
TRHUG 2015 - Veloxity Big Data Migration Use Case
21
TRHUG 2015 Veloxity Migration Use Case v1.2
-
Upload
hakan-ilter -
Category
Technology
-
view
1.236 -
download
1
Transcript of TRHUG 2015 - Veloxity Big Data Migration Use Case

TRHUG 2015
Veloxity Migration Use Casev1.2
About Me
● Hakan Ilter
○ GittiGidiyor / eBay■ Software Platform & Research Manager■ Java, Spring, Microservices
○ devveri.com■ Big Data Consultant and Blogger
○ Search, Big Data, NoSQL

About Veloxity
● Veloxity
○ Wireless Telecom Company■ Based in Sunnyvale, California
○ Founded in 2013■ by two Turkish entrepreneurs
○ CXM solutions■ Mobile consumer experience management
○ Powerful SDK
○ “Actionable” Analytics
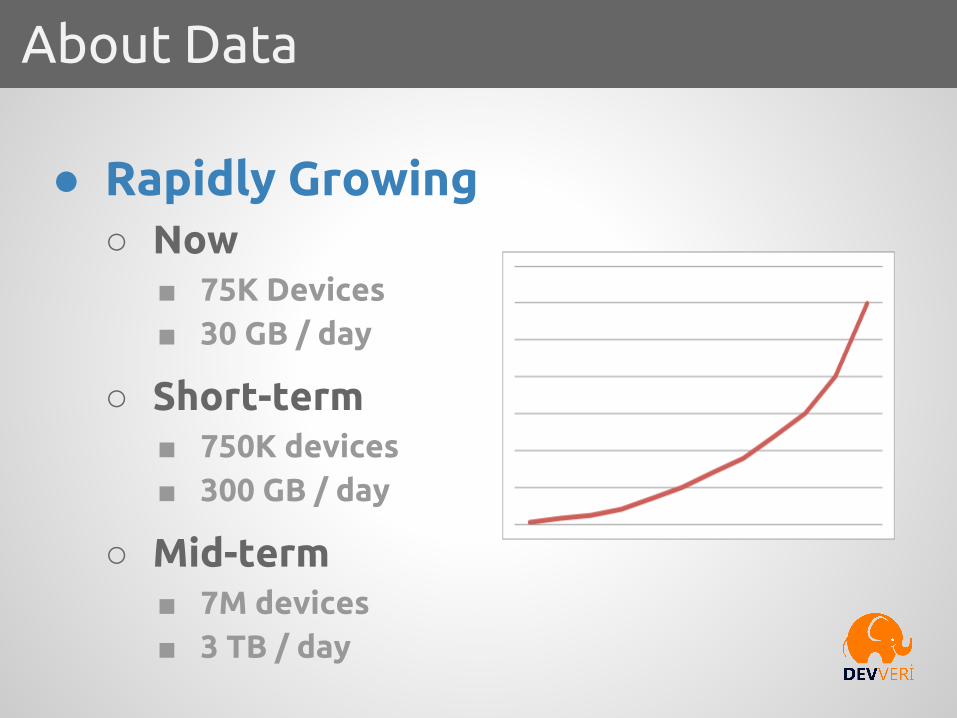
● Rapidly Growing○ Now
■ 75K Devices■ 30 GB / day
○ Short-term■ 750K devices■ 300 GB / day
○ Mid-term■ 7M devices■ 3 TB / day
About Data

● Legacy System
○ RDBMS-Centric Architecture■ .NET Codebase■ MSSQL Server
○ Stored Procedures■ Hundreds of SPs■ Thousands of lines of code
○ Works fine (for a while)
Before Migration

● Legacy System Problems
○ RDBMS-Centric Architecture■ .NET doesn’t fit■ Can’t scale MSSQL Server
○ Stored Procedures■ Hard to develop/maintain■ Stored Procedure Hell!
○ Looking for another solution
Before Migration

● Hadoop
○ MapReduce■ Can process large amounts of data
○ Hive■ SQL over unstructured data
○ Impala■ Massive parallel processing SQL engine
○ Cloudera CDH 5.x■ Enterprise-ready Big Data Platform
The answer is Hadoop

● MapReduce + Hive + Impala
○ MapReduce■ Processes JSON input■ Creates major tables ■ Parquet columnar format as output
○ Hive■ Query over raw data
○ Impala■ Builds aggregation tables■ Analytics based on these tables
Veloxity Big Data v1

● Spark + Impala
○ Spark■ Replaces MapReduce■ Better Developer Productivity■ Better Performance■ Rich APIs for Java, Scala, Python■ In-memory storage
○ Impala■ Fastest MPP SQL Engine■ Better than Hive or Spark SQL
Veloxity Big Data v2
Big Data Architecture
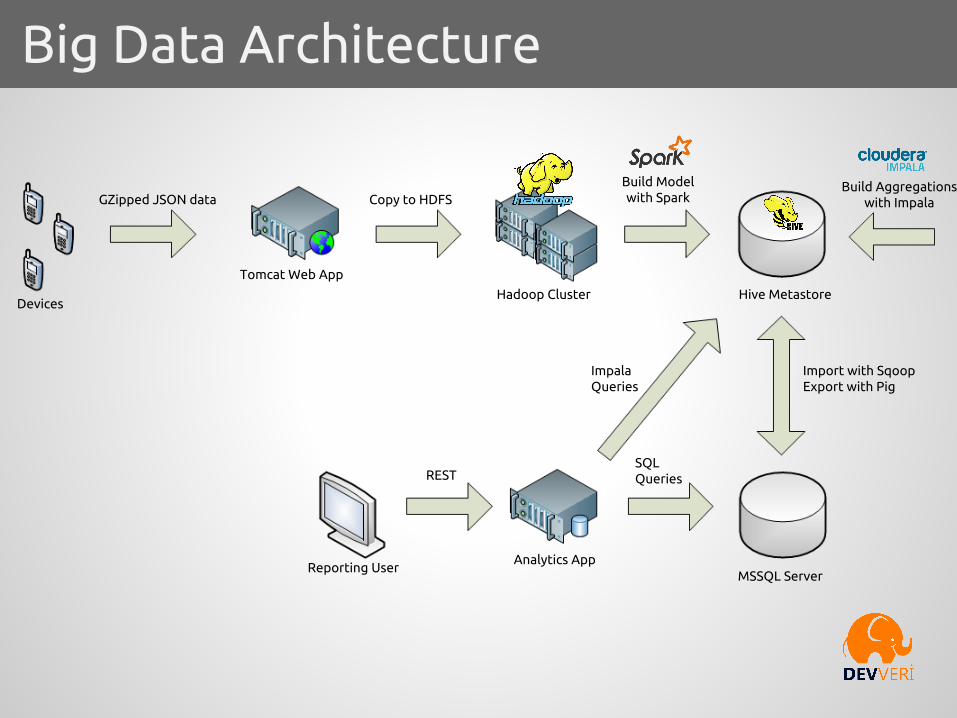
Devices
GZipped JSON data
Tomcat Web App
Copy to HDFS
Hadoop Cluster
Build Model with Spark
Hive Metastore
Build Aggregationswith Impala
MSSQL ServerAnalytics App
Reporting User
REST
Impala Queries
SQLQueries
Import with SqoopExport with Pig

Veloxity Big Data v2
● Other Tools
○ Java■ Spring Framework, Tomcat App Server
○ Bash Script■ For task executions, flows, etc.■ Because of Oozie!
○ Sqoop■ Great (only) for imports
○ Pig■ Good for data cleaning and exports

● Data Process & Query Performance
○ Hardware■ Amazon EC2■ m3.2xlarge■ 8 Core, 30 GB Ram, Standard disk■ 1 Name Node, 3 Data Nodes
○ Software■ Cloudera CDH 5.3.2■ Impala 2.1.2■ Hive 0.13.1■ Spark 1.2.0
Performance Comparison

● Input Data○ 4 GB Gzip compressed○ 12 GB uncompressed○ 859 files
● Task○ Process JSON files○ Validate each record○ Fix problems○ Build a model○ Save as Parquet Format
Data Process Performance
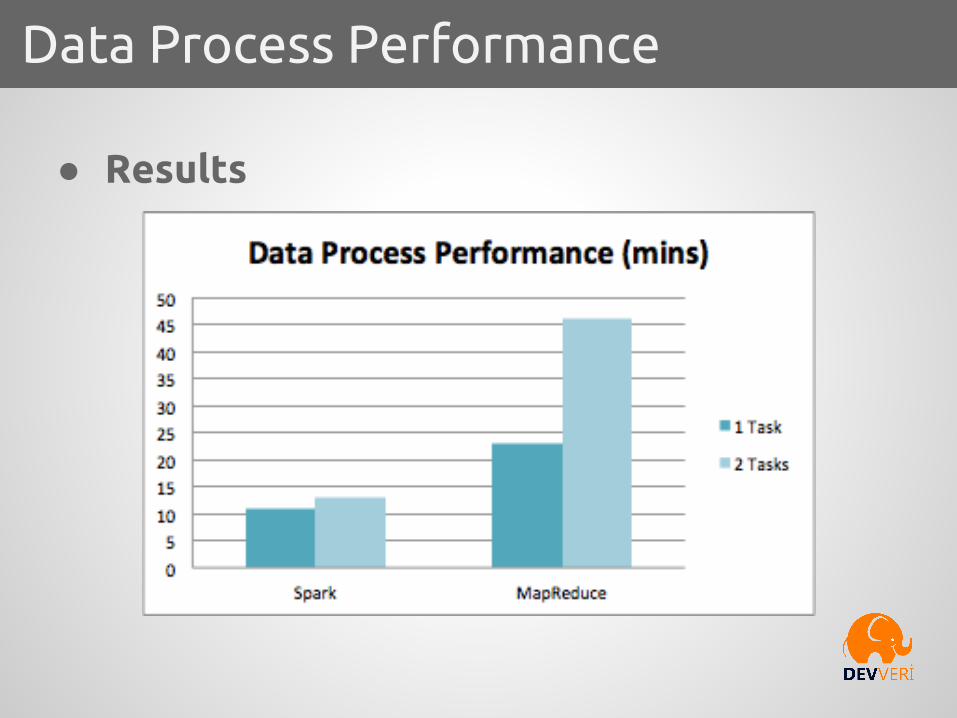
● Results
Data Process Performance

● Input Data○ 542 MB Snappy compressed○ 1.6 GB uncompressed○ 11 M rows○ 468 Parquet files
● QuerySELECT
deviceId, COUNT(*), AVG(rxSpeed), MAX(rxSpeed), AVG
(txSpeed), MAX(txSpeed), SUM(rxData), SUM(txData)
FROM stats
GROUP BY deviceId
ORDER BY deviceId
LIMIT 100
Query Performance
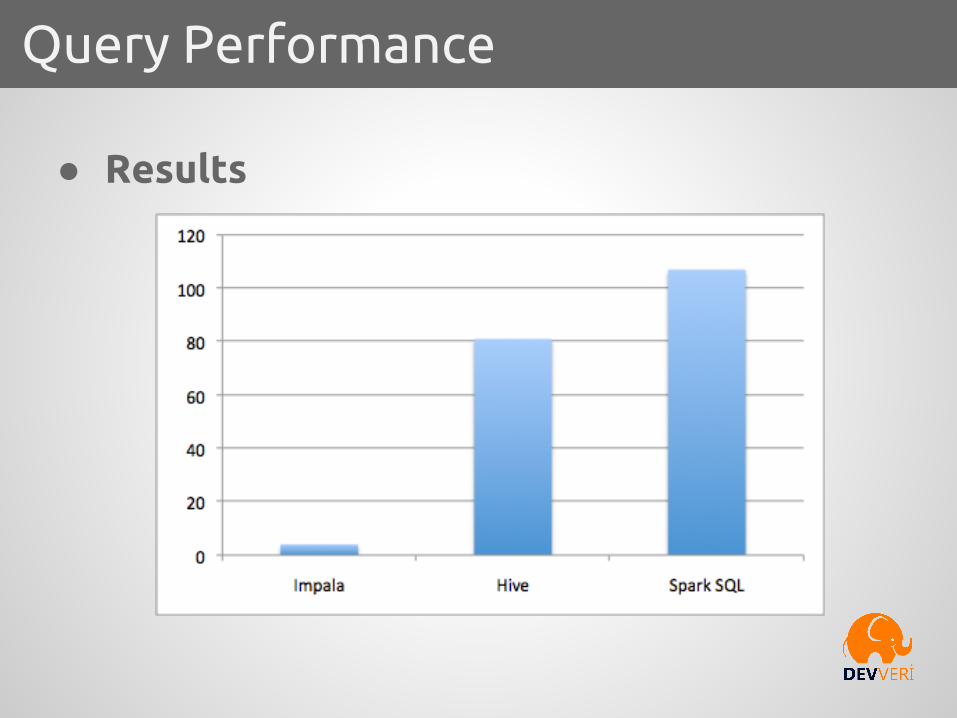
● Results
Query Performance

● Lessons Learned
● CDH updates are critical○ Always test first!○ Use VMs for testing
● Install Spark manually○ The latest Spark version 1.5.0○ CDH 5.4.x still comes with Spark 1.3
● The small files problem○ Merge small files often
Lessons Learned

● More...
● Partitioning○ Use partitions wisely○ Too many partitions = slower queries
● Metadata management○ Improvement is needed○ Can’t remove a partition with query
● Don’t use Google Gson for JSON○ Extremely slow○ Use Boon Project instead
Lessons Learned

Veloxity Big Data v3
● Future Plans
● Vert.x○ Lightweight, Non-blocking IO
● Apache Kafka ○ Enables streaming data
● Spark Streaming○ Real-time data processing
● Spark Data Frames○ No need for other tools (Sqoop, Pig, etc.)

● More...
● Cloudera Kudu○ New Storage for Fast Analytics on Fast Data
■ https://github.com/cloudera/kudu
● Project Tungsten○ Bringing Spark Closer to Bare Metal
■ http://bit.ly/1KPpFBC
● Impala Roadmap○ Nested Types○ Performance Improvements
Veloxity Big Data v3

Thanks!


















