
Toward MPI Asynchronous Progress on Cray XE Systems · MPICH2 on XE Basics (2) The eager protocol...
32
Toward MPI Asynchronous Progress on Cray XE Systems Howard Pritchard – [email protected] 5/3/2012 Cray User Group Proceedings 2012 1 Howard Pritchard – [email protected] Duncan Roweth David Henseler Paul Cassella Cray, Inc.
Transcript of Toward MPI Asynchronous Progress on Cray XE Systems · MPICH2 on XE Basics (2) The eager protocol...

Toward MPI Asynchronous Progress on Cray XE Systems
Howard Pritchard – [email protected]
5/3/2012 Cray User Group Proceedings 20121
Howard Pritchard – [email protected] Duncan RowethDavid HenselerPaul Cassella
Cray, Inc.

Overview
● MPI Progress - what is it?● XE6 (Gemini) Features relevant to MPI progress● MPICH2 Enhancements for MPI progress on Gemini● Core Specialization and MPI progress● Benchmark and application results● Future work
5/3/2012 Cray User Group Proceedings 20122
● Future work

● Determines how an MPI communication operation completes once it has been initiated
● Strict interpretation ● Once a communication has been initiated no further MPI calls are
required in order to complete it
MPI Progress Rule
5/3/2012 Cray User Group Proceedings 20123
● Weak interpretation● An application must make further MPI library calls in order to make
progress
● Primarily an issue for point-to-point calls, but al so relevant to non-blocking collectives – to be introduced in MP I version 3.
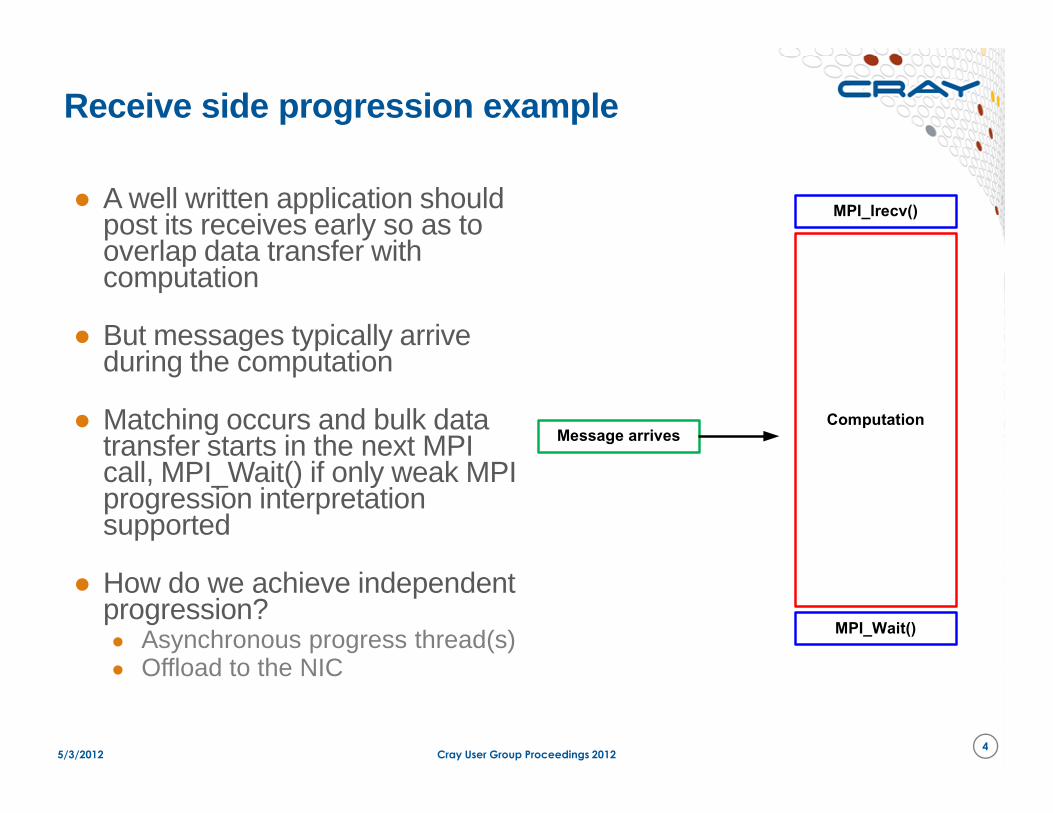
Receive side progression example
● A well written application should post its receives early so as to overlap data transfer with computation
● But messages typically arrive during the computation
● Matching occurs and bulk data
MPI_Irecv()
5/3/2012 Cray User Group Proceedings 20124
● Matching occurs and bulk data transfer starts in the next MPI call, MPI_Wait() if only weak MPI progression interpretation supported
● How do we achieve independent progression?● Asynchronous progress thread(s) ● Offload to the NIC
Computation
MPI_Wait()
Message arrives

What Gemini Hardware Provides
5/3/2012 Cray User Group Proceedings 20125

Gemini Hardware Features and MPI Progress
● DMA Engine with four virtual channels● Local interrupt can be generated along with a Completion Queue
Event (CQE) upon completion of a TX descriptor (RDMA transaction)● Remote interrupt and remote CQE can be generated at a target node
when a RDMA transaction has completed● RDMA fence capability
● Completion Queues configurable for polling or block ing
5/3/2012 Cray User Group Proceedings 20126
● Completion Queues configurable for polling or block ing (interrupt driven)
● Gemini has low overhead method for a process operat ing in user-space to generate an interrupt at a remote node (along with a CQE)
● No explicit support for MPI

MPICH2 Enhancements to SupportAsynchronous Progress
5/3/2012 Cray User Group Proceedings 20127
Asynchronous Progress

MPICH2 on XE - Basics
● Based on Argonne National Lab (ANL) MPICH2 Nemesis CH3 channel
● A GNI Nemesis Network Module (Netmod) interfaces t he upper part of MPICH2 to the XE network software sta ck
● Full support for MPI -2 thread safety level
5/3/2012 Cray User Group Proceedings 20128
● Full support for MPI -2 thread safety level MPI_THREAD_MULTIPLE
● Progress thread infrastructure (although simplistic ) already exists in the library

MPICH2 on XE Basics (2)
● The eager protocol both for intra-node and inter-no de messaging is CPU intensive and not suitable for asynchronous progress
● The rendezvous path for intra-node messages is also CPU intensive and not suitable for asynchronous progres s
5/3/2012 Cray User Group Proceedings 20129
● The rendezvous – Long Message Transfer (LMT) – path f or inter-node messages is not CPU intensive (usually):● Rendezvous messages up to 4 MB in size normally use a RDMA read
LMT protocol● Messages larger than 4 MB, or in the case of shorter messages when
hardware resource depletion is occurring, use a cooperative RDMA write LMT protocol
● The Gemini DMA engine (BTE) is normally used for these transfers

Enhancing MPICH2 on XE for Better MPI Progress - Goals
● Keep complexity/new software to a minimum
● Minimize impact on short message latency/message ra te
● Don’t focus on a single message transfer protocol p ath for providing MPI progress (e.g. don’t focus just on RD MA read protocol)
5/3/2012 Cray User Group Proceedings 201210
read protocol)
● First phase focuses on better progression of longer message sizes (32 – 64 KB or longer)

……
… …
MPICH2 - Progress Thread Model
● Each MPI rank on a node starts an extra progress thread during MPI_Init.
● An extra completion queue (CQ) is created with blocking attribute during MPI_Init
● The progress threads call GNI_CqWait and remain
5/3/2012 Cray User Group Proceedings 201211
… …
application threadprogress thread
● The progress threads call GNI_CqWait and remain blocked in the kernel until an interrupt is delivered by the Gemini NIC indicating progress on an MPI message receive or send
● Interrupts are only generated when progressing inter-node LMT (rendezvous) messages

LMT RDMA Write Path – No Progress
Sender ReceiverSMSG Mailboxes
PE 1
PE 82
PE 5PE 22
PE 96
4. Register Chunk of App 2. Register Chunk4. Register Chunk of App Send Buffer
2. Register Chunkof App Recv Buffer
Cray User Group Proceedings 201212
5/3/2012

LMT RDMA Write Path – With Progress
Sender ReceiverSMSG Mailboxes
PE 1
PE 82
PE 5PE 22
PE 96
4. Register Chunk of App 2. Register Chunk4. Register Chunk of App Send Buffer
2. Register Chunkof App Recv Buffer
Cray User Group Proceedings 201213
5/3/2012
BTE RX CQ

Core Specialization and MPI Progress
5/3/2012 Cray User Group Proceedings 201214
Progress

Core Specialization
● Modifications to the Linux kernel to allow for dyna mic partitioning of the cores on a node between applica tion threads and OS kernel threads and system daemons
● Provides an interface to allow application librarie s to specify whether threads/processes it creates are to be scheduled on the application partition or the OS pa rtition
5/3/2012 Cray User Group Proceedings 201215
scheduled on the application partition or the OS pa rtition
● User of a parallel application specifies at launch time how many cores, if any, per node to reserve for the OS partition

Core Specialization and MPI progress
● Typical HPC application threads tend to run hot , i.e. they don’t typically make calls that result in yielding of the core on which they are scheduled
● Because of this, MPI progress threads need to have at least one core of a compute unit available per node for efficient handling of interrupts received from Gemi ni
5/3/2012 Cray User Group Proceedings 201216
efficient handling of interrupts received from Gemi ni
● Core Specialization provides a convenient way to pa rtition cores on a node between hot application threads, and coolsystem service daemon threads as well as MPI progre ss threads.

Job Container/Corespec Example
int disable_job_aff_algo(void) {
int rc;
int fd = open("/proc/job", O_WRONLY);
if (fd == -1){
return -1;
}
rc = write(fd, "disable_affinity_apply", strlen("disable_affinity_apply"));
if (rc < 0){
close(fd);
return -1;
}
close(fd);
Tell job container package that the next thread/process created by this process should not be placed like an application thread/process.
5/3/2012 Cray User Group Proceedings 201217
close(fd);
return 0;
}
int task_is_not_app(void) {size_t count;FILE *f;char zero[]="0";char filename[PATH_MAX];
snprintf(filename, sizeof(filename),"/proc/self/tas k/%ld/task_is_app",syscall(SYS_gettid));
f = fopen(filename, "w");if (!f) {
return -1;}
count = fwrite(zero,sizeof(zero),1,f);if (count != 1) {
fclose(f);return -1;
}fclose(f);return 0;
}
Tell CoreSpec package that this task (thread) should be scheduled on OS partition if one is available, otherwise use default Linux scheduler policy.

MPI Asynchronous Progress - enabling
● export MPICH_NEMESIS_ASYNC_PROGRESS=1
● export MPICH_MAX_THREAD_SAFETY=multiple
5/3/2012 Cray User Group Proceedings 201218

Results
5/3/2012 Cray User Group Proceedings 201219

Sandia MPI Benchmark (mpi_overhead)
Measures MPI message overhead:
iter_twork_t
overhead = iter_t – work_t
5/3/2012 Cray User Group Proceedings 201220
MPI_Irecv()
MPI_Wait()base_t
Measures application availability:
avail = 1 – (iter_t – work_t)/base_t
http://www.cs.sandia.gov/smb/index.html

SMB – Receive side 64 KB message size (no progress)
100
120
140
160
180
base_tsecs
5/3/2012 Cray User Group Proceedings 201221
0
20
40
60
80base_twork_titer_t
µse
cs
work loop iterations

SMB – Receive side 64 KB message size(progress enabled)
100
120
140
160
180
base_tsecs
5/3/2012 Cray User Group Proceedings 201222
0
20
40
60
80base_twork_titer_t
work loop iterations
µse
cs

Availability – no progress
60
70
80
90
100
Ava
ilabi
lity
(%)
5/3/2012 Cray User Group Proceedings 201223
0
10
20
30
40
50
0 2 4 8 16 32 64 128
256
512
1K 2K 4K 8K 16K
32K
64K
128K
256K
512K 1M 2M 4M 8M 16M
SenderReceiverA
vaila
bilit
y (%
)
Message length
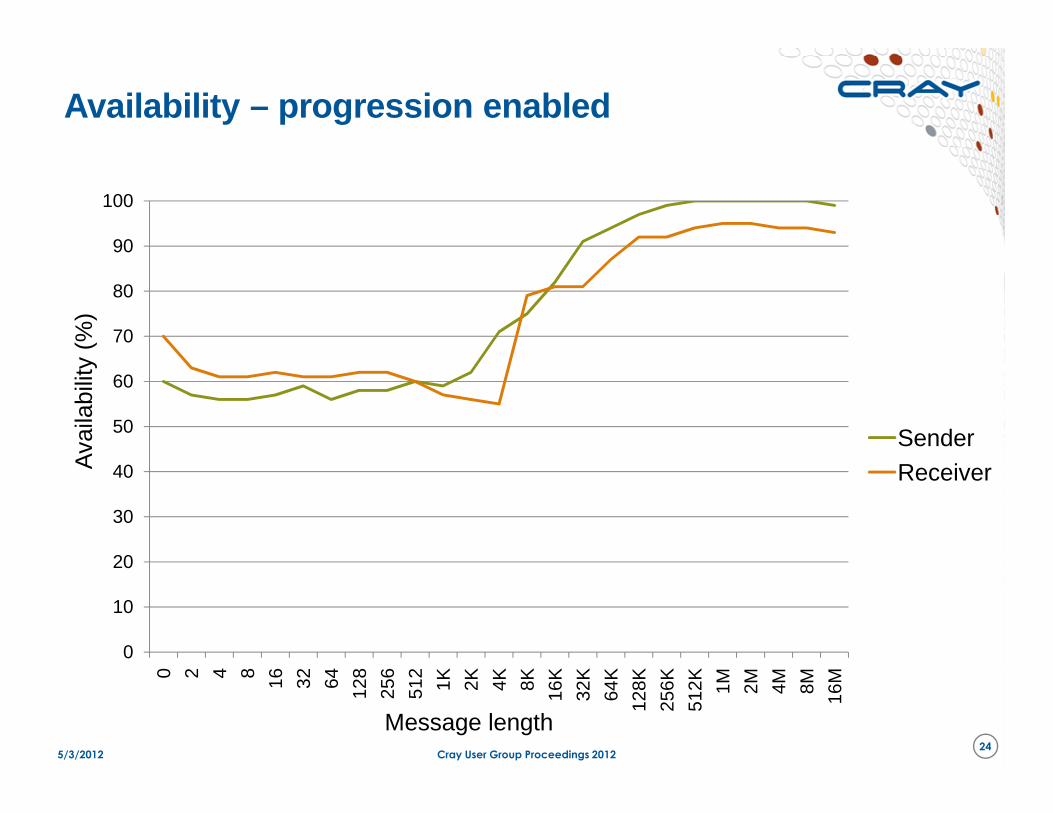
Availability – progression enabled
60
70
80
90
100
Ava
ilabi
lity
(%)
5/3/2012 Cray User Group Proceedings 201224
0
10
20
30
40
50
0 2 4 8 16 32 64 128
256
512
1K 2K 4K 8K 16K
32K
64K
128K
256K
512K 1M 2M 4M 8M 16M
SenderReceiverA
vaila
bilit
y (%
)
Message length

S3D Application
● Hybrid MPI/OpenMP● Joint work by ORNL and
Cray to prepare app foreither using acceleratorsor OpenMP only on node
● Large messages for thedata set considered
|-------------------------------------------------- ----
| Time% | Time | -- | Calls |Total
|-------------------------------------------------- ----
100.0% | 333.554284 | -- | 2022296 |Total
|-------------------------------------------------- ----
| 56.7% | 189.059471 | -- | 605408 |USER
||================================================= ====
| 38.3% | 127.905679 | -- | 869027 |MPI
||------------------------------------------------- ----
5/3/2012 Cray User Group Proceedings 201225
● Large messages for thedata set considered || 23.7% | 78.906595 | -- | 61200 |mpi_waitall_
|| 11.8% | 39.426609 | -- | 6960 |mpi_wait_
|| 2.4% | 7.933348 | -- | 399480 |mpi_isend_
||================================================= ====
| 4.1% | 13.729663 | -- | 546009 |OMP
|…
MPI Msg
Bytes
MPI Msg
Count
< 16 Bytes 16 – 256B
Bytes
256 – 4K
Bytes
4K – 64K
Bytes
64 K – 1M
Bytes
2223830363
6
401311 1795 27 100806 2 298681
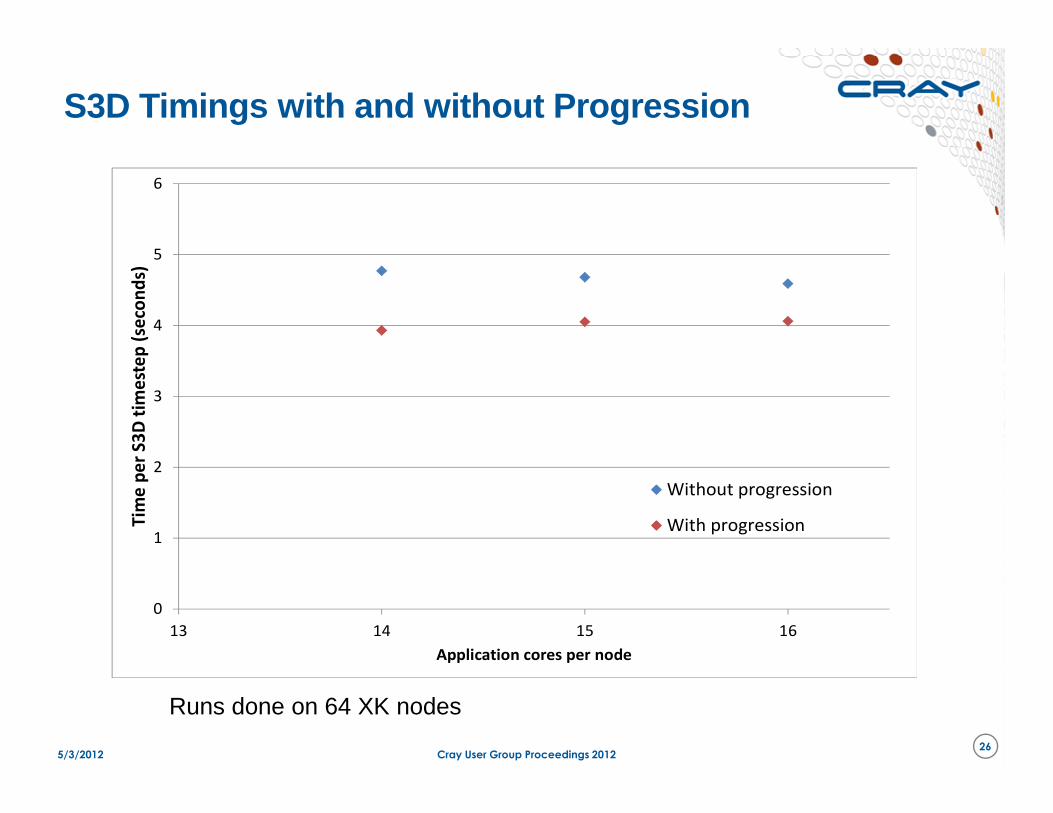
S3D Timings with and without Progression
3
4
5
6
Tim
e p
er
S3
D t
ime
ste
p (
seco
nd
s)
5/3/2012 Cray User Group Proceedings 201226
0
1
2
13 14 15 16
Tim
e p
er
S3
D t
ime
ste
p (
seco
nd
s)
Application cores per node
Without progression
With progression
Runs done on 64 XK nodes

MILC Application
● Flat MPI application● Message sizes more varied, both eager and
rendezvous protocols are being used● Significant amount of intra-node
messaging
1.2E+06
1.4E+06
mes
sage
cou
nt
5/3/2012 Cray User Group Proceedings 201227
0.0E+00
2.0E+05
4.0E+05
6.0E+05
8.0E+05
1.0E+06
1.2E+06
Message length
mes
sage
cou
nt

MILC Application – MPI_Wait time
● App was modified to measure time spent in core gather/scatter communication scheme
● Non-blocking send/recvs used with some intervening work
● Max MPI_Wait time reduced significantly
1000
1200
5/3/2012 Cray User Group Proceedings 201228
0
200
400
600
800
2048 4096 8192
avg. wait time with progress
max wait time with progress
avg. wait time no progress
max wait time, no progress
seco
nds
2048 runs had to be run 16 ranks/per nod due to memory size

MILC Application – actual runtime
● The actual runtime changed much more modestly● Load imbalance and MPI_Allreduce sync points may lim it
the actual speedup for this particular job type for MILC● ~8 % improvement at 8192 ranks● ~2 % improvement at 4096 ranks
3500
4000
4500
5/3/2012 Cray User Group Proceedings 201229
seco
nds
0
500
1000
1500
2000
2500
3000
3500
2048 4096 8192
no progress
with progress

Conclusions
● Thread-based method to progress does show some promise based on micro-benchmarks
● The current approach can be effective for applicati ons with larger messages (at least 32 KB), but a mixtur e of messages using eager and rendezvous path limits the usefulness of the progress threads
5/3/2012 Cray User Group Proceedings 201230
usefulness of the progress threads
● Not shown in the data here, but in the paper, that for flat MPI codes, CoreSpec is highly recommended when tryin g to use this thread-based progress mechanism

Future Work
● Enhance GNI interface to allow for more efficient u se of the DMA (BTE) engine, allowing for better handling of shorter MPI messages (< 32KB)
● Use extensions to the CoreSpec/job package to sched ule the progress threads on unused hyperthreads for next generation of Gemini interconnect
5/3/2012 Cray User Group Proceedings 201231
generation of Gemini interconnect
● Enhancements to GNI to more efficiently wake up progress threads
● Integrate the improved progress thread framework ba ck into mainline Nemesis MPICH2 code

Acknowledgements
● John Levesque and Steve Whalen for assistance with MILC and S3D.
This material is based upon work supportedby the Defense Advanced Research Projects Agency under its Agreement No. HR0011-07-9-0001. Any opinions,
5/3/2012 Cray User Group Proceedings 201232
Projects Agency under its Agreement No. HR0011-07-9-0001. Any opinions, findings and conclusions or recommendations expressed in this material arethose of the author(s) and do not necessarily reflect the views ofthe Defense Advanced Research Projects Agency. This work was supported in part by the Office of Advanced Scientific Computing Research, Office of Science, U.S. Department of Energy, under Contract DE-AC02-06CH11357










![IA 1A Periodic Table of the Elements H He · Electron Configuration Electron Shells 1 IA 1A 1 2 3 ... [Xe]5d16s2 [Xe]4f15d16s2 [Xe]4f36s2 [Xe]4f46s2 [Xe]4f56s2 [Xe]4f66s2 [Xe]4f76s2](https://static.fdocuments.in/doc/165x107/5b6b1a407f8b9a9f1b8d06f3/ia-1a-periodic-table-of-the-elements-h-he-electron-configuration-electron-shells.jpg)







