
TRANSMITEREA ŞI CODAREA INFORMAŢIEI - ac.upg-ploiesti.roac.upg-ploiesti.ro/gpanaitescu/tci.pdf ·...
200
1 Gheorghe M.Panaitescu TRANSMITEREA ŞI CODAREA INFORMAŢIEI Note de curs Universitatea “Petrol-Gaze” Ploieşti Departamentul Automaticǎ, Calculatoare şi Electronicǎ 2015 An evaluation version of novaPDF was used to create this PDF file. Purchase a license to generate PDF files without this notice.
Transcript of TRANSMITEREA ŞI CODAREA INFORMAŢIEI - ac.upg-ploiesti.roac.upg-ploiesti.ro/gpanaitescu/tci.pdf ·...

1
Gheorghe M.Panaitescu
TRANSMITEREA ŞI CODAREA INFORMAŢIEI
Note de curs
Universitatea “Petrol-Gaze” Ploieşti Departamentul Automaticǎ, Calculatoare şi Electronicǎ
2015
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

2
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

3
CUVÂNT INTRODUCTIV Lucrarea prezentǎ este suportul cursului cu numele din titlu, tinut pe durata unui semestru, trei ore pe sǎptǎmânǎ, la anul II specializarea Electronicǎ aplicată din cadrul Facultǎtii de Inginerie mecanicǎ si electricǎ a Universitǎtii “Petrol-Gaze” Ploieşti. Este produsul unei experiente de predare care se întinde pe un interval de peste cinsprezece ani. Versiunea de faţǎ este revǎzutǎ si adǎugitǎ în 2015 pentru instruirea unei noi promoţii de la specializarea amintitǎ. Textul cuprins între copertile virtuale ale acestei lucrǎri constituie aproape un manual de Transmiterea şi codarea informaţiei. S-a subliniat cuvântul “aproape” deoarece în unele sectiuni ale lucrǎrii se poate observa o expunere mai curând rezumativǎ a temelor aduse în discutie. De aceea a fost mentinut subtitlul Note de curs, dat fiind caracterul multor pasaje mai curând de ghid al expunerilor celui care predǎ disciplina sau, ocazional, de posibilǎ referintǎ concisǎ a initiatilor în domeniu. În acele sectiuni nu sunt continute toate explicatiile şi comentariile care cu sigurantǎ ar fi necesare pentru ca textul lucrǎrii sǎ devinǎ pe de-a-ntregul un manual. Asemenea adaosuri se fac de obicei la expunerea oralǎ şi, în afarǎ de asta, în cursul predǎrii pot apǎrea actualizǎri “din mers” ale unor teme, într-o dinamicǎ “micǎ” a disciplinei, produsǎ de lecturile curente ale titularului cursului. Aşadar, pentru studenti, lectura celor scrise mai departe nu poate suplini total audierea cursului. Dacǎ lucrarea se difuzeazǎ în formatul acesta, se difuzeazǎ mai ales ca un ajutor în întelegerea notiţelor proprii, în vederea pregǎtirii testelor intermediare şi a examenului. Studentii sunt îndemnati sǎ consulte concomitent bibliografia indicatǎ, atât pentru subiectele care nu se regǎsesc aici cât şi pentru subiectele care sunt preluate din sursele citate si reformulate în Notele de curs de mai jos. Alături de prezentele Note de curs, cititorul poate accesa şi consulta on line, pentru studiu individual sau în timpul orelor de aplicatii prevăzute în orar, un volum de Aplicaţii la disciplina Transmiterea şi codarea informaţiei.
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

4
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

5
C U P R I N S INTRODUCERE p.9 SURSE DE INFORMAŢIE 13 Informaţie. Surse de informaţie. Entropie Entropia relativă Surse de informatie multiple Surse de informatie cu memorie. Modelul Markov Legea numerelor mari şi AEP (Asymptotic Equipartition Property) Entropia diferenţială Discretizarea Entropiile diferenţiale combinate, condiţionate şi relative CANALE DE TRANSMITERE A INFORMAŢIEI 35 Generalitǎti Entropii a priori, entropii a posteriori. Informaţia mutualǎ (transinformaţia) Tipuri speciale de canale Capacitatea canalelor Modelul de canal AWGN (Additive White Gaussian Noise) O problemǎ specialǎ privind canalele Canale de tip continuu CODURI PENTRU CANALE FĂRĂ ZGOMOT 51 Generalitǎti despre coduri Particularitǎţi ale codurilor Inegalitatea lui Kraft şi teorema lui McMillan Lungimea medie a unui cod. Coduri compacte Teorema de codare a lui Shannon Teorema lui Shannon pentru surse Markov Teorema lui Shannon şi capacitatea canalelor Coduri compacte – coduri Huffman Principii generale pentru compresia de date Codarea run-length
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

6
Codoare Markov Codarea aritmetică Compresia LZW (Lempel, Ziv, Welch) Compresia cu pierdere de informaţie Codarea rată-distorsiune Măsuri ale distorsiunii Proprietăţi ale functiei R(D) Funcţia rată-distorsiune şi informaţia CRIPTAREA 101 Primalitatea numerelor întregi Criptografia şi algoritmul RSA (Rivest, Shamir, Adleman) Semnături electronice Criptografia RSA şi teorema restului chinezesc Teorema lui Euler Autentificarea Utilizarea practicǎ a criptării RSA CODAREA PENTRU CANALE AFECTATE DE PERTURBAŢII 109 Observaţii generale Debit de informatie (rata) Reguli de decizie la decodare Distanţa Hamming. Decodarea bazată pe distanţa Hamming Detectarea şi corectarea erorilor prin distanta Hamming Coduri cu paritate constantǎ Coduri cu repetiţie Probabilitatea de eroare în bloc şi debitul de informaţie Coduri binare liniare Generarea biţilor de control, sindromul Decodarea prin sindrom Proiectarea matricii de verificare Coduri perfecte pentru corectarea erorilor Tipuri de erori, probabilităţi ale erorilor nedetectate/nedetectabile Alte coduri detectoare sau corectoare de erori Coduri polinomiale/ciclice Coduri polinomiale Coduri ciclice Coduri convoluţionale
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

7
Anexa 1: COMPLEMENTE DE TEORIA PROBABILITǍTILOR ŞI DE STATISTICǍ MATEMATICǍ 183 Spatiul evenimentelor Probabilitǎti, probabilitǎti conditionate Variabile aleatoare B I B L I O G R A F I E 199
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

8
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

9
INTRODUCERE Informatia este generatǎ şi vehiculatǎ în foarte multe împrejurǎri. Observarea unui fenomen, lectura unei cǎrti, experimentele stiintifice de pildǎ sunt generatoare de informatie. Frecvent, informatia trebuie transmisǎ la distantǎ si/sau stocatǎ eficient şi în conditii de sigurantǎ. Ideea principalǎ a cursului Transmiterea şi codarea informatiei este de a descrie şi a prelucra informatia astfel încât ea sǎ poatǎ fi cuantificatǎ la sursǎ, adaptatǎ la particularitătile mediilor de transmitere sau de stocare, recuperatǎ în formǎ utilizabilǎ la locul receptiei sau dupǎ un interval de timp de depozitare. Existǎ asadar surse care genereazǎ informatie. Informatia trebuie mǎsuratǎ Canalele de transmitere şi operatiile de memorare trebuie sǎ lucreze optim. Receptoarele, utilizatorii trebuie sǎ recupereze informatia din canal sau din memorie într-o manierǎ care sǎ o facǎ utilizabilǎ, inteligibilǎ. Astfel de subiecte sunt abordate de-a lungul acestui curs şi în bunǎ parte în aceste Note de curs. Într-o sumarǎ enumerare, obiectivele acestei discipline sunt: caracterizarea informatiei generate de surse diverse, transmise prin canale
variate, receptionate de receptoare de genuri diferite; optimizarea transmiterii şi stocǎrii informatiei (de regulǎ prin utilizarea unor
coduri); transmiterea protejatǎ prin medii/canale, stocarea eficientǎ în conditii sigure
în diverse tipuri de memorie (protectia la perturbatii şi erori). Într-o primǎ fazǎ, în centrul atentiei sunt sursele de informatie discrete şi informatia discretǎ/discretizatǎ. Discutia se va extinde ori de câte ori va fi cazul şi la sursele continue generatoare de informatie. Un exemplu simplu aduce cititorul mai aproape de câteva aspecte de bază ale teoriei informatiei: Se presupune cǎ din localitatea A se transmit spre localitatea B, după un anumit program, informatii despre starea vremii din A. Simplificând lucrurile, presupunem cǎ în A poate sǎ strǎluceascǎ soarele, cerul poate fi înnorat, poate sǎ plouǎ sau poate sǎ fie ceaţǎ, acestea fiind descrieri exhaustive. Starea vremii din A poate fi caracterizatǎ asadar ca însoritǎ, înnoratǎ, ploioasǎ sau cetoasǎ. Lista aceasta de descriptori ai stǎrii vremii în A alcǎtuieste un alfabet al sursei. Fiecare din acesti descriptori este un simbol al sursei de informatie şi o secvenţǎ de astfel de referiri la vremea din A, chiar şi foarte scurtă – formată dintr-un singur simbol – se constituie într-un mesaj. Este convenabil şi în mare mǎsurǎ natural ca informatia sǎ fie legatǎ cantitativ de gradul de incertitudine în care se aflǎ receptorul/utilizatorul faţǎ în fatǎ cu ceea ce se transmite şi/sau se receptioneazǎ. Dacǎ, de pildǎ, vremea în A este uzual însoritǎ (65% din cazuri) receptionarea mesajului de un simbol “însoritǎ” este
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

10
purtǎtor de relativ putinǎ informatie: este de asteptat într-o mare mǎsurǎ ca în A sǎ fie soare. În schimb, simbolul “cetoasǎ” (5% din cazuri) este mult mai informativ deoarece prezenta cetei în A este în oarecum surprinzǎtoare pentru receptorul din B. Grade intermediare de incertitudine şi cantitǎti de informatie pe mǎsurǎ poartǎ simbolurile “înnoratǎ” (20% din cazuri) şi “ploioasǎ” (10% din cazuri). De observat cǎ teoria informatiei se ocupǎ numai de observare-transmitere-receptionare şi nu de continutul semantic al mesajelor transmise. Teoria informatiei nu se ocupǎ de adevǎrul sau de semnificatia mesajelor. Într-o viziune mai generalǎ, o sursǎ de informatie discretǎ genereazǎ un numǎr de simboluri (grupate într-un alfabet) asociate cu anumite probabilitǎti de generare. Pentru sursa de informare a unui receptor din localitatea B despre vremea din localitatea A, tabelul urmǎtor contine aceste douǎ elemente.
Simbol de caracterizare
a vremii din A însoritǎ înnoratǎ ploioasǎ cetoasǎ
Probabilitatea aparitiei 0,65 0,20 0,10 0,05
Într-o zi oarecare, un mesaj transmis poate fi: însoritǎ însoritǎ însoritǎ însoritǎ însoritǎ înnoratǎ înnoratǎ ploioasǎ cetoasǎ. Mesajul ar putea fi transmis într-o formǎ binarǎ. Un cod asociat ar putea fi cel din tabelul care urmeazǎ:
Simbol de caracterizare
a vremii din A însoritǎ înnoratǎ ploioasǎ cetoasǎ
Cod (a) 00 01 10 11
şi transmisia efectivǎ ar fi 00 00 00 00 00 01 01 10 11, în total 18 biti. Daca se foloseste un alt cod, cel din tabelul care urmeazǎ:
Simbol de caracterizare
a vremii din A însoritǎ înnoratǎ ploioasǎ cetoasǎ
Cod (b) 0 10 110 111 atunci se transmite secventa 0 0 0 0 0 10 10 110 111 care numǎrǎ 15 biti. Apare cǎ transmiterea în codificarea a doua (b) este mai economicǎ, în mai putini biti, cu mai putin timp de ocupare a canalului de transmitere. Existǎ o limitǎ în ceea ce priveste acesti “mai putini biti”, care va fi investigatǎ într-unul din capitolele acestor Note de curs. Anticipând putin, numǎrul de biti utilizat pentru transmitere fǎrǎ pierdere de informatie sugereazǎ cuvinte de cod mai scurte
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

11
pentru simbolurile mai probabile şi cuvinte de cod mai lungi pentru simboluri mai putin probabile. De aici o dublǎ sugestie: de a mǎsura informatia în biti şi de a observa o relatie de crestere concomitentǎ a informatiei şi a inversului (valorii reciproce a) probabilitǎtii atasate simbolurilor. O definire logaritmicǎ a cantitǎtii de informatie pare în acest context foarte potrivitǎ
Informatia purtatǎ de un simbol = log(1/Probabilitatea acelui simbol) Cu aceastǎ definire logaritmicǎ (logaritmii în baza 2) se pot face evaluǎri ale surselor de informatie şi ale canalelor prin care informatia se transmite. Dar, dupǎ cum cititorul a observat, s-au utilizat aici unele notiuni care se cer explicate. Anexele acestui curs şi sectiunile urmǎtoare vor (re)introduce unele elemente de calcul al probabilitǎtilor, de teorie a codurilor etc., care vor aduce o luminǎ mai completǎ asupra caracterizǎrii informatiei în împrejurǎri variate. În ceea ce priveste siguranta stocǎrii/transmiterii informatiei, codurile protectoare la erori au un rol determinant. Despre ce erori este vorba? Sunt posibile erori datorate unei functionǎri neconforme a aparaturii implicate în operatii de transmitere/stocare, sunt posibile interferente ale unor perturbatii numite frecvent zgomote etc. Desigur, acest vast subiect nu poate fi evitat, ci dimpotrivǎ, va fi foarte prezent în paginile care urmeazǎ ca şi în versiunea vorbitǎ a acestui curs.
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

12
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

13
SURSE DE INFORMAŢIE Informaţie. Surse de informaţie. Entropie Fie un câmp de probabilitate discret An (v.Anexa 1) format din n evenimente elementare A1, …, An care alcătuiesc o familie exhaustivă; Fie p1, …, pn probabilitǎtile acestor evenimente. Probabilităţile satisfac obligatoriu relaţiile
n
kkk pnkp
11,1,0
Definitie. Se numeste entropie a câmpului finit An, notatǎ cu Hn(An), valoarea datǎ de expresia
Hn(An) =
n
kkknn ppppH
11 log),...,(
unde logaritmul este luat de obicei în baza 2. Într-o bazǎ diferitǎ a
Hn(An) =
n
kkaknn ppappH
121 loglog),...,(
Entropia poate fi consideratǎ o mǎsurǎ a gradului (mediu) de nedeterminare în câmpul de probabilitate finit An. Observatie. Oricare dintre termenii sumei din expresia de definitie a entropiei, de pildǎ cel de indice k, se mai poate scrie sub forma pklog(1/pk), prin transferarea semnului “–“ din fata sumei la fiecare termen şi apoi sub logaritm. Termenul este produsul dintre probabilitatea pk şi valoarea informatiei purtate de evenimentul Ak. Revenind la expresia de calcul al mediei unei functii de o variabilǎ aleatoare (vezi Anexa), variabilǎ care ia în particular valorile log(1/pk) cu probabilitǎtile pk, k = 1, …, n, rezultǎ cǎ entropia este în acelaşi timp informatia medie pe simbol a sursei de informatie care genereazǎ simbolurile A1, …, An din alfabetul sursei. Proprietǎti ale entropiei: 1. Nenegativitate
H p pn n( ,..., )1 0 2. Dacǎ p p k i k ni k 1 0 1, , , , atunci
Hn( p1, …, pn) = 0 cu alte cuvinte un câmp cu un eveniment elementar sigur, celelalte fiind imposibile, nu are nici o nedeterminare.
3. Entropia satisface inegalitatea
H p p Hn nn n n( ,..., ) ,...,11 1
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

14
Demonstratia face apel la inegalitatea lui J.L.Jensen conform cǎreia fiind datǎ o functie realǎ convexǎ pe intervalul [a, b], y = f(x), fiind date n valori arbitrare x1, …, xn ale argumentului ei, situate în intervalul de convexitate şi n numere nenegative 1, …, n care însumate dau unitatea, atunci are loc inegalitatea
kk
n
k k kk
n
f x f x
1 1
( )
Aplicarea acestei inegalitǎti pentru functia f(x) = – xlogx, pentru xk = pk şi n = 1/n, 1 k n conduce la
1 1 1
1 1 1np p
np
np
k
n
k k kk
n
kk
n
log log
si, întrucât pkk
n
1
1, rezultǎ
1 1 11n
H p pn nn n( ,..., ) log
adicǎ
H p p Hn nn n n( ,..., ) ,...,11 1
Proprietatea aceasta aratǎ cǎ entropia este maximǎ atunci când probabilitǎtile p1, …, pn sunt egale. Orice câmp de probabilitate cu probabilitǎti asociate evenimentelor elementare componente altfel decât egale este redundant.
4. Are loc egalitatea Hn+1( p1, …, pn, 0) = Hn( p1, …, pn)
ceea ce aratǎ cǎ douǎ câmpuri de probabilitate care diferǎ prin adǎugarea unui eveniment, şi acela imposibil au aceeaşi nedeterminare.
Entropia relativă Se admite că o variabilă aleatoare are distributia teoretică p. Apoi, cum se va vedea în capitolele despre codare, variabila aceasta se poate reprezenta printr-un cod caracterizat în mare măsură de entropia H(p). Dar, datorită unor informatii incomplete, distributia p nu este cunoscută şi de aceea se foloseste o distributie diferită q. În acest caz, codul va fi afectat negativ în performantele lui. Cantitatea care cuantifică diferenta de performantă este notată uzual cu D(p||q) şi este cunoscută sub numele de entropia relativă, în unele lucrări sub numele de i-divergenţă. Definitie. Entropia relativă sau distanţa Kullback-Leibler între două functii de probabilitate p(x) şi q(x) se defineste ca
)(
)(log)()(log)()||(
xqxpE
xqxpxpqpD p
x
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

15
De observat că entropia relativă nu este simetrică în argumentele sale şi că al doilea argument, q apare numai la numitor. Câteva proprietăti ale entropiei relative: 1. Nenegativitate. Entropia relativă este totdeauna nenegativă, D(p||q) ≥ 0, cu
egalitate dacǎ şi numai dacǎ p = q. 2. Semicontinuitate inferioarǎ. Pentru un şir de functii de probabilitate (pn, qn),
n = 1, 2, …, care converg cǎtre (p, q), )||()||(inflim qpDqpD nnn
Dacǎ q(x) > 0 pentru orice x X , atunci D(p||q) este continuǎ pentru perechea (punctul) (p, q).
3. Convexitate. Pentru orice [0, 1] şi pentru orice p1, q1, p2, q2 ))1(||)1(()||()1()||( 21212211 qqppDqpDqpD
4. Inegalitatea partiţiei. Dacǎ A = {A1, …, AK} este o partitie a lui X, adicǎ X =
K
i iA1
şi ji AAji şi se definesc
pA(i) = iAx
xp )( , i = 1, …, K
qA(i) = iAx
xq )( , i = 1, …, K
atunci D(p||q) ≥ D(pA||qA)
cu egalitate dacǎ şi numai dacǎ p(x/x Ai) = q(x/x Ai), x Ai, pentru toţi indicii i.
5. Inegalitatea procesǎrii datelor. Dacǎ W este o matrice stochasticǎ |X|×|Y| (cu liniile având suma elementelor egală cu unitatea) şi dacǎ se definesc
p W(x, y) = p(x)W(y/x), x X, y Y q W(x, y) = q(x)W(y/x), x X, y Y
pW(y) = Xx
yxWp ),( , y Y
qW(y) = Xx
yxWq ),( , y Y
atunci D(p||q) ≥ D(pW||qW)
cu egalitate dacǎ numai şi numai dacǎ probabilitatea a posteriori a lui x când se dǎ y este aceeaşi pentru orice y în ambele distribuţii combinate P W şi Q W.
6. Inegalitatea lui Pinsker. Distanţa variaţionalǎ între douǎ functii de probabilitate
Xx
xqxpqpd |)()(|),(
este mǎrginitǎ superior de entropia relativă a celor douǎ funcţii de probabilitate în sensul cǎ
D(p||q) ≥ 21 d2(p, q)
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

16
7. Identitatea paralelogramului. Pentru funcţiile de probabilitate p, q şi r
D(p||r) + D(q||r) =
2||
2||||
22 qpqDqppDrqpD
Acum, o inegalitate foarte utilǎ în demonstrarea relaţiilor de mai sus: Inegalitatea log-sumǎ. Fie n
iia 1}{ şi niib 1}{ secvenţe de numere nenegative. Fie
n
i iaa1
şi
n
i ibb1
. Atunci
baa
baa
n
i i
ii loglog
1
cu egalitate dacǎ şi numai dacǎ ai/bi = c pentru toţi indicii i, cu c o constantǎ. Demonstratie: Mai întâi se observǎ cǎ: este suficient a demonstra inegalitatea pentru ai > 0. Ignorarea indicilor i
pentru care ai = 0 nu schimbǎ partea din stânga a inegalitǎtii şi poate numai sǎ facǎ mai mare partea din dreapta prin posibila reducere a sumei b;
este suficient a demonstra inegalitatea pentru bi > 0, altminteri, partea stângǎ este +∞ şi nu mai este nimic de demonstrat;
este suficient a demonstra inegalitatea pentru a = b. Inegalitatea este invariantǎ la scalarea numerelor bi deoarece
n
ii
i
ii
n
i i
ii a
baa
baa
11
1logloglog
şi 1logloglog a
baa
baa
i
Asadar, este suficient ca pentru niia 1}{ şi n
iib 1}{ cu ai, bi > 0 şi a = b sǎ se arate cǎ
0log1
n
i i
ii b
aa
cu egalitate dacǎ şi numai dacǎ ai = bi pentru orice i = 1, …, n. Se reaminteşte faptul cǎ
log t ≤ t – 1 pentru t > 0 cu egalitate numai pentru t = 1. Mai departe, punând ti = ai/bi, se obtine succesiv
n
iii
n
iii
n
iii
n
i i
ii abtata
baa
1111
)()1(loglog
ceea ce dovedeşte inegalitatea urmăritǎ, concomitent cu conditia de egalitate. Surse de informatie multiple În continuare, fie câmpurile
An =
n
n
ppAA
...
...
1
1 şi Bm =
m
m
qqBB
...
...
1
1
ambele finite, independente, complete, adicǎ cu sumele probabilitǎtilor egale cu unitatea
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

17
pkk
n
1
1 şi qi
i
m
1
1
Probabilitatea producerii concomitente a evenimentelor Ak şi Bi este în acest caz ki = pk qi. Totalitatea evenimentelor de forma (Ak, Bi), 1 k n , 1 i m şi probabilitǎtile atasate ki formeazǎ un câmp de probabilitate notat cu An×Bm. Dacǎ An şi Bm sunt douǎ câmpuri de probabilitate finite independente atunci
Hnm(An×Bm) = Hn(An) + Hm(Bm) Demonstratia urmeazǎ relatia de definitie a entropiei
Hnm(An×Bm) =
)log(loglog1 11 1
ik
n
k
m
iikki
n
k
m
iki qpqp
i
m
ii
n
kkk qqpp loglog
11
= Hn(An) + Hm(Bm)
Dacǎ cele douǎ câmpuri nu sunt independente, atunci probabilitǎţile eveni-mentelor (Ak , Bi), 1 k n , 1 i m se calculeazǎ diferit: ki = pk qi/k, cu qi/k probabilitatea evenimentului Bi conditionat de Ak. Dacǎ se defineste mai întâi o entropie conditionatǎ de evenimentul/simbolul Ak
Hm(Bm/Ak) =
m
ikiki qq
1// log
apoi se defineste entropia conditionatǎ câmp/câmp
Hm(Bm/An) =
n
kkp
1Hm(Bm/Ak)
rezultǎ imediat proprietatea: Dacǎ An şi Bm sunt douǎ câmpuri de probabilitate finite oarecare atunci
Hnm(An×Bm) = Hn(An) + Hm(Bm/An) exprimat în cuvinte, nedeterminarea asociatǎ celor douǎ câmpuri rezultǎ din nedeterminarea unui câmp la care se adaugǎ nedeterminarea celuilalt câmp condiţionatǎ de primul câmp de probabilitate. Fiind date douǎ câmpuri de probabilitate finite An şi Bm, are loc inegalitatea
Hm(Bm/An) ≤ Hm(Bm) Demonstratia apeleazǎ din nou la inegalitatea lui Jensen pentru f(x) = – xlogx, xk = qi/k şi k = pk, 1 k n . În prima fazǎ
p q q p q p q q qk i k i kk
n
k i kk
n
k i kk
n
i i/ / / /log log log1 1 1
şi dupǎ însumarea dupǎ indicele i
p q q q qk i k i ki
m
k
n
i ii
m
/ /log log11 1
ceea ce nu este altceva decât Hm(Bm/An) ≤ Hm(Bm)
În cuvinte, cunoasterea unor rezultate din câmpul An nu poate duce decât la diminuarea nedeterminǎrii câmpului Bm. Dacǎ An şi Bm sunt douǎ câmpuri de probabilitate finite oarecare atunci
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

18
Hnm(An×Bm) ≤ Hn(An) + Hm(Bm) ceea ce rezultǎ din două proprietǎti de mai sus. Fiind date douǎ câmpuri de probabilitate finite oarecare An şi Bm, atunci
Hn(An/Bm) = Hm(Bm/An) + Hn(An) – Hm(Bm) Pentru demonstratie, se scriu relatiile
Hnm(An×Bm) = Hn(An) + Hm(Bm/An) Hnm(An×Bm) = Hm(Bm) + Hn(An/Bm)
şi de aici rezultǎ proprietatea. Câmpurile de probabilitate An şi Bm pot fi surse de informatie, iar evenimentele componente pot consta în generarea de simboluri purtǎtoare de informatie. Sursele discutate pânǎ acum sunt din categoria celor fǎrǎ memorie, adicǎ la fiecare generare a unui nou simbol, probabilitǎtile de aparitie a unui simbol sau a altuia sunt aceleasi, indiferent de simbolul/simbolurile generat(e) anterior. În continuare modificǎm notatiile deoarece numǎrul de simboluri/evenimente (trecute până acum la indice) nu mai are foarte mare relevanţǎ. Schimbarea notatiilor aduce şi o facilitare a scrierii unor proprietǎti legate de sursele multiple, surse pentru care mulţimile alfabetice sunt produsul cartezian al mai multor multimi alfabetice simple. Pe baza celor prezentate relativ la perechile de surse simple, se poate stabili acum, recursiv, entropia unei surse multiple. Fie n surse simple fǎrǎ memorie S1, S2, …, Sn cu numǎrul de simboluri q1, q2, …, qn. Din aproape în aproape se poate stabili relatia
H(S1, S2, …, Sn) = H(Sn/S1, S2, …, Sn–1) + H(S1, S2, …, Sn–1) = = H(Sn/S1, S2, …, Sn–1) + H(Sn–1 /S1, S2, …, Sn–2) + … + H(S1) =
1
0121 ),...,,/(
n
iinin SSSSH
întreaga demonstratie fiind o chestiune de calcul. Relatia ultimǎ are o consecintǎ importantǎ exprimatǎ de relatia
H(Sn/S1, S2, …, Sn–1) ≤ H(Sn) care spune cǎ entropia unei surse nu creşte niciodatǎ prin condiţionare. Surse de informatie cu memorie. Modelul Markov Aşa cum s-a mentionat, sursele de pânǎ acum au fost considerate fǎrǎ memorie, adicǎ probabilitǎtile ataşate simbolurilor sursei nu depindeau în nici un fel de simbolurile generate anterior. Aceastǎ situatie nu corespunde decât unui numǎr limitat de surse din lumea realǎ. Uzual, existǎ o legǎturǎ, o conditionare între simbolurile succesive generate de sursele de informatie. Şirurile de caractere din limba englezǎ sunt ilustrative în acest sens : dupǎ grupul “th” foarte probabil urmeazǎ “e”, “o”, “r”, “a”, “u”, “i”; grupului “ac” îi succede mai curând “c”, “t”, “q”, “h” şi mai rar, dacǎ nu extrem de rar alte caractere. Efecte şi determinǎri similare pot fi observate în orice limbǎ scrisǎ, în particular în limba românǎ. Asadar, probabilitǎţile de producere a unor simboluri noi depind în oarecare mǎsurǎ de contextul simbolurilor produse deja. Pentru astfel de surse sunt necesare modele perfecţionate care sǎ transforme sursa într-una cu un
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

19
anumit gen de memorie. Probabilitǎţile asociate simbolurilor, constante în cazul surselor fǎrǎ memorie trebuie înlocuite cu probabilitǎti conditionate. Modelul cel mai utilizat pentru sursele cu memorie este modelul Markov. Modelul Markov de ordinul m introduce în calcule probabilitǎti pentru simbolul curent care depind de m simboluri generate de sursǎ anterior. O sursǎ Markov de ordinul m cu un alfabet de q simboluri are probabilitǎtile conditionate de forma
)/Pr(),...,,/Pr(21
mijjji Ssssss
m
scrisǎ pentru toti indicii },...,2,1{,...,,, 21 qjjji m , în care S m noteazǎ starea curentǎ a sursei. Această stare curentǎ este descrisǎ de secventa imediat precedentǎ de simboluri generate. Pentru n > m, relatia de condiţionare de mai sus se scrie
)/Pr(),...,,/Pr(),...,,/Pr(2121
mijjjijjji Ssssssssss
mn
şi pentru m = 0 , deci pentru surse fǎrǎ memorie, aceasta devine )Pr(),...,,/Pr(
21 ijjji sssssn
pentru orice n > m = 0 . Cu un alfabet de q simboluri, o sursǎ Markov de ordinul m are qm stǎri distincte cu qm+1 probabilitǎti de trecere (de tranziţie) de la o stare la alta. Un graf al tranziţiilor ilustreazǎ foarte bine o asemenea sursǎ. Pe un exemplu, cel al unei surse Markov de ordinul 2 cu alfabet binar, se poate constata cǎ sunt patru (22) stǎri, 00, 01, 10, 11 şi opt (23) tranziţii posibile, cu probabilitǎtile respective de producere, de pildǎ
Pr(0/S2 = 00) = Pr(0/00) = 0,8 Pr(1/S2 = 11) = Pr(1/11) = 0,8
Pr(0/11) = Pr(1/00) = 0,2 Pr(0/01) = Pr(0/10) = Pr(1/01) = Pr(1/10) = 0,5
Graful tranziţiilor acestei surse este cel din figurǎ.
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

20
Cum lucreazǎ sistemul se poate exemplifica pe un caz particular. Se considerǎ secventa observatǎ “00100110…” şi starea iniţialǎ 00. Secventa de stǎri ale sistemului este 00 00 00 01 10 00 01 11 10… şi se obtine prin deplasarea progresivǎ cu o pozitie spre dreapta a unei “ferestre” de lǎrgime 2, în lungul secventei de simboluri generate, completatǎ în prima parte cu starea initialǎ a sistemului (scrisǎ cu literǎ distinctǎ). Evenimentele succesive se descriu astfel: Starea initialǎ 00 şi generarea primului 0 produce tranzitia în starea 00; Starea 00 şi generarea următorului 0 produce tranzitia în starea 00; Starea 00 şi generarea lui 1 produce tranzitia în starea 01; Starea 01 şi generarea lui 0 produce tranzitia în starea 10 ş.a.m.d. Un sistem Markov de ordinul m este definit de o matrice P a probabilitǎtilor de tranzitie astfel: 1. Se enumerǎ stǎrile, Sm;1, Sm;2, …, Sm;n unde n = qm este numǎrul de stǎri ale
sistemului. Matricea P are dimensiunile n×n şi elementul din pozitia (i, j), linia i şi colana j este probabilitatea ca pornind din starea
mjjjim sssS ...
21
; , simbolul urmǎtor generat sǎ fie si şi, în consecinţǎ, starea urmǎtoare a sursei sǎ fie ijjj
jm ssssSm
...32
; . Asadar )/Pr( ;; imjmij SSp .
2. Suma probabilitǎtilor pe fiecare linie a matricii P trebuie sǎ fie egalǎ cu unitatea.
3. Pentru trecerea de la S m;i la S m;j în urma a k tranzitii succesive şi pentru generarea a k simboluri, matricea probabilitǎtilor de trecere este exact P k.
Pentru exemplul de mai devreme matricea discutatǎ este
8,02,000005,05,05,05,000
002,08,0
P
cu stǎrile mentionate acolo şi elementele )/Pr( ;; imjmij SSp .
Sursele Markov ergodice reprezintǎ o clasǎ importantǎ de surse Markov. O sursǎ Markov ergodicǎ este una care observatǎ timp îndelungat genereazǎ o secventǎ de simboluri care este tipicǎ. Cele mai multe surse Markov sunt ergodice. O sursǎ neergodicǎ este datǎ în figura alǎturatǎ.
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

21
Dupǎ un timp suficient de îndelungat aceastǎ sursǎ eşueazǎ în secvenţa 000000… sau în secvenţa 111111… care nu sunt tipice. Mai mult decât atât, odatǎ ajunsǎ în starea 00 sau în starea 11 sursa intrǎ într-o “fundǎturǎ” fǎrǎ iesire deoarece Pr(1/00) = 0 şi Pr(0/11) = 0. Aceasta este o sursǎ Markov tipic neergodicǎ. Prin definitie o sursǎ Markov este ergodicǎ dacǎ dupǎ un numǎr finit de paşi existǎ posibilitatea de a trece, cu probabilitǎti nenule, în orice stare. O proprietate importantǎ a surselor Markov ergodice este staţionaritatea. Distributia stǎrilor sistemului dupǎ un numǎr foarte mare de tranzitii este independentǎ de starea initialǎ. Starea sistemului/sursei tinde cǎtre o stare numitǎ stationarǎ, independentǎ de starea de pornire. Distribuţia stationarǎ a stǎrilor unei surse ergodice este caracterizatǎ de matricea T = P k şi se atinge atunci când k → ∞. Cu alte cuvinte tranzitia de la starea S m;i la starea S m;j în k paşi se apropie de starea stationarǎ dacǎ numǎrul k devine din ce în ce mai mare. Mai mult, starea finalǎ S m;j este mereu aceeaşi şi independentǎ de starea de plecare S m;i. Prin urmare matricea n×n
n
n
n
kk
ttt
tttttt
TP
...............
...
...
lim
21
21
21
are liniile identice. Matricea T este numitǎ matricea de distributie stationarǎ a stǎrilor şi este deplin determinatǎ de una din liniile ei. În exemplul de mai devreme
64,016,01,01,025,025,01,04,04,01,025,025,01,01,016,064,0
2 PPP
562,0178,01,016,025,01,0205,0445,0445,0205,01,025,016,01,0178,0562,0
23 PPP
şi urmǎrind puterile succesive ale matricei P, se poate spune cǎ sunt semne de convergenţǎ. Evaluarea elementelor din matricea T prin continuarea calculelor pentru puteri k din ce în ce mai mari nu este tocmai productivǎ şi nici foarte precisǎ. Calea de determinare a elementelor matricii T este alta, şi anume aceea care tine seama cǎ
PTPPPT kk
kk
limlim 1
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

22
ceea ce este un sistem liniar de ecuatii în elementele matricii de distributie stationarǎ a stǎrilor, sistem care produce soluţia exactǎ. Scrierea ecuatiei în formǎ transpusǎ
PTTT = TT
este mai convenabilǎ deoarece din aceasta se obtine imediat
nn
T
t
tt
t
tt
P......
2
1
2
1
un sistem în necunoscutele t1, t2, …, tn care trebuie rezolvat cu îndeplinirea conditiei 1...21 nttt . Exemplul de mai devreme produce
357,0145
41 tt şi 143,0142
32 tt
adicǎ probabilitǎtile asociate stǎrii stationare sunt Pr(00) = Pr(11) = 0,357 şi Pr(01) = Pr(10) = 0,143
Entropia unei surse Markov se calculeazǎ pornind de la aceleaşi relatii prezentate la sursele fǎrǎ memorie. Este natural ca în locul probabilitǎtilor permanent constante ale simbolurilor din cazul surselor fǎrǎ memorie, în cazul surselor Markov sǎ fie folosite probabilitǎtile conditionate de simbolurile generate anterior. Dacǎ sursa Markov de ordinul m cu q simboluri este în starea
)...(21 mjjj
m sssS atunci probabilitatea de aparitie a simbolului si ca simbol
urmǎtor este )/Pr( mi Ss şi informatia purtatǎ de acel simbol este
)/Pr(1log)/( mi
mi Ss
SsI
Informatia medie pe simbol este atunci
q
i
mi
mi
m SsISsSSH1
)/()/Pr()/(
O mediere pe toate cele qm stǎri posibile produce entropia sursei
mm
m
S
q
i
mi
mi
m
S
q
i
mi
mi
m
S
mm
SsISsSSsISsS
SSHSSH
11)/()/Pr()Pr()/()/Pr()Pr(
)/()Pr()(
şi, în cele din urmǎ
1 )/Pr(
1log)Pr()(mS
mi
im
SssSSH
cu operatorul de sumare
1 1m mS S
q
i şi cu )...(
21 ijjjim sssssS
m .
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

23
is 2S )/Pr( 2Ssi )Pr( 2S )Pr( 2isS
0 0,8 4/14 1
00 0,2
5/14 1/14
0 0,5 1/14 1 01 0,5 2/14 1/14 0 0,5 1/14 1 10 0,5 2/14 1/14 0 0,2 1/14 1 11 0,8 5/14 4/14
Pentru exemplul enuntat mai sus şi reluat de mai multe ori, tabelul alǎturat faciliteazǎ evaluarea entropiei sistemului şi conduce la entropia sursei
81,08,0
1log144...
5,01log
141
2,01log
141
8,01log
144
)/Pr(1log)Pr()(
32
2
S i
i SssSSH
mǎsuratǎ în biti/simbol. Un model alternativ pentru aceeaşi sursǎ este sursa adjunctǎ. Sursa adjunctǎ este sursa fǎrǎ memorie, cu simboluri mutual independente, specificate deplin de probabilitǎtile )Pr(),...,Pr(),Pr( 21 qsss . Faţǎ de o sursǎ
oarecare S, sursa adjunctǎ S este echivalenta acesteia dar fǎrǎ memorie şi calculul entropiei )(SH se face cu formula de la sursele de tipul respectiv. Pentru o sursǎ Markov de ordinul m, sursa adjunctǎ S se defineste prin evaluarea probabilitǎtilor
mS
mmii SSssP )Pr()/Pr()( . Datǎ fiind dependenţa
simbolului curent de starea sistemului generator, conform unei discuţii din prima parte a sectiunii de faţǎ
)()( SHSH cu egalitate atunci când simbolurile produse sunt independente statistic de starea curentǎ a sistemului. Aşadar, la sursele Markov cunoasterea simbolurilor precedente reduce incertitudinea asupra simbolului care urmeazǎ a fi generat. Ca de obicei, cunostintele în plus diminueazǎ ignoranţa. Revenind la sursa Markov de ordinul 2 din exemplul de mai devreme, sǎ stabilim sursa adjunctǎ. Se poate calcula Pr(0) fie pe calea
5,0)11Pr()11/0Pr()10Pr()10/0Pr()01Pr()01/0Pr()00Pr()00/0Pr(
)Pr()/0Pr()0(2
22
S
SSP
fie pe calea alternativǎ 5,0)01Pr()00Pr()Pr()0Pr( 2
SS
Analog sau prin diferentǎ Pr(1) = 0,5. Rezultǎ 1)( SH şi inegalitatea aşteptatǎ
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

24
1)(81,0)( SHSH În continuare se discutǎ calitatea unor modele variate ale surselor de informatie foarte generale. Fie
),...,,/()~/()ˆ( 21 mmm SSSSHSSHSH
entropia unei surse reale, evaluatǎ pe baza unui model Markov de ordinul m. Cazul particular )ˆ( 0SH corespunde unui model de ordinul 0, deci al unei surse fǎrǎ memorie. Pe baza unui rezultat obtinut relativ la sursele multiple este de observat cǎ
)ˆ()ˆ(...)ˆ()ˆ( 011 SHSHSHSH mm şi, mǎrind pe m, se obtine
)ˆ(lim)ˆ( mm SHSH
care poartǎ numele de entropia realǎ a sursei. Pentru cazul unui model Markov perfect de ordinul k se poate scrie
)ˆ(...)ˆ()ˆ()ˆ( 21 SHSHSHSH kkk În unele cazuri este mai la îndemânǎ a se lucra cu blocuri de simboluri şi nu cu simboluri simple, izolate. Se naşte astfel extensia unei surse de informatie. Dacǎ sursa S genereazǎ simbolurile },...,,{ 21 qsss atunci extensia ei de ordinul n, notatǎ Sn este o sursǎ cu qn simboluri },...,,{ 21 nq
, secvenţe distincte de
lungime n alcǎtuite cu simbolurile sursei S. Dacǎ sursa S este fǎrǎ memorie, probabilitǎţile acestor blocuri sunt
)Pr()...Pr()Pr()Pr( 21 iniii sss iar dacǎ sursa este foarte generalǎ
)Pr()...,...,,/Pr(),...,,/Pr()Pr( 1)2(21)1()1(21 iniiininiiiini sssssssss Dacǎ sursa S este lipsitǎ de memorie atunci extensiile ei sunt toate fǎrǎ memorie. Dacǎ sursa originarǎ este markovianǎ de ordinul m atunci extensia ei de ordinul n este markovianǎ de un ordin egal cu primul întreg superior sau egal numărului m/n. Fie ca exemplu sursa S = {0, 1} cu q = 2. Extensia a doua se prezintǎ sub forma
}11,10,01,00{ 43212 S
iar extensia urmǎtoare, a treia, are opt simboluri
}111,110,101,100,011,010,001,000{
8765
43213
S
Dacǎ sursa S este fǎrǎ memorie, atunci extensia ei Sn este tot fǎrǎ memorie. Dacǎ S este o sursǎ Markov cu m = 2 atunci S 2 este o sursǎ Markov de ordinul 1. Evaluarea probabilitǎtii Pr(101) se face în cazul sursei fǎrǎ memorie cu relatia Pr(101) = Pr(1)Pr(0)Pr(1). În cazul Markov, probabilitatea aceluiaşi simbol compus se calculeazǎ pe calea mai complicatǎ Pr(101) = Pr(1/10)Pr(10)
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

25
= Pr(1/10)Pr(0/1)Pr(1) unde în fiecare şir de simboluri simbolul cel mai din dreapta este cel mai recent generat. Descompunerea Pr(101) = Pr(1/01)Pr(01) este corectǎ matematic, dar nu este de valoare practicǎ deoarece probabilitatea condiţionatǎ care apare în relatie include dependenţa de simboluri viitoare care nu sunt accesibile decât mai târziu. Revenind în cadrul general, pentru o sursǎ fǎrǎ memorie, conform relatiei pentru entropia surselor multiple (dar identice) datǎ mai devreme, se evalueazǎ
H(Sn) = H(S1, S2, …, Sn) = = H(Sn/S1, S2, …, Sn–1) + H(Sn–1 /S1, S2, …, Sn–2) + … + H(S2/S1) + H(S1) =
= H(Sn) + H(Sn–1) + … + H(S2) + H(S1) = nH(S) Se propune ca exemplu de calcul extensia a doua a unei surse cu trei simboluri şi probabilitǎtile 0,5, 0,25, 0,25. Fie acum o sursǎ Markov S de ordinul m. Entropia extensiei ei de ordinul n se calculeazǎ pas cu pas pornind de la
)~/()( mnn SSHSH Apoi
)(...)~/()~/()( 12
11 SHSSHSSHSH n
nn
nn
care conditionatǎ de mS~ se transformǎ în )~/(...)~~/()~~/()~/( 1
21
1 mnmn
nmn
mn SSHSSSHSSSHSSH
Expresia )~~/( 1imi SSSH defineşte entropia unei surse Markov de un ordin egal
cu m + i – 1. Dar sursa Markov are ordinul m aşa încât )()~/(),...,,/()~~/( 11
1 SHSSHSSSSHSSSH miimimii
imi
şi în final
)()~/()~/(...)~/()~/()~/()(
11 SnHSSnHSSHSSHSSHSSHSH
mmmn
mn
mnn
Într-un exemplu tratat mai devreme (sursa Markov de ordinul 2) H(S) = 0,81. Iatǎ o interpretare a extensiei S2 şi a entropiei acestei extensii. Deoarece m = 2 şi n = 2 sursa S2 este markovianǎ de ordinul 1 în raport cu simbolurile
)( 21 iii ss . Probabilitǎtile condiţionate ale sursei extinse sunt )/Pr()/Pr()/Pr()/Pr( 2122112121 jjijjijjiiji ssssssssss
şi este destul de clar cǎ matricea P2 este aceea care descrie şi tranziţiile ei. Astfel, 62,1)81,0(2)(2)( 2 SHSH biti/simbol (dublul entropiei sursei simple). În stabilirea unui ordin potrivit pentru modelul Markov al unei surse reale care este vǎdit cu memorie, este de interes o relatie între entropiile H(Sn) şi H(S/Sn−1) care poate servi la apropierea asimptoticǎ de entropia realǎ a sursei, )ˆ( SH . O cale de a face modelul mai adecvat la o sursă dependentǎ de toate simbolurile generate anterior, oricât de multe, este a defini un model de ordinul m şi cu relatia )ˆ()~/( mm SHSSH , prin cresterea treptatǎ a lui m, se poate ajunge oricât de aproape de entropia )ˆ( SH . Functia )ˆ( mSH este descrescǎtoare cu m
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

26
astfel încât aceasta ar putea fi un sondaj relativ cât de scǎzutǎ poate ajunge valoarea entropiei reale )ˆ( SH . Efortul de calcul este însǎ foarte mare deoarece complexitatea modelului Markov creşte exponenţial cu ordinul m. O alternativǎ este evaluarea entropiei H(Sn) ca estimare a entropiei )ˆ( SH . Intuitiv, evaluǎrile înlǎnţuite
)Pr()...,...,,/Pr(),...,,/Pr(),...,,Pr( 1)2(21)1()1(2121 iniiininiiiininii ssssssssssss includ şi efectul istoriei sursei. Urmeazǎ
)ˆ(...)ˆ()ˆ()(...)~/()~/()(
0211
21
1
SHSHSHSHSSHSSHSH
nn
nn
nn
n
de unde rezultǎ )ˆ()( 1 nn SnHSH
şi dacǎ se utilizeazǎ un rezultat de mai sus, nSHSH nn /)()ˆ( , se obtine rezultatul important
)ˆ()ˆ( 1 nn SHSH care dǎ o limitare inferioarǎ a entropiei pe simbol, simbol multiplu de ordinul n. Cu rezultatul ultim şi cu relatia de mai sus se poate scrie succesiv
)()ˆ()( 11 nnn SHSHSH
)()()( 1 nn
n SHnSHSH
)()()( 1 nnn SnHSHSnH
1)()( 1
nSH
nSH nn
Rezultǎ cǎ entropiile combinate pe simbol sunt în relatia )(ˆ)(ˆ 1 nn SHSH
Dar )ˆ(lim)ˆ( nn SHSH
aşa încât )ˆ()(ˆlim SHSH n
n .
Aceasta este o modalitate mult mai la îndemânǎ de a estima )ˆ( SH . Entropiile )(ˆ nSH se evalueazǎ mult mai uşor decât )ˆ( mSH . Mai mult, pentru n din ce în
ce mai mare, probabilitǎtile atasate unor şiruri de lungime n, ),...,,Pr( 21 inii sss se diferenţiazǎ. Unele se situeazǎ la valori semnificative şi constant semnificative, altele tind cǎtre valori apropiate de zero. Apare aşadar o clasǎ a mesajelor de lungime n foarte probabile şi o altǎ clasǎ a mesajelor de aceeaşi lungime, care sunt, dimpotrivǎ, foarte putin probabile. Într-un exemplu simplu, cel al unei surse fǎrǎ memorie, cu alfabetul S = {0,1}, şi probabilităţile simbolurilor P(0) = 0,75 şi P(1) = 0,25, sunt produse secvenţe de zerouri şi unitǎti binare variate între care şirul de lungime n format numai din 0 şi, asemenea, sirul de lungime n format numai din 1, cu probabilitǎtile (0,75)n, respectiv (0,25)n. Pentru n = 4 probabilitǎtile sunt 3,210–1 şi 3,910–3, iar pentru n = 16 probabilitǎtile evolueazǎ cǎtre 1,010–2 şi 2,610–10, asadar
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

27
sirul alcǎtuit numai din 0 devine comparativ din ce în ce mai probabil pe când sirul alcǎtuit numai din 1 devine din ce în ce mai puţin probabil. Alte mesaje arbitrare au probabilitǎti de forma in
nC (0,75)i(0,25)n–i, cu i numǎrul zerourilor din secvenţa-mesaj. Expresia probabilitǎtilor este bernoullianǎ, datǎ fiind ordinea variatǎ în care pot apǎrea zerourile şi unitǎtile binare. Variatia probabilitǎtilor cu cresterea lui i de la 0 la n este mai întâi crescǎtoare apoi descrescǎtoare, cum se întâmplǎ obişnuit cu termenii unei dezvoltǎri binomiale. Este momentul sǎ fie aduse acum în discutie detaliile comportǎrii surselor extinse la n foarte mare, acea proprietate de echipartitie asimptoticǎ, cunoscutǎ mai ales în versiunea prescurtatǎ, AEP – Asymptotic Equipartition Property. Legea numerelor mari şi AEP (Asymptotic Equipartition Property) Legea numerelor mari afirmă că pentru variabilele aleatoare X1, X2, ..., Xn independente şi identic distribuite (i.i.d.), suma
n
iiX
n 1
1
este apropiată de valoarea medie E[X]. AEP mai înseamnă şi că pentru variabile aleatoare i.i.d. valoarea
),...,,(1log1
21 nXXXpn
este apropiată de entropia H(X). Exprimat altfel, faptul poate fi scris ca
p(x1, x2, …, xn) 2 – nH Exemplul 1: Fie X {0, 1} cu p(1) = p, p(0) = q. Probabilitatea secventei i.i.d. X1, X2, …, Xn este ii XnX qp . Dacă în particular, p(0) = 0,7 şi p(1) = 0,3 probabilitătile secvenţelor de lungime n = 10 sunt trecute în tabelul alăturat.
Secvenţa Probabilitatea secvenţei
Numărul secvenţelor
Probabilitatea secvenţelor
0000000000 0,0282 1 0,0282 0000000001 0,0121 10 0,121 0000000011 0,005 45 0,225 0000000111 0,0022 120 0,264 0000001111 0,00095 210 0,1995 0000011111 0,0004 252 0,1008 0000111111 0,00017 210 0,036 0001111111 0,000075 120 0,009 0011111111 0,000032 45 0,00144 0111111111 0,0000138 10 0,000138 1111111111 0,0000059 1 0,0000059
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

28
Este vizibil că nu toate cele 2n secvenţe de lungime n au aceeaşi probabilitate. Secventele cu numărul de unităti binare de aproximativ np au cea mai mare probabilitate totală: acestea sunt tipice. Proprietatea aceasta devine mai evidentă pe măsură ce n creste. Care este probabilitatea p(X1, X2, ..., Xn) a rezultatului X1, X2, ..., Xn? Se dovedeste că foarte probabil p(X1, X2, ..., Xn) are o valoare de cca. 2 – nH. Adică
Pr{(X1, X2, ..., Xn)| p(X1, X2, ..., Xn) = 2 – n(H + )} 1 Deoarece entropia este o măsură a “surprizei” la observarea rezultatului unei variabile aleatoare, se poate aprecia această regulă în sumar ca: “Aproape toate evenimentele sunt la fel de surprinzătoare”. Altfel spus, cele mai multe evenimente se produc cu o probabilitate în relatie cu entropia ansamblului. În exemplul particular de mai sus, se afirmă simplu că numărul de unităti observate este apropiat de np (cu mare probabilitate) şi toate aceste secvente au grosier aceeaşi probabilitate. Aceasta nu este altceva decât legea numerelor mari. Convergenţa în probabilitate: Înainte de a ajunge la teoremă este necesară o discutie despre convergenţa în probabilitate. Există o varietate de moduri în care se tratează convergenţa în sfera probabilitătilor. Există o convergenţă în distributie (ca la teorema limită centrală), există convergenţa aproape sigură (care este foarte tare), există convergenţa în media pătratică şi există convergenţa în probabilitate. Se pot consuma săptămâni pentru studiul semnificatiei acestor fapte cu implicatii reciproce. Totuşi, pentru moment este suficientă o oprire asupra convergentei în probabilitate. Definitia 1. O secventă X1, X2, …, Xn este convergentă la X în probabilitate dacă Pr[|X – Xn| > ] 0 odată cu n . Rememorând definitia convergentei de la siruri, se poate spune: pentru orice > 0 şi pentru orice > 0 există un n0 astfel încât P[|X – Xn| < ] > 1 – oricare ar fi n > n0. Exemplul 2. Fie Xi (i = 1, 2, …, n) o secvenţă de variabile aleatoare i.i.d. şi fie
n
iin X
nS
1
1 media de selecţie. Fie S = E[X] media reală, teoretică. Atunci (din
nou legea numerelor mari în varianta slabă) P[|Sn – S| > ] 0 odată cu n . Mai pe scurt, se spune Sn S în probabilitate. O modalitate de apreciere a convergentei o constituie inegalitatea lui Markov: pentru o variabilă aleatoare pozitivă şi pentru orice > 0, are loc inegalitatea P[X ] E[X]/. De aici se poate deriva inegalitatea lui Cebîşev: pentru o variabilă aleatoare Y cu media şi dispersia 2, are loc inegalitatea P[|Y – | > ] 2/2. Se poate arăta apoi convergenta mediei de selectie (legea numerelor mari în varianta slabă). Acum despre AEP – Asymptotic Equipartition Property:
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

29
Teorema 1 (AEP). Dacă X1, X2, ..., Xn sunt variabile aleatoare i.i.d. cu
distribuţia p(x), atunci )(),...,,(log121 XHXXXp
n n în probabilitate.
Demonstratie: Deoarece Xi (i = 1, 2, ..., n) sunt variabile aleatoare i.i.d., la fel sunt şi log p(Xi). Din independenţă şi WLLN – Weak Low of Large Numbers
)()]([log)(log1),...,,(log121 XHXpEXp
nXXXp
n iin
în probabilitate. Mulţimea secventelor care apar cel mai frecvent (potrivit legii probabilistice a variabilei aleatoare) sunt secvenţe tipice. Tipicalitatea este definită astfel: Definiţia 2. Multimea tipică )(nA în raport cu distribuţia p(x) este mulţimea de secvente x1, x2, ..., xn Xn cu proprietatea
))((21
))(( 2),...,,(2 XHnn
XHn xxxp Aşadar secvenţele tipice apar cu o probabilitate care este în apropierea numărului 2 – nH(X). Exemplul 3. Revenim la primul exemplu, H(X) = 0,88129 şi nH(X) = 8,8129. Atunci 2–nH(X) = 0,00223 ceea ce este foarte aproape de probabilitatea unei secvenţe cu trei unităti binare, restul zerouri. O multime tipică )(nA are următoarele proprietăţi: Teorema 2. 1. Dacă )(
21 ),...,,( nn Axxx atunci
H(X) – ),...,,(121 nxxxp
n H(X) +
2. Pentru n suficient de mare, 1}Pr{ )(nA . 3. ))(()( 2||
XHnnA , cu |A| numărul de elemente din multimea A.
4. Pentru n suficient de mare, ))(()( 2)1(|| XHnnA .
Interpretări: Din proprietatea 1: aproape toate elementele dintr-o multime tipică sunt practic echiprobabile. Din proprietatea 2: mulţimea tipică apare cu o probabilitate apropiată de unitate (de aceea este denumită tipică!). Din proprietăţile 3 şi 4: numărul de elemente ale unei multimi tipice este apropiat de 2nH(X). Demonstratie. 1. Se ia – (1/n) şi logaritmul (în baza 2) din relatia de definiţie a multimii
tipice:
)))(((1),...,,(log1)))(((121 XHn
nxxxp
nXHn
n n
2. Din definiţia multimilor tipice, AEP şi definitia convergentei în probabilitate: 1}),...,,(|),...,,Pr{( )(
2121 nnn AXXXXXX concomitent cu
n . Aceasta înseamnă că pentru orice > 0 există un n0 astfel încât
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

30
pentru n n0 are loc 1}|)(),...,,(log1Pr{| 21 XHXXXpn n . Se
pune = şi se obtine proprietatea 2. 3. Succesiv, 1 =
nXx
xp )( )(
)(nAx
xp
)(
))((2nAx
XHn
= ||2 )())(( nXHn A .
4. Pentru n suficient de mare, 1}Pr{ )(nA şi de aici }Pr{1 )(nA
)(
))((2nAx
XHn
= ||2 )())(( nXHn A .
Aceste detalii privind proprietatea de echipartitie asimptotică (AEP) sunt de interes aparte în compresia de date. Entropia diferenţială O variabilă aleatoare continuă (pentru uzul acestui curs) este una pentru care functia de distributie F(x) este continuă: nu există salturi (iesiri/valori discrete). Definita 1. Entropia diferentială h(x) a unei variabile aleatoare continue X cu densitatea de probabilitate f(x) şi suportul S este
Sdxxfxfxh )(log)()(
Exemplul 1. Fie X ~ U(0, a) o variabilă distribuită uniform pe intervalul (0, a). Atunci
adxaa
xha
log1log1)(0
Se observă că entropia diferenţială poate fi negativă (dacă a < 1). De aceea se numeste entropia diferenţială, deoarece entropia în general trebuie să fie pozitivă. Exemplul 2. Pentru variabila normală
)(2
1~ )2/( 22
xeX x
de medie zero, entropia diferenţială în naţi (unităţi în baza logaritmilor naturali) este
)ln(21)2ln(
21
2][
)2ln(2
)(ln)(
222
2
2
2
eXE
dxxxdxxh
Cu notiunea de entropia diferenţială clarificată, se pot reformula acum lucruri deja definite pentru variabilele aleatoare discrete. Proprietatea de echipartiţie asimptoticǎ (AEP – Asymptotic Equipartition Property) Teorema 1. Fie X1, …, Xn o secventă de valori ale unor variabile aleatoare i.i.d. descrise de functia de repartitie f(x). atunci
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

31
)()](log[),...,(log11 XhXfEXXf
n n
cu convergenţa în probabilitate. Demonstratie: Este vorba exact de aceeaşi WLLN. Definitia 2. Mulţimi tipice. Pentru orice > 0 şi orice n, o multime tipică )(nA în raport cu f(x) este
|)(),...,(log1|),...,( 11)( Xhxxf
nSxxA n
nn
n
cu alte cuvinte, )(nA este multimea pentru care entropia diferentială empirică este apropiată de entropia diferentială. Pentru variabilele aleatoare discrete, se vorbeşte de numărul de elemente dintr-o multime tipică. Pentru variabilele aleatoare continue, conceptul analog este cel de volum al unei multimi tipice. Definitia 3. Volumul unei multimi A Rn este
vol(A) = A
ndxdxdx ...21
Teorema 2. O multime tipică are următoarele proprietăţi: 1. Pentru n suficient de mare, Pr( )(nA ) > 1 – (valorile cuprinse în multimile
tipice apar foarte frecvent). 2. Pentru orice n, vol( )(nA ) 2n(h(X) + ) 3. Pentru n suficient de mare, vol( )(nA ) (1 – )2n(h(X) – ). Demonstratie: 1. Din nou, exact prin WLLN. 2. Se observă că
)(vol2...2
...),...,(...),...,(1
)())((1
))((
1111
)(
)(
nXhn
An
Xhn
Ann
snn
Adxdx
dxdxxxfdxdxxxf
n
nn
3. Dacă n este suficient de mare, atunci proprietatea 1 este adevărată si )(vol2...2...),...,(1 )())((
1))((
11)()(
nXhn
An
Xhn
Ann Adxdxdxdxxxf
nn
Discretizarea Dacă o variabilă aleatoare X cu distributie continuă este studiată pe domenii adiacente, atunci (teorema valorii medii) există o valoare xi în fiecare domeniu care verifică egalitatea
f(xi) =
)1()(
i
idxxf
Fie X variabila aleatoare cuantizată definită ca X = xi cu probabilitatea pi = f(xi). Entropia variabilei aleatoare cuantizate este
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

32
H(X) = )log)((log)())(log()( iiii xfxfxfxf La limită, când 0 egalitatea se transformă în
H(X) h(f) Entropia unei cuantizări pe n biti a unei variabile aleatoare continue creste cu n. Entropiile diferenţiale combinate, condiţionate şi relative Alte definitii: Entropia diferentială combinată:
h(X1, ..., Xn) = nnn dxdxxxfxxf ...),...,(log),...,( 111 Entropia diferentială conditionată:
h(X|Y) = dxdyyxyxf )|log(),( Un caz special important: Teorema 3. Fie X1, ..., Xn o distributie normală multivariabilă cu media şi matriea de covariaţie K. Pentru această variabilă aleatoare, entropia este
h(X1, ..., Xn) = ||)2log(21 Ke n
în biti. Demonstratie: Fără a pierde din generalitate, este convenabil a se presupune = 0. Şi atunci
||)2(ln21))((
21
||)2(ln21)(
21
||)2(ln21)()(
,
1
,
1
21
1
KKxxE
KxKxE
dxKxKxxffh
n
jiijij
n
jijiji
nT
||)2(ln21||)2(ln
21
21
||)2(ln21)(
21||)2(ln
21)(
21 11
KeKn
KKKKKK
nn
n
jjj
n
j iijji
Entropia relativă are expresia
gffgfD log)||(
Retinem o functie numită informatie mutuală care are în cazul variabilelor aleatoare continue expresia
I(X;Y) = ))()(||),(()()(
),(log),( yfxfyxfDdxdyyfxf
yxfyxf
în care apare şi o entropie relativă.
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

33
Unele proprietăti cunoscute, adaptate variabilelor aleatoare continue: 1. D(f||g) 0 2. I(X;Y) 0 3. H(X|Y) h(X)
4. Regula lanţului: h(X1, ..., Xn) =
n
iii XXXh
111 ),...,|(
5. h(X + c) = h(X) (deplasarea nu afectează entropia) 6. h(aX) = h(X) + log|a|. Pentru a dovedi aceasta, fie Y = aX; atunci fY(y) =
(1/|a|)fX(y/a). 7. h(AX) = h(X) + log|A| Un rezultant important este următorul: Teorema 4. Fie un vector aleator X de medie zero şi de covaianţă K = E[XXT]. Atunci h(X) (1/2)log(2pe)n|K|, cu egalitate dacă şi numai dacă X ~ N(0,K). Asta înseamnă că pentru o covarianţă dată, distributia normală (gaussiană) are acea covarianţă care maximizează entropia. Demonstratie: Fie g(x) o distributie cu aceeaşi covariaţie şi fie densitatea gaussiană. 0 D(g||f) = )()(log)(log)()/log( hghghgghgg Pasul cheie al demonstratiei constă în observatia că
)(log 1xKxgag T şi că atât g cât şi au aceleaşi momente de ordinul al doilea.
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

34
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

35
CANALE DE TRANSMITERE A INFORMAŢIEI Generalitǎti Definitie. Un canal de transmisie este descris pe deplin dacǎ se dau un alfabet de intrare riaA i ,...,2,1},{ , un alfabet de iesire sjbB j ,...,2,1},{ şi un set de probabilitǎti conditionate P(bj/ai) pentru toti indicii i şi j. Probabilitatea P(bj/ai) corespunde evenimentului constând în receptionarea simbolului bj când s-a transmis simbolul ai. Alfabetul de intrare A reprezintǎ multimea simbolurilor aplicate la intrarea canalului. Alfabetul de ieşire B este multimea simbolurilor observate la iesirea canalului. Uzual, simbolurile receptionate sunt aceleaşi cu cele transmise, dar de cele mai multe ori aşa-numitele zgomote, perturbatii din canal pot schimba simbolurile transmise în alte simboluri, pot modifica continutul fluxului informational transferat de la intrare cǎtre iesire. Din acest motiv, pentru generalitate, se considerǎ cǎ cele douǎ multimi alfabetice sunt diferite. Un canal are ataşatǎ o matrice care are ca elemente exact probabilitǎtile conditionate din definitie. Matricea are r linii şi s coloane şi pentru simplitate probabilitǎtile P(bj/ai) sunt notate mai scurt cu Pij. Aşadar, matricea canalului se scrie
rsrr
s
s
PPP
PPPPPP
P
...............
...
...
21
22221
11211
Matricea P are câteva proprietǎti: 1. Fiecare linie corespunde unui simbol de intrare; 2. Fiecare coloanǎ corespunde unui simbol de iesire; 3. Deoarece expedierea simbolului ai produce la ieşire totdeauna unul din
simbolurile bj (sistem complet de evenimente),
s
jijP
1
1 pentru fiecare i =
1, 2, …, r, adicǎ suma probabilitǎtilor de pe fiecare linie este egalǎ cu unitatea.
Exemple de canale de transmitere a informatiei şi reprezentarea lor prin matrici:
a) un canal binar fǎrǎ zgomot,
1001
P
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

36
b) un canal binar simetric cu zgomot (1% din biti sunt inversati),
99,001,001,099,0
P
c) un canal binar cu zgomot foarte general, pentru care alterarea celor douǎ
simboluri se produce în proportii diferite,
7,03,02,08,0
P .
O altă posibilǎ reprezentare a unui canal este printr-un graf orientat cu probabilitǎtile Pij înscrise pe arce.
Douǎ tipuri de canale au o importanţǎ practicǎ aparte:
canalele binare simetrice care au matricea
pqqp
P simetricǎ şi
canalele binare cu anulare (sau cu ştergere) care au matricea de forma
pqqp
P0
0 şi care produc la ieşire un simbol în plus asociat unei
imposibilităţi de a decide dacǎ s-a transmis un simbol sau altul din cele aplicate la intrare.
Între probabilitǎtile asociate simbolurilor de la intrare şi cele asociate simbolurilor de la iesire existǎ relatia
r
iiijj aabb
1)Pr()/Pr()Pr(
oricare ar fi indicele j (formula probabilităţii totale). Aşadar, cunoaşterea sursei de la intrare şi a canalului face cunoscutǎ sursa observatǎ la iesire. Calculul inversat, al probabilitǎtilor la intrare din cele de la ieşirea canalului este în general imposibil. Aplicarea la intrarea canalului de simboluri din alfabetul A asociate cu alte probabilitǎti sǎ producǎ la iesire simboluri cu aceleaşi probabilitǎti. Dacǎ însǎ este datǎ o listǎ de probabilitǎti pentru simbolurile din A atunci probabilitǎtile pentru simbolurile din B sunt unic determinate. Din formulele pentru probabilitǎti conditionate rezultǎ relatia
)Pr(),Pr(
)Pr()Pr()/Pr(
)/Pr(j
ji
j
iijji b
bab
aabba
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

37
care exprimǎ probabilitatea de a se fi generat simbolul ai dacǎ s-a receptionat simbolul bj. Entropii a priori, entropii a posteriori. Probabilitǎtile Pr(ai) se numesc probabilitǎti a priori ale simbolurilor la intrarea canalului. Probabilitǎtile )/Pr( ji ba se numesc probabilitǎti a posteriori ale simbolurilor respective. Pe baza celor douǎ secvenţe de numere se pot evalua entropia a priori a sursei de la intrare
A a
aAH)Pr(
1log)Pr()(
şi entropia a posteriori
A j
jj bababAH
)/Pr(1log)/Pr()/(
a aceleiaşi surse, la observarea la ieşire a simbolului bj. Exemplu: Pentru un canal binar cu Pr(a = 0) = 3/4, Pr(a = 1) = 1/4 şi cu matricea
109
101
31
32
P
entropia a priori este H(A) = 0,811 şi entropiile a posteriori sunt H(A/b = 0) = 0,2762 şi H(A/b = 1) = 0,9980. Aşadar, în acest exemplu, la apariţia la ieşire a simbolului 0 incertitudinea asupra valorii simbolului aplicat la intrare scade, iar la apariţia simbolului 1 la ieşire incertitudinea asupra simbolului transmis creşte. Informaţia mutualǎ (transinformaţia) Cu entropia a priori şi cu entropia a posteriori relative la alfabetul de intrare se poate calcula asa-numita echivocatie a intrǎrii la iesire
B BA ba
babAHbBAH)/Pr(
1log),Pr()/()Pr()/(
Exprimat altfel, H(A) este informatia sau incertitudinea medie la intrare înainte de a observa iesirea canalului, iar H(A/B) este informatia sau incertitudinea medie la intrarea canalului dupǎ observarea ieşirii. Diferenţa H(A) – H(A/B) este o măsură a lucrării canalului care constă în a transmite informatia generatǎ de sursă şi aplicată la intrarea lui. Diferenţa este numitǎ informatie mutualǎ sau transinformatie şi se noteazǎ
I(A;B) = H(A) – H(A/B) Valoarea I(A;B) reprezintǎ informatia furnizatǎ de canal asupra sursei A de la intrare. Este de aşteptat ca într-un canal fǎrǎ zgomote I(A;B) = H(A). Dacǎ
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

38
zgomotele sunt prezente, atunci H(A) se reduce cu incertitudinea H(A/B). Dacǎ nivelul de zgomot este foarte mare, atunci H(A/B) se apropie de H(A) şi I(A;B) se apropie de zero. Asadar, H(A/B) se poate considera un indicator al nivelului de zgomot din canal. Expresii alternative pentru informatia mutualǎ:
BAA ba
baa
aBAI)/Pr(
1log),Pr()Pr(
1log)Pr();(
BABA ba
baa
baBAI)/Pr(
1log),Pr()Pr(
1log),Pr();(
BA a
babaBAI)Pr(
)/Pr(log),Pr();(
BA bPa
babaBAI)()Pr(
),Pr(log),Pr();(
În exemplul prezentat mai devreme, sursa producea entropia a priori H(A) = 0,811 şi entropiile a posteriori evaluate după cunoaşterea ieşirii erau H(A/b = 0) = 0,2762, H(A/b = 1) = 0,9980. În acel exemplu informatiile mutuale relativ la sursa A sunt în particular o datǎ pozitivǎ, altǎ datǎ negativǎ. Ce se poate spune despre semnul informatiei mutuale medii I(A;B)? Se poate afirma şi se poate demonstra conform celor prezentate în capitolul anterior cǎ 0);( BAI , cu egalitate în cazul Pr(a, b) = Pr(a)Pr(b) pentru toate perechile (a, b), adicǎ atunci când sursele observate la intrare şi la ieşire sunt independente. Una din formele expresiei pentru transinformatie, ultima în lista de mai sus evidenţiazǎ simetria ei, adicǎ
I(A;B) = I(B;A) Aşadar informatia pe care canalul o oferǎ asupra intrǎrii A prin observarea ieşirii B este aceiaşi cu informatia pe care o avem asupra lui B atunci când se transmite din B către A. Din formulele simetrice de mai sus se deduce
I(A;B) = I(B;A) = H(B) – H(B/A) în care
B b
bBH)Pr(
1log)Pr()(
şi
BA ab
baABH)/Pr(
1log),Pr()/(
Ultima expresie este o echivocaţie a lui B condiţionatǎ de A sau o eroare medie de transmitere. O figurǎ sugestivǎ pentru relatia între numerele caracteristice ale unui canal este prezentatǎ alǎturat. Figura ca şi calculul direct aratǎ cǎ
)/()()/()();()()(),( BAHBHABHAHBAIBHAHBAH O exprimare în cuvinte a acestei egalităţi multiple: incertitudinea totalǎ în A şi B este suma incertitudinilor din A şi din B minus informatia transferatǎ prin canal sau este suma incertitudinii în A cu incertitudinea în B dupǎ ce este dat A.
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

39
Tipuri speciale de canale Canale lipsite de zgomot sunt acele canale pentru care simbolurile de la intrare se aplicǎ pe submulţimi disjuncte ale alfabetului de iesire. În acest caz, totdeauna, oricare ar fi simbolul produs la iesire, simbolul de la intrare este identificat fǎrǎ echivoc. Un exemplu este dat de canalul caracterizat de matricea
100000030/1930/110000004/14/12/1
P
Matricea are particularitatea cǎ pe fiecare coloanǎ are un singur element nenul. În cazul exemplificat, multimea B, de elemente b care poartǎ indici de la 1 la 6 se partitioneazǎ în }{},,{},,,{ 654321 bbbbbb , astfel încât posibilitatea de confuzie asupra identitǎtii simbolului transmis, a1, a2 sau a3 este exclusǎ. Odatǎ cunoscut simbolul produs la ieşire, una din probabilitǎtile condiţionate devine o mǎsurǎ a certitudinii, 1)/Pr( jk ba , iar celelalalte se anuleazǎ: kiba ji ,0)/Pr( . Echivocaţia calculatǎ este nulǎ, ceea ce este de aşteptat deoarece în canal nu sunt prezente zgomote. Asadar, H(A/B) = 0 şi I(A;B) = H(A) deoarece nu existǎ nici o incertitudine asupra intrǎrii când este observatǎ iesirea şi informatia produsǎ de canal la ieşire este aceeaşi cu cea aplicatǎ la intrarea canalului. Canalele deterministe sunt acelea pentru care simbolurile de la intrare care produc la iesire acelaşi simbol se grupeazǎ în submultimi disjuncte. Se întelege cǎ un asemenea canal poate avea în multimea A mai multe simboluri decât în multimea B, întocmai cum un canal fǎrǎ zgomote poate avea un alfabet de iesire B cu mai multe elemente decât alfabetul de intrare A. La un canal determinist, odatǎ cunoscut simbolul de la intrare se poate spune exact care va fi simbolul de la iesire. Un exemplu este canalul caracterizat de matricea
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

40
T
P
110000001110000001
care are particularitatea cǎ pe fiecare linie are un singur element nenul şi acela egal cu 1. Pe matrice se poate citi cǎ odatǎ cunoscut simbolul la intrare, asupra simbolului de la iesire nu mai existǎ nici o incertitudine. Echivocatia/eroarea medie este nulǎ, H(B/A) = 0 şi informatia mutualǎ devine I(A;B) = H(B). Canalele în cascadǎ sunt conectate astfel încât, succesiv iesirea unui canal constituie intrarea altui canal. Într-un lanţ de numai douǎ canale de pildǎ, se utilizeazǎ trei multimi alfabetice, A, B şi C cu r, s, respectiv t simboluri, cu B un alfabet intermediar, alfabet de iesire din primul canal şi de intrare în al doilea. Dacǎ se transmite simbolul ai, la iesirea primului canal se poate observa simbolul bj. Acesta este aplicat la intrarea canalului al doilea care produce la iesirea sa simbolul ck. Dacǎ simbolul intermediar bj este cunoscut atunci probabilitatea ca la iesire sǎ aparǎ simbolul ck depinde numai de bj
)/Pr(),/Pr( jkjik bcbac relatie care este o definitie a canalelor în cascadǎ. Într-un parcurs invers are loc
)/Pr(),/Pr( jikji bacba Calculul diferenţei de entropii H(A/C) – H(A/B) conduce la expresiile succesive
CBA
CBACBA
CABA
cabacba
bacba
cacba
baba
cacaBAHCAH
)/Pr()/Pr(log),,Pr(
)/Pr(1log),,Pr(
)/Pr(1log),,Pr(
)/Pr(1log),Pr(
)/Pr(1log),Pr()/()/(
Cu relatia
ACBCBA
cbacbcba ),/Pr(),Pr(),,Pr(
şi cu o relatie expusǎ mai devreme se poate deduce
ACB ca
cbacbacbBAHCAH)/Pr(),/Pr(log),/Pr(),Pr()/()/(
Din inegalitatea binecunoscutǎ xx
11ln pentru )1,0(x rezultǎ
0)/()/( BAHCAH cu egalitate dacǎ şi numai dacǎ din Pr(a/c) = Pr(a/b, c), caz în care rezultǎ Pr(a/c) = Pr(a/b). Detaliile demonstratiei rǎmân în seama cititorului. Relatia ultimǎ se mai poate scrie şi sub forma )/()/( BAHCAH . Deoarece
)/()();( BAHAHBAI şi )/()();( CAHAHCAI rezultǎ de aici un fapt important:
);();( CAIBAI
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

41
cu egalitate dacǎ şi numai dacǎ )/Pr()/Pr( baca . Relatia ultimǎ aratǎ cǎ existǎ o pierdere de informatie pe canalele succesive şi informatia de la iesire nu este niciodatǎ mai mare (este uzual mai micǎ) faţǎ de orice punct intermediar în cascada de canale. Informatia mutualǎ intrare-iesire se calculeazǎ cu relatia
CACA ca
cacaa
cacaCAI)Pr()Pr(
),Pr(log),Pr()Pr()/Pr(log),Pr();(
Dacǎ tronsonul al doilea este lipsit de zgomote, atunci I(A;C) = I(A;B) (Se propune ca exercitiu dovedirea acestei afirmaţii). Cu toate acestea, conditia Pr(a/c) = Pr(a/b) nu obligǎ la lipsa zgomotelor în tronsonul secund al cascadei de canale. Un exemplu ilustreazǎ aceasta. Fie canalele descrise de matricile
3/23/103/13/20
001,
2/12/103/13/13/1
III PP
Canalul secund nu este lipsit de zgomote şi totuşi I(A;C) = I(A;B). Calculul verificǎ afirmatia.
IIII PPPP
2/12/103/13/13/1
Problema aditivitǎtii informaţiei mutuale are sens dacǎ intereseazǎ informatia medie datǎ de o secventǎ de simboluri de iesire despre o secventǎ de simboluri de intrare. Cazul apare când un acelaşi simbol de intrare este repetat de mai multe ori şi transmis printr-un canal cu zgomote sau când un simbol de intrare este receptionat la iesire ca o secvenţǎ de simboluri de iesire. Ideea generalǎ este cǎ informatia asupra unui simbol transmis este în câştig prin efectuarea mai multor observatii. De pildǎ, pentru fiecare simbol transmis se pot receptiona douǎ simboluri la iesirea canalului (v.figura).
Alfabetul de intrare are r simboluri, mulţimile alfabetice de iesire au s, respectiv t simboluri. Ordinea în care sosesc şi sunt citite simbolurile la ieşirea canalului se presupune a fi bj, ck. Pentru intrarea A, probabilitǎtile a priori ale simbolurilor sunt Pr(ai), probabilitǎtile a posteriori sunt Pr(ai/bj), probabilitǎtile “mai” a posteriori sunt Pr(ai/bj, ck). Conform formulelor deja cunoscute, se pot scrie entropiile a priori H(A) şi a posteriori H(A/bj) şi, mai departe, entropia “mai” a posteriori
A kj
kjkj cbacbacbAH
),/Pr(1log),/Pr(),/(
Prin medierea pe B a entropiei a posteriori se obţine
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

42
B
bAHbBAH )/()Pr()/(
Prin medierea pe B×C a entropiei “mai” a posteriori se obţine
CB
cbAHcbCBAH ),/(),Pr()/(
Este cunoscut cǎ I(A;B) = H(A) – H(A/B). Analog, I(A;B×C) = H(A) – H(A/B×C). Acestea sunt expresii ale informatiei mutuale pentru canalul AB şi pentru canalul A(B×C). Diferenţa lor este suplimentul de informatie asupra lui A obţinut prin utilizarea cvasiconcomitentǎ a canalelor AB şi AC cu lectura ieşirii C întrucâtva întârziatǎ fatǎ de B. Mai concret
);();()/()/()/;( BAICBAICBAHBAHBCAI cu sensul unei informatii mutuale de la A la C în condiţiile cunoaşterii lui B. Relaţia ultimǎ rescrisǎ sub forma
);()/;();( CBAIBCAIBAI exprimǎ aditivitatea adusă în discuţie mai devreme. În cuvinte, informatia furnizatǎ de canalul AB plus informatia furnizatǎ (condiţionat) de canalul AC reprezintǎ informatia totalǎ pe care o furnizeazǎ canalelele AB şi AC reunite. Mai rezultǎ faptul cǎ pentru canalele aditive AB şi AC are loc inegalitatea
);();( BAICBAI , cu egalitate dacǎ şi numai dacǎ entropiile H(A/B) şi H(A/B×C) sunt egale. Aşadar informatia asupra lui A este de regulǎ mai bogatǎ dacǎ se folosesc ambele canale AB şi AC decât dacǎ se foloseste numai unul din ele. Ca exerciţiu, cititorul poate aprofunda cazul egalitǎtii informatiilor mutuale din relatia de mai sus cu aprecieri mai detaliate asupra canalului AC. Între mai multe posibilitǎti de a calcula transinformatia suplimentarǎ existǎ şi fornula
CBACBA cba
cbacbaa
cbacbaCBAI),Pr()Pr(
),,Pr(log),,Pr()Pr(
),/Pr(log),,Pr();(
Pentru o altǎ relatie utilǎ, se defineste entropia
CBA acb
cbaACBH)/,Pr(
1log),,Pr()/(
şi cu I(A;B×C) = I(B×C) – I(B×C/A)
analoga relatiei I(A;B) = I(B;A) = H(B) – H(B/A) datǎ mai devreme, se scrie )/;();();( CBAICAICBAI
ceea ce este reluarea unei relatii de mai sus, cu ordinea simbolurilor la iesire inversatǎ: ck , bj în loc de bj , ck, ordine care apare ca irelevantǎ în calculul informaţiei mutuale pe combinatia de canale AB, AC. Fie acum ca exemplu un canal binar simetric prin care fiecare simbol ai se transmite prin canal de douǎ ori. Se recepţioneazǎ bj mai întâi şi ck mai apoi. Deoarece se utilizeazǎ acelaşi canal, matricile
pqqp
PP ACAB
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

43
sunt egale. Simbolurile de la intrare sunt considerate echiprobabile. Se pune intrebarea: dublarea transmiterii este de naturǎ sǎ aducǎ mai multǎ informaţie la iesire? Se calculeazǎ pentru aceasta I(A;B) şi I(A;B×C).
ppBAI 1log1log1);(
Acum, pentru calculul informatiei mutuale I(A;B×C) se completeazǎ tabelul care urmeazǎ.
a b c Pr(a,b,c) Pr(b,c) Tip
0 0 0 2
21 p X
1 0 0 2
21 q
)(21 22 qp
Y
0 0 1 pq21 Z
1 0 1 pq21
pq Z
0 1 0 pq21 Z
1 1 0 pq21
pq Z
0 1 1 2
21 q Y
1 1 1 2
21 p
)(21 22 qp
X
Prin înlocuire în formula
CBA cba
cbacbaCBAI),Pr()Pr(
),,Pr(log),,Pr();(
se obtine (se recomandǎ verificarea ca exercitiu)
22
22
22
22 2log2log);(
qpqq
qpppCBAI
Graficul alǎturat aratǎ în culori diferite variaţia în functie de eroarea q a celor douǎ informatii mutuale, I(A;B) şi I(A;B×C). Se observǎ trei puncte în care are loc egalitatea: punctele extreme, când transmiterea se face fǎrǎ erori (chiar dacǎ la q = 1 are loc o inversare a biţilor) şi punctul central, q = 0,5, când nu existǎ nici o diferenţǎ între transmiterea corectǎ sau eronatǎ, inversată a simbolurilor sursei A.
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

44
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 10
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
Probabilitatea inversarii bitilor
Info
rmat
ia m
utua
la m
axim
a
I(A;B)I(A;BxC)
Capacitatea canalelor Capacitatea unui canal este o noţiune de mare importanţǎ practicǎ şi se leagǎ de faptul cǎ informatia mutuală
BA ba
babaBAI)Pr()Pr(
),Pr(log),Pr();(
depinde nu numai de canal, de probabilitǎtile condiţionate care-l definesc, ci şi de probabilitǎtile simbolurilor de la intrare.
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 10
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
Probabilitatea primului simbol al sursei
Tran
sinf
orm
atia
Eroare 1%Eroare 10%
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

45
O sugestie asupra modului în care variazǎ informatia mutualǎ (sau trans-informatia) cu probabilitǎţile simbolurilor aplicate la intrare, în cazul simplu al canalelor binare simetrice produce graficul alǎturat, trasat pentru douǎ niveluri diferite ale erorilor introduse de canal. Se observǎ cǎ informatia mutualǎ are de fiecare datǎ un maxim pentru cazul în care simbolurile aplicate la intrarea canalului sunt echiprobabile. Acest extrem are valoarea (a se calcula ca exercitiu)
ppBAI 1log1log1);( max
Pentru o sursǎ A mai generalǎ, asimetricǎ şi/sau cu mai multe simboluri, stabilirea maximului transinformatiei nu este o operatie uşoarǎ. Dar de fiecare datǎ când un simbol al sursei de intrare are aparitie certǎ, Pr(ai) = 1 şi celelalte sunt excluse, informatia mutualǎ este nulǎ. Valoarea maximǎ a informatiei mutuale aratǎ limita de sus a performanţei canalului în transmiterea informatiei generate de sursa de la intrare. Se poate defini acum capacitatea canalului: maximum de transinformaţie pe multimea de surse care pot fi conectate la intrarea canalului
C = maxP(a)I(A;B) = maxP(a)[H(A) – H(A/B)] Aşadar, capacitatea unui canal este deteminatǎ exclusiv de matricea canalului, notatǎ mai devreme cu P. În cazul canalelor binare simetrice cu nivelul erorilor q = 0,1 şi q = 0,01 reprezentate în graficul de mai devreme, capacitatea variazǎ în raport cu nivelul zgomotului: la nivel scǎzut (q = 0,01) capacitate mai mare, la nivel mai mare (q = 0,1) capacitate mai redusǎ. Lipsa totalǎ a zgomotelor aduce certitudinea în transmitere şi face capacitatea canalului maximalǎ. Incertitudinea totalǎ de la p = q = 0,5 aduce anularea capacitǎtii de transmitere a canalului. Cum s-a mai spus, calculul capacitǎtii unui canal este oarecum delicat: este vorba de stabilirea unui extrem în condiţiile satisfacerii unor restricţii. Un caz mai simplu şi interesant sub aspect practic îl reprezintǎ canalele uniforme. Un canal este calificat ca uniform dacǎ matricea P ataşatǎ are particularitatea cǎ elementele ei sunt de aşa naturǎ încât fiecare linie şi fiecare coloanǎ este o permutare distinctǎ a elementelor de pe prima linie. Rezultǎ imediat cǎ alfabetul de iesire are acelaşi numǎr de simboluri ca şi alfabetul de la intrare. Un canal binar simetric este uniform, un canal binar cu anulare nu este uniform. Canalele cu matricile de probabilitǎti conditionate
7.03.03.07.0
,3.05.02.02.03.05.05.02.03.0
sunt uniforme, dar canalele
2.03.05.03.02.05.05.03.02.0
,2.07.01.01.02.07.0
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

46
nu sunt uniforme. Pentru un canal uniform oarecare calculul porneşte de la relatia
B i
iA
i ababaBHABHBHBAI
)/Pr(1log)/Pr()Pr()()/()();(
Suma a doua este suma unei linii din matricea P şi este mereu aceeaşi oricare ar fi linia i luatǎ în considerare. Cum 1)Pr(
Aia rezultǎ
B i
i ababBHBAI
)/Pr(1log)/Pr()();(
cu termenul al doilea constant, independent de probabilitǎtile P(ai). În aceste conditii speciale
B iiaPaP ab
abBHBAICii )/Pr(
1log)/Pr()(max);(max )()(
şi problema se reduce la a stabili un maxim pentru entropia H(B) pe mulţimea de valori a probabilitǎtilor Pr(ai). Se ştie în general cǎ entropia unei surse, fie ea cea observată la iesire, este maximǎ dacǎ simbolurile ei sunt echiprobabile. Nu existǎ vreo garanţie cǎ sursa de la intrare ar putea produce simboluri cu probabilitǎti Pr(ai) care sǎ facǎ simbolurile de la iesirea canalului echiprobabile. Pentru un canal uniform, faptul cǎ liniile matricei P sunt permutǎri distincte ale uneia dintre ele face ca sumele elementelor pe coloane sǎ fie totdeauna egale cu unitatea şi din simboluri echiprobabile la intrare se obtin simboluri echiprobabile şi în acelaşi numǎr la iesire. Entropiile maxime sunt
)(loglog)( BHsrAH , capacitatea canalului este
B
iiB i
i ababrab
abrC )/Pr(log)/Pr(log)/Pr(
1log)/Pr(log
şi se atinge atunci când simbolurile la intrare au toate aceeaşi probabilitate, Pr(a) = 1/r. Mai devreme s-au dat ca exemplu canale care sunt uniforme. Un calcul (propus ca exercitiu) pentru canalul uniform alimentat de o sursǎ cu trei simboluri produce C = 0,0995, capacitate atinsǎ la probabilitǎti egale pentru simbolurile de la intrare, 1/3, 1/3, 1/3. Pentru un canal oarecare extremul este de tipul cu restricţii şi se stabileste prin metoda multiplicatorilor Lagrange sau prin altǎ metodǎ specificǎ. Restricţiile constau în conditia ca numerele Pr(ai) sǎ fie nenegative şi subunitare şi suma lor sǎ fie egalǎ cu unitatea. Modelul de canal AWGN (Additive White Gaussian Noise) Perturbatiile care afectează canalele de transmitere a informatiei se manifestă şi lucrează asupra informatiei vehiculate în forme variate. De aceea, cuprinderea lor într-o descriere cantitativă unică, utilizabilă în orice împrejurare practică este o iluzie. În consecinţă, în operatiile de analiză şi de proiectare a sistemelor
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

47
de comunicatie, se recurge la modele particulare, dacă acestea există, potrivite cu una sau alta dintre aplicatii. Un model utilizat frecvent de specialiştii în domeniu este cel al unui canal în care semnalul transmis este deformat, modificat, corupt în principal de un zgomot alb gaussian care se suprapune aditiv peste semnalul util (modelul AWGN – Additive White Gaussian Noise – zgomot alb gaussian aditiv). Modelul AWGN este o distributie de tensiuni care poate fi descrisă în orice moment printr-o lege statistică normală (sau gaussiană). Distributia aceasta are media nulă şi o deviatie standard care intervine în aşa-numitul raport semnal-zgomot (SNR – Signal-to-Noise-Ratio) un parametru important caracteristic unei transmisii. Pentru ilustrare, fie un semnal al cărui nivel este fixat. Dacă raportul semnal-zgomot este mare atunci deviatia standard este mică, iar dacă dimpotrivă raportul semnal-zgomot este mic atunci deviatia standard este comparativ mai mare. În comunicatiile digitale raportul semnal-zgomot se exprimă ca Eb/N0, un raport între energia pe bit şi densitatea energetică a zgomotului. Un exemplu: Fie un sistem în care bitul “1” al canalului este transmis ca o tensiune de –1 volt şi bitul “0” ca o tensiune de +1 volt. Acesta este un sistem bipolar fără revenire la zero (NRZ – Non-Return-to-Zero). Se mai numeste şi sistem binar “antipodal” deoarece cele două stări sunt opuse una alteia. Receptorul contine un comparator care decide că bitul receptionat este “1” dacă tensiunea este sub 0 volti şi “0” dacă tensiunea este egală cu sau mai mare de 0 volti. Ar fi de dorit ca iesirea comparatorului să fie eşantionată/măsurată în mijlocul fiecărui interval de timp dedicat unui bit. Să vedem cum functionează acest sistem, întâi când raportul semnal/zgomot este mare, apoi când acelaşi raport este redus.
-4 -3 -2 -1 0 1 2 3 40
0.5
1
1.5
2
2.5
3
3.5
4DISTRIBUTIA TENSIUNILOR LA S/Z = 20 dB
volti
Den
sita
tea
de p
roba
bilit
ate
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

48
Figura alăturată arată densitatea de repartitie a tensiunilor la intrarea în receptor, sumă a tensiunilor semnalului şi zgomotului, la un nivel al raportului semnal-zgomot Eb/N0 de 20 dB, adică atunci când tensiunea semnalului este de 10 ori mai mare decât tensiunea medie pătratică (deviatia standard) a zgomotului. Se observă două distributii identice ca formă, bine separate, una centrată pe tensiunea de –1 volt, cealaltă centrată pe tensiunea de +1 volt. Receptorul simplu din exemplul în discutie, aproape sistematic detectează bitul 1 dacă tensiunea este negativă şi detectează bitul 0 dacă tensiunea este nulă sau pozitivă. Receptorul nu are dificultăti prea mari în a primi şi a interpreta corect un semnal precum cel din figură. Vor apărea, dacă vor apărea, foarte putine erori la receptie. Într-o simulare a unei transmisii constând în 1.000.000 de biti, cu raportul semnal-zgomot Eb/N0 de 20 dB, un 0 transmis n-a fost niciodată receptionat ca 1 şi nici vreun 1 transmis n-a fost receptionat ca 0. Deocamdată lucrurile merg practic fără cusur. Figura următoare arată alte distributii ale tensiunilor receptionate tot printr-un canal AWGN dar la un raport semnal-zgomot Eb/N0 scăzut la 6 dB, adică atunci când tensiunea semnalului este numai dublul tensiunii medii pătratice a zgomotului.
-4 -3 -2 -1 0 1 2 3 40
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8DISTRIBUTIA TENSIUNILOR LA S/Z = 6 dB
volti
Den
sita
tea
de p
roba
bilit
ate
Se observă acum că cele două distributii centrate pe –1 volt şi pe +1 volt nu mai sunt atât de net separate: partea din dreapta extremă a curbei centrate pe –1 volt trece peste 0, iar partea stângă a curbei centrate pe +1 volt trece la rându-i sub 0. Erorile de interpretare/detectie sunt acum greu de evitat: mai multe unităti binare pot fi interpretate ca zero binar, mai multe zerouri binare pot fi interpretate ca unităti. Într-o simulare a unei transmisii întinsă tot pe 1.000.000 biti, 0 a fost receptionat ca 1, la fel 1 a fost interpretat ca 0 de un număr apreciabil de ori. Apare o rată a erorilor care nu mai poate fi ignorată (Se propune ca exercitiu stabilirea proportiei de erori în transmisia simulată).
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

49
Ceea ce se întâmplă de data aceasta nu este tocmai în regulă, mai ales când se efectuează o transmisie de date în care precizia este de mare importanţă. O problemǎ specialǎ privind canalele Inginerii de telecomunicatii au de rezolvat uneori problema urmǎtoare: Fie un canal cu banda de trecere W Hz. Canalul este afectat de perturbaţii. Ce debit de informaţie se poate transmite prin acel canal la un raport semnal/zgomot cunoscut? Dacǎ sursa cu alfabetul A are entropia H(A) atunci ea genereazǎ în medie H(A) biţi per simbol. Dacǎ prin canal se transmite 1 simbol/secundǎ atunci prin canal se transmit în medie H(A) biţi/secundǎ. Zgomotul din canal reduce aceastǎ vitezǎ cu echivocatia H(A/B). Aşadar canalul nu poate produce la iesire o ratǎ, un debit de informaţie mai mare decât R = I(A;B) = H(A) – H(A/B) biţi/secundǎ. Capacitatea canalului este valoarea maximǎ a transinformatiei I(A;B) şi ea poate fi numeric egalǎ cu viteza maximǎ cu care se pot alimenta simboluri la intrarea canalului de transmisie. Urmeazǎ acum dezvoltarea unei expresii specifice pentru capacitatea canalului. O teoremǎ a eşantionǎrii spune cǎ dacǎ un semnal este eşantionat de N ori pe secundǎ atunci semnalul respectiv este limitat ca spectru de frecvente la N/2 Hz. Sau, pentru un semnal de bandǎ limitatǎ de mediul de transmisie la W Hz, numǎrul de eşantioane pe secundǎ trebuie să depǎşeascǎ Nmin = 2W pentru a putea fi reconstituit din eşantioanele sale. Fie acum P puterea semnalului şi = N0W puterea zgomotului în canal, cu N0 densitatea spectralǎ de putere a zgomotului presupusǎ constantǎ în banda de frecvenţe a semnalului transmis (zgomot alb). Rǎdǎcina pǎtratǎ a unei puteri are dimensiunea unei tensiuni (curent) dacǎ sarcina este rezistivǎ de 1 ohm. Se admite cǎ transmiterea informatiei se face în trepte de tensiune care nu pot fi mai mici decât tensiunea eficace a zgomotului. Numǎrul de trepte se calculeazǎ prin raportarea a douǎ tensiuni (curenţi)
22
2
1
PPS
urmată de o rotunjire la un număr întreg apropiat. Cu S niveluri ale semnalului (altfel spus cu un alfabet cu S simboluri) entropia maximǎ se obţine atunci când nivelurile au aceeaşi probabilitate
2
11log
21loglog1
PSS
S
S
i
Dacǎ se preiau Nmin = 2W eşantioane pe secundǎ şi fiecare eşantion poartǎ logS biţi de informaţie, atunci viteza maximǎ de transmitere este Rmax = 2WlogS biţi pe secundǎ şi din
2max 1log
212log2
PWSWCR
rezultǎ
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

50
21log
PWC
expresia unei teoreme (Shannon-Hartley) asupra capacitǎtii unui canal definitǎ din unghiul de vedere al inginerului de telecomunicatii, în functie de raportul semnal/zgomot, P/2 şi de banda de frecvenţe a semnalului. Logaritmii sunt în baza 2 şi rezultatul este în biţi/secundǎ. Un exemplu: Care este nivelul minim al raportului semnal/zgomot al unui canal telefonic dacǎ el trebuie sǎ serveascǎ un modem de 56 kbps (kilobiţi pe secundǎ)? Viteza de 56 kbps necesitǎ o capacitate a canalului de cel puţin C = 56000 biti/secundǎ (bps). Lǎrgimea benzii unui canal telefonic W este de cca. 3,6 kHz. Ecuaţia
21log360056000
P
are solutia P/2 48160. Uzual, raportul semnal/zgomot se exprimǎ în dB (decibelli) (P/2)dB = 10 lg(P/2), cu logaritmul în baza 10. Rezultatul problemei este P/2 = 46,8 dB. Un exercitiu propus: care este limita capacitǎtii unui canal când W → ∞? O indicaţie: trebuie avut în vedere cǎ = N0W, cu N0 densitatea spectralǎ de putere a zgomotului presupusǎ constantǎ pe întreg spectrul de frecvenţe. Canale de tip continuu Pentru sursele şi canalele continue, informatia mutualǎ (transinformatia) are expresia
dxdyxf
yxfyxfdxdyyfxf
yxfyxfYXI)(
)/(log),()()(
),(log),();(
Transinformatia este totdeauna finitǎ şi nenegativǎ. Are aceleaşi proprietǎti ca şi în cazul discret.
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

51
CODURI PENTRU CANALE FĂRĂ ZGOMOT Generalitǎti despre coduri Pentru dezvoltarea subiectului care urmeazǎ este necesarǎ mai întâi precizarea câtorva aspecte de terminologie. Se va vorbi în continuare de multimi de litere, sau de simboluri, sau de caractere, multimi care poartǎ numele generic de alfabet. Cu elementele unui alfabet se pot forma cuvinte sau mesaje care sunt secvenţe finite de litere/simboluri/caractere din acel alfabet. Cuvintele au o lungime reprezentatǎ de numǎrul de litere/simboluri/caractere din cuvânt. Fie mulţimea de simboluri S = {s1, s2, …, sq} alfabetul unei surse de informatie. Fie mulţimea de simboluri X = {x1, x2, …, xr} un alt alfabet numit mai departe alfabetul codului. O aplicatie a simbolurilor si din S pe mulţimea cuvintelor alcǎtuite cu caractere din X
niiiii xxxXs ...21
face o operatie de codare. Operaţia inversă, de revenire de la cuvintele Xi la simbolurile si face o decodare. Secvenţele de lungime n alcătuite din simboluri din S sunt considerate a fi generate de o sursă care poartă numele de extensia a n-a a sursei S, notată frecvent şi cu Sn. O aplicatie a secvenţelor bloc din Sn, secvenţe de lungime n, pe secvenţele corespunzǎtoare de cuvinte de cod ),...,,(
21 niii XXX se numeste extensia a n-a a codului. Particularitǎţi ale codurilor Câteva definitii: Cod nesingular: un cod alcǎtuit din cuvinte distincte. Cod bloc: un cod nesingular cu cuvintele având aceeaşi lungime. Un cod este unic decodabil dacǎ şi numai dacǎ extensia n-a a codului este
nesingularǎ pentru orice n finit (aceasta este o definitie corectǎ şi completǎ). Un cod este unic decodabil dacǎ nu existǎ împrejurǎri de neunicitate (de
ambiguitate) la decodare pentru nici unul din cuvintele de cod posibile (aceasta este o definitie operationalǎ).
De notat cǎ toate codurile de utilitate practicǎ trebuie sǎ fie unic decodabile. Rezultǎ din definitiile de mai sus cǎ un cod bloc de lungime n care este nesingular este şi unic decodabil.
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

52
De ce este necesarǎ codarea? Codarea este necesarǎ pentru a trece de la reprezentarea prin alfabetul sursei la reprezentarea prin alfabetul canalului de transmisie sau al spatiului de memorare. Un exemplu îl constituie reprezentarea textelor în limba englezǎ în binar prin codarea ASCII (a se citi "aschii"). Prin codare se poate exploata redundanţa surselor (diferenta faţă de entropia maximǎ), pentru o reprezentare mai eficientǎ în cod (la entropie înaltǎ). Un exemplu în acest sens este compresia de date fǎrǎ pierdere de informatie. În continuare se va uza din plin de codarea binarǎ, X = {0, 1}, deoarece acesta este alfabetul de memorare şi de transmitere în comunicatiile numerice şi în sistemele de calcul. Vor fi utilizate uneori şi coduri ternare, cu X = {0, 1, 2}, deoarece, chiar dacă mai rar şi acestea servesc ca bază a unor tehnici de codare în transmiterea semnalelor. Scopul major al codǎrii surselor de informatie este gǎsirea unor strategii de reprezentare care prin intermediul codurilor unic decodabile sǎ facǎ transmiterea si/sau stocarea posibilă şi eficientǎ.
În tabelul urmǎtor sunt prezentate trei exemple de codare în cazul simplu al unei surse cu alfabetul S = {s1, s2, …, sq}, q = 4 şi cu alfabetul codului binar, X = {0, 1}.
Simboluri ale sursei Codul A Codul B Codul C
1s 0 0 00
2s 11 11 01
3s 00 00 10
4s 11 010 11
Se observǎ imediat cǎ primul cod, A nu este nesingular deoarece X2 = X4 = 11. Codul B este nesingular deoarece cuvintele de cod sunt distincte, dar nu este unic decodabil deoarece secvenţa 00 poate fi decodatǎ fie ca s3, fie ca s1s1, asadar decodarea nu este unicǎ. Codul C este un cod bloc nesingular de lungime 2 şi este unic decodabil. Este de observat cǎ nu este uşor a califica un cod ca fiind sau nu unic decodabil, cu exceptia poate a unor cazuri speciale cum este cel al codurilor bloc. Un cod nu este unic decodabil dacǎ existǎ fie şi numai un caz de decodare neunicǎ. Despre un cod unic decodabil se spune cǎ este instantaneu dacǎ orice cuvânt dintr-o secventǎ se poate decoda fǎrǎ referire la simboluri care aparţin altor cuvinte succesive ale codului. Pentru a obtine o decodare corectǎ, un cod care este unic decodabil dar nu este instantaneu cere ca un numǎr de cuvinte de cod anterioare şi/sau ulterioare, precum şi cuvântul curent sǎ fie memorate temporar la receptie. O codare care se face cu un cod instantaneu permite receptorului sǎ
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

53
decodeze cuvintele de cod la simbolul codat transmis, imediat şi corect, de îndată ce cuvântul codului a fost integral recepţionat. Se vorbeşte de o decodare “din mers”. Exemplul care urmeazǎ ia în considerare aceeaşi sursǎ din exemplul anterior şi din nou codul cu alfabetul binar X = {0, 1}. Se considerǎ trei coduri distincte, A, B şi C ca în tabelul alǎturat.
Simboluri ale sursei Codul A Codul B Codul C
1s 0 0 00
2s 10 01 01
3s 110 011 011
4s 1110 0111 111 Cele trei coduri sunt unic decodabile deoarece în nici o împrejurare nu existǎ decodǎri neunice, dar numai codul A este instantaneu. De ce? Fie secvenţa
21121342101000100101110110 sssssssss În momentul când apare simbolul terminal “0” receptorul poate imediat sǎ facǎ decodarea. Simbolul “0” are aici rol de separator şi decodarea este instantanee (şi codul este unic decodabil). Fie acum secventa
1142300110101110 sssss codatǎ cu codul B. Şi acum simbolul “0” are rol de separator, dar pentru o decodare corectǎ a cuvântului curent este necesarǎ citirea primului caracter din cuvântul urmǎtor. De exemplu cuvântul 011 nu poate fi interpretat ca s3 decât dupǎ ce avem confirmarea prin lecturǎ cǎ urmǎtorul caracter este primul (“0”) din cuvântul urmǎtor. Dacǎ urmǎtorul simbol este 1 atunci decodarea corectǎ este 40111 s . Deşi codul B este unic decodabil, separatorul “0” garanteazǎ această calitate, dar el nu este un cod instantaneu. În cazul codului C argumentarea este încǎ mai convingǎtoare. Pentru aceasta se ia secventa 01111111. Receptorul este incapabil sǎ decodeze pânǎ nu primeste un simbol “0” sau un marcaj de final de transmisie. Este clar cǎ acest cod nu este instantaneu şi receptorul trebuie sǎ fie în partea de decodare complicat pe mǎsurǎ. Codul este totuşi unic decodabil, simbolul “0” joacǎ şi aici rol de separator. Conditia de prefix. Fie
niiii xxxX ...21
un cuvânt de cod de lungime n. Secvenţa de simboluri )...(
21 jiii xxx cu j n este numitǎ prefix al cuvântului de cod Xi . Conditia necasarǎ şi suficientǎ ca un cod sǎ fie instantaneu este ca nici un cuvânt al codului sǎ nu fie prefix al vreunui alt cuvânt de cod. Se impune a observa cǎ deoarece un cod instantaneu este unic decodabil conditia de prefix este o conditie suficientǎ (dar nu necesarǎ) pentru ca un cod sǎ fie unic decodabil.
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

54
Dacǎ se reia ultimul exemplu se constatǎ: codul A este instantaneu (conditia de prefix îndeplinitǎ); codul B nu este instantaneu (s1 este prefix pentru s2 etc.); codul C nu este instantaneu (s2 este prefix pentru s3 ). Construirea codurilor instantanee. Fie o sursă capabilă a genera m simboluri. Acestea trebuie codate cu m cuvinte de cod de lungimi l1, l2, …, lm. Se cere un cod instantaneu alcǎtuit din cuvinte de exact aceste lungimi. Prin utilizarea proprietǎtii de prefix se poate construi un cod instantaneu prin reţinerea cuvântului cel mai scurt şi prin dezvoltarea cuvintelor urmǎtoare fǎrǎ a viola condiţia de prefix. Un mod sistematic de a face această dezvoltare este de a numǎra pe alfabetul codului.
De exemplu, se presupune cǎ se cere proiectarea unui cod binar instantaneu cu lungimile 3, 2, 3, 2, 2. În faza primǎ se reordoneazǎ nedescrescǎtor lungimile cuvintelor de cod: 2, 2, 2, 3, 3. Întrucât primele trei cuvinte de cod sunt de aceeaşi lungime, se numǎrǎ simplu 0, 1, 2 în binar, adicǎ 00, 01, 10. Pentru urmǎtoarele cuvinte, de lungime 3, se numǎrǎ pânǎ la 3 pe primele douǎ simboluri şi se numǎrǎ apoi 0, 1 pe al treilea. Concret: 00, 01, 10, 110, 111 şi codul obtinut este instantaneu. Dacǎ se cere proiectarea unui cod ternar instantaneu cu lungimile 2, 3, 1, 1, 2, dupǎ ordonarea lungimilor, 1, 1, 2, 2, 3, se obtine prin numărare codul cerut: 0, 1, 20, 21, 220. Dar ce se întâmplǎ dacǎ se cere proiectarea unui cod binar instantaneu cu lungimile 2, 3, 2, 2, 2? Dupǎ ordonarea nedescrescǎtoare a lungimilor, se obtine 2, 2, 2, 2, 3. În faza de specificare a cuvintelor codului, se obtine succesiv 00, 01, 10, 11 şi ?? – numǎrǎtoarea se încheie înainte de vreme, continuarea nu-i posibilǎ. Problema este imposibil de rezolvat. Decodarea codurilor instantanee. Pentru decodare se foloseste un arbore de decodare ca în figura alǎturatǎ. În arbore s-au notat cu R (Read) citirile de caractere – cu SR (Start Reading) lectura primului caracter din cuvântul de cod – cu rezultatul fiecǎrei citiri, 0 sau 1, pe verticalǎ. Acest arbore reprezintǎ decodarea primului din codurile proiectate mai devreme, codul binar instantaneu cu lungimile cuvintelor de 3, 2, 3, 2, 2. Iatǎ acum motivele pentru care codurile instantanee sunt atât de apreciate. codurile instantanee sunt uşor de verificat prin conditia de prefix codurile instantanee sunt uşor de proiectat
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

55
codurile instantanee sunt uşor şi ieftin de decodat. Dar codurile unic decodabile care nu sunt instantanee ar putea avea alte avantaje. În secţiunea urmǎtoare se va arăta cǎ dacǎ lungimea cuvintelor conteazǎ în primul rând, atunci codurile unic decodabile care nu sunt instantanee nu pot fi mai interesante decât cele instantanee.
Inegalitatea lui Kraft şi teorema lui McMillan Într-unul din exemplele de mai devreme am văzut cǎ fiind date lungimile cuvintelor de cod, gǎsirea unui cod instantaneu nu este totdeauna posibilǎ. Nici mǎcar existenţa unui cod unic decodabil nu este totdeauna certǎ. Se pune întrebarea: existǎ o cale de a spune dinainte dacǎ un set dat de lungimi ale cuvintelor de cod permite sau nu sǎ se proiecteze un cod unic, separabil sau instantaneu? Rǎspunsul este afirmativ: da, prin verificarea inegalitǎtii lui Kraft. O altǎ întrebare este: dacǎ tot ce ne intereseazǎ este un cod unic decodabil cu cuvintele de cod de lungimi date, se pierde ceva dacǎ proiectarea se restrânge la codurile instantanee? Rǎspunsul este nu, nu se pierde nimic şi adevǎrul acesta se verificǎ prin teorema lui McMillan. Inegalitatea lui Kraft va rezulta dintr-un calcul demonstrativ. Fie o sursǎ S = {s1, s2, …, sq} cu q simboluri şi (X1, X2, …, Xm) m = q cuvinte de cod aranjate în ordinea crescǎtoare a lungimilor, l1 ≤ l2 ≤ … ≤ lm. Fiecare cuvânt este alcǎtuit din cele r simboluri din alfabetul codului X = {x1, x2, …, xr}. Demonstraţia urmǎreste proiectarea unui cod instantaneu pe baza lungimilor date, care începe cu X1 şi se încheie cu Xm. Numǎrul de cuvinte de cod X1 posibile, de lungime l1 este 1lr . Numǎrul de cuvinte X1 permise este tot 1lr .
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

56
Numǎrul cuvintelor X2, de lungime l2, cu X1 ca prefix este 12 llr deoarece se pot alege arbitrar l2 – l1 digiti care urmeazǎ prefixului X1. Numǎrul cuvintelor X2 posibile este 2lr . Numǎrul cuvintelor X2 permise este numǎrul cuvintelor posibile din care se scade numǎrul cuvintelor cu prefixul X1, adicǎ 122 lll rr . Analog, numǎrul cuvintelor X3 permise este 13233 lllll rrr şi, în general, numǎrul cuvintelor Xi permise este 121 ... lllllll iiiiii rrrr . Pentru a fi posibilǎ construirea codului instantaneu dorit este necesar ca numǎrul cuvintelor permise sǎ fie cel putin 1, pentru fiecare indice i = 1, 2, …, m, adicǎ
11 lr 1122 lll rr
113233 lllll rrr . . . . . . . . . . . . . . . . . . .
1... 121 lllllll mmmimmm rrrr Prin împǎrtirea inegalitǎtii generice i cu ilr se obtine sirul de inegalitǎti
11 lr 121 ll rr
1231 lll rrr . . . . . . . . . . . . . . . . . . . . . . . . .
121 ...1 llll rrrr mmm Dacǎ inegalitatea ultimǎ este îndeplinitǎ, atunci şi celelalte sunt satisfǎcute, aşa încât este suficient sǎ avem
11
q
i
lirK
şi construirea codului instantaneu este posibilǎ. Inegalitatea ultimǎ este inegalitatea lui Kraft. Satisfacerea acestei inegalitǎti este conditia necesarǎ şi suficientǎ ca un cod cu lungimile cuvintelor l1, l2, …, lq sǎ existe. Sunt de notat câteva fapte: 1. Inegalitatea lui Kraft arată cǎ un cod instantaneu cu lungimile cuvintelor l1,
l2, …, lq existǎ. Aceastǎ inegalitate nu spune care este acel cod şi nici dacǎ un cod care a fost proiectat sǎ îndeplineascǎ inegalitatea este instantaneu.
2. Prin verificarea condiţiei de prefix se poate determina dacǎ un cod care satisface inegalitatea este sau nu instantaneu.
3. Inegalitatea lui Kraft previne cǎutarea unui cod care nu existǎ şi ajutǎ la a aprecia dacǎ strategia adoptatǎ în cǎutarea unui cod poate produce un cod instantaneu.
4. Inegalitatea lui Kraft dǎ lungimile minime ale cuvintelor de cod care pot fi utilizate la proiectarea unui cod instantaneu.
Câteva exemple interesante sunt date în tabelul alǎturat. În legǎturǎ cu codurile din tabel, se pot formula câteva întrebǎri: Codurile binare (r = 2) din tabel sunt instantanee? Dacǎ nu, pot fi ele reproiectate pentru a fi instantanee?
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

57
Dacǎ da, reproiectarea este posibilǎ, cum se realizeazǎ codul în forma instantanee?
Sursa Codul A Codul B Codul C
s1 0 0 0 s2 100 100 10 s3 110 110 110 s4 111 11 11
Codul A. Conditia de prefix este satisfǎcutǎ. Codul este instantaneu. Conform asteptǎrilor
18722222 3331
4
1
1
i
lK
adicǎ inegalitatea lui Kraft este verificatǎ. Codul B. Cuvântul de cod pentru s4 este prefix pentru cuvântul de cod asociat cu s3. Conditia de prefix nu este îndeplinitǎ. Codul nu este instantaneu. Se calculeazǎ
122222 23314
1
1
i
lK
Inegalitatea lui Kraft este satisfǎcutǎ. Codul poate fi reproiectat pentru a deveni instantaneu: 0, 110, 111, 10. Codul C. Cuvântul de cod pentru mesajul s4 este prefix pentru cuvântul de cod asociat mesajului s3. Conditia de prefix nu este îndeplinitǎ. Codul nu este instantaneu. Se calculeazǎ
122222 23214
1
1
i
lK
Inegalitatea lui Kraft nu este satisfǎcutǎ. Asadar, codul nu poate fi reproiectat pentru a fi instantaneu. Teorema lui McMillan sustine în fond cǎ orice cod unic decodabil satisface inegalitatea lui Kraft. Se cuvin a fi fǎcute urmǎtoarele observatii: Teorema lui McMillan sugereazǎ cǎ pentru fiecare cod neinstantaneu unic
decodabil poate fi stabilit un cod instantaneu cu aceleaşi lungimi ale cuvintelor.
Deoarece uzual lungimea cuvintelor de cod este problema centralǎ şi nu codul în sine, cercetarea poate fi limitatǎ în conditii de siguranţǎ la codurile instantanee.
Întrucât codurile instantanee sunt o subclasǎ a codurilor unic decodabile, inegalitatea lui Kraft este o conditie suficientǎ pentru decodabilitate unicǎ. Dar conform teoremei lui McMillan ea este şi necesarǎ.
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

58
Asadar, o reformulare a teoremei lui McMillan este urmǎtoarea: conditia necesarǎ şi suficientǎ de existentǎ a unui cod unic decodabil cu lungimile de cuvânt l1, l2, …, lq este
11
q
i
lirK
cu r numǎrul cardinal, numǎrul de caractere al alfabetului codului. Un exemplu deplin ilustrativ este proiectarea unui cod ternar cu lungimile cuvintelor de cod de 1, 2, 2, 2, 2, 2, 3, 3, 3 simboluri. Mai întâi se testeazǎ teorema lui McMillan
13.33.53 321 K ceea ce aratǎ cǎ proiectarea este posibilǎ. Conform teoremei lui McMillan se poate construi un cod instantaneu care este şi unic decodabil. Acest cod este 0, 10, 11, 12, 20, 21, 220, 221, 222. O privire recapitulativǎ asupra modului cum se analizeazǎ sistematic proprietǎtile unui cod conduce la urmǎtorul algoritm: Pasul 1. Satisface codul conditia de prefix? DA: atunci codul este instantaneu şi este unic decodabil. NU: se continuǎ cu pasul 2. Pasul 2. Este verificatǎ inegalitate lui Kraft/McMillan? DA: se continuǎ cu pasul 3. NU: codul nu este unic decodabil si, cu lungimile de cuvinte propuse, nu poate fi reproiectat pentru a fi unic decodabil. Pasul 3 (pasul ultimei şanse). Se determinǎ pe altǎ cale dacǎ codul este unic decodabil. DA: problema este rezolvatǎ dar vezi şi NU. NU: se poate reproiecta un cod instantaneu cu aceleaşi lungimi ale cuvintelor. Lungimea medie a unui cod. Coduri compacte Pentru un alfabet al sursei dat se pot construi mai multe coduri instantanee şi unic decodabile. Existǎ oare un criteriu de a alege dintre ele coduri mai bune sau mai proaste? Un criteriu pentru aprecierea unui cod bun este lungimea cuvintelor. Fǎrǎ alte consideratii, un cod cu lungimea medie a cuvintelor de cod micǎ este de preferat oricǎrui alt cod cu lungimea medie a cuvintelor mai mare deoarece cu cât un cod este mai scurt (în medie) şi în consecintǎ mai rapid, cu atât este mai economic în utilizarea aparaturii şi canalelor de comunicatie. Cum se comparǎ douǎ coduri? Cu ce metodǎ se poate aprecia şi mǎsura efectul mediu al codurilor cu lugimi de cuvinte diferite? O mǎsurǎ adecvatǎ, bazatǎ pe lungimile cuvintelor de cod este lungimea medie a codului. Fie un cod pentru o sursǎ fǎrǎ memorie sau pentru adjuncta uneia cu memorie ale cǎrei simboluri s1, s2, …, sq sunt codificate prin cuvintele de cod X1, X2, …, Xq. Fie probabilitǎţile asociate simbolurilor sursei p1, p2, …, pq şi lungimile cuvintelor de cod l1, l2, …, lq. Se numeste lungimea medie a codului mǎrimea
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

59
q
iiilpL
1
Sunt interesante codurile unic decodabile cu lungimea medie cea mai micǎ. Fie o sursǎ şi simbolurile/mesajele ei aplicate pe o multime de cuvinte de cod unic decodabile, care folosesc un alfabet cu r simboluri. Acest cod este compact dacǎ lungimea lui medie este mai micǎ sau cel mult egalǎ cu lungimea medie a oricǎrui alt cod unic decodabil care utilizeazǎ acelaşi alfabet pentru codarea simbolurilor/mesajelor sursei date. Problema determinǎrii codurilor compacte este fundamentalǎ pentru codarea unei surse de informatie. Întrucât intereseazǎ lungimea medie a cuvintelor de cod şi nu cuvintele de cod particulare, cercetarea poate fi restrânsǎ numai la codurile compacte instantanee. Teorema lui McMillan permite aceasta. Câteva observaţii referitoare la codurile compacte: Lungimea medie a unui cod bloc (cu cuvinte de lugime n) este chiar n şi cea
mai micǎ lungime medie a unui cod bloc este log2q/log2r. Pentru a obtine o lungime medie micǎ este necesar a se atribui celor mai
probabile simboluri, cuvintele de cod cele mai scurte. Aceastǎ procedurǎ are sens deplin deoarece cu cât se atribuie cuvinte mai scurte unor simboluri, cu atât mai lungi sunt cuvintele de cod rǎmase a fi atribuite.
Exemple suport pentru aceste asertiuni: Coduri de lungime cuvintelor egalǎ (coduri bloc)
00 01 10 11 Coduri inegale ca lungime
frecventeputinmaisimboluri-lungimaicoduri
frecventemaisimboluri - scurtemaicoduri
111110100
Un exemplu-problemǎ este prezentat în tabelul care urmeazǎ.
Simboluri pi Codul A Codul B s1 0,5 00 1 s2 0,1 01 000 s3 0,2 10 001 s4 0,2 11 11
Întrebǎri: a) Care sunt lungimile medii ale codurilor din tabel? b) Care cod este mai bun sub aspectul lungimii medii? Codul A are lungimea medie LA = 2 biţi/simbol. Codul B are lungimea medie LB = 0,51 + 0,13 + 0,23 + 0,22 = 1,8 biţi/simbol. Codul B este mai bun decât codul A deoarece LB < LA.
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

60
Se poate formula şi o altă întrebarea: existǎ un cod C cu lungimea medie încǎ mai redusǎ, sau codul B este un cod compact? Problema gǎsirii unui cod compact poate fi reformulatǎ astfel: sǎ se gǎseascǎ lungimile l1, l2, l3, l4 astfel încât a) 12222 4321 llllK b) Lungimea medie L = 0,5l1 + 0,1l2 + 0,2l3 + 0,2l4 sǎ fie minimǎ. Problema este departe de a fi facilǎ. Se pune problema existenţei unei limite inferioare a lungimii medii pentru o sursǎ datǎ şi pentru un alfabet de cod precizat. Rǎspunsul este dat mai departe cu explicatia necesarǎ. Entropia şi lungimea medie a codului sunt în strânsǎ legǎturǎ una cu cealaltǎ. Orice cod instantaneu pentru o sursǎ S, care foloseşte un alfabet cu r simboluri are o lungime medie L legatǎ de entropia sursei H(S) prin relatia
L Hr(S) = H(S)/log2r cu egalitate în cazul în care il
i rP pentru toti indicii i. În relatie apare şi entropia calculatǎ în baza r
rSH
pp
rppSH
q
i ii
q
i irir
212
21 log)(1log
log11log)(
Urmeazǎ demonstraţia relaţiei limitative pentru lungimea medie L a cuvintelor de cod:
q
il
ii
q
ilri
q
i iri
q
iii
q
i irir
ii rpp
rrp
pp
lpp
pLSH
111
11
1lnln11log1log
1log)(
Cum pentru x > 0 lnx x – 1, rezultǎ
1ln1
ln11
ln111
ln1)(
1111
q
i
lq
ii
q
il
q
il
iir
i
iir
rp
rrrrpp
rLSH
Dar inegalitatea lui Kraft spune cǎ
11
q
i
lir
aşa încât 0)( LSH r
ceea ce era de demonstrat. Egalitatea are loc într-adevǎr când il
i rP pentru toti indicii i. Definirea entropiei H(S) ca un numǎr de biţi per simbol capǎtǎ un sens. H(S) este lungimea medie a unui cod binar mǎsuratǎ în biţi per simbol. Hr(S) este lungimea medie cea mai micǎ a unui cod bazat pe un alfabet cu r simboluri şi este mǎsuratǎ în numǎrul de simboluri pe alfabetul codului. Nu existǎ o garanţie cǎ se poate obtine în fapt un cod cu lungimea medie L = Hr(S), dar relatia dintre L şi Hr(S) exprimǎ o eficienţǎ a codului prin
= Hr(S)/L
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

61
iar diferenţa faţă de unitate Cred = 1 – = [L – Hr(S)]/L
se numeşte redundanţa codului. Se poate spune cǎ un cod este redundant în mǎsura în care el poate reprezenta mai mult decât informatia generatǎ de sursǎ. Cu alte cuvinte un cod redundant poate servi la codarea unei alte surse care genereazǎ mai multǎ informatie, cu entropia mai mare decât Hr(S). Un cod cu L = Hr(S) este 100% eficient şi 0% redundant. Exemplul anterior reluat conduce la lungimea medie minimǎ (entropia) în biţi per simbol
H(S) = – 0,5log 0,5 – 0,1log 0,1 – 2(0,2log 0,2) = 1,761 Pentru oricare din coduri, lungimea medie L este superioarǎ acestei valori. Codul A are lungimea medie LA = 2, aşadar este eficient în proportie de = 100(1,761/2) = 88% şi redundant în proportie de 12%. Codul B ale lungimea medie LB = 1,8, asadar este eficient în proporţie de = 100(1,761/1,8) = 98% şi redundant în proporţie de numai 2%. Deloc surprinzǎtor: codul B este şi compact. Este putin probabil sǎ se gǎseascǎ o altǎ codare care sǎ aibe o lungime medie cuprinsǎ între 1,761 şi 1,8. Sǎ vedem acum ce se întâmplǎ dacǎ se schimbǎ alfabetul codului din binar în ternar. Calculul bazat pe tabelul alǎturat produce LC = 1,3.
Simboluri pi Codul C s1 0,5 0 s2 0,1 21 s3 0,2 1 s4 0,2 20
Lungimea medie minimǎ trebuie reevaluatǎ deoarece este vorba acum de un alt alfabet al codului. Limita inferioarǎ a numerelor LC este
H3(S) = H(S)/log23 = 1,761/1,585 = 1,111 Aşadar, codul C este eficient la nivelul 85%, mai slab chiar decât codul A. Este codul C compact? Foarte probabil deoarece puţin mai poate fi fǎcut (sau nimic) pentru creşterea eficienţei acestui cod. În general L Hr(S) şi eficienţa este inferioarǎ unitǎtii. Cum se pot obtine totuşi eficienţe mai apropiate de 100%? Conform demonstratiei de mai sus, aceasta se întâmplǎ atunci când pentru toţi indicii i au loc egalitǎţile il
i rP ceea ce este posibil rar, pentru sursele numite surse speciale. În alti termeni, prin surse speciale înţelegem sursele care au probabilitǎtile pi asociate simbolurilor astfel încât numerele logr(1/pi) sunt întregi. Pentru sursele speciale, un cod pe un alfabet cu r simboluri, cu lungimile cuvintelor li = logr(1/pi) satisface condiţiile
ili rP şi de aici rezultă L = Hr(S). Se atinge efectiv marginea inferioarǎ a
lungimilor medii ale codurilor pentru acea sursǎ şi acel alfabet. Eficienta de
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

62
100% este atinsǎ şi este atinsǎ implicit şi lungimea medie cea mai micǎ posibilǎ pentru un cod compact. Câteva surse speciale sunt prezentate în tabelele care urmeazǎ.
Sursa pi Cod s1 0,25 00 s2 0,25 01 s3 0,25 10 s4 0,25
Probabilitǎtile sunt toate de forma 22 ceea ce pentru r = 2 produce un cod binar compact de lungime medie de exact 2, adicǎ de eficienţǎ
maximǎ 11
Sursa pi Cod s1 0,5 0 s2 0,25 10 s3 0,125 110 s4 0,125
Probabilitǎtile sunt respectiv de forma 3321 2,2,2,2 ceea ce pentru r = 2 produce un
cod binar compact de lungime medie de exact 1,75, adicǎ, din nou, de eficientǎ maximǎ 111
Sursa pi Cod
s1 1/3 0 s2 1/3 1 s3 1/9 20 s4 1/9 21 s5 1/27 220 s6 1/27 221 s7 1/27
Probabilitǎtile sunt de forma il3 ceea ce pentru r = 3 produce un cod binar compact de
lungime medie de exact 13/9, cât este şi entropia sursei calculatǎ în baza 3, adicǎ de
eficientǎ maximǎ
222 Teorema de codare a lui Shannon O versiune mai tare a rezultatului demonstrat mai devreme o constituie teorema de codare pentru canale fǎrǎ zgomot datoratǎ lui Shannon. Teorema impune şi o limitǎ superioarǎ pentru lungimea medie L a codurilor compacte şi aratǎ cum este posibilǎ obtinerea unui cod eficient prin extinderi ale schemei de codare. Sursele speciale din categoria celor de mai sus sunt extrem de rare. Pare deci rezonabil ca pentru o sursǎ oarecare sǎ se caute coduri compacte de lungimi egale cu cei mai mici întregi superiori numerelor logr(1/pi), caz în care se obtine
11log1log i
rii
r pl
p
Ideea nu este extraordinarǎ dar poate fi folositǎ în strategia de proiectare a unui cod compact pentru stabilirea unei limitǎri superioare. Pentru un cod D se pot afirma urmǎtoarele: 1. Limita inferioarǎ a lungimii unui cuvânt particular, logr(1/pi) ≤ li poate fi
utilizatǎ pentru a dovedi cǎ inegalitatea lui Kraft este satisfǎcutǎ şi codul este unic decodabil (instantaneu). Faptul implicǎ totodatǎ inegalitatea Hr(S) ≤ LD ceea ce este în concordanţǎ cu un rezultat discutat mai sus.
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

63
2. Limita superioarǎ a lungimii cuvântului i datǎ de li ≤ logr(1/pi) + 1 produce prin multiplicare cu probabilitatea pi şi însumare dupǎ indicele i
q
ii
q
iiri
q
iii ppplp
111)/1(log
adicǎ are loc relaţia LD ≤ Hr(S) + 1. Acum, prin combinarea celor douǎ inegalitǎti se obtine
1)()( SHLSH rDr Dar prin definiţie un cod compact are L LD şi HD(S) L, de unde
1)()( SHLLSH rDr În final se obtine relatia
1)()( SHLSH rr Pentru extensia a n-a a sursei S se scrie o relatie similarǎ
1)()( nrn
nr SHLSH
în care cu Ln se noteazǎ lungimea medie a cuvintelor de cod care corespund simbolurilor i ale extensiei a n-a a sursei S. Cu rememorarea unui rezultat obtinut mai devreme conform cǎruia
Hr(Sn) = nHr(S) se scrie
1)()( SnHLSnH rnr şi în cele din urmǎ
nSH
nLSH r
nr
1)()(
care este expresia importantei teoreme de codare a lui Shannon pentru canale fǎrǎ perturbatii: Pentru orice sursǎ de informatie S, lungimea medie L a unui cod compact este legatǎ de entropia Hr(S) prin relatia
1)()( SHLSH rr şi lungimea medie Ln a extensiei a n-a a codului acelei surse verificǎ relatia
nSH
nLSH r
nr
1)()(
Prin trecere la limitǎ se obtine
)(lim SHnL
rn
n
Observatii Ln /n este lungimea medie a cuvântului de cod în cazul codǎrii extensiei a n-
a a sursei S. Asadar, lungimea Ln /n este într-un fel echivalentǎ cu L. Teorema lui Shannon implicǎ faptul cǎ lungimea medie Ln/n se poate
împinge oricât de aproape de limita Hr(S) (şi eficienţa oricât de aproape de 100%) dacǎ sunt utilizate extensii ale sursei S de ordin din ce în ce mai mare. Preţul plǎtit este majorarea exponenţialǎ (qn) a numǎrului de simboluri de codat şi implicit a codului însusi.
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

64
Problema extensiilor are o valoare aparte când sursa şi codul folosesc acelaşi alfabet. Desigur, pentru o sursǎ binarǎ şi un canal digital binar codarea nu se face în scopul unei conversii alfabetice. Un exemplu plin de sensuri îl constituie cazul sursei cu douǎ mesaje din tabelul alǎturat.
Mesaje pi s1 0,8 s2 0,2
Codarea cea mai comunǎ este s1 0, s2 1 cu un cod compact care poate fi apreciat ca trivial. Este acest cod cel mai bun? Cu Ln = L = 1 şi H2(S) = 0,722 eficienţa este de numai 72,2%. Conform teoremei de codare a lui Shannon pentru canale fǎrǎ perturbaţii
1)()( 212 SHLSH ceea ce numeric se scrie 0,722 < 1 < 1,722. Prin luarea unor extensii se poate face lungimea medie Ln/n sǎ tindǎ cǎtre 0,722. Extensia a doua a sursei se prezintǎ sub forma
Mesaje pi Codul compact s1s1 0,64 0 s1s2 0,16 10 s2s1 0,16 110 s2s2 0,04 111
Probabilitǎtile s-au calculat tinând seamǎ cǎ sursa este fǎrǎ memorie. Acum, lungimea medie a cuvântului de cod este L2 = 1(0,64) + 2(0,16) + 3(0,16) + 3(0,04) = 1,56 biţi pe perechea de simboluri. Valoarea L2/2 = 0,78 este mult mai apropiatǎ de 0,722, iar în termeni de eficienţǎ se aflǎ la nivelul de 92,6%. Se verificǎ şi de data aceasta cǎ
21)(
2)( 2
22 SHLSH
ceea ce numeric înseamnǎ 0,722 < 0,78 < 1,222. Sugerǎm ca problemǎ studierea apropierii de eficienta maximǎ de 100% în cazul codului pentru extensia a treia. Teorema lui Shannon pentru surse Markov Pânǎ acum s-au luat în considerare surse fǎrǎ memorie. Ce se întâmplǎ în cazul surselor Markov, surse cu memorie? Fie o sursǎ Markov S. Se admite modelul sursei fǎrǎ memorie, adicǎ se codeazǎ sursa adjunctǎ S . Deoarece sursa adjunctǎ este fǎrǎ memorie se aplicǎ formula de mai sus
1)()( SHLSH rr
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

65
şi pentru extensia a n-a, tot o sursǎ fǎrǎ memorie 1)()( n
rnn
r SHLSH Pentru o sursǎ Markov de ordinul m, )()( SHSH aşa încât
mrmn
rn
r SnHSHSH )()()( unde m este un numǎr nenegativ oarecare. Atunci
1)()( mrnmr SnHLSnH şi
nnSH
nL
nSH m
rnm
r1)()(
o dublă inegalitate care spune acelaşi lucru ca în cazul surselor fǎrǎ memorie: pe mǎsurǎ ce n creste, Ln /n se apropie de Hr(S), entropia sursei. Aşadar: Teorema de codare a lui Shannon pentru canale fǎrǎ perturbatii se menţine
la limitǎ, atât pentru sursele fǎrǎ memorie cât şi pentru sursele Markov. Limita inferioarǎ a lungimii medii este Hr(S). Aceastǎ entropie depinde însǎ
de modelul care se utilizeazǎ pentru sursǎ. Entropia unei surse descreşte la ordine din ce în ce mai mari ale modelului Markov pânǎ când este atinsǎ entropia adevǎratǎ )( SH r
. Atunci, pentru a obtine o eficienţǎ ridicată,
codarea trebuie sǎ se bazeze pe entropia adevǎratǎ a sursei deoarece aceasta produce limita cea mai scǎzutǎ a lungimii medii L.
Un exemplu aproape trivial în susţinerea rezultatului de mai sus este cel al sursei binare care genereazǎ şirul alternativ de simboluri 0, 1, 0, 1, 0, 1, 0, … Dacǎ discuţia se restrânge la cazul fǎrǎ memorie atunci P(0) = P(1) = 0,5 şi H(S) = 1. Codul binar compact reproduce sursa însǎsi, 0 0, 1 1, pentru care L = 1 şi se pare ca acest cod este 100% eficient. Aşa sǎ fie oare? Rezultatul de mai sus vorbeste despre modelul adevǎrat al sursei, care este un model Markov de ordinul întâi cu reprezentarea din figura alǎturată. Şi de data aceasta
0)()( 1 SHSH
şi eficienta decade la 0%.
Desigur, cum este de aşteptat
101)()(
nLSH
nLSH nn
Pentru extensia a doua
Sursa pi Cod 00 0 - 01 0,5 0
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

66
10 0,5 1 11 0 -
Codul compact este 01 0 şi 10 1 (se ignorǎ secvenţele de douǎ simboluri identice deoarece ele nu apar niciodatǎ) şi are L2 = 1, iar L2 /2 = 0,5 = L. Pentru extensia a n-a L Ln/n = 1/n şi L 0 când n . Teorema lui Shannon şi capacitatea canalelor În continuare este tratatǎ teorema lui Shannon şi codarea în cazul canalelor fǎrǎ perturbaţii în legǎturǎ cu capacitatea canalelor. Se considerǎ pentru aceasta schema alǎturatǎ.
în care sursa are q simboluri, codul şi intrarea canalului au r simboluri. Dacǎ sursa produce 1 simbol în unitatea de timp atunci sursa transmite în medie o informatie de H(S) biţi în unitatea de timp. Simbolurile sursei sunt codate cu cuvinte de cod cu lungimea medie de L simboluri ale codului. Viteza codorului de transmitere prin canal R este definitǎ ca numǎrul mediu de biţi de informatie pe simbolul de cod R = H(S)/L. Un rezultat de mentionat: dintr-o relatie doveditǎ mai devreme, L H(S)/logr rezultǎ R logr. Dar pentru un canal fǎrǎ zgomote, cu un alfabet de intrare cu r simboluri, capacitatea este C = logr, prin urmare R C, cu egalitate atunci când codul este eficient în proporţie de 100%. Aşadar, un cod 100% eficient utilizeazǎ canalul la întreaga lui capacitate. Acum teorema lui Shannon relativ la canalele fǎrǎ perturbatii se poate reformula în varianta ei fundamentalǎ: Teorema fundamentalǎ a lui Shannon (în varianta pentru canale fǎrǎ perturbatii): Pentru un canal fǎrǎ perturbatii este posibil ca o sursǎ S, prin extensiile ei sǎ fie codatǎ astfel încât debitul informatiei transmise R sǎ fie oricât de apropiat de capacitatea C a canalului
CRSHnL
nrn
n lim)(lim
unde capacitatea canalului fǎrǎ perturbatii este C = logr şi debitul de informatie este R = H(S)/L = [Hr(S)/(Ln/n)]logr. Se pot face câteva observaţii, unele necesitând o (amânatǎ pentru moment) demonstraţie: Debitul de informatie R mǎsoarǎ efectiv entropia mesajelor codate.
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

67
O eficienţǎ a codǎrii de 100% este posibilǎ când simbolurile codului sunt echiprobabile deoarece R = C = logr este entropia maximǎ a unui alfabet de cod.
Tendinţa de a obtine o eficienţǎ a codǎrii de 100% coincide cu tendinţa de a utiliza canalul la maxima sa capacitate, ceea ce se produce când simbolurile codului devin (practic) echiprobabile.
Exemplu. Fie secvenţa 0001100100 generatǎ de o sursǎ. Pe baza acestei secvente se poate pune (poate numai provizoriu) Pr(0) = 0,7 şi Pr(1) = 0,3 din care rezultǎ H(S) = 0,88. În ipoteza lipsei de memorie a sursei, extensia a doua a ei, codatǎ cu un cod compact produce mai întâi codul din tabel
s1s2 Pr(s1s2) Cod 00 0,49 0 01 0,21 10 10 0,21 110 11 0,09 111
şi apoi
L2/2 = 0,905 L şi = H(S)/L = 0,88/0,905 = 0,972 Codarea sursei are ca efect transmiterea în canal a secventei 0 10 110 10 0 caz în care o estimare a probabilitǎtilor celor douǎ simboluri conduce la Pr(0) = 5/9, Pr(1) = 4/9 şi H(S) = 0,99, mai aproape de entropia maximǎ. Modul cum au fost evaluate probabilitǎtile în acest exemplu este contestabil, dar serveşte destul de convingǎtor la ilustrarea relatiei debit de informatie – capacitate a canalului. Coduri compacte – coduri Huffman Am arǎtat mai devreme cǎ pânǎ şi pentru o sursǎ simplǎ poate fi necesar uneori a se lucra cu extensii de ordine încǎ mai mari de 2 sau 3. Stabilirea unui cod compact este simplǎ numai în cazul unor surse generatoare de puţine mesaje. Pentru extensiile lor şi pentru surse cu o listǎ mai bogatǎ de mesaje, codurile compacte nu mai sunt atât de evidente. Este necesarǎ aşadar o algoritmizare a codǎrii prin coduri compacte. O metodǎ simplǎ a fost pusǎ la punct de Huffman în 1952. Este încǎ utilizatǎ datoritǎ simplitǎţii ei. Mai departe este dezvoltat cazul codurilor compacte binare, deci cu un alfabet al codului din douǎ simboluri. Sursa redusǎ. Se considerǎ o sursǎ S cu simbolurile s1, s2, …, sq, şi cu probabilitǎtile de aparitie p1, p2, …, pq. Se considerǎ totodatǎ cǎ probabilitǎtile sunt ordonate descrescǎtor, p1 ≥ p2 ≥ … ≥ pq. Prin combinarea ultimelor douǎ simboluri într-unul singur cu însumarea probabilitǎtilor lor, se obtine o nouǎ sursǎ, o sursǎ redusǎ a sursei S, care are acum numai q – 1 simboluri. Fie aceasta S1. Dupǎ eventuala reordonare a probabilitǎtilor şi a simbolurilor, prin combinarea din nou a ultimelor douǎ simboluri se obtine o altǎ redusǎ a sursei
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

68
S, fie aceasta S2, care are şi ea un simbol mai putin. Pe aceastǎ cale se obţine o succesiune de surse reduse S1S2S3…, ultima din succesiune cu numai douǎ simboluri. Dacǎ pentru una din sursele reduse Sj codul compact este cunoscut, atunci codul compact pentru sursa (redusǎ) precedentǎ Sj–1, care poate fi în cele din urmă chiar sursa iniţialǎ se construieste astfel: Se identificǎ simbolurile din Sj–1, s, scare au produs prin reunire simbolul s din Sj . Simbolurilor din Sj–1, exceptând s sli se atribuie aceleaşi cuvinte de cod ca şi în Sj. Simbolurilor s, sli se atribuie cuvinte de cod noi obtinute prin adǎugarea la cuvântul de cod al simbolului s, a unui 0, respectiv a unui 1. Şi acum algoritmul de codare binarǎ al lui Huffman 1. Se reduce sursa S la S1 şi mai departe la S2, S3 etc. pânǎ la sursa redusǎ
compusă numai din douǎ simboluri (sau pânǎ la una pentru care stabilirea unui cod compact este facilǎ).
2. Se atribuie sursei ultime un cod compact. Dacǎ este cu numai douǎ simboluri se face atribuirea trivialǎ 0 şi 1.
3. Se parcurge invers secvenţa de surse reduse modificând sau nu cuvintele de cod dupǎ reţeta de mai sus. Codul atribuit sursei iniţiale este codul compact Huffman.
Ca exemplu, fie o sursǎ cu şase simboluri/mesaje cu probabilitǎtile de apariţie date imediat mai jos
s1 s2 s3 s4 s5 s6 0,3 0,4 0,04 0,1 0,1 0,06
Dupǎ ordonarea descrescǎtoare a probabilitǎtilor se obtine ordinea din tabelul care urmează. Acelaşi tabel contine sursele reduse cu probabilitǎtile ordonate necrescǎtor. S-au marcat prin subliniere probabilitǎtile simbolurilor rezultate prin reunirea a douǎ simboluri din sursa redusǎ precedentǎ.
S p p/S1 p/S2 p/S3 p/S4 s2 0,4 0,4 0,4 0,4 0,6 s1 0,3 0,3 0,3 0,3 0,4 s5 0,1 0,1 0,2 0,3 s4 0,1 0,1 0,1 s3 0,06 0,1 s6 0,04
La parcurgerea inversǎ a surselor reduse se obtin coduri compacte la fiecare etapǎ, pentru fiecare sursă redusă, inclusiv pentru sursa originarǎ:
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

69
S p p/S1 p/S2 p/S3 p/S4 s2 0,4 1 0,4 1 0,4 1 0,4 1 0,6 0 s1 0,3 00 0,3 00 0,3 00 0,3 00 0,4 1 s5 0,1 011 0,1 011 0,2 010 0,3 01 s4 0,1 0100 0,1 0100 0,1 011 s3 0,06 01010 0,1 0101 s6 0,04 01011
Se poate scrie acum o variantǎ a tabelului de codare, ordonatǎ în raport cu indicele simbolurilor generate de sursǎ:
s1 00 s2 1 s3 01010 s4 0100 s5 011 s6 01011
Codul are o lungime medie de L = 2,2 biţi/simbol, entropia sursei este H(S) = 2,1435, prin urmare eficienta codului este de cca. 97%. Sunt de retinut urmǎtoarele: Codul nu este unic: la realizarea surselor reduse sunt puncte unde sunt
posibile alegeri alternative ale simbolurilor care urmeazǎ a fi reunite într-unul singur, iar atribuirea de 0 şi 1 în cuvintele de cod poate fi inversatǎ.
Alegerea posibilǎ în unele etape poate conduce la cuvinte de cod de lungimi diferite. dar niciodatǎ lungimea medie nu se modificǎ.
Nu este necesar a merge pânǎ la o ultimǎ sursǎ redusă de numai douǎ simboluri. Dacǎ pe parcurs se identificǎ o codare pentru o sursǎ redusǎ mai bogatǎ în simboluri parcursul invers poate fi initiat imediat
Un exemplu de cod alternativ este prezentat în tabelul care urmeazǎ. Acesta se deosebeşte de cel de mai devreme prin alegerea diferitǎ a ordinei simbolurilor în sursa redusǎ S1: simbolul rezultat prin reunirea a douǎ simboluri din sursa originarǎ este plasat diferit în lista ordonatǎ.
S p p/S1 p/S2 p/S3 p/S4 s2 0,4 1 0,4 1 0,4 1 0,4 1 0,6 0 s1 0,3 00 0,3 00 0,3 00 0,3 00 0,4 1 s5 0,1 0100 0,1 011 0,2 010 0,3 01 s4 0,1 0101 0,1 0100 0,1 011 s3 0,06 0110 0,1 0101 s6 0,04 0111
Lungimea medie a acestui cod compact este tot L = 2,2 biţi/simbol.
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

70
Pentru obtinerea de coduri compacte Huffman în cazul mai general, r > 2, procedura este asemǎnǎtoare celei din cazul r = 2. 1. Sursele reduse se obtin prin reunirea a r simboluri ale sursei primare sau
anterioare pentru a obtine o sursǎ cu r – 1 simboluri mai puţin. 2. La scrierea codului compact pentru o sursǎ redusǎ Sj–1 pe baza codului
compact pentru sursa redusǎ Sj se adaugǎ cuvântului de cod al simbolului s simbolurile de cod 0, 1, ..., r – 1.
3. Dacǎ ultima sursǎ redusǎ are exact r simboluri, ceea ce se întâmplǎ numai dacǎ sursa originarǎ are r + (r – 1) simboluri, cu natural, se procedează ca în cazul binar. În caz contrar, se adaugă la sursa primarǎ un numǎr minim de simboluri fictive cu probabilitatea de aparitie nulǎ, astfel încât sursa să aibă r + (r – 1) simboluri cu natural.
Un exemplu, o codare cu un alfabet al codului cuaternar, r = 4, pentru o sursǎ generatoare de 11 simboluri.
s1 0,22 2 0,22 2 0,23 1 0,40 0 s2 0,15 3 0,15 3 0,22 2 0,23 1 s3 0,12 00 0,12 00 0,15 3 0,22 2 s4 0,10 01 0,10 01 0,12 00 0,15 3 s5 0,10 02 0,10 02 0,10 01 s6 0,08 03 0,08 03 0,10 02 s7 0,06 11 0,07 10 0,08 03 s8 0,05 12 0,06 11 s9 0,05 13 0,05 12 s10 0,04 100 0,05 13 s11 0,03 101
Mai întâi se verificǎ relatia r + (r – 1) = 11. Relatia produce 2,33. Se pune acest numǎr egal cu cel mai mic întreg superior lui 2,33, adicǎ . Aceasta aratǎ cǎ numǎrul de simboluri ale sursei ar trebui sǎ fie 13, prin urmare se adaugǎ douǎ simboluri care în realitate nu sunt produse de sursǎ niciodatǎ din cauza probabilitǎtii lor nule. În tabelul alǎturat aceste simboluri nici măcar nu figurează, dar sunt subîntelese. Codul are lungimea medie L = 1,7, entropia sursei este H4(S) = 1,6137 şi, în consecinţǎ, eficienţa codului este ≈ 95%. Principii generale pentru compresia de date Compresia de date este posibilǎ ori de câte ori se existǎ redundanţǎ în acele date şi se realizeazǎ prin reducerea sau chiar eliminarea acelei redundanţe. Cu cât redundanţa este mai mare cu atât necesitatea de comprimare este mai acutǎ şi mai interesantǎ. Datele comprimate pot fi transmise şi/sau memorate mai eficient pentru cǎ sunt mai puţin redundante. Cu toate acestea redundanţa este utilǎ în cresterea toleranţei la erori. Prin reducerea redundanţei, datele devin
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

71
mai puţin robuste, mai vulnerabile în faţa perturbaţiilor/zgomotelor. Dacǎ numai câţiva biţi sunt eronaţi într-un fisier comprimat sau într-un flux de informaţie transmisǎ comprimat, faptul poate compromite întregul fişier sau transmisia în totalitatea ei. Dacǎ într-un fişier redundant sau într-un şir cu redundanţe transmis câţiva biţi sunt corupţi, este posibil ca informaţia sǎ fie recuperatǎ integral. De pildǎ din şirul eronat
T?? c?t s?t on th? m?t se poate recupera propoziţia în limba engleză
The cat sat on the mat tocmai pe baza redundanţelor limbii engleze. Ca exerciţiu se sugereazǎ codarea Huffman pentru un text eronat şi recuperarea lui prin decodare. Existǎ patru tipuri de redundanţe: 1. De distribuţie a caracterelor: frecvenţele de apariţie a simbolurilor sunt
diferite. 2. De repetare a caracterelor: unele simboluri sunt repetate în secvenţele în
care apar. 3. Legate de utilizarea frecventǎ a unor şabloane: apar frecvent anumite
grupuri de simboluri. 4. Redundanţe poziţionale: când apar, unele simboluri apar periodic sau într-o
aceeaşi localizare relativǎ. Exemple: Distribuţia caracterelor: În limbile europene vocalele apar mai frecvent, consoane ca X ori Z mult
mai rar. Fişierele de date conţin foarte frecvent cifre. Un program sursǎ scris în C conţine foarte frecvent caracterele { şi }. Sursele fǎrǎ memorie sunt tipice prin diversitatea de distribuire a
caracterelor. Repetarea caracterelor: În tabele, liste etc. separatorii ca spaţiile, caracterele tab apar repetat. În imagini apar informaţii repetate prin pixelii de reprezentare a fondului. Şabloane frecvente: În limba englezǎ apar frecvent succesiunile th, sym, for, but, în schimb
secvenţa tz este aproape exclusǎ. Sursele Markov sunt frecvent şablonarde. Redundanţe poziţionale: Delimitatorii de câmpuri din bazele de date, din tabele, cuvintele de
indexare apar mereu în acceaşi poziţie. Deocamdatǎ au fost luate în considerare numai extensii ale unei surse şi codarea Huffman cu scopul de a proiecta coduri compacte cât mai eficiente. Sunt însǎ unele inconveniente de ordin practic pentru aceastǎ tratare.
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

72
Tabelul de codare trebuie inclus alǎturi de lista de simboluri ale sursei. Pentru extensia a n a sursei sunt necesare qn linii ale tabelului ceea ce poate deveni prohibitiv în operaţia de crestere a eficienţei codului.
Complexitatea codǎrii şi decodǎrii (memorie, timp de calcul etc.) creşte aproximativ de acelaşi ordin, qn.
Codurile de lungime variabilǎ necesitǎ arbori de decodare complicaţi (în contrast cu codurile de lungime fixǎ, codurile bloc, când se foloseste o operaţie simplǎ de indexare).
Este necesar a se evalua statistica sursei, deci sursa trebuie vǎzutǎ de douǎ ori. De aici necesitatea stabilirii unui buffer pentru memorarea temporarǎ a caracteristicilor sursei şi dacǎ statistica sursei se modificǎ este necesară reformularea codului şi retransmiterea.
Codarea Huffman poate trata eficient numai redundanţa sursei derivatǎ din repartiţia caracterelor. Pentru utilizarea altor redundanţe sunt necesare extensiile sursei.
Unele ajustǎri de fineţe ale codurilor Huffman la implementare pot ameliora o parte din neajunsurile inventariate mai sus. Şi desigur, implementarea unei scheme de codare este la fel de importantǎ ca şi schema însǎşi. Pentru situaţii speciale se utilizeazǎ algoritmi speciali de codare cum sunt: Codarea Run-Length pentru codarea rapidǎ a redundanţelor datorate
secvenţelor repetitive. Codarea aritmeticǎ utilizatǎ ca o alternativǎ mai eficientǎ la codarea
Huffman. Pentru utilizarea cât mai eficientǎ a redundanţelor existǎ tehnici de codare moderne, care pot fi grupate în douǎ clase largi: 1. Codarea Markov bazatǎ pe modelele Markov (DMC, PPM etc.) 2. Codarea adaptivǎ prin tehnicile de codare cu dicţionar LZ (LZ77, LZ78
etc.) Codarea run-length Codarea run-length este o tehnicǎ specializatǎ care face codarea/decodarea rapidǎ şi exploateazǎ redundanţele legate de repetarea caracterelor. Codul inlocuieste o secvenţǎ de caractere repetate prin rezultatul operaţiei de numǎrare a acelor caractere. Pentru a indica înlocuirea se utilizeazǎ un caracter special. Codul run-length înlocuieste o secvenţǎ de caractere X repetate prin ScXCc în care Sc este simbolul special, X este caracterul repetat şi Cc este numǎrul de caractere. Un exemplu în tabelul alǎturat
Sirul originar Sirul codat $******55.72 $Sc*655.72 --------- Sc-9
Guns_______butter GunsSc_7butter
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

73
Observaţii: Şirul ScXCc este un descriptor compus din cel puţin trei caractere. Asadar,
codarea este eficace dacǎ repetarea caracterului X se produce de cel puţin 4 ori.
Caracterul de numǎrare Cc este mǎrginit de numǎrul de biţi pe care este reprezentat. Pe 8 biţi el nu poate depǎşi 255. Pe 16 biţi valoarea acceptatǎ creste cu lungirea concomitentǎ a descriptorului Cc.
Alfabetul sursei poate sǎ nu permitǎ un caracter special. În asemenea cazuri este necesar un tratament special (de pildǎ în cazul transmiterii de la o sursǎ binarǎ) (De judecat: de ce nu este posibil a se utiliza un caracter special pentru o sursǎ binarǎ?)
Codoare Markov Un sumar al cunostinţelor acumulate pânǎ la acest moment pune în evidenţǎ urmǎtoarele: Limita inferioarǎ a lungimii medii a unui cod este entropia sursei sau mai
exact spus entropia evaluată pe baza unui model al sursei. Prin considerarea unor extensii ale sursei, lungimea aceasta minimǎ poate fi aproape atinsǎ şi codul devine mai eficient.
Modelul Markov pentru o sursǎ poate avea entropii semnificativ mai reduse decât sursa adjunctǎ, entropia realǎ )ˆ( SH fiind cea mai micǎ entropie deci limita de jos a lungimii medii a cuvintelor de cod.
Aşadar un codor aproape ideal al unei surse cu memorie ar trebui sǎ foloseascǎ un model Markov de un ordin m atfel încât entropia )ˆ( mSH sǎ fie cât mai apropiatǎ de )ˆ( SH . Apoi o a n-a extensie a modelului Markov de ordinul m, cu un n suficient de mare pentru ca lungimea medie a cuvintelor de cod sǎ fie cât mai apropiatǎ de )ˆ( mSH . În cazul codǎrii Huffman apar dificultǎţi de implementare datorate incomo-dităţii de a estima statistica modelului Markov al sursei pe baza unui volum finit de date. Mai apare apoi şi problema stabilirii unui cod pentru o extensie a sursei de un ordin n mare. Codarea Huffman necesitǎ memorii şi calcule de ordinul qn, aşadar, pentru spaţiul de memorare şi pentru timpul de calcul se înregistreazǎ o creştere exponenţialǎ cu n. Dar nu-i mai puţin adevǎrat cǎ pentru n foarte mare nu este necesar a fi cunoscute toate cuvintele de cod cu probabilitǎţile lor deoarece din mulţimea de mesaje în numǎr de qn numai unele pot apǎrea efectiv, multe fiind cu totul improbabile. O alternativǎ la codarea Huffman este codarea aritmeticǎ. Aceasta se bazeazǎ pe faptul cǎ suma probabilitǎţilor )...Pr(
21 niii sss ale celor qn cuvinte ale extensiei unei surse este egalǎ cu unitatea. Toate numerele acestea se situeazǎ în intervalul [0, 1) şi este important a fi localizat subintervalul în care numǎrul
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

74
)...Pr(21 niii sss se situeazǎ pentru ca apoi sǎ fie transmişi suficienţi biţi pentru
identificarea fǎrǎ echivoc a acelui subinterval. Existǎ modalitǎţi variate de a implementa aceastǎ tehnicǎ de codare. Fǎrǎ a intra în toate detaliile, una dintre ele este prezentatǎ în secţiunile urmǎtoare. Codarea aritmetică Codarea Huffman a fost consideratǎ multǎ vreme ca aproape optimǎ pânǎ când în anii ’70 ai secolului trecut a apǎrut ideea codǎrii aritmetice. Codul rezultat este foarte apropiat ca lungime medie de entropia sursei şi chiar o egaleazǎ în cazuri speciale. Dezavantajele codǎrii Huffman constau în relativ complicata generare a arborelui asociat şi în limitarea la a coda simbolurile sau grupele de simboluri ca atare. În ceva mai multe detalii, un cod Huffman binar este asociat unui arbore binar echilibrat pe care se aproximeazǎ probabilitǎtile simbolurilor: se porneşte din rǎdǎcina arborelui şi se cautǎ nodul asociat unui anumit simbol. Ramurile sunt etichetate binar, astfel încât cuvântele de cod se regǎsesc ca succesiuni de ramuri. Deoarece numǎrul de ramuri parcurse la o trecere este totdeauna numǎr întreg, fiecare simbol este codat de fiecare datǎ de o secvenţǎ de biţi de lungime numǎr intreg. Aceastǎ restricţie nu mai apare dacǎ se adoptǎ codarea aritmeticǎ. Codarea aritmeticǎ utilizeazǎ un tabel de probabilitǎti unidimensional în loc de un arbore. Acest gen de codare cuprinde dintr-o datǎ întregul mesaj. În acest mod devine posibilǎ codarea simbolurilor folosind şi fragmente de biţi. Numai că nu se poate accesa cuvântul de cod la întâmplare: utilizând codarea Huffman se pot specifica marcaje care sǎ permitǎ decodarea pornind din interiorul secvenţei de biţi. Desigur, mesajele se pot diviza şi în codarea aritmeticǎ, dar divizarea limiteazǎ eficienţa deoarece utilizarea fragmentelor de biti la limite este dificilǎ. Ce se urmǎreste aici este cǎutarea unei modalitǎti de a coda un mesaj fǎrǎ a atribui un cod binar fix fiecǎrui simbol. Examinarea probabilitǎtilor asociate cu simbolurile aratǎ cǎ toate probabilitǎtile sunt numere în intervalul [0, 1), care însumate dau totdeauna unitatea. Acest interval contine extrem de multe numere reale, astfel cǎ este posibil a coda orice secvenţǎ posibilǎ printr-un numǎr din intervalul [0, 1). Intervalul se partiţioneazǎ potrivit probabilitǎtilor asociate simbolurilor sursei. Prin iterarea acestei partiţionǎri pentru fiecare simbol din mesaj, se rafineazǎ intervalul la un rezultat unic care reprezintǎ întregul mesaj. Orice numǎr din intervalul ultim este un cod valid. Fie pentru aceasta un model M care atribuie o probabilitate PM(ai) fiecǎrui simbol ai care compune mesajul. Intervalul [0,1) se poate acum diviza folosind aceste valori deoarece suma este totdeauna egalǎ cu 1. Întinderea subinter-valului i corespunde exact probabilitǎtii simbolului ai. Un exemplu de creare a intervalelor. Fie M un model care utilizeazǎ alfabetul A = {a, b, c, d} şi fie probabilitǎtile simbolurilor în mesaj
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

75
PM(a) = 0,5 PM(b) = 0,25 PM(c) = 0,125 PM(d) = 0,125 Intervalul [0, 1) este divizat ca în figurǎ
Definirea unor limite superioare şi inferioare. De la acest punct, limitele supe-rioarǎ şi inferioarǎ ale intervalului curent vor fi numite high şi low. Limitele subintervalelor sunt calculate din probabilitǎti cumulate:
K(ak) =
k
iiM aP
1)(
Valorile high şi low se schimbǎ în procesul de codare, dar probabilitǎtile cumulate rǎmân constante (pentru cǎ modelul ales M este invariant în timp). Aceste probabiltǎti sunt utilizate pentru a actualiza cele douǎ valori high şi low. În cazul exemplificat valorile sunt conform tabelului
Divizarea intervalului unitar [0, 1) depinde de model. Pentru moment, aici se presupune cǎ diviziunea este datǎ de un tabel de probabilitǎti cumulate K(ai) mereu acelasi. Tipul acesta de model existǎ în realitate şi este denumit model static. Codarea începe cu initializarea intervalului I = [low, high) la valorile low = 0 şi high = 1. La citirea primului simbol s1, intervalul I este redimensionat în acord cu simbolul. Cum sunt calculate limitele lui? Fie s1 = ak. Atunci, limita inferioarǎ este
)()( 1
1
1
k
k
iiM aKaPlow
şi limita superioarǎ este
)()(1
k
k
iiM aKaPhigh
Noul interval I’ este pus acum a fi [low, high). Calculul nu este o noutate: el este conform cu metoda matematicǎ folositǎ la construcţia figurii de mai sus. Aspectul cel mai relevant al acestei metode este cǎ subintervalul I’ este mai larg pentru un simbol s1 mai probabil. Cu cât este mai larg intervalul cu atât mai redus este numǎrul de cifre dupǎ virgulǎ şi cuvâtul de cod este mai scurt. Toate numerele care vor fi generate în iteratiile următoare vor fi localizate în intervalul I’ deoarece acesta este utilizat ca interval de bazǎ, asa cum a fost mai devreme intervalul I = [0, 1).
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

76
Se procedeazǎ analog cu simbolul urmǎtor, s2 = aj. Apare acum o problemǎ diferită: modelul M s-a asociat cu o partiţie a intervalului I = [0, 1) şi nu cu o partiţie a intervalui I’ nou calculat. Intervalul I’ trebuie scalat şi limitele lui deplasate pentru a se potrivi cu intervalul nou. Scalarea se obtine prin multiplicarea lungimii intervalului cu diferenta high – low. Deplasarea se face prin adunarea valorii low. Rezultatul este
)()()()( 1
1
1
j
j
iiM aKlowhighlowaPlowhighlowwlo
)()()()(1
j
j
iiM aKlowhighlowaPlowhighlowhhig
Aceastǎ regulǎ este valabilǎ pentru toti paşii, în particular şi pentru primul când low = 0 şi high – low = 1. Deoarece vechile limite nu mai sunt necesare, ele se pot înlocui, se pot suprascrie: low low’; high high’. Calculul acesta iterativ poate pǎrea complicat, dar un exemplu simplu va lǎmuri lucrurile. Fie S secvenţa abaabcda sub modelul ideal M de mai sus. La început se ia intervalul [0, 1) şi primul simbol din S. Deoarece s1 = a noile limite calculate sunt
low = 0 high = 0 + 0,5·1 = 0,5
Intervalul nou rezultat este [0, 0,5). Iteraţia urmǎtoare codeazǎ un b şi low = 0 + 0,5·(0,5 − 0) = 0,25
high = 0 + 0,5·(0,5 − 0) + 0,25·(0,5 − 0) = 0,375 Urmeazǎ un a şi
low = 0,25 high = 0,25 + 0,5·(0,375 − 0,25) = 0,3125
apoi încǎ un a low = 0,25
high = 0,25 + 0,5·(0,3125 − 0,25) = 0,28125 Al cincilea caracter este un b
low = 0,25 + 0,5·(0,28125 − 0,25) = 0,265625 high = 0,25 + 0,5·(0,28125 − 0,25) + 0,25·(0,28125 − 0,25) = 0,2734375
urmat de un c low = 0,265625 + 0,5·(0,2734375 − 0,265625) + 0,25·(0,2734375 − 0,265625)
= 0,271484375 high = 0,265625 + 0,5·(0,2734375 − 0,265625) + 0,25·(0,2734375 − 0,265625)
+ 0,125·0,25·(0,2734375 − 0,265625) = 0,2724609375
un d low = 0,271484375 + (0,5 + 0,25 + 0,125)·(0,2724609375 − 0,271484375)
= 0,2723388672 high = 0,2724609375
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

77
şi în cele din urmǎ un alt a low = 0,2723388672
high = 0,2723388672 + 0,5·(0,2724609375 − 0,2723388672) = 0,2723999024.
Aşadar intervalul rezultat în final este [0,2723388672 0,2723999024). Figura urmǎtoare ilustreazǎ aceste calcule.
Acum se stabileşte codul număr real. Ar trebui specificat intervalul calculat. S-ar putea memora limitele de sus şi de jos ale intervalului, dar aceasta ar fi o schemǎ ineficientǎ. Ştiind cǎ intervalul în întregime este unic pentru un mesaj, se poate memora în siguranţǎ un singur numǎr din acest interval. Lema urmǎtoare contureazǎ aceastǎ tehnicǎ. Lemă. Codurile tuturor mesajelor de aceeaşi lungime formeazǎ o partitie a intervalului I = [0, 1). Acest rezultat transpare limpede din figura alǎturată. O concluzie a lemei derivǎ din observatia cǎ fragmentele/clasele partiţiei devin infinit de mici pentru mesaje infinit de lungi. În practicǎ nu existǎ mesaje infinit de lungi, dar existǎ mesaje foarte lungi şi partiţiile mǎrunte rezultate pot crea probleme în calculatoarele obişnuite, care utilizeazǎ o aritmetică finită. Soluţia este o operatie de re-scalare.
În exemplul prezentat mai devreme se poate memora 0,27234 sau oricare altǎ valoare din interval. Se admite suplimentar faptul cǎ se cunoaşte plasarea finalului de mesaj, deşi nu acesta este cazul în general (de pildǎ în transmiterea
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

78
la distanţǎ). Manipularea finalului de mesaj este o problemă aparte. Pentru moment este dat un sumar al codǎrii: low =0; high=1; do { temp = read_symbol(); ival = model->get_interval(temp);
\\ returns the interval containing temp low = calculate_lower_bound(ival); high = calculate_upper_bound(ival); } while (!end_of_sequence()); return(value_in_interval(low,high)); Decodarea. Pentru a decoda o secvenţǎ, trebuie parcursǎ codarea cumva în sens invers. Este datǎ valoarea V = Code(S) şi trebuie recuperatǎ secvenţa originarǎ S. Se admite cǎ lungimea mesajului este cunoscutǎ: l. La prima iteraţie se comparǎ V cu fiecare interval I = [K(ak–1), K(ak)) pentru a-l gǎsi pe acela care corespunde primului simbol s1 din secventa S. Pentru a calcula simbolul urmǎtor, trebuie modificatǎ partiţia probabilisticǎ în acelaşi mod în care s-a procedat la codare:
low′ := low + K(ai−1)·(high − low) high′ := low + K(ai)·(high − low)
cu i îndeplinind condiţia low ≤ V ≤ high
şi cu ai simbolul urmǎtor în secvenţa de decodat. Şi de data aceasta, cazul de pornire este caz special în formula generalǎ. Iteratia este foarte asemănǎtoare celei de la codare aşa încât implementarea n-ar trebui sǎ ridice probleme. Exemplu de decodare. Pe acelaşi exemplu de mai sus, codul rezultat era V = 0,27234 şi se presupune cǎ lungimea secventei codate este cunoscutǎ: l = 8. Se porneşte cu low = 0 şi high = 1 şi se observǎ cǎ V se situeazǎ în primul interval [0, 0,5). Simbolul corespunzǎtor este a şi se pun
low = 0 high = 0,5
În iteratia urmǎtoare se observǎ cǎ 0,27234 se plaseazǎ între limitele low = 0 + 0,5·(0,5 − 0) = 0,25
high = 0 + 0,75·(0,5 − 0) = 0,3125 şi se decodeazǎ un b. La iteratia urmǎtoare
low = 0,25 + 0·(0,3125 − 0,25) = 0,25 high = 0,25 + 0,5·(0,3125 − 0,25) = 0,28125
evidenţiazǎ un a. Iteratiile urmǎtoare sunt foarte asemǎnǎtoare. De aceea sunt omise, cu trecerea imediatǎ la ultima iteratie:
low = 0,2723388672 + 0·(0,2724609375 − 0,2723388672) = 0,2723388672 high = 0,2723388672 + 0,5·(0,2724609375 − 0,2723388672) = 0,2723999024
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

79
Aici se identificǎ a-ul final din secvenţa codatǎ abaabcda. Din motive de similitudine, se poate folosi şi aici figura de mai sus, cea cu partiţiile succesive. Algoritmul de decodare poate fi sumarizat astfel: seq = ’’; low = 0; high = 1; do { low’ = model->lower_bound(Value,low,high); high’ = model->upper_bound (Value,low,high); low = low’; high = high’; seq .= model->symbol_in_interval(low,high); } while ( !end_of_sequence() ); return(seq); Pentru a calcula limitele low, high la fircare etapă, s-a utilizat aritmetica în virgulǎ mobilǎ. Dacǎ nu se recurge la mijloace suplimentare, se poate ajunge la numere cu foarte multe cifre dupǎ virgulǎ, chiar infinit de multe (cum este cazul cu 1/3). Numerele de acest gen sunt dificil de manipulat într-o aritmetică finită. Prevenirea unor asemenea situaţii este subiectul paragrafului urmǎtor. Unicitatea reprezentǎrii. Fie pentru ai codul C(ai) definit ca
)(21)()( 1 iMii aPaKaC
C(ai) este centrul intervalului ai. Codul C(ai) poate fi scurtat la lungimea
1)(
1log)(
iMi aP
al
cu logaritmul în baza 2 (se folosesc aici notaţiile şi pentru a extrage dintr-un număr real “” întregul egal sau imediat superior, respectiv întregul egal sau imediat inferior). Se defineşte )()(
ialiaC ca fiind codul pentru ai scurtat la l(ai) digiţi. Exemplu. Fie S = s1s2s3s4 o secvenţǎ pe alfabetul A = {a1, a2, a3, a4}. Fie probabilitǎtile calculate pe baza modelului M
PM(a1) = 1/2, PM(a2) = 1/4, PM(a3) = 1/8, PM(a4) = 1/8 Tabelul urmǎtor aratǎ o codare binarǎ posibilǎ pentru secvenţa propusǎ.
Reprezentarea binarǎ pentru C(ai), dupǎ scurtare la lungimile 1)(
1log
iM aP,
a produs codul din tabel.
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

80
Demonstraţie. Se demonstreazǎ unicitatea codului generat în modul arǎtat. Mai întâi se alege codul C(ai) ca reprezentant al simbolului ai. Dar şi orice altǎ valoare din intervalul [K(ai−1), K(ai)) poate fi definitǎ ca un cod unic pentru ai. Pentru a arǎta cǎ )()(
ialiaC este şi el un cod unic pentru ai este suficient a arǎta că acest cod apartine intervalului [K(ai−1), K(ai)). Deoarece pentru a obtine )()(
ialiaC s-a trunchiat reprezentarea binarǎ a lui C(ai), este satisfǎcutǎ inegalitatea urmǎtoare:
)()(ialiaC ≤ C(ai)
sau mai în detaliu
0 ≤ C(ai) – )()(ialiaC ≤ )(2
1ial
Deoarece C(ai) este prin definitie mai mic decât K(ai) rezultǎ cǎ )()(
ialiaC < K(ai) Pe de altǎ parte
2)(
)(12
1
22
1
2
1
2
12
1
)(1log1
)(1log1
)(1log
)(iM
iM
aPaPaPal
aP
aPiMiMiM
i
Dar prin definiţie
)()(2
)(1 ii
iM aKaCaP
de unde
)(1 21)()(
ialii aKaC
şi )()(
ialiaC ≥ K(ai–1) cu concluzia finalǎ
K(ai–1) ≤ )()(ialiaC < K(ai)
S-a dovedit astfel cǎ )()(ialiaC este o reprezentare pentru C(ai) lipsitǎ de
ambiguitǎţi. Pentru a arǎta cǎ nici la decodare nu apar ambiguitǎţi, trebuie dovedit cǎ acest cod îndeplineste condiţia de prefix. Fe un numǎr x din intervalul [0, 1) şi reprezentarea lui binarǎ x1x2…xn. Este evident cǎ orice alt numǎr y care în reprezentare binarǎ are prefixul x1x2…xn se situeazǎ în intervalul [x, x + 1/2n). Este ştiut cǎ dacǎ simbolurile ai şi aj sunt
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

81
diferite, atunci valorile asociate )()(ialiaC şi )(
)(jaljaC aparţin unor intervale
disjuncte [K(ai−1), K(ai)), respectiv [K(aj−1), K(aj)). Ar trebui arǎtat cǎ pentru orice simbol ai, intervalul
)()()( 2
1)(,)(iii alaliali aCaC
este continut în intervalul [K(ai−1), K(ai)), ceea ce ar face imposibil ca simbolul ai sǎ aibǎ un cod care sǎ fie prefix pentru codul unui alt simbol aj, diferit. O inegalitate stabilitǎ mai devreme
)()(ialiaC ≥ K(ai–1)
sprijinǎ demonstraţia pentru limita inferioarǎ. Este acum suficient a arǎta cǎ
K(ai) – )()( 21)(
ii alaliaC
Inegalitatea aceasta este evidentǎ deoarece
)()( 21
2)()()()()(
ii aliM
iialiiaPaCaKaCaK
Aşadar, codul este liber de prefix. În particular, scurtarea lui C(ai) la l(ai) biţi produce un cod decodabil fǎrǎ ambiguitǎti. S-a rezolvat astfel problema utilizǎrii aritmeticii finite în cazul codurilor în virgulǎ mobilǎ. Codarea ca o secventǎ de biti. Pentru a implementa eficient codarea aritmeticǎ, trebuie ţinut seamǎ de unele restricţii: nu existǎ numere reale infinit de lungi şi implementǎrile cu întregi pure sunt un mod mai rapid de calcul pentru procesoarele de genul celor din faxuri (care utilizeazǎ codarea aritmeticǎ sub protocolul G3). Existǎ cel puţin o implementare care consumǎ foarte putinǎ memorie (un singur registru de 32 de biti pentru limite) şi numai câteva instructiuni simple în numere întregi. Ieşirea este o secvenţǎ de biţi fǎrǎ ambiguitǎti, care poate fi memoratǎ sau expediatǎ din mers. Compresia LZW Compresia LZW işi datorează numele realizatorilor ei, A.Lempel şi J.Ziv (1978) şi Terry A.Welch (1984), cel care a completat lucrarea primilor doi. Din cauza simplitătii şi versatilităţii ei, este tehnica cea mai avansată pentru comprimarea datelor de uz general. Tipic, este de aşteptat ca algoritmul LZW să comprime fişiere text, fişiere executabile şi alte genuri de fişiere similare la circa jumătate din dimensiunea lor înainte de comprimare. Tehnica LZW este deosebit de performantă în cazul fisierelor extrem de redundante, cum sunt tabelele, fişierele sursă, semnalele obtinute prin sistemele de achiziţie de date. Pentru aceste cazuri, rapoarte de compresie de 1:5 sunt foarte uzuale. LZW este baza unor utilităti pentru calculatorul personal care pretind dublarea capacitătii discului. Comprimarea LZW este totdeauna folosită pentru fişierele imagine GIF şi oferă o optiune de luat în considerare pentru fisierele TIFF şi PostScript.
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

82
Compresia LZW utilizează un tabel de coduri precum cel prezentat mai jos. Într-o alegere obişnuită, se asigură un tabel cu 4096 de linii. Datele codate LZW întru comprimare constau în totalitate din numere pe 12 biti, fiecare număr referindu-se la una din poziţiile din tabelul de coduri, un gen de dicţionar. Decomprimarea se execută prin luarea fiecărui cod din fişierul comprimat şi traducerea lui folosind tabelul de coduri, la caracterul sau caracterele pe cale îl/le reprezintă. Codurile de la 0 la 255 din tabelul dat ca exemplu sunt totdeauna atribuite reprezentării caracterelor de un singur byte lungime din fisierul de intrare, cel a cărui comprimare se urmăreşte. De pildă, dacă s-ar utiliza numai aceste prime 256 de coduri, fiecare byte ar fi convertit la 12 biti în fişierul codat LZW, ceea ce ar produce un fişier cu 50% mai mare. În timpul decomprimării fiecare cod de 12 biti din fisierul codat LZW ar fi tradus invers, prin intermediul tabelului cu coduri, în bytes/octeţi unici. Desigur, acest mod de a trata lucrurile nu este de vreo utilitate.
Coduri Traducere 0000 0 0001 1
… … 0255 255 0256 145 201 4 0256 248 245
… …
4095 xxx xxx xxx
Tabel de coduri (exemplu) Metoda LZW realizează compresia prin utilizarea de coduri de la 256 la 4095 pentru a reprezenta secvenţe de bytes. De exemplu, codul 523 poate reprezenta secventa de trei bytes 231 124 134. De fiecare dată când algoritmul de comprimare întâlneşte această secvenţă în fişierul de intrare, în fişierul codat este plasat codul 523. În timpul decomprimării, codul 523 este tradus cu ajutorul tabelului de coduri pentru a re-crea secvenţa originară de trei bytes. Cu cât secvenţa atribuită unui singur cod este mai lungă şi cu cât secventa apare repetată de mai multe ori, cu atât mai importantă este compresia obtinută. Deşi tratarea aceasta pare simplă, sunt două obstacole majore de depăşit: cum se determină secvenţele care trebuie să fie cuprinse în tabelul-dicţionar
de coduri si cum se furnizează programului de decomprimare acelaşi tabel-dicţionar de
coduri utilizat la comprimare. Algoritmul LZW rezolvă strălucit ambele probleme. Când programul LZW începe codarea unui fişier, tabelul de coduri contine numai primele 256 de linii, numai codurile alfabetului de bază. Celelalte echivalenţe rămân a fi completate. Aceasta înseamnă că primele coduri care merg în fişierul comprimat sunt pur şi simplu bytes/octeţi singulari din fisierul
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.
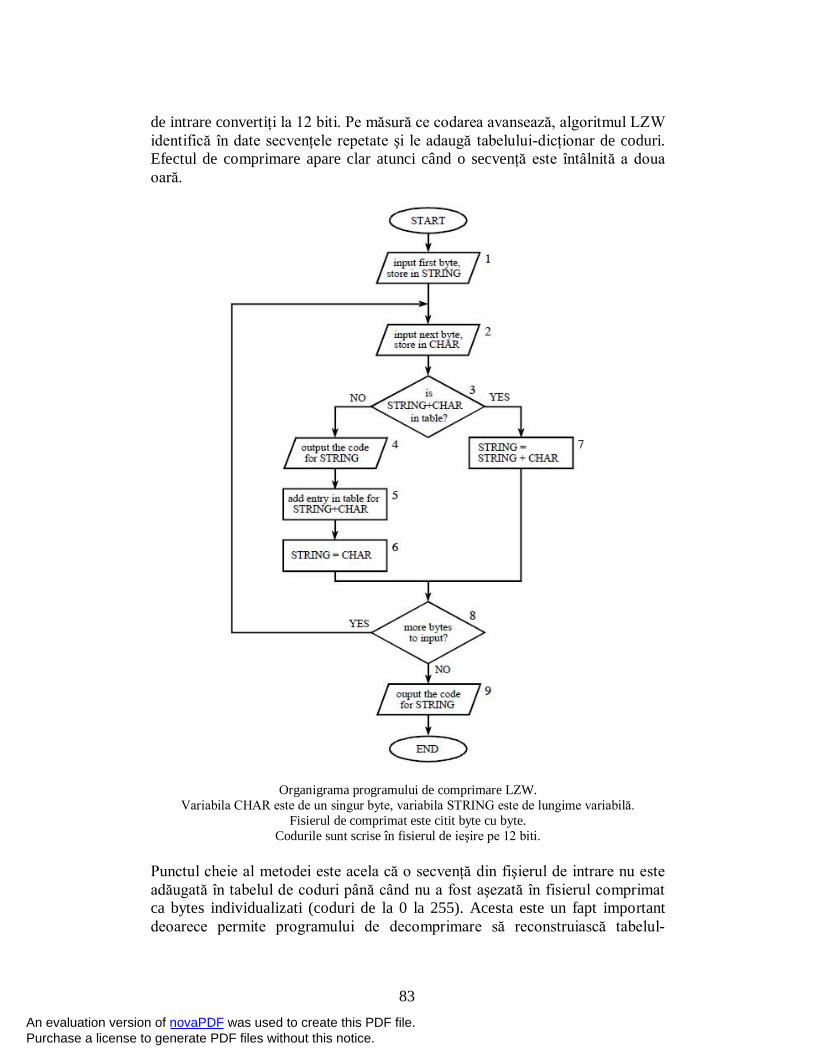
83
de intrare convertiţi la 12 biti. Pe măsură ce codarea avansează, algoritmul LZW identifică în date secvenţele repetate şi le adaugă tabelului-dicţionar de coduri. Efectul de comprimare apare clar atunci când o secvenţă este întâlnită a doua oară.
Organigrama programului de comprimare LZW. Variabila CHAR este de un singur byte, variabila STRING este de lungime variabilă.
Fisierul de comprimat este citit byte cu byte. Codurile sunt scrise în fisierul de ieşire pe 12 biti.
Punctul cheie al metodei este acela că o secvenţă din fişierul de intrare nu este adăugată în tabelul de coduri până când nu a fost aşezată în fisierul comprimat ca bytes individualizati (coduri de la 0 la 255). Acesta este un fapt important deoarece permite programului de decomprimare să reconstruiască tabelul-
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

84
dictionar de coduri din datele comprimate fără a fi necesară transmiterea separată a acelui dicţionar. Figura de mai sus arată schema logică (organigrama) a comprimării LZW. Tabelul care urmează reprezintă pas-cu-pas detaliile algoritmului pentru un fisier de intrare alcătuit din numai 45 de bytes, un text ASCII în limba engleză:
the/rain/in/Spain/falls/mainly/on/the/plain/
CHAR STRING+ CHAR
Este în tabel? Iesire Adaugare
în tabel Noul
STRING Comentarii
1 t t t Nici o actiune 2 h th Nu t 256 = th h 3 e he Nu h 257 = he e 4 / e/ Nu e 258 = e/ / 5 r /r Nu / 259 = /r r 6 a ra Nu r 260 = ra a 7 i ai Nu a 261 = ai i 8 n in Nu i 262 = in n 9 / n/ Nu n 263 = n/ / 10 i /i Nu / 264 = /i i 11 n in Da (262) in Prima potrivire 12 / in/ Nu 262 265 = in/ / 13 S /S Nu / 266 = /S S 14 p Sp Nu S 267 = Sp p 15 a pa Nu p 268 = pa a 16 i ai Da (261) ai ai, în tabel, ain, nu 17 n ain Nu 261 269 = ain n ain adăugat în tabel 18 / n/ Da (263) n/ 19 f n/f Nu 263 270 = n/f f 20 a fa Nu f 271 = fa a 21 l al Nu a 272 = al l 22 l ll Nu l 273 = ll l 23 s ls Nu l 274 = ls s 24 / s/ Nu s 275 = s/ / 25 m /m Nu / 276 = /m m 26 a ma Nu m 277 = ma a 27 i ai Da (261) ai 28 n ain Da (269) ain ain mai lung, în tabel 29 l ainl Nu 269 278 = ainl l 30 y ly Nu l 279 = ly y 31 / y/ Nu y 280 = y/ / 32 o /o Nu / 281 = /o o 33 n on Nu o 282 = on n 34 / n/ Da (263) n/ 35 t n/t Nu 263 283 = n/t t 36 h th Da (256) th 37 e the Nu 256 284 = the e 38 / e/ Da (258) e/ 39 p /p Nu 258 285 = /p p 40 l pl Nu p 286 = pl l 41 a la Nu l 287 = la a
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

85
42 i ai Da (261) ai 43 n ain Da (269) ain 44 / ain/ Nu 269 288 = ain/ /
45 EOF / / EOF, STRING la ieşire
Când algoritmul preia din fisierul de intare caracterul “a” de pildă, el citeste valoarea 01100001 (97 reprezentat pe 8 biţi), codul ASCII pentru “a”. Când scrie caracterul “a” în fişierul codat, scrie de fapt 00000110001 (97 reprezentat pe 12 biti). Algoritmul de comprimare utilizează două variabile: CHAR şi STRING. Variabila CHAR reţine un singur caracter, o valoare între 0 şi 255. Variabila STRING stochează un şir de lungime variabilă, un grup de unul sau mai multe caractere, cu fiecare caracter în calitatea de byte. În pasul 1 din organigrama din figură, programul preia primul byte din fişierul de intrare şi-l plasează în variabila STRING. Tabelul cu operatia de comprimare arată actiunea aceasta în linia 1. Urmează o buclă a algoritmului parcursă pentru fiecare byte din fisierul de intrare, cel de comprimat, cu depozitare în variabila CHAR. Apoi, tabelul de coduri este parcurs în căutarea unei secvente deja depuse, aceeaşi cu STRING+CHAR concatenate (pasul 3). Dacă nu se găseste o potrivire cu vreunul din şirurile din tabel, se execută trei actiuni conform pasşilor 4, 5 şi 6. În pasul 4, se trece în fisierul comprimat codul pe 12 biţi corespunzător şirului STRING. În pasul 5, se crează în tabel un nou cod pentru concatenatul STRING+CHAR. În pasul 6, variabila STRING ia valoarea variabilei CHAR. Un exemplu de astfel de actiuni succesive este arătat în liniile 2 la 10 din tabel, pentru primii 10 bytes/caractere din fisierul exemplu. Când are loc o potrivire între un cod din tabel, concatenatul STRING+CHAR este depus în variabila STRING fără vreo altă actiune (pasul 7). Aşadar, dacă în tabel se identifică o secvenţă care se potriveşte, nu se întreprinde nimic înainte de a stabili dacă vreo secvenţă încă mai lungă se regăseste în tabelul de echivalenţe. Un exemplu se poate vedea în linia 11 din tabel, unde secvenţa STRING+CHAR = in este identificată ca având deja un cod în tabel. În linia următoare, se adaugă la secvenţă caracterul următor din fişierul de intrare, /, şi se caută în tabel secvenţa in/. Secvenţa aceasta mai lungă nu este în tabelul de coduri şi de aceea ea se adaugă în tabel şi se trimite la iesire codul secvenţei mai scurte care este în tabel (codul 262) şi se porneşte de la cap căutarea de secvenţe care încep cu caracterul /. Această derulare de evenimente se continuă până la epuizarea fişierului de intrare. Programul este încheiat cu codul valorii curente din variabila STRING care este scrisă în fişierul comprimat (pasul 9 din figură, linia 45 din tabel).
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

86
Organigrama programului de decomprimare [8]. Variabilele OCODE şi NCODE (oldcode şi newcode) retin codurile pe 12 biti din fisierul
comprimat. CHAR retine un singur byte, STRING retine un sir de bytes.
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

87
Organigrama algoritmului de decomprimare este dată în figura de mai sus. Fiecare cod este citit din fisierul comprimat şi comparat cu tabelul de coduri în scopul traducerii. Pe măsură ce fiecare cod este prelucrat astfel, tabelul-dictionar de coduri este actualizat astfel încât el este mereu reproducerea fidelă până la acea etapă a tabelului folosit la comprimare. Totusi, apare uneori o mică complicatie în rutina de decomprimare. În cazul unor anumite combinaţii de date, algoritmul de decomprimare primeşte un cod care nu există încă în tabelul-dictionar de coduri. O astfel de situatie este rezolvată în paşii 4, 5 şi 6. Pentru cele mai elementare programe bazate pe algoritmul LZW, este necesar numai un număr redus de linii de program. Dificultatea reală se află în administrarea eficientă a tabelului de coduri. Tratarea brută a acestei probleme are ca rezultat un necesar de memorie mare şi o execuţie a programelor lentă. În programele de comprimare LZW comerciale sunt folosite mai multe trucuri, artificii pentru a creste performanţa lor. De pildă, problema memoriei alocate apare deoarece nu se cunoaşte dinainte cât de lung va fi fiecare şir de caractere pentru fiecare cod. Multe programe LZW rezolvă problema aceasta prin exploatarea naturii redundante a tablelului de coduri. De exemplu, să revedem linia 29 din tabelul de mai sus, unde codul 278 este asociat cu şirul ainl. În loc să se memoreze acesti 4 bytes, codul 278 poate fi memorat sub forma codul 269 + l, cu codul 269 deja definit ca asociat cu ain în linia 17. Asemănător, codul 269 s-ar putea memora sub forma codul 261 + n, cu codul 261 asociat mai devreme cu ai în linia 7. Acest mod de tratare funcţionează totdeauna: orice cod poate fi exprimat ca un cod anterior plus un caracter nou. Timpul de execuţie al algoritmului de decomprimare este afectat de căutarea în tabelul de coduri a unei ehivalenţe. Prin analogie, se poate face referire la căutarea numelui unei persoane într-o carte de telefon mai specială, singura la dispozitie, care este ordonată după numărul de telefon şi nu după nume, alfabetic. Această ordine cere o căutare pagină cu pagină pentru a găsi numele dorit. Situatia este la fel de înclinată spre ineficienţă în cazul căutării printre cele 4096 de coduri a unuia care să se potrivească cu un anumit şir de caractere. Răspunsul: organizarea tabelului de coduri astfel încât ceea ce se caută să spună şi unde trebuie căutat (cum ar fi o carte de telefon parţial ordonată alfabetic). Cu alte cuvinte, a nu se atribui cele 4096 coduri în locaţii de memorie una după alta. Mai degrabă se împarte memoria în secţiuni pe baza secvenţelor care vor fi depuse acolo. De pildă, se presupune că se urmăreste în tabel existenţa secvenţei codul 329 + x. Tabelul de coduri trebuie organizat astfel încât x-ul să indice unde trebuie începută căutarea. Sunt multe scheme de acest gen pentru gestionarea tabelelor şi ele tind să devină destul de complicate. Acest aspect aduce în discuţie ultimul comentariu asupra schemelor de comprimare LZW şi similare: este vorba de un domeniu foarte competitiv. Dacă bazele compresiei de date sunt relativ simple, tipurile de programe comerciale de comprimare/decomprimare sunt extrem de sofisticate. Companiile fac bani buni din vânzarea acestor programe şi de aceea protejează cu grijă secretele producţiei prin patente şi altele asemenea. Aşteptarea din partea amatorilor de a realiza aceleaşi performanţe în doar câteva ore de muncă este iluzorie.
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

88
Compresia cu pierdere de informaţie Mai întâi, prin câteva exemple, o scurtă revedere a compresiei fără pierderi. Schema bloc a codării fără pierderi este următoarea:
sursă X = {X1, X2, …} codor B(X) = {B1, B2, …} canal . . .
. . . canal {B1, B2, …} decodor {X1, X2, …} Operatiile de codare şi de decodare reproduc la iesirea din canal secvenţa generată de sursa de informatie. Exemplul 1 ilustrează modul cum poate lucra compresia de date la memorarea sau transmiterea datelor. Se presupune că sursa de date este o imagine digitală oarecare de dimensiunile geometrice 512×512, în 256 de tonuri. Fiecare ton este reprezentat de o valoare a intensităţii din multimea {0, 1, 2, …, 255}. Matematic, această imagine este o structură matricială 512×512, cu elemente din mulţimea mentionată (elemetele se numesc pixeli). Intensitatea cu care este caracterizat fiecare pixel poate fi reprezentată pe 8 biţi. Astfel, dimensiunea informaţională a sursei de date este 8×512×512 = 221 biti, adică circa 2,1 megabytes (MB). Un disc cu capacitatea de 1 GB poate stoca fără compresie, numai vreo 476 imagini de acest gen. Se presupune acum că fiecare din aceste imagini poate fi comprimată de 8 ori (8:1). De data aceasta se pot stoca în acelaşi spaţiu de 1 GB cca. 3800 de imagini. Dacă este necesară transmiterea imaginii necomprimate pe un canal telefonic capabil a prelua 30.000 de biti/secundă, operatia consumă 221/30.000 ≈ 70 de secunde. În versiunea comprimată în raportul 8:1 consumul de timp scade la mai putin de 9 secunde. Exemplul 2 ilustrează cum compresia de date face posibilă transmiterea printr-un canal dat a datelor generate de o sursă chiar şi atunci când în varianta necomprimată acele date nu se pot transmite. Alfabetul sursei este {1, 2, 3, 4}. Fiecare generare a unui simbol Xi este modelată de o variabilă aleatoare cu distributia
Pr(1) = 8/15, Pr(2) = 4/15, Pr(3) = 2/15, Pr(4) = 1/15. Sursa generează un simbol la fiecare milisecundă. Canalul are capacitatea de 1,75 biti/milisecundă. Se admite că nu se face o comprimare. Se utilizează un cod fără compresie
1 → 00, 2 → 01, 3 → 10, 4 → 11. Rata de iesire a codorului este de 2 biti/milisecundă şi este mai mare decât capacitatea canalului. Aşadar, datele nu pot fi transmise prin canalul dat fără o prealabilă comprimare. Se presupune acum că se recurge la un alt codor care face codarea
1 → 0, 2 → 10, 3 → 110, 4 → 111. Numărul mediu statistic de biti pe simbol al codului este în acest caz
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

89
1∙Pr(1) + 2∙Pr(2) + 3∙Pr(3) + 3∙Pr(4) = 5/3. Cu acest codor, rata de iesire obtinută este de numai 1,67 biti/milisecundă şi este sub capacitatea de 1,75 a canalului. Codul cel nou asigură transmiterea fără probleme a informatiei prin canalul dat. Exemplul 3. Fie o imagine 4×4 în 4 culori, R, O, Y, G (Red, Orange, Yellow, Green). Se supune compresiei.
R R O Y R O O Y O O Y G Y Y Y G
Prin scanarea pe orizontală a acestei imagini, prin asocierea “intensitătilor” 3, 2, 1, 0 culorilor R, O, Y, G, respectiv, imaginea se poate reprezenta prin vectorul X = (3, 3, 2, 1, 3, 2, 2, 1, 2, 2, 1, 0, 1, 1, 1, 0). Vectorul se comprimă conform tabelului
Codare Intensitate Cuvânt de cod
3 001 2 01 1 1 0 000
Înlocuirea intensitătii fiecărui pixel cu codul binar din tabel conduce la secventa binară
B(X) = 0010010110010101101011000111000 Raportul de compresie este r = 32/31 sau 1,0323:1. Primul număr, 32 face trimitere la codarea banală prin 2 biti pe pixel, codare posibilă deoarece numărul de simboluri ale alfabetului sursei este 4 şi log24 = 2. Exemplul 4 face o comparatie între două codări diferite pentru vectorul de date
X = ABRACADABRA Primul codor este fără memorie ca în exemplul anterior (cu alte cuvinte simbolurile cuprinse în vectorul X sunt codate independent unul de altul) şi rezultatul este cuprins în tabelul următor
Codarea I Caracter Cuvânt de cod
A 0 B 10 R 110 C 1110 D 1111
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

90
Al doilea codor ia în considerare şi simbolul precedent în afară de cel curent, pentru a determina codul pentru acesta din urmă (uzează de o fereastră glisantă de lărgime 2):
Codarea II Caracter, caracter premergător Cuvânt de cod
A, − 1 B, A 0 C, A 10 D, A 11 R, B 1 A, R 1 A, C 1 A, D 1
Cele două modalităti de codare conduc la secventele binare
B1(X) = 01011001110011110101100 B2(X) = 1011101111011
Ratele în biti/simbol sunt foarte diferite: 23/11, respectiv 13/11. Codorul al doilea pare a face o treabă mult mai bună. Exemple de codare cu pierderi:
sursă X = {X1, X2, …} cuantificator x = {x1, x2, …} codor . . .
. . . codor B(x) = {B1, B2, …} decodor x = {x1, x2, …} Exemplul 5. Vectorul de date
X = (0,8 1,2 1,0 1,8 1,2 1,4 1,6 1,6 1,4 1,8 2,7 2,8 1,7 2,6 3,7 3,6) este cuantificat prin rotunjire şi prin aceasta devine
x = (1 1 1 2 1 1 2 2 1 2 3 3 2 3 4 4) Codorul fără memorie propus imediat
Codare Eşantion cuantizat Cuvânt de cod
1 00 2 01 3 10 4 11
produce iesirea
B(x) = 00000001000001010001101001101111
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

91
Rata codului R şi distorsiunea D introdusă de acest cod se calculează cu relaţiile R = (lungimea lui B(x))/16 = 32/16 = 2 biti/simbol
D = ||X – x||2/16 = 0,0919 Exemplul 6. O imagine 256×256 este alcătuită din 65536 pixeli Xi,j (i, j = 1, 2, …, 256). Intensitatea fiecărui pixel Xi,j este considerată o variabilă aleatoare distribuită uniform pe alfabetul {0, 1, 2, …, 255}. Imaginea se comprimă cu pierderi prin cuantizarea şi codarea intensităţilor astfel:
Xi,j jiX ,ˆ Cuvânt de cod
0 – 31 15,5 000 32 – 63 47,5 001 64 – 95 79,5 010
96 – 127 111,5 011 128 – 159 143,5 100 160 – 191 175,5 101 192 – 223 207,5 110 224 – 255 239,5 111
Rata codării este R = 3 biti/pixel. Distorsiunea D se calculează ca o medie statistică a pătratelor diferenţelor între informatia generată şi informatia receptionată.
D = ]310|)ˆ[(])ˆ[( ,2
,,2
,, jijijijiji XXXEXXE
=
31
0
2)5,15(321
kk = 85,25
Aceeaşi tehnică poate fi utilizată pentru codarea imaginii la alte rate R = 0, 1, 2, …, 8. La fiecare rată R se divid valorile de la 0 la 255 în părti egale, de 256/2R niveluri fiecare. Apoi se asociază fiecare Xi,j la valoarea mediană a fiecărei părti/grupe de care apartine. Ieşirea codorului constă în cei R biti care se identifică cu grupa de care Xi,j apartine. Se poate verifica următoarea formulă pentru distorsiunea D(R), dependentă de aceste rate R:
R
kR
R
kRD
2256
12256
21
)(
12/256
0
2
, R = 0, 1, 2, …, 8
Perechile rată-distorsiune se pot grupa într-un tabel
R 0 1 2 3 4 5 6 7 8 D(R) 5461,25 1365,25 341,25 85,25 21,25 5,25 1,25 0,25 0
sau se pot reprezenta grafic. Graficul ilustrează dependenţa distorsiune-rată la asa-numita diviziune în timp. Dacă punctele sunt unite cu o linie frântă, atunci, de pildă, punctul (3,D(3)) + (1 – )(4,D(4)) pentru 0 < < 1 reprezintă
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

92
perechea rată-distorsiune pentru 100% pixeli cuantizati şi reprezentati pe 3 biti şi 100(1 – )% pixeli cuantizati şi reprezentati pe 4 biti.
0 1 2 3 4 5 6 7 80
1000
2000
3000
4000
5000
6000
Rata (biti/pixel)
Dis
tors
iune
a
Orice pereche rată-distorsiune (R, D) pe curbă sau deasupra ei se poate obtine prin codarea cu pierdere de informatţie. Cu alte cuvinte, fiind dată o pereche (R, D) pe curbă, există o schemă de codare cu rata de compresie superioară lui R şi cu o distorsiune mai mare decât D. Astfel de curbe rată-distorsiune sunt suportul compresiei la sursă, cu pierderi de informatie. Prin examinarea unei curbe rată-distorsiune se pot identifica imediat perechile rată-distorsiune care pot fi obtinute printr-o codare la sursă, cu pierderi şi se poate observa şi înţelege mai bine compromisul între rată şi distorsiune la codarea cu pierderi a unei surse. Cum se obtine o curbă care separă toate perechile rată-distorsiune fezabile (de deasupra curbei) de cele de neatins (situate toate sub curbă) este un alt subiect. Cea mai bună curbă rată-distorsiune de acest gen se numeste functia rată-distorsiune a sursei de informatie. Codarea rată-distorsiune Codarea rată-distorsiune este o notiune sinonimă cu codarea sursei cu pierderi de informaţie sau adesea cu cuantizarea vectorială. Se admite o anumită distorsiune, o diferentă între secventa generată de sursă Xn şi versiunea ei codată nX , adică se admite numai o egalitate aproximativă între
nX şi Xn. Apar aici două probleme echivalente: Fiind date o sursă (prin distributia ei) şi o măsură a distorsiunii care este distorsiunea medie minimă D care se poate atinge pentru o rată
dată R?
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

93
care este rata minimă R la care se poate obtine o distorsiune medie D dată? O întrebare mai cuprinzătoare: ce perechi (R, D) pot fi realizate practic? Codarea rată-distorsiune se poate aplica atât pentru surse discrete cât şi pentru surse continue. Un exemplu simplu: cuantizarea unei variabile aleatoare gaussiene X ~ N(0, 2). Variabila X trebuie reprezentată folosind R biţi pe eşantion, adică prin numai aproximativ N = 2R valori. Măsura distorsiunii poate fi eroarea pătratică. Atunci, trebuie stabilite valorile de diviziune a domeniului de definitie, {x1, …, xN+1} şi valorile aproximante {y1, …, yN} care să minimizeze media pătratelor diferenţelor între valorile reprezentate şi valorile care le reprezintă:
N
i
x
xi
i
i
dxyxxfXXE1
221
))(()ˆ(
Solutia generală se poate obtine pa calea
1...,,1,0)ˆ( 2 NiXXExi
NiXXEyi
...,,1,0)ˆ( 2
ceea ce conduce la xi = (yi + yi – 1)/2 (conditia de vecin-cel-mai-apropiat)
şi
1
1
)(
)(i
i
i
ix
x
x
xi
dxxf
dxxxfy (conditia de centroid)
Pentru R = 1
02
02
ˆx
xx
şi distorsiunea medie minimă 22*
D
Măsuri ale distorsiunii Fie Xn = (X1, …, Xn) o secvenţă de variabile aleatore independente şi identic distribuite (i.i.d.) cu Xi ~ p(x) şi Xi X (alfabetul sursei). Fie )ˆ...,,ˆ(ˆ
1 nn XXX secvenţa reproductivă cu XX i
ˆˆ (alfabetul care reproduce aproximativ sursa). Câteva exemple:
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

94
Distorsiunea Hamming
xxxx
xxdˆ0ˆ1
)ˆ,(
Distorsiunea eroare absolută |ˆ|)ˆ,( xxxxd
Distorsiunea eroare pătratică 2)ˆ()ˆ,( xxxxd
Distorsiunea pentru două secvente, xn şi nx se defineste astfel:
n
iii
nn xxdn
xxd1
)ˆ,(1)ˆ,(
adică media aritmetică a distorsiunilor pe fiecare simbol, pe fiecare literă. Pentru distorsiunea eroare pătratică, de pildă,
2
1
2 ||ˆ||1)ˆ(1)ˆ,( ii
n
iii
nn xxn
xxn
xxd
Revenim acum la codarea rată-distorsiune. În figura alăturată
Xn = (X1, …, Xn) este o secvenţă de n variabile aleatoare i.i.d. (un vector aleator n-dimensional). Distribuţiile Xi ~ p(x) pot fi discrete sau continue. Pentru simplitate se consideră aici variabile aleatoare discrete. Extinderea la variabile aleatoare continue este practic imediată. Componentele Xi aparţin unui alfabet discret al sursei, X. Definiţie: Un cod rată-distorsiune (N, n) (un cuantizor vectorial) cu rata R = (log2N)/n constă în: o aplicaţie de codare
}...,,1{: NXf nn
(o aplicatie many-to-one deoarece |Xn| ≥ N). o aplicaţie de decodare
nn XNg }...,,1{:
cu )}(ˆ...,),1(ˆ{ˆ NXXX nnn un dicţionar al codului (o aplicaţie biunivocă). Notă: Pentru n mare, aproximativ 2nH(X) secvenţe de intrare aplicate pe 2nR secvenţe de ieşire (R ≤ H(X)). f – 1(1), …, f – 1(N) sunt mulţimi sau regiuni de atribuire. Dacă Xi sunt variabile aleatoare discrete, atunci f – 1(∙) sunt mulţimi de secvenţe; dacă sunt continue atunci sunt volume în Rn.
Xn nX I {1, 2, …, N} Codor fn
Decodor gn
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

95
Distorsiunea medie a codului D = E[d(Xn, gn(fn(Xn)))] =
nx
nnn
nn xfgxdxp )))((,()(
Definitie: O pereche rată-distorsiune (R, D) este accesibilă dacă se poate găsi o secvenţă de coduri (fn, gn) de rată-distorsiune (2nR, n) astfel încât
limn → ∞E[d(Xn, gn(fn(Xn)))] ≤ D cu alte cuvinte, prin creşterea lungimii secvenţei (dimensiunii vectorului), se pot găsi coduri cu distorsiunea medie nu mai mare decât D şi cu rata nu mai mare decât R. Observatie: Dacă perechea (R, D) este accesibilă, atunci (R’, D) şi (R, D’) sunt de asemenea accesibile oricare ar fi R’ ≥ R şi D’ ≥ D. Regiunea rată-distorsiune pentru o sursă şi o măsură a distorsiunii date este mulţimea (închisă) a tuturor perechilor (R, D) accesibile. Funcţia rată-distorsiune R(D) pentru o sursă dată, pentru o măsură a distorsiunii şi o distorsiune D este rata minimă R pentru care (R, D) este în regiunea rată-distorsiune. Funcţia distorsiune-rată D(R) pentru o sursă dată, pentru o măsură a distorsiunii şi o rată R este distorsiunea minimă D pentru care (R, D) este în regiunea rată-distorsiune. Observaţie: Functia R(D) şi functia D(R) sunt descrieri echivalente ale frontierei regiunii rată-distorsiune. Proprietăţi ale functiei R(D) R(D) este necrescătoare. R(D) este convexă. Fie *x estimarea cea mai bună a lui X pe baza cunoştintelor a priori asupra
probabilităţilor p(x). Atunci, R(D) = 0 pentru D ≥ D*, unde D* = E[d(X, *x )].
R(0) = H(X). Funcţia rată-distorsiune şi informaţia Fiind dată o sursă X ~ p(x) şi o măsură a distorsiunii d(x, x ) şi o valoare a distorsiunii D ≥ 0
)ˆ;(min)( )]ˆ,([:)|ˆ()( XXIDR DXXdExxp
I
altfel exprimat, se minimizează )ˆ,( XXI peste toate multimile reproductive X care satisfac
Dxpxxpxxdx x
)()|ˆ()ˆ,(
Canalul ipotetic arată ca în figură.
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

96
Observatie: Deoarece X este o fumcţie deterministă de X, )ˆ()ˆ,( XHXXI . Teorema rată-distorsiune: Functia rată-distorsiune R(D) pentru o anumită sursă este egală cu functia rată-distorsiune informatională R(I)(D), adică rata minimă R la care poate fi atinsă distorsiunea medie D este R(I)(D). Accesibilitate: Toate perechile (R, D) pentru care R ≥ R(I)(D) sunt accesibile. Reciproc, orice cod rată-distorsiune cu distorsiunea medie inferioară lui D trebuie să aibă R ≥ R(I)(D). Demonstrarea reciprocei acestei teoreme: Se observă mai întâi că
NXH n2log)ˆ(
)ˆ()ˆ,( XHXXI
n
iii
nn XXdEn
XXdE1
)]ˆ,([1)]ˆ,([
Apoi,
iii
I
iii XXdERXXInR )]ˆ,([)ˆ,( )(
Deoarece R(I)(D) este o funcţie convexă, utilizând inegalitatea lui Jensen
)()ˆ,()ˆ,(1 )()(
1
)( DnRXXEdnRXXEdn
nRnR InnIn
iii
I
Exemple de funcţii R(D) : 1. Sursă Bernoulli şi distorsiune Hamming:
P(X = 0) = p, P(X = 1) = 1 – p De observat că Dmax = min{p, 1 – p}.
R(D) =
max
max220
0)()(DD
DDDHpH
2. Sursă gaussiană şi distorsiune eroare pătratică: X ~ N(0, 2)
De observat că Dmax = 2.
max
max
2
2
0
0log21
)(DD
DDDDR
Pentru sursa gaussiană D(R) = 22 – 2R
adică fiecare bit descriptiv suplimentar reduce distorsiunea medie cu un factor de 4 (6 dB). Pentru R = 1 (cuantizare pe un bit), D(1) = 0,25 2. Se consideră acum cuantizarea (scalară) unidimensională (n = 1) şi se demon-strează că E[d(X, X )] = 0,3633 2.
DXXdEX )]ˆ,([|ˆ X ~ p(x) )|ˆ( xxp
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

97
De unde diferenta? (Demonstrarea accesibilităţii cere ca n → ∞) 3. Sursă Gauss-Markov:
Xn = Xn – 1 + Wn în care 0 < ≤ 1 şi Wn este o secventă gaussiană i.i.d. Pentru R ≥ log2(1 + ) (altminteri nu există o formă închisă)
D(R) = (1 – 2) 2 2 – 2R De observat ce se întâmplă când → 1. 4. Calculul functiei R(D) în general se face după algoritmul Blahut-Arimoto
(optimizarea numerică a transinformatiei I(X, X ), aceeaşi utilizată în cazul calculului capacitătii canalelor).
Codarea R-D este o acoperire cu sfere. Se consideră codarea pentru o sursă X ~ N(0, 2) cu minimizarea MSE (erorii medii pătratice). Toate secventele sursei Xn Rn se situează în interiorul unei hipersfere de rază
2n . Fiecare cuvânt de cod este un punct în această (hiper)sferă. La rata R se codează 2nR astfel de puncte. Apoi, toate secventele sursei codate într-un anumit cuvânt de cod la o distorsiune de cel mult D este o sferă de rază nD centrată pe acel cuvânt de cod. Numărul minim M al cuvintelor de cod necesare asigurării unei distorsiuni inferioare cel mult egale cu D este numărul de sfere de rază 2n necesare pentru a acoperi o sferă de rază nD :
2
22
)()(2
nDnM nR
DR
2
log21
(în contrast cu “împachetarea” în sfere pentru codarea în cazul canalului gaussian). Descrierea simultană a variabilelor independente gaussiene: Fiind dată o rată a bitilor totală R, cum se pot aloca acesti biţi unei multimi de variabile aleatoare gaussiene X1, …, Xm astfel încât MSE (eroarea medie pătratică) totală să fie minimizată? Se minimizează
m
iiDD
1
supusă la restricţiile
RRm
ii
1 şi Ri ≥ 0, i = 1, …, m
Termenii din suma de minimizat sunt ])ˆ[( 2
iii XXED
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

98
Deoarece X1, …, Xm sunt variabile gaussiene independente, este uşor de arătat că
i
ii
iimm DRXXhXhXXI )()]ˆ|()([)ˆ;( ,
în care
i
ii D
DR2
log21)(
Prin codarea independentă a fiecărei componente Xi şi prin utilizarea unor valori ),0(~ˆ 2 DNX ii se pot obtine egalităţile în expresia cu inegalităti de mai sus, adică
i
imm
XXfm DRXXIDR mm )()ˆ;(min)( )|ˆ(
)(
De acum, se cere aflarea unui set de puncte (R(Di), Di), i = 1, …, m, astfel încât iR(Di) = R şi suma iDi să fie minimă. De observat că şi Ri = R(i
2) = 0 poate fi o soluţie. Se presupune că toţi Xi au Di < i
2, adică iRii eD 22 şi Ri > 0.
Atunci se urmăreşte stabilirea unor (R1, ..., Rm) astfel încât să aibă loc
i
RiRR
i
me 22
...,,1min
în conditiile restrictive iRi – R = 0, cu toti Ri > 0. Lagrangeanul este
RReRRJ
ii
i
Rim
i 221 )...,,(
Apoi,
0
iRJ , i = 1, …, m
dau iR
i e 22
2
pentru orice indice i. Rezultă regula alocării bitilor astfel încât toate variabilele să aibă distorsiunea ’ egală. Dar ’ trebuie să satisfacă relatia
Ri
i
2
log21
de unde Re 22
în care 2 este media geometrică a dispersiilor 12, …, m
2 şi mRR / este rata medie pe variabilă.
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

99
Acum, dacă ’ > i2 pentru vreun indice i, atunci solutia nu este validă. Se
ignoră Xi (se pune Ri = 0) şi se repetă procedura de mai sus până când rămâne o mulţime de variabile pentru care ’ < i
2. Aceasta este problema umplerii-cu-apă cu răsturnare.
Se alocă biţi numai acelor variabile care nu sunt sub nivelul apei . Teorema separării sursă-canal: Secventa Vn de variabile i.i.d. poate fi transmisă cu distorsiunea medie D printr-un canal fără memorie cu capacitatea C dacă şi numai dacă C > R(D).
Reciproc: Pentru o distorsiune D, rata R(D) trebuie să fie inferioară capacitătii C a canalului. Codarea rată-distorsiune optimă (cuantizarea vectorială) urmată de o codare de canal optimă este asimptotic optimă (cu n) în ansamblul ei. Exemplu: Care este distorsiunea minimă care poate fi atinsă pentru o sursă i.i.d. gaussiană cu dispersia 2 pe un canal binar simetric (BSC) cu probabilitatea de eroare p?
2i
21
D1
D2
D3
24
D4
D5
X1 X2 X3 X4 X5
Vn Xn(Vn) Canal de
capacitate C Yn nV
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

100
CRIPTAREA Primalitatea numerelor întregi În teoria numerelor se recunoaşte unanim complexitatea a douǎ probleme de calcul foarte importante şi foarte legate una de alta: Primalitatea: Fiind dat un întreg, este el prim? Factorizarea: Fiind dat un întreg, care sunt factorii primi ai acestuia? Evident, calitatea de a fi prim a unui numǎr întreg (primalitatea) nu poate fi mai dificil de stabilit decât factorii lui, deoarece dacǎ se cunoaşte cum se stabileşte un factor, ar trebui sǎ se cunoascǎ şi cum se face testarea primalitǎtii. Ceea ce este surprinzǎtor dar fundamental – şi baza criptografiei moderne – este cǎ problema primalităţii este uşoarǎ în timp ce factorizarea este dificilǎ! Cum se ştie, primalitatea poate fi rezolvatǎ trivial într-un timp O(x) – de fapt sunt de testat numai factorii eventuali care sunt ca valoare sub rădăcina pătrată a lui x. Dar, e limpede, algoritmii aceştia sunt exponenţiali – exponenţiali în numǎrul n de biţi ai lui x, o mǎsurǎ mai precisǎ şi mai plinǎ de sens a dimensiunii problemei (vǎzut astfel, timpul de rulare a algoritmului devine respectiv O(2n), O(2n/2)). În fapt, urmarea acestei linii (de testare a din ce în ce mai puţini factori) nu duce nicǎieri: deoarece factorizarea este dificilǎ, singura speranţǎ de a gǎsi un algoritm rapid pentru primalitate este de a cǎuta unul care sǎ decidǎ dacǎ un numǎr n este sau nu prim fǎrǎ a evidenţia neapǎrat un factor al lui n, în cazul în care rǎspunsul este negativ. Imediat, este descris un astfel de algoritm. Acest algoritm se bazeazǎ pe faptul urmǎtor relativ la exponenţierea modulo un-numǎr-prim. Teorema 1 (Mica teoremǎ a lui Fermat): Dacǎ p este numǎr prim, atunci pentru orice a ≠ 0 mod p are loc a p – 1 = 1 mod p. Demonstraţie: Se considerǎ toate numerele nenule modulo p, = {1, 2, …, p – 1}. Acum, dacǎ se ia un număr a din aceastǎ mulţime şi dacǎ se multiplicǎ toate numerele din cu a modulo p, se obţine o altǎ multime a = {a1, a2, …, a(p – 1)}, toate modulo p. Se poate afirma cǎ toate cele p – 1 numere din a sunt distincte şi în consecintǎ a = . Ca demonstraţie, dacǎ ai = aj mod p, atunci, prin multiplicarea ambilor membri cu a– 1 mod p (deoarece p este prim şi a ≠ 0 mod p se stie cǎ a are un invers) se obtine i = j. Prin urmare, produsele x
x
şi axx sunt egale, adicǎ
(a1).(a2)….(a (p – 1)) = 12…(p – 1) mod p Acum, prin multiplicarea egalitǎtii cu 1–1 mod p, apoi cu 2–1 mod p ş.a.m.d. pânǎ la (p – 1)–1 mod p se obtine teorema.
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

101
Teorema 1 sugereazǎ un test de primalitate pentru p: se ia un numǎr a ≠ 0 mod p şi se ridicǎ la puterea a (p – 1) modulo p. Dacǎ rezultatul nu este 1, atunci ştim cǎ p nu este prim. Dar dacǎ a p – 1 = 1 mod p? Putem fi siguri cǎ p este prim? Nu! Vor exista totdeauna numere a care satisfac ecuatia (1 şi p – 1 sunt douǎ exemple foarte la îndemânǎ). Reciproca teoremei 1 nu este adevǎratǎ. Tot ce se poate dovedi este cǎ: Teorema 2: Dacǎ x nu este prim şi dacǎ x nu este un numǎr Carmichael1 atunci pentru cele mai multe numere a ≠ 0 mod x, a x – 1 ≠ 1 mod x. Teorema (a cǎrei demonstratie ar fi un pic deturnantǎ la acest moment) este o reciprocǎ slabǎ a teoremei 1: ea spune cǎ dacǎ x este compus (are şi alţi factori înafară de 1 şi x) şi dacǎ x se întâmplǎ a fi printre excepţiile extrem de rare numite numere Carmichael, atunci testul de primalitate sugerat de mica teoremǎ a lui Fermat vorbeşte despre faptul cǎ x nu este prim, cu probabilitate de 50%. Discutia de mai sus sugereazǎ urmǎtorul algoritm randomizat pentru primalitate: algorithm prime(x) repeat K times: pick an integer a between 1 and x at random if a x – 1 ≠ 1 mod x then return (“x is not a prime”) return (“with probability at least 1 – 2–K, x is either a prime or a Carmichael number”) Probabilitatea de corectitudine reclamatǎ este uşor de probat: dacǎ x nu este nici prim şi nici numǎr Carmichael, atunci teorema 2 spune cǎ fiecare exponenţiere va expune aceasta cu o probabilitate de cel putin 0,5. Deoarece toate aceste K încercǎri sunt independente (adicǎ se alege de fiecare datǎ a fǎrǎ a interesa valorile a anterioare), probabilitatea ca toti K sǎ eşueze în a expune x este 2–K. Luând K = 100 (şi reamintind cǎ numerele Carmichael sunt extrem de rare), se stabileste primalitatea la un grad de încredere (0,999… pânǎ la treizeci de nouǎ) care depǎseste toate celelalte aspecte ale vieţii şi calculelor. Pentru a face un test se consumǎ O(Kn3) pasi, unde n este numǎrul de biţi ai lui x, deoarece el constǎ în K exponenţieri. Incidental, existǎ un algoritm aleator de detectare de numere Carmichael, întrucâtva mai elaborat, astfel existǎ un algoritm aleator polinomial pentru primalitate. Acel algoritm mai elaborat nu este discutat aici. Numerele prime nu sunt numai uşor de detectat dar sunt şi relativ abundente: Teorema 3 (Teorema numerelor prime): Numǎrul de numere prime între 1 şi x este de circa x/lnx (cu alte cuvinte, dacǎ se ia un numǎr aleator cu D digiţi 1 Un numǎr c este un numǎr Carmichael dacǎ nu este prim şi încǎ pentru toti divizorii primi ai lui c cu d > 1 se întâmplǎ astfel cǎ d – 1 sǎ dividǎ pe c – 1. Cel mai mic numǎr Carmichael este 561 = 3.11.17 (se observǎ, desigur, cǎ 3 – 1, 11 – 1 şi 17 – 1 divid fiecare pe 561 – 1). Dacǎ c este un numǎr Carmichael şi a este relativ prim cu c, atunci ac – 1 = 1 mod c. Puteti demonstra asta?
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

102
zecimali, şansa ca acel număr sǎ fie prim este putin mai micǎ de 1 la 2D (una din circa 26 de persoane are codul numeric personal numǎr prim). Teorema numerelor prime este un fapt dintre cele fundamentale în matematici şi este foarte greu de demonstrat. Dar împreunǎ cu algoritmul de mai devreme, ea ne abiliteazǎ sǎ gǎsim uşor numere prime mari (încercaţi câteva şi retineţi unul care verificǎ conditia de primalitate) şi acesta este ingredientul cheie al algoritmului RSA. Un alt ingredient este varianta urmǎtoare a teoremei 1: Teorema 4: Dacǎ p şi q sunt prime, atunci pentru orice a ≠ 0 modulo pq avem a(p – 1)(q – 1) = 1 modulo pq. Demonstratia teoremei 4 este aceeaşi cu aceea a teoremei 1 cu excepţia faptului cǎ se considerǎ multimea tuturor numerelor 1, 2, …, pq – 1 care sunt relativ prime cu pq. Se observǎ cǎ existǎ (p – 1)(q – 1) astfel de numere – ca verificare, unul din fiecare p numere între 0 şi pq este divizibil cu p şi unul din fiecare q numere este divizibil prin q şi pq(1 – 1/p)(1 – 1/q) = (p – 1)(q – 1). Exemplu: Fie p = 3 şi q = 5. Dintre toate numerele modulo pq = 15, şi anume {0, 1, 2, …, 14}, o treime sunt divizibile cu 3 ({0, 3, 6, 9, 15}) şi din cele 10 rǎmase o cincime sunt divizibile cu 5 ({5, 10}). Toate numerele rǎmase, în numǎr de (p – 1)(q – 1) = 8 ( = {1, 2, 4, 7, 8, 11, 13, 14}) sunt prime cu 15 şi prin urmare ele au toate un invers modulo 15. Aceasta face posibilǎ demonstratia teoremei 1 prin luarea lui a oricare dintre aceste 8 numere. Criptografia şi algoritmul RSA (Rivest, Shamir, Adleman) Criptografia se ocupǎ de scenarii de genul urmǎtor: douǎ persoane A şi B doresc sǎ comunice în prezenţa unei alte persoane deosebit de curioase E. Se presupune cǎ A vrea sǎ trimitǎ lui B mesajul x. Criptografia oferǎ soluţii în forma urmǎtoare: A calculeazǎ o funcţie de x, e(x), utilizând o cheie secretǎ şi trimite e(x) pe canalul ascultat (şi) de E. B primeşte e(x) şi prin utilizarea cheii sale (care în criptografia tradiţionalǎ este aceeaşi cu cheia deţinută de A, dar în criptografia modernǎ este diferită) calculeazǎ o funcţie d(e(x)) = x, recuperând astfel mesajul. Se prezumǎ cǎ E este incapabil sǎ recupereze x din e(x) deoarece nu are cheia. O metodǎ criptograficǎ clasicǎ constă în substituirea de litere. A şi B au cǎzut de acord asupra unei permutǎri de litere A, …, Z şi un mesaj m = a1a2…an alcǎtuit din n litere devine e(m) = (a1)(a2)…(an). În pofida faptului cǎ existǎ 26! chei posibile, acesta este un sistem de criptare foarte slab, expus la atacul evident prin frecvenţa literelor. Cu concursul calculatoarelor, criptografii pot crea sisteme de criptare în care sunt substituite blocuri întregi de litere (sau biţi), rezistente astfel la atacul prin frecvenţe. Cel mai de succes dintre ele este Data Encryption Standard (DES), o metodǎ de criptare sponsorizatǎ de guvernul american, propusǎ în 1976. DES utilizeazǎ o cheie pe 64 de biti (pentru codarea fişierelor mai mari, acestea se sparg în blocuri de 8 biti). Cei care au propus DES pretind cǎ este sigur. Sunt şi detractori care-l suspecteazǎ cǎ la modul subtil nu este atât de sigur.
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

103
Dimensiunea cheii de 56 de biti este în general consideratǎ inadecvatǎ pentru criptografia serioasǎ, deoarece 256 nu mai este un numǎr mare. Cam la acelaşi moment când DES a fost inventat, a fost propusǎ o idee nouǎ foarte atractivǎ: criptografie cu cheie publicǎ (public-key cryptography). Persoana B ar avea douǎ chei, cheia sa privatǎ kd, cunoscutǎ numai de el, şi cheia lui publicǎ, kc. (Poate cǎ este sugestiv a considera kc un gen de lacǎt şi kd o cheie a lacǎtului.). kc este cunoscutǎ tuturor – este pe pagina gazdǎ (home psge) a lui B, de pildǎ. (Continuând cu metafora oarecum dubioasǎ cu care am început, este ca şi cum ar exista mai multe cópii ale lacǎtului, cu care oamenii pot închide cutii care conţin mesaje trimise lui B.) Dacǎ cineva, de pilǎ A, doreşte sǎ trimitǎ un mesaj x lui B, atunci îl cripteazǎ sub forma e(x) care utilizeazǎ cheia publicǎ. B decripteazǎ pe e(x) folosindu-se de cheia sa privatǎ. Partea inteligentǎ este cǎ (1) decriptarea este corectǎ, adicǎ d(e(x)) = x şi (2) nu se poate calcula fezabil cheia privatǎ a lui B din cheia lui publicǎ sau x din e(x), astfel cǎ protocolul este sigur (exact cum nu existǎ o cale de a imagina cheia pentru un lacǎt bun). RSA – de la iniţialele numelor a celor trei cercetǎtori (Ron Rivest, Adi Shamir şi Len Adleman) care l-au inventat – este un mod inteligent de a realiza ideea de cheie publicǎ. Iatǎ cum lucreazǎ aceasta: Generarea cheii. B stabileşte douǎ numere prime mari, p şi q. (mare în
zilele noastre înseamnă câteva sute de digiţi zecimali, foarte curând ar putea să însemne peste o mie). Pentru a gǎsi asemenea numere, B genereazǎ repetat întregi din aceastǎ gamǎ şi îi supune testului Fermat pânǎ când douǎ din ele trec testul. Apoi B calculeazǎ n = pq. De asemenea, B genereazǎ la întâmplare un întreg e < n, cu singura restricţie de a fi prim cu (p – 1) şi cu (q – 1). Perechea (n, e) este cheia publicǎ a lui B şi o face cunoscutǎ. (Practic, pentru a face codarea mai uşoarǎ (a se vedea mai jos), e este adesea luat 3. Desigur, trebuie evitate numerele prime care sunt 1 mod 3.) Acum B poate genera cheia lui secretǎ. Tot ce are de fǎcut este să calculeze (prin algoritmul lui Euclid) d = e– 1 mod (p – 1)(q – 1). Perechea (n, d) este cheia privatǎ a lui B.
Operarea. Ori de câte ori A sau oricine altcineva doreste sǎ-i trimitǎ un mesaj lui B procedeazǎ astfel:
o Fragmenteazǎ mesajul în şiruri de biţi de lungime nlog (este vorba din nou de mai multe sute de biţi). Se codeazǎ fiecare şir de biţi prin algoritmul care urmeazǎ.
o Fie x un astfel de şir de biţi care se considerǎ a fi un întreg mod n. A calculeazǎ xe mod n. Acesta aste mesajul codat e(x) pe care A îl trimite lui B.
o La primirea lui e(x), B calculeazǎ e(x)d mod n. Puţinǎ algebrǎ (şi apelând din nou la mica teoremǎ a lui Fermat pentru produsul a douǎ numere prime, prezentatǎ în secţiunea precedentǎ) produce:
e(x)d = xd.e = x1 + m(p – 1)(q – 1) = x mod n
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

104
De observat cǎ aceastǎ secvenţǎ de ecuaţii stabileşte faptul cǎ B decodeazǎ corect. Prima ecuaţie reaminteşte de definiţia lui e(x). A doua decurge din faptul cǎ d este inversul lui e mod (p – 1)(q – 1) şi astfel dacǎ se multiplicǎ d cu e se obtine 1 plus un multiplu al numărului (p – 1)(q – 1). Ultima egalitate aminteşte de mica teoremǎ a lui Fermat: x(p – 1)(q – 1) = 1 mod n (desigur, cu excepţia cazului în care x este un multiplu de p sau de q, o posibilitate foarte improbabilǎ). Astfel, multiplul de (p – 1)(q – 1) din exponent se poate ignora. Astfel, A poate coda folosind cheia publicǎ a lui B. B poate decoda utilizând cheia privatǎ pe care numai el o ştie. Dar ce se poate spune despre “curioşi”? Dacǎ E preia e(x) = xe mod n, poate face mai multe lucruri. Poate încerca toti x-ii posibili, sǎ-i codeze cu cheia publicǎ a lui B şi sǎ gǎseascǎ x-ul corect – dar asta ia mult prea mult timp. Sau, poate sǎ calculeze d = e–1 mod (p – 1)(q – 1) şi din asta e(x)d mod n care este x. Dar pentru a proceda aşa E trebuie sǎ ştie numărul (p – 1)(q – 1). Şi dacǎ ştie atât pq cât şi (p – 1)(q – 1), atunci ştie p şi q (puteţi spune de ce?). Altfel spus, E poate factoriza pe n, un produs arbitrar de douǎ numere prime mari, dar nimeni nu stie cum sǎ facǎ operaţia asta rapid. Sau, în sfârşit, E şi-ar putea utiliza propria ei metodǎ ingenioasǎ pentru a decoda e(x) fǎrǎ factorizarea lui n – este o convingere largǎ cǎ nu existǎ o asemenea metodǎ. Astfel, dupǎ toate dovezile accesibile, sistemul RSA este sigur pentru un n potrivit de mare. Semnǎturi electronice Criptografia cu cheie privatǎ nu este numai o idee remarcabilǎ şi radical contraintuitivǎ. Ea este o idee fundamentalǎ de acest gen. Deoarece, odatǎ în posesia cuiva, mai multe treburi care par imposibile pot fi efectuate. De exemplu, semnǎtura digitalǎ. Sǎ presupunem cǎ A vrea sǎ-i trimitǎ lui B un mesaj semnat. Adicǎ vrea sǎ expedieze un mesaj m.s(m), cu m un mesaj obişnuit şi cu s(m) o semnǎturǎ, o bucatǎ de text care depinde de m şi care identificǎ în mod unic pe A (adicǎ B este sigur cǎ mesajul vine de la A şi nu de la un impostor. De asemenea, B poate convinge o curte, un tribunal, cǎ sigur A i-a trimis acel mesaj). Sunǎ imposibil, nu-i asa? Iatǎ cum se face aceasta: s(m) = d’(m) unde d’() este funcţia de decodare a lui A. Adicǎ A îşi imagineazǎ pentru o secundǎ cǎ mesajul m pe care e aproape sǎ-l trimitǎ lui B a fost primit de ea de la altcineva şi i-a aplicat algoritmul ei de decodare (ridicǎ la cheia ei secretǎ modulo cheia ei publicǎ). De îndatǎ ce B primeste m.s(m), el este plauzibil sigur cǎ A l-a trimis deoarece numai A are cheia privatǎ care poate transforma pe m în s(m). Şi existǎ multe multe fapte contraintuitive care pot fi îndeplinite prin aplicarea criptografiei cu cheie publicǎ: jocul de poker pe Net şi demonstrarea cuiva cǎ o teoremǎ este adevǎratǎ fǎrǎ a spune ceva despre adevǎr (astfel de demonstratii sunt cunoscute ca zero-knowledge proofs).
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

105
Criptografia RSA şi teorema restului chinezesc Sǎ presupunem cǎ avem un sistem de ecuatii simultane, poate ca acesta care urmeazǎ:
x ≡ 2 (mod 5) x ≡ 5 (mod 7)
Ce putem spune despre x? Putem spune cǎ o solutie este x = 12 deoarece x = 12 satisface ambele ecuatii. Aceasta nu este însă singura solutie. De pildǎ x = 12 + 35 este de asemenea o solutie, dar şi x = 12 + 70 şi x = 12 + 105 ş.a.m.d. Evident, adunând orice multiplu de 35 la o soluţie se obtine o altǎ solutie validǎ, astfel cǎ putem scrie concis cǎ x ≡ 12 (mod 35) este o solutie a sistemului de ecuatii dat. Dar mai sunt şi alte solutii? Pentru acest exemplu nu existǎ o altǎ solutie: orice solutie este de forma x ≡ 12 (mod 35). Dar de ce n-ar exista şi altele? Dacǎ admitem existenta unei alte solutii x’, atunci din prima ecuatie se ştie cǎ x ≡ 2 (mod 5) şi x’ ≡ 2 (mod 5) şi de aici x ≡ x’ (mod 5). Similar x ≡ x’ (mod 7). Dar prima congruenţǎ spune cǎ 5 este un divizor al diferentei x – x’, din a doua rezultǎ cǎ şi 7 este un divizor al diferentei x – x’, astfel cǎ x – x’ trebuie sǎ fie un multiplu de 35 (s-a utilizat aici faptul cǎ gcd(5, 7) = 1)2, care înseamnǎ x ≡ x’ (mod 35). Cu alte cuvinte, toate solutiile sunt aceleaşi modulo 35: sau, echivalent, dacǎ tot ce ne preocupǎ este x mod 35, solutia este unicǎ. Puteti verifica: aceleaşi lucruri sunt adevǎrate dacǎ se înlocuiesc numerele 5, 7, 2, 5 cu oricare altele. Singurul lucru impus a fost cǎ gcd(5, 7) = 1. Iatǎ acum o generalizare: Teorema 5: (Teorema restului chinezesc) Fie m, n relativ prime şi fie a, b arbitrare. Perechea de ecuatii x ≡ a (mod m), x ≡ b (mod n) are o soluţie unicǎ în x mod mn. Mai mult, solutia x poate fi calculatǎ eficient (ca exerciţiu, cititorul poate verifica modul de a face calculul). Teorema restului chinezesc este utilǎ adesea când se face aritmeticǎ modularǎ cu un modul compus; dacǎ dorim sǎ calculǎm o valoare necunoscutǎ modulo mn, un truc standard este a o calcula modulo m, de a o calcula modulo n şi apoi a deduce valoarea ei modulo mn utilizând teorema restului chinezesc (CRT – Chinese remainder theorem). Teorema lui Euler Într-un paragraf anterior am vǎzut mica teoremǎ a lui Fermat, care spune ceva despre ce se întâmplǎ cu exponenţierea când modulul este prim. Putem generaliza acum la cazul când se lucreazǎ cu modulo un produs de douǎ numere prime.
2 Notatia gcd este prescurtarea de la greatest common divisor – cel mei mare divizor comun.
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

106
Teorema 6: Fie p, q douǎ numere prime distincte. Fie n = pq. Atunci numǎrul x(p – 1)(q – 1) ≡ 1 (mod n) pentru orice x care satisface conditia gcd(x, n) = 1. Demonstratie: Mai întâi sǎ reducem modulo p ambele pǎrti ale congruenţei din enunţ (este permis deoarece p divide pe n). Gǎsim cǎ
x(p – 1)(q – 1) ≡ (x(p – 1))(q – 1) ≡ (1)(q – 1) ≡ 1 (mod p) unde s-a folosit mica teoremǎ a lui Fermat pentru a conchide cǎ xp – 1 ≡ 1 (mod p). Similar avem x(p – 1)(q – 1) ≡ 1 (mod q). Se obtine un sistem de douǎ ecuatii
x(p – 1)(q – 1) ≡ 1 (mod p) x(p – 1)(q – 1) ≡ 1 (mod q)
De reţinut cǎ gcd(p, q) = 1. Aşadar, dupǎ teorema restului chinezesc, trebuie sǎ existe o solutie unicǎ pentru x(p – 1)(q – 1) mod pq. Se poate vedea cǎ x(p – 1)(q – 1) ≡ 1 (mod pq) este una din solutiile posibile şi în virtutea unicitǎţii, aceasta trebuie sǎ fie singura posibilitate. Adevǎrul teoremei decurge de aici. Sǎ recapitulǎm. Mica teoremǎ a lui Fermat spune cǎ xp – 1 ≡ 1 (mod p) şi tocmai am vǎzut cǎ x(p – 1)(q – 1) ≡ 1 (mod pq). Care este aici pattern-ul general? De unde vin aceşti exponenti magici? Existǎ vreo relatie generalizabilǎ între p – 1 şi p şi (p – 1)(q – 1) şi pq? Da, existǎ. Conceptul de care avem nevoie este acela de functie totient a lui Euler, (n). Numǎrul (n) este definit ca numǎrul de întregi pozitivi mai mici ca n şi mutual primi cu n. Se poate vedea cǎ (p) = p – 1 când p este prim, deoarece întregii 1, 2, …, p – 1 sunt toti mai mici decât p şi relativ primi cu p. Cu putin efort de numǎrare se poate determina şi (n) când n = pq, un produs de douǎ numere prime. Se obtine rezultatul urmǎtor: Lema 1: Fie p, q douǎ numere prime distincte şi n = pq. Atunci (n) = (p – 1)(q – 1). Demonstratie: Câti întregi sunt mai mici decât n şi sunt relativ primi cu n? Întregii p, 2p, 3p, …, (q – 1)p nu se pun: ei au un factor comun cu n. Dintr-un motiv similar nu se numǎrǎ nici q, 2q, 3q, …, (p – 1)q. Acestea sunt toate excepţiile şi cele douǎ liste de numere sunt disjuncte. Dacǎ din cele n – 1 numere mai mici ca n le eliminǎm pe acestea, se obtine cea ce urmǎrim. În final, prima listǎ contine q – 1 exceptii, a doua, p – 1 exceptii. Aşadar, sunt n – 1 – (p – 1) – (q – 1) = pq – p – q – 1 = (p – 1)(q – 1) întregi pozitivi mai mici decât n şi relativ primi cu n. La acest moment este natural a formula conjectura conform cǎreia funcţia totient a lui Euler croieşte cǎrarea cǎtre o generalizare a micii teoreme a lui Fermat. Şi, desigur, se poate demonstra urmǎtorul rezultat: Teorema 7 (Teorema lui Euler): x(n) ≡ 1 (mod n) pentru orice x care satisface conditia gcd(x, n) = 1. Demonstratie: Demonstratia este exact ca aceea pentru mica teoremǎ a lui Fermat. Se considerǎ o multime de întregi pozitivi mai mici decât n şi relativ primi cu n. Dacǎ alegem oricare element x din obtinem o altǎ multime x = {ix mod n: i}. De notat cǎ toate elementele din x sunt distincte (deoarece x este inversabil) şi relativ prime cu n, asadar = x. În consecintǎ, produsele
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

107
i
i şi xi
i sunt egale modulo n. Dar i
i ≡ xi
i (mod n), asadar x|| ≡ 1
(mod n). În final, notând || = (n), rezultǎ teorema. Cititorul poate verifica mica teoremǎ a lui Fermat ca un caz special al teoremei lui Euler. Acum, folosind teorema lui Euler, oferim o dovadǎ cǎ un sistem RSA lucreazǎ corect, adicǎ decriptarea unui mesaj criptat RSA restituie mesajul initial. Fie n = pq produsul a douǎ numere prime şi fie e un numǎr cu gcd(e, (n)) = 1, astfel ca cheia publicǎ RSA este datǎ de perechea (n, e). Se reaminteste cǎ o criptare a unui mesaj m este definitǎ ca
e(m) ≡ me (mod n) Similar, decriptarea unui text cifrat c este definitǎ ca:
d(c) ≡ cd (mod n) cu d ≡ e–1 (mod (n)). Vom dovedi cǎ decriptarea este inversa criptǎrii. Aceasta dǎ siguranta cǎ receptorul poate recupera mesajul originar, criptat prin folosirea cheii sale private, cum trebuie sǎ fie într-o schemǎ de criptare corectǎ. Teorema 8: d(e(m)) ≡ m (mod n) ori de âte ori gcd(m, n) = 1. Demonstratie: Rememorǎm cǎ e ≡ d –1 (mod (n)) astfel ed ≡ 1 (mod (n)) sau cu alte cuvinte, ed – 1 este un multiplu al numărului (n), sǎ spunem k(n). Apoi calculǎm
d(e(m)) ≡ (me)d ≡ med ≡ m1 + k(n) ≡ m(m(n))k ≡ m.1k ≡ m (mod n) În calcul s-a utilizat teorema lui Euler pentru a conchide cǎ m(n) ≡ 1 (mod n). Observatia 1: Sunt suficiente numere prime pentru a facilita gǎsirea a douǎ din ele. Existǎ aproximativ x/lnx numere prime între 1 şi x. Observatia 2: Functia de criptare şi functia de decriptare pot fi aplicate în orice ordine. Autentificarea O situatie de discutat: mesajul nu este necesarmente secret dar este de dorit o asigurare asupra autorului lui. A creazǎ o semnǎturǎ digitalǎ S pentru mesajul ei M: S = Md mod n, unde (d, n) este cheia privatǎ a lui A. A poate atunci sǎ cripteze semnǎtura utilizând cheia publicǎ a lui B. La primirea mesajului, B o va decripta uzând de cheia lui privatǎ, apoi va aplica cheia publicǎ a lui A pentru a se asigura cǎ aceasta vine de la A şi nu s-a produs vreo interferenţǎ nedoritǎ. Ceea ce se întâmplǎ în realitate este cǎ A semneazǎ un digest (un rezumat) al mesajului M format prin aplicarea unei functii hash3 mesajului M, apoi ataşeazǎ versiunea mai scurtǎ semnatǎ a mesajului, la mesajul M real; B aplicǎ aceeaşi functie hash mesajului M pentru a obtine digest-ul, apoi aplicǎ semnǎturii cheia publicǎ a lui A şi comparǎ rezultatul cu h(M). De notat cǎ A semneazǎ în esentǎ
3 O functie hash este o amprentǎ numericǎ redusǎ produsǎ/rezultată din orice gen de date. Functii hash sunt utilizate şi în criptografie.
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

108
orice mesaj care se rezumǎ prin hash la acelaşi digest; acest lucru reprezintǎ un risc de securitate. Recent, SHA-1 (Secure Hash Algorithm – 1, unul dintr-o serie de algoritmi siguri de obtinere de versiuni hash, SHA-1, SHA-224, SHA-256, SHA-384 şi SHA-512), o functie hash pentru acest scop, a fost compromisǎ; s-a gǎsit o functie mai simplǎ care produce aceleaşi valori ca şi SHA-1. Un certificat dǎ asigurarea cǎ cheia publicǎ a lui A este corectǎ. Certificatul adaugǎ o semnǎturǎ (de genul Verisign) la cheia publicǎ care verificǎ autenticitatea. Existǎ de asemenea autoritǎţi time-stamp pentru verificarea timpului la care mesajul a fost compus şi/sau trimis. Utilizarea practicǎ a criptării RSA Algoritmii cu cheie privatǎ sunt mult mai rapizi (de cca. 1000 de ori). În general, exponentul public este de obicei mult mai mic decât exponentul privat, ceea ce înseamnǎ cǎ decriptarea unui mesaj este mai rapidǎ decât criptarea şi verificarea unei semnǎturi este mai rapidǎ decât semnarea; aceasta-i foarte bine deoarece semnarea şi criptarea sunt fǎcute numai o datǎ, în timp ce verificarea unei semnǎturi date se poate repeta de mai multe ori. RSA este utilizatǎ deobicei pentru a coda o cheie care poate fi apoi utilizatǎ cu un sistem de cheie privatǎ. SSH (Secure Shell). Programul ssh-keygen genereazǎ o pereche de chei publicǎ-privatǎ prin alegerea aleatoare de numere prime mari; aceastǎ operaţie consumǎ câteva minute pe un minicomputer Nova. În particular, cheia privatǎ este depusǎ în .ssh2/id_dsa_2048_a; cheia publicǎ este depusǎ în .ssh2/id_dsa_2048_a.pub. Procedura de logare din contul A la contul B: SSH de pe A trimite un identificator de sesiune semnat (cunoscut numai clientului şi serverului, criptat cu cheia privatǎ a lui A) serverului SSH al lui B. B se asigurǎ cǎ cheia publicǎ a lui A se aflǎ într-un fişier denumit authorized_keys şi este corectǎ. Dacǎ aşa este, serverul SSH al lui B permite logarea la B. SSH menţine şi verificǎ totodatǎ o bazǎ de date care contine informatii de identificare pentru fiecare host cu care a lucrat vreodatǎ; dacǎ un host se schimbǎ, utilizatorul este avertizat. Toate comunicatiile în orice directie sunt criptate cu o metodǎ de cheie privatǎ.
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

109
CODAREA PENTRU CANALE AFECTATE DE PERTURBAŢII Observaţii generale În cazul canalelor fǎrǎ perturbatii, schema transmiterii informatiei este uzual aceea din figura urmǎtoare:
Prezenţa perturbatiilor conduce mai mult sau mai putin accidental la alterarea informatiei. Fenomenul se combate prin introducerea unei codǎri şi a unei decodǎri suplimentare care sǎ protejeze informatia în faţa posibilelor deteriorǎri datorate perturbatiilor. Pentru aceasta, schema de transmitere de mai sus se completeazǎ astfel:
În aceastǎ sectiune, discutia este dedicatǎ aproape exclusiv canalelor binare. Codorul canalului preia mesaje de lungime fixǎ L produse de codorul sursei şi le aplicǎ pe o multime de cuvinte de cod de lungime N > L, de asemenea fixǎ. Biţii suplimentari în numǎr de N – L reprezintǎ biţii de control, biţii de verificare a integritǎtii informatiei vehiculate prin canal. Cu L biti se pot alcǎtui 2L cuvinte distincte. Cu N biti se pot alcǎtui 2N cuvinte. Este de la sine înţeles cǎ sunt necesare numai 2L cuvinte de cod pentru a realiza codarea secundarǎ. Numai 2L cuvinte de cod vor fi acceptate ca reprezentând cuvinte generate de codorul sursei. Celelalte 2N – 2L cuvinte vor contine biti detectabili ca eronaţi. Rezerva de cuvinte de cod şi biţii suplimetari sunt de exploatat pentru detectarea şi/sau corectarea erorilor de transmitere prin canal. În transmiterea de informatie prin canale afectate de perturbatii, unele sisteme fac numai o detectare a erorilor şi apoi (imediat) solicitǎ emitǎtorului sǎ repete
Codor Canal Decodor mesaj mesaj codat
mesaj codat, fără erori
mesaj
Perturbatii
Canal Codor canal
Decodor canal
Decodor sursă
Codor sursă
Conexiune inversă
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

110
transmiterea. Sistemele de acest gen necesitǎ un circuit fiabil (sigur în funcţionare) pantru comunicarea inversǎ prin care receptorul înstiinţeazǎ emiţǎtorul de corectitudinea sau, mai ales, de incorectitudinea cuvintelor primite. Sistemul este menţionat în literaturǎ şi recunoscut de specialisti prin trei iniţiale: ARQ de la Automatic-Repeat-Request. Un asemenea sistem utilizeazǎ conexiunea inversǎ reprezentatǎ în figura cu dublǎ codificare, prin linii fragmentate. Alte sisteme realizeazǎ la receptie atât detecţia erorilor cât şi corectarea lor. Iniţialele FEC de la Forward-Error-Correction identificǎ în literatura de profil sistemele din aceastǎ categorie. În reţelele de comunicatie se practicǎ transferul informatiei în pachete. Pachetele se numesc frames, sau packets, sau segments, denumire dependentǎ de nivelul/rangul reţelei în care se vehiculeazǎ informatia. Pachetele au uzual un header şi/sau un trailer care au rolul de a marca un mesaj la început şi/sau la sfârşit. Pe baza unei verificǎri sistematice a erorilor posibile se utilizeazǎ un ARQ foarte eficient. Debit de informatie (rata) Condiţia N > L aratǎ cǎ debitul de informatie (rata) la intrarea în canal este mai mare decât debitul primit de codorul canalului. Dacǎ ns = 1/s este debitul fix al codului sursei (bps – biţi pe secundǎ) şi nc = 1/c este debitul prin canal atunci
s
c
c
s
nnLLN
Dacǎ se întâmplǎ ca relaţia de mai sus sǎ nu producǎ un numǎr N întreg atunci este necesar ca din timp în timp sǎ se transmitǎ câte un bit fǎrǎ semnificaţie (dummy). Se folosesc uneori urmǎtoarele caracterisitici ale codurilor de canal: a) Debitul relativ al codului
c
s
s
c
nn
NLR
b) Redundanţa codului
LN
RCred
1
c) Excesul de redundanţǎ
LLN
REred
11
Douǎ exemple: 1. Codorul sursei are debitul 2 bps, codorul de canal are debitul 4 bps. Dacǎ L
= 3 atunci N = 6 şi la fiecare cuvânt trei biti sunt disponibili pentru controlul fluxului de informatie.
2. Codorul de sursǎ are debitul 3 bps, codorul canalului are debitul 4 bps. Acum N = (4/3)L. Dacǎ L = 3, atunci N = 4 şi un bit din fiecare cuvânt poate
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

111
fi utilizat pentru verificarea exactitǎţii transmisiei. Acum, dacǎ L = 5, rezultǎ N = (4/3)·5 ≈ 6 şi din nou un bit la fiecare cuvânt este utilizabil pentru control. Se observǎ însǎ o nepotrivire de viteze (rate) între cele douǎ fluxuri de biti şi atunci apare necesitatea transmiterii unor biti fǎrǎ semnificatie (dummy). Din relaţia de calcul a numǎrului N se extrage partea fracţionarǎ în formǎ redusǎ (ca raport a douǎ numere naturale cele mai mici posibile). Fracţia aceasta este raportul dintre numǎrul biţilor de umpluturǎ (dummy) şi numǎrul cuvintelor dintr-o perioadǎ dupǎ care acei biţi trebuie introduşi pentru a asigura sincronismul. În cazul în discutie d/n = 2/3 şi schema transmisiei este x x x x x x x x x x x x x x x x x x * * cu biţii de control marcati prin subliniere, cu biţii suplimentari (dummy) marcati prin steluţe. În aceste codiţii la 15 biti proveniţi de la codorul sursei se transmit prin canal 20 de biti ceea ce corespunde relatiei de bazǎ N = (4/3)L. Atât bitii suplimentari din fiecare cuvânt de cod cât şi bitii de umpluturǎ pot fi utilizati pentru controlul corectitudinii fluxului transmis.
Reguli de decizie la decodare Pentru canalele fǎrǎ perturbaţii simbolul transmis este identificat la iesire cu certitudine. Canalele cu perturbatii altereazǎ informatia, semnalul se deghizeazǎ în variate moduri posibile şi e necesar ca pe baza informatiei recepţionate şi a unor reguli de decizie sǎ se identifice simbolurile efectiv transmise. În notatia de-acum încetǎţenitǎ, cu cele douǎ multimi alfabetice, de intrare A = {ai}, i = 1, 2, …, r şi de iesire B = {bj}, j = 1, 2, …, s, se poate decide fie pe baza unei reguli simbol-la-simbol, d(bj), care asociazǎ fiecǎrui simbol bj observat la iesire un simbol unic la intrarea canalului, fie pe baza unei reguli cuvânt-la-cuvânt, d(b), care asociazǎ fiecǎrui cuvânt b de la iesire un cuvânt unic la intrare. O regulǎ de decizie bunǎ ar trebui sǎ minimizeze riscul de a decide gresit. O decodare care asigurǎ o probabilitate minimǎ de eroare este aceea în care d(bj) = a*, face din a* acel simbol de intrare pentru care
P(a*/bj) ≥ P(ai/bj) oricare ar fi indicele i. Relatia ultimǎ se poate scrie şi sub forma
)()()/(
)()()/( **
j
iij
j
j
bPaPabP
bPaPabP
si apoi P(bj/a*)P(a*) ≥ P(bj/ai)P(ai)
relatie care implicǎ nu numai probabilitǎtile din matricea care descrie canalul ci şi probabilitǎtile a priori ale simbolurilor de intrare, probabilitǎti care nu sunt decât rareori cunoscute. Decodarea care asigurǎ verosimilitatea maximǎ foloseste exclusiv relatiile d(bj) = a*, cu a* acel simbol de la intrare pentru care
P(a*/bj) ≥ P(ai/bj)
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

112
pentru orice i. Aceastǎ metodǎ are avantajul cǎ nu necesitǎ probabilitǎţile a priori, cele de la intrarea canalului. Cu toate cǎ în general nu asigurǎ riscul minim de eroare, metoda verosimilitǎtii maxime este cu eroare minimǎ dacǎ simbolurile la intrarea canalului sunt echiprobabile, ceea ce îndeobşte se urmăreşte. Probabilitatea deciziilor eronate se calculeazǎ având în vedere cǎ dacǎ P[a* = d(bj)/bj] este asociatǎ deciziei corecte atunci probabilitatea erorii în aceleaşi conditii de receptie a simbolului bj este
P(E/bj) = 1 – P[a* = d(bj)/bj] Evident, o probabilitate maximǎ a deciziei corecte se obtine concomitent cu o probabilitate minimǎ de eroare, de unde şi denumirea uneia dintre metodele de detectie enunţatǎ mai devreme. Riscul general de a comite erori de decizie este dat de media
B
jjE bPbEPP )()/(
şi, echivalent, de
AiiE aPaEPP )()/(
şi
Bb
ii abPaEP )/()/(
cu ultima sumǎ efectuatǎ pe simbolurile alfabetului B pentru care ij abd )( . O aplicatie-exemplu pentru canalul caracterizat de matricea
4,03,03,05,03,02,02,03,05,0
][P
cu probabilitǎtile simbolurilor de intrare presupuse cunoscute, P(a1) = 0,3, P(a2) = 0,3, P(a3) = 0,4 sau, sintetic, P(a) = [0,3 0,3 0,4] se conduce ca mai jos. Decodarea maximum verosimilǎ. Regula de decizie este formulatǎ în acest caz prin reţinerea probabilitǎtii maxime pe fiecare coloanǎ: d(b1) = a1, d(b2) = a1, d(b3) = a2. De observat cǎ decizia d(b2) are alternative, d(b2) = a2, d(b2) = a3, care sunt la fel de bune, la fel de nefericite ca şi aceea deja reţinutǎ ca regulǎ de decizie. Pentru calculul probabilitǎtii de a decide eronat se foloseste relaţia
A A Bb
iiiiE abPaPaPaEPP )/()()()/(
Pentru a obtine probabilitatea deciziei gresite
Bb
ii abPaEP )/()/( , se fac
sume pe liniile matricii [P], cu omiterea pozitiilor pentru care d(bj) = ai. Într-o scriere ordonatǎ
40,04,00,115,03,05,006,03,02,0
4,03,03,05,03,02,02,03,05,0
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

113
Pe coloana ultimǎ sunt înscrise probabilitǎtile erorilor în cazul transmiterii simbolurilor a1, a2, respectiv a3, produse ale numerelor din coloanele premergǎtoare care sunt P(E/ai) şi P(ai), pentru i = 1, 2, 3. Însumând aceste probabiltǎti se obtine un numǎr dezamǎgitor: 0,61. Asadar, în 61% din cazuri decizia este gresitǎ ceea ce nu este prea încurajator, dar acestea sunt rezultatele şi calculul (cu valoare didacticǎ, desigur) este corect. În cazul de fatǎ, un mare handicap al metodei verosimilitǎtii maxime este acela cǎ dacǎ se transmite simbolul a3, niciodatǎ decizia nu va fi d(bj) = a3, ceea ce se poate observa şi cantitativ: P(E/a3) = 1. Decodarea având în vedere probabilitate minimǎ de a comite erori necesitǎ probabilitǎtile simbolurilor de la intrare, care de data aceasta sunt disponibile. Se calculeazǎ P(bj/a*)P(a*) pentru fiecare bj şi se retine valoarea maximǎ. Calculul sistematic include multiplicarea
33
32
11
)()()(
16,012,012,015,009,006,006,009,015,0
][)(abdabdabd
PaP
dupǎ care se calculeazǎ probabilitatea erorii ca şi la metoda anterioarǎ
12,04,03,030,03,00,115,03,05,0
4,03,03,05,03,02,02,03,05,0
Semnificaţia ultimei coloane este aceeaşi ca mai sus, la fel a factorilor din a cǎror multiplicare rezultǎ, cu deosebirea cǎ primul factor este altfel ales. Prin însumarea coloanei din dreapta extremǎ, se obtine o probabilitate de eroare mai micǎ (0,57) decât în cazul verosimilitǎtii maxime, dar tot dezamǎgitor de mare. Se întâmplǎ asa ceva în practica curentǎ? Rǎspunsul este redat în continuare. Canalele moderne sunt binare simetrice (BSC – Binary Symmetric Channel). Probabilitatea q de transmitere eronatǎ a unui bit este uzual foarte micǎ şi în relatia q << p cu probabilitatea p a absenţei erorii, p = 1 – q. Probabilitǎtile P(ai) sunt foarte apropiate ca valoare datoritǎ codǎrii aproape optime a sursei. Se poate dovedi cǎ metoda verosimilitǎţii maxime şi metoda probabilitǎţii minime a erorii dau aceleasi reguli de decizie şi probabilitǎti de eroare foarte apropiate sau chiar egale. Aproape totdeauna regulile de decizie sunt d(0) = 0, d(1) = 1 şi probabilitatea erorilor este PE = q. Regulile de decizie se bazeazǎ totusi pe cuvinte: având un cuvânt de cod recepţionat, de lungime N, se decide asupra cuvântului de cod de lungime N transmis prin canal. Problema se pune astfel: Fie a un cuvânt de cod transmis prin canal şi fie b cuvântul recepţionat. Mesajele au lungimea de L biti, cuvintele de cod au lungimea de N biti. Se pot forma 2N cuvinte cu N biti, dar numai 2L sunt necesare pentru a coda mesajele bloc de lungime L. La recepţie pot apǎrea cele 2L cuvinte valide asociate cu cuvintele de la intrare, dar prin alterarea datoritǎ perturbatiilor pot sǎ aparǎ şi oricare din celelalte 2N – 2L cuvinte, care contin însǎ erori. Erorile nu sunt atât de multe încât sǎ transforme un cuvânt de cod valid în alt cuvânt de cod tot
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

114
valid. Codorul canalului trebuie sǎ asocieze un cuvânt b cu cuvântul a cel mai probabil trimis prin canal. Distanţa Hamming. Decodarea bazată pe distanţa Hamming Fiind date douǎ cuvinte de aceeasi lungime, a = a1a2…an şi b = b1b2…bn, prin definiţie, distanta Hamming dintre ele este numǎrul de pozitii prin care a şi b diferǎ. Se noteazǎ cu d(a,b) şi d(a,b) = numǎrul de poziţii în care ai ≠ bi. Pentru orice alfabet şi pentru un n dat, distanta Hamming are pe mulţimea tuturor cuvintelor de lungime n toate caracteristicile unei metrici: 1. d(a, b) ≥ 0, cu egalitate dacǎ şi numai dacǎ a = b 2. d(a, b) = d(b, a) 3. d(a, b) + d(b, c) ≥ d(a, c) (inegalitatea triunghiului) S-a arǎtat mai devreme cǎ în sistemele moderne de transmisiuni, metoda verosimilitǎtii maxime şi metoda probabilitǎtii minime de eroare conduc la aceleaşi rezultate. Regula prin care se decide care cuvânt a de N biti a fost trimis prin canal dacǎ s-a receptionat cuvântul de N biti b trebuie sǎ maximizeze probabilitatea P(b/a). Admitem cǎ distanta Hamming între cuvântul trimis şi cel receptionat este d(a,b) = D. Aceasta înseamnǎ cǎ exact D biti sunt eronati, fiecare cu probabilitatea q. Ceilalti N – D biti sunt corecti, cu probabilitatea individualǎ p = 1 – q. Probabilitatea coditionatǎ menţionatǎ este aşadar
P(b/a) = q Dp N – D Deoarece q < 0,5 se retine cuvântul a pentru care distanta d(a,b) = D este minimǎ deoarece acela maximizeazǎ probabilitatea P(b/a). Se poate stabili o regulǎ de decizie pe baza distantelor Hamming: a) dacǎ b = ai pentru un i particular, adicǎ exact unul din cuvintele care se
aplicǎ la intrare, atunci s-a transmis ai b) dacǎ b ≠ ai pentru orice i, atunci se cautǎ cuvântul de cod a* cel mai
apropiat (în sensul distanţei Hamming) de cuvântul receptionat adicǎ acel cuvânt pentru care d(a*, b) ≤ d(ai, b) oricare ar fi i. Dacǎ cuvântul a* este unic, atunci acel cuvât de cod s-a transmis: el are erori care sunt (pot fi) şi corectate. Dacǎ solutia nu este unicǎ atunci erorile sunt numai detectate fǎrǎ posibilitatea de a le şi corecta.
Urmeazǎ o discutie pe un exemplu simplu.
Mesaje (L = 2) 00 01 10 11 Coduri (N = 3) 000 001 011 111
Sunt, dupǎ cum se observǎ, 4 cuvinte de cod necesare pentru codarea celor 4 mesaje. Cu 3 biti se pot alcǎtui 8 cuvinte distincte: 4 din ele vor fi cuvinte de cod, 4 din ele nu vor fi cuvinte ale codului. Cu regula de decizie prin distante Hamming, la receptionarea cuvintelor 010, 100, de pildǎ, se procedeazǎ ca în tabelul alǎturat.
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

115
b = b1b2b3 Codu(ri)l(e) cel(e) mai
apropiat(e) Decizie/Acţiune
010 000, 011 Eroare detectatǎ 100 000 Eroare corectatǎ
Cititorul este îndemnat sǎ completeze ca exercitiu tabelul cu alte posibile cuvinte receptionate. Detectarea şi corectarea erorilor prin distanta Hamming Se numeşte distantǎ minimǎ d(K) a unui cod K cea mai micǎ distantǎ Hamming între douǎ cuvinte distincte ale codului:
d(K) = min{d(a,b) cu a, b în K, distincte} Un cod K se zice cǎ poate detecta toate combinatiile de t erori dacǎ pentru fiecare cuvânt transmis a şi fiecare cuvânt receptionat b obtinut prin alterarea a t biti în a, b nu este un cuvânt de cod. Codurile de acest gen sunt importante în sistemele ARQ (Automatic Repeat Request). Proprietate: Un cod detecteazǎ toate cuvintele în care t biti sunt eronati dacǎ distanta lui minimǎ este superioarǎ lui t, d(K) > t. Demonstratie: Fie a* cuvântul transmis şi b cel recepţionat. Dacǎ t biti sunt eronati rezultǎ cǎ d(b, a*) = t. Pentru a detecta erorile cuprinse în b trebuie arǎtat cǎ b nu poate fi un alt cuvânt de cod ai, adicǎ d(b,ai) > 0 pentru orice i. Inegalitatea triunghiului
d(a*, b) + d(b, ai) ≥ d(a*, ai) se mai scrie
d(b, ai) ≥ d(a*, ai) – d(a*, b) şi pentru siguranta detectǎrii erorilor din b este necesar ca
d(a*, ai) – d(a*, b) > 0 adicǎ
d(a*, ai) > d(a*, b) = t De aici rezultǎ cǎ d(K) > t. Un cod se spune cǎ este capabil a corecta t erori (la recepţie), dacǎ la transmiterea unui cuvânt a al codului, orice cuvânt b receptionat (de fapt cuvântul a cu t biti alterati) poate fi asociat prin metoda de detectie a verosimilitǎtii maxime cu un cuvânt de cod unic, care nu poate fi decât a. Sistemele FEC (Forward-Error-Correction) utilizeazǎ aceastǎ proprietate a codurilor. Proprietate: Un cod poate corecta la recepţie t biti eronati, dacǎ distanta lui minimǎ este mai mare decât 2t, d(K) > 2t. Demonstratie: Fie a* cuvântul de cod transmis, altfel oarecare între cuvintele codului, şi b cuvântul receptionat. Dacǎ t biti sunt eronati rezultǎ cǎ d(a*, b) = t. Pentru a detecta faptul cǎ b este eronat şi pentru ca soluţia detectiei prin verosimilitatea maximǎ sǎ fie unicǎ este suficient ca d(a*, b) < d(b, ai) pentru orice alt cuvânt de cod ai diferit de a*.
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

116
Inegalitatea triunghiului pentru orice alt cuvânt ai d(a*, b) + d(b, ai) ≥ d(a*, ai)
se rescrie ca d(b, ai) ≥ d(a*, ai) – d(a*, b)
şi pentru a avea siguranta cǎ d(b, ai) > d(a*, b) este necesar ca d(a*, ai) – d(a*, b) > d(a*, b)
de unde rezultǎ d(a*, ai) > 2d(a*, b) = 2t
adicǎ d(K) > 2t. În continuare este discutatǎ capacitatea câtorva coduri simple de a detecta şi/sau de a corecta erori. Coduri cu paritate constantǎ Codurile cu paritate constantǎ au particularitatea cǎ N = L + 1, în notatia de acum familiarǎ. Se adaugǎ un bit la codul originar care sǎ facǎ suma bitilor de o acceasi paritate. În tabelul imediat urmǎtor se exemplificǎ codarea de acest gen pentru coduri sursǎ de lungime L = 2.
Mesaje 00 01 10 11 Coduri 000 011 101 110
Bitul suplimentar este alǎturat bitilor mesajului (scris diferit în tabel) şi valoarea lui este aleasǎ astfel ca suma bitilor din cuvintele de cod sǎ fie parǎ. Se verificǎ uşor cǎ distanta minimǎ a codului este d(K) = 2. Conform asteptǎrii, acest cod poate detecta cuvintele cu un bit eronat deoarece d(K) = 2 > t = 1. Coduri cu repetiţie Codurile cu repetiţie, ca acela din tabelul urmǎtor se definesc şi se utilizeazǎ numai pentru L = 1 şi N impar.
Mesaje 0 1 Coduri 000 111
Codarea se face prin simpla repetare a bitului originar de încǎ N – 1 ori. În cazul exemplificat, distanţa Hamming minimǎ este d(K) = 3. Pentru t = 2, d(K) > t, ceea ce aratǎ capacitatea codului de a detecta cuvintele cu doi biti alterati. Pentru t = 1, d(K) > 2t, ceea ce indicǎ proprietatea codului de a corecta un bit eronat într-un cuvânt receptionat care nu apartine codului. Proprietatea de a corecta o eroare poate fi exploatatǎ şi prin retinerea ca mesaj corect a bitului majoritar. Stabilirea bitului majoritar se implementeazǎ mai usor decât orice altǎ metodǎ de a corecta erori bazatǎ pe distanta Hamming.
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

117
Într-un exemplu prezentat mai devreme, pentru o sursǎ de cuvinte de lungime L = 2 biti şi unde se utilizeazǎ cuvinte de cod de lungime N = 3 (se reia mai jos acel tabel) distanta Hamming este d(K) = 1.
Mesaje (L = 2) 00 01 10 11 Coduri (N = 3) 000 001 011 111
Un astfel de cod nu poate detecta erori şi, cu atât mai mult, nu poate nici sǎ le corecteze. Dacǎ se trimite cuvântul de cod 000 şi se receptioneazǎ cuvântul 001 eroarea nu poate fi detectatǎ şi rǎmâne ca o eroare deoarece cuvântul (eronat) receptionat apartine codului. Codul care urmeazǎ, notat cu K6 este definit astfel:
Mesaje 000 001 010 011 Coduri 000000 001110 010101 011011 Mesaje 100 101 110 111 Coduri 100011 101101 110110 111000
Se poate constata cǎ distanta minimǎ este d(K) = 3. Aşadar codul poate corecta un bit eronat. De pildǎ, dacǎ se transmite a = 010101 şi se receptioneazǎ b = 010111, cuvântul de cod cel mai apropiat de b este a = 010101 şi eroarea este localizatǎ şi corectatǎ cu uşurintǎ. Proprietatea se extinde la orice cuvânt transmis şi la orice bit alterat. Cu 6 cifre binare se pot forma 64 de cuvinte, dar din acestea numai M = 2L = 8 sunt utilizate în operatia de codare. Limita superioarǎ B[N, d(K)] a numǎrului de cuvinte de cod. Distanţa minimǎ d(K) a unui cod bloc K determinǎ capacitatea acelui cod de a detecta (sau de a corecta) erori. Dacǎ se cere proiectarea unui cod de lungime N cu distanta minimǎ d(K), care este limita B[N, d(K)] asupra lui M şi, implicit, asupra lui L pentru o pereche [N, d(K)] datǎ? Aceasta este denumitǎ uneori problema centralǎ a teoriei codǎrii. Câteva rezultate:
B(N, 1) = 2N B(N, 2) = 2N – 1
B(N, 3) = 2N/(N + 1) B(N, 4) = 2N – 1/N
În general B(N, 2t + 1) = B(N +1, 2t +2)
pentru t = 0, 1, 2, ..., astfel încât dacǎ se cunoaşte limita pentru distanta minimǎ d(K) parǎ, se poate calcula limita pentru distanta minimǎ d(K) imparǎ. Pentru distanta d(K) parǎ existǎ o limitǎ datǎ relatia lui Plotkin
B[N, d(K)] = 2d(K)/[2d(K) – N] în conditiile d(K) ≤ N < 2d(K). Pentru cazul L = 2 (M = 4) de pildǎ, care este lungimea minimǎ a cuvintelor de cod pentru detectarea unei erori şi apoi pentru corectarea unei erori?
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

118
Pentru detectarea unui bit eronat distanţa minimǎ trebuie sǎ fie mai mare decât 1, deci d(K) = 2. Din M = 4 ≤ B(N, 2) = 2N – 1 rezultǎ N = 3 (cel mai mic N). Codul cu L = 2, N = 3 este un cod cu paritate constantǎ, ca acela discutat puţin mai devreme. Pentru corectarea unui bit eronat distanţa minimǎ trebuie sǎ fie mai mare decât 2, deci d(K) = 3. Din M = 4 ≤ B(N, 3) = 2N/(N + 1) rezultǎ N = 5 (cel mai mic N). Codul cu L = 2, N = 5 poate fi, de pildǎ, urmǎtorul
Mesaje (L = 2) 00 01 10 11 Coduri (N = 5) 00000 01011 10111 11100
Codul poate detecta doi biti eronati, cu detaliul cǎ la detectie se stabileşte deosebirea cuvântului receptionat de oricare dintre cuvintele de cod, b ≠ ai. Pentru corectarea a doi biti eronati distanta minimǎ trebuie sǎ fie mai mare decât 4, deci d(K) = 5. Conform formulei lui Plotkin
B(N, 5) = B(N + 1, 6) = 2d(K)/[2d(K) – (N + 1)] = 12/(11 – N) Din M = 4 ≤ 12/(11 – N) rezultǎ N = 8. Acesta numǎrul cel mai mic de biti în cuvintele de cod pentru a asigura d(K) = 5. Problema principalǎ a codǎrii şi decodǎrii pe baza distantelor Hamming este aceea a implementǎrii dificile. Dificultatea constǎ în creşterea exponentialǎ cu L a numǎrului de cuvinte de cod care, în procesul decodǎrii, trebuie memorate şi comparate cu cuvintele efectiv recepţionate. Aceste elemente cer memorii mai mari şi capacitǎti de calcul mai importante pe mǎsurǎ ce L creşte. O singurǎ implemetare este convenabilǎ, aceea din cazul transmiterii repetitive, când sistemul retinerii bitului majoritar este simplu şi foarte eficient. Mai departe vor fi discutate alte coduri, cu implementare eficientǎ, codurile binare liniare. Probabilitatea de eroare în bloc şi debitul de informaţie Se noteazǎ: Kn – un cod bloc de lungime n ≡ N; Pe(Kn) – probabilitatea ca decodarea unui bloc eronat sǎ se facǎ la un cuvânt de cod diferit de cel efectiv transmis; Peb(Kn) – probabilitatea erorii asupra unui bit; R(Kn) – debitul de informatie asociat codului bloc Kn. În compararea codurilor, probabilitatea Pe(Kn) este cea mai importantǎ deoarece este legatǎ de cea mai slabǎ performantǎ a codului. Existǎ însǎ o relatie între cele douǎ probabilitǎti şi exemplul urmǎtor ilustreazǎ aceastǎ relatie. Fie codul repetitiv L = 1, N = 3 discutat mai sus, uitilizat pentru transmitere printr-un canal binar simetric cu Peb(K3) = q = 0,001. Regula de detectie care constǎ în retinerea bitului majoritar conduce la rezultate false dacǎ doi sau trei biti sunt eronati, de fapt inversati, 0 în 1 şi 1 în 0. Probabilitatea ca doi din cei trei biti sǎ fie eronati este C3
2q2p = 3q2p, iar probabilitatea alterǎrii tuturor celor trei biti este q3. Probabilitatea erorii de identificare a cuvântului de cod transmis
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

119
este suma acestora douǎ: q3 + 3q2p ≈ 3∙10 – 6, mult mai micǎ decât probabilitatea erorii per bit q = 0,001. Dar cu ce cost: R(K3) = 1/3. Codul repetitiv L = 1, N = 5, în aceleasi conditii de eroare per bit, Peb(K5) = q = 0,001, are probabilitatea de bloc/cuvânt eronat datǎ de relatia Pe(K5) = q5 + 5q4p + 10q3p2 ≈ 10 – 8, care cumuleazǎ probabilitǎtile ca 5, 4 sau 3 biti din cei N = 5 sǎ fie eronati. Situatia este mai bunǎ dar debitul relativ scade la R(K5) = 1/5. Lucrurile stau încǎ mai rǎu sub aspectul vitezelor relative la codurile repetitive cu N mai mare. Existǎ o soluţie pentru acest inconvenient? Rǎspunsul este afirmativ. Pentru ilustrare se considerǎ din nou un canal binar simetric cu eroarea de bit probabilǎ în proportia Peb(Kn) = q = 0,001. Se proiecteazǎ un cod cu cuvinte de N = 4 biti şi unul cu cuvinte de N = 6 biti, notate cu K4, respectiv K6, într-o tentativǎ de a coborî probabilitatea Pe(Kn) şi de a mentine R(Kn) = 1/2. Codul K4 (N = 4, L = 2)
Mesaje 00 01 10 11 Coduri 0000 0111 1000 1111
transmite o datǎ bitul prim şi de trei ori bitul al doilea. Se efectueazǎ o corectie conditionatǎ: se admite cǎ primul bit este corect, b1 = a1 şi apoi bitul al doilea este stabilit prin procedeul majoritar aplicat pe sirul de biti b2b3b4. Decodarea este corectǎ dacǎ a) cuvântul receptionat are toti bitii corecti sau dacǎ b) cuvântul receptionat are bitul prim corect şi între bitii ceilalti unul şi numai unul este alterat. Probabilitǎtile asociate celor douǎ situatii sunt p4, respectiv C3
1qp3 = 3qp3. Prin urmare, 1 – Pe(K4) = p4 + 3qp3 şi Pe(K4) = 1 – (p4 + 3qp3) ≈ 0,001. Codul K6 dintr-un exemplu schitat mai devreme, cu N = 6, L = 3 poate corecta eroarea de un bit per cuvânt, dar va produce cuvinte eronate ori de câte ori numǎrul de biti eronati din cuvânt este t > 1. Decodarea este corectǎ când toti bitii sunt corecti (probabilitate p6) sau unul din biti este eronat (probabilitate 6qp5). Prin urmare probabilitatea unei erori de cuvânt este Pe(K6) = 1 – (p6 + 6qp5) ≈ 0,000015, ceea ce este mult mai putin decât 0,001. Solutia a doua, K6 dǎ o reducere a probabilitǎtii erorilor în cuvânt cu douǎ ordine de marime fǎrǎ a reduce debitul relativ de informatie. Exemplele tratate şi comparate îndeamnǎ la câteva întrebǎri: a) Se poate gǎsi un cod (cu N chiar mai mare) care sǎ facǎ Pe(Kn) oricât de mic
cu R(Kn) = 1/2, constant? b) Poate fi un cod oricât de fiabil dorim la R(Kn) = 0,9? c) Poate fi un cod oricât de fiabil dorim la R(Kn) = 0,99? Teorema fundamentalǎ a lui Shannon dǎ unele rǎspunsuri la întrebǎri de genul celor formulate mai sus. Pentru un canal binar simetric fǎrǎ perturbatii capacitatea este C = log 2 = 1 bit, ceea ce înseamnǎ cǎ dacǎ se transmite prin canal 1 bit de informatie se receptioneazǎ acel 1 bit de informatie.
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

120
Pentru un canal binar simetric afectat de perturbatii este posibilǎ o capacitate C = 0,5 biti. Aceasta se traduce prin faptul cǎ la transmiterea a N biti de informatie numai N/2 biti pot fi extrasi la receptie, admitând cǎ acel canal se utilizeazǎ la capacitate totalǎ. Debitul relativ este în acest caz R = 0,5 şi din R = L/N = 1/2 rezultǎ N = 2L, adicǎ se pot extrage la receptie 0,5N = 0,5(2L) = L biti de informatie adicǎ exact necesarul pentru a recupera mesajul care este de lungime L. Prin introducerea unor redundanţe, s-au depǎsit problemele datorate erorilor introduse de canal. Teorema fundamentalǎ a lui Shannon spune cǎ dacǎ R < C, pentru N suficient de mare se poate face o codare care înlǎturǎ orice eroare provenitǎ din canal. Teoremǎ: Pentru orice canal binar simetric de capacitate C se poate gǎsi un cod oricât de fiabil, cu R(Kn) ≤ C, oricât de apropiat de C. Cu alte cuvinte, existǎ un sir de coduri K1, K2, K3, … astfel încât Pe(Kn) tinde cǎtre zero şi R(Kn) tinde cǎtre C pe mǎsurǎ ce n creste
limn → ∞Pe(Kn) = 0, limn → ∞R(Kn) = C Demonstratia riguroasǎ nu este uşoarǎ. De aceea în continuare este prezentată o demonstratie oarecum inginereascǎ. Fie un numǎr 1 > 0 arbitrar de mic. Pentru proiectarea unui cod Kn care sǎ aibǎ viteza relativǎ R(Kn) = C – 1 este necesar ca informatia sǎ fie de lungimea L = n(C – 1) pentru ca
R(Kn) = [n(C – 1)]/n = C – 1 Prin urmare, sunt necesare )( 12 CnM cuvinte de cod. Prin alegerea la întâmplare a unor cuvinte în numǎr de M din cele 2n posibile, se obtine (aleator) un cod Kn pentru care Pe(Kn) are toate particularitǎtile unei variabile aleatoare. Media acestei variabile aleatoare, )]([~
nee KPMP are proprietatea (admisǎ tacit ca adevǎratǎ, dar nedoveditǎ în aceastǎ demonstratie inginereascǎ)
0~lim en P
De aici rezultǎ cǎ pentru 1, 2 > 0 oricât de mici, existǎ n pentru care 2~ eP si,
implicit, existǎ Kn cu Pe(Kn) < 1. Partea surprinzǎtoare sub aspect practic a teoremei lui Shannon este aceea cu alegerea la întâmplare a unui cod Kn. Cum se poate alege la întâmplare un cod care sǎ facǎ probabilitatea Pe(Kn) convenabil de micǎ? Rǎspunsul la aceastǎ întrebare nu a fost dat de nimeni pânǎ acum. De aceea problema codǎrii tinde sǎ ignore teorema şi sǎ se concentreze asupra procedurilor practice de a proiecta coduri care sǎ corecteze erori multe la viteze de transmitere încǎ rezonabile. O reciprocǎ a teoremei lui Shannon spune cǎ pentru orice canal binar simetric de capacitate C, ori de câte ori un cod Kn cu cuvinte de lungime n este transmis cu o vitezǎ cel putin egalǎ cu C + 1 (1 > 0), codul devine din ce în ce mai nesigur pe mǎsurǎ ce n creste
R(Kn) ≥ C + 1 limn → ∞Pe(Kn) = 0 În consecinţǎ, pentru un canal binar simetric cu probabilitatea de bit eronat q = 0,001, capacitatea canalului este C = 1 + plogp + qlogq ≈ 0,9886 şi cu teorema
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

121
fundamentalǎ a lui Shannon se pot da rǎspunsuri la întrebǎrile formulate mai devreme. Rǎspunsurile sunt: a) pozitiv; b) pozitiv; c) negativ. Coduri binare liniare Se admit a fi cunoscute operatiile binare (mod 2) de adunare şi de înmultire. Adunarea, echivalentǎ unui SAU exclusiv (XOR)
+ 0 1 0 0 1 1 1 0
Multiplicarea, echivalentǎ operatiei logice ŞI (AND)
* 0 1 0 0 0 1 0 1
În relatiile urmǎtoare se poate observa o schimbare de notatii: n pentru lungimea N a cuvintelor de cod, k pentru numǎrul L al bitilor informationali, care acced la codorul de canal. În plus, în discutia care urmeazǎ se va nota cu xi bitul al i-lea dintr-un cuvânt de cod sau, uneori, dintr-un cuvânt care s-ar putea sǎ nu apartinǎ codului. Un cod binar liniar are particularitatea cǎ cele 2k cuvinte de lungime n satisfac n – k ecuatii liniare în bitii xi , i = 1, 2, …, n. Mai mult, orice sistem liniar şi omogen de n – k ecuatii cu n necunoscute binare poate fi asociat unui cod liniar. Este stiut cǎ în conditii de rang maximal pentru matricea sa, un sistem de n – k ecuatii cu n necunoscute are n – (n – k) = k necunoscute independente. Cum totul se întâmplǎ în binar avem 2k solutii distincte, cum era de asteptat. Codurile cu repetitie de lungime n imparǎ sunt liniare deoarece verificǎ ecuatiile
0...
00
...
1
31
21
1
13
12
nn xx
xxxx
xx
xxxx
care sunt în numǎr de n – 1. Codurile cu paritate constantǎ sunt de asemenea coduri liniare deoarece
0...21 nxxx Matricea de verificare este exact matricea sistemului omogen
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

122
0...
2
1
nx
xx
H sau 0Hx
(în scriere martricială) şi H are n – k linii şi n coloane. Matricile de verificare pentru codurile cu repetitie şi codurile cu paritate constantǎ pară se pot scrie imediat (exercitiu). Dacǎ x este cuvânt de cod atunci Hx = 0. Dacǎ y este cuvânt de cod atunci Hy = 0. Rezultǎ imediat cǎ z = x + y este tot un cuvânt de cod. Într-adevǎr, Hz = H(x + y) = Hx + Hy = 0 + 0 = 0. De unde o altǎ definitie pentru codurile linare: coduri pentru care suma a douǎ cuvinte de cod este tot un cuvânt de cod. Proprietatea se verificǎ usor pentru codurile repetitive şi pentru codurile de paritate constantǎ parǎ. Se propune ca exercitiu verificarea liniaritǎtii codului K4 discutat mai devreme. Tot ca exercitiu se propune a se verifica dacǎ codul K6 descris mai devreme este un cod liniar. Codul
Mesaje 00 01 10 11 Coduri 000 001 011 111
discutat putin mai sus nu este liniar deoarece, de pildǎ, 001 + 011 = 010. Rezultatul însumǎrii celor douǎ cuvinte de cod nu este un cuvânt de cod. Coduri rectangulare (produs). Între codurile construite în mod intuitiv se aflǎ şi codurile matriciale r×s utilizate pentru transmiterea informatiei în forma unor matrici bidimensionale, matrici cu r – 1 linii şi s – 1 coloane, completate cu încǎ o linie şi încǎ o coloanǎ alcǎtuite din biti de control/verificare a paritǎtii. De pildǎ codul rectangular 3×4
1211109
8765
4321
xxxxxxxxxxxx
cu 765321 ,,,,, xxxxxx biti informationali şi restul biti de control. Fiecare bit de control/verificare este ales pentru a satisface regula paritǎtii pe orizontalǎ şi pe verticalǎ, pe linii şi pe coloane, adicǎ:
04321 xxxx 08765 xxxx 01211109 xxxx
pentru paritatea pe linii şi 0951 xxx 01062 xxx
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

123
01173 xxx 01284 xxx
pentru paritatea pe coloane. Ecuatiile sunt mai multe cu una faţǎ de necesar. Sistemul de relatii este redundant dar el se scrie şi se utilizeazǎ ca atare. Matricea de verificare pentru codul rectangular 3×4 exemplificat apare în expresia
0
...
...
010001000100001000100010000100010001111100000000000011110000000000001111
12
6
2
1
x
x
xx
Hx
Coduri liniare sistematice sunt codurile liniare în care partea informationalǎ nemodificatǎ este separatǎ de cea de control şi de aceea este imediat vizibilǎ şi recuperabilă. În cuvântul de cod se disting primii k biti şi urmǎtorii n – k biti
knkTTT bbbmmmbmx ......| 2121
Aşadar, cuvântul de cod se stabileşte prin adǎugarea la cuvântul-mesaj care trebuie codat a n – k biti de control/verificare. În literatură, indexarea se face uneori începând cu zero, adicǎ
110110 ......| knkTTT bbbmmmbmx
ceea ce nu schimbǎ problema în esenţa ei. De aici înainte se va discuta aproape exclusiv despre codurile sistematice. Din codurile exemplificate pânǎ acum, codurile cu repetiţie sunt sistematice. La fel codurile cu paritate constantǎ (parǎ) sunt sistematice. Se poate observa/dovedi (exercitiu) cǎ şi codurile K4 şi K6 aduse deja de câteva ori în discutie sunt sistematice. Dacǎ biţii mesajului, kmmm ,...,, 21 sunt considerati independenţi şi biţii de verificare, de control knbbb ,...,, 21 se fac dependenţi de acestia, atunci biţii de verificare pot fi exprimati prin functii explicite de cei dintâi. Rezultatul interesant sub aspect practic este cǎ biţii de control se ataşeazǎ biţilor informationali la codare, iar la decodare, dupǎ corectarea eventualelor erori şi recuperarea cuvântului de cod corect, bitii de control se omit pur şi simplu. Forma sistematicǎ a matricei H. Cu notaţiile b pentru vectorul cu n – k componente al biţilor de control; m pentru vectorul cu k componente al biţilor de informatie; c pentru vectorul cu n componente al biţilor care alcǎtuiesc cuvântul de cod
c = [mT | bT]T ≡ x; P pentru o matrice (n – k)×k a coeficienţilor (din corpul cu două elemente 0
şi 1, adăugat cu operaţiile de adunare, “sau-exclusiv” şi de multiplicare, “şi”;
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

124
G pentru o matrice n×k generatoare; H pentru matricea de verificare cu dimensiunile (n – k)×n se scriu relaţiile care urmeazǎ: Mai întâi,
b = Pm care permite calculul biţilor de control din biţii de informaţie. Apoi, având în vedere cǎ G = [Ik | PT]T, cu Ik matricea unitate de ordinul k, se scrie
c = Gm = [Ik | PT]Tm = [mT | (Pm)T]T = [mT | bT]T succesiune de egalitǎţi care este (în variante) relaţia de generare a cuvintelor de cod. În final, cu H = [P | In – k], în care In – k este matricea unitate de ordinul n – k
Hc = [P | In – k] [mT | bT]T = Pm + b = b + b = 0 este relaţia de verificare a cuvintelor de cod. Forma H = [P | In – k] a matricei H, cu matricea unitate aşezatǎ uneori în stânga se numeşte forma sistematicǎ a matricii de control sau de verificare. Se propune ca exerciţiu dovedirea relaţiei HG = 0. Forma sistematicǎ a matricei H face extrem de facilǎ separarea matricei P şi, în continuare, scrierea matricei generatoare şi generarea cuvintelor de cod. Dacǎ matricea H nu este în forma sistematicǎ verificarea cuvintelor de cod necesitǎ o anumitǎ strategie care poate fi înlocuitǎ cu o manipulare algebrică prealabilǎ a liniilor ei (în genul eliminării Gauss) pentru a deveni sistematicǎ. Se recomandǎ ca exerciţiu scrierea relaţiilor generale de mai sus pentru câteva din codurile liniare particulare discutate mai devreme, de pildǎ pentru codul cu repetiţie şi pentru codul cu paritate constantǎ. O tratare a codǎrii şi decodǎrii ar putea utiliza un tabel care sǎ dea echivalenţa cuvânt de codificat – cuvânt de decodificat. Codarea ar fi atunci o operatie de cǎutare în acest tabel, decodarea ar fi tot aşa, dupǎ corectarea eventualelor erori (prin distanţe Hamming de pildǎ), o cǎutare în acelasşi tabel. Operatia poate fi incomodǎ din cauza creşterii exponenţiale a volumului acestui dicţionar odatǎ cu cresterea numǎrului k. O cale mai eficientǎ pentru codare aplicatǎ în practicǎ este aceea a unor operatii logice simple asupra şirului de k biti purtǎtori de informatie. La decodare, este evaluat printr-o operatie logicǎ asupra cuvintelor de lungime n receptionate aşa-numitul sindrom. Operatia este întrucâtva mai simplǎ deoarece este de parcurs un tabel mai restrâs, cu numai 2n – k perechi de cuvinte. Generarea biţilor de control, sindromul Dacǎ c este un cuvânt de cod şi r este cuvântul recepţionat la transmiterea lui, cu posibile erori, atunci
e = c + r
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

125
este vectorul eroare. Vectorul eroare are 1 pe pozitiile eronate şi 0 pe poziţiile corecte ale cuvântului receptionat: ri = ci ei = 0, ri ≠ ci ei = 1, pentru fiecare indice i. Relatiile c = r + e şi r = c + e sunt echivalente cu relatia de definiţie a vectorului eroare. Cu aceste relatii se poate calcula cuvântul de cod dacǎ se dau cuvântul receptionat şi vectorul eroare sau se poate calcula cuvântul recepţionat dacǎ se cunosc cuvântul transmis şi eroarea introdusǎ de canal. În practica transmisiunilor este cunoscut numai cuvântul receptionat
r = ci + e rezultat prin efectul erorilor e asupra unui cuvânt de cod ci efectiv transmis. Problema practicǎ este a stabili vectorul de eroare e exclusiv pe baza cuvântului r receptionat. Dacǎ eroarea e este cunoscutǎ, atunci, foarte simplu, se identificǎ cuvântul transmis efectiv:
ci = r + e Cum se poate stabili vectorul eroare? Se considerǎ
Hr = Hci + He = 0 + He = s Vectorul cu (n – k) componente s se numeste vectorul sindrom sau, simplu, sindrom. Acum, prin scrierea matricei de control detaliatǎ la nivelul coloanelor ei şi a vectorului eroare detaliat la componentele sale rezultǎ
He =[h1 | h2 | … | hn][e1 e2 … en]T = e1h1 + e2h2 + ... + enhn = s Vectorul sindrom este o sumǎ de coloane ale matricei de control, a acelor coloane care au acelaşi indice cu componentele nenule ale vectorului eroare. Vectorul sindrom, deşi este calculat pe baza cuvântului receptionat depinde numai de vectorul eroare. Din pǎcate vectorul eroare e nu poate fi calculat din vectorul sindrom pentru simplul motiv cǎ matricea de control H nu este inversabilǎ, iar acelaşi vector sindrom poate rezulta în general din mai mult decât o singurǎ combinatie (liniară) de coloane din H. Dacǎ ei şi ej dau acelasi sindrom atunci
Hei + Hej = s + s = 0 asadar suma ei + ej este un cuvânt de cod sau cei doi vectori eroare diferǎ printr-un cuvânt de cod. Altfel spus, un cuvânt cu eroare şi acelasi cuvânt la care se adaugǎ un cuvânt de cod produc acelasi sindrom. Mulţimea vectorilor eroare care produc un acelaşi sindrom este un aşa-numit codomeniu al codului. Sunt 2n vectori de eroare posibili. Un calcul simplu aratǎ cǎ sunt 2n/2k = 2n – k codomenii distincte şi disjuncte, fiecare cu 2k vectori. Se pune întrebarea care este vectorul eroare corect? Pe baza distanţelor Hamming, vectorul eroare cu cele mai puţine componente nenule este cel mai probabil. Minimul acesta este 1, deci se reţine acel vector eroare care reprezintǎ o singurǎ eroare, numit curent şi liderul codomeniului. Prin selectarea liderului şi prin adunarea la cuvântul recepţionat se obtine cel mai probabil cuvânt de cod transmis prin canal. Dacǎ într-un codomeniu existǎ mai mult de un lider, atunci eroarea nu poate fi corectatǎ, codul nu este capabil a corecta eroarea.
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

126
Codarea în cazul codurilor sistematice. Dacǎ matricea H este sistematicǎ atunci extragerea matricei P este imediatǎ. Dacǎ H nu este sistematicǎ se poate proceda la sistematizarea ei prin operatii cu linii. De pildǎ pentru matricea
011101001001001
H
ataşatǎ codului
Mesaje 00 01 10 11 Coduri 00000 01101 10110 11011
sistematizarea se obţine prin urmǎtoarele operatii succesive: a) permutarea liniilor 2 şi 3 b) permutarea liniilor 1 şi 2 c) adunarea liniei 2 la linia 1 Rezultatul este
Hsistematic =
100100100100111
100111
P
şi se pot genera biţii de control pentru fiecare mesaj
2
1
100111
mm
Pmb
23
12
211
mbmb
mmb
25
14
213
xxxx
xxx
ceea conduce la o regǎsire a tabelului cu cuvintele de cod dat mai sus. Decodarea prin sindrom Pentru a decoda un cuvânt receptionat r se procedeazǎ astfel: 1. Se calculeazǎ sindromul s = Hr 2. Pentru detectarea erorilor:
a. s ≠ 0 aratǎ prezenta erorilor şi se cere (eventual) retransmiterea b. s = 0 confirmǎ transmiterea fǎrǎ eroare
3. Pentru corectarea erorii: a. cu sindromul s evaluat se stabileste liderul (unic al) codomeniului ec şi
se calculeazǎ c = r + ec b. dacǎ sunt mai multi vectori lider în codomeniu, corectarea nu-i posibilǎ,
cuvântul recepţionat este detectat ca eronat şi se cere retransmiterea lui 4. Se extrage mesajul m prin renunţarea la biţii de control atasati lui m, care
completează cuvântul de cod c. Rǎmâne de discutat cum se stabileşte liderul (vectorii lider ai) unui codomeniu. Douǎ cǎi sunt sugerate de discutia de pânǎ la acest stadiu.
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

127
1. Se cautǎ numǎrul minim de coloane din H care adunate dau sindromul s; localizarea coloanelor dau componentele nenule ale liderului de codomeniu
2. Se cautǎ o combinatie oarecare de coloane din H care dǎ sindromul s; se determinǎ vectorul eroare corespunzǎtor prin atribuirea valorii 1 acelor pozitii din e corespondente coloanelor din H prezente în combinatie; se genereazǎ ceilalti vectori eroare din codomeniu prin adunarea pe rând a celor 2k cuvinte de cod; este retinut liderul
Operatiile acestea sunt costisitoare. Practic se procedeazǎ la înzestrarea initialǎ a decodorului cu vectorii lider ai fiecǎrui codomeniu pentru vectorii sindrom posibili. Liderul potrivit se gǎseste prin cǎutarea într-un tabel cu 2n – k intrǎri. În cazul unui singur bit eronat sindromul s coincide cu una şi numai cu una din coloanele matricei de verificare, fie aceea coloana i. Vectorul eroare are un singur bit nenul, pe pozitia i. Stabilirea unui lider de codomeniu este de prisos, corectarea erorii este imediatǎ. Se propune ca exercitiu decodarea cuvintelor receptionate 01111 şi 00111 pentru exemplul (n = 5, k = 2) prezentat mai devreme. Ponderea Hamming a unui cuvânt, w(x), este definitǎ ca numǎrul de biţi nenuli din acel cuvânt. Pentru orice cod netrivial K cea mai micǎ pondere a unui cuvânt diferit de 0T = [00…0] este ponderea minimǎ a acelui cod, w(K). Exemple: w(111) = 3, w(101000) = 2, w(110110) = 4. Codul cu repetiţie de n ori are ponderea w(K) = n, codul de paritate constantǎ are w(K) = 2, pentru codul K4 discutat mai sus ponderea este w(K4) = 1, iar pentru K6 este w(K6) = 3. Pentru un cod rectangular r×s nu este necesar a fi scrise toate cuvintele de cod. Ponderea se poate calcula având în vedere dubla verificare a paritǎtii şi numǎrul minim de biţi nenuli necesari într-un cuvânt de cod corect. Rezultatul este w(K) = 4 pentru orice cod rectangular. Pentru orice cod binar liniar netrivial distanţa minimǎ este egalǎ cu ponderea minimǎ adicǎ d(K) = w(K). Se poate spune aşadar cǎ un cod liniar corecteazǎ (detecteazǎ) t erori dacǎ şi numai dacǎ ponderea sa minimǎ este mai mare decât 2t (respectiv decât t). Câteva exemple: Codul cu repetiţie de lungime n are ponderea w(K) = n, poate detecta (n – 1)
biti eronati şi poate corecta (n – 1)/2 biti alterati. Codul cu paritate constantǎ, w(K) = 2, poate detecta 1 bit eronat. Codul K4, w(K4) = 1 nu este deloc protejat la erori. Codul K6, w(K6) = 3 detecteazǎ douǎ erori, corecteazǎ un bit eronat. Codul rectangular simplu, w(K) = 4 corecteazǎ un bit eronat, detecteazǎ
pânǎ la trei biţi eronati. Proiectarea matricii de verificare Fie x un cuvânt de cod cu ponderea egalǎ cu ponderea codului w(K). Dacǎ H este matricea de verificare a codului K atunci Hx = 0. Prin definitie, cuvântul x are exact w(K) biti nenuli. Asadar, operatia Hx = 0 însumeazǎ coloane ale
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

128
matricii de verificare H pentru a rezulta vectorul nul. Coloanele sunt cele poziţionate la fel cu componentele nenule ale cuvântului x. În urma acestui calcul simplu sunt de reţinut urmǎtoarele: 1. Dacǎ un cod liniar K are matricea de verificare H, atunci numǎrul minim de
coloane din H care adunate dau vectorul nul este n atunci w(K) = n. 2. Dacǎ un cod liniar K are matricea de verificare H şi suma oricǎror n sau mai
puţin de n coloane este nenulǎ, atunci w(K) > n. Pentru detectarea unui bit eronat este necesar ca un cod sǎ aibǎ ponderea w(K) > 1, adicǎ cel puţin w(K) = 2, aşadar nici o coloanǎ din H nu trebuie sǎ fie alcǎtuitǎ numai din elemente nule. Pentru corectarea unui bit eronat este necesar ca un cod sǎ aibǎ ponderea w(K) > 2, adicǎ cel puţin w(K) = 3, aşadar nici o coloanǎ nu trebuie sǎ fie alcǎtuitǎ numai din elemente nule şi nici o pereche de coloane însumate nu trebuie sǎ conducǎ la vectorul nul. Dacǎ o matrice binarǎ cu r linii trebuie sǎ aibǎ coloane nenule distincte douǎ câte douǎ, aceasta înseamnǎ cǎ numǎrul de coloane trebuie sǎ fie strict mai mic decât 2r. Pentru o matrice cu (n – k) linii şi n coloane este necesar ca n < 2n – k dar, desigur, un este şi suficient. Un exemplu: codul cel mai eficient în corectarea unei erori, cel pentru care cu k = 2. Codul trebuie sǎ aibǎ rata R = k/n = 2/n maximǎ, ceea ce implicǎ o lungime n minimǎ. Din relatia n < 2n – 2 rezultǎ n = 5. Acesta este cel mai mic n permis. Matricea H de verificare are (n – k) = 3 linii şi n = 5 coloane. Pentru corectarea unei erori este necesar ca cele cinci coloane sǎ fie douǎ câte douǎ distincte. Dacǎ matricea trebuie sǎ fie şi sistematicǎ, atunci o soluţie posibilǎ este
100100101100101
H
25
214
13
xxxxx
xx
Deoarece în matricea H nu sunt coloane nule şi coloanele sunt douǎ câte douǎ distincte rezultǎ ponderea w(K) = 3 şi corectarea unei erori este totdeauna posibilǎ. Codul este dat în tabelul următor
Mesaje 00 01 10 11 Coduri 00000 01011 10110 11101
şi are ponderea w(K) = 3 cum era de asteptat, dar nu este şi unic. Într-un alt exemplu se cere corectarea eficientǎ a doi biţi eronati într-un cuvânt de cod, tot în cazul când numărul biţilor de informaţie este k = 2. Este necesar de data aceasta ca ponderea codului sǎ fie w(K) = 5. Pentru a stabili lungimea n minimǎ se poate recurge la calculul limitei superioare B(n, 5) conform unei relatii prezentate mai devreme. În cazul de aici M = 4, d(K) = 5 şi L = 2 ceea ce produce N ≡ n = 8 şi, implicit, (n – k) = 6. Matricea de control H trebuie sǎ aibǎ dimensiunile 6×8. Din condiţia de a fi sistematicǎ rezultǎ o parte importantǎ a matricii, acea submatrice identicǎ cu matricea unitate I6. Rǎmân de stabilit –
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

129
rǎmâne de vǎzut cum anume – douǎ coloane din H, care se constituie în matricea P. În procesul de alegere a celor douǎ coloane, deoarece w(K) = 5, este necesar ca nici o combinatie de 4 sau mai putine coloane din H sǎ nu aibǎ suma nulǎ. Iatǎ o soluţie:
100000010100000100100010000100110000101000000111
H
18
17
26
215
24
213
xxxxxx
xxxxx
xxx
care corespunde codului
Mesaje 00 01 10 11 Coduri 00000000 01111100 10101011 11010111
Se poate verifica imediat cǎ ponderea minimǎ a codului este w(K) = 5. Viteza relativǎ este R = 2/8 = 1/4, ceea ce nu este foarte bine. Pentru o transmitere mai eficientǎ este necesar a se mǎri k. Coduri perfecte pentru corectarea erorilor Un cod liniar (n, k) este compus din 2k cuvinte de lungime n. Numǎrul total de cuvinte care pot fi alcǎtuite din n biti este 2n dintre care numai 2k sunt cuvinte ale codului. Celelalte 2n – 2k nu apartin codului. Dacǎ codul corecteazǎ cel mult t erori atunci cuvintele din categoria ultimǎ pot fi cuvinte la distanţa t sau mai puţin faţǎ de un anumit cuvânt de cod, ceea ce
înseamnǎ cǎ în acel cuvânt se pot corecta t sau mai puţini biţi. cuvinte la distanţǎ mai mare de t faţǎ de douǎ sau mai multe cuvinte ale
codului, ceea ce înseamnǎ cǎ erorile pot fi numai detectate. Dacǎ toate cuvintele din afara codului sunt de primul tip atunci codul este perfect. Codurile perfecte sunt capabile a corecta cele mai probabile erori din orice cuvânt recepţionat. În altǎ formulare, existǎ totdeuna un singur lider de codomeniu. Codurile perfecte garanteazǎ viteza de transmitere a informatiei maximǎ pentru corectarea a t biti. În aceste condiţii, cuvinte de tipul al doilea nu existǎ şi de aceea sunt mai puţine cuvinte şi mai scurte. Un cod perfect care corecteazǎ t erori are cea mai micǎ distanţǎ minimǎ îngǎduitǎ şi anume 2t +1. O definiţie conceptualǎ a unui cod perfect: un cod liniar de lungime n este perfect dacǎ pentru orice cuvânt r de lungime n existǎ un singur cuvânt de cod la distantǎ Hamming t sau mai micǎ faţǎ de r.
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

130
O definiţie operaţionalǎ a unui cod perfect: numai în cuvintele de lungime r care nu aparţin codului şi sunt de tipul prim pot fi corectate t erori. Cei 2n – k vectori sindrom s = Hr trebuie sǎ fie în acelaşi numǎr ca şi posibilele combinatii de 1, 2, …, t – 1, t biţi eronaţi într-un cuvânt de lungime n (la care se adugǎ si sindromul nul, zero erori). Aşadar, un cod liniar (n, k) este perfect dacǎ
t
i
in
kn C0
2
Reluând exemplul codului (5, 2) de mai devreme şi admitând cǎ s-a recepţionat cuvântul 00111, se constatǎ cǎ nu este la distanţa t = 1 sau mai puţin de numai un cuvânt de cod şi este în fapt la distanta 2 de douǎ cuvinte de cod, 01011 şi 10110, prin urmare nu este un cod perfect. În plus, 25 – 2 = 8 ≠ C5
0 + C51 = 6.
Codurile Hamming prezentate în acest paragraf alcǎtuiesc o clasǎ importantǎ de coduri perfecte corectoare de o eroare. Pentru corectarea unei singure erori, t = 1, un cod perfect trebuie sǎ îndeplineascǎ condiţia
t
i
in
kn nC0
12 12 mn
în care s-a notat cu m diferenţa n – k. Înlocuirea duce la relatia k = 2m – m – 1. Un cod Hamming (n, k) are lungimea cuvântului/blocului n = 2m – 1 cu m ≥ 3, are partea informaţionalǎ de lungimea k = 2m – m – 1, distanţa minimǎ d(K) = 3 şi este capabil a corecta o eroare, adicǎ un bit eronat. Pentru corectarea unei erori, matricea de control H trebuie sǎ aibǎ toate coloanele nenule şi diferite douǎ câte douǎ. Pentru m linii nu pot exista mai mult de 2m – 1 coloane distincte şi diferite de colana nulǎ. Asadar, n ≤ 2m – 1. Deoarece R = k/n = (n – m)/n pentru m fixat, cu cât n este mai mare cu atât rata este mai mare. Cazul egalitǎtii, n = 2m – 1 produce cea mai bunǎ ratǎ de transmitere. Asadar, un cod Hamming are matricea de control H cu m linii şi cu 2m – 1 coloane, fiecare numǎr binar nenul de m cifre regǎsindu-se printre coloanele matricei H. Decodarea prin sindrom a codurilor Hamming este mijlocul cel mai simplu şi mai direct de a extrage informatia din cuvintele recepţionate. Deoarece codurile Hamming sunt coduri perfecte pentru corectarea unui bit pe cuvânt, cele 2n cuvinte sunt fie cuvinte de cod, fie cuvinte care nu aparţin codului, dar care sunt cuvinte de cod cu unul din biti corupt, modificat. În mod necesar, pentru fiecare sindrom s liderul oricǎrui codomeniu este unic. Procedura de decodare pentru cuvântul generic r este urmǎtoarea: 1. Se calculeazǎ sindromul s = Hr. 2. Dacǎ s este nul atunci nu existǎ nici o eroare, r = c este un cuvânt de cod. 3. Dacǎ s este nenul atunci el coincide cu una din coloanele matricei H, de
pildǎ cea de a i-a; se corecteazǎ bitul din pozitia i a cuvântului r şi se obţine cuvântul de cod c.
4. Se renuntǎ la (n – k) biti ataşati biţilor informationali în cuvântul c şi se obtine informatia m.
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

131
Propunem ca exemplu cazul codului Hamming (7, 4). Matricea lui de control are m = (n – k) = 3 linii şi n = 7 coloane, izomorfe cu cele 23 – 1 numere binare nenule exprimate pe trei cifre. Cuvintele care trebuie codate au k = 4 biti. În varianta nesistematicǎ, matricea H are înfǎţişarea
101010111001101111000
H
Dupǎ sistematizare ea devine
Hsist =
100101101011010011110
4217
4316
4325
xxxxxxxxxxxx
cu relaţiile de calcul al biţilor de control alǎturi. Tabelul complet al codului este dat în tabelul care urmeazǎ.
Mesaje 0000 0001 0010 0011 Coduri 0000000 0001111 0010110 0011001 Mesaje 0100 0101 0110 0111 Coduri 0100101 0101010 0110011 0111100 Mesaje 1000 1001 1010 1011 Coduri 1000011 1001100 1010101 1011010 Mesaje 1100 1101 1110 1111 Coduri 1100110 1101001 1110000 1111111
Ca exercitiu, decodaţi prin sindrom urmǎtoarele cuvinte recepţionate: 0001111, 0110101, 0110100, 1101100. Codul (7, 4) prezentat în detaliu aici nu este singurul cod Hamming. Tabelul urmǎtor prezintǎ trei coduri Hamming din multe altele – fiecare capabil a detecta un bit eronat – şi caracteristicile lor.
k n m R 4 7 3 4/7 11 15 4 11/15 26 31 5 26/31
Se observǎ cǎ rata R = k/n = (n – m)/n = 1 – m/(2m – 1) tinde rapid cǎtre 1, dar cu o protectţie din ce în ce mai slabǎ la erori (codurile pot corecta un singur bit din 7, din 15, din 31 biţi). Probabilitatea erorii într-un bloc/cuvânt este
22112
120121
m
m
m
m qpCpCPe cu notatiile p şi q adoptate pentru un canal binar simetric, reprezentând probabilitatea unui bit corect, respectiv probabilitatea unui bit eronat.
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

132
Codurile Golay sunt coduri perfecte de asemenea. Deţinând cunoştinte exclusiv despre codul Hamming (7, 4), Marcel J.E.Golay a generalizat ideea lui Hamming la coduri perfecte corectoare de o eroare într-o bază oarecare care este număr prim. După ce a epuizat acest subiect, Golay a trecut la căutarea de coduri perfecte corectoare de mai multe erori. Unul din codurile Golay este de interes special deoarece a fost utilizat mai târziu pentru a genera pachete într-un spaţiu cu dimensiunea 24. Se ştie, un cod corector de t erori trebuie să aibă o distanţă Hamming minimă de cel putin 2t + 1. Pentru ca un cod să fie perfect, numărul de vârfuri ale unui n-cub unitar dintr-o sferă de rază t care-l conţine trebuie să fie o putere a lui r, unde r este baza codului. În cazul binar trebuie ca
kt
i
inC 2
0
pentru un anumit întreg k. Aceasta este suma primilor t + 1 coeficienţi/elemente din linia a n-a a triunghiului lui Pascal. Triunghiul lui Pascal este o structură triunghiulară de numere naturale care are pe linii coeficienţii binomiali
1510105114641
1331121
111
11520201561 etc.
Golay a găsit două asemenea numere
122
090 2
i
iC şi 113
023 2
i
iC
În cazul n = 90 Golay a arătat că nu există nici un cod perfect (90, 78) corector a două erori. Pentru n = 23 Golay a găsit un cod (23, 12) corector de 3 erori şi a şi dat o matrice pentru el
111111111110101100001111110001010111011010100111010110011011100011101011001101110011001011011101010101101101100110110101111000111001
P
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

133
Prin alăturarea la aceasta a matricii unitate I11, se obţine o matrice de verificare de aceeasi formă cu acelea pentru codurile perfecte corectoare de o eroare: H = [P | I11]. Pentru a construi codul, din digiţii mesajului m1, …, mk se evaluează digiţii de control (de paritate) b1, …, bn – k astfel încât
2mod012
1
j
jiji mab , i = 1, 2, …, 11
sau, deoarece codul este binar
2mod12
1
j
jiji mab , i = 1, 2, …, 11
Cuvintele de cod au forma m1, …, mr, b1, …, bn – k cu digiţii de paritate plasaţi în partea din urmă a cuvântului. Tipuri de erori, probabilităţi ale erorilor nedetectate/nedetectabile În situatia în care se transmite cuvântul ci şi se recepţioneazǎ cuvântul r se pot enumera urmǎtoarele situatii: 1. Nici o eroare: sindromul s = 0, cuvântul receptionat r = ci, caz ideal 2. Detectarea de erori (sindromul s ≠ 0, cuvântul receptionat r ≠ ci, i oarecare),
cu subcazurile: a. Eroarea se poate corecta (liderul de codomeniu unic: + r = ci), caz
deplin tratabil b. Eroarea nu poate fi corectatǎ (doi sau mai multi lideri de codomeniu),
caz încǎ tratabil c. Eroarea se corecteazǎ incorect (liderul de codomeniu unic: + r = cj ≠
ci), caz fatal, dintr-o eroare se ajunge în alta bine ascunsǎ, insinuată. 3. Eroare nedetectatǎ (s = 0, r = cj ≠ ci), caz fatal, intratabil. Dacǎ transmisia este de tipul FEC, situatiile (2c) şi (3) sunt fatale, intratabile. Tot fatalǎ poate fi şi (2b) dacǎ nu existǎ facilitǎţi ARQ. Pentru sistemele de transmisie ARQ numai situatia (3) este fatalǎ, celelalte sunt tratabile prin solicitarea unei retransmiteri. Multe dintre sistemele de transmisie sunt (si) ARQ asa încât problema rǎmâne intratabilǎ numai în situatia ultimǎ (3). O eroare nedetectabilǎ apare atunci când cuvântul receptionat este r = c j şi, de fapt, s-a transmis un alt cuvânt ci. Dacǎ aşa stau lucrurile atunci
e = c j + r = ci + c j şi eroarea este ea însǎşi un cuvânt de cod nenul. Aşadar, o eroare nedetectatǎ se produce dacǎ şi numai dacǎ vectorul eroare e este un cuvânt de cod nenul. Probabilitatea unei erori nedetectate, Pned(K) este suma probabilitǎţilor de apariţie a vectorilor eroare care sunt cuvinte de cod nenule. Dacǎ un vector eroare semnaleazǎ i biţi eronaţi, probabilitatea lui este qipn–i. Deoarece intereseazǎ numai vectorii e care reproduc cuvinte de cod nenule, punem Ai numǎrul de cuvinte de cod cu ponderea Hamming i şi evaluǎm
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

134
Pned(K) =
n
i
inii pqA
1
Dacǎ ponderea minimǎ a codului este d(K) atunci 0... 1)(21 KdAAA şi relatia de mai sus se modificǎ
Pned(K) =
n
Kdi
inii pqA
)(
Pentru codul Hamming (7, 4), d(K) = 3 şi A3 = 7, A4 = 7, A5 = A6 = 0 şi A7 = 1. Probabilitatea cuvintelor cu erori nedetectabile este
Pned(K) = 73443 77 qpqpq Pentru q = 0,01 aceastǎ probabilitate este de cca. 7·10–6, adicǎ 7 cuvinte dintr-un milion pot avea erori nedetectabile. Alte coduri detectoare sau corectoare de erori La examinarea şi alegerea codurilor este de avut în vedere: Tipul codului, sistematic sau nesistematic. Viteza relativǎ (rata), câti biţi se transmit pentru un bit al mesajului. Protecţia la erori, câti biţi eronati se pot detecta sau corecta. Rezolutia în diagnosticarea erorilor, domeniul de acţiune în detectarea
şi/sau corectarea erorilor: o lungime a cuvântului de cod mai mare implicǎ o rezolutie mai slabǎ.
Latenţa erorilor, ce cantitate de informaţie trebuie recepţionatǎ pentru ca eroarea sǎ fie detectatǎ şi/sau corectatǎ: lungimea cuvântului de cod mai mare aduce o latenţǎ mai mare.
Acoperirea, ce poziţii ale bitului sau ale cuvâtului sunt protejate şi cum. Tipul erorilor, cât de potrivit este codul pentru detectarea şi/sau corectarea
erorilor aleatoare sau a celor incidentale. Discuţia s-a limitat pânǎ acum la erorile care apar aleator, ceea ce se întâmplǎ într-un canal aşa-numit fǎrǎ memorie. Se observǎ însă uneori erori care persistǎ pe un şir de biţi consecutivi, ca şi cum canalul ar avea memorie: o secvenţǎ de l biţi suportǎ modificǎri din cauza unui incident cu urmǎri care treneazǎ. De pildǎ, un tip particular de erori incidentale sunt cele numite erori multiple unidirecţionale. Acestea forţeazǎ un numǎr de biţi consecutivi sǎ fie constant 0 sau constant 1. Erorile acestea sunt produse uzual de defecte ale memoriei şi/sau ale magistralelor, prin grupuri de celule sau de linii care “merg” la fel, jos (0) sau sus (1), care se “agaţǎ” la o anumitǎ valoare din cele douǎ. Dar acestea nu sunt singurele genuri de erori incidentale. În telecomunicatii în general, erorile incidentale (în limba englezǎ burst errors) apar ca o secvenţǎ contiguǎ de simboluri receptionatǎ printr-un canal, secvenţǎ în care primul şi ultimul simbol sunt eronate şi nu existǎ vreo subsescvenţǎ contiguǎ de m simboluri receptionate corect în acea secvenţǎ incidental eronatǎ. Parametrul
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

135
întreg m este numit banda de gardǎ a erorii incidentale. Ultimul simbol dintr-o secvenţǎ incidental eronatǎ este separat de primul simbol dintr-o secventǎ urmǎtoare incidental eronatǎ de m sau mai multi biti corecti. Parametrul m trebuie specificat atunci când este descrisǎ o eroare incidentalǎ. Lungimea unei erori incidentale este definitǎ ca numǎrul de biti de la primul simbol eronat la ultimul afectat de eroare, inclusiv. Cele mai multe coduri sunt gândite spre a detecta şi/sau a corectar erori independente, întâmplǎtoare. Este, de pildǎ, cazul codurilor Hamming. Existǎ însǎ metode speciale pentru corectarea erorilor incidentale pe secvenţe de l biti, de genul celor semnalate mai devreme. Intercalarea biţilor este una din aceste metode. Intercalarea se face într-o manierǎ bine precizatǎ, iar la recepţie se face de-intercalarea dupǎ aceeaşi regulǎ, dar inversatǎ. Prin procedeul intercalǎrii se realizeazǎ o randomizare (de la englezescul random – aleator) a plasării erorilor. Erorile din sistematice devin (fals) aleatoare. Schema transmisiei este urmǎtoarea:
Intercalarea se poate face în moduri variate. Tabelele următoare ilustrează trei dintre ele: prin lectura biţilor înscrişi într-o structură virtuală rectangulară, nu pe linii
ci pe coloane, prin lectura biţilor trecuţi în acceaşi structură rectangulară, într-o manieră
helicoidală şi printr-o citire a biţilor în ordine alternativă, pară-impară, după o utilizare
prealabilă a altor două reguli de intercalare. De fiecare dată se efectuează în fond o permutare a indicilor care dau ordinea biţilor, totdeauna inversabilă pentru a putea fi utilizată la deintercalarea de dinaintea decodării.
Intrare
b1 b2 b3 b4 b5 b6 b7 b8 b9 b10 b11 b12 b13 b14 b15
Codare Intercalare
Canal cu erori
incidentale
Deintercalare Decodare
Canal cu erori (fals) aleatoare
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

136
Ieşirea la intercalarea linii-coloane b1 b6 b11 b2 b7 b12 b3 b8 b13 b4 b9 b14 b5 b10 b15
Ieşirea la intercalarea helicoidală b11 b7 b3 b14 b10 b1 b12 b8 b4 b15 b6 b2 b13 b9 b5
Ieşirea la intercalarea par-impar Ieşirea codorului fără intercalare
b1 b2 b3 b4 b5 b6 b7 b8 b9 b10 b11 b12 b13 b14 b15 y1 - y3 - y5 - y7 - y9 - y11 - y13 - y15
Ieşirea codorului cu intercalarea linii-coloane b1 b6 b11 b2 b7 b12 b3 b8 b13 b4 b9 b14 b5 b10 b15 - z6 - z2 - z12 - z8 - z4 - z14 - z10 -
Ieşirea codorului finală, combinată y1 z6 y3 z2 y5 z12 y7 z8 y9 z4 y11 z14 y13 z10 y15 Cu o asemenea tratare, şirul de cincisprezece biţi b1 b2 b3 b4 b5 b6 b7 b8 b9 b10 b11 b12 b13 b14 b15, se transformă după intercalare dintr-un şir cu erorile original grupate incidental, într-un şir cu erorile acum dispersate şi dacǎ, de pildǎ, apare o secvenţǎ de patru biţi succesivi alterati, atunci intercalarea plasează erorile în cuvinte diferite, ceea ce măreşte şansa de a putea fi corectaţi cu un cod corector de erori a cărui capacitate corectoare este limitată. Tot pentru tratarea secvenţelor eronate sunt gândite codurile m din n. Cuvintele de cod sunt toate de aceeasi lungime n şi numǎrul biţilor unitari continuţi este fix, mereu acelaşi. Ca exemplu, codul 2 din 5 aratǎ ca în tabelul urmǎtor:
Mesaj nr. 1 2 3 4 5 Cod 00011 00101 01001 10001 00110 Mesaj nr. 6 7 8 9 10 Cod 01010 10010 01100 10100 11000
Proprietǎtile codului sunt: Codul este nesistematic (necesitǎ utilizarea unui tabel de echivalenţe) Detecteazǎ o singurǎ eroare Detecteazǎ erori multiple unidirecţionale Se utilizeazǎ aproape exclusiv la codarea semnalelor de control. Deoarece codul este nesistematic utilizarea lui este limitatǎ. Semnalele de control nu trebuie decodate ci numai interpretate. Ele pot fi configurate ca 2 din 5 şi orice eroare pe magistrala de control este semnalatǎ. În caz de eroare numǎrul de biti nenuli se schimbǎ şi prin aceasta eroarea este detectatǎ. Dacǎ se transmite mesajul 7, adicǎ 10010 şi primii trei biti sunt adusi toti la 0, ceea ce se întâmplǎ când trei celule de memorie adiacente sau trei linii vecine ale magistralei suferǎ o defecţiune comunǎ cum ar fi scurtcircuitul, atunci se receptioneazǎ 00010, cuvânt 1 din 5, asadar este detectatǎ o eroare. Dacǎ
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

137
acelasi cuvânt transmis este alterat tot pe primii trei biţi, mesajul recepţionat este 11110, cuvânt 4 din 5 care din nou pune în evidenţǎ o eroare de tipul unidirecţional, incidental. Codurile sumǎ de control (Check Sum) sunt dedicate aceluiasi tip de erori, erori unidirecţionale. Aceste coduri sunt generate prin adǎugarea unui cuvânt de control prin sumǎ, de lungime n, la fiecare bloc de s cuvinte informaţionale de lungime n. Cuvântul de control se obtine prin însumarea modulo 2n a celor s cuvinte purtǎtoare de informatie. Aşadar, codarea se face într-un sumator de s cuvinte de lungime n cu omiterea transferului dincolo de puterea maximă 2n. Sumatorul genereazǎ cuvântul de control prin sumǎ. Decodarea se realizeazǎ într-un sumator identic care însumeazǎ s cuvinte receptionate, rezultatul este pus într-un circuit SAU EXCLUSIV cu cuvântul de control. Dacǎ rezultatul este nul transmisia este consideratǎ bunǎ. În caz contrar, în transmitere au apǎrut erori. Proprietǎtile unui cod cu sumǎ de control sunt: Simplu şi ieftin, deci larg utilizat Detecteazǎ cel putin o eroare Detectia erorilor multiple depinde de numǎrul s şi de pozitia bitilor în
cuvinte; acoperirea erorilor este foarte bunǎ pentru biţii de ordin redus Acoperirea erorilor poate fi controlatǎ prin ponderarea diferitǎ a bitilor
şi/sau prin sume de control reprezentate pe mai mult de n biti Latenţa erorilor este îndelungatǎ, adică trebuie sǎ se termine transmiterea
blocului de s cuvinte pentru a face posibilă verificarea corectitudinii Diagnoza are o rezolutie redusǎ, eroarea poate fi în diferite locuri din blocul
de s cuvinte. Utilizǎri ale codǎrii cu sumǎ de control: dipozitive de memorare secvenţiale, periferice cu transfer în blocuri, memorii “read-only”, dispozitive numǎrǎtoare seriale etc. Un exemplu cu n = 8, s = 8 cu o sumǎ de control Ck modulo 28 tot de 8 biti dupǎ fiecare secventǎ de 8 cuvinte (octeţi, bytes, fiecare în lungime de 8 biţi). Dacǎ se transmit urmǎtorii octeţi (exprimaţi în hexadecimal): 32, 62, 01, FA, 22, 02, E3, A1, octetul de control este Ck = 337 mod 100 = 37 (şi acesta tot în hexadecimal). Acoperirea erorilor multiple poate fi încǎ sporitǎ prin utilizarea unei sume de control cu reprezentare extinsǎ la m biţi pentru date transmise exprimate pe n biti, m > n şi a sumei de control modulo 2m. De pildǎ, n = 8 şi m = 16 produce un cuvânt-sumǎ de control de 2 octeţi pentru o secventǎ de s octeti transmişi. Din lumea editorilor de carte este cunoscut codul ISBN-ul (International Standard Book Number). Acesta are o parte care reprezintǎ o sumǎ de verificare. De pildǎ secventa ISBN de 10 simboluri 0-13-283796-X (care cu exceptia cratimelor identificǎ ţara, editorul, cartea) conţine un ultim simbol reprezentat de o cifrǎ zecimalǎ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9 sau de X în loc de 10. Acest ultim simbol este adǎugat pentru verificarea unei sume de control mai complicate, în care cifrele din codul ISBN intrǎ ponderate cu ordinul lor
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

138
10
111
iik iaC
Suma aceasta trebuie sǎ fie divizibilǎ cu 11 dacǎ ISBN-ul este corect, dacǎ este valid. Inconvenientul principal al codurilor cu sumǎ de control este acela cǎ rezultatul obtinut prin însumarea de cuvinte nu este suficient de complex, suma cuvintelor nu este suficient de reactivǎ la erorile pe unul sau mai multi biţi, reactivitate utilǎ la detectarea şi/sau corectarea acestora. O operatie aritmeticǎ relativ simplǎ, dar mai eficientǎ este împǎrţirea cuvintelor de cod şi retinerea restului împǎrţirii. Aceastǎ operatie suplimentarǎ este larg utilizatǎ în cazul codurilor polinomiale, în particular în cazul codurilor ciclice. Coduri polinomiale/ciclice Anticipând întrucâtva, codurile polinomiale au proprietatea de liniaritate: suma a douǎ cuvinte de cod este şi ea un cuvânt de cod. Proprietatea derivǎ din liniaritatea operaţiei de adunare a polinoamelor. În anumite codiţii, codurile polinomiale au şi proprietatea de ciclicitate: orice permutare circularǎ a unui cuvânt de cod este tot un cuvânt de cod. Condiţiile acestea particulare se referǎ la mulţimea de coeficienti ai polinoamelor şi la algebra lor mai mult sau mai puţin specificǎ. Polinoamele sunt definite peste un corp finit, numit în general corp Galois, nume atribuit în onoarea postumă a matematicianului Évariste Galois (1811-1832). Corpurile Galois cele mai frecvent utilzate de specialiştii în codare sunt GF(2) şi GF(2n) (GF vine de la Galois Field, cum se numesc corpurile Galois în literatura în limba engleză). Detalii despre aceste corpuri finite vor fi date ceva mai departe. Revenind la proprietatea ciclicitǎţii, într-un cod ciclic, dacǎ 00100110 este un cuvânt al codului, atunci şi 00010011, şi 10001001, dar şi 00101001 sunt cuvinte care aparţin codului, prin permutare circularǎ primele douǎ, prin însumarea cuvântului iniţial cu urmǎtorul pentru cel din urmă. Codurile ciclice sunt construite şi analizate eficient nu prin vectori binari şi matrici binare, ci mai curând prin polinoame cu coeficienti într-un corp finit. De aceea, în literaturǎ codurile ciclice se mai numesc şi coduri polinomiale: o seamǎ de operaţii cu cuvintele de cod au echivalenţe în operatii cu polinoame. Deoarece sunt coduri liniare, codurile ciclice au implementǎri convenabile atât sub aspectul complexitǎţii cât şi în ceea ce priveste viteza codǎrii şi decodǎrii. Proprietǎţile codurilor ciclice le fac eficiente în utilizǎri cum ar fi tratarea erorilor multiple aleatoare sau incidentale, unidirecţionale sau nu. Nu întâmplǎtor în transmisiunile moderne se folosesc pentru detectarea sau corectarea erorilor codurile ciclice, în particular codurile CRC (Cyclic Redundancy Check). S-a spus deja, codurile ciclice se genereazǎ şi se studiazǎ convenabil în raport cu mulţimea polinoamelor în nedeterminata X
a0X 0 + a1X 1 + … + an – 1X n – 1
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

139
cu coeficienţi într-un corp finit, în particular cel izomorf cu corpul claselor de resturi modulo 2. Pentru simplitate, coeficienţii vor lua mai departe valorile 0 şi 1. Ei se vor aduna şi se vor multiplica dupǎ regulile din corpul de caracteristicǎ 2 menţionat. Mulţimea polinoamelor cu coeficienţi într-un inel (corp) dat este ea însǎsi un inel raportatǎ la operaţiile de adunare şi multiplicare a polinoamelor, este chiar un inel comutativ. Operaţiile cu polinoame sunt adunarea
(a0X 0 + a1X 1 + … + an – 1X n – 1) + (b0X 0 + b1X 1 + … + bn – 1X n – 1) = = (a0 + b0)X0 +(a1 + b1)X1 + … + (an – 1 + bn – 1) X n – 1
cu sumele coeficientilor luate modulo 2 şi înmultirea (a0X 0 + a1X 1 + … + an – 1X n – 1)·(b0X 0 + b1X 1 + … + bn – 1X n – 1) =
= c0X 0 + c1X 1 + … + c2(n – 1)X 2(n – 1)) cu coeficienţii polinomului produs calculati (convolutiv) cu relatiile
c0 = a0b0 c1 = a0b1 + a1b0
. . . . . . . . . . . . . . . . . . . ck = a0bk + a1bk – 1 + … + ak – 1b1 + akb0
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Toate operaţiile cu coeficienţi se fac tot dupǎ regulile de adunare şi multiplicare ale inelului (corpului) din care acestia provin. Operatia de scǎdere a polinoamelor nu este altceva decât tot o adunare: fiecare coeficient al polinomului care se scade dintr-un altul are un opus al sǎu ceea ce face din scǎderea a douǎ polinoame o adunare de coeficienti şi de coeficienti opuşi în corpul numeric din care provin. În particular, dacǎ coeficienţii sunt dintr-un corp cu douǎ elemente, fiecare element este propriul sǎu opus astfel încât x + x = 0 oricare ar fi x. Operatia de împǎrtire a douǎ polinoame nu este nici ea exclusǎ. Fiind date douǎ polinoame a(x) şi b(x), primul diferit de polinomul cu toţi coeficientii nuli, existǎ totdeauna alte douǎ polinoame q(x) numit cât şi r(x) numit rest, acesta din urmǎ de grad inferior lui a(x), astfel încât
b(X) = a(X)q(X) + r(X) Relatia aceasta este cunoscutǎ şi ca teorema împǎrţirii întregi a polinoamelor b(x) şi a(x). Existǎ multe similitudini între aceastǎ teoremǎ şi teorema împǎrtirii întregi cunoscutǎ din aritmetica numerelor întregi. Existǎ şi alte similitudini remarcabile între aritmetica numerelor întregi şi aritmetica polinoamelor. De pildǎ, între divizibilitatea numerelor întregi şi divizibilitatea polinoamelor cu coeficienti într-un inel numeric se poate face o paralelǎ de foarte mare utilitate în definirea unor coduri eficiente detectoare şi/sau corectoare de erori. Este ceea ce aducem în discutie în sectţiunile urmǎtoare.
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

140
Algoritmul lui Euclid şi împărţirea în corpuri finite. Cel mai mare divizor comun al unei perechi de numere întregi r şi s, gcd(r, s)4, este cel mai mare întreg care divide atât pe r cât şi pe s. Algoritmul lui Euclid este o metodă eficientă de a găsi gcd(r, s); este mult mai rapid decât factorizarea lui r şi s urmată de reţinerea factorilor comuni. Ca produs secundar al algoritmului lui Euclid, se pot găsi întregii a şi b astfel încât d = gcd(r, s) = ar + bs. Dacă gcd(r, s) = 1 atunci algoritmul produce valoarea reciprocă (inversă) a lui r în inelul întregilor modulo s. Ideea algoritmului lui Euclid este de a reduce calculul lui gcd(r, s) pentru întregii r, s pozitivi la calculul lui gcd(r’, s’) cu perechea de numere (r’, s’) mai mici decât cele din perechea (r, s). Mai mici înseamnă aici că ambele componente ale perechilor (r, s), (r’, s’) sunt în relatia r’ ≤ r, s’ ≤ s, dar fie r’ < r, fie s’ < s. Dacă r < s atunci (s mod r) < r aşa încât (r’, s’) = (r mod s, r) reprezintă o problemă mai redusă, mai mică potrivit acestei definiţii. Algoritmul lui Euclid generează o secvenţă descrescătoare r1 > r2 > … > rn > 0 în care fiecare ri este obtinut din două numere anterioare prin ri = ri – 2 mod ri – 1 şi valoarea ultimă este rn = gcd(r, s). Resturile sunt definite iterativ astfel:
s = Q1r + r1 0 < r1 < |r| r = Q2r1 + r2 0 < r2 < r1 r1 = Q3r2 + r3 0 < r3 < r2
. . . . . . . . . . . . . . . . . . . . . . rn – 2 = Qnrn – 1 + rn 0 < rn < rn – 1
rn – 1 = Qn + 1rn Procedura se încheie după un număr finit de paşi deoarece fiecare rest este un număr pozitiv mai mic decât restul precedent. Resturile succesive satisfac relatia de recurenţă liniară
ri = ri – 2 – Qiri – 1 cu condiţiile initiale r–1 = s şi r0 = r. Decurge de aici că fiecare divizor comun al numerelor ri – 1 şi ri – 2 divide şi pe ri, iar fiecare divizor comun al numerelor ri şi ri – 1 divide şi pe ri – 2. Asşadar gcd(ri, ri – 1) = gcd(ri – 1, ri – 2) pentru orice indice i. În particular, rn = gcd(rn, rn – 1) = gcd(r0, r– 1) = gcd(r, s). Fiecare rest ri este o combinaţie liniară întreagă a celor două resturi anterioare. Astfel, prin inducţie, restul ultim este o combinatie liniară a primelor două resturi r0 = r şi r–1 = s, adică rn = gcd(r, s) = ar + bs cu a şi b întregi. Este evident că a şi b au în mod necesar semne diferite. Coeficientii a şi b pot fi calculaţi iterativ prin generarea secventelor {ai} şi {bi} în modul
ri = air + bis i = –1, 0, 1, …, n Valorile iniţiale pentru {ai} şi {bi} sunt evident a–1 = 0, b–1 = 1 şi a0 = 1, b0 = 0. Perechile ai, bi se pot determina din ai – 1, ai – 2, bi – 1, bi – 2 astfel:
ri = – Qiri – 1 + ri – 2 = – Qi(ai – 1r +bi – 1s) + (ai – 2r +bi – 2s) = = (– Qiai – 1 + ai – 2)r + (– Qibi – 1 + bi – 2)s = air + bis
4 gcd(r, s) – greatest common divisor, notaţie preferată în textul prezent pentru scurtimea ei faţă de poate mai uzuala prescurtare c.m.m.d.c. – cel mai mare divizor comun.
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

141
Se observă că secvenţele {ai} şi {bi} satisfac aceeaşi relatie de recursivitate care defineste secvenţa de resturi {ri}:
ai = – Qiai – 1 + ai – 2 bi = – Qibi – 1 + bi – 2
Exemplu: Stabilirea numerelor a şi b astfel încât gcd(17, 37) = 17a + 37b.
ri Qi ai bi 37 – 0 1 17 – 1 0
3 2 –2 1 2 5 11 –5 1 1 –13 6 0 2 – –
Verificarea rezultatului: 17·(−13) + 37∙6 = −221 + 222 = 1. O aplicaţie importantă a algoritmului lui Euclid extins este calculul reciprocelor (inverselor) în corpuri finite5 GF(p), cu p un număr prim. Dacă r este un element nenul din GF(p) atunci 0 < r < p şi r este relativ prim cu p, aşa încât gcd(r, p) = 1. Algoritmul lui Euclid în varianta extinsă produce întregii a şi b astfel încât 1 = ar + bp. Aşadar, reciprocul lui r este r – 1 = a mod p. Exemplul parcurs mai sus arată că reciprocul lui 17 în GF(37) este –13 = 24. La utilizarea algoritmului lui Euclid pentru aflarea de valori reciproce în GF(p), coloana bi este numai pentru verificare. Se poate arăta că valoarea an dată de algoritm este totdeauna mai mică (în modul) decât p, astfel că a mod p este fie a, fie p + a. Algoritmul lui Euclid aşa cum a fost prezentat mai sus pare a implica împărţiri repetate. Pentru a garanta că fiecare rest este mic, 0 ≤ ri < ri – 1, câturile trebuie definite ca Qi = 12 / ii rr , raportul trunchiat al două resturi succesive. În fapt, sunt suficiente şi divizări mai grosiere şi alegeri diferite pentru Qi. Calea aceasta poate fi mai eficientă din punct de vedere volumului de calcul. Alegând pe Qi ca puterea lui 2 cea mai mare dar inferioară raportului dintre ri – 2 şi ri – 1, se obtine o implementare a algoritmului lui Euclid de complexitate nu mult diferită de aceea a algoritmului uzual de împărţire binară. Exemplu: Aflarea inversului lui 32 în corpul Galois GF(109) prin diviziune incompletă.
ri Qi ai bi 109 – 0 1
32 – 1 0
5 Un exemplu la îndemână de corp finit este cel al claselor de resturi modulo p, cu p un număr prim, cu operatiile uzuale de adunare şi de multiplicare a claselor. Reamintim, notatia GF(p) vine de la sintagma în limba engleză “Galois Field” (câmp Galois – corp Galois). şi această notatie aste mentinută de-a lungul întregii expuneri.
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

142
45 2 –2 1 32 0 1 0 13 1 –3 1
6 2 7 –2 1 2 –17 5 0 6 – –
Asşadar, în corpul Galois GF(109) valoarea reciprocă a lui 32 este –17 = 92. O altă metodă de calcul al celui mai mare divizor comun (gcd), care evită împărtirea este algoritmul binar datorat lui Stein. Algoritmul lui Euclid pentru polinoame. Algoritmul lui Euclid poate fi utilizat şi pentru calculul divizorului comun cel mai mare ca grad al polinoamelor cu coeficienti într-un corp. Algoritmul euclidian extins pentru polinoame produce polinoamele a(x) şi b(x) astfel încât
gcd(r(x), s(x)) = a(x)r(x) + b(x)s(x) Dacă r(x) şi s(x) sunt relativ prime, atunci a(x) este reciprocul lui r(x) în inelul polinoamelor mod s(x). Dacă s(x) este ireductibil, atunci orice polinom nenul r(x) de grad mai mic decât al lui s(x) este relativ prim cu s(x), astfel că toate polinoamele nenule din inelul polinoamleor mod s(x) au un reciproc. Decurge de aici că polinoamele cu aritmetica modulo un polinom ireductibil formează un corp. Exemplu: A se afla reciprocul lui x3 + x2 modulo x4 + x + 1 peste corpul Galois GF(2).
ri(x) Qi(x) ai(x) ri(x) Qi(x) ai(x) x4 + x + 1 – 0 10011 – 0 x3 + x2 – 1 1100 – 1 x2 + x + 1 x + 1 x + 1 111 11 11 x x x2 + x + 1 10 10 111 1 x + 1 x3 + x 1 11 1010 0 x – 0 10 –
Asadar, (x3 + x2) – 1 mod (x4 + x + 1) = x3 + x. Partea din dreapta a tabelului contine reprezentarea compactă a polinoamelor ca vectori de biti (primul bit, cel mai semnificativ). Reprezentarea aceasta este naturală pentru implementarea pe calculatoare de aritmetici polinomiale atât software cât şi hardware. Adunarea şi scăderea sunt simple operatii sau-exclusiv bit-cu-bit, multiplicarea şi împărtirea cer şi etape de deplasare în registrele de memorie pe lângă operatiile sau-exclusiv bit-cu-bit. Implementarea algoritmului lui Euclid pentru polinoame poate fi simplificată prin alegerea câturilor Qi(x) ca fiind monoame xj şi nu rezultatul unei împărtiri complete ri – 2/ri – 1. Această versiune a algoritmului necesită uzual mai multi paşi decât versiunea cu Qi(x) obtinut prin împărţirea polinomială completă, dar calculul câtului, al restului şi al lui ai(x) este mult facilitat la fiecare pas.
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

143
Exemplu: A se găsi reciprocul lui x3 + x + 1 modulo x5 + x2 + 1 în corpul Galois GF(2) prin divizări incomplete.
ri(x) Qi(x) ai(x) 100101 – 0
1011 – 1 1001 100 100
10 1 101 1 100 10000 0 10 –
Asadar, (x3 + x + 1) – 1 mod (x5 + x2 + 1) = x4. În legătură cu complexitatea calculelor pentru algoritmul lui Euclid, o cale de a evalua timpul de calcul pentru întregi constă în a număra paşii de diviziune. Un pas de diviziune reduce problema cu puţin când câtul este mic, de pildă când Qi = 1. În medie însă, resturile din algoritmul euclidian descresc exponenţial la o rată nu mai mică decât = (1 + 5 )/2 ≈ 1,61803 (celebrul număr cunoscut ca proporţia de aur). Cazul cel mai dezavantajos pentru algoritmul lui Euclid se întâlneste atunci când se evaluează cel mai mare divizor comun (gcd) pentru doi termeni succesivi ai sirului Fibonacci. Algoritmul lui Euclid cere mai multi paşi pentru a găsi gcd(34, 21), 34 şi 21 sunt două numere consecutive din sirul Fibonacci, decât a găsi cel mai mare divizor comun pentru perechile de numere mai mari, vecine (35, 21) şi (34, 22). Stabilirea elementelor inverse/reciproce în GF(2m) – corpul Galois cu 2m elemente –, folosind algoritmul lui Euclid extins la polinoame poate fi efectuat în cca. m cicluri ale calculului uzând de deplasări în registre largi de m biti şi de operaţia sau-exclusiv. Intrările algoritmului lui Euclid sunt p(x), polinomul prim peste GF(2) de gradul m care defineste aritmetica în GF(2m) şi r(x), un polinom de grad inferior lui m al cărui reciproc/invers multiplicativ în GF(2m) trebuie calculat. Fiecare pas de diviziune de polinoame produce un rest al cărui grad este mai mic decât gradul restului anterior. Sunt necesari cel mult m paşi de diviziune pentru a obtine gcd (care e cunoscut în avans a fi 1) şi polinomul a(x) care satisface relatia a(x)r(x) = 1 mod p(x). Unii paşi de diviziune cer mai multe cicluri deoarece împărtirea printr-un polinom de grad mult mai mic decât cel al împărţitorului reclamă cicluri suplimentare. Dar în acest caz, restul rezultat este de grad mic. Calculul în general constă într-un amestec de pasi de diviziune facili şi dificili, dar numărul total de cicluri necesar este O(m) în cel mai nefericit caz. (Constanta multiplicativă ascunsă în notaţia O(m)6 este mică, apropiată de 1 în cazul unei implementări îngrijite.)
6 O(m) – de ordinul lui m.
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

144
Coduri polinomiale În teoria codării, un cod polinomial este un cod liniar bloc cu mulţimea de cuvinte valide formată din acele polinoame care sunt divizibile cu un polinom fixat, numit polinom generator. Definitii: Fie un corp finit GF(q), ale cărui elemente se numesc mai departe simboluri. Pentru a construi coduri polinomiale, se identifică secvenţele ordonate de n simboluri an – 1 … a0 cu polinoamele an – 1xn – 1 + … + a1x + a0, cu coeficienti în corpul GF(q). Se aleg doi întregi pozitivi m ≤ n şi fie g(x) un polinom de gradul m numit polinomul generator. Codul polinomial generat de g(x) este codul în care cuvintele de cod corespund acelor polinoame de grad inferior lui n, care sunt divizibile cu g(x). Un exemplu: Fie codul polinomial peste corpul GF(2) = {0, 1}, cu n = 5, m = 2 şi polinomul generator g(x) = x2 + x + 1. Acest cod constă din următoarele cuvinte de cod:
0·g(x), 1·g(x), x·g(x), (x + 1)·g(x), x2·g(x), (x2 + 1)·g(x), (x2 + x)·g(x), (x2 + x + 1)·g(x).
sau explicit 0, x2 + x + 1, x3 + x2 + x, x3 + 1,
x4 + x3 + x2, x4 + x3 + x + 1, x4 + x, x4 + x2 + 1. Echivalent, în exprimare binară
00000, 00111, 01110, 01001, 11100, 11011, 10010, 10101.
De observat că orice cod polinomial este un cod liniar: orice combinaţie liniară de cuvinte de cod este la rându-i un cuvânt de cod. În cazuri ca acesta, cu corpul GF(2) ca bază, combinaţiile liniare se fac cu operatia SAU-EXCLUSIV (XOR), de pildă 00111 XOR 10010 = 10101. Codarea. Într-un cod polinomial peste corpul finit GF(q) cu lungimea cuvâtului n şi polinomul generator g(x) de gradul m, sunt exact qn – m cuvinte de cod. Prin definitie, p(x) este un cuvânt al codului dacă şi numai dacă acesta este de forma p(x) = g(x)·q(x) cu q(x) – câtul – de grad inferior numărului n – m. Deoarece sunt numai qn – m asemenea câturi, codul are tot atâtea cuvinte, n – m. În consecintă, cuvintele de date, cuvintele informaţionale trebuie să fie de lungimea n – m. Unii autori, cum sunt Lidl şi Pilz (1999), discută de aplicatia q(x) → g(x)·q(x) ca o atribuire de cuvinte de date cuvintelor de cod. Alternativ, se folseşte adesea metoda următoare pentru a crea un cod sistematic: fiind dat un cuvânt de date d(x) de lungime n – m, se multiplică mai întâi d(x) cu xm, ceea ce are ca efect deplasarea lui d(x) cu m pozitii spre stânga. În general, xm·d(x) nu este divizibil cu g(x), deci nu este un cuvânt de cod. Există însă un cuvânt de cod unic care se poate obtine prin modificarea a m simboluri cele mai din dreapta ale polinomului xm·d(x). Pentru această operatie se calculează restul împărtirii lui xm·d(x) prin g(x):
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

145
xm·d(x) = g(x)·q(x) + r(x) unde r(x) este de grad mai mic decât m. Cuvântul de cod care corespunde cuvântului de date d(x) este atunci
p(x) = xm·d(x) – r(x) De observat proprietăţile următoare: p(x) = g(x)·q(x) este divizibil cu g(x). În particular, p(x) este un cuvânt de
cod valid. Deoarece r(x) este de grad mai mic decât m, simbolurile cele mai din stânga
ale lui p(x) sunt aceleasi cu ale polinomului xm·d(x). Cu alte cuvinte, primele n – m simboluri ale cuvântului de cod sunt aceleasi cu cele ale cuvâtului de date/informaţional codat. Cele m simboluri rămase sunt numite simboluri de verificare sau simboluri de checksum.
Exemplu: Pentru codul de mai sus, cel cu n = 5, m = 2 şi polinomul generator g(x) = x2 + x + 1, se obtine următoarea atribuire cuvinte de date – cuvinte de cod:
000 → 00000 001 → 00111 010 → 01001 011 → 01110 100 → 10010 101 → 10101 110 → 11011 111 → 11100
Codul este sistematic: în lista de mai sus, în cuvintele de cod biţii de informatie sunt reprezentati diferit de cei ce control/verificare. Decodarea. Un mesaj eronat poate fi detectat prin împărţire cu polinomul generator. Un rest nenul indică un mesaj cu erori. Admitând că cuvântul de cod este primit fără eroare, la un cod sistematic decodarea este simplă: se renunţă la cei m digiţi de verificare. Dacă sunt erori, corectarea erorilor trebuie făcută înainte de decodare. Pentru coduri polinomiale particulare cum sunt de pildă codurile BCH (Bose şi Ray-Chaudhuri), există algoritmi de corectare şi decodare eficienţi. Proprietăti ale codurilor polinomiale. Ca pentru oricare dintre codurile digitale, capacitatea codurilor polinomiale de a detecta şi/sau a corecta erorile este determinată de distanţa Hamming minimă. Deoarece codurile polinomiale sunt coduri liniare, distanţa Hamming minimă este egală cu ponderea minimă a cuvintelor de cod nenule. În exemplul de mai sus distanta Hamming minimă este 2 deoarece 01001 este un cuvânt de cod şi nu există un cuvânt de cod nenul cu numai un bit nenul. Proprietăţile aparte ale unui cod polinomial sunt legate adesea de proprietăti speciale ale polinomului generator. Iată câteva exemple de astfel de proprietăti: Un cod este ciclic dacă şi numai dacă polinomul generator este un divizor al
polinomului xn – 1.
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

146
Dacă polinomul generator este primitiv – polinom minimal cu coeficienti din GF(p) care generează corpul GF(pn) – atunci codul rezultat are distanţa Hamming minimă de cel putin 3, dat fiind că n ≤ 2m – 1.
În cazul codurilor BCH polinomul generator se alege astfel încât să aibă anumite rădăcini într-un corp extins, ceea ce asigură distanţe Hamming minime mari.
Natura algebrică a codurilor polinomiale, alegerea judicioasă a polinoamelor generatoare sunt elemente care pot fi adesea exploatate pentru a găsi algoritmi eficienţi de corectare a erorilor. Este de pildă cazul codurilor BCH. Printre familiile remarcabile de coduri polinomiale sunt de menţionat: Codurile ciclice – un cod ciclic este totodată un cod polinomial; un exemplu
binecunoscut îl constituie codurile CRC (Cyclic Redundancy Check). Codurile BCH (Bose şi Ray-Chaudhuri) – o familie de coduri ciclice cu
distanţe Hamming minime mari şi pentru care s-au dezvoltat algoritmi algebrici eficienti de corectare a erorilor.
Codurile Reed-Solomon – un subset important al codurilor BCH cu o structură deosebită prin eficienţa lor.
Coduri ciclice În teoria codării, codurile ciclice propriu-zise sunt coduri bloc liniare corectoare de erori care au o structură algebrică convenabilă pentru corectarea şi detectarea eficientă a erorilor. Definiţie: Fie C un cod liniar peste corpul GF(q) cu lungimea blocului de n simboluri. C este numit cod ciclic dacă pentru orice cuvânt de cod c = (c1, …, cn) din C, cuvântul (cn, c1, …, cn – 1) din GF(qn), obtinut prin permutarea circulară a simbolurilor este la rându-i cuvânt al codului. La fel se întâmplă la deplasarea spre stânga. O deplasare circulară spre dreapta este tot una cu n – 1 deplasări spre stânga şi reciproc. Aşadar, codul liniar C este ciclic atunci când este invariant la orice permutare circulară a digiţilor componenţi ai cuvintelor sale. Fată de alte coduri, codurile ciclice au anumite restricţii structurale speciale. Aceste coduri se bazează pe corpurile Galois şi datorită proprietătilor lor structurale sunt foarte utile în tratarea erorilor. Structura lor este strâns legată de corpurile Galois şi de aceea algoritmii de codare şi de decodare pentru codurile ciclice sunt foarte eficienti din punctul de vedere al calculului. Structura algebrică: Codurile ciclice pot fi puse în legătură cu ideale ale unor anumite inele. Fie R = A[x]/(xn – 1) un inel de polinoame peste corpul finit A = GF(q). Elementele codului ciclic C se identifică cu polinoame din R astfel încât (c0, …, cn – 1) se asociază polinomului c0 +c1x + … + cn – 1xn – 1: astfel, multiplicarea cu x corespunde unei deplasări ciclice. Atunci C este un ideal al lui R şi este un ideal principal, deoarece R este un inel cu ideale principale, adică xR şi Rx sunt ideale ale lui R. Idealul este generat de un element monic unic din C, de grad minim, polinomul generator g. Acesta trebuie să fie un
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

147
divizor al lui xn – 1. Decurge de aici că orice cod ciclic este un cod polinomial. Dacă polinomul generator g are gradul d, atunci rangul codului C este n – d. Idempotentul codului C este un cuvânt de cod e pentru care e2 = e (adică e este un element idempotent al lui C) şi e este o identitate pentru cod, e·c = c pentru orice cuvânt de cod c. Un astfel de cuvânt există totdeauna şi este unic; el este un generator al codului. Un cod ireductibil este un cod ciclic în care codul ca ideal este minimal în R astfel că generatorul său este un polinom ireductibil. Exemple: Dacă A = GF(2) şi n = 3, mulţimea cuvintelor de cod continute în codul ciclic al lui 110 este exact
000, 110, 011, 101. El corespunde idealului GF(2)[x]/(x3 + 1) generat de (1 + x). De observat că (1 + x) este un polinom ireductibil în inelul polinoamelor şi de aceea codul este un cod ireductibil. Idempotentul acestui cod este polinomul x + x2 care corespunde cuvântului de cod 011. Exemple triviale de coduri ciclice sunt An însusi şi codul care contine numai cuvântul nul. Acestea corespund respectiv polinoamelor generatoare 1 şi xn + 1, polinoame care divid totdeauna pe xn + 1. Peste GF(2), codul cu paritate constantă alcătuit din toate cuvintele de pondere pară corespunde generatorului x + 1. Şi acesta este totdeauna un factor al polinomului xn + 1. Submulţimile de polinoame generate prin multiplicarea cu un polinom fix a tuturor celorlalte polinoame se numesc ideale ale inelului respectiv. Teorema împǎrtirii întregi pentru polinoame conduce la o împǎrtire a polinoamelor în clase dupǎ schema explicatǎ de relatia urmǎtoare
b(X) = a(X)q(X) + r(X) Polinomul b(X) apartine clasei de resturi r(X) modulo a(X). Restul r(X) este un polinom de grad strict mai mic decât gradul polinomului a(X) prin care se face împǎrtirea. Dacǎ a(X) este polinomul care genereazǎ pe calea arǎtatǎ un ideal I atunci idealul respectiv coincide cu clasa de resturi r(X) = 0, adicǎ toate polinoamele din idealul I se împart exact (fǎrǎ rest) la polinomul a(X). Prin adunarea la polinoamele din idealul I a unui polinom oarecare r X( ) 0 , de un grad inferior polinomului a(X) se obtine o altǎ clasǎ de resturi, clasa de resturi r(X) modulo a(X). Operatiile cu polinoame se transformǎ în operatii cu clase şi operatiile cu clase sunt deplin reprezentate prin operatiile cu resturile r(X) specifice. Asadar, oricare din clasele de resturi va fi reprezentatǎ de polinomul de cel mai mic grad din clasa respectivǎ. Clasele astfel definite pot fi privite şi ca vectori cu n componente, componentele fiind coeficientii polinoamelor de grad n – 1, a0X 0 + a1X 1 + … + an – 1X n – 1: a = a0a1…an–1. Vectorii de acest gen pot fi multiplicati scalar. Produsul scalar coincide cu produsul de clase dacǎ polinomul a(X) este de forma
a(X) = X n + 1
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

148
si rezultatul a(X)b(X) = 0 implicǎ anularea produsului scalar al vectorilor a şi b. Într-adevǎr, dacǎ a(X)b(X) = 0 rezultǎ anularea coeficientului
0... 011221101 babababac nnnnn ceea ce aratǎ cǎ în produsul scalar, ordinea componentelor unuia dintre vectori trebuie sǎ fie inversatǎ. Mai mult, permutarea circularǎ a coeficientilor unuia dintre factori conduce de asemenea la un produs nul
a b a b a b a b a b a bi i i i n n i n i0 1 1 0 1 1 2 2 1 1 0 ... ... pentru orice i = 1, 2, …, n – 1. Cuvintele de cod ca elemente ale unui ideal. Din mulţimea de cuvinte (în număr total de 2n) alcǎtuite din coeficienţii polinoamelor reprezentante ale claselor de resturi modulo a(X) = Xn + 1, se selecţioneazǎ 2k cuvinte cu sens. Cuvintele cu sens trebuie sǎ aibe o proprietate comunǎ şi exclusivǎ care sǎ le distingǎ de celelalte. Se alege un aşa-numit polinom generator g(X) dintre divizorii polinomului a(X). Polinomul g(X) genereazǎ un ideal I. Prin definiţie un cuvânt aparţine codului (este un cuvânt cu sens) dacǎ aparţine idealului I. Pentru orice polinom g(X) existǎ un alt polinom h(X) astfel încât
a(X) = g(X)h(X) =X n + 1 Acest al doilea polinom h(X) genereazǎ un alt ideal J care reprezintǎ aşa-numitul spaţiu nul al idealului I. Altfel spus, un cuvât v(X) este un cuvânt de cod dacǎ şi numai dacǎ el se gǎseşte în spatiul nul al idealului generat de polinomul h(X)
v(X)h(X) = 0 În algebra polinoamelor modulo a(X) se pot alege n polinoame particulare, 1, X, X2, …, Xn – 1, care pot fi considerate o bazǎ în construcţia codurilor. Oricare dintre polinoamele de grad mai mic decât n poate fi scris sub forma a0X 0 + a1X1 + … + an–1X n – 1. În plus, dacǎ g(X) este polinomul generator atunci, pe lângǎ cuvântul g0g1…gm asociat acestui polinom, toate polinoamele Xg(X), …, Xk – 1g(X), de gradul maxim m + k – 1 = n – 1, sunt asociate unor cuvinte cu sens. Într-adevǎr, oricare din polinoamele din aceastǎ secventǎ are proprietatea
X g X h X X g X h Xi i( ) ( ) [ ( ) ( )] 0 pentru orice i = 1, 2, …, k – 1 = n – m – 1. Este de reţinut matricea
m
mm
m
gg
gggggg
G
.........00.....................0......00...0...
0
10
10
matrice cu k = n – m linii care conţine pe linii codurile asociate polinoamelor g(X), Xg(X), …, Xk – 1g(X). Orice polinom combinaţie liniarǎ a polinoamelor din aceastǎ listǎ este de asemenea asociat unui cuvât cu sens, unui cuvânt al codului. Matricea G de mai sus este numitǎ matricea generatoare a codului
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

149
ciclic. Ea are k linii liniar independente din care se pot forma 2k cuvinte de cod. Din relatia funcţionalǎ
g(X)h(X) = Xn + 1 echivalentǎ în mulţimea cuvintelor cu
v(X)h(X) = 0 rezultǎ matricea de control al parităţii H cu proprietatea
HvT = 0 Matricea H este legatǎ de coeficienţii plinomului
h(X) = h0 + h1 X + … + hk Xk şi are forma
Hh h h
h h
h h h
k k
k k
k k
0 0 00 0 0
0
1 0
1
1 0
... ...
... ... ...... ... ... ... ... ... ... ...
... ... ... ...
cu m linii independente liniar, ceea ce face din relatia HvT = 0 un sistem de m ecuaţii care permite determinarea celor m simboluri de control în funcţie de cele k simboluri purtǎtoare de informaţie. Observând structura matricei H, se poate afirma cǎ dacǎ
v a a an0 0 1 1 ( ... ) este cuvânt de cod, atunci şi
v a a a a a ai i i n i i ( ... ... )1 1 0 2 1 este cuvânt de cod, cuvânt cu sens. Ciclicitatea este evidentǎ. Exemplu: Clasele de resturi modulo 1 + X3 sunt tabelate (prin reprezentare la gradul cel mai mic) în continuare
0 1 X 1 + X X 2 1 + X 2 X + X 2 1 + X + X 2 Polinomul poate fi descompus astfel
1 + X 3 = (1 + X)(1 + X + X 2) Cazul I. m = 0, k = 3; g(X) = 1, h(X) = 1 + X 3 Baza pentru cuvintele cu sens este g(X), Xg(X), X2g(X) adicǎ 1, X, X2, şi matricea generatoare este
G
1 0 00 1 00 0 1
cu vectori liniar independenţi pe liniile matricei. Acesti vectori sunt ei înşişi cuvinte de cod. Celelalte cuvinte de cod se obtin prin luarea altor combinatii liniare ale vectorilor din bazǎ
1 1 1 00 1 1
1 1 0 11 1 1 1
2
2
2
XX X
XX X
( )( )
( )( )
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

150
Matricea de control al parităţii este datǎ de polinomul 1 + X 3 din clasa 0, asadar matricea de control este
H [ ]0 0 0 Nu se pot sesiza erorile eventuale, nu se pot corecta, deoarece ponderea minimǎ este d = 1 (la fel distanţa minimǎ între douǎ cuvinte distincte). Cazul II. m = 1, k = 2; g(X) = 1 + X, h(X) = 1 + X + X 2. Matricea generatoare este în acest caz
G
1 1 00 1 1
cuvintele de cod sunt cele douǎ înscrise pe liniile matricii, la care se adaugǎ combinatia liniarǎ (unicǎ)
1 1 0 12 X ( ) Matricea de control este datǎ de polinomul h(X) = 1 + X + X 2 şi este
H [ ]1 1 1 Deoarece ponderea minimǎ este d = 2 se poate detecta o eroare. Cuvintele de cod verificǎ relatia
HvT = 0 Cazul III. m = 2. k = 1; g(X) = 1 + X + X 2, h(X) = 1 + X. Matricea generatoare este
G [ ]1 1 1 şi existǎ un singur vector cuvânt de cod diferit de cuvântul nul. Ponderea este d = 3 şi permite corectarea unei erori. Matricea de control este
H
0 1 11 1 0
Este vorba aici de codul cu repetiţie, cu transmiterea fiecǎrui bit de trei ori. Generarea sistematicǎ a cuvintelor de cod. Fie i X a a X a Xn k n k n
k( ) ...
1 11 polinomul de grad strict mai mic decât
k = n – m, cu coeficientii biţi purtǎtori de informatie. Polinomul Xmi(X) de grad mai mic decât n contine în partea finalǎ, cea cu ordinele cele mai mari, aceiasi biţi. Teorema împǎrtirii întregi pentru acest polinom
Xmi(X) = g(X)q(X) + r(X) conduce la câtul q(X) de grad mai mic decât k şi la restul r(X) de grad mai mic decât m. Cuvâtul
v(X) = r(X) + Xmi(X) este divizibil cu g(X), aşadar este cuvânt de cod. Restul r(X) are drept coeficienţi, adicǎ simboluri de control, combinatii liniare ale simbolurilor purtǎtoare de informatie. Prin operatii elementare algebrice, matricea generatoare poate fi adusǎ la forma
G P Ik [ ] cu Ik matricea unitate de ordinul k. Cuvintele de cod se pot scrie conform relatiei matriciale
v = iG
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

151
Corpuri Galois. Un corp este o multime de elemente care satisfac axiomele corpurilor relativ la adunare şi înmultire
Proprietǎti Adunare Înmulţire Comutativitate abba baab Asociativitate )()( cbacba )()( bcacab Distributivitate acabcba )( bcaccba )( Element neutru aaa 00 aaa .11. Inversabilitate aaaa )(0)( aaaa 11 1 , dacǎ 0a
Un corp cu numǎr finit de elemente este un corp finit sau un corp Galois (denumit astfel în onoarea lui Évariste Galois, 1811-1832). Deoarece elementele neutre sunt diferite unul de celǎlalt, un corp trebuie sǎ continǎ cel putin douǎ elemente. Exemple de corpuri: corpul numerelor complexe, corpul numerelor reale, corpul numerelor rationale dar nu multimea numerelor intregi, care este un inel. Pentru un corp finit numǎrul de elemente alcǎtuitoare, cardinalul sǎu se mai numeste şi ordinul corpului. Ordinul unui corp finit este totdeauna un numǎr prim sau o putere întreagǎ pozitivǎ a unui numǎr prim. Pentru fiecare putere a unui numǎr prim existǎ un corp finit şi numai unul GF(pn) (fǎcând abstractie de un izomorfism). GF(p) este numit corp prim de ordinul p şi este corpul claselor de resturi modulo p, iar elementele lui se noteazǎ cu 0, 1, ..., p – 1. Egalitatea a = b în GF(p) este tot una cu a ≡ b (mod p). A se observa cǎ în inelul resturilor modulo 4, 2×2 ≡ 0 (mod 4), asadar 2 nu are invers pentru operatia de înmultire şi inelul claselor de resturi modulo 4 este altceva decât corpul finit cu patru elemente. Pentru claritate, corpurile finite cu k = pn se scriu GF(pn) şi nu GF(k). Corpul finit GF(2) contine elementele 0 şi 1 care se adunǎ şi se înmultesc conform binecunoscutelor table de adunare şi înmulţire
+ 0 1 0 0 1 1 1 0
× 0 1 0 0 0 1 0 1
Dacǎ o submultime S a unui corp finit GF satisface axiomele de mai devreme atunci ea este un subcorp. Corpurile finite sunt larg utilizate în studiul codurilor corectoare de erori. Când n > 1, corpul Galois GF(pn) poate fi reprezentat ca un corp al unor clase de echivalenţǎ de polinoame cu coeficienti în GF(p). Orice polinom ireductibil
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

152
de gradul n produce acelasi corp pânǎ la un izomorfism. De exemplu, pentru GF(23), polinomul generator poate fi x3 + x2 + 1, x3 + x + 1 sau orice alt polinom ireductibil de gradul 3, dacǎ mai existǎ vreunul. Dacǎ se retine x3 + x + 1 atunci elementele corpului GF(23) – scrise ca 0, x0, x1, ..., secvenţǎ în care apar toate puterile unui element x oarecare, diferit de elementul nul şi de elementul unitate obligatorii în orice corp – pot fi reprezentate ca polinoame de grade inferioare lui 3. De pildǎ
13 xx xxx 24
125 xxx 126 xx
17 x Acum, în tabelul care urmeazǎ sunt date câteva reprezentǎri diferite ale corpului finit de mai sus
Elemente Polinoame Vectori binari Exprimare zecimalǎ
0 0 (000) 0 x0 1 (001) 1 x1 x (010) 2 x2 x2 (100) 4 x3 x + 1 (011) 3 x4 x2 + x (110) 6 x5 x2 + x + 1 (111) 7 x6 x2 + 1 (101) 5 x7 1 (001) 1
Mulţimea de polinoame din coloana a doua a tabelului este închisǎ la adunare şi multiplicare modulo x3 + x + 1 şi operatiile se supun axiomelor pentru corpuri. Acest corp particular este numit un corp extensie de gradul 3 a corpului GF(2), este notat GF(23), iar corpul GF(2) este numit baza corpului GF(23). Dacǎ un polinom ireductibil genereazǎ toate elementele în acest mod, acel polinom se numeste ireductibil primitiv. Pentru orice numǎr prim q sau putere întreagǎ pozitivǎ a lui şi pentru orice întreg pozitiv n existǎ un polinom ireductibil de grad n peste GF(q). Pentru orice element c din GF(q) este valabilǎ relatia cq = c şi pentru orice element d nenul din GF(q) se verificǎ egalitatea dq–1 = d. Existǎ un întreg pozitiv n cel mai mic pentru care suma cu n termeni e + e + ... + e se anuleazǎ pentru orice element e din GF(q). Acel numǎr se numeste caracteristica corpului finit GF(q). Caracteristica este un numǎr prim pentru fiecare corp finit şi relatia
(x + y)p = xp + yp
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

153
este valabilǎ pentru orice x şi y din corpul finit GF(q) dacǎ p este tocmai caracteristica lui. Cuvinte de cod prin rǎdǎcinile polinomului generator. Un polinom oarecare v(x), de grad n – 1 este cuvânt de cod dacǎ şi numai dacǎ are printre rǎdǎcini rǎdǎcinile polinomului generator g(x). Aceasta înseamnǎ cǎ polinomul v(x) este divizibil cu g(x) şi face parte din idealul generat de acesta din urmǎ. Polinomul g(x) este divizor pentru xn + 1 ceea ce face ca rǎdǎcinile lui şi ale poilnomului v(x) sǎ fie şi rǎdǎcini ale polinomului xn + 1. Numǎrul rǎdǎcinilor polinomului xn + 1 generator al claselor de resturi modulo p(x) = xn + 1 este n. Dacǎ n = 2m – 1 atunci polinomul xn + 1 are ca rǎdǎcini elementele nenule ale corpului Galois GF(2m) în numǎr de n = 2m – 1, notate n – 1. Corpul Galois GF(2m) contine clasele de resturi generate de un polinom ireductibil q(x) de gradul m. Pentru fiecare grad m existǎ un polinom ireductibil q(x) şi sunt tabele cu astfel de polinoame. Dacǎ q(x) este şi primitiv atunci toate elementele nenule ale corpului Galois GF(2m), respectiv toate rǎdǎcinile polinomului x
m2 1 1 , pot fi exprimate ca puteri ale uneia din rǎdǎcinile polinomului primitiv q(x). Fie acea rǎdǎcinǎ . Lista completǎ a rǎdǎcinilor este 1, n–1 cu n = 2m – 1. Un caz particular ar putea fi acela în care polinomul generator g(x) este chiar q(x). Exemplu: Fie n = 2m – 1 = 15, adicǎ m = 4. Elementele nenule ale corpului Galois GF(24) sunt generate de polinomul ireductibil de gradul patru q(x) = 1 + x + x4 care are rǎdǎcina primitivǎ . Cele 15 elemente nenule din GF(24) sunt date în tabelul urmǎtor:
Puteri ale lui
Clasele de resturi modulo q(x) = 1 + x + x4 În binar
0 1 1000
1 0100
2 0010
3 0001
4 1 + 1100
5 0110
6 0011
7 1 + + 1101
8 1 + 1010
9 + 0101
10 1 + + 1110
11 + + 0111
12 1 + + + 1111
13 1 + + 1011
14 1 + 1001
15 1 1000
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

154
Se observǎ corespondenţa biunivocǎ între puterile rǎdǎcinii şi clasele de resturi modulo q(x) = 1 + x + x4. Rǎdǎcina corespunde polinomului x. Celelalte rǎdǎcini sunt 2 4 2 1
, ,...,m
. Întrucât q(x) este primitiv, elementele corpului Galois GF(24) pot fi exprimate în funcţie de oricare dintre rǎdǎcinile enumerate. Polinom minimal asociat unei rǎdǎcini i este polinomul ireductibil de gradul cel mai mic pentru care i este rǎdǎcinǎ, notat mai jos mi(x) cu mi(i) = 0. Dacǎ un polinom v(x) are ca rǎdǎcinǎ pe i atunci el se divide cu mi(x), polinomul minimal al acelei rǎdǎcini. Un cuvât de cod, altfel spus un polinom din algebra polinoamelor modulo p(x) = xn + 1, poate fi caracterizat prin rǎdǎcinile lui, elemente ale unui corp Galois GF(2m), rǎdǎcini ale polinomului xn + 1. Se presupune cǎ rǎdǎcinile acelea sunt distincte, r, oricare dintre elementele corpului GF(2m). Polinoamele minimale ale acestor rǎdǎcini mi(x), i = 1, 2, ..., r divid cuvântul de cod, polinomul v(x). Acesta este divizibil şi cu cel-mai-mic-multiplu-comun
g x c m m m c m x m x m xr( ) . . . . .[ ( ), ( ),..., ( )] 1 2 care este exact polinomul generator. Codul/polinomul v(x) aparţine idealului generat de g(x). Asadar, un cuvânt de cod poate fi pus în legǎturǎ cu anumite rǎdǎcini ale polinomului xn + 1 care apartin unui corp Galois GF(2m) dat cu n = 2m – 1. Echivalent, v(x) apartine spatiului nul al unui polinom h(x) care verificǎ împǎrtirea întreagǎ fǎrǎ rest xn + 1 = h(x)g(x). Exemplu: Se considerǎ codul v(x) care are ca rǎdǎcini din corpul Galois GF(24). Polinomul minimal pentru = este un polinom ireductibil care are ca rǎdǎcini pe şi deoarece = = , prin urmare va fi un polinom de gradul patru. El rezultǎ a fi m1(x) = 1 + x + x4. Polinomul minimal pentru = este acelasi, m2(x) = m1(x), deci nimic nou în lista divizorilor lui v(x). Pentru = polinomul minimal m3(x) este altul şi are rǎdǎcinile şi tinând seamǎ cǎ el este tot de gradul patru. În spetǎ m3(x) = 1 + x + x2 + x3 + x4. O cale de a calcula coeficientii polinoamelor minimale este cea directǎ. O cale mai comodǎ se bazeazǎ pe observatia cǎ polinomul de gradul patru m3(x) de pildǎ poate fi scris ca
m x a a x a x a x x3 0 1 22
33 4( )
şi cum îi este rǎdǎcinǎ m a a a a3
30 1
32
63
9 12 0( ) Prin înlocuire conform tabelului de mai sus rezultǎ
a a a a0 1 2 3
1000
0001
0011
0101
1111
0
egalitate echivalentǎ cu sistemul
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

155
aaa
a a a
0
3
2
1 2 3
1 01 01 0
1 0
care conduce la a1 = a2 = a3 = a4 = 1 şi la expresia lui m3(x) de mai sus. Matricea de control. Dacǎ cuvântul de cod v(x) are ca rǎdǎcini r atunci
v a a ai i i nn( ) ... .
00
11
11 0
pentru toţi indicii i = 1, 2, ..., r. Scriind matricea
H
n
n
r r r rn
10
11
12
11
20
21
22
21
0 1 2 1
...
...... ... ... ... ...
...
şi vectorul v a a a an [ ... ]0 1 2 1 , rezultǎ HvT = 0
care este o condiţie de inteligibilitate, de apartenenţǎ la cod a cuvâtului v(x). În matricea de mai sus elementele 10 i . Rǎdǎcinile i se aleg dintre cele 2m – 1 elemente nenule ale corpului GF(2m) astfel încât ele sǎ aibǎ polinoame minimale distincte. Astfel produsul polinoamelor minimale dau polinomul generator
g x m x m x m xr( ) ( ) ( )... ( ) 1 2 care este chiar produsul lor deoarece sunt mutual prime. Suplimentarea cu alte rǎdǎcini ale polinoamelor minimale nu aduc modificǎri polinomului generator, dupǎ cum s-a vǎzut mai devreme. Rangul matricei H este egal cu gradul polinomului generator. Exemplul anterior continuat conduce la matricea
H
0 1 2 14
0 3 6 42......
în care se substituie puterile lui conform tabelului de mai sus şi se obtine
H
0 0 0 10 0 1 00 1 0 01 0 0 10 1 1 10 0 1 10 0 0 11 0 0 1
...
...
...
...
...
...
...
...
matrice cu rangul 8 deoarece polinomul generator g x m x m x x x x x x x( ) ( ) ( ) ( )( ) 1 3
4 2 3 41 1 este de gradul 8. Rǎdǎcina nu aduce nimic nou. Matricea H are proprietatea importantǎ cǎ are liniile liniar independente.
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

156
Corectarea erorilor. Pentru a corecta e erori independente este necesar ca sumele de câte e coloane diferite din H sǎ fie distincte, aricare 2e coloane din H sǎ fie liniar independente. Se pune problema legǎturii dintre numǎrul de erori corectabile şi numǎrul de rǎdǎcini ale polinomului g(x). Rǎdǎcinile 22e–1 conduc la un cod capabil sǎ corecteze e erori independente. Exemplul continuat. Fie e = 1 şi cuvântul de cod de lungime n = 24 – 1 = 15. Simbolurile de control al parităţii sunt în numǎr de m = 4, simboluri purtǎtoare de informatie sunt k = 11. Din cele 15 elemente nenule ale corpului GF(24) se alege ca rǎdǎcinǎ a cuvintelor de cod. Matricea de control este
H 0 1 2 3 14... sau
H
0 0 0 1 10 0 1 0 00 1 0 0 01 0 0 0 1
...
...
...
...
Polinomul generator este g(x) = 1 + x + x4. Corectorul. Fie ... ... ...i ie1
cu ik 1 plasat pe pozitia ik.
Matricea de control se pune sub forma H h h hn 0 1 1...
în care vectorii coloanǎ sunt
hi
i
i
e i
1
3 1
2 1 1
( )
( )( )...
Sindromul este atunci
eiiT hhHz ...
1
o sumǎ de e coloane din H, una din sumele diferite de e coloane diferite. Rezultǎ corectori distincţi pentru situaţii diferite. În cazul corectǎrii unei singure erori, matricea de control este
H n 0 1 2 1... Dacǎ eroarea apare în pozitia i atunci expresia sindromului este
z = i Acelaşi rezultat se obtine şi dacǎ cuvântul receptionat v’(x) = v(x) + (x) se împarte cu polinomul generator g(x)
v x a x g x r x( ) ( ) ( ) ( ) Restul acestei împǎrtiri produce pentru x = tocmai sindromul r’() = z = i. Coduri convoluţionale
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

157
Codurile convolutionale sunt specificate uzual prin trei numere întregi pozitive, (n, k, m), numărul de biti la iesire, numărul de biti la intrare, respectiv numărul registrelor de memorie. Raportul k/n este numit rata codului şi este uzual o măsură a eficienţei codului. De obicei k şi n sunt de la 1 la 8, m de la 2 la 10 şi rata codului de la 1/8 la 7/8 cu exceptia aplicatiilor spaţiale la mare distantă când ratele codului pot fi şi de 1/100 sau chiar mai mici. Producătorii de echipamente de codare specifică parametrii codurilor convoluţionale putin diferit: (n, k, L). Numărul L este aşa-numita restrictie de lungime a codului şi se calculează din k şi m cu relatia L = k(m – 1). Restrictia de lungime L reprezintă numărul de biti din memoria codorului care servesc la generarea celor n biţi de la iesire. Restrictia de lungime se notează ocazional cu K (majusculă), ceea ce ar putea duce uneori la confundarea cu litera mică definită mai sus ca reprezentând altceva. Unele surse consideră pe K drept produsul dintre k şi m. Alte surse definesc un cod convolutional prin perechea (r, K) în care r este rata k/n a codului şi K este restricţia de lungime, de fapt L – 1. În textul care urmează, specificarea codurilor convoluţionale se face exclusiv prin tripla valoare (n, k, m). Parametrii codului convoluţional şi structura codorului. Structura codorului convoluţional (în varianta grafică) se extrage uşor din parametrii lui. Mai întâi se desenează m casete reprezentând cele m registre de memorie. Apoi se pun pe figură n sumatoare modulo 2 care produc cele n ieşiri. Registrele de memorie se conectează la sumatoare conform unor polinoame generatoare (v.figura alăturată).
Acesta este un codor convolutional (3, 1, 3). Generează la iesire 3 biţi pentru fiecare bit introdus la intrare şi are 3 registre de memorie. Este alimentat la intrare de fiecare dată cu 1 bit (intrare bit-cu-bit). Codul generat are aşadar rata de 1/3. Restrictia de lungime a codului este 2. Cum s-a menţionat deja, cei 3 biti de la iesire sunt rezultatul însumării selective modulo 2 a unor biti din registrele de memorie, în 3 sumatoare distincte. Selectarea bitilor pentru fiecare iesire se face conform unor aşa-numite polinoame generatoare. De pildă, primul bit de
m1 m0 m – 1
m1 m0 m – 1
m0 m – 1
m1 m – 1
v1
v2
v3
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

158
iesire are ca polinom generator pe (1, 1, 1), bitul al doilea are pe (0, 1, 1) şi al treilea pe (1, 0, 1). Astfel,
v1 = (m1 + m0 + m–1) mod 2 v2 = (m0 + m–1) mod 2 v3 = (m1 + m–1) mod 2
sau într-o scriere cu operatorul sau-exclusiv v1 = (m1 m0 m–1)
v2 = (m0 m–1) v3 = (m1 m–1)
Polinoamele dau codului calitatea unică de a proteja la erori. Un cod convoluţional (3, 1, 3) poate avea proprietăţi diferite de ale altuia definit prin altă alegere a plinoamelor generatoare. Alegerea polinoamelor gneratoare. Oricare ar fi ordinul m al codului, sunt multe alegeri posibile ale polinoamelor generatoare. Nu toate produc secvenţe de iesire care să protejeze eficient la erori. În cartea “Error-Correcting Codes”, W.W.Peterson şi E.J.Weldon sunt date liste cuprinzătoare de polinoame generatoare adecvate. Polinoamele potrivite se obtin de obicei prin simulare pe calculator. Pentru rata 1/2, tabelul alăturat oferă polinoame de acest gen.
Restrictia de lungime g1 g2
3 110 111 4 1101 1110 5 11010 11101 6 110101 111011 77 110101 110101 8 110111 1110011 9 110111 111001101 10 110111001 1110011001
Starea unui codor. Starea unui codor este dată de o secventă de biti. Codoarele rafinate au restrictia de lungime mare, cele simple au restrictia mai redusă şi numărul de stări mai restrâns. Codul (2, 1, 4) din figura alăturată are o restrictie de lungime 3. Registrele umbrite detin bitii de stare. Registrul clar detine bitul abia sosit. Asta înseamnă că după valorile bitilor din cele trei registre de memorie, codorul are 8 stări distincte. Aceste 8 combinatii şi bitul proaspăt sosit determină valorile de iesire obtinute pentru v1 şi v2, bitii din secvenţa codată.
7 Surse variate reproduc acest tabel care dă pentru restrictia de lungime 7 două polinoame generatoare identice. Probabil că este vorba de o eroare neobservată, propagată de la o sursă la alta.
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

159
Combinatiile de biti din registrele umbrite sunt numite stările codorului. Numărul de stări este 2L, cu L = k(m – 1) restrictia de lungime a codului. Stările unui cod indică ce contin la un moment dat registrele de memorie, cu exceptia registrului/registrelor de intrare. Despre stările codului/codorului se poate vorbi ca despre o succesiune de conditii momentane. Bitii produşi la iesire depind de bitii tocmai aplicati la intrare şi de această conditie momentană a codorului pe care o găsesc şi care se schimbă succesiv. Coduri perforate (punctured). Pentru cazul special k = 1, ratele codurilor 1/2, 1/3, 1/4, 1/5, 1/7 sunt denumite uneori coduri mamă. Aceste coduri rezultate dintr-o intrare bit-cu-bit pot fi combinate pentru a produce coduri perforate care au alte rate, mai avantajoase, diferite de 1/n. Utilizând concomitent două coduri/codoare cu rata de 1/2 ca în figura alăturată şi apoi transmitând numai unul din biţii generati de unul din codoare, această implementare a ratei 1/2 se poate converti într-un cod cu rata 2/3: 2 biti sosesc şi 3 sunt produsi la iesire. Acest concept este numit perforare (puncturing). La receptie, biţii şterşi (dummy), care nu afectează metrica decodării sunt inserati eventual înainte de decodare în locurile adecvate. Revenind la figură, două codoare convolutionale (2, 1, 3) produc 4 biti la iesirile lor. Un bit este “perforat” asa încât rezultă o combinatie care este un cod (3, 2, 3).
m1 m0 m – 1
m1 m0 m – 1
m0 m – 1
v1
v2
u1
m1 m0 m – 1
m1 m0 m – 1 m – 2
m1 m0 m – 2
v1
v2
m – 2
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

160
Această tehnică permite producerea de coduri la rate variate uzând de numai o schemă hardware simplă. Deşi se poate construi direct un codor pentru rata 2/3, avantajul unui cod perforat este acela că ratele pot fi schimbate dinamic (prin software) în functie de conditiile în care canalul functionează, cum ar fi cele atmosferice, meteorologice etc. O implementare fixă, deşi poate mai uşor de realizat, nu permite o asemenea flexibilitate. Structura unui codor cu k > 1. Asa cum s-a afirmat puţin mai sus, se pot crea coduri şi se pot implementa codoare şi pentru k mai mare decât 1. Iată un codor cu rata 2/3 care codează k = 2 biti prin 3 biti, fără a recurge la perforare.
Polinoamele generatoare sunt în cazul acesta (1, 0, 0, 1, 1), (1, 1, 1, 0, 1), (0, 1, 0, 1) şi (1, 0, 1, 1). Un alt exemplu este codul convolutional (4, 3, 3), care preia 3 biti şi produce 4 biti (vezi figura alăturată). Numărul de registre de capacitate triplă este 3. Restrictia de lungime este L = 32 = 6. Codul are 26 = 64 de stări şi necesită polinoame generatoare de gradul 9. Blocurile umbrite reprezintă prin numărul lor restrictia de lungime. Procedura de reprezentare sub formă grafică a structurii unui codor (n, k, m) cu k mai mare ca 1 urmează paşii descrişi imediat. Mai întâi se desenează k multimi de m casete. Apoi se desenează cele n sumatoare modulo 2. Se conectează cele n sumatoare la registrele de memorie urmând coeficientii unuia, mereu altul, dintre cele n polinoame generatoare de
m1 m0 m – 1
v1
v2
v3
m – 2 m – 3
m’1 m’0
m’– 1 m’– 2
u1
u2
m1 m0 m – 1
m1 m0 m – 1
m0 m – 1
v3
v4
u2
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

161
gradul (km). Ceea ce se obtine este o structură ca aceea din figura alăturată. Aceasta reprezintă codorul convolutional (4, 3, 3). Codorul are 9 registre de memorie, 3 biti la intrare şi 4 biti la iesire. Registrele umbrite contin biti “vechi” şi reprezintă starea curentă.
Coduri convoluţionale sistematice şi nesistematice. O formă specială a codurilor convolutionale este cea în care iesirea contine secventa de biti de la intrare usor de recunoscut şi usor de separat. Aceasta este forma sistematică a codului. Vesiunea sistematică a codului convolutional (4, 3, 3) descris mai sus este dată de un codor ca acela din figura care urmează. Codorul sistematic are acelasi număr de registre de memorie, 3 biti la intrare şi 4 biti la iesire. Bitii de la iesire constau în cei 3 biti originari şi un al patrulea bit “de paritate”.
Codurile sistematice sunt adesea preferate celor nesistematice deoarece permit extragerea rapidă a informatiei. Totodată necesită pentru codare un hardware mai restrâns. O altă proprietate importantă: codurile sistematice nu sunt “catastrofale”, erorile nu se propagă catastrofal. Aceste proprietăti le fac foarte apreciate. Codurile sistematice sunt utilizate şi în modulaţia codată pe spalier (TCM – Trellis Coded Modulation). Proprietătile protectoare la erori rămân aceleasi cu ale codurilor nesistematice. Codarea unei secvenţe de intrare. Secventa de iesire poate fi calculată printr-o convolutie a secventei de intrare cu răspunsul impulsional g al codorului, v = u*g, sau, mai detaliat, prin mijlocirea formulelor
m3 m2 m1
m0 m–1 m–2 m–3 m–4 m–5 u3u2u1
v4 u3u2u1
m3 m2 m1
(0,1,0,0,1,0,1,0,1)
(0,0,1,1,0,1,0,1,0) (1,0,1,0,1,0,0,0,0)
v1
v2 v3
m0 m–1 m–2 m–3 m–4 m–5 u3u2u1
(0,1,0,0,0,1,1,0,1)
v4
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

162
m
i
jiil
jl guv
0
în care vjl este bitul l de la iesirea j a codorului, ul – i sunt biti aplicati la intrare şi
gij este coeficientul i din polinomul generator j.
Ca un exemplu, fie de codat secventa de doi biti 10, cu un cod convoluţional (2, 1, 4). Codorul lucrează ca în figurile următoare, comentate în ordinea firească a liniilor şi de la stânga la dreapta.
Mai întâi se introduce în codor bitul 1, cum se vede în prima figură, apoi bitul 0 cum se vede în figura următoare. Apoi un număr de biti nuli (de purjare), până când codorul revine la starea cu toate registrele de memorie continând 0. a. La momentul t = 0 starea initială a codorului este 000 (bitii în număr de L
situati în registrele pozitionate spre dreapta, cu fondul umbrit). Bitul de intrare 1 şi bitii de stare produc la iesire doi biti: 11. Cum? Prin însumarea modulo 2 a tuturor bitilor din registre, respectiv prin însumarea modulo 2 a trei biti.
b. La t = 1, bitul de intrare de la momentul anterior se deplasează în registrul vecin spre dreapta. La fel se deplasează şi ceilalti biţi. Registrul de intrare primeşte acum bitul 0 din secvenţa de codat. Codorul este deja în starea 100. Biţii de iesire calculati la fel ca la punctul anterior sunt din nou 11.
c. La t = 2, bitii din registre se deplasează din nou cu o pozitie spre dreapta. Starea codorului devine 010 şi în registrul de intrare se introduce un nou bit nul, primul din cei 3 de purjare. Bitii de la iesire sunt acum 10.
0 0 0 0
0
0
0 0 0 0
0
0
0 0 0 1
1
1
0 0 1 0
1
0
0 1 0 0
1
1
1 0 0 0
1
1
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

163
d. La momentul t = 3, unicul bit unitar introdus la intrare ajunge prin deplasări succesive în ultimul registru şi starea devine 001. Bitul nul următor introdus la intrare este tot un bit de purjare şi bitii de stare produc iesirea 11.
e. La momentul t = 4, bitul 1 introdus la început a trecut complet prin codor. Codorul a ajuns în starea 000 cu bitul ultim din secvenţa mesaj. Ieşirea codorului este 00.
f. Un ultim bit de purjare aduce codorul în starea 000. Este acum pregătit pentru secvenţa de intrare următoare.
De observat că doi biţi au produs o ieşire de 12 biţi cu toate că rata nominală a codului este 1/2. Faptul arată că pentru secvenţe de codat scurte overhead-ul de codare este relativ mare. În cazul secvenţelor lungi overhead-ul rămâne la fel, dar ocupă o altă proportie în secvenţa de biti generati de codor, în timpul consumat cu codarea. Gestiunea biţilor ultimi, generati de codor în faza de purjare este simplă: ignorarea. În exemplul acesta se poate evidenţia separat răspunsul codorului la singurul bit unitar din secvenţa supusă codării. Acest răspuns este 11 11 10 11 şi este denumit răspunsul la intrarea impuls unitar sau răspunsul impulsional al codorului. Şi bitul 0 are un răspuns propriu, 00 00 00 00, care nu este însă tot aşa de important. Prin convolutia secventei de intrare cu polinoamele generatoare ale codului, se obtin aceste două secvenţe de ieşire. Este un motiv pentru care aceste coduri se numesc convoluţionale. Din principiul suprapunerii (liniare) a efectelor se poate obtine acum iesirea codată corespunzătoare secvenţei de doi biţi propusă. Dacă secvenţa de intrare care trebuie codată este de pildă 1011, este suficent a aduna versiuni deplasate ale răspunsurilor impulsionale asociate fiecărui bit aplicat la intrare. Bit la intrare Răspuns impulsional
1 11 11 10 11 0 00 00 00 00 1 11 11 10 11 1 11 11 10 11 Adunare modulo 2 pentru a obtine răspunsul: 1 0 1 1 11 11 01 11 01 01 11
În figura care urmează este verificată tratarea prin calcul pe baza introducerii în codor a bitilor secventei 1011, unul câte unul. Rezultatul obtinut este acelaşi. Aşadar, modelul de calcul prin convoluţie este corect.
0 1 0 0
1
1
1 0 0 0
1
1
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

164
Rezultatul codării de mai devreme este prezentat şi în tabelul următor:
t Bit la intrare Biţi la iesire Biţii de stare 0 1 11 000 1 0 11 100 2 1 01 010 3 1 11 101 4 0 01 110 5 0 01 011 6 0 11 001
Secvenţa de cod este 11 11 01 11 01 01 11. Proiectarea codorului. Cele două metode de codare prezentate mai sus arată ce se întâmplă matematic într-un codor. Pentru a realiza efectiv codarea, un codor convoluţional hardware ar putea face uz de tabele în care să caute: 1. Bitul de intrare 2. Starea codorului, una din 8 posibile pentru codul (2, 1, 4) 3. Biţii de iesire, grupe de doi biti pentru acelaşi cod (2, 1, 4) 4. Starea următoare, starea care va determina codul următorului bit introdus la
intrare. Pentru codul (2, 1, 4), cu polinoamele generatoare deja specificate, se poate completa tabelul care urmează:
0 0 0 0
0
0
0 0 0 1
1
1
0 0 1 1
0
1
0 1 1 0
0
1
1 1 0 1
1
1
1 0 1 0
0
1
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

165
Bit de intrare
Starea de
plecare
Biţi la iesire
Starea de sosire
u s1s2s38 v1v2 s1’s2’s3’
0 000 00 000 1 000 11 100 0 001 11 000 1 001 00 100 0 010 10 001 1 010 01 101 0 110 01 001 1 110 10 101 0 100 11 010 1 100 00 110 0 101 00 010 1 101 11 110 0 110 01 011 1 110 10 111 0 111 10 011 1 111 01 111
Acest tabel descrie în mod unic codul (2, 1, 4). Tabelul este diferit pentru alte coduri şi depinde de coeficienţii polinoamelor generatoare utilizate. În explicarea codării convoluţionale şi a decodării, se recurge frecvent la grafică. Un codor are toate elementele unui automat finit. De aceea este natural ca diagramele de stare şi arborii să fie printre reprezentările sale. Dar cea mai frecventată reprezentare pare a fi diagrama spalier (trellis). Aceasta pentru că o diagramă spalier cuprinde în aceeaşi imagine şi aspectul temporal al proceselor de codare şi de decodare. Diagrama spalier (trellis). Diagramele spalier sunt numite astfel pentru că arată precum unele structuri similare utilizate în cultivarea unor plante, în sălile de sport etc. În cazul codurilor convoluţionale grafurile spalier sunt aparent încurcate, greu de descifrat. Cu toate acestea sunt preferate în general grafurilor de stare sau grafurilor arbore deoarece reprezintă mai direct şi mai complet aspectele secvenţiale, temporale ale codării convoluţionale. Într-un graf spalier, chiar dacă nu este figurată, pe axa absciselor este subînteles timpul discret alcătuit din momentele în care au loc evenimente determinante pentru operaţia de codare. Pe verticală sunt arătate toate stările posibile ale codului. Scurgerea timpului se traduce printr-o deplasare pe spalier în sensul pozitiv, spre dreapta.
8 Mai condensat, stările codului se pot reprezenta în octal. Aceasta este reprezentarea aleasă în unele puncte ale discutiei despre codurile convolutionale. Cititorul va fi avertizat la momentul potrivit.
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

166
Fiecare tranziţie înseamnă sosirea unui nou bit din secvenţa care trebuie codată. Tranziţiile sunt iniţiate/stimulate de acei biţi.
Diagrama spalier se obtine prin trasarea a 2L linii orizontale (echidistante). Apoi fiecare stare se conectează cu stările următoare prin secvenţele de cod admisibile pentru acea stare. În cazul k = 1, numai două alegeri sunt posibile pentru fiecare stare. Acestea sunt determinate de sosirea la intrarea codorului fie a unui 0, fie a unui 1. Săgeţile indică tranziţiile iniţiate de bitul de intrare: cele care merg în sus (cu suportul linie continuă) sunt iniţiate de bitul 0, cele care merg în jos (cu suportul linie întreruptă), de bitul 1. Diagramele spalier complete conţin şi biţii de ieşire, cei ai codului. Diagrama spalier este unică pentru fiecare cod, la fel cum şi diagrama de stare şi cea arborescentă sunt unice. Spalierul poate fi desenat pentru intervale multiple. De la un moment încolo, fiecare interval între două tranziţii repetă structura grafică a spalierului. Starea de început este totdeauna cea numită nulă, în particular, pentru cazul în discuţie, 000. Pornind de aici, spalierul se dezvoltă şi în L pasi devine populat cu toate tranziţiile posibile. De la acel punct structura grafică care reprezintă tranziţiile se repetă. Codarea pe graful spalier. În figura următoare biţii care sosesc sunt arătati în partea de sus a diagramei spalier. Se porneşte obligatoriu de la punctul corespunzător stării iniţiale nule, 000. Codarea este uşoară: simplu, deplasare în sus pentru un 0, deplasare în jos puntru un 1. Calea urmată pentru secvenţa 1011000 aleasă ca exemplu este reprezentată prin segmente (orientate) puse cap la cap. Diagrama spalier produce aceeasi secvenţă codată ca şi celelalte metode de reprezentare, adică de metoda răspunsului impulsional sau de uzul unei diagrame arborescente.
000
001
010
011
100
101
110
111
S t
ă r
i
Repetare
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

167
Drumul colorat produce la iesire secventa 11 01 11 11 10 10 11. Decodarea. Pentru decodarea codurilor convoluţionale se cunosc mai multe soluţii. Acestea sunt grupate în două categorii: 1. Decodarea secvenţială – algoritmul lui Fano. 2. Decodarea prin metoda verosimilităţii maxime – decodarea Viterbi. Cele două grupe de tehnici de decodare reprezintă tratări diferite ale codurilor convoluţionale. Fiecare din ele utilizează aceeasi idee privind decodarea. Ideea de bază a decodării. Se presupune să se trimit 3 biti codati la rata de 1/2. Sunt receptionaţi 6 biţi (se ignoră în această fază a discuţiei biţii de purjare). Secvenţa celor 6 biti poate să conţină erori. Se stie din discutia despre procesul de codare că bitii aceştia 6, la iesirea din codor sunt generati în mod unic: o secventă de 3 biti dată produce o secvenţă de 6 biti unică. Dar datorită “lucrării” canalului asupra secvenţei transmise, poate fi receptionată în principiu oricare din succesiunile posibile de 6 biti. Exprimate prin 3 biti, la intrarea codorului se pot aplica 8 secvenţe distincte. Fiecare din acestea are un corespondent unic în secvenţele de 6 biti ale codului. Acestea formează mulţimea de secvenţe admisibile şi decodorul trebuie să determine care din ele a fost codată şi expediată. Tabelul alăturat dă măsura coincidenţei pentru cele 8 secvenţe de 6 biti valide.
Intrare Secventa de cod validă
Secventa primită
Potrivirea de biţi
Distanţa Hamming
000 000000 2 4 001 000011 0 6 010 001111 2 4 011 001100 4 2 100 111110 5 1 101 111101 5 1 110 110001 3 3 111 110010
111100
3 3
000
001
010
011
100
101
110
111
S t
ă r
i
Biti la intrare: 1 0 1 1 0 0 0
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

168
Fie secvenţa recepţionată 111100. Vizibil imediat, ea nu este printre secvenţele admisibile. Cum se poate decoda această secvenţă? Sunt două modalităţi de a o interpreta: 1. Se poate compara secvenţa sosită cu fiecare din secvenţele admisibile şi se
poate reţine dintre ele aceea situată la cea mai mică distanţă Hamming faţă de secvenţa de decodat.
2. Se poate evalua repetat corelaţia între secvenţa primită şi fiecare dintre secvenţele admisibile. Se reţine secvenţa admisibilă cea mai strâns corelată cu secvenţa primită prin canal.
Primul procedeu se află în spatele decodării prin decizii cunoscute în literatură ca decizii hard. Al doilea procedeu apartine de decodarea prin decizii soft. Coincidenţa biţilor sau distanţa Hamming ca şi produsul scalar între secvenţa primită şi cuvintele admisibile dau adesea un răspuns ambiguu. Pe baza unui răspuns ambiguu nu se poate decide care anume secvenţă s-a expediat prin canal. Pe de altă parte, pe măsură ce numărul biţilor codaţi creşte, volumul calculelor necesare pentru decodare creşte, astfel că nu pare a fi practică vreuna din aceste modalităti de abordare a decodării. Se cer metode mai eficiente, care să nu examineze chiar toate variantele şi să fie capabile a rezolva ambiguităţile de genul răspunsului dublu, cum se poate vedea în tabelul de mai sus. Dacă este primit un mesaj de lungime s, atunci numărul de secvenţe codate posibile este de 2s. Problema care cere rezolvare în primul rând este cum se poate face decodarea fără a verifica fiecare din aceste 2s secvenţe. Ideea de bază este tratarea problemei decodării în manieră secvenţială. Decodarea secvenţială propriu-zisă a fost una dintre primele metode propuse pentru decodarea secventelor de biti codate convolutional. În prima ei variantă, decodarea secventială a fost propusă de Wozencraft. Ulterior, Fano a oferit o versiune ameliorată. Decodarea secventială poate fi explicată destul de bine printr-o analogie. Către o destinatie anume pot fi parcurse mai multe drumuri divizate în etape. Etapele acestea sunt marcate prin jaloane (landmarks). Persoana care a jalonat variatele parcursuri n-a făcut o treabă perfectă astfel încât din când în când marcajul nu poate fi recunoscut: când şi când, drumul urmat pare a fi greşit şi deoarece alte jaloane nu sunt vizibile, simţământul erorii se accentuează. Nesiguranţa aceasta îndeamnă la a merge înapoi pe drumul deja parcurs până când un punct de ramificaţie anterior oferă alternativa unui alt drum pe care se văd alte noi jaloane. Revenirea poate fi practicată de mai multe ori în raport cu cât de bune au fost direcţiile alese până la un anumit moment. În cele din urmă se atinge destinaţia. În decodarea secventială, drumul către secvenţa originară se parcurge similar. În orice moment se poate renunţa la o portiune de drum şi se poate reveni pentru a urma o altă variantă. Faptul important este acela că de fiecare dată se parcurge un drum şi numai unul.
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

169
Decodarea secvenţială permite deplasarea înainte şi înapoi pe un graf spalier (trellis). Decodorul reţine deciziile sale într-o memorie, inclusiv când decide la modul ambiguu. Dacă numărul deciziilor ambigue creşte dincolo de un anumit prag, decodorul renunţă la acel drum şi revine la ultimul, cel mai recent punct de ramificatie până la care deciziile sunt mai puţine decât pragul menţionat. Un exemplu: Fie codul (2, 1, 4), cel cu care am făcut mai devreme codarea secvenţei de biti 1011000, cu ultimii trei biti folosiţi pentru purjare. Biţii aceştia se mai numesc şi biţi de final – trail bits. Dacă nu apare vreo eroare, secvenţa recepţionată ar trebui să fie 11 11 01 11 01 01 11, dar se recepţionează 01 11 01 11 01 01 11. A apărut o eroare: primul bit primit este un 0 şi nu un 1 cum ar fi trebuit. La decodare, eroarea trebuie corectată. Iată în continuare o descriere a modului cum lucrează decodorul în varianta care foloseste un algoritm secvenţial analog în bună măsură cu cel schiţat pentru cazul parcursului jalonat. Decodarea prin algoritmul de decodare secvenţial. Decodorul secvential are un contor de erori. Primele operatii sunt cea de setare la zero a acestui contor şi cea de atribuire a unei valori prag pentru numărul de erori, în cazul de fată 3, pe baza statisticii canalului. Apoi: 1. Decodorul primeste primii doi biti, 01. Prin consultarea tabelului de mai sus
(cel cu tranzitiile codorului şi bitii de cod generati), sesizează existenta unei erori: bitii primi nu pot fi decât 00 sau 11. Dar care dintre cei doi biti este eronat? Decodorul alege arbitrar 00 pentru început (eroare pe bitul al doilea). La 00 corespunde bitul de intrare 0. Depune un 1 în contorul de erori.
2. Decodorul preia următorii doi biti, 11. Prin consultarea aceluiasi tabel,
decide că un 1 a fost trimis spre codare, ceea ce corespunde exact cu unul din cuvintele de cod. Contorul de erori rămâne neschimbat.
3. Bitii receptionati în continuare sunt 01. Alegerile posibile pentru cuvântul de cod sunt 11 sau 00. Apare o nouă eroare şi contorul de erori este incrementat cu 1. Contorul de erori contine deocamdată o valoare tot mai
Biti la intrare: 01 11 01 11 01
000
001
010
011
100
101
110
111
Retur
Decizii: 1 2 3 4,5
S t
ă r
i
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

170
mică decât valoarea de prag 3. Decodorul poate continua avansul pe aceiaşi rută.
4. Decodorul selectează arbitrar ramura superioară (un 0 s-a codat şi codul lui s-a expediat prin canal). Aici recunoaşte o altă eroare deoarece bitii primiti sunt 11, iar alegerile admise ale cuvântului de cod sunt 10 sau 01. Contorul de erori creste la 3 ceea ce arată că decodorul trebuie să facă drumul înapoi.
5. Decodorul revine la punctul de decizie nr.3 unde contorul de erori era mai
mic decât pragul 3 şi face cealaltă alegere. Întâlneste din nou o conditie de eroare. Bitii receptionati sunt 11 dar cuvintele de cod posibile sunt 01 şi 10. Contorul de erori ajunge din nou la 3. Decodorul se întoarce din nou din drum.
6. Ambele ramuri posibile din punctul nr.3 au fost epuizate. Decodorul trebuie să meargă încă mai înapoi, la punctul nr.2. Dacă urmează ramura neexplorată încă, contorul de erori ajunge din nou la pragul 3. De aceea, decodorul trebuie să meargă încă mai înapoi, la punctul de decizie nr.1.
Biti la intrare: 01 11 01 11
000
001
010
011
100
101
110
111
Retur
Decizii: 1 2 3 5
S t
ă r
i
Retur
Biti la intrare: 01 11 01 11 01
000
001
010
011
100
101
110
111
Retur
Decizii: 1 2 3 4,5
S t
ă r
i
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

171
7. Din punctul 1, întreaga secvenţă de alegeri care urmează se potriveşte cu cuvinte valide şi decodorul decodează cu succes mesajul 1011000.
Necesarul de memorie pentru decodarea secvenţială este relativ uşor de acoperit şi astfel această metodă este utilizabilă chiar şi pentru coduri cu restrictia de lungime mare, când raportul semnal/zgomot este redus. Multe legături de comunicare cu misiunile interplanetare NASA au utilizat codurile convoluţionale cu decodare secvenţială. Decodarea maximum verosimilă (decodarea Viterbi). Metoda Viterbi este cea mai cunoscută metodă de decodare din clasa celor calificate ca fiind cu verosimilitate maximă. Metoda are meritul de neignorat că numǎrul opţiunilor de parcurs se reduce sistematic aproape la fiecare etapă. Condiţiile ipotetice exploatate pentru reducerea numărului de alegeri sunt: 1. Erorile apar rar, probabilitatea apariţiei lor este redusă. 2. Probabilitatea apariţiei a două sau a mai multor erori în succesiune contiguă
este mult mai mică decât probabilitatea unei singure erori, izolate. Cu alte cuvinte, erorile nu sunt grupate, ci sunt distribuite aleator.
Un decodor Viterbi examinează o înteagă secvenţă recepţionată, de o lungime dată. Decodorul calculează o metrică pentru fiecare drum din graful spalier şi decide pe baza acestei metrici. Sunt urmate toate drumurile admisibile până când cel putin două dintre ele ajung într-un acelaşi nod. Aici, un drum cu metrica mai bunǎ este reţinut, un drum cu metrica mai slabă este respins. Drumurile rǎmase dupǎ aceste selecţii sunt numite drumuri supravieţuitoare. La lungimea de N biţi, numărul total de secvenţe posibile este 2N. Dintre acestea numai 2kL sunt secvenţe valide. Pentru a limita compararea la numai 2kL drumuri supravieţuitoare, în loc de a verifica toate cele 2N drumuri, algoritmul Viterbi aplică principiul verosimilităţii maxime. Metrica cea mai folosită este distanţa Hamming. Există însă şi alte metrici care pot fi utilizate în decodarea Viterbi. În cazul în discuţie (rata codului 1/2), se evaluează distanţele Hamming între perechile de simboluri (binare) recepţionate şi perechile posibile/admisibile în
Biti la intrare: 01 11 01 11 01 01 11
000
001
010
011
100
101
110
111 Decizii: 1
S t
ă r
i
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

172
raport cu starea curentă a codului. Pentru fiecare ramificatie, metrica aceasta nu poate fi decât 0, 1 sau 2. Metricile evaluate pas-cu-pas sunt acumulate pentru fiecare parcurs, aşa încât în orice moment decizional este reţinut drumul cu cea mai mică valoare a metricii cumulate. Acum, algoritmul Viterbi în acţiune: Se decodează secvenţa recepţionată 01 11 01 11 01 01 11, aceeasi ca mai sus. 1. La t = 0 se recepţionează biţii 01. Decodorul porneşte totdeauna din starea
000. Din acest punct sunt două ramuri admisibile, la starea 000 şi la starea 100, dar nici una nu duce la generarea biţilor primiţi de decodor. Decodorul evaluează metrica celor două ramuri şi continuă să urmărească concomitent evoluţia pe ambele ramuri. Metrica ambelor ramuri este 1, ceea ce înseamnă că numai unul din cei doi biţi admisibili se potriveşte cu unul din biţii sosiţi. Şi graful spalier, şi tabelul însoţitor redau calculele de etapă.
Starea de plecare9 0 0 Biti admisibili 00 11
Biti primiti 01 Distanta Hamming 1 1
Starea de sosire 0 4 2. La t = 1, decodorul ramifică cele două stări posibile către patru stări.
Metricile ramurilor sunt calculate prin compararea bitilor sositi la decodare, 11, cu perechile admisibile. Noile metrici (cumulate) sunt înscrise în partea dreaptă a desenului. Metricile de etapă sunt înscrise şi în tabelul însoţitor.
9 De aici şi până la finalul decodării se foloseste reprezentarea stărilor în octal.
Biti la intrare: 01
000
001
010
011
100
101
110
111
S t
ă r
i
Metrici
1
1
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

173
Starea de plecare 0 0 4 4 Biti admisibili 00 11 11 00
Biti primiti 11 Distanta Hamming 2 0 0 2
Starea de sosire 0 4 2 6 3. La t = 2, cele patru stări tranzitează la opt stări pentru a evidenţia toate căile
posibile. Metricile căilor pentru biţii 01 sunt calculate şi adăugate metricilor de la momentul anterior t = 1.
Starea de plecare 0 0 2 2 4 4 6 6 Biti admisibili 00 11 10 01 11 00 01 10
Biti primiti 01 Distanta Hamming 1 1 2 0 1 1 0 2
Starea de sosire 0 4 1 5 2 6 3 7 4. La t = 3, spalierul este deplin populat. Fiecare nod/stare are cel puţin un
drum care soseste în el/ea. Metricile cumulate apar în figură.
Biti la intrare: 01 11 01
000
001
010
011
100
101
110
111
S t
ă r
i
Metrici
4
3
2
3
4
1
2
5
Biti la intrare: 01 11
000
001
010
011
100
101
110
111
S t
ă r
i
Metrici
3
1
1
3
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.
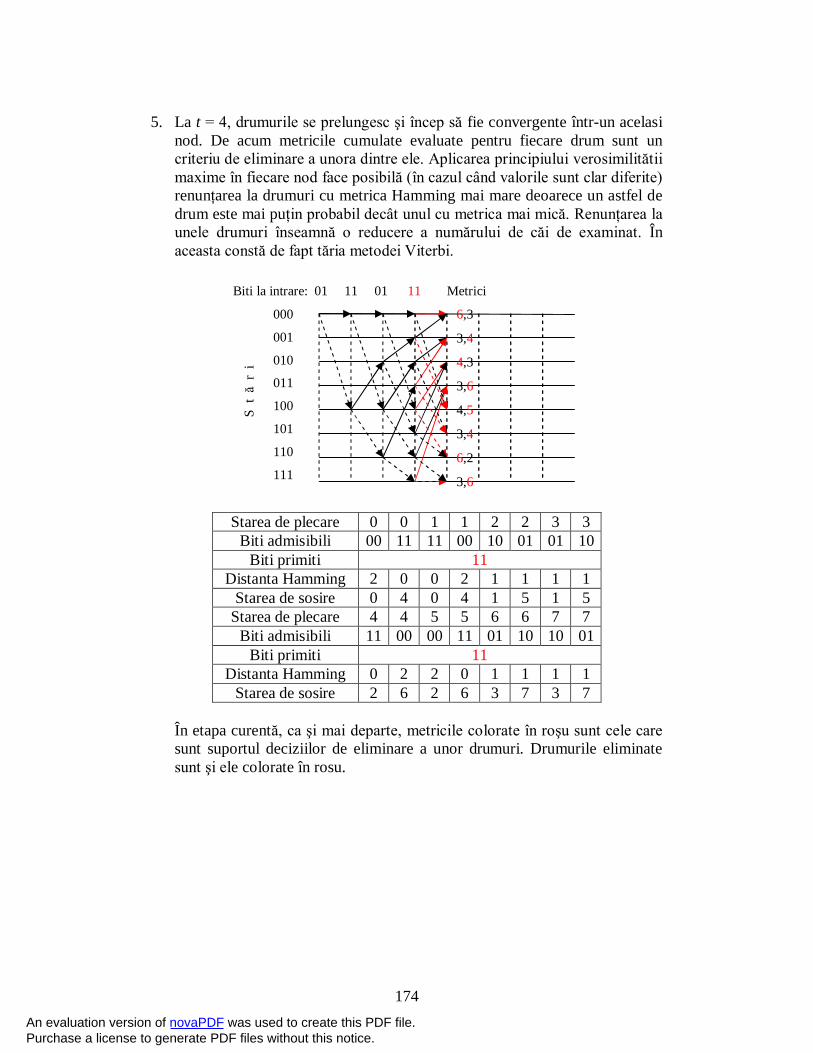
174
5. La t = 4, drumurile se prelungesc şi încep să fie convergente într-un acelasi nod. De acum metricile cumulate evaluate pentru fiecare drum sunt un criteriu de eliminare a unora dintre ele. Aplicarea principiului verosimilitătii maxime în fiecare nod face posibilă (în cazul când valorile sunt clar diferite) renunţarea la drumuri cu metrica Hamming mai mare deoarece un astfel de drum este mai puţin probabil decât unul cu metrica mai mică. Renunţarea la unele drumuri înseamnă o reducere a numărului de căi de examinat. În aceasta constă de fapt tăria metodei Viterbi.
Starea de plecare 0 0 1 1 2 2 3 3 Biti admisibili 00 11 11 00 10 01 01 10
Biti primiti 11 Distanta Hamming 2 0 0 2 1 1 1 1
Starea de sosire 0 4 0 4 1 5 1 5 Starea de plecare 4 4 5 5 6 6 7 7
Biti admisibili 11 00 00 11 01 10 10 01 Biti primiti 11
Distanta Hamming 0 2 2 0 1 1 1 1 Starea de sosire 2 6 2 6 3 7 3 7
În etapa curentă, ca şi mai departe, metricile colorate în roşu sunt cele care sunt suportul deciziilor de eliminare a unor drumuri. Drumurile eliminate sunt şi ele colorate în rosu.
Biti la intrare: 01 11 01 11
000
001
010
011
100
101
110
111
S t
ă r
i
Metrici
6,3
3,4
4,3
3,6
4,5
3,4
6,2
3,6
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

175
Starea de plecare 0 0 1 1 2 2 3 3 Biti admisibili 00 11 11 00 10 01 01 10
Biti primiti 01 Distanta Hamming 1 1 1 1 2 0 0 2
Starea de sosire 0 4 0 4 1 5 1 5 Starea de plecare 4 4 5 5 6 6 7 7
Biti admisibili 11 00 00 11 01 10 10 01 Biti primiti 01
Distanta Hamming 1 1 1 1 0 2 2 0 Starea de sosire 2 6 2 6 3 7 3 7
6. La t = 5, drumurile se prelungesc din nou cu încă un pas de timp şi se
evaluează noi metrici. Din nou se reţin drumurile cu metrici minime.
Starea de plecare 0 0 1 1 2 2 3 3 Biti admisibili 00 11 11 00 10 01 01 10
Biti primiti 01 Distanta Hamming 1 1 1 1 2 0 0 2
Biti la intrare: 01 11 01 11 01 01
000
001
010
011
100
101
110
111
S t
ă r
i
Metrici
5,4
5,4
6,2
5,4
4,5
4,4
5,4
6,3
Biti la intrare: 01 11 01 11 01
000
001
010
011
100
101
110
111
S t
ă r
i
Metrici
4,4
5,3
5,4
4,4
2,5
3,3
5,4
4,3
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

176
Starea de sosire 0 4 0 4 1 5 1 5 Starea de plecare 4 4 5 5 6 6 7 7
Biti admisibili 11 00 00 11 01 10 10 01 Biti primiti 01
Distanta Hamming 1 1 1 1 0 2 2 0 Starea de sosire 2 6 2 6 3 7 3 7
7. La t = 6, biţii recepţionaţi sunt 11. Din nou sunt calculate metricile pentru
fiecare drum. Se elimină drumurile cu metricile cumulate mai mari, se menţin ambele drumuri convergente într-un nod dacă metricile lor cumulate sunt egale.
Starea de plecare 0 0 1 1 2 2 3 3 Biti admisibili 00 11 11 00 10 01 01 10
Biti primiti 11 Distanta Hamming 2 0 0 2 1 1 1 1
Starea de sosire 0 4 0 4 1 5 1 5 Starea de plecare 4 4 5 5 6 6 7 7
Biti admisibili 11 00 00 11 01 10 10 01 Biti primiti 11
Distanta Hamming 0 2 2 0 1 1 1 1 Starea de sosire 2 6 2 6 3 7 3 7
La pasul acesta graful spalier este parcurs complet; nu mai sunt perechi de biti recepţionate care să fie decodate. Într-o procedură a parcursului invers, se examinează graful şi se retine drumul cu cea mai mică metrică. Drumul trasat prin stările 000, 100, 010, 101, 110, 011, 001, 000 este cel care corespunde secvenţei decodate 1011000.
Biti la intrare: 01 11 01 11 01 01 11
000
001
010
011
100
101
110
111
S t
ă r
i
Metrici
6,2
5,5
4,6
5,4
4,4
5,5
6,4
5,4
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

177
Lungimea acestui graf spalier (legată de durata decodării) este de 4 + m biţi. Poate că ar fi ideal ca lungimea acestui drum să fie legată strict de lungimea mesajului codat. În acest caz, la mesaje mai lungi ar fi necesară o memorie mai mare, fapt care ar putea deveni neconvenabil. Printr-un proces de fragmentare, necesarul de memorie poate fi redus şi decodarea nu trebuie întârziată până la finalul secvenţei transmise. Lungimea tipică utilizată este de 128 de biţi sau de 5 până la 7 ori restricţia de lungime. Decodarea Viterbi este importantă şi pentru că se aplică şi la decodarea unor coduri bloc. Forma de graf-spalier este utilizată şi la modularea codată pe spalier (TCM – Trellis-Coded Modulation). Decodarea prin decizii soft. Spectrele de valori ale celor două semnale utilizate pentru a reprezenta pe 0 şi pe 1 pot face procesul decizional dificil când acele semnale sunt corupte de perturbatii. Semnalul este difuz şi energia unuia se scurge către celălalt. Figurile următoare ilustrează cazuri cu valori diferite ale raportului semnal/zgomot. Dacă zgomotul este redus (cantitativ: varianţa lui este mică), difuzarea energiei este şi ea redusă. Intuitiv, se poate bănui că erorile decizionale sunt mai mari dacă raportul semnal/zgomot este mai mic. Figurile reprezintă cele două semnale care reprezintă biţii 1 şi 0 la un raport semnal/zgomot foarte mare, apoi distributia tensiunilor la un raport semnal/zgomot de 12 dB şi, în final, distribuţia tensiunilor la un raport semnal/zgomot de 6 dB. Se observă numaidecât proporţia scurgerii de energie de la o regiune de decizie la alta. O elabora o decizie hard înseamnă a avea un prag de decizie simplu, care este situat uzual între cele două semnale, ales astfel ca o diferenţă pozitivă sau negativă fată de acel prag să fie interpretată ca 0 sau ca 1.
Biti la intrare: 01 11 01 11 01 01 11
000
001
010
011
100
101
110
111
S t
ă r
i
Metrici
2
5
4
4
4
5
4
4
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

178
-3 -2 -1 0 1 2 30
20
40DISTRIBUTIA TENSIUNILOR LA S/Z FOARTE MARE
-3 -2 -1 0 1 2 30
0.5
1DISTRIBUTIA TENSIUNILOR LA S/Z = 12 dB
-3 -2 -1 0 1 2 30
0.5
1DISTRIBUTIA TENSIUNILOR LA S/Z = 6 dB
volti
În termeni rezumativi cam aceasta înseamnă decodarea maximum verosimilă. Eroarea făcută se poate cuantifica cu acest mod de a decide. Probabilitatea de inversare a bitilor este reprezentată de ariile comune de sub curbele din figurile de mai sus. Zona de sub 0 volti reprezintă energia care aparţine semnalului asociat cu bitul 1; zona de peste 0 volti se situează în zona care aparţine semnalului asociat cu valoarea binară 0. Dacă se trimite prin canal un 1, probabilitatea ca el să fie decodat ca 0 este
22
11
te
vAerfcP
cu vt tensiunea prag de decizie, 0 în cazul de faţă, cu 2 varianţa zgomotului sau puterea lui. Funcţia erfc este cunoscuta functie de eroare (error function). Relatia aceasta se poate rescrie şi ca
ZSerfcPe 2
11
Aceasta este relatia familiară pentru rata biţilor eronaţi. Se admite că decizia hard este cea adoptată. Dar ce se întâmplă dacă s-ar proceda altfel: în loc de două regiuni decizionale s-ar împărţi intervalul de tensiuni în patru regiuni decizionale?
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

179
-4 -3 -2 -1 0 1 2 3 40
0.05
0.1
0.15
0.2
0.25
0.3
0.35
0.4PATRU REGIUNI DE DECIZIE
volti
Arii-probabilităti: 0.5793 0.2621 0.1227 0.0359
Aceste regiuni de decizie în număr de patru trebuie să delimiteze sub curbele de repartiţie arii cât mai egale. Probabilitatea ca decizia să fie corectă sau incorectă se calculează din aceste arii de sub curbele gaussiene asociate valorilor 0 şi 1. Dacă se definesc patru regiuni: Regiunea 1, tensiunea măsurată la recepţie este mai mare decât 0,8V Regiunea 2, tensiunea recepţionată este mai mare decât 0V dar mai mică
decât 0,8V Regiunea 3, tensiunea recepţionată este mai mare decât – 0,8V dar mai mică
decât 0V Regiunea 4, tensiunea observată la recepţie este mai mică decât – 0,8V. Întrebare: dacă tensiunea observată la recepţie este în regiunea 3, care este probabilitatea de eroare dacă s-a trimis prin canal un 1? Cu decizia hard răspunsul este facil: probabilitatea aceasta poate fi calculată din ecuatia dată mai sus. Cum se calculează probabilităţi similare pentru cazul deciziei pe mai multe regiuni? Se utilizează funcţia de repartiţie normală particularizată cu mediile şi dispersia tensiunilor observate la iesirea din canal. Dacă funcţia (densitate) de probabilitate a unei variabile aleatoare de medie şi dispersie (varianţă) 2 este
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

180
f(x) = 2
2
2)(
21
x
e
atunci functia de repartiţie (de probabilitate cumulată) este
F(x) =
x
dttf )(
şi este tabelată în surse bibliografice diverse sau se poate calcula (recurgând de pildă la funcţia Matlab consacrată). Probabilitatea asociată unui interval (a, b) se calculează cu relatia
Pr[a < x b] = b
a
dttf )( = F(b) – F(a)
Pentru partiţionarea axei reale în patru regiuni prin punctele de delimitare a zonelor de decizie –0,8, 0 şi 0,8, pentru un raport semnal/zgomot = 1 şi mediile celor două tensiuni 1V, calculul decurge ca mai jos. S-a presupus că nivelurile corespunzătoare lui 0 şi 1 sunt echiprobabile (probabilităti apriori egale, cum se spune), ceea ce este valabil în general, cu exceptia semnalelor radar unde probabilitătile apriori sunt de obicei necunoscute. Probabilităţile de apartenenţă a tensiunilor observate la o zonă sau alta, conditionate de bitul transmis sunt date în tabelul alăturat.
Bit trimis Regiunea 1 Regiunea 2 Regiunea 3 Regiunea 410 0 0,5793 0,2621 0,1227 0,0359 1 0,0359 0,1227 0,2621 0,5793
Acest proces de decizie prin divizarea în mai mult de două părti a spaţiului decizional este cunoscut ca proces de decizie soft. Probabilităţile de genul celor din tabel, reprezentate şi în graf sunt numite şi probabilităti de tranziţie. Sunt valori ale tensiunii cu 4 apartenenţe posibil diferite pentru fiecare semnal recepţionat care serveşte la elaborarea deciziei. Ca şi în viaţa reală, şi în cazul semnalelor mai multă informaţie înseamnă decizii mai bine fundamentate. Deciziile soft măresc sensibilitatea metricilor folosite la decodare şi ameliorează performanţa cu până la 3 dB în cazul unei decizii soft pe 8 niveluri.
10 Numerotarea regiunilor se face de la dreapta spre stânga.
0 1
1 2 3 4 1 2
0 1
0,58 0,04 0,12 0,26
0,04 0,12 0,26 0,56 0,95 0,05
0,95 0,05
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

181
Graful probabilităţilor condiţionate de a decoda un 0 sau un 1
în functie de tensiunea observată, când acea tensiune este cuantizată pe 4 niveluri sau pe 2 niveluri.
Pentru a defini o metrică pentru decizia soft se completează mai întâi un tabel de probabilităti în genul celui de mai sus. Se ia apoi logaritmul fiecăreia din ele şi se normalizează astfel încât una din valori să fie 0. După oarecare manipulare aritmetică se obtine tabelul:
Bit trimis Regiunea 1 Regiunea 2 Regiunea 3 Regiunea 4 0 0 –0,79 –1,55 –2,78 1 –2,78 –1,55 –0,79 0
În secţiunea care se referă la decodarea hard s-a utilizat o metrică Hamming. Acelasi lucru se execută şi acum cu deosebirea că în loc să se primească 0 şi 1, se recepţionează tensiuni. Decodorul caută metrica pentru acea tensiune în tabelul disponibil în memorie şi face calcule asemănătoare. De pildă, admiţând că s-a observat perechea de tensiuni (v3, v2) şi cuvintele de cod permise sunt 01, 10, se evaluează: metrica pentru 01: Pr[0|v3] + Pr[1|v2]; metrica pentru 10: Pr[1|v3] + Pr[0|v2]. Aceste două valori arată care din cele două succesiuni de biti, 01 sau 10 este mai probabilă. Când metricile acestea se adună, suma exagerează întrucâtva diferenţele între drumurile din spalier, ceea ce facilitează decizia. Raportul log-likelihood. Sunt multe posibilităţi de a ameliora performanţa la decodare prin alegerea metricilor. O metrică mult utilizată este metrica log-likelihood (logaritmul probabiltăţilor). Aceasta ia în considerarea probabilitatea de eroare introdusă de canal, 0 ≤ p ≤ 0,5, în raport cu care se definesc o metrică a concordantei = log[2(1 – p)], o metrică a discordantei = log(2p) şi
o metrică sintetică 01log
p
pL , nulă în cazul în care concordanţa şi
discordanţa coincid (p = 0,5). Algoritmul lui Fano pentru decodarea secvenţială utilizează această metrică. Metrica log-likelihood asigură o sensibilitate apreciabilă a algoritmului (soft) de decodare. Două aspecte cer o atenţie specială: independenţa statistică a valorilor tensiunilor observate la iesirea din canal şi cunoaşterea parametrilor zgomotului.
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

182
Prima problemă care poate influenta negativ eficienţa decodării se rezolvă prin operatii de intercalare-deintercalare care fac măsurătorile succesive temporar şi artificial “depărtate” cu o decorelare notabilă dacă nu totală. Problema a doua se poate rezolva recursiv. J.Hagenauer şi P.Hoeher (1989) propun un asemenea algoritm recursiv de actualizare a parametrilor statistici ai perturbatiilor, pe baza observaţiilor curente.
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

183
Anexa 1: COMPLEMENTE DE TEORIA PROBABILITǍTILOR ŞI DE STATISTICǍ MATEMATICǍ Întreaga teorie a generǎrii, transmiterii şi stocǎrii informatiei face apel la elemente de teoria probabilitǎtilor şi de statisticǎ matematicǎ. Aceste elemente sunt predate uzual la disciplinele matematice, poate mai teoretic şi mai bogat în unele aspecte, uneori cu un decalaj temporal nepotrivit fatǎ de necesitǎtile acestui curs. Aici sunt date/reluate unele elemente mai specifice dar strict necesare în tratarea cantitativǎ a informatiei. Spatiul evenimentelor Un experiment oarecare, în particular observarea unei surse de informatie poate avea rezultate diverse. Aceste rezultate sunt numite evenimente. Aria exemplelor posibile este foarte cuprinzǎtoare. De aceea sǎ ilustrǎm problema cu douǎ exemple din zona jocurilor. Astfel, rostogolirea unui zar perfect pe o suprafatǎ planǎ poate avea ca rezultat aparitia pe faţa de deasupra a, sǎ spunem, cinci puncte. S-a produs asadar evenimentul aparitiei deasupra a fetei cu cinci puncte şi sunt şase asemenea evenimente. Tot aşa, în spiritul definitiei de mai sus, extragerea valetului de cupǎ dintr-un pachet de cǎrti de joc complet şi bine amestect este un eveniment şi sunt în total 52 de astfel de evenimente. De retinut “contributia” hazardului la producerea unuia sau altuia dintre evenimente. Fie E multimea tuturor evenimentelor posibile relativ la un experiment. Pentru multimea E se utilizeazǎ şi termenul de spaţiu al evenimentelor. Evenimentele unui astfel de spatiu se pot gǎsi în anumite relatii, iar cu evenimentele acelui spatiu se pot face unele operatii. O relatie posibilǎ între evenimente este aceea de implicatie. Implicatia se noteazǎ A B şi se citeste evenimentul A implicǎ evenimentul B, ceea ce înseamnǎ cǎ producerea evenimentului A conduce la producerea sigurǎ, automatǎ a evenimentului B; implicatia reciprocǎ, A B şi B A este un mod de a exprima egalitatea (echivalenţa) celor douǎ evenimente. Între operatiile cu evenimente sunt de retinut deocamdatǎ trei: una din ele este unarǎ în sensul cǎ implicǎ un singur argument, celelalte douǎ sunt binare, adicǎ implicǎ douǎ argumente. Operatia de luare a contrarului unui eveniment dat este unarǎ, opereazǎ cu un singur eveniment. Reuniunea şi intersectia de evenimente sunt operatii binare, implicǎ în forma elementarǎ, definitorie douǎ evenimente. Luarea contrarului unui eveniment constǎ în a specifica acel eveniment care se produce când nu se produce evenimentul al cǎrui contrar se exprimǎ. Dacǎ
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

184
evenimentul asupra cǎruia se opereazǎ este A atunci evenimentul contrar este notat cu A . De ce “contrar” se va explica dupǎ definirea celor douǎ operatii binare mentionate mai devreme. Reuniunea a douǎ evenimente se noteazǎ A B şi este evenimentul care constǎ în producerea cel putin a unuia din cele douǎ evenimente. Intersectia a douǎ evenimente se noteazǎ A B şi este evenimentul care constǎ în producerea ambelor evenimente. Existǎ douǎ evenimente speciale care se includ în multimea E. Unul este evenimentul imposibil, notat cu , şi celǎlalt este evenimentul sigur notat cu E (alteori cu ). Evenimentul imposibil nu se produce niciodatǎ, evenimentul sigur se produce de fiecare datǎ. O relatie de forma A B exprimǎ incompatibilitatea reciprocǎ a douǎ evenimente, adicǎ producerea unuia exclude producerea celuilalt. Acum se poate formula mai precis raportul dintre un eveniment şi contrarul lui: A A , A A E . Cu alte cuvinte un eveniment este incompatibil cu
contrarul sǎu, producerea unui eveniment sau a contrarului sǎu este sigurǎ. Este momentul sǎ se aducǎ precizarea cǎ contrarul contrarului unui eveniment este acel eveniment. Simbolic: A A . Multimea E este partial ordonatǎ şi relatia de ordine este implicatia. Multimea E împreunǎ cu operatiile de luare a contrarului unui eveniment, de reunire şi de intersectare a evenimentelor se organizeazǎ ca o algebrǎ booleanǎ. Între evenimentele dintr-o multime E se disting atomi sau evenimente elementare şi evenimente compuse. De pildǎ, prin aruncarea zarului se pot produce între altele evenimentele A2 şi A5 care constau în aparitia pe fata de deasupra, a numǎrului de puncte trecut ca indice. Ambele sunt atomi sau evenimente elementare în sensul cǎ nu sunt alte evenimente încǎ mai simple decât ele. Reuniunea A A2 5 este însǎ un eveniment compus. Fie acum mulţimea evenimentelor elementare dintr-o multime finitǎ E de evenimente. Evident . O submultime de pǎrti ale lui , )( PK se organizeazǎ ca un corp dacǎ
KAKA KBAKBA , KBAKBA ,
În aceste coditii perechea (, K) este un corp de evenimente şi este un -corp sau corp borelian dacǎ orice reuniune sau intersectie de evenimente din K, finite sau infinite apartin multimii K. Într-un spatiu E complet şi atomic, orice eveniment A se poate scrie ca o reuninune de elemente din
A ii
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

185
O multime de evenimente KAi (i = 1, 2, …, n) mutual incompatibile, altfel spus care satisfac relatiile A Ai j pentru KAA ji , cu ji , este o partitie a unui eveniment KA dacǎ
A Aii
n
1
Dacǎ A = atunci evenimentele KAi (i = 1, 2, …, n) cu proprietǎtile mentionate alcǎtuiesc un sistem complet de evenimente. Din cele expuse pânǎ acum, se observǎ prezenţa multor elemente de scriere similare cu cele din teoria multimilor. Este o observatie corectǎ în principiu, numai cǎ semnificatia şi lectura relatiilor scrise este diferitǎ aici fatǎ de aceea din cazul multimilor. Probabilitǎti, probabilitǎti conditionate Pe multimea evenimentelor din corpul K se defineste o functie realǎ P, numitǎ probabilitate, care are proprietǎtile: 1. 0)( AP pentru KA 2. P() = 1 3. )( ii APAP pentru KAi şi A Ai j dacǎ ji Dacǎ ultima proprietate are loc şi pentru reuniuni numerabile, atunci probabilitatea P se numeste complet aditivǎ (sau aditivǎ) pe corpul (borelian) de evenimente (, K). Tripletul (, K, P) se numeste câmp (borelian) de probabilitate. Dacǎ este o multime finitǎ, atunci (, K, P) este un câmp de probabilitate discret. Din proprietǎtile fundamentale de mai sus derivǎ alte câteva proprietǎti importante ale probabilitǎtii P. Astfel 4. Probabilitatea evenimentului imposibil
P( ) 0 5. Relatia dintre probabilitǎtile evenimentelor contrare
)(1)( APAP 6. Probabilitatea evenimentului diferentǎ, BABA
P A B P A P A B( ) ( ) ( ) 7. Limitele inferioarǎ şi superioarǎ a valorilor functiei P, functia probabilitate
0 1 P A( ) 8. Probabilitatea evenimentului )()( ABBABA , numit diferentǎ
simetricǎ P A B P A P B P A B( ) ( ) ( ) ( ) 2
9. Probabilitatea reuniunii a douǎ evenimente oarecare P A B P A P B P A B( ) ( ) ( ) ( )
O extindere a relatiei ultime pentru reuniunea a n evenimente oarecare este
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

186
n
jj
jn
ii SAP
1
1
1
)1( cu S P A A j nj i ii i i n
j
j
( ... ), ,...,
1
1 2
.
Dacǎ IiiAF este o familie numerabilǎ de evenimente mutual exclusive
atunci 0
IiiAP . Dacǎ familia IiiAF este şi exhaustivǎ, adicǎ este un
sistem complet de evenimente, atunci 1
IiiAP .
Evenimentele se pot afla în relatie de condiţionare reciprocǎ în sensul cǎ un eveniment odatǎ produs poate modifica probabilitatea de producere a altui eveniment. Relatia de bazǎ pentru calculul probabilitǎtilor condiţionate este
P A P A B P A B P BB ( ) ( / ) ( ) / ( ) cu evenimentul B care conditioneazǎ producerea evenimentului A trecut ca indice sau pe pozitia a doua în argumentul functiei probabilitate. În general,
p A B P A( / ) ( ) şi P B A P B( / ) ( ) ceea ce indicǎ o dependenţǎ, o conditionare între cele douǎ evenimente. Dacǎ are loc egalitatea în ambele relatii atunci evenimentele sunt independente. Dacǎ probabilitatea unei intersectii finite de evenimente este nenulǎ
01
n
iiAP
atunci probabilitatea respectivǎ se poate calcula cu formula
)()/(/ 112
1
11
APAAPAAPAPn
iin
n
ii
care se demonstreazǎ inductiv pornind de la relatia de conditionare pentru douǎ evenimente. Dacǎ ( ) ,Ai i n1 este o partitie a câmpului atunci probabilitatea unui eveniment oarecare se poate calcula cu relatia
P A P A P A Ai ii
n
( ) ( ) ( / )
1
cunoscutǎ ca formula probabilitǎtii totale. Mai este de reţinut formula lui Bayes
P A A P A P A A P A P A Ai i i i ii
n
( / ) ( ) ( / ) / ( ) ( / )
1
care în aceleaşi conditii, ( ) ,Ai i n1 o partiţie a câmpului , permite calculul probabilitǎtii fiecǎrui eveniment al partiţiei, condiţionatǎ de producerea evenimentului KA , altfel oarecare. Variabile aleatoare
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

187
O variabilǎ aleatoare este o functie X R: cu proprietatea RxKxXxX ,})(/{}{
O variabilǎ aleatoare simplǎ ia numai un numǎr finit de valori. De exemplu funcţia indicator a unui eveniment KA
AA
A
10
este o variabilǎ aleatoare simplǎ care ia douǎ valori, 0 şi 1. Dacǎ X este o variabilǎ aleatoare definitǎ pe câmpul (, K, P), atunci pentru oricare douǎ valori x x R x x1 2 1 2, , toate intervalele finite sau infinite delimitate de cele douǎ valori corespund unor evenimente din K şi, prin generalizare, pentru orice multime I reuniune de intervale din R, se poate calcula probabilitatea P I P X I P X IX ( ) [ ( ) ] [ ( )] 1 . Probabilitatea PX(I) reprezintǎ distributia de probabilitate a variabilei aleatoare X. Se poate vorbi despre PX şi ca despre o probabilitate definitǎ pe câmpul (R, KX) în care
KIXRIK X )(/ 1 . Dacǎ variabila aleatoare X ia valori într-o mulţime cel mult numerabilǎ
{ / , , }x x R i I I Ni i atunci ea se numeste variabilă aleatoare discretǎ şi
P xX ii I
( ) 1
Jx
XiXXi
KJxPJP )()(
Dacǎ X variazǎ continuu pe un interval XKI atunci
P I f x dxX XI
( ) ( )
şi este o functie absolut continuǎ de x. Functia fX(x) este densitatea de probabilitate sau densitatea de repartiţie a variabilei aleatoare X, este nenegativǎ pentru orice x real şi are proprietatea
f x dxX ( )
1
Se numeşte functie de repartiţie a variabilei aleatoare X functia F x P X x P xX X( ) [ ( ) ] [( , )]
Functia de repartitie este nedescrescǎtoare pe întreaga axǎ realǎ a b F a F b a b RX X ( ) ( ) ,
şi este continuǎ la stânga în fiecare punct
RaaFxFaxax XX
)()(
,lim
Valorile minimǎ şi maximǎ ale unei functii de repartitie sunt date respectiv de
0)(lim xFx X şi 1)(lim xFx X
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

188
Eventualele discontinuitǎti sunt de specia primǎ şi sunt cel mult numerabile. Reciproc, orice functie cu proprietǎtile de mai sus poate fi pusǎ în corespondentǎ cu un câmp de probabilitate. Pentru o variabilǎ aleatoare discretǎ are loc relatia
F x P xX X ix xi
( ) ( )
şi functia de repartiţie este o functie în scarǎ, iar pentru o variabilǎ aleatoare continuǎ
x
XX dxxfxF )()( şi )()( xFdxdxf XX
Pentru orice interval [ , )a b R P a b F b F aX X X{[ , )} ( ) ( )
şi dacǎ variabila este de tip continuu P aX ( ) 0
Se noteazǎ cu V(, K, P) multimea tuturor variabilelor aleatoare definite pe câmpul de probabilitate (, K, P). Dacǎ ),,(, PKVYX atunci suma, produsul celor douǎ variabile aleatoare, modulul, puterea, în general o functie mǎsurabilǎ Borel de oricare dintre ele sunt toate variabile aleatoare din multimea V(, K, P). Ori de câte ori nu este pericol de confuzie, variabila aleatoare trecutǎ ca indice al functiei de repartitie sau al fuctiei de densitate de repartitie se poate omite. Dacǎ se reia exemplul foarte frecventat în manualele de teoria probabilitǎtilor, cel al zarului perfect care este fǎcut la fiecare experientǎ sǎ se rostogoleascǎ pe o suprafatǎ planǎ, orizontalǎ, atunci multimea evenimentelor elementare (atomi) este alcǎtuitǎ din aparitiile deasupra a celor sase fete, marcate uzual cu unu pânǎ la sase puncte. Multimea de pǎrti ale lui este alcǎtuitǎ din toate reuniunile posibile de evenimente elementare la care se adaugǎ evenimentul imposibil. Multimea K organizatǎ ca un corp de evenimente coincide chiar cu multimea de pǎrti P(), iar functia numitǎ probabilitate ia valoarea 1/6 pentru fiecare din evenimentele elementare deoarece fetele zarului au sanse egale de a apǎrea deasupra. O variabilǎ aleatoare poate fi chiar numǎrul de puncte afisat pe fata de deasupra. În acest caz probabilitǎtile şi functia de repartitie se prezintǎ ca în prima pereche de diagrame care urmeazǎ şi este este vizibilǎ functia în scarǎ despre care s-a vorbit. Dar pe acelaşi câmp de probabilitate se pot defini şi alte variabile aleatoare. Pe câmpul asociat zarului perfect se poate imagina, de pildǎ, functia X R: definitǎ astfel
5,10862,35,11654321
şi atunci probabilitǎtile şi functia de repartitie se prezintǎ diferit, conform perechii a doua de diagrame din figura urmǎtoare.
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

189
0 1 2 3 4 5 6 70
0.5
1
p(x)
PROBABILITATI
0 1 2 3 4 5 6 70
0.5
1
x
F(x)
FUNCTIA DE REPARTITIE
-2 0 2 4 6 8 100
0.5
1
p(x)
PROBABILITATI
-2 0 2 4 6 8 100
0.5
1
x
F(x)
FUNCTIA DE REPARTITIE
Aşadar, multimea V(, K, P) este foarte bogatǎ. De variabilele aleatoare sunt legate câteva valori remarcabile. Una foarte importantǎ este media
dxxxfxMm )()(
care face parte din lista nesfârsitǎ a momentelor de diferite ordine ale variabilei, acesta fiind momentul de ordinul unu.
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

190
Similar se poate calcula media unei functii g(x) de variabila aleatoare x
M g x g x f x dx[ ( )] ( ) ( )
şi dacǎ g(x) = xr cu r natural, avem tocmai momentul de ordinul r despre care s-a amintit. În cazul particular g x x M x( ) [ ( )] 2 se obtine o altǎ valoare importantǎ relativ la variabila aleatoare descrisǎ de functia de repartitie F(x) sau de densitatea de repartitie f(x), şi anume dispersia. Rǎdǎcina pǎtratǎ pozitivǎ a dispersiei se numeste abatere medie pǎtraticǎ sau abaterea standard. Dispersia notatǎ uzual cu este momentul centrat de ordinul doi al variabilei aleatoare, unul din multiplele momente centrate de ordine diferite ale variabilei. Nu numai variabilele aleatoare continue au momente, medii, dispersii ci şi cele discrete. În cazul discret, formulele de calcul contin sume în locul integralelor şi variabila parcurge întreaga listǎ de valori posibile, iar densitatea de repartitie este înlocuitǎ de probabilitǎtile asociate valorilor pe care variabila le poate lua. Astfel, media se calculeazǎ cu relatia
Ii
ii xpxMm )(
şi dispersia, cu relatia
Ii
ii mxp 22 )(
Pentru media unei functii de variabila aleatoare X, relatia integralǎ de mai sus se transformǎ în
Ii
ii xgpxgM )()]([
o relatie de mare utilitate pentru caracterizarea surselor de informatie discrete. Peste tot, indicele i parcurge multimea de indici I, o multime finitǎ sau numerabilǎ. Iatǎ acum câteva legi de repartitie teoretice utilizate în practica inginereascǎ. Legea binomialǎ (Bernoulli)
P m C p pnm m n m( ) ( ) 1
cu 0 m n şi p un numǎr în intervalul [0,1] este de tip discret. Variabila aleatoare este m şi are media np şi dispersia np(1 – p). Modelul fizic îl constituie urna cu bile de douǎ culori, iar evenimentele (compuse) constau în extragerea repetatǎ a câte unei bile dupǎ care bila extrasǎ este reintrodusǎ în urnǎ. Variabila m reprezintǎ numǎrul bilelor de o anumitǎ culoare din cele douǎ, în n extrageri succesive, conform schemei cu bila returnatǎ. Numǎrul p reprezintǎ proportia de bile de acea culoare în urnǎ, cu alte cuvinte probabilitatea de obtinere la o extragere simplǎ a unei bile de culoarea respectivǎ. Legea Poisson
P mm
m
( )!
exp( )
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

191
cu > 0 şi m natural ca variabilǎ aleatoare. Media variabilei este , dispersia ei este, de asemenea, . Un modelul fizic îl reprezintǎ numǎrul dezintegrǎrilor radioactive, numǎrul de apeluri telefonice solicitate într-o centralǎ etc. într-un interval de timp precizat, scurt. Legea normalǎ (Gauss) care este datǎ de densitatea de probabilitate
f x ex m
( )( )
12
2
22
în care m este media variabilei x şi 2 este dispersia ei. Legea normalǎ este perceputǎ ca o lege limitǎ pentru sumele de variabile aleatoare. Un fenomen afectat de foarte multi factori aleatori se prezintǎ de cele mai multe ori ca un fenomen aleator descris de o lege normalǎ. Variabilele aleatoare din expunerea teoreticǎ sau din exemplele prezentate mai sus au fost pânǎ acum simple, adicǎ a fost vorba în toate cazurile de o singurǎ functie X R: legatǎ de un câmp de probabilitate (, K, P) unic. Se pot imagina variabile aleatoare cu mai multe componente, variabile aleatoare sub forma unor vectori cu componente aleatoare definite relativ la un acelaşi câmp de probabilitate sau la câmpuri de probabilitate diferite. Astfel legea urmǎtoare se referǎ la o variabilǎ aleatoare vectorialǎ. Legea normalǎ multidimensionalǎ este datǎ de densitatea de repartitie
)()(21
2
1
det)2(
1)(mxWmx
n
T
eW
xf
cu media m, un vector cu n componente şi cu matricea de covariatie W, o matrice (nxn) pozitiv definitǎ. Pentru ca exemplul sǎ aibǎ consistenta necesarǎ, trebuie definitǎ mai clar matricea W. Este de comentat mai întâi problema corelatiei a douǎ variabile aleatoare care pot fi independente, caz în care valorile pe care le ia una nu influenteazǎ în nici un fel valorile pe care le poate lua cealaltǎ, dar pot fi mai mult sau mai putin dependente ceea ce înseamnǎ cǎ dacǎ una din variabile a luat o valoare atunci legea de repartitie a celeilalte se modificǎ în functie de acea valoare a primei variabile. Fiind date douǎ variabile aleatoare x şi y de medii nule, media produsului lor M(xy) se numeste covariatie. Dacǎ covariatia este nulǎ se poate spune în general cǎ cele douǎ variabile nu sunt corelate. Dimpotrivǎ, dacǎ M(xy) ≠ 0 variabilele sunt corelate, existǎ o corelatie între ele, existǎ o dependentǎ între valorile pe care ele le iau în sensul arǎtat putin mai devreme. Dacǎ mediile sunt diferite de zero, afirmatia şi definitia se mentin pentru abaterile de la medie. Întrucât covariatia M(xy) poate lua valori foarte diferite, pentru o apreciere cantitativǎ mai riguroasǎ a tǎriei corelatiei se utilizeazǎ coeficientul de corelatie
M xy
M x M y( )
( ) ( )2 2
care ia valori numai în intervalul [–1, 1] şi în expresia cǎruia se disting dispersiile celor douǎ variabile, M(x2) şi M(y2). O valoare apropiatǎ de
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

192
extremele intervalului indicǎ o corelatie strânsǎ, o valoare apropiatǎ de zero exprimǎ o corelatie slabǎ. Componentele unui vector aleator, privite ca variabile aleatoare simple sunt mutual mai mult sau mai putin corelate. Se defineste ca matrice a covariatiilor unui vector aleator x media produsului xxT, media produsului acelui vector (coloanǎ) cu transpusul sǎu. Se obtine o matrice pǎtratǎ simetricǎ care are pe diagonalǎ dispersiile individuale ale componentelor. Aceasta este matricea W utilizatǎ în expresia densitǎtii de repartitie a variabilei aleatoare normale multidimensionale din exemplul de mai sus. Dacǎ matricea covariatiilor este diagonalǎ (are toate elementele nule cu exceptia celor de pe diagonala principalǎ) atunci componentele sunt mutual independente. Împǎrtirea fiecǎrui element al matricei covariatiilor cu abaterile medii pǎtratice ale componentelor corespunzǎtoare ale vectorului x produce o matrice a coeficientilor de corelatie, cu 1 pe diagonalǎ, cu valori in intervalul [–1, 1] în rest. Generarea de numere aleatoare. În modelarea şi mai ales în simularea sistemelor este necesarǎ deseori generarea de numere aleatoare a cǎror aparitie sǎ se producǎ conform unei anumite legi de repartitie. În sprijinul acestei cerinte, aproape toate limbajele de programare evoluate au în biblioteca lor, alǎturi de alte functii, functii generatoare de numere aleatoare uniform repartizate pe un interval precizat, de regulǎ pe intervalul (0, 1). În PASCAL, de pildǎ, existǎ functia random, cu sau fǎrǎ argument, care genereazǎ astfel de numere. Subprogramul randomize invocat înaintea primului apel la functia random asigurǎ secvente de numere diferite la fiecare nouǎ utilizare succesivǎ într-un program, a functiei de bibliotecǎ generatoare de numere aleatoare. Versiunea fǎrǎ argument a functiei random produce numere reale (în sens numeric) în intervalul (0, 1), uniform repartizate pe acel interval. Versiunea cu argument de tip word, random(w), produce numere aleatoare de tipul word, cuprinse între 0 şi w – 1. Pentru cazul continuu al functiei random fǎrǎ argument, se poate figura functia densitate de repartitie şi functia de repartitie conform graficelor alǎturate. Cu generatorul de numere aleatoare random sau cu generatoarele similare din alte limbaje se pot genera numere aleatoare repartizate dupǎ legi diferite de cea uniformǎ. Pentru aceasta se pot utiliza metode analitice sau o metodǎ directǎ care are în vedere functia de repartitie a variabilei care trebuie generatǎ. Legea de repartitie normalǎ normatǎ (de medie nulǎ şi de de dispersie 1) este legatǎ de legea de repartitie uniformǎ prin una sau alta dintre relatiile urmǎtoare
u x x1 1 22 2 ln cos( )
u x x2 1 22 2 ln sin( ) în care x1 şi x2 sunt douǎ numere aleatoare independente, cu repartitie uniformǎ pe intervalul (0, 1). Este un exemplu de generare analiticǎ a unor numere aleatoare supuse unei legi de repartitie diferitǎ de cea uniformǎ.
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

193
-1 -0.5 0 0.5 1 1.5 20
0.5
1
f(x)
DENSITATEA DE PROBABILITATE
-1 -0.5 0 0.5 1 1.5 20
0.5
1
x
F(x)
FUNCTIA DE REPARTITIE
Un alt exemplu este cel al generǎrii de numere aleatoare uniform repartizate pe un interval finit (a, b) oarecare. Trecerea la noua variabilǎ se realizeazǎ prin mijlocirea relatiei
u = a + (b – a) x cu x generat de functia de bibliotecǎ random. Variabila u este uniform repartizatǎ pe intervalul finit specificat. Varianta analiticǎ de generare a unor numere aleatoare repartizate conform unei legi particulare nu este totdeauna posibilǎ. Modul de generare alternativ este descris în continuare. Se admite cǎ este datǎ functia de repartitie F(u) a unei variabile u sau functia ei densitate de repartitie f(u) din care se poate calcula F(u). Se genereazǎ valori x uniform repartizate pe intervalul (0, 1) cu ajutorul functiei de bibliotecǎ random sau similara ei din alte limbaje de programare. Se calculeazǎ de fiecare datǎ u = F–1(x), unde F–1(.) este inversa functiei de repartitie a variabilei u de generat. Functia de repartitie este totdeuna o functie monotonǎ, deci este inversabilǎ pentru orice x ( , )0 1 . Intervalul (0, 1) este multimea de valori comunǎ tuturor functiilor de repartitie. Variabila aleatoare u este cu sigurantǎ repartizatǎ conform legii date de functia F(u) sau de functia densitate f(u). Raportul experiment-lege de repartitie teoreticǎ. Variabilele aleatoare pot fi observate prin valorile pe care ele le iau efectiv. Numǎrul observatiilor este inevitabil finit. Forma matematicǎ a legii de repartitie precum şi parametrii ei teoretici, inclusiv cei mai simpli cum sunt media şi dispersia, sunt elemente care trebuie estimate din aceste observatii experimentale. Inferenta statisitcǎ este apoi utilizatǎ pentru a stabili valabilitatea acestor estimǎri. Inferenta statisticǎ este operatia logicǎ prin care se admite o judecatǎ al cǎrui adevǎr nu
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

194
este verificat direct ci în virtutea unei legǎturi a ei cu alte judecǎti considerate adevǎrate. Verficarea adecvǎrii legilor de repartiţie. Cu toate cǎ ipoteza normalitǎtii unei variabile aleatoare este satisfǎcǎtoare în foarte multe cazuri, în special atunci când fenomenul este rezultatul actiunii întâmplǎtoare a unui numǎr foarte mare de factori, uneori reprezentativitatea legii de repartitie însǎşi trebuie verificatǎ. Verificarea se face, desigur, pe baza unui volum limitat de observatii experimentale. Pentru o astfel de verificare, observatiile experimentale, fie acestea x x xn1 2, ,..., , sunt mai întâi sortate pe m intervale Ik (k = 1, 2, …, m), care alcǎtuiesc o partitie a axei reale. Sortarea se face în raport cu apartenenta lor la unul sau altul din acele intervale. Se calculeazǎ frecventele absolute nk (k = 1, 2, …, m) pentru fiecare interval adicǎ numǎrul de valori observate care apartin unuia sau altuia din intervalele Ik. Cu aceste frecvente sau cu frecventele relative obtinute prin împǎrtirea lor la numǎrul total de valori observate n se poate trasa un grafic sub forma unor dreptunghiuri cu baza cât fiecare interval şi înǎltimea egalǎ cu frecventa. Aceste grafice sunt denumite histograme ale frecventelor relative sau absolute. Prin cumularea ordonatǎ a frecventelor se obtine un grafic numit poligonul frecventelor relative sau absolute cumulate. Cele douǎ functii grafice sunt pentru colectia de date experimentale ceea ce pentru variabila aleatoare sunt probabilitǎtile sau densitatea de repartitie şi functia de repartitie. În termeni de frecvente relative functiile sub formǎ de grafic, care au ca sursǎ experimentul ar trebui sǎ estimeze functiile teoretice corespondente. Dacǎ ele sunt sau nu estimatii ale acelor functii teoretice, dacǎ legea de reparttie teoreticǎ reprezintǎ într-adevǎr variabila aleatoare observatǎ se apreciazǎ prin calculul unei valori
m
k k
kk
npnpn
1
22 )(
în care intervin atât frecventele experimentale cât şi probabilitǎtile teoretice p P x Ik k ( ) , (k = 1, 2, …, m) şi care este o variabilǎ aleatoare deoarece,
evident, la un nou set de observatii se obtine aproape sigur altǎ valoare. Variabila este consacratǎ în statistica matematicǎ şi este definitǎ ca o sumǎ de pǎtrate ale unor variabile aleatoare normale normate (de medie nulǎ şi de dispersie egalǎ cu unitatea). Variabila are un numǎr de grade de libertate egal cu numǎrul de termeni din suma definitorie. Functia de repartitie a variabilei este tabelatǎ sau poate fi evaluatǎ şi este folositǎ în verificarea ipotezelor statistice de natura celei formulate mai devreme sau de altǎ naturǎ. Intuitiv, valoarea calculatǎ din observatii experimentale ar trebui sǎ fie cât mai apropiatǎ de zero. Atunci, probabilitǎtile pk ar fi foarte apropiate de frecventele relative nk/n rezultate din experiment. Ipoteza conform cǎreia modelul teoretic este verificat de observatiile experimentale (H0) se opune ipotezei alternative (H1) dupǎ care modelul teoretic pe cale de a fi adoptat nu este verificat de observatiile experimentale. Pragul discriminator între cele douǎ
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

195
adevǎruri mutual exclusive este stabilit ca limita superioarǎ a unui interval definit pentru un nivel de semnificatie sau pentru un nivel de încredere precizat q (uzual 0,95), interval care grupeazǎ 100q% din valorile firesti, plauzibile în cazul valabilitǎtii ipotezei H0. Schema acceptǎrii (sau respingerii) uneia sau alteia dintre ipoteze este
20
1
2
H
Hq
cu valoarea de provenientǎ experimentalǎ în stâga semnului discriminator, cu valoarea teoreticǎ tebelarǎ sau evaluatǎ în dreapta acelui semn. Pe calea aceasta se poate selecta legea de repartitie adecvatǎ prin eventuala repetare a evaluǎrilor pentru alte functii de repartitie. Estimarea şi verificarea parametrilor unei legi de repartitie teoretice. Aşa cum s-a arǎtat, legea de repartitie cea mai frecvent utilizatǎ în modelarea şi simularea dinamicii sistemelor este legea normalǎ. Ipotezele şi verificǎrile parametrice discutate în cele ce urmeazǎ se referǎ în exclusivitate la variabile aleatoare repartizate normal sau, cum se mai spune, gaussian. Selectie, parametri de selectie. O listǎ de valori observate x x xn1 2, ,..., ale unei variabile aleatoare poartǎ numele consacrat de selectie. Numele ar putea pǎrea impropriu prin prisma etimologiei cuvântului “selectie” şi de aceea trebuie subliniat cǎ valorile din lista de observatii nu comportǎ nici un proces subiectiv de alegere. Prin selectie se întelege numai observarea experimentalǎ şi retinerea unui numǎr finit de valori ale variabilei aleatoare din numǎrul extrem de mare de valori pe care aceasta le poate lua. Se admite cǎ variabila are o repartitie normalǎ cu media şi dispersia . Se defineste ca medie de selectie media aritmeticǎ a valorilor observate
n
xx
n
ii
1
Ea este o estimatie absolut corectǎ a mediei şi se repartizeazǎ normal ca şi variabila x observatǎ, cu aceeaşi medie dar cu dispersia /n. Din datele care alcǎtuiesc selectia se pot calcula douǎ dispersii de selectie
sx
n
ii
n
2
2
1
( )
si
sx x
n
ii
n
2
2
1
1
( )
Ambele sunt estimǎri absolut corecte ale dispersiei , prima cu n grade de libertate, a doua, mai uzualǎ deoarece nu necesitǎ cunoasterea mediei teoretice , cu n – 1 grade de libertate.
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

196
Sintagma “estimatie absolut corectǎ” exprimǎ faptul cǎ media unei astfel de estimatii este exact valoarea parametrului estimat. Verificarea de ipoteze asupra parametrilor unei legi de repartitie normale. Asupra mediei, ipoteza cea mai frecventǎ are forma = şi se noteazǎ cu H0. Opusa ei se noteazǎ cu H1. Uneori se formuleazǎ ipoteze în foma unilateralǎ, caz în care semnul egal este înlocuit cu un semn de inegalitate. Verificarea uneia sau alteia dintre ipoteze se face în baza unei selectii. Dacǎ dispersia este cunoscutǎ atunci se poate calcula o valoare
z x
n
0
care este o variabilǎ aleatoare repartizatǎ normal şi este chiar normatǎ adicǎ are media nulǎ şi dispersia egalǎ cu unitatea. Se stabileste un nivel de încredere sau de semnificatie q, uzual de 0,95 (95%), pentru care în tabele sau prin calcul se gǎseste un zq, în particular z0,95 = 1,96. Aceastǎ valoare delimiteazǎ un interval (–zq, +zq), numit interval de încredere, care contine 95% din valorile z calculate din datele selectiilor de tipul şi de volumul specificat mai devreme. Prin urmare valorile din afara intervalului de încredere nu sunt excluse dar sunt cu totul improbabile, probabilitatea lor fiind complementara pânǎ la unitate, 1 – q. Aparitia unei valori z din aceastǎ categorie pune sub semnul unei serioase îndoieli valabilitatea ipotezei formulate. Asadar, dacǎ valoarea calculatǎ z z zq q ( , ) ipoteza se acceptǎ, în caz contrar se respinge sau într-o exprimare care pune în evidentǎ ambele ipoteze, mutual exclusive
zH
Hzq
0
1
Dacǎ dispersia nu este cunoscutǎ, se utilizeazǎ variabila Student, în care intervine radicalul pozitiv al dispersiei de selectie
t xsn
0
Variabila Student este o variabilǎ aleatoare în legǎturǎ cu care se mentioneazǎ şi un numǎr de grade de libertate, acelaşi cu al estimatiei s2. Se stabileste un nivel de încredere q şi un interval de încredere (–tq, +tq). Tabelele dau aceste valori pentru diverse niveluri de încredere, cel mai uzual fiind acelaşi 0,95, dar şi pentru grade de libertate diferite. Desigur, valorile tq pot fi foarte bine evaluate numeric. Ipoteza H0 se confirmǎ dacǎ valoarea Student calculatǎ se situeazǎ în interiorul intervalului de încredere. Ipoteza se respinge în caz contrar. Sintetic
tH
Htq
0
1
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

197
Ipoteze se fac, de asemenea, şi asupra dispersiei. Ipotezele acestea trebuie la rândul lor verificate. Astfel, fiind date douǎ estimatii ale aceleiaşi dispersii s1
2 şi s2
2, valoarea bazatǎ pe experiment
F ss
12
22
are cracteristicile unei variabile aleatoare şi se spune cǎ are f1 şi f2 grade de libertate, egale respectiv cu gradele de libertate ale celor douǎ estimaţii care apar în raport. Variabila este cunoscutǎ in statistica matematicǎ sub numele de variabila F (Fisher-Snedecor). În particular gradele de libertate pot fi f1 şi ∞ şi atunci
F s 1
2
2
este o variabilǎ F cu f1 şi ∞ grade de libertate. O ipotezǎ 202 se poate
verifica prin calcularea unei valori F cu 02 la numitor. Un nivel de
semnificatie q delimiteazǎ şi în acest caz un interval de încredere. Un F calculat din date experimentale superior lui Fq, tabelar sau calculat, cu gradele de libertate corespunzǎtoare impune respingerea ipotezei H0 şi acceptarea ipotezei alternative H1. Cazul contrar face ca ipoteza H0 sǎ fie acceptatǎ. Schema globalǎ este cuprinsǎ în exprimarea
FH
HFq
0
1
Criteriul F se aplicǎ de obicei unilateral. Variabila z normalǎ normatǎ şi variabilele aleatoare t şi F care sunt în conexiune directǎ cu legea de repartitie normalǎ permit formularea şi testarea unui numǎr important de alte ipoteze statistice. O altǎ variabilǎ aleatoare importantǎ legatǎ de variabila repartizatǎ normal este variabila despre care s-a vorbit la verificarea calitǎtii unei legi de repartitie teoretice de a fi un model adecvat al unei variabile aleatoare observate experimental. Variabila este o sumǎ de pǎtrate ale unor variabile normale normate independente şi are gradele de libertate egale cu numǎrul de termeni din sumǎ. Variabila permite ea însǎşi verificarea de ipoteze asupra dispersiei, dat fiind faptul cǎ într-o estimatie s2 a dispersiei teoretice se poate separa o sumǎ de pǎtrate de variabile z normale normate independente si, implicit, o variabilǎ . Tabele sau calculul direct dau şi în cazul acesta valori q
2 care constituie pragul discriminator de ipoteze la un nivel de semnificatie q precizat.
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

198
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

199
B I B L I O G R A F I E 1. E.Bodden, M.Clasen şi J.Kneis Arithmetic Coding revealed A guided tour
from theory to praxis, Sable Research Group, McGill University, Montréal, Québec, http://www.sable.mcgill.ca, 2007
2. Gh.Cartianu Semnale, circuite si sisteme Editura Didacticǎ si Pedagogicǎ, Bucuresti, 1980
3. M.Clancy si D.Wagner Discrete Mathematics for CS http://www-static.cc.gatech.edu/~vigoda/1050/Lectures/lecture11-70.pdf
4. S.Guiasu si R.Theodorescu Teoria matematicǎ a informatiei Editura Academiei RSR, 1966
5. S.Khudanpur, Information Theoretic Methods in Statistics, http://www.jhu.edu/~sanjeev/520.674/notes/I-divergence-properties.pdf, 2007.
6. A.Mihǎescu Teoria statisticǎ a transmisiunii informatiei Universitatea “Politehnica” Timisoara, 1995
7. Y.Monsef Modélisation et simulation des systèmes complexes. Technique & Documentation, Londres, Paris, New York, 1996
8. S.W.Smith The Scientist and Engineer's Guide to Digital Signal Processing, California Technical Publishing, 2007
9. Al.Spǎtaru Teoria transmisiunii informatiei vol.1 si 2, Editura Tehnicǎ, Bucuresti, 1965, 1968
10. Al.Spǎtaru (coordonator) Teoria transmisiunii informatiei. Probleme Editura Didacticǎ si Pedagogicǎ, Bucuresti, 1983
11. R.Togneri si Ch.J.S. deSilva Fundamentals of Information Theory and Coding Design Chapman & Hall/CRC, 2003
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.

200
An evaluation version of novaPDF was used to create this PDF file.Purchase a license to generate PDF files without this notice.


















