
Utilizing Underlying Synchronization Mechanisms for ...anastop/files/papers/upc_presentation.pdf ·...
48
Utilizing Underlying Synchronization Mechanisms for Efficient Support of Different Programming Models Nikos Anastopoulos Computing Systems Laboratory School of Electrical and Computer Engineering National Technical University of Athens [email protected] http://www.cslab.ece.ntua.gr July 26, 2009 CSLab National Technical University of Athens
Transcript of Utilizing Underlying Synchronization Mechanisms for ...anastop/files/papers/upc_presentation.pdf ·...

Utilizing Underlying Synchronization Mechanisms forEfficient Support of Different Programming Models
Nikos Anastopoulos
Computing Systems LaboratorySchool of Electrical and Computer Engineering
National Technical University of [email protected]
http://www.cslab.ece.ntua.gr
July 26, 2009
CSLabNational Technical University of Athens

Talk Outline
1 Lab Profile
2 Part I: Supporting Efficient Synchronization of Asymmetric Threadson Hyper-Threaded Processors
3 Part II: Combining TM with Helper Threads for Exploiting OptimisticParallelism
N. Anastopoulos (cslab@NTUA) ARCO, UPC, Barcelona July 26, 2009 2 / 43

Talk Outline
1 Lab Profile
2 Part I: Supporting Efficient Synchronization of Asymmetric Threadson Hyper-Threaded Processors
3 Part II: Combining TM with Helper Threads for Exploiting OptimisticParallelism
N. Anastopoulos (cslab@NTUA) ARCO, UPC, Barcelona July 26, 2009 3 / 43

General Info
People:
Nectarios Koziris (Associate Professor, NTUA)
4 post-doc researchers
more than 15 graduate students
N. Anastopoulos (cslab@NTUA) ARCO, UPC, Barcelona July 26, 2009 4 / 43

Research Areas
High performance computingI Optimizations for challenging applications
- Lack of inherent parallelism- Memory bandwidth saturation (e.g. SpMxV, Floyd-Warshall)- Memory latency (graph algorithms)
I Studies of architectures’ impact on applicationsI Different architectures (PC clusters, CMPs, GPGPUs, Cell B/E)
N. Anastopoulos (cslab@NTUA) ARCO, UPC, Barcelona July 26, 2009 5 / 43

Research Areas
Computer architectureI Caches for CMPs (e.g. cache-partitioning)I SMTs (e.g. thread synchronization, speculative precomputation)
High performance systems and interconnectsI Study the effects of shared resources on SMP clustersI Focus on I/O and scheduling techniques
Grid computing & P2P networks and distributed systems
More info at lab’s wiki:http://www.cslab.ece.ntua.gr/cgi-bin/twiki/view/CSLab/
N. Anastopoulos (cslab@NTUA) ARCO, UPC, Barcelona July 26, 2009 6 / 43

Recent Work (HPC)
Transformations to increase data localityI “Loop Transformations for Cache-Friendlier Floyd-Warshall”,
(submitted to ACM Journal of Experimental Algorithms)
Data compression to decrease memory trafficI “Optimizing Sparse Matrix-Vector Multiplication Using Index and
Value Compression”, (Comp. Frontiers 2008)I “Improving the Performance of Multithreaded Sparse Matrix-Vector
Multiplication Using Index and Value Compression”, (ICPP 2008)
Optimizing communication for message-passing applicationsI “Overlapping Computation and Communication in SMT Clusters with
Commodity Interconnects”, (CLUSTER 2009)
N. Anastopoulos (cslab@NTUA) ARCO, UPC, Barcelona July 26, 2009 7 / 43

Recent Work (CA)
CMP cachesI “An Adaptive Bloom Filter Cache Partitioning Scheme for Multicore
Architectures”, (SAMOS 2008)
SMT processorsI “Facilitating Efficient Synchronization of Asymmetric Threads on
Hyper-Threaded Processors”, (MTAAP 2008)
Transactional memoryI “Early Experiences on Accelerating Dijkstra’s Algorithm Using
Transactional Memory”, (MTAAP 2009)I “Employing Transactional Memory and Helper Threads to Speedup
Dijkstra’s Algorithm”, (ICPP 2009)
N. Anastopoulos (cslab@NTUA) ARCO, UPC, Barcelona July 26, 2009 8 / 43

Talk Outline
1 Lab Profile
2 Part I: Supporting Efficient Synchronization of AsymmetricThreads on Hyper-Threaded Processors
3 Part II: Combining TM with Helper Threads for Exploiting OptimisticParallelism
N. Anastopoulos (cslab@NTUA) ARCO, UPC, Barcelona July 26, 2009 9 / 43

Application Model - Motivation
Threads with asymmetric workloadsexecuting on a single HT processor,synchronizing on a frequent basis
In real applications, usually a helper threadthat facilitates a worker
speculative precomputation
network I/O & message processing
disk request completions
How should synchronization be implementedfor this model?
resource-conservant
worker: fast notification
helper: fast resumption
workerthread
helperthread
exitbarrier1
exitbarrier2
exitbarrier3
exitbarrier4
exitbarrier5
busy periodidle period
barrier
T0 T1
HT processor
N. Anastopoulos (cslab@NTUA) ARCO, UPC, Barcelona July 26, 2009 10 / 43

Option 1: spin-wait loops
commonplace as building blocks of synchronization in MP systems
pros: simple implementation, high responsiveness
cons: spinning in resource hungry!I loop unrolled multiple timesI costly pipeline flush penaltyI spins a lot faster than actually needed
wait loop:ld eax,spinvarcmp eax,0jne wait loop
IPIP
TraceCache
ITLBRegisterRename
ITLBAllocator
memory
general
Registers
Store Buffer
L1 D-CacheRegisters
Re-OrderBuffer
N. Anastopoulos (cslab@NTUA) ARCO, UPC, Barcelona July 26, 2009 11 / 43

Option 2: spin-wait, but loosen the spinning. . .
slight delay in the loop (∼pipeline depth)
spinning thread effectively de-pipelined → dynamically sharedresources to peer thread
I execution units, caches, fetch-decode-retirement logic
statically partitioned resources are not released (but still unused)I uop queues, load-store queues, ROBI each thread can use at most half of total entries
up to 15-20% deceleration of busy thread
wait loop:pauseld eax,spinvarcmp eax,0jne wait loop
IPIP
TraceCache
ITLBRegisterRename
ITLBAllocator
memory
general
Registers
Store Buffer
L1 D-CacheRegisters
Re-OrderBuffer
N. Anastopoulos (cslab@NTUA) ARCO, UPC, Barcelona July 26, 2009 12 / 43

Option 3: spin-wait, but “HALT”. . .
partitioned resources recombined for full use by busy thread(ST-mode)
IPIs to wake up sleeping thread, resources then re-partitioned(MT-mode)
system call needed for waiting and notification /
multiple transitions between ST/MT incur extra overhead
wait loop:haltld eax,spinvarcmp eax,0jne wait loop
IPIP
TraceCache
ITLBRegisterRename
ITLBAllocator
memory
general
Registers
Store Buffer
L1 D-CacheRegisters
Re-OrderBuffer
N. Anastopoulos (cslab@NTUA) ARCO, UPC, Barcelona July 26, 2009 13 / 43

Option 4: MONITOR/MWAIT loops
while (spinvar!=NOTIFIED) {MONITOR(spinvar,0,0)MWAIT
}
condition-wait close to the hardware level
all resources (shared & partitioned) relinquished
require kernel privileges
obviate the need for (expensive) IPI delivery for notification ,
sleeping state more responsive than this of HALT ,
Contribution:
framework that enables use of MONITOR/MWAIT at user-level, withleast possible kernel involvement
I so far, in OS code mostly (scheduler idle loop)
explore the potential of multithreaded programs to benefit fromMONITOR/MWAIT functionality
N. Anastopoulos (cslab@NTUA) ARCO, UPC, Barcelona July 26, 2009 14 / 43

Option 4: MONITOR/MWAIT loops
while (spinvar!=NOTIFIED) {MONITOR(spinvar,0,0)MWAIT
}
condition-wait close to the hardware level
all resources (shared & partitioned) relinquished
require kernel privileges
obviate the need for (expensive) IPI delivery for notification ,
sleeping state more responsive than this of HALT ,
Contribution:
framework that enables use of MONITOR/MWAIT at user-level, withleast possible kernel involvement
I so far, in OS code mostly (scheduler idle loop)
explore the potential of multithreaded programs to benefit fromMONITOR/MWAIT functionality
N. Anastopoulos (cslab@NTUA) ARCO, UPC, Barcelona July 26, 2009 14 / 43

Implementing Basic Primitives with MONITOR/MWAIT
condition-wait:I must occur in kernel-space → syscall overhead the least that should be
paid. . .I must check continuously status of monitored memory
where to allocate the region to be monitored?I in user-space. . .
F notification requires single value update ,F on each condition check kernel must copy contents of monitored region
from process address space (e.g. via copy from user) /I in kernel-space. . .
F additional system call to enable update of monitored memory fromuser-space /
I in kernel-space, but map it to user-space for direct access ,
N. Anastopoulos (cslab@NTUA) ARCO, UPC, Barcelona July 26, 2009 15 / 43
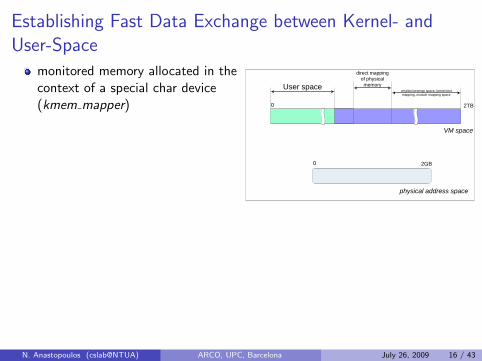
Establishing Fast Data Exchange between Kernel- andUser-Space
monitored memory allocated in thecontext of a special char device(kmem mapper)
load module
I kmalloc page-frameI initialize kernel pointer to show
at monitored region within frame
open kmem mapper
I initialize monitored region(MWMON ORIGINAL VAL)
mmap kmem mapper
I page-frame remapped touser-space (remap pfn range)
I pointer returned points tobeginning of monitored region
unload module
I page kfree’d
physical address space
0 2GB
0 2TB
VM space
direct mapping of physical
memoryUser spacevmalloc/ioremap space, kernel text mapping, module mapping space
mmapped dev mem: used by notificationprimitive at user-space to update monitoredmemorymwmon mmap area: used by condition-waitprimitive at kernel-space to check monitoredmemory
N. Anastopoulos (cslab@NTUA) ARCO, UPC, Barcelona July 26, 2009 16 / 43

Establishing Fast Data Exchange between Kernel- andUser-Space
monitored memory allocated in thecontext of a special char device(kmem mapper)load module
I kmalloc page-frameI initialize kernel pointer to show
at monitored region within frame
open kmem mapper
I initialize monitored region(MWMON ORIGINAL VAL)
mmap kmem mapper
I page-frame remapped touser-space (remap pfn range)
I pointer returned points tobeginning of monitored region
unload module
I page kfree’d
physical address space
0 2GB
0 2TB
VM space
direct mapping of physical
memoryUser spacevmalloc/ioremap space, kernel text mapping, module mapping space
mmapped dev mem: used by notificationprimitive at user-space to update monitoredmemorymwmon mmap area: used by condition-waitprimitive at kernel-space to check monitoredmemory
N. Anastopoulos (cslab@NTUA) ARCO, UPC, Barcelona July 26, 2009 16 / 43
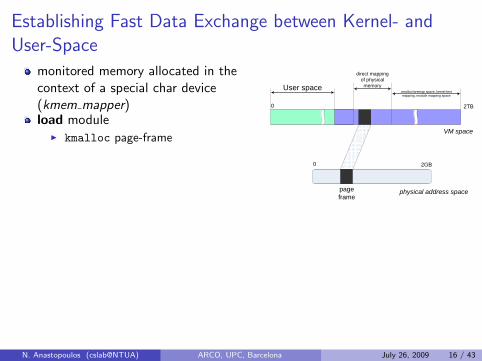
Establishing Fast Data Exchange between Kernel- andUser-Space
monitored memory allocated in thecontext of a special char device(kmem mapper)load module
I kmalloc page-frame
I initialize kernel pointer to showat monitored region within frame
open kmem mapper
I initialize monitored region(MWMON ORIGINAL VAL)
mmap kmem mapper
I page-frame remapped touser-space (remap pfn range)
I pointer returned points tobeginning of monitored region
unload module
I page kfree’d
physical address space
0 2GB
0 2TB
VM space
direct mapping of physical memory
page frame
User spacevmalloc/ioremap space, kernel text mapping, module mapping space
mmapped dev mem: used by notificationprimitive at user-space to update monitoredmemorymwmon mmap area: used by condition-waitprimitive at kernel-space to check monitoredmemory
N. Anastopoulos (cslab@NTUA) ARCO, UPC, Barcelona July 26, 2009 16 / 43

Establishing Fast Data Exchange between Kernel- andUser-Space
monitored memory allocated in thecontext of a special char device(kmem mapper)load module
I kmalloc page-frameI initialize kernel pointer to show
at monitored region within frame
open kmem mapper
I initialize monitored region(MWMON ORIGINAL VAL)
mmap kmem mapper
I page-frame remapped touser-space (remap pfn range)
I pointer returned points tobeginning of monitored region
unload module
I page kfree’d
physical address space
0 2GB
0 2TB
*mwmon_mmap_areaVM space
direct mapping of physical memory
page frame
User spacevmalloc/ioremap space, kernel text mapping, module mapping space
mmapped dev mem: used by notificationprimitive at user-space to update monitoredmemorymwmon mmap area: used by condition-waitprimitive at kernel-space to check monitoredmemory
N. Anastopoulos (cslab@NTUA) ARCO, UPC, Barcelona July 26, 2009 16 / 43

Establishing Fast Data Exchange between Kernel- andUser-Space
monitored memory allocated in thecontext of a special char device(kmem mapper)load module
I kmalloc page-frameI initialize kernel pointer to show
at monitored region within frame
open kmem mapperI initialize monitored region
(MWMON ORIGINAL VAL)
mmap kmem mapper
I page-frame remapped touser-space (remap pfn range)
I pointer returned points tobeginning of monitored region
unload module
I page kfree’d
physical address space
0 2GB
0 2TB
*mwmon_mmap_areaVM space
direct mapping of physical memory
page frame
User spacevmalloc/ioremap space, kernel text mapping, module mapping space
mmapped dev mem: used by notificationprimitive at user-space to update monitoredmemorymwmon mmap area: used by condition-waitprimitive at kernel-space to check monitoredmemory
N. Anastopoulos (cslab@NTUA) ARCO, UPC, Barcelona July 26, 2009 16 / 43

Establishing Fast Data Exchange between Kernel- andUser-Space
monitored memory allocated in thecontext of a special char device(kmem mapper)load module
I kmalloc page-frameI initialize kernel pointer to show
at monitored region within frame
open kmem mapperI initialize monitored region
(MWMON ORIGINAL VAL)
mmap kmem mapper
I page-frame remapped touser-space (remap pfn range)
I pointer returned points tobeginning of monitored region
unload module
I page kfree’d
physical address space
0 2GB
0 2TB
*mwmon_mmap_areaVM space
direct mapping of physical memory
page frame
User spacevmalloc/ioremap space, kernel text mapping, module mapping space
mmapped dev mem: used by notificationprimitive at user-space to update monitoredmemorymwmon mmap area: used by condition-waitprimitive at kernel-space to check monitoredmemory
N. Anastopoulos (cslab@NTUA) ARCO, UPC, Barcelona July 26, 2009 16 / 43

Establishing Fast Data Exchange between Kernel- andUser-Space
monitored memory allocated in thecontext of a special char device(kmem mapper)load module
I kmalloc page-frameI initialize kernel pointer to show
at monitored region within frame
open kmem mapperI initialize monitored region
(MWMON ORIGINAL VAL)
mmap kmem mapperI page-frame remapped to
user-space (remap pfn range)
I pointer returned points tobeginning of monitored region
unload module
I page kfree’d
remap_pfn_range
physical address space
0 2GB
0 2TB
*mwmon_mmap_areaVM space
direct mapping of physical memory
page frame
User spacevmalloc/ioremap space, kernel text mapping, module mapping space
mmapped dev mem: used by notificationprimitive at user-space to update monitoredmemorymwmon mmap area: used by condition-waitprimitive at kernel-space to check monitoredmemory
N. Anastopoulos (cslab@NTUA) ARCO, UPC, Barcelona July 26, 2009 16 / 43

Establishing Fast Data Exchange between Kernel- andUser-Space
monitored memory allocated in thecontext of a special char device(kmem mapper)load module
I kmalloc page-frameI initialize kernel pointer to show
at monitored region within frame
open kmem mapperI initialize monitored region
(MWMON ORIGINAL VAL)
mmap kmem mapperI page-frame remapped to
user-space (remap pfn range)I pointer returned points to
beginning of monitored region
unload module
I page kfree’d
remap_pfn_range
physical address space
0 2GB
0 2TB
*mwmon_mmap_areaVM space
*mmapped_dev_mem
direct mapping of physical memory
page frame
User spacevmalloc/ioremap space, kernel text mapping, module mapping space
mmapped dev mem: used by notificationprimitive at user-space to update monitoredmemorymwmon mmap area: used by condition-waitprimitive at kernel-space to check monitoredmemory
N. Anastopoulos (cslab@NTUA) ARCO, UPC, Barcelona July 26, 2009 16 / 43

Establishing Fast Data Exchange between Kernel- andUser-Space
monitored memory allocated in thecontext of a special char device(kmem mapper)load module
I kmalloc page-frameI initialize kernel pointer to show
at monitored region within frame
open kmem mapperI initialize monitored region
(MWMON ORIGINAL VAL)
mmap kmem mapperI page-frame remapped to
user-space (remap pfn range)I pointer returned points to
beginning of monitored region
unload moduleI page kfree’d
remap_pfn_range
physical address space
0 2GB
0 2TB
*mwmon_mmap_areaVM space
*mmapped_dev_mem
direct mapping of physical memory
page frame
User spacevmalloc/ioremap space, kernel text mapping, module mapping space
mmapped dev mem: used by notificationprimitive at user-space to update monitoredmemorymwmon mmap area: used by condition-waitprimitive at kernel-space to check monitoredmemory
N. Anastopoulos (cslab@NTUA) ARCO, UPC, Barcelona July 26, 2009 16 / 43

Establishing Fast Data Exchange between Kernel- andUser-Space
monitored memory allocated in thecontext of a special char device(kmem mapper)load module
I kmalloc page-frameI initialize kernel pointer to show
at monitored region within frame
open kmem mapperI initialize monitored region
(MWMON ORIGINAL VAL)
mmap kmem mapperI page-frame remapped to
user-space (remap pfn range)I pointer returned points to
beginning of monitored region
unload moduleI page kfree’d
remap_pfn_range
physical address space
0 2GB
0 2TB
*mwmon_mmap_areaVM space
*mmapped_dev_mem
direct mapping of physical memory
page frame
User spacevmalloc/ioremap space, kernel text mapping, module mapping space
mmapped dev mem: used by notificationprimitive at user-space to update monitoredmemorymwmon mmap area: used by condition-waitprimitive at kernel-space to check monitoredmemory
N. Anastopoulos (cslab@NTUA) ARCO, UPC, Barcelona July 26, 2009 16 / 43

Use example - System call interface
worker thread helper thread
fd = open(“/dev/kmem_mapper”,…)
mwmem = mmap(0,PAGE_SIZE,…,fd,PAGE_SIZE)
*mwmem = MWMON_NOTIFIED_VAL
mwmon_mmap_sleep()
mainthread
munmap(mwmem,PAGE_SIZE)
close(fd)
asmlinkage long sys_mwmon_mmap_sleep(void){
do { local_irq_disable(); monitor(mwmon_mmap_area,0,0); local_irq_enable(); if(*mwmon_mmap_area == MWMON_NOTIFIED_VAL) break;
mwait(0,0); } while (*mwmon_mmap_area != MWMON_NOTIFIED_VAL); *mwmon_mmap_area = MWMON_ORIGINAL_VAL;
return 0;}
N. Anastopoulos (cslab@NTUA) ARCO, UPC, Barcelona July 26, 2009 17 / 43

System Configuration
ProcessorI Intel [email protected] (Prescott core), 2 hyper-threadsI 16KB L1-D, 1MB L2, 64B line size
Linux 2.6.13, x86 64 ISA
gcc-4.12 (-O2), glibc-2.5
NPTL for threading operations, affinity system calls for threadbinding on LPs
rdtsc for accurate timing measurements
N. Anastopoulos (cslab@NTUA) ARCO, UPC, Barcelona July 26, 2009 18 / 43

Case 1: Barriers - Simple Scenariosimple execution scenario:
I worker: 512×512 matmul (fp)I helper waits until worker enters barrier
direct measurements:I Twork → reflects amount of interference
introduced by helperI Twakeup → responsiveness of wait primitiveI Tcall → call overhead of notification primitive
condition-wait/notification primitives asbuilding blocks for actions of intermediate/lastthread in barrier
workerthread
helperthread
wor
k
Twor
k
Tcall Twakeup
slee
p
notify
Intermediate thread (condition-wait) Last thread (notification)
OS? OS?
spin-loops spin-wait loop + PAUSE in loop body NO single value update NO
spin-loops-halt spin-wait loop + HALT in loop body YES single value update + IPI YES
pthreads futex(FUTEX WAIT,...) YES futex(FUTEX WAKE,...) YES
mwmon mwmon mmap sleep YES single value update NO
N. Anastopoulos (cslab@NTUA) ARCO, UPC, Barcelona July 26, 2009 19 / 43

Case 1: Barriers - Simple Scenario
mwmon best balances resourceconsumption and responsiveness/calloverhead
I 24% less interference compared tospin-loops
I 4× lower wakeup latency, 3.5× lowercall overhead, compared to pthreads
workerthread
helperthread
wor
k
Twor
k
Tcall Twakeup
slee
p
notify
Twork (seconds) Twakeup (cycles) Tcall (cycles)
lower is better
spin-loops 4.3897 1236 1173
spin-loops-halt 3.5720 49953 51329
pthreads 3.5917 45035 18968
mwmon 3.5266 11319 5470
N. Anastopoulos (cslab@NTUA) ARCO, UPC, Barcelona July 26, 2009 20 / 43

Case 2: Barriers - Fine-grain Synchronization
varying workload asymmetryI unit of work = 10×10 matmul (fp)I heavy thread: always 10 unitsI light thread: 0-10 units
106 synchronized iterations
overall completion time reflects throughput ofeach barrier implementation
heavythread
lightthread
×106
×106
wor
k
wor
k
Ttot
alN. Anastopoulos (cslab@NTUA) ARCO, UPC, Barcelona July 26, 2009 21 / 43

Case 2: Barriers - Fine-grain Synchronization
20
25
30
35
40
45
50
55
0 2 4 6 8 10
Ove
rall
exec
utio
n tim
e (s
econ
ds)
Amount of work for light thread
mwmonpthreads
spin-loops
Across all levels of asymmetry mwmon outperforms pthreads by 12% andspin-loops by 26%
converges with spin-loops as threads become symmetricconstant performance gap w.r.t. pthreads
N. Anastopoulos (cslab@NTUA) ARCO, UPC, Barcelona July 26, 2009 22 / 43

Case 3: Barriers - Speculative Precomputation (SPR)
Thread based prefetching of top L2cache-missing loads (delinquent loads − DLs)
In phase k helper thread prefetches for phasek+1, then throttled
phases or prefetching spans: executiontraces where memory footprint of DLs < 1
2L2 size
Benchmarks
Application Data Set
LU decomposition 2048×2048, 10×10 blocks
Transitive closure 1.6K vertices, 25K edges, 16×16 blocks
NAS BT Class A
SpMxV 9648×77137, 260785 non-zeroes
workerthread
helperthread
exitbarrier1
exitbarrier2
exitbarrier3
exitbarrier4
exitbarrier5
span1
span2
span3
span4
span5
Prefetch for span2
Prefetch for span3
Prefetch for span4
Prefetch for span5
busy period
idle period
N. Anastopoulos (cslab@NTUA) ARCO, UPC, Barcelona July 26, 2009 23 / 43

Case 3: SPR Speedups and Miss Coverage
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9
1 1.1 1.2 1.3 1.4 1.5 1.6
SVBTTCLU
Spe
edup
serialspin-loopspthreadsmwmon
mwmon offers best speedups, between1.07 (LU) and 1.35 (TC)
with equal miss-coverage abilitysucceeds in boosting“interference-sensitive”applicationsnotable gains even when workerdelayed in barriers and prefetcherhas large workload
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
SVBTTCLU
Rel
ativ
e L2
mis
ses
incr
ease
serialspin-loops
pthreadsmwmon
0
10
20
30
40
50
60
70
80
90
100
SVBTTCLU
mw
mon
pthr
eads
spin
-loop
sm
wm
onpt
hrea
dssp
in-lo
ops
mw
mon
pthr
eads
spin
-loop
sm
wm
onpt
hrea
dssp
in-lo
ops
mw
mon
pthr
eads
spin
-loop
sm
wm
onpt
hrea
dssp
in-lo
ops
mw
mon
pthr
eads
spin
-loop
sm
wm
onpt
hrea
dssp
in-lo
ops
Per
cent
age
of to
tal c
ycle
s (%
)W-synchW-workP-synchP-work
N. Anastopoulos (cslab@NTUA) ARCO, UPC, Barcelona July 26, 2009 24 / 43

Conclusions
mwmon primitives make the best compromise between low resource wasteand low call & wakeup latency
efficient use of resources on HT processors
MONITOR/MWAIT functionality should be made available to theuser
Possible directions
mwmon-like hierarchical schemes in multi-SMT systems (e.g. treebarriers)
other “producer-consumer” models (disk/network I/O applications,MPI programs, work-queuing models, etc.)
multithreaded applications with irregular parallelism
N. Anastopoulos (cslab@NTUA) ARCO, UPC, Barcelona July 26, 2009 25 / 43

Talk Outline
1 Lab Profile
2 Part I: Supporting Efficient Synchronization of Asymmetric Threadson Hyper-Threaded Processors
3 Part II: Combining TM with Helper Threads for ExploitingOptimistic Parallelism
N. Anastopoulos (cslab@NTUA) ARCO, UPC, Barcelona July 26, 2009 26 / 43

Motivation
TM community needs real-world applications
Graph algorithms are described as good candidates for TM, due toirregular accesses of data structures
Dijkstra’s algorithmI fundamental SSSP algorithmI widely usedI inherently serial, thus challenging to parallelizeI previous attempts resulted in major changes in algorithm’s semantics
(e.g. ∆-stepping, Boost implementation)
Early results published in MTAAP’09, extended version will appear inICPP’09
N. Anastopoulos (cslab@NTUA) ARCO, UPC, Barcelona July 26, 2009 27 / 43

Main IdeaConventional use of TM: optimistic synchronization
x
Our view of TM: optimistic parallelization
x
Loop i i+1 i+2 i+3
N. Anastopoulos (cslab@NTUA) ARCO, UPC, Barcelona July 26, 2009 28 / 43

Main IdeaConventional use of TM: optimistic synchronization
x
Our view of TM: optimistic parallelization
x
Loop i i+1 i+2 i+3
N. Anastopoulos (cslab@NTUA) ARCO, UPC, Barcelona July 26, 2009 28 / 43

The Basics of Dijkstra’s Algorithm
Serial algorithm
Input : G = (V ,E), w : E → R+,source vertex s, min Q
Output : shortest distance array d ,predecessor array π
foreach v ∈ V dod [v ]← inf;π[v ]← nil;Insert(Q, v);
endd [s]← 0;
while Q 6= ∅ dou ← ExtractMin(Q);foreach v adjacent to u do
sum← d [u] + w(u, v);if d [v ] > sum then
DecreaseKey(Q, v , sum);d [v ]← sum;π[v ]← u;
end
end
50
55
60 65
70
5
2
10
10 15
20
7
S
A
B
CD
E
8
8
8
N. Anastopoulos (cslab@NTUA) ARCO, UPC, Barcelona July 26, 2009 29 / 43

The Basics of Dijkstra’s Algorithm
5
7 8
12 9
15 17 13 16
10 13
12 14
i
j
k
4
6 5
7 9
15 12 13 16
8 13
10 14
i:17 6
4
6 5
7 9
15 12 13 16
8 13
10 14
j
k:12 4i:17 6
3
5 8
7 9
15 12 13 16
10 13
12 14
ki:17 3
j:9 2
x
x
Min-priority queue implemented as binary min-heap
maintains all but the settled (“optimal”) vertices
min-heap property: ∀i : d(parent(i)) ≤ d(i)
amortizes the cost of multiple ExtractMin’s and DecreaseKey’sI O((|E |+ |V |)log |V |) time complexity
N. Anastopoulos (cslab@NTUA) ARCO, UPC, Barcelona July 26, 2009 30 / 43

Straightforward Parallelization
Fine-grain parallelization at the inner loop level
Fine-Grain Multi-Threaded
/* Initialization phase same to the serialcode */
while Q 6= ∅ doBarrierif tid = 0 then
u ← ExtractMin(Q);Barrierfor v adjacent to u in parallel do
sum← d [u] + w(u, v);if d [v ] > sum then
Begin-AtomicDecreaseKey(Q, v , sum);End-Atomicd [v ]← sum;π[v ]← u;
end
end
Issues
speedup bounded by averageout-degree
concurrent heap updates due toDecreaseKey’s
barrier synchronization overhead
Evaluation
conventional synch. mechanismsyield major slowdowns
TMI better performanceI highlights optimistic
parallelismI suffers from barriers overhead
N. Anastopoulos (cslab@NTUA) ARCO, UPC, Barcelona July 26, 2009 31 / 43

Helper-Threading Scheme
Motivation
expose more parallelism to each threadeliminate costly barrier synchronization
Rationale
in serial, updates are performed onlyfrom definitely optimal vertices
allow updates from possibly optimalvertices
I main thread operates as in the serialcase
I helper threads are assigned the nextminimum vertices (xk ) and performupdates from them
50
55
60 65
70
5
2
10
10 15
20
7
i-1
i
S
A
B
CD
E
8
8
8
speculation on the status of xk
I if already optimal , main thread will be offloadedI if not optimal , any suboptimal relaxations will be corrected eventually by
main thread
N. Anastopoulos (cslab@NTUA) ARCO, UPC, Barcelona July 26, 2009 32 / 43

Execution Pattern
ste
p k
ste
p k
+1
ste
p k
+2
Main
Th
read
1
Th
read
2
Th
read
3
Th
read
4
ste
p k
ste
p k
+1
ste
p k
+2
kill kill
killM
ain H
elp
er 1
Help
er 2
Help
er 3
kill
kill
ste
p k
ste
p k
+1
ste
p k
+2
extract-min
relax edges
read tidth-min
Serial FGMT Helper Threads
Decoupling of sequential/parallel parts is achieved through TM
the main thread stops all helpers at the end of each iteration
unfinished work will be corrected, as with mis-speculated distances
N. Anastopoulos (cslab@NTUA) ARCO, UPC, Barcelona July 26, 2009 33 / 43

Helper-Threading Scheme
Main thread
while Q 6= ∅ dou ← ExtractMin(Q);done ← 0;foreach v adjacent to u do
sum← d [u] + w(u, v);Begin-Xactif d [v ] > sum then
DecreaseKey(Q, v , sum);d [v ]← sum;π[v ]← u;
End-Xactend
Begin-Xactdone ← 1;End-Xact
end
Helper thread
while Q 6= ∅ dowhile done = 1 do ;x ← ReadMin(Q, tid)stop ← 0foreach y adjacent to x and while stop = 0 do
Begin-Xactif done = 0 then
sum← d [x] + w(x , y)if d [y ] > sum then
DecreaseKey(Q, y , sum)
d [y ]← sumπ[y ]← x
elsestop ← 1
End-Xactend
end
Why with TM?
composableI all dependent atomic sub-operations composed into a large atomic
operation, without limiting concurrency
optimisticeasily programmable
N. Anastopoulos (cslab@NTUA) ARCO, UPC, Barcelona July 26, 2009 34 / 43

Performance Evaluation
0.8 0.9
1 1.1 1.2 1.3 1.4 1.5 1.6 1.7 1.8 1.9
2 4 6 8 10 12 14 16 18 20 22 24 26 28 30 32
Mul
tithr
eade
d sp
eedu
p
Number of threads
10Kx10K (⇒ ideal speedup: 1.46 - 2.22)
rand-helperrmat-helperssca-helper
0.8 0.9
1 1.1 1.2 1.3 1.4 1.5 1.6 1.7 1.8 1.9
2 4 6 8 10 12 14 16 18 20 22 24 26 28 30 32
Mul
tithr
eade
d sp
eedu
p
Number of threads
10Kx200K (⇒ ideal speedup: 2.41 - 2.63)
rand-helperrmat-helperssca-helper
0.8 0.9
1 1.1 1.2 1.3 1.4 1.5 1.6 1.7 1.8 1.9
2 4 6 8 10 12 14 16 18 20 22 24 26 28 30 32
Mul
tithr
eade
d sp
eedu
p
Number of threads
10Kx1000K (⇒ ideal speedup: 4.42 - 4.64)
rand-helperrmat-helperssca-helper
0
0.5
1
1.5
2
2.5
3
2 4 6 8 10 12 14 16 18 20 22 24 26 28 30 32
Abo
rt r
ate
Number of threads
rmat-10Kx200K
overallmain thread
0
20
40
60
80
100
120
140
160
0 2 4 6 8 10 12 14 16 18 20 22 24 26 28 30 32% D
ecre
aseK
ey o
ps w
.r.t.
ser
ial e
xecu
tion
Number of threads
rmat-10Kx200K
serialHT-mainHT-helperHT-all
0
1e+07
2e+07
3e+07
4e+07
5e+07
6e+07
2 4 6 8 10 12 14 16 18 20 22 24 26 28 30 32
Mai
n th
read
cyc
le b
reak
dow
n
Number of threads
10Kx200K
total cyclesnon-xact cyclesxact cyclesxact overhead cycles
Simics 3.0.31, GEMS 2.1, LogTM-SE
speedups in 15 out of 18 graphs, up to 1.84 (max ideal speedup = 4.64)
main thread not obstructed by helpers (<1% abort rate in all cases)
N. Anastopoulos (cslab@NTUA) ARCO, UPC, Barcelona July 26, 2009 35 / 43

Conclusions
HT+TM scheme
exposes more parallelism and eliminates barrier synchronization
noteworthy speedups with minimal code extensions
Future work
TM for optimistic parallelizationI HT+TM as a programming model for other graph problems (MSTs,
maximum flow, SSSP) and other similar (“greedy”) applicationsI adjustments of existing TM systems for explicitly supporting
speculative parallelization
N. Anastopoulos (cslab@NTUA) ARCO, UPC, Barcelona July 26, 2009 36 / 43

Thank you!Questions?
N. Anastopoulos (cslab@NTUA) ARCO, UPC, Barcelona July 26, 2009 37 / 43


















