
Thesis Example 5 - Informatics at IUPUI
54
THE EFFECT OF THINK-ALOUD ON TIMED PERFORMANCE IN USABILITY TESTING Timothy H. Altom Submitted to the faculty of the University Graduate School in partial fulfillment of the requirements for the degree Master of Science in the School of Informatics Indiana University August 2006
Transcript of Thesis Example 5 - Informatics at IUPUI

THE EFFECT OF THINK-ALOUD ON TIMED PERFORMANCE
IN USABILITY TESTING
Timothy H. Altom
Submitted to the faculty of the University Graduate School in partial fulfillment of the requirements
for the degree Master of Science
in the School of Informatics Indiana University
August 2006
i

Accepted by the Faculty of Indiana University;
in partial fulfillment of the requirements for the degree of Master of Sciencein Human-Computer Interaction
Master's Thesis Committee
Mark Larew, PhD
Anthony Faiola, PhD
Lois Ann Scheidt, MIS, MPA
ii

DEDICATION
To my wife, Diana, who dared me to get the degree in the first place.
iii

TABLE OF CONTENTS
Page LIST OF TABLES vii
LIST OF FIGURES ix
ACKNOWLEDGEMENTS xi
ABSTRACT xiii
CHAPTER ONE: INTRODUCTION AND BACKGROUND 1 Introduction to Subject 1 Importance of Subject 4
CHAPTER TWO: LITERATURE REVIEW 5 Think-Aloud Protocols 5 Time-on-Task as Performance Measurement 8 Use of Dyads 10 Hypothesis 12
CHAPTER THREE: METHODOLOGY 13 Participants 13 Treatments 13 Procedures 23 Analysis 25
CHAPTER FOUR: RESULTS 26 Time-on-Task 26 Verbalizations 28
CHAPTER FIVE: DISCUSSION 32 Explanation of Outcomes 32
CHAPTER SIX: CONCLUSIONS 36 Limitations 36 Future Research 36 Summary 37
REFERENCES 38
APPENDICES 42 Appendix A: Screener 42 Appendix B: Raw Data, Time 43 Appendix C: Raw Data, Verbalization 45
VITA 46
iv

LIST OF TABLES
Page
Table 4-1: ANOVA Results of Time-On-Task for Each Task 33
Table 4-2: Monad-Think-Aloud and Dyad Verbalization Counts 34
v

LIST OF FIGURES
Page Figure 3-1: Optimal Path For Task 1 18
Figure 3-2: Starting Page For Task 1 18
Figure 3-3: Search Page For Task 1 19
Figure 3-4: Optimal Path For Task 2 20
Figure 3-5: Target Page For Task 2 20
Figure 3-6: Optimal Path For Task 3 21
Figure 3-7: Target Page For Task 3 21
Figure 3-8: Optimal Path For Task 4 22
Figure 3-9: Target Page For Task 4 22
Figure 3-10: Optimal Path For Task 5 23
Figure 3-11: Search Page For Task 5 23
Figure 3-12: Optimal Path For Task 6 24
Figure 3-13: Target Page For Task 6 24
Figure 3-14: Optimal Path For Task 7 25
Figure 3-15: Home Page For Task 7 With Link 25
Figure 3-16: Target Page For Task 7 26
Figure 3-17: Optimal Path For Task 8 27
Figure 3-18; Search Page For Task 8 27
Figure 4-1: Graph of Mean Times for All Groups on All Tasks. 31
Figure 4-2: Monad-Think-Aloud Scatterplot Verbalizations and Time 35
Figure 4-3: Dyad Scatterplot of Verbalizations and Time 36
vi

ACKNOWLEDGEMENTS
As odd as it may seem, I will begin by thanking someone I’ve never met in person, and
who does not know me at all. Her name is Andrea Ames. She works for IBM as a
usability specialist. It was her stunning presentation during a Society for Technical
Communication annual conference in 2002 that convinced me that I wanted to be a
usability specialist full-time.
I would like thank in particular my thesis chair, Dr. Mark Larew, whose direction and
patience made this thesis the learning experience it was meant to be.
I would also like to thank Dr. Anthony Faiola, the dynamo who injected so much life and
energy into my program.
Further, I am grateful to Lois Ann Scheidt, whose insights into groups and technology
have enlightened, delighted, and inspired me.
There are many other influences and individuals I have to thank, including Josh Plaskoff,
who taught me the intricacies of information and knowledge; Michael Downey and
Melinda Buher, two friends who pushed me when I needed it, which was all too often;
and Ed Sullivan, Bob Orr, and William Watson, faculty, colleagues, and friends who
helped me, supported me, and took chances on me.
I also want to thank all those friends, colleagues, and utter strangers who recruited test
participants for me, and were test participants for me. And I want to acknowledge the
immeasurable assistance of my wife, who was friend, confidant, sympathetic shoulder,
budget analyst, and fellow researcher.
vii

ABSTRACT
Timothy H. Altom
THE EFFECT OF THINK-ALOUD ON TIMED PERFORMANCE
IN USABILITY TESTING
Eight tasks on a website were performed by participants in three Conditions: Monad-
Silent, in which a single participant was asked to remain silent while performing the
tasks, Monad-Think-Aloud, in which a single participant was instructed to “think aloud”
while performing the tasks, and Dyad, in which two participants were instructed to work
together to complete the tasks. Time-on-task was measured and verbalizations were
counted. Results indicated that participants in the Monad-Silent Condition completed
tasks in less time than in the other Conditions – but only for tasks that required a
relatively long time (> 60 sec) to complete. The times for Monad-Think-Aloud and Dyad
Conditions did not differ significantly. These results suggest that verbalization slows task
performance in usability testing. Implications are discussed for use of time-on-task
measures in usability tests involving verbalizations.
viii

CHAPTER ONE: INTRODUCTION AND BACKGROUND
Introduction to Subject
There is an apocryphal story about a very young but avid television fan in the late
1950s who suddenly and unaccountably developed a limp. Doctor visits and tests
revealed nothing. The boy was healthy in all respects, yet limped everywhere he went.
Finally, in desperation a doctor asked “Son, why are you limping?” The youngster
brightened and responded “My name’s Chester; I work for Mr. Dillon!” Chester Goode,
played by Dennis Weaver, was Matt Dillon’s club-footed deputy on the TV show
Gunsmoke.
The story illustrates the importance of asking why in situations where there is
misunderstanding or mystery about what. In human factors work, we often face
mysterious circumstances, and it is frequently necessary to ask just that question of our
participants: why? Letting test participants tell us why as they execute tasks has become
formalized in “think-aloud protocols.”
Think-aloud protocols have come to occupy an important place in human factors
practice and research. This is hardly surprising, given the nature of human factors work.
The Human Factors and Ergonomics Society has defined the field of human factors
broadly as:
Ergonomics (or human factors) is the scientific discipline concerned
with the understanding of interactions among humans and other
elements of a system, and the profession that applies theory,
principles, data, and other methods to design in order to optimize
1

human well-being and overall system performance. (What is human
factors/ergonomics? 2005)
Of the two components of the interactions that the Society uses in its definition, it
is the human side that is most difficult to evaluate. The “other elements of the system,”
which are engineered devices, are relatively narrower in scope and application compared
with their human counterparts in the interaction process, and display little difference in
activity from unit to unit from the same batch. Humans, by contrast, are general-purpose
devices with wide variability from person to person. Further, the non-human “other
elements” are generally easy to observe and measure. Electronic circuits have currents
and voltages. Mechanical devices have movements. These can be tracked for later study.
Essentially, designed devices are extremely transparent in their activities. They hold few
mysteries, although they may spontaneously offer surprises.
On the human side, behaviors can be observed too, but these are often not enough
to satisfy the needs of testing or design. Engineered devices have only how and what to
present to us. Humans add the dimension of why. Observing behavior alone in human test
participants tells us only what those persons did, but cannot tell us why. While
undoubtedly valuable, knowing only how and what cannot adequately help us predict
future human behaviors. It is prediction that is our holy grail, our fondest hope and
highest goal. Describing only past behaviors is like driving without looking away from
the rear-view mirror. It is imperative that we be able to say with some confidence what
will happen in the future when others manipulate the systems we are designing.
Unfortunately, recording only the behavior of evaluative test participants does not give us
thorough insight into how their successors will respond in the same situations. Humans
2

are not collections of behaviors, and observing behavior alone can take us only so far in
design.
That being said, it should be acknowledged that behaviors can take us quite far
indeed on their own. If the goal is to find major stumbling blocks in users’ ability to
manipulate an interface, behavior by itself is enormously valuable. Nielsen and Landauer
(1993) pointed out that it is possible mathematically to get by with only five users in
usability testing, if there is only a fairly small number of problems whose discovery
pattern fits a Poisson distribution. In such a case, simple behavioral observation is enough
to find the vast majority of significant problems. Although the actual number of users
needed was disputed later by Spool and Schroeder (2001), the basic premise was
unshaken, that behavior observation alone was enough to find enough problems that,
when corrected, make an interface usable.
However, simple behavioral observation has drawbacks. Although it can identify
wrong paths through Web sites, for example, it cannot explain why the users took those
wrong paths, and therefore it is difficult to know just how to fix the problem. If all five of
Nielsen’s users click the wrong button, obviously something is amiss with the button or
something concerning the button’s context. But without having participants’ thoughts to
supplement their behaviors, it can be a hit-or-miss proposition to correct the problem.
The obvious way to elicit users’ thought is to ask them to simply talk while
performing test tasks. Proponents of this “think-aloud” approach believe that it offers
great improvements on behavioral observation alone. (Wright & Monk, 1991; Snyder,
2003).
3

Yet, it must be recognized that we do not understand completely what happens
during think-aloud sessions. Psychological research is helpful in this regard. However,
even the most current psychological literature does not answer critical questions for
usability practitioners and academics, such as whether talking about a task while
performing that task slows down the user in timed tests. Can we obtain the valuable
think-aloud verbalizations while also timing users in their tasks as they solve the
problems in unfamiliar interfaces? If so, testing can become much more efficient, because
we can capture both quantitative and qualitative data simultaneously. But does the
cognitive loading of speech interfere with the user’s problem-solving capacity, such that
both cannot be invoked at the same time without an unacceptable penalty that renders the
testing itself less valuable, or even suspect altogether?
The present study addresses this question, using both single verbalizing
participants (monad-think-alouds) and paired participants (dyads), comparing them to a
Condition in which a single participant completes tasks silently (monad-silent). The
reason for including dyads is the growing prevalence of using two participants in testing
rather than one, because pairs (dyads) can produce many more verbalizations than
monads. Dyads by their nature are think-aloud participants.
Importance of Subject
There can be great benefit derived from both qualitative and quantitative testing.
Combining the two could produce greater efficiencies in design, but could also permit
enhanced interpretation of quantitative results – providing a why to go with the how
much. This can be done, however, only if it can be shown that verbalizing during testing
does not impose a time penalty.
4

CHAPTER TWO: LITERATURE REVIEW
Think-Aloud Protocols
Think-aloud protocols have become extremely popular for usability testing,
especially in prototype testing, as a way of exploring user mental operations (Wright &
Monk, 1991; Snyder, 2003). Borrowed from a psychological research technique, think-
aloud testing protocols call for the testing participant to verbalize, or speak aloud,
whatever occurs to him at that moment. The intent is to capture his thoughts, not just his
actions, and thereby contribute to an understanding of the average user’s mental model
(Davidson et al, 1997).
However, some practitioners have expressed reservations about think-aloud
protocols in testing (Ramey et. al., 2006; Guan et. al, 2006). Wildman (1995) points out
several potential problems with think-aloud: 1) The higher cognitive loading of
verbalizing in addition to problem-solving; 2) Overcoming many participants’ natural
aversion to speaking continually; 3) The wide variability of participants’ volubility,
articulateness, self-awareness, and other attributes; 4) The unreliability of think-aloud
actually reflecting participants’ thoughts.
Some of Wildman’s points are undoubtedly valid. Many participants do, indeed,
have difficulty speaking well or often. However, Wildman offers no evidence in the
article for his contention that verbalization increases cognitive loading, nor that think-
aloud is not representative of participants’ thoughts. He merely asserts the points. Still, he
speaks for many practitioners who mistrust think-aloud even as they use the technique.
5

Many claim that think-aloud produces far more usable data than behavior
observation alone, when measured by the number of problems found, and there is
empirical evidence to support the contention (Ebling & John, 2000; Haak et al, 2003).
Psychologists in the early decades of the 20th century investigated and utilized
what they termed “introspection” (Duncker, 1945) but which later investigators called
“think-aloud protocols”. Think-aloud proved to be particularly efficacious for creating
expert systems, when experts could verbalize while performing tasks at which they were
particularly skilled (Someren, Barnard, & Sandberg, 1994). Think-aloud has proven to be
useful in the study of clinical decision-making. Henry, LeBreck, and Holzemer (1989)
conducted a study in which verbalization was assessed as a possible impediment to
cognitive operations in a clinical simulation. The authors found no impairment.
Still other researchers came to doubt the usefulness of think-aloud, and some
declared it to be nearly worthless, because of the impossibility of an individual actually
knowing his own cognitive operations (Nisbett & Wilson, 1977).
In the midst of the controversy, two advocates for think-aloud protocols, K.
Anders Ericsson and Herbert A. Simon, wrote the book Protocol Analysis: Verbal
Reports as Data (Ericsson and Simon, 1984). Ericsson and Simon were primarily
interested in developing a model and mechanism for analyzing verbal reports as data, but
in the process they created a unified theory of verbalization and its validity in revealing
what is in the subject’s short-term memory. They postulated three levels of verbalization
tasks.
Level 1 tasks are often called “talk-aloud” rather than “think-aloud” because they
are not expected to involve real thought at all, but merely the vocalizing of what is
6

already orally encoded. Even problem-solving at a level 1 is not considered to be
significantly impaired by vocalizing.
Level 2 tasks involve stating thoughts associated with performing the task. This is
not simple recitation, but an actual string of statements about task performance as it
occurs.
Level 3 tasks are statements about reasoning, answering “why” instead of “how”
or “what”.
For Ericsson and Simon, level 1 and 2 task verbalizations are valid as data if
certain other Conditions are met. Based on this model, usability test participants who
merely “sing along” with their instinctive reactions will not experience substantial
cognitive loading from verbalizing on top of the cognitive loading of problem-solving. In
short, when doing simple tasks and not explaining themselves, most think-aloud
participants should not experience much, if any, time increases over silent participants.
The acceptance of Ericsson and Simon’s theories into usability testing has been
mixed at best. Boren and Ramey (2000) have criticized practitioners for ignoring
Ericsson and Simon’s admonitions about not prompting test participants so as to force
them into level 3 verbalizations. Nielsen, Clemmensen, and Yssing (2002) go further and
call the entire theory into question from a practical standpoint. The authors point out that
in the Ericsson and Simon model, test participants can be viewed only as relatively
mechanistic processing units, while in reality participants are as complex and multivariate
in their reactions as anyone else, and should be treated that way.
7

Time-on-Task as Performance Measurement
Empirical research into the performance of silent versus think-aloud monadic
problem-solving has further been complicated by the variety of ways that performance
has been gauged in various studies. For example, in one experiment by Dickson et al
(2000) looking at the effects of verbalizing during time-critical, dynamic decision-
making tasks, a group of participants was given training and practice time with a software
package called “Fire Chief”, which simulated fighting forest fires. The investigators were
examining whether the verbalization of the bases of decisions would degrade
performance, with performance defined as task completion or fewest number of errors.
They cite earlier research that showed with fair uniformity that such verbalization, which
corresponds to Ericsson and Simon’s level 3 tasks, actually result in better performance
in the laboratory. But they also note that such simple situations as were previously
investigated are not reflective of real-world circumstances, in that they were not time-
critical or dynamic (changing as the task progressed). When they used Fire Chief it
introduced those aspects, and they then found that verbalizing the bases of decisions
during time-critical, dynamic operations degraded performance, in this case measured by
the amount of forest saved at the end of the timed test period.
Few studies have focused on time-on-task as a measurement of performance
during verbalization. One study by Strayer et al (2003) that came close to using time-on-
task, indicated a direct link between verbalization and reaction time as a result of using
cell phones while driving. The study found that cell phone conversations increased
reaction time by creating large amounts of inattention blindness. This would not be
8

unexpected given Ericsson and Simon’s contention that level 3 verbalizations, as cell
phone conversations inevitably would be, involve considerable cognitive overhead.
A study done by Loeffler and Polkehn (2000) examined the use of verbalization
on monads in usability testing, but again used completion rate as a measurement. As
others had seen before, they found that in some tasks, think-aloud enhanced task
completion performance when tasks were untimed and not dynamic. However, they also
found the effect to be stronger in some tasks than in others.
This prior research would seem to indicate the basic validity of Ericsson and
Simon’s three-tier model of verbalization, as it relates to performance. In essence, if a test
participant is being asked to verbalize the reasons for his choices, performance
measurements can either increase or decrease, depending on the nature of the task,
possibly because level 3 verbalization involves cognitive overhead that interferes with
time and attention, but enhances decision-making.
This would not seem to bode well for combining think-aloud and time-on-task
protocols. In usability testing, participants can spontaneously switch between levels 1, 2,
and 3, constantly invoking and shedding higher cognitive functions. Further, practitioners
can unintentionally push participants into level 3 verbalizations (Boren & Ramey, 2000).
It is apparent that despite intensive research over the last five decades, think-aloud
is still poorly understood, even as it continues to be of enormous benefit in usability
testing. And, if Ericsson and Simon are right, then time-on-task and think-aloud may
indeed be compatible, so long as the test participant does not spend much time in Level 3
conversation, something the test facilitator may be able to control to some degree.
9

Use of Dyads
As noted previously, one way that verbalization can be enhanced is with the use
of dyads in testing. This approach was originally set out by Miyake (1982). Others, such
as O’Malley, Draper, and Riley (1984) took up the idea and developed it further. The
essential benefit to what Miyake called “constructive interaction” and what is here called
“dyads” is that both participants talk more often and in greater depth than merely asking
them to talk to themselves or to a monitor while alone.
The addition of a second participant, however, would seem to add a great many
new factors that could skew time-on-task measurements, perhaps so many that measuring
time-on-task would again become impractical, even if the participants were strictly held
to Levels 1 and 2 interactions.
The use of dyad groups has proven to be potentially helpful in a variety of
situations. For example, pair programming, where two individuals program together in an
organized fashion, produces more code overall, as well as more reliable code. And pair
programming has been shown to be advantageous in teaching programming, as well
(Williams & Kessler, 2000; Cockburn, 2001; McDowell et al, 2003; McDowell et al,
2002). There is also contradictory evidence of pair programming’s effectiveness. Hulkko
and Abrahamsson (2005) subjected four case studies to statistical analysis, and it was
found that neither productivity nor quality rose as a result of pair programming’s use. But
the authors also note that their study was limited and that more studies were needed.
There is somewhat more research being done around dyadic learning in education.
Much of this research indicates that students working together learn more and are less
likely to drop courses (McDowell et al, 2002).
10

In decision-making competitive situations, pairs have been found to be more
strategic, and to be more effective, than individuals (Cooper & Kagle, 2005).
In usability, the use of dyads has been, if anything, even less fully studied than it
has been elsewhere, although it has been championed by some writers on the basis of
personal experience (Snyder, 2003). Some research has focused on children’s dyads
(often referred to as “constructive interaction”) and the effects on usability testing. Als,
Jensen, and Skov (2005) looked into monad and dyad performance with children and
found that dyad pairs of children found more problems in products during usability
testing. Similar studies have explored children’s ability to verbalize their thoughts
concurrently (during testing) as opposed to respectively (after testing) (Robinson, 2001).
It is unclear how much this research generalizes to adult usability testing, nor whether it
applies to time-on-task measurements from usability tests.
One oft-cited study by Hackman and Biers focused on determining whether think-
aloud individuals in solitude, think-aloud individuals with an observer present, or dyads
(called “teams” in the study) would produce more and better verbalization. Although the
study was most interested in the quality and quantity of verbalization, it also recorded the
time-on-task data as a measure of task performance. It was found that the three groups
did not differ significantly in their timed performance, and that although there were more
verbalizations in the team Condition that were of value to designers, the investigators
concluded that overall the think-aloud protocol was not outstandingly productive of
useful feedback from users (Hackman and Biers, 1992). It should be noted that in this
study, there was no silent control group, so time-on-task measurements could not be
compared between think-aloud and silent Conditions.
11

At least one study has shown that monads and dyads do not differ significantly in
their time-on-task. Two groups worked on several tasks on interactive TV. One group
performed the tasks as monads, while the other group worked in dyad pairs. The results
suggest that across all tasks there were no significant differences between monad and
dyad task completion times, although one task, performing a search, did reach
significance (Grondin et. al., 2002).
It is reasonable to assume that the addition of a social element and its attendant
cognitive overhead to the dyad structure will increase time-on-task. Likewise, it is also
reasonable to presume that the cognitive load of speech, however slight, may well impose
at least a small time penalty over silent problem-solving.
Hypotheses
H1: Think-aloud monads will display longer times-on-task than silent monads.
H2: Dyads will have comparable times-on-task to think-aloud monads.
12

CHAPTER THREE: METHODOLOGY
Participants
Participants were recruited through notices placed in public areas. These included IUPUI,
two churches, and several workplaces. A screener was used to filter out those who could
qualify for testing (see Appendix 1). The participants were almost evenly split in gender,
with 14 males and 18 females, between the ages of 18 and 50. All completed the
preliminary screener, and all declared themselves to be at least moderately skilled in both
navigating the Web and performing common search functions in environments such as
Google. They also self-declared that they had not previously visited the Indianapolis-
Marion County Public Library (IMCPL) site. Two participants proved to have too low a
proficiency level with Web navigation and search, and were replaced.
Treatments
The research design was a three-group independent sample approach using
samples of eight in each of three treatment levels: monad-silent, monad-think-aloud, and
dyad. The independent variable is the treatment level; the dependent variables are the
time-on-task, recorded in seconds, and the number of verbalizations. In addition, because
Tasks are highly varied in complexity, cognitive difficulty, and demand for problem-
solving abilities, the Tasks themselves can be considered independent variables for
analysis.
Hardware. Two laptops were used. One was an IBM R51, with a TrackPoint
pointer, two mouse buttons, and a touchpad. This laptop had a built-in wireless card, a
1.7GHz Intel processor, 2.00 GB of RAM, and ran Windows XP Professional Version
13

2002, Service Pack 2. The other laptop was an IBM T22 with a Pentium III, 128 Meg
RAM, external wireless card, TrackPoint pointer, two mouse buttons, Windows 2000
5.00.2195 Service Pack 4. Both machines were set to the same resolution of 1024 X 769
for testing purposes. Sound was muted off.
Software. Both machines were equipped with Mozilla Firefox version 1.5.0.4.
Both copies of Firefox were equipped with the Web Developer’s Toolbar, but it was
switched off for testing purposes.
Testing website. An existing public website was chosen for testing,
www.imcpl.com, the website for the Indianapolis – Marion County Public Library
(IMCPL). The site was chosen for several reasons. 1) It presents a significant challenge to
first-time users; 2) It does not change dramatically in a short period of time, providing a
relatively stable testing artifact; 3) The site offers many opportunities for testing
scenarios, from simple navigational Tasks to formidable search functionality; 4) It
replicates well the type of site most commonly designed for multiple users, offering
several paths in navigation and search.
Tasks. Eight Tasks were constructed, and phrased as questions to be answered
from the site.
Task 1. Is the copy of Profiles in Courage by John F. Kennedy checked in at the
Glendale branch? (You may use the library’s book search function for this question)
This Task requires the use of the library’s search capability, which is difficult for
most users to manipulate. It requires considerable thought and planning. This Task
probably requires the most problem-solving ability. See Figure 3-1 for an optimal path.
See Figure 3-2 for a screen shot of the home page, from which the participant must
14

determine where to find the appropriate search function. See Figure 3-3 for a screen shot
of the actual search screen.
Home Page(Search library
catalog link)Search Page Results Page Target Page
Figure 3-1: Optimal path for Task 1.
Figure 3-2: Starting page for Task 1.
Figure 3-3: Search page for Task 1.
15

Task 2. What is the replacement charge for a lost library card?
This is a straightforward Task in navigation, but requires the user to scroll. See
Figure 3-4 for an optimal path to the page. See Figure 3-5 for a screen shot of the
scrolling page.
Home Page Using YourLibrary
Getting aLibrary Card
Figure 3-4: Optimal path for Task 2.
Figure 3-5: Target page for Task 2.
16

Task 3. Who is the chief executive officer of the library?
This is another straightforward navigation Task, but this one has two or three
locations on the target page where users could find the name of the CEO. See Figure 3-6
for an optimal path. See Figure 3-7 for the page on the optimal path with the information.
Home Page(Search library
catalog link)
About theLibrary
Figure 3-6: Optimal path for Task 3.
Figure 3-7: Target page for Task 3.
17

Task 4. What time does the Decatur branch library close on Saturday?
This is another navigational Task that requires scrolling and determination of
location from a map. See Figure 3-8 for an optimal path. See Figure 3-9 for the page on
the optimal path with the information.
Home Page(Locations and
Hours link)
LibraryLocations
Figure 3-8: Optimal path for Task 4.
Figure 3-9: Target page for Task 4.
18

Task 5. Is there a special event being held next Sunday?
Navigational Task that requires mentally categorizing and eliminating dates. The
target page has event search that must be properly used to complete the Task. See Figure
3-10 for an optimal path. See Figure 3-11 for the page on the optimal path with the
information.
Home Page Events andClasses
Figure 3-10: Optimal path for Task 5.
Figure 3-11: Search page for Task 5.
19

Task 6. What is the number for Call-a-Story?
This Task requires the participant to discover that Call-a-Story is a children’s
feature. This Task is made more difficult because the site co-names the function “Call a
Pacer” or “Call an Indianapolis Indian”. See Figure 3-12 for an optimal path. See Figure
3-13 for the page on the optimal path with the information.
Home Page(Just for Kids >
Call-a-Story)Just for Kids
Figure 3-12: Optimal path for Task 6.
Figure 3-13: Target page for Task 6.
20

Task 7. What is the minimum age a person must be to qualify for employment as a
library page?
Requires the user to read text on the target page and use the headings as text
markers. See Figure 3-14 for an optimal path. See Figure 3-15 for the home page with the
link. See Figure 3-16 for the page on the optimal path with the information.
Home Page(EmploymentOpportunities,
bottom of page)
EmploymentOpportunities
Figure 3-14: Optimal path for Task 7
Figure 3-15: Home page for Task 7 with link.
21

Figure 3-16: Target page for Task 7.
22
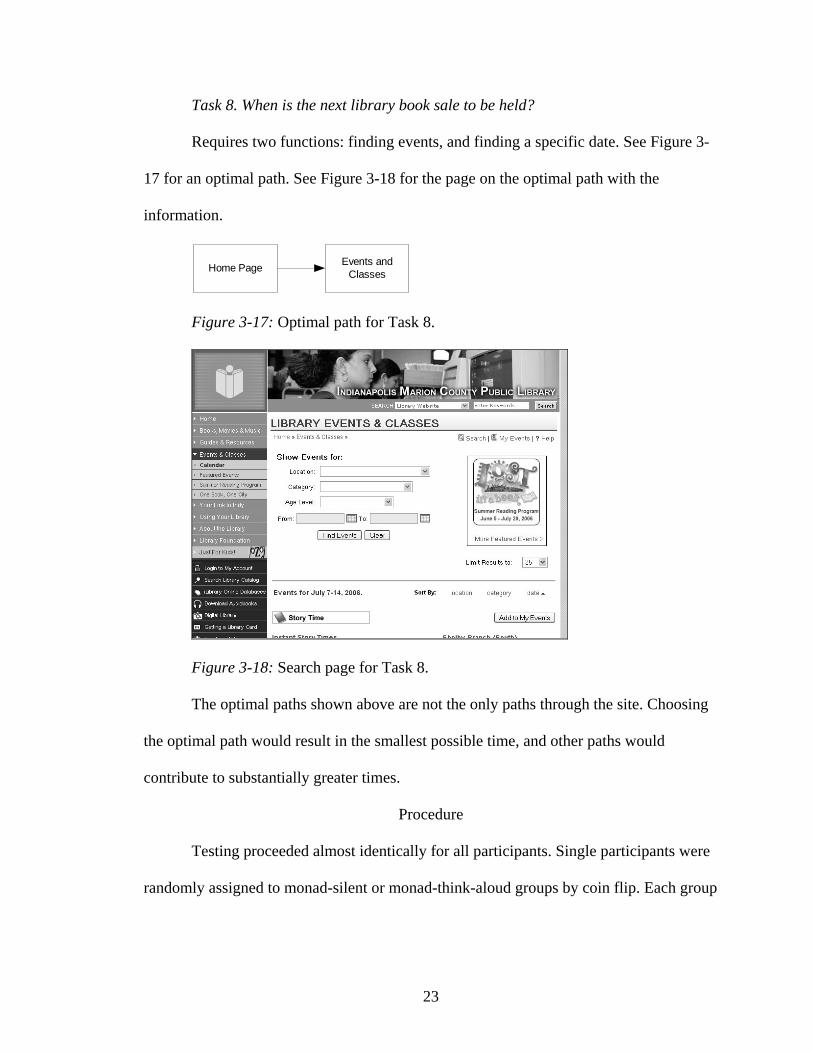
Task 8. When is the next library book sale to be held?
Requires two functions: finding events, and finding a specific date. See Figure 3-
17 for an optimal path. See Figure 3-18 for the page on the optimal path with the
information.
Home Page Events andClasses
Figure 3-17: Optimal path for Task 8.
Figure 3-18: Search page for Task 8.
The optimal paths shown above are not the only paths through the site. Choosing
the optimal path would result in the smallest possible time, and other paths would
contribute to substantially greater times.
Procedure
Testing proceeded almost identically for all participants. Single participants were
randomly assigned to monad-silent or monad-think-aloud groups by coin flip. Each group
23

was fixed at eight participants each. Assignment to the dyad Condition was made by
convenience, when two participants could be scheduled together.
The participants were seated comfortably in front of the laptops. For dyads, one
participant sat directly in front of the screen, while the partner sat just to the side. For
dyads, one participant was the “driver” who manipulated the machine, while the partner
assisted with advice and suggestions. The participant was given a familiarization period
to play with the controls and feel confident with them.
In two cases, dyad members switched roles once between Tasks. In each case the
exchange was made once during the testing session, early on. The request was made
because in each case the “driving” participant did not feel comfortable in his role. To
avoid the possible time bias of a frustrated or flustered “driver”, this was permitted.
Monad-silent participants were specifically told not to verbalize during testing.
Monad-think-alouds were told to verbalize continuously, and if their production of
verbalizations diminished, they were prompted with the term “Please keep talking”.
Utterances for monad-think-alouds were counted. Dyads were also told to keep talking
continuously while testing, and their verbalizations were counted and added together. The
verbalizations were recorded as tick marks on the data sheet. A Task verbalization was
generally defined as a verbalization that was recognizable as a semantically permissible
verbalization and was functionally related to the Task at hand. This eliminated such
verbalizations as “uh” and “hmmm”.
The researcher was positioned to the side of the participant. The stack of Tasks
was preordered into the randomized sequence specified on the materials packet for that
session. An online random number generator was employed to produce a string of digits
24

from 1 through 8, in random order. This string was noted on the outside of the envelope
containing the session materials and Tasks were presented in the order specified.
The site offered more than one search mechanism, any one of which might skew
the results for navigational Tasks. Therefore, all participants were told not to use search
capability, unless the researcher approved such use for a Task.
Each Task began with the investigator reading the Task aloud, then placing the
sheet with the Task on the table within reading distance of the participant. The timing for
each Task began when the participant made the first “progressive move”, which is here
defined as a keyclick, mouse movement, or other manipulation of the computer controls
in furtherance of the Task. Timing stopped when the participant verbalized the answer to
the Task question. Either a stopwatch or digital watch was used for timing.
Analysis
The first analysis was conducted with an overall ANOVA, using a planned
comparison of monad silent < monad-think-aloud = dyad. The comparisons were
Condition, Task, and Condition x Task. Each Task was then individually subjected to an
ANOVA, using the planned comparison of monad-silent < monad-think-aloud=dyad. The
correlation between number of verbalizations and time-on-task was examined for monad-
think-aloud and dyad, along with an F-test for significance between those Conditions.
Post-hoc tests were conducted as was deemed appropriate.
25

CHAPTER FOUR: RESULTS
Time on Task.
Figure 4-1 shows the mean Task completion times for the three treatment groups
for all eight Tasks, along with standard errors of the mean.
20
60
100
140
180
220
260
300
340
380
420
Task #
S T D
1 2 3 4 5 6
S T D S T D S T D S T D S T D S T D S T D
7 8
Seco
nds
460
Monad-silentMonad-think-aloudDyad
Figure 4-1: Graph of mean times for all groups on all Tasks.
Several patterns are notable in Figure 4-19:
There is wide variation in the completion times across Tasks. The mean
completion time across Conditions for Task 1 is 323.0 sec, whereas the
26

mean completion times across Conditions for Tasks 2, 3, and 4 are 33.0,
31.7, and 46.3 sec, respectively. The mean completion times for the
remaining Tasks range from 61.3 sec to 123.0 sec.
Although there is no apparent pattern of differences across Conditions for
the Tasks that were completed the fastest (Tasks 2, 3, and 4), the mean
completion time for monad-silent is lower than for monad-think-aloud and
dyad in four of the other five Tasks (Tasks 1, 5, 6, and 8).
Task 7 presents a unique ordering of completion times with monad-silent
taking longer than monad-think-aloud and dyad.
An overall ANOVA, using a planned comparison of monad-silent < monad-think-
aloud = dyad, indicated that the effect of Task was significant (F(7,147)=30.89; p < .01),
that the planned comparison of Condition approached significance (F(1,21)=2.79; p=.11),
and that the interaction of Condition x Task also approached significance
(F(14,147)=1.41; p=.16).
Each Task was individually subjected to an ANOVA using the planned
comparison of monad-silent < monad-think-aloud = dyad to test for significance between
treatment Condition. The results of these analyses are presented in Table 1. Only Task 1
approached a conventional level of significance with p < .10.
27

Task F (1, 21) p 1 3.24 0.09
2 1.06 > 0.30
3 < 1 > 0.30
4 < 1 > 0.30
5 1.61 0.23
6 < 1 > 0.30
7 1.61 0.22
8 1.12 0.30
Table 4-1: ANOVA results of time-on-task for each Task.
Newman-Keuls post-hoc tests indicated that Task 1 was different from all of the
other Tasks; that Tasks 5 and 6 are different from Tasks 1, 2, and 3; and that Task 6 is
also different from Task 4 (all were at p<.05; all other comparisons p>.05).
Because it appears that a common pattern of results was observed in Tasks 1, 5,
and 6 and these Tasks had significantly longer completion times than the other Tasks, a
separate ANOVA was conducted on only these Tasks with the planned comparison of
monad-silent < monad-think-aloud = dyad. This analysis indicated a significant effect of
Condition (F(1,21)=4.53; p < .05 and a significant effect of Task (F(2,42)=23.80; p < .01,
but the interaction of Condition x Task was not significant (F(2,42)=1.10; p > .20.
Verbalizations
Table 4-2 shows the mean number of verbalizations for all Tasks for the monad-
think-aloud and dyad Conditions. It can be noted that the number of verbalizations varies
across Tasks, with Task 1 resulting in a mean number of verbalizations greater than 30,
28
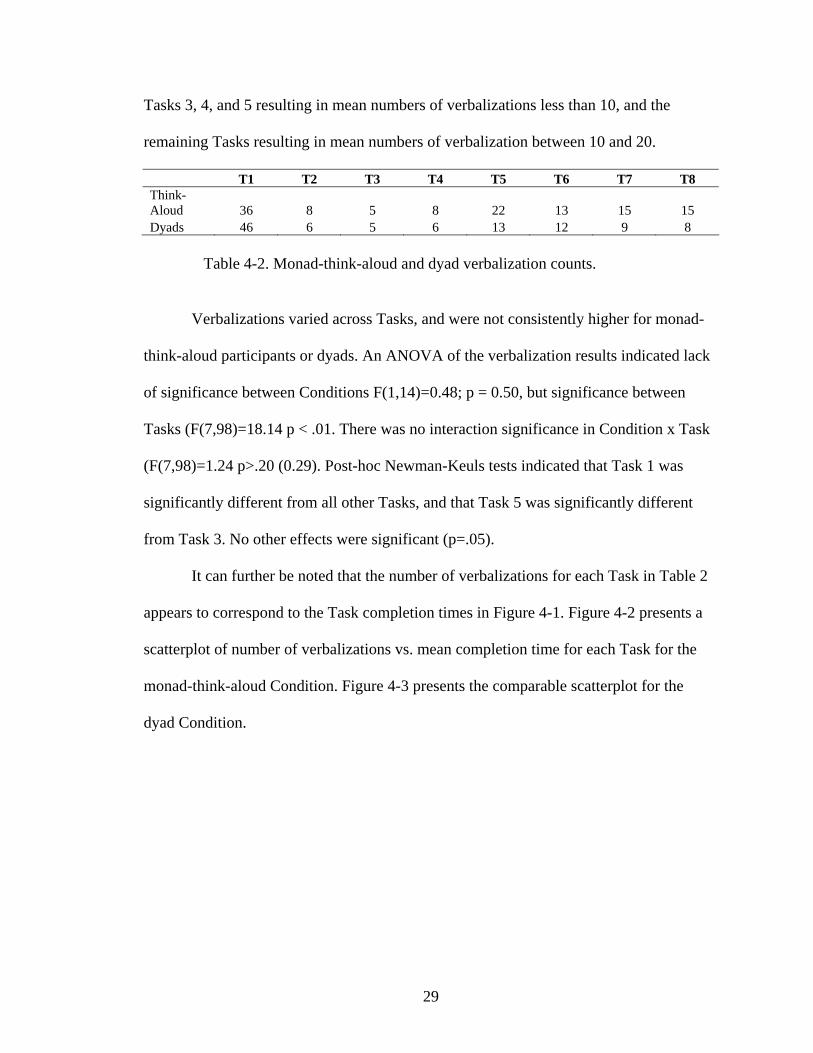
Tasks 3, 4, and 5 resulting in mean numbers of verbalizations less than 10, and the
remaining Tasks resulting in mean numbers of verbalization between 10 and 20.
T1 T2 T3 T4 T5 T6 T7 T8 Think-Aloud 36 8 5 8 22 13 15 15 Dyads 46 6 5 6 13 12 9 8
Table 4-2. Monad-think-aloud and dyad verbalization counts.
Verbalizations varied across Tasks, and were not consistently higher for monad-
think-aloud participants or dyads. An ANOVA of the verbalization results indicated lack
of significance between Conditions F(1,14)=0.48; p = 0.50, but significance between
Tasks (F(7,98)=18.14 p < .01. There was no interaction significance in Condition x Task
(F(7,98)=1.24 p>.20 (0.29). Post-hoc Newman-Keuls tests indicated that Task 1 was
significantly different from all other Tasks, and that Task 5 was significantly different
from Task 3. No other effects were significant (p=.05).
It can further be noted that the number of verbalizations for each Task in Table 2
appears to correspond to the Task completion times in Figure 4-1. Figure 4-2 presents a
scatterplot of number of verbalizations vs. mean completion time for each Task for the
monad-think-aloud Condition. Figure 4-3 presents the comparable scatterplot for the
dyad Condition.
29

0
50
100
150
200
250
300
350
0 5 10 15 20 25 30 35 40
Verbalizations
Tim
e in
Sec
onds
Figure 4-2: Monad-think-aloud scatterplot of verbalizations and time.
0
50
100
150
200
250
300
350
400
450
0 10 20 30 40 5
Verbalizations
Tim
e in
Sec
onds
0
Figure 4-3: Dyad scatterplot of verbalizations and time.
The scatterplots indicate a strong linear relationship between the factors of time
and number of verbalizations, and this holds for both monad-think-aloud participants and
dyads. The correlation for the monad-think-aloud Condition was r(6)=.97; p < .01 and for
the dyad Condition was r(6)=.99; p < .01.
30

CHAPTER FIVE: DISCUSSION
The results show that, as anticipated, verbalizations increased with longer time-
on-task, and verbalizing participants took somewhat longer to perform the Tasks than did
participants who did not verbalize. Also as expected, there are variations between Tasks.
Explanation of Outcomes
It should be noted that there was found only limited support for the hypothesis
that verbalization necessarily increases time-on-task. Analysis showed that the main
effect of Task is significant, while the main effect of Condition approached significance.
Similarly, the interaction of the two factors approached significance, but did not reach it.
Of all the individual Tasks, only Task 1 closely approached significance between
Conditions. Generally, then, one might conclude that the amount of verbalization
exhibited during a test might have no effect whatsoever on timed performance. But a
closer examination of three Tasks provided intriguing evidence to the contrary.
Tasks 1, 5, and 6 were distinctive because they took longer to complete, and post-
hoc analysis revealed that they were indeed significantly different from the others. Tasks
1 and 5 were search Tasks; previous studies have found that search Tasks can take longer
than navigation Tasks (Grondin et. al., 2002). Task 6, however, was a navigation Task,
and its inclusion in this group of lengthier Tasks requires some examination.
Of all the Tasks, Task 1, a search Task, was undoubtedly the most difficult for
most participants to perform. It involved the most thought, the most Web pages, and the
most key and mouse clicks. Participants frequently had to start over or take alternative
paths. In Task 1, the participant was asked to find out if a particular book title was
31

currently on the shelf at a particular branch. This was possible to achieve only through
the site’s book search functionality. However, there are various distracters that appear in
the website, such as a prominently displayed search text box on the home page that,
unfortunately, does not work for this Task. Participants had to find the appropriate search
function, then interpret the results.
Given these hurdles, it is not remarkable that Task 1 displayed by far the highest
times of any Task. However, what is worthy of a remark is that the dyad Condition
exhibited the highest average time. In previous studies, it has been fairly well established
that dyads consistently perform better in Task completion measures. Here, Task
completion was not measured, and all participants completed all Tasks, but it is
interesting to speculate that if both completion rate and time-on-task were to be combined
in a study of difficult and lengthy Tasks, the higher dyad completion rates might come at
the price of similarly elevated dyad time-on-task measures.
Task 5 was likewise a searching Task, albeit a less complex one than Task 1.
Unlike in Task 1, in Task 5, participants quickly found the correct search page, but were
then presented with several selection controls. Participants frequently tried more than one
combination of control attributes before finding a set that would provide the answer.
Task 6 was not a search Task. It was, in fact, a navigational Task, little different
in nature from Tasks 2, 3, 4, and 8. The higher times for Task 6 as compared with Tasks
2, 3, 4, and 8 may simply be due to navigational difficulties with this particular website
while performing Task 6.
What is one to make of the fact that in general longer Tasks exhibited the most
difference in Condition? It is possible that the main effect of verbalization on
32

performance is simply more salient when Tasks take longer, and that Tasks 2, 3, 4, and 8
present smaller effects simply because they did not last as long. If it is postulated that
each verbalization takes a finite and specific, though very small, time lapse that interferes
with or pauses Task operations, then it would not be unexpected that Tasks requiring
more numerous or more frequent verbalizations would accumulate more verbalization
time lapses, as well. Work by Grondin et. al. (2002) suggested this when they found that
the only Task in which monads and dyads approached significant time differences was in
a search Task that took longer than the others. The verbalization count data certainly
suggests that there is a high correlation between verbalization numbers and time. On the
other hand, participants did not pause noticeably while verbalizing, so any definable
“time penalty” for each verbalization would likely be very short. The exact time lost in
any particular verbalization would be material for later study.
Verbalization levels as defined by Ericsson and Simon (1993) may also have
taken part in the effect. There was no attempt to analyze the verbalizations as data, as
Ericsson and Simon did, and to determine the verbalization levels. Ericsson and Simon
would hold that level 3 verbalizations would increase the times, and it is possible that the
more obvious differences between the Task grouping of 1, 5, and 6 and the grouping of 2,
3, 4, and 8 are due to the fact that 1, 5, and 6 took longer by the nature of their Tasks, and
that therefore there were more opportunities for level 3 verbalizations to be inserted.
Task 7 is a distinct anomaly, reversing the pattern seen in 1, 5, and 6, in that
monad-silent participants had the highest time scores. There was no significant effect of
Condition within this Task. No good explanation presents itself for the pattern reversal of
33

Task 7, which was a navigational Task similar to Task 6, except that Task 7 may merely
be an artifact of chance. Further research might answer this question more thoroughly.
Many studies have shown think-aloud protocols to be helpful in a number of
situations, including clinical applications (Henry, LeBreck, & Holzemer, 1989) and
expert thought process elicitation (Someren, Barnard, & Sandberg, 1994). There is good
evidence that think-aloud can increase Task completion rates (Loeffler & Polkehn, 2000).
But until more is known about verbalization and its effect on performance in timed
testing, usability testing practitioners should be cautious when combining think-aloud
protocols with time-on-task measurements. Further, investigators should undertake more
research into these potential interactions.
34

CHAPTER SIX: CONCLUSION
Limitations
The present study had several potential confounding factors that may have
skewed times: 1) the nature of the website, having alternative paths for most Tasks (Task
selection); 2) participants’ apparent skills variability, despite having been screened; 3)
small sample sizes, 4) very small pilots (two monad participants).
The website itself was a commercially available one, and therefore its various
paths and controls were not under experimental control. There were a great many
alternative paths for some Tasks, which complicated the timing picture.
Participants exhibited widely variable skills. Some had better search skills, but did
not have a mental model that matched that used for navigation in the site. Others had the
opposite attributes. Likewise, there was no screening or control for various other factors
that may, in hindsight, have affected the outcome.
There were only two small pilot tests, each with a monad. Some of the Task
differences may have been capable of adjustment if more pilot tests could have been
conducted.
Future Research
Several aspects of the current study would seem to merit further work: 1) the
higher times and closer approach to significance for Task 1 would indicate that Tasks
with longer expected times should be undertaken, to see if longer times and significance
are related; 2) testing for specific Task types to determine if Task type has a direct effect
on time-on-task measurements and patterns, as in Task 7; 3) testing on other types of
35

sites, both those built especially for testing, and those in general use; 4) exploration of
possible confounding factors, such as possible differences in gender interaction or
verbalization performance; 5) determining what the size of a “time penalty” for each
verbalization might be.
Summary
This study investigated the effect of verbalization on time-on-task performance of
monads and dyads. A direct effect was found between Conditions that, while not found to
be statistically significant across all Tasks, was nonetheless significant between Tasks
that took longer to perform. This is noteworthy, and has potential for future study. A
significant direct effect was also found between Tasks, indicating a possibly fruitful area
for later work.
36

REFERENCES
What is human factors/ergonomics? (2005). Retrieved August 3, 2006, from
http://www.hfes.org/web/AboutHFES/about.html
Als, B. S., Jensen, J. J., & Skov, M. B. (2005, June 8-10). Comparison of think-aloud and
constructive interaction in usability testing with children. Paper presented at the
IDC 2005, Boulder, CO.
Boren, M. T., & Ramey, J. (2000). Thinking aloud: Reconciling theory and practice.
IEEE Transactions on Professional Communication, 43(3), 261-278.
Cockburn, A., & Williams, L. (2001). The costs and benefits of pair programming. In
Extreme programming examined. Boston, MA, USA: Addison-Wesley Longman
Publishing Co., Inc.
Cooper, D. J., & Kagel, J. H. (2005). Are two heads better than one? Team versus
individual play in signaling games. The American Economic Review, 95(3).
Davidson, G. C., Vogel, R. S., & Coffman, S. G. (1997). Think-aloud approaches to
cognitive assessment and the articulated thoughts in simulated situations
paradigm. Journal of Consulting and Clinical Psychology, 65(6), 950-958.
Dickson, J., Mclennan, J., & Omodei, M. M. (2000). Effects of concurrent verbalization
on a time-critical, dynamic decision-making task. Journal of General Psychology,
127(2), 217-228.
Duncker, K. (1945). On problem-solving. In Psychological Monographs (Vol. 58, pp. 1-
114). Washington, DC: The American Psychological Association, Inc.
Ericsson, K. A., & Simon, H. A. (1984). Protocol analysis: Verbal reports as data.
Cambridge, Massachusetts: MIT Press.
37

Grondin, N., Bastien, J. M. C., & Agopian, B. (2002). Les tests utilisateurs : avantages et
inconvénients des passations individuelles et par paires. Paper presented at the
IHM 2002.
Guan, Z., Lee, S., Cuddihy, E., & Ramey, J. (2006, April 22-27). The validity of the
stimulated retrospective think-aloud method as measured by eye tracking. Paper
presented at the CHI 2006, Montreal, Quebec.
Haak, M. J. V. D., Jong, M. D. T. D., & Schellens, P. J. (2003). Retrospective vs.
concurrent think-aloud protocols: testing the usability of an online library
catalogue. Behaviour and Information Technology, 22(5), 339-351.
Hackman, G. S., & Biers, D. W. (1992). Team usability testing: Are two heads better
than one? Paper presented at the Proceedings of the Human Factors Society, 36th
Annual Meeting.
Henry, S., LeBreck, D., & Holzemer, W. (1989). The effect of verbalization of cognitive
processes on clinical decision making. Research and Nursing Health, 12(3), 187-
193.
Hulkko, H., & Abrahamsson, P. (2005). A multiple case study on the impact of pair
programming on product quality. Paper presented at the ICSE '05, St. Louis, MO.
Loeffler, J., & Polkein, K. (2005, March 21-23). The influence of thinking aloud on the
quality of task completion in user tests. Paper presented at the GOR-General
Online Research Conference 2005, Zurich, Switzerland.
McDowell, C., Werner, L., Bullock, H., & Fernald, J. (2002, February 27-March 3). The
effects of pair-programming on performance in an introductory programming
course. Paper presented at the SIGCSE 02, Covington, KY.
38

McDowell, C., Werner, L., Bullock, H. E., & Fernald, J. (2003). The impact of pair
programming on student performance, perception and persistence. Paper
presented at the 25th International Conference on Software Engineering.
Miyake, N. (1982). Constructive interaction. San Diego: University of California, Center
for Human Information Processing.
Nielsen, J., Clemmensen, T., & Yssing, C. (2002, October 19-23). Getting access to what
goes on in people's heads? Reflections on the think-aloud technique. Paper
presented at the NordiCHI Arhus, Denmark.
Nielsen, J., & Landauer, T. K. (1993, April 24-29). A mathematical model of the finding
of usability problems. Paper presented at the SigCHI Conference on human
factors in computing systems, Amsterdam, The Netherlands.
Nisbett, & Wilson. (1977). Telling more than we can know: Verbal reports on mental
processes. Psychological Review, 84(3), 231-259.
O'Malley, C., Draper, S., & Riley, M. (1984). Constructive interaction: a method for
studying user-computer-user interaction. Paper presented at the IFIP
INTERACT'84 First International Conference on Human-Computer Interaction.
Proctor, R. W., & Zandt, T. V. (1994). Human factors in simple and complex systems.
Boston: Allyn and Bacon.
Robinson, K. M. (2001). The validity of verbal reports in children's subtraction. Journal
of Educational Psychology, 93(1), 211-222.
Snyder, C. (2003). Paper prototyping: The fast and easy way to design and refine user
interfaces: Morgan Kaufmann.
39

Someren, M. W. v., Barnard, Y. F., & Sandberg, J. A. C. (1994). The think aloud method:
A practical guide to modelling cognitive processes. London: Academic Press.
Spool, J., & Schroeder, W. (2001). Testing web sites: five users is nowhere near enough.
Paper presented at the Conference on Human Factors in Computing Systems,
Seattle, WA, USA.
Wildman, D. (1995). Getting the most from paired-user testing. Interactions, 2(3), 21-27.
Williams, L. A., & Kessler, R. R. (2000). All I really need to know about pair
programming I learned in kindergarten. Communications of the ACM, 43(5), 108-
114.
Wright, P. C., & Monk, A. F. (1991). The use of think-aloud evaluation methods in
design. SIGCHI Bulletin, 23(1), 55-57.
40

APPENDICES
Appendix A: Screener NAME: _______________________________________________________ PHONE: _____________________ EMAIL:______________________ PROFESSION: ____________________________________________ How would you rate your ability to use the WEB? OUTSTANDING _____AVERAGE _____BASIC______ NONE ______ Have you performed searches on the WEB using search engines such as Google?
YES_____ NO ___ Which of these websites have you ever visited?
IUPUI Library (www.ulib.iupui.edu) ______________ Indianapolis/Marion County Public Library (www.imcpl.com) ________ Google (www,google.com) ______________________ Centers for Disease Control (www.cdc.gov) _________
41
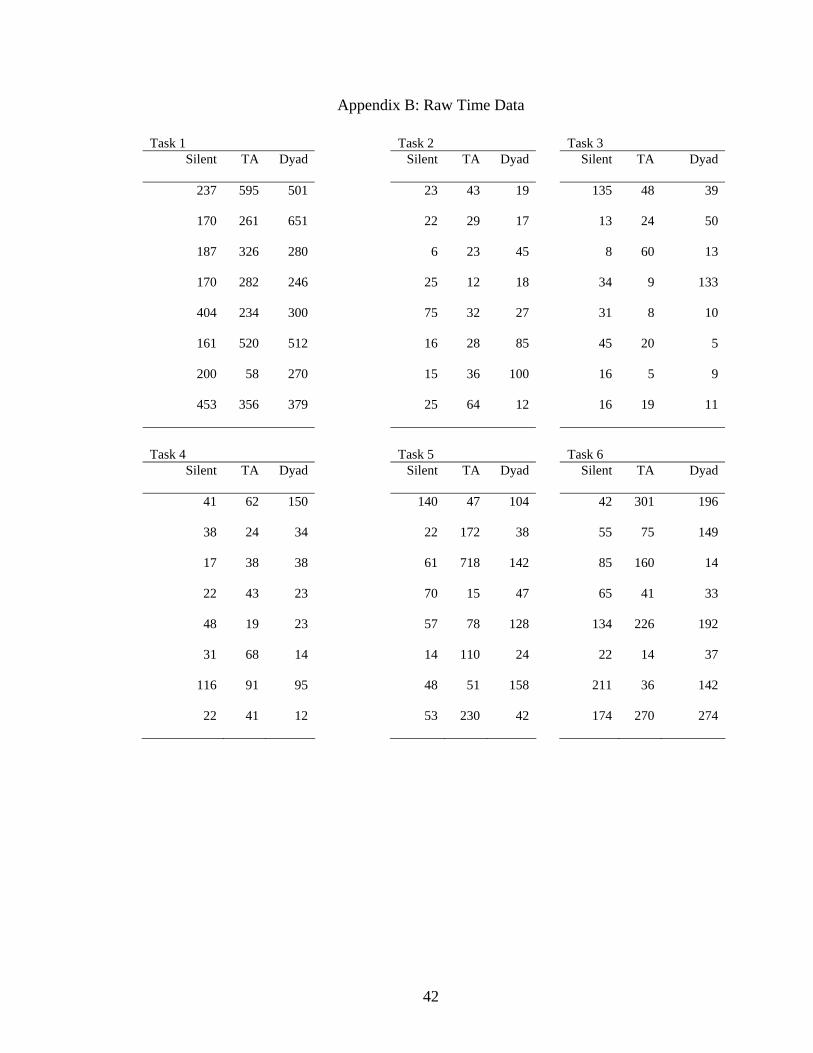
Appendix B: Raw Time Data
Task 1 Task 2 Task 3 Silent TA Dyad
Silent TA Dyad
Silent TA Dyad
237 595 501
23 43 19
135 48 39
170 261 651
22 29 17
13 24 50
187 326 280
6 23 45
8 60 13
170 282 246
25 12 18
34 9 133
404 234 300
75 32 27
31 8 10
161 520 512
16 28 85
45 20 5
200 58 270
15 36 100
16 5 9
453 356 379
25 64 12
16 19 11
Task 4 Task 5 Task 6
Silent TA Dyad
Silent TA Dyad
Silent TA Dyad
41 62 150
140 47 104
42 301 196
38 24 34
22 172 38
55 75 149
17 38 38
61 718 142
85 160 14
22 43 23
70 15 47
65 41 33
48 19 23
57 78 128
134 226 192
31 68 14
14 110 24
22 14 37
116 91 95
48 51 158
211 36 142
22 41 12
53 230 42
174 270 274
42

Task 7
Task 8
Silent TA Dyad
Silent TA Dyad
64 83 261 38 55 78
118 56 29 86 35 73
170 190 38 42 51 45
92 29 27 66 55 36
34 48 25 61 101 84
169 48 55 21 48 29
286 185 113 23 30 116
37 57 9 44 235 22
43
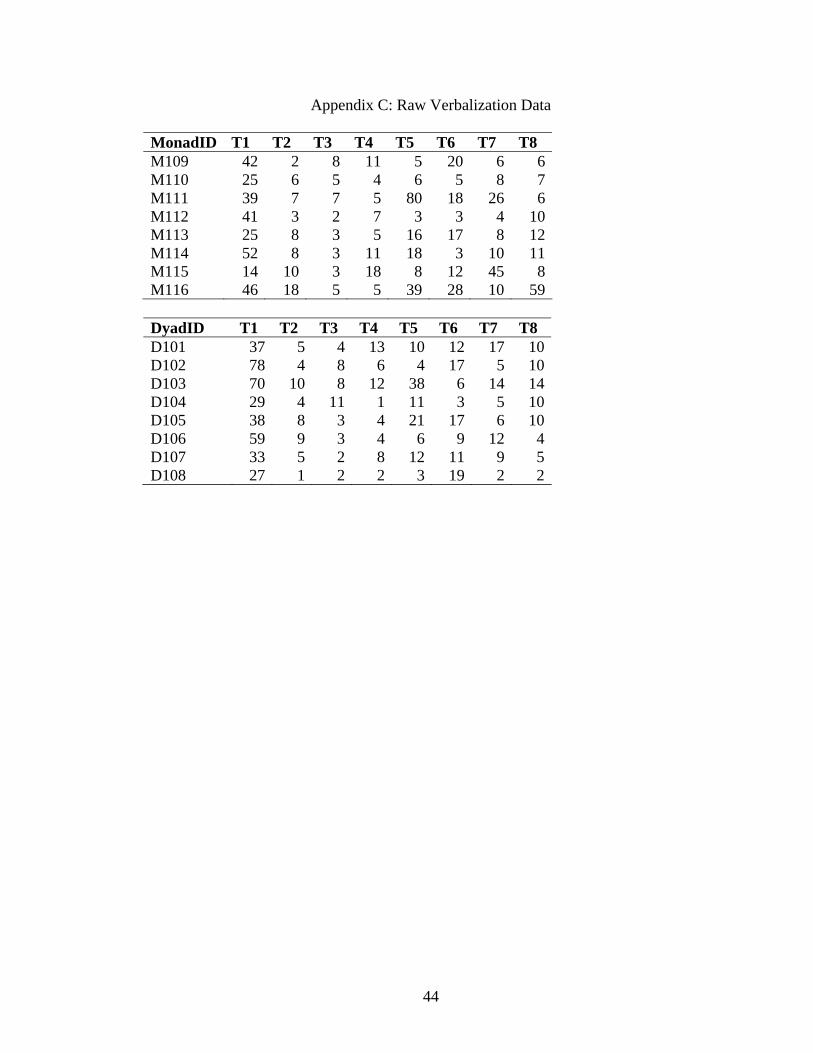
Appendix C: Raw Verbalization Data
MonadID T1 T2 T3 T4 T5 T6 T7 T8 M109 42 2 8 11 5 20 6 6M110 25 6 5 4 6 5 8 7M111 39 7 7 5 80 18 26 6M112 41 3 2 7 3 3 4 10M113 25 8 3 5 16 17 8 12M114 52 8 3 11 18 3 10 11M115 14 10 3 18 8 12 45 8M116 46 18 5 5 39 28 10 59
DyadID T1 T2 T3 T4 T5 T6 T7 T8 D101 37 5 4 13 10 12 17 10D102 78 4 8 6 4 17 5 10D103 70 10 8 12 38 6 14 14D104 29 4 11 1 11 3 5 10D105 38 8 3 4 21 17 6 10D106 59 9 3 4 6 9 12 4D107 33 5 2 8 12 11 9 5D108 27 1 2 2 3 19 2 2
44

VITA
Timothy H. Altom Education
Master’s of Science in Human-Computer Interaction, Expected August 2006 Indiana University-Purdue University at Indianapolis Advisor: Dr. Anthony Faiola Bachelor of Arts, English, May 1990 Indiana University-Purdue University at Indianapolis
Research Interests • Use of technology in facilitation of group activities • Technology as enabler of distributed cognition • Statistical techniques for determining user experience and behavior
Teaching Interests • Statistics for technology • Usability
Related Experience Employment Senior Business Consultant Perficient, Inc. July 2005-Present
• Consulting, information architecture • Consulting, Web analytics • Consulting, user-centered design
Systems Interaction Designer Indiana University January 2005-July 2005
• Represented IU to the Sakai tools team • Acted as resource and liaison to IU Support and Implementation Team
for Oncourse CL • Participated in Sakai tool redesign • Performed accessibility testing • Performed usability testing
Contract Position Eli Lilly and Company May 2004-December 2005
• Participated in software quality project • Responsible for data acquisition and analysis for change management
process Technical Communications Manager Solutions Technology Inc. June 2001-May 2004
• Responsible for all technical communications issuing from company • Initiated incorporation of usability into consulting
45

• Created online education for product familiarization Vice President and Head Technodude Simply Written Inc. January 1995-June 2001
• Head of technical development, in fields such as SGML, XML, HTML, Web delivery
• Co-creator of the Clustar System for structured writing Teaching Adjunct Faculty Computer and Information Technology, School of Engineering and Technology, IUPUI August 2004-Present
• Descriptive statistics, undergraduate • To teach inferential statistics in Spring of 2007, undergraduate
Adjunct Faculty School of Informatics, IUPUI August 2005-Present
• Usability, undergraduate Publications
• Altom, T., Buher, M., Downey, M. and Faiola, A. (2004). Using 3D landscapes to navigate file systems: The MountainView interface. Proceedings of the 8th International Conference on Information Visualization, 645-649.
• Faiola, A., Altom, T., and Groth, D. (2005) Integrating the visualization of personal histories of file usage into 3D landscapes: Enhancing desktop file searching using TerraSearch+. Publication pending.
• Altom, T. (2003). XML in motion: the scalable vector graphic. Intercom. 50 (6): 10-13
• Columnist for Indianapolis Business Journal. 2002-Present. Return on Technology.
• Altom, T. (1999). Programming with Python. Prima Publishing. • Altom, T., et al. (1999). Microsoft Office 2000 User Manual. Que
Publishing. • Altom, T., Chapman, M. (1999). Hands-On HTML. Prima Publishing. • Altom, T. (1997). Designing for dyslexics. Intercom. 44 (4): 8-10 • Altom, T. 1996. How to get along with impossible co-workers Intercom.
43 (8): 16-20 • Altom, T. 1996. The future form of online help files. Intercom. 43(7):16-
18 Professional Associations
• Senior member, Society for Technical Communication. Twice president of local chapter.
• Founding member, local chapter of Usability Professionals Association • Member, SIGCHI
46


















