
Turning Unstructured Content into Kernels of Ideas
71
Turning Unstructured Content into Kernels of Ideas Jason Kessler Data Scientist, CDK Global Data Day Seattle, 2016 @jasonkessler www.jasonkessler.com Code used in talk: https://github.com/JasonKessler/scattertext
-
Upload
jason-kessler -
Category
Software
-
view
685 -
download
2
Transcript of Turning Unstructured Content into Kernels of Ideas

Turning Unstructured Content into Kernels of IdeasJason KesslerData Scientist, CDK Global
Data Day Seattle, 2016
@jasonkesslerwww.jasonkessler.com
Code used in talk:https://github.com/JasonKessler/scattertext

1. Case studies on mining documents for knowledge
2. Old, new, and obscure algorithms and tools

Customer-Written Product Reviews
Good Ad Content

Naïve Approach: Indicators of Positive Sentiment
"If you ask a Subaru owner what they think of their car, more times than not they'll tell you they love it," -Alan Bethke, director of marketing communications for Subaru of America (via Adweek)

But does positivity imply engagement?

Finding Engaging Content
…I was very skeptical giving up my truck and buying an "Economy Car." I'm 6' 215lbs, but my new career has me driving a personal vehicle to make sales calls. I am overly impressed with my Cruze…
Rating: 4.4/5 Stars
Example Review Appearing on a 3rd Party Automotive Site
# of users who read review: 20
Text:Car Reviewed: Chevy Cruze

Finding Engaging Content
…I was very skeptical giving up my truck and buying an "Economy Car." I'm 6' 215lbs, but my new career has me driving a personal vehicle to make sales calls. I am overly impressed with my Cruze…
Rating: 4.4/5 Stars
Example Review Appearing on a 3rd Party Automotive Site
# of users who read review:
# who went on to visit a Chevy dealer’s website: 15
20Text:Car Reviewed: Chevy Cruze

Finding Engaging Content
…I was very skeptical giving up my truck and buying an "Economy Car." I'm 6' 215lbs, but my new career has me driving a personal vehicle to make sales calls. I am overly impressed with my Cruze…
Rating: 4.4/5 Stars
Example Review Appearing on a 3rd Party Automotive Site
# of users who read review:
# who went on to visit a Chevy dealer’s website: 15
20
Review Engagement Rate:
15/20=75%Text:Car Reviewed: Chevy Cruze

Finding Engaging Content
…I was very skeptical giving up my truck and buying an "Economy Car." I'm 6' 215lbs, but my new career has me driving a personal vehicle to make sales calls. I am overly impressed with my Cruze…
Rating: 4.4/5 Stars
Example Review Appearing on a 3rd Party Automotive Site
# of users who read review:
# who went on to visit a Chevy dealer’s website: 15
20
Review Engagement Rate:
15/20=75%Text:Car Reviewed: Chevy Cruze
Median Review Engagement Rate:
22%


Are words and phrases more precise predictors?

Positive SentimentLoveComfortableFeaturesSolidAmazing
Sentiment vs. Persuasiveness: SUV-Specific
Negative SentimentTransmissionProblemIssueDealershipTimes

Positive Sentiment High EngagementLove ComfortableComfortable Front [Seats]Features AccelerationSolid Free [Car Wash, Oil Change]Amazing Quiet
Sentiment vs. Persuasiveness: SUV-Specific
Negative SentimentTransmissionProblemIssueDealershipTimes

Positive Sentiment High EngagementLove ComfortableComfortable Front [Seats]Features AccelerationSolid Free [Car Wash, Oil Change]Amazing Quiet
Sentiment vs. Persuasiveness: SUV-Specific
Negative Sentiment Low EngagementTransmission Money [spend my, save]Problem FeaturesIssue DealershipDealership AmazingTimes Build Quality [typically positive]

Sentiment vs. Persuasiveness: SUV-Specific
Negative Sentiment Low EngagementTransmission Money [spend my, save]Problem FeaturesIssue DealershipDealership AmazingTimes Build Quality [typically positive]
• The worst thing to say when reviewing an SUV:
“I saved money and got all these amazing features!”

Milquetoast positivity
Persuasiveness

High Sentiment TermsLoveAwesome
Fantastic
Handled
Perfect

Engagement TermsBlind (spot, alert)
Contexts from high engagement reviews- “The techno safety features
(blind spot, lane alert, etc) are reason for buying car...”
- “Side blind Zone Alert is truly wonderful…”
- …

BLIND SPOT ALERT.

Can better science improve messaging?
BLIND SPOT ALERT.
Engagement TermsBlind
White (paint, diamond)
Contexts
- “White with cornsilk interior.”- “My wife fell in love with the
Equinox in White Diamond”- “The white diamond paint is
to die for”

Can better science improve messaging?
BLIND SPOT ALERT.

Can better science improve messaging?
BLIND SPOT ALERT.
Engagement TermsBlind
White
Climate (geography, a/c)
Contexts- “Love the front wheel drive
in this northern Minn. Climate”
- “We do live in a cold climate (Ontario)”
- …climate control…

BLIND SPOT ALERT.

Just recently, VW has produced very similar commercials.

Finding useful class-differentiating terms is complicated.
But simple methods work well.

OKCupid: How does gender and ethnicity affect self-presentation on online dating profiles?
Christian Rudder: http://blog.okcupid.com/index.php/page/7/
Which words and phrases statistically distinguish ethnic groups and genders?
hobos
almond butter 100 Years of
Solitude
Bikram yoga

Source: Christian Rudder. Dataclysm. 2014.
Ranking with everyone else
The smaller the distance from the top left, the higher the association with white men
High distance: but ignore K-Pop
Low distance: white guysdisproportionately like Phish

Source: Christian Rudder. Dataclysm. 2014.
my blue eyes

The Rudder Score:
¿∨¿1,0>−<Φ ( ¿𝑤𝑜𝑟𝑑 ,¬𝑐𝑎𝑡𝑒𝑔𝑜𝑟𝑦 ) ,Φ (¿𝑤𝑜𝑟𝑑,𝑐𝑎𝑡𝑒𝑔𝑜𝑟𝑦 )>¿∨¿2¿
The percentile functionranks counts along a scale of [0,1],

Source: http://blog.okcupid.com/index.php/page/7/ (Rudder 2010)
Words and phrases that distinguish white men.
OKCupid: How do ethnicities’ self-presentation differ on a dating site?

Source: http://blog.okcupid.com/index.php/page/7/ (Rudder 2010)
Words and phrases that distinguish Latino men.
Explanation
OKCupid: How do ethnicities’ self-presentation differ on a dating site?

How can we make money with this?• Genre of insurance or investment ads
– Montage of important events in the life of a person.
• With these phrase sets, the ads practically write themselves:
• What if you wanted to target Latino men? – Grows up boxing– Meets girlfriend salsa dancing– Becomes a Marine– Tells a joke at his wedding– Etc…

Word clouds.

The good:
• Word clouds force you to hunt for the most impactful terms
• You end up examining the long tail in the process
• Compactly represent a lot of phrases
Lyle Ungar 2013 AAAI Tutorial
Above: words found in Facebook status message predictive of women authors.

Lyle Ungar 2013 AAAI Tutorial
Above: words found in Facebook status message predictive of male authors.
The bad:
• “Mullets of the Internet” --Jeffrey Zeldman
• Longer phrases are are more prominent
• Ranking is unclear
• Does size indicate higher frequency?

Word clouds done right.
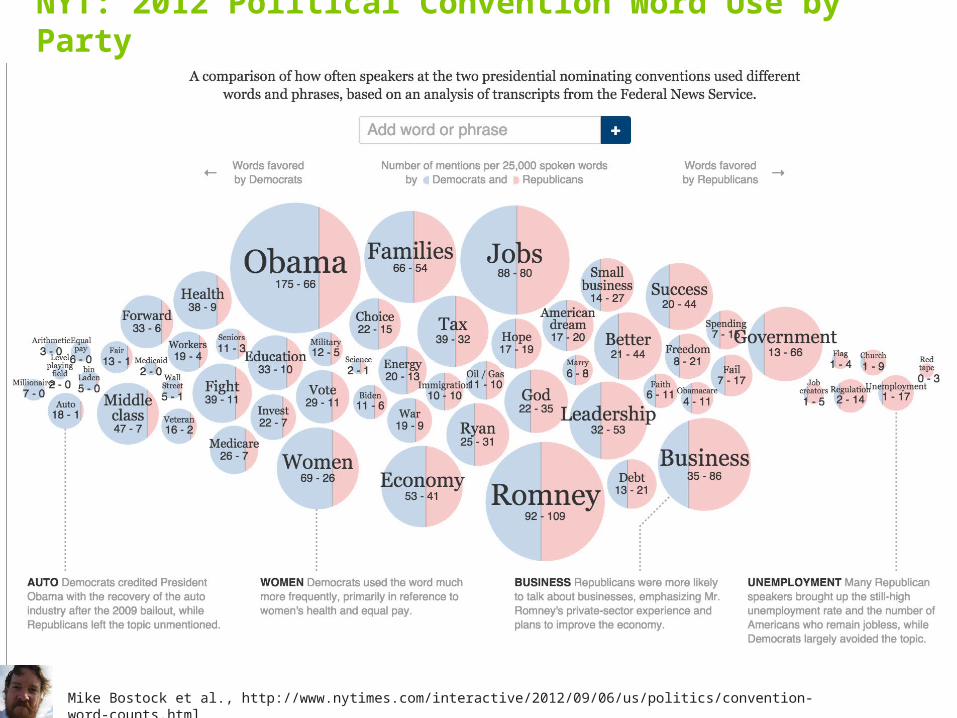
NYT: 2012 Political Convention Word Use by Party
Mike Bostock et al., http://www.nytimes.com/interactive/2012/09/06/us/politics/convention-word-counts.html

2012 Political Convention Word Use by Party
Mike Bostock et al., http://www.nytimes.com/interactive/2012/09/06/us/politics/convention-word-counts.html

Predicting a movie’s revenue from its reviews.

- Data:- 1,718 movie reviews from 2005-2009 7 different publications
(e.g., Austin Chronicle, NY Times, etc.)- Various movie metadata like rating and director- Gross revenue
- Task:- Predict revenue from text, couched as a regression problem- Regressor used: Elastic Net
- l1 and l2 penalized linear regression- 2009 reviews were held-out as test data
- Features:- Ngrams: unigrams, bigrams and trigrams- Dependency relation triples: <dependent, relation, head>- Versions of features labeled for each publication (i.e. domain)
- “Ent. Weekly: comedy_for”, “Variety: comedy_for”- Essentially the same algo as Daume III (2007)
- Performed better than naïve baseline, but worse than metadata
Predicting Box-Office Revenue From Movie Reviews (Joshi et al., 2010)
Joshi et al. Movie Reviews and Revenues: An Experiment in Text Regression. NAACL 2010 Daume III. Frustratingly Easy Domain Adaptation. ACL 2007.

Predicting Box-Office Revenue From Movie Reviews
Joshi et al. Movie Reviews and Revenues: An Experiment in Text Regression. NAACL 2010
manually labeled feature categories
Feature weight (“Weight ($M)”) in linear model indicates how much features are “worth” in millions of dollars.
The learned coefficients.

• The corpus used in Joshi et al. 2010 is freely available.• Can we use the Rudder algorithm to find interesting associated
terms? How does it compare?– Rudder algorithm requires two or more classes.– We can partition the the dataset into high and low revenue partitions.
• High being movies in the upper third of revenue, low in the bottom third
– Find words that are associated with high vs. low (throwing out the middle third) and vice versa
Univariate approach to predicting revenue from text

• Observation definition is really important!– Recall that the same movie may have multiple reviews.– We can treat an observation as
• a single review• a single movie (concatenation of all reviews)• word frequencies: # observations words appear in
– The response variable remains the same– movie revenue
Univariate approach to predicting revenue from text

• Observation definition is really important!– Recall that the same movie may have multiple reviews.– We can treat an observation as
• a single review• a single movie (concatenation of all reviews)• word frequencies: # observations words appear in
– The response variable remains the same– movie revenue
Univariate approach to predicting revenue from text
Top 5 high revenue terms (Rudder algorithm)Review-level observations Movie-level observationsBatman Computer generated
Borat Superhero
Rodriguez The franchise
Wahlberg Comic book
Comic book Popcorn

• Observation definition is really important!– Recall that the same movie may have multiple reviews.– We can treat an observation as
• a single review• a single movie (concatenation of all reviews)• word frequencies: # observations words appear in
– The response variable remains the same– movie revenue
Univariate approach to predicting revenue from textOve
rfit!
Top 5 high revenue terms (Rudder algorithm)Review-level observations Movie-level observationsBatman Computer generated
Borat Superhero
Rodriguez The franchise
Wahlberg Comic book
Comic book Popcorn

Univariate approach to predicting revenue-category from text
Top 5 (all movies)Computer generated
Superhero
The franchise
Comic book
Popcorn
Bottom 5 (all movies)exclusively
[Phone number]
Festival
Tribeca
With English
Failed to produce term associations around content ratings (e.g., “g-rated” or “adult). Rating is strongly correlated to revenue.
Let’s look exclusively at PG-13 movies.
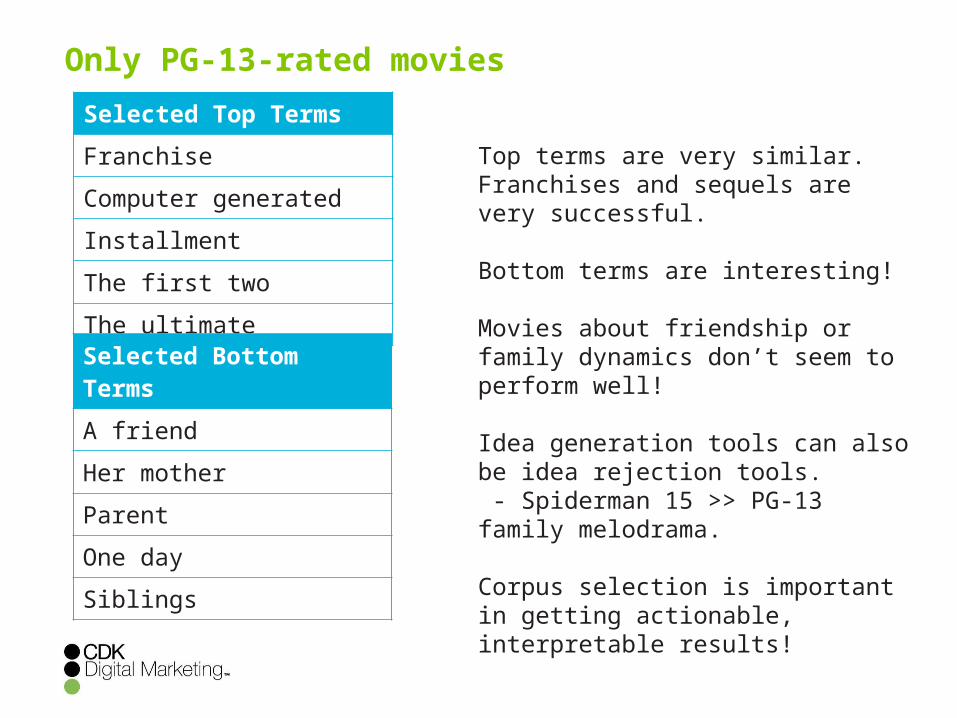
Only PG-13-rated moviesSelected Top TermsFranchise
Computer generated
Installment
The first two
The ultimate
Selected Bottom TermsA friend
Her mother
Parent
One day
Siblings
Top terms are very similar. Franchises and sequels are very successful.
Bottom terms are interesting!
Movies about friendship or family dynamics don’t seem to perform well!
Idea generation tools can also be idea rejection tools. - Spiderman 15 >> PG-13 family melodrama.
Corpus selection is important in getting actionable, interpretable results!

Deep dive on term-importance algorithms

The code for these experiments are available: https://github.com/JasonKessler/scattertext/
• 138k words total. By modern standards, a pretty small corpus. – 78k words spoken by Democrats, and 58k by Republicans– The Brown Corpus (1961) is 1mm words– But, often you have small amounts of data
• We can compare the word frequencies against a list of English word frequencies.
• We’ll look at three methods to do this:– Statistical: Fisher’s Exact Test– Geometirc: Rudder Scores– Information retrieval: F-Score
What terms are characteristic the 2012 conventions?

The code for these experiments are available: https://github.com/JasonKessler/scattertext/
• 1. Hypothesis testing: comparing word, class frequencies in a 2x2 contingency table using Fisher’s Exact test.
What terms are characteristic the 2012 conventions?
Convention Speeches
General English Frequencies
”Romney” count 570 695,398~” Romney” count 137,966 - 570 369 billion - 695,398
Fisher’s Exact test:Odds ratio: 3508.61P: 0.0
- Numerical issues can cause p-values to be zero, wreaking havoc on Bonferroni corrections.- Rank by p-values, and break ties on odds ratios.

The code for these experiments are available: https://github.com/JasonKessler/scattertext/
• Frequencies in convention dataset are listed next to term
• Fisher is sorted by p-value, then OR (mostly p = 0 here)
• Fisher’s test selects characteristic terms, but includes stop words
• The Rudder score selects for terms not seen elsewhere, like names, neologisms and foreign words
What terms are characteristic the 2012 conventions?Top Fisher Terms Top Rudder Termsobama (702) obamacare* (33)
barack (248) romneys* (8)
romney (570) yohana* (3)
mitt (501) nevadan* (2)
republican (228) solyndra* (2)
president (1049) breth* (2)
thank (366) outeducate* (2)
america (689) vouchercare* (2)
u (529) bendiga* (2)
american (653) gjelsvik* (2)
be (4298) carlette* (1)
we (2464) valora* (1)
* term was not found in background corpus

The code for these experiments are available: https://github.com/JasonKessler/scattertext/
• Characteristic terms appear a lot in convention speeches– In other words, have a high recall-- a high P(term | convention
speech)– However, so do a lot of stop words
• If you encounter a characteristic term, there’s a good chance you’re reading a convention speech
– Have a high precision– a high P(convention speech|term)– However, this may be true for random low-frequency words
• Because of the two caveats, both probabilities need to be “high”.
• F-score = HarmoicMean(P(term|category), P(category|term))
Intuition behind F-Score

The code for these experiments are available: https://github.com/JasonKessler/scattertext/
F-score looks pretty good hereTop Fisher Terms Top Rudder Terms Top F-score Terms
obama (702) obamacare* (33) obama (702)
barack (248) romneys* (8) romney (570)
romney (570) yohana* (3) mitt (501)
mitt (501) nevadan* (2) barack (248)
republican (228) solyndra* (2) republican (228)
president (1049) breth* (2) bless (132)
thank (366) outeducate* (2) president (1049)
america (689) vouchercare* (2) democrat (127)
u (529) bendiga* (2) elect (102)
american (653) gjelsvik* (2) biden (46)
be (4298) carlette* (1) governor (172)
we (2464) valora* (1) obamacare* (33)

A problem with F-Score

The code for these experiments are available: https://github.com/JasonKessler/scattertext/@jasonkessler
Using F-Score to Find Differences between Democratic and Republican Speakers
F-Scorethe (3399:2531)and (2707:2232)to (2337:1664)be (2326:1972)a (1596:1346)of (1565:1372)that (1400:1051)we (1318:1146)
• When class-label distributions are about equal, term recalls become far lower than term precisions.
Top democratic speech predictors (dem:rep frequencies)

The code for these experiments are available: https://github.com/JasonKessler/scattertext/@jasonkessler
Using F-Score to Find Differences between Democratic and Republican Speakers
F-Scorethe (3399:2531)and (2707:2232)to (2337:1664)be (2326:1972)a (1596:1346)of (1565:1372)that (1400:1051)we (1318:1146)
• When class-label distributions are about equal, term recalls become far lower than term precisions.
• P(the|dem) ~= P(the) ~= 0.04• P(dem|the) ~= P(dem) ~= 0.57• F-score = 0.073 (> 0.039)
• P(dem|auto) = 1.00• P(auto|dem) ~= 0.0005• F-score = 0.0009
Top democratic speech predictors (dem:rep frequencies)

The code for these experiments are available: https://github.com/JasonKessler/scattertext/@jasonkessler
Using F-Score to Find Differences between Democratic and Republican Speakers
F-Scorethe (3399:2531)and (2707:2232)to (2337:1664)be (2326:1972)a (1596:1346)of (1565:1372)that (1400:1051)we (1318:1146)
• When class-label distributions are about equal, term recalls become far lower than term precisions.
• P(the|dem) ~= P(the) ~= 0.04• P(dem|the) ~= P(dem) ~= 0.57• F-score = 0.073 (> 0.039)
• P(dem|auto) = 1.00• P(auto|dem) ~= 0.0005• F-score = 0.0009
• We can correct for this without having to mess with β
Top democratic speech predictors (dem:rep frequencies)

The code for these experiments are available: https://github.com/JasonKessler/scattertext/@jasonkessler
A new modification to F-Score
F-Scorethe (3399:2531)and (2707:2232)to (2337:1664)be (2326:1972)a (1596:1346)of (1565:1372)that (1400:1051)we (1318:1146)
Top democratic speech predictors (dem:rep frequencies) • Solution: normalize probabilities
• (P(dem|auto)) ~= 0.99 (avg. pctl)• (P(auto|dem)) ~= 0.66• F-score = 0.78
• (P(dem|the)) ~= 0.19• (P(the|dem)) ~= 1.0• F-score = 0.33

The code for these experiments are available: https://github.com/JasonKessler/scattertext/@jasonkessler
A new modification to F-Score
F-Score F-Score Scaled (NormCDF)
the (3399:2531) fight for (108:7)and (2707:2232) auto (37:0)to (2337:1664) fair (47:3)be (2326:1972) insurance company (28:0)a (1596:1346) america forward (28:0)of (1565:1372) middle class (149:18)that (1400:1051) president barack (47:4)we (1318:1146) auto industry (24:0)
Top democratic speech predictors (dem:rep frequencies) • Solution: normalize probabilities
• (P(dem|auto)) ~= 0.99 (avg. pctl)• (P(auto|dem)) ~= 0.66• F-score = 0.78
• (P(dem|the)) ~= 0.19• (P(the|dem)) ~= 1.0• F-score = 0.33

I’ve written software to create the plots of term frequencies, similar to Rudder (2014).
This shows Democratic vs. Republican language, colored with Scaled F-Scores.
The code is available at https://github.com/JasonKessler/scattertext/

Colored with L1-penalized logistic regression coefficients
The code is available at https://github.com/JasonKessler/scattertext/

CDK Global’sLanguageVisualizationTool



• Suppose you are selling a car to a typical person, how would you describe the car’s performance?
• Should you say– This car has 162 ft-lbs of torque.– OR– People who bought this car tell us it makes passing on two lane roads
easy.• Having an idea generation (and rejection) tool makes this very
easy.
Informing dealer talk tracks.

• Corpus and document selection are important– Documents: movie-level instead of review-level– Corpus: rating-specific
• Use a variety of approaches– Univariate and multivariate approaches can highlight different terms
• Visualize your data set– the pre-alpha text-to-ideas package can let you do that. https://github.com/JasonKessler/text-to-ideas/
• More phrase context is better than less
• Add a narrative behind to you analysis, no matter how speculative.
Recommendations

What you learn from corpora is often more important than classification accuracy.
• Thank you!
• Check out https://github.com/JasonKessler/scattertext/ for code• $ pip install scattertext
• We’re hiring– talk to me or, if you can’t, go to CDKJobs.com– http://www.jasonkessler.com to contact me
• Special thanks to the CDK Global Data Science team, including Michael Mabale (thoughts on word clouds), Iris Laband, Peter Kahn, Michael Eggerling, Kyle Lo, Iris Laband, Chris Mills, Phil Burger, Dengyao Mo, and many others.
Acknowledgements

Questions?
• Data Scientist• UI/UX Development
& Design• Software Engineer –
all levels• Product Manager
Is this you?
• Find “Jobs by Category”
• Click Technology
• Have your Resume ready
• Click “Apply”!
Head to CDKJobs.co
m-or-
talk to me
@jasonkessler
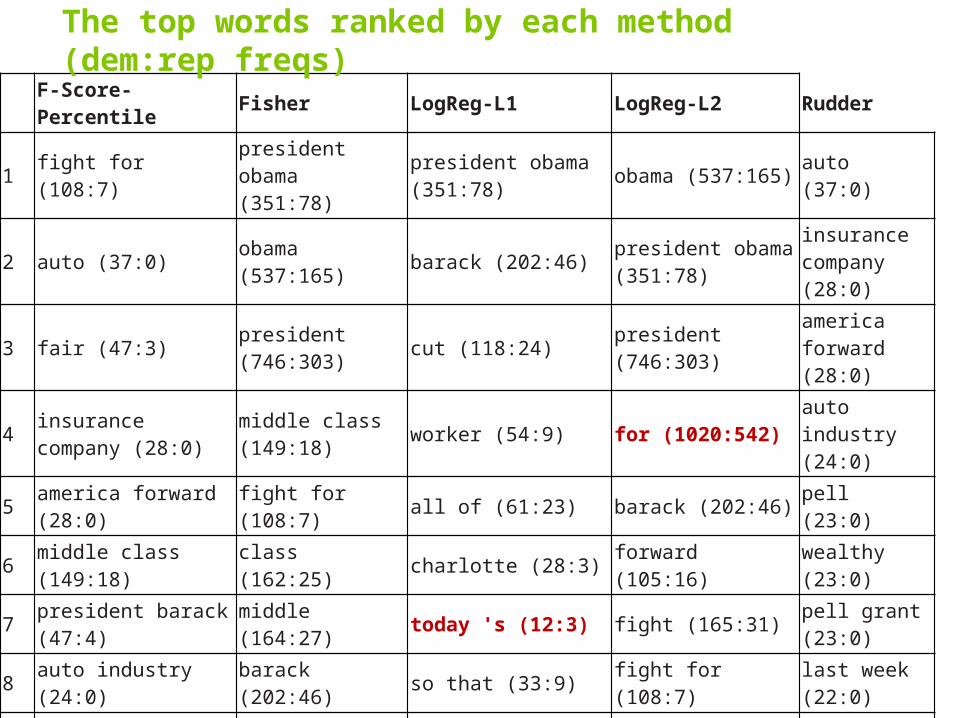
F-Score-Percentile Fisher LogReg-L1 LogReg-L2 Rudder
1 fight for (108:7) president obama (351:78)
president obama (351:78) obama (537:165) auto (37:0)
2 auto (37:0) obama (537:165) barack (202:46) president obama (351:78)
insurance company (28:0)
3 fair (47:3) president (746:303) cut (118:24) president (746:303) america
forward (28:0)
4 insurance company (28:0)
middle class (149:18) worker (54:9) for (1020:542) auto industry
(24:0)
5 america forward (28:0) fight for (108:7) all of (61:23) barack (202:46) pell (23:0)
6 middle class (149:18) class (162:25) charlotte (28:3) forward (105:16) wealthy (23:0)
7 president barack (47:4) middle (164:27) today 's (12:3) fight (165:31) pell grant
(23:0)
8 auto industry (24:0) barack (202:46) so that (33:9) fight for (108:7) last week (22:0)
9 pell grant (23:0) fight (165:31) forward (105:16) class (162:25) the wealthy (21:0)
10 pell (23:0) forward (105:16) that ' (236:91) barack obama (164:45)
romney say (21:0)
11 wealthy (23:0) for (1020:542) make (299:200) middle class (149:18)
millionaire (20:0)
The top words ranked by each method (dem:rep freqs)

This is a Rudder diagram colored with Rudder scores.
The code is available at https://github.com/JasonKessler/text-to-ideas/


















