
The GIOD Project (Globally Interconnected Object Databases) For High Energy Physics A Joint Project...
24
The GIOD Project (Globally Interconnected Object Databases) For High Energy Physics A Joint Project between Caltech(HEP and CACR), CERN and Hewlett Packard http://pcbunn.cithep.caltech.edu/ I2-DSI Applications Workshop Julian Bunn/Caltech & CERN March 1999
-
date post
20-Dec-2015 -
Category
Documents
-
view
219 -
download
1
Transcript of The GIOD Project (Globally Interconnected Object Databases) For High Energy Physics A Joint Project...

The GIOD Project(Globally Interconnected Object Databases)
For High Energy Physics
A Joint Project between Caltech(HEP and CACR), CERN and Hewlett Packard
http://pcbunn.cithep.caltech.edu/
I2-DSI Applications Workshop
Julian Bunn/Caltech & CERNMarch 1999

March 5th. 1999
I2-DSI workshop: J.J.Bunn
CERN’s Large Hadron Collider- 2005 to >2025
Biggest machine yet Biggest machine yet built: a proton-proton built: a proton-proton collidercollider
Four experiments: Four experiments: ALICE, ATLAS, CMS, ALICE, ATLAS, CMS, LHCbLHCb

March 5th. 1999
I2-DSI workshop: J.J.Bunn
WorldWide Collaboration
CMS CMS >1700 physicists>1700 physicists 140 institutes140 institutes 30 countries30 countries
100 Mbytes/sec from online 100 Mbytes/sec from online systemssystems
~1 Pbyte/year raw data~1 Pbyte/year raw data ~1 Pbyte/year reconstructed data~1 Pbyte/year reconstructed data Data accessible across the globeData accessible across the globe

March 5th. 1999
I2-DSI workshop: J.J.Bunn
Data Distribution Model
Online System
Offline Processor Farm ~10 TIPS
CERN Computer Centre
USA Regional Centre ~1 TIPS
France Regional Centre
Italy Regional Centre
Germany Regional Centre
InstituteInstituteInstituteInstitute ~0.1TIPS
Physicist workstations
~100 MBytes/sec
~100 MBytes/sec
~622 Mbits/sec
or Air Freight (deprecated)
~622 Mbits/sec
~1 MBytes/sec
There is a “bunch crossing” every 25 nsecs.
There are 100 “triggers” per second
Each triggered event is ~1 MByte in size
Physicists work on analysis “channels”.
Each institute will have ~10 physicists working on one or more channels
Data for these channels should be cached by the institute server
Physics data cache
~PBytes/sec

March 5th. 1999
I2-DSI workshop: J.J.Bunn
Large Hadron Collider - Computing Models
Requirement:Requirement: Computing Hardware, Network and Software systems to Computing Hardware, Network and Software systems to support timely and competitive analysis by a worldwide collaborationsupport timely and competitive analysis by a worldwide collaboration
Solution:Solution: Hierarchical networked ensemble of heterogeneous, data- Hierarchical networked ensemble of heterogeneous, data-serving and processing computing systemsserving and processing computing systems
Key technologies:Key technologies:
Object-Oriented SoftwareObject-Oriented Software
Object Database Management Systems (ODBMS)Object Database Management Systems (ODBMS)
Sophisticated middleware for query brokering (Agents)Sophisticated middleware for query brokering (Agents)
Hierarchical Storage Management Systems Hierarchical Storage Management Systems
Networked Collaborative EnvironmentsNetworked Collaborative Environments

March 5th. 1999
I2-DSI workshop: J.J.Bunn
Build a small-scale prototype Regional Centre using:
Object Oriented software, tools and ODBMS
Large scale data storage equipment and software
High bandwidth LAN and WANs
Measure, evaluate and tune the components of the Centre
for LHC Physics
Confirm the viability of the proposed LHC Computing Models
Use measurements of the prototype as input to simulations of
realistic LHC Computing Models for the future
The GIOD Project Goals

March 5th. 1999
I2-DSI workshop: J.J.Bunn
Why ODBMS ?
OO programming paradigm is the modern, industry direction supported by C++, Java high level languages excellent choice of both free and commercial class libraries suits our problem space well: rich hierarchy of complex data types (raw data, tracks,
energy clusters, particles, missing energy, time-dependent calibration constants) Allows us to take full advantage of industry developments in software technology
Need to make some objects “persistent” raw data newly computed, useful, objects
Need an object store that supports an evolving data model and scales to many PetaBytes (1015 Bytes)
(O)RDBMS wont work: For one year’s data would need a virtual table with 109 rows and many columns
Require persistent heterogeneous object location transparency, replication
Multiple platforms, arrays of software versions, many applications, widely distributed in collaboration
Need to banish huge “logbooks” of correspondences between event numbers, run numbers, event types, tag information, file names, tape numbers, site names etc.

March 5th. 1999
I2-DSI workshop: J.J.Bunn
ODBMS - choice of Objectivity/DB
Commercial ODBMS embody hundreds of person-years of effort to develop tend to conform to standards offer rich set of management tools & language bindings At least one (Objectivity/DB) - seems capable of handling PetaBytes.
Objectivity is the best choice for us right now Very large databases can be created as “Federations” of very many
smaller databases, which themselves are distributed and/or replicated amongst servers on the network
Features data replication and fault tolerance I/O performance, overhead and efficiency are very similar to
traditional HEP systems OS support (NT, Solaris, Linux, Irix, AIX, HP-UX, etc..) Language bindings (C++, Java, [C, SmallTalk, SQL++ etc.]) Commitment to HEP as target business sector Close relationships built up with the company, at all levels Attractive licensing schemes for HEP

March 5th. 1999
I2-DSI workshop: J.J.Bunn
Storage management - choice of HPSS
Need to “backend” the ODBMS Using a large scale media management system Because:
““Tapes” are still foreseen to be most cost effectiveTapes” are still foreseen to be most cost effective (May be DVDs in practice)(May be DVDs in practice)
System reliability not enough to avoid “backup copies”System reliability not enough to avoid “backup copies”
Unfortunately, large scale data archives are a Unfortunately, large scale data archives are a nicheniche market market
HPSS is currently the best choice:
Appears scale into the PetaByte storage range Heavy investment of CERN/Caltech/SLAC… effort to make HPSS
evolve in directions suited for HEP Unfortunately, only supported on a couple of platforms
A layer between the ODBMS and an HPSS filesystem has been developed: it is interfaced to Objectivity’s Advanced Multithreaded Server. This is one key to development of the system middleware.

March 5th. 1999
I2-DSI workshop: J.J.Bunn
ODBMS worries
Bouyancy of the commercial marketspace?
+Introduction of Computer Associates “Jasmine” pure ODBMS (targetted at multimedia data)
+Oracle et al. paying lip-service to OO with Object features “bolted on” to their fundamentally RDBMS technology
- Breathtaking fall of Versant stock!
- Still no IPO for Objectivity Conversion of “legacy” ODBMS data
from one system to another? 100 PetaBytes via an ODMG-
compliant text file?! Good argument for keeping raw data
outside the ODBMS, in simple binary files (BUT doubles storage needs)

March 5th. 1999
I2-DSI workshop: J.J.Bunn
Federated Database - Views of the Data
Hit
Track
Detector

March 5th. 1999
I2-DSI workshop: J.J.Bunn
ODBMS tests
Results Application is platform
independent Database is platform independent No performance loss for remote
client Fastest access: objects are
“indexed” Slowest: using predicates
Wavelength Wavelength
Database 1 Database 2
Match using indexes, predicates or cuts
• Developed simple scaling application: matching 1000s of sky objects at different wavelengths
• Runs entirely in cache (can neglect disk I/O performance), applies matching algorithm between pairs of objects in different databases.
• Looked at usability, efficiency and scalability for
•number of objects•location of objects•object selection mechanism•database host platform

March 5th. 1999
I2-DSI workshop: J.J.Bunn
ODBMS tests Other Tests:
Looked at Java binding performance (~3 times slower) Created federated database in HPSS managed storage, using NFS
export Tested database replication from CERN to Caltech
0
2 0 0 0
4 0 0 0
6 0 0 0
8 0 0 0
1 0 0 0 0
1 2 0 0 0
1 4 0 0 0
1 6 0 0 0
1 8 0 0 0
2 0 0 0 0
0 5 0 1 0 0 1 5 0 2 0 0 2 5 0
U p d a t e N u m b e r ( T i m e o f D a y )
mil
ise
co
nd
s
c r e a t e L A N
c r e a t e W A N
c o m m i t L A Nc o m m i t W A N
S a t u r a t e d h o u r s ~ 1 0 k b i t s / s e c o n d U n s a t u r a t e d ~ 1 M b i t s / s e c o n d

March 5th. 1999
I2-DSI workshop: J.J.Bunn
ODBMS tests Caltech Exemplar used as a convenient
testbed for Objy multiple-client tests
Results: Exemplar very well suited for this workload. With two (of four) node filesystems it was possible to utilise 150 processors in parallel with very high efficiency.
Outlook: expect to utilise all processors with near 100% efficiency when all four filesystems are engaged.
Evaluated usability and performance of Versant ODBMS, Objectivity’s main competitor.
Results: Versant a decent “fall-back” solution for us

March 5th. 1999
I2-DSI workshop: J.J.Bunn
GIOD - Database of “real” LHC events
Would like to evaluate system performance with realistic Event objects
Caltech/HEP submitted a successful proposal to NPACI to generate ~1,000,000 fully-simulated multi-jet QCD events Directly study Higgs backgrounds for first time Computing power of Caltech’s 256-CPU (64 Gbyte shared memory) HP-
Exemplar makes this possible in ~few months
Event production on the Exemplar since May ‘98 ~ 1,000,000 events of 1 MByte.
Used by GIOD as copious source of “raw” LHC event data
Events are analysed using Java Analysis Studio and “scanned” using a Java applet

March 5th. 1999
I2-DSI workshop: J.J.Bunn
Large data transfer over CERN-USA link to Caltech
Try one file ... Let it rip Tidy up ...HPSS fails
Transfer of ~31 GBytes of Objectivity databases from Shift20/CERN to HPSS/Caltech
Achieved ~11 GBytes/day (equivalent to ~4 Tbytes/year, equivalent to 1 Pbyte/year on a 622 Mbits/sec link)
HPSS hardware problem at Caltech , not network, caused transfer to abort

March 5th. 1999
I2-DSI workshop: J.J.Bunn
Over 200,000 fully simulated di-jet events in the database
Population continuing using parallel jobs on the Exemplar (from a pool of over 1,000,000 events)
Building the TAG database For optimising queries, each event
is summarised by a small object, shown opposite, that contains the salient features.
The TAG objects are kept in a dedicated database, which is replicated to client machines
Preparing for WAN test with SDSC Preparing for HPSS/AMS installation
and tests For MONARC: Making a replica at
Padua/INFN (Italy)
GIOD - Database Status
March 5th. 1999
I2-DSI workshop: J.J.Bunn
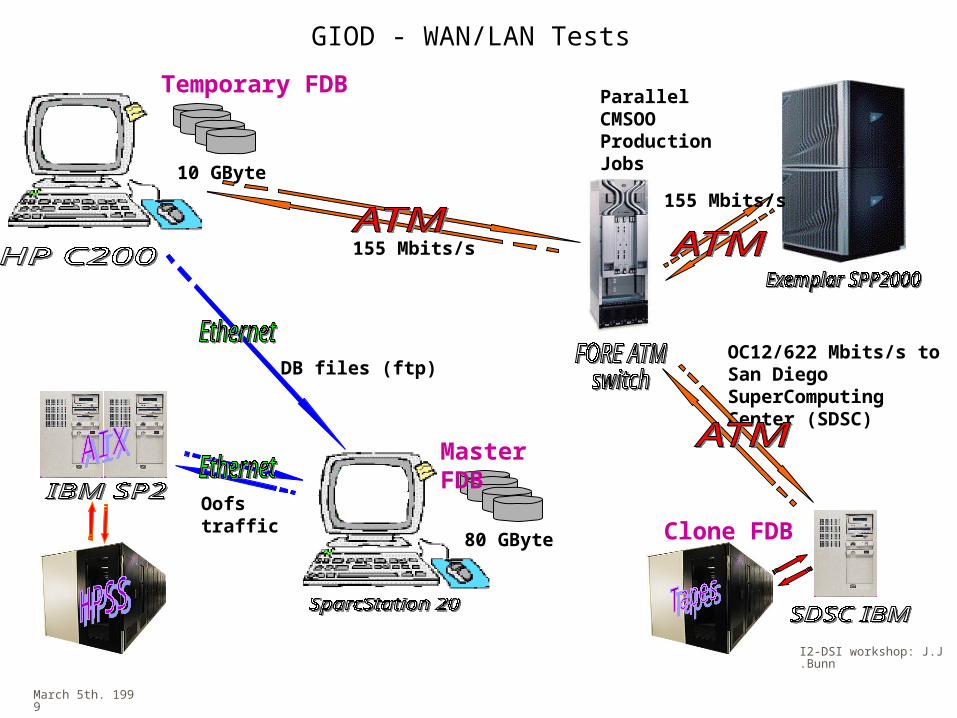
GIOD - WAN/LAN Tests
OC12/622 Mbits/s to San Diego SuperComputing Center (SDSC)
Oofs traffic
155 Mbits/s
155 Mbits/s
DB files (ftp)
80 GByte
Master FDB
Clone FDB
Parallel CMSOO Production Jobs
10 GByte
Temporary FDB

March 5th. 1999
I2-DSI workshop: J.J.Bunn
MONARC - MMONARC - Models odels OOf f NNetworked etworked AAnalysis At nalysis At RRegional egional CCentersenters
Caltech, CERN, FNAL, Heidelberg, Caltech, CERN, FNAL, Heidelberg, INFN, INFN,
KEK, Marseilles, Munich, Orsay, KEK, Marseilles, Munich, Orsay, Oxford, Tufts, …Oxford, Tufts, …
GOALS Specify the main parameters Specify the main parameters
characterizing the Model’s characterizing the Model’s performance: throughputs, latenciesperformance: throughputs, latencies
Determine classes of Computing Determine classes of Computing Models feasible for LHC (matched to Models feasible for LHC (matched to network capacity and data handling network capacity and data handling resources)resources)
Develop “Baseline Models” in the Develop “Baseline Models” in the “feasible” category“feasible” category
Verify resource requirement baselines: Verify resource requirement baselines: (computing, data handling, networks)(computing, data handling, networks)
REQUIRESREQUIRES Define the Define the Analysis ProcessAnalysis Process Define Define Regional Centre ArchitecturesRegional Centre Architectures Provide Provide Guidelines for the final ModelsGuidelines for the final Models
Desktops
CERN107 MIPS200 Tbyte
Robot
Caltechn.106MIPS50 Tbyte Robot
FNAL2.106 MIPS200 Tbyte
Robot
622
Mbi
ts/s
622
Mbi
ts/s
622Mbits/s
622 Mbits/s
Desktops
Desktops

March 5th. 1999
I2-DSI workshop: J.J.Bunn
JavaCMS - 2D Event Viewer Applet
Created to aid in Track Fitting algorithm development
Fetches objects directly from the ODBMS
Java binding to the ODBMS very convenient to use

March 5th. 1999
I2-DSI workshop: J.J.Bunn
CMSOO - Java 3D Applet Attaches to any GIOD database and allows to view/scan all events in the
federation, at multiple detail levels Demonstrated at the Internet-2 meeting in San Francisco in Sep’98 and at
SuperComputing’98 in Florida at the iGrid, NPACI and CACR stands
Running on a 450 MHz HP “Kayak” PC with fx4 graphics card: excellent frame rates in free rotation of a complete event (~ 5 times performance of Riva TNT)
Developments:“Drill down” into the database for picked objects, Refit tracks

March 5th. 1999
I2-DSI workshop: J.J.Bunn
Java Analysis Studiopublic void processEvent(final EventData d) {
final CMSEventData data = (CMSEventData) d; final double ET_THRESHOLD = 15.0;
Jet jets[] = new Jet[2]; Iterator jetItr = (Iterator) data.getObject("Jet");
if(jetItr == null) return;
int nJets = 0; double sumET = 0.; FourVectorRecObj sum4v = new FourVectorRecObj(0.,0.,0.,0.);
while(jetItr.hasMoreElements()) { Jet jet = (Jet) jetItr.nextElement(); sum4v.add(jet); double jetET = jet.ET(); sumET += jetET;
if(jetET > ET_THRESHOLD) { if(nJets <= 1) { jets[nJets] = jet; nJets++; } }
}
njetHist.fill( nJets );
if(nJets >= 2) { // dijet event! FourVectorRecObj dijet4v = jets[0]; dijet4v.add( jets[1] ); massHist.fill( dijet4v.get_mass() ); sumetHist.fill( sumET ); missetHist.fill( sum4v.pt() ); et1vset2Hist.fill( jets[0].ET(), jets[1].ET() ); }}

March 5th. 1999
I2-DSI workshop: J.J.Bunn
GIOD - Summary
LHC Computing models specify Massive quantities of raw, reconstructed and analysis data in
ODBMS Distributed data analysis at CERN, Regional Centres and Institutes Location transparency for the end user
GIOD is investigating Usability, scalability, portability of Object Oriented LHC codes In a hierarchy of large-servers, and medium/small client machines With fast LAN and WAN connections Using realistic raw and reconstructed LHC event data
GIOD has Constructed a large set of fully simulated events and used these to
create a large OO database Learned how to create large database federations Developed prototype reconstruction and analysis codes that work
with persistent objects Deployed facilities and database federations as useful testbeds for
Computing Model studies

March 5th. 1999
I2-DSI workshop: J.J.Bunn
GIOD - Interest in I2-DSI
LHC Computing: timely access to powerful resourcesLHC Computing: timely access to powerful resources Measure the Measure the prevailing network conditionsprevailing network conditions Predict and Predict and managemanage the (short term) the (short term) future conditionsfuture conditions Implement Implement QoS with policiesQoS with policies on end to end links, on end to end links, Provide for Provide for movement of large datasetsmovement of large datasets Match the Match the Network, Storage, and ComputeNetwork, Storage, and Compute resources to the needs resources to the needs Synchronize their Synchronize their availability in real timeavailability in real time Overlay the distributed, Overlay the distributed, tightly coupled ODBMStightly coupled ODBMS on a loosely- on a loosely-
coupled set of heterogeneous coupled set of heterogeneous servers on the WANservers on the WAN Potential Areas of Research with I2-DSIPotential Areas of Research with I2-DSI
Test ODBMS replicationTest ODBMS replication Burst mode, using I2 backbones up to the Gbits/sec rangeBurst mode, using I2 backbones up to the Gbits/sec range
Experiment with data “localization” strategiesExperiment with data “localization” strategies Roles of caching, mirroring, channelingRoles of caching, mirroring, channeling Interaction with Objectivity/DBInteraction with Objectivity/DB
Experiment with policy-based resource allocationExperiment with policy-based resource allocationstrategiesstrategies
Evaluate Autonomous Agent ImplementationsEvaluate Autonomous Agent Implementations


















