
Unified Communication X (UCX) - openucx.org · Non-blocking API for all one-sided operations...
56
UCF Consortium Project Unified Communication X (UCX) ISC 2019
Transcript of Unified Communication X (UCX) - openucx.org · Non-blocking API for all one-sided operations...

UCF Consortium Project
Unified Communication X (UCX)
ISC 2019

© 2018 UCF Consortium 2
UCF Consortium
Mission: • Collaboration between industry, laboratories, and academia to create production grade communication
frameworks and open standards for data centric and high-performance applications
Projects• UCX – Unified Communication X
• Open RDMA
Board members• Jeff Kuehn, UCF Chairman (Los Alamos National Laboratory)
• Gilad Shainer, UCF President (Mellanox Technologies)
• Pavel Shamis, UCF treasurer (ARM)
• Brad Benton, Board Member (AMD)
• Duncan Poole, Board Member (NVIDIA)
• Pavan Balaji, Board Member (Argonne National Laboratory)
• Sameh Sharkawi, Board Member (IBM)
• Dhabaleswar K. (DK) Panda, Board Member (Ohio State University)
• Steve Poole, Board Member (Open Source Software Solutions)

© 2018 UCF Consortium 3
UCX - History
LA
MPI
MXM
Open
MPI
2000 2004
PAMI
2010
UCX
2011 2012
UCCS
A new project based
on concept and ideas
from multiple
generation of HPC
networks stack
• Performance
• Scalability
• Efficiency
• Portability
Modular
Architecture
APIs, context,
thread safety,
etc.
APIs, software
infrastructure
optimizations
Network
Layers
APIs, Low-level
optimizations
Decades of community and
industry experience in
development of HPC network
software

© 2018 UCF Consortium 4
UCX High-level Overview

© 2018 UCF Consortium 5
UCX Framework
UCX is a framework for network APIs and stacks
UCX aims to unify the different network APIs, protocols and implementations into a single framework
that is portable, efficient and functional
UCX doesn’t focus on supporting a single programming model, instead it provides APIs and
protocols that can be used to tailor the functionalities of a particular programming model efficiently
When different programming paradigms and applications use UCX to implement their functionality, it
increases their portability. As just implementing a small set of UCX APIs on top of a new hardware
ensures that these applications can run seamlessly without having to implement it themselves

© 2018 UCF Consortium 6
UCX Development Status
© 2018 UCF Consortium 7
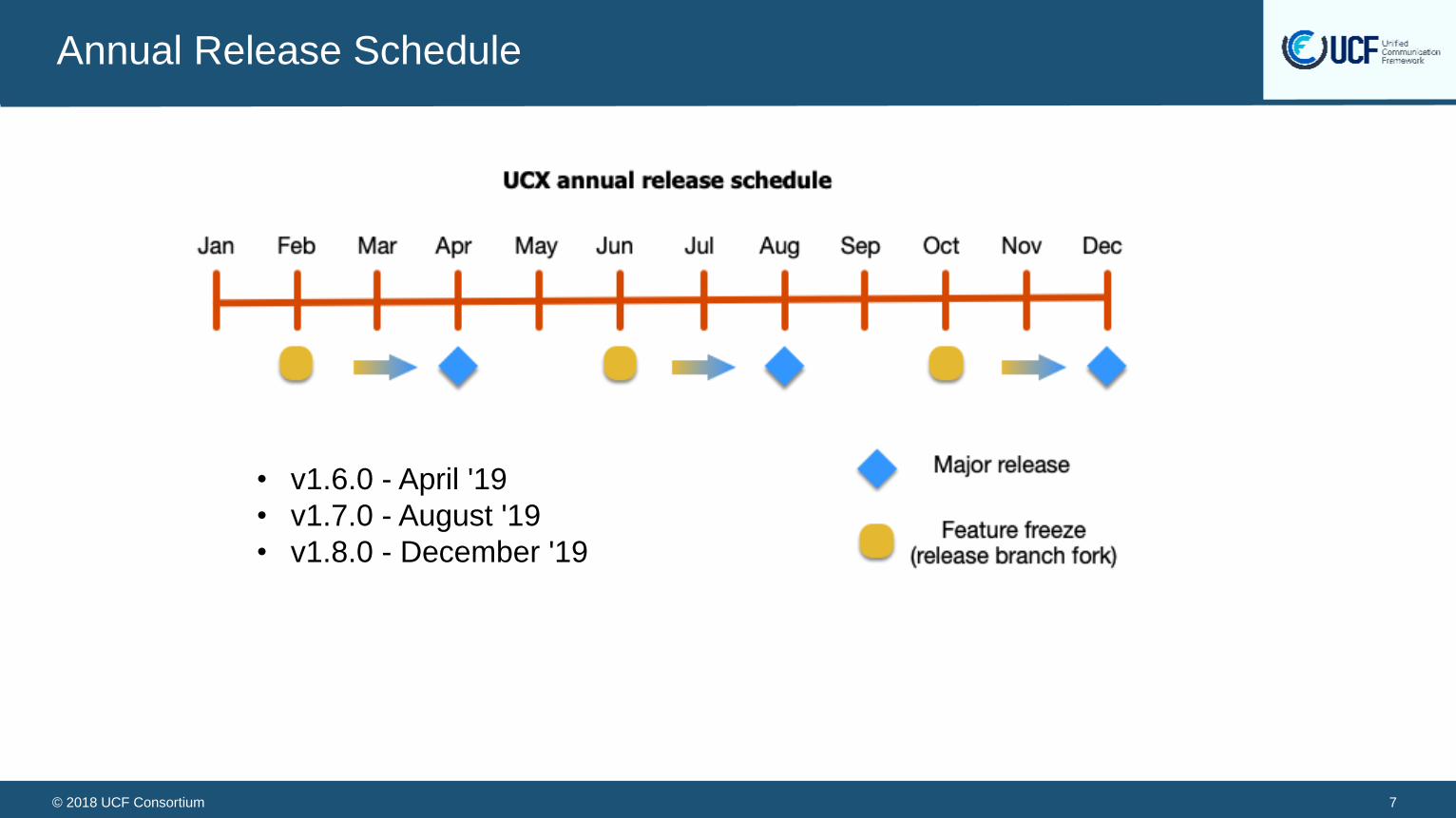
Annual Release Schedule
• v1.6.0 - April '19
• v1.7.0 - August '19
• v1.8.0 - December '19

© 2018 UCF Consortium 8
UCX at Scale

© 2018 UCF Consortium 9
UCX Portability
Support for x86_64, Power 8/9, Arm v8
Runs on Servers, Raspberry PI like platforms, SmartNIC, Nvidia Jetson platforms, etc.
NVIDIA Jetson
Arm ThunderX2
Bluefield SmartNIC
Odroid C2

© 2018 UCF Consortium 10
RECENT DEVELOPMENT v1.5.x
UCP emulation layer (atomics, rma)
Non-blocking API for all one-sided operations
Client/server connection establishment API
Malloc hooks using binary instrumentation instead of symbol override
Statistics for UCT tag API
GPU-to-Infiniband HCA affinity support based on locality/distance (PCIe)
GPU - Support for stream API and receive side pipelining

© 2018 UCF Consortium 11
RECENT DEVELOPMENT v1.6.x
AMD GPU ROCm transport re-design: support for managed memory, direct copy, ROCm GDR
Modular architecture for UCT transports
Random scheduling policy for DC transport
OmniPath support (over verbs)
Optimized out-of-box settings for multi-rail
Support for PCI atomics with IB transports
Reduced UCP address size for homogeneous environments

© 2018 UCF Consortium 12
Coming Soon !
Python bindings ! + Integration
with Dask and Rapids AI
Java bindings ! + Integration with
SparkRDMA
iWARP support
GasNET over UCX
Collectives
FreeBSD support
MacOS support
Moving CI to Jenkins and Azure
Pipelines
TCP performance optimizations
Hardware tag matching
optimizations

© 2018 UCF Consortium 13
UCX Machine Layer in Charm++

© 2018 UCF Consortium 14
UCX Machine Layer in Charm++
Charm++ is an object-oriented and message-driven parallel programming model with an adaptive
runtime system that enables high-performance applications to scale.
The Low-level Runtime System (LRTS) is a thin software layer in the Charm++ software stack
that abstracts specific networking functionality, which supports uGNI, PAMI, Verbs, MPI, etc.
UCX is a perfect fit for Charm++ machine layer:
• Just ~1000 LoC is needed to implement all LRTS APIs (MPI takes ~2700 LoC, Verbs takes ~8000LoC)
• UCX provides ultra low latency and high bandwidth sitting on top of RDMA Verbs stack
• UCX provides much less intrusive and close-to hardware API for one-sided communications than MPI

© 2018 UCF Consortium 15
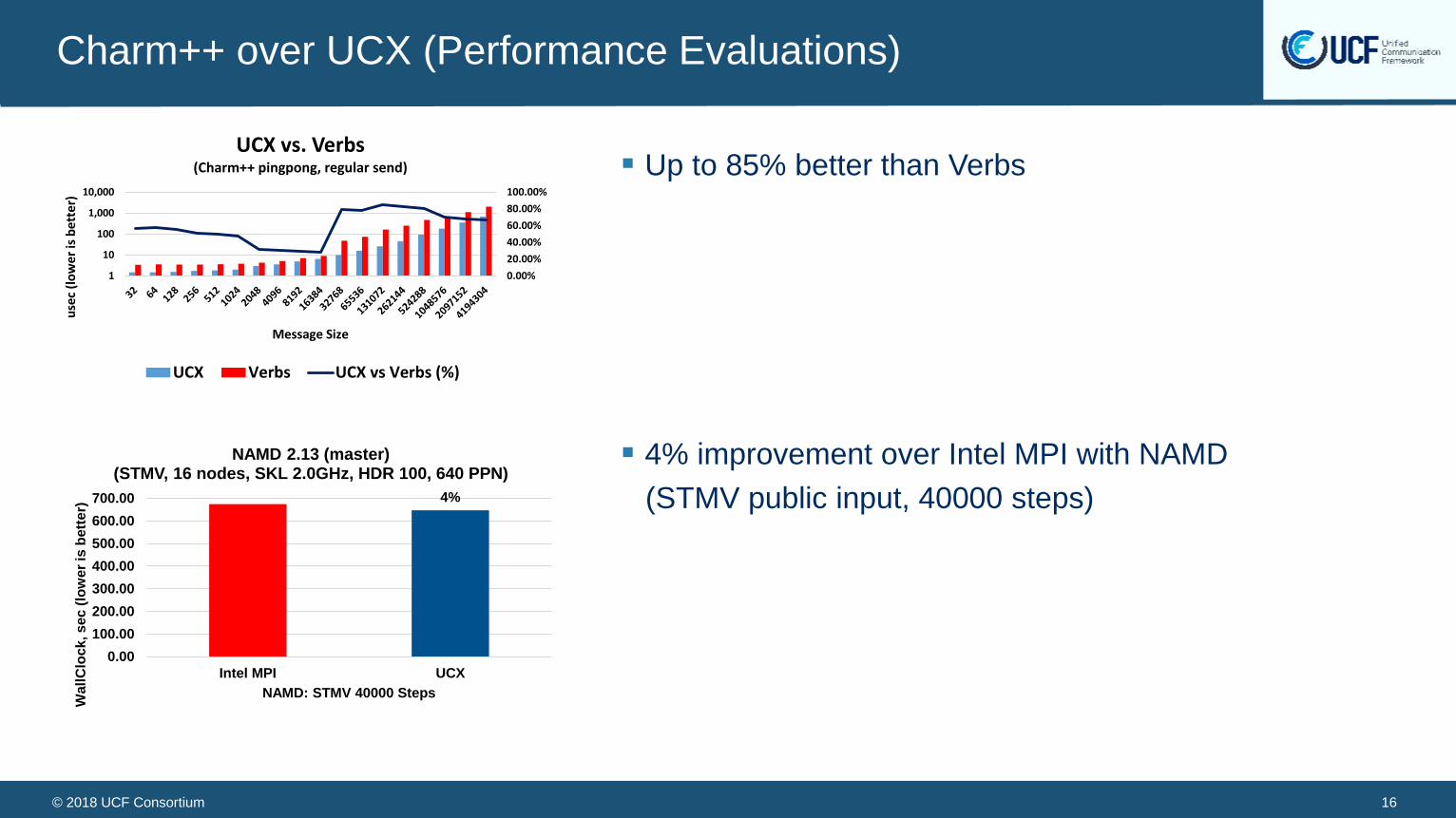
Charm++ over UCX (Performance Evaluations)
Up to 63% better than Intel MPI
0.00%
10.00%
20.00%
30.00%
40.00%
50.00%
60.00%
70.00%
1
10
100
1,000
use
c (l
ow
er
is b
ett
er)
Message Size
UCX vs. Intel MPI(Charm++ pingpong, regular send)
UCX Intel MPI UCX vs Intel MPI (%)
-10.00%
-5.00%
0.00%
5.00%
10.00%
15.00%
20.00%
1
10
100
1,000
use
c (l
ow
er is
bet
ter)
Message Size
UCX vs. OpenMPI(Charm++ pingpong, regular send)
UCX OpenMPI UCX vs OpenMPI (%)
Up to 15% better than Open MPI (thru UCX pml)
© 2018 UCF Consortium 16
Charm++ over UCX (Performance Evaluations)
4% improvement over Intel MPI with NAMD
(STMV public input, 40000 steps)
0.00%
20.00%
40.00%
60.00%
80.00%
100.00%
1
10
100
1,000
10,000
use
c (l
ow
er
is b
ett
er)
Message Size
UCX vs. Verbs(Charm++ pingpong, regular send)
UCX Verbs UCX vs Verbs (%)
4%
0.00
100.00
200.00
300.00
400.00
500.00
600.00
700.00
Intel MPI UCX
Wa
llC
lock
, s
ec
(lo
we
r is
bett
er)
NAMD: STMV 40000 Steps
NAMD 2.13 (master)(STMV, 16 nodes, SKL 2.0GHz, HDR 100, 640 PPN)
Up to 85% better than Verbs

UCX Support in MPICH
Yanfei Guo
Assistant Computer Scientist
Argonne National Laboratory
Email: [email protected]

MPICH layered structure: CH4
MPI Layer
Platform independent code• Collectives• Communicator
management
ucx ofi portals4
“Netmods”• Provide all functionality either
natively, or by calling back to “generic” implementation
CH4
SHM
posix xpmem cma
“Shmmods”• Implements some mandatory
functionality• Can override any amount of
optional functionality (e.g. better bcast, better barrier)
CH4 Generic
“Generic”• Packet headers +
handlers
UCX BoF @ ISC 2019 18

Benefit of using UCX in MPICH
Separating general optimizations and device specific optimizations
– Lightweight and high-performance communication
• Native communication support
– Simple and easy to maintain
– MPI can benefit from new hardware quicker
Better hardware support
– Accelerated verbs with Mellanox hardware
– Support for GPUs
UCX BoF @ ISC 2019 19

MPICH/UCX with Accelerated Verbs
UCX_TLS=rc_mlx5,cm
Lower overhead
– Low latency
– Higher message rate
UCX BoF @ ISC 2019 20
0
1000000
2000000
3000000
4000000
5000000
6000000
7000000
8000000
1 2 4 8 16 32 64 128 256 512 1024 2048 4096
Mes
sage
Rat
e
Message Size
Message Rate
Accel Verbs
OSU Latency: 0.99usOSU BW: 12064.12 MB/sArgonne JLSE Thing Cluster- Intel E5-2699v3 @ 2.3 GHz- Connect-X 4 EDR- HPC-X 2.2.0, OFED 4.4-2.0.7

MPICH/UCX with Accelerated Verbs
UCX BoF @ ISC 2019 21
0
0.5
1
1.5
2
2.5
3
3.5
4
0 1 2 4 8 16 32 64 128 256 512 1024 2048 4096
Late
ncy
(us)
Message Size
pt2pt latency
Accel Verbs
0
0.5
1
1.5
2
2.5
3
3.5
4
1 2 4 8 16 32 64 128 256 512 1024 2048 4096
Late
ncy
(us)
Message Size
MPI_Get Latency
Accel Verbs
0
0.5
1
1.5
2
2.5
3
3.5
1 2 4 8 16 32 64 128 256 512 1024 2048 4096
Late
ncy
(us)
Message Size
MPI_Put Latency
Accel Verbs
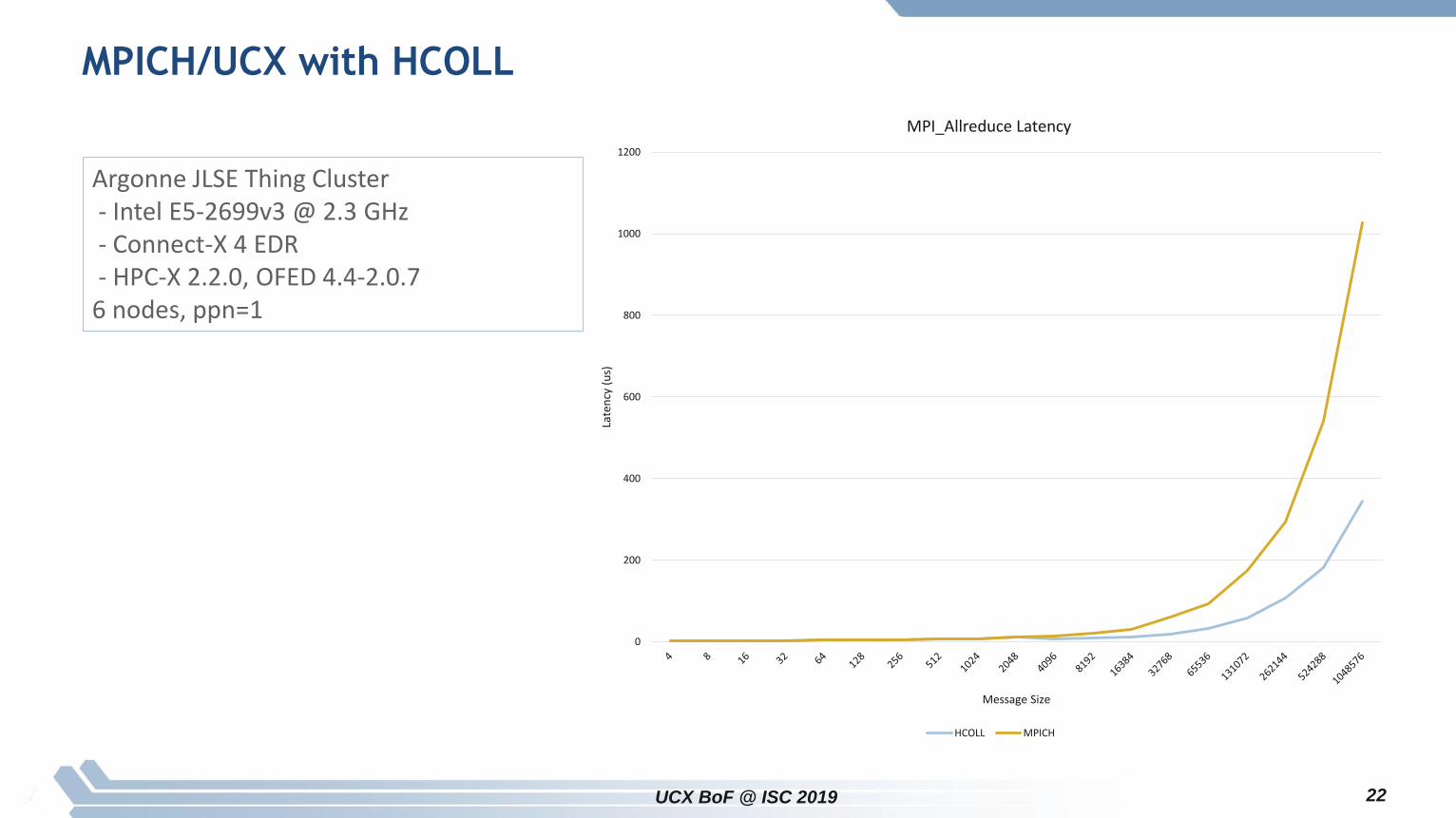
MPICH/UCX with HCOLL
UCX BoF @ ISC 2019 22
0
200
400
600
800
1000
1200
Late
ncy
(us)
Message Size
MPI_Allreduce Latency
HCOLL MPICH
Argonne JLSE Thing Cluster- Intel E5-2699v3 @ 2.3 GHz- Connect-X 4 EDR- HPC-X 2.2.0, OFED 4.4-2.0.7
6 nodes, ppn=1

UCX Support in MPICH
UCX Netmod Development
– MPICH Team
– Mellanox
– NVIDIA
MPICH 3.3.1 just released
– Includes an embedded UCX 1.5.0
Native path
– pt2pt (with pack/unpack callbacks for non-contig buffers)
– contiguous put/get rma for win_create/win_allocate windows
Emulation path is CH4 active messages (hdr + data)
– Layered over UCX tagged API
Not yet supported
– MPI dynamic processes
UCX BoF @ ISC 2019 23

Hackathon on MPICH/UCX
Earlier Hackathons with Mellanox
– Full HCOLL and UCX integration in MPICH 3.3
• Including HCOLL non-contig datatypes
– MPICH CUDA support using UCX and HCOLL, tested and documented
• https://github.com/pmodels/mpich/wiki/MPICH-CH4:UCX-with-CUDA-support
– Support for FP16 datatype (non-standard, MPIX)
– IBM XL and ARM HPC Compiler support
– Extended UCX RMA functionality, under review
• https://github.com/pmodels/mpich/pull/3398
Upcoming hackathons with Mellanox and NVIDIA
UCX BoF @ ISC 2019 24

Upcoming plans
Native UCX atomics
– Enable when user supplies certain info hints
– https://github.com/pmodels/mpich/pull/3398
Extended CUDA support
– Handle non-contig datatypes
– https://github.com/pmodels/mpich/pull/3411
– https://github.com/pmodels/mpich/issues/3519
Better MPI_THREAD_MULTIPLE support
– Utilizing multiple workers (Rohit looking into this now)
Extend support for FP16
– Support for C _Float16 available in some compilers (MPIX_C_FLOAT16)
– Missing support when GPU/Network support FP16 but CPU does not
UCX BoF @ ISC 2019 25












Enhancing MPI Communication using Accelerated Verbs and Tag Matching:
The MVAPICH Approach
Dhabaleswar K. (DK) Panda
The Ohio State University
E-mail: [email protected]
http://www.cse.ohio-state.edu/~panda
Talk at UCX BoF (ISC ‘19)
by

Network Based Computing Laboratory ISC’19
Introduction, Motivation, and Challenge
• HPC applications require high-performance, low overhead data paths that provide
– Low latency
– High bandwidth
– High message rate
• Hardware Offloaded Tag Matching
• Different families of accelerated verbs available
– Burst family
• Accumulates packets to be sent into bursts of single SGE packets
– Poll family
• Optimizes send completion counts
• Receive completions for which only the length is of interest
• Completions that contain the payload in the CQE
• Can we integrate accelerated verbs and tag matching support in UCX into existing HPC
middleware to extract peak performance and overlap?

Network Based Computing Laboratory ISC’19
The MVAPICH Approach
High Performance Parallel Programming Models
Message Passing Interface(MPI)
PGAS(UPC, OpenSHMEM, CAF, UPC++)
Hybrid --- MPI + X(MPI + PGAS + OpenMP/Cilk)
High Performance and Scalable Communication RuntimeDiverse APIs and Mechanisms
Point-to-
point
Primitives
Collectives
Algorithms
Energy-
Awareness
Remote
Memory
Access
I/O and
File Systems
Fault
ToleranceVirtualization
Active
MessagesJob Startup
Introspectio
n & Analysis
Support for Modern Networking Technology(InfiniBand, iWARP, RoCE, Omni-Path)
Transport Protocols Modern Interconnect Features
RC XRC UD DC UMR ODPSR-
IOV
Multi
Rail
Accelerated Verbs Family*
Burst Poll
Modern Switch Features
Multicast SHARP
* Upcoming
Tag
Match

Network Based Computing Laboratory ISC’19
Verbs-level Performance: Message Rate
0
2
4
6
8
10
12
1 8 64 512 4096
Mill
ion
Mes
sage
s /
seco
nd
Message Size (Bytes)
Read
regular acclerated
0
2
4
6
8
10
12
1 8 64 512 4096
Mill
ion
Mes
sage
s /
seco
nd
Message Size (Bytes)
Write
regular acclerated
0
2
4
6
8
10
12
1 8 64 512 4096
Mill
ion
Mes
sage
s /
seco
nd
Message Size (Bytes)
Send
regular acclerated
ConnectX-5 EDR (100 Gbps), Intel Broadwell E5-2680 @ 2.4 GHzMOFED 4.2-1, RHEL-7 3.10.0-693.17.1.el7.x86_64
7.418.05
8.978.73
9.66 10.2010.47

Network Based Computing Laboratory ISC’19
Verbs-level Performance: Bandwidth
10
100
1000
2 8 32 128 512
Mill
ion
Byt
es /
sec
on
d
Message Size (Bytes)
Read
regular
acclerated
ConnectX-5 EDR (100 Gbps), Intel Broadwell E5-2680 @ 2.4 GHzMOFED 4.2-1, RHEL-7 3.10.0-693.17.1.el7.x86_64
12.21
16.39
10
100
1000
2 8 32 128 512
Mill
ion
Byt
es /
sec
on
d
Message Size (Bytes)
Write
regular
acclerated
10
100
1000
2 8 32 128 512
Mill
ion
Byt
es /
sec
on
d
Message Size (Bytes)
Send
regular
acclerated
14.72
18.35
14.13
16.10

Network Based Computing Laboratory ISC’19
• Offloads the processing of point-to-point MPI messages
from the host processor to HCA
• Enables zero copy of MPI message transfers
– Messages are written directly to the user's buffer without extra
buffering and copies
• Provides rendezvous progress offload to HCA
– Increases the overlap of communication and computation
43
Hardware Tag Matching Support

Network Based Computing Laboratory ISC’19 44
Impact of Zero Copy MPI Message Passing using HW Tag Matching
0
50
100
150
200
250
300
350
400
32K 64K 128K 256K 512K 1M 2M 4M
Late
ncy
(u
s)
Message Size (byte)
osu_latency
Rendezvous Message Range
MVAPICH2 MVAPICH2+HW-TM
0
1
2
3
4
5
6
7
8
0 1 2 4 8 16 32 64 128 256 512 1K 2K 4K 8K 16K
Late
ncy
(u
s)
Message Size (byte)
osu_latency
Eager Message Range
MVAPICH2 MVAPICH2+HW-TM
Removal of intermediate buffering/copies can lead up to 35% performance
improvement in latency of medium messages
35%
Network Based Computing Laboratory ISC’19 45
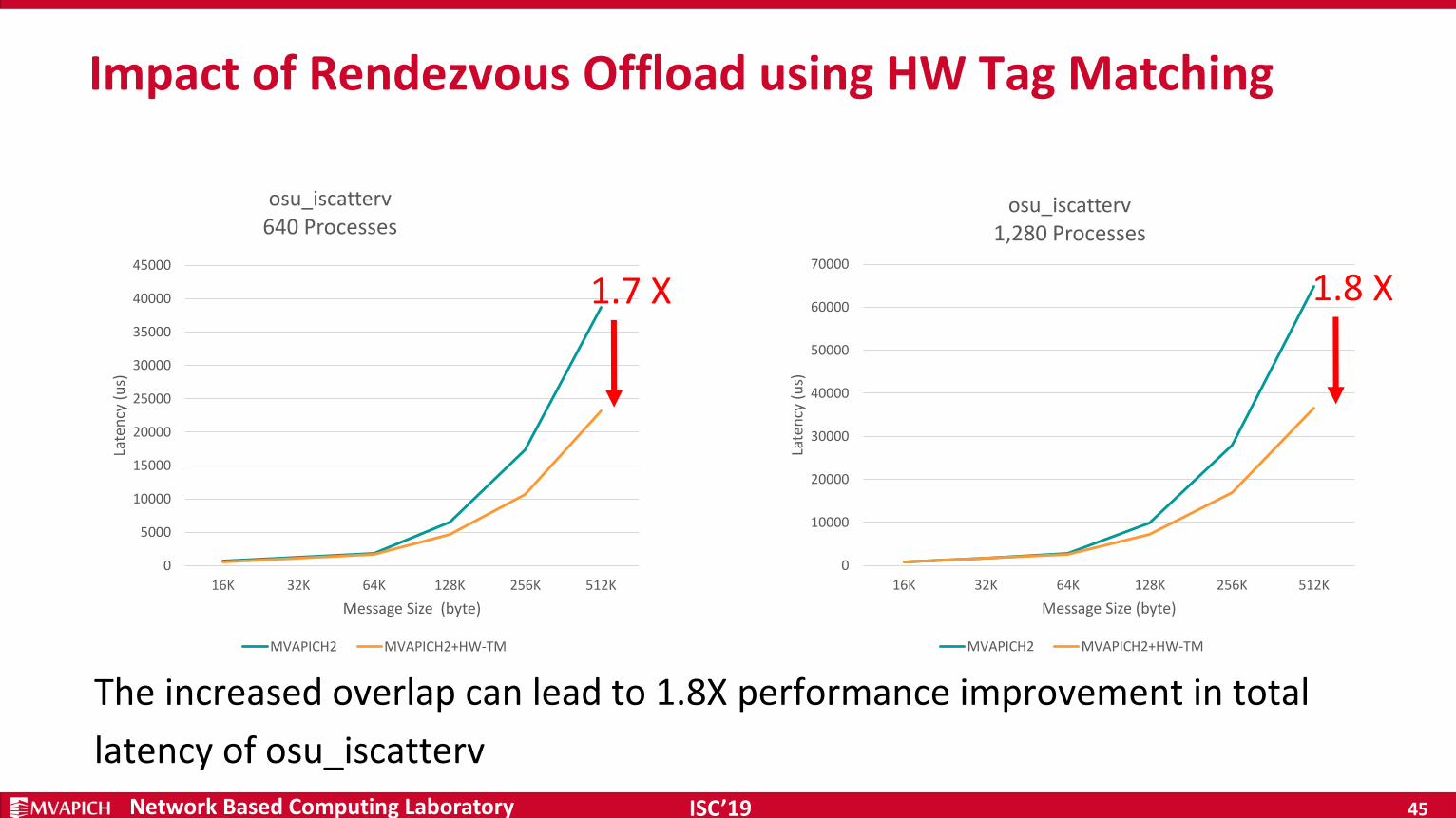
Impact of Rendezvous Offload using HW Tag Matching
0
10000
20000
30000
40000
50000
60000
70000
16K 32K 64K 128K 256K 512K
Late
ncy
(u
s)
Message Size (byte)
osu_iscatterv
1,280 Processes
MVAPICH2 MVAPICH2+HW-TM
0
5000
10000
15000
20000
25000
30000
35000
40000
45000
16K 32K 64K 128K 256K 512K
Late
ncy
(u
s)
Message Size (byte)
osu_iscatterv
640 Processes
MVAPICH2 MVAPICH2+HW-TM
The increased overlap can lead to 1.8X performance improvement in total
latency of osu_iscatterv
1.7 X 1.8 X

Network Based Computing Laboratory ISC’19
• Complete designs are being worked out
• Will be available in the future MVAPICH2 releases
46
Future Plans

June, 2019
UCX CUDA ROADMAP UPDATE

48
LEVERAGING CUDA & GPU DIRECTCUDA-awareness in UCX
Mellanox MPI effort is PML UCX
MPICH and OpenMPI use UCX
Move CUDA-related features to UCX
GPU-accelerated Data Science projects under RAPIDS starting to leverage UCX directly
Open MPI
OB1 PMLCUDA aware
openib,
smcuda BTLCUDA aware
UCX PML / OSC
UCXCUDA aware

49
CURRENT SUPPORTCode contributions from Mellanox and NVIDIA
GPUDirectRDMA + GDRCopy for inter-node transfers
CUDA-IPC + GDRCopy for intra-node transfers
Pointer cache through interception mechanisms; CUDA-IPC mapping cache
Managed memory support
Automatic HCA selection based on GPU-affinity (UCX 1.5 release)
Python-bindings for UCX (ucx-py, https://github.com/rapidsai/ucx-py)

50
UCX-CUDA PERFORMANCEResults with 2 DGX-1 nodes: approach peak with big enough buffers
0
0.5
1
1.5
2
2.5
3
3.5
4
4.5
0 1 2 4 8 16 32 64 128 256 512 1k 2k 4k
Late
ncy (
us)
Message size (bytes)
ucx perf short messages
ping-pong
0
5000
10000
15000
20000
25000
8k 16k 32k 64k 128k 256k 512k 1M 2M 4M
Bandw
idth
(G
B/s)
Message Size (bytes)
ucx perf large messages
unidirectional bidirectional

51
UCX-PY PERFORMANCEResults with 2 DGX-1 nodes: approach peak with big enough buffers
0
2
4
6
8
10
12
10MB 20MB 40MB 80MB 160MB 320MB
Bandw
idth
GB/s
Message Size
ucx-py perf: blocking mode
cupy native

52
UPCOMING TARGETS
Short term:
3-stage pipeline optimizations (for imbalanced GPU-HCA configurations)
Pipelining over NVLINK path (for managed memory; memory footprint)
Automatic HCA selection based on GPU-affinity (general availability)
Long term:
Persistent request support: memoize xfer info for repeated use
Non-contig Datatypes optimizations
One-sided UCX-CUDA; stream-based UCX operations

© 2018 UCF Consortium 53
Join the UCX Community

© 2018 UCF Consortium 54
Save the date !
UCX F2F meeting is planed on the week of December 9
3 days meeting
Austin, TX

© 2018 UCF Consortium 55
UCXUnified Communication - X
Framework
WEB:
www.openucx.org
https://github.com/openucx/ucx
Mailing List:
https://elist.ornl.gov/mailman/listinfo/ucx-group

Thank YouThe UCF Consortium is a collaboration between industry, laboratories, and academia to create production grade communication frameworks and open standards for data centric and high-performance applications.


















