
Unidad 1 Distribuciones de Frecuencia
39
~ 1 ~ CAPÍTULO 1 Distribuciones de frecuencia OBJETIVOS Al concluir el capítulo, será capaz de: Comprender la razón por la que estudia estadística. Describir lo que es población y muestra. No pecar de ignorancia con las nociones del muestreo. Explicar los conceptos de estadística descriptiva y estadística inferencial. Distinguir entre una variable cualitativa y una variable cuantitativa. Describir la diferencia entre una variable cualitativa nominal y una variable cualitativa ordinal. Describir la diferencia entre una variable discreta y una variable continua. Distinguir entre los niveles de medición nominal, ordinal, de intervalo y de razón. Redondear correctamente datos numéricos. Manejar adecuadamente la notación sumatoria. Convertir los datos sin procesar en información útil. Representar una distribución de frecuencias en un histograma, en un polígono de frecuencias y en una ojiva. Crear e interpretar distintas gráficas, digamos por ejemplo, de líneas, de barras, circulares, de puntos y gráficas de tallo y hojas.
description
UNIDAD 1 DISTRIBUCIONES DE FRECUENCIA
Transcript of Unidad 1 Distribuciones de Frecuencia

~ 1 ~
CAPÍTULO 1
Distribuciones de frecuencia
OBJETIVOS Al concluir el capítulo, será capaz de:
Comprender la razón por la que estudia estadística. Describir lo que es población y muestra. No pecar de ignorancia con las nociones del muestreo. Explicar los conceptos de estadística descriptiva y
estadística inferencial. Distinguir entre una variable cualitativa y una variable
cuantitativa. Describir la diferencia entre una variable cualitativa
nominal y una variable cualitativa ordinal. Describir la diferencia entre una variable discreta y una
variable continua. Distinguir entre los niveles de medición nominal, ordinal, de
intervalo y de razón. Redondear correctamente datos numéricos. Manejar adecuadamente la notación sumatoria. Convertir los datos sin procesar en información útil. Representar una distribución de frecuencias en un
histograma, en un polígono de frecuencias y en una ojiva. Crear e interpretar distintas gráficas, digamos por ejemplo,
de líneas, de barras, circulares, de puntos y gráficas de tallo y hojas.

~ 2 ~
§ PANORAMA GENERAL DE LA ESTADÍSTICA Una meta común e importante de la materia de la estadística es la siguiente: aprender acerca de un grupo grande examinando los datos de algunos de sus miembros. En dicho contexto, los términos muestra y población adquieren importancia. Las definiciones formales de estos y otros términos básicos se presentan a continuación, en la siguiente sección.
§ DESCRIPCIÓN DE LOS DATOS El propósito esencial del contenido que se desarrolla en este capítulo es aprender a organizar, resumir y presentar datos de manera informativa. Datos tales como la edad de una población, la altura de los estudiantes de una escuela, la temperatura en los meses del año, etcétera.
§ ¿QUÉ ES ESTADÍSTICA? La estadística desempeña un significativo papel en casi todos los aspectos del adelanto humano. Inicialmente solo era aplicada a los asuntos del Estado, de donde viene su nombre; pero ahora la influencia de la estadística se amplía a la agricultura, biología, ciencias políticas, comunicaciones, economía, educación, electrónica, física, medicina, negocios, psicología, química, sociología y otros muchos campos de la ciencia e ingeniería.
«Estadística es un conjunto de métodos para planear estudios y experimentos,
obtener datos y luego organizar, resumir, presentar, analizar, interpretar y llegar
a conclusiones basadas en los datos»
Los datos son las observaciones recolectadas (como mediciones, géneros, respuestas de encuestas, resultados de censos, etcétera). Un censo es el conjunto de datos de cada uno de los miembros de la población.
§ ¿POR QUÉ ESTUDIAR ESTADÍSTICA? Una razón imprescindible consiste en que la información numérica prolifera por todas partes. Si se revisan periódicos (El Comercio, El Hoy, La Hora…), revistas de información (Vistazo, Muy Interesante…), revistas de negocios (Líderes), publicaciones de interés general (Hogar), revistas femeninas (Vanidades), o revistas de deportes (Estadio, Carburando), y quedará sorprendido con la cantidad de información numérica que contienen, más aún, si navega en la Internet. Existen por lo menos tres razones para estudiar estadística:
1. Los datos proliferan por todas partes. 2. Las técnicas estadísticas se emplean en la toma de decisiones que influyen
en su vida.

~ 3 ~
3. Sin importar la carrera que elija, tomará decisiones profesionales que incluyan datos. Una comprensión de los métodos estadísticos permite tomar decisiones con mayor eficacia.
§ POBLACIÓN Y MUESTRA La población es el conjunto de todos los elementos (puntuaciones, personas, mediciones, etcétera) a estudiar. Esta colección es completa, pues incluye a todos los sujetos que se estudiarán. La muestra es un subconjunto de miembros seleccionados de una población. Cuando la población es numerosa, realizar el estudio de una (o varias variables) es complicado, molesto y se invierte mucho tiempo y dinero, sería deseable tomar un subconjunto de la población cuyas características sean similares a ésta. A ese subconjunto lo vamos a llamar muestra. Tomar una muestra en lugar de la población presenta ventajas notables pues al disminuirse el número de elementos se reducen los costes y se invierte menos tiempo en el estudio. Por otro lado hay casos en los que no se puede tomar toda la población, supongamos que queremos estudiar el funcionamiento de unos fuegos artificiales, habrá que tomar una muestra de los fuegos y probarla, porque si usamos toda la población nos quedamos sin fuegos artificiales.
El problema se presenta cuando hay que elegir una muestra que sea representativa de la población. Para ello veremos distintas técnicas de muestreo que se elegirán en función de las características de la población que se quiere estudiar.
§ MUESTREO Y TIPOS DE MUESTREO Muestreo es el proceso seguido para la extracción de una muestra. En la siguiente red se indican los tipos de muestreo.
Muestreo
Aleatorio
Simple Sistemático Estratificado
No aleatorio

~ 4 ~
§ TIPOS DE MUESTREO Muestreos no aleatorios y muestreos aleatorios.
§ MUESTREOS NO ALEATORIOS Se eligen los elementos, en función de que sean representativos, «según la opinión o conveniencia del investigador» EJEMPLO
El líder de un grupo elige 5 personas de entre 23, de acuerdo a su experiencia o criterio personal, para efectuar cierta actividad administrativa.
SOLUCIÓN
Esta persona, utilizando su experiencia o criterio propio, escogerá a 5 personas de entre las 23 disponibles.
§ MUESTREOS ALEATORIOS Todos los miembros de la muestra han sido elegidos al azar, de forma que cada miembro de la población tuvo igual oportunidad de salir en la muestra.
§ MUESTREO ALEATORIO SIMPLE Elegido el tamaño «𝑛» de la muestra, los elementos que la compongan se han de elegir aleatoriamente entre los «N» de la población. Con calculadora u ordenador: se utilizan los números aleatorios (Un número aleatorio es aquel obtenido al azar, es decir, que todo número tenga la misma oportunidad de ser elegido y que la elección de uno no dependa de la elección del otro. El ejemplo clásico más utilizado para generarlos es el lanzamiento repetitivo de una moneda o un dado)
§ MUESTREO ALEATORIO SISTEMÁTICO Se ordenan previamente los individuos de la población; después se elige uno de ellos al azar, a continuación, a intervalos constantes, se eligen todos los demás hasta completar la muestra.
§ MUESTREO ALEATORIO ESTRATIFICADO Se divide la población total en clases homogéneas, llamadas estratos; por ejemplo, por grupos de edades, por género, por barrios o sectores, etcétera. Hecho esto la muestra se escoge aleatoriamente en número proporcional al de los componentes de cada clase o estrato.

~ 5 ~
EJEMPLO
Un colegio tiene 120 alumnos de bachillerato se quiere extraer una muestra de 30 alumnos. Obtener la muestra mediante: a) Mediante muestreo aleatorio simple. b) Mediante muestreo aleatorio sistemático. c) Mediante muestreo estratificado.
SOLUCIÓN
a) Mediante muestreo aleatorio simple Se numeran los alumnos del 1 al 120. Se sortean 30 números de entre los 120. La muestra estará formada por los 30 alumnos a los que les correspondan los números obtenidos. b) Mediante muestreo aleatorio sistemático Se numeran los alumnos del 1 al 120. Se calcula el intervalo constante,
N (población)
n (muestra)=
120
30= 4
Sorteamos un número del 1 al 4. Supongamos que sale el número 3. El primer alumno seleccionado para la muestra sería el número 3, los siguientes alumnos se obtendrían sumando 4, hasta llegar a obtener 30 alumnos. Los alumnos seleccionados para la muestra son los que corresponden a los números:
3, 7, 11, ⋯ , 119 A continuación se indican otras posibilidades.
1er alumno seleccionado 2º 3º ⋯ 30º
1 5 9 ⋯ 117 2 6 10 ⋯ 118 3 7 11 ⋯ 119 4 8 12 ⋯ 120
c) Mediante muestreo aleatorio estratificado Clasificamos los alumnos, digamos por género, en mujeres y hombres. Supongamos que hay 67 mujeres y 53 hombres. El número de mujeres a tomar para la muestra sería entonces:
67
120× 30 = 16,75 ≈ 17
y el número de hombres, lógicamente sería 13. Finalmente hacemos un muestreo aleatorio, simple o sistemático, en cada estrato «mujeres» y «hombres».∎

~ 6 ~
EJEMPLO De una población de N=50 individuos (Población) deseamos extraer una muestra de tamaño n=5. Mediante el uso de los números aleatorios, se designa cuáles son los 5 individuos que componen la muestra.
SOLUCIÓN
Con el uso de Excel, o con una calculadora científica, se pueden generar los números aleatorios y así obtener una muestra para este caso, así: Numeramos los elementos de la población (en otras palabras codificamos o etiquetamos la población). En la hoja de Excel se busca: fórmulas «matemáticas y trigonométricas» Luego se busca «aleatorio» y el resultado se multiplica por N (50 en nuestro caso). Finalmente se toma la parte entera del producto así obtenido, con lo cual ya tendremos el elemento a tomar para la muestra.∎
§ ESTADÍSTICA DESCRIPTIVA E INFERENCIAL La estadística se divide en dos grandes áreas: la estadística descriptiva y la estadística inferencial. La estadística descriptiva, que incluye métodos para organizar, resumir y presentar
datos de manera informativa.
Una aglomeración de datos desorganizados –como el censo de población, los salarios mensuales de miles de empleados y las respuestas de millones de votantes registrados para elegir presidente de Ecuador− resulta de poca utilidad. No obstante, las técnicas de la estadística descriptiva permiten organizar esta clase de datos y darles significado. La estadística descriptiva, se dedica a la descripción, visualización y resumen de datos originados a partir de los fenómenos de estudio. Los datos pueden ser resumidos numérica o gráficamente.
La estadística inferencial, que comprende un conjunto de métodos para determinar una propiedad de una población con base en la información de una muestra.
La estadística inferencial, se dedica a la generación de los modelos, inferencias y predicciones asociadas a los fenómenos en cuestión teniendo en cuenta la aleatoriedad de las observaciones. Si una muestra es «representativa» de una población, se pueden deducir importantes conclusiones acerca de ésta, a partir del análisis de la muestra. Por ejemplo una encuesta reciente mostró que solamente 46% de los estudiantes del último grado de secundaria podían resolver problemas que incluyen fracciones, decimales y porcentajes. Además sólo el 77% de los estudiantes del último año de secundaria pudo sumar correctamente el costo de una ensalada, una hamburguesa, unas papas fritas y un refresco de cola, que figuraban en el menú de un restaurante. Ya que éstas son inferencias relacionadas con una población (todos los estudiantes de último año de secundaria), basadas en datos de una muestra, se trata de estadística inferencial.

~ 7 ~
§ TIPOS DE VARIABLES ESTADÍSTICAS En virtud de que la estadística analiza los datos y estos son resultado de las mediciones, necesitamos dedicar cierto tiempo al estudio de las variables. Una variable estadística es cada una de las características o cualidades que poseen los individuos de una población. En la siguiente red se indican los tipos de variables estadísticas.
Existen dos tipos de variables estadísticas: cualitativas y cuantitativas.
§ VARIABLE CUALITATIVA Las variables cualitativas se refieren a características o cualidades que no pueden ser medidas con números. Podemos distinguir dos tipos: variable cualitativa nominal y variable cualitativa ordinal.
§ VARIABLE CUALITATIVA NOMINAL Una variable cualitativa nominal presenta modalidades no numéricas que no admiten un criterio de orden. Por ejemplo, el estado civil, con las siguientes modalidades: soltero, casado, separado, divorciado y viudo.
§ VARIABLE CUALITATIVA ORDINAL Una variable cualitativa ordinal presenta modalidades no numéricas, en las que existe un orden. Por ejemplo, la «nota» en un examen: suspenso, aprobado, notable, sobresaliente. El puesto conseguido en una prueba deportiva: 1º, 2º, 3º,… Las medallas de una prueba deportiva: oro, plata, bronce.
Variable estadística
Cualitativa
Nominal Ordinal
Cuantitativa
Discreta Continua

~ 8 ~
§ VARIABLE CUANTITATIVA Una variable cuantitativa es la que se expresa mediante un número, por tanto se pueden realizar operaciones aritméticas con ella. Podemos distinguir dos tipos: Variable cuantitativa discreta y variable cuantitativa continua.
§ VARIABLE CUANTITATIVA DISCRETA Una variable discreta es aquella que toma valores aislados, es decir no admite valores intermedios entre dos valores específicos y, normalmente, existen «agujeros» entre dichos valores. Por ejemplo, el número de hermanos de 5 amigos: 2, 1, 0, 1, 3. No se admiten valores como 2,35.
§ VARIABLE CUANTITATIVA CONTINUA Una variable continua es aquella que puede tomar valores comprendidos entre dos números, es decir, puede asumir cualquier valor dentro de un intervalo específico. Por ejemplo, la estatura, en metros, de los 5 amigos: 1,73; 1,82; 1,77; 1,69; 1,75. En la práctica medimos la estatura con dos decimales, pero también se podría dar con tres o más decimales.
En general, una variable se representa con un símbolo, tal como 𝑥, 𝑦 o 𝑧, que puede tomar un valor cualquiera de un conjunto determinado de ellos, llamado dominio de la variable. Si la variable puede tomar solamente un valor se llama constante. Por ejemplo, en una familia el número 𝑛 de hijos puede tomar cualquiera de los valores {0, 1, 2, … }, pero no puede ser 2,5 o 3,842; es, pues, una variable discreta. Así, también, el tiempo 𝑡 que los autos tardan en un viaje de Ibarra a Quito, puede ser, por ejemplo, 1 hora 30 minutos 54 segundos, 1 hora 50 minutos 14 segundos o 1 hora 10 minutos 30 segundos, dependiendo de la exactitud de medida que nos dé el cronómetro utilizado; es una variable continua.
En la siguiente tabla, se muestran otros ejemplos de variables estadísticas discretas o continuas, con sus dominios respectivos.
Variable Continua Discreta Dominio
Número w de litros de agua en una máquina de lavar.
Continua Cualquier valor de 0 litros hasta la capacidad de la máquina.
Número b de libros de un estante de librería.
Discreta 0, 1, 2, 3,…, hasta el mayor número de libros que puedan entrar en el estante.
Suma s de puntos obtenidos en el lanzamiento de un par de dados.
Discreta {2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12}
Diámetro d de una esfera. Continua Todos los valores de cero a más infinito.
Países p de América. Discreta
Brasil, Argentina, Ecuador, etc., que pueden representarse numéricamente por 1, 2, 3, etc.

~ 9 ~
La investigación de problemas en temas como educación, salud, importaciones, producción, y salarios por hora generalmente requiere de datos publicados (periódicos, revistas especializadas, etc.) Pero, no siempre se encuentran datos publicados sobre cada tema de interés. Se puede solicitar información a las personas en un centro comercial, en sus hogares, por teléfono, o por correo. La Internet está cambiando la forma en la que vivimos y en la que se hacen los negocios. Es una fuente de información excelente.
§ TIPOS DE DATOS Una forma común de clasificar los datos consiste en usar cuatro niveles de medición: nominal, ordinal, de intervalo y de razón. Cuando se aplica la estadística a problemas reales, el nivel de medición de los datos es un factor importante para determinar el procedimiento a utilizar. Poco a poco, encontraremos algunas referencias a estos niveles de medición; sin embargo, lo importante aquí se basa en el sentido común: no hay que hacer cálculos ni utilizar métodos estadísticos que no sean apropiados para los datos.
Por ejemplo, no tendría sentido calcular el promedio de los números del
seguro social, ya que estos números son datos que se utilizan como identificación, y no representan mediciones o conteos de algo. Por la misma razón, no tendría sentido calcular un promedio de los números que aparecen en las camisetas de los jugadores de fútbol.
§ NIVEL DE MEDICIÓN NOMINAL El nivel de medición nominal se caracteriza por datos que consisten exclusivamente en nombres, etiquetas o categorías. Los datos no se pueden acomodar en un esquema de orden (como del más bajo al más alto). Considere los siguientes ejemplos.
1. Sí/no/indeciso: Respuestas de sí, no e indeciso en una encuesta.
2. Colores: Los colores de los automóviles conducidos por estudiantes universitarios (rojo, negro, azul, blanco, magenta, púrpura, etcétera)
Puesto que los datos nominales carecen de orden y no tienen un significado numérico, no se deben utilizar para hacer cálculos. En ocasiones se asignan números a las distintas categorías (especialmente cuando los datos se codifican para utilizarse en computadoras), pero estos números no tienen un significado computacional real y cualquier promedio que se calcule carece de sentido.
§ NIVEL DE MEDICIÓN ORDINAL Los datos están en el nivel de medición ordinal cuando pueden acomodarse en algún orden, aunque no es posible determinar diferencias entre los valores de los

~ 10 ~
datos o tales diferencias carecen de significado. Los siguientes ejemplos ilustran el nivel de medición ordinal.
1. Las calificaciones de un curso: Un profesor universitario asigna calificaciones de A, B, C, D, E o F. Tales calificaciones se pueden ordenar, aunque no es posible determinar diferencias entre tales calificaciones. Por ejemplo, sabemos que A es mayor que B (por lo que hay un orden); pero no podemos restar B de A (por lo que no se puede calcular la diferencia)
2. Rangos: Con base en varios criterios, una revista ordena las ciudades de acuerdo con su “habitabilidad”. Dichos rangos (primero, segundo, tercero, etcétera) determinan un orden. Sin embargo, las diferencias entre los rangos no tienen ningún significado. Por ejemplo, una diferencia «del segundo menos el primero» sugeriría 2 − 1 = 1, pero esta diferencia de 1 no tiene significado porque no es una cantidad exacta que sea comparable con otras diferencias de este tipo. La diferencia entre la primera y la segunda ciudades no es la misma que la diferencia entre la segunda y la tercera ciudades. Utilizando los rangos de la revista, la diferencia entre la ciudad de Quito y Cuenca no se puede comparar de forma cuantitativa con la diferencia entre Guayaquil y Manta.
Los datos ordinales proporcionan información sobre comparaciones relativas,
pero no las magnitudes de las diferencias. Por lo general, los datos ordinales no deben utilizarse para hacer cálculos como promedios, aunque en ocasiones esta norma se infringe (como sucede cuando utilizamos calificaciones con letras para calcular una calificación promedio).
§ NIVEL DE MEDICIÓN DE INTERVALO El nivel de medición de intervalo se parece al nivel ordinal, pero con la propiedad adicional de que la diferencia entre dos valores de datos cualesquiera tiene un significado. Sin embargo, los datos en este nivel no tienen punto de partida cero natural inherente (donde nada de la cantidad está presente). Los siguientes ejemplos ilustran el nivel de medición de intervalo.
1. Temperaturas: Las temperaturas corporales de 98,2°F y 98,6°F son ejemplos de datos a nivel de medición de intervalo. Dichos valores están ordenados, y podemos determinar su diferencia de 0,4°F. Sin embargo, no existe un punto de inicio natural. Pareciera que el valor de 0°F es un punto de inicio; sin embargo, éste es arbitrario y no representa la ausencia total de calor. Puesto que 0°F no es un punto de partida cero natural, sería incorrecto decir que 50°F es dos veces más caliente que 25°F.
2. Años: Los años 1000, 2008, 1776 y 1492. (El tiempo no inició en el año 0,
por lo que el año 0 es arbitrario y no constituye un punto de partida cero natural que represente «la ausencia de tiempo»).

~ 11 ~
§ NIVEL DE MEDICIÓN DE RAZÓN El nivel de medición de razón es similar a nivel de intervalo, pero con la propiedad adicional de que sí tiene un punto de partida cero natural (donde el cero indica que nada de la cantidad está presente). Para valores a este nivel, tanto las diferencias como las proporciones tienen significado. Los siguientes son ejemplos de datos al nivel de medición de razón. Observe la presencia de un valor cero natural, así como el uso de proporciones que significan «dos veces» y «tres veces».
1. Pesos: Los pesos (en quilates) de anillos de compromiso de diamante (el 0 realmente representa la ausencia de peso y 4 quilates es dos veces el peso de 2 quilates).
2. Precios: Los precios de libros de texto universitarios ($0 realmente
representa ningún costo y un libro de $90 es tres veces más caro que un libro de $30).
Este nivel de medición se denomina de razón porque el punto de partida cero hace que las razones o cocientes tengan significado. Entre los cuatros niveles de medición, la principal dificultad surge al distinguir entre los niveles de intervalo y de razón. Sugerencia: Para simplificar esta diferencia, utilice una sencilla «prueba de razón»: Considere dos cantidades en las cuales un número es dos veces el otro y pregúntese si «dos veces» sirve para describir correctamente las cantidades. Puesto que un peso de 200 libras es dos veces más pesado que un peso de 100 libras, pero 50°F no es dos veces más caliente que 25°F, los pesos están en el nivel de razón, mientras que las temperaturas Fahrenheit están en el nivel de intervalo. Para una comparación y un repaso concisos, estudie el gráfico subsiguiente, que señala las diferencias entre los cuatro niveles de medición.
§ PARÁMETRO POBLACIONAL Y ESTADÍSTICO MUESTRAL El parámetro poblacional es una medición numérica que describe algunas características de una población. El estadístico muestral (o la estadística muestral) es una medición numérica que describe algunas características de una muestra. Los siguientes ejemplos muestran la diferencia entre parámetro y estadístico.
1. Parámetro: En la ciudad de Quito hay 325 botones para caminar, que los peatones emplean en las intersecciones de tránsito. Se descubrió que el 77% de dichos botones no funciona. La cifra del 77% es un parámetro porque está basada en la población de todos los 325 botones para peatones.

~ 12 ~
2. Estadístico: Con base en una muestra de 87 ejecutivos encuestados, se encontró que el 45% de ellos no contrataría a alguien con un error ortográfico en su solicitud de empleo. Esta cifra del 45% es un estadístico, ya que está basada en una muestra y no en la población completa de todos los ejecutivos.
§ REDONDEO DE DATOS El resultado de «redondear» un número tal como 72,8 al entero más próximo es 73, puesto que 72,8 está más cerca de 73 que de 72. Análogamente, 72,8146 redondeado al número decimal con dos decimales será 72,81, puesto que 72,8146 está más cerca de 72,81 que de 72,82. En el redondeo de 72,465 a un decimal con aproximación de centésimas, nos encontramos con el dilema de que 72,465 está justamente a la mitad de recorrido entre 72,46 y 72,47. Se acostumbra en tales casos redondear al número par más próximo que antecede al 5. Así, 72,465 se redondea a 72,46; 183,475 se redondea a 183,48; redondeando 112500000 con aproximación de millones será 112000000. Esta práctica es especialmente útil al minimizar la acumulación de errores de redondeo cuando se abarca un número grande de operaciones. EJEMPLO
Sumar los números 4,35; 8,65; 2,95; 12,45; 6,65; 7,55 y 9,75 a) Directamente. b) Redondeando de acuerdo con el criterio del «par más próximo» c) Redondeando todos los datos por exceso.
SOLUCIÓN
Y así, tenemos:
Niveles de medición
Nominal
Los datos sólo se
clasifican
-Número de camiseta de los jugadores de fútbol
-Marca de automóvil
Ordinal
Los datos se ordenan
-Su número de lista en clase
-Posición de los equipos dentro de los diez grandes
Intervalo
Diferencia significativa
entre valores
-Temperatura
-Talla
Razón
Punto 0 significativo
y razón entre valores
-Número de pacientes atendidos
-Número de llamadas de ventas realizadas
-Distancia a clase

~ 13 ~
a) 4,35+8,65+2,95+12,45+6,65+7,55+9,75 = 52,35 b) 4,4+8,6+3,0+12,4+6,6+7,6+9,8 = 52,4 c) 4,4+8,7+3,0+12,5+6,7+7,6+9,8 = 52,7 Nótese que el método b) es más exacto que el c), puesto que la acumulación de errores se minimiza en el método b).∎
§ NOTACIÓN SUMATORIA O NOTACIÓN SIGMA El símbolo 𝑥𝑖 (léase «𝑥 𝑠𝑢𝑏 𝑖») representa cualesquiera de los 𝑛 valores 𝑥1, 𝑥2, 𝑥3, ⋯ , 𝑥𝑛, que una variable 𝑥 puede tomar. La letra 𝑖 en 𝑥𝑖 , la cual puede representar cualquiera de los números 1, 2, 3, … , 𝑛 se llama índice o subíndice. Análogamente puede utilizarse como subíndice cualquier otra letra distinta de 𝑖, como 𝑗 o 𝑘, por ejemplo. El símbolo ∑ 𝑥𝑖
𝑛𝑖=1 , se utiliza para indicar la suma de
todas las 𝑥𝑖 desde 𝑖 = 1 hasta 𝑖 = 𝑛, es decir que, por definición,
∑ 𝑥𝑖 =
𝑛
𝑖=1
𝑥1 + 𝑥2 + 𝑥3 + ⋯ + 𝑥𝑛
Cuando no cabe confusión posible, se representa esta suma por la notación más simplificada,
∑ 𝑥
El símbolo ∑ es la letra griega mayúscula sigma, denotando sumatoria. La notación ∑ se llama, a veces, «notación sigma». Por ejemplo,
∑ 𝑥𝑖𝑦𝑖 =
𝑛
𝑖=1
𝑥1𝑦1 + 𝑥2𝑦2 + 𝑥3𝑦3 + ⋯ + 𝑥𝑛𝑦𝑛
También,
∑ 𝑎𝑥𝑖
4
𝑖=1
= 𝑎𝑥1 + 𝑎𝑥2 + 𝑎𝑥3 + 𝑎𝑥4
∑ 𝑎𝑥𝑖
4
𝑖=1
= 𝑎(𝑥1 + 𝑥2 + 𝑥3 + 𝑥4)
∑ 𝑎𝑥𝑖
4
𝑖=1
= 𝑎 ∑ 𝑥𝑖
4
𝑖=1
siendo a una constante. Más sencillamente, ∑ 𝑎𝑥 = 𝑎 ∑ 𝑥 EJEMPLO
Si 𝒂, 𝒃 y 𝒄 son constantes cualesquiera, entonces, puede demostrarse que:

~ 14 ~
∑(𝒂𝒙 + 𝒃𝒚 − 𝒄𝒛) = 𝒂 ∑ 𝒙 + 𝒃 ∑ 𝒚 − 𝒄 ∑ 𝒛
SOLUCIÓN
Y así tenemos que, para 𝑛 = 3:
∑(𝑎𝑥𝑖 + 𝑏𝑦𝑖 − 𝑐𝑧𝑖)
3
1
= (𝑎𝑥1 + 𝑏𝑦1 − 𝑐𝑧) + (𝑎𝑥2 + 𝑏𝑦2 − 𝑐𝑧2) + (𝑎𝑥3 + 𝑏𝑦3 − 𝑐𝑧3)
∑(𝑎𝑥𝑖 + 𝑏𝑦𝑖 − 𝑐𝑧𝑖)
3
1
= (𝑎𝑥1 + 𝑎𝑥2 + 𝑎𝑥3) + (𝑏𝑦1 + 𝑏𝑦2 + 𝑏𝑦3) − (𝑐𝑧1 + 𝑐𝑧2 + 𝑐𝑧3)
∑(𝑎𝑥𝑖 + 𝑏𝑦𝑖 − 𝑐𝑧𝑖)
3
1
= 𝑎 ∑ 𝑥𝑖
3
𝑖=1
+ 𝑏 ∑ 𝑦𝑖
3
𝑖=1
− 𝑐 ∑ 𝑧𝑖
3
𝑖=1
Se puede demostrar para toda n, de manera similar (ver el ejercicio E12) ∎
§ DISTRIBUCIÓN DE FRECUENCIAS La distribución de frecuencias es una lista de datos ya sea de manera individual (datos sin agrupar) o por grupos de intervalos (datos agrupados), junto con sus frecuencias (o conteos) correspondientes.
§ DISTRIBUCIÓN DE FRECUENCIAS CON DATOS SIN AGRUPAR La distribución de frecuencias es la representación estructurada, en forma de tabla, de toda la información que se ha recogido sobre la variable que se estudia. Veamos un ejemplo demostrativo. EJEMPLO
Medimos la talla de 30 niños de una clase y obtenemos los siguientes resultados en metros (tabla subsiguiente)
Alumno Estatura Alumno Estatura Alumno Estatura
Alumno 1 1,25 Alumno 1 1,23 Alumno 21 1,21
Alumno 2 1,28 Alumno 12 1,26 Alumno 22 1,29
Alumno 3 1,27 Alumno 13 1,30 Alumno 23 1,26
Alumno 4 1,21 Alumno 14 1,21 Alumno 24 1,22
Alumno 5 1,22 Alumno 15 1,28 Alumno 25 1,28
Alumno 6 1,29 Alumno 16 1,30 Alumno 26 1,27
Alumno 7 1,30 Alumno 17 1,22 Alumno 27 1,26
Alumno 8 1,24 Alumno 18 1,25 Alumno 28 1,23
Alumno 9 1,27 Alumno 19 1,20 Alumno 29 1,22
Alumno 10 1,29 Alumno 20 1,28 Alumno 30 1,21
SOLUCIÓN
~ 15 ~
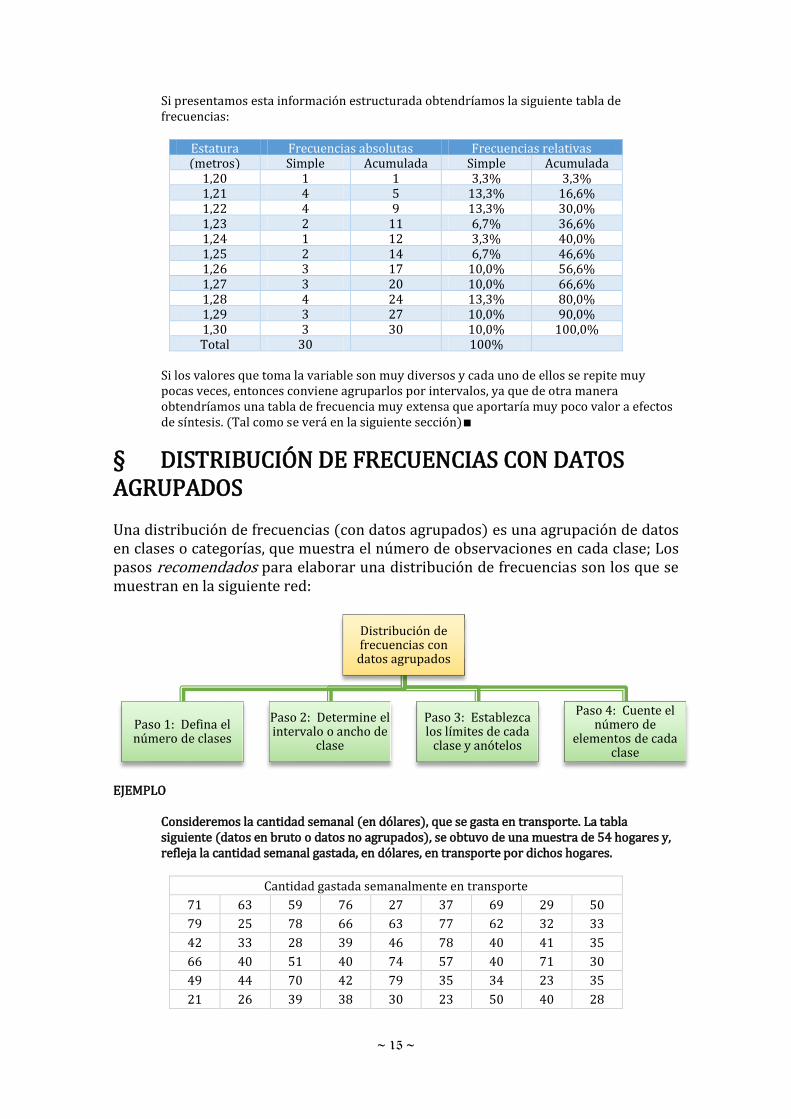
Si presentamos esta información estructurada obtendríamos la siguiente tabla de frecuencias:
Estatura Frecuencias absolutas Frecuencias relativas (metros) Simple Acumulada Simple Acumulada
1,20 1 1 3,3% 3,3% 1,21 4 5 13,3% 16,6% 1,22 4 9 13,3% 30,0% 1,23 2 11 6,7% 36,6% 1,24 1 12 3,3% 40,0% 1,25 2 14 6,7% 46,6% 1,26 3 17 10,0% 56,6% 1,27 3 20 10,0% 66,6% 1,28 4 24 13,3% 80,0% 1,29 3 27 10,0% 90,0% 1,30 3 30 10,0% 100,0% Total 30 100%
Si los valores que toma la variable son muy diversos y cada uno de ellos se repite muy pocas veces, entonces conviene agruparlos por intervalos, ya que de otra manera obtendríamos una tabla de frecuencia muy extensa que aportaría muy poco valor a efectos de síntesis. (Tal como se verá en la siguiente sección)∎
§ DISTRIBUCIÓN DE FRECUENCIAS CON DATOS AGRUPADOS Una distribución de frecuencias (con datos agrupados) es una agrupación de datos en clases o categorías, que muestra el número de observaciones en cada clase; Los pasos recomendados para elaborar una distribución de frecuencias son los que se muestran en la siguiente red:
EJEMPLO
Consideremos la cantidad semanal (en dólares), que se gasta en transporte. La tabla siguiente (datos en bruto o datos no agrupados), se obtuvo de una muestra de 54 hogares y, refleja la cantidad semanal gastada, en dólares, en transporte por dichos hogares.
Cantidad gastada semanalmente en transporte
71 63 59 76 27 37 69 29 50
79 25 78 66 63 77 62 32 33
42 33 28 39 46 78 40 41 35
66 40 51 40 74 57 40 71 30
49 44 70 42 79 35 34 23 35
21 26 39 38 30 23 50 40 28
Distribución de frecuencias con datos agrupados
Paso 1: Defina el número de clases
Paso 2: Determine el intervalo o ancho de
clase
Paso 3: Establezca los límites de cada
clase y anótelos
Paso 4: Cuente el número de
elementos de cada clase

~ 16 ~
¿Cuántas clases recomendaría? ¿Qué, ancho de clase o intervalo de clase sugeriría? Establezca los límites de clase, es decir construya los intervalos de clase. Construya la distribución de frecuencias.
SOLUCIÓN
Paso 1 : Defina el número de clases
El objetivo consiste en emplear suficientes agrupamientos o clases, de manera tal que se perciba la forma de la distribución. Aquí se necesita criterio. Una gran cantidad de clases o muy pocas podrían no permitir ver la forma fundamental del conjunto de datos. Demasiadas clases o muy pocas pueden no revelar la forma básica del conjunto de datos. Una receta útil para determinar el número de clases es la regla «2 a la k» o regla de Sturges. Esta regla sugiere utilizar como número de clases el menor número k tal que 2k sea mayor que el número de observaciones n, esto es:
𝑀í𝑛 {𝑘}, 𝑡𝑎𝑙 𝑞𝑢𝑒 2𝑘 > 𝑛 𝑘 = número de clases 𝑛 = número de datos
O bien,
𝑘 = 𝐼𝑛𝑡𝑔 (1 +𝑙𝑜𝑔 𝑛
𝑙𝑜𝑔 2)
𝑘 = número de clases 𝑛 = número de datos
En nuestro caso, tenemos 54 observaciones. Si probamos con k = 5, entonces 25 = 32 es menor que 54. Por tanto 5 clases no son suficientes. Si escogemos k = 6, entonces 26 = 64, que es mayor que 54. En consecuencia, el número de clases que se recomienda utilizar es 6. De otra manera:
𝑘 = 𝐼𝑛𝑡𝑔(1 + 𝑙𝑜𝑔 54/𝑙𝑜𝑔 2 ) = 6 𝑐𝑙𝑎𝑠𝑒𝑠, 𝑐𝑜𝑚𝑜 𝑎𝑛𝑡𝑒𝑠.
Paso 2: Determine el intervalo o ancho de clase
Generalmente el intervalo (o ancho) de clase deberá ser el mismo para todas las clases. Todas las clases juntas deben cubrir por lo menos la distancia que hay desde el menor hasta el mayor valor que se tiene en los datos sin procesar. Expresado esto mediante una fórmula tenemos:
𝑐 ≥𝑥𝑀𝐴𝑋 − 𝑥𝑚𝑖𝑛
𝑘
𝑐 = tamaño del intervalo de clase 𝑥𝑀𝐴𝑋 = mayor valor observado 𝑥𝑚𝑖𝑛 = menor valor observado 𝑘 = número de clases
En nuestro caso, el dato mínimo es 21, el máximo 79 y el número de clases k, encontrado en el paso 1, es 6, por lo tanto:
𝑐 ≥𝑥𝑀𝐴𝑋 − 𝑥𝑚𝑖𝑛
𝑘=
79 − 21
6= 9,67
Entonces, redondeamos c al entero más cercano, 10. Psicológicamente, preferimos (o nos gusta) trabajar con números «redondos», (terminados en cero) porque son más «sencillos» para realizar cálculos. Por eso, se sugiere aproximar al entero redondo más próximo, siempre que esto, sea posible.

~ 17 ~
Paso 3 Establezca los límites de cada clase y anótelos
Es necesario establecer los límites de clase de manera que cada observación pertenezca sólo a una clase. Por ejemplo, clases (en dólares) como las siguientes: «1300-1400» y «1400-1500», no deberían usarse porque no es claro si el valor de 1400 dólares pertenece a la primera o a la segunda clase. Pero, si quedamos que el intervalo 1300-1400 es el intervalo [1300; 1400[, es decir que 1400 no está incluido, no habrá ninguna confusión. En la clase «1300-1400», 1300 es el límite inferior de clase y 1400 el límite superior de dicha clase. Recuerde, el límite superior de clase no está incluido. El primer límite inferior de clase que debe establecerse, es el correspondiente a la primera clase; asimismo, se sugiere, como en el paso 2, un número redondo en lo posible, pero si no es el caso, no importa.
En nuestro caso, el valor más bajo es 21, por lo tanto, 20 sería el límite inferior sugerido de la primera clase: «20-30». Ahora, se construye la tabla:
Cantidad gastada semanalmente (dólares)
20-30 30-40 40-50
50-60 60-70 70-80
Nótese que ésta cubre todos los datos observados. Fíjese, que otra tabla sugerida podría ser la mostrada a continuación:
Cantidad gastada semanalmente (dólares)
21-31
31-41
41-51
51-61
61-71
71-81
No perder de vista, que también cubre todos los datos observados. Preferimos la primera opción a la segunda, por lo que se comentó antes, acerca de números redondos.
Paso 4: Cuente el número de elementos de cada clase
Al distribuir (realizando el conteo) los datos sin procesar en las distintas clases, ubicando dichos datos en cada clase, creamos la distribución de frecuencia buscada. Una vez establecidas las «clases» o, más correctamente, los intervalos de clase, procedemos al conteo y clasificación de los datos en la distribución de frecuencias, tal como se muestra a continuación; recuerde que si un dato aparece en dos clases, el límite superior no está incluido. Para comenzar, la primera cantidad gastada en transporte en la tabla del ejemplo es de $71. Este se anota en la clase 70 − 80. La segunda cantidad en la segunda columna de dicha tabla es $63. El que se anota en la clase 60 − 70. Los demás valores de gastos en transporte, se cuadran de forma similar. Cuando todos los gastos en transporte se hayan registrado, la tabla tendrá la siguiente apariencia:

~ 18 ~
Cantidad gastada semanalmente (dólares)
Frecuencia
20-30 9 30-40 13
40-50 11
50-60 5
60-70 6
70-80 10
Total 54
A continuación se formalizan algunas definiciones, otras se complementan y otras se introducen. La frecuencia f es el número de observaciones en cada clase; por ejemplo, la frecuencia de la clase «20 − 30», es decir, de la primera clase, es 9. El intervalo de clase c es la diferencia entre los límites superior e inferior de cualquier clase, así:
c = 30 − 20 = 40 − 30 = 50 − 40 = 60 − 50 = 70 − 60 = 80 − 70 = 10 El punto medio de clase, conocido mejor como marca de clase se calcula sumando el límite inferior de la clase al límite superior de la misma clase, y dividiendo el resultado entre 2. En nuestro ejemplo, la marca de clase de la clase «40 − 50», es decir, de la tercera clase, es 45, obtenida como sigue:
40 + 50
2= 45
La frecuencia relativa es el porcentaje de observaciones en cualquier clase.
𝑓𝑟𝑒𝑐𝑢𝑒𝑛𝑐𝑖𝑎 𝑟𝑒𝑙𝑎𝑡𝑖𝑣𝑎 =𝑓𝑟𝑒𝑐𝑢𝑒𝑛𝑐𝑖𝑎 𝑑𝑒 𝑐𝑙𝑎𝑠𝑒
𝑠𝑢𝑚𝑎 𝑑𝑒 𝑡𝑜𝑑𝑎𝑠 𝑙𝑎𝑠 𝑓𝑟𝑒𝑐𝑢𝑒𝑛𝑐𝑖𝑎𝑠
Por ejemplo, la frecuencia relativa de la clase «50 − 60», de nuestro ejemplo, es 9,26%, obtenida así:
2
54= 0,926 = 9,26%
La suma de las frecuencias relativas de todas las clases es evidentemente 1 ó 100%. La frecuencia acumulada de una clase es la suma de las frecuencias para esa clase y todas las clases previas. Así, por ejemplo, la frecuencia acumulada hasta el intervalo de clase «40-50» en nuestro ejemplo, es 9+13+11 = 33, significando que 33 hogares consumen semanalmente en alimentos menos de 50 dólares.

~ 19 ~
§ VISUALIZACIÓN DE LOS DATOS Se pueden visualizar los datos, mediante los histogramas, los polígonos de frecuencia o las ojivas. En la siguiente red, se muestran los gráficos estadísticos más comunes.
Para construir dichos gráficos estadísticos, se requiere la siguiente «tabla de trabajo o de cálculos», en donde se resume todo lo requerido, para poder realizar gráficos estadísticos.
Tabla de cálculos
Clases Marca
de clase
Frecuencias absolutas
Frecuencias relativas
Simple Acumulada Simple
(%) Acumulada
(%)
EJEMPLO
Consideremos la cantidad semanal (en dólares), que se gasta en transporte. La tabla siguiente (datos en «bruto» o datos no agrupados), se obtuvo de una muestra de 54 hogares y, refleja la cantidad semanal gastada, en dólares, en transporte por dichos hogares.
Cantidad gastada semanalmente en transporte
Grá
fico
s es
tad
ísti
cos
Histogramas
Absolutos
Relativos
Polígonos de frecuencias
Absolutos
Relativos
Ojivas
Absolutas
Porcentuales
Otros

~ 20 ~
71 63 59 76 27 37 69 29 50
79 25 78 66 63 77 62 32 33
42 33 28 39 46 78 40 41 35
66 40 51 40 74 57 40 71 30
49 44 70 42 79 35 34 23 35
21 26 39 38 30 23 50 40 28
Llene la tabla de cálculos (tabla de frecuencias)
SOLUCIÓN
Del ejemplo previo utilizamos la distribución de frecuencias para llenar la tabla de frecuencias siguiente.
Tabla de Frecuencias
Cantidad gastada
semanalmente (dólares)
Marca de clase
Frecuencias absolutas Frecuencias relativas
Simple Acumulada Simple
(%) Acumulada
(%)
20-30 25 9 9 17 17
30-40 35 13 22 24 41
40-50 45 11 33 20 61
50-60 55 5 38 9 70
60-70 65 6 44 11 81
70-80 75 10 54 19 100
Total 54 100
§ HISTOGRAMAS Un histograma (en realidad histograma de frecuencias absolutas), es una representación gráfica, que muestra el número de frecuencia en cada clase, en forma de rectángulos que tienen sus bases en el eje horizontal con centros en las marcas de clase y ancho igual a los intervalos de clase. Las frecuencias de clase están representadas por las alturas de las barras, y éstas se colocan adyacentes una a otra (sin espacios entre ellas). Si el histograma muestra la frecuencia relativa en cada clase, se llama histograma porcentual. Guarda la misma forma del histograma común, con una diferencia, en vez de las frecuencias absolutas simple se utilizan las frecuencias relativas simples.
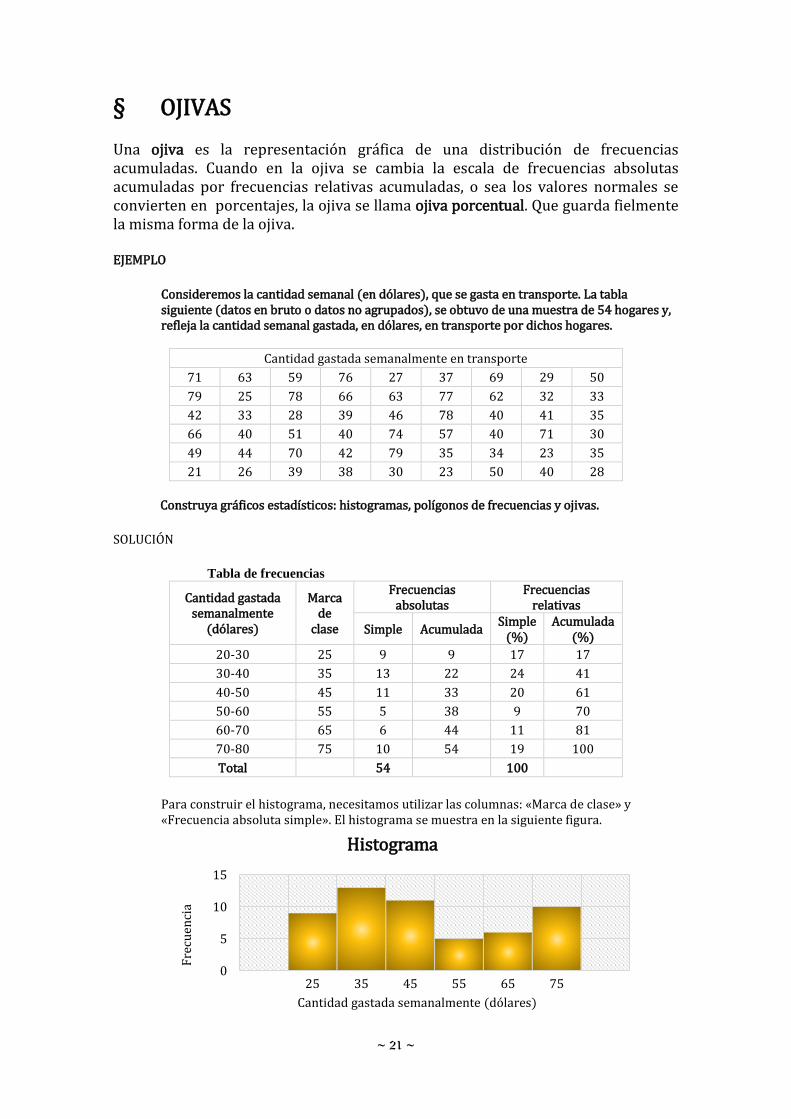
§ POLÍGONOS DE FRECUENCIAS Un polígono de frecuencias (absolutas) está formado por segmentos de recta que unen los puntos determinados por las intersecciones provenientes de las marcas de clase y las frecuencias de clase. Estos segmentos forman un polígono o «figura de varios lados» Se deben agregar las marcas de clase inferior y superior inmediatas a las establecidas en la tabla de trabajo, para poder «cerrar» el polígono de frecuencias. Si en lugar de las frecuencias absolutas se utilizan las frecuencias relativas, se tiene el polígono de frecuencias relativas, que guarda exactamente la misma forma que la del polígono de frecuencias.
~ 21 ~
§ OJIVAS Una ojiva es la representación gráfica de una distribución de frecuencias acumuladas. Cuando en la ojiva se cambia la escala de frecuencias absolutas acumuladas por frecuencias relativas acumuladas, o sea los valores normales se convierten en porcentajes, la ojiva se llama ojiva porcentual. Que guarda fielmente la misma forma de la ojiva. EJEMPLO
Consideremos la cantidad semanal (en dólares), que se gasta en transporte. La tabla siguiente (datos en bruto o datos no agrupados), se obtuvo de una muestra de 54 hogares y, refleja la cantidad semanal gastada, en dólares, en transporte por dichos hogares.
Cantidad gastada semanalmente en transporte
71 63 59 76 27 37 69 29 50
79 25 78 66 63 77 62 32 33
42 33 28 39 46 78 40 41 35
66 40 51 40 74 57 40 71 30
49 44 70 42 79 35 34 23 35
21 26 39 38 30 23 50 40 28
Construya gráficos estadísticos: histogramas, polígonos de frecuencias y ojivas.
SOLUCIÓN
Tabla de frecuencias
Cantidad gastada semanalmente
(dólares)
Marca de
clase
Frecuencias absolutas
Frecuencias relativas
Simple Acumulada Simple
(%) Acumulada
(%)
20-30 25 9 9 17 17
30-40 35 13 22 24 41
40-50 45 11 33 20 61
50-60 55 5 38 9 70
60-70 65 6 44 11 81
70-80 75 10 54 19 100
Total 54 100
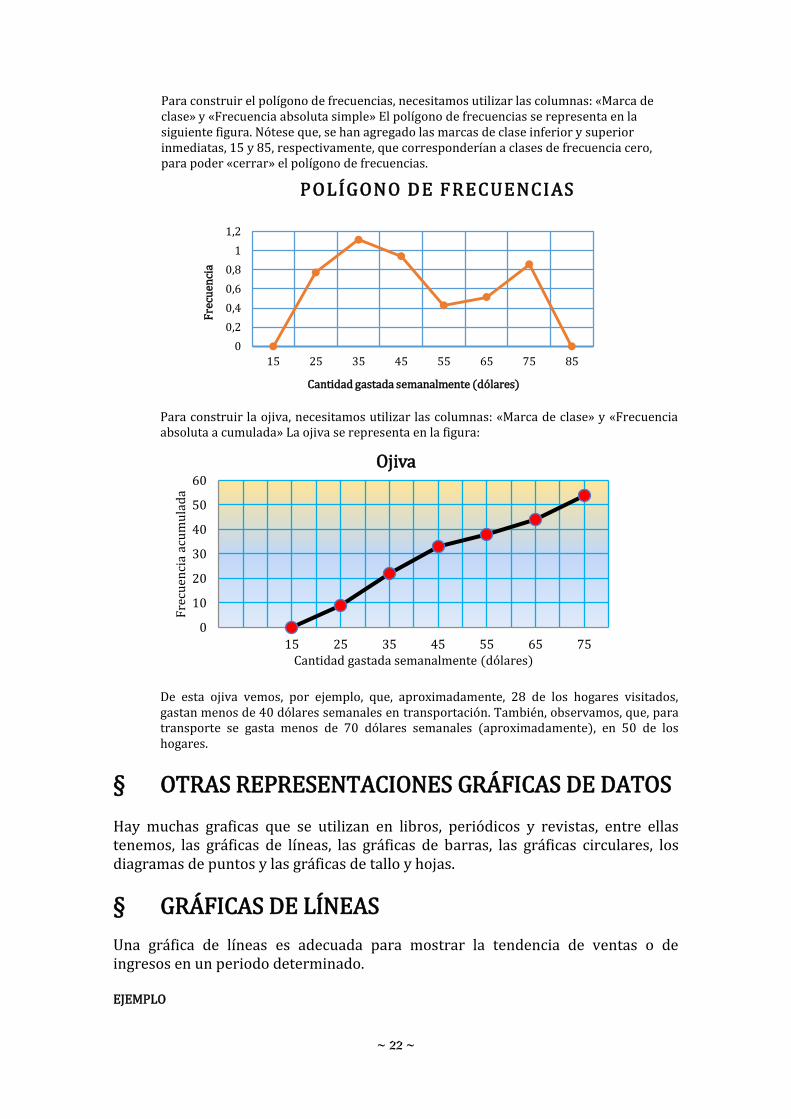
Para construir el histograma, necesitamos utilizar las columnas: «Marca de clase» y «Frecuencia absoluta simple». El histograma se muestra en la siguiente figura.
0
5
10
15
25 35 45 55 65 75
Fre
cuen
cia
Cantidad gastada semanalmente (dólares)
Histograma
~ 22 ~
Para construir el polígono de frecuencias, necesitamos utilizar las columnas: «Marca de clase» y «Frecuencia absoluta simple» El polígono de frecuencias se representa en la siguiente figura. Nótese que, se han agregado las marcas de clase inferior y superior inmediatas, 15 y 85, respectivamente, que corresponderían a clases de frecuencia cero, para poder «cerrar» el polígono de frecuencias.
Para construir la ojiva, necesitamos utilizar las columnas: «Marca de clase» y «Frecuencia absoluta a cumulada» La ojiva se representa en la figura:
De esta ojiva vemos, por ejemplo, que, aproximadamente, 28 de los hogares visitados, gastan menos de 40 dólares semanales en transportación. También, observamos, que, para transporte se gasta menos de 70 dólares semanales (aproximadamente), en 50 de los hogares.
§ OTRAS REPRESENTACIONES GRÁFICAS DE DATOS Hay muchas graficas que se utilizan en libros, periódicos y revistas, entre ellas tenemos, las gráficas de líneas, las gráficas de barras, las gráficas circulares, los diagramas de puntos y las gráficas de tallo y hojas.
§ GRÁFICAS DE LÍNEAS
Una gráfica de líneas es adecuada para mostrar la tendencia de ventas o de ingresos en un periodo determinado. EJEMPLO
0
0,2
0,4
0,6
0,8
1
1,2
15 25 35 45 55 65 75 85
Fre
cuen
cia
Cantidad gastada semanalmente (dólares)
POLÍGONO DE F RECUENCIAS
0
10
20
30
40
50
60
15 25 35 45 55 65 75
Fre
cuen
cia
acu
mu
lad
a
Cantidad gastada semanalmente (dólares)
Ojiva

~ 23 ~
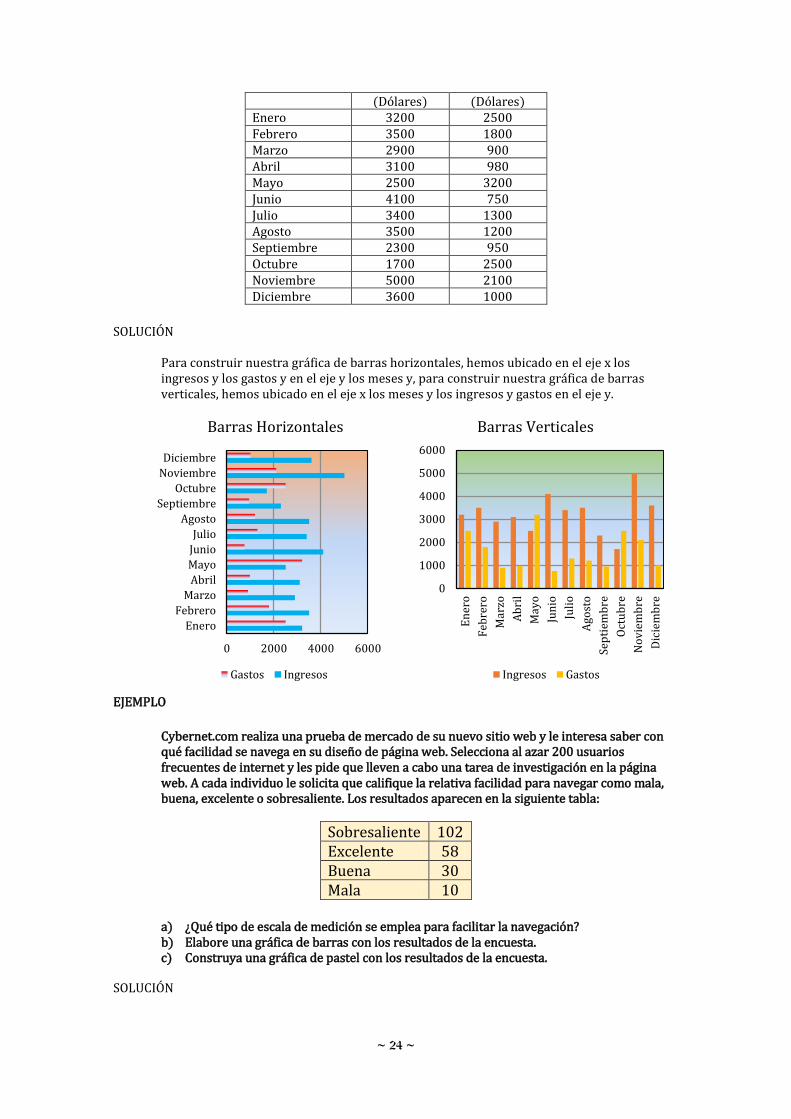
Los ingresos y los gastos mensuales de una microempresa, se registran a continuación.
Mes Ingresos
(Dólares) Gastos
(Dólares) Enero 3200 2500 Febrero 3500 1800 Marzo 2900 900 Abril 3100 980 Mayo 2500 3200 Junio 4100 750 Julio 3400 1300 Agosto 3500 1200 Septiembre 2300 950 Octubre 1700 2500 Noviembre 5000 2100 Diciembre 3600 1000
SOLUCIÓN
Para construir nuestra gráfica de líneas, hemos ubicado en el eje x los meses y en el eje y los ingresos y los gastos.
§ GRÁFICAS DE BARRAS Las gráficas de barras son similares a las gráficas de líneas, y resultan útiles para mostrar cambios en un negocio o datos económicos en un lapso de tiempo, pudiendo ser barras horizontales o verticales. También se utilizan con datos cualitativos. EJEMPLO
Los ingresos y los gastos mensuales de una microempresa, se registran a continuación.
Mes Ingresos Gastos
0
1000
2000
3000
4000
5000
6000
MES
Ingresos Gastos
~ 24 ~
(Dólares) (Dólares) Enero 3200 2500 Febrero 3500 1800 Marzo 2900 900 Abril 3100 980 Mayo 2500 3200 Junio 4100 750 Julio 3400 1300 Agosto 3500 1200 Septiembre 2300 950 Octubre 1700 2500 Noviembre 5000 2100 Diciembre 3600 1000
SOLUCIÓN
Para construir nuestra gráfica de barras horizontales, hemos ubicado en el eje x los ingresos y los gastos y en el eje y los meses y, para construir nuestra gráfica de barras verticales, hemos ubicado en el eje x los meses y los ingresos y gastos en el eje y.
Barras Horizontales Barras Verticales
EJEMPLO
Cybernet.com realiza una prueba de mercado de su nuevo sitio web y le interesa saber con qué facilidad se navega en su diseño de página web. Selecciona al azar 200 usuarios frecuentes de internet y les pide que lleven a cabo una tarea de investigación en la página web. A cada individuo le solicita que califique la relativa facilidad para navegar como mala, buena, excelente o sobresaliente. Los resultados aparecen en la siguiente tabla:
Sobresaliente 102 Excelente 58 Buena 30 Mala 10
a) ¿Qué tipo de escala de medición se emplea para facilitar la navegación? b) Elabore una gráfica de barras con los resultados de la encuesta. c) Construya una gráfica de pastel con los resultados de la encuesta.
SOLUCIÓN
0 2000 4000 6000
Enero
Febrero
Marzo
Abril
Mayo
Junio
Julio
Agosto
Septiembre
Octubre
Noviembre
Diciembre
Gastos Ingresos
0
1000
2000
3000
4000
5000
6000E
ner
o
Feb
rero
Mar
zo
Ab
ril
May
o
Jun
io
Juli
o
Ago
sto
Sep
tiem
bre
Oct
ub
re
No
vie
mb
re
Dic
iem
bre
Ingresos Gastos

~ 25 ~
a) Los datos se miden de acuerdo con una escala ordinal. Es decir, que la escala se gradúa en conformidad con la facilidad relativa y abarca de malo a sobresaliente. Además, el intervalo entre cada calificación se desconoce, así que resulta imposible, por ejemplo, concluir que una buena calificación representa el doble de una mala calificación.
b) Es posible usar una gráfica de barras para representar los datos. La escala vertical
muestra la frecuencia relativa y la horizontal los valores relativos a la facilidad de medida de navegación.
c) También se emplea una gráfica de pastel para representar estos datos. La gráfica de pastel hace hincapié en que más de la mitad de los encuestados calificaron de sobresaliente la relativa facilidad para utilizar el sitio web.
§ GRÁFICAS CIRCULARES (O DE PASTEL) Las gráficas circulares son útiles para mostrar datos cualitativos o porcentajes. Una gráfica circular presenta datos cualitativos como si fueran rebanadas de un pastel. EJEMPLO
Se está verificando la calidad del servicio telefónico. Algunas de las quejas en contra de las compañías telefónicas incluyen los cambios, es decir, se cambia de compañía al cliente sin su consentimiento, y el cobro forzoso de cargos no autorizados. Datos recientes mostraron que las quejas en contra de las compañías telefónicas eran las siguientes:
0
0,1
0,2
0,3
0,4
0,5
0,6
Mala Buena Excelente Sobresaliente
Fre
cuen
cia
rela
tiv
a, %
Facilidad de navegación: Gráfica de barras
5%
15%
29%
51%

~ 26 ~
Descripción Número de quejas
Tarifas y servicios 447
Marketing 100
Llamadas internacionales 77
Cargos de acceso 61
Servicios de operadora 53
Cambios sin consentimiento 1248
Forzamiento 121
Total 2107
En una gráfica circular represente los porcentajes de las quejas más comunes hacia las compañías telefónicas.
SOLUCIÓN
El diagrama circular correspondiente las quejas en contra de las compañías telefónicas, se verá así:
§ GRÁFICAS DE PUNTOS Una gráfica de puntos consiste en una gráfica en donde se marca cada valor de un dato como un punto a lo largo de una escala de valores. Los puntos que representan valores iguales se amontonan. Un diagrama de puntos se asemeja a un histograma en el sentido de que consiste en una representación gráfica de una distribución de los valores de los datos. Sin embargo, se diferencia de éste en que los valores se representan individualmente, en lugar de agruparse en clases. Los diagramas de puntos se aplican preferentemente a pequeños conjuntos de datos y son particularmente útiles en la comparación de dos conjuntos de datos diferentes, o de dos subgrupos de un conjunto de datos.
Cambios sin consentimiento;
1248
Tarifas y servicios; 447
Forzamiento; 121
Marketing; 100
Llamadas internacionales;
77
Cargos de acceso; 61
Servicios de operadora; 53
Cambios sin consentimiento Tarifas y servicios
Forzamiento Marketing
Llamadas internacionales Cargos de acceso
Servicios de operadora

~ 27 ~
EJEMPLO En un condominio viven 10 familias (identificadas por un número del 1 al 10), constituidas por padres e hijos. La cantidad de hijos por familia está dada en la siguiente tabla:
Familia Nº 1 2 3 4 5 6 7 8 9 10
Cantidad de hijos 0 5 1 1 2 0 1 4 3 3
En una gráfica de puntos, represente el número de hijos que tienen las familias. Conocido el gráfico de puntos y/o la tabla resumen, se puede hacer algunas preguntas de interés. Por ejemplo: a) ¿En cuántas familias hay tres hijos? b) ¿Cuántos hijos viven en el condominio? c) ¿Cuántos hijos no son únicos?
SOLUCIÓN
La gráfica de puntos queda así:
Ahora podemos contestar las preguntas: a) En dos familias hay tres hijos. b) Veinte hijos. c) Diecisiete hijos no son únicos.∎
§ GRÁFICAS DE TALLO Y HOJAS Una gráfica de tallo y hojas es una representación de un conjunto de datos estadísticos, de la siguiente forma. Cada valor numérico se divide en dos partes, el dígito principal se convierte en el tallo y los dígitos secundarios en las hojas. El tallo se localiza a lo largo del eje vertical y los valores de las hojas se apilan unos contra otros a lo largo del eje horizontal. Esta representación tiene la ventaja de que no se pierde la identidad de cada observación. EJEMPLO
La tabla siguiente, muestra la cantidad de espacios publicitarios de 30 segundos en radio, que compró cada uno de los 45 locales comerciales de la cadena de ventas del Centro Comercial CCM, el año pasado. Organice los datos en una representación de tallo y hojas.
0 1 2 3 4 5 6
Número de hijos
Gráfica de puntos

~ 28 ~
96 93 88 117 127 95 113 96 108 94 148 156
139 142 94 107 125 155 155 103 112 127 117 120
112 135 132 111 125 104 106 139 134 119 97 89
118 136 125 143 120 103 113 124 138
SOLUCIÓN
Se advierte que la menor cantidad de anuncios es 88, por tanto el primer valor del tallo es 8. El valor más grande es 156, por lo que los valores de tallo comenzarán en 8 y continuarán hasta 15. El primer valor en la tabla es 96, que tendrá un valor de tallo de 9 y un valor de hoja de 6. Recorriendo el renglón superior, el segundo valor es 93 y el tercero es 88, y así sucesivamente. Después de organizar todos los datos, tenemos:
Tallo Hojas
8 8 9 9 6 3 5 6 4 4 7
10 8 7 3 4 6 3 11 7 3 2 7 2 1 9 8 3 12 7 5 7 0 5 5 0 4 13 9 5 2 9 4 6 8 14 8 2 3 15 6 5 5
El procedimiento final es ordenar los valores de las hojas, de menor a mayor. Así:
Tallo Hojas
8 8 9 9 3 4 4 5 6 6 7
10 3 3 4 6 7 8 11 1 2 2 3 3 7 7 8 9 12 0 0 4 5 5 5 7 7 13 2 4 5 6 8 9 9 14 2 3 8 15 5 5 6
Es posible deducir algunas conclusiones del diagrama de tallo y hojas. Por ejemplo, la cantidad mínima de espacios publicitarios comprados es de 88, y la máxima de 156; dos almacenes compraron menos de 90 espacios, y tres compraron 150 o más. Observe, por ejemplo, que los tres almacenes que compraron más de 150 espacios, en realidad compraron 155,155 y 156 espacios. La «concentración» de la cantidad de espacios se encuentra entre 110 y 130. Hubo 17 almacenes que compraron entre 110 y 130 espacios publicitarios.∎
Existen otros diagramas estadísticos, tales como los diagramas de dispersión, los diagramas de caja o de cuadro, los pictogramas, etc., algunos de los cuales se revisarán más adelante.

~ 29 ~
§ EJERCICIOS E1 Decir de las variables siguientes cuáles son discretas y cuáles continuas.
a) Temperaturas registradas cada media hora en un observatorio. b) Peso de las cajas registradas en un contenedor. c) Número de billetes de veinte dólares circulando a la vez en Ecuador. d) Estudiantes matriculados en la PUCE-SI en un este semestre. e) Velocidad de un automóvil en kilómetros por hora. f) Número de libros en un estante de librería. g) Países de Europa. h) Número de galones de gasolina en un tanque de automóvil. i) Longitud de un cuarto. j) Suma de puntos obtenidos en el lanzamiento de un par de dados. k) Número de kilogramos de trigo producidos por hectárea en una
granja en un determinado número de años. l) Número de individuos de una familia. m) Tiempo de vuelo de un avión. n) Estado civil de un individuo. o) Número de pétalos de una flor.
E2 Ubique las variables en la siguiente tabla de clasificación.
a) Salario. b) Género. c) Volumen de ventas de reproductores de MP3. d) Preferencia por los refrescos. e) Temperatura (Co) f) Lugar que ocupa un estudiante en clase, en lo que a rendimiento
académico se refiere. g) Cantidad de computadoras domésticas. h) Calificaciones de un profesor de Programación.
Cualitativa Cuantitativa Nominal Ordinal Discreta Continua
E3 Suponga que las variables del ejercicio E2 generan datos. Ubique estos
datos en la siguiente tabla de clasificación.
Discreto Continuo Nominal Ordinal Intervalo Razón
~ 30 ~
E4 Suponga que estamos investigando sobre el porcentaje de alumnos que trabajan de una población de 20 alumnos de un curso de la Universidad.
Base de datos de la población
Número Nombre Alumno ¿Trabaja? Número
Nombre Alumno ¿Trabaja?
1 Juan SI 11 María NO
2 Alicia NO 12 Fernanda NO
3 Pedro NO 13 Julio SI
4 Marcos NO 14 Rosa NO
5 Alberto SI 15 Fabián NO
6 Jorge SI 16 Ana NO
7 José NO 17 Laura NO
8 Carlos NO 18 Enrique NO
9 Miguel NO 19 Carmen SI
10 Victoria SI 20 Marcelo SI
Elija una muestra aleatoria simple de tamaño n=4 de esta población.
a) Mediante muestreo aleatorio simple. b) Mediante muestreo aleatorio sistemático. c) Mediante muestreo estratificado («hombres» y «mujeres»). d) Mediante muestreo estratificado («trabaja» y «no trabaja»).
E5 En cada caso identifique la muestra y la población.
a) Un reportero de El Comercio se para en una esquina y pregunta a 100 adultos si creen que el presidente actual está haciendo un buen trabajo.
b) Una encuestadora especializada en estudios de mercadotecnia encuesta a 200 amas de casa seleccionadas al azar y encuentra que el 19% utiliza como lavavajillas «Axion» a la hora de lavar la vajilla.
c) Una estudiante graduada de la universidad realizó un proyecto de investigación acerca de cómo se comunican los adultos ecuatorianos. Empezó por una encuesta que envió por correo a 150 adultos que ella conocía. Les pidió que le enviaran por correo la respuesta a esta pregunta: « ¿Prefiere usted usar el correo electrónico o el correo tortuga? » Ella recibió a vuelta de correo 20 respuestas y 7 de ellas indicaron una preferencia por el correo tortuga.
d) Un fabricante afirma con razón en virtud de su experiencia, que la carga promedio que soportan los cables de acero producidos por su compañía es de 4006 libras. Un cliente pone en duda dicha afirmación y para comprobarlo toma 10 de dichos cables y encuentra que la carga media soportada por éstos es de 4003 libras. ¿Cuál es la muestra?, ¿Cuál es la población?
E6 Suponga usted, que una organización no gubernamental, quiere hacer una investigación sobre el desempleo y el subempleo en la provincia de

~ 31 ~
Imbabura y que para tal efecto ha reflexionado y deliberado ampliamente sobre los objetivos que se persiguen y sobre la justificación de dicha investigación, encontrando con ello vía libre para iniciar la investigación. ¿Qué aspectos tomaría en cuenta usted antes de emprender la investigación?
E7 Redondear cada uno de los siguientes números a la aproximación indicada.
a) 48,6 aproximando a unidades. b) 136,5 aproximando a unidades. c) 2,484 aproximando a centésimas. d) 0,0435 aproximando a milésimas. e) 4,50001 aproximando a unidades. f) 143,95 aproximando a décimas. g) 368 aproximando a centenas. h) 24448 aproximando a unidades de millar (mil). i) 5,56500 aproximando a centésimas. j) 2345,6751 aproximando a centésimas.
E8 Hallar el valor de las siguientes expresiones, sabiendo que:
a = 4, b = −7, x = 3, y = −5
a) 2x − 3y b) −8x + 4y + 28
c) ax+by
bx−ay
d) x2 − 3xy − 2y2 e) 2(x + 3y) − 4(x − 2y)
f) x2−y2
b2−a2+1
g) √1 + x2 + y2 + a2 + b2
h) √bx+ya
2+ 3
i) log 𝑎 + log 𝑏 j) ln(−b) − ln(−y)
E9 Escribir los sumandos de cada una de las siguientes sumas indicadas y
simplificar si es posible.
a) ∑ xi6i=1
b) ∑ (xi − 3)24i=1
c) ∑ ani=1
d) ∑ (fixi)9i=3
e) ∑ (xi − a)5i=1
E10 Expresar cada una de las siguientes sumas mediante la notación Σ.
a) x12 + x2
2 + x32 + ⋯ + x20
2

~ 32 ~
b) (x1 + y1) + (x2 + y2) + (x3 + y3) + ⋯ + (x100 + y100) c) f1x1
2 + f2x22 + f3x3
2 + ⋯ + f50x502
d) a1b1 + a2b2 + a3b3 + ⋯ + anbn e) (x1 + x2 + x3 + ⋯ +xn)(y1 + y2 + y3 + ⋯ +yn)
E11 Dos variables X y Y toman los valores, mencionados en la siguiente lista:
x1 = 2 y1 = −3 x2 = −3 y2 = −6 x3 = 5 y3 = 4 x4 = 7 y4 = 8
Llene la tabla siguiente, y calcule lo que se pide a continuación.
x y xy x2 y2 xy2 (x + y)(x − y)
Suma
a) ∑ x b) ∑ y c) ∑ xy d) ∑ x2 e) ∑ y2 f) (∑ x)(∑ y) g) ∑ xy2 h) ∑[(x + y)(x − y)]
E12 Demuestre que: ∑(ax + by − cz) = a ∑ x + b ∑ y − c ∑ z. Siendo a, b y c
constantes cualesquiera. E13 El número de hermanos de los alumnos de una clase es el siguiente: 0, 1, 0,
0, 3, 2, 1, 4, 0, 0, 1, 1, 2, 0, 1, 1, 2, 0, 1, 1, 2, 1, 3, 0, 0, 2, 1, 2, 3, 5, 2, 4, 3, 6. Elabore una tabla de frecuencias con datos no agrupados en las que se incluyan: frecuencia absoluta, absoluta acumulada, relativa y relativa acumulada.
a) ¿Qué porcentaje de alumnos son hijos únicos? b) ¿Cuántos alumnos tienen más de un hermano?
E14 El número de goles metidos por partido por un cierto equipo es el siguiente:
0, 1, 0, 2, 3, 2, 1, 3, 0, 0, 1, 0, 3, 0, 1, 1, 0, 0, 1, 1, 2, 1, 2, 0, 1, 2, 1, 5, 3, 5. Elabore una tabla con las cuatro frecuencias y el porcentaje, para datos no agrupados.
a) ¿Qué porcentaje de partidos han metido al menos un gol? b) ¿Cuántos partidos han jugado?

~ 33 ~
E15 En una encuesta sobre vivienda se pregunta, entre otras cosas, cuántas personas viven en la casa, obteniéndose las siguientes respuestas: 4, 4, 8, 1, 3, 2, 1, 3, 4, 2, 2, 7, 0, 3, 8, 0, 1, 5, 6, 4, 2, 3, 1, 5, 2, 6, 4, 8, 9, 2, 4, 2, 5, 3, 3, 4, 5, 6, 8, 6, 2, 5, 3, 3, 5, 4, 6, 2, 0, 4, 3, 6, 1, 3, 5, 4, 6, 3, 4, 5, 4, 7.
a) Elabore una tabla en la que se recojan las cuatro frecuencias, para
datos agrupados. b) ¿Cuántas viviendas fueron objeto de estudio? c) ¿En cuántas de ellas no vive nadie? d) ¿Qué porcentaje de viviendas está ocupado por más de cinco
personas? e) Dibuje un diagrama de circular. f) Dibuje una ojiva.
E16 En un estudio estadístico sobre el número de horas que duran 12 pilas de
una determinada marca se obtuvieron los siguientes datos: 10, 12, 12, 11, 12, 10, 13, 11, 13, 11, 13, 9.
a) Agrupar los datos en una tabla de frecuencias y porcentajes. b) Representar los datos en un diagrama de barras y en un diagrama de
circular. E17 La siguiente tabla refleja las calificaciones de 30 alumnos en un examen de
Matemáticas:
Nota 2 4 5 6 7 8 9 10 Número de alumnos 2 5 8 7 2 3 2 1
a) ¿Cuántos alumnos aprobaron, si la nota mínima para aprobar es al
menos 7? b) ¿Cuántos alumnos sacaron como máximo un 7? c) ¿Cuántos sacaron como mínimo un 6?
E18 Los pesos, en kg, de los 65 empleados de una fábrica vienen dados por la
siguiente tabla:
Peso [50,60) [60,70) [70,80) [80,90) [90,100) [100,110) [110,120)
f 8 10 16 14 10 5 2
Representar el histograma y el polígono de frecuencias.
E19 A partir de la siguiente gráfica de barras sobre los gustos deportivos:

~ 34 ~
a) Calcular la tabla de frecuencias. b) ¿A qué porcentaje de las personas no le gusta el ciclismo? c) Convierta a diagrama circular.
E20 En una encuesta a 35 personas se les preguntaba sobre sus preferencias a la
hora de ver películas. Los resultados se recogieron en la siguiente gráfica:
a) ¿Cómo se llama la gráfica? b) Construya la tabla de frecuencias. c) ¿A qué porcentaje de las personas encuestadas les gustan las películas
de amor? d) ¿Y las de ciencia-ficción?
E21 Consulte lo que es un «pictograma», e inserte uno cualquiera de su agrado. E22 Se ha lanzado un dado 20 veces y se han obtenido los siguientes resultados:
3, 4, 5, 2, 1, 4, 6, 1, 3, 2, 5, 5, 3, 2, 4, 4, 1, 2, 5, 6.
a) Construir la tabla de frecuencias. b) Representar los datos con un diagrama de barras y un diagrama de
puntos.
0
1
2
3
4
5
6
atletismo ciclismo baloncesto natación
Nú
mer
o d
e p
erso
nas
Deporte favorito
12
16
54
8
AVENTURAS AMOR MISTERIO CIENCIA-FICCIÓN
HUMOR
Nú
mer
o d
e p
erso
nas
Tipo de película

~ 35 ~
E23 Realizar una «pirámide de población» (¿no sabe qué es?, consulte: http://www.youtube.com/watch?v=QZdEPAeVqTw), con las edades de los hermanos de los compañeros de clase (incluido el alumno). Calcular porcentajes por edades y géneros. Hacer la gráfica respectiva.
E24 Un conjunto de datos consiste en 83 observaciones. ¿Cuántas clases
recomendaría para una distribución de frecuencias? E25 Un conjunto de datos consta de 145 observaciones que van desde 56 hasta
490. ¿Qué tamaño de intervalo de clase recomendaría? E26 A continuación, en la tabla, se presenta el número de minutos para viajar
desde el hogar al trabajo, en una ciudad grande, para un grupo de ejecutivos con automóvil.
a) ¿Cuántas clases recomendaría? b) ¿Qué intervalo de clase es de sugerir? c) ¿Qué recomendaría como límite inferior de la primera clase? d) Organice los datos en una distribución de frecuencias.
E27 El administrador local del centro comercial Santa María está interesado en
conocer el número de veces que un cliente realiza compras en su almacén durante un periodo de un mes. Las respuestas de 80 clientes fueron como se describen en la tabla:
5 3 3 1 4 4 5 6 4 2 6 6 6 7 1 1 14 1 2 4 4 4 5 6 3 5 3 4 5 6 8 4 7 6 5 9 11 3 12 4 7 6 5 15 1 1 10 8 9 2 12 1 2 3 4 3 2 5 4 3 4 4 3 3 2 4 1 1 1 1 2 3 4 4 5 6 7 8 7 6
a) Comenzando con el 0 como el límite inferior de la primera clase y
utilizando un intervalo de clase igual a 3, organice los datos en una distribución de frecuencias.
b) Convierta la distribución en una distribución de frecuencias relativas.
c) Construya un histograma de frecuencias. d) Construya un polígono de frecuencias. e) Construya una ojiva.
E28 La figura siguiente, es un histograma que muestra las calificaciones de un
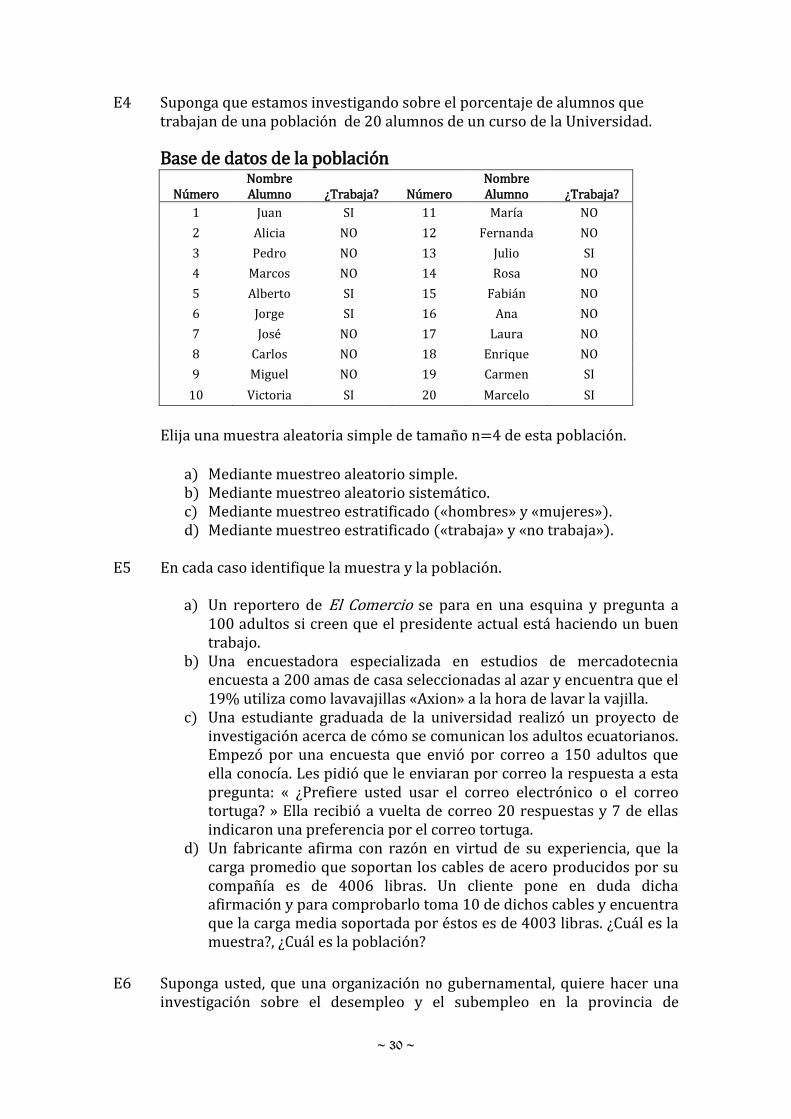
primer examen de estadística de un curso.
a) ¿Cuántos estudiantes hicieron el examen? b) ¿Cuál es el intervalo de clase?
28 25 48 37 41 19 32 26 16 23 23 29 36 31 26 21 32 25 31 43 35 42 38 33 28
~ 36 ~
c) ¿Cuál es el punto medio de clase para la primera de ellas? d) ¿Cuántos estudiantes obtuvieron una calificación menor que 70?
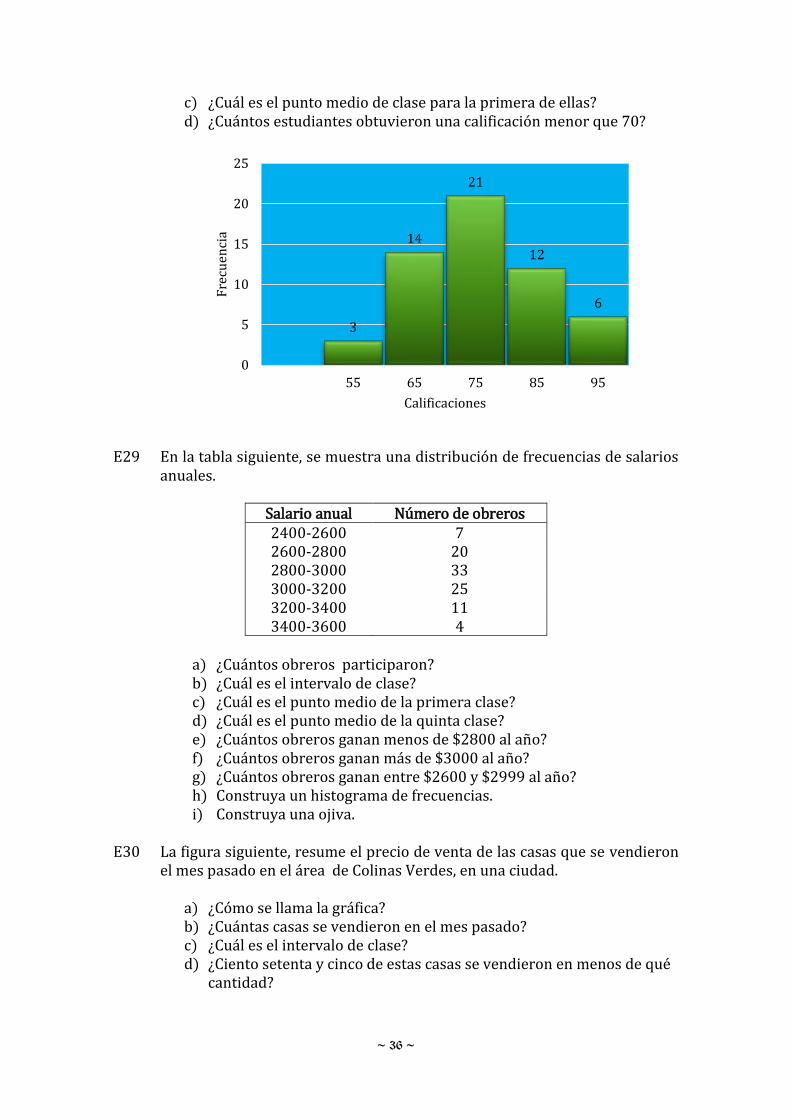
E29 En la tabla siguiente, se muestra una distribución de frecuencias de salarios anuales.
Salario anual Número de obreros 2400-2600 7 2600-2800 20 2800-3000 33 3000-3200 25 3200-3400 11 3400-3600 4
a) ¿Cuántos obreros participaron? b) ¿Cuál es el intervalo de clase? c) ¿Cuál es el punto medio de la primera clase? d) ¿Cuál es el punto medio de la quinta clase? e) ¿Cuántos obreros ganan menos de $2800 al año? f) ¿Cuántos obreros ganan más de $3000 al año? g) ¿Cuántos obreros ganan entre $2600 y $2999 al año? h) Construya un histograma de frecuencias. i) Construya una ojiva.
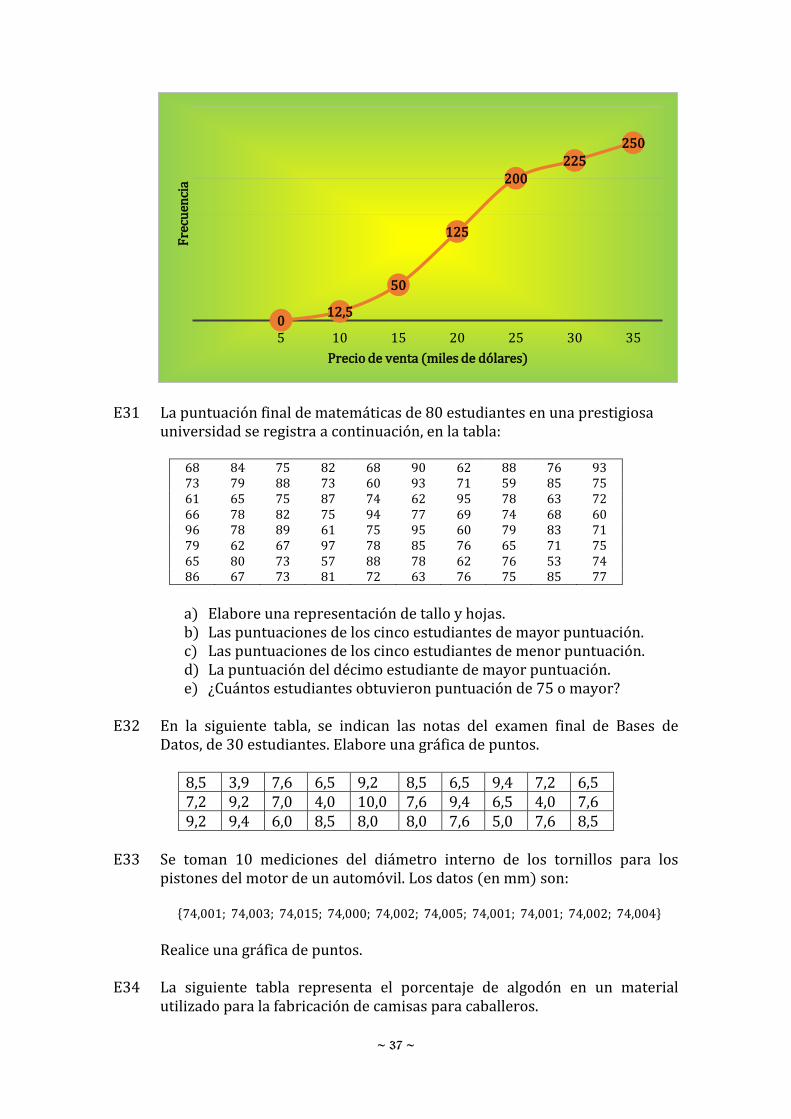
E30 La figura siguiente, resume el precio de venta de las casas que se vendieron
el mes pasado en el área de Colinas Verdes, en una ciudad.
a) ¿Cómo se llama la gráfica? b) ¿Cuántas casas se vendieron en el mes pasado? c) ¿Cuál es el intervalo de clase? d) ¿Ciento setenta y cinco de estas casas se vendieron en menos de qué
cantidad?
3
14
21
12
6
0
5
10
15
20
25
55 65 75 85 95
Fre
cuen
cia
Calificaciones
~ 37 ~
E31 La puntuación final de matemáticas de 80 estudiantes en una prestigiosa
universidad se registra a continuación, en la tabla:
68 84 75 82 68 90 62 88 76 93 73 79 88 73 60 93 71 59 85 75 61 65 75 87 74 62 95 78 63 72 66 78 82 75 94 77 69 74 68 60 96 78 89 61 75 95 60 79 83 71 79 62 67 97 78 85 76 65 71 75 65 80 73 57 88 78 62 76 53 74 86 67 73 81 72 63 76 75 85 77
a) Elabore una representación de tallo y hojas. b) Las puntuaciones de los cinco estudiantes de mayor puntuación. c) Las puntuaciones de los cinco estudiantes de menor puntuación. d) La puntuación del décimo estudiante de mayor puntuación. e) ¿Cuántos estudiantes obtuvieron puntuación de 75 o mayor?
E32 En la siguiente tabla, se indican las notas del examen final de Bases de
Datos, de 30 estudiantes. Elabore una gráfica de puntos.
8,5 3,9 7,6 6,5 9,2 8,5 6,5 9,4 7,2 6,5 7,2 9,2 7,0 4,0 10,0 7,6 9,4 6,5 4,0 7,6 9,2 9,4 6,0 8,5 8,0 8,0 7,6 5,0 7,6 8,5
E33 Se toman 10 mediciones del diámetro interno de los tornillos para los
pistones del motor de un automóvil. Los datos (en mm) son:
{74,001; 74,003; 74,015; 74,000; 74,002; 74,005; 74,001; 74,001; 74,002; 74,004}
Realice una gráfica de puntos.
E34 La siguiente tabla representa el porcentaje de algodón en un material
utilizado para la fabricación de camisas para caballeros.
012,5
50
125
200
225
250
5 10 15 20 25 30 35
Fre
cuen
cia
Precio de venta (miles de dólares)

~ 38 ~
Datos del porcentaje de algodón
33,1 35,3 34,2 33,6 33,6 33,1 37,6 33,6
34,5 34,7 33,4 32,5 35,4 34,6 37,3 34,1
35,6 35,0 34,7 34,1 34,6 35,9 34,6 34,7
36,3 35,4 34,6 35,1 33,8 34,7 35,5 35,7
35,1 36,2 35,2 36,8 37,1 33,6 32,8 36,8
34,7 36,8 35,0 37,9 34,0 32,9 32,1 34,3
33,6 35,1 34,9 36,4 34,1 33,5 34,5 32,7
32,6 33,6 33,8 34,2 34,6 34,7 35,8 37,8
Elabore una gráfica de tallo y hojas para los anteriores datos.
E35 El número de estrellas de los hoteles de una ciudad viene dado por el siguiente conjunto, donde cada elemento representa a un hotel: {3, 3, 4, 3, 4, 3, 1, 3, 4, 3, 3, 3, 2, 1, 3, 3, 3, 2, 3, 2, 2, 3, 3, 3, 2, 2, 2, 2, 2, 3, 2, 1, 1, 1, 2, 2, 4, 1}
Bosqueje una gráfica de puntos.
E36 La figura siguiente, es una representación de tallo y hojas muestra el número de unidades producidas por día en una fábrica.
3 8 4 5 6 6 0 1 3 3 5 5 9 7 0 2 3 6 7 7 8 8 5 9 9 0 0 1 5 6
10 3 6
a) ¿Cuántos días se estudiaron? b) ¿Cuántas observaciones hay en la primera clase? c) ¿Cuáles son el valor más pequeño y el valor más grande? d) Indique los valores reales en el cuarto renglón. e) Indique los valores reales en el segundo renglón. f) ¿Cuántos valores son inferiores a 70? g) ¿Cuántos valores son iguales o superiores a 80? h) ¿Cuál es el valor intermedio? i) ¿Cuántos valores hay entre 60 y 89 inclusive?
E37 Resuelva las ecuaciones siguientes.
a) 1
2(x −
7
3) −
1
3(x −
7
4) +
1
4(x −
7
5) = 0
b) 2y2 −6y
11−
3y
4=
22y2
3−
9
44−
11y
4

~ 39 ~
E38 Resuelva los siguientes sistemas de ecuaciones.
a) {x
2+
y
3+
1
4=
x
5+
y
6+
1
7
2x + 3y + 4 = 5x + 6y + 7
b) {ax + by = ecx + dy = f
E39 Resuelva las desigualdades siguientes.
a) 5x−1
3−
2x
5≥
x−1
2+ 4
b) −2y ≤ 3 +1
2(y − 12) < 8
E40 Evalúe las integrales definidas:
a) ∫ x2dx2
0
b) ∫ (x3 − x2 + 5x + 1)dx
1
0


















