
Time Bounds for Shared Objects in Partially Synchronous Systems Jennifer L. Welch Dagstuhl Seminar...
30
Time Bounds for Shared Objects in Partially Synchronous Systems Jennifer L. Welch Dagstuhl Seminar on Consistency in Distributed Systems Feb 2013
-
Upload
mervyn-alexander -
Category
Documents
-
view
216 -
download
0
Transcript of Time Bounds for Shared Objects in Partially Synchronous Systems Jennifer L. Welch Dagstuhl Seminar...

Time Bounds for Shared Objects
in Partially Synchronous Systems
Jennifer L. WelchDagstuhl Seminar on
Consistency in Distributed Systems Feb 2013

Acknowledgment
Joint work with Jiaqi WangHyunyoung LeeEdward Talmage
Jiaqi Wang’s M.S. thesis, CSE, TAMU, 2011
PODC 2011 brief announcement
2

3
Model Fixed set of n nodes Nodes communicate through reliable
message-passingdelay in range [d−u,d]
Nodes have approximately synchronized clocks with skew εε ≥ (1−1/n)u [Lundelius and Lynch
1984]no clock drift
No node failures

Problem
Each node runs an application process Application processes communicate
through (logically) shared variables arbitrary data types
How to implement the shared variables that the application processes use?
Desired consistency condition is linearizability
Focus on elapsed time of implemented operations
4

Related Work: Lower Bounds
Lipton and Sandberg 1988 |read|+|write| ≥ d (for sequential
consistency)
Attiya and Welch 1991, 1994 |read| ≥ u/4 |write/enq/push| ≥ u/2
Mavronicolas and Roth 1991, 1992, 1999 |read/write| ≥ min{ε/2,u/2} |read|+|write| ≥ d + min{ε/2,u/2} 5

Related Work: Lower Bounds
Kosa 1994, 1999 Generalize arguments in Attiya & Welch for arbitrary
data types Inspired by classification of operations by Weihl 1988
based on commutativity for op that "does not commute w/ itself”:
|op| ≥ d implies |deq/pop| ≥ d
for op1 and op2 that “immediately do not commute”: |op1| + |op2| ≥ d implies
|read/deq|+|write/enq| ≥ d for op that is a “pure mutator”:
|op| ≥ u/2 implies |write/enq/push| ≥ u/2
for op that is an “accessor”: |op| ≥ u/2 implies |read/peek| ≥ u/2
6

7
Related Work: Upper Bounds for Read-Write Registers Mavronicolas and Roth 1991, 1992,
1999: |read| ≤ βd+3u+min{ε,u}+γ |write| ≤ (1−β)d + 3uβ is tradeoff parameter in [o,1−u/d)γ is a small constant
Chaudhuri, Gawlich and Lynch 1993: |read| ≤ u + c |write| ≤ d + u − cc is tradeoff parameter in [0,d]

Related Work: General Upper Bounds
Folklore algorithm #1: centralized (single copy):
send operation invocation to node with the copy
node with copy serializes invocations and updates the copy
node with copy sends response to invoker. Each operation takes 2d time
8

Related Work: General Upper Bounds
Folklore algorithm #2: Use atomic broadcast (full replication):
broadcast invocation upon receipt do the operation invoker waits for broadcast time and
provides response Each operation takes h time, where h is
broadcast time: h = 2d
9

Overview of Our Results
Lower bound #1: (1 – 1/n)u for operations which can be
executed in any order but result in different states for different orders
includes write, push and enq improves previously known bound of
u/2uses classic shifting technique
10

Overview of Results
Lower bound #2:d + min{ε,u,d/3} for operations that
“immediately” do not commute with themselves (invalidate each other)
includes RMW, pop, deq improves previous lower bound of d uses a new shifting technique which
provides a larger bound by shifting by a larger amount, then manipulating the new execution to fix message delays that are too big or too small
11

Overview of Results
New generic algorithm for any data type Partitions operations into
pure accessors (don’t change state) pure mutators (don’t observe state) other
Upper bounds are, for any X in [0,d+ε−u], d + ε − X for pure accessor ε + X for pure mutator d + ε for other
Improves on folklore algorithms (2d time per op)
12

Bounds for Read-Modify-Write Register
13
operation lower bound upper bound
read-modify-write
d + min{ε,u,d/3} d + ε (all X)
read u/2 [Kosa] u (X = d+ε−u)
write (1−1/n)u ε (X = 0)
read + write
d [Lipton & Sandberg]
d + 2ε (all X)Recall ε can be as small as (1−1/n)u

Bounds for Queue
14
operation lower bound upper bound
enq (1−1/n)u ε (X = 0)
deq d + min{ε,u,d/3} d + ε (all X)
peek u/2 [Kosa] u (X = d+ε−u)
peek + enq
d + min{ε,u,d/3} d + 2ε (all X)
Recall ε can be as small as (1−1/n)u
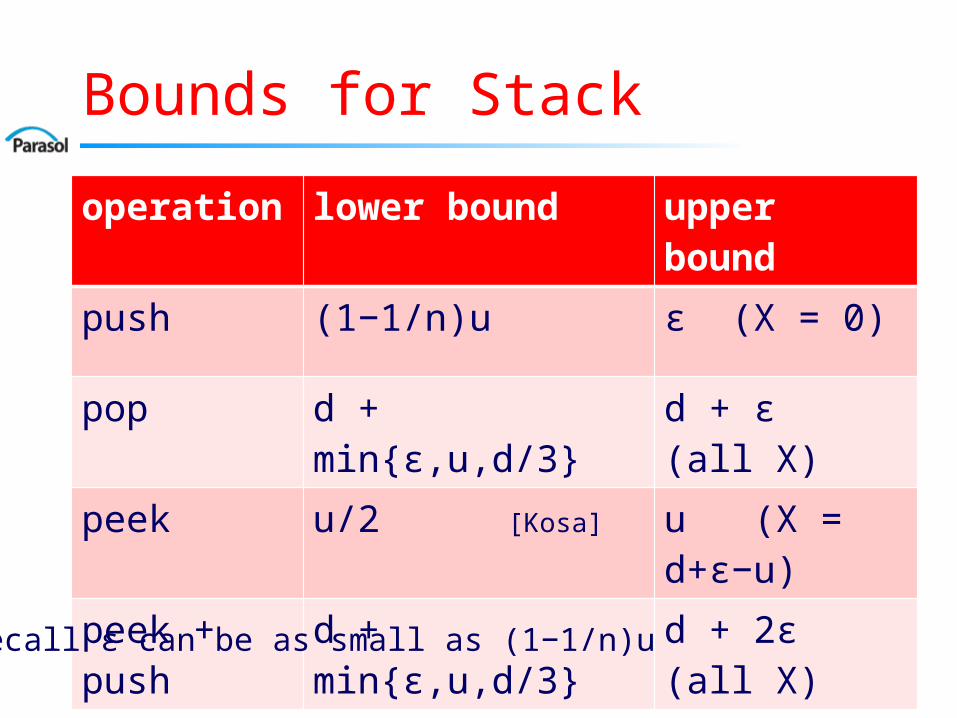
Bounds for Stack
15
operation lower bound upper bound
push (1−1/n)u ε (X = 0)
pop d + min{ε,u,d/3} d + ε (all X)
peek u/2 [Kosa] u (X = d+ε−u)
peek + push
d + min{ε,u,d/3} d + 2ε (all X)
Recall ε can be as small as (1−1/n)u

Terminology
operation: operation w/o arg and return value. Ex: read 0peration instance: operation w/ arg and return value.
Ex: read(-,3). legal op sequence: one of the sequences in the
sequential spec of the data type. Ex: for register, every read returns value of latest preceding write
equivalent sequences of ops, ρ1 and ρ2: for all op sequences ρ3, ρ1.ρ3 is legal iff ρ2.ρ3 is legal
OP is a mutator: there exist op sequence ρ and op instance in OP s.t. ρ.op and ρ are not equivalent
OP is an accessor: there exist legal op sequence ρ and op instance in OP s.t. ρ.op is illegal
Pure mutator: mutator but not accessor Pure accessor: accessor but not mutator 16

Lower Bound #1 (write, push, enq, etc.)
If for all operation sequences ρ and all
instances op1 and op2 of OP, ρ.op1 and ρ.op2 legal => ρ.op1.op2 and ρ.op2.op1 are both legal, and
there exists operation sequence ρ and instances op1,op2,...,opn of OP s.t.
ρ.opi is legal, i = 1,...,n andfor all permutations π1 and π2 of op1,...,opn,
last(π1) ≠ last(π2) => ρ.π1 and ρ.π2 are not equivalent
then |OP| ≥ (1 − 1/n)u.
17

Classic Shifting Proof Idea
Assume in contradiction there is an implementation with |OP| < (1 − 1/n)u
Specify a carefully designed reference execution Specify which operations are invoked when, message
delays, and clock skews
Shift the real times when events occur in reference execution to get a new execution that still should be correct, but because of the shifting, the semantics of OP are violated Carefully design shift amounts to keep msg delays and
clock skews within bounds
18
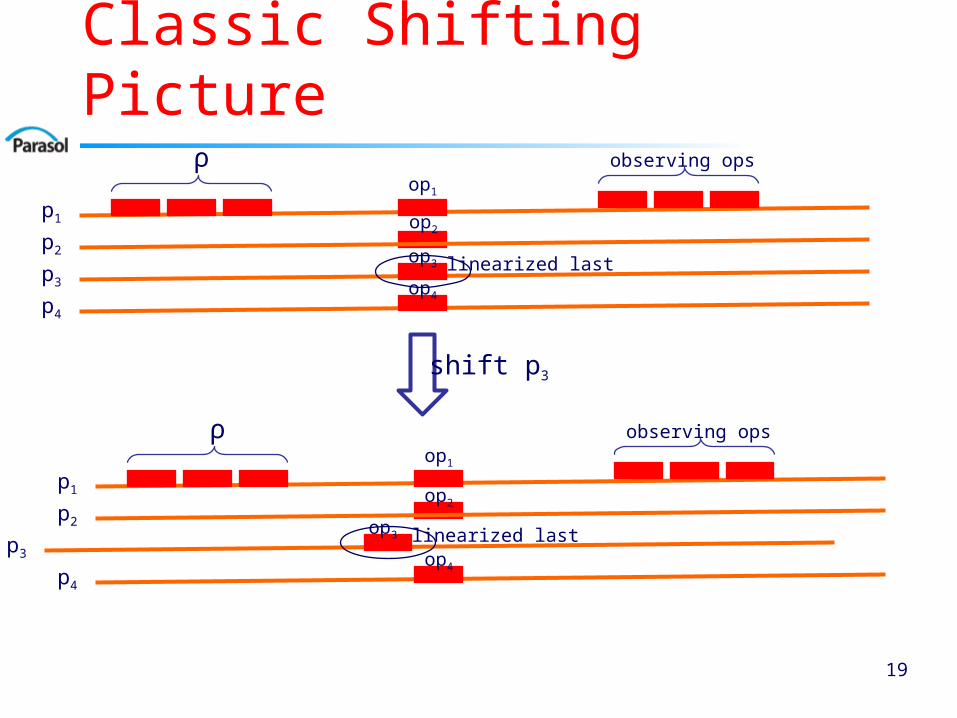
19
Classic Shifting Picture
p1
ρ observing ops
p2
p3
p4
linearized last
p1
ρ observing ops
p2
p4
p3linearized last
Wrong!shift p3
op1
op2
op3
op4
op1
op2
op3
op4

Shifting Proof Idea: Some Details
Reference execution: Execute ρ sequentially (from 2nd condition) Have n procs concurrently invoke op1,...,opn
Argue that the responses of the concurrent operations are the same as for the opi’s
Execute a sequence of operations that “observe” the result of the concurrent operations
Specify the message delays carefully Identify the last operation of the permutation into which the
opi’s are linearized Shift carefully so that this last operation finishes before the
first one starts => permutation in which the operations are linearized in shifted execution has different last operation
Since different last operations produce non-equivalent states, “observer” sequence is incorrect, contradiction
20

Lower Bound #2 (rmw, pop, deq, etc.)
Ifthere exist operation sequence ρ
and instances op1 and op2 of OP s.t. ρ.op1 and ρ.op2 are both legal and ρ.op1.op2 and ρ.op2.op1 are both illegal
then |OP| ≥ d + min{ε,u,d/3}.
21

Proof Idea
New shifting method:Shift reference execution by a (larger)
amount so that there is one pair of nodes with too large message delay
Chop the shifted execution as late as possible before first violation of message delay bound
Different nodes are chopped at different, carefully chosen, points that form a consistent cut
Extend prefix of shifted execution from the cut to have correct message delays
22
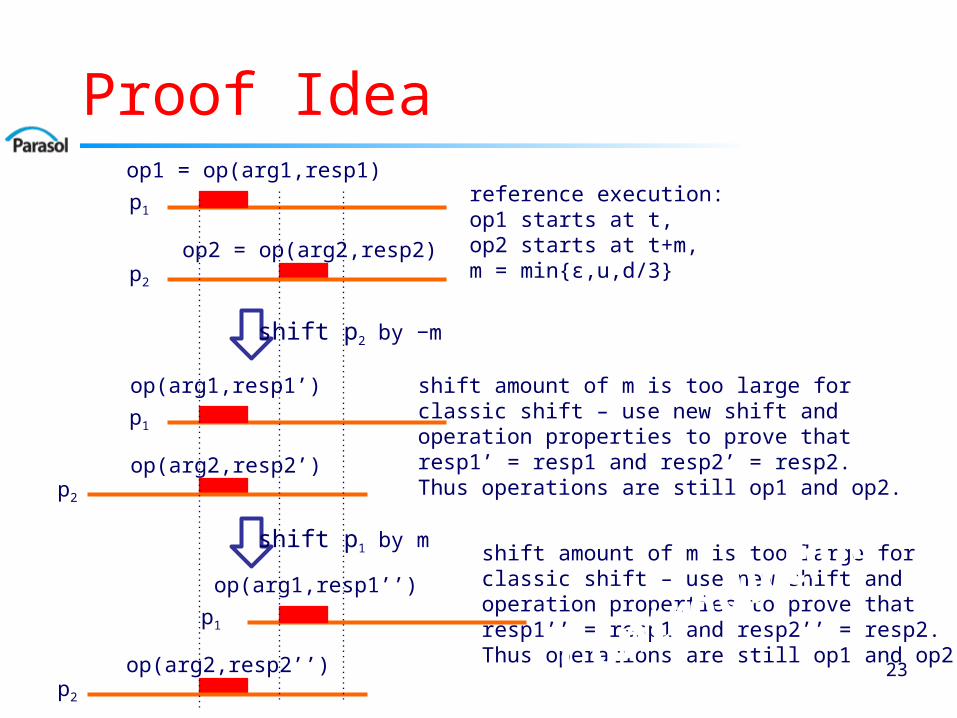
23
Proof Idea
p1
p2
op1 = op(arg1,resp1)
op2 = op(arg2,resp2)
reference execution: op1 starts at t,op2 starts at t+m,m = min{ε,u,d/3}
shift p2 by −m
p1
p2
op(arg1,resp1’)
op(arg2,resp2’)
shift amount of m is too large forclassic shift – use new shift andoperation properties to prove thatresp1’ = resp1 and resp2’ = resp2.Thus operations are still op1 and op2.
p1
p2
op(arg1,resp1’’)
op(arg2,resp2’’)
shift p1 by mshift amount of m is too large forclassic shift – use new shift andoperation properties to prove thatresp1’’ = resp1 and resp2’’ = resp2.Thus operations are still op1 and op2.Con
tradiction

Algorithm Intuition for Mutators
Mutators must be executed in same order at every node
On invocation, broadcast to all nodes w/ timestamp If pure mutator, wait ε+X and return to user
wait d−u to simulate minimum message delay to self, when broadcast is received, add to pending set
Wait long enough (u+ε) to ensure that no operation with smaller timestamp can be received and then execute locally all pending ops with smaller or equal timestamp If not pure mutator, then return to user
24

Algorithm Intuition for Pure Accessors
Pure accessors only need to execute locally so no need to exchange messages
This allows squeezing the timing, since we only have to make sure no remote invocations with smaller timestamps will arrive after the pure accessor executes and returns
Give pure accessor a special timestamp X in the past
Wait d+ε−X time, then execute locally all pending ops with smaller timestamp, execute locally the pure accessor, and return to user
25

Algorithm when a pure accessor aop(arg) is
invoked at node i at clock time T: set timer to respond to (aop,arg,
(T−X,i)) for d+ε−X in the future when timer to respond to
(aop,arg,ts) expires: execute all ops in pending set with
timestamp < ts, in timestamp order, and cancel associated execute timers
execute aop respond to user
when a non pure accessor op(arg) is invoked at node i at clock time T:
if op is a pure mutator then set timer to respond to (op,arg,(T,i)) for ε+X in the future
set timer to add (op,arg(,T,i)) to pending set for d−u in the future
send (op,arg,(T,i)) msg to all other nodes
when timer to respond to pure mutator (mop,arg,ts) expires:
respond to user
when timer to add (op,arg,ts) to pending set expires or (op,arg,ts) msg is received:
add (op,arg,ts) to pending set timer to execute (op,arg,ts)
for u+ε in the future
when timer to execute (op,arg,ts) expires:
execute all ops in pending set with timestamp ≤ ts, in timestamp order, and cancel associated execute timers
if i is the invoker of (op,arg,ts) then respond to user
26

Algorithm Example: Operations in Isolation
27
p0
t
p1
real time
p2
t+d+ε−X
invoke readexecute readreturn read
t+ε+X t+d−u t+d+ε
invoke write respond write add write execute write
execute write
add write
execute write
add write
invoke RMW add RMWexecute RMWrespond RMW
execute RMWadd RMW
add RMW execute RMW
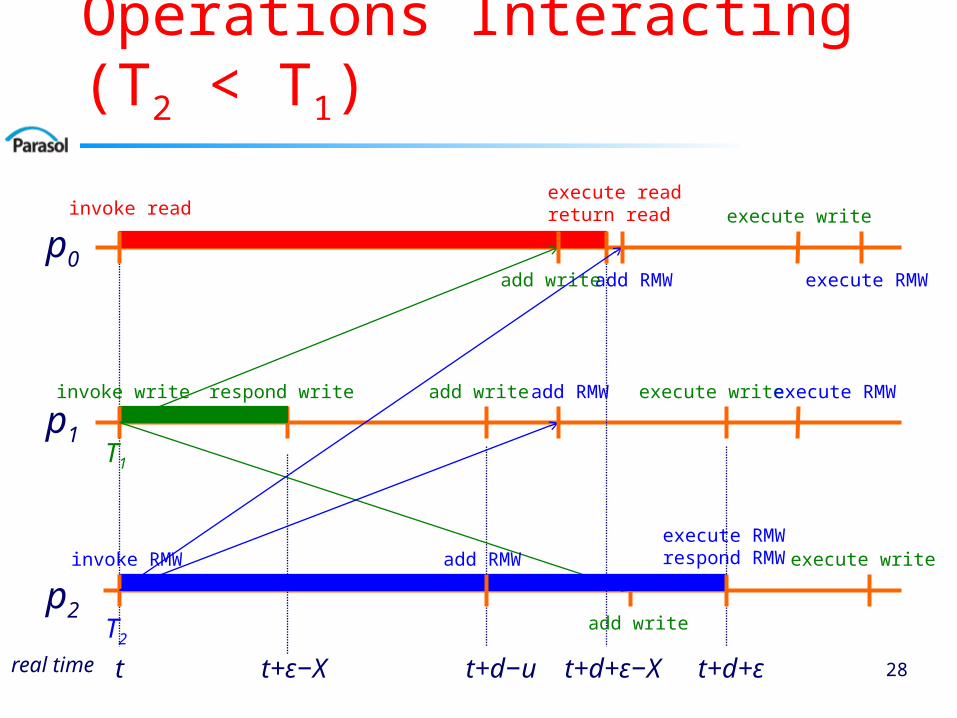
Algorithm Example: Operations Interacting (T2 < T1)
28
p0
t
p1
real time
p2
t+d+ε−X
invoke readexecute readreturn read
t+ε−X t+d−u t+d+ε
invoke write respond write add write execute write
execute write
add write
execute write
add write
invoke RMW add RMWexecute RMWrespond RMW
execute RMWadd RMW
add RMW execute RMW
T1
T2

Algorithm Analysis
Linearizability shown in a standard way (provide an ordering of the operations and show it satisfies the properties) Mutators are linearized by timestamps Accessors fit in between to reflect what they
saw Time bounds:
pure accessor: timer ensures d+e−X pure mutator: timer ensures e+X other: two timers ensure (d−u)+(u+e) =
d+e X is a parameter to trade off the time of pure accessors and
pure mutators (as in [Mavronicolas and Roth 1999] for registers)
29

Conclusion
Summary: Showed improved lower bounds on elapsed
time of operations for linearizable implementations of arbitrary data types in partially synchronous systems
Presented generic algorithm for the problem Tight and almost tight bounds in many cases
for some common data types Open problems:
Tighten gaps Consider clock drift, failures, churn,… Other consistency conditions? 30


















