. I nästa steg ska värden frånden första raden i matrisen sorteras, för att sen läggas in i den nyskapade arrayen. Det ärdock inte alla värdena som är aktuella, utan endast de som på motsvarande position i radtvå har en nolla. Figur 5.1 visar ett exempel på hur detta kan gå till. Programkod 5.4 visarhur en lösning för ovanstående operationer kan se ut i C.
11

Figur 5.1: Matrisens rad 2 innehåller 3 stycken 0-värden och därmed skapas en arraymed 3 element. De 3 värdena ur rad 1, vars motsvarande position i rad 2 innehåller ett0-värde plockas ut och sorteras, för att sedan läggas in i arrayen.
...array=([1 sum(matrix(2,:)==0)]);array=sort(matrix(1,find(matrix(2,:)==0)));...
Programkod 5.3: Storleksbestämning av array samt uppsökning av värden i MatLab.
double ∗array;...i=0;zero_counter=0;while(i<size){
if(matrix[1][i]==0) zero_counter = zero_counter+1;i++;
}array = calloc(zero_counter, sizeof(double));i=0;j=0;while(i<size){
if(matrix[1][i]==0){
array[j]=matrix[0][i];j++;
}i++;
}qsort(array,zero_counter, sizeof(double), double_compare);...
Programkod 5.4: Storleksbestämning av array samt uppsökning av värden i C.
12

Översättningen från MatLab till C visade sig ta upp en betydligt större del av arbetetän planerat. En god hjälp till att förstå vad MatLabs funktioner egentligen utför har [3]och [10] varit. För att kunna lösa allehanda svårigheter som stötts på under implementerin-gen i C, har [11] samt [12] använts flitigt och de har varit två väldigt informativa källortill kunskap.
5.2 Exponentiell modell
Den matematiska beskrivningen av modellen i avsnitt 6.1 visar att följande värden skabestämmas innan simulering kan påbörjas:
• Antal simuleringar som ska utföras
• Den övre intervallsgränsen på tidsskalan (intervall)
• Tidsdifferentialen (dt)
• Antal individer vid start
• λ (födelsekonstanten)
Med utgång från dessa värden skapas väl anpassade variabler och variabelkonstruk-tioner. En av de viktigare konstruktionerna är en tidsarray. Denna innehåller alla de tid-punkter, då den aktuella populationens individantal ska registreras. Tidsskalan sträckersig från 0 till den förutbestämda övre intervallsgränsen och antal tidpunkter styrs av dt.Under testerna används en tidsarray av formen [0; 0,01; 0,02; 0,03; . . . ;2], då dt är satt till0,01 och intervall till 2.
5.2.1 Deterministisk differentialekvation
En array, av samma storlek som tidsarrayen, skapas för att senare lagra resultaten avuträkningarna. På position n i den nya arrayen lagras resultatet av den deterministiskauträkningen, se ekvation (6.1), där värdet på position n i tidsarrayen ingår som en kom-ponent. Resultatarrayen innehåller vid slutet av körningen information om hur mångaindivider populationen består av vid var och en av tidpunkterna i tidsarrayen.
5.2.2 Diffusionsapproximerad differentialekvation
Variabelkonstruktioner så som matriser och arrayer skapas i en del olika utförande, föratt kunna användas senare i programkoden. I en loop, som itererar så många gånger somsimuleringarna ska genomföras, utförs ekvation (4.1) där normalfördelade slumptal ingår.Ekvationen utförs en gång för varje tidpunkt i tidsarrayen. Resultatet lagras på aktuellplats i en matris, av storleken antal simuleringar ∗ antal tidpunkter i tidsarrayen. Då re-sultatet av ekvationen kan bli negativt, måste detta fångas upp och i sådana fall ändras tillnoll, då en population inte kan bestå av ett negativt antal individer. När simuleringarnaär slutförda är resultatet en matris, där raderna motsvarar var och en av simuleringarnaoch kolumnerna innehåller antal individer i populationerna för motsvarande tidpunkt itidsarrayen.
Nästa steg är att räkna ut medelvärdena av resultaten från simuleringarna. Medelvärdetberäknas rad för rad i varje kolumn i matrisen. Dessa värden lagras i en array, där positio-nen motsvarar tidpunkten på samma position i tidsarrayen. Därmed kan information lättnås om hur många individer det finns i medel vid en viss tidpunkt.
Ett 95-procentigt konfidensintervall ska sedan räknas ut och även här är det värdenakolumnvis i matrisen som är intressanta. Varje kolumn gås igenom och sorteras. Sedan
13

väljs de högsta och lägsta värdena ut, som håller sig innanför konfidensintervallet. Dessavärden lagras i två arrayer, som nu innehåller de övre och undre kurvorna för konfidens-intervallet.
5.2.3 Födelsedödsprocess
Ett antal olika variabelkonstruktioner skapas för kommande behov. Loopen, där uträkning-arna utförs, itererar så många gånger som simuleringar ska ske. Först beräknas det, medhjälp av slumptal mellan 0 och 1, vid vilken tidpunkt en förökning ska komma att ske. Omtidpunkten visar sig vara inom det förbestämda tidsintervallet, lagras denna i en array. I ennästlad loop, som itererar så länge som en uträknad tidpunkt håller sig inom tidsinterval-let, räknas nästkommande tidpunkter fram enligt födelsedödsmodellen, se figur 4.1. Nären tidpunkt hamnat utanför intervallet, lagras det antal förökningar som hann ske innandetta inträffade och det antal motsvarar individantalet i populationen.
När simuleringarna slutförts har alla tidpunkter då en förökning skett, lagrats i en tid-punktsmatris. Matrisen består av lika många rader som antal utförda simuleringar ochvarje rads längd bestäms av antal förökningar som hann ske inom tidsintervallet i denaktuella simuleringen. Aktuellt antal individer då en förökning skett sparas, i en stor-leksmässigt identisk individsmatris, på motsvarande rad och kolumn. En array har för varoch en av simuleringarna lagrat antal framräknade förökningar som hunnits med.
Medelvärdet ska räknas ut på liknande sätt som för den diffusionsapproximerade ek-vationen. Skillnaden nu är att förökningarna inte skett vid förutbestämda tidpunkter, utanhar kunnat ske när som helst. För att få fram ett redovisbart medelvärde, räknas det hurmånga förökningar som skett mellan två efterföljande tidpunkter i den tidigare användatidsarrayen. Då blir det hanterbara värden och det är möjligt att redovisa medelvärdettidpunkt för tidpunkt.
Även uträkningen av konfidensintervallen får utföras på ett litet annorlunda sätt. Allasimuleringarnas populationsutvecklingar läggs på en och samma rad i en matris. På radenunder i den matrisen lagras tidpunkterna som hör samman med populationsutvecklingar-na. Genom att jämföra den undre raden med tidpunkterna mot tidsarrayen, går det att fåut hur många förökningar det skett mellan två tidpunkter i tidsarrayen och därmed ocksåfå fram ett konfidensintervall. Även här skapas två arrayer, en för den övre kurvan och enför den undre i konfidensintervallet.
5.3 Logistisk modell
Den matematiska beskrivningen av modellen i avsnitt 6.2 visar att följande värden skabestämmas innan simulering kan påbörjas:
• Antal simuleringar som ska utföras
• Den övre intervallsgränsen på tidsskalan (intervall)
• Tidsdifferentialen (dt)
• Antal individer vid start
• a1, a2, b1, b2 (positiva konstanter som reglerar födelse- och dödsintensiteten)
På samma sätt som i den exponentiella delen, används dessa värden för att skapa lämpligavariabler och variabelkonstruktioner. Även här har en tidsarray, som innehåller de tidpunk-ter då förändringar i populationens individantal ska ske, en viktig funktion. Tidsskalansträcker sig från 0 till den förutbestämda övre intervallsgränsen och antal tidpunkter styrs
14

av dt. Under testerna används en tidsarray av formen [0; 0,02; 0,04; 0,06; . . . ;25], då dt ärsatt till 0,02 och intervallsgränsen till 25.
5.3.1 Deterministisk differentialekvation
En resultatarray, vars storlek är identisk med tidsarrayen, skapas för senare lagring avuträkningarnas resultat. I den deterministiska uträkningen ingår värden ur tidsarrayen, seekvation (6.4). När tidpunkten på position n i tidsarrayen använts i uträkningen, lagras re-sultatet av uträkningen på position n i resultatarrayen. Då körningen är avklarad innehållerresultatarrayen antal individer i populationen för varje tidpunkt i tidsarrayen.
5.3.2 Diffusionsapproximerad differentialekvation
Variabelkonstruktioner så som matriser och arrayer skapas i en del olika utförande, föratt kunna användas senare i programkoden. I en loop, som itererar lika många gångersom efterfrågat antal simuleringar, sker uträkningarna av populationstillväxterna. Självauträkningen av tidpunkten för förändringen i populationen, där normalfördelade slumptalingår, sker i en nästlad loop och upprepas en gång för varje tidpunkt i tidsarrayen, se ek-vation (4.5). Resultaten lagras på aktuell plats i en matris, av storleken antal simuleringar∗ antal tidpunkter i tidsarrayen. Blir resultatet negativt, sätts värdet till noll då det intekan finnas ett negativt antal individer i en population. När alla simuleringar är slutförda,är resultatet en matris där populationssimuleringarna representeras på raderna och antalindivider för varje tidpunkt i tidsarrayen, i kolumnerna.
En medelvärdesberäkning utförs sedan kolumn för kolumn i matrisen, på de värdensom är större än noll. Värdena lagras i en resultatarray av identisk storlek som tidsarrayen,där varje position i resultatarrayen visar hur många individer det fanns i medeltal för varjetidpunkt i tidsarrayen.
Kolumnvis hämtas värdena ur matrisen och sorteras, för att sedan användas i uträknin-gen av det 95-procentiga konfidensintervallet. Om det visar sig att en population är utdödvid den aktuella tidpunkten, ska denna inte tas med i beräkningarna. Kurvorna som visarkonfidensintervallet lagras i två arrayer, en för den övre och en för den undre, där båda ärav samma storlek som tidsarrayen.
5.3.3 Födelsedödsprocess
Variabelkonstruktioner såsom arrayer och matriser skapas för att hantera olika slags vär-den. I en loop, som itererar lika många gånger som det antal simuleringar som efterfrågas,utförs beräkningarna gällande populationerna. Dessa beräkningar, se figur 4.2, som skermed hjälp av slumptal mellan 0 och 1 upprepas så länge som den uträknade tidpunktenför förändringen håller sig inom tidsintervallet. Alla tider lagras i en tidpunktsmatris, därantal rader styrs av antal simuleringar och längden på raderna av antal förökningar somhann ske inom tidsintervallet. I en individmatris av samma storlek lagras antal individerför varje framräknad tidpunkt. En array innehåller antal förökningar eller förminskningarför var och en av simuleringarna.
På samma sätt som medelvärdesberäkningen utfördes för födelsedödsdelen i den ex-ponentiella modellen, upprepas även här. Antal förändringar i populationsstorleken somskett mellan två tidpunkter i tidsarrayen, är det som är det intressanta. Skillnaden nu äratt här kan även populationer dö ut och detta måste det tas hänsyn till. Alla tidpunkter dåen population har dött ut, lagras i en array. Detta för att kontrollera om en population hardött ut vid den aktuella tidpunkten i tidsarrayen. Om så är fallet ska den utdöde popula-tionen inte tas med i medelvärdesberäkningen. Resultatet blir att det går att redovisa antalindivider i medeltal för varje tidpunkt i tidsarrayen.
15

Uträkningarna av konfidensintervallen sker på ett liknande sätt som för födelsedöds-delen i den exponentiella modellen. Det som skiljer sig är att endast de värden som ärstörre än noll, är intressanta här. All information om simuleringarnas ökning eller minsk-ning av individantalen lagras på en rad i en matris. På raden under finns alla tidpunkterdå förändringarna skett. På så sätt går det att utläsa hur många förändringar det har skettmellan två efterföljande tidpunkter i tidsarrayen. Utifrån detta sorteras värdena kolumnvisoch det största samt det minsta värdet inom konfidensintervallet identifieras. Dessa värdenlagras i två arrayer som representerar den över och den undre kurvan i konfidensinterval-let.
16

6 Bearbetning av modellernaDetta kapitel är uppdelat i tre delar och i varje del förklaras hur respektive problem lösts.
6.1 Exponentiell populationstillväxt
Lösningen av den rena födelsemodellen som beskrevs i avsnitt 4.1 delas upp i tre steg.Först studeras den deterministiska lösningen, sedan den diffusionsapproximerade differ-entialekvationen och slutligen den modell formulerad som en födelsedödsprocess.
Den deterministiska lösningen till ekvation (4.3) med avseende på tiden t är elementärt:
dNdt
= λN ⇔
dNN
= λdt ⇔∫ 1N
dN =∫
λdt ⇔
logN = λ t + c⇔N = ceλ t ⇔
N(t) = ceλ t ,c ∈ N.
Konstanten c bestäms genom bivillkoret N(0) = n0 och där n0 är hur många individerpopulationen innehåller vid tiden 0. Lösningen till ekvation (4.3) blir
N(t) = n0eλ t . (6.1)
Uppritning av den deterministiska lösningen, med n0 = 1 och λ = 1, som ges av ekva-tion (6.1) ses i figur 6.1. I figuren visas hur populationen växer exponentiellt.
Figur 6.1: Deterministisk lösning av dN(t) = λN(t)dt. På x-axeln kan tiden läsas av ochpå y-axeln syns hur populationen förändras.
Genomgående i detta avsnitt används värdena λ = 1, n0 = 1 och tidsintervallet [0,2].Dessa värden kan enligt [6] väljas utan att förlora kvalitativa egenskaper vid andra val av
17

parametrar. Eftersom lösningen till ekvation (4.3) kommer att se likadan ut, sånär på enskalning, har det ingen betydelse vilka värden som väljs, så länge samma värden användskonsekvent.
Att lösa den stokastiska motsvarigheten av samma födelsemodell är lite svårare efter-som varje simulering är slumpartad och därmed unik. Att bara köra en enda simuleringskulle därför inte vara tillräckligt för att få fram statistiska egenskaper hos den stokastiskalösningen, som till exempel väntevärde, standardavvikelse och konfidensintervall, efter-som det inte går att förutspå exakt vad som händer. Därför är det av intresse att göra mångasimuleringar. Att modellera på detta sätt har vissa fördelar jämfört med den klassiska de-terministiska lösningen eftersom det nu även går att fånga upp spridningen, genom attkonstruera ett konfidensintervall för de olika simuleringarna.
För att göra många simuleringar krävs det ett datorprogram. Att simulera ekvation (4.1)görs genom att först bestämma hur många individer populationen har vid t = 0. För enkel-hetens skull väljs en individ vid t = 0. För att räkna ut hur många individer som befinnersig i populationen vid nästa tid används en loop, enligt
N̄(t) = N̄(t−∆t)+λ N̄(t−∆t)∆t +√
λ N̄(t−∆t)∆W, ∆W =√
∆tN(0,1),
där t är iterationsvariabeln som ökar med steglängden ∆t. Innan simuleringen påbörjasmåste ∆t bestämmas. Enligt [6] är en tumregel att antal simuleringar ska vara ungefär likamed antal tidssteg i kvadrat. Storleken på ∆t bör vara i storleksordningen
∆t ≈ T√n,
där T är slutpunkten på tidsaxeln och n är antal simuleringar. Men detta är bara en tum-regel, storleken på ∆t kan väljas mindre om så önskas eftersom ju mindre steglängd, destobättre precision ger Eulersimuleringarna. Då Malthus modell är ganska enkel att simulerahar steglängden valts till 0,01.
Hur en stokastisk simulering av ekvation (4.1) ser ut kan ses i figur 6.2, där fyra simu-leringar gjorts. I figuren syns tydligt att simuleringarna ger upphov till olika realiseringar.För att få bra värden på en medelvärdesbildad lösning krävs det många simuleringar.
Enligt [6] kan olikheten2z0,025
σ√n
< ε, (6.2)
användas för att försöka uppskatta hur många simuleringar som krävs. I (6.2) är σ stan-dardavvikelsen av processens värde vid sluttidpunkten och z0,025 = 1,96. Om (6.2) gällerär sannolikheten ungefär 95 procent att skillnaden mellan medelvärdet av realiseringarnavid sluttidpunkten och dess väntevärde mindre än ε . Detta uttrycks lättast i en formel,
P(|1n
n
∑i=1
N̄(i)(T )−E[N̄(T )]|< ε)≈ 0,95.
En annan regel är att välja n så atts√n
< ε, (6.3)
där s är stickprovsstandardavvikelsen av processens värde vid sluttidpunkten. Om (6.3)gäller är medelfelet av skattningen av E[N̄(T )] mindre än ε , det vill säga stickprovs-standardavvikelsen av medelvärdet 1
n ∑ni=1 N̄(i)(T ) är mindre än ε . För att lättare förstå
uttrycks detta i en formel,√E[(
1n
n
∑i=1
N̄(i)(T )−E[N̄(T )])2] < ε.
18

Stickprovsstandardavvikelsen räknas fram genom att titta på hur simuleringarna är förde-lade vid slutpunkten på x-axeln och i detta specialfall slutar x-axeln på 2. Simuleringarvisar att s≈ 7. En rimlig uppskattning av ε i detta fallet är att ε = 0,1; vilket ger att antalsimuleringar bör vara i storleksordningen
n >s2
ε2 =72
0,12 = 4900.
För enkelhetens skull väljs antal simuleringar till 5000. Trots att antal simuleringar väljstill 5000 går det inte med säkerhet säga att skillnaden mellan processens väntevärde ochmedelvärde är mindre än 0,1 vid tiden 2 eftersom detta bara är en uppskattning.
I figur 6.3 har 5000 simuleringar gjorts. I figur 6.4 syns medelvärdet av 5000 simu-leringar tillsammans med den deterministiska lösningen. Eftersom många simuleringarhar utförts, går det nu att beräkna ett 95-procentigt konfidensintervall för simuleringarna.Ett sådant konfidensintervall syns i figur 6.5.
Figur 6.2: Eulersimuleringar av dN(t) = λN(t)dt +√
λN(t)dW. På x-axeln kan tidenläsas av och på y-axeln syns hur populationen förändras. I figuren har fyra olika simu-leringar gjorts.
19

Figur 6.3: Eulersimuleringar av dN(t) = λN(t)dt +√
λN(t)dW. På x-axeln kan tidenläsas av och på y-axeln syns hur populationen förändras. I figuren har 5000 olika simu-leringar gjorts.
Figur 6.4: Eulersimulerad medelvärdesbildad lösning av dN(t) = λN(t)dt +√
λN(t)dW.På x-axeln kan tiden läsas av och på y-axeln syns hur populationen förändras. I figurenrepresenterar den gröna grafen medelvärdet av 5000 olika simuleringar medan den blågrafen representerar den deterministiska lösningen.
20

Figur 6.5: I figuren har ett 95-procentigt konfidensintervall för 5000 Eulersimuleringar avdN(t) = λN(t)dt +
√λN(t)dW gjorts. På x-axeln kan tiden läsas av och på y-axeln syns
hur populationen förändras. De gröna graferna är den övre respektive undre gränsen förkonfidensintervallet, medan den blå grafen är den deterministiska lösningen.
Att lösa problemet som en födelsedödsprocess med födelseintensiteten λn = nλ ochmed dödsintensiteten µn = 0 är lite svårare, eftersom denna mer verklighetstrogna modellbara kan anta diskreta värden på populationsstorleken. För att lösa födelseprocessen be-höver simuleringar göras i en dator. Svårigheten med att lösa problemet är att först måsteett begränsat tidsintervall bestämmas för att sedan ta reda på när de olika födslarna underdet givna intervallet kommer att komma. Eftersom tiderna mellan födslarna är slumpmäs-siga går det inte i förväg att veta hur många födslar som sker under en given tid, utandet kan vara allt mellan inga födslar till väldigt många. Figur 6.6 illustrerar detta. Tidenmellan två födslar är en exponentialfördelad slumpvariabel enligt Exp( 1
λn). Enligt [2] kan
den tiden även fås fram av(− log(Y )
λn
), där Y är ett slumptal mellan 0 och 1. Ett sätt att
simulera födelseprocessen är att gå tillväga på följande sätt:
1. Bestäm ett tidsintervall samt skapa en variabel τ som kommer att innehålla hopp-tiderna och sätt τ = 0.
2. Beräkna λn.
3. Välj ett slumptal Y så att Y ∈ (0,1].
4. Hitta nästa hopptid τ enligt τ = τ +(− log(Y )
λn
)och kontrollera att hopptiden inte
ligger utanför tidsintervallet. Om det ligger innanför tidsintervallet gå till nästa steg,annars avbryt.
5. Ändra N till N +1.
6. Gå tillbaka till steg 2.
För att fånga statistiska egenskaper krävs många simuleringar. I figur 6.7 har 5000simuleringar gjorts och i figur 6.8 syns medelvärdet av dessa tillsammans med lösningen
21

för den deterministiska ekvationen. I figur 6.9 syns ett 95-procentigt konfidensintervallför de 5000 olika simuleringarna, för att illustrera hur stor spridningen är.
Figur 6.6: Simulerad lösning av födelseprocessen med födelseintensiteten λn = nλ ochmed dödsintensiteten µn = 0. På x-axeln kan tiden läsas av och på y-axeln illustreras hurpopulationen förändras. I figuren har fyra olika simuleringar gjorts och det syns tydligtatt varje simulering är unik.
Figur 6.7: Simulerad lösning av födelseprocessen med födelseintensiteten λn = nλ ochmed dödsintensiteten µn = 0. På x-axeln kan tiden läsas av och på y-axeln syns hur popu-lationen förändras. I figuren har 5000 olika simuleringar gjorts. Den röda grafen i figurenär medelvärdet av alla simuleringar.
22

Figur 6.8: Medelvärdesbildad simulerad lösning av 5000 födelseprocesser med födelsein-tensiteten λn = nλ och med dödsintensiteten µn = 0. På x-axeln kan tiden läsas av ochpå y-axeln visas hur populationen förändras. I figuren är den röda grafen medelvärdetav 5000 olika simuleringar och den blå grafen är den deterministiska lösningen av ekva-tion (4.3).
Figur 6.9: I figuren syns ett 95-procentigt konfidensintervall för 5000 simulerade lös-ningar av födelseprocessen med födelseintensiteten λn = nλ och med dödsintensitetenµn = 0. På x-axeln kan tiden läsas av och på y-axeln syns hur populationen förändras.De röda graferna är den övre respektive undre gränsen för konfidensintervallet, medanden blå grafen är den deterministiska lösningen.
6.2 Logistisk populationstillväxt
Lösningen av den logistiska modellen, som beskrevs i avsnitt 4.2, delas upp i tre steg.Först studeras den deterministiska lösningen, sedan studeras den modell som formulerassom en födelsedödsprocess och slutligen den diffusionsapproximerade modellen.
23

Att hitta den deterministiska lösningen av ekvation (4.6) med avseende på tiden t fåsav följande beräkningar:
dNdt
= N(r− sN)⇔
dNdt
= Nr− sN2 ⇔
dNNr− sN2 = dt ⇔∫ 1
Nr− sN2 dN =∫
dt ⇔
logN− log(r− sN)r
= t + c1 ⇔
logN− log(r− sN) = r(t + c1)⇔
logN
r− sN= r(t + c1)⇔
Nr− sN
= er(t+c1) ⇔
N = (r− sN)er(t+c1) ⇔N = rer(t+c1)− sNer(t+c1) ⇔
N + sNer(t+c1) = rer(t+c1) ⇔N(1+ ser(t+c1)) = rer(t+c1) ⇔
N =rer(t+c1)
1+ ser(t+c1)⇔
N =r
e−r(t+c1) + s.
För att bestämma konstanten c1, anta att N(0) = n0, det vill säga att vid tiden noll är därn0 antal individer. Då bestäms c1 enligt:
N(t) =r
e−r(t+c1) + s, N(0) = n0 ⇒
n0 =r
e−rc1 + s⇔
n0(e−rc1 + s) = r ⇔
e−rc1 + s =r
n0⇔
e−rc1 =r
n0− s⇔
−rc1 = log(r
n0− s)⇔
c1 =1−r
log(r
n0− s).
Detta ger slutligen lösningen:
N(t) =r
e−r(t+ 1−r log( r
n0−s)) + s
, (6.4)
där N(t) är antal individer vid tiden t, n0 är antal individer vid t = 0, r är en konstant somger ett mått på den naturliga tillväxten och s är en konstant som begränsar tillväxten avpopulationen.
24
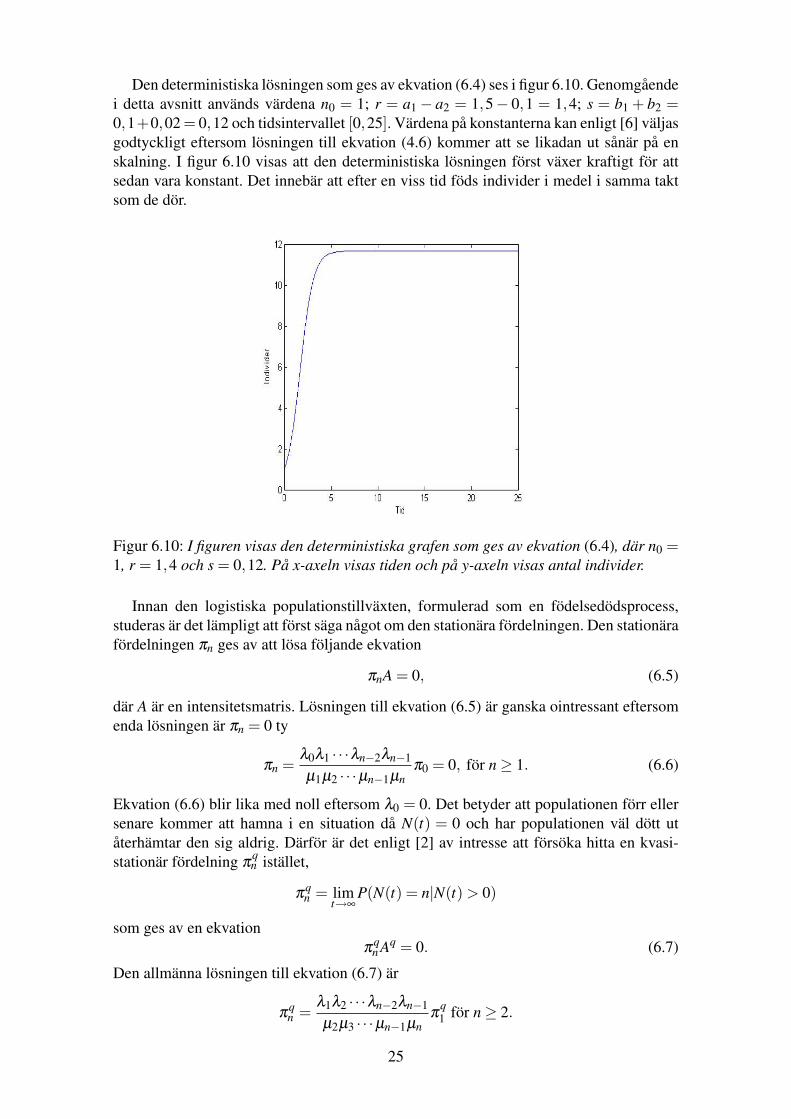
Den deterministiska lösningen som ges av ekvation (6.4) ses i figur 6.10. Genomgåendei detta avsnitt används värdena n0 = 1; r = a1 − a2 = 1,5− 0,1 = 1,4; s = b1 + b2 =0,1+0,02 = 0,12 och tidsintervallet [0,25]. Värdena på konstanterna kan enligt [6] väljasgodtyckligt eftersom lösningen till ekvation (4.6) kommer att se likadan ut sånär på enskalning. I figur 6.10 visas att den deterministiska lösningen först växer kraftigt för attsedan vara konstant. Det innebär att efter en viss tid föds individer i medel i samma taktsom de dör.
Figur 6.10: I figuren visas den deterministiska grafen som ges av ekvation (6.4), där n0 =1, r = 1,4 och s = 0,12. På x-axeln visas tiden och på y-axeln visas antal individer.
Innan den logistiska populationstillväxten, formulerad som en födelsedödsprocess,studeras är det lämpligt att först säga något om den stationära fördelningen. Den stationärafördelningen πn ges av att lösa följande ekvation
πnA = 0, (6.5)
där A är en intensitetsmatris. Lösningen till ekvation (6.5) är ganska ointressant eftersomenda lösningen är πn = 0 ty
πn =λ0λ1 · · ·λn−2λn−1
µ1µ2 · · ·µn−1µnπ0 = 0, för n≥ 1. (6.6)
Ekvation (6.6) blir lika med noll eftersom λ0 = 0. Det betyder att populationen förr ellersenare kommer att hamna i en situation då N(t) = 0 och har populationen väl dött utåterhämtar den sig aldrig. Därför är det enligt [2] av intresse att försöka hitta en kvasi-stationär fördelning π
qn istället,
πqn = lim
t→∞P(N(t) = n|N(t) > 0)
som ges av en ekvationπ
qn Aq = 0. (6.7)
Den allmänna lösningen till ekvation (6.7) är
πqn =
λ1λ2 · · ·λn−2λn−1
µ2µ3 · · ·µn−1µnπ
q1 för n≥ 2.
25

Eftersom den kvasi-stationära fördelningen endast är definierad för populationer skildafrån noll, studeras alla beräkningar i denna modell hädanefter bara i de tidpunkter dåN(t) 6= 0.
Täthetsfunktionen till den teoretiska kvasi-stationära fördelningen kan ses i figur 6.11.I figuren går det att utläsa att sannolikheten att populationen innehåller elva individer ärstörre än att populationen innehåller fem individer.
Figur 6.11: I figuren syns den teoretiska kvasi-stationära täthetsfunktionen för det studer-ade specialfallet.
Att lösa problemet formulerat som en födelsedödsprocess blir nu möjligt eftersom denkvasi-stationära fördelningen är definierad. Att simulera och därmed lösa problemet somen födelsedödsprocess med födelseintensiteten λn = n(a1 − b1n) och dödsintensitetenµn = n(a2 + b2n) är lite svårare, eftersom varje simulering är unik och tiden mellan dåtvå händelser inträffar är en exponentialfördelad slumpvariabel enligt Exp( 1
λn+µn). San-
nolikheten för att det är en födelse som inträffar är λnλn+µn
och för att det är död sominträffar är µn
λn+µn. Precis som i den exponentiella födelsedödsmodellen går det inte att i
förväg veta hur många födelsedödssituationer som inträffar under en given tid. Därför be-hövs en dator användas för att utföra simuleringarna. Ett tillvägagångssätt för att simulerafödelsedödsprocessen är att göra följande:
1. Bestäm ett tidsintervall samt skapa en variabel τ som kommer att innehålla hopp-tiderna och sätt τ = 0.
2. Beräkna λn och µn.
3. Välj två slumptal Y1 och Y2 så att Y1 ∈ (0,1] och Y2 ∈ [0,1].
4. Hitta nästa hopptid τ enligt τ = τ +(− log(Y1)
λn+µn
)och kontrollera att hopptiden inte
ligger utanför tidsintervallet. Om det ligger innanför tidsintervallet gå till nästa steg,annars avbryt.
5. Om 0≤ Y2 ≤ λnλn+µn
är nästa händelse en födelse, annars är det en död.
26

6. Ändra N till N +1 för födelse eller till N−1 för död.
7. Kontrollera om N > 0. Om så är fallet gå till steg 2, annars avbryt.
I figur 6.12 har fyra simuleringar gjorts för att ge en bild av problematiken och för attvisa vilka situationer som kan uppstå. I figuren syns tydligt att varje simulering är unik.Extra intressant är att en population dör medan de andra tre fortsätter att leva vidare. Dåvarje simulering är unik krävs det många simuleringar för att fånga statistiska kvaliteter.Eftersom den deterministiska lösningen förklarar hur populationen beter sig i medeltalberäknas, som jämförelse, den medelvärdesbildade lösningen bara av de stokastiska simu-leringar som är skilda från noll i varje tidpunkt t. Genom att göra många simuleringar ärdet möjligt att fånga upp spridningen för den medelvärdesbildade lösningen.
Enligt [6] kan olikheten (6.2) användas för att försöka uppskatta hur många simu-leringar som krävs, se tidigare diskussion. I detta specialfall utnyttjas den kvasi-stationäratäthetsfunktionen, som kan ses i figur 6.11, för att beräkna σ = 1,7416. Antal simuleringarbör då vara i storleksordningen
n > 3,92σ2
ε2 = 3,921,74162
0,12 ≈ 1189.
För enkelhetens skull väljs antal simuleringar till 1200. Notera att n = 1200 grundar sig påteoretiska beräkningar och är därför inte helt tillförlitligt för de stokastiska simuleringar-na. Men n = 1200 borde ge en rimlig uppskattning om hur många simuleringar som krävs.
I figur 6.13 syns 1200 simuleringar och i figur 6.14 syns medelvärdet av dessa tillsam-mans med lösningen för den deterministiska ekvationen. I figur 6.15 syns ett 95-procentigtkonfidensintervall för de 1200 olika simuleringarna, för att illustrera hur stor spridningenär.
Figur 6.12: I figuren visas fyra simuleringar av en födelsedödsprocess med födelseinten-siteten λn = n(a1 − b1n) och dödsintensiteten µn = n(a2 + b2n). På x-axeln syns tidenoch y-axeln representerar antal individer. Det syns tydligt i figuren att varje simuleringär unik. Notera att i början av simuleringen dör en population.
27

Figur 6.13: I figuren visas 1200 simuleringar av en födelsedödsprocess med födelseinten-siteten λn = n(a1−b1n) och dödsintensiteten µn = n(a2 +b2n). På x-axeln syns tiden ochy-axeln representerar antal individer. Den röda grafen i figuren är medelvärdet av alla1200 simuleringar.
Figur 6.14: Medelvärdesbildad simulerad lösning av 1200 födelsedödsprocesser medfödelseintensiteten λn = n(a1− b1n) och dödsintensiteten µn = n(a2 + b2n). På x-axelnkan tiden läsas av och på y-axeln illustreras hur populationen förändras. I figuren är denröda grafen medelvärdet av 1200 olika simuleringar och den blå grafen är den determin-istiska lösningen av ekvation (4.6).
28

Figur 6.15: I figuren visas ett 95-procentigt konfidensintervall för 1200 simulerade lös-ningar av födelsedödsprocessen med födelseintensiteten λn = n(a1−b1n) och dödsinten-siteten µn = n(a2 + b2n). På x-axeln kan tiden läsas av och på y-axeln syns hur popula-tionen förändras. De röda graferna är den övre respektive undre gränsen för konfidensin-tervallet, medan den blå grafen är den deterministiska lösningen.
Att lösa den diffusionsapproximerade differentialekvationen av samma logistiska prob-lem görs även den med hjälp av simuleringar. Enklast är att använda en loop där t äriterationsvariablen,
N̄(t) =N̄(t−∆t)+ N̄(t−∆t)(r− sN̄(t−∆t))∆t
+√
N̄(t−∆t)((a1 +a2)+(b2−b1)N̄(t−∆t))∆W, ∆W =√
∆tN(0,1).
Innan loopen behövs konstanterna r och s väljas samt hur många individer populationeninnehåller vid t = 0. Steglängden har valts till 0,02. I figur 6.16 syns fyra simuleringar avdenna typ och det syns tydligt att varje simulering är unik. Notera hur den ena populatio-nen dör ut, medan de andra tre fortsätter att leva.
I figur 6.17 har 1200 simuleringar gjorts och i figur 6.18 syns medelvärdet av dessatillsammans med lösningen för den deterministiska ekvationen. I figur 6.19 syns ett 95-procentigt konfidensintervall för de 1200 olika simuleringarna.
Eftersom det har visat sig att de stokastiska simuleringarna förr eller senare dör ut, trotsatt den deterministiska lösningen lever vidare, har en figur som visar på detta fenomen tag-its fram. I figur 6.20 visas medelvärdet av 10 olika simuleringarna och att simuleringarnadör ut, medan den deterministiska lösningen lever vidare. För att illustrera på ett kortaretidsintervall har konstanterna a1, a2, b1 och b2 valts på ett sådant sätt att populationen dörut relativt fort. I figur 6.20 illustreras en logistisk simulering med konstanterna a1 = 2,6;a2 = 0,2; b1 = 0,2 och b2 = 0,2.
29

Figur 6.16: I figuren visas fyra Eulersimuleringar av dN(t) = N(t)(r − sN(t))dt +√N(t)((a1 +a2)+(b2−b1)N(t))dW. På x-axeln syns tiden och på y-axeln illustreras
hur populationen förändras. Det syns tydligt i figuren att varje simulering av ekvationenär unik. Notera att en population dör precis i början av simuleringen.
Figur 6.17: I figuren visas 1200 Eulersimuleringar av dN(t) = N(t)(r − sN(t))dt +√N(t)((a1 +a2)+(b2−b1)N(t))dW. På x-axeln syns tiden och på y-axeln syns hur pop-
ulationen förändras.
30

Figur 6.18: I figuren visas medelvärdet av 1200 Eulersimuleringar av dN(t) = N(t)(r−sN(t))dt +
√N(t)((a1 +a2)+(b2−b1)N(t))dW tillsammans med den deterministiska
lösningen av ekvation (4.6). På x-axeln syns tiden och på y-axeln visas antal individer.
Figur 6.19: I figuren visas ett 95-procentigt konfidensintervall för 1200 Eulersimuleringarav dN(t) = N(t)(r− sN(t))dt +
√N(t)((a1 +a2)+(b2−b1)N(t))dW. På x-axeln kan
tiden läsas av och på y-axeln syns hur populationen förändras. De gröna graferna ärden övre respektive undre gränsen för konfidensintervallet, medan den blå grafen är dendeterministiska lösningen.
31

Figur 6.20: I figuren syns medelvärdet från 10 olika simuleringar. Ju längre tiden går,desto fler simuleringar dör och till slut har alla simuleringar dött. Den deterministiskagrafen lever vidare i all oändlighet. Den röda grafen är medelvärdet medan den blå grafenär den deterministiska lösningen.
6.3 Lotka-Volterra
Lösningen av Lotka-Volterras jägarebytesekvation som beskrivs i avsnitt 4.3 delas upp itre steg. Först studeras en möjlig metod för att lösa det ursprungliga ekvationssystemet,sedan studeras det diffusionsapproximerade differentialekvationssystemet och slutligenden modell som formuleras som en födelsedödsprocess.
För att lösa ekvationssystemet (4.7) är det lämpligt att använda sig av en numeriskmetod. MatLab har en färdig funktion som använder sig av Runge-Kuttas metod föratt lösa differentialekvationer numeriskt. I [1] kapitel 8 förklaras Runge-Kuttas metod.Runge-Kuttas metod löser begynnelsevärdesproblem som är på formen
dydt
= f (t,y), y(t0) = y0.
Metoden löser problemet genom att iterera sig fram enligt
yn+1 = yn +h(
kn1 +2kn2 +2kn3 + kn4
6
),
där h är steglängden och
kn1 = f (tn,yn),
kn2 = f (tn +12
h,yn +12
hkn1),
kn3 = f (tn +12
h,yn +12
hkn2),
kn4 = f (tn +h,yn +hkn3).
Lösningen till (4.7) kan ses i tre olika figurer: i figur 6.21 visas hur populationen N1 vari-erar med tiden, i figur 6.22 visas hur populationen N2 varierar med tiden och i figur 6.23
32

syns hur de olika populationerna förhåller sig till varandra. I figur 6.23 syns det tydligtatt när den ena populationen är stor är den andra liten och tvärtom. Genomgående i allafigurer har konstanterna r1 = 1; r2 = 1 och b1 = 0,05 valts eftersom de är lätta att arbetamed. Som startvärde på population N1 har antal individer valts till 20 och som startvärdetill N2 har 15 individer valts. Värdena på konstanterna kan enligt [6] väljas godtyckligt,då figurerna kommer att se ut på liknande sätt eftersom det endast rör sig om en skalningpå respektive axlar.
Figur 6.21: I figuren visas hur lösningen av ekvation (4.7) ser ut när tiden illustreras påx-axeln och populationen N1 på y-axeln.
33

Figur 6.22: I figuren visas hur lösningen av ekvation (4.7) ser ut när tiden syns på x-axelnoch populationen N2 på y-axeln.
Figur 6.23: I figuren visas hur lösningen av ekvation (4.7) ser ut när populationen N1visas på x-axeln och populationen N2 på y-axeln.
34

Precis som i den logistiska modellen kommer de stokastiska simuleringarna att dö uttrots att den deterministiska lösningen lever vidare. Därför kan beräkningar bara utföraspå de simuleringar som är skilda från noll i en viss tidpunkt. Att till exempel beräknamedelvärdet av alla simuleringar, döda som levande, skulle ge ett missvisande resultat.
Att lösa Lotka-Volterras diffusionsapproximerade differentialekvationssystem görsmed hjälp av simuleringar. Enklast är att använda en loop som itererar över tiden,[
N̄1(t)N̄2(t)
]=
[N̄1(t−∆t)N̄2(t−∆t)
]+
[N̄1(t−∆t)(r1−b1N̄2(t−∆t))
N̄2(t−∆t)(−r2 +b1N̄1(t−∆t))
]∆t +C
[∆W1∆W2
].
Steglängden har valts till 0,01 eftersom det har visat sig att det ger ett relativt bra resultat.Hur en sådan stokastisk simulering kan se ut syns i figur 6.24. I figuren har fyra olikasimuleringar gjorts och det syns tydligt att varje simulering är unik. I figur 6.25 syns hurN2 varierar med tiden och i figur 6.26 syns hur de olika populationerna beror på varandra.Eftersom varje simulering är stokastisk och unik måste många simuleringar göras för attfå en så bra medelvärdesbildad lösning som möjligt.
Enligt [6] kan olikheten (6.3) användas för att försöka uppskatta hur många simu-leringar som krävs. Stickprovsstandardavvikelsen har med hjälp av simuleringar upp-skattats till ungefär 15. Eftersom dessa simuleringar är otroligt prestandakrävande väljs ε
till 0,2. Detta ger att antal simuleringar bör vara i storleksordningen
n >s2
ε2 =152
0,22 = 5625.
För enkelhetens skull väljs antal simuleringar till 5700 stycken. Trots att antal simu-leringar väljs till 5700 är det inte säkert att skillnaden mellan processens medelvärdeoch väntevärde kommer att vara mindre än 0,2 eftersom detta endast är en uppskattning.I figur 6.27, 6.28 och 6.29 syns medelvärdet av 5700 simuleringar. I figur 6.30 och 6.31syns ett 95-procentigt konfidensintervall för 5700 simuleringar.
Figur 6.24: I figuren syns fyra Eulersimuleringar av ekvation (4.8), när population N1visas på y-axeln och tiden på x-axeln.
35

Figur 6.25: I figuren visas fyra Eulersimuleringar av ekvation (4.8), när population N2syns på y-axeln och tiden på x-axeln.
Figur 6.26: I figuren visas fyra Eulersimuleringar av ekvation (4.8), när population N1illustreras på x-axeln och population N2 på y-axeln.
36

Figur 6.27: I figuren visas medelvärdet av 5700 Eulersimuleringar av ekvation (4.8) till-sammans med den deterministiska lösningen av Lotka-Volterras ekvation. Förändringenav N1 ges på y-axeln och tiden återspeglas på x-axeln. Medelvärdet ges av den röda grafenoch den deterministiska lösningen av den blå grafen.
Figur 6.28: I figuren visas medelvärdet av 5700 Eulersimuleringar av ekvation (4.8) till-sammans med den deterministiska lösningen av Lotka-Volterras ekvation. Förändringenav N2 ges på y-axeln och tiden återspeglas på x-axeln. Medelvärdet ges av den röda grafenoch den deterministiska lösningen av den blå grafen.
37

Figur 6.29: I figuren visas medelvärdet av 5700 Eulersimuleringar av ekvation (4.8) till-sammans med den deterministiska lösningen av Lotka-Volterras ekvation. Förändringenav N2 ges på y-axeln och förändringen av N1 återspeglas på x-axeln. Medelvärdet ges avden röda grafen och den deterministiska lösningen av den blå grafen.
Figur 6.30: I figuren visas ett 95-procentigt konfidensintervall för 5700 Eulersimuleringarav ekvation (4.8) tillsammans med den deterministiska lösningen av Lotka-Volterras ek-vation. Förändringen av N1 ges på y-axeln och tiden återspeglas på x-axeln. De övre ochundre konfidensgränserna ges av de röda graferna och den deterministiska lösningen avden blå grafen.
38

Figur 6.31: I figuren visas ett 95-procentigt konfidensintervall för 5700 Eulersimuleringarav ekvation (4.8) tillsammans med den deterministiska lösningen av Lotka-Volterras ek-vation. Förändringen av N2 ges på y-axeln och tiden återspeglas på x-axeln. De övre ochundre konfidensgränserna ges av de röda graferna och den deterministiska lösningen avden blå grafen.
För att lösa problemet formulerat som en födelsedödsprocess, med födelseintensiteter-na B1 = r1N1 och B2 = b1N1N2 samt dödsintensiteterna D1 = b1N1N2 och D2 = r2N2,används en dator. Tiden fram tills en ny händelse inträffar är exponentialfördelad enligtExp( 1
B1+B2+D1+D2). Sannolikheten att den nya händelsen är en födsel för population N1
är B1B1+B2+D1+D2
och sannolikheten att det är en död för population N1 är D1B1+B2+D1+D2
. Påsamma sätt är sannolikheten för en födsel respektive en död för population N2 lika med
B2B1+B2+D1+D2
respektive D2B1+B2+D1+D2
. Eftersom tiderna mellan händelserna är en slump-variabel går det inte i förväg att säga hur många födelsedödssituationer som inträffar underen given tid. Ett sätt att utföra en simulering är att göra på följande sätt:
1. Bestäm ett tidsintervall samt skapa en variabel τ som innehåller hopptiderna ochsätt τ = 0.
2. Beräkna B1, B2, D1, och D2. Sätt R = B1 +B2 +D1 +D2.
3. Kontrollera att R 6= 0, om R = 0 avbryt, annars gå vidare till nästa steg.
4. Välj två slumptal Y1 och Y2 så att Y1 ∈ (0,1] och Y2 ∈ [0,1].
5. Hitta nästa hopptid τ enligt τ = τ +(− log(Y1)
R
)och kontrollera att hopptiden inte
ligger utanför tidsintervallet. Om hopptiden ligger innanför tidsintervallet gå tillnästa steg, annars avbryt.
6. Om 0≤ Y2 ≤ B1R är händelsen en födelse för population N1, det vill säga uppdatera
N1 till N1 +1.
7. Om föregående steg inte är uppfyllt men Y2 ≤ B1+D1R är händelsen en död för popu-
lation N1, det vill säga uppdatera N1 till N1−1.
39

8. Om föregående steg inte är uppfyllt men Y2 ≤ B1+D1+B2R är händelsen en födelse för
population N2, det vill säga uppdatera N2 till N2 +1.
9. Om varken steg 6,7 eller 8 är uppfyllt är händelsen en död för population N2, detvill säga uppdatera N2 till N2−1.
10. Gå tillbaka till steg 2.
I figur 6.32 syns hur fyra simuleringar kan se ut när Lotka-Volterras ekvation simulerassom en födelsedödsprocess och i figuren syns hur N1 förändras med tiden. Det syns tydligti figuren att simuleringarna är unika och att det därför krävs många simuleringar för attfånga statistiska egenskaper. I figur 6.33 syns hur fyra olika simuleringar kan se ut när N2är på y-axeln och tiden på x-axeln. I figur 6.34 syns hur populationerna beror på varandra,med N1 på x-axeln och N2 på y-axeln. I figur 6.35, 6.36 och 6.37 syns medelvärdet av5700 simuleringar. I figur 6.38 och 6.39 syns ett 95-procentigt konfidensintervall för 5700simuleringar.
Simuleringar har visat att de stokastiska simuleringarna har svårt att överleva en längretid, trots att den deterministiska lösningen lever vidare i all oändlighet. I figur 6.40 synsmedelvärdet av 10 olika simuleringar och att de stokastiska simuleringarna dör ut. I fig-uren har konstanterna r1 = 1, r2 = 1 och b1 = 0,15 valts för att simuleringarna snabbareska dö ut, men principen är den samma för andra värden på konstanterna.
Figur 6.32: I figuren visas hur fyra simulerade lösningar av Lotka-Volterras modell kanse ut när problemet har formulerats som en födelsedödsprocess. Tiden går att utläsa påx-axeln och populationen N1 på y-axeln.
40

Figur 6.33: I figuren visas hur fyra simulerade lösningar av Lotka-Volterras modell kanse ut när problemet har formulerats som en födelsedödsprocess. Tiden går att utläsa påx-axeln och populationen N2 på y-axeln.
Figur 6.34: I figuren visas hur fyra simulerade lösningar av Lotka-Volterras modell kanse ut när problemet har formulerats som en födelsedödsprocess. På x-axeln syns popula-tionen N1 och på y-axeln populationen N2.
41

Figur 6.35: I figuren visas medelvärdet av 5700 simulerade födelsedödsprocesser sombygger på Lotka-Volterras ekvation tillsammans med den deterministiska lösningen.Förändringen av N1 ges på y-axeln och tiden återspeglas på x-axeln. Medelvärdet gesav den röda grafen och den deterministiska lösningen av den blå grafen.
Figur 6.36: I figuren visas medelvärdet av 5700 simulerade födelsedödsprocesser sombygger på Lotka-Volterras ekvation tillsammans med den deterministiska lösningen.Förändringen av N2 ges på y-axeln och tiden återspeglas på x-axeln. Medelvärdet gesav den röda grafen och den deterministiska lösningen av den blå grafen.
42
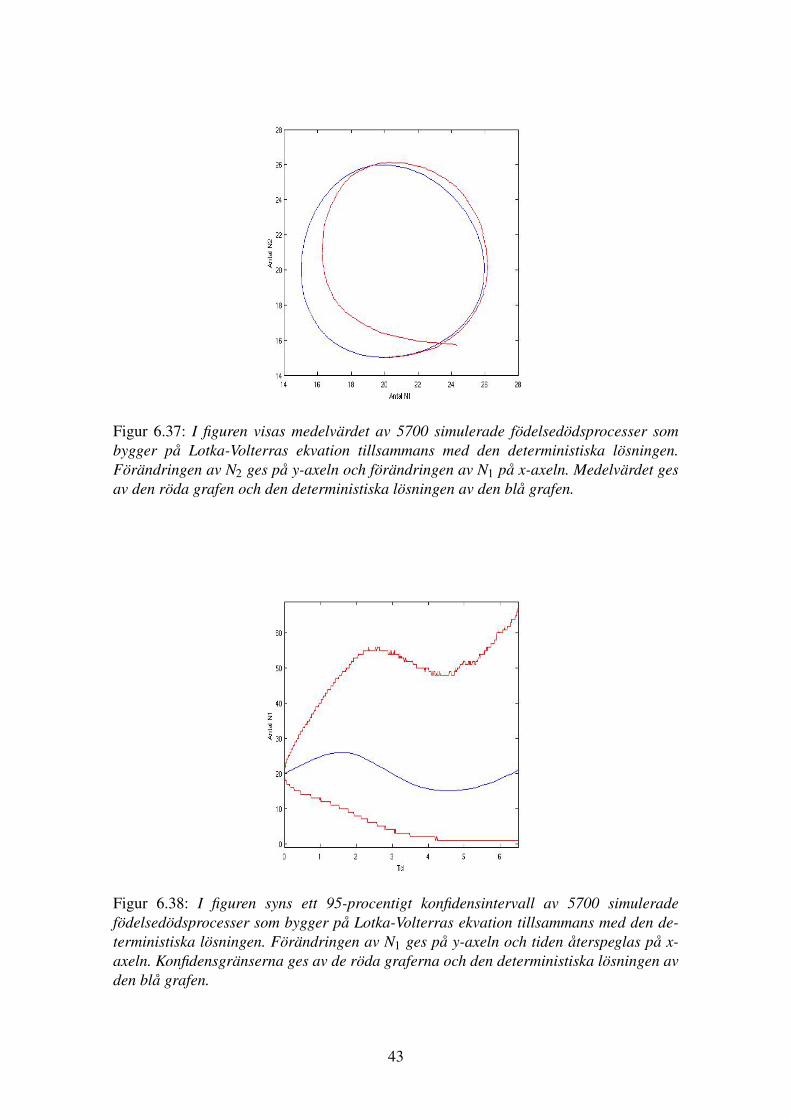
Figur 6.37: I figuren visas medelvärdet av 5700 simulerade födelsedödsprocesser sombygger på Lotka-Volterras ekvation tillsammans med den deterministiska lösningen.Förändringen av N2 ges på y-axeln och förändringen av N1 på x-axeln. Medelvärdet gesav den röda grafen och den deterministiska lösningen av den blå grafen.
Figur 6.38: I figuren syns ett 95-procentigt konfidensintervall av 5700 simuleradefödelsedödsprocesser som bygger på Lotka-Volterras ekvation tillsammans med den de-terministiska lösningen. Förändringen av N1 ges på y-axeln och tiden återspeglas på x-axeln. Konfidensgränserna ges av de röda graferna och den deterministiska lösningen avden blå grafen.
43

Figur 6.39: I figuren syns ett 95-procentigt konfidensintervall av 5700 simuleradefödelsedödsprocesser som bygger på Lotka-Volterras ekvation tillsammans med den de-terministiska lösningen. Förändringen av N2 ges på y-axeln och tiden återspeglas på x-axeln. Konfidensgränserna ges av de röda graferna och den deterministiska lösningen avden blå grafen.
Figur 6.40: I figuren syns medelvärdet från 10 olika simuleringar. Ju längre tiden går,desto fler simuleringar dör och till slut har alla simuleringar dött. Den deterministiskagrafen lever vidare i alla oändlighet. Den röda grafen är medelvärdet medan den blågrafen är den deterministiska lösningen.
44

7 Resultatdiskussion kring modellernaI detta avsnitt förklaras vilka resultat som har observerats för respektive modell samt endiskussion runt dessa.
7.1 Exponentiell populationstillväxt
Efter att ha genomfört många simuleringar och jämfört de medelvärdesbildade lösningar-na med den deterministiska dras slutsatsen att de sammanfaller bra, se figur 6.4 och 6.8.Ju fler simuleringar som utförts, desto bättre överensstämmelse med den deterministiskalösningen fås.
Då många simuleringar utförts har det varit möjligt att fånga upp ett 95-procentigt kon-fidensintervall över de olika simuleringarna. Konfidensintervallet ger en bra och illustrativbild över hur variationen växer i förhållande till tiden. I början av simuleringarna är kon-fidensintervallet litet för att sedan växa som en tratt, se figur 6.5 och 6.9. Ju längre tidengår, desto större blir konfidensintervallet och därmed även osäkerheten i modellen.
Att utföra simuleringarna har varit tidskrävande och det har visat sig att den diffusions-approximerade differentialekvationen går snabbare att simulera än modellen formuleradsom en födelsedödsprocess på större tidsintervall. Anledningen till tidsskillnaden är attnär födelsedödsprocessen väl har börjat hoppa kommer hoppen att komma tätare ochtätare, vilket innebär att antal iterationer ökar och således även tidsåtgången. Utförs simu-leringar på korta tidsintervall är födelsedödsprocessen i regel snabbare eftersom processeninte hinner hoppa så många gånger. Då resultatet från dessa två olika sätt att simulera ärrelativt lika och med hänsyn till tidsåtgången är det att föredra att simulera denna modellsom en diffusionsapproximerad differentialekvation.
7.2 Logistisk populationstillväxt
Den deterministiska lösningen beskriver hur populationen beter sig i medeltal och närtiden går mot oändligheten stabiliseras populationen. Däremot säger de stokastiska simu-leringarna att populationen så småningom kommer att dö ut med sannolikheten 1. Meddetta i åtanke när jämförelser mellan de medelvärdesbildade lösningarna och den deter-ministiska lösningen utförs, går det endast att titta på de simuleringar som i varje tidpunktär skilda från noll. Att jämföra medelvärdet av alla simuleringar, döda och levande, skullesåledes ge ett felaktigt resultat.
Den medelvärdesbildade lösningen stämmer till en början bra överens med den de-terministiska, se figur 6.14 och 6.18. Men ju längre tiden går, desto mer avviker densimulerade lösningen från den deterministiska för att så småningom dö ut. Gällande det95-procentiga konfidensintervallet är det till en början smalt för att sedan hålla sig relativtkonstant när populationen väl har ställt in sig, se figur 6.15 och 6.19. När tiden går motoändligheten kommer populationerna att dö ut och det innebär att konfidensintervalletkommer att bli något bredare med tiden.
I regel kommer det simulerade medelvärdet att bete sig på det sätt som illustreras ifigur 6.18, det vill säga att ligga något under den deterministiska lösningen. Simuleringarhar visat att den logistiska modellen är känslig för vilka värden som väljs på konstanternaa1, a2, b1 och b2. Ett exempel på detta är att det går att välja a1− a2 = r på olika sätt.Kombinationen a1 = 2 och a2 = 0,01 ger samma r som att välja a1 = 6 och a2 = 4,01.Trots att r antar samma värden och tillhörande logistiska ekvation har samma determin-istiska lösning kommer de medelvärdesbildade lösningarna att skilja sig åt. Ett sätt attbestämma vilka värden som ger lämpliga figurer och rimligt tidskrävande simuleringar äratt pröva sig fram. I figur 7.1 och figur 7.2 syns medelvärdet från 5000 simuleringar av
45

ekvation (4.5) med samma deterministiska lösning men med olika värden på konstanternaa1 och a2. I figur 7.1 sammanfaller medelvärdet bättre än i figur 7.2. En anledning till attmedelvärdet blir annorlunda skulle kunna vara att simuleringarna i figur 7.2 har lättare föratt dö ut än i figur 7.1. En annan anledning skulle kunna vara att medelvärdesbildningaröver de stokastiska populationerna helt enkelt inte sammanfaller vid vissa intensiteter λnoch µn. I [2] tycks det hävdas överensstämmelse men bevis för detta saknas. Då det ur-sprungliga syftet med arbetet inte är att hitta en process som i medel sammanfaller medden deterministiska lösningen, undersöks det inte hur konstanterna ska förhålla sig tillvarandra för att få överensstämmelse. Därför konstateras att medelvärdet av de stokastiskasimuleringarna inte alltid sammanfaller med den deterministiska lösningen. Dock kan detvara värt att notera att den deterministiska lösningen ligger innanför konfidensintervalletför samtliga simuleringar.
Eftersom det är tidskrävande att utföra många stokastiska simuleringar är det givetvisav intresse att det ska gå så snabbt som möjligt. Det har visat sig att den diffusionsap-proximerade differentialekvationen går snabbare och är betydligt enklare att simulera änfödelsedödsprocessen. Då resultaten från de två olika sätten att simulera är relativt likaoch med hänsyn till tidsåtgången är det att föredra att simulera denna modell med hjälpav en diffusionsapproximerad differentialekvation.
Värt att notera är att medelvärdesbildningar av födelsedödsprocesserna och dess diffu-sionsapproximationer tycks sammanfalla, vilket indikerar på att diffusionsapproximatio-nen är giltig, jämför med teoriavsnittet i kapitel 3.
Figur 7.1: I figuren syns medelvärdet av 5000 Eulersimuleringar av typen dN(t) =N(t)(r− sN(t))dt +
√N(t)((a1 +a2)+(b2−b1)N(t))dW med a1 = 2; a2 = 0,01; b1 =
0,01 och b2 = 0,01. Den gröna grafen är medelvärdet medan den blå grafen är den de-terministiska lösningen.
46

Figur 7.2: I figuren syns medelvärdet av 5000 Eulersimuleringar av typen dN(t) =N(t)(r− sN(t))dt +
√N(t)((a1 +a2)+(b2−b1)N(t))dW med a1 = 6; a2 = 4,01; b1 =
0,01 och b2 = 0,01. Den gröna grafen är medelvärdet medan den blå grafen är den de-terministiska lösningen.
7.3 Lotka-Volterra
Den deterministiska lösningen beskriver hur populationerna beter sig i medeltal och attpopulationerna alltid kommer att leva och bero på varandra. Dock dör de stokastiskasimuleringarna lätt ut, vilket inte alls stämmer överens med den deterministiska lösnin-gen. Simuleringar har visat att de flesta stokastiska simuleringar dör ut redan efter ett partidscykler. Anledningen till att det blir på detta sätt är att när jägarpopulationen är stor ärbytesdjurspopulationen liten och då är sannolikheten stor att jägarna äter upp alla bytes-djur och sedan dör ut av sig själva. Ibland kan det motsatta inträffa, nämligen att allajägare dör ut och då kan bytesdjuren föröka sig fritt vilket resulterar i att populationenväxer sig stor, precis som i Malthus modell.
För att få en bra medelvärdesbildad lösning måste simuleringar utföras på korta tidsin-tervall. Att simulera på stora tidsintervall och dessutom få medelvärdet att sammanfallamed den deterministiska lösningen är svårt. Då bör Lotka-Volterras modell förbättras ellerrentav en annan modell användas. Svårigheten med att simulera Lotka-Volterras modellär att spridningen blir stor redan efter en tidscykel. Anledningen till att medelvärdet i fig-ur 6.37 avviker från den deterministiska lösningen är att ett antal av simuleringarna förpopulation N2 har dött ut och då ökar tillhörande simuleringar för population N1 exponen-tiellt. Denna situation inträffar relativt ofta, vilket innebär att medelvärdet inte stämmerspeciellt bra överens med den deterministiska lösningen på långa tidsintervall.
Gällande konfidensintervallet kommer det att bli större och större ju längre tiden gåreftersom många simuleringar dör ut. När simuleringar utförs på ett kort tidsintervall hållerkonfidensintervallet sig relativt konstant runt den deterministiska lösningen, se figur 6.30.Att illustrera hur konfidensområdet ser ut när N1 och N2 visas på respektive axlar har intekunnat genomföras, trots stor arbetsinsats. Men en sådan figur borde innehålla dels dendeterministiska lösningen dels två elipsformade konfidensgränser, en inre och en yttre.
Vid beräkning av hur många simuleringar som krävs för att skillnaden mellan simu-leringarnas medelvärde och processens väntevärde ska vara i storleksordningen 0,2 borde
47

en kvasi-stationär täthetsfunktion användas, precis som i den logistiska modellen. Men attbestämma den kvasi-stationära fördelningen för Lotka-Volterras modell är på en allt förhög kunskapsnivå för detta examensarbete. Därför valdes samma metod som i Malthusmodell när det gällde att uppskatta stickprovsstandardavvikelsen samt hur många simu-leringar som krävs för att skillnaden ska vara i storleksordningen 0,2.
48

8 Metod för testernaI detta avsnitt beskrivs hur testerna i och mellan de båda språken genomförts.
8.1 Värde för simuleringar
Efter diskussion med handledaren beslutades det om vilka värden som tycks vara bästlämpade för att användas vid simuleringarna av populationsväxterna. De utvalda värdenager bra resultat med tanke på olika felmarginaler.För den exponentiella modellen gäller följande värden:
• 5000 simuleringar
• 1 individ att starta med
• Tidsintervall mellan 0 och 2
• Tidsdifferential (dt) sätts till 0,01
• λ (födelsekonstant) ska vara 1
För den logistiska modellen gäller följande värden:
• 1200 simuleringar
• 1 individ att starta med
• Tidsintervall mellan 0 och 25
• Tidsdifferential (dt) sätts till 0,02
• a1: 1,5
• a2: 0,1
• b1: 0,1
• b2: 0,02
8.2 Slumptalshantering
Med hjälp av värdena som presenterats ovan, kan antal slumptal som kommer att be-höva användas i respektive del av testerna även räknas ut. Slumptalen genereras i Mat-Lab, för att sen sparas till en fil. För att testerna mellan MatLab och C ska bli rättvisa,läses slumptalen in från fil i samma ordning och lagras i arrayer, istället för att genererasav respektive språks slumptalsgenerator. Inläsning av slumptal tas inte med i den senarebeskrivna tidtagningen. Detta är en lösning för att kunna garantera att både MatLab ochC ska få identiska slumptal i samma ordning.
Den exponentiella modellen behöver ha:
• 1 000 000 normalfördelade slumptal
• 1 000 000 slumptal mellan 0 och 1
Den logistiska modellen behöver ha:
• 1 500 000 normalfördelade slumptal
• 3 000 000 slumptal mellan 0 och 1
49

8.3 Tidtagning
I C hanteras tidtagningen på så sätt att genom att anropa funktionen clock() returnerasdet aktuella tidsvärdet, som förslagsvis lagras i en variabel. Nästa gång clock() anropas,returneras det aktuella tidsvärdet igen och bör lagras i en ny variabel. Genom att beräknaskillnaden mellan det första och det andra tidsvärdet och sedan dividera resultatet med eni biblioteket time.h fördefinierad konstant, CLOCKS_PER_SEC, går det att utläsa tidensom förflutit i sekunder [11].
För att starta en timer i MatLab används kommandot ”tic” och för att kunna läsa avtimern används kommandot ”toc”, som redovisar tidsåtgången i sekunder sedan tic an-ropades [3].
Tider större än 0,01 sekunder kommer att registreras och arbetas med och tidtagningar-na börjar och slutar på samma ställen i programkoderna i både MatLab och C.I den deterministiska tidtagningen ingår:
• Skapande av resultatarrayen
• Uträkning av alla värdena
I tidtagningen för både den diffusionsapproximerade modellen samt för födelsedödsmod-ellens ingår:
• Skapande av alla arrayer och matriser som behövs
• Uträkning av alla värdena
• Lagra värdena i matriser
• Beräkna medelvärden
• Beräkna konfidensintervallen
8.4 Omfattning av testerna
Grundtanken är att köra både den i MatLab implementerade ursprungliga versionen av denexponentiella modellen samt den ursprungliga version som finns i C mot samma slumptal,för att se om det blir någon skillnad i tidsåtgången. Det utförs samma beräkningar i bådaprogramkoderna och tiderna blir intressanta att jämföra mot varandra. På samma sätt skajämförelser ske mellan MatLab och C även när det gäller den logistiska modellen.
Den ursprungliga planeringen var att upprepa exekveringarna av både MatLab ochC tio gånger mot varje set med slumptalsfiler och att detta sen skulle utföras mot treolika set. Efter utvärdering av resultaten då detta utförts, visade det sig att tiderna mellande tio olika exekveringarna mot samma set med slumptalsfiler knappt skiljdes åt, menatt variationerna i tid mellan de olika seten av slumptalsfiler var betydligt större. Därförändrades strategin till att istället för att ha tio upprepningar av exekveringarna mot varderaset med slumptalsfiler till att ha fem. Dock utökades antal set med slumptalsfiler från tretill fem, för att få så bra medelvärden som möjligt men ändå kunna hålla sig inom rimligagränser för tidsåtgången av testerna. Fem exekveringar utförs på var och ett av fem olikaset med slumptalsfiler under testerna, så länge inget annat anges.
Både den exponentiella och den logistiska modellen testas. Namngivningen av filernasom testats och optimerats baseras på vilken version av filen det är, samt om det är denexponentiella eller den logistiska modellen. Filändelserna visar på om det är en C- (*.c)
50

eller en MatLabfil (*.m). Ett exempel är att 01-exponentiell.c visar att det är den ursprung-liga versionen för den exponentiella modellen, implementerad i C medan 03-logistisk.mvisar att det är den tredje versionen från den ursprungliga programkoden för den logistiskamodellen, implementerad i MatLab.
Efter att ett test är utfört, genomförs det försök till tidsoptimering av den testade ver-sionen av implementeringen. Detta för att kunna göra jämförelser mellan tiderna innanoch efter optimeringsförsöket. Antal försök till ytterligare tidsoptimeringar kommer attbegränsas, då tidsramen för utförandet av testerna är begränsad i arbetet.
Så fort några som helst ändringar har utförts i implementeringen, har det genomförtstestkörningar för att se så att alla uträkningar fortfarande fungerar på ett matematisktfelfritt sätt.
51

9 Genomförandet av testerna
Kapitlet behandlar information om utförda tester mellan språken, både när det gäller vilkaförändringar som gjorts i försök till tidsoptimering, resultaten från tidtagningarna samtresultatdiskussioner.
9.1 Exponentiell - Test 01
Filer som använts i testet: 01-exponentiell.m och 01-exponentiell.c.
9.1.1 Beskrivning av programkod
I det här läget är programkoderna så lika den ursprungliga koden i MatLab som de bådaspråken tillåter. Så fort en array eller en matris skapas i MatLab läggs värden in, oavsettom de behövs eller ej. Oftast är det en sorts nollställning det rör sig om, vilket i MatLabvanligen utförs med hjälp av funktionen zeros(). För att implementeringarna ska vara sålika varandra som möjligt, utförs även procedurerna med nollställning i C.
9.1.2 Tidsresultat samt resultatdiskussion
Först redovisas medelvärdena av tiderna, där fem körningar har utförts på respektive setmed slumptalsfiler. Som figur 9.1 visar går den deterministiska delen så snabbt att körai både MatLab och C, att dess tidsåtgång inte överstiger 0,01 sekunder och därmed interedovisas här. Den diffusionsapproximerade delen av programkoden visar sig ta mycketlängre tid att genomföra i MatLab än i C. Körningen då slumptalen från det fjärde setetmed slumptalsfiler använts, går över 70 sekunder snabbare att genomföra i C än i Mat-Lab. Födelsedödsdelen visar även den på att C är betydligt snabbare än MatLab, även omtidsskillnaden här inte är lika stor som i den diffusionsapproximerade delen. Medelvär-dena av alla tider som registrerats under testerna presenteras i figur 9.2. Den visar på enhäpnadsväckande stor tidsskillnad mellan MatLab och C just under den diffusionsapprox-imerade delen.
Figur 9.1: Medelvärde i sekunder för fem körningar med 01-exponentiell.m och 01-exponentiell.c mot fem olika set med slumptalsfiler.
52

Figur 9.2: Medelvärde i sekunder för alla tider och körningar med 01-exponentiell.m och01-exponentiell.c
9.2 Exponentiell - Test 02
Filer som använts i testet: 01-exponentiell.m, 01-exponentiell.c, 02-exponentiell.m och02-exponentiell.c.
9.2.1 Beskrivning av programkod
Under föregående tester har programkoderna innehållit mängder av nollställningar vidskapandet av arrayer och matriser. I MatLab väcker det inte mycket uppmärksamhet närnollställning utförs, men i C lyfts det fram på ett helt annat sätt. De två olika tillvä-gagångssätten skiljer sig åt på flera plan. Programkod 9.1 och programkod 9.2 visar påskillnaderna mellan språken.
...matrix=zeros([size1, size2]);...
Programkod 9.1: Skapande samt nollställning av matris i MatLab.
...double ∗∗matrix;matrix=calloc(size1, sizeof(double ∗));
for (k=0;k<size1; k++){
matrix[k]= calloc(size2, sizeof(double));}for (k=0;k<size1; k++){
for(j=0;j<size2; j++){
matrix[k][j]=0;}
}...
Programkod 9.2: Skapande samt nollställning av matris i C.
Då ovanstående mönster upprepas en mängd gånger i programkoden, valdes detta utsom första försök till tidsoptimering. Loopar och framförallt då nästlade sådana borde omnågot vara tidskrävande, även om de inte är så framträdande som i C utan istället dolda ifunktioner så som zeros().
Nästan alla nollställningar i MatLab går att plocka bort utan att stöta på några som helstproblem. Dock är det på två ställen som MatLab under körning varnar för att efterfrågatvärde ligger utanför allokerat minne. Båda dessa befinner sig i födelsedödsdelen. Det rörsig om den matris där alla framsimulerade tider ska komma att sparas i samt den matris
53

där alla tidpunkter ska sparas på en och samma rad, för att kunna genomföra uträkningenav konfidensintervallet. Av den orsaken finns två nollställningar av matriser kvar, både iMatLab och C, inför den här testomgången. Alla andra nollställningar är bortplockade.Förutom borttagningen av nollställning vid skapandet av arrayer och matriser, har ingaförändringar genomförts i 02-exponentiell.m och 02-exponentiell.c utan de är i övrigtidentiska med 01-exponentiell.m och 01-exponentiell.c.
9.2.2 Tidsresultat samt resultatdiskussion
I figur 9.3 redovisas medelvärdena av tiderna, där fem körningar har utförts på respektiveset med slumptalsfiler. Det visar sig av testerna att borttagningen av alla nollställningar avarrayer och matriser får i MatLab en helt motsatt effekt än förväntad. C visar emellertidpå marginellt men likafullt snabbare körning utan alla loopar för nollställning än med.Hur kan det då ta längre tid att köra en programkod utan en mängd till synes onödigatilldelningssatser än med dem?
Efter att ha upprepat testerna några gånger extra, för att vara säker på att resultatenverkligen stämmer, inleds sökandet efter en förklaring till fenomenet. Den mest troligaförklaringen är att med användningen av just zeros() eller ones() allokeras så mycketminne som kommer behövas för att fylla hela matrisen redan från början, som både hand-ledaren kom fram till och som det står beskrivet på webbplatsen [13]. Om zeros() uteslutsanvänder sig MatLab av dynamisk minnesallokering varje gång något nytt värde läggs ini matrisen.
Figur 9.3: Medelvärde i sekunder för fem körningar med 01-exponentiell.m, 02-exponentiell.m, 01-exponentiell.c och 02-exponentiell.c mot fem olika set med slumptals-filer.
I figur 9.4 presenteras medelvärdena av alla de tider som registreras under testerna.Där går det att utläsa att det skiljer i medel över 60 sekunder mellan en körning i MatLabmed nollställningar och med en utan. Sammanfattningsvis var försöket till tidsoptimeringgenom att ta bort nollställningar ett misslyckande, men nya insikter om MatLab har dockerhållits.
54

Figur 9.4: Medelvärde i sekunder för alla tider och körningar med 01-exponentiell.m,02-exponentiell.m, 01-exponentiell.c samt 02-exponentiell.c.
9.3 Exponentiell - Test 03
Filer som använts i testet: 01-exponentiell.m, 01-exponentiell.c och 03-exponentiell.m.
9.3.1 Beskrivning av programkod
Då MatLab visade sig fungera bättre med all nollställning än utan, utgår den här pro-gramkoden från 01-exponentiell.m, som hitintills visat sig vara snabbast. Eftersom attdet var stor skillnad i tidsåtgången mellan 01-exponentiell.c och 01-exponentiell.m justunder det avsnittet av programkoden som behandlar den diffusionsapproximerade delen,blev det nu aktuellt att närmre undersöka vad det egentligen är i koden som är så tidskrä-vande. Programkoden delas upp i fyra olika avsnitt och bit för bit undersöks tidsåtgången.De fyra olika avsnitten behandlar följande steg:
1. Skapande av arrayer och matriser
2. Simuleringsloopen
3. Uträkning av medelvärden
4. Uträkning av konfidensintervallen
Likadana tidsundersökningar gjordes i 01-exponentiell.c för att ha något att jämföramed och resultaten presenteras i figur 9.5. Det visade sig att det är i det avsnittet av pro-gramkoden som hanterar uträkningen av konfidensintervallen för den diffusionsapprox-imerade delen, som det finns något mycket tidskrävande i MatLab-koden.
Figur 9.5: Tidsåtgång i sekunder för fyra olika avsnitt i den diffusionsapproximerade delenav 01-exponentiell.m och 01-exponentiell.c.
Det avsnitt av programkoden i MatLab som behandlar konfidensintervallen gicksigenom en extra gång och jämfördes med motsvarande del i C, för att försöka identifierade kritiska delarna. Två anrop till funktionen clear() i en loop är den största skillnadenmellan programkoderna. Det verkar som om dessa måste finnas där för att uträkningarnaska fungera på ett tillfredsställande sätt. På motsvarande plats i C-koden finns inget lik-nande, men där hanteras å andra sidan längderna av alla arrayer och matriser med hjälpav positionsräknare. Att utföra ett test bedömdes ändå som intressant, för att ta reda omdet är anropen till clear() som kräver mycket tid eller ej. Programkod 9.3 visar de tvåfunktionsanrop som skiljer 03-exponentiell.m från 01-exponentiell.m i nuläget.
55

...clear tmp_nsm_col_matrixclear tmp_col...
Programkod 9.3: Anrop till clear() i MatLab.
9.3.2 Tidsresultat samt resultatdiskussion
I figur 9.6 redovisas tiderna från testkörningarna med och utan clear() i MatLab samtoförändrad i C. Det här testet har dock inte utförts fem gånger mot fem olika slumptals-filer, utan endast tre körningar mot en slumptalsfil genomfördes. Resultaten mellan de treolika körningarna som utfördes skiljde sig endast åt med några hundradels sekunder. Dådet var så små skillnader i tidsåtgången har inget medelvärde av tiderna räknats ut. Över70 sekunder snabbare blev uträkningen av konfidensintervallet när clear() togs bort. Precissom vid tidigare tester kontrollerades resultaten från de matematiska uträkningarna ochde stämde. Innan fler slumptalsfiler skapades för att köras mot, inleddes en diskussion omvarför funktionen clear() behövdes. Testerna utfördes mot ännu en slumptalsfil, men nuvisade det sig att de matematiska uträkningarna inte längre stämde helt och hållet. Eftermycket funderande och diskuterande kom vi fram till att om clear() skulle kunna undvikasatt använda, måste stora delar av programkoden i MatLab skrivas om. Om MatLab-kodensstruktur hade ändrats för att bli mer lik den struktur som C har, hade anropen till clear()inte längre behövts. Tiden räcker dock inte till för att under det här arbetet genomföradessa förändringar.
Figur 9.6: Tidsåtgången i sekunder för fyra olika avsnitt i den diffusionsapproximeradedelen av 01-exponentiell.m, 03-exponentiell.m och 01-exponentiell.c.
9.4 Logistisk - Test 01
Filer som använts i testet: 01-logistisk.m och 01-logistisk.c.
9.4.1 Beskrivning av programkod
De logistiska implementeringarna i MatLab och C som används här, har utvecklats frånden ursprungliga programkoden i MatLab. Då det här testet utfördes samtidigt som Expo-nentiell - Test 01, finns det många likheter mellan dessa två. Alla matriser och arrayer somskapas och som inte får något värde tilldelat direkt, nollställs med hjälp av funktionernazeros() och ones() i MatLab och i loopar med tilldelningssatser i C.
9.4.2 Tidsresultat samt resultatdiskussion
I figur 9.7 redovisas medelvärdena av tiderna, där fem körningar har utförts på respek-tive set med slumptalsfiler. Skillnaderna i tidsåtgång mellan MatLab och C är ännu mermarkanta här än under testen i den exponentiella delen. Det skiljer till exempel cirka 245
56

sekunder mellan körningen av födelsedödsdelen i MatLab och i C, då det första setet medslumptalsfiler används. Det är cirka 4 minuters skillnad i tidsåtgången, vilket är mycketnär man tar hänsyn till att C utför samma beräkningar på mindre än 1 minut. Medelvär-dena av alla tider som registrerats under testerna presenteras i figur 9.8. Här syns det klartoch tydligt att tidsskillnaderna är enorma.
MatLabs egna funktioner används oftare nu när det är den logistiska modellen som ärimplementerad. Dessa funktioner är kanske inte uppbyggda på det mest optimala sättet förvarje situation de används, då de är väldigt generiska. I C, där de flesta de funktionerna intefinns att tillgå, är motsvarande kodavsnitt specialanpassat just för det aktuella problemet,och behöver inte vara generiskt. Det kan vara en förklaring till varför C utför arbetetsnabbare.
Figur 9.7: Medelvärde i sekunder för fem körningar med 01-logistisk.m och 01-logistisk.cmot fem olika set med slumptalsfiler.
Figur 9.8: Medelvärde i sekunder för alla tider och körningar med 01-logistisk.m och01-logistisk.c.
9.5 Logistisk - Test 02
Filer som använts i testet: 01-logistisk.m, 01-logistisk.c, 02-logistisk.m och 02-logistisk.c.
9.5.1 Beskrivning av programkod
Då testerna av den logistiska och den exponentiella modellen utfördes parallellt, föll valetäven här på att först och främst utesluta alla till synes onödiga nollställningar, på sammasätt som i Exponentiell - Test 02. Nu innehåller 02-logistisk.m och 02-logistisk.c betydligtfärre nollställningar än vad deras föregångare gör, men det är också den enda skillnadenmellan dessa. I MatLab kunde alla nollställningar utom två tas bort, utan att det påverkade
57

varken körning eller matematiskt resultat. Programkoden i C har modifierats på likadantsätt, för att jämförelserna ska bli rättvisa.
9.5.2 Tidsresultat samt resultatdiskussion
I figur 9.9 redovisas medelvärdena av tiderna, där fem körningar har utförts på respektiveset med slumptalsfiler. Här syns det tydligt hur mycket extra tid det tar för MatLab attexekvera programkoden utan alla nollställningar än med dem. C visar på små men ändåmätbara förbättringar i tidsåtgången utan alla dessa för C onödiga loopar, där tilldelningav värde sker. Orsaken till att MatLabs tidsåtgång ökats så drastiskt mellan 01-logistisk.moch 02-logistisk.m redogörs det för i motsvarande stycke i den del av rapporten som be-handlar de exponentiella testerna av 02-filerna. I figur 9.10 presenteras medelvärdena avalla de tider som registreras under testerna. En intressant reflektion är att medelvärdetav körningarna med 02-logistisk.m under den differentialapproximerade delen är aningenmindre än det för körningarna med 01-logistisk.m. Dock är skillnaden inte så pass stor attnågra direkta slutsatser kan dras av de resultaten.
Figur 9.9: Medelvärde i sekunder för fem körningar med 01-logistisk.m, 02-logistisk.m,01-logistisk.c och 02-logistisk.c mot fem olika set med slumptalsfiler.
Figur 9.10: Medelvärde i sekunder för alla tider och körningar med 01-logistisk.m, 02-logistisk.m, 01-logistisk.c samt 02-logistisk.c.
58

10 Slutdiskussion
I detta avsnitt redovisas slutsatser av arbetet, vilka problem, oklarheter och svårighetersom infunnit sig samt förslag till framtida undersökningar.
10.1 Slutsats
Det matematiska syftet var att undersöka om stokastiska medelvärdesbildade lösningarsammanfaller med deterministiska samt att beräkna konfidensintervall. De populations-modeller som har undersökts är Malthus exponentiella, Verhulsts logistiska och Lotka-Volterras jägarebytesmodell.
För den exponentiella modellen dras slutsatsen att de stokastiska simuleringarna stäm-mer i medel bra överens med den deterministiska lösningen. Konfidensintervallet visar påatt osäkerheten i modellen ökar när tiden ökar eftersom konfidensintervallet blir bredareoch bredare med tiden. Se avsnitt 7.1.
Resultatet av jämförelsen mellan den logistiska modellens deterministiska lösning ochdet framsimulerade medelvärdet visar på att de inte sammanfaller helt och hållet. En storskillnad mellan den deterministiska lösningen och de stokastiska simuleringarna är attsimuleringarna så småningom dör ut när tiden går mot oändligheten. Gällande konfi-densintervallet håller det sig relativt konstant runt den deterministiska lösningen, vilketinnebär att variationen i modellen är ungefär lika stor hela tiden. Se avsnitt 7.2.
Undersökningen visar att i Lotka-Volterras modell börjar den stokastiska medelvärdes-bildade lösningen avvika från den deterministiska redan efter en tidscykel. Konfidensin-tervallet för simuleringarna blir större och större, vilket visar på att osäkerheten ökar medtiden. Precis som i den logistiska modellen dör de stokastiska simuleringarna ut förr ellersenare även i Lotka-Volterras modell, när simuleringar utförs på stora tidsintervall. Seavsnitt 7.3.
Värt att notera är att medelvärdesbildningarna över de stokastiska modellerna intealltid sammanfaller med de klassiska modellerna, trots att det tycks utläsas från [2].Observera att det inte är trivialiteter då medelvärdesbildningarna gjordes över de simu-leringar som ännu inte dött ut.
Den datalogiska ansatsen i detta arbete var att undersöka huruvida det kunde vara enidé att implementera modeller för populationstillväxter i C istället för i MatLab, för attvinna tid under genomförandet av simuleringarna utan att förlora allt för mycket tid närdet gäller implementeringen. Även försök till tidsoptimering skulle utföras.
Resultatet av den datalogiska undersökningen kan sammanfattas med att om en ochsamma modell med tillhörande resultathantering ska provas med en mängd olika värdenoch därmed köras upprepade gånger, är C utan tvekan det mest fördelaktiga alternativet.Är det däremot ett flertal olika modeller som ska implementeras för att endast användastillfälligt, verkar det som om MatLab och dess matematiskt anpassade miljö är det bästavalet.
Motiveringarna för detta är att tillvägagångssättet för en del av de modeller som dethär arbetet är uppbyggt runt, visade sig vara väldigt omständliga att implementera i C.Mycket tid gick åt till att hålla ordning på vilka positioner i arrayer och matriser somanvändes från gång till gång, till variabelhantering och till andra strukturella svårigheter.Många av de standardfunktioner som kunde nyttjas i MatLab fick skrivas helt från början iC, vilket var både tidskrävande och bitvis besvärligt. Därav resonemanget om att MatLaboch dess tillhörande matematiska funktioner är mer lämpligt att använda då det rör sig ommånga olika modeller som ska implementeras. Se avsnitt 5.1.
Testresultaten visade emellertid tydligt på att C är betydligt snabbare än vad MatLab är
59

under körning. Så om det är väldigt många körningar som ska utföras på få modeller, kandet mycket väl vara värt besväret med att implementera dessa i C istället för i MatLab.Detta för att tidsåtgången för implementeringen kan tjänas in under själva utförandet avberäkningarna, som i C sker snabbare än i MatLab. Se avsnitt 9.1.2.
När det gäller tidsoptimering av de framarbetade programkoderna i MatLab och C,finns det goda möjligheter för att genomföra detta. Det har genom undersökningen iden-tifierats kritiska partier i programkoderna, där alternativa lösningar skulle kunna minskatidsåtgången avsevärt. Se till exempel avsnitt 9.3. Dock fanns det inte utrymme för attgenomföra dessa i detta arbete och förslag på tidsoptimeringar finns i avsnittet Öppnafrågor 10.3.
10.2 Svårigheter
Det var inte förrän väldigt sent under arbetets gång som det uppdagades att det fannsen tumregel, som säger att antal simuleringar ska vara ungefär lika med antal tidssteg ikvadrat. Den datalogiska delen av arbetet hade vid den tidpunkten redan hunnit så passlångt, att större delen av tidtagningsproceduren redan genomförts med de värden somtidigare överenskommits. Men då Eulersimuleringarna blir bättre med ju mindre steglängdsom används, blir inte resultatet missvisande. Dock påverkas tidsåtgången för att utförasimuleringarna.
Arbetet med att uppskatta hur många simuleringar som krävs för att skillnaden mellande medelvärdesbildade Eulersimuleringarna och väntevärdet av diffusionsprocessens vidslutpunkten ska vara mindre än något godtyckligt ε , har inte kunnat genomföras till fulloeftersom flera faktorer spelar in. Dels finns det ett statistiskt fel (från antal simuleringar)dels ett numeriskt fel (från valet av steglängd). Trots att antal simuleringar inte har kunnatuppskattas har ändå ett försök gjorts.
Det har även varit svårt att hitta bra litteratur angående hur diffusionsapproximatio-nen fungerar. Detta har resulterat i att frågor rörande diffusionsapproximationen har tag-it längre tid att lösa än planerat. När frågor angående hur MatLabs funktioner fungerarhar webbplatsen [14] ofta kunnat ge svar. Grundläggande statistiska formler samt tillvä-gagångssätt för att använda dessa går att läsa i [15].
Ur en datalogisk synvinkel har den absolut största svårigheten under arbetets gång varitatt in i detalj förstå programkod som någon annan har skrivit, speciellt då denne inte harså mycket erfarenhet av programmering. Särskilt svårt har det varit då den programkodsom använts som utgångspunkt har skapats för eget bruk, utan några som helst tankar påatt någon annan senare ska förstå och använda den. Variabelnamnen har varierat från attha varit någorlunda förståeliga till helt omöjliga att ens ha en kvalificerad gissning om vadde innehåller. Några exempel är: tmp4, tmp5, N, pos95 med flera. De få kommentarer somfanns i programkoden beskrev inte några viktiga saker, utan användes mer som rubrikeröver de olika delarna. Om det hade funnits en genomtänkt beskrivning över vad det ärsom utförs för varje del av programkoden, hade det underlättat arbetet kolossalt samtgjort att det inte hade tagit så lång tid som det faktiskt gjorde. Det här med att tänka på attvälja lämpliga variabelnamn, att vara noggrann med kommentering och dokumentationhar varit återkommande inslag under utbildningen, men det är inte förrän nu vikten avdetta helt har förståtts. Det är en lärdom som kommer att följa med till kommande projekti framtiden.
Från att aldrig tidigare arbetat i MatLab till att ge sig på att förstå, implementera samtförsöka tidsoptimera i MatLab, var steget större än väntat. Ofta sägs det att om man kanprogrammera i ett språk kan man programmera i alla. Våra erfarenheter visar att det är ensanning med viss modifikation. Visst kan man, men det tar tid.
60

De strikt matematiska inslagen i arbetet låg på en betydligt mer avancerad nivå änförväntat. Avsaknaden av rätt matematisk kompetens visade sig att bli ett större problemän vad som var väntat vid arbetets början. För att ens kunna ha en möjlighet att imple-mentera modellerna på rätt sätt, var det viktigt att varje liten del av uträkningarna förstodshelt och fullt. Utöver alla andra lärdomar som vunnits med arbetet, har även en ökadmatematisk förståelse tillgodogjorts.
10.3 Öppna frågor
Eftersom Lotka-Volterras modell visade sig vara mycket svårare att arbeta med än planer-at, har bearbetningen av denna modell inte kunnat utföras lika utförligt som de andra tvåmodellerna. Ett problem med att jobba med modellen är att spridningen för simuleringar-na blir väldigt stor. Två frågetecken i arbetet är hur den kvasi-stationära fördelningenbestäms samt hur ett konfidensområde ser ut när N1 och N2 visas på respektive axlar.
När medelvärdesbildningarna till den logistiska modellen skulle beräknas var det intehelt lätt att förstå att medelvärdet endast skulle beräknas på de simuleringarna som ärskilda från noll. Det var heller inte enkelt att inse att modellen är känslig för vilka värdenpå konstanterna som väljs. Från början antogs det att oavsett vilka värden som valdes påkonstanterna i kombination med tillräckligt många simuleringar, skulle medelvärdet sam-manfalla med den deterministiska lösningen. Men så verkar fallet inte vara trots omfat-tande undersökningar av detta. För att den medelvärdesbildade lösningen ska sammanfal-la bättre med den deterministiska lösningen ska kanske intensiteterna λn och µn väljas påett annat sätt än vad [2] föreslår? En tillfredsställande förklaring till varför medelvärdes-bildningarna inte sammanfaller bättre med den deterministiska lösningen har heller intekunnat ges. Detta är intressanta frågor som lämnas öppna.
Från ett datalogiskt perspektiv hade det varit intressant om tid funnits för att helt frånbörjan implementera simuleringarna och dess beräkningar i MatLab på datalogiska pre-misser istället för på matematiska, som det varit under det här arbetets gång. Det hade nogkunnat bli en relativt stor skillnad mellan hur problemen angripits och eventuellt även iförlängningen skillnader i tidsåtgången.
Försök till tidsoptimering av programkoden i C som det inte fanns utrymme för attrealisera i det här arbetet, men som hade varit av intresse att prova, hade varit att användaparallellt itererande loopar för uträkning av både medelvärde och konfidensintervall i ma-triser. Själva uträkningen av populationstillväxten i både den differentialapproximeradedelen samt födelsedödsdelen hade förmodligen kunnat genomföras snabbare med rekur-sion, då varje ny uträkning bygger på resultatet från föregående uträkning.
Fenomenet som uppdagades under testerna av 02-exponentiell.m och 02-logistisk.mmed att det går åt mycket mer tid under körning då nollställningar av matriser utesluts ändet gör då de finns med, kan vara intressant att utreda närmre. Eftersom att MatLab fak-tiskt har stöd för att skapa en matris genom att ange antal rader och antal kolumner utanatt använda zeros() eller dylikt (se programkod 10.1), så är frågan vad meningen med attange storleken egentligen då är? Om det vid varje inlägg av ett värde ändå ska allokerasnytt minne, borde ett skapande av en matris utan användandet av zeros() vara lika med attinte ange några storleksvärden alls? Var går brytningspunkten för när det är en tidsmässigförtjänst med att nollställa matriser? Är det storleken på rader eller kolumner som spelarin, eller är det den totala storleken av matrisen? Finns det någon tumregel att följa, somtill exempel att vid skapandet av matriser mindre än 100 ∗ 100 bör zeros() undvikas, dådet går snabbare att låta den dynamiska minneshanteringen ha sin gång, medan större ma-triser fungerar tidsmässigt bättre med att initieras vid skapandet? Tyvärr saknas det bådekunskap i MatLab samt tid för att göra ytterligare fördjupningar i ämnet. Men det borde
61

vara intressant att i framtiden undersöka det, då det vid både första och tredje anblickenter sig som helt ologiskt att mata in stora mängder värden i en matris som aldrig kommeratt användas och som senare skrivs över.
...matrix=[size1, size2];...
Programkod 10.1: Skapandet av matris utan nollställning i MatLab.
En sak som också kunnat vara intressant att undersöka, är användandet av clear() i Mat-Lab. Detta uppmärksammas i testet av 03-exponentiell.m och det är väldigt tidskrävande.Kan det vara en idé att, som med implementeringen i C, använda positionsvariabler för attha kontroll över vilka värden det är som ska användas i de olika itereringarna istället föratt anropa clear()? Det borde finnas något sätt att undvika dessa tidskrävande lösningar.
62

Referenser[1] Boyce, William & DiPrima, Richard (2005). Elementary differential equations and
boundary value problems. Åttonde upplagan. New York: John Wiley & Sons, Inc.
[2] Renshaw, Eric (1991). Modelling biological populations in space and time. Cam-bridge: Universitypress.
[3] Pärt-Enander, Eva, Sjöberg, Anders, Melin, Bo & Isaksson, Pernilla (1996). The MAT-LAB Handbook. Essex: Addison-Wesley.
[4] Nationalencyklopedin (1993-1996). Höganäs: Bra Böcker.
[5] Arkansas State University (senast uppdaterad 2008). A Chronology of SignificantHistorical Developments in the Biological Sciences. (Elektronisk) Tillgänglig:<http://www.clt.astate.edu/aromero/History%20of%20Biology/CHRONO.HTM>(2008-05-27)
[6] Pettersson, Roger, lektor vid Växjö Universitet, muntlig källa maj 2008.
[7] Ethier, Stewart & Kurtz, Thomas (1986). Markov processes: characterization andconvergence. New York: John Wiley & Sons, Inc.
[8] Nisbet, R. M. & Gurney, W. S. C. (1982). Modelling Fluctuating Populations. NewYork: John Wiley & Sons Ltd.
[9] Gardiner, Crispin (2004). Handbook of stochastic methods for physics, chemistry andthe natural sciences. Tredje upplagan. Berlin: Springer-Verlag.
[10] Jönsson, Per (2004). MATLAB - beräkningar inom teknik och naturvetenskap. Lund:Studentlitteratur.
[11] Kelley, Al & Pohl, Ira (1998). A Book on C. Fjärde upplagan. Massachusetts:Addison-Wesley.
[12] Kernighan, Brian W. & Ritchie, Dennis M. (2000). Programmeringsspråket C. Es-sex: Prentice Hall.
[13] The MathWorks (senast uppdaterad 2008-05-16). How do I pre-allocate memory when using MATLAB? (Elektronisk) Tillgänglig:<http://www.mathworks.com/support/solutions/data/1-18150.html?solution=1-18150> (2008-05-20)
[14] The MathWorks (senast uppdaterad 2008). Search (Elektronisk) Tillgänglig:<http://www.mathworks.com/> (2008-04-18)
[15] Milton, Janet & Arnold, Jesse (2003). Introduction to probability and statistics:principles and applications for engineering and the computing sciences. Fjärde up-plagan. New York: McGraw-Hill.
63

A Programkod exponentiell modell
...malthus_array=zeros(1,length(time_array));malthus_array=starting_no∗exp(lambda∗time_array);...
Programkod A.1: Följande programkod visar hur Malthus deterministiska ekvationberäknas i MatLab (01-exponentiell.m).
void calculateExpDeterm(double time_array[]){
double determ_array[size];int i=0;...determ_array[0]=starting_no;while(i<size){
determ_array[i]=starting_no∗exp(lambda∗time_array[i]);i++;
}...
}
Programkod A.2: Följande programkod visar hur Malthus deterministiska ekvationberäknas i C (01-exponentiell.c).
...simulations_matrix=ones([no_of_simulations, length(time_array)]);simulations_matrix(:,1)=starting_no;j=0;for k=1:no_of_simulations
for i=2:length(time_array)j=j+1;simulations_matrix(k,i)=simulations_matrix(k,i−1)+lambda.∗
simulations_matrix(k,i−1).∗dt+sqrt(lambda.∗simulations_matrix(k,i−1)).∗sqrt(dt).∗normal_random(1,j);
if simulations_matrix(k,i)<=0simulations_matrix(k,i)=0;
endend
end...
Programkod A.3: Programkoden visar hur Eulersimuleringar av ekvation (4.1) utförs iMatLab (01-exponentiell.m).
64

void calculateExpDiff( double random[]){
int j, k, r;double ∗∗simulations_matrix;...r=0;for (k=0;k<no_of_sims; k++){
for(j=1;j<size; j++){
simulations_matrix[k][j]=simulations_matrix[k][j−1] +lambda ∗ simulations_matrix[k][j−1] ∗ dt + sqrt(lambda ∗ simulations_matrix[k][j−1]) ∗ sqrt(dt) ∗random[r];
if(simulations_matrix[k][j]<0){
simulations_matrix[k][j]=0;}r++;
}}...
}
Programkod A.4: Programkoden visar hur Eulersimuleringar av ekvation (4.1) utförs i C(01-exponentiell.c).
...popsize_simulations_matrix=zeros([no_of_simulations, length(time_array)]);timestamps_simulations_matrix=zeros([no_of_simulations, length(time_array)]);noOfTimestamps_simulations_array=zeros([no_of_simulations, 1]);w=1;for c=1:no_of_simulations
a=starting_no;b=1;y=random_01(w);jump=−log(y)/(a∗lambda);timestamps_array(b)=0;if jump <= interval
b=b+1;timestamps_array(b)=jump;while timestamps_array(b) <= interval
a=a+1;b=b+1;w=w+1;y=random_01(w);timestamps_array(b)=timestamps_array(b−1)+(−log(y)/(a∗lambda));
endnumber_of_jumps=length(timestamps_array);N=(starting_no:(starting_no+number_of_jumps−1));
65

popsize_simulations_matrix(c,(1:number_of_jumps))=N;timestamps_simulations_matrix(c,(1:number_of_jumps))=timestamps_array;noOfTimestamps_simulations_array(c,1)=number_of_jumps;
elseN=(starting_no:starting_no+1);number_of_jumps=(length(timestamps_array)+1);timestamps_array(2)=jump;popsize_simulations_matrix(c,(1:2))=N;timestamps_simulations_matrix(c,(1:2))=timestamps_array(1:2);noOfTimestamps_simulations_array(c,1)=2;
endtimestamps_array=0;w=w+1;
end...
Programkod A.5: Följande programkod är skriven i MatLab (01-exponentiell.m) och densimulerar den exponentiella födelsedödsprocessen.
void calculateExpBirthDeath(double random_array[]){
int a, c, i, p, rand_counter, timestamps_array_usage_size;double y, jump;double timestamps_array[timestamps_array_sim_size];int noOfTimestamps_simulations_array[timestamps_array_sim_size];int ∗∗popsize_simulations_matrix;double ∗∗timestamps_simulations_matrix;...rand_counter=0;for(c=0;c<no_of_sims;c++){
a=starting_no;timestamps_array_usage_size=0;y=random_array[rand_counter];rand_counter=rand_counter+1;jump=−log(y)/(a∗lambda);timestamps_array[timestamps_array_usage_size]=0;timestamps_array_usage_size=timestamps_array_usage_size+1;if(jump<=interval){
timestamps_array[timestamps_array_usage_size]=jump;while(timestamps_array[timestamps_array_usage_size]<=
interval){
a=a+1;timestamps_array_usage_size=
timestamps_array_usage_size+1;y=random_array[rand_counter];timestamps_array[timestamps_array_usage_size]=
timestamps_array[timestamps_array_usage_size−1]+(−log(y)/(a
66

∗lambda));}popsize_simulations_matrix[c][0]=starting_no;for(p=1;p<=timestamps_array_usage_size; p++){
popsize_simulations_matrix[c][p]=popsize_simulations_matrix[c][p−1]+1;
}for(p=0;p<=timestamps_array_usage_size; p++){
timestamps_simulations_matrix[c][p]=timestamps_array[p];
}noOfTimestamps_simulations_array[c]=
timestamps_array_usage_size+1;}else{
popsize_simulations_matrix[c][0]=starting_no;popsize_simulations_matrix[c][1]=starting_no+1;timestamps_simulations_matrix[c][0]=0;timestamps_simulations_matrix[c][1]=jump;noOfTimestamps_simulations_array[c]=2;
}}...
}
Programkod A.6: Följande programkod är skriven i C (01-exponentiell.c) och densimulerar den exponentiella födelsedödsprocessen.
67

B Programkod logistisk modell
...deterministic_array=zeros(1,length(time_array));deterministic_array=r./(exp(−r∗(time_array+(1/(−r))∗log(r/starting_no−s)))+s);...
Programkod B.1: Följande programkod visar hur Verhulsts deterministiska ekvationberäknas i MatLab (01-logistisk.m).
void calculateLogDeterm(double time_array[], double r, double s){
double deterministic_array[size];int i=0;...deterministic_array[i]=starting_no;while(i<size){
deterministic_array[i]=r/(exp(−r∗(time_array[i]+(1/(−r))∗log(r/starting_no−s)))+s);
i++;}...
}
Programkod B.2: Följande programkod visar hur Verhulsts deterministiska ekvationberäknas i C (01-logistisk.c).
...noice_simulations_matrix=ones([no_of_sims, length(time_array)]);noice_simulations_matrix(:,1)=starting_no;k=0;for j=1:no_of_sims
for i=2:length(time_array)k=k+1;noice_simulations_matrix(j,i)=noice_simulations_matrix(j,i−1)+
noice_simulations_matrix(j,i−1)∗(r−s∗noice_simulations_matrix(j,i−1))∗dt+sqrt(noice_simulations_matrix(j,i−1)∗((a1+a2)+(b2−b1)∗noice_simulations_matrix(j,i−1)))∗normal_random(1,k)∗sqrt(dt);
if noice_simulations_matrix(j,i)<=0noice_simulations_matrix(j,i)=0;
endend
end...
Programkod B.3: Programkoden visar hur Eulersimuleringar av ekvation (4.5) utförs iMatLab (01-logistisk.m).
68

void calculateLogDiff(double random[], double r, double s){
double ∗∗simulations_matrix;int i, j, rand;...for (i=0;i<no_of_sims; i++){
simulations_matrix[i][0]=starting_no;}rand=0;for (j=0;j<no_of_sims; j++){
for(i=1;i<size; i++){
simulations_matrix[j][i]=simulations_matrix[j][i−1]+simulations_matrix[j][i−1]∗(r−s∗simulations_matrix[j][i−1])∗dt+sqrt(simulations_matrix[j][i−1]∗((a1+a2)+(b2−b1)∗simulations_matrix[j][i−1]))∗random[rand]∗sqrt(dt);
rand++;if(simulations_matrix[j][i]<0){
simulations_matrix[j][i]=0;}
}}...
}
Programkod B.4: Programkoden visar hur Eulersimuleringar av ekvation (4.5) utförs i C(01-logistisk.c).
...popsize_sim_matrix=zeros([no_of_sims length(time_array)]);timestamps_simulations_matrix=zeros([no_of_sims length(time_array)]);tmp_pop_array=zeros([1, length(time_array)]);noOfTimestamps_simulations_array=zeros([no_of_sims 1]);steps=0;w=1;for j=1:no_of_sims
pop_no=starting_no;i=1;tmp_pop_array(1)=starting_no;jumps_array(1)=0;while jumps_array(i)<=interval && pop_no~=0
i=i+1;y1=random_01(1,w);w=w+1;y2=random_01(1,w);w=w+1;
69

jumps_array(i)=jumps_array(i−1)+((−log(y2))/((pop_no∗(a1−b1∗pop_no)+pop_no∗(a2+b2∗pop_no))));
if y1 <= (pop_no∗(a1−b1∗pop_no)/(pop_no∗(a1−b1∗pop_no)+pop_no∗(a2+b2∗pop_no)))pop_no=pop_no+1;
elsepop_no=pop_no−1;
endtmp_pop_array(i)=pop_no;steps=steps+1;
endpopsize_sim_matrix(j,1:length(tmp_pop_array))=tmp_pop_array;timestamps_simulations_matrix(j,1:length(jumps_array))=jumps_array;noOfTimestamps_simulations_array(j)=steps;tmp_pop_array=0;jumps_array=0;steps=0;
endnoOfTimestamps_simulations_array=noOfTimestamps_simulations_array+1;...
Programkod B.5: Följande programkod är skriven i MatLab (01-logistisk.m) och densimulerar den logistiska födelsedödsprocessen.
void calculateLogBirthDeath(double random_array[]){
int i, j, k, pop_no, steps, rand_counter;double y1, y2;int ∗∗bd_popsize_sim_matrix;int ∗tmp_pop_array;int ∗bd_noOfTimestamps_simulations_array;double ∗jumps_array;double ∗∗bd_timestamps_simulations_matrix;...steps=0;rand_counter=0;for(j=0;j<no_of_sims;j++){
pop_no=starting_no;i=0;k=0;tmp_pop_array[0]=starting_no;jumps_array[0]=0;pop_no=starting_no;while((jumps_array[i]<=interval)&&(pop_no>0)){
i=i+1;y1=random_array[rand_counter];rand_counter=rand_counter+1;y2=random_array[rand_counter];rand_counter=rand_counter+1;
70

jumps_array[i]=jumps_array[i−1]+((−log(y2))/((pop_no∗(a1−b1∗pop_no)+pop_no∗(a2+b2∗pop_no))));
if(y1<=(pop_no∗(a1−b1∗pop_no)/(pop_no∗(a1−b1∗pop_no)+pop_no∗(a2+b2∗pop_no))))
{pop_no=pop_no+1;
}else{
pop_no=pop_no−1;}tmp_pop_array[i]=pop_no;steps=steps +1;
}k=0;while(k<=i){
bd_popsize_sim_matrix[j][k]=tmp_pop_array[k];k++;
}k=0;while(k<=i){
bd_timestamps_simulations_matrix[j][k]=jumps_array[k];k++;
}bd_noOfTimestamps_simulations_array[j]=steps+1;steps=0;
}...
}
Programkod B.6: Följande programkod är skriven i C (01-logistisk.c) och den simulerarden logistiska födelsedödsprocessen.
71



Växjöuniversitet
Matematiska och systemtekniska institutionenSE-351 95 Växjö
tel 0470-70 80 00, fax 0470-840 04www.msi.vxu.se


















