
Using text mining techniques to support the expansion of controlled vocabularies Irena Spasić...
32
Using text mining techniques to support the expansion of controlled vocabularies Irena Spasić [email protected] http://www.cbr-masterclass.org/
-
date post
18-Dec-2015 -
Category
Documents
-
view
223 -
download
0
Transcript of Using text mining techniques to support the expansion of controlled vocabularies Irena Spasić...

Using text mining techniques to support
the expansion of controlled vocabularies
Irena Spasić[email protected]
http://www.cbr-masterclass.org/

Project
• title: Population of a taxonomy referring to NMRtechniques based on evidence
automaticallyextracted from the scientific literature
• timeline: 06-Nov-2006 to 17-Nov-2006
• partners: Irena Spasić1,2, MCISBDaniel Schober2, EBIDietrich Rebholz-Schuhmann1, EBISusanna-Assunta Sansone2, EBI1 text mining, 2 MSI Ontology WG
• funding: Semantic Mining Network of Excellence,EU Information Society Technologies 6th Framework Programme

Metabolomics Society
• http://www.metabolomicssociety.org
• founded in 2004
• the most recent community-wide initiative to coordinate the efforts in standardising reporting structures of metabolomic experiments
• 5 WGs founded to cover the key areas for describing metabolomic experiments:– biological sample context
– chemical analysis
– data analysis
– ontology
– data exchange

MSI OWG
• Metabolomics Standardisation Initiative Ontology WG
• http://msi-ontology.sourceforge.net
• goal: consistent semantic annotation of metabolomics experiments to enable the community to consistently interpret and integrate their data across disparate electronic resources (software tools and databases)
• the OWG will tackle the semantics issue by: reaching a consensus on a core set of controlled vocabularies (CVs) and developing a corresponding ontology
• work coordinated by Dr Susanna-Assunta Sansone
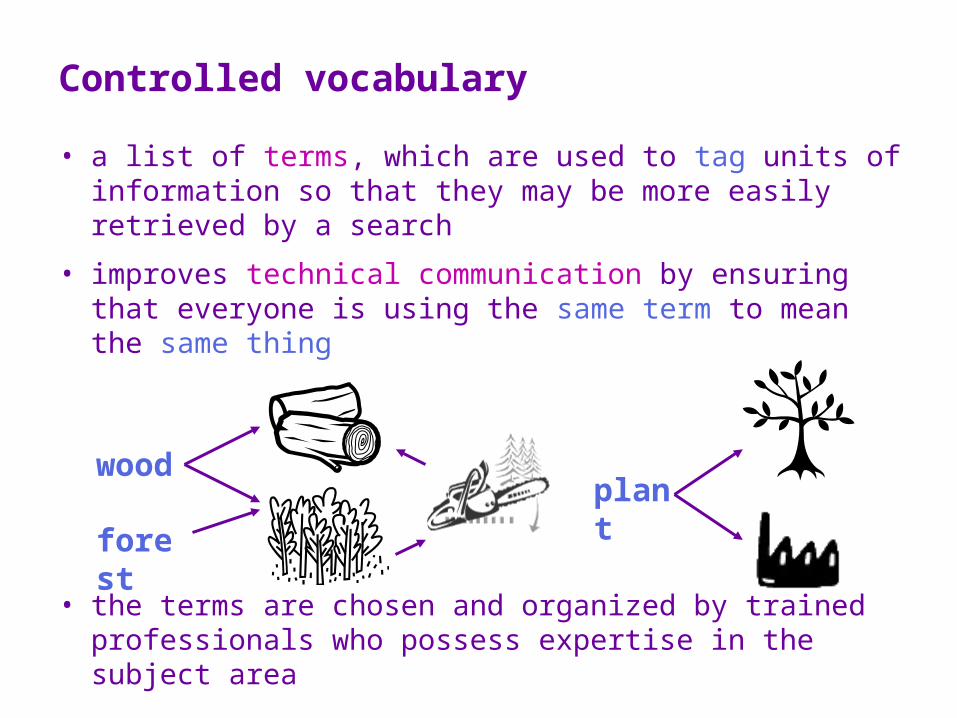
Controlled vocabulary
• a list of terms, which are used to tag units of information so that they may be more easily retrieved by a search
• improves technical communication by ensuring that everyone is using the same term to mean the same thing
• the terms are chosen and organized by trained professionals who possess expertise in the subject area
woodforest
plant

Ontology
• an explicit conceptualisation of a domain through a set of concepts, their definitions and relations between them (Uschold, 1996)
• the purpose of an ontology is to provide effective means of communication within a domain, which can be between humans and/or computer systems
• Altman et al. (1999) emphasise the communication aspect: ontologies are scientific models that support clear communication between users, and, on the other hand, store information in a structured form, thus providing support for automated processing

MSI OWG
• to facilitate the development, the OWG has divided the CVs coverage into two main components:– the general experimental component (e.g. design, sample
characteristics, treatments)
– the technology-dependant subcomponents (e.g. nuclear magnetic resonance, mass spectrometry, chromatography)
• strategy:
1. build a seed CV for each subcomponent manually
2. expand each CV semi-automatically using text mining
3. integrate the CV terms into the overall ontology

Current focus
• nuclear magnetic resonance (NMR) spectroscopy
• NMR = a technique which exploits the magnetic properties of nuclei in order to identify atom environments, and in some cases the number of atoms of each type, within a sample
• important in metabolomics because of the ability to observe mixtures of small molecules in cells and their extracts
• three main topics in the NMR ontology: method, instrument & protocol (covering the experimental parameters)

Current status of the NMR CV/ontology
• the seed CV collected by the members of the MSI OWG
• an ontology for NMR is under development
• the initial ontology compiled by Dr Daniel Schober
• the ontology currently contains around 250 hand-picked NMR-related terms
• it is expected to collect a total of around 1K terms in order to complete the ontology

Current status of the NMR CV/ontology
• the ontology is available in the OWL format
• http://www.w3.org/TR/owl-features/
• listed under OBO (Open Biomedical Ontologies)
• OBO = an umbrella web address for well-structured controlled vocabularies for shared use across different biological and medical domains
• http://obo.sourceforge.net/

Current work on the NMR CV/ontology
• using text mining to expand the coverage of the CV
• extracting currently unidentified NMR-related terms from the relevant literature
• text mining work done by Dr Irena Spasić in collaboration with Dr Dietrich Rebholz-Schuhmann

1st step: information retrieval
• in order to ensure the completeness of the NMR ontology, we propose a text mining approach over a relevant corpus of documents, which can be:– abstracts
– full papers* (especially the Material and Methods sections) where available
• relevant resources:– MEDLINE (abstracts)
http://www.nlm.nih.gov/pubs/factsheets/medline.html
– PubMed Central (full papers) http://www.pubmedcentral.gov/

Information retrieval (IR)
• in order to retrieve the relevant documents, a few approaches may be used and preferably combined:
– identifying a relevant set of MeSH terms
– using the terms currently described in the ontology as search terms
– collecting an initial corpus from domain experts

IR using MeSH terms
• MeSH = Medical Subject Headings
• http://www.nlm.nih.gov/mesh/
• MeSH is the NLM's CV used for indexing articles for MEDLINE/PubMed
• MeSH terminology provides a consistent way to retrieve information that may use different terminology for the same concepts

IR using MeSH terms
• finding the relevant MeSH terms using the MeSH browser
• http://www.nlm.nih.gov/mesh/MBrowser.html
• look up: NMR
• resulting MeSH term(s): Magnetic Resonance Spectroscopy
• PubMed query: Magnetic Resonance Spectroscopy [MeSH Terms]
• returns:
– 119,589 abstracts from MEDLINE
– 5,905 full papers from PMC

IR of full papers
• NMR (or any other analytical technique used in metabolomics) is rarely itself the focus of a metabolomics study it is expected only for the results discovered to be reported in an abstract and not for the experimental conditions leading to these results
• the experimental conditions are typically reported within “Materials & Methods” sections or as part of the supplementary material it is important to process the full text articles as opposed to abstracts only
• as a consequence, an IR approach based on MeSH terms or search terms limited to abstracts will result in a low recall (i.e. many of the relevant articles will be overlooked)
NMR
NMR
NMR
NMR
MEDLINE(abstracts)
PubMed Central
(full papers)
biomedical literature

IR of full papers
• objective: to increase the recall and obtain papers that describe research that utilises the NMR technology, but which do not deal with NMR per se and therefore are not indexed by NMR-related MeSH terms
• approach: use NMR ontology terms as search terms over full-text articles

IR of full papers: strategy
1. for each term obtain the number of papers returned from PMC
2. sort the terms by the number of paper they return; set a cut-off point to remove the terms that return too many papers, as they are likely to be broad terms not limited to NMR and therefore would introduce a lot of noise
3. for each remaining term retrieve the PMC IDs of the papers they retrieve
4. sort the PMC IDs according to the number of times they are retrieved; set a cut-off point to remove the ones that do not contain a sufficient number of known NMR terms
5. retrieve the full papers from PMC

IR: selecting the search terms
2400
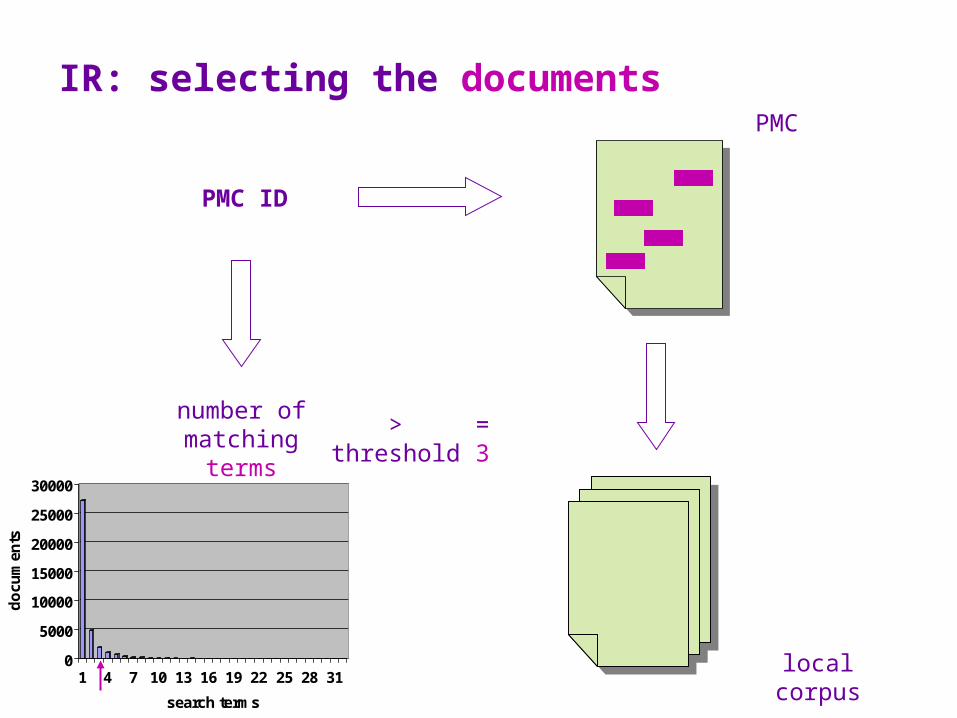
IR: selecting the documents
PMC ID
number of matching
terms
> threshold
PMC
local corpus0
5000
10000
15000
20000
25000
30000
do
cum
ents
1 4 7 10 13 16 19 22 25 28 31
search terms
= 3

Automatic term recognition (ATR)
• C-value – domain independent ATR method, which combines linguistic knowledge and statistical analysis
• linguistic part:
– used as a filter to select term candidates
– includes part-of-speech tagging, syntactic pattern matching and a stop list
• statistical part:
– used to estimate the termhood of candidate terms
– includes frequency of occurrence, frequency of nested occurrence, length

C-value: linguistic part
• part-of-speech (POS) tagging is the process of tagging the words in a text as corresponding to a particular part of speech (e.g. noun, verb, adjective) based on its definition and a particular context (i.e. in relation to adjacent and related words)beta/ADJ isoforms/N of/PREP glucocorticoid/N receptor/N
• the POS information is used later during syntactic pattern matching, which is used to extract only those words sequences that conform to certain syntactic rules
• the patterns used in the C-value method describe the typical inner structure of terms, e.g.(ADJ | N)+ | ((ADJ | N)* [N PREP] (ADJ | N)*) N

C-value: statistical analysis
• termhood of each candidate term t is calculated using:
– |t| its length as the number of words
– f(t) its frequency of occurrence
– S(t) the set of other candidate terms containing
it as a subphrase
)( if ,))(|)(|
1)((||ln
)( if ,)(||ln)(
)(
tSsftS
tft
tStfttC
tSs
Using the C-value method
• http://www.nactem.ac.uk/batch.php

Problem
• C-value extracts statistically significant terms
• C-value does not differentiate between the “NMR terms” and the terms representing the study subjects in which NMR is used only as an analytical technique, but itself is not the focus of a study
• we need to reduce the number of terms not directly related to the NMR technique
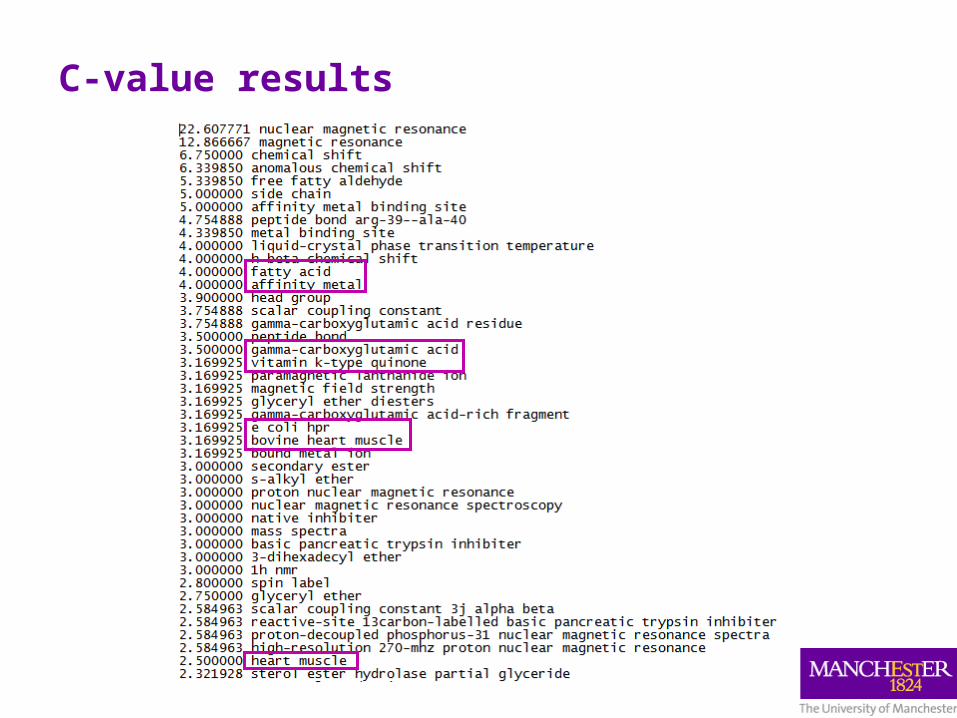
C-value results

A solution
• the initial inspection of automatically extracted terms revealed the main types of concepts studied using NMR: substances, organisms, organs, conditions/diseases…
• a straightforward approach to filtering out such terms is to use the existing dictionaries of these terms and match it against the list of automatically extracted terms

Unified Medical Language System (UMLS)
• UMLS = an “ontology” which merges information from over 100 biomedical source vocabularies
• http://umlsks.nlm.nih.gov
• UMLS contains the following semantic classes relevant to our problem:
Organism A.1.1Anatomical Structure A.1.2Substance A.1.4Biological Function B.2.2.1Injury or Poisoning B.2.3
• we used these classes to automatically extract the corresponding terms from the UMLS thesaurus
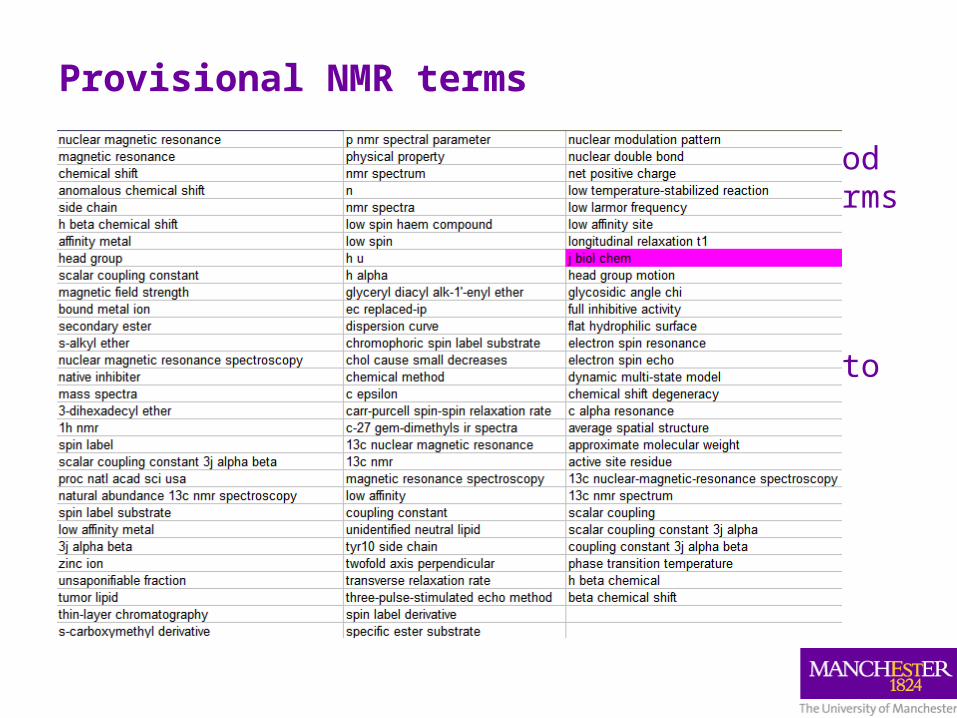
Provisional NMR terms
• the terms extracted by the C-value method which contain any of the chosen UMLS terms are removed from the final list of “NMR terms”
• in this manner, 88 terms have been extracted from abstracts and passed on to the curators
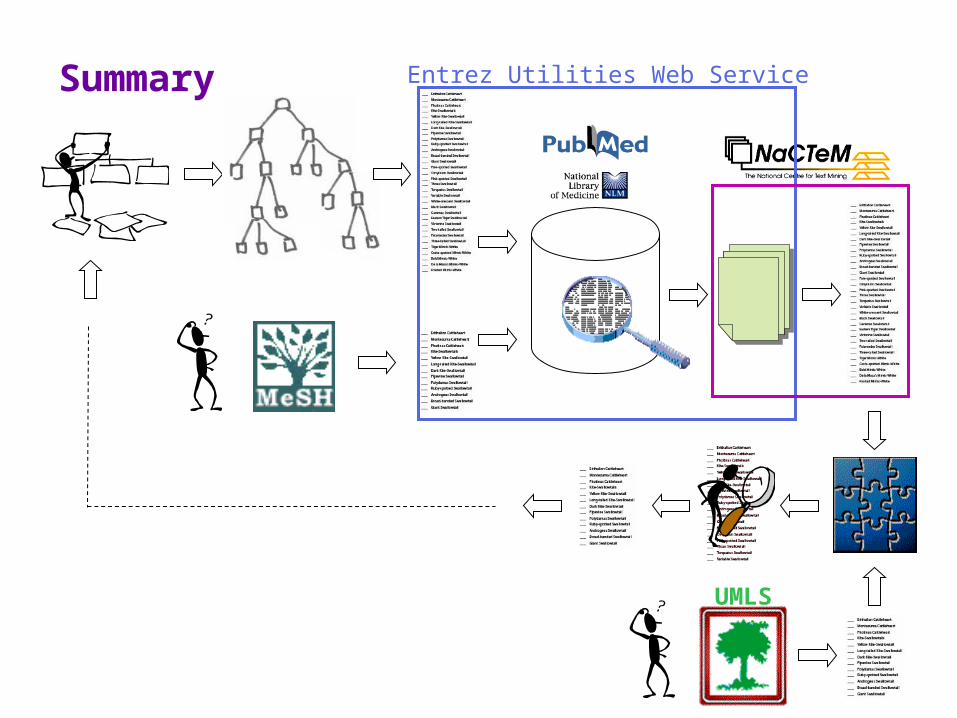
Summary Entrez Utilities Web Service
UMLS

The End

Motivation
NMR
NMR
NMR
NMR
MEDLINE(abstracts)
PubMed Central
(full papers)
biomedical literature


















