
Financing of therapy with highly expensive medicin es by the National Health Fund Rafał Zyśk
Upload
lucidworksCategory
view
188download
6
OCTOBER 11-14, 2016 • BOSTON, MA

Tuning Solr and its Pipeline for LogsRafał Kuć and Radu Gheorghe
Software Engineers, Sematext Group, Inc.

3
01Agenda
Designing a Solr(Cloud) cluster for time-series data
Solr and operating system knobs to tune
Pipeline patterns and shipping options

4
01Time-based collections, the single best improvement
14.10
indexing

5
01Time-based collections, the single best improvement
14.10
indexing
15.10

6
01Time-based collections, the single best improvement
14.10
indexing
15.10
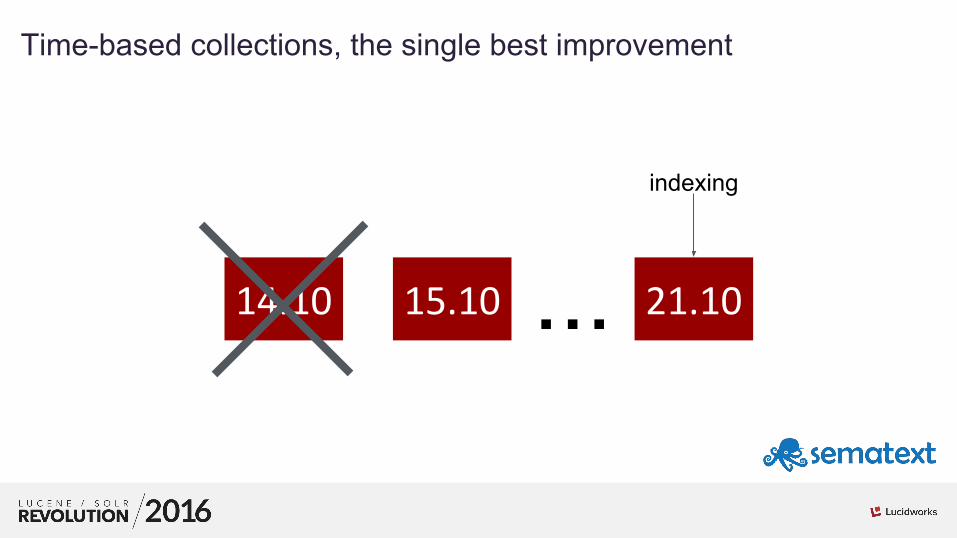
7
01Time-based collections, the single best improvement
14.10 15.10 ... 21.10
indexing
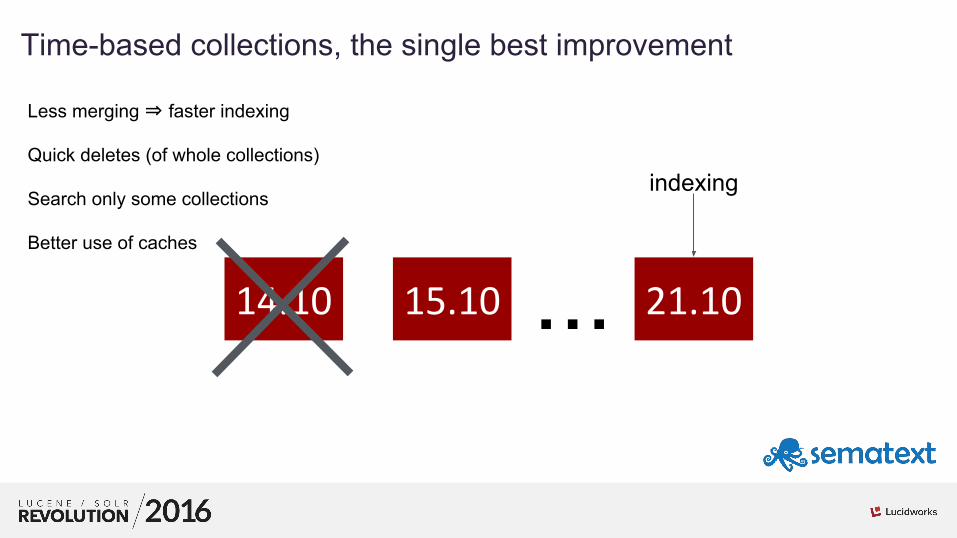
8
01Time-based collections, the single best improvement
14.10 15.10 ... 21.10
indexing
Less merging ⇒ faster indexing
Quick deletes (of whole collections)
Search only some collections
Better use of caches

9
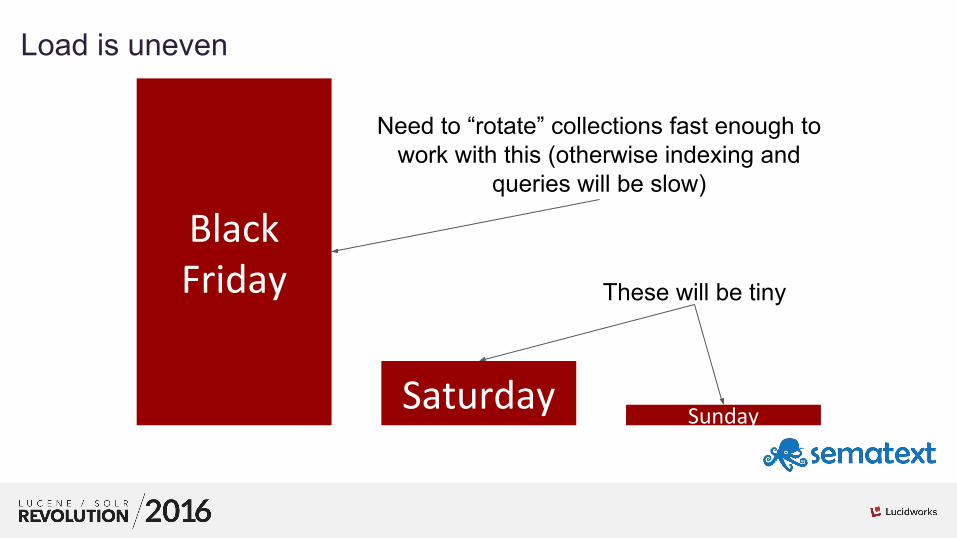
01Load is uneven
BlackFriday
SaturdaySunday
10
01Load is uneven
Need to “rotate” collections fast enough to work with this (otherwise indexing and
queries will be slow)
These will be tiny
BlackFriday
SaturdaySunday

11
01
If load is uneven, daily/monthly/etc indices are suboptimal:
you either have poor performance or too many collections
Octi* is worried:
* this is Octi →

12
01Solution: rotate by size
indexing
logs01
Size limit

13
01Solution: rotate by size
indexing
logs01
Size limit

14
01Solution: rotate by size
indexing
logs01logs02
Size limit

15
01Solution: rotate by size
indexing
logs01logs02
Size limit

16
01Solution: rotate by size
indexing
logs01
logs08...logs02

17
01Solution: rotate by size
indexingPredictable indexing and search performance
Fewer shards
logs01
logs08...logs02

18
01Dealing with size-based collections
logs01
logs08...logs02
app (caches results)
stats
2016-10-11 2016-10-13 2016-10-12 2016-10-14
2016-10-18doesn’t matter,
it’s the latest collection

19
01
Size-based collections handle spiky load better
Octi concludes:
20
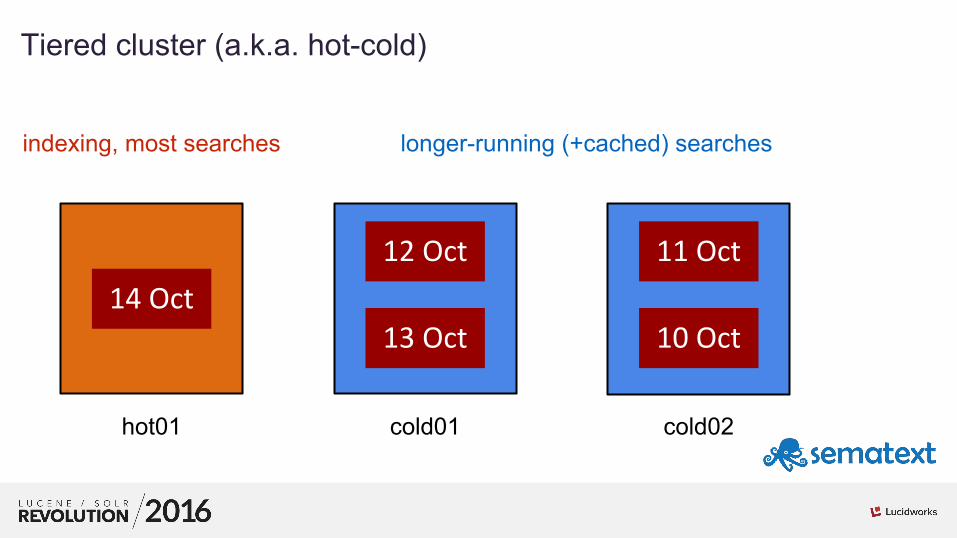
01Tiered cluster (a.k.a. hot-cold)
14 Oct
11 Oct
10 Oct
12 Oct
13 Oct
hot01 cold01 cold02
indexing, most searches longer-running (+cached) searches

21
01Tiered cluster (a.k.a. hot-cold)
14 Oct
11 Oct
10 Oct
12 Oct
13 Oct
hot01 cold01 cold02
indexing, most searches longer-running (+cached) searches
⇒ Good CPU and IO* ⇒ Heap. Decent IO for replication&backup
* Ideally local SSD; avoid network storage unless it’s really good

22
01Octi likes tiered clusters
Costs: you can use different hardware for different workloadsPerformance (see costs): fewer shards, less overheadIsolation: long-running searches don’t slow down indexing

23
01AWS specificsHot tier:
c3 (compute optimized) + EBS and use local SSD as cache* c4 (EBS only)
Cold tier:d2 (big local HDDs + lots of RAM)m4 (general purpose) + EBSi2 (big local SSDs + lots of RAM)
General stuff:EBS optimizedEnhanced NetworkingVPC (to get access to c4&m4 instances)
* Use --cachemode writeback for async writing: https://access.redhat.com/documentation/en-US/Red_Hat_Enterprise_Linux/6/html/Logical_Volume_Manager_Administration/lvm_cache_volume_creation.html

PIOPS is best but expensive
HDD - too slow (unless cold=icy)
⇒ General purpose SSDs
24
01EBS
Stay under 3TB. More smaller (<1TB) drives in RAID0 give better, but shorter IOPS bursts
Performance isn’t guaranteed ⇒ RAID0 will wait for the slowest disk
Check limits (e.g. 160MB/s per drive, instance-dependent IOPS and network)
http://docs.aws.amazon.com/AWSEC2/latest/UserGuide/EBSVolumeTypes.htmlhttp://docs.aws.amazon.com/AWSEC2/latest/UserGuide/EBSPerformance.html
3 IOPS/GB up to 10K (~3TB), up to 256kb/IO, merges up to 4 consecutive IOs

25
01Octi’s AWS top picks
c4s for the hot tier: cheaper than c3s with similar performance
m4s for the cold tier: well balanced, scale up to 10xl, flexible storage via EBS
EBS drives < 3TB, otherwise avoids RAID0: higher chances of performance drop

26
01Scratching the surface of OS options
Say no to swap
Disk scheduler: CFQ for HDD, deadline for SSD
Mount options: noatime, nodiratime, data=writeback, nobarrier
For bare metal: check CPU governor and THP*
because strict ordering is for the weak
* often it’s enabled, but /proc/sys/vm/nr_hugepages is 0

27
01Schema and solrconfig
Auto soft commit (5s?)
Auto commit (few minutes?)
RAM buffer size + Max buffered docs
Doc Values for faceting+ retrieving those fields (stored=false)
Omit norms, frequencies and positions
Don’t store catch-all field(s)

28
01Relaxing the merge policy*Merges are the heaviest part of indexing
Facets are the heaviest part of searching
Facets (except method=enum) depend on data size more than # of segments
Knobs:
segmentsPerTier: more segments ⇒ less merging
maxMergeAtOnce < segmentsPerTier, to smooth out those IO spikes
maxMergedSegmentMB: lower to merge more small segments, less bigger ones
* unless you only do “grep”. YMMV, of course. Keep an eye on open files, though
⇒ fewer open files
29
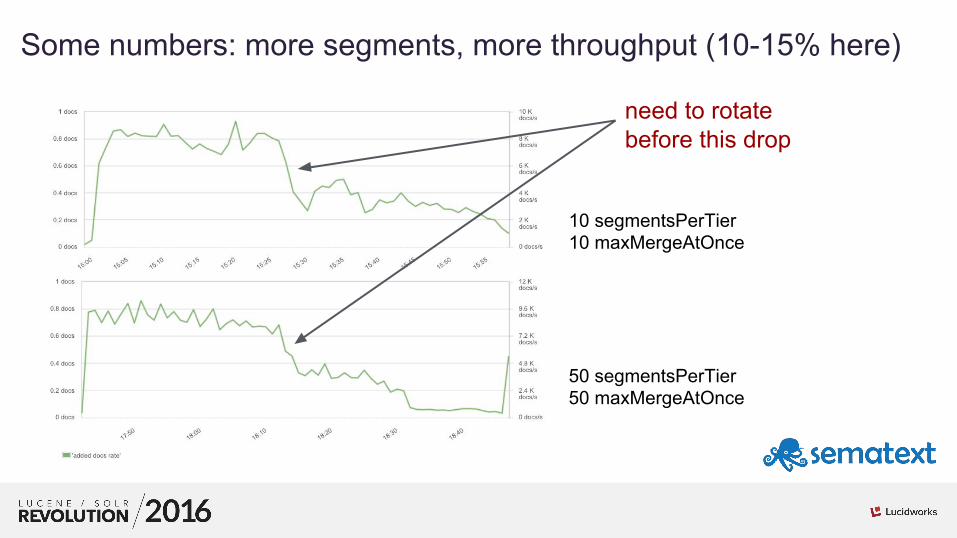
01Some numbers: more segments, more throughput (10-15% here)
10 segmentsPerTier10 maxMergeAtOnce
50 segmentsPerTier50 maxMergeAtOnce
need to rotate before this drop

30
01Lower max segment (500MB from 5GB default)
less CPU fewer segments
31
01There’s more...
SPM screenshots from all tests + JMeter test plan here:
https://github.com/sematext/lucene-revolution-samples/tree/master/2016/solr_logging
We’d love to hear about your own results!
correct spelling: sematext.com/spm

32
01
Increasing segments per tier while decreasing max merged segment (by an order of magnitude) makes indexing better and
search latency less spiky
Octi’s conclusions so far

33
01Optimize I/O and CPU by not optimizing
Unless you have spare CPU & IO (why would you?)
And unless you run out of open files
Only do this on “old” indices!

34
01Optimizing the pipeline*
logslog shipper(s)
Ship using which protocol(s)?
Buffer
Route to other destinations?
Parse
* for availability and performance/costs
Or log to Solr directly from app(i.e. implement a new, embedded log shipper)
35
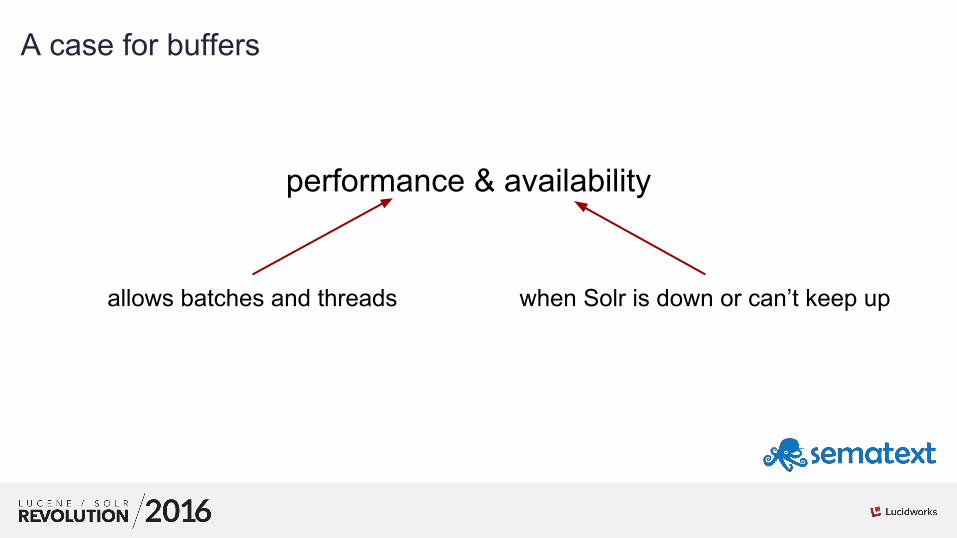
01A case for buffers
performance & availability
allows batches and threads when Solr is down or can’t keep up

36
01Types of buffers
Disk*, memory or a combination
On the logging host or centralized
* doesn’t mean it fsync()s for every message
file or local log shipperEasy scaling; fewer moving partsOften requires a lightweight shipper
Kafka/Redis/etc or central log shipperExtra features (e.g. TTL)One place for changes
bufferapp
bufferapp

37
01Multiple destinations
* or flat files, or S3 or...
input buffer
processing
Outputs need to be in sync
input Processing may cause backpressure
processing
*

38
01Multiple destinations
input
Solroffset
HDFSoffset
input
processing
processing

39
01
Just Solr and maybe flat files? Go simple with a local shipper
Custom, fast-changing processing & multiple destinations? Kafka as a central buffer
Octi’s pipeline preferences

40
01Parsing unstructured data
Ideally, log in JSON*
Otherwise, parse
* or another serialization format
For performance and maintenance(i.e. no need to update parsing rules)
Regex-based (e.g. grok)Easy to build rulesRules are flexibleTypically slow & O(n) on # of rules, but:
Move matching patterns to the top of the listMove broad patterns to the bottomSkip patterns including others that didn’t match
Grammar-based(e.g. liblognorm, PatternDB)
Faster. O(1) on # of rulesNumbers in our 2015 session: sematext.com/blog/2015/10/16/large-scale-log-analytics-with-solr/

41
01Decide what gives when buffers fill up
input shipper
Can drop data here, but better buffer
when shipper buffer is full, app can block or drop data
Check:Local files: what happens when files are rotated/archived/deleted?UDP: network buffers should handle spiky load*TCP: what happens when connection breaks/times out?UNIX sockets: what happens when socket blocks writes**?
* you’d normally increase net.core.rmem_max and rmem_default
** both DGRAM and STREAM local sockets are reliable (vs Internet ones, UDP and TCP)
42
01
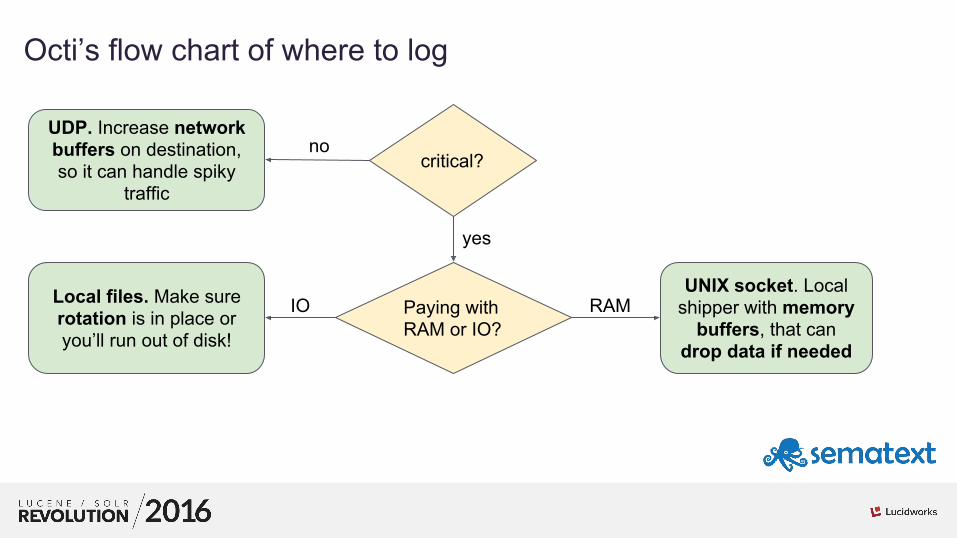
Octi’s flow chart of where to log
critical?
UDP. Increase network buffers on destination, so it can handle spiky
traffic
Paying with RAM or IO?
UNIX socket. Local shipper with memory
buffers, that can drop data if needed
Local files. Make sure rotation is in place or you’ll run out of disk!
no
IO RAM
yes

43
01Protocols
UDP: cool for the app, but not reliable
TCP: more reliable, but not completely
Application-level ACKs may be needed:
No failure/backpressure handling needed
App gets ACK when OS buffer gets it ⇒ no retransmit if buffer is lost*
* more at blog.gerhards.net/2008/05/why-you-cant-build-reliable-tcp.html
sender receiverACKs
Protocol Example shippers
HTTP Logstash, rsyslog, Fluentd
RELP rsyslog, Logstash
Beats Filebeat, Logstash
Kafka Fluentd, Filebeat, rsyslog, Logstash

44
01
Octi’s top pipeline+shipper combos
rsyslog
app UNIX socket
HTTP
memory+disk buffercan drop
app
fileKafka
consumer
Filebeat
HTTP
simple & reliable

45
01Conclusions, questions, we’re hiring, thank you
The whole talk was pretty much only conclusions :)
Feels like there’s much more to discover. Please test & share your own nuggets
http://www.relatably.com/m/img/oh-my-god-memes/oh-my-god.jpg
Scary word, ha? Poke us:@kucrafal @radu0gheorghe @sematext...or @ our booth here









![infoShare 2013: Rafał Brzoska - InPost - Challanger from Poland [EN].](https://static.fdocuments.in/doc/165x107/548472c7b4af9fd2568b4ab2/infoshare-2013-rafal-brzoska-inpost-challanger-from-poland-en.jpg)








