
Towards Neurocomputational Speech and Signal …. ROUA T, 30 April 09, McGill •First •Prev...
51
J. ROUAT, 30 April 09, McGill •First •Prev •Next •Last •Go Back •Full Screen •Close •Quit Towards Neurocomputational Speech and Signal Processing Jean ROUAT Neurocomputational and Intelligent Signal Processing Research group NECOTIS http://www.gel.usherbrooke.ca/rouat/ UNIVERSIT ´ E DE SHERBROOKE D´ epartement de GEGI McGill Univ. 30 April 2009
Transcript of Towards Neurocomputational Speech and Signal …. ROUA T, 30 April 09, McGill •First •Prev...

J. ROUAT, 30 April 09, McGill
•First •Prev •Next •Last •Go Back •Full Screen •Close •Quit
Towards Neurocomputational Speech andSignal Processing
Jean ROUATNeurocomputational and Intelligent Signal Processing
Research groupNECOTIS
http://www.gel.usherbrooke.ca/rouat/UNIVERSITE DE SHERBROOKE
Departement de GEGI
McGill Univ.30 April 2009

J. ROUAT, 30 April 09, McGill
•First •Prev •Next •Last •Go Back •Full Screen •Close •Quit
Signal Processing and Computational Neuro-science• Explore the brain code : synchronization and sequence of spikes for signal
processing & recognition;
• Integrate speech processing with auditory perception:
– The auditory features are multiple, simultaneous, and time structured;
– There is no disjunction between analysis and recognition;
– The auditory objects have a structure.
• Develop new signal processing and pattern recognition technics:
– Polysensoriality and sensory substitution: visual and auditory interac-tions;
– Source separation and cocktail party processing.

J. ROUAT, 30 April 09, McGill
•First •Prev •Next •Last •Go Back •Full Screen •Close •Quit
Rate and synchronization coding in the brain
Rate coding
Many neurons should respond to conjunctions of properties (orientation, motionand color in vision) (tonotopic frequency, amplitude modulation, transient inaudition).With a rate code the number of neurons should be quite large to encode alltargets potentially shown to the sensory systems. Their is an explosion of thefeature combinations and the spatial organization of the characteristics are lost.
Synchronization
Synchronization by coincidence Synchronization of pulses without oscilla-tory behavior: coincidence detector in the auditory system for fast computation.
Synchronization with oscillatory neuronal assemblies Oscillatory rhythmsfor memory, perception, etc. One hypothesis : A non stimulated brain (brain atrest) exhibits oscillations in large networks of oscillatory neurons. A stimulationis then a perturbation of this oscillatory mode [1] a.
aBuzsaki, 2006

J. ROUAT, 30 April 09, McGill
•First •Prev •Next •Last •Go Back •Full Screen •Close •Quit
1. The auditory system in very very brief!
The peripheral auditory system
? OHC active and IHC passive processes [2] a
Thecoderin action (R.Pujol etal.).? Innervation [2] b
Innervation of the cilia cells.ahttp://www.cochlee.org/bhttp://www.cochlee.org/

J. ROUAT, 30 April 09, McGill
•First •Prev •Next •Last •Go Back •Full Screen •Close •Quit
Cochlear Nuclei
(A) and (C): Dorsal and ventral cochlear nuclei in cross section; (B): Theventral cochlear nucleus extends rostral to the dorsal nucleus. From Henkel
1997 [3]

J. ROUAT, 30 April 09, McGill
•First •Prev •Next •Last •Go Back •Full Screen •Close •Quit
Responses of Cochlear Nucleus neurons
Cell types in the cochlear nucleus, typical responses and major ascendingconnections. Bushy cells (Primary-like): timing and phase− > binaural
hearing; multipolar cells (Chopper): changes in sound pressure level (AM)− > direct monaural pathway; octopus cells (Onset) with broad frequency
tuning− > monaural indirect pathway. From Henkel 1997 [3]

J. ROUAT, 30 April 09, McGill
•First •Prev •Next •Last •Go Back •Full Screen •Close •Quit
2. The auditory signal preprocessing1. Peripheral auditory model (Cochlea and Cochlear Nucleus) [4] [5] [6] [7] a
(for the source separation system).
2. Segmentation of the auditory peripheral representations with networks ofoscillatory neurons [8] b and Dynamic Link Matching between neurons forsource separation [9] [10] [11] c.
3. Rank Order Coding (ROC) for sequence recognition [12, 13] d (for thespeech recognition application).
4. Complete auditory model [14] e for the speech recognition application.aRouatet al. 1993, 1995, 1996, 1997bRouat, 2002cPichevar & Rouat, 2003dThorpe, 1996, van Rullen 2005eShamma 2003

J. ROUAT, 30 April 09, McGill
•First •Prev •Next •Last •Go Back •Full Screen •Close •Quit
3. Exploration in speech recognitionwith Stephane Loiselle, Ph.D. stud. & CERCO Toulouse. Published atIJCNN’05, NIPS’06 workshop and LNCS Springer, 2007:nonlinear speechprocessinga
• Oded Ghitza proposed in 1994 and 1995 the use of an auditory peripheralmodel for speech recognition [15, 16] b that takes into account the variability ofneuron’s internal threshold.• He introduces the notion of EnsembleInterval Histograms (EIH). That rep-resentation is an average of the spike time intervals information coming from apopulation of primary fibers. Speech recognition results were mitigate and therecognizer was still based on Hidden Markov Chains.• What about preserving theorder of the neuron’s discharges? We explore thefeasibility by using the Rank Order Coding as introduced par S. Thorpe and histeam [12, 17] c on a small speech recognition [18] d problem.
aLoiselle 2005; Rouat 2006, 2007bGhitza 1994, Sandhu 1995cThorpe 1996, 2001dLoiselle 2005

J. ROUAT, 30 April 09, McGill
•First •Prev •Next •Last •Go Back •Full Screen •Close •Quit
Definition of the EIH
Cochlear filterbank outputs are compared to thresholds to generate spikes;figure from [15] a.
aGhitza 1994

J. ROUAT, 30 April 09, McGill
•First •Prev •Next •Last •Go Back •Full Screen •Close •Quit
Four speech recognizer system architectures
The auditory models
– A simple cochlear channelsanalysis module;– A more sophisticated analysis system that includes mid–brain and corticalrepresentations of sounds (Shamma’s work);
The neuron models
– Thresholdmodels (3 thresholds for each auditory channel) with an infiniterefractory period;– Conventionalleaky integrate and fireneurons (LIAF).

J. ROUAT, 30 April 09, McGill
•First •Prev •Next •Last •Go Back •Full Screen •Close •Quit
Example of spikes generation with the simple cochlear filterbank andthe use of threshold neurons
(a)
45 50 55 60
5
10
15
20
(b)
Sequence generation on a French digit ’un’ [˜E] with the cochlear channel analysis and threshold
neurons.(a) For each channel, three threshold neurons are used with different threshold values.
If the amplitude in the channel reaches one of the neuron’s threshold, a spike is generated. After
firing, a neuron becomes inactive for the remaining time of the stimulus.(b) White stars represent
spikes. The x-axis is the time samples (sampling frequency of 16 kHz) and the y-axis shows the
filter-bank channels. Center frequencies of channels 1 and 20 are respectively equal to 8000 and
100 Hz.

J. ROUAT, 30 April 09, McGill
•First •Prev •Next •Last •Go Back •Full Screen •Close •Quit
Rank Order coding
If, as in b), the order of arrival does not agree withthat of the weights, activation may not build upsufficiently to cross the threshold and fire This isbecause the weights are uniformly decreased witheach input arrival as in c).
Let the input lines @1,.@4 have increasing weights. If,as in a), stimulation on these lines arrives in this sameorder then the activation might increase with eacharrival and a pulse generated after the last arrival.
Order-of-Arrival neurons
input
@1 @2 @3 @4
activation
output
@1
@2
@3
@4
input
@4 @3 @2 @1
activation
output
a) b)
threshold
Weightmodificationfactor
Input arrival order
c)
Neuron N fires on a specific sequence (A,B,C,D,E). Other sequences will notexcite N (inhibition from neuron I increases with time) [19, 20] a.
avan Rullen 2002, Zeigler 2003

J. ROUAT, 30 April 09, McGill
•First •Prev •Next •Last •Go Back •Full Screen •Close •Quit
A passive representation of the cochlea frequency analysis
0 500 1000 1500 2000 2500 3000 3500 40000
0.2
0.4
0.6
0.8
1
Cochlear Frequencies (Hz)
Amplitudes
The filter center frequencies follow the perceptive Bark scale [21] a.aPatterson 1976

J. ROUAT, 30 April 09, McGill
•First •Prev •Next •Last •Go Back •Full Screen •Close •Quit
Example of spikes generation with the simple cochlear filterbank,(contd)
Sequence with the spike order of the first 20 cochlear channels/threshold numbers to produce a
spike and generated weightski
Sequence order Weight (k(i))Threshold index Threshold index
Channel 1 2 3 1 2 356 5 16789 3 1810 4 8 17 1311 1 6 12 20 15 912 2 7 17 19 14 413 9 13 19 12 8 214 10 15 11 615 16 516 18 317 11 1018 14 719 20 120

J. ROUAT, 30 April 09, McGill
•First •Prev •Next •Last •Go Back •Full Screen •Close •Quit
Training
Very simple: compute the weightsk(i) for each reference. Store thesek(i).
Similarity computation with Rank Order Coding
Relative time
Spike Rank Order
Inhibition
Inhibitor
chan
nels
con
nect
ion
wei
ghts
Strong similarity
Weak similarity
Similarity
Body
Dendrite
Example of similarity computation with a neuron already tuned to the channel sequence (13, 12,
14, 15, 11, 10, 9, . . . ); inhibition increasing in time.

J. ROUAT, 30 April 09, McGill
•First •Prev •Next •Last •Go Back •Full Screen •Close •Quit
Experiments and data
– French digits spoken by 5 men and 4 women and French vowels spoken bythe same 5 men and 5 women. Each speaker pronounced ten times the samedigits and vowels. For each digit (or vowel), 2 reference models are used for therecognizer.– Recognition performed on all pronunciations of each speaker.– Experiments conducted with: the cochlear filter–bank analysis with simplethreshold neurons and the complete auditory model with LIAF neurons.– The sequence length is limited toN = 40 spikes.

J. ROUAT, 30 April 09, McGill
•First •Prev •Next •Last •Go Back •Full Screen •Close •Quit
Reference System: HMM
A Hidden Markov Model based system has been trained on the same trainingset. The system uses hidden Markov models and twelve cepstral coefficients foreach time frame [22, 18] a.
Each word is modeled by a Gaussian Hidden Markov Model with five states.aLoiselle 2001, 2005

J. ROUAT, 30 April 09, McGill
•First •Prev •Next •Last •Go Back •Full Screen •Close •Quit
Recognition of vowels
Averaged recognition rates on the five French vowels [a@ioy] for the HMM, the
Cochlear–Treshold and Complete-LIAF recognizersHMM Cochlear–TresholdComplete-LIAF90% 89% 94%
The Cochlear–Threshold recognizer does relatively well (recall that it usesonly one spike per channel/threshold neuron) even if it uses only the first sig-nal frames. On the opposite, the HMM uses the full vowel signal while theComplete-LIAF system uses only the firstN spikes.
French digit recognition
Recognition for ten French digits; Cochlear filter analysis combined with the one time threshold
neuron and MFCC with HMM.Cochlear–Threshold Total Recognition Rate: 65 %
Digits 1 2 3 4 5 6 7 8 9 0Scores (%) 93 76 64 75 46 75 13 75 60 67
MFCC–HMM Total Recognition Rate: 52 %Digits 1 2 3 4 5 6 7 8 9 0
Scores (%) 16 61 46 36 90 80 33 5 49 100

J. ROUAT, 30 April 09, McGill
•First •Prev •Next •Last •Go Back •Full Screen •Close •Quit
Discussion
– The Complete–LIAF system uses a shorter length of the test signal than theHMM system without the stationary assumption of the MFCC analysis.– The simple Cochlear–Threshold system has better results on the consonantsof the digits.– One reference speaker per sex with only one occurrence is not sufficient totrain the HMM. Furthermore, the transient cues from the consonants are spreadout with the stationary MFCC analysis.– With only one spike per neuronal model (reported results with the Cochlear–Threshold system) the recognition is still promising.– It is interesting to link this with the arguments of Thorpe and col-leagues [12] [17] a: First spike latencies provides a fast and efficient code ofsensory stimuli.– The statistical HMM speech recognizer and our ROC prototypes are com-plementary. A mixed speech recognizer, that reliesi) on a Perceptive & ROCapproach for the transients andii) on the MFCC & HMM approach for thevoiced segments could be viable.
aThorpe 1996, 2001

J. ROUAT, 30 April 09, McGill
•First •Prev •Next •Last •Go Back •Full Screen •Close •Quit
4. Binding
Definition
From the Webster’s :
1a To make secure by tying;
12 To fasten together;
1. Promotes cohesion in loosely assembled substances
From Wikipedia:
1. Neural binding: synchronous activity of neurons and neuronal ensembles;
2. The binding problem, or how we assemble disparate perceptual inputs tocreate consciousness;
From Scholarpedia:
1. Binding problem (Author: Christoph von der Malsburg)
2. Binding by synchrony (Curator: Wolf Singer)

J. ROUAT, 30 April 09, McGill
•First •Prev •Next •Last •Go Back •Full Screen •Close •Quit
Binding (ctd)
The compactum concept by Legendy
From Legendy, 1970 [23]:
/. . . / We outline a scheme in which the neurons ’hit hardest’ by an eventwill come to be tied togother and form a group; though the ties willlie dormant almost all the time, and show their existence only at timeswhen the proper event recurs./. . . /
Synchronization for attention by Milner, 1974
From Milner 1974 [24]
Synchronization of impulses as a means of separating one figure fromanother during sensory processing is obviously a mechanism that hasimplications for attention, and these will be discussed later in a sectiondevoted to that topic.

J. ROUAT, 30 April 09, McGill
•First •Prev •Next •Last •Go Back •Full Screen •Close •Quit
Binding: definition by Malsburg, 1981
From Malsburg, [25, 26] a:
”Synaptic modulation according to which synapses switch between aconducting and a non-conducting state. The dynamics of this variableis controlled on a fast time scale by correlations in the temporal finestructure of cellular signals.”
av.d. Malsburg 1981, 1999

J. ROUAT, 30 April 09, McGill
•First •Prev •Next •Last •Go Back •Full Screen •Close •Quit
Spiking neurons for image segmentationWang & Terman, 1997 [27] use bi-dimensional oscillators with local excita-tion and global inhibition (LEGION) to segment images. Before, many at-tempts were made but with fully connected oscillators (Wanget al., 1990 [28],Sompolinskyet al., 1991, 1994 [29, 30], von der Malsburg and Buhmann,1992 [31]).
From Wang & Terman 1997

J. ROUAT, 30 April 09, McGill
•First •Prev •Next •Last •Go Back •Full Screen •Close •Quit
Networks of spiking neurons for bindingKonen [32] a is using a rate based code for binding operations;It is not suitable for fast binding to the perception of objects.We proposed a system that is based on spiking neurons for a fast bindingb.
From Molotchnikoff & Rouat 2009aKonenet al., Neural Networks, 1994bPichevaret al. 2003–2007

J. ROUAT, 30 April 09, McGill
•First •Prev •Next •Last •Go Back •Full Screen •Close •Quit
5. A sound source separation systemwith Ramin Pichevar. Published in EURASIP–JASP June 2005, SpringerLNCS 2005, Neurocomputing 2007
– How far can we go in the separation of sound sources without integrating anya priori knowledge on the sources?.– We assume that sound segregation is a generalized classification problem, inwhich we want to bind features – extracted from the auditory image representa-tions – in different regions of a neural network map.– Different sources are disjoint in the auditory image representation space;masking of the undesired sources is feasible.– We use the Computational Auditory Scene Analysis framework based on theimplementation of ideas exposed by Bregman [33] a.
aBregman 1990

J. ROUAT, 30 April 09, McGill
•First •Prev •Next •Last •Go Back •Full Screen •Close •Quit
The spiking neural models we used for source separation
We made various implementations of the same binding procedure [34] a:
• Wang and Terman relaxation oscillators;
• Chaotic neurons;
• Integrate and fire neurons
Example of neuron’s output for the Wang-Terman oscillator implementation.aPichevar, Ph.D. thesis, 2004

J. ROUAT, 30 April 09, McGill
•First •Prev •Next •Last •Go Back •Full Screen •Close •Quit
Auditory Scene Analysis
• Find a suitable signal representation (auditory image representation)
(a) Spectrogram of a /di/ and /da/ mixture. (b) Spectrogram of /di/ plus sirenmixture.
• Analyse the auditory scene and segmentobjects.• Segregate objects belonging to the same source (use a mask).

J. ROUAT, 30 April 09, McGill
•First •Prev •Next •Last •Go Back •Full Screen •Close •Quit
Auditory Scene Analysis (Bregman) [33]
From :http://dactyl.som.ohio-state.edu/Huron/Publications/huron.Bregman.review.html• Analogies with the the visual system.• Most sounds have a history. The mental images of lines of sound areauditorystreams. Study of the behavior of such images is: auditory streaming.

J. ROUAT, 30 April 09, McGill
•First •Prev •Next •Last •Go Back •Full Screen •Close •Quit
Auditory Scene Analysis (ctd)
• Auditory streaming is fundamental to the recognition of auditory events sinceit depends upon the proper assignment of auditory properties to different soundsources.• How sounds cohere to form a sense of continuation is the subject of streamfusion. Since more than one source can sound concurrently, a second domainof study is how concurrent activities retain their independent identities – thesubject of stream segregation . Stream-determining factors include: timbre(spectral shape), fundamental frequency (pitch) proximity, temporal proximity,harmonicity, intensity, and spatial origin. In addition, when sounds evolve withrespect to time, it is possible for them to share similarities by virtue of evolvingin the same way. In Gestalt psychology, this perceptual co-evolution of partsis known as the principle of common fate . Bregman has pointed out that theformation of an auditory stream is governed largely by this principle.

J. ROUAT, 30 April 09, McGill
•First •Prev •Next •Last •Go Back •Full Screen •Close •Quit
Proposed System Strategy
FFT
Sound MixtureAnalysis filterbank
Envelopeand
FFT
Channels
Channels
CSM
CAM
Freque
ncy Channels
Freq
uenc
y Freq
uenc
y
Channel bindingspiking network
Generated masks Synthesis filterbank
Separated signals
Switch
Choppers (C.N. ) Primary-like (C.N.)
Source Separation System with two auditory images simultaneously generated. The first layer of
the network segregates the auditory objects and the second layer binds the channels that are
dominated by the same stream.

J. ROUAT, 30 April 09, McGill
•First •Prev •Next •Last •Go Back •Full Screen •Close •Quit
Example of CAM parametrisation
Example of a twenty–four channels CAM for a mixture of /di/ and /da/pronounced by two speakers; mixture atSNR = 0 dB and frame center at
t = 166 ms.

J. ROUAT, 30 April 09, McGill
•First •Prev •Next •Last •Go Back •Full Screen •Close •Quit
Example of CSM parametrisation
CSM of the mixture of /di/ and a siren at (a) t=50 ms (b) t=200 ms.

J. ROUAT, 30 April 09, McGill
•First •Prev •Next •Last •Go Back •Full Screen •Close •Quit
Network architecture
Jean Rouat, NOLISP03, 20 May 2003, Le CroisicUniv. de Sherbrooke
Neural Architecture
Fully Connected NetworkGlobalController
PartiallyConnectedNetwork
Architecture of the Two-Layer Bio-inspired Neural Network. G: Stands forglobal controller (the global controller for the first layer is not shown on the
figure). One long range connection is shown in the figure.

J. ROUAT, 30 April 09, McGill
•First •Prev •Next •Last •Go Back •Full Screen •Close •Quit
The neural network processing
– The two-layered network of spiking neurons is used to perform cochlear chan-nel selection based on temporal correlation: neurons associated to those chan-nels belonging to the same sound source synchronize.– The network can be viewed as a cascade of feature extractors that allowsrecognition.

J. ROUAT, 30 April 09, McGill
•First •Prev •Next •Last •Go Back •Full Screen •Close •Quit
Neurons on the second layer: Temporal Correlation
• Each 256 neurons represents a cochlear channel of the analysis/synthesis fil-terbank.• For each presented auditory map, binding is established between neuronswhich entry is dominated by the same source.• Neurons belonging to the same source synchronize (same spiking phase);neurons belonging to the other source desynchronize (different spiking phase).

J. ROUAT, 30 April 09, McGill
•First •Prev •Next •Last •Go Back •Full Screen •Close •Quit
Criteria and example for separationTwo criteria to separate the sources:
• Firing instants (neurons whith the same firing instant phase characterizechannels dominated by the same source) of the neurons from the secondlayer.
Note• The Neural Network does not have any prior knowledge about the nature ofthe signals.• Each subnetwork characterize a feature;• Each neuron on the second layer has a receptive field specific to a cochlearchannel. Channels with similar feature behavior will be binded via these neu-rons.

J. ROUAT, 30 April 09, McGill
•First •Prev •Next •Last •Go Back •Full Screen •Close •Quit
Results
Criteria
• The following noises have been tested: 1 kHz tone, FM siren, white noise,trill telephone noise, and speech.• TheLSD (Log Spectral Distortion) is used as performance criterion:
LSD =1
L
L−1∑l=0
√√√√ 1
K
K−1∑k=0
(20 log10|I(k, l)| + ε
|O(k, l)| + ε)2 (1)
WhereI(k, l) andO(k, l) are the FFT ofI(t) (ideal source signal) andO(t)(separated source) respectively.L is the number of frames,K is the number offrequency bins andε is meant to prevent extreme values (equal to .001 in ourcase).• We compare with systems from Wang & Brown [35], Hu & Wang [36], Jang& Lee [37] and with a speech enhancement system by Bahoura & Rouat [38,39, 40].

J. ROUAT, 30 April 09, McGill
•First •Prev •Next •Last •Go Back •Full Screen •Close •Quit
Separation performance
Data inhttp://www-edu.gel.usherbrooke.ca/pichevar/Demos.htm
SNR of the initial P-R W-B H-W B-RIntrusion mixture(dB)
LSD LSD LSD LSD
Tone -2 dB 5.38 18.87 13.59 9.77Siren -5 dB 8.93 20.64 13.40 18.94
Tel. ring 3 dB 16.43 18.35 14.05 16.18White noise -5 dB 16.82 35.25 26.51 14.84Male (da) 0 dB 14.92 N/A N/A 17.70
Female (di) 0 dB 19.70 N/A N/A 24.04
The log spectral distortion (LSD) for four different methods: P-R (our proposed approach), W-B
(the method proposed by [41]), H-W (the method proposed by [42]), and B-R (the method
proposed in [39]). The intrusion noises are as followsa) 1 kHz pure tone,b) FM siren,c)
telephone ring,d) white noise,e)male-speaker intrusion (/di/) for the French /di//da/ mixture,f)
female-speaker intrusion (/da/) for the French /di//da/ mixture. Except for the last two tests, the
intrusions are mixed with a sentence taken from Martin Cooke’s database.

J. ROUAT, 30 April 09, McGill
•First •Prev •Next •Last •Go Back •Full Screen •Close •Quit
Separation performance, (contd)
Mixture Separated P-R J-L B-Rsources (LSD) (LSD) LSD
Music & female music 8.01 21.25 14.00(AF) voice 17.54 16.49 18.16
LSD for two different methods: P-R (our proposed approach), J-L ([37]), andB-R ([38] and [39]). The mixture comprises a female voice with musical rockbackground.
PESQ evaluation
PESQ has been proposed by the ITU (International Telecommunication Union)under the recommendation P.862.
Mixture Separated P-R J-Lsources (PESQ) (PESQ)
Music & female music 1.70 0.35(AF) voice 0.55 0.63
PESQ for two different methods: P-R (our proposed approach), J-L ([37]). Themixture comprises a female voice with musical rock background.
J. ROUAT, 30 April 09, McGill
•First •Prev •Next •Last •Go Back •Full Screen •Close •Quit
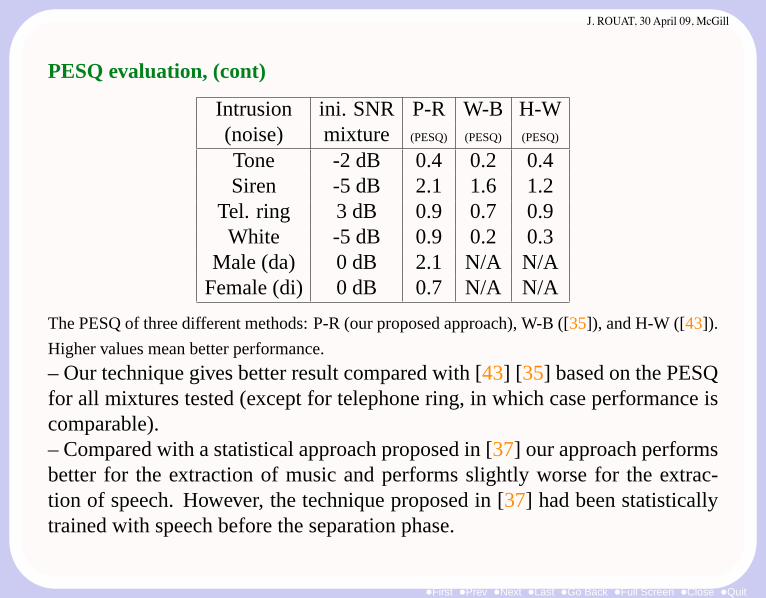
PESQ evaluation, (cont)
Intrusion ini. SNR P-R W-B H-W(noise) mixture (PESQ) (PESQ) (PESQ)
Tone -2 dB 0.4 0.2 0.4Siren -5 dB 2.1 1.6 1.2
Tel. ring 3 dB 0.9 0.7 0.9White -5 dB 0.9 0.2 0.3
Male (da) 0 dB 2.1 N/A N/AFemale (di) 0 dB 0.7 N/A N/A
The PESQ of three different methods: P-R (our proposed approach), W-B ([35]), and H-W ([43]).
Higher values mean better performance.
– Our technique gives better result compared with [43] [35] based on the PESQfor all mixtures tested (except for telephone ring, in which case performance iscomparable).– Compared with a statistical approach proposed in [37] our approach performsbetter for the extraction of music and performs slightly worse for the extrac-tion of speech. However, the technique proposed in [37] had been statisticallytrained with speech before the separation phase.

J. ROUAT, 30 April 09, McGill
•First •Prev •Next •Last •Go Back •Full Screen •Close •Quit
Example: separation of speech from telephone trill
Time (s)0 1.51
0
4000
Fre
quen
cy (
Hz)
Time (s)0 1.51
0
4000
Fre
quen
cy (
Hz)
Mixture of the utterance ”Why were you all weary?” with a trill telephonenoise.
Time (s)0 1.51
0
4000
Fre
quen
cy (
Hz)
Time (s)0 1.51
0
4000
Fre
quen
cy (
Hz)
Left: The synthesised ”Why were you all weary?” after separation.Right:The synthesised trill phone after separation.

J. ROUAT, 30 April 09, McGill
•First •Prev •Next •Last •Go Back •Full Screen •Close •Quit
Other listenings: Demo web page
Discussion
– We use a perceptive analysis to extract multiple and simultaneous time struc-tured features to be processed by a spiking neural network.– There is no need to tune-up the neural network when changing the nature ofthe signal and there is no training or recognition phase. Weights are computedbased on the feature differences.– Even with a crude approximation such as binary masking with non overlap-ping and independent time window, we obtain relatively good synthesis intelli-gibility.How far can we go in monophonic sound source separation when using no priorknowledge (numbers, nature, etc.) of the sources but by using simultaneousrepresentations and by preserving short–time structures?Surprisingly far!

J. ROUAT, 30 April 09, McGill
•First •Prev •Next •Last •Go Back •Full Screen •Close •Quit
6. Conclusion for the audio part of thisprensentation
– Starting in the mid ’80s, auditory models preserving time organized featureswere already proposed.– The understanding of the performance of the ROC (with little training data)in relation with Bayesian learning methods is certainly an interesting researchissue for the future.– It is also important to note that interesting monophonic source separations canbe performed without prior knowledge by using the temporal correlation.– Of course, when possible, a more robust system would combine both Bayesianlearning and temporal correlation.

J. ROUAT, 30 April 09, McGill
•First •Prev •Next •Last •Go Back •Full Screen •Close •Quit
7. Image Processing via binding with spikingneurons
Examples of objects recognition
Oscillatory Dynamic Link Matching for Pattern Recognition , R. Pichevar& J. Rouat [11], Neurocomputing, 69 (2006).
1. Image Segmentation
2. Dynamic Link Matching between 2 layers of spiking neurons for imagecomparisons.
Network architecture

J. ROUAT, 30 April 09, McGill
•First •Prev •Next •Last •Go Back •Full Screen •Close •Quit
Example in face recognition application (FERET database)
Illustration of the principle from a video:Video of 2 layers spiking N.N. with the same face
The color encodes the phase of the spikes (i.e. the relative instants of firing).Each neuron (after stabilization of the network activity) has the same firing
frequency

J. ROUAT, 30 April 09, McGill
•First •Prev •Next •Last •Go Back •Full Screen •Close •Quit
Interpretation of the neural network behavior
Same people with a different mouth position: f13 et f13b. The majority of theneurons fire in synchrony.
Two different people: f13 et f15. The majority of the neurons fire in synchronyexcept the neurons on the second face. This area will never synchronyze.

J. ROUAT, 30 April 09, McGill
•First •Prev •Next •Last •Go Back •Full Screen •Close •Quit
Research team
Video of 2 layers spiking N.N. with the same face
Research team on spiking neurons.Two Ph.D. positions are open: Cocktail party processing, Multisensory System

J. ROUAT, 30 April 09, McGill
•First •Prev •Next •Last •Go Back •Full Screen •Close •Quit
References
[1] Gyorgy Buzsaki. Rhythms of the Brain. Oxford University Press, 2006.
[2] R. Pujolet al. Cric, montpellier : Audition promenade round cochlea.www.iurc.montp.inserm.fr/cric/audition/english.
[3] C. K. Henkel. The Auditory System. In Duane E. Haines, editor,Fondamental Neuroscience. Churchill Livingstone,1997.
[4] Jean Rouat. Nonlinear operators for speech analysis. In M. Cooke, S. Beet, and M. Crawford, editors,Visual representa-tions of speech signals, pages 335–340. J. Wiley and Sons, 1993.
[5] Jean Rouat. A nonlinear speech analysis based on modulation information. In A. Rubio and J. Soler, editors,SpeechRecognition and Coding, New Advances and Trends, pages 341–344. Springer-Verlag, 1995.
[6] Ping Tang and Jean Rouat. Modeling neurons in the anteroventral cochlear nucleus for amplitude modulation (AM)processing: Application to speech sound. InProc. Int. Conf. on Spok. Lang. Proc., page Th.P.2S2.2, Oct 1996.
[7] Ping Tang , Pierre Dutoit, Alessandro Villa, and Jean Rouat. Effect of the membrane time constant in a model of achopper-S neuron of the anteroventral cochlear nucleus : a neuroheuristic approach. InAssoc. for Res. in Oto., 20th. res.meeting, pages P–472, feb 1997. http://www.aro.org/archives/1997/472.html.
[8] J. Rouat and R. Pichevar . Nonlinear speech processing with oscillatory neural networks for speaker segregation. Inproceedings of EUSIPCO 2002, Sept. 2002. Invited.
[9] R. Pichevar and J. Rouat. Double-vowel segregation through temporal correlation: A bio-inspired neural networkparadigm. InNOLISP03, Non Linear Speech Processing, 20–23 May 2003.
[10] R. Pichevar and J. Rouat. Cochleotopic/AMtopic (CAM) and Cochleotopic/Spectrotopic (CSM) MAP based sound sourceseparation using relaxation oscillatory neurons. InIEEE Workshop on Neural Networks for Signal Processing, pages 657–666, September 15-17 2003.
[11] R. Pichevar and J. Rouat. Oscillatory dynamic link matching for pattern recognition. In5th neural coding workshop,September 2003.
[12] S. Thorpe, D. Fize, and C. Marlot. Speed of processing in the human visual system.Nature, 381(6582):520–522, 1996.

J. ROUAT, 30 April 09, McGill
•First •Prev •Next •Last •Go Back •Full Screen •Close •Quit
[13] Rufin VanRullen, Rudy Guyonneau, and Simon J. Thorpe. Spike times make sense.Trends in Neurosciences, 28(1):4,January 2005.
[14] Shibab Shamma. Physiological foundations of temporal integration in the perception of speech.Journal of Phonetics,31:495–501, 2003.
[15] Oded Ghitza. Auditory models and human performance in tasks related to speech coding and speech recognition.IEEETrSAP, 2(1):115–132, 1 1994.
[16] Sumeet Sandhu and Oded Ghitza. A comparative study of mel cepstra and EIH for phone classification under adverseconditions.ICASSP, pages 409–412, 1995.
[17] S. Thorpe, A. Delorme, and R. Van Rullen. Spike-based strategies for rapid processing.Neural Networks, 14(6-7):715–725, 2001.
[18] Stephane Loiselle , Jean Rouat, Daniel Pressnitzer, and Simon Thorpe. Exploration of rank order coding with spikingneural networks for speech recognition. InInternational Joint Conference on Neural Networks, 2005. August 2005.
[19] Rufin VanRullen and Simon J. Thorpe. Surfing a spike wave down the ventral stream.Vision Research, 42(23):2593–2615,August 2002.
[20] Bernard P. Zeigler. Discrete event abstraction: An emerging paradigm for modeling complex adaptative systems.Adap-tation and Evolution, Oxford Press, 2003.
[21] R.D. Patterson. Auditory filter shapes derived with noise stimuli.JASA, 59(3):640–654, 1976.
[22] StEphane Loiselle. SystEme de reconnaissance de la parole pour la commande vocale desEquations mathEmatiques.Technical report, UniversitE du QuEbec‡ Chicoutimi, August 2001.
[23] Legendy.Progress in Cybernetics, volume 1, chapter II-6: The brain and its information trapping device, pages 309–338.Gordon and Breach, 1970.
[24] P.M. Milner. A model for visual shape recognition.Psychological Review, 81:521–535, 1974.
[25] Ch. v. d. Malsburg. The correlation theory of brain function. Technical Report Internal Report 81-2, Max-Planck Institutefor Biophysical Chemistry, 1981.

J. ROUAT, 30 April 09, McGill
•First •Prev •Next •Last •Go Back •Full Screen •Close •Quit
[26] Ch. v. d. Malsburg. The what and why of binding: The modeler’s perspective.Neuron, pages 95–104, 1999.
[27] D.L. Wang and D. Terman. Image segmentation based on oscillatory correlation.Neural Computation, 9:805–836, 1997.
[28] Buhmann J. Wang, D. L. and C. v. d. Malsburg. Pattern segmentation in associative memory.Neural Computation,2:95–107, 1990.
[29] Golomb D. Sompolinsky, H. and D. Kleinfeld. Cooperative dynamics in visual processing.Physical Review A, 43:6990–7011, 1991.
[30] H. Sompolinsky and M. Tsodyks. Segmentation by a network of oscillators with stored memories.Neural Comput.,6(4):642–657, 1994.
[31] C. von der Malsburg and J. Buhmann. Sensory segmentation with coupled neural oscillators.Biological Cybernetics,54:29–40, 1992.
[32] W. Konen, T. Maurer, and C. Von der Malsburg. A fast dynamic link matching algorithm for invariant pattern recognition.Neural Networks, pages 1019–1030, 1994.
[33] Al Bregman.Auditory Scene Analysis. MIT Press, 1990.
[34] R. Pichevar, J. Rouat, C. Feldbauer, and G. Kubin. A bio-inspired sound source separation technique in combination withan enhanced FIR gammatone Analysis/Synthesis filterbank. InEUSIPCO Vienna, 2004.
[35] D. Wang and G. J. Brown. Separation of speech from interfering sounds based on oscillatory correlation.IEEE Tr. onNeural Networks, 10(3):684–697, May 1999.
[36] G. Hu and D.L. Wang. Monaural speech segregation based on pitch tracking and amplitude modulation. Technical report,Ohio State University, 2002.
[37] G. Jang and T. Lee. A maximum likelihood approach to single-channel source separation.IEEE-SPL, pages 168–171,2003.
[38] M. Bahoura and J. Rouat. Wavelet speech enhancement based on the Teager Energy Operator.IEEE Signal ProcessingLetters, 8(1):10–12, Jan 2001.

J. ROUAT, 30 April 09, McGill
•First •Prev •Next •Last •Go Back •Full Screen •Close •Quit
[39] M. Bahoura and J. Rouat. A new approach for wavelet speech enhancement. Inproceedings of Eurospeech 2001, Septem-ber 2001. Paper nb: 1937.
[40] M. Bahoura and J.Rouat. Wavelet speech enhancement based on time–space adaptation.Speech Communication,48(12):1620–1637, 2006.
[41] D. Wang and G. J. Brown. Separation of speech from interfering sounds based on oscillatory correlation.IEEE Transac-tions on Neural Networks, 10(3):684–697, May 1999.
[42] G. Hu and D.L. Wang. Separation of stop consonants. InICASSP, 2003.
[43] G. Hu and D.L. Wang. 2004.


















