
University of Michigan Electrical Engineering and Computer Science 1 Integrating...
15
1 University of Michigan Electrical Engineering and Computer Science Integrating Post- programmability Into the High-level Synthesis Equation* Scott Mahlke Advanced Computer Architecture Laboratory University of Michigan Ann Arbor, MI USA * This is work done by Kevin Fan and Manjunath Kudlur at UM
-
Upload
pauline-scott -
Category
Documents
-
view
215 -
download
0
Transcript of University of Michigan Electrical Engineering and Computer Science 1 Integrating...

1 University of MichiganElectrical Engineering and Computer Science
Integrating Post-programmability Into the High-level Synthesis Equation*
Scott Mahlke
Advanced Computer Architecture LaboratoryUniversity of Michigan
Ann Arbor, MI USA
* This is work done by Kevin Fan and Manjunath Kudlur at UM

2 University of MichiganElectrical Engineering and Computer Science
Application Engines Differentiate Consumer SoCs
Slide Courtesy of Synfora
3 University of MichiganElectrical Engineering and Computer Science
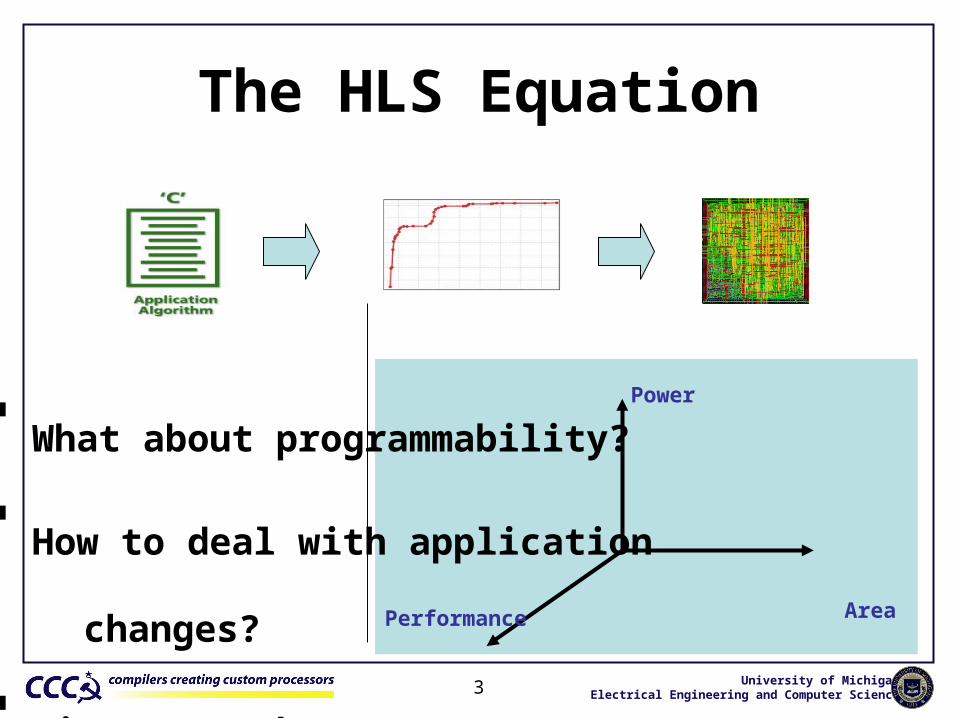
The HLS Equation
Area
Power
Performance
What about programmability?
How to deal with application
changes?
Time to market

4 University of MichiganElectrical Engineering and Computer Science
Substrate Determines Programmability
MAC
Unit
Addr
Gen
P
Prog Mem
Embedded Processor
(lpArm)
Direct MappedHardware
EmbeddedFPGA
DSP(e.g. TI 320CXX )
Fle
xib
ility
Area or Power
Reconfigurable Processors (Maia)
Factor of 100-1000
100-1000 MOPS/mW
10-100MOPS/mW
.5-5MOPS/mW

5 University of MichiganElectrical Engineering and Computer Science
for(k=0; k<N4; k++) { ... real = Z1[k][0]; img = Z1[k][1];
Z1[k][0] = real * sincos[k][0] - img*sincos[k][1];
Z1[k][0] = Z1[k][0] << 1; if(b_scale) { Z1[k][0] = Z1[k][0] * scale; }}
Version 1.40
for(k=0; k<N4; k++) { ... uint16_t n = k << 1; ComplexMult(...);
X_out[ n] = -RE(x); X_out[N2 - 1 - n] = IM(x); X_out[N2 + n] = -IM(x); X_out[N - 1 - n] = RE(x);}
Version 1.34
for(k=0; k<N4; k++) { ... uint16_t n = k << 1; ComplexMult(...);
X_out[ n] = RE(x); X_out[N2 - 1 - n] = -IM(x); X_out[N2 + n] = IM(x); X_out[N - 1 - n] = -RE(x);}
Version 1.33
Bug fix
in faad2
How Much Programmability?
for(k=0; k<N4; k++) { ... real = Z1[k][0]; img = Z1[k][1];
Z1[k][0] = real * sincos[k][0] - img*sincos[k][1];
Z1[k][0] = Z1[k][0] << 1;}
Version 1.39
New feature
in faad2
Just Enough!

6 University of MichiganElectrical Engineering and Computer Science
StreamRoller Approach
FrameType?
Loop 2 Loop 3
Loop 1
Loop 4
Application
…
Block 5
Loop Accelerator Template Architecture
Point-to-point Connections
+
… …
&
… …
MEM
… …
LocalMem
FSM
Controlsignals
CRF
BR

7 University of MichiganElectrical Engineering and Computer Science
LA Programmability Shortcomings
Point-to-point Connections
+
… …
&
… …
MEM
… …
LocalMem
FSM
Controlsignals
CRF
BR
1. Point-to-point interconnect:
Only dataflow in the original
application is supported
2. Fixed functionality:
Only operators in the original
application are supported3. Hardwired control and
unaddressable register
storage

8 University of MichiganElectrical Engineering and Computer Science
Programmable Loop Accelerator
Point-to-point Connections
+/-
… …
&/|
… …
MEM
… …
LocalMem
ControlMemory
Controlsignals
CRF
BR
RR RRRRRR
Literals
Bus
1. Low-cost functionality generalization 2. Addressable rotating registers
3. Low bandwidth full connectivity path 4. Enable input swapping
5. Programmable literals 6. Memory for decoded control

9 University of MichiganElectrical Engineering and Computer Science
Mapping New Loops onto a PLA
MoveInsertion
SMTScheduling
RegisterAllocation
LoopControl SignalsMachine
descriptionIncrement II
• Large search space, few solutions• Op-centric approaches unable to find solutions• Satisfiability Modulo Theory (SMT) formulation to
solve linear and SAT constraints simultaneously

10 University of MichiganElectrical Engineering and Computer Science
Area Comparison – 130nm Library
0
0.2
0.4
0.6
0.8
1
1.2
1.4b
ffo
rm
dca
c
de
qu
an
t
fft
fir
fmra
dio
fse
d
he
at lu
sob
el
ave
rag
e
Are
a (m
m2)
LA
PLA
OR1K
LA = single function accelerator, PLA = programmable accelerator, OR1K = OR-1200 processor
11 University of MichiganElectrical Engineering and Computer Science
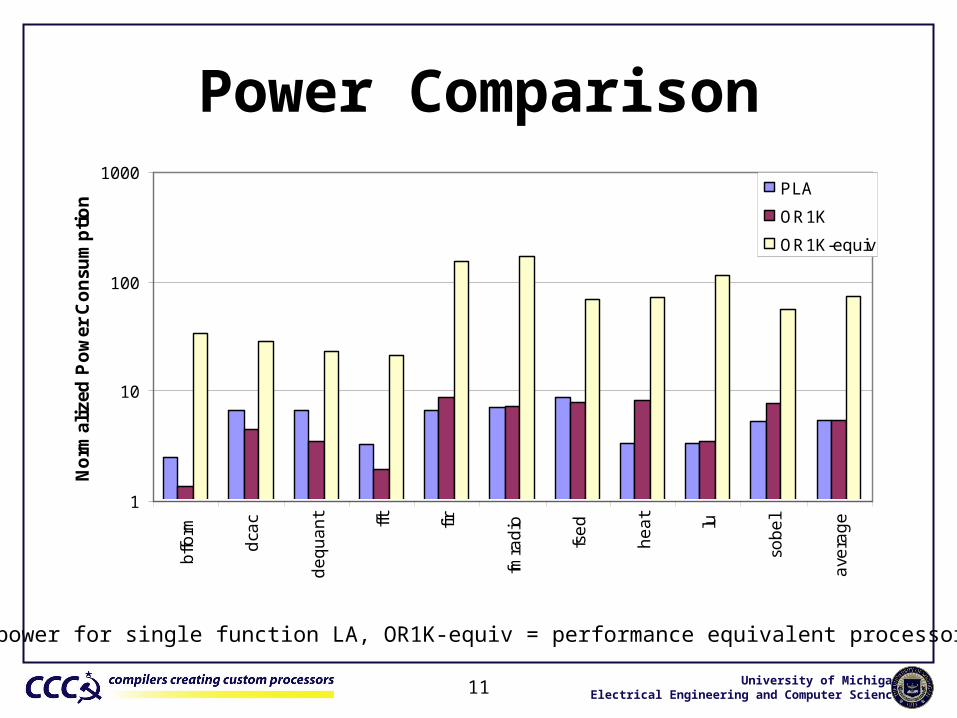
Power Comparison
1
10
100
1000b
fform
dca
c
de
qu
an
t fft fir
fmra
dio
fse
d
he
at
lu
sob
el
ave
rag
e
No
rmal
ized
Po
wer
Co
nsu
mp
tio
n
PLA
OR1K
OR1K-equiv
1.0 = power for single function LA, OR1K-equiv = performance equivalent processor

12 University of MichiganElectrical Engineering and Computer Science
Efficiency Comparison
0
200
400
600
800
1000
1200
1400
0 10 20 30 40 50 60
Power Consumption (mW)
Pe
rfo
rma
nc
e (
MIP
S)
LA
PLA
OR1K
20 MIPS/mW
2 MIPS/mW
200 MIPS/mW
13 University of MichiganElectrical Engineering and Computer Science
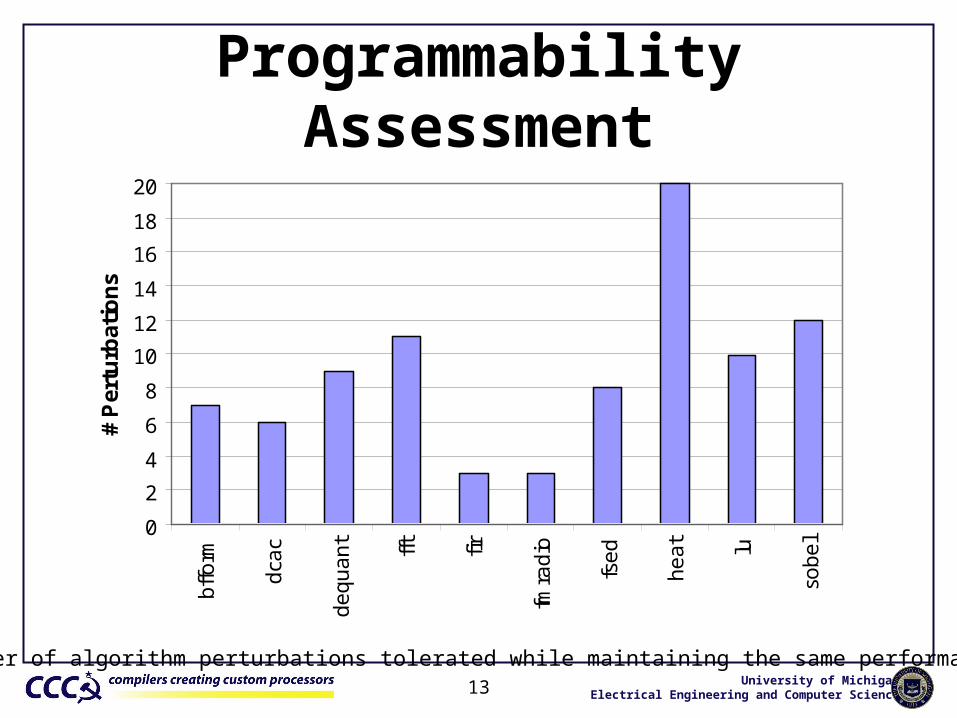
Programmability Assessment
0
2
4
6
8
10
12
14
16
18
20b
ffo
rm
dca
c
de
qu
an
t
fft
fir
fmra
dio
fse
d
he
at lu
sob
el
# P
ertu
rbat
ion
s
Number of algorithm perturbations tolerated while maintaining the same performance

14 University of MichiganElectrical Engineering and Computer Science
Final Thoughts
• Programmability not an all or nothing issue– Application accelerators need to be able to evolve– HLS + targeted design generalizations yield a highly customized,
but semi-programmable ASIC• Bottom line tradeoffs
– PLA vs OR-1200: 4 - 34x more power efficient, 30x smaller – PLA vs ASIC: 2 - 9x worse power, 2x larger
• Cost breakdown– Addressable register storage and generalized FUs most costly– Interconnect extensions less costly

15 University of MichiganElectrical Engineering and Computer Science
For More Information
http://cccp.eecs.umich.edu
• “Modulo Scheduling for Highly Customized Datapaths to Increase Hardware Reusability,” K. Fan, H. Park, M. Kudlur, and S. Mahlke, Proc. 2008 International Symposium on Code Generation and
Optimization, Apr. 2008, pp. 124-133. • “Orchestrating the Execution of Stream Programs on Multicore
Platforms,” M. Kudlur and S. Mahlke, Proc. ACM SIGPLAN 2008 Conference on Programming Languages Design and Implementation, Jun. 2008.


















