
The cost of cognitive control as a solution to the ...
1
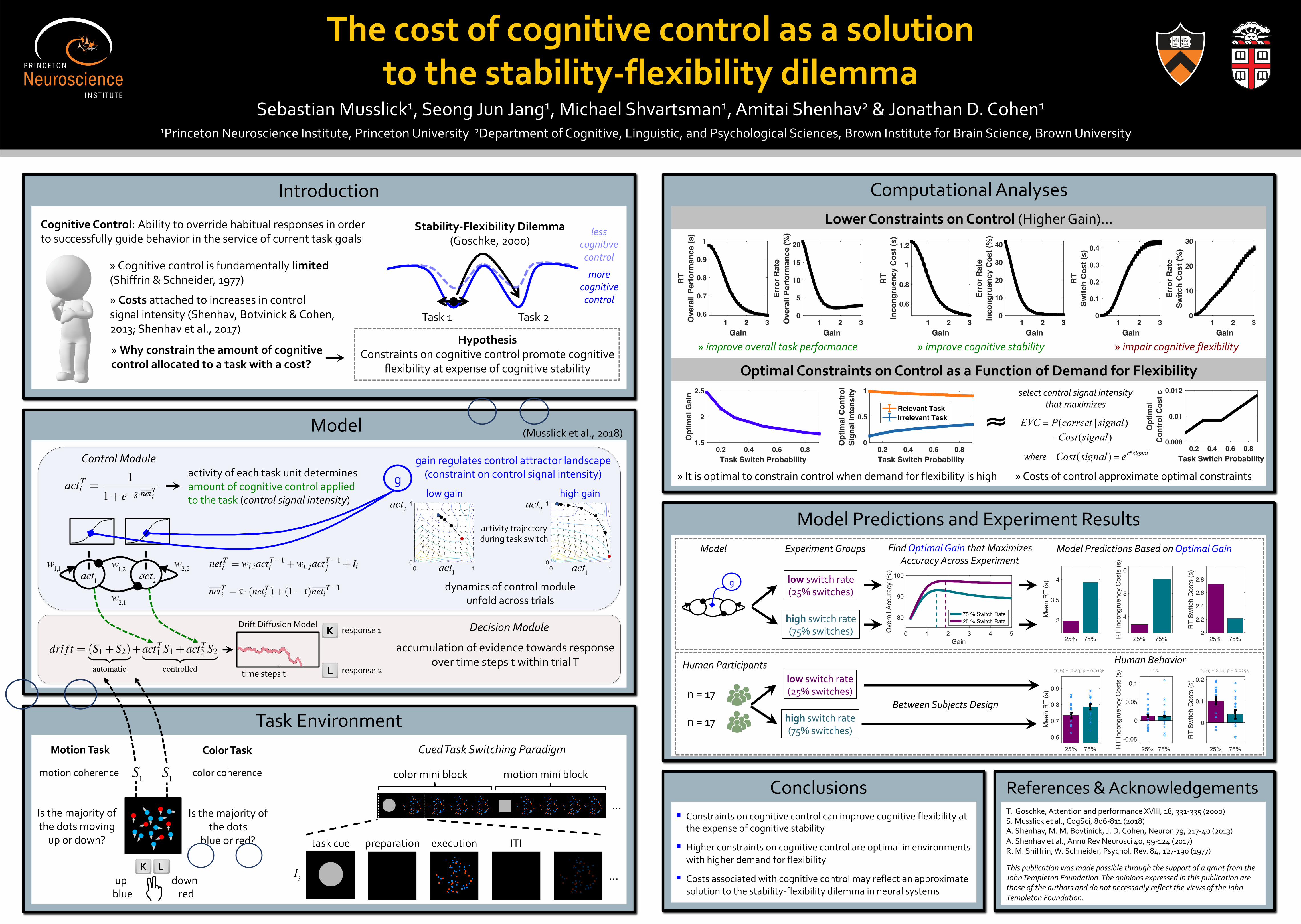
The cost of cognitive control as a solution to the stability-flexibility dilemma Sebastian Musslick 1 , Seong Jun Jang 1 , Michael Shvartsman 1 , Amitai Shenhav 2 & Jonathan D. Cohen 1 1 Princeton Neuroscience Institute, Princeton University 2 Department of Cognitive, Linguistic, and Psychological Sciences, Brown Institute for Brain Science, Brown University Introduction Model Computational Analyses Lower Constraints on Control (Higher Gain)... Optimal Constraints on Control as a Function of Demand for Flexibility Model Predictions and Experiment Results Conclusions References & Acknowledgements » improve overall task performance » improve cognitive stability » impair cognitive flexibility Task Environment low switch rate (25% switches) high switch rate (75% switches) g Experiment Groups Find Optimal Gain that Maximizes Accuracy Across Experiment Model Predictions Based on Optimal Gain Human Behavior Model n = 17 n = 17 low switch rate (25% switches) high switch rate (75% switches) » It is optimal to constrain control when demand for flexibility is high 1 2 3 Gain 0.6 0.7 0.8 0.9 1 RT Overall Performance (s) 1 2 3 Gain 0 5 10 15 20 Error Rate Overall Performance (%) 1 2 3 Gain 0.6 0.8 1 1.2 RT Incongruency Cost (s) 1 2 3 Gain 0 10 20 30 40 Error Rate Incongruency Cost (%) 1 2 3 Gain 0 0.1 0.2 0.3 0.4 RT Switch Cost (s) 1 2 3 Gain 0 10 20 30 Error Rate Switch Cost (%) 0 1 2 3 4 5 Gain 80 90 100 Overall Accuracy (%) 75 % Switch Rate 25 % Switch Rate Human Participants 25% 75% 0 0.1 0.2 RT Switch Costs (s) 25% 75% -0.05 0 0.05 0.1 RT Incongruency Costs (s) 25% 75% 0.6 0.7 0.8 0.9 Mean RT (s) t(16) = -2.43, p = 0.0138 n.s. t(16) = 2.11, p = 0.0254 25% 75% 4 5 6 RT Incongruency Costs (s) 25% 75% 2 2.2 2.4 2.6 2.8 RT Switch Costs (s) 25% 75% 3 3.5 4 Mean RT (s) T. Goschke, Attention and performance XVIII, 18, 331-335 (2000) S. Musslick et al., CogSci, 806-811 (2018) A. Shenhav, M. M. Bovtinick, J. D. Cohen, Neuron 79, 217-40 (2013) A. Shenhav et al., Annu Rev Neurosci 40, 99-124 (2017) R. M. Shiffrin, W. Schneider, Psychol. Rev. 84, 127-190 (1977) This publication was made possible through the support of a grant from the John Templeton Foundation. The opinions expressed in this publication are those of the authors and do not necessarily reflect the views of the John Templeton Foundation. Between Subjects Design § Constraints on cognitive control can improve cognitive flexibility at the expense of cognitive stability § Higher constraints on cognitive control are optimal in environments with higher demand for flexibility § Costs associated with cognitive control may reflect an approximate solution to the stability-flexibility dilemma in neural systems Is the majority of the dots moving up or down? Is the majority of the dots blue or red? K L up down blue red CuedTask Switching Paradigm … task cue execution preparation ITI motion mini block color mini block … g Control Module net T i = w i,i act T -1 i + w i, j act T -1 j + I i net T i = t · (net T i )+(1 - t) net i T -1 gain regulates control attractor landscape (constraint on control signal intensity) Decision Module drift =(S 1 + S 2 ) | {z } automatic + act T 1 S 1 + act T 2 S 2 | {z } controlled w 2,1 act 1 act 2 w 2,2 w 1,2 w 1,1 0 1 0 1 low gain act 1 0 1 0 1 high gain act 1 act T i = 1 1 + e -g· net T i gain parameter that re activity of each task unit determines amount of cognitive control applied to the task (control signal intensity) dynamics of control module unfold across trials activity trajectory during task switch act 2 act 2 S 1 accumulation of evidence towards response over time steps t within trial T time steps t response 1 S 1 color coherence motion coherence Motion Task Color Task Cognitive Control: Ability to override habitual responses in order to successfully guide behavior in the service of current task goals » Cognitive control is fundamentally limited (Shiffrin & Schneider, 1977) » Costs attached to increases in control signal intensity (Shenhav, Botvinick & Cohen, 2013; Shenhav et al., 2017) more cognitive control Task 1 Task 2 less cognitive control Hypothesis Constraints on cognitive control promote cognitive flexibility at expense of cognitive stability » Why constrain the amount of cognitive control allocated to a task with a cost? Stability-Flexibility Dilemma (Goschke, 2000) K response 2 L (Musslick et al., 2018) » Costs of control approximate optimal constraints 0.2 0.4 0.6 0.8 Task Switch Probability 0.008 0.01 0.012 Optimal Control Cost c Cost ( signal ) = e c*signal 0.2 0.4 0.6 0.8 Task Switch Probability 0 0.5 1 Optimal Control Signal Intensity Relevant Task Irrelevant Task 0.2 0.4 0.6 0.8 Task Switch Probability 1.5 2 2.5 Optimal Gain EVC = P ( correct | signal ) − Cost ( signal ) select control signal intensity that maximizes where ≈ I i Drift Diffusion Model
Transcript of The cost of cognitive control as a solution to the ...
Thecostofcognitivecontrolasasolutiontothestability-flexibilitydilemma
SebastianMusslick1,SeongJunJang1,MichaelShvartsman1,AmitaiShenhav2&JonathanD.Cohen11PrincetonNeuroscienceInstitute,PrincetonUniversity2DepartmentofCognitive,Linguistic,andPsychologicalSciences,BrownInstituteforBrainScience,BrownUniversity
Introduction
Model
ComputationalAnalysesLowerConstraintsonControl(HigherGain)...
OptimalConstraintsonControlasaFunctionofDemandforFlexibility
ModelPredictionsandExperimentResults
Conclusions References&Acknowledgements
»improveoveralltaskperformance »improvecognitivestability »impaircognitiveflexibility
TaskEnvironment
lowswitchrate(25%switches)
highswitchrate(75%switches)
g
ExperimentGroups FindOptimalGainthatMaximizesAccuracyAcrossExperiment
ModelPredictionsBasedonOptimalGain
HumanBehavior
Model
n=17
n=17
lowswitchrate(25%switches)
highswitchrate(75%switches)
»Itisoptimaltoconstraincontrolwhendemandforflexibilityishigh
1 2 3Gain
0.6
0.7
0.8
0.9
1
RT
Ove
rall
Perf
orm
ance
(s)
1 2 3Gain
0
5
10
15
20
Erro
r Rat
eO
vera
ll Pe
rfor
man
ce (%
)
1 2 3Gain
0.6
0.8
1
1.2
RT
Inco
ngru
ency
Cos
t (s)
1 2 3Gain
0
10
20
30
40
Erro
r Rat
eIn
cong
ruen
cy C
ost (
%)
1 2 3Gain
0
0.1
0.2
0.3
0.4
RT
Switc
h C
ost (
s)
1 2 3Gain
0
10
20
30
Erro
r Rat
eSw
itch
Cos
t (%
)
0 1 2 3 4 5Gain
80
90
100
Ove
rall
Accu
racy
(%)
75 % Switch Rate25 % Switch Rate
HumanParticipants
25% 75%
0
0.1
0.2
RT
Switc
h C
osts
(s)
25% 75%-0.05
0
0.05
0.1
RT
Inco
ngru
ency
Cos
ts (s
)
25% 75%
0.6
0.7
0.8
0.9
Mea
n R
T (s
)
t(16)=-2.43,p=0.0138 n.s. t(16)=2.11,p=0.0254
25% 75%
4
5
6
RT
Inco
ngru
ency
Cos
ts (s
)
25% 75%2
2.2
2.4
2.6
2.8
RT
Switc
h C
osts
(s)
25% 75%
3
3.5
4
Mea
n R
T (s
)
T.Goschke,AttentionandperformanceXVIII,18,331-335(2000)S.Musslicketal.,CogSci,806-811(2018)A.Shenhav,M.M.Bovtinick,J.D.Cohen,Neuron79,217-40(2013)A.Shenhavetal.,AnnuRevNeurosci40,99-124(2017)R.M.Shiffrin,W.Schneider,Psychol.Rev.84,127-190(1977)ThispublicationwasmadepossiblethroughthesupportofagrantfromtheJohnTempletonFoundation.TheopinionsexpressedinthispublicationarethoseoftheauthorsanddonotnecessarilyreflecttheviewsoftheJohnTempletonFoundation.
BetweenSubjectsDesign
§ Constraintsoncognitivecontrolcanimprovecognitiveflexibilityattheexpenseofcognitivestability
§ Higherconstraintsoncognitivecontrolareoptimalinenvironmentswithhigherdemandforflexibility
§ Costsassociatedwithcognitivecontrolmayreflectanapproximatesolutiontothestability-flexibilitydilemmainneuralsystems
Isthemajorityofthedotsmovingupordown?
Isthemajorityofthedots
blueorred?
K Lup downblue red
CuedTaskSwitchingParadigm
…
taskcue executionpreparation ITI
motionminiblockcolorminiblock
…
g
ControlModule
different task when the environment changes. This is evi-dent empirically in the form of costs to performance whenswitching from one task to another, which are magnifiedwith increases in the allocation of control to the initial task(Goschke, 2000). The dilemma is consistent with the task-set inertia hypothesis, according to which the task-set of apreviously performed task persists and interferes with initialperformance of a subsequent task following a switch (Allport,Styles, & Hsieh, 1994).
We use a recurrent neural network model of task perfor-mance and control to explore how different choices of aglobal control parameter (gain modulation) that determinesits maximal intensity, influence the stability and flexibilityof performance in a task switching environment. Critically,we determine the optimal value of this parameter as a func-tion of the demand for flexibility in the task environment,and show how these results can explain differences in hu-man task switch costs as a function of task switch probability.Finally, we conclude with a discussion about how computa-tional dilemmas such as the stability-flexibility tradeoff mayhelp provide a normative account of previously unexplained –and what may otherwise appear to be irrational – constraintson cognitive control. The code for all simulations used in thiswork is available at github.com/musslick/CogSci-2018b.
Recurrent Neural Network Model
To explore the effect of constraints on the intensity of con-trol, we simulate control configurations as activity states ofprocessing units in a neural network (control module) that un-fold over the course of trials. Within each trial, the process-ing units of the network engage an evidence accumulationprocess that integrates information about the stimulus, and isused to generate a response (decision module). In this sectionwe describe the processing dynamics for both the control anddecision modules, as well as the environments in which themodel is tasked to perform.
Control Module
We simulate the intensities of two different control signals asactivities of two processing units indexed by i, i 2 {1,2} in arecurrent neural network. The activity of each processing unitunit i at a given trial T represents the intensity of the controlsignal for one of two tasks and is determined by its net input
netTi = wi,iactT�1
i +wi, jactT�1j + Ii (1)
that is a linear combination of the unit’s own activity at theprevious trial actT�1
i multiplied by the self-recurrent weightwi,i, the activity of the other unit j 2 1,2, j 6= i at the previ-ous trial actT�1
j multiplied by an inhibitory weight wi, j, aswell as an external input Ii provided to the unit (see Figure 1).The self-recurrent and mutually-inhibitory weights induce at-tractors within the control module, such that it can maintainits activity over time in one state or the other, but not both.The latter implements a capacity constraint on control with
regard to the number of control-dependent tasks the networkcan support. These weights also determine the activity of theunits in each attractor state, that is also regulated by a gainparameter that we use to implement the intensity constraint,as discussed further below. The external input acts as a gat-ing signal to the corresponding control unit (Braver & Cohen,1999) and is set to 1 if the task represented by the control unitneeds to be performed and set to 0 otherwise. The net inputof each unit is averaged over time
netTi = t · (netT
i )+(1� t)netiT�1 (2)
where netiT�1 corresponds to the time averaged net inputat the previous trial and t 2R : 0 t 1 is the rate constant.A higher t leads to a faster change in activation for both units.Finally, the activity of each unit is a sigmoid function of itstime averaged net input
actTi =
11+ e�g·netT
i(3)
where g is a gain parameter that regulates the slope ofthe activation function. The sigmoid activation function con-strains the activity of both units to lie between 0 and 1. Thegain of the activation function effectively regulates the dis-tance between the two control states, with lower gain leadingto a lower activation of the currently relevant control unit. Inthis model, we use g to implement a constraint on the inten-sity of control, and explore its effect on the network’s balancebetween stability and flexibility.
!"," !",$ !$,$%&'" %&'$
($("ControlModule
DecisionModule
StimulusDimensions
)" )$
timestepswithintrial*+,-' = )" + )$ +)"%&'" + )$%&'$
Response2
Response1!$,"
Figure 1: Recurrent neural network model used in simula-tions. Each of the two processing units in the control module(blue) receive an external input signal I1, I2 that indicates thecurrently relevant task. The dynamics of the network unfoldover the course of trials and are determined by recurrent con-nectivity w1,1,w2,2 for each unit, as well as mutual inhibitionw1,2,w2,1 between units. The activity of each control unit bi-ases the processing of a corresponding stimulus dimension ona given trial. On each trial, the decision module accumulatesevidence for both stimulus dimensions towards one of tworesponses until a threshold is reached.
Decision Module
On each trial the decision module integrates informationalong two stimulus dimensions S1 and S2 of a single stim-ulus to determine a response. Each dimension (e.g., color or
different task when the environment changes. This is evi-dent empirically in the form of costs to performance whenswitching from one task to another, which are magnifiedwith increases in the allocation of control to the initial task(Goschke, 2000). The dilemma is consistent with the task-set inertia hypothesis, according to which the task-set of apreviously performed task persists and interferes with initialperformance of a subsequent task following a switch (Allport,Styles, & Hsieh, 1994).
We use a recurrent neural network model of task perfor-mance and control to explore how different choices of aglobal control parameter (gain modulation) that determinesits maximal intensity, influence the stability and flexibilityof performance in a task switching environment. Critically,we determine the optimal value of this parameter as a func-tion of the demand for flexibility in the task environment,and show how these results can explain differences in hu-man task switch costs as a function of task switch probability.Finally, we conclude with a discussion about how computa-tional dilemmas such as the stability-flexibility tradeoff mayhelp provide a normative account of previously unexplained –and what may otherwise appear to be irrational – constraintson cognitive control. The code for all simulations used in thiswork is available at github.com/musslick/CogSci-2018b.
Recurrent Neural Network Model
To explore the effect of constraints on the intensity of con-trol, we simulate control configurations as activity states ofprocessing units in a neural network (control module) that un-fold over the course of trials. Within each trial, the process-ing units of the network engage an evidence accumulationprocess that integrates information about the stimulus, and isused to generate a response (decision module). In this sectionwe describe the processing dynamics for both the control anddecision modules, as well as the environments in which themodel is tasked to perform.
Control Module
We simulate the intensities of two different control signals asactivities of two processing units indexed by i, i 2 {1,2} in arecurrent neural network. The activity of each processing unitunit i at a given trial T represents the intensity of the controlsignal for one of two tasks and is determined by its net input
netTi = wi,iactT�1
i +wi, jactT�1j + Ii (1)
that is a linear combination of the unit’s own activity at theprevious trial actT�1
i multiplied by the self-recurrent weightwi,i, the activity of the other unit j 2 1,2, j 6= i at the previ-ous trial actT�1
j multiplied by an inhibitory weight wi, j, aswell as an external input Ii provided to the unit (see Figure 1).The self-recurrent and mutually-inhibitory weights induce at-tractors within the control module, such that it can maintainits activity over time in one state or the other, but not both.The latter implements a capacity constraint on control with
regard to the number of control-dependent tasks the networkcan support. These weights also determine the activity of theunits in each attractor state, that is also regulated by a gainparameter that we use to implement the intensity constraint,as discussed further below. The external input acts as a gat-ing signal to the corresponding control unit (Braver & Cohen,1999) and is set to 1 if the task represented by the control unitneeds to be performed and set to 0 otherwise. The net inputof each unit is averaged over time
netTi = t · (netT
i )+(1� t)netiT�1 (2)
where netiT�1 corresponds to the time averaged net inputat the previous trial and t 2R : 0 t 1 is the rate constant.A higher t leads to a faster change in activation for both units.Finally, the activity of each unit is a sigmoid function of itstime averaged net input
actTi =
11+ e�g·netT
i(3)
where g is a gain parameter that regulates the slope ofthe activation function. The sigmoid activation function con-strains the activity of both units to lie between 0 and 1. Thegain of the activation function effectively regulates the dis-tance between the two control states, with lower gain leadingto a lower activation of the currently relevant control unit. Inthis model, we use g to implement a constraint on the inten-sity of control, and explore its effect on the network’s balancebetween stability and flexibility.
!"," !",$ !$,$%&'" %&'$
($("ControlModule
DecisionModule
StimulusDimensions
)" )$
timestepswithintrial*+,-' = )" + )$ +)"%&'" + )$%&'$
Response2
Response1!$,"
Figure 1: Recurrent neural network model used in simula-tions. Each of the two processing units in the control module(blue) receive an external input signal I1, I2 that indicates thecurrently relevant task. The dynamics of the network unfoldover the course of trials and are determined by recurrent con-nectivity w1,1,w2,2 for each unit, as well as mutual inhibitionw1,2,w2,1 between units. The activity of each control unit bi-ases the processing of a corresponding stimulus dimension ona given trial. On each trial, the decision module accumulatesevidence for both stimulus dimensions towards one of tworesponses until a threshold is reached.
Decision Module
On each trial the decision module integrates informationalong two stimulus dimensions S1 and S2 of a single stim-ulus to determine a response. Each dimension (e.g., color or
gainregulatescontrolattractorlandscape(constraintoncontrolsignalintensity)
DecisionModule
shape) can take one of two values (e.g., red or green; roundor square), each of which is associated with one of two re-sponses (e.g. pressing left or right button). Each of the twotasks requires mapping the current value of one of the twostimulus dimensions to its corresponding response, while ig-noring the other dimension. Since both tasks involve the samepair of responses, stimuli can be congruent (stimulus valuesin both dimensions associated with the same response) or in-congruent (associated with different responses). We simu-late the response integration process using a drift diffusionmodel (DDM, Ratcliff, 1978), in which the drift is determinedby the combined stimulus information from each dimension,weighted by input received from the control module (as de-scribed below), and evidence is accumulated over time untilone of two response thresholds is reached. The drift rate isdecomposed into an automatic and controlled component
dri f t = (S1 +S2)| {z }automatic
+actT1 S1 +actT
2 S2| {z }controlled
(4)
where the automatic component reflects automatic process-ing of each stimulus dimension that is unaffected by control.The absolute magnitude of S1,S2 depends on the strength ofthe association of each stimulus with a given response andits sign depends on the response (e.g. S1 < 0 if the associatedresponse is to press the left button, S1 > 0 if the associated re-sponse is to press the right button). Thus, for congruent trialsS1 and S2 have the same sign, and the opposite sign for incon-gruent (conflict) trials. For the simulations described below,the strength of the associations was equal along the two stim-ulus dimensions. The controlled component of the drift rateis the sum of the two stimulus values, each weighted by theactivation of the corresponding control unit. Thus, each unitin the control module biases processing towards one of thestimulus dimensions, similar to other computational modelsof cognitive control (e.g. Cohen et al., 1990; Mante, Sus-sillo, Shenoy, & Newsome, 2013; Musslick et al., 2015). Asa result, progressively greater activation of a control unit im-proves performance – speeds responses and improves accu-racy – for the corresponding task. Mean reaction times (RTs)and error rates for a given parameterization of drift rate attrial T are derived from an analytical solution to the DDM(Bogacz, Brown, Moehlis, Holmes, & Cohen, 2006).
Task Environment and Processing Dynamics
We used the model to simulate performance while switchingbetween 100 mini-blocks of the two tasks (Meiran, 1996).Each mini-block consisted of six trials of the same task. Atask cue presented before and throughout each mini-block in-structed the model to adjust control signals to the currentlyrelevant task i, by setting Ii to 1 for the task-relevant controlunit and I j 6=i to 0 for the other. On each trial, a stimulus waspresented comprised of a value along each dimension S1 andS2, the decision module integrated the input, and generateda response that was deemed correct if it corresponded to the
one associated with the stimulus value along the dimensionindicated by the task cue.
Effects of Network Gain
on Stability and Flexibility
The intensity of the control signals is functionally constrainedby the gain parameter of the activation function in Equation 3:lowering gain lowers the activity of a control unit for a givenpositive net input, and thus constrains the maximum signalintensity of the task-relevant control unit. Here, we exam-ine how manipulations of gain influence the model’s perfor-mance, and in particular measures of stability and flexibilityin the task switching design described above.
To do so we varied g from 0.1 to 3 in steps of 0.1. The con-trol module of each model was parameterized with balancedrecurrent and inhibitory weights, wi,i = 1,wi, j =�1 and a rateconstant of t = 0.9. The decision module (DDM) was pa-rameterized1 with a threshold of z = 0.0475, a non-decisiontime of T0 = 0.2 and a noise of c = 0.04. We simulated per-formance of each model on 10 different randomly permutedtask switching sequences of the type described above. Eachsequence was generated with a 50% task switch rate (i.e. onehalf of the mini-blocks required to switch to another task withrespect to the previous mini-block whereas the other half ofthe mini-blocks required to repeat the previous task). Tasktransitions were counterbalanced with each task and responsecongruency conditions.
For each simulation, we assessed the mean difference inreaction times (RTs) and error rates between incongruentand congruent trials as a measure of cognitive stability. In-congruent trials typically lead to slower reaction times andhigher error rates than congruent trials due to response con-flict, referred to as the incongruency effect. The stability-flexibility dilemma suggests that increased control intensity(implemented here by higher values of g) should augmentsensitivity to the task-relevant stimulus dimensions and di-minish it to the task irrelevant dimension, thereby reducingthe incongruency effect (Goschke, 2000). We also measuredmean task performance as an index of task stability. Finally,we assessed the flexibility in terms of performance costs as-sociated with a task switch relative to a task repetition fromone mini-block to another. Specifically, we computed the per-formance difference between the first trial of switch vs. rep-etition mini-blocks. We predicted that increasing g would in-crease task switch costs, as this would increase the distancebetween the attractors in the control module and thus makeit harder to switch between them. We evaluated the effect ofgain on each of these measures by regressing each against thegain of the network across all task sequences and networks.
The results in Figure 2a indicate that all tested models
1The parameter values were chosen to yield reasonable modelperformance, i.e. an average task accuracy higher than chance.While each parameter has a quantitative effect on the results de-scribed below, the qualitative (direction) of the effects remainsrobust across a wide range of parameter values (for details, seegithub.com/musslick/CogSci-2018b).
w2,1
nety2
act y2
nety2
act y2
act1 act2w2,2w1,2w1,1 0 1
0
1lowgain
act1 0 10
1highgain
act1
different task when the environment changes. This is evi-dent empirically in the form of costs to performance whenswitching from one task to another, which are magnifiedwith increases in the allocation of control to the initial task(Goschke, 2000). The dilemma is consistent with the task-set inertia hypothesis, according to which the task-set of apreviously performed task persists and interferes with initialperformance of a subsequent task following a switch (Allport,Styles, & Hsieh, 1994).
We use a recurrent neural network model of task perfor-mance and control to explore how different choices of aglobal control parameter (gain modulation) that determinesits maximal intensity, influence the stability and flexibilityof performance in a task switching environment. Critically,we determine the optimal value of this parameter as a func-tion of the demand for flexibility in the task environment,and show how these results can explain differences in hu-man task switch costs as a function of task switch probability.Finally, we conclude with a discussion about how computa-tional dilemmas such as the stability-flexibility tradeoff mayhelp provide a normative account of previously unexplained –and what may otherwise appear to be irrational – constraintson cognitive control. The code for all simulations used in thiswork is available at github.com/musslick/CogSci-2018b.
Recurrent Neural Network Model
To explore the effect of constraints on the intensity of con-trol, we simulate control configurations as activity states ofprocessing units in a neural network (control module) that un-fold over the course of trials. Within each trial, the process-ing units of the network engage an evidence accumulationprocess that integrates information about the stimulus, and isused to generate a response (decision module). In this sectionwe describe the processing dynamics for both the control anddecision modules, as well as the environments in which themodel is tasked to perform.
Control Module
We simulate the intensities of two different control signals asactivities of two processing units indexed by i, i 2 {1,2} in arecurrent neural network. The activity of each processing unitunit i at a given trial T represents the intensity of the controlsignal for one of two tasks and is determined by its net input
netTi = wi,iactT�1
i +wi, jactT�1j + Ii (1)
that is a linear combination of the unit’s own activity at theprevious trial actT�1
i multiplied by the self-recurrent weightwi,i, the activity of the other unit j 2 1,2, j 6= i at the previ-ous trial actT�1
j multiplied by an inhibitory weight wi, j, aswell as an external input Ii provided to the unit (see Figure 1).The self-recurrent and mutually-inhibitory weights induce at-tractors within the control module, such that it can maintainits activity over time in one state or the other, but not both.The latter implements a capacity constraint on control with
regard to the number of control-dependent tasks the networkcan support. These weights also determine the activity of theunits in each attractor state, that is also regulated by a gainparameter that we use to implement the intensity constraint,as discussed further below. The external input acts as a gat-ing signal to the corresponding control unit (Braver & Cohen,1999) and is set to 1 if the task represented by the control unitneeds to be performed and set to 0 otherwise. The net inputof each unit is averaged over time
netTi = t · (netT
i )+(1� t)netiT�1 (2)
where netiT�1 corresponds to the time averaged net inputat the previous trial and t 2R : 0 t 1 is the rate constant.A higher t leads to a faster change in activation for both units.Finally, the activity of each unit is a sigmoid function of itstime averaged net input
actTi =
11+ e�g·netT
i(3)
where g is a gain parameter that regulates the slope ofthe activation function. The sigmoid activation function con-strains the activity of both units to lie between 0 and 1. Thegain of the activation function effectively regulates the dis-tance between the two control states, with lower gain leadingto a lower activation of the currently relevant control unit. Inthis model, we use g to implement a constraint on the inten-sity of control, and explore its effect on the network’s balancebetween stability and flexibility.
!"," !",$ !$,$%&'" %&'$
($("ControlModule
DecisionModule
StimulusDimensions
)" )$
timestepswithintrial*+,-' = )" + )$ +)"%&'" + )$%&'$
Response2
Response1!$,"
Figure 1: Recurrent neural network model used in simula-tions. Each of the two processing units in the control module(blue) receive an external input signal I1, I2 that indicates thecurrently relevant task. The dynamics of the network unfoldover the course of trials and are determined by recurrent con-nectivity w1,1,w2,2 for each unit, as well as mutual inhibitionw1,2,w2,1 between units. The activity of each control unit bi-ases the processing of a corresponding stimulus dimension ona given trial. On each trial, the decision module accumulatesevidence for both stimulus dimensions towards one of tworesponses until a threshold is reached.
Decision Module
On each trial the decision module integrates informationalong two stimulus dimensions S1 and S2 of a single stim-ulus to determine a response. Each dimension (e.g., color or
activityofeachtaskunitdeterminesamountofcognitivecontrolappliedtothetask(controlsignalintensity)
dynamicsofcontrolmoduleunfoldacrosstrials
activitytrajectoryduringtaskswitch
act2 act2
S1
accumulationofevidencetowardsresponseovertimestepstwithintrialT
timestepst
response1
S1 colorcoherencemotioncoherence
MotionTask ColorTask
CognitiveControl:Abilitytooverridehabitualresponsesinordertosuccessfullyguidebehaviorintheserviceofcurrenttaskgoals
»Cognitivecontrolisfundamentallylimited(Shiffrin&Schneider,1977)
»Costsattachedtoincreasesincontrolsignalintensity(Shenhav,Botvinick&Cohen,2013;Shenhavetal.,2017)
morecognitivecontrol
Task1 Task2
lesscognitivecontrol
HypothesisConstraintsoncognitivecontrolpromotecognitive
flexibilityatexpenseofcognitivestability
»Whyconstraintheamountofcognitivecontrolallocatedtoataskwithacost?
Stability-FlexibilityDilemma(Goschke,2000)
K
response2L
(Musslicketal.,2018)
»Costsofcontrolapproximateoptimalconstraints
0.2 0.4 0.6 0.8Task Switch Probability
0.008
0.01
0.012
Opt
imal
Con
trol
Cos
t c
Cost(signal) = ec*signal0.2 0.4 0.6 0.8Task Switch Probability
0
0.5
1
Opt
imal
Con
trol
Sign
al In
tens
ity
Relevant TaskIrrelevant Task
0.2 0.4 0.6 0.8Task Switch Probability
1.5
2
2.5
Opt
imal
Gai
n
EVC = P(correct | signal)−Cost(signal)
selectcontrolsignalintensitythatmaximizes
where
≈
Ii
DriftDiffusionModel





![Investigative Analysis of Cognitive Radio Wireless Model ...2.1 Cognitive Radio Cognitive radio was inspired by [10] as evolving technology from software defined radio to offer solution](https://static.fdocuments.in/doc/165x107/5f050a4e7e708231d410f601/investigative-analysis-of-cognitive-radio-wireless-model-21-cognitive-radio.jpg)












