Unit 1 Data Structure
33
Escuela Superior de Informática de Ciudad Real Universidad de Castilla-La Mancha Data Structures Unit 1 General Concepts
description
Unit 1 Data Structure
Transcript of Unit 1 Data Structure

Escuela Superior de Informática de Ciudad Real
Universidad de Castilla-La Mancha
Data Structures
Unit 1
General Concepts

© Escuela Superior de Informática de Ciudad Real (UCLM) 2
Objectives and competencies
UNIT 1: GENERAL CONCEPTS
Competencies
BA3 Capacidad para comprender y dominar los conceptos básicos de matemática discreta, lógica, algorítmica y complejidad computacional, y su aplicación para la resolución de problemas propios de la ingeniería.
CO6 Conocimiento y aplicación de los procedimientos algorítmicos básicos de las tecnologías informáticas para diseñar soluciones a problemas, analizando la idoneidad y complejidad de los algoritmos propuestos.
CO7 Conocimiento, diseño y utilización de forma eficiente de los tipos y estructuras de datos más adecuados para la resolución de un problema.
INS1 Capacidad de análisis, síntesis y evaluación.
INS4 Capacidad de resolución de problemas aplicando técnicas de ingeniería.
SIS1 Razonamiento crítico.
SIS3 Aprendizaje autónomo.
UCLM2 Capacidad para utilizar las Tecnologías de la Información y la Comunicación.
Learning outcomes
Saber manejar tipos de datos, estructuras de datos y tipos abstractos de datos de forma correcta y adecuada a los problemas, así como su especificación formal, implementación y utilización de los tipos abstractos de datos lineales y no lineales.
Diseñar soluciones a problemas, analizando la idoneidad y complejidad de los algoritmos propuestos

© Escuela Superior de Informática de Ciudad Real (UCLM) 3
References
UNIT 1: GENERAL CONCEPTS
Basic references
B. Meyer, “Construcción de Software Orientado a Objetos”, Capítulo 6: TiposAbstractos de Datos. Segunda edición, Prentice-Hall (1999)
M. T. Goodrich & R. Tamassia, “Data Structures and Algorithms in Java”, Chapter 4 6th Edition. International Student Version, John Wiley (2011).
PowerPoint PDF Handouts:
http://bcs.wiley.com/he-bcs/Books?action=chapter&bcsId=8950&itemId=1118808576&chapterId=101146
Specific references
J. V. Guttag, E. Horowitz and D. R. Musser, “Abstract Data Types and the Development of Data Structures”, Communications of ACM, 20, 396-404 (1977)
J. V. Guttag, E. Horowitz and D. R. Musser, “Abstract Data Types and Software Validation”, Communications of ACM, 21, 1048-1064 (1978)

© Escuela Superior de Informática de Ciudad Real (UCLM) 4
Outline
UNIT 1: GENERAL CONCEPTS
1. Introduction
2. Data structures and Abstract Data Types (ADTs)
3. ADTs specification
3.1. UML based specification
3.2. Algebraic specification
3.2.1. Syntactic specification
3.2.2. Semantic specification
4. Analysis of algorithms
4.1. RAM model
4.2. Primitive operations
4.3. Big-Oh notation
4.4. Asymptotic analysis
5. Useful tips (reminder)

© Escuela Superior de Informática de Ciudad Real (UCLM) 5
1. Introduction (I) This is a course about what in computer science are called data
structures. What is that?
A data structure is a data container (it stores and supplies data).
A data structure is related to the concepts of data type and abstract
data type.
Remember, a data type represents a set of values (recall the
primitive data types).
A structured data is a set of variables of, possibly, different data
types.
An abstract data type involves a structured data plus a set of
operations available for it.
A data structure will correspond to an ADT.

© Escuela Superior de Informática de Ciudad Real (UCLM) 6
1. Introduction (II) Data structures are fundamental components of algorithms (which
are specifically considered in “Programming
Methodology/Metodología de la Programación” in the second
semester).
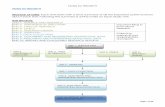
In this course, we will consider the most common data structures:
Lists
Stacks Queues
Trees
Data structures
Linear Nonlinear
Graphs

© Escuela Superior de Informática de Ciudad Real (UCLM) 7
1. Introduction (III)
Very important: THIS COURSE IS NOT FOCUSED ON
PROGRAMMING.
Programming will be mainly a tool for implementing examples
using data structures.
The goal is not, specifically, to implement data structures.
In fact, most of the data structures are already available in standard
packages.
Let’s consider in more detail both, data structures and abstract data
types.

© Escuela Superior de Informática de Ciudad Real (UCLM) 8
2. Data structures and ADTs (I)
It is convenient to start considering the concept of Abstract Data
Type (ADT) introduced in the 1970’s. So, what’s an Abstract Data
Type?
Aho, Hopcroft & Ullman definition: An ADT is a mathematical
model, together with several operations defined on the model.
NIST (National Institute of Standards and Technology) definition:
In very practical terms, an ADT is a set of data (variables) and
functions (methods) acting on that data.
ADT: A set of data values and associated operations that are precisely specified independent
of any particular implementation.

© Escuela Superior de Informática de Ciudad Real (UCLM) 9
2. Data structures and ADTs (II)
An ADT is an abstract model. Then, how do we use an ADT in a
computer?
Data structures can be described as ADTs.
A data structure is a set of variables responding to the set of
methods that represent an ADT.
Remember: An ADT has a correspondence with the concept of
class in object orientation.

© Escuela Superior de Informática de Ciudad Real (UCLM) 10
2. Data structures and ADTs (III)
From the object orientation standpoint, the data structure
corresponds to a class that implements the ADT methods.
In lay terms, a data structure is (or corresponds to) the practical
realization of an ADT.
Thus, to describe a data structure we must specify the
corresponding ADT.

© Escuela Superior de Informática de Ciudad Real (UCLM) 11
2. Data structures and ADTs (IV)
Extremely important: The ADT (or the data structure) is defined by
its specification not by its implementation.
The key point is that the operations define the ADT. The ADT is NOT
defined by the data it contains.
Therefore, the way to work with an ADT is through its operations
(just by calling the methods in a class).
You NEVER work with an ADT (data structure) by accessing its data
because those data depend on the implementation used.
However, the operations do not depend on the implementation.

© Escuela Superior de Informática de Ciudad Real (UCLM) 12
3. ADTs specification
How can we describe, specify, the behavior of an ADT?
The basic idea is to be able to describe the operations of the ADT
(remember, the ADT is defined by its operations not by its data).
There is not a single specification approach.
We can use different approaches: the syntax of a language, UML
notation, or, the traditional algebraic specification.
Let’s present a simple specification based on UML.

© Escuela Superior de Informática de Ciudad Real (UCLM) 13
3.1. UML based specification
To describe the behavior of the operations in the ADT we can use
the method specification notation of UML:
method1 (parameter1: type, parameter2: type,…): return type
Thus, we can specify the data that the method acts on (the formal
parameters) and the result produced (the return type).
We should specify every method (operation) associated to the ADT.
However, the most complete (sometimes “too” complete)
specification method is the traditional algebraic specification.

© Escuela Superior de Informática de Ciudad Real (UCLM) 14
3.2. Algebraic specification (I)
The algebraic specification was initially developed in the late 1970’s
by groups in Europe and US.
The idea was to use algebraic specification as a formal
specification technique for abstract data types.
An algebraic data type specification consists of a syntactic and a
semantic specification.
The syntactic specification defines the names, domains and ranges
of the ADT’s operations (how to use the operation: form).
The semantic specification contains a set of axioms in the form of
equations that relate the operations of the ADT to each other (what
the operation does: meaning).

© Escuela Superior de Informática de Ciudad Real (UCLM) 15
3.2. Algebraic specification (II)
The syntactic specification corresponds to the previously
presented UML specification.
The semantic specification is needed for formal verification
techniques (to prove that the ADT does what it is supposed to do).
Since we are not performing formal verifications, in the rest of the
course we will restrict ourselves to the syntactic specification
(algebraic or other) of the considered ADT’s.

© Escuela Superior de Informática de Ciudad Real (UCLM) 16
3.2.1. Syntactic specification (I)
We will use algebraic notation (some authors use some kind of
programming notation).
In the syntactic specification (or simply syntax) we identify the type
and signature of the operations.
We must specify:
– The ADT (as a general entity, for instance a stack, not “a stack of
integers”, or “a stack of doubles”)
– Auxiliary types used in the specification
– The operations. We define the operation using the concept (and
syntax) of functions. We specify the name of the operation, the set
to which each data belongs and the set the result belongs to.
Example: consider the addition (add) of natural numbers:
› add: N x N → N
– add is the name of the operation, N represents the natural numbers,
x the Cartesian product, and the arrow (→) the result.

© Escuela Superior de Informática de Ciudad Real (UCLM) 17
3.2.1. Syntactic specification (II)
The aspect of a syntactic specification for the stack ADT is:
Partial functions: in some cases the operation is not defined
(Exception)
Type: stack
Sorts: el (element), boolean, natural
Operations:
init : stack
push : stack x el stack
pop : stack / stack
top : stack / el
isEmpty : stack boolean
size : stack natural
Syntax
Partial
functions

© Escuela Superior de Informática de Ciudad Real (UCLM) 18
3.2.2. Semantic specification (I)
With the syntax we could have data structures with the same
specification but with different behavior (a stack and a queue, for
instance). The semantics breaks the ambiguity.
Here, in the semantics, we specify the behavior of each operation
using axioms.
Remember, in traditional logic, an axiom or postulate is a
proposition that is not proved or demonstrated but considered to
be self-evident. An axiom is a logical statement that is assumed to
be true.
For each operation, we define an axiom.

© Escuela Superior de Informática de Ciudad Real (UCLM) 19
3.2.2. Semantic specification (II)
The aspect of a semantic specification is:
From now on we will focus just on the syntactic specification.
p stack, e element
Axioms:
isEmpty(init) true
isEmpty(push(p, e)) false
top(init) error
top(push(p, e)) e
size (init) 0
size (push(p, e)) size (p)+1
pop(init) error
pop(push(p, e)) p

© Escuela Superior de Informática de Ciudad Real (UCLM) 20
4. Analysis of algorithms (I)
An algorithm can be analyzed in terms of
time efficiency or space utilization. We
will consider only the former right now.
The running time of an algorithm
typically grows with the input size.
Types of analysis
– Best case: Lower bound on cost.
Determined by “easiest” input.
– Worst case: Upper bound on cost.
Determined by “the most difficult”
input.
– Average case: Expected cost for a
random input. Need of a model for
defining what “random input” is.
Average case time is often difficult to
determine. We focus on the worst case
running time.
0
20
40
60
80
100
120
Ru
nn
ing
Tim
e
1000 2000 3000 4000
Input Size
best case
average case
worst case

© Escuela Superior de Informática de Ciudad Real (UCLM) 21
4. Analysis of algorithms (II)
Example: Comparing the growth of the running time, as the input
grows, to the growth of known functions.
Time efficiency: log n < n < n log n < n² < n³ < 2ⁿ
Input Size (n) n log n n log n n² n³ 2ⁿ
5 5 3 15 25 125 32
10 10 4 33 100 10³ 10³
100 100 7 664 104 106 1030
1000 1000 10 104 106 109 10300
10000 10000 13 105 108 1012 103000

© Escuela Superior de Informática de Ciudad Real (UCLM) 22
A picture is worth a thousand words

© Escuela Superior de Informática de Ciudad Real (UCLM) 23
4. Analysis of algorithms (III)
To analyze an algorithm we have two options:
– To perform an experimental study.
– To perform a theoretical analysis.
Problems with the experimental approach:
– It is necessary to implement the algorithm, which may be difficult.
– Results may not be indicative of the running time on other inputs not included in the experiment.
– In order to compare two algorithms, the same hardware and software environments must be used.

© Escuela Superior de Informática de Ciudad Real (UCLM) 24
4. Analysis of algorithms (IV)
Advantages of the theoretical approach:
– Only needs a high-level description of the algorithm instead of an
implementation.
– Characterizes running time as a function of the input size, n.
– Takes into account all possible inputs.
– Allows us to evaluate the speed of an algorithm independently of
the hardware/software environment.
We present here the theoretical approach.
In it, we describe the algorithm using pseudo-code.
First of all, we need a model for computing the operations the
algorithm performs.

© Escuela Superior de Informática de Ciudad Real (UCLM) 25
4.1. RAM model (I)
The Random Access Machine (RAM) model is a
simple model to quantify algorithms.
The model considers:
– A single (sequential) CPU
– A potentially unbounded bank of memory cells,
each of which can hold an arbitrary number or
character.
– Memory cells are numbered and accessing any
cell in memory takes unit time.
The goal is counting operations, so we must
now consider what are the basic, primitive
operations we want to count.
01
2

© Escuela Superior de Informática de Ciudad Real (UCLM) 26
4.1. RAM model (II)
What are the basic operations?
– Basic computations performed by an algorithm
– Identifiable in pseudo-code
– Largely independent from the programming language
– Exact definition not important (we will see why later)
– Assumed to take a constant amount of time in the RAM model. The
time is the same for every operation.

© Escuela Superior de Informática de Ciudad Real (UCLM) 27
4.1. RAM model (III)
Examples of basic operations:
– Evaluating an expression
– Assigning a value to a variable
– Indexing into an array
– Calling a method
– Returning from a method
By inspecting the pseudo-code, we can determine the maximum
number of primitive operations executed by an algorithm, as a
function of the input size.
Let’s see an example:

© Escuela Superior de Informática de Ciudad Real (UCLM) 28
4.1. RAM model (IV)
Example: find maximum element of an array (the worst case is
when the maximum value is the last element of the array)
Algorithm arrayMax(A, n) # operations
currentMax A[0] 2
for i 1 to n 1 do 2n+1
if A[i] currentMax then 2(n 1)
currentMax A[i] 2(n 1)
{ increment counter i } 2(n 1)
return currentMax 1
Total 8n 2
Best case? We never execute currentMax A[i]
Total 6n

© Escuela Superior de Informática de Ciudad Real (UCLM) 29
1
10
100
1.000
10.000
1 10 100 1.000
n
3n
2n+10
n
4.3. Big-Oh notation (I)
Big-Oh notation characterizes functions according to their growth
rates (how fast the function grows).
Let’s go back to the worst case scenario.
Given functions f(n) and g(n), we say that f(n) is O(g(n)) (“f(n) is
order of g(n)”) if there are positive constants c and n0 such that
f(n) c · g(n) for n n0
We say f(n) “is big-oh” g(n)
Example: 2n + 10 is O(n) since:
– 2n + 10 c · n, then
– (c 2) n 10, then
– n 10/(c 2), then
– Pick c = 3, then n0 = 10 and that’s it
From n=10, the growth rate is the same for the two functions.

© Escuela Superior de Informática de Ciudad Real (UCLM) 30
4.3. Big-Oh notation (II)
The big-Oh notation gives an upper bound (remember, the worst
case) on the growth rate of a function.
The statement “f(n) is O(g(n))” means that the growth rate of f(n) is
no more than the growth rate of g(n). Your function does not grow
faster than g(n).
We can use the big-Oh notation to rank functions according to their
growth rate.
f(n) is O(g(n)) g(n) is O(f(n))
g(n) grows more Yes No
f(n) grows more No Yes
Same growth Yes Yes

© Escuela Superior de Informática de Ciudad Real (UCLM) 31
4.4. Asymtotic analysis
Now, for comparing algorithms, we apply the Big-Oh notation to the
running time (# operations). This is called asymptotic analysis. With
this, the running time is expressed in big-Oh notation.
To perform the asymptotic analysis
– We find the worst-case number of primitive operations executed as
a function of the input size, T(n).
– We are interested in what happens with T(n) when n ∞ (the limit)
– We express the resulting function with big-Oh notation.
Example:
– We determine that algorithm arrayMax executes at most 8n 2
primitive operations.
– T(n) = 8n when n ∞
– We say that algorithm arrayMax “runs in O(n) time”
Since constant factors and lower-order terms are eventually
dropped anyhow, we can disregard them when counting primitive
operations.

© Escuela Superior de Informática de Ciudad Real (UCLM) 32
5. Useful tips (Reminder)
We collect here the concepts needed in this course from
“Programming Fundamentals I“ and “Programming Fundamentals
II”.
Programming Fundamentals I (Fundamentos de Programación I) :
– Recursion
Programming Fundamentals II (Fundamentos de Programación II) :
– Class definition
– Inheritance
– Polymorphism
– Interfaces
– Exceptions
– Generics
– Linked list/variables
JoséÁngel
Resaltado
JoséÁngel
Resaltado

© Escuela Superior de Informática de Ciudad Real (UCLM) 33
Recommended activities
UNIT 1: GENERAL CONCEPTS
Recommended readings
http://www.informatik.uni-bremen.de/agbkb/forschung/formal_methods/completed_projects/compass/7years_e.htm
http://en.wikipedia.org/wiki/Exponential_growth
http://en.wikipedia.org/wiki/Wheat_and_chessboard_problem
Recommended activities
Invent some ADTs, and develop the corresponding specification.
Solve the unsolved problems from the list proposed.
Apply the asymptotic analysis to your own algorithms.